Asynchronous Feedback Network for Perceptual Point Cloud Quality Assessment
Abstract
Recent years have witnessed the success of the deep learning-based technique in research of no-reference point cloud quality assessment (NR-PCQA). For a more accurate quality prediction, many previous studies have attempted to capture global and local features in a bottom-up manner, but ignored the interaction and promotion between them. To solve this problem, we propose a novel asynchronous feedback quality prediction network (AFQ-Net). Motivated by human visual perception mechanisms, AFQ-Net employs a dual-branch structure to deal with global and local features, simulating the left and right hemispheres of the human brain, and constructs a feedback module between them. Specifically, the input point clouds are first fed into a transformer-based global encoder to generate the attention maps that highlight these semantically rich regions, followed by being merged into the global feature. Then, we utilize the generated attention maps to perform dynamic convolution for different semantic regions and obtain the local feature. Finally, a coarse-to-fine strategy is adopted to merge the two features into the final quality score. We conduct comprehensive experiments on three datasets and achieve superior performance over the state-of-the-art approaches on all of these datasets. The code will be available at https://github.com/zhangyujie-1998/AFQ-Net.
Index Terms:
Point cloud quality assessment, Asynchronous learning, Coarse-to-fine learningI Introduction
With recent advancements in 3D capturing devices, point clouds have become a prominent media format for representing 3D visual content in various immersive applications. Point clouds consist of a collection of points distributed in 3D space, where each point has spatial coordinates and additional attributes such as RGB values. Before reaching the user-client, point clouds undergo a wide variety of stages, including acquisition, compression, transmission, and rendering. Any stage might cause degradation in visual quality. Accordingly, it is essential to develop an effective metric that pervades human perception into the research of point cloud quality assessment (PCQA), especially in the common no-reference (NR) situation where pristine reference point clouds are not available.


In the past years, deep-learning-based PCQA methods [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12] have shown remarkable performance on multiple benchmarks, which can be applied directly for original 3D data or for projected 2D images. To achieve a more robust prediction, some visual-related methods [13, 4, 3, 6, 14] advertise learning discriminative features, where two types of feature are usually considered: global feature and local feature. Many previous studies [13, 4], whether based on 3D or 2D operations, have sought to extract the two features in a bottom-up manner, seeing Fig. 1 (a). Given a multi-layer neural network, features of shallow and deep layers are separately extracted as local and global feature due to the gradually increasing receptive field size. The two types of feature are then simply fused (e.g., concatenation, addition) to regress into the final quality score.
Although promising results have been reported with the existing methods, several problems remain for the utilization of global and local features. First, the bottom-up manner usually depends on a cascaded convolutional structure following a progressive feature extraction order, which fails to exploit the interaction between two types of feature. Actually, quality perception to deformations can vary across different semantical regions, and the sensitivity of a certain local distortion can be reduced or highlighted due to global characteristics [15]. Ignoring the guidance effect of global feature can lead to a limited ability to capture degradation. Second, current models with the projected image from 3D content as input is easily polluted with background information [16]. When the model uses a 2D CNN-based network as the backbone, the model intends to perform in a filter-sharing manner for both meaningless image backgrounds and rendered point cloud content, which may impair the final performance and is contradictory to subjective observation. In fact, human observers can easily distinguish the background pixels and focus on the point cloud content, which also can assist humans perceive global and local characteristics. Nevertheless, this aspect is seldom taken into account in most existing methods.
To address these problems, we draw two main inspirations from human visual perception mechanisms: i) recent studies [17, 18] have highlighted the distinct visual processing of global and local feature in different areas of the brain. Specifically, the left and right hemispheres of the brain are specialized in processing global and local information, respectively. These findings suggest the presence of a dual-stream processing mechanism in our brain, challenging existing methods that seek to capture distinct features using a single branch. ii) Mounting evidence [19, 20, 21] has indicated that there exists an asynchronous process in visual perception. In general, human visual cortex can first perceive the global feature, which is then used to guide the extraction of the local feature through a feedback connection. For example, when presented with a human body point cloud or its projected images, individuals can initially identify various semantic regions (e.g., head, trunk, or background) and then perform fine-grained observation for different regions. Based on these insights, we expect to design a new feature learning strategy for NR-PCQA to overcome the shortcomings of previous studies.
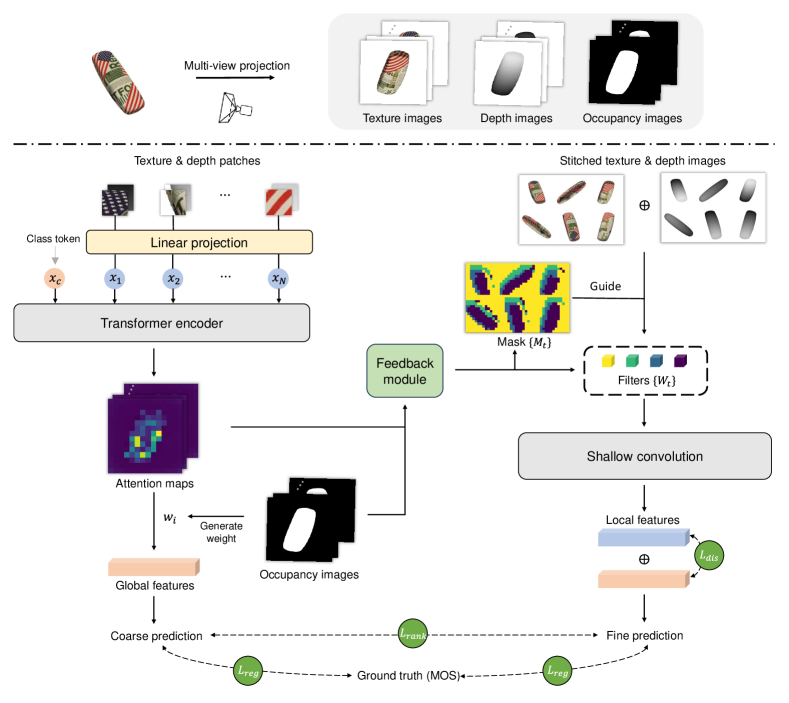
In this paper, we propose a new NR-PCQA method, called Asynchronous Feedback Quality Prediction Network (AFQ-Net). Motivated by the human visual perception mechanisms, AFQ-Net employs a dual-branch structure to deal with global and local feature (called the global branch and the local branch), and a feedback module is constructed between branches, seeing Fig. 1 (b). More specifically, the input distorted point cloud is first projected into three types of multi-view images: texture images, depth images, and occupancy images. For the global branch, the texture and depth images are fed into a transformer-based encoder to generate the attention maps that highlight these semantically rich regions. The attention maps are then merged into the global feature through an occupancy-weighted multi-view fusion, which can reduce the influence of useless background information.
After obtaining the global feature, a feedback module is established to promote the feature extraction process of the local branch. Concretely, inspired by the merits of region-aware convolution [22], we leverage the generated attention maps to perform dynamic convolution for different semantic regions of the original projected images and obtain the needed local feature. Finally, a coarse-to-fine strategy is adopted to merge the two features into the quality score. We propose a feature disentangling loss to improve feature discrepancy and a branch-wise quality ranking loss to maintain a progressive quality prediction. The latter loss enables the network to first take the coarse prediction from the global feature and gradually approach the finer-grained prediction by refining the local feature. We summarize the main contributions as follows:
-
•
We propose a new NR-PCQA method named AFQ-Net, which is consistent with human visual perception. Through the feedback module between the two branches, the global feature can effectively guide the extraction of local feature.
-
•
We propose a coarse-to-fine quality learning strategy. This strategy enables the network to effectively fuse the global and local feature and to achieve a progressive quality prediction.
- •
II Related Works
Point Cloud Quality Assessment. NR-PCQA aims to evaluate the perceptual quality of distorted point clouds without available references. NR metrics can be performed either over the 2D projection of point clouds or directly on the raw 3D data. For the projection-based methods, Liu et al. [1] proposed to project point clouds to multiple planes and leverage distortion classification information as an auxiliary feature to assist in the training of the network. Zhang et al.[25] integrated the point cloud projection into a video, followed by the utilization of video quality assessment methods to evaluate the quality of point clouds. Xie et al. [6] first obtained four types of projected images (texture, normal, depth, and roughness) and then developed a graph-based feature fusion module to fuse different features. For the methods performed directly on raw 3D data, Liu et al. [13] first transformed point clouds into voxels and then adopted an end-to-end sparse convolution network to learn the quality representation of point clouds. Shan et al. [3] modeled point clouds using graph structures and then inferred perceptual quality using a multi-task graph neural network. Tliba et al. [2] first divided point clouds into local patches and then employed a PointNet-based [26] architecture to extract features. In addition, some methods have been developed to leverage both point cloud projection and raw 3D data to extract integrated features. For example, Zhang et al. [4] utilized 2D and 3D encoders to separately extract features from point clouds and the corresponding projections and fused features using the attention mechanism. Wang et al. [27] proposed a collaborative cross-modal adversarial learning strategy to enhance the fused features extracted from two modalities.
Recently, some research [28, 29, 14, 30, 31, 32] has aimed to measure point cloud quality using payload information extracted from the compressed bitstream, which benefits real-time and nonintrusive quality monitoring. For example, Liu et al. [29] studied the relationship between the perceptual quality and the texture/geometry quantization parameter in video-based point cloud compression (V-PCC) algorithm and proposed a no-reference bitstream-layer model. In [30], Lv et al. proposed a new texture distortion model for lossless geometric coding in geometry-based point cloud compression (G-PCC) and integrated it with the position quantization scale (PQS) results for quality prediction.
Global-Local Feature Learning. Global-local feature learning is a prevalent strategy in quality assessment research, which is based on the fact that perceptual quality is determined by both high-level semantic and low-level details. Many previous studies [13, 4] separately extract the output of shallow and deep layers of networks as local and global feature and perform parallel processing, ignoring the interaction and promotion between features. In image/video quality assessment scenarios, researchers have proposed several methods to better utilize the two types of feature. An intriguing way [33] is to utilize the global feature to generate a hyper network [34] to replace the common quality regression module, where the hyper network represents the perception rule for a specific sample. In [35] and [36], Chen et al. and Hu et al. both proposed cross-scale fusion mechanisms that allow information to propagate between features. In [37], Chen et al. proposed an attention module to assign weight for multi-scale features by their importance. However, the above improvements focus more on feature post-processing, that is, how to increase the interaction between already generated features, ignoring the intrinsic temporal order of feature extraction in brain mechanisms. In comparison, we intend to use global feature directly to guide the “generation” of local feature, which is an asynchronous process and shows more conformity to visual perception.
III Method
III-A Overview
The aforementioned analysis reveals that human perception is a dual-stream asynchronous process, and global feature are usually first perceived to guide the extraction of local feature. On the basis of the philosophy, as illustrated in Fig. 2, the framework of our model is divided into three stages: i) First, global feature are extracted based on the projected three types of multi-view point cloud images (i.e., texture, depth, and occupancy). We divide the texture and depth images into patches and feed them into one vision transformer (ViT) [38] pre-trained on ImageNet [39]. The attention maps of the class token (a learnable embedding for semantic prediction) in the ViT are merged into the global feature. ii) Second, we utilize the attention maps to guide the extraction of local feature. We use the attention maps to generate a mask map and several regional filters, the former highlighting multiple semantic regions. Based on the generated mask map and regional filters, we perform dynamic convolution for different regions of the original projected images and obtain the compact local feature, which are then fused with the global feature. iii) Third, we perform a coarse-to-fine quality prediction. The global and fused features are both supervised by the overall quality score, and a branch-wise quality ranking loss is applied to guarantee a progressive quality prediction.



III-B Preprocessing
Instead of inferring point cloud quality directly in 3D space, we project point clouds into 2D images to better leverage mature 2D pre-trained models targeted for semantic-related tasks (e.g., classification). Given a point cloud , we render it into multi-view images from six perpendicular perspectives (that is, along the positive and negative directions of the x,y,z axes). To reduce information loss during the projection process, we obtain three different types of image to represent : texture images, depth images, and occupancy images. More specifically, we use the PointsRenderer function in the Pytorch3D [40] library for point cloud projection. The renderer uses an orthographic camera, and applies alpha compositing to generate the pixel values (please refer to [41] for more details). The acquired former two types of image reflect the original color and geometry information and are normalized to the range . The occupancy images are binary images locating the point cloud contents, where “1” indicates the point cloud contents while “0” indicates background areas. We separately denote the three types of multi-view images of as , and , where denotes the -th viewpoint.
III-C Attention-aware Global Feature Extraction
The vision transformer (ViT) has been shown to be capable of building long-term dependencies and prioritizing low-frequency information more than CNN [42, 43], making it a good choice for global feature extraction. To make the projected images compatible with the ViT, for and from an arbitrary perspective, we first partition them into non-overlapping patches.
Encoding by Vision Transformer. Given a texture patch and its corresponding depth patch , we separately map two patches into two vector representations and simply fuse them with position embedding (denoted by ), i.e.,
| (1) |
where is the token embedding; are two independent embedding operations.
Next, we follow [38] to prepend a learnable embedding named class token to the sequence of embedded patches. The token sequence can be represented as , where denotes the patch number. We then input into the ViT, which consists of consecutive identical transformer blocks and is initialized with the optimized weights on ImageNet. Taking the -th block as an example, it takes the output of the previous -th block as input to compute its output .


Attention Map Extraction. The ViT effectively models the relationship between patches using multi-head self-attention operation [44]. For the -th head of , the computational process can formulated as follows:
| (2) | ||||
where represent the -th self-attention operation, ; denote the layer normalization [45]; denotes the projection matrix; denotes the attention matrix. According to Eq. (2), we can see that each element of the attention matrix indicates the pairwise correlation between two patch representations in . Furthermore, the class token collects information from all patches via the self-attention operation. In traditional classification tasks, the output of the class token (i.e., ) will be transformed into a semantic prediction via a small MLP [38]. Therefore, the correlation between the class token and an arbitrary patch representation can effectively reflect the relevance between the patch and semantics, which facilitates the generation of needed global feature. We define the attention maps of the class token as:
| (3) | ||||
where denotes the concatenation operation. To better illustrate the semantic sensitivity of the attention maps, we visualize in Fig. 3 (b), from which we can observe that the attention maps accurately emphasize the content information in the projected images.
Global feature Generation. After extracting the attention maps of the class token, we further transform in the last transformer block into global feature. Specifically, for the -th viewpoint, the attention maps are processed by a convolution and an adaptive average pooling operation to generate a vector representation . Given the different proportions of content among perspectives, we follow [46] to adopt a simple occupancy-weighted fusion strategy, that is,
| (4) |
where denotes the occupancy ratio, that is, the proportion of “1” in the occupancy image . We take as the final global feature.
| Module | Layer | Input Size | Output Size |
|---|---|---|---|
| Filter Generation | Avg Pool | ||
| Conv | |||
| Conv | |||
| Mask Prediction | Conv | ||
| Interpolation | |||
| Argmax | |||
| Local Branch | DRConv | ||
| Conv | |||
| Max Pool | |||
| Conv | |||
| Global Max Pool |
III-D Feedback-guided Local Feature Extraction
As mentioned in Section I, human observers can easily distinguish different semantic regions with a glance, and feedback connections add details for each region with scrutiny. Therefore, instead of learning only one convolution kernel for all positions, we intend to adaptively generate filters for different regions based on the attention maps. Considering that the same semantic regions may share among different viewpoints, we first concatenate the texture and depth images of and compose the multi-view images into a stitched image denoted as , which corresponds to a stitched occupancy image denoted as .
Region-aware Feedback. In order to dynamically process different semantic regions, we choose DRConv [22] to take advantage of its idea of producing region-wise filters. Unlike the original DRConv that learns different filters and region divisions directly from the input images, we learn the two terms from the attention maps. This type of design can better exploit the guiding role of global feature.
Specifically, the attention maps of different viewpoints are first stitched as . Considering that the occupancy images directly distinguish the blank backgrounds using “0”, it is reasonable to merge the occupancy information into the attention maps to achieve better region division. For this purpose, the stitched occupancy image is first resized to the size of , and then multiply with each channel of , i.e.,
| (5) |
where is element-wise multiplication.
After enhancing the attention maps with occupancy information, we feed into a dual-stream embedder, which includes two modules: mask prediction module and filter generation module (see Fig. 4 (a) for the explicit structure). The former module outputs a guided mask representing the region division, in which pixel values vary from 0 to and indicate different semantic regions. The latter module generates groups of filter as , where the filter corresponds to the region , . The feature sizes of the feedback module are listed in Table I. Furthermore, we illustrate the generated masks used in Fig. 3 (c). From the figure, we can observe that the masks can distinguish different semantic regions (e.g., head, background), which is consistent with the HVS.
Based on and , we perform the region-aware convolution for the stitched image , which can be formulated as:
| (6) |
where denote the feature output in the position ; is the 2D convolution operation. By applying a specific convolution kernel on a specific region, we enable the network to differentiate regions of different semantics, which promotes the extraction of local feature.
Local Feature Generation. After performing a region-aware convolution for the stitched image , we propose to extract local feature through a shallow convolutional network, seeing Fig. 4. As illustrated in the figure, we use filters with a very small receptive field ( and ), which makes that the extracted features are localized and usually refer to some image details (e.g., edges, contours). We show some feature maps of the local branch in the Fig. 5. The feature maps mainly concern the contour details of point clouds, which is complementary to the semantic information indicated by the attention maps. Finally, we obtain the local feature indicated by .

III-E Coarse-to-fine Quality Prediction
After obtaining the global feature and the local feature , to increase the feature discrepancy, we define the feature disentangling loss as follows:
| (7) |
According to Eq. (7), when the cosine similarity between and becomes 0, it indicates that there is no linear correlation between the two features. A margin was given to the loss function because being exactly opposite could harm the representation ability [47].
Then we intend to make a coarse-to-fine quality prediction. Specifically, we define two quality regression heads for two branches:
| (8) | ||||
where is a full-connection layer; and denote the coarse-grained and fine-grained predicted quality scores respectively. Denoting the subjective mean opinion score (MOS) as , both two predictions are supervised by the regression loss as:
| (9) |
where the superscript “” denotes the -th samples in a mini-batch with the size of . To achieve a progressive quality prediction, we further propose a branch-wise quality ranking loss as:
| (10) |
where denotes the Spearman rank-order correlation coefficient between the predictions and the ground truths in the mini-batch. Note that we refer to [48] to create the differentiable implementation of the ranking metric. Eq. (10) enforces during training. Such a design can enable networks to take the coarse prediction from the global feature and gradually approach the finer-grained prediction by supplementing the local feature.
Finally, the overall loss function for training is defined as
| (11) |
where and are the weighting factors.
IV Experiments
IV-A Databases and Evaluation Protocols
Datasets. Our experiments are based on three commonly used PCQA datasets, including LS-PCQA Part I[13], SJTU-PCQA [23], and WPC [24]. LS-PCQA Part I consists of 930 annotated point clouds impaired by 31 types of distortion, which are generated from 85 references. SJTU-PCQA includes 9 reference point clouds and 378 distorted samples impaired with 7 types of distortions (e.g., color noise, downsampling) under 6 levels. WPC contains 20 reference point clouds and 740 distorted samples disturbed by 5 types of distortions (e.g., compression, gaussian noise).
Evaluation Metrics. Three widely adopted evaluation metrics are employed to quantify the level of agreement between predicted quality scores and the MOS: Spearman rank order correlation coefficient (SROCC), Pearson linear correlation coefficient (PLCC), and root mean square error (RMSE). To ensure consistency between predicted scores and MOSs, a nonlinear Logistic-4 regression is applied to map the predicted scores to the same dynamic range, following the recommendations suggested by the Video Quality Experts Group (VQEG) [49], i.e.,
| (12) |
where , , , and are the parameters fitted by minimizing the sum of squared errors.
| Type | Databases | SJTU-PCQA[23] | WPC[24] | LS-PCQA[13] | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| PLCC | SROCC | RMSE | PLCC | SROCC | RMSE | PLCC | SROCC | RMSE | ||
| FR | MSE-p2po[50] | 0.896 | 0.810 | 1.046 | 0.588 | 0.566 | 18.385 | 0.427 | 0.301 | 0.744 |
| MSE-p2pl [50] | 0.783 | 0.696 | 1.471 | 0.482 | 0.445 | 19.890 | 0.454 | 0.286 | 0.734 | |
| HD-p2po [50] | 0.787 | 0.708 | 1.428 | 0.384 | 0.258 | 21.055 | 0.393 | 0.273 | 0.757 | |
| HD-p2pl[50] | 0.755 | 0.688 | 1.552 | 0.371 | 0.308 | 21.169 | 0.405 | 0.271 | 0.751 | |
| [50] | 0.764 | 0.762 | 1.513 | 0.574 | 0.551 | 18.579 | 0.527 | 0.482 | 0.699 | |
| PCQM [51] | 0.836 | 0.874 | 2.378 | 0.702 | 0.749 | 22.823 | 0.208 | 0.426 | 0.789 | |
| GraphSIM [52] | 0.896 | 0.874 | 1.040 | 0.698 | 0.685 | 16.171 | 0.358 | 0.331 | 0.767 | |
| MS-GraphSIM [53] | 0.933 | 0.903 | 0.841 | 0.722 | 0.713 | 15.569 | 0.441 | 0.404 | 0.733 | |
| pointSSIM [54] | 0.751 | 0.725 | 1.539 | 0.479 | 0.461 | 19.905 | 0.225 | 0.164 | 0.804 | |
| MPED [55] | 0.903 | 0.900 | 1.000 | 0.695 | 0.681 | 16.313 | 0.613 | 0.609 | 0.646 | |
| TCDM [56] | 0.952 | 0.929 | 0.713 | 0.810 | 0.806 | 13.313 | 0.438 | 0.413 | 0.739 | |
| NR | PQA-Net[1] | 0.898 | 0.875 | 1.340 | 0.789 | 0.774 | 12.224 | 0.607 | 0.595 | 0.697 |
| ResSCNN[13] | 0.889 | 0.880 | 0.878 | 0.817 | 0.799 | 13.082 | 0.648 | 0.620 | 0.615 | |
| IT-PCQA[57] | 0.609 | 0.602 | 1.559 | 0.581 | 0.562 | 13.889 | 0.447 | 0.423 | 0.899 | |
| GPA-Net[3] | 0.901 | 0.891 | 0.864 | 0.796 | 0.775 | 12.976 | 0.623 | 0.602 | 0.705 | |
| MM-PCQA [4] | 0.939 | 0.910 | 0.805 | 0.846 | 0.844 | 12.028 | 0.644 | 0.605 | 0.621 | |
| GMS-3DQA [7] | 0.916 | 0.886 | 0.931 | 0.818 | 0.814 | 13.032 | 0.666 | 0.645 | 0.606 | |
| 3DTA [8] | 0.948 | 0.931 | 0.910 | 0.886 | 0.886 | 11.636 | 0.609 | 0.604 | 0.660 | |
| AFQ-Net | 0.957 | 0.930 | 0.678 | 0.897 | 0.899 | 9.971 | 0.690 | 0.680 | 0.583 | |
IV-B Implementation Details
We implement our model by PyTorch and conduct training and testing on the NVIDIA 3090 GPUs. All point clouds are rendered into three types of projected images with a spatial resolution of by PyTorch3D [40]. The used vision transformer is ViT-B [38].
Dataset Split. Considering the limited scale of the data set, the k-fold cross-validation strategy is used for the experiment to accurately estimate the performance of the proposed method. Following [4], 9-fold and 5-fold cross-validation is selected for SJTU-PCQA (9 references) and WPC (20 references). For LS-PCQA (85 references), we apply a 5-fold cross-validation. Note that there is no content overlap between the training and testing sets for the three databases. Specifically, the ratios of content in the training set and test set are 8:1, 16:4, and 68:17 for the three databases. For each fold, the performance on the test set with minimal training loss is recorded, and the average performance across all folds is recorded as the final result.
Training Strategy. All databases are trained for 50 epochs with a batch size of 8. During the training process, all training images are deployed with the traditional data enhancement strategy, i.e., randomly cropping the images to size such as [33, 4]. During the testing stage, following [33], 10 patches with size are randomly sampled and their corresponding prediction scores are average pooled to obtain the final quality score. We use the Adam [58] optimizer with weight decay . The learning rate is set separately as and for the pre-trained model and other parts, and is reduced by a rate of 0.9 every 5 epochs.
Network Details. To make the projected images compatible with ViT-B, the input patch size of the global branch is . The MSA head number is set by default as . The number of regions in the guided mask is set to and the kernel size of region-wise filters is set to . The global and local feature both have a dimension of . The weighting factors in the loss function are simply set to .
| M-PCCD | PQA-Net | GPA-Net | ResSCNN | IT-PCQA | MM-PCQA | GMS-3DQA | 3DTA | AFQ-Net |
|---|---|---|---|---|---|---|---|---|
| PLCC | 0.554 | 0.383 | 0.298 | 0.310 | 0.829 | 0.818 | 0.703 | 0.816 |
| SROCC | 0.478 | 0.396 | 0.267 | 0.315 | 0.810 | 0.826 | 0.765 | 0.834 |
| RMSE | 0.886 | 0.847 | 1.004 | 0.996 | 0.693 | 0.702 | 0.995 | 0.740 |
| BASICS | PQA-Net | GPA-Net | ResSCNN | IT-PCQA | MM-PCQA | GMS-3DQA | 3DTA | AFQ-Net |
| PLCC | 0.655 | 0.391 | 0.367 | 0.465 | 0.793 | 0.895 | 0.896 | 0.905 |
| SROCC | 0.387 | 0.352 | 0.344 | 0.369 | 0.738 | 0.807 | 0.825 | 0.793 |
| RMSE | 0.797 | 0.975 | 0.997 | 0.878 | 0.628 | 0.472 | 0.488 | 0.449 |

IV-C Performance Comparison
Overall Performance Comparison. Table II lists the experimental results on META-3D . The proposed method, AFQ-Net, is compared with 11 FR-PCQA metrics, and 7 NR-PCQA metrics. we run all published codes to produce the results. We strictly retrain the available baselines with the same database split set up to keep the comparison fair. In addition, for the FR-PCQA methods that require no training, we simply validate them on the same testing sets and record the average performance.


For each database, the top two performance results for each evaluation criterion are highlighted in boldface and underline. We can see that the proposed AFQ-Net exhibits outstanding performance across all three datasets. Especially, the proposed AFQ-Net presents remarkable performance on the LS-PCQA, a database with wide diversity in terms of both content and distortion type, which demonstrates the adaptability and robustness of our model. In comparison, the performance of the existing FR and NR methods varies significantly across different datasets. For example, GMS-3DQA demonstrates strong performance on LS-PCQA but exhibits poor performance on WPC; 3DTA works well on SJTU-PCQA but presents inferior performance on LS-PCQA. IT-PCQA performs poorly because it is based on domain adaptation, in which the labels of point clouds are not utilized in the training. Meanwhile, it should be noted that our method presents competitive performance compared to the FR-PCQA methods despite the inaccessibility of the reference information.
To further validate the model performance in compression scenarios, we test the model performance on two PCQA databases that consist only of compressed samples, i.e., the M-PCCD database (232 distorted samples corresponding to 8 references) [59] and the BASICS database (1494 distorted samples corresponding to 75 references) [60]. 4-fold and 5-fold cross-validations are applied for the two databases, respectively. We report the performance of different NR-PCQA metrics on M-PCCD and BASICS in Tab III. According to the table, we can see that AFQ-Net provides the best SROCC on M-PCCD and the best PLCC and RMSE on BASICS, which demonstrates that the proposed method is sensitive to compression distortions. MM-PCQA and 3DTA both presents inferior performance on one database (MM-PCQA on BASICS and 3DTA on M-PCCD). GMS-3DQA works well, which is also based on 2D projection. Based on the results, it seems that metrics using 3D information present unstable performance on different databases. This may be because those metrics only utilize some local patches for quality prediction, which lacks global perception and is easily affected by point density. However, for those metrics that only leverage 2D projection, how to mimic different rendering strategies for different databases has not yet been explored in depth.
We also show some examples of distorted point clouds with the subjective MOS, the predicted score of the proposed AFQ-Net and other NR-PCQA models in Fig. 6, where two point clouds are impaired by G-PCC trisoup compression and additive noise. It can be seen that the predicted score provided by AFQ-Net aligns well with subjective perception. In comparison, other models are not sensitive to quality changes because their predicted scores for two point clouds are relatively close.
Qualitative Analysis. To demonstrate that our model can attentively capture the critical features related to distortions, we also present a qualitative analysis using a prevalent tool for network explanation, that is, Grad-CAM++ [61]. As illustrated in Fig. 7, subfigure (a) presents three samples with the same content but impaired by three different distortions (i.e., Rayleigh noise, V-PCC compression, and G-PCC compression), and subfigure (b) presents their Grad-CAM++ maps that reflect what makes the network perform decision. Note that the extracted activation maps correspond to the last convonlutional layer on the local branch (i.e., the Conv in Fig. 4 (b)). From the figure, we have the following observations: i) the activation map associated with Rayleigh noise distortion mostly highlights these flat regions. This is mainly because Rayleigh noise is located at isolated points. According to texture masking effect [62], noise in complex texture regions (e.g., orange box) is generally harder to perceive than noise in homogeneous regions (e.g., blue box). ii) For two types of compression distortion, attribute quantization in V-PCC leads to abnormal color mutations, whereas Octree decomposition in G-PCC causes a sparse point distribution. Consequently, the activation maps associated with V-PCC and G-PCC emphasize the whole point cloud because these deformations are severe and not localized. Based on these instances, we can see that the proposed AFQ-Net can effectively capture and distinguish various distortions.
| Train | Test | PQA-Net | GPA-Net | ResSCNN | IT-PCQA | MM-PCQA | GMS-3DQA | 3DTA | AFQ-Net |
|---|---|---|---|---|---|---|---|---|---|
| LS | SJTU | 0.403 | 0.618 | 0.567 | 0.366 | 0.715 | 0.811 | 0.671 | 0.777 |
| SJTU | LS | 0.281 | 0.333 | 0.338 | 0.303 | 0.373 | 0.366 | 0.288 | 0.354 |
| LS | WPC | 0.427 | 0.506 | 0.435 | 0.331 | 0.323 | 0.696 | 0.545 | 0.753 |
| WPC | LS | 0.285 | 0.346 | 0.339 | 0.278 | 0.515 | 0.451 | 0.386 | 0.625 |
| WPC | SJTU | 0.255 | 0.549 | 0.568 | 0.395 | 0.740 | 0.517 | 0.726 | 0.558 |
| SJTU | WPC | 0.266 | 0.420 | 0.271 | 0.310 | 0.301 | 0.523 | 0.339 | 0.385 |
Cross-Dataset Evaluation. The cross-dataset evaluation is conducted to test the generalizability of the NR-PCQA methods when encountering various data distributions. In Table IV, we first train the compared models on one database and test the trained model on another database, and then swap the training set and the test set. Note that we use the whole database for training or testing. For each validation, we record the result with minimal training loss and report the results in Table IV. From the table, we can see that: i) AFQ-Net achieves good performance when trained on LS-PCQA, which shows the generalizability of our model when rich content categories are provided. ii) Almost all methods (including AFQ-Net) show poor performance when trained on SJTU-PCQA and tested on LS-PCQA and WPC (denoted by SJTU2LS and SJTU2WPC validation). This is largely due to the limited and extremely biased content in SJTU-PCQA (5 out of 9 contents are about the human body). iii) AFQ-Net trained on WPC shows opposite trends when validated on SJTU-PCQA and LS-PCQA. More specifically, AFQ-Net performs the best when validated on LS-PCQA but presents relatively inferior performance when validated on SJTU-PCQA. This may be due to the large difference in content categories between SJTU-PCQA and WPC (human body vs. object). Notably, some recent methods demonstrate superior cross-dataset performance on several validations. For instance, MM-PCQA and 3DTA perform well on the WPC2SJTU validation, likely due to their use of 3D information as input, which enables them to capture common density variations in SJTU-PCQA more effectively. GMS-3DQA achieves the best results on the SJTU2WPC validation, potentially because of its mini-patch sampling strategy. The mini-patch map in GMS-3DQA preserves the distortion patterns of point clouds while blurring content information, which appears advantageous when there are substantial content differences between databases. To enhance the performance of AFQ-Net, a promising approach would be to replace the stitched image in the local branch with the mini-patch map, thus improving its capacity to evaluate local distortions. Additionally, directly applying the asynchronous feedback strategy for 3D data is also a practical and intriguing avenue.

| Index | Global | Local | Feedback | WPC | LS-PCQA | ||
|---|---|---|---|---|---|---|---|
| PLCC | SROCC | PLCC | SROCC | ||||
| (1) | ✓ | ✗ | ✗ | 0.8291 | 0.8233 | 0.6736 | 0.6512 |
| (2) | ✗ | ✓ | ✗ | 0.3940 | 0.2766 | 0.4502 | 0.4129 |
| (3) | ✓ | ✓ | ✗ | 0.8701 | 0.8692 | 0.6786 | 0.6662 |
| (4) | ✓ | ✓ | ✓ | 0.8974 | 0.8987 | 0.6902 | 0.6796 |
IV-D Ablation Studies
Ablation Study for the Key Modules. To verify the effectiveness of the key modules in the AFQ-Net, we further investigate the contribution of different components and report the results in Table V. In the table, the index (1) and (2) denote using only global branch or local branch for quality prediction respectively. (3) indicates one dual-branch network without feedback connection (i.e., replacing the DRConv in Fig. 4 (b) with convolution), while (4) represents the full model. From the table, we have the following observations: i) Seeing (1) and (2), we see that using only the global branch performs better than using only the local branch structure. This is mainly because the parameter size of the global branch is significantly larger than that of the local branch; consequently, the global branch has stronger fitting ability. Meanwhile, the pre-trainning on ImageNet inject the global branch some quality-related prior knowledge, which boosts its performance. ii) Comparing (1) or (2) with (3), the dual-branch structure performs significantly better than the single-branch structure, demonstrating the complementarity of the two features; iii) Seeing (3) and (4), the feedback module further brings a noticeable gain, which verifies the effectiveness of the feedback mechanism in visual quality assessment.

Ablation Study for the Region Count. We test the performance of AFQ-Net under different values to investigate the influence of the division granularity and report the results in Fig. 8. We see that SJTU-PCQA, WPC and LS-PCQA respectively provide the best performance with and . This may be due to the different amount of content in the three databases. SJTU-PCQA has limited and extremely biased content, so few divisions can distinguish different semantic regions while too many divisions cause over-segmentation for the same region. In comparison, WPC and LS-PCQA have more references (20 for WPC and 85 for LS-PCQA) and richer content including different object categories, for which cases large values can benefit the model performance.
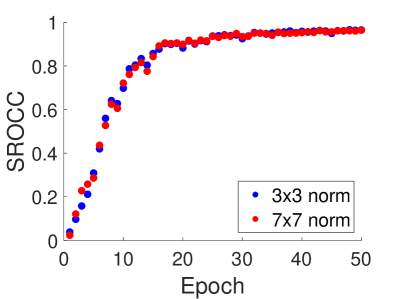
Ablation Study for the Kernel Size. We test the performance of AFQ-Net under different values to investigate the influence of the kernel size of region-wise filters and report the results in Fig. 9 (a) and (b). We see that when the kernel size is too large (e.g., ), the model performance will decrease. Especially, kernel causes inferior results on LS-PCQA. Further looking at this case, we find that larger kernel size in DRConv will generate larger element values in the local feature, which will make the local feature contribute more to the prediction, thus affecting the convergence speed of the network. More specifically, given the local feature , we define its average absolute value of as .We have illustrated the SROCC (on the training set) trend and the trend versus the training epoch for and kernel in Fig. 10 (a) and (b). From Fig. 10 (b), we can see the of kernel is significantly larger than that of kernel; according to Fig. 10 (a), the corresponding SROCC on the training set converges more slowly. In fact, DRConv tends to generate element values in the range of for convolution kernels, therefore causing larger results with increasing kernel size. Meanwhile, the complexity of LS-PCQA make the network harder to converge compared to WPC and SJTU-PCQA. A reasonable solution is to add a normalization factor for different kernel size, such as for kernel and for kernel. We report the SROCC and the trend of two normalized kernels in Fig. 10 (c) and (d). We can see the normalized and kernels present similar trends in both two sub-figures. Meanwhile, the final [PLCC,SROCC,RMSE] criteria for the two normalized kernels are and respectively, which demonstrates that the normalization can effectively eliminate the performance drop caused by large kernels.



Ablation Study for the Input Image Types. Three types of image are generated during the preprocessing stage. The depth images serve as a supplement to texture images in the network input stage, while the occupancy images help perform multi-view fusion and region-aware feedback. We conduct experiments to validate the effectiveness of the three types of input and list the results in Table VI. In the table, index (1) and (2) represent using only texture or depth images for quality prediction respectively. (3), (4), and (5) denote pairwise combinations of different image types, including “texture+depth”, “depth+occupancy”, and “texture+occupancy”, while (6) indicates the full model. Note that the framework using only occupancy images is infeasible because they are only used to generate some weights and masks. From the table, we can observe: i) based on (1) and (2), model using texture images performs far better than that using depth images. It is reasonable because texture images generally contain visual information than depth images. ii) Comparing (1) with (3), introducing the depth images brings a marginal gain and even impairs the model performance. This is due to the fact that geometry distortions can also be reflected in texture images, therefore reducing the importance of depth information. Especially, most distortion types in LS-PCQA do not cause any geometry deformation, which result in relatively inferior performance when injecting depth information. iii) Seeing (1) and (5), (3) and (6), the introduction of occupancy images leads to noticeable improvements for the three criteria, demonstrating the importance of occupancy information in our model.
Ablation Study for the Loss Functions. The proposed network is trained using the regression loss , the feature disentangling loss , and the quality ranking loss . We evaluate the effect of each loss function and report the results in Table VII. In the table, index (1), (2) and (3) represent using single loss term for quality prediction respectively. (3), (4), and (5) denote pairwise combinations of different loss terms, including , , and , while (6) indicates the full loss. From the table, it is observed: i) seeing (1), (4), and (5), both and benefit the model performance, demonstrating the effectiveness of the two loss functions. ii) According to (6) and (7), the full loss provides noticeable gain over the combination of on LS-PCQA but presents marginal gain on WPC. The reason may be that also achieves feature disentanglement to some extent, which weakens the effect of . Considering only measures the linear similarity between global and local features, one possible avenue for further improvement is to minimize non-linear dependence between two features, such as mutual information.
| Index | Texture | Depth | Occupancy | WPC | LS-PCQA | ||
| PLCC | SROCC | PLCC | SROCC | ||||
| (1) | ✓ | ✗ | ✗ | 0.8815 | 0.8850 | 0.6734 | 0.6583 |
| (2) | ✗ | ✓ | ✗ | 0.3374 | 0.2128 | 0.2354 | 0.0485 |
| (3) | ✓ | ✓ | ✗ | 0.8821 | 0.8826 | 0.6655 | 0.6508 |
| (4) | ✗ | ✓ | ✓ | 0.3908 | 0.2548 | 0.2398 | 0.0154 |
| (5) | ✓ | ✗ | ✓ | 0.8971 | 0.8979 | 0.6907 | 0.6744 |
| (6) | ✓ | ✓ | ✓ | 0.8974 | 0.8987 | 0.6902 | 0.6796 |
V Conclusion
In this paper, we aim to solve the problem of global-local feature learning in NR-PCQA and propose an asynchronous feedback network based on the human visual mechanisms. Taking into account the guiding role of global feature in quality perception, our network is implemented by a dual-branch architecture connected by a feedback module. Utilizing the attention maps generated by the global branch, we perform region-aware convolution to derive the local feature. A coarse-to-fine learning strategy is also adopted to fuse the global and local feature into the final quality prediction. The proposed AFQ-Net shows a consistent and reliable correlation with subjective evaluation on three PCQA benchmarks. Further ablation studies have supported the model design by examining its key modules and parameter values.
| Index | WPC | LS-PCQA | |||||
| PLCC | SROCC | PLCC | SROCC | ||||
| (1) | ✓ | ✗ | ✗ | 0.8851 | 0.8868 | 0.6696 | 0.6538 |
| (2) | ✗ | ✓ | ✗ | 0.1985 | 0.1133 | 0.3097 | 0.0236 |
| (3) | ✗ | ✗ | ✓ | 0.3724 | 0.2317 | 0.2428 | 0.0660 |
| (4) | ✓ | ✓ | ✗ | 0.8898 | 0.8908 | 0.6704 | 0.6571 |
| (5) | ✗ | ✓ | ✓ | 0.4247 | 0.3418 | 0.2802 | 0.1379 |
| (6) | ✓ | ✗ | ✓ | 0.8970 | 0.8981 | 0.6704 | 0.6600 |
| (7) | ✓ | ✓ | ✓ | 0.8974 | 0.8987 | 0.6902 | 0.6796 |
References
- [1] Q. Liu, H. Yuan, H. Su, H. Liu, Y. Wang, H. Yang, and J. Hou, “PQA-Net: Deep no reference point cloud quality assessment via multi-view projection,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 31, no. 12, pp. 4645–4660, 2021.
- [2] M. Tliba, A. Chetouani, G. Valenzise, and F. Dufaux, “A novel no-reference point clouds quality metric using transformer similar architecture,” in GRETSI’23: XXIXème Colloque Francophone de Traitement du Signal et des Images, 2023.
- [3] Z. Shan, Q. Yang, R. Ye, Y. Zhang, Y. Xu, X. Xu, and S. Liu, “GPA-Net: No-reference point cloud quality assessment with multi-task graph convolutional network,” IEEE Transactions on Visualization and Computer Graphics, vol. 30, no. 8, pp. 4955–4967, 2024.
- [4] Z. Zhang, W. Sun, X. Min et al., “MM-PCQA: Multi-modal learning for no-reference point cloud quality assessment,” in International Joint Conference on Artificial Intelligence, 2023, pp. 1–1.
- [5] R. Tu, G. Jiang, M. Yu, T. Luo, Z. Peng, and F. Chen, “V-PCC projection based blind point cloud quality assessment for compression distortion,” IEEE Transactions on Emerging Topics in Computational Intelligence, vol. 7, no. 2, pp. 462–473, 2022.
- [6] W. Xie, K. Wang, Y. Ju, and M. Wang, “pmBQA: Projection-based blind point cloud quality assessment via multimodal learning,” in Proceedings of the 31st ACM International Conference on Multimedia, 2023, pp. 3250–3258.
- [7] Z. Zhang, W. Sun, H. Wu, Y. Zhou, C. Li, Z. Chen, X. Min, G. Zhai, and W. Lin, “GMS-3DQA: Projection-based grid mini-patch sampling for 3D model quality assessment,” ACM Transactions on Multimedia Computing, Communications and Applications, 2023.
- [8] L. Zhu, J. Cheng, X. Wang, H. Su, H. Yang, H. Yuan, and J. Korhonen, “3DTA: No-reference 3D point cloud quality assessment with twin attention,” IEEE Transactions on Multimedia, 2024.
- [9] B. Mu, F. Shao, X. Chai, Q. Liu, H. Chen, and Q. Jiang, “Multi-view aggregation transformer for no-reference point cloud quality assessment,” Displays, vol. 78, p. 102450, 2023.
- [10] X. Chai, F. Shao, B. Mu, H. Chen, Q. Jiang, and Y.-S. Ho, “Plain-PCQA: No-reference point cloud quality assessment by analysis of plain visual and geometrical components,” IEEE Transactions on Circuits and Systems for Video Technology, 2024.
- [11] Z. Shan, Y. Zhang, Q. Yang, H. Yang, Y. Xu, J.-N. Hwang, X. Xu, and S. Liu, “Contrastive pre-training with multi-view fusion for no-reference point cloud quality assessment,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 25 942–25 951.
- [12] W. Chen, Q. Jiang, W. Zhou, L. Xu, and W. Lin, “Dynamic hypergraph convolutional network for no-reference point cloud quality assessment,” IEEE Transactions on Circuits and Systems for Video Technology, 2024.
- [13] Y. Liu, Q. Yang, Y. Xu, and L. Yang, “Point cloud quality assessment: Dataset construction and learning-based no-reference metric,” ACM Transactions on Multimedia Computing, Communications and Applications, vol. 19, no. 2s, pp. 1–26, 2023.
- [14] H. Su, Q. Liu, H. Yuan, Q. Cheng, and R. Hamzaoui, “Support vector regression-based reduced-reference perceptual quality model for compressed point clouds,” IEEE Transactions on Multimedia, 2023.
- [15] D. Li, T. Jiang, W. Lin, and M. Jiang, “Which has better visual quality: The clear blue sky or a blurry animal?” IEEE Transactions on Multimedia, vol. 21, no. 5, pp. 1221–1234, 2018.
- [16] Q. Yang, J. Jung, H. Wang, X. Xu, and S. Liu, “TSMD: A database for static color mesh quality assessment study,” in IEEE International Conference on Visual Communications and Image Processing, 2023, pp. 1–5.
- [17] Y. Shinohara, H. Hirase, M. Watanabe, M. Itakura, M. Takahashi, and R. Shigemoto, “Left-right asymmetry of the hippocampal synapses with differential subunit allocation of glutamate receptors,” Proceedings of the National Academy of Sciences, vol. 105, no. 49, pp. 19 498–19 503, 2008.
- [18] R. Kawakami, Y. Shinohara, Y. Kato, H. Sugiyama, R. Shigemoto, and I. Ito, “Asymmetrical allocation of nmda receptor 2 subunits in hippocampal circuitry,” Science, vol. 300, no. 5621, pp. 990–994, 2003.
- [19] D. Navon, “Forest before trees: The precedence of global features in visual perception,” Cognitive psychology, vol. 9, no. 3, pp. 353–383, 1977.
- [20] C. Cao, X. Liu, Y. Yang, Y. Yu, J. Wang, Z. Wang, Y. Huang, L. Wang, C. Huang, W. Xu et al., “Look and think twice: Capturing top-down visual attention with feedback convolutional neural networks,” in Proceedings of the IEEE international conference on computer vision, 2015, pp. 2956–2964.
- [21] Q. Zhang, J. Lai, Z. Feng, and X. Xie, “Seeing like a human: Asynchronous learning with dynamic progressive refinement for person re-identification,” IEEE Transactions on Image Processing, vol. 31, pp. 352–365, 2021.
- [22] J. Chen, X. Wang, Z. Guo, X. Zhang, and J. Sun, “Dynamic region-aware convolution,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 8064–8073.
- [23] Q. Yang, H. Chen, Z. Ma, Y. Xu, R. Tang, and J. Sun, “Predicting the perceptual quality of point cloud: A 3D-to-2D projection-based exploration,” IEEE Transactions on Multimedia, vol. 23, pp. 3877–3891, 2020.
- [24] Q. Liu, H. Su, Z. Duanmu, W. Liu, and Z. Wang, “Perceptual quality assessment of colored 3D point clouds,” IEEE Transactions on Visualization and Computer Graphics, 2022.
- [25] Z. Zhang, W. Sun, Y. Zhu et al., “Treating point cloud as moving camera videos: A no-reference quality assessment metric,” arXiv preprint arXiv:2208.14085, 2022.
- [26] C. R. Qi, H. Su, K. Mo, and L. J. Guibas, “PointNet: Deep learning on point sets for 3D classification and segmentation,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 652–660.
- [27] J. Wang, W. Gao, and G. Li, “Applying collaborative adversarial learning to blind point cloud quality measurement,” IEEE Transactions on Instrumentation and Measurement, 2023.
- [28] Q. Liu, H. Yuan, R. Hamzaoui, H. Su, J. Hou, and H. Yang, “Reduced reference perceptual quality model with application to rate control for video-based point cloud compression,” IEEE Transactions on Image Processing, vol. 30, pp. 6623–6636, 2021.
- [29] Q. Liu, H. Su, T. Chen, H. Yuan, and R. Hamzaoui, “No-reference bitstream-layer model for perceptual quality assessment of V-PCC encoded point clouds,” IEEE Transactions on Multimedia, vol. 25, pp. 4533–4546, 2022.
- [30] J. Lv, H. Su, Q. Liu, and H. Yuan, “No-reference bitstream-based perceptual quality assessment of octree-lifting encoded 3D point clouds,” IEEE Transactions on Visualization and Computer Graphics, 2024.
- [31] D. Duan, H. Su, Q. Liu, H. Yuan, W. Gao, J. Song, and Z. Wang, “Perceptual quality assessment of octree-raht encoded 3D point clouds,” arXiv preprint arXiv:2410.06729, 2024.
- [32] J. Long, H. Su, Q. Liu, H. Yuan, W. Gao, J. Song, and Z. Wang, “Perceptual quality assessment of trisoup-lifting encoded 3D point clouds,” arXiv preprint arXiv:2410.06689, 2024.
- [33] S. Su, Q. Yan, Y. Zhu, C. Zhang, X. Ge, J. Sun, and Y. Zhang, “Blindly assess image quality in the wild guided by a self-adaptive hyper network,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 3667–3676.
- [34] D. Ha, A. Dai, and Q. V. Le, “Hypernetworks,” arXiv preprint arXiv:1609.09106, 2016.
- [35] C. Chen, J. Mo, J. Hou, H. Wu, L. Liao, W. Sun, Q. Yan, and W. Lin, “TOPIQ: A top-down approach from semantics to distortions for image quality assessment,” arXiv preprint arXiv:2308.03060, 2023.
- [36] B. Hu, G. Zhu, L. Li, J. Gan, W. Li, and X. Gao, “Blind image quality index with cross-domain interaction and cross-scale integration,” IEEE Transactions on Multimedia, vol. 26, pp. 2729–2739, 2023.
- [37] B. Chen, L. Zhu, G. Li, F. Lu, H. Fan, and S. Wang, “Learning generalized spatial-temporal deep feature representation for no-reference video quality assessment,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 32, no. 4, pp. 1903–1916, 2021.
- [38] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly et al., “An image is worth 16x16 words: Transformers for image recognition at scale,” arXiv preprint arXiv:2010.11929, 2020.
- [39] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in 2009 IEEE Conference on Computer Vision and Pattern Recognition. Ieee, 2009, pp. 248–255.
- [40] N. Ravi, J. Reizenstein, D. Novotny, T. Gordon, W.-Y. Lo, J. Johnson, and G. Gkioxari, “Accelerating 3D deep learning with pytorch3d,” arXiv preprint arXiv:2007.08501, 2020.
- [41] O. Wiles, G. Gkioxari, R. Szeliski, and J. Johnson, “SynSin: End-to-end view synthesis from a single image,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 7467–7477.
- [42] A. Ghiasi, H. Kazemi, E. Borgnia, S. Reich, M. Shu, M. Goldblum, A. G. Wilson, and T. Goldstein, “What do vision transformers learn? a visual exploration,” arXiv preprint arXiv:2212.06727, 2022.
- [43] N. Park and S. Kim, “How do vision transformers work?” arXiv preprint arXiv:2202.06709, 2022.
- [44] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” Advances in neural information processing systems, vol. 30, 2017.
- [45] J. L. Ba, J. R. Kiros, and G. E. Hinton, “Layer normalization,” arXiv preprint arXiv:1607.06450, 2016.
- [46] X. Wu, Y. Zhang, C. Fan, J. Hou, and S. Kwong, “Subjective quality database and objective study of compressed point clouds with 6DoF head-mounted display,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 31, no. 12, pp. 4630–4644, 2021.
- [47] M. Kim, M. Cho, and S. Lee, “Feature disentanglement learning with switching and aggregation for video-based person re-identification,” in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2023, pp. 1603–1612.
- [48] M. Blondel, O. Teboul, Q. Berthet, and J. Djolonga, “Fast differentiable sorting and ranking,” in International Conference on Machine Learning. PMLR, 2020, pp. 950–959.
- [49] J. Antkowiak, J. Baina, V. Baroncini et al., “Final report from the video quality experts group on the validation of objective models of video quality assessment,” march 2000.
- [50] MPEG reference software. [Online]. Available: http://mpegx.int-evry.fr/software/MPEG/PCC/mpeg-pcc-dmetric.git
- [51] G. Meynet, Y. Nehmé, J. Digne, and G. Lavoué, “PCQM: A full-reference quality metric for colored 3D point clouds,” in QoMEX, 2020, pp. 1–6.
- [52] Q. Yang, Z. Ma, Y. Xu, Z. Li, and J. Sun, “Inferring point cloud quality via graph similarity,” IEEE transactions on pattern analysis and machine intelligence, vol. 44, no. 6, pp. 3015–3029, 2020.
- [53] Y. Zhang, Q. Yang, and Y. Xu, “MS-GraphSIM: Inferring point cloud quality via multiscale graph similarity,” in Proceedings of the 29th ACM International Conference on Multimedia, 2021, pp. 1230–1238.
- [54] E. Alexiou and T. Ebrahimi, “Towards a point cloud structural similarity metric,” in ICMEW, 2020, pp. 1–6.
- [55] Q. Yang, Y. Zhang, S. Chen, Y. Xu, J. Sun, and Z. Ma, “MPED: Quantifying point cloud distortion based on multiscale potential energy discrepancy,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 5, pp. 6037–6054, 2022.
- [56] Y. Zhang, Q. Yang, Y. Zhou, X. Xu, L. Yang, and Y. Xu, “TCDM: Transformational complexity based distortion metric for perceptual point cloud quality assessment,” IEEE Transactions on Visualization and Computer Graphics, vol. 30, no. 10, pp. 6707–6724, 2024.
- [57] Q. Yang, Y. Liu, S. Chen, Y. Xu, and J. Sun, “No-reference point cloud quality assessment via domain adaptation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 21 179–21 188.
- [58] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014.
- [59] E. Alexiou, I. Viola, T. M. Borges, T. A. Fonseca, R. L. De Queiroz, and T. Ebrahimi, “A comprehensive study of the rate-distortion performance in MPEG point cloud compression,” APSIPA Transactions on Signal and Information Processing, vol. 8, p. e27, 2019.
- [60] A. Ak, E. Zerman, M. Quach, A. Chetouani, A. Smolic, G. Valenzise, and P. Le Callet, “BASICS: Broad quality assessment of static point clouds in a compression scenario,” IEEE Transactions on Multimedia, 2024.
- [61] A. Chattopadhay, A. Sarkar, P. Howlader, and V. N. Balasubramanian, “Grad-CAM++: Generalized gradient-based visual explanations for deep convolutional networks,” in 2018 IEEE winter conference on applications of computer vision (WACV). IEEE, 2018, pp. 839–847.
- [62] Y. Zhang, Q. Yang, Y. Xu, and S. Liu, “Perception-guided quality metric of 3D point clouds using hybrid strategy,” IEEE Transactions on Image Processing, vol. 33, pp. 5755–5770, 2024.