Asynchronous Byzantine Approximate Consensus in Directed Networks
Abstract.
In this work, we study the approximate consensus problem in asynchronous message-passing networks where some nodes may become Byzantine faulty. We answer an open problem raised by Tseng and Vaidya, 2012, proposing the first algorithm of optimal resilience for directed networks. Interestingly, our results show that the tight condition on the underlying communication networks for asynchronous Byzantine approximate consensus coincides with the tight condition for synchronous Byzantine exact consensus. Our results can be viewed as a non-trivial generalization of the algorithm by Abraham et al., 2004, which applies to the special case of complete networks. The tight condition and techniques identified in the paper shed light on the fundamental properties for solving approximate consensus in asynchronous directed networks.
1. Introduction
The extensively studied fault-tolerant consensus problem (Pease et al., 1980) is a fundamental building block of many important distributed computing applications (Lynch, 1996). The FLP result (Fischer et al., 1985b) states that it is impossible to achieve exact consensus in asynchronous networks where nodes may crash (exact consensus requires nonfaulty nodes to reach an agreement on an identical value). The FLP impossibility result led to the study of weaker variations, including approximate consensus (Dolev et al., 1986). With approximate consensus, nonfaulty nodes only need to output values that are within of each other for a given . Practical applications of approximate consensus range from sensor fusion (Benediktsson and Swain, 1992) and load balancing (Cybenko, 1989), to natural systems like flocking (Vicsek et al., 1995) and opinion dynamics (Hegselmann and Krause, 2002). The feasibility of achieving consensus depends on the type of faults considered in the system. The literature has mainly focused on crash and Byzantine faults, the latter being the worst case since the misbehavior of faults may be arbitrary. In this work, we focus on the asynchronous Byzantine approximate consensus problem under the existence of at most faults.
Another important parameter affecting the feasibility is the topology of the underlying communication network in which nodes represent participants that reliably exchange messages through edges. The relation between network topology and feasibility in undirected networks was studied shortly after the introduction of the respective problems (e.g., (Lynch, 1996; Dolev, 1982)). For , connectivity of the network and upper bound on the number of faults, Table 1 summarizes the well-known necessary and sufficient topological conditions for achieving exact consensus and approximate consensus in various settings where is undirected. In undirected networks, satisfying the necessary graph conditions in Table 1 also implies feasibility of reliable message transmission (RMT) (cf. (Dolev et al., 1993)), which can be exploited to simulate algorithms designed for complete networks.
| Crash fault | Byzantine fault | |
|---|---|---|
|
Synchronous system
(exact consensus) |
and
(Lynch, 1996) |
and
(Dolev, 1982) |
|
Asynchronous system
(approximate consensus) |
and
(Lynch, 1996) |
and
(Fischer et al., 1985a; Abraham et al., 2004; Dolev et al., 1993) |
The study of consensus in directed graphs is largely motivated by wireless networks wherein different nodes may have different transmission range, resulting in directed communication links. While the necessary and sufficient conditions for undirected graphs have been known for many years, their generalizations for directed graphs appeared only after 2012, e.g., (Tseng and Vaidya, 2012, 2015; LeBlanc et al., 2013; Vaidya et al., 2012). This is mainly due to the fact that no direct relation appears between reliable message transmission and consensus in directed graphs.
As Table 2 summarizes, for directed graphs, Tseng and Vaidya (Tseng and Vaidya, 2015, 2012) obtained necessary and sufficient conditions for solving consensus in the presence of crash faults in synchronous and asynchronous systems both. However, they were able to obtain such conditions for Byzantine faults only for synchronous systems. The determination of a tight condition for the asynchronous Byzantine model remains open since 2012. This paper closes this gap in the results. We identify a family of new conditions which we prove equivalent to the ones obtained in (Tseng and Vaidya, 2012, 2015), offering an important intuition, which essentially leads to the answer of this open question. Our condition family consists of 1-reach, 2-reach and 3-reach conditions, which are later defined in Section 2.111The general k-reach condition family, presented in the appendix, encompasses conditions 1-reach, 2-reach, 3-reach and may be of further interest. Results from (Tseng and Vaidya, 2012, 2015) imply that the 3-reach condition is tight for exact Byzantine consensus in synchronous systems. A key contribution of this paper is to show that the 3-reach condition is also necessary and sufficient for asynchronous Byzantine consensus in directed graphs.
| Crash fault | Byzantine fault | |
|---|---|---|
|
Synchronous system
(Exact consensus) |
1-reach condition (see Section 2)
Tseng and Vaidya 2015 (Tseng and Vaidya, 2015) |
3-reach condition (see Section 2)
Tseng and Vaidya 2015 (Tseng and Vaidya, 2015) |
|
Asynchronous system
(Approximate consensus) |
2-reach condition (see Section 2)
Tseng and Vaidya 2012, 2015 (Tseng and Vaidya, 2012, 2015) |
3-reach condition (this paper)
open problem since 2012 |
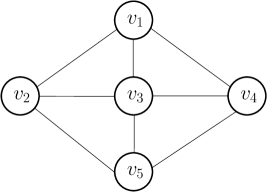
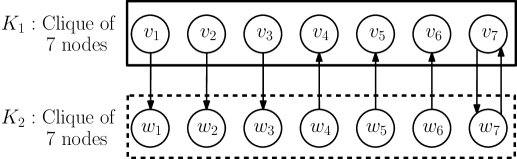
Essentially, obtaining the tight graph conditions for directed graphs is much more difficult than the undirected case, since consensus may be possible even if reliable message transmission (RMT) is not possible between every pair of nodes. This is unlike the case of undirected graphs, as observed previously. For instance, Figure 1(a) presents an undirected network, where synchronous exact Byzantine consensus is possible for . In this graph, all-pair RMT is possible, since allows any pair of nodes to communicate through at least disjoint paths. Note that removing any edge will reduce , which will make both RMT and consensus impossible. Such an all-pair RMT is not necessary in directed graphs. In particular, Figure 1(b) shows a network that satisfies the 3-reach condition (stated later in Section 2) – this network includes two cliques, each containing 7 nodes, and eight additional directed edges as shown (edges within each clique are not shown in the figure). Observe that there are pairs of nodes (e.g., and ) that are connected via only disjoint paths. Clearly, all-pair RMT is not feasible in this case but consensus can still be achieved, as shown by (Tseng and Vaidya, 2012) and our results. The difficulty posed by directed graphs is further compounded by asynchrony. In this work, we show that the 3-reach condition is necessary and sufficient for asynchronous Byzantine approximate consensus in directed graphs – note that this condition is identical to that proved by Tseng and Vaidya (Tseng and Vaidya, 2015) for synchronous Byzantine exact consensus.
Related work
Additional related work includes studies of the special class of iterative algorithms, which only utilize local knowledge of the network topology and employ local communication between nodes. A tight condition for iterative approximate Byzantine consensus has been presented in (Vaidya et al., 2012; LeBlanc et al., 2013). A family of tight conditions for approximate Byzantine consensus under the more general class of -hop iterative algorithms has been presented recently in (Su and Vaidya, 2017) but is restricted to synchronous systems. The feasibility of asynchronous crash-tolerant consensus with respect to the -hop iterative algorithms has been considered in (Sakavalas et al., 2018). A series of works (Litsas et al., 2013; Pagourtzis et al., 2017a, b) studies the effects of topology knowledge on the feasibility of RMT, and consequently exact consensus in undirected networks with Byzantine faults.
2. Preliminaries and Main Result
For the approximate consensus problem (Dolev et al., 1986), each node is given a real-valued input, and the algorithm needs to satisfy the three properties below.
Definition 0.
Approximate consensus is achieved if the following conditions are satisfied for a given .
-
(1)
Convergence: the output values of any pair of nonfaulty nodes are within of each other.
-
(2)
Validity: the output of any nonfaulty node is within the range of the inputs of the nonfaulty nodes.
-
(3)
Termination: all nonfaulty nodes eventually output a value.
System Model
We consider an asynchronous message-passing network. The underlying communication network is modeled as a simple directed graph , where is the set of nodes, and is the set of directed edges between the nodes in . Node can reliably transmit messages to node if and only if the directed edge . Each node can send messages to itself as well; however, for convenience, we exclude self-loops from set . A link is assumed to be reliable, but the message delay is not known a priori.
In the system, at most nodes may become Byzantine faulty during an execution of the algorithm. A faulty node may misbehave arbitrarily. The faulty nodes may potentially collaborate with each other.
New Graph Conditions
Hereafter, we will use the notation to denote the complement of set . The subgraph of induced by node set will be denoted by . For a given node set , we now define the reach set of node under , originally introduced in (Tseng and Vaidya, 2015).
Definition 0 (Reach set of under ).
For node and node set , define
Observe that a node belongs to if is reachable from in the subgraph of induced by node set . Trivially, is in . With the definition of a reach set, we introduce the 1-reach, 2-reach and 3-reach conditions referred in Section 1. Intuitively speaking, in the definitions below, the sets , , represent potential sets of faulty nodes; thus, these sets are chosen to be of size . In the following, recall that denotes the set .
Definition 0 (Reach Conditions).
We define three conditions:
-
•
1-reach: For any such that and any nodes , we have
-
•
2-reach: For any nodes and any node subsets , such that , , and , we have
-
•
3-reach: For any nodes and any node subsets , , such that , , and , we have
It is easy to verify that in a clique, 1-reach, 2-reach, and 3-reach are equivalent with , and respectively. Details can be found in Appendix A.
Main Results
As noted previously, Tseng and Vaidya (Tseng and Vaidya, 2015) obtained necessary and sufficient conditions enumerated in Table 2. We have shown, in Appendix A, that each of their conditions to be equivalent to a respective reach condition in Definition 3 above. In particular, based on the results in (Tseng and Vaidya, 2015), we can prove Theorems 4, 5 and 6 below. These results are not used to prove our main results; hence, we defer the presentation of the original conditions in (Tseng and Vaidya, 2015) and the equivalence proofs to Appendix A.
Theorem 4.
Synchronous exact consensus is possible in network in the presence of up to crash faults if and only if satisfies 1-reach condition.
Theorem 5.
Asynchronous approximate consensus is possible in network in the presence of up to crash faults if and only if satisfies 2-reach condition.
Theorem 6.
Synchronous exact consensus is possible in network in the presence of up to Byzantine faults if and only if satisfies 3-reach condition.
Main Result
Theorem 7.
Asynchronous approximate consensus is possible in network in the presence of up to Byzantine faults if and only if 3-reach is satisfied.
This result solves the open problem in Table 2 in Section 1.
Proving the main result: The sufficiency of the 3-reach condition for asynchronous Byzantine approximate consensus is demonstrated constructively in Section 4, using Algorithm 1 for achieving this goal. The necessity of the 3-reach condition for asynchronous Byzantine approximate consensus follows by standard indistinguishability arguments; the proof is deferred to Appendix B.
Technique Outline: Our result generalizes the result of (Abraham et al., 2004), which shows the sufficiency of condition for asynchronous Byzantine approximate consensus in a clique. Note that the condition coincides with the tight condition for the synchronous case (cf. Table 1). For directed graphs, we show that 3-reach is the tight condition for both the synchronous and asynchronous cases. Condition 3-reach states that there exists a node that has (i) a directed path to node in the subgraph induced by the node subset , and also (ii) a directed path to node in the subgraph induced by the node subset . This “source of common influence” for any pair of nodes is crucial for achieving consensus. We outline two techniques used towards our generalization, since they may provide useful intuition for other fault-tolerant settings.
Maximal Consistency: We simplify the Reliable-Broadcast subroutine of (Abraham et al., 2004) by essentially replacing several rounds of communication between nodes with flooding. Even in a clique, communication rounds can be simulated by flooding through propagation paths 222Observe that the definition of a path also applies in a clique network. of length at most . The receiver of all these propagated messages can then detect the existence of faults in certain propagation paths if the propagated values are inconsistent (i.e., values from different paths do not match). The technique appears in the use of the Maximal-Consistency condition in Algorithm 1; this simple condition provides similar properties as Reliable-Broadcast of (Abraham et al., 2004).
Witness node: The witness technique used in (Abraham et al., 2004) relies on the fact that for any pair of nodes, there is a nonfaulty witness node which provides them with enough common information. The existence of an analogous nonfaulty witness for directed networks is implied by the 3-reach condition. Intuitively, even if two nodes “suspect” different sets to be faulty, the existence of a common nonfaulty witness guarantees the flow of common information to both. Guaranteeing that all pairs of nonfaulty nodes gather enough common values while ensuring that nonfaulty nodes with wrongly suspected faulty set are always able to proceed appeared to be the most challenging part of the proposed algorithm. This technique appears in how each node verifies the messages that it has received at line 1 in Algorithm 1. Generally speaking, a node tries to collect as many “verified messages” as possible while it cannot wait for messages that might never arrive (i.e., message tampered by faulty nodes).
3. Useful Terminology
Recall that directed graph represents the network connecting the nodes in the system. Thus, . We will sometimes use the notation to represent the set of nodes in graph . In the following, we will use the terms edge and link interchangeably. We now introduce some graph terminology to facilitate the discussion.
-
•
A path is represented by an ordered list of vertices. In particular, is a directed path comprising of nodes and directed edges , where .
-
•
and , will be used to denote the initial node and terminal node of a path .
-
•
A -path is a path with and .
-
•
Operation denotes the concatenation of path with node assuming that . Analogously, if , then denotes the concatenation of paths and .
-
•
Redundant path: a path is a redundant path if for some simple paths and ( and have no cycles) and one of may be empty. Note that a redundant path may contain cycles and its length is upper bounded by .
-
•
The set of all redundant paths in graph (defined above) will be denoted as .
-
•
Fully nonfaulty path: a path consisting entirely of nonfaulty nodes.
-
•
-paths: given a set and a node , an -path is a path with and .
When convenient, we will interpret a path as the set of nodes in the path. The next few definitions use this interpretation for a node set and paths , .
-
•
will denote the intersection .
-
•
We will say that if .
-
•
By , we will denote the node intersection of paths and .
Definition 0 (-cover of a path set).
For a set of paths , a node set is a -cover of , if , and
.
Definition 0 (Reduced Graph).
For graph , and sets , such that , reduced graph has set of vertices , and the set of edges is obtained by removing from all the outgoing links at each node in . That is,
Definition 0 (Source Component).
For graph , and sets , such that , source component is defined as the set of those nodes in the reduced graph that have directed paths to all the nodes in .
By definition, the nodes in form a strongly connected component in . The source component has other desirable properties that will be introduced when we prove the correctness of our algorithm later.
4. Asynchronous approximate consensus in directed networks
We next present an algorithm for approximate Byzantine consensus in asynchronous directed networks. The algorithm is optimal in terms of resilience, meaning that it matches the impossibility condition of the problem, i.e., the algorithm works in any graph that satisfies 3-reach. Our solution is inspired by the asynchronous approximate consensus algorithm of (Abraham et al., 2004) as explained in Section 2. However, the tools used in the algorithm of (Abraham et al., 2004) prove highly non-trivial to generalize in the case of a partially-connected directed network. This is due to the constraint of directed edges. In complete graphs considered in (Abraham et al., 2004), information can flow both directions, and each node can use the same rule to collect information. In the case of directed networks, information may only be able to flow in one direction. We need to devise new tools for nodes to exchange and filter values so that enough common information is shared between any pair of nonfaulty nodes.
Outline of the algorithm
In our algorithm, each node maintains a state value , which is updated regularly, with denoting the real-valued input of node . Value represents the -th update of the state value of node ; we will also refer to it as the state value of in (asynchronous) round . Observe that in asynchronous systems, updates the value every time it receives enough messages of a certain type (i.e., an event-driven algorithm), thus creating the sequence . The -th value update of a node may happen at a different real time than the respective update of another node .
The proposed algorithm is structured in two parts presented in Algorithm 1: Byzantine Witness (BW) and Algorithm 3: Filter-and-Average (FA). Algorithm BW intuitively guarantees that all nonfaulty nodes will gather enough common information in any given (asynchronous) round. The value update in each round is described in Algorithm FA, where we propose an appropriate way for a node to filter values received in Algorithm BW and obtain the state value for next round as an average of the filtered values. Each node needs to filter potentially faulty values to guarantee validity.
4.1. Algorithm Preliminaries
The proposed algorithm utilizes the propagation of values through certain redundant paths (defined in Section 3). We then describe tools for handling information received by a node through different paths
Messages and Message Sets.
In our algorithm, the messages propagated are of the form where is the propagated value and corresponds to the (redundant) path through which the value is propagated, i.e., its propagation path. For a message , we will use the notation and to denote the propagated value and propagation path, respectively. For simplicity, we will also use the terminology receives value from whenever node receives through some path initiating at node . A message set is a set of messages of the form where is the value reported though propagation path . Given , we will use to denote the set of all propagation paths in , i.e.,
As defined below, given a node set and a message set , the exclusion of on consists of the messages of that are propagated on paths that do not include any node in .
Definition 0 (Exclusion of message set).
Given a message set and , the exclusion of on is the set
The notions of a consistent message set and full message set, presented below, are used to facilitate fault detection. A message set is consistent if all value-path tuples initiating at the same initial node report the same value.
Definition 0 (Consistent message set).
A message set is consistent if
Given a consistent message set , if and , then we define . That is, for a node that appears as an initial node of a path in , denotes the unique value corresponding to . Note that the value is guaranteed to be unique owing to the the definition of a consistent message set.
We say that the received message set is a full message set for , whenever a node receives messages from all possible incoming redundant paths excluding node set . The formal definition follows.
Definition 0 (Full message set).
Given and , a message set is full for if
4.2. Algorithm Byzantine Witness (BW)
The Byzantine Witness (BW) algorithm, presented as Algorithm 1, intuitively guarantees that all nonfaulty nodes will receive enough common state values in a specific asynchronous round of the algorithm; eventually, this common information guarantees convergence of local state values at all nonfaulty nodes. The algorithm is event-driven. That is, whenever a new message is received, each node checks whether a certain set of conditions are satisfied, and whether it should take an action. (In particular, Line 6, Line 8, Line 10, and Line 12 of Algorithm 1 will be triggered upon receipt of a new message.)
Parallel executions.
For the sake of succinctness, we present a parallel version of Algorithm BW; the algorithm makes use of parallel executions (threads) for any potential fault set . Note that there are exponential number of threads. In the parallel thread for set , a node “guesses” that the actual fault set of this execution is , and checks for inconsistencies to reject this guess. Observe that in lines 1-1 of Algorithm BW, the usage of a shared boolean variable guarantees that a node will proceed to the next round during at most one parallel execution; we will later prove that there always exists such a parallel execution that proceeds to the next round. For each round , during this unique parallel execution, the node will execute Algorithm Filter-and-Average (FA), presented as Algorithm 3, through which the value is updated.
Suppose that a node’s parallel thread for set proceeds to the next round. It is possible that is not the actual faulty set. Our algorithm is designed in a way that even if the guess is incorrect, the node is still able to collect enough common values and make progress. Moreover, the parallel thread for set , where is the actual fault set, is guaranteed to make progress at every nonfaulty node.
Atomicity
Algorithm BW uses the shared variables and ; includes all values received by node and is updated whenever receives a new flooded value while indicates if a parallel thread has proceeded to the next (asynchronous) round. For certain parts of the algorithm we need access to shared variables to be atomic, i.e., reads and writes to shared variables can be performed only by a parallel thread at a time. For clarity of the latter, we make use of the functions lock() and unclock() which indicate the parts of the code performed in an atomic fashion.
We next describe a flooding subroutine used to propagate state values throughout redundant paths in the network.
RedundantFlood (Redundant Flood) algorithm
In the beginning of each asynchronous round, in algorithm 1, all nodes will flood their values throughout the network. The difference between RedundantFlood algorithm and the standard flooding is that each flooded message is propagated through any redundant path in the network, not just through simple paths. The details of the algorithm are deferred to the Appendix E.
FIFO flooding of messages
During the execution of the algorithm, we will employ the FIFO Flood and FIFO Receive procedures which ensure that the order of messages sent from a sender is preserved during reception of these messages by any receiver, when the propagating path is fully comprised of nonfaulty nodes. For the correctness of our algorithm, we only need to FIFO-flood messages through simple paths in the network.333It is possible to use RedundantFlood everywhere. For efficiency, we only use RedundantFlood to propagate state values at the very beginning of each round. Thus, a node will propagate a message during FIFO-Flood, only if the resulting propagation path does not contain any cycle. We present a high-level description of the FIFO Flood and FIFO Receive procedures in the Appendix F.
Algorithm BW: Pseudo-code
Algorithm BW is presented in Algorithm 1. We stress that Algorithm BW is executed for each asynchronous round . Thus, all messages sent in round will be tagged with corresponding round identifier . For simplicity, we omit round numbers in the presentation and the analysis of the algorithm. The properties of Algorithm BW are proved hold for any specific asynchronous round . For brevity, the pseudo-code does not include the termination condition. We defer the discussion on termination to Section 4.6.
Function
We first remind the reader that denotes the source component of reduced graph as defined in Definitions 2, 3. Observe that due to function called in line 1, a node essentially waits to receive additional messages to the ones it received upon considering possible faulty set (during the parallel execution for ) before it proceeds to update its value through Algorithm Filter-and-Average. Intuitively, for some received message , waits for the confirmation of the values in through enough redundant paths from a source component. We will later prove that if message is not faulty (i.e., tampered) then will eventually be able to “confirm” the values in . For the sake of simplicity, whenever the function at node is true for some given , we will simply state that condition is satisfied.
4.3. Properties of Algorithm BW
In the following, we introduce some notions necessary for the analysis of Algorithm BW. We first borrow the notion of propagation from (Tseng and Vaidya, 2012, 2015).
Definition 0 (Propagation between sets).
Given sets with , , set is said to propagate in to set if either (i) , or (ii) for each node , there exist at least node-disjoint -paths in the node subgraph of induced by node set , i.e., . We will denote the fact that set propagates in to set by .
Note that the disjoint paths implied in Definition 4, are entirely contained in . Next, observe that by Definition 3, for any sets it holds that . The following theorem is repeatedly used in our analysis; its proof is based on Corollary 2 in (Tseng and Vaidya, 2012) and the equivalence of 3-reach condition with the condition in (Tseng and Vaidya, 2012) (proof in Appendix A). Intuitively, Theorem 5 below states that if 3-reach is satisfied then there are at least disjoint paths, excluding nodes in , that connect a source component with any node outside the source component.
Theorem 5.
Suppose that graph satisfies condition 3-reach. Then, for any and , such that , and hold.
Using the notions above, we will next show some important properties of Algorithm BW. As defined in line 1, we will say that node satisfies the Maximal-Consistency Condition for node set if it receives the message set and is consistent and full for .
Lemma 6.
For any nonfaulty node , the Maximal-Consistency condition will eventually be satisfied during a parallel execution for some set .
Proof.
Consider ’s parallel execution for set , where is the actual faulty set of the execution. If the Maximal-Consistency condition has not been satisfied already, it will eventually be satisfied during the parallel execution for . This will happen since every node in behaves correctly and thus will eventually receive consistent values from all incoming paths in , i.e., will be consistent and full for . ∎
Lemma 7.
Consider two nonfaulty nodes that satisfy the Maximal-Consistency condition on the same set . Let the message sets and be the sets that are used to pass Maximal-Consistency condition at and , respectively. Then, the two sets contain the same unique value .
Proof.
We first prove that for each , both nodes and will receive a unique value corresponding to , contained in the respective sets and . Observe that for any and , by Theorem 5 and the fact that any source component is strongly connected, there exists a simple -path in . Since is full for , will contain some value corresponding to . Note that this value might not be the value sent by , since the above simple path might contain some faulty node. Next, recall that we also require to be consistent. Therefore, the previously mentioned value contained in must be unique . The same argument applies to , too.
The 3-reach condition implies the existence of a node for the actual faulty set . By definition, is nonfaulty and is connected to both through fully nonfaulty simple paths and respectively. By Theorem 5, either or there exist simple disjoint -paths in . In both cases, there exists a simple -path in . Note that there might be some faulty nodes in , since might not be the actual faulty node set.
This observation implies that in , there exist a redundant -path and a redundant -path such that the first part is identical in both paths. Note that the -reach condition only implies that and are fully nonfaulty. Hence, it is possible that the value sent by node is , but the message(s) propagated through and are different. Since and are full; nodes and will receive some value from paths and , respectively. The value received by and must be identical. This is because (i) the two redundant paths have a common first part ; and (ii) and are fully nonfaulty by assumption. Let this value be (which may or may not equal to , the original value sent by ). Finally, since is consistent, all the other messages propagated through paths with and must also be , the value forwarded by . The same argument applies to . Thus, For each , there exists a common value in both and .
∎
Next we prove the main Lemma for the correctness of Algorithm BW. With FIFO-Receive-all condition we refer to the condition stated in the event handler of line 1.
Lemma 8.
Consider a nonfaulty node such that the FIFO-Receive-All condition is satisfied at node for some parallel execution. If by the time the FIFO-Receive-All condition is satisfied, receives from a fully nonfaulty path with , then will eventually receive a message set such that the condition will be satisfied at node .
Proof.
First observe that since path is fully nonfaulty, is nonfaulty; also lines 1,1 of BW imply that since it propagates . Consider any with and any . Let be the actual faulty set of the execution. Note that since nonfaulty receives from a fully nonfaulty path with , node must have FIFO-Flooded this message during the execution. By the 3-reach condition of Definition 2, we have the following.
| (1) |
This, for any , implies the existence of a fully nonfaulty simple -path and a fully nonfaulty simple -path in graphs and , respectively.444Set is not to be confused with the set during the parallel execution of which satisfies the FIFO-Receive-All condition. Set is arbitrary in the proof. Note that might even receive values from paths intersecting with in order to satisfy the condition during its parallel execution for . This might occur if is a wrong “guess” of the actual fault set. We consider the following two cases for ,
-
•
Case I: .
We first prove the following key claim.
Claim 1:
Both and receive an identical value from node .
Proof of Claim: Since is strongly connected, there exists a simple -path in graph . This implies the existence of the redundant -path in . Recall that by assumption, is nonfaulty and FIFO-Floods . This means that has received a unique value through all redundant -paths in , particularly through path . Note that since might contain some faulty nodes, might be different from the value originally sent by node . Observe that there also exists the redundant -path in which will eventually propagate the same value to . This is because is fully nonfaulty and the initial part is identical in both and .
Claim 2:
Node will eventually receive from a set of paths with no -cover .
Proof of Claim: Recall that Claim 1 holds for any , with . Then will eventually receive from all redundant paths for any being a -path with . This is because all these paths are fully nonfaulty and the initial part propagates as implied by Claim 1. The set of all these paths does not have an -cover . If there was such an -cover , this would contradict Equation (1) because it would mean that no fully nonfaulty -path would exist in .555Observe that if and receives from a single path that entirely consists of nodes in , then no -cover exists for this path. This is because by definition.
-
•
Case II: .
Theorem 5 implies that there exist simple disjoint -paths in . This together with the observation that is strongly connected imply the existence of simple -paths which trivially do not have an -cover . Similarly with the previous case, since FIFO-Floods , it must have received the same value from all redundant paths . Since and is fully nonfaulty, one of the paths will also eventually propagate value to .
Using the same argument for Claim 2 in Case I, will eventually receive from a set of paths with no -cover .
In both cases, any such value received by will be consistent with values propagated by , and thus will eventually satisfy the condition.
∎
In the following, we will consider the case where a node executes Algorithm Filter-and-Average through line 1, during its parallel execution for set . In this case, has already satisfied the Maximal-Consistency condition corresponding to as well as the conditions for all messages it has received by the time it satisfied the FIFO-Receive-All condition. Intuitively, this means that has received redundant messages corresponding to “suspicious sets” by the time it executes Filter-and-Average. Note that there exists only one such parallel execution during which Filter-and-Average is executed; this follows easily from the atomic updates of shared variable and lines 1-1 of Algorithm BW. We will use the following notion in our proofs.
Definition 0 (Informed node).
A node that executes Filter-and-Average during its parallel execution for a set is informed about set if , or has satisfied the condition after receiving message from a fully nonfaulty path with .
Theorem 10.
Any nonfaulty node will eventually execute Filter-and-Average during a parallel execution for a set .
The proof of Theorem 10 relies on the observation that algorithm Filter-and-Average will be executed during parallel execution for actual fault set if not during any other parallel execution. The full proof is presented in Appendix D.
Theorem 11.
Let any pair of nonfaulty nodes which execute Filter-and-Average during their parallel executions for sets and , respectively. Then, both nodes and will be informed about a node set , where , and will both receive a common value for each . More specifically, each value will be the unique value corresponding to node that node received by the time it satisfied its Maximal-Consistency condition.
Proof.
Theorem 10 implies that sets are well defined. Observe that, if the theorem holds trivially due to Definition 9 and Lemma 7; this is because both nodes will trivially be informed about the same set, according to the first part of the definition of an informed node. Thus, we focus on the case where . The FIFO-Receive-All condition for nodes and is satisfied in the parallel execution for respectively by assumption. Let be the actual fault set. Due to the 3-reach condition, there exists a node which is nonfaulty by definition of the reach set and is connected to through fully nonfaulty simple paths and respectively. Note that both nodes will only satisfy their FIFO-Receive-All conditions only if they receive messages of the form and , respectively, from through the existing nonfaulty paths respectively; this holds since due to Line 1, node (analogously node ) will wait until it receives from all paths entirely comprising of nodes in which include all nodes on . Thus, must have sent both , messages. Since these messages are FIFO-flooded from and there are fully nonfaulty paths connecting with both , one of the two nodes will receive both , messages before satisfying the FIFO-Receive-All condition. Assume without loss of generality that this node is . We will then show that the theorem holds for .
Similar arguments 666This follows from the first paragraph of the proof of Lemma 7 for being any of the nodes . to the ones used in the proof of Lemma 7 imply that must have received a unique value for each from redundant paths in in order to satisfy its Maximal-Consistency condition during the parallel execution for set . Similarly with previous arguments, by Theorem 5 and the strong connectivity of , there exists a simple -path in , which propagates this value to . Since, by assumption, executes Filter-and-Average during its parallel execution for , by the Maximal-Consistency condition, will also receive the same unique value , for each such node , propagated by redundant path because is fully nonfaulty and entirely contained in . As argued previously, will receive by a fully nonfaulty path . Consequently, by Lemma 8, will satisfy the condition and thus, due to Definition 9, will be informed about . For the condition to be satisfied at node , it must receive the respective values which are consistent with the ones in , received through the fully nonfaulty path . Thus, by definition of the condition, will also receive the same values for each .
∎
Finally, we introduce notions that will be useful for our analysis later.
Definition 0.
Assume nonfaulty nodes which execute Filter-and-Average during their parallel executions for sets and , respectively. Let be the set about which both are informed and both receive a common value for each , as implied by Theorem 11. We will refer to set as the common fault set of , and to as the leading node of the pair. Considering the common values received by both , for any set with , , we define the common value set as:
| (2) |
4.4. Value Update
We next present Algorithm Filter-and-Average (FA), proposing a way for a node to filter its received messages in order to update its state value by an averaging procedure. Following the intuition of (Su and Vaidya, 2017), a node first sorts all the values in received message set , which results to a sorted vector in round . In the next step, the node computes the maximal set of lowest values that might have been tampered by a faulty set (i.e., such that their propagation paths have an -cover) and trims (removes) them from sorted vector . Analogously, the node also trims from the maximal set of the highest values that may have been tampered by a faulty set. Finally, Finally, the remaining sorted values, denoted as , are averaged as is usual in the majority of the approximate consensus literature (e.g., (Dolev et al., 1986; Kieckhafer and Azadmanesh, 1994; Bonomi et al., 2016)).
Towards proving the convergence property, we will first show that for any nonfaulty nodes running Algorithm Filter-and-Average in round , there will be a common value in the trimmed vectors and of the two nodes. For simplicity of presentation, we will omit the round variable in the following discussion. The theorems presented next guarantee the existence of this common element.
4.5. Properties of Algorithm Filter-and Average
According to the notation of Definition 12, Theorem 11 implies that for any pair of nonfaulty nodes executing Algorithm Filter-and-Average, there exists the common fault set such that both of nodes and will be informed about and will obtain the same common value sets for all . The following theorem guarantees that for , there will be some source components whose values will appear in the trimmed vector of regardless of the sets used to trim their vectors. Recall that the notion of common fault set and leading node are introduced in Definition 12.
Theorem 13.
Let be any pair of nonfaulty nodes, their common fault set, and the leading node. Then for and -covers as identified in Algorithm 3, common value set will be included in the vector after removing , and common value set will be included in the vector after removing .
Proof.
Without loss of generality, assume that . We first consider the validity of the theorem for node . The fact that implies that is the set corresponding to the parallel execution during which executes Filter-and-Average. By Theorem 5 and the strong connectivity of , if , it must have received each value of (as defined in Definition 12) from disjoint -paths in to satisfy its Maximal-Consistency condition. Since there will be at least one path propagating each value of in . If , by the strong connectivity of , will receive from paths entirely within , i.e., paths in . Thus, in both cases, common value set will be included in vector after removing . Similar arguments hold for the case of .
Next, we consider node and assume that it executes Filter-and-Average during its parallel execution for . Since , node has satisfied the condition after receiving message from a nonfaulty path initiating at ; this holds by an argument identical to that of the proof of Theorem 11. Similarly with the proof of Theorem 11, will propagate all values of to through its FIFO-flooded message . Since satisfies , it receives each value of through a path set with no -cover . Consequently, since and , one of the paths of will not contain any node in . This means that for any value , there exists a path in from which will receive , and thus, all values of will be included in . Similar arguments hold for the case of . ∎
The next theorem facilitates the analysis later; it states that there is always an overlap between certain pairs of source components of reduced graphs. Its proof is deferred to the Appendix C.
Theorem 14.
Suppose that graph satisfies condition 3-reach. For any three sets , with and , .
We next define some notions, helpful to determine the existence of a common value in the intersection of for any pair of nonfaulty nodes . As before, we assume that is the common fault set of .
Definition 0.
Let be two nonfaulty nodes and their common fault set. For and , let , i.e., the minimum common value for the source component . Define the maximum of all these minimum values over all possible as
and let , be a source component that includes the common value , i.e., . Analogously, let be the maximum common value for the source component and define minimum of these maximum values as
Similar to before, we assume that is a source component that includes the common value .
Lemma 16.
For any two nonfaulty nodes ,
Proof.
By way of contradiction, assume that
| (3) |
Then by Definition 15, we have the following two inequalities:
| (4) |
| (5) |
Now we make two observations:
Theorem 17.
For nonfaulty nodes , after the termination of Algorithm Filter-and-Average, we have .
Proof.
We will argue that a common value contained in will be included in both the trimmed vectors , for . For any with chosen by any , define as the minimum value contained in . Then by the definition of , we have .
Due to Theorem 13, value will be contained in after removal of set . Thus, due to the definition of , any value contained in will satisfy , i.e., only values less or equal to will be removed from due to removal of and the value will remain in the trimmed . Note that, in the event that there are multiple values identical to , then at least one instance of remains in .
Next, observe that for and any choice of , holds, where is the maximum value contained in , due to the definition of . Due to Theorem 13, will be contained in after removal of set . Similarly with the previous argument, any value contained in will satisfy and the value will remain in the trimmed . Note that, in the event that there are multiple values identical to , then at least one instance of remains in . Now, by Lemma 16 we have that,
| (6) |
Consequently, the only values removed from will be less or equal to , greater or equal to , and values will not be trimmed. Thus, due to Equation (6), and will be included in the final trimmed vector for .
∎
4.6. Correctness of Algorithm BW
For a given execution round , recall that is the state variable maintained at node at the end of round . Value is assumed to be the input given to node . We denote by , the maximum and the minimum state value at nonfaulty nodes by the end of round . Since the initial state of each node is equal to its input, and is equal to the maximum and minimum value of the initial input of the nodes, respectively. Consequently, the convergence and validity requirements of approximate consensus can be stated as follows.
-
•
Convergence :
-
•
Validity: .
We next prove the convergence of the proposed algorithm which is based on the following lemma.
Lemma 18.
For every round , it holds that
Proof.
For any , consider any pair of nonfaulty nodes . Without loss of generality, assume . We prove the lemma by showing that
| (7) |
Observe that by Theorem 17, the existence of element with is proved. This implies that .777Since is a sorted message set with respect to values, we define and to be the maximum and minimum value respectively, included in this set as the first component of its messages-pairs. Moreover, holds, since if for node , , then all actual faulty values are removed from from resulting to trimmed vector . Thus, for any remaining value in , it holds that . If , then there exists a nonfaulty node such that , state value at node in round , is trimmed, and hence, is smaller than any . Therefore for any , holds. Consequently, since and , due to line 3 of Algorithm Filter-and-Average, we have that
Lemma 18 and simple arithmetic operations imply the Convergence property (details appear in the termination study of Algorithm BW presented below). Validity is based on the observation that all the extreme values will be eliminated by each nonfaulty node owing to the way the trimmed vector is derived. The arguments are similar to that of the proof of Lemma 18. The proof is presented Appendix G.
Theorem 19 (Validity).
and
Termination of Algorithm BW
Recall that the termination requirement for approximate consensus (Definition 1) requires that all nonfaulty nodes should output a value. We follow the approach in (Tseng and Vaidya, 2015, 2012). Suppose that the input is within the range , where is known a priori. If , then the problem is trivial, so it is assumed that . Repeated application of Lemma 18 implies that . This implies that for given , the state values of the nonfaulty nodes will be within of each other after round . Since are a priori known , each node can locally compute and output its value in the first round such that .
Acknowledgements.
Nitin Vaidya’s work is supported in part by the Army Research Laboratory under Cooperative Agreement W911NF-17-2-0196, and by the National Science Foundation award 1842198. The views and conclusions contained in this document are those of the authors and should not be interpreted as representing the official policies, either expressed or implied, of the Army Research Laboratory, National Science Foundation or the U.S. Government.References
- (1)
- Abraham et al. (2004) Ittai Abraham, Yonatan Amit, and Danny Dolev. 2004. Optimal Resilience Asynchronous Approximate Agreement. In OPODIS. 229–239.
- Benediktsson and Swain (1992) J. A. Benediktsson and P. H. Swain. 1992. Consensus theoretic classification methods. IEEE Transactions on Systems, Man, and Cybernetics 22, 4 (July 1992), 688–704. https://doi.org/10.1109/21.156582
- Bonomi et al. (2016) S. Bonomi, A. D. Pozzo, M. Potop-Butucaru, and S. Tixeuil. 2016. Approximate Agreement under Mobile Byzantine Faults. In 2016 IEEE 36th International Conference on Distributed Computing Systems (ICDCS). 727–728. https://doi.org/10.1109/ICDCS.2016.68
- Cybenko (1989) George Cybenko. 1989. Dynamic Load Balancing for Distributed Memory Multiprocessors. J. Parallel Distrib. Comput. 7, 2 (1989), 279–301. https://doi.org/10.1016/0743-7315(89)90021-X
- Dolev (1982) Danny Dolev. March 1982. The Byzantine Generals Strike Again. Journal of Algorithms 3(1) (March 1982).
- Dolev et al. (1993) Danny Dolev, Cynthia Dwork, Orli Waarts, and Moti Yung. 1993. Perfectly Secure Message Transmission. J. ACM 40, 1 (Jan. 1993), 17–47. https://doi.org/10.1145/138027.138036
- Dolev et al. (1986) Danny Dolev, Nancy A. Lynch, Shlomit S. Pinter, Eugene W. Stark, and William E. Weihl. 1986. Reaching approximate agreement in the presence of faults. J. ACM 33 (May 1986), 499–516. Issue 3. https://doi.org/10.1145/5925.5931
- Fischer et al. (1985a) Michael J. Fischer, Nancy A. Lynch, and Michael Merritt. 1985a. Easy impossibility proofs for distributed consensus problems. In Proceedings of the fourth annual ACM symposium on Principles of distributed computing (PODC ’85). ACM, New York, NY, USA, 59–70. https://doi.org/10.1145/323596.323602
- Fischer et al. (1985b) Michael J. Fischer, Nancy A. Lynch, and Michael S. Paterson. 1985b. Impossibility of Distributed Consensus with One Faulty Process. J. ACM 32, 2 (April 1985), 374–382. https://doi.org/10.1145/3149.214121
- Georgiou et al. (2013) Chryssis Georgiou, Seth Gilbert, Rachid Guerraoui, and Dariusz R. Kowalski. 2013. Asynchronous Gossip. J. ACM 60, 2, Article 11 (May 2013), 42 pages. https://doi.org/10.1145/2450142.2450147
- Hegselmann and Krause (2002) Rainer Hegselmann and Ulrich Krause. 2002. Opinion dynamics and bounded confidence: Models, analysis and simulation. Journal of Artificial Societies and Social Simulation 5 (2002), 1–24.
- Kieckhafer and Azadmanesh (1994) Roger M. Kieckhafer and Mohammad H. Azadmanesh. 1994. Reaching Approximate Agreement with Mixed-Mode Faults. IEEE Trans. Parallel Distrib. Syst. 5, 1 (1994), 53–63. https://doi.org/10.1109/71.262588
- LeBlanc et al. (2013) H. LeBlanc, H. Zhang, X. Koutsoukos, and S. Sundaram. April 2013. Resilient Asymptotic Consensus in Robust Networks. IEEE Journal on Selected Areas in Communications: Special Issue on In-Network Computation 31 (April 2013), 766–781.
- Litsas et al. (2013) Chris Litsas, Aris Pagourtzis, and Dimitris Sakavalas. 2013. A Graph Parameter That Matches the Resilience of the Certified Propagation Algorithm. In Ad-hoc, Mobile, and Wireless Network - 12th International Conference, ADHOC-NOW 2013, Wrocław, Poland, July 8-10, 2013. Proceedings (Lecture Notes in Computer Science), Jacek Cichon, Maciej Gebala, and Marek Klonowski (Eds.), Vol. 7960. Springer, 269–280. https://doi.org/10.1007/978-3-642-39247-4_23
- Lynch (1996) Nancy A. Lynch. 1996. Distributed Algorithms. Morgan Kaufmann. 177–182 pages.
- Pagourtzis et al. (2017a) Aris Pagourtzis, Giorgos Panagiotakos, and Dimitris Sakavalas. 2017a. Reliable broadcast with respect to topology knowledge. Distributed Computing 30, 2 (2017), 87–102. https://doi.org/10.1007/s00446-016-0279-6
- Pagourtzis et al. (2017b) Aris Pagourtzis, Giorgos Panagiotakos, and Dimitris Sakavalas. 2017b. Reliable Communication via Semilattice Properties of Partial Knowledge. In Fundamentals of Computation Theory - 21st International Symposium, FCT 2017, Bordeaux, France, September 11-13, 2017, Proceedings (Lecture Notes in Computer Science), Ralf Klasing and Marc Zeitoun (Eds.), Vol. 10472. Springer, 367–380. https://doi.org/10.1007/978-3-662-55751-8_29
- Pease et al. (1980) M. Pease, R. Shostak, and L. Lamport. 1980. Reaching Agreement in the Presence of Faults. J. ACM 27, 2 (April 1980), 228–234. https://doi.org/10.1145/322186.322188
- Sakavalas and Tseng (2018) Dimitris Sakavalas and Lewis Tseng. 2018. Delivery Delay and Mobile Faults. In 17th IEEE International Symposium on Network Computing and Applications, NCA 2018, Cambridge, MA, USA, November 1-3, 2018. IEEE, 1–8. https://doi.org/10.1109/NCA.2018.8548345
- Sakavalas and Tseng (2019) Dimitris Sakavalas and Lewis Tseng. 2019. Network Topology and Fault-Tolerant Consensus. Morgan & Claypool Publishers. https://doi.org/10.2200/S00918ED1V01Y201904DCT016
- Sakavalas et al. (2018) Dimitris Sakavalas, Lewis Tseng, and Nitin H. Vaidya. 2018. Effects of Topology Knowledge and Relay Depth on Asynchronous Appoximate Consensus. In 22nd International Conference on Principles of Distributed Systems, OPODIS 2018, December 17-19, 2018, Hong Kong, China (LIPIcs), Jiannong Cao, Faith Ellen, Luis Rodrigues, and Bernardo Ferreira (Eds.), Vol. 125. Schloss Dagstuhl - Leibniz-Zentrum fuer Informatik, 14:1–14:16. https://doi.org/10.4230/LIPIcs.OPODIS.2018.14
- Su and Vaidya (2017) Lili Su and Nitin H. Vaidya. 2017. Reaching approximate Byzantine consensus with multi-hop communication. Inf. Comput. 255 (2017), 352–368. https://doi.org/10.1016/j.ic.2016.12.003
- Tseng and Vaidya (2012) Lewis Tseng and Nitin H. Vaidya. 2012. Exact Byzantine Consensus in Directed Graphs. CoRR abs/1208.5075 (2012). arXiv:1208.5075 http://arxiv.org/abs/1208.5075
- Tseng and Vaidya (2015) Lewis Tseng and Nitin H. Vaidya. 2015. Fault-Tolerant Consensus in Directed Graphs. In Proceedings of the 2015 ACM Symposium on Principles of Distributed Computing (PODC ’15). ACM, New York, NY, USA, 451–460. https://doi.org/10.1145/2767386.2767399
- Vaidya et al. (2012) Nitin H. Vaidya, Lewis Tseng, and Guanfeng Liang. 2012. Iterative Approximate Byzantine Consensus in Arbitrary Directed Graphs. In Proceedings of the thirty-first annual ACM symposium on Principles of distributed computing (PODC ’12). ACM.
- Vicsek et al. (1995) Tamás Vicsek, András Czirók, Eshel Ben-Jacob, Inon Cohen, and Ofer Shochet. 1995. Novel Type of Phase Transition in a System of Self-Driven Particles. Phys. Rev. Lett. 75 (Aug 1995), 1226–1229. Issue 6. https://doi.org/10.1103/PhysRevLett.75.1226
Appendix A The -reach condition family
In this section, we summarize the tight topological conditions related with consensus in directed networks that have appeared in the literature along with their equivalents from the family of -reach conditions, for . The topological conditions CCS (abbreviating Crash-Consensus-Synchronous), CCA (Crash-Consensus-Asynchronous) and BCS (Byzantine-Consensus-Synchronous) were introduced in (Tseng and Vaidya, 2015) and proven tight for the cases of synchronous crash consensus, asynchronous approximate crash consensus and synchronous Byzantine consensus respectively. The determination of the necessary and sufficient topological condition for solving approximate Byzantine consensus in asynchronous systems, has been an open problem since 2012.
We next present some additional definitions that facilitate our presentation.
For set , process is said to be an incoming (resp. outgoing) neighbor of set if , and there exists such that (resp. ). The incoming and outgoing neighborhood of a node are the sets of its incoming and outgoing neighbors respectively and will be denoted with respectively. We extend the notion to the incoming (resp. outgoing) neighborhood of a set , denoted with (resp. ) and defined as the set of all incoming (resp. outgoing) neighbors of . Given subsets of nodes and , set is said to have incoming neighbors in set if contains distinct incoming neighbors of . Next, we define a notion which concerns the connectivity of any two node sets of the graph as presented in (Tseng and Vaidya, 2015).
Definition 0.
Given disjoint non-empty subsets of nodes and , we will say that holds, if has at least incoming neighbors in . The negation of will be denoted by .
We also introduce the following useful generalization fo the reach set notion. The notion denotes all the multi-hop incoming neighbors of node in graph .
Definition 0 (Reach set of under ).
For a subgraph of , node and node set , we will use the following notation,
Whenever we will omit the superscript and simply use the notation .
The definitions of conditions CCS, CCA, BCS defined in (Tseng and Vaidya, 2015) follow.
Definition 0 (Condition CCS).
For any partition of , where and are both non-empty, and , at least one of the following holds:
-
•
-
•
Definition 0 (Condition CCA).
For any partition of , where and are both non-empty, at least one of the following holds:
-
•
-
•
Definition 0 (Condition BCS).
For any partition of , where and are both non-empty, and , at least one of the following holds:
-
•
-
•
Observe that while BCS requires a 4-set partition of , condition CCA only requires a 3-set partition of .
We next present an equivalent condition to CCS, CCA, BCS, based on reach sets of any two nodes of the graph.
Definitions 1.
In the following, sets intuitively represent possible faulty sets and thus are of cardinality at most , i.e., . We define the three following conditions,
-
•
1-reach: For any such that and any nodes , we have
-
•
2-reach: For any nodes and any node subsets , such that , , and , we have
-
•
3-reach: For any nodes and any node subsets , , such that , , and , we have
Observe that in a clique, it holds that . Thus, for example condition 3-reach in a clique is equivalent with,
which is equivalent with the well known clique condition , tight for byzantine consensus. Analogously, one can show that in a clique, 1-reach and 2-reach are equivalent with and respectively.
We next present the generalization of the above conditions -reach which determines the family of conditions encompassing the above.
Definition 1.
For any sets , each of cardinality at most
In the following theorem, we show that conditions 1-reach, 2-reach, and 3-reach prove are equivalent to CCS, CCA, and BCS respectively.
Theorem 7.
-
(a)
CCS 1-reach
-
(b)
CCA 2-reach
-
(c)
BCS 3-reach
Proof.
Condition 1-reach is trivially equivalent with the existence of a directed rooted tree in as presented in (Tseng and Vaidya, 2015). In turn, the equivalence of the latter condition with CCS has been proven in (Tseng and Vaidya, 2015; Sakavalas and Tseng, 2019).
Direction“” is implicitly proven in (Tseng and Vaidya, 2015)888The claim is implied by the proof of Lemma 7 in (Tseng and Vaidya, 2015) proves the direction. We next prove direction ““.
If CCA does not hold in , then there exists a partition of with such that and .
Observe that . This is because is a partition of and thus, and ; since CCA is not satisfied, the claim holds. Subsequently, let ; these nodes exist since as per CCA definition. Note that there exist two sets of cardinality at most such that the following holds,
and thus condition 2-reach does not hold.
For any sets with and node we will use as defined in Definition 3. Note that by definitions 4 and 5, Condition BCS is equivalent to the following condition: for all sets with , CCA holds in .
Due to the equivalence of CCA with 2-reach in the previous step , it holds that BCS is equivalent with the following condition: For all sets with ,
Thus BCS is equivalent to,
which coincides with condition 3-reach.
∎
Appendix B Necessity of condition 3-reach
We next show that condition 3-reach is necessary for asynchronous byzantine approximate consensus to be achieved in a network. With we will denote the fact that that execution is indistinguishable from execution with respect to node (cf. (Lynch, 1996)). Note that, considering an approximate consensus algorithm, implies that node will output the same value in both executions . To facilitate the proof, for we will use the notation to denote all edges from set to set .
Theorem 1 (Impossibility of Approximate Consensus).
Byzantine asynchronous approximate consensus is impossible in networks where condition 3-reach is not satisfied.
Proof.
Consider a network where condition 3-reach is not satisfied and assume the existence of algorithm that achieves asynchronous approximate consensus in . This means that there exist sets with , and nodes , such that:
| (8) |
We define the following three executions of determined by the set of faulty nodes and their behavior, the inputs of all nodes and the communication delay. Observe that a Byzantine fault may simply deviate from the protocol by crashing and not sending any message since the Byzantine fault model is strictly stronger than the crash fault. Also, note that we can assume an external notion of time (global clock), not directly observable by the nodes, to facilitate the explicit description of delays. The latter technique has been considered in (Georgiou et al., 2013; Sakavalas and Tseng, 2018).
-
()
The input of every node is , all nodes in have crashed from the beginning of the execution and all other nodes are nonfaulty; the latter is possible since .
-
()
The input of every node is , all nodes in have crashed from the beginning of the execution and all other nodes are nonfaulty; the latter is possible since .
-
()
Inputs: The input of every node is , the input of every node is ; these inputs are well defined because of Eq. 8. All remaining nodes in have arbitrary inputs.
Delivery delays: Message deliveries delays are the same as and except the delays of all messages transmitted through edges , and all messages transmitted through edges . We assume that the delivery delay of the latter messages is lower bounded by an arbitrary number of time-steps. The exact value of will be defined in the following. Message deliveries though all other edges are instant.
Faulty set behavior: Node set is faulty and behaves towards as in and towards as in . More concretely, all messages transmitted through edges in are identical to the messages transmitted through in and all messages transmitted through edges in are identical to the messages transmitted in . Observe that Eq 8 implies that and thus the latter behavior is well defined. This holds because if there exists an edge , then and ; the latter contradicts Eq, 8. Also, this behavior is possible under the Byzantine faults model since and Byzantine faults can have any arbitrary behavior 999This is a standard argument used towards indistinguishability in distributed systems. Details proving that this faulty behavior is well defined can be found in (Pagourtzis et al., 2017a)..
Note that all three executions are well defined due to the fact that 3-reach condition is not satisfied (Eq. 8). Since is a well defined execution of , there will be a specific time point by which, node will terminate in . Moreover, in order to satisfy the validity condition will output the value upon termination of . Similarly, since is a well defined execution of , there will be a specific time point by which, node will terminate in by outputting value . We now assume that the lower bound for all delivery delays described in execution is any with
Now consider execution ; all messages received by are the same in executions . Therefore holds and by the previous argument will output in execution . Similarly holds and will output in execution . Thus, the convergence property is violated.
∎
Appendix C Proof of Theorem 14
The next theorem states that there is always an overlap between certain pairs of source components of reduced graphs. For ease of presentation we prove the theorem for condition BCS, which was proved equivalent to 3-reach in Theorem 7.
Theorem 1.
Suppose that graph satisfies condition 3-reach. For any three sets , with and ,
Proof.
Observe that by definition of a source component of a reduced graph it holds that
| (9) | |||
| (10) |
If then we can consider the following partition of .
We will next show that and . First, observe that by the definition of source component and the fact that BCS holds. Moreover, we have that,
Appendix D Proof of Theorem 10
Theorem 1.
Any nonfaulty node will eventually execute Filter-and-Average during a parallel execution for a set .
Proof.
Assume that does not execute Filter-and-Average for any parallel execution. Due to lines 1-1 of BW, this means that the shared variable will be false. Consider the parallel execution for , where is the actual faulty set. Next observe that due to Lemma 6, will satisfy Maximal-Consistency condition. The same holds for all other nonfaulty nodes. Consequently, since all nodes in are nonfaulty, they will all eventually FIFO-Flood and will eventually FIFO-receive all of these messages through nonfaulty paths in , satisfying the FIFO-Receive-All condition. Finally, by Lemma 8, will eventually satisfy the condition corresponding to any received message, since all these messages will be received through fully nonfaulty paths and thus function will be assigned to true. Finally, since the variable is assigned to false, node will execute Filter-and-Average. ∎
Appendix E The Redundant Flood algorithm (RedundantFlood)
We next present the natural algorithm for flooding a message throughout all redundant paths in the network. To avoid a trivial adversary attack where the adversary lies about the propagation path, each time a node receives a message from node we assume that checks if and rejects the message if this is not the case. This is a feasible check since edges represent reliable communication channels where the recipient knows the identity of the sender.
Appendix F The FIFO-Flood and FIFO-Receive procedures
In the following we present a high-level description of the FIFO Flood and FIFO Receive procedures used in algorithm 1.
FIFO-Flood. During this procedure, each node maintains a FIFO-counter which is incremented any time the node sends a message. The counter is appended to every message sent by node . We stress that this counter is a shared variable between all parallel threads at node .
FIFO-Receive. We will say that node FIFO-receives a message from node propagated through a FIFO-Flood procedure if has also received all previous messages (with respect to FIFO-counter) sent by . More concretely, if FIFO-receives with FIFO-counter initiated by node , then must have received all messages initiated by with FIFO-counters .
The latter procedures clearly implement FIFO channels between nonfaulty nodes which are connected via fully nonfaulty paths. Trivially, the ordering of messages propagated through fully nonfaulty paths will be maintained since all FIFO-counters will be propagated correctly. In the case of a path containing a faulty node, it is obvious that message order is impossible to maintain since the adversary can change the order arbitrarily under any protocol; this holds since the adversary can filter all information propagated through this path.
Appendix G Proof of Theorem 19
Theorem 1 (Validity).
and
Proof.
We prove the claim by induction on the round index . For both inequalities trivially hold. Assume that the claim holds for round . For any nonfaulty node we can show that and with identical arguments used in the proof of Lemma 18. Consequently, we have that since , holds. ∎