Asynchronous Interaction Aggregation for Action Detection
Abstract
Understanding interaction is an essential part of video action detection. We propose the Asynchronous Interaction Aggregation network (AIA) that leverages different interactions to boost action detection. There are two key designs in it: one is the Interaction Aggregation structure (IA) adopting a uniform paradigm to model and integrate multiple types of interaction; the other is the Asynchronous Memory Update algorithm (AMU) that enables us to achieve better performance by modeling very long-term interaction dynamically without huge computation cost. We provide empirical evidence to show that our network can gain notable accuracy from the integrative interactions and is easy to train end-to-end. Our method reports the new state-of-the-art performance on AVA dataset, with 3.7 mAP gain ( relative improvement) on validation split comparing to our strong baseline. The results on dataset UCF101-24 and EPIC-Kitchens further illustrate the effectiveness of our approach. Source code will be made public at: https://github.com/MVIG-SJTU/AlphAction.
Keywords:
Action Detection Video Understanding Interaction Memory1 Introduction
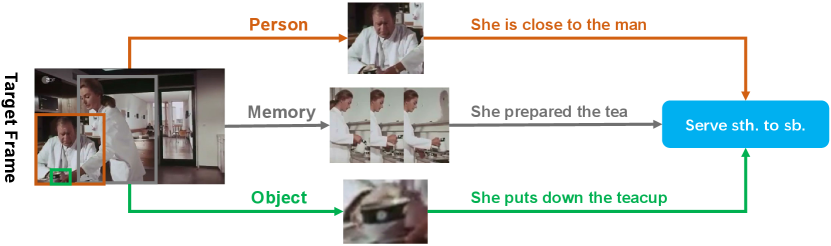
The task of action detection (spatio-temporal action localization) aims at detecting and recognizing actions in space and time. As an essential task of video understanding, it has a variety of applications such as abnormal behavior detection and autonomous driving. On top of spatial representation and temporal features [19, 25, 3, 9], the interaction relationships [12, 37, 45, 27] are crucial for understanding actions. Take Figure 1 for example. The appearance of the man, the tea cup as well as the previous movement of the woman help to predict the action of the woman. In this paper, We propose a new framework who emphasizes on the interactions for action detection.
Interactions can be briefly considered as the relationship between the target person and context. Many existing works try to explore interactions in videos, but there are two problems in the current methods: (1) Previous methods such as [12, 14] focus on a single type of interaction (eg. person-object). They can only boost one specific kind of actions. Methods such as [44] intend to merge different interactions, but they model them separately. Information of one interaction can’t contribute to another interaction modeling. How to find interactions correctly in video and use them for action detection remains challenging. (2) The long-term temporal interaction is important but hard to track. Methods which use temporal convolution [19, 25, 9] have very limited temporal reception due to the resource challenge. Methods such as [39] require a duplicated feature extracting pre-process which is not practical in reality.
In this work, we propose a new framework, the Asynchronous Interaction Aggregation network (AIA), who explores three kinds of interactions (person-person, person-object, and temporal interaction) that cover nearly all kinds of person-context interactions in the video. As a first try, AIA makes them work cooperatively in a hierarchical structure to capture higher level spatial-temporal features and preciser attentions. There are two main designs in our network: the Interaction Aggregation (IA) structure and the Asynchronous Memory Update (AMU) algorithm.
The former design, IA structure, explores and integrates all three types of interaction in a deep structure. More specifically, it consists of multiple elemental interaction blocks, of each enhances the target features with one type of interaction. These three types of interaction blocks are nested along the depth of IA structure. One block may use the result of previous interactions blocks. Thus, IA structure is able to model interactions precisely using information across different types.
Jointly training with long memory features is infeasible due to the large size of video data. The AMU algorithm is therefore proposed to estimate intractable features during training. We adopt a memory-like structure to store the spatial features and propose a series of write-read algorithm to update the content in memory: features extracted from target clips at each iteration are written to a memory pool and they can be retrieved in subsequent iterations to model temporal interaction. This effective strategy enables us to train the whole network in an end-to-end manner and the computational complexity doesn’t increase linearly with the length of temporal memory features. In comparison to previous solution [39] that extracted features in advance, the AMU is much simpler and achieves better performance.
In summary, our key contributions are: (1) A deep IA structure that integrates a diversity of person-context interactions for robust action detection and (2) an AMU algorithm to estimate the memory features dynamically. We perform an extensive ablation study on the AVA [16] dataset for spatio-temporal action localization task. Our method shows a huge boost on performance, which yields the new state-of-the-art on both validation and test set. We also test our method on dataset UCF101-24 and a segment level action recognition dataset EPIC-Kitchens. Results further validate its generality.
2 Related Works
Video Classification. Various 3D CNN [19, 32, 31, 34] have been developed to handle video input. To leverage the huge image dataset, I3D [3] has been proposed to benefit from ImageNet[6] pre-training. In [25, 7, 33, 42, 4], the 3D kernels in above models are simulated by temporal filters and spatial filters which can significantly decrease the model size. SlowFast Network [9] introduces a two-stream method [28, 10].
Spatio-temporal Action Detection. Action detection is more difficult than action classification because the model needs to not only predict the action labels but also localize the action in time and space. Most of recent approaches [16, 11, 9, 17, 40] follow the object detection frameworks [13, 26] by classifying the features generated by the detected bounding boxes. In contrast to our method, their results depend only on the cropped features. While all the other information is discarded and contributes nothing to the final prediction.
Attention Mechanism for Videos. The transformer [35] consists of several stacked self-attention layers and fully connected layers. Non-Local [36] concludes that the previous self-attention model can be viewed as a form of classical computer vision method of non-local means [2]. Hence a generic non-local block[36] is introduced. This structure enables models to compute the response by relating the features at different time or space, which makes the attention mechanism applicable for video-related tasks like action classification. The non-local block also plays an important role in [39] where the model references information from the long-term feature bank via a non-local feature bank operator.

3 Proposed Method
In this section, we will describe our method that localizes actions in space and time. Our approach aims at modeling and aggregating various interactions to achieve better action detection performance. In Section 3.1, we describe two important types of instance level features in short clips and the memory features in long videos. In Section 3.2, the Interaction Aggregation structure (IA) is explored to gather knowledge of interactions. In Section 3.3, we introduce the Asynchronous Memory Update algorithm (AMU) to alleviate the problem of heavy computation and memory consumption in temporal interaction modeling. The overall pipeline of our method is demonstrated in Figure 2.
3.1 Instance Level and Temporal Memory Features
To model interactions in video, we need to find correctly what the queried person is interacted with. Previous works such as [36] calculate the interactions among all the pixels in feature map. Being computational expensive, these brute-force methods struggle to learn interactions among pixels due to the limited size of video dataset. Thus we go down to consider how to obtain concentrated interacted features. We observe that persons are always interacting with concrete objects and other persons. Therefore, we extract object and person embedding as the instance level feature. In addition, video frames are always highly correlated, thus we keep the long-term person features as the memory features.
Instance level features are cropped from the video features. Since computing the whole long video is impossible, we split it to consecutive short video clips . The -dimensional features of the clip is extracted using a video backbone model: where is the parameters.
A detector is applied on the middle frame of to get person boxes and object boxes. Based on the detected bounding boxes, we apply RoIAlign to crop the person and object features out from extracted features . The person and object features in are denoted respectively as and .
One clip is only a short session and misses the temporal global semantics. In order to model the temporal interaction, we keep tracks of memory features. The memory features consist of person features in consecutive clips: , where is the size of clip-wise reception field. In practice, a certain number of persons are sampled from each neighbor clip.
The three features above have semantic meaning and contain concentrated information to recognize actions. With these three features, we are now able to model semantic interactions explicitly.
3.2 Interaction Modeling and Aggregation
How do we leverage these extracted features? For a target person, there are multiple detected objects and persons. The main challenge is how to correctly pay more attention to the objects or the persons that the target person is interacted with. In this section, we introduce first our Interaction Block that can adaptively model each type of interactions in a uniform structure. Then we describe our Interaction Aggregation (IA) structure that aggregates multiple interactions.
Overview. Given different human , object and memory features , the proposed IA structure outputs action features , where denotes the parameters in the IA structure. is then passed to the final classifier for final predictions.
The hierarchical IA structure consists of multiple interaction blocks. Each of them is tailored for a single type of interactions. The interaction blocks are deep nested with other blocks to efficiently integrate different interactions for higher level features and more precise attentions.
Interaction Block. The structure of interaction block is adapted from Transformer Block originally proposed in [35] whose specific design basically follows [36, 39]. Briefly speaking, one of the two inputs is used as the query and the other is mapped to key and value. Through the dot-product attention, which is the output of the softmax layer in Figure 3 a, the block is able to select value features that are highly activated to the query features and merge them to enhance the query features. There are three types of interaction blocks, P-Block, O-Block and M-Block.
-P-Block: P-Block models person-person interaction in the same clip. It is helpful for recognizing actions like listening and talking. Since the query input is already the person features or the enhanced person features, we take the key/value input the same as the query input.
-O-Block: In O-Block, we aim to distill person-object interactions such as pushing and carrying an object. Our key/value input is the detected object features . In the case where detected objects are too many, we sample based on detection scores. Figure 3a is an illustration of O-Block.
-M-Block: Some actions have strong logical connections along the temporal dimension like opening and closing. We model this type of interaction as temporal interactions. To operate this type, we take memory features as key/value input of an M-Block.

Interaction Aggregation Structure. The Interaction Blocks extract three types of interaction. We now propose two IA structures to integrate these different interactions. The proposed IA structures are the naive parallel IA, the serial IA and the dense serial IA. For clarity, we use , , and to represent the P-Block, O-Block, and M-Block respectively.
-Parallel IA: A naive approach is to model different interactions separately and merge them at last. As displayed in Figure 4a., each branch follows similar structure to [12] that treats one type of interactions without the knowledge of other interactions. We argue that the parallel structure struggles to find interaction precisely. We illustrate the attention of the last P-Block in Figure 4c. by displaying the output of the softmax layer for different persons. As we can see, the target person is apparently watching and listening to the man in red. However, the P block pays similar attention to two men.

-Serial IA: The knowledge across different interactions is helpful for recognizing interactions. We propose the serial IA to aggregate different types of interactions. As shown in Figure 3b., different types of interaction blocks are stacked in sequence. The queried features are enhanced in one interaction block and then passed to an interaction block of a different type. Figure 4f. and 4g. demonstrate the advantage of serial IA: The first P block can not differ the importance of the man in left and the man in middle. After gaining knowledge from O-block and M-block, the second P-block is able to pay more attention to man in left who is talking to the target person. Comparing to the attention in parallel IA (Figure 4c.), our serial IA is better in finding interactions.
-Dense Serial IA: In above structures, the connections between interaction blocks are totally manually designed and the input of an interaction block is simply the output of another one. We expect the model to further learn which interaction features to take by itself. With this in mind, we propose the Dense Serial IA extension. In Dense Serial IA, each interaction block takes all the outputs of previous blocks and aggregates them using a learnable weight. Formally, the query of the block can be represent as
| (1) |
where denotes the element-wise multiplication, is the set of indices of previous blocks, is a learnable -dimenional vector normalized with a Softmax function among , is the enhanced output features from the block. Dense Serial IA is illustrated in Figure 3c.
3.3 Asynchronous Memory Update Algorithm

Long-term memory features can provide useful temporal semantics to aid recognizing actions. Imagine a scene where a person opens the bottle cap, drinks water, and finally closes the cap, it could be hard to detect opening and closing with subtle movements. But knowing the context of drinking water, things get much easier.
Resource Challenge. To capture more temporal information, we hope our can gather features from enough clips, however, using more clips will increase the computation and memory consumption dramatically. Depicted with Figure 5, when jointly training, the memory usage and computation consumption increase rapidly as the temporal length of grows. To train on one target person, we must forward and backward video clips at one time, which consumes much more time, and even worse, cannot make full use of enough long-term information due to limited GPU memory.
Insight. In the previous work [39], they pre-train another duplicated backbone to extract memory features to avoid this problem. However, this method make use of frozen memory features, whose representation power can not be enhanced as model training goes. We expect the memory feature can be updated dynamically and enjoy the improvement from parameter update in training process. Therefore, we propose the asynchronous memory update method which can generate effective dynamic long-term memory features and make the training process more lightweight. The details of training process with this algorithm are presented in Algorithm 1.
Inspired by [38], our algorithm is composed of a memory component, the memory pool and two basic operations, READ and WRITE. The memory pool records memory features. Each feature in this pool is an estimated value and tagged with a loss value . This loss value logs the convergence state of the whole network. Two basic operations are invoked at each iteration of training:
-READ: At the beginning of each iteration, given a video clip from the video, memory features around the target clip are read from the memory pool , which is and specifically.
-WRITE: At the end of each iteration, personal features for the target clip are written back to the memory pool as estimated memory features , tagged with current loss value.
-Reweighting: The features we READ are written at different training steps. Therefore, some early written features are extracted from the model whose parameters are much different with current ones. Therefore, we impact a penalty factor to discard badly estimated features. We design a simple yet effective way to compute such penalty factor by using loss tag. The difference between the loss tag and current loss value is expressed as,
| (2) |
which should be very close to 1 when the difference is small. As the network converges, the estimated features in the memory pool are expected to be closer and closer to the precise features and approaches to 1.
As shown in Figure 5, the consumption of our algorithm has no obvious increase in both GPU memory and computation as the length of memory features grows, and thus we can use long enough memory features on current common devices. With dynamic updating, the asynchronous memory features can be better exploited than frozen ones.
4 Experiments on AVA
The Atomic Visual Actions(AVA) [16] dataset is built for spatio-temporal action localization. In this dataset, each person is annotated with a bounding box and multiple action labels at 1 FPS. There are 80 atomic action classes which cover pose actions, person-person interactions and person-object interactions. This dataset contains 235 training movie videos and 64 validation movie videos.
Since our method is originally designed for spatio-temporal action detection, we use AVA dataset as the main benchmark to conduct detailed ablation experiments. The performances are evaluated with official metric frame level mean average precision(mAP) at spatial IoU and only the top 60 most common action classes are used for evaluation, according to [16].
4.1 Implementation Details
Instance Detector. We apply Faster R-CNN [26] framework to detect persons and objects on the key frames of each clip. A model with ResNeXt-101-FPN [41, 21] backbone from maskrcnn-benchmark [23] is adopted for object detection. It is firstly pre-trained on ImageNet [6] and then fine-tuned on MSCOCO [22] dataset. For human detection, we further fine-tune the model on AVA for higher detection precision.
Backbone. Our method can be easily applied to any kind of 3D CNN backbone. We select state-of-the-art backbone SlowFast [9] network with ResNet-50 structure as our baseline model. Basically following the recipe in [9], our backbone is pre-trained on Kinetics-700 [3] dataset for action classification task. This pre-trained backbone produces 66.34% top-1 and 86.66% top-5 accuracy on the Kinetics-700 validation set.
Training and Inference. Initialized from Kinetics pre-trained weights, we then fine-tune the whole model on AVA dataset. The inputs of our network are 32 RGB frames, sampled from a 64-frame raw clip with one frame interval. Clips are scaled such that the shortest side becomes 256, and then fed into the fully convolution backbone. We use only the ground-truth human boxes for training and the randomly jitter them for data augmentation. For the object boxes, we set the detection threshold to 0.5 in order to higher recall. During inference, detected human boxes with a confidence score larger than 0.8 are used. We set for memory features in our experiments. We train our network using the SGD algorithm with batch size 64 on 16 GPU(4 clips per device). BatchNorm(BN) [18] statistics are set frozen. We train for 27.5k iterations with base learning rate 0.004 and the learning rate is reduced by a factor 10 at 17.5k and 22.5k iteration. A linear warm-up [15] scheduler is applied for the first 2k iterations.
4.2 Ablation Experiments
Three Interactions. We first study the importance of three kinds of interactions. For each interaction type, we use at most one block in the experiment. These blocks are then stacked in serial. To evaluate the importance of person-object interaction, we remove the O-Block in the structure. Other interactions are evaluated in the same way. Table 5(a) compares the model performance, where used interaction types are marked with ”✓”. A backbone baseline without any interaction is also listed in this table. Overall we observe that removing any of these three type interactions results in a significant performance decrease, which confirms that all these three interactions are important for action detection.
Number of Interaction Blocks. We then experiment with different settings for the number of interaction blocks in our IA structure. The interaction blocks are nested in serial structure in this experiment. In Table 5(b), denotes blocks are used for each interaction type, with the total number as . We find that with setting the our method can achieve the best performance, so we use this as our default configuration.
| mAP | |||
|---|---|---|---|
| 26.54 | |||
| ✓ | ✓ | 28.04 | |
| ✓ | ✓ | 28.86 | |
| ✓ | ✓ | 28.92 | |
| ✓ | ✓ | ✓ | 29.26 |
| blocks | mAP |
|---|---|
| 29.26 | |
| 29.64 | |
| 29.61 |
| order | mAP | order | mAP |
|---|---|---|---|
| 29.48 | 29.46 | ||
| 29.51 | 29.53 | ||
| 29.44 | 29.64 |
| structure | mAP |
|---|---|
| Parallel | 28.85 |
| Serial | 29.64 |
| Dense Serial | 29.80 |
| model | params | FLOPs | mAP |
|---|---|---|---|
| Baseline | 26.54 | ||
| LFB(w/o AMU) | 27.02 | ||
| LFB(w/ AMU) | 28.57 | ||
| IA(w/o AMU) | 28.07 | ||
| IA(w/ AMU) | 29.64 |
| model | mAP |
|---|---|
| Baseline | 26.54 |
| +NL | 26.85 |
| +IA(w/o ) | 28.23 |
Interaction Order. In our serial IA, different type of interactions are alternately integrated in sequential. We investigate effect of different interaction order design in Table 5(c). As shown in this experiment, the performance with different order are quite similar, we thus choose the slightly better one as our default setting.
Interaction Aggregation Structure. We analyze different IA structure in this part. Parallel IA, serial IA and the dense serial IA extension are compared in Table 5(d). As we expect, the parallel IA performs much worse than serial structure. With dense connections between blocks, our model is able to learn more knowledge of interactions, which further boosts the performance.
Asynchronous Memory Update. In the previous work LFB [39], the memory features are extracted with another backbone, which is frozen during training. In this experiment we compare our asynchronous memory features with the frozen ones. For fair comparison, we re-implement LFB with SlowFast backbone, and also apply our AMU algorithm to LFB. In Table 5(e), we find that our asynchronous memory features can gain much better performance than the frozen method with nearly half of the parameters and computation cost. We argue that this is because our dynamic features can provide better representation.
Comparison to Non-local Attention. Finally we compare our interaction aggregation method with prior work non-local block [36]. Following [9], we augment the backbone with a non-local branch, where attention is computed between the person instance features and global pooled features. Since there is no long-term features in the non-local block, we use only and in this experiment. In Table 5(f), we see that our serial IA works significantly better than non-local block. This confirms that our method can better learn to find potential interactions than non-local block.
4.3 Main Results

Finally, we compare our results on AVA with previous methods in Table 2. We show our results on both AVA v2.1 and v2.2. Our method surpass all previous works on both versions.
The AVA v2.2 dataset, is the newer benchmark used in ActivityNet challenge 2019 [8]. On the validation set, our method reports a new state-of-the-art 33.11 mAP with one single model, which outperforms the strong baseline SlowFast networks by 3.7 mAP. On the test split, we train our model on both training and validation splits and use a relative longer scheduler due to more data. With an ensemble of three models with different learning rates and aggregation structures, our method achieves better performance than the winning entry of AVA action detection challenge 2019 (an ensemble with 7 SlowFast networks). The per category results for our method and SlowFast baseline is illustrated in Figure 6. We can observe the performance gain for each category, especially for those who contain interactions with video context.
We note that we use a new larger Kinetics-700 for pre-training. As shown in Table 2, the backbone we implement in this work has a similar performance to the official model pre-trained with Kinetics-600. This comparison proves that the very most part of performance gain is from our method.
5 Experiments on UCF101-24
UCF101-24 [30] is an action detection set with 24 action categories. In this dataset, the bounding boxes of each action instance are annotated frame by frame. We conduct experiments on the first split of this dataset following previous works. We use the corrected annotations provided by Singh et al. [29].
5.1 Implemetnation Details
Since the bounding boxes are annotated in frame level, we choose to use a ResNet50-C2D proposed in [36] as our video backbone model. To receive single image as input, we remove all temporal poolings in it. We pre-train it on the Kinetics-400 dataset. Other settings are basically the same as AVA experiments. More implementation details are provided in Supplementary Material.
5.2 Quantitative Evaluation
| method | mAP | method | mAP | method | mAP |
|---|---|---|---|---|---|
| T-CNN [17] | 41.4 | STEP [43] | 75.0 | C2D (ours) | 75.5 |
| Peng et al. [24] | 65.7 | Gu et al. [16] | 76.3 | AIA-Serial | 78.5 |
| ACT [20] | 69.5 | Zhang et al. [44] | 77.9 | AIA-Dense-Serial | 78.8 |
Table 3 shows the result on UCF101-24 test split in terms of Frame-mAP with 0.5 IOU threshold. As we can see in the table, AIA achieves 3.3% mAP gain comparing to our C2D baseline. Moreover, with only a lightweight 2D backbone (other works could use some 3D backbone), our method still achieves very competitive results.
6 Experiments on EPIC-Kitchens
| Verbs | Nouns | Actions | ||||
|---|---|---|---|---|---|---|
| top-1 | top-5 | top-1 | top-5 | top-1 | top-5 | |
| Baradel [1] | 40.9 | - | - | - | - | - |
| LFB NL [39] | 52.4 | 80.8 | 29.3 | 54.9 | 20.8 | 39.8 |
| SlowFast (ours) | 56.8 | 82.8 | 32.3 | 56.7 | 24.1 | 42.0 |
| AIA-Parallel | 57.6 | 83.9 | 36.3 | 63.0 | 26.4 | 47.4 |
| AIA-Serial | 59.2 | 84.2 | 37.2 | 63.2 | 27.7 | 48.0 |
| AIA-Dense-Serial | 60.0 | 84.6 | 37.2 | 62.1 | 27.1 | 47.8 |
To demonstrate the generalizability of AIA, we evaluate our method on the segment level dataset EPIC-Kitchens [5]. In EPIC Kitchens, each segment is annotated with one verb and one noun. The action is defined by their combination. Following [1], We split the original training set into a new training set and a new validation set. Verb models and noun models are trained separately. Actions are obtained by combining their predictions.
6.1 Implementation Details
For both verb model and noun model, we use the extracted segment features (global average pooling of ) as query input for IA structure. Hand features and object features are cropped and then fed into IA to model person-person and person-object interactions. For verb model, the memory features are the segment features. For noun model, the memory features are the object features extracted from object detector feature map, thus the AMU algorithm is only applied to the verb model. Other experimental details different from AVA setting are provided in Supplementary Material.
6.2 Quantitative Evaluation
We observe from Table 4 a significant gain for all three tasks. All the variants of AIA outperform the strong baseline SlowFast. Among them, the dense serial IA achieves the best performance for the verbs test, leading to 3.2% improvement on top-1 score. The serial IA results in 4.9% for the nouns test and 3.6% for the action test.
7 Conclusion
In this paper, we present the Asynchronous Interaction Aggregation network and its performance in action detection. Our method reports the new start-of-the-art on AVA dataset. Nevertheless, the performance of action detection and the interaction recognition is far from perfect. The poor performance is probably due to the limited video dataset. Transferring the knowledge of action and interaction from image could be a further improvement for AIA network.
References
- [1] Baradel, F., Neverova, N., Wolf, C., Mille, J., Mori, G.: Object level visual reasoning in videos. In: Proceedings of the European Conference on Computer Vision (ECCV). pp. 105–121 (2018)
- [2] Buades, A., Coll, B., Morel, J.M.: A non-local algorithm for image denoising. In: 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05). vol. 2, pp. 60–65. IEEE (2005)
- [3] Carreira, J., Zisserman, A.: Quo vadis, action recognition? a new model and the kinetics dataset. In: proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 6299–6308 (2017)
- [4] Christoph, R., Pinz, F.A.: Spatiotemporal residual networks for video action recognition. Advances in Neural Information Processing Systems pp. 3468–3476 (2016)
- [5] Damen, D., Doughty, H., Maria Farinella, G., Fidler, S., Furnari, A., Kazakos, E., Moltisanti, D., Munro, J., Perrett, T., Price, W., et al.: Scaling egocentric vision: The epic-kitchens dataset. In: Proceedings of the European Conference on Computer Vision (ECCV). pp. 720–736 (2018)
- [6] Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: Imagenet: A large-scale hierarchical image database. In: 2009 IEEE conference on computer vision and pattern recognition. pp. 248–255. Ieee (2009)
- [7] Diba, A., Fayyaz, M., Sharma, V., Mahdi Arzani, M., Yousefzadeh, R., Gall, J., Van Gool, L.: Spatio-temporal channel correlation networks for action classification. In: Proceedings of the European Conference on Computer Vision (ECCV). pp. 284–299 (2018)
- [8] Fabian Caba Heilbron, Victor Escorcia, B.G., Niebles, J.C.: Activitynet: A large-scale video benchmark for human activity understanding. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 961–970 (2015)
- [9] Feichtenhofer, C., Fan, H., Malik, J., He, K.: Slowfast networks for video recognition. In: Proceedings of the IEEE International Conference on Computer Vision. pp. 6202–6211 (2019)
- [10] Feichtenhofer, C., Pinz, A., Zisserman, A.: Convolutional two-stream network fusion for video action recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 1933–1941 (2016)
- [11] Girdhar, R., Carreira, J., Doersch, C., Zisserman, A.: A better baseline for AVA. CoRR abs/1807.10066 (2018), http://arxiv.org/abs/1807.10066
- [12] Girdhar, R., Carreira, J., Doersch, C., Zisserman, A.: Video action transformer network. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 244–253 (2019)
- [13] Girshick, R.: Fast r-cnn. In: Proceedings of the IEEE international conference on computer vision. pp. 1440–1448 (2015)
- [14] Gkioxari, G., Girshick, R., Dollár, P., He, K.: Detecting and recognizing human-object interactions. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 8359–8367 (2018)
- [15] Goyal, P., Dollár, P., Girshick, R., Noordhuis, P., Wesolowski, L., Kyrola, A., Tulloch, A., Jia, Y., He, K.: Accurate, large minibatch sgd: Training imagenet in 1 hour. arXiv preprint arXiv:1706.02677 (2017)
- [16] Gu, C., Sun, C., Ross, D.A., Vondrick, C., Pantofaru, C., Li, Y., Vijayanarasimhan, S., Toderici, G., Ricco, S., Sukthankar, R., et al.: Ava: A video dataset of spatio-temporally localized atomic visual actions. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 6047–6056 (2018)
- [17] Hou, R., Chen, C., Shah, M.: Tube convolutional neural network (t-cnn) for action detection in videos. In: Proceedings of the IEEE International Conference on Computer Vision. pp. 5822–5831 (2017)
- [18] Ioffe, S., Szegedy, C.: Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv preprint arXiv:1502.03167 (2015)
- [19] Ji, S., Xu, W., Yang, M., Yu, K.: 3d convolutional neural networks for human action recognition. IEEE transactions on pattern analysis and machine intelligence 35(1), 221–231 (2012)
- [20] Kalogeiton, V., Weinzaepfel, P., Ferrari, V., Schmid, C.: Action tubelet detector for spatio-temporal action localization. In: Proceedings of the IEEE International Conference on Computer Vision. pp. 4405–4413 (2017)
- [21] Lin, T.Y., Dollár, P., Girshick, R., He, K., Hariharan, B., Belongie, S.: Feature pyramid networks for object detection. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 2117–2125 (2017)
- [22] Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft coco: Common objects in context. In: European conference on computer vision. pp. 740–755. Springer (2014)
- [23] Massa, F., Girshick, R.: maskrcnn-benchmark: Fast, modular reference implementation of Instance Segmentation and Object Detection algorithms in PyTorch. https://github.com/facebookresearch/maskrcnn-benchmark (2018), accessed: 2020-2-29
- [24] Peng, X., Schmid, C.: Multi-region two-stream r-cnn for action detection. In: European conference on computer vision. pp. 744–759. Springer (2016)
- [25] Qiu, Z., Yao, T., Mei, T.: Learning spatio-temporal representation with pseudo-3d residual networks. In: proceedings of the IEEE International Conference on Computer Vision. pp. 5533–5541 (2017)
- [26] Ren, S., He, K., Girshick, R., Sun, J.: Faster r-cnn: Towards real-time object detection with region proposal networks. In: Advances in neural information processing systems. pp. 91–99 (2015)
- [27] Sigurdsson, G.A., Divvala, S., Farhadi, A., Gupta, A.: Asynchronous temporal fields for action recognition. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (July 2017)
- [28] Simonyan, K., Zisserman, A.: Two-stream convolutional networks for action recognition in videos. In: Advances in neural information processing systems. pp. 568–576 (2014)
- [29] Singh, G., Saha, S., Sapienza, M., Torr, P.H., Cuzzolin, F.: Online real-time multiple spatiotemporal action localisation and prediction. In: Proceedings of the IEEE International Conference on Computer Vision. pp. 3637–3646 (2017)
- [30] Soomro, K., Zamir, A.R., Shah, M.: Ucf101: A dataset of 101 human actions classes from videos in the wild. arXiv preprint arXiv:1212.0402 (2012)
- [31] Taylor, G.W., Fergus, R., LeCun, Y., Bregler, C.: Convolutional learning of spatio-temporal features. In: European conference on computer vision. pp. 140–153. Springer (2010)
- [32] Tran, D., Bourdev, L.D., Fergus, R., Torresani, L., Paluri, M.: C3d: generic features for video analysis. CoRR, abs/1412.0767 2(7), 8 (2014)
- [33] Tran, D., Wang, H., Torresani, L., Ray, J., LeCun, Y., Paluri, M.: A closer look at spatiotemporal convolutions for action recognition. In: Proceedings of the IEEE conference on Computer Vision and Pattern Recognition. pp. 6450–6459 (2018)
- [34] Varol, G., Laptev, I., Schmid, C.: Long-term temporal convolutions for action recognition. IEEE transactions on pattern analysis and machine intelligence 40(6), 1510–1517 (2017)
- [35] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, L.u., Polosukhin, I.: Attention is all you need. In: Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R. (eds.) Advances in Neural Information Processing Systems 30, pp. 5998–6008. Curran Associates, Inc. (2017), http://papers.nips.cc/paper/7181-attention-is-all-you-need.pdf
- [36] Wang, X., Girshick, R., Gupta, A., He, K.: Non-local neural networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 7794–7803 (2018)
- [37] Wang, X., Gupta, A.: Videos as space-time region graphs. In: Proceedings of the European conference on computer vision (ECCV). pp. 399–417 (2018)
- [38] Weston, J., Chopra, S., Bordes, A.: Memory networks. arXiv preprint arXiv:1410.3916 (2014)
- [39] Wu, C.Y., Feichtenhofer, C., Fan, H., He, K., Krahenbuhl, P., Girshick, R.: Long-term feature banks for detailed video understanding. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (June 2019)
- [40] Xia, J., Tang, J., Lu, C.: Three branches: Detecting actions with richer features. arXiv preprint arXiv:1908.04519 (2019)
- [41] Xie, S., Girshick, R., Dollár, P., Tu, Z., He, K.: Aggregated residual transformations for deep neural networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 1492–1500 (2017)
- [42] Xie, S., Sun, C., Huang, J., Tu, Z., Murphy, K.: Rethinking spatiotemporal feature learning for video understanding. arXiv preprint arXiv:1712.04851 1(2), 5 (2017)
- [43] Yang, X., Yang, X., Liu, M.Y., Xiao, F., Davis, L.S., Kautz, J.: Step: Spatio-temporal progressive learning for video action detection. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 264–272 (2019)
- [44] Zhang, Y., Tokmakov, P., Hebert, M., Schmid, C.: A structured model for action detection. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 9975–9984 (2019)
- [45] Zhou, B., Andonian, A., Oliva, A., Torralba, A.: Temporal relational reasoning in videos. In: Proceedings of the European Conference on Computer Vision (ECCV). pp. 803–818 (2018)