Attribution Mask: Filtering Out Irrelevant Features By Recursively Focusing Attention on Inputs of DNNs
Abstract
Attribution methods calculate attributions that visually explain the predictions of deep neural networks (DNNs) by highlighting important parts of the input features.
In particular, gradient-based attribution (GBA) methods are widely used because they can be easily implemented through automatic differentiation.
In this study, we use the attributions that filter out irrelevant parts of the input features and then verify the effectiveness of this approach by measuring the classification accuracy of a pre-trained DNN.
This is achieved by calculating and applying an attribution mask to the input features and subsequently introducing the masked features to the DNN, for which the mask is designed to recursively focus attention on the parts of the input related to the target label.
The accuracy is enhanced under a certain condition, i.e., no implicit bias, which can be derived based on our theoretical insight into compressing the DNN into a single-layer neural network.
We also provide Gradient * Sign-of-Input (GxSI) to obtain the attribution mask that further improves the accuracy.
As an example, on CIFAR-10 that is modified using the attribution mask obtained from GxSI, we achieve the accuracy ranging from 99.8% to 99.9% without additional training.
222All code will be available here:
http://github.com/j-pong/AttentionMask
1 Introduction and Related Works
A deep neural network (DNN) is a powerful function that can express various types of functions given only input features and target labels without a specific model design. However, explaining the prediction of a DNN is difficult owing to its complex structure. Existing studies (Ribeiro et al., 2016; Lundberg & Lee, 2017; Kindermans et al., 2017; Sundararajan et al., 2017; Shrikumar et al., 2017) have approached this problem using an attribution method that visually explains the prediction of DNNs by highlighting important parts of the input features. In particular, gradient-based attribution (GBA) methods are widely used because they can be easily implemented through automatic differentiation.
Initially, (Simonyan et al., 2014) proposed calculating gradients with respect to the input features of a DNN to obtain a saliency map that highlights important parts of an image. Subsequently, Guided Backpropagation (Springenberg et al., 2014) obtained attributions that look similar to the target object by forcing the negative components of the gradient obtained from the DNN to zeros. Meanwhile, Gradient * Input method obtained attributions through an element-wise product between the gradients and the input features (Ancona et al., 2017; Kindermans et al., 2017). In a similar context, Integrated Gradients (Sundararajan et al., 2017) integrate the gradients obtained by gradually changing the input features to the baselines, for which the integrated gradients are multiplied to the difference between the input features and the baselines to calculate the attributions. In particular, this method satisfies two axioms: sensitivity and implementation invariance. However, it has a drawback of requiring numerous computations. From a different perspective, Learning Important Features Through Propagating Activation Differences (Shrikumar et al., 2017) introduced DeepLIFT, which has a computational advantage while violating implementation invariance of the aforementioned axioms. In addition, DeepSHAP combined DeepLIFT and Shapley values (Shapley, 1953), which was proposed by the SHAP (Lundberg & Lee, 2017).
These methods were mainly evaluated by judging attributions as visualization. Alternatively, there are attempts to measure the accuracy of a DNN after applying attributions to input features (Hooker et al., 2018; Kim et al., 2019; Chalasani et al., 2020; Shi et al., 2020; Phang et al., 2020). Especially, the ROAR score (Hooker et al., 2018) is calculated by retraining the model from scratch through masking relevant image parts to zero. Meanwhile, (Adebayo et al., 2018) proposed a sanity check, where the “randomized” attributions are computed using a DNN, whose parameters of certain layers are randomly assigned, and subsequently compared to the “original” attributions through a Structural Similarity Index Measure (SSIM). Moreover, with this sanity check, (Sixt et al., 2020) found that attributions of GBA methods, except for DeepLIFT, are independent of the parameters of the later layers. They also explained how the information of the layer is lost through cosine similarity convergence (CSC). These measures are used to evaluate the sensitivity of an attribution method for the later layers of a DNN. However, these measures require human judgment to determine whether a test is passed and additional metrics for images. Instead, we focus on how much the attributions obtained from GBA methods can improve the classification accuracy of a DNN without retraining.
Before proposing our approach, we theoretically provide a no implicit bias condition that is necessary to improve the accuracy. This condition is derived by compressing a DNN into a single-layer neural network and separating the noise terms. From the perspective of compressing a DNN, we reinterpret the gradient computed with GBA methods and show the condition of the gradient toward reducing the noise of input features.
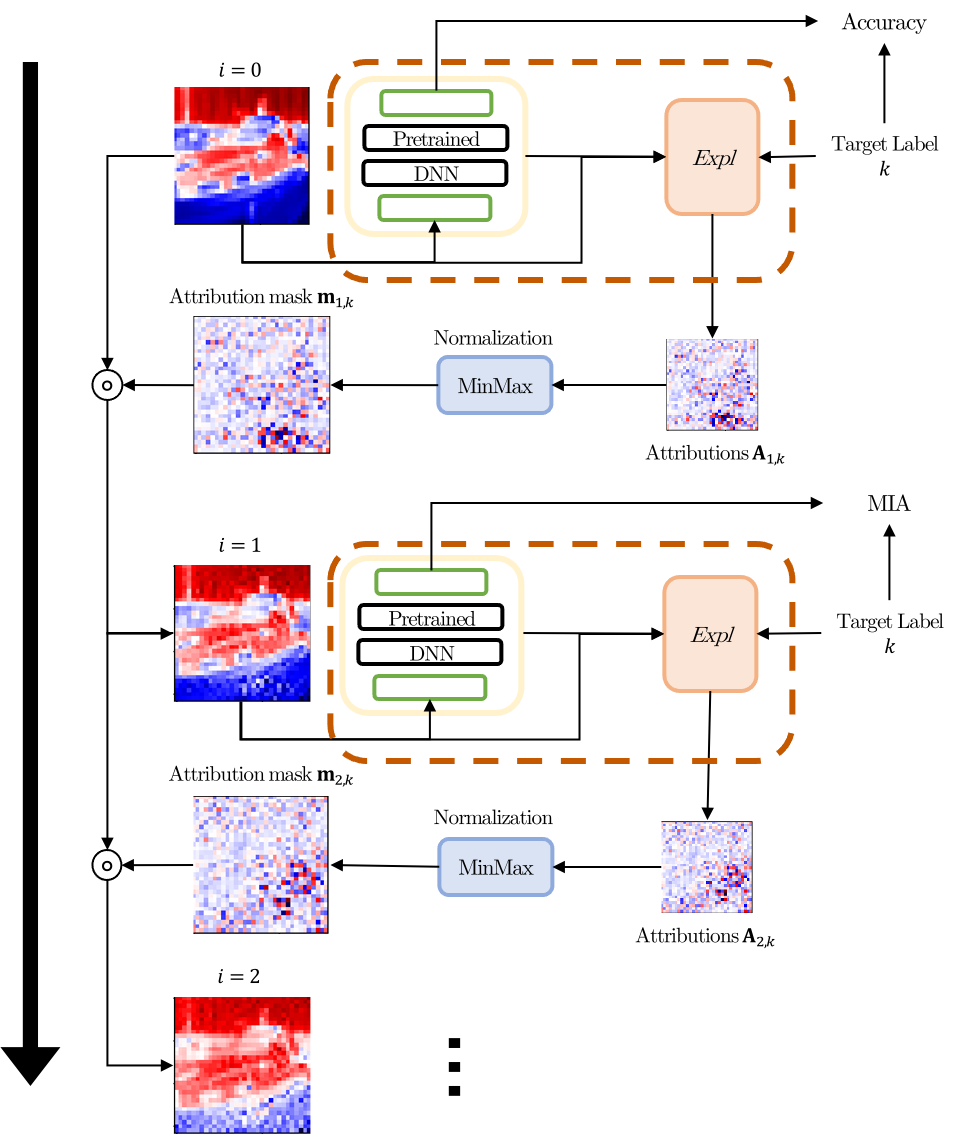
Our approach transforms the attributions obtained from a pre-trained DNN into an attribution mask, multiply it to the input features, and subsequently introduce these masked features as an input to the DNN. This mask is designed to recursively focus attention on the parts of the input related to the target label. To evaluate this approach, we measure the masked input accuracy (MIA), which denotes the accuracy obtained by feeding the masked features to the DNN. Furthermore, we provide Gradient * Sign-of-Input (GxSI), a new GBA method to achieve better MIA score than existing methods.
We measure the MIA of the GBA methods on CIFAR-10 and CIFAR-100. In our experiments, we show the followings:
-
•
GBA methods of calculating the gradient that satisfy the no implicit bias condition achieve a higher MIA scores compared to other methods.
-
•
While the existing GBA methods fail to maintain or increase the MIA score as the number of iterative attribution masking increases, the proposed GxSI method does not suffer from this problem. For example, on CIFAR-10, we achieve the MIA 99.8%99.9% by masking each image in both the training and test set.
-
•
By employing the masked features, obtained using GxSI and the attribution mask, to train and test another DNN, we achieve the image classification accuracy ranging from 99.7% to 100.0% on CIFAR-10.
These results imply that our approach effectively filters out parts of the input features not related to the target label.
2 Compression of DNNs and No Implicit Bias
Before proposing our approach, we reinterpret the gradient used by the existing GBA methods. The nonlinearity is locally linearized and the DNN is compressed into a single-layer neural network (Section 2.1). To remove the noise in the compressed DNN, we constrain the model to a certain condition (Section 2.2). In Section 2.3, we show that the noise of gradient can be reduced under this condition.
2.1 Linearization and compression of DNNs
A single-layer neural network is an easy-to-interpret model because it simplifies the relationship between the target class and the input features to an affine transform. Therefore, to create an interpretable DNN, we compress a DNN into a single-layer neural network through local linearization. Suppose that a pre-trained DNN to be compressed has a total of layers, and the number of dimensions of the -th layer is , where . Let be a hidden output of each layer. Here, the input of nonlinearity is , the weight and the bias are and , and the input features are .
To locally linearize a DNN, we focus on the nonlinearity of the DNN. The nonlinearity can be classified into two categories, element-wise and non-element-wise nonlinearity. The element-wise nonlinearity (e.g., Rectified Linear Unit (ReLU), Tanh, etc.) denotes a function that does not change the dimensions of the input features, and the non-element-wise nonlinearity (e.g., MaxPool, AvgPool, etc.) means that the input dimension changes. First, applying the Taylor decomposition (Kindermans et al., 2016; Montavon et al., 2017) to the element-wise nonlinearity function with respect to an input of the function , we obtain
| (1) |
where and . The baseline is and is an element-wise product. Next, for a non-element-wise nonlinearity , the Taylor decomposition provides
| (2) |
where . Because there is no bias in the result of the local linearization, we can absorb the function in another linear layer. Therefore, we only need to consider the element-wise nonlinearity containing bias and apply the linearized nonlinearity to the DNN including CNNs (Nie et al., 2018). We then have
| (3) |
Lemma 1.
Let , and . Then,
where .
Proof.
∎
Lemma 1 is applied to Equation 3 of the locally linearized DNN for the input features and is derived as follows:
| (4) |
where
| (5) |
| (6) |
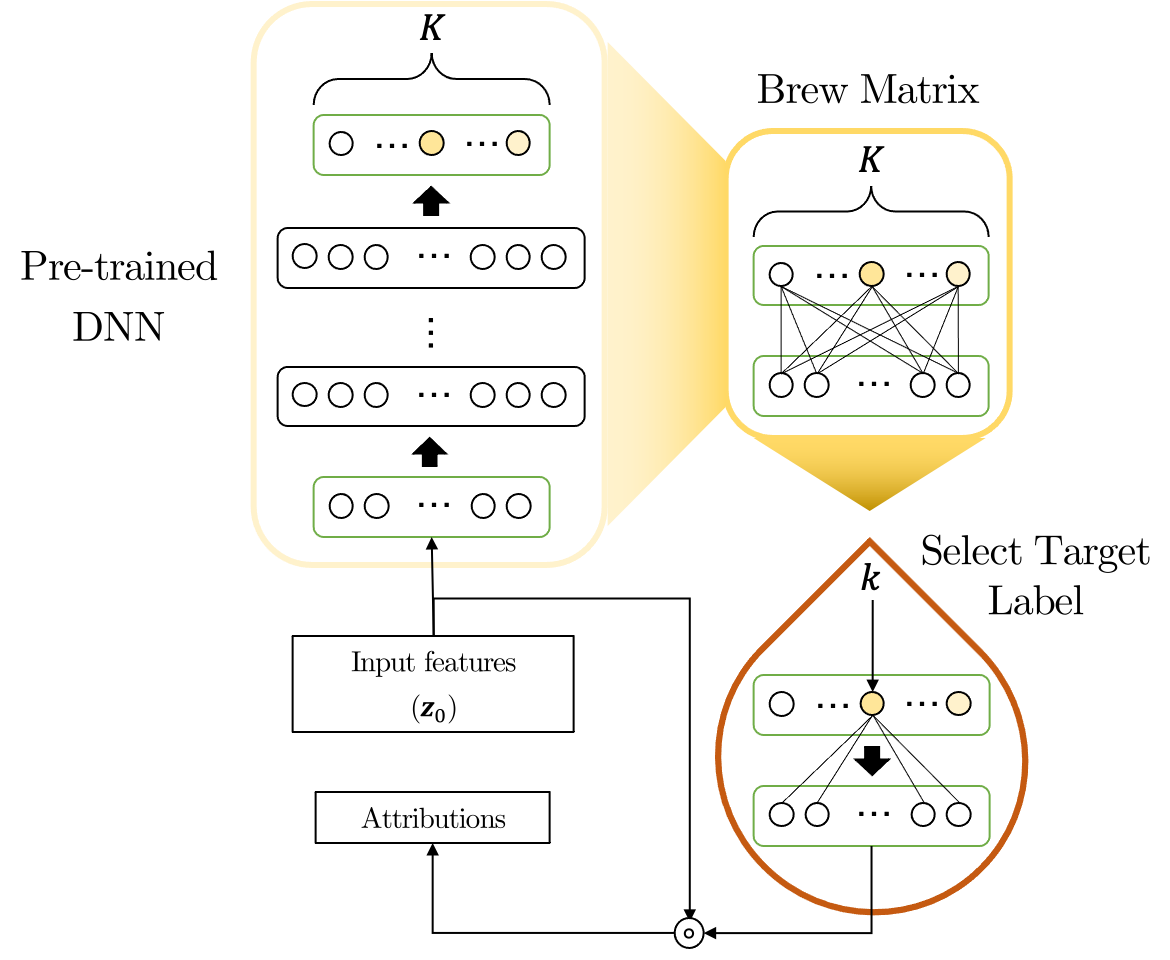
Assuming there is that satisfies for compressing the DNN into a weight matrix, Equation 4 is derived as follows:
| (7) |
Thus, the brew matrix and the additive input feature can be obtained for the input features .
2.2 No implicit bias model for noise reduction
The additive input features is generated by the total bias , which can work as noise for the input features and is consistent with what was claimed in (Mohan et al., 2019; Wang et al., 2019). To remove , we use a no implicit bias (NIB) model, a condition that forces all and in Equation 6 to zeros.
First, to force , we eliminate the biases of all layers as well as the mean parameters of batch normalization (Ioffe & Szegedy, 2015). Next, we use the Taylor decomposition under the baselines to find the nonlinearity such that it satisfies the condition . Therefore, we only consider functions such that satisfy this condition (e.g., ReLU or MaxPool). For example, in the case of ReLU, and for , and thus Equation 1 is calculated as . In the other case, as in Equation 2, MaxPool satisfies the condition because the function is locally linearized as a linear layer without bias. These two conditions, and , lead to in Equation 6. We thus can derive Equation 7 as follows:
| (8) |
Consequently, denotes the noise-reduced brew matrix. When using a DNN as a classifier, which means that is the same as the number of classes , the simplified matrix fully contains the information regarding the target class . Therefore, because the matrix is calculated using only the input features excluding , we simply use the -th row of the matrix to obtain information about the target label.
In terms of the brew matrix, attributions satisfy the efficiency properties of Shapley when the attributions are defined as Shapley values (Sundararajan & Najmi, 2020). In other words, the sum of all elements is equivalent to the prediction for the -th class of the DNN.
2.3 No implicit bias condition
Existing GBA methods calculate attributions along with input features by modifying the gradient obtained from a DNN. Among such methods, Gradient * Input, which is the basis, obtains attributions by applying the gradient without additional manipulation. Given the -layer DNN and the input features , the gradient of this method is calculated through an automatic differentiation as follows:
| (9) |
Here, is a locally linearized nonlinearity and is a weight matrix . Therefore, Equation 9 is identical to Equation 5 under two conditions, and . Thus, the brew matrix can also be computed as follows:
| (10) |
Based on this result, the gradient calculated using the GBA methods ignores the additive noise term, which means that this noise is always included in the attributions when the NIB model is not used.
Definition 1.
Given a DNN , the input features are and function modifies the gradient of this model. For the baselines that satisfy , if , we state that GBA method satisfies the NIB condition.
The NIB condition guarantees that the gradient does not contain additive noise. DeepLIFT and Integrated Gradients, which are designed for Completeness (Sundararajan et al., 2017), satisfy this condition by introducing the baselines, although finding such baselines is a difficult problem. Therefore, we compute the gradient under the NIB model to enhance the model accuracy through attributions. Under this model, Gradient * Input, DeepLIFT and Integrated Gradients satisfy the NIB condition (see Appendix A).
3 Attribution Mask and Proposed Attribution Method
We now describe our approach for measuring and improving the accuracy of DNNs with attributions. To achieve this, we propose an attribution mask that is recursively calculated from the GBA method (Section 3.1). We also provide a new attribution method for improving the performance (Section 3.2).
3.1 Attribution mask and the masked input accuracy (MIA)
The gradient, which is denoted as a specific row of the brew matrix, is attributed to the class . Each row is trained using several input features corresponding to each class within the dataset. Because these features contain some redundant information other than that related to the target class, we suppress this information by focusing attention on important parts of input features through the attributions.
First, we propose an attribution mask that recursively focuses attention on parts of an input of a pre-trained DNN . Let attributions with Expl denotes the GBA method, where the attribution mask for the target class is and the number of iterations is . The mask is calculated using MinMax normalization (Patro & Sahu, 2015) as follows:
| (11) |
where the initial mask is , and . This method normalizes the mask value to between zero and 1, leaving only the ratio of the relative values between the attributions, and thus the repeated multiplications of the mask does not diverge. In the case of an image, which is the target data of this study, is , and we conduct normalization for each .
Next, the attribution mask is multiplied by the input features and then the masked features are fed into the DNN. Let be a test dataset that has the input features paired with the target label . Then, the accuracy of the DNN with the mask is calculated as follows:
| (12) |
where is an indicator function, which is when and has a value of for the others. This accuracy, i.e., the MIA, is used to quantify the loss of information that occurs when target label information passes through DNN layers by the backpropagation process. For example, if decreases from the baseline accuracy () for , the target label information is not properly backpropagated to the attributions, indicating that the irrelevant part is incorrectly removed.
3.2 Gradient * Sign-of-Input (GxSI)
The existing GBA methods use the gradient that already has the physical dimension of the input features and create nonlinear attributions under the perspective of the brew matrix. To make linear attributions, we only use the sign of the input features. Next, we propose the attribution method, which is calculated as follows:
| (13) |
We label this method Gradient * Sign-of-Input (GxSI), which increases the attribution value when the gradient element and the input feature have the same sign. This method is based on the intuition that the input features that improve the prediction of the DNN are an important part. Unlike the Gradient * Input, this method is designed so that the gradient value affects attributions by only using the sign of the input instead of its value.
4 Experiment Setup
We tested our approach on two image datasets CIFAR-10 and CIFAR-100. For these datasets, the mean-variance normalization was used. This normalization was conducted for each R, G and B channel, the means of which were 0.507, 0.487, and 0.441, and the standard deviations were 0.267, 0.256, and 0.276, respectively. We trained the DNN based on PyTorch (Paszke et al., 2019) and used the open-source Captum (Kokhlikyan et al., 2020) based on PyTorch to test the existing GBA methods. To improve the performance of the DNN, we used a random crop and random horizontal flip on the images during training. Weights are randomly initialized prior to training. The optimizer used for training the DNN applied stochastic gradient descendent (SGD), and the momentum was 0.9 and the weight decay is 0.0005. By allocating 88 batches for each of the 4 GPUs, the total batch size was 352. The learning rate starts with 0.1 and uses a learning rate decay method that reduces the learning rate in a specific epoch. The specific epoch depends on the dataset, and for CIFAR-10, the learning rate was multiplied by 0.1 in 60 out of a total of 70 epochs. For CIFAR-100, the learning rate was multiplied by 0.1 in 100 and 150 out of a total of 175 epochs.
4.1 Model
NIB VGG To construct the NIB model, we removed all parameters corresponding to the mean of batch normalization in VGG (Simonyan & Zisserman, 2014) and the additive bias of all layers. In this model, a kernel size of 3 and a padding of 1 were used for all conv2d layers, and a kernel size of 2 and a stride size of 2 were used for MaxPool. To experiment with NIB models of different depths, we started with NIB VGG13 and constructed the model by reducing the number of conv2d layer by 2 to a total of 7 layers (see Table 1). Their models are labeled NIB VGG13-2, NIB VGG13-4, and NIB VGG13-6, respectively.
| NIB VGG13-6 | NIB VGG13-4 | NIB VGG13-2 | NIB VGG13 | NIB VGG16 | |||||||
|
|||||||||||
|
|||||||||||
| - |
|
|
|||||||||
| - | - |
|
|
||||||||
| - | - | - |
|
|
|||||||
| FC-4096 | |||||||||||
| FC-4096 | |||||||||||
| FC-10 or FC-100 | |||||||||||
4.2 Attribution methods
We targeted the following GBA methods: Gradient * Input (GxI), Guide Backpropagation (GBP), Integrated Gradient (IG), DeepLIFT (DL), Positive-Gradient * Input (PGxI) and Gradient x Sign-of-Input (GxSI). Our implementations of GBA method are identical to those of (Adebayo et al., 2018), except for PGxI and GxSI. First, in the case of the proposed attribution method, GxSI, we implemented Equation 13. Next, in the case of PGxI, we implemented the saliency map of (simonyan2013deep) by multiplying the input by the following element: , where is a target class and . Among the other methods, IG and DL need the baselines, and because we use the NIB model, the attributions were calculated with the baselines set to zeros. In particular, in the case of IG, we calculated the attributions with a step size of 50 to numerically calculate the integral.
5 Evaluation and Discussion
We compare the performance of the GBA methods through the MIA (Section 5.1). We test the effectiveness of GxSI (Section 5.2 and Section 5.3). We modify a dataset with the attribution masks obtained by GxSI and subsequently use this dataset to train another DNN model (Section 5.4). Some ablation studies are provided in Section 5.5.
5.1 MIA score of GBA methods
To verify the effect of the NIB condition on the MIA score, we measured this score of the existing GBA methods. Whether the methods satisfy the condition or not depends on the gradient modification and a pre-trained model. We used NIB VGG16 among the pre-trained NIB models to demonstrate the effect of the gradient modification (see the details in Section 4.1).
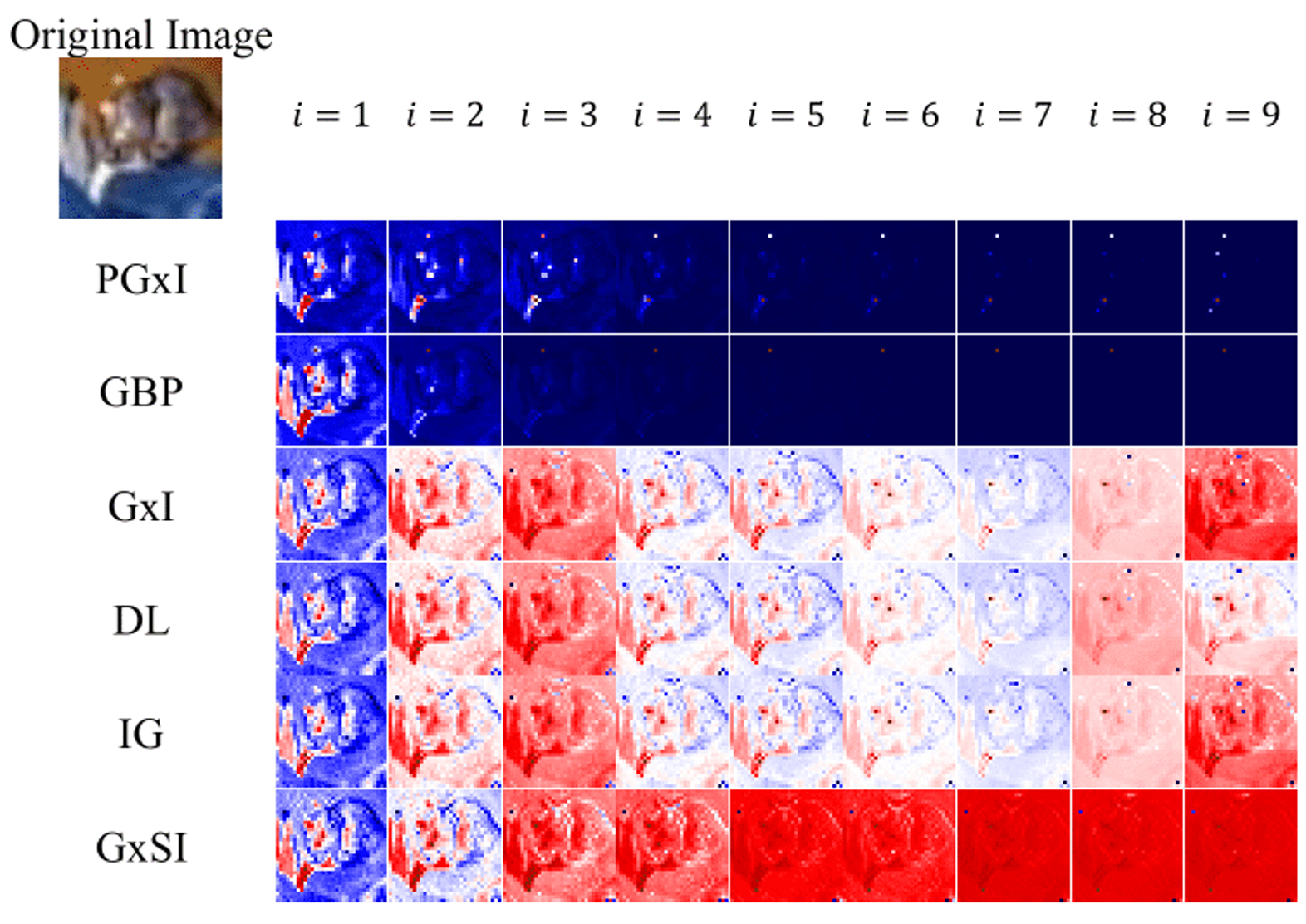
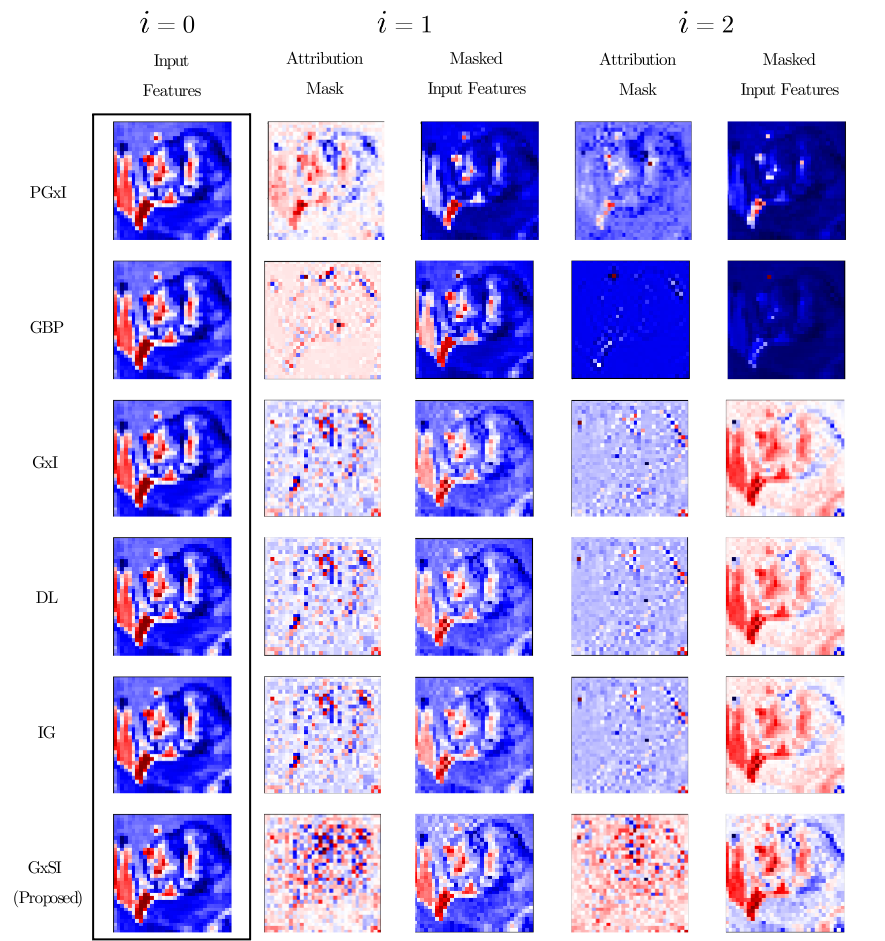
As shown in Table 2, GxI, DL, and IG have the same MIA value under the NIB model. We also see that these methods produce better performance than other methods. In particular, on CIFAR-10, the performance was 96.3%, which is close to 100%. However, as shown in Figure 3, PGxI and GBP methods reduce the performance despite the attribution mask looking more similar to the input image than with the other approaches. This deterioration in performance is because the object in this image disappears as the mask recursively modifies the input image (Figure 3 col. 1, col. 2). The baseline accuracy (i.e., the accuracy at ) of the DNN on CIFAR-100 is inferior to that of CIFAR-10. However, we can see that the methods, which satisfy the NIB condition, have a higher performance than the other methods.
According to the above results, methods using gradients that satisfy the NIB condition can increase the MIA compared to the other methods. Meanwhile, these results are contrary to the fact that GxI and other GBA methods failed the sanity check (Adebayo et al., 2018; Sixt et al., 2020), the reason for which is that these methods do not satisfy the NIB condition because the model used in the previous study was not the NIB model.
5.2 Improvement of the MIA through GxSI
| Dataset | Method | Iteration | ||||
|---|---|---|---|---|---|---|
| (%) | (%) | |||||
| CIFAR-10 | PGxI | 91.5 | 80.6 | -10.5 | 64.5 | -26.0 |
| GBP | 85.8 | -5.7 | 69.8 | -21.7 | ||
| GxI | 90.2 | -1.3 | 96.3 | 4.8 | ||
| DL | 90.2 | -1.3 | 96.3 | 4.8 | ||
| IG | 90.2 | -1.3 | 96.3 | 4.8 | ||
|
94.1 | 2.6 | 98.2 | 6.7 | ||
| CIFAR-100 | PGxI | 69.8 | 50.5 | -19.3 | 30.1 | -39.7 |
| GBP | 61.4 | -8.4 | 38.2 | -31.6 | ||
| GxI | 57.5 | -12.3 | 64.1 | -5.7 | ||
| DL | 57.5 | -12.3 | 64.1 | -5.7 | ||
| IG | 57.5 | -12.3 | 64.1 | -5.7 | ||
|
66.2 | -3.6 | 75.9 | 6.1 | ||

To validate that GxSI improves the performance, we compare its MIA score with that of the methods discussed in Section 5.1. As we can see in Table 2, the proposed method achieves superior performance compared to the other attribution methods, and the gradient satisfies the property. This superiority becomes more pronounced when the number of iterations increase to 3 or more.
In Figure 4 (a), we can see that the proposed method, unlike the other approaches, continuously increased its MIA and reached a performance close to the ideal value of 100%. In particular, on CIFAR-10, the performance reached 99.8% with 7 iterations, 99.9% with 10 iterations, and then fluctuated between 99.8% and 99.9%. Meanwhile, for GxI, IG, and DL, the measured value increased only until the second iteration and then gradually decreased to 52%. Moreover, for PGxI and GBP, the performance decreased continuously to 18.3% and 10.9%, respectively. In Figure 4 (b), on CIFAR-100, we can also see that the MIA value measured using the GxSI increases continuously, and we achieved 90.2% of the MIA with 12 iterations despite the relatively low baseline accuracy (see Appendix B).
These results imply that the attribution mask of the GxSI can recursively filter information not related to the target label more effectively than existing methods.
5.3 MIA of GxSI and DNN configuration
| Name | # of layer | Iteration | ||||
|---|---|---|---|---|---|---|
| NIB VGG13-6 | 7 | 83.3 | 98.4 | 15.1 | 99.9 | 16.6 |
| NIB VGG13-4 | 9 | 89.0 | 97.5 | 8.5 | 99.7 | 10.7 |
| NIB VGG13-2 | 11 | 90.9 | 97.2 | 6.3 | 99.6 | 8.7 |
| NIB VGG13 | 13 | 91.4 | 96.5 | 5.1 | 99.1 | 7.7 |
| NIB VGG16 | 16 | 91.5 | 94.1 | 2.6 | 98.2 | 6.7 |
| Student Model | Student Acc. w/o Teacher |
|
|||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
|
|||||||||
| NIB VGG13-6 | 83.3 | 99.7 | 99.1 | 99.5 | |||||||
| NIB VGG13-4 | 89.0 | 99.8 | 99.6 | 99.8 | |||||||
| NIB VGG13-2 | 90.9 | 99.9 | 99.7 | 99.9 | |||||||
| NIB VGG13 | 91.4 | 99.9 | 99.7 | 99.9 | |||||||
| NIB VGG16 | 91.5 | 99.9 | 99.6 | 99.9 | |||||||
| WRN-40-4 | 94.3 | 100.0 | 99.8 | 100.0 | |||||||
| WRN-28-10 | 95.1 | 100.0 | 99.8 | 100.0 | |||||||
| Model | Method | Iteration | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| (%) | |||||||||||
| NIB VGG16 + BNB +LB | GxI | 92.6 | 77.2 | 83.1 | 67.3 | 37.6 | 20.7 | 16.0 | 15.0 | 14.8 | 14.7 |
| GxSI | 78.1 | 80.0 | 66.5 | 40.0 | 22.0 | 13.5 | 11.2 | 10.6 | 10.5 | ||
| NIB VGG16 + BNB | GxI | 92.9 | 75.4 | 83.0 | 73.6 | 45.9 | 24.3 | 18.3 | 17.0 | 16.7 | 16.6 |
| GxSI | 76.0 | 80.2 | 71.4 | 47.1 | 25.5 | 15.6 | 12.7 | 11.8 | 11.5 | ||
| NIB VGG16 + LB | GxI | 92.0 | 89.4 | 91.1 | 72.2 | 26.9 | 11.7 | 10.6 | 10.5 | 10.5 | 10.4 |
| GxSI | 92.2 | 91.4 | 75.8 | 36.8 | 14.4 | 10.3 | 10.1 | 10.0 | 10.0 | ||
| NIB VGG16 | GxI | 91.5 | 90.2 | 96.3 | 93.9 | 91.7 | 87.0 | 82.8 | 76.8 | 72.0 | 67.5 |
| GxSI | 94.0 | 98.2 | 99.3 | 99.6 | 99.7 | 99.7 | 99.8 | 99.8 | 99.8 | ||
To measure the performance of GxSI according to the configurations of a DNN, we constructed the NIB model of various depths (see Table 1).
As shown in Table 3, in general, the depth of the DNN and the baseline accuracy are proportional, but the performance of the proposed method was rather reduced. In particular, at , the performance of the proposed method for NIB VGG13-6 was 1.7% higher than that for NIB VGG16. However, as shown in Figure 4, the performance of GxSI for NIB VGG16 increased to 99.9 %.
Therefore, these results indicates that the convergence speed of performance decreases according to the model depth, and the deeper DNNs lead to a difficulty in the attributions required to obtain the information of the target label. However, we can overcome this problem by applying the attribution mask to the input feature recursively.
5.4 Easy-to-understand features from the attribution mask
We modified the input features with the attribution mask obtained using GxSI under the NIB model and applied it for training other models. In this way, we tested for arbitrary DNNs in which the mask transforms the input features into easy-to-understand features. For this experiment, the model that obtains the attribution mask is called the teacher model, and the model to be trained from the input features modified with this mask is called the student model. For this teacher model, NIB VGG13 and NIB VGG16 were used to use the attribution mask showing the high MIA values. Specifically, for NIB VGG16, to introduce an attribution mask showing various MIA scores, this mask was obtained by repeating the process 3 and 10 times. The CIFAR-10 dataset was modified by multiplying the mask to the image of the training and test set. The student model NIB VGGs and WRNs were trained using this dataset.
As shown in Table 4, the accuracy of all student models was increased compared to the original accuracy. For the student model NIB VGG16, the accuracy was 99.9%, 99.6%, and 99.8% with respect to each teacher model, whereas it was 99.7%, 99.1%, and 99.5% for the student model NIB VGG13-6. We can see that the difference in classification accuracy between the two student models was not large. For the student model WRN-40-4 and WRN-28-10, through the teacher model with an MIA score of 99.8% and 99.9%, 100% accuracy was achieved when the input features contained all of the target label information. As we can see in the last two columns of Table 4, the accuracy of NIB VGG16 was higher on average than NIB VGG16.
These results indicate that the MIA score is a value that generally represents the ability to filter information other than the target label of the attribution mask from the input features. If the mask is only effective for the DNN from which it was obtained, the masked input features should depends on the model and lose the generality. Thus, the masked input features, which allow to achieve a high accuracy, are generally easy-to-understand features for an arbitrary DNN. Furthermore, we can see that the configuration of the model does not need to be complicated when the arbitrary dataset is masked with the attribution mask.
5.5 Ablation study
In the previous Sections, we conducted experiments using the NIB model and saw that the NIB condition is necessary for improving the MIA score. We revoked this condition and then conducted an experiment to measure the change in the MIA score on CIFAR-10. Accordingly, layer bias (LB) and batch normalization bias (BNB) were added to NIB VGG16 for GxI and GxSI among GBA methods, and we measured this score for 10 iterations and compared the maximum MIA score with the baseline accuracy.
As described in Table 5, there were two problems, one was that the MIA was small compared to the baseline accuracy, and the other was that the MIA decreased as the iterations increased. For the model with both LB and BNB added, the MIA scores of GxI and GxSI were decreased to 10.5% and 12.5%, respectively, and the maximum MIA was also lower than the baseline accuracy. The same phenomenon was observed for the model with BNB added, and the two GBA methods showed 16.6% and 11.5% MIA scores at 9th iteration, respectively. For the model with LB added, the maximum MIA of GxSI was slightly increased, but the score eventually fell to 10.0.
This result empirically shows that when the gradient calculated by the GBA methods does not satisfy the NIB condition, the performance is reduced by additive noise as we expected.
6 Conclusion
In this study, we proposed the attribution mask that filters out irrelevant parts of the input features and introduced it into the input of a pre-trained DNN to measure the MIA. For improving the performance of filtering, quantified through the MIA, we also provide the NIB condition and a new attribution method, GxSI. Through extensive experiments, we measured the performance of GBA methods. We found that the attribution methods, which satisfy the NIB condition, outperformed the methods that did not. Remarkably, GxSI showed superior MIA scores compared to the existing methods. We also modified each image in both training and test set with the mask obtained by this method. With this modified dataset, we trained a new DNN from scratch and achieved a classification accuracy of 100% on the test set. These results imply that our approach effectively removes parts of input features not related to the target label and is capable of generating easy-to-understand features from the perspective of the DNN.
References
- Adebayo et al. (2018) Adebayo, J., Gilmer, J., Muelly, M., Goodfellow, I., Hardt, M., and Kim, B. Sanity checks for saliency maps. Advances in Neural Information Processing Systems, 31:9505–9515, 2018.
- Ancona et al. (2017) Ancona, M., Ceolini, E., Öztireli, C., and Gross, M. Towards better understanding of gradient-based attribution methods for deep neural networks. arXiv preprint arXiv:1711.06104, 2017.
- Burgess et al. (2019) Burgess, C. P., Matthey, L., Watters, N., Kabra, R., Higgins, I., Botvinick, M., and Lerchner, A. Monet: Unsupervised scene decomposition and representation. arXiv preprint arXiv:1901.11390, 2019.
- Chalasani et al. (2020) Chalasani, P., Chen, J., Chowdhury, A. R., Wu, X., and Jha, S. Concise explanations of neural networks using adversarial training. In International Conference on Machine Learning, pp. 1383–1391. PMLR, 2020.
- Hinton (2007) Hinton, G. E. Learning multiple layers of representation. Trends in cognitive sciences, 11(10):428–434, 2007.
- Hooker et al. (2018) Hooker, S., Erhan, D., Kindermans, P.-J., and Kim, B. A benchmark for interpretability methods in deep neural networks. arXiv preprint arXiv:1806.10758, 2018.
- Ioffe & Szegedy (2015) Ioffe, S. and Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In International Conference on Machine Learning, pp. 448–456. PMLR, 2015.
- Kim et al. (2019) Kim, B., Seo, J., Jeon, S., Koo, J., Choe, J., and Jeon, T. Why are saliency maps noisy? cause of and solution to noisy saliency maps. In 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), pp. 4149–4157. IEEE, 2019.
- Kindermans et al. (2016) Kindermans, P.-J., Schütt, K., Müller, K.-R., and Dähne, S. Investigating the influence of noise and distractors on the interpretation of neural networks. arXiv preprint arXiv:1611.07270, 2016.
- Kindermans et al. (2017) Kindermans, P.-J., Schütt, K. T., Alber, M., Müller, K.-R., Erhan, D., Kim, B., and Dähne, S. Learning how to explain neural networks: Patternnet and patternattribution. arXiv preprint arXiv:1705.05598, 2017.
- Kokhlikyan et al. (2020) Kokhlikyan, N., Miglani, V., Martin, M., Wang, E., Alsallakh, B., Reynolds, J., Melnikov, A., Kliushkina, N., Araya, C., Yan, S., et al. Captum: A unified and generic model interpretability library for pytorch. arXiv preprint arXiv:2009.07896, 2020.
- Lakkaraju et al. (2020) Lakkaraju, H., Arsov, N., and Bastani, O. Robust and stable black box explanations. In International Conference on Machine Learning, pp. 5628–5638. PMLR, 2020.
- Lundberg & Lee (2017) Lundberg, S. M. and Lee, S.-I. A unified approach to interpreting model predictions. In Advances in Neural Information Processing Systems, pp. 4765–4774, 2017.
- Mohan et al. (2019) Mohan, S., Kadkhodaie, Z., Simoncelli, E. P., and Fernandez-Granda, C. Robust and interpretable blind image denoising via bias-free convolutional neural networks. arXiv preprint arXiv:1906.05478, 2019.
- Montavon et al. (2017) Montavon, G., Lapuschkin, S., Binder, A., Samek, W., and Müller, K.-R. Explaining nonlinear classification decisions with deep taylor decomposition. Pattern Recognition, 65:211–222, 2017.
- Nie et al. (2018) Nie, W., Zhang, Y., and Patel, A. A theoretical explanation for perplexing behaviors of backpropagation-based visualizations. In International Conference on Machine Learning, pp. 3809–3818. PMLR, 2018.
- Paszke et al. (2019) Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., et al. Pytorch: An imperative style, high-performance deep learning library. arXiv preprint arXiv:1912.01703, 2019.
- Patro & Sahu (2015) Patro, S. and Sahu, K. K. Normalization: A preprocessing stage. arXiv preprint arXiv:1503.06462, 2015.
- Phang et al. (2020) Phang, J., Park, J., and Geras, K. J. Investigating and simplifying masking-based saliency methods for model interpretability. arXiv preprint arXiv:2010.09750, 2020.
- Ribeiro et al. (2016) Ribeiro, M. T., Singh, S., and Guestrin, C. ” why should i trust you?” explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining, pp. 1135–1144, 2016.
- Shapley (1953) Shapley, L. S. A value for n-person games. Contributions to the Theory of Games, 2(28):307–317, 1953.
- Shi et al. (2020) Shi, B., Zhang, D., Dai, Q., Zhu, Z., Mu, Y., and Wang, J. Informative dropout for robust representation learning: A shape-bias perspective. In International Conference on Machine Learning, pp. 8828–8839. PMLR, 2020.
- Shrikumar et al. (2017) Shrikumar, A., Greenside, P., and Kundaje, A. Learning important features through propagating activation differences. In International Conference on Machine Learning, pp. 3145–3153. PMLR, 2017.
- Simonyan & Zisserman (2014) Simonyan, K. and Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014.
- Simonyan et al. (2014) Simonyan, K., Vedaldi, A., and Zisserman, A. Deep inside convolutional networks: Visualising image classification models and saliency maps. 2014.
- Sixt et al. (2020) Sixt, L., Granz, M., and Landgraf, T. When explanations lie: Why many modified bp attributions fail. In International Conference on Machine Learning, pp. 9046–9057. PMLR, 2020.
- Springenberg et al. (2014) Springenberg, J. T., Dosovitskiy, A., Brox, T., and Riedmiller, M. Striving for simplicity: The all convolutional net. arXiv preprint arXiv:1412.6806, 2014.
- Sundararajan & Najmi (2020) Sundararajan, M. and Najmi, A. The many shapley values for model explanation. In International Conference on Machine Learning, pp. 9269–9278. PMLR, 2020.
- Sundararajan et al. (2017) Sundararajan, M., Taly, A., and Yan, Q. Axiomatic attribution for deep networks. In International Conference on Machine Learning, pp. 3319–3328. PMLR, 2017.
- Wang et al. (2019) Wang, S., Zhou, T., and Bilmes, J. Bias also matters: Bias attribution for deep neural network explanation. In International Conference on Machine Learning, pp. 6659–6667. PMLR, 2019.
- Watanabe et al. (2018) Watanabe, S., Hori, T., Karita, S., Hayashi, T., Nishitoba, J., Unno, Y., Soplin, N. E. Y., Heymann, J., Wiesner, M., Chen, N., et al. Espnet: End-to-end speech processing toolkit. arXiv preprint arXiv:1804.00015, 2018.
- Zagoruyko & Komodakis (2016) Zagoruyko, S. and Komodakis, N. Wide residual networks. arXiv preprint arXiv:1605.07146, 2016.
Appendix A GBA methods that satisfy the NIB condition under the NIB model
We show the reason why some GBA methods are satisfied with the NIB condition. A DNN takes the input features to predict the target label . The model is used as a classifier, and the dimension of the predictions, , is equivalent to the number of the target classes .
Gradient * Input takes the modified gradient function as
For the NIB model, is equivalent to as shown in Equation 8. Here, the baselines are zeros and . Thus, GxI satisfies the NIB condition.
DeepLIFT computed with is equivalent to Gradient * Input when applied to a model with only ReLU as a nonlinear function and no additive biases (Ancona et al., 2017). This model is kind of the NIB model for which Gradient * Input satisfy the NIB condition. Thus, DeepLIFT also satisfies the condition.
Integrated Gradients integrate the gradient calculated with respect to the input features. This integration leads the modified gradient function as follow:
For the NIB model, is zero when because the model does not contain any additive noise. Integrated Gradients is designed for the Completeness. Thus, the prediction is equivalent to the integration, and this attribution method satisfies the NIB condition.
Appendix B The MIA score of GBA methods according to iteration
In this section, we describe the MIA score over the entire iteration ().
| Dataset | CIFAR-10 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Method | PGxI | GBP | GxI | DL | IG |
|
||||
| Iteration | 91.50 | |||||||||
| (%) | 80.60 | 85.80 | 90.20 | 90.20 | 90.20 | 94.10 | ||||
| 64.50 | 69.80 | 96.30 | 96.30 | 96.30 | 98.20 | |||||
| 49.50 | 39.10 | 93.90 | 93.90 | 93.90 | 99.30 | |||||
| 36.70 | 19.50 | 91.70 | 91.70 | 91.70 | 99.60 | |||||
| 28.70 | 13.70 | 87.00 | 87.00 | 87.10 | 99.70 | |||||
| 24.30 | 12.10 | 82.80 | 82.80 | 82.70 | 99.70 | |||||
| 21.70 | 11.70 | 76.80 | 76.80 | 76.90 | 99.80 | |||||
| 20.30 | 11.20 | 72.00 | 72.00 | 72.20 | 99.80 | |||||
| 19.40 | 11.00 | 67.50 | 67.40 | 67.60 | 99.80 | |||||
| 19.00 | 10.90 | 63.60 | 63.70 | 63.60 | 99.80 | |||||
| 18.80 | 10.90 | 60.60 | 60.60 | 60.40 | 99.90 | |||||
| 18.70 | 10.90 | 59.00 | 59.20 | 58.80 | 99.90 | |||||
| 18.50 | 11.00 | 57.40 | 57.30 | 57.60 | 99.80 | |||||
| 18.50 | 10.90 | 56.20 | 55.90 | 55.90 | 99.90 | |||||
| 18.50 | 10.90 | 54.80 | 54.60 | 54.70 | 99.90 | |||||
| 18.50 | 10.90 | 53.80 | 53.90 | 53.70 | 99.80 | |||||
| 18.60 | 10.90 | 53.00 | 53.00 | 53.20 | 99.80 | |||||
| 18.50 | 10.90 | 52.50 | 52.40 | 52.60 | 99.90 | |||||
| 18.30 | 10.90 | 51.90 | 52.00 | 51.90 | 99.80 | |||||
| Dataset | CIFAR-100 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Method | PGxI | GBP | GxI | DL | IG |
|
||||
| Iteration | 69.80 | |||||||||
| (%) | 50.50 | 61.40 | 57.50 | 57.50 | 57.50 | 66.20 | ||||
| 30.10 | 38.20 | 64.10 | 64.10 | 64.10 | 75.90 | |||||
| 18.20 | 13.50 | 55.60 | 55.60 | 55.80 | 81.30 | |||||
| 11.60 | 0.04 | 47.30 | 47.30 | 47.40 | 83.10 | |||||
| 0.08 | 0.02 | 39.90 | 39.90 | 40.00 | 83.80 | |||||
| 0.06 | 0.01 | 33.80 | 33.90 | 34.00 | 85.20 | |||||
| 0.05 | 0.01 | 29.00 | 29.00 | 29.00 | 86.60 | |||||
| 0.04 | 0.01 | 24.90 | 25.00 | 25.10 | 87.60 | |||||
| 0.04 | 0.01 | 21.30 | 21.30 | 21.00 | 88.10 | |||||
| 0.04 | 0.01 | 18.90 | 18.90 | 18.50 | 89.00 | |||||
| 0.04 | 0.01 | 16.80 | 16.70 | 16.60 | 90.00 | |||||
| 0.04 | 0.01 | 14.60 | 14.50 | 14.70 | 90.20 | |||||
| 0.04 | 0.01 | 13.50 | 13.30 | 13.20 | 89.80 | |||||
| 0.04 | 0.01 | 12.50 | 12.30 | 12.00 | 89.80 | |||||
| 0.04 | 0.01 | 11.50 | 11.40 | 11.40 | 90.00 | |||||
| 0.03 | 0.01 | 10.90 | 11.00 | 10.50 | 89.70 | |||||
| 0.04 | 0.01 | 10.10 | 10.20 | 10.40 | 89.70 | |||||
| 0.04 | 0.01 | 0.10 | 0.10 | 0.10 | 89.60 | |||||
| 0.04 | 0.01 | 0.10 | 0.10 | 0.10 | 89.70 | |||||
Appendix C The MIA score of GxSI methods according to model configurations.
In this section, we describe the MIA score over the entire iteration () according to model configurations.
| Name | NIB VGG13-6 | NIB VGG13-4 | NIB VGG13-2 | NIB VGG13 | NIB VGG16 | ||
|---|---|---|---|---|---|---|---|
| # of layer | 7 | 9 | 11 | 13 | 16 | ||
| Iteration | 83.3 | 89.0 | 90.9 | 91.4 | 91.5 | ||
| 98.4 | 97.5 | 97.2 | 96.5 | 94.1 | |||
| 99.9 | 99.7 | 99.6 | 99.1 | 98.2 | |||
| 100.0 | 100.0 | 99.9 | 99.8 | 99.3 | |||
| 100.0 | 100.0 | 100.0 | 99.9 | 99.6 | |||
| 99.9 | 100.0 | 100.0 | 99.9 | 99.7 | |||
| 99.7 | 100.0 | 100.0 | 100.0 | 99.7 | |||
| 99.4 | 100.0 | 100.0 | 99.9 | 99.8 | |||
| 98.9 | 100.0 | 100.0 | 99.9 | 99.8 | |||
| 98.3 | 100.0 | 100.0 | 99.9 | 99.8 | |||
Appendix D Additional visualization of masked input features
We provide representations of the masked input features with each attribution method for NIB VGG16. The features are sampled on test set of CIFAR-10 .