Audio-Visual Fusion Layers for Event Type Aware Video Recognition
Abstract
Human brain is continuously inundated with the multisensory information and their complex interactions coming from the outside world at any given moment. Such information is automatically analyzed by binding or segregating in our brain. While this task might seem effortless for human brains, it is extremely challenging to build a machine that can perform similar tasks since complex interactions cannot be dealt with single type of integration but requires more sophisticated approaches. In this paper, we propose a new model to address the multisensory integration problem with individual event-specific layers in a multi-task learning scheme. Unlike previous works where single type of fusion is used, we design event-specific layers to deal with different audio-visual relationship tasks, enabling different ways of audio-visual formation. Experimental results show that our event-specific layers can discover unique properties of the audio-visual relationships in the videos. Moreover, although our network is formulated with single labels, it can output additional true multi-labels to represent the given videos. We demonstrate that our proposed framework also exposes the modality bias of the video data category-wise and dataset-wise manner in popular benchmark datasets.
1 Introduction

Real-world events around us consist full of different multisensory signals and their complex interactions with each other. In-the-wild videos of real-life events and moments capture a rich set of multi-modalities and their complex interactions therein. Thus, it is essential to leverage multisensory information for better video understanding, but their diversity and complex nature make it challenging. While some of these events – such as hearing an engine sound and seeing a race car in the video – have corresponding multi-modalities, some others can have non-corresponding multi-modal signals. For example, sometimes sounds are produced by events that we do not see in the field of view (e.g., ‘voice over’), or some visual events do not make any distinctive sounds (e.g., ‘hand shaking’). Even though audio and vision signals are congruent, the way they relate are also different. All these events have different types of temporal regularity, as shown in Figure 1, which we call them as event types. That is, understanding video contents require to understand and properly deal with such diverse and complex associations and relationships.
In the computer vision field, there have been vast efforts, e.g. [26, 34, 44, 49, 24, 29, 52], to implement a machine perception for multi-modal video analysis. They model multi-modal fusion mechanisms with a fundamental assumption that all audio-visual events are highly correlated and continuous throughout the video. This uniform assumption is flawed in its ability to model real-world multisensory events as illustrated in Figure 1.111Let us consider the car video in Figure 3. A group of spectators talk for a long time while recording the scene before race car passes, but the only useful moment for audio-visual integration is the short moment car passes by. The common fusion method, e.g., [3, 55, 26, 49], which is concatenating or average-pooling both modalities over the entire sequence, smooths out sparse important moments and leads to wrong prediction (e.g., in a race event, ‘crowd’ sound is dominant instead of ‘car sound’ in terms of the global-pooling based fusion method). Thus, in contrast to the prior methods which all use an one-size-fits-all fusion, we present a new perspective that incorporates event-specific layers to improve video understanding.
We developed a model that incorporates multiple types of audio-visual relationships to improve video understanding. Our development is motivated by the way humans perceive the world. Humans are spontaneously capable of combining relevant heterogeneous signals from the same events or objects, or distinguishing a signal from one another if the source events of the signals are different; thereby, we are able to understand events around us. Such multisensory integration has been widely studied as binding vs. segregation of unimodal stimuli in cognitive science [23, 40, 41]. However, it is challenging to identify all possible types of binding and segregation for all existing event types in the world. We postulate that most of existing events may be effectively spanned by combinations of a few dominant event types previously identified by the cognitive science studies, such as continuous, onset and instant event.
Motivated by these observations, we attach individual modality and audio-visual event-specific layers into the model in a multi-task learning scheme. Each layer is designed to look for different characteristics in the videos such as audio only, visual only, continuous, onset and instant event layers. We show that our method improves video classification performance and also enables reliable multi-label prediction. Our proposed model leads to better interpretability of the videos such as understanding the audio and visual signals independently or jointly based on the characteristics of the events as well as providing naïve modality confidence scores. This allows us to conduct interesting existing dataset analyses and potential applications such as multi-labeling, category-wise and dataset-wise modality bias, and sound localization.
2 Related Work
Cognitive Science.
Our work is motivated by the findings in the numerous biology, psychology, and cognitive science research investigations on multisensory integration and causal inference in the brain [42, 40, 41, 23, 32, 33, 8]. Evidences in these studies show that brain solves two problems: 1) to bind or segregate the different sensory modalities depending on they originate from a common or separate causes (events or objects); 2) if they go together, how to integrate them properly. These studies suggest human brain uses different types of perceptual factors - such as temporal, spatial, semantic and structural - while integrating different sensory signals. In our work, we take inspiration from these studies and formalize the multisensory binding vs. segregation and the causal inference problems by designing multisensory event-specific layers in multitask learning scheme.
Audio-Visual Representation Learning.
Recent years have witnessed significant progress in audio-visual learning and some used audio or visual information as supervisory signal to the other one [6, 36, 35] or leverage both of them in self-supervised learning to learn general representations assuming that there is a natural correspondence between them [3, 4, 20, 7, 26, 34]. Self-supervised learning methods use different tasks such as correspondence [3, 4, 7], synchronization [26, 34] or clustering [2]. Furthermore, recent explorations use audio-visual multimodal signals as self-supervision to cluster or label the unlabelled videos [5, 2]. These existing approaches assume that multisensory data is always semantically correlated and temporally aligned. As a result, they apply simple fusion techniques such as concatenation or average pooling. However, in real world videos, multisensory data are not always naturally co-occurring. Our work investigates more diverse multisensory relationships and propose different integration approaches in audio-visual events.
Audio-Visual Activity Recognition.
Various deep learning approaches have been proposed to boost action recognition accuracy by incorporating audio as another modality [29, 27, 24, 52, 18, 49]. While most of the existing work simply concatenate the audio and visual features with naive approaches, Gao et al. [18] uses multi-modal distillation from a video model to an image-audio model for action recognition. Besides these existing work, Wang et al. [49] investigates that naive approaches may not be the optimal solution to training multimodal classification networks and proposes to use joint training by adding the two separate modalities with weighted blending. Our learning mechanism is similar to this approach in terms of multi-task joint training but our training scheme is applied to multiple event-specific layers to address proper multisensory integration.
Broader Audio-Visual Learning Tasks.
Recent work on audio-visual learning use the natural correspondence between auditory and visual signals on different tasks than representation learning and action recognition, including audio-visual sound separation [12, 13, 14, 16, 17, 1, 59, 56, 57, 53, 47], sound source localization [38, 4, 39, 46, 21], audio generation [60, 31, 15, 58, 54] and audio-visual event localization [28, 44, 51]. Different from all the previous work, we focus on incorporating audio and visual modalities for multisensory integration without the assumption that they are always correspondent.
3 Approach


3.1 Problem Formulation
The goal of our model is to understand and predict the accurate label that represents the video from the perspective of each multisensory layer. Most of the existing work [29, 27, 24, 52, 49] used a clip level classifier that took a short ( or sec.) clip and then computed video-level predictions by averaging classification scores of each clip. These clip classifiers are learned by leveraging naïvely fused (e.g., simple concatenation) audio-visual features with the assumption of audio and visual data are correlated and temporally aligned.
As aforementioned (Section 1), these existing approaches for video classification and understanding might be improved by considering more complex associations. First, audio and visual events in a video may not occur with a close association all the time. They can occur separately in each individual modality as well. Second, this audio-visual correspondences can have different characteristics such as continuous, rhythmic or isolated instant events [40, 42]. Our proposed architecture addresses these concerns by using various multisensory layers.
Backbone Networks.
Given a video clip with its corresponding audio , our backbone networks extract features for each modality. We use a two-stream architecture, that leverages each modality separately, similar to other existing audio-visual learning works. Our backbone networks take entire 10 sec. video and audio frames and extract features per-frame for each modality. The video network is a spatio-temporal network, similar to MC [45]. It takes a video of frames as input and generates a video embedding with dimensions . The audio stream takes the log-mel spectrogram of 10 frames and passes it through a stack of 2D convolution layers to extract an audio embedding with dimensions similar to video features. Thus, there is a corresponding audio feature for every video feature and we do not need any replication or tile operations to match audio and video feature dimensions.
3.2 Multisensory Event-Specific Layers
To deal with different multi-modal event types, we design those expert layers as multi-task heads of the multi-modal network as shown in Figure 2. Defining the index of each layer, the layer takes and from backbone networks and outputs video-level prediction by applying assigned task to itself. We explain each layer in detail below.
Continuous Event Layer.
This layer is designed to integrate audio and visual signals by performing temporal aggregation to each frame features from both modalities with the assumption of audio and visual signals are temporally correlated and aligned throughout the video. This temporal congruency between audio and visual signals play a key role for audio-visual sensory integration not only in cognitive science [40, 41] but also in audio-visual learning works [34, 44, 26, 19]. The integrated audio-visual feature can be computed as follows:
| (1) |
where denotes the concatenation of two vectors and denotes time step. The continuous layer feature is obtained by temporal aggregation over all time steps by average pooling.
Instant Event Layer.
Another type of audio-visual event that can occur is the sparse and isolated instant ones. These actual interesting actions happen when both audio and visual signals are semantically correlated and synced for a short period as a few important moments rather than long temporal correspondence. The assigned task for this layer is performed by finding the time steps (moments) that have the highest correlation scores between audio and visual features, and respectively. Figure 3 shows that moments with highest scores are located only in the last part of the video which can be easily understood since car appears in the scene and it is correlated with the car sound (visualized as colored frames). Remaining parts of the video are not useful for audio-visual integration as it only shows empty road like visual information. Correlation scores are computed by pairwise dot products between audio and visual embeddings [19, 1] at the same time step and audio-visual feature is computed as follows:
| (2) |
where score list is defined as and represents sorted time steps by . The instant layer feature is obtained by averaging the features at top- time steps.
Onset Event Layer.
There is another type of audio-visual event that can be integrated on the event occurrences at regular points in time, i.e., rhythm [42, 8]. For example, sounds occur rhythmically and repetitively in dancing, musical instruments and bird calling events as they have prominent property in audio modality aligned with visual signals. Onset event layer is designed to leverage audio onsets. Audio onsets usually give information about the rhythms and beats [11, 48], musical notes and as well as beginning of the audio events [37, 25]. As can be seen in Figure 3, visual event (typebar hits the screen) occurs at the same time as onset moments which can be easily understood since this action makes rhythmic typebar sound. Furthermore, almost equal time gap between onset moments show that this event is rhythmic. Audio onsets are computed by using existing audio libraries [30] for the given audio as . This return a set of time stamp indices that onsets exist in the range of . We compute as follows:
| (3) |
Visual Event Layer.
Our multisensory layers are inspired from human cognitive ability for multisensory integration as binding the multimodal signals if they are correlated and separating them otherwise. Considering some actions are soundless (“massaging legs”, “stretching leg”, etc.) or some scenes have irrelevant sounds, integrating this irrelevant sound signals to visual features acts as noise and affects the correct prediction ability. Thus, this visual event layer is designed to recognize the events only from visual perspective. It performs the task of assigning zero-valued audio features for each visual frame feature and applying Eq. (1) to output .
Audio Event Layer.
Conversely to the visual event layer, scenes might have events that are outside of the field of view but still hearable or visual signal may be completely unrelated to the accompanying audio. Additionally, some videos might have poor visual signal. To make our network use audio only modality, this layer assigns zero-valued visual features to each audio frame feature and applies Eq. (1) to compute .
3.3 Training
With the proposed backbone and event-specific layers, we obtain different representations from each layer by given identical inputs, i.e. audio-visual features from the backbone networks. To make each layer produces the final -class prediction output , letting be the index of each layer, separate fully-connected layers are used as in Figure 2. Thus, we propose a multi-task joint learning with multiple objectives. This training methodology uses individual layers with their loss functions and supervisory label, where the same single label is given for each task. Considering this as a classification problem, cross entropy loss for each layer is computed as
| (4) |
where , is the cross entropy loss, is the linear classifier, and are the prediction output and ground-truth label respectively. The final learning objective of the network is minimizing the sum of individual losses:
| (5) |
where each loss has equal weight. This kind of losses (auxiliary losses) are commonly used in multi-task learning schemes and we use it for multimodal learning as in [49].
4 Experiments
4.1 Datasets
We train and validate our method on five video dataset below: VGGSound [10] is a recently released audio-visual dataset, Kinetics-400 [22] is a standard benchmark dataset for action recognition, Kinetics-Sound [3] is a subset of Kinetics for audio-visual learning, AVE [44] is audio-visual dataset formed for audio-visual event localization and LLP [43] is a multi-label dataset for audio-visual video parsing. See Supp. for details of these datasets.
4.2 Implementation Details
For all experiments, we sample audio data with 16kHz sampling rate and input audio is 10 seconds. Following previous works [1, 52], we compute log-mel spectrogram with size of . We use MC3-18 [45] as the video network and it takes 100 frames of size as input. Thus, time steps in Section 3.1. is set to 10 for instant event layer computation. The network is trained using SGD optimizer with starting learning rate and reduced by a factor of 10 if validation accuracy does not increase for 3 epochs. See Supp. for network architectures and audio pre-processing details.
| Dataset | Uni-Audio | Uni-Vision | Naive AV | Ours |
| VGGSound | 47.0 | 40.9 | 57.1 | 59.1 |
| Kinetics-Sound | 64.2 | 80.5 | 86.1 | 88.3 |
| AVE | 79.1 | 76.1 | 86.0 | 87.8 |
| LLP | 48.3 | 43.8 | 55.1 | 56.6 |
| Kinetics | 21.4 | 61.0 | 66.6 | 67.0 |
We apply the same training steps for each dataset as follows. First, we train audio backbone network from scratch with given target dataset. Then, the video backbone network is initialized by using MC3-18 trained on Kinetics-400 and fine-tuned on the target dataset. Last, we train our multi-task model with event-specific layers end-to-end by using these pre-trained backbone networks as initialization. We repeat the above step for all five datasets. Different from the others, LLP is a multi-label dataset. Since our training recipe is designed with single label, we randomly pick a label among the annotated multi-labels per sample.
4.3 Quantitative Results
Video-Level Classification
Video classification is a task to classify a video by a single label. Since our model outputs multiple predictions from event-specific layers, we integrate them by majority voting to output a single prediction for a video-level classification task as follows:
| (6) |
where is an indication function, is a predicted label defined as , and is an index of the vector . In case of disagreement between the layers, that no majority consensus is obtained, the label from the most confident layer is selected.
We conduct a series of experiments to show how well our model predicts video-level labels. We compare the performance of our model with baselines on different datasets (Table 1). Note that our goal here is not to compete on classification accuracy with any other expensive video recognition models, but rather to show that our model analyzes a video from different modalities and different video characteristics which leads to improvement in classification.
Accuracies on uni-modal networks in Table 1 depicts the accuracy of the backbone networks trained with single stream modalities. Naïve audio-visual model represents audio-visual networks that leverage late fusion approach (simple concat.) for final representation as used in previous works [49, 26, 29]. As results show in Table 1, our approach offers improvement to overall performance in benchmark datasets. Our model is more effective on the datasets that are designed with audio-visual correspondence, e.g. VGGSound, Kinetics-Sound, and AVE, with the improvement around . Our performance improvement is less significant on Kinetics since it is a visual-dominant dataset, where many videos’ sound are not correlated to visual signals.
| Dataset | Ours | Naive AV | ||||
| Top-1 | Top-2 | Top-3 | Top-4 | Top-5 | ||
| LLP | 0.72 | 0.66 | 0.70 | 0.63 | 0.56 | 0.50 |
Multi-Label Prediction
Our network contains multiple event-specific layers and each layer outputs a label prediction. The collection of each layer’s prediction form a multi-label prediction set. Let be a predicted label from the event-specific layer. Then a set of label predictions can be defined as follows:
| (7) |
The function accepts a predicted label if and only if when the value is higher than the other layer values . This process filters out label predictions with low confidence and only highly confident predictions are gathered in a multi-label prediction set. In our implementation, we utilize five types of layers, therefore, the cardinality of the prediction set is bounded by . When our network is evaluated on the VGGSound dataset, the cardinality of , i.e. the average number of predicted labels is .
This analysis leads to the question of “Are the multi-label predictions of our network are correct? or Does the VGGSound dataset contain multiple events but only annotated with a single label?”. To answer these questions, we need a multi-label evaluation. However, there is no multi-label ground truth for VGGSound dataset. Therefore, we make subjects annotate the multiple video-level predictions of our network that match with the given video for 1200 videos. Note that candidate labels for annotation are limited to the labels predicted by our model. We check how many of the total predictions from our network actually do match with human answers. The user study shows that of all predicted labels match with human selections, which means our network on average outputs correct labels per sample. This study shows that VGGSound is indeed a multi-label dataset and single label prediction is insufficient to properly describe the videos.
To further evaluate the correctness of the multi-labels predicted by our network, we also conduct another experiment by using LLP as it contains multi-labels per video, i.e. the average number of labels is . In this experiment, even though our network is trained with randomly selected single labels, it still has the ability to predict correct multi-labels for a given video. This is due to multiple layers that can output multiple contents by looking for different properties in the video. We compare our results with top-N results of Naive-AV model. The F1 metric is used to evaluate the performance of our model and Table 2 shows the results. Our model outputs multi-label predictions dynamically depending on whether the event-specific layers make consensus or not, while the top-N approach fixes the number of predictions. Although, the Top-2 performance is comparable to ours, without knowing the number of ground truth multi-labels in advance, we can not know the number of Top-N that should be selected. For example, the video shown in row of Figure 5 contains people playing more than two instruments. In this case, Top-2 only outputs two predictions while our model outputs more than two predictions. In the other case, when there is only one dominant event, our model outputs only one prediction while the Top-2 baseline still outputs two predictions.
| Dataset | Continuous | Instant | Onset | Visual | Audio | Total |
| VGGSound | 62 | 39 | 68 | 41 | 99 | 309 |
| Kinetics-Sound | 2 | 5 | 13 | 11 | 0 | 31 |
| AVE | 10 | 4 | 9 | 1 | 4 | 28 |
| LLP | 4 | 5 | 6 | 3 | 7 | 25 |
| Kinetics | 73 | 89 | 69 | 167 | 2 | 400 |
Dataset Modality Bias
We apply our method on understanding the modality biases of the datasets [50]. Each dataset has different modality properties such as large portion of the videos may contain specific modality dominantly, i.e., Kinetics is visually heavy dataset. We pose the problem as finding the most dominant modality in a given dataset by analyzing every video. Our network outputs five different logits corresponding to the each event-specific layer. We use true class label to get confidence scores of the test video. Since this is ground truth class, the layer that is highly activated (highest confidence score for given ) reveals the interpretable modality information.
With this technique, we find the modality biases of the datasets as well as each category in the dataset. We apply majority voting rule within each category among all the videos and assign the modality label to the categories. See Supp. for the category-wise modality assignment. Table 3 shows the number of categories that are assigned to each layer for every dataset. Our analysis shows consistent results with the prior knowledge about these benchmark datasets. Results on Kinetics clearly shows that it is visual dominant dataset. AVE dataset is curated for audio-visual learning and our method validates this as one of the AV layers is dominant. LLP [43] reports that majority of the annotated events are audio events. Our analysis also confirms that LLP has tendency to the audio modality.
Additionally, we perform an experiment to see how many categories of Kinetics-Sound (created by selecting categories manually from Kinetics in [3]) matches with the categories that our audio-visual event-specific layers filter in Kinetics. This reveals that of the Kinetics-Sound categories are matched. Thus, our modality bias selection gives consistent results with human selections. Please see Supp. for details.
| Dataset | Continuous | Instant | Onset | (Ins.Ons.) (Cont.) |
| VGGSound | 354 | 407 | 230 | 778 |
| Kinetics-Sound | 18 | 18 | 9 | 34 |
| AVE | 7 | 4 | 3 | 12 |
| LLP | 25 | 47 | 22 | 74 |
| Kinetics | 366 | 567 | 258 | 985 |
Layer Differences
At first glance, the differences between each audio-visual event layer may not look significant. However, they indeed look for different audio-visual characteristics in the videos. We count the number of unique videos that one of these layers classifies correctly while the rest two layers fail, and also the samples that continuous layer fails but instant or onset layer predict correctly in Table 4. The number of uniquely correct samples for each layer is comparable to each other and the last column shows that the instant and onset layers capture significant amount of correct samples compared to the continuous layer. This shows that the proposed multisensory layers are complementary. As a consequence, the model enables a more in-depth interpretation of videos.
Continuous event layer pools information from every time step features of both modality without consideration of their correspondence. Therefore, number of the informative features may be less than uninformative ones for some videos, as in “car” example of Figure 3. Thus, using informative subset of these every time step features, i.e., instant or onset, may improve the accuracy for these videos since it will be less contaminated. Furthermore, the difference between instant and onset event layer can be also seen in the “car” example of Figure 3. Onset event layer uses the onset moments, i.e. pink dots, that are grouped in the part before the real action starts whereas instant event layer captures the instant, highly audio-visual correlated moments of the video, i.e. blue dotted box.
4.4 Qualitative Results
Audio-Visual Attention. As aforementioned in Section 3.2, instant event layer is leveraged to use highly correlated audio-visual moments. Thus, to gain a better understanding of these moments, we visualize the localization response where , is the visual activation from the last convolution layer of video backbone network and is the audio embedding at moment [39, 1].
We qualitatively show in Figure 4 that features from our backbone networks can locate the sound source without any separate training mechanism for this task. The localization response only activates when the girl plays flute, otherwise inactivated. This confirms that our model not only attends where the source appear in the video spatially but also attends when the event sound occurs time-wise.
We perform an additional experiment to show the potential of our model quantitatively. We use a recently released VGG-SS dataset[9] which is curated from VGGSound that contains around 5K samples. Following the same setup as [9], we compute the 3 sec. time average of localization responses around mid-frame. As shown in Table 5, even though our method is not trained with the sound localization objective, it still achieves competitive results to explicitly trained state-of-the-art sound localization method [9].

| Method | IoU | AUC |
| Attention. [38] | 0.185 | 0.302 |
| AVEL [44] | 0.291 | 0.348 |
| AVobject [1] | 0.297 | 0.357 |
| LVS [9] | 0.303 | 0.364 |
| Ours | 0.309 | 0.354 |
Multi-Labeling Videos.
We qualitatively show the multi-labeling ability of our network even though the network is trained on single labels. Figure 5 shows predicted multi-labels are consistent with the human perception.
 |
 |
 |
 |

Layer Visualizations.
In order to have a better insight on what each event-specific layer learned, we visualize some of the videos that are maximally activated by a certain layer. Figure 6 displays some videos for each audio-visual layer. As it can be seen, instant event layer has short period high intensity-like patterns; onset event layer captures rhythmic-like patterns; and continuous event layer shows temporally constant-like events. Note that these patterns show similarities to abstract event visualizations in Figure 1. We also visualize that representations from these assigned layers may be more proper for given videos as only that certain layer makes correct prediction.
5 Concluding Remarks
We present a multisensory model with event-specific layers that incorporates different audio-visual relationships and demonstrate the efficacy of our model on five different video datasets with a diverse set of videos. Unlike previous audio-visual models, our event-specific layers output multiple predictions with modality confidences. This leads to new future research directions for audio-visual understanding. We propose interesting potential applications that can be built based on our model and discuss the limitations of our work.
Limitations.
Our system can predict a multiple labels with confidence. Yet this raw predictions is not normalized. In other words, a prediction with highest confidence is not necessarily more dominant or accurate than the other predictions. A proper calibration of the confidences will enable our model to select a most prominent event in a video. Another limitation is false positives in multi-label predictions. Although majority of our model’s multi-label prediction aligns with human perception as in Table 2 and Figure 5, there is still gap in the quantitative results. One possible future direction is to design a prediction fusion mechanism to keep semantically meaningful predictions while removing false predictions.
Modality-level Video Understanding.
Even for a single video clip, at different timestamps, different modality might play the key role in video understanding. For example, a part of the video may not be informative due to motion blur or occlusion and the audio modality may be more indicative of what is happening. Similarly, video can be more indicative modality when the microphone is accidentally blocked. Our method can tell which modality to rely to understand ongoing events in a video using a confidence from each layer. This kind of modality-level video understanding, as oppose to category-level, is crucial and complementary to existing methods. One can use our network to decide which modality is playing the key role and apply the right specialized inference network to get the actual predictions.
Missing Label Detection.
Given single label datasets as input, we demonstrate that our system can discover accurate multiple labels automatically (See Figure 5). In the manual annotation process, it is common to only label the most salient objects or events. The future of datasets should have more detailed labels, beyond the sole event in the scene. For example, in Figure 5 “alligators” video, only the label “alligators” is annotated. However, clearly there are other audio-visual contents such as lions growling, lions roaring, and water splashing sound by the alligator present in the video that are not properly annotated. Our system can automatically discover these potential labels in the same video and therefore build up more comprehensive dataset.
Dataset Retargeting / Cleanup.
Our work could be used to pre-screen any video dataset to curate specific modalities that are of interests to training. Datasets, especially those constructed from user-uploaded YouTube videos, are highly biased towards certain modalities (see Table 3). If one tries to use Kinetics dataset for an audio-oriented training, the outcome would be bad since only 2 out of 400 categories are audio-focused, according to our analysis. Our proposed method can identify the modality distribution of dataset and only select those videos that match the requirements of the target application. For example, sound localization requires strong correspondences between audio and visual domain, video classification may be sufficient with strong visual information like Kinetics. More specifically, we can select only the audiovisual videos from Kinetics and construct a Kinetics-AV which would have a high efficacy in audiovisual learning tasks. Combining with the label prediction from those modalities, we foresee a significantly easier process to create application-specific datasets in the future.
References
- [1] Afouras, T., Owens, A., Chung, J.S., Zisserman, A.: Self-supervised learning of audio-visual objects from video. In: European Conference on Computer Vision (2020)
- [2] Alwassel, H., Mahajan, D., Korbar, B., Torresani, L., Ghanem, B., Tran, D.: Self-supervised learning by cross-modal audio-video clustering. In: Advances in Neural Information Processing Systems (2020)
- [3] Arandjelović, R., Zisserman, A.: Look, listen and learn. In: IEEE International Conference on Computer Vision (2017)
- [4] Arandjelović, R., Zisserman, A.: Objects that sound. In: IEEE International Conference on Computer Vision (2017)
- [5] Asano, Y.M., Mandela, P., Rupprecht, C., Vedaldi, A.: Labelling unlabelled videos from scratch with multi-modal self-supervision. In: Advances in Neural Information Processing Systems (2020)
- [6] Aytar, Y., Vondrick, C., Torralba, A.: Soundnet: Learning sound representations from unlabeled video. In: Advances in Neural Information Processing Systems (2016)
- [7] Aytar, Y., Vondrick, C., Torralba, A.: See, hear, and read: Deep aligned representations. arXiv preprint arXiv:1706.00932 (2017)
- [8] Bremner, A., Lewkowicz, D., Spence, C.: Multisensory Development. Oxford University Press (2012)
- [9] Chen, H., Xie, W., Afouras, T., Nagrani, A., Vedaldi, A., Zisserman, A.: Localizing visual sounds the hard way. In: IEEE Conference on Computer Vision and Pattern Recognition (2021)
- [10] Chen, H., Xie, W., Vedaldi, A., Zisserman, A.: Vggsound: A large-scale audio-visual dataset. In: IEEE International Conference on Acoustics, Speech, and Signal Processing (2020)
- [11] Davis, A., Agrawala, M.: Visual rhythm and beat. In: ACM Transactions on Graphics (Proceedings of SIGGRAPH) (2018)
- [12] Ephrat, A., Mosseri, I., Lang, O., Dekel, T., Wilson, K., Hassidim, A., Freeman, W.T., Rubinstein, M.: Looking to listen at the cocktail party: A speaker-independent audio-visual model for speech separation. ACM Transactions on Graphics (Proceedings of SIGGRAPH) (2018)
- [13] Gan, C., Huang, D., Zhao, H., Tenenbaum, J.B., Torralba, A.: Music gesture for visual sound separation. In: IEEE Conference on Computer Vision and Pattern Recognition (2020)
- [14] Gao, R., Feris, R., Grauman, K.: Learning to separate object sounds by watching unlabeled video. European Conference on Computer Vision (2018)
- [15] Gao, R., Grauman, K.: 2.5d visual sound. In: IEEE Conference on Computer Vision and Pattern Recognition (2019)
- [16] Gao, R., Grauman, K.: Co-separating sounds of visual objects. In: IEEE International Conference on Computer Vision (2019)
- [17] Gao, R., Grauman, K.: Visualvoice: Audio-visual speech separation with cross-modal consistency. In: IEEE Conference on Computer Vision and Pattern Recognition (2021)
- [18] Gao, R., Oh, T.H., Grauman, K., Torresani, L.: Listen to look: Action recognition by previewing audio. In: IEEE Conference on Computer Vision and Pattern Recognition (2020)
- [19] Halperin, T., Ephrat, A., Peleg, S.: Dynamic temporal alignment of speech to lips. In: IEEE International Conference on Acoustics, Speech, and Signal Processing (2019)
- [20] Hu, D., Nie, F., Li, X.: Deep multimodal clustering for unsupervised audiovisual learning. In: IEEE Conference on Computer Vision and Pattern Recognition (2019)
- [21] Hu, D., Qian, R., Jiang, M., Tan, X., Wen, S., Ding, E., Lin, W., Dou, D.: Discriminative sounding objects localization via self-supervised audiovisual matching. In: Advances in Neural Information Processing Systems (2020)
- [22] Kay, W., Carreira, J., Simonyan, K., Zhang, B., Hillier, C., Vijayanarasimhan, S., Viola, F., Green, T., Back, T., Natsev, P., Suleyman, M., Zisserman, A.: The kinetics human action video dataset. arXiv preprint arXiv:1705.06950 (2017)
- [23] Kayser, C., Shams, L.: Multisensory causal inference in the brain. PLoS Biol 13(2), e1002075 (2015)
- [24] Kazakos, E., Nagrani, A., Zisserman, A., Damen, D.: Epic-fusion: Audio-visual temporal binding for egocentric action recognition. In: IEEE International Conference on Computer Vision (2019)
- [25] Kong, Q., Xu, Y., Sobieraj, I., Wang, W., Plumbley, M.D.: Sound event detection and time-frequency segmentation from weakly labelled data. arXiv preprint arXiv:1804.04715 (2018)
- [26] Korbar, B., Tran, D., Torressani, L.: Cooperative learning of audio and video models from self-supervised synchronization. In: Advances in Neural Information Processing Systems (2018)
- [27] Korbar, B., Tran, D., Torressani, L.: Scsampler: Sampling salient clips from video for efficient action recognition. In: IEEE International Conference on Computer Vision (2019)
- [28] Lin, Y.B., Li, Y.J., Wang, Y.C.F.: Dual-modality seq2seq network for audio-visual event localization. In: IEEE International Conference on Acoustics, Speech, and Signal Processing (2019)
- [29] Long, X., Gan, C., De Melo, G., Wu, J., Liu, X., Wen, S.: Attention clusters: Purely attention based local feature integration for video classification. In: IEEE Conference on Computer Vision and Pattern Recognition (2018)
- [30] McFee, B., Raffel, C., Liang, D., Ellis, D.P., McVicar, M., Battenberg, E., Nieto, O.: librosa: Audio and music signal analysis in python. In: Proceedings of the 14th python in science conference. vol. 8 (2015)
- [31] Morgado, P., Vasconcelos, N., Langlois, T., Wang, O.: Self-supervised generation of spatial audio for video. In: Advances in Neural Information Processing Systems (2018)
- [32] Nahorna, O., Berthommier, F., Schwartz, J.L.: Binding and unbinding the auditory and visual streams in the mcgurk effect. The Journal of the Acoustical Society of America 132, 1061–1077 (2012)
- [33] Nahorna, O., Berthommier, F., Schwartz, J.L.: Audio-visual speech scene analysis: characterization of the dynamics of unbinding and rebinding the mcgurk effect. The Journal of the Acoustical Society of America 137, 362–277 (2015)
- [34] Owens, A., Efros, A.A.: Audio-visual scene analysis with self-supervised multisensory features. In: European Conference on Computer Vision (2018)
- [35] Owens, A., Isola, P., McDermott, J., Torralba, A., Adelson, E.H., Freeman, W.T.: Visually indicated sounds. In: IEEE Conference on Computer Vision and Pattern Recognition (2016)
- [36] Owens, A., Wu, J., McDermott, J., Freeman, W.T., Torralba, A.: Ambient sound provides supervision for visual learning. In: European Conference on Computer Vision (2016)
- [37] Pankajakshan, A., Bear, H.L., Benetos, E.: Onsets, activity, and events: A multi-task approach for polyphonic sound event modelling. Proc. of the Detection and Classification of Acoustic Scenes and Events 2019 Workshop (DCASE ’19), New York, NY, USA (2019)
- [38] Senocak, A., Oh, T.H., Kim, J., Yang, M.H., Kweon, I.S.: Learning to localize sound source in visual scenes. In: IEEE Conference on Computer Vision and Pattern Recognition (2018)
- [39] Senocak, A., Oh, T.H., Kim, J., Yang, M.H., Kweon, I.S.: Learning to localize sound source in visual scenes: Analysis and applications. In: IEEE Transactions on Pattern Analysis and Machine Intelligence (2019 To appear)
- [40] Spence, C.: Audiovisual multisensory integration. Acoustical Science and Technology 28(2), 61–70 (2007)
- [41] Spence, C.: Crossmodal correspondences: A tutorial review. Attention, Perception and Psychophysics 73, 971–95 (05 2011)
- [42] Su, Y.H.: Content congruency and its interplay with temporal synchrony modulate integration between rhythmic audiovisual streams. Frontiers in Integrative Neuroscience 8 (2014)
- [43] Tian, Y., Li, D., Xu, C.: Unified multisensory perception: Weakly-supervised audio-visual video parsing. In: European Conference on Computer Vision (2020)
- [44] Tian, Y., Shi, J., Li, B., Duan, Z., Xu, C.: Audio-visual event localization in unconstrained videos. In: European Conference on Computer Vision (2018)
- [45] Tran, D., Wang, H., Torresani, L., Ray, J., LeCun, Y., Paluri, M.: A closer look at spatiotemporal convolutions for action recognition. In: IEEE Conference on Computer Vision and Pattern Recognition (2018)
- [46] Tsiami, A., Koutras, P., Maragos, P.: Stavis: Spatio-temporal audiovisual saliency network. In: IEEE Conference on Computer Vision and Pattern Recognition (2020)
- [47] Tzinis, E., Wisdom, S., Jansen, A., Hershey, S., Remez, T., Ellis, D.P.W., Hershey, J.R.: Into the wild with audioscope: Unsupervised audio-visual separation of on-screen sounds. In: International Conference on Learning Representations (2021)
- [48] Wang, J., Fang, Z., Zhao, H.: Alignnet: A unifying approach to audio-visual alignment. In: IEEE Winter Conference on Applications of Computer Vision (2020)
- [49] Wang, W., Tran, D., Feiszli, M.: What makes training multi-modal classification networks hard? In: IEEE Conference on Computer Vision and Pattern Recognition (2020)
- [50] Winterbottom, T., Xiao, S., McLean, A., Al Moubayed, N.: On modality bias in the tvqa dataset. In: British Machine Vision Conference (2020)
- [51] Wu, Y., Zhu, L., Yan, Y., Yang, Y.: Dual attention matching for audio-visual event localization. In: IEEE International Conference on Computer Vision (2019)
- [52] Xiao, F., Lee, Y.J., Grauman, K., Malik, J., Feichtenhofer, C.: Audiovisual slowfast networks for video recognition. arXiv preprint arXiv:2001.08740 (2020)
- [53] Xu, X., Dai, B., Dahua, L.: Recursive visual sound separation using minus-plus net. In: IEEE International Conference on Computer Vision (2019)
- [54] Yang, K., Russell, B., Salamon, J.: Telling left from right: Learning spatial correspondence of sight and sound. In: IEEE Conference on Computer Vision and Pattern Recognition (2020)
- [55] Zhang, Y., Shao, L., Snoek, C.G.M.: Repetitive activity counting by sight and sound. In: IEEE Conference on Computer Vision and Pattern Recognition (2021)
- [56] Zhao, H., Gan, C., Ma, W.C., Torralba, A.: The sound of motions. In: IEEE International Conference on Computer Vision (2019)
- [57] Zhao, H., Gan, C., Rouditchenko, A., Vondrick, C., McDermott, J., Torralba, A.: The sound of pixels. In: European Conference on Computer Vision (2018)
- [58] Zhou, H., Liu, Z., Xu, X., Luo, P., Wang, X.: Vision-infused deep audio inpainting. In: IEEE International Conference on Computer Vision (2019)
- [59] Zhou, H., Xu, X., Dahua, L., Wang, X., Liu, Z.: Sep-stereo: Visually guided stereophonic audio generation by associating source separation. In: European Conference on Computer Vision (2020)
- [60] Zhou, Y., Wang, Z., Fang, C., Bui, T., Berg, T.L.: Visual to sound: Generating natural sound for videos in the wild. In: IEEE Conference on Computer Vision and Pattern Recognition (2018)
Appendix
Supplementary Material
In this supplementary material, we present additional details pertaining to the experiments that are not included in the main text due to space constraints. All figures and references in this supplementary material are self-contained.
The contents included in this supplementary material are as follows: 1) Details of the backbone network architectures, audio pre-processing, and datasets, 2) Layer analysis with VGGSound categories, 3) Additional sound localization results, 4) Potential applications.
1 Architecture Details of Backbone Networks
In Table 6(b), we provide the architecture of the backbone networks. We use two-stream network architecture, video network and audio network, as in existing audio-visual learning works. The video network is a spatio-temporal ResNet mixed convolution network, similar to MC [45], borrowed from official PyTorch implementation222https://pytorch.org/vision/0.8/models.html#torchvision.models.video.mc3_18 (mc3_18). Audio network is a custom network built with 2D convolution layers. Batch Normalization and ReLU activation function are used after every convolution layer.
| Layer | # filters | K | S | P | Output |
| input | 1 | - | - | - | |
| conv1 | 64 | (1,3,3) | (1,2,1) | (0,1,1) | |
| conv2 | 64 | (1,3,3) | (1,1,2) | (0,1,1) | |
| maxpool2 | - | (1,1,3) | (1,1,2) | (0,0,0) | |
| conv3 | 192 | (1,3,3) | (1,1,1) | (0,1,1) | |
| maxpool3 | - | (1,3,3) | (1,2,2) | (0,0,0) | |
| conv4 | 256 | (1,3,3) | (1,1,1) | (0,1,1) | |
| conv5 | 256 | (1,3,3) | (1,1,1) | (0,1,1) | |
| conv6 | 256 | (1,3,3) | (1,1,1) | (0,1,1) | |
| maxpool6 | - | (1,3,2) | (1,2,2) | (0,0,0) | |
| conv7 | 512 | (1,4,4) | (1,1,1) | (0,1,0) | |
| fc8 | 512 | (1,1,1) | (1,1,1) | (0,0,0) | |
| fc9 | 512 | (1,1,1) | (1,1,1) | (0,0,0) |
| Layer | # filters | K | S | P | Output |
| input | 3 | - | - | - | |
| conv1 | 64 | (3,7,7) | (1,2,2) | (1,3,3) | |
| conv2 | 64 | (3,3,3) | (1,1,1) | (1,1,1) | |
| conv3 | 64 | (3,3,3) | (1,1,1) | (1,1,1) | |
| conv4 | 64 | (3,3,3) | (1,1,1) | (1,1,1) | |
| conv5 | 64 | (3,3,3) | (1,1,1) | (1,1,1) | |
| conv6 | 128 | (1,3,3) | (1,2,2) | (0,1,1) | |
| conv7 | 128 | (1,3,3) | (1,1,1) | (0,1,1) | |
| res-conv8 | 128 | (1,1,1) | (1,2,2) | (0,0,0) | |
| conv9 | 128 | (1,3,3) | (1,1,1) | (0,1,1) | |
| conv10 | 128 | (1,3,3) | (1,1,1) | (0,1,1) | |
| conv11 | 256 | (1,3,3) | (1,2,2) | (0,1,1) | |
| conv12 | 256 | (1,3,3) | (1,1,1) | (0,1,1) | |
| res-conv13 | 256 | (1,1,1) | (1,2,2) | (0,0,0) | |
| conv14 | 256 | (1,3,3) | (1,1,1) | (0,1,1) | |
| conv15 | 256 | (1,3,3) | (1,1,1) | (0,1,1) | |
| conv16 | 512 | (1,3,3) | (1,2,2) | (0,1,1) | |
| conv17 | 512 | (1,3,3) | (1,1,1) | (0,1,1) | |
| res-conv18 | 512 | (1,1,1) | (1,2,2) | (0,0,0) | |
| conv19 | 512 | (1,3,3) | (1,1,1) | (0,1,1) | |
| conv20 | 512 | (1,3,3) | (1,1,1) | (0,1,1) | |
| avgpool | - | (1,7,7) | - | (0,0,0) |
| Dataset | Train | Test | Val. | Total |
| VGGSound | 170384 | 0 | 13675 | 184059 |
| Kinetics | 208552 | 33595 | 17019 | 259166 |
| Kinetics-Sound | 19931 | 2677 | 1351 | 23959 |
| AVE | 3697 | 402 | 0 | 4099 |
| LLP | 9620 | 1162 | 624 | 11406 |
2 Audio Pre-processing Details
We sample audio data with 16kHz sampling rate and input audio is 10 seconds. STFT is computed using , , , , and and log-mel spectrogram is produced with 80 mel filterbanks by using PyTorch. Audio onsets are computed using librosa [30] onset detection function with a pre-computed onset envelopes.
3 Datasets
We train and validate our method on five video datasets using standard evaluation metrics. VGGSound [10] is a recently released audio-visual dataset which contains around 200K videos obtained from YouTube and labelled with 309 categories. Kinetics-400 [22] is a large-scale standard benchmark dataset for action recognition with 240K training and 20K validation videos containing 400 human action classes. Kinetics-Sound [3] is created by choosing 34 classes from Kinetics dataset that are assumed to have audio and visual characteristics and it has total 22k videos. AVE [44] is another audio-visual dataset formed for audio-visual event localization and it contains around 4K videos covering 28 event categories. LLP [43] is a multi-label dataset consisting of 12k videos labeled by 25 categories and formed for audio-visual video parsing.
However, some of the videos are removed or not accessible from the web because of privacy or regional settings. Hence, our datasets may be slightly smaller than official numbers for some datasets (See Table 7). Additionally, the original 34 classes in Kinetics-Sound are based on the earlier version of the Kinetics. Some classes are removed currently. Therefore, we use available 31 classes.
4 Category-wise Layer Analysis
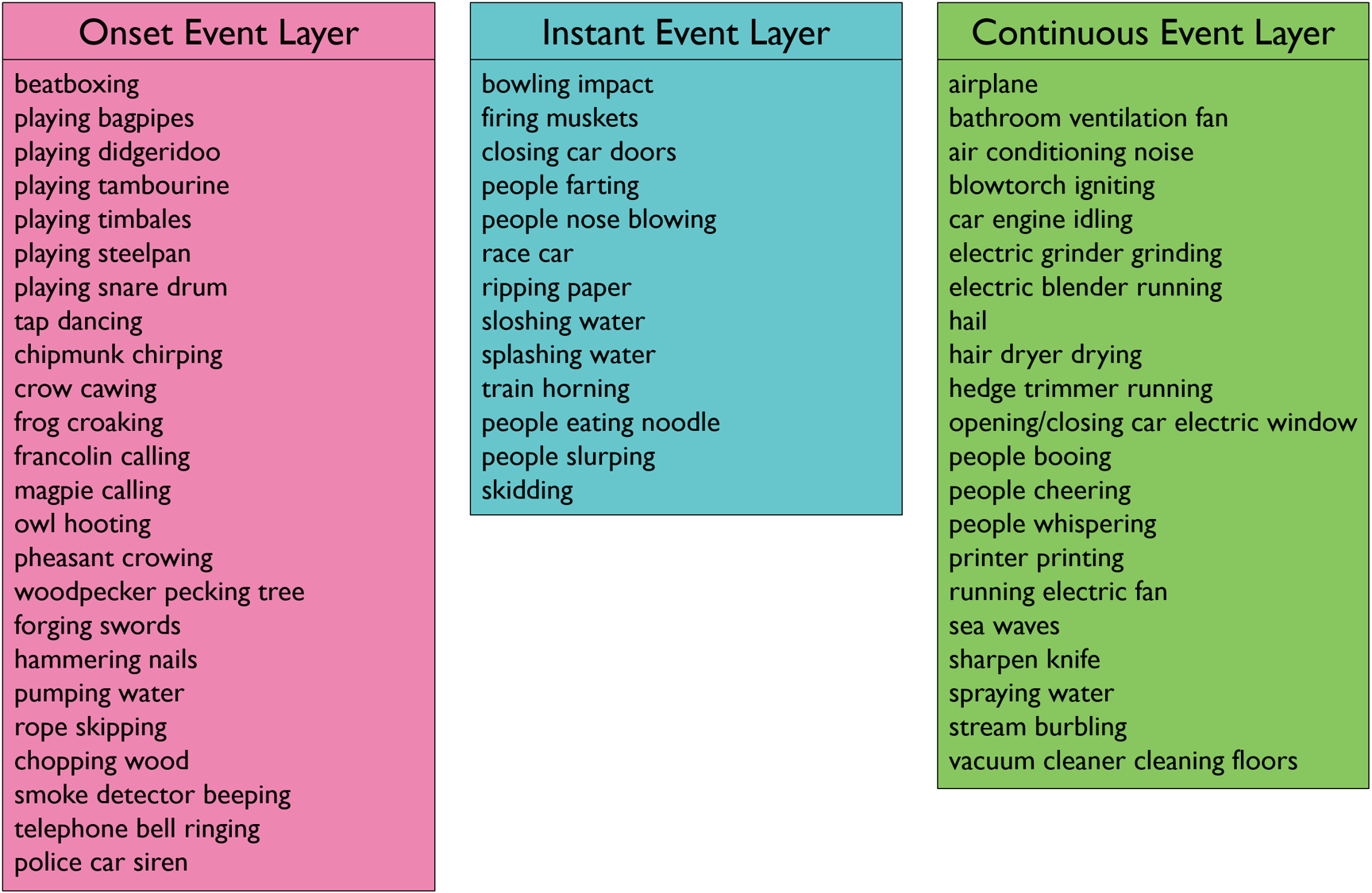
In Figure 7, we list the VGGSound categories that are assigned to each Audio-Visual event-specific layer of our network. To obtain these results, we apply majority voting rule among all the videos within each category and assign the layer label to the categories as we explain in “Dataset Modality Bias” subsection of the main paper. We show some of these categories (due to the limited space) for each audio-visual event layers in Figure 7.
The onset event layer predicts categories that are related to music, animal and repetitive actions or sounds as shown in Figure 7. As aforementioned in the main paper, musical instruments such as “playing tambourine”, “playing steelpan”, “beatboxing” or animal vocalization sounds – “frog croaking”, “francolin calling”, “chipmunk chirping” – and some actions such as “hammering nails”, “forging swords”, “smoke detector beeping” all tend to have rhythmic and repetitive characteristics. This aligns with our design motivation that onset event layer learns rhythmic, repetitive and periodic events as listed categories contain these characteristics.
The instant event layer focuses on the categories that contain impact events like “bowling impact”, “closing car doors” or sudden events like “people nose blowing”, “train horning” or explosion-kind of events such as “firing muskets”, “splashing water” and “people farting”. This also matches with our intuition that instant event layer predicts sudden, sparse highly audio-visual correlated instant events.
Finally, the categories that are highlighted by the continuous event layer have temporally constant-like characteristics such as “bathroom ventilation fan”, “blowtorch igniting”, “hair dryer drying” or slowly evolving sounds like “airplane” or “sea waves”. The results also show that our intuition on the continuous event layer matches with these categories.
 |
 |
 |
 |
5 Qualitative Results of Sound Localization
Figure 8 shows additional qualitative results of the sound localization attempt, spatially and time-wise, by using the features from our backbone networks throughout videos.
We also visualize the attention maps of VGG-SS test samples in Figure 9 and compare them with the state- of-the-art [9] method on this dataset. This figure shows how two different approaches response to the same samples.
 |
 |
 |
 |
 |
6 Potential Applications
In “Concluding Remarks” section of the main paper, we have discussed potential applications that can be built based on our model. In this supplementary material, we present some examples for these applications.
6.1 Dataset Retargeting / Cleanup
As an example to dataset retargeting application, we use our proposed method to identify the modality distribution of Kinetics dataset and only select the categories that fall under the audio-visual event layers. Kinetics-Sound dataset is constructed to have a high efficacy in audio-visual learning tasks. Based on the subset we construct, we perform an experiment to see how many categories of Kinetics-Sound matches with the categories that our audio-visual event layers filter. This experiment reveals that of the Kinetics-Sound categories are matched. Kinetics-Sound categories that intersect with the categories that our audio-visual event layers filtered from Kinetics are listed in Figure 10.

6.2 Modality-level Video Understanding
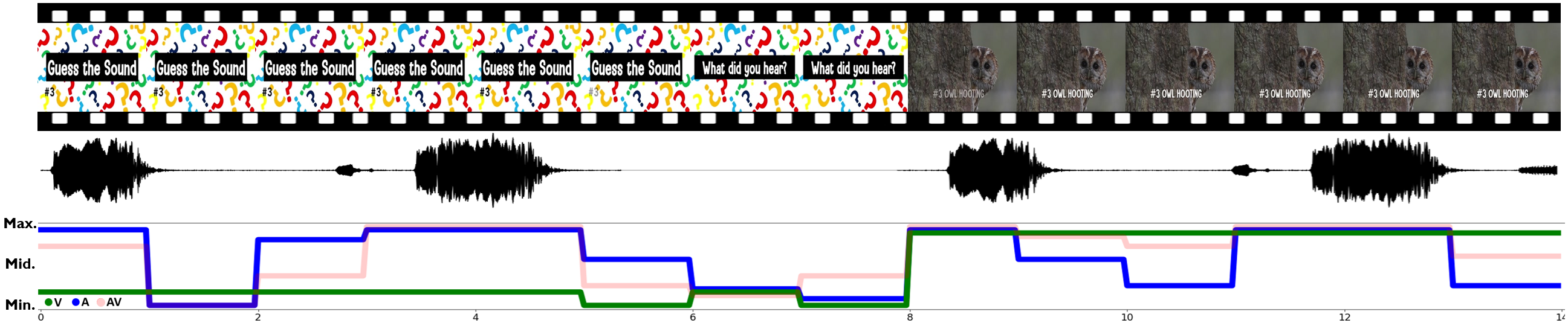
We present an example of modality-level video understanding in Figure 11. As shown in the figure, the modality confidence of each layer is highly activated only when there is meaningful signal. The audio modality confidence level aligns with the audio signal presence. Similarly, vision modality confidence is activated when the meaningful frames, i.e., frames with owl, appear. The audio-visual modality, which is per second continuous layer in this example, is activated when either modality is confident.
6.3 Missing Label Detection
Often, a video contains multiple objects and events with complex interactions. It is difficult to fully represent contents of a video with a single label. Moreover, humans make mistakes during annotations by missing annotation. Our model outputs multiple labels using event-specific layers which capture different characteristics of a video. We provide multi-label prediction examples using videos from VGGSound in Figure 12. The examples show that our model can capture diverse contents of a video that are not annotated.
 |
 |
 |
 |