Asyn2F: An Asynchronous Federated Learning Framework with Bidirectional Model Aggregation
Abstract
In federated learning, the models can be trained synchronously or asynchronously. Many research works have focused on developing an aggregation method for the server to aggregate multiple local models into the global model with improved performance. They ignore the heterogeneity of the training workers, which causes the delay in the training of the local models, leading to the obsolete information issue. In this paper, we design and develop Asyn2F, an Asynchronous Federated learning Framework with bidirectional model aggregation. By bidirectional model aggregation, Asyn2F, on one hand, allows the server to asynchronously aggregate multiple local models and results in a new global model. On the other hand, it allows the training workers to aggregate the new version of the global model into the local model, which is being trained even in the middle of a training epoch. We develop Asyn2F considering the practical implementation requirements such as using cloud services for model storage and message queuing protocols for communications. Extensive experiments with different datasets show that the models trained by Asyn2F achieve higher performance compared to the state-of-the-art techniques. The experiments also demonstrate the effectiveness, practicality, and scalability of Asyn2F, making it ready for deployment in real scenarios.
Index Terms:
Federated learning, asynchronous training, deep learning, platform implementation1 Introduction
The proliferation of the Internet of Things, mobile devices and edge computing enables the collection of a huge amount of data, usually personal data at a large scale[1]. Learning representation and generalization of this distributed data has been a grand challenge for both academia and industry. Federated learning has been developed to address the above challenge and becomes an effective method enabling the training of a global model on datasets stored across a number of storage sites [2]. Without moving data out of premises (which is not allowed by regulations in some scenarios [3]) to a centralized server (e.g., cloud), federated learning also addresses the problem of data privacy.
A federated learning system is composed of a server and a number of distributed training workers [4]. The workers perform model training on their local (private) data. The server aggregates the models received from the workers and updates the global model before sending it back to the workers for the next training iteration. Many works in the literature have focused on two challenging issues of federated learning: (i) optimizing the performance of the global model trained in federated learning (e.g., accuracy) to that of the model trained in a centralized manner [5, 6]; and (ii) reducing the communication costs between the workers and server due to the transmission of the global and local models [7, 5, 8]. For the former, these works propose various approaches for the server to aggregate the local models and update the global model. For the latter, model pruning or model compression has been proposed to reduce the size of the models exchanged between the server and workers. The above works make an assumption that whenever there is a training request from the server, all the workers are ready and have sufficient computational resources for model training. The server will wait for the responses from all the requested workers before doing model aggregation and updating the global model. We refer this to as synchronous federated learning.
With the emergence of machine learning marketplace [9, 10] implementing federated learning, many data providers (maybe with limited computational resources) can contribute their data to train models of the market customers without worrying about data privacy. Many training requests could be sent to the same data provider or the computational resources of data providers are heterogeneous, making the above assumption no longer valid. Synchronous federated learning becomes harder to achieve as the server has to unnecessarily wait for a longer time for all the workers to complete their training. Thus, there is a need for a novel approach that allows the server to asynchronously update the global model once a training worker has completed its training epoch, referred to as asynchronous federated learning. While there are a few works that consider this challenge [11, 12, 13, 14, 15, 16, 17, 18], they mainly focus on developing an aggregation method for the server to aggregate multiple local models into the global model with an aim to approximate the performance of the global model to its counterpart trained in a centralized manner. The training workers need to finish a training epoch (iteration) before receiving the new global model from the server. Due to the heterogeneity of training workers, the global model could have been updated several times from the local models obtained from other workers, and the local model of a slow worker becomes obsolete, thus wasting time and computational resources.
Yet, less research looks into the practical implementation of a federated learning framework considering the security policies of data providers. With the increasing security threats, most networks close all ports by default (even common ports such as port , which is used for remote access). This forces the implementation of federated learning frameworks (or marketplaces) to use registered (and well-known) services for the communications between the server and workers whether it is control messages or data. This is to say that conventional socket programming using ephemeral ports may not be suitable.
In this paper, we design and develop Asyn2F, an Asynchronous Federated learning Framework with bidirectional model aggregation that addresses the above challenges. We develop two novel aggregation algorithms used for the server and training workers, respectively. On the server side, the aggregation algorithm allows the server to asynchronously aggregate multiple local models into the global model without waiting for all the training workers to submit their local model. On the worker side, the aggregation algorithm allows the workers to aggregate the new version of the global model into the local model, which is being trained even in the middle of a training epoch, thus reducing the impact of the obsolete information issue. The aggregation algorithms take into account the level of obsolete information, the quality of training data, and the performance of local models, represented by the loss value.
We present the design and implementation of Asyn2F in which we employ advanced message queuing protocols for controlling messages exchanged between the server and workers. We use cloud storage (e.g., AWS S3) for storing models and retrieving requests. As these technologies are common, the network traffic will not be blocked by the network firewall of the data provider’s infrastructure. We address several practical challenges such as optimizing the communication costs and synchronizing the learning rate among training workers. We implement a training quality monitoring service that allows end-users to closely monitor the performance of the local models obtained from the workers as well as the global model after aggregation by the server. This monitoring service could be very useful to optimize resource utilization and costs: training can be stopped if the model no longer improves its performance. We perform extensive experiments with various datasets to demonstrate the effectiveness of the proposed method and the developed framework (Asyn2F).
2 Related Work
Asynchronous training has been widely used in traditional distributed Stochastic Gradient Descent [19] for the heterogeneous environment to avoid the blocking time (or delay) of the training process caused by the low performance of computing resources/devices, sometimes called stragglers. The latency of the network bandwidth in a heterogeneous environment also makes the synchronous training process less efficient. Recently, several asynchronous algorithms have been proposed to solve the limitation of synchronous federated learning [11, 12, 13, 14, 15, 16, 18] by removing the delay of stragglers due to both computing performance and network bandwidth. Xie et al. [11] defined an algorithm that allows the server to update the global model by weighted average immediately whenever receiving a local model from a worker. The server then pushes the newly-updated global model back to the worker for the next training round without waiting for other workers. However, this approach leads to the problem of obsolete information discussed above. Considering a peer-to-peer training platform where there is no central coordinator, the workers communicate with each other like a graph topology, Assran et al. [14] and Even et al. [12] proposed to use the asynchronous gossip algorithm [20] to optimize the models. In these works, each worker has one sending buffer and one receiving buffer; the method repeats two steps until reaching the stop condition. In the first step, each worker locally optimizes the model by epochs (or training rounds). In the second step, the worker sends its model to the neighboring workers after completing a training round/epoch. At the same time, it updates its local model using all the models in the receiving buffer before starting a new training round.
Liu et al. [13] proposed an asynchronous federated learning mechanism, named Fed2A, that focuses on reducing the communication cost without damaging the overall learning performance. In this mechanism, workers can start training and uploading their local models based on their own decisions, e.g., after a predefined number of training epochs. To reduce the communication cost, the workers divide the model into two parts: i) shallow layers (i.e., feature extraction such as convolutional layers), and ii) deep layers (i.e., classification/regression such as fully connected layers). Each part has a different uploading decision. The server also defines its own aggregation condition, e.g., after receiving a predefined number of local models from workers. When the aggregation condition is satisfied, the server combines the time of transmission delay, data size, and difference in weights between the global model and local models to create a new global model, and then broadcast again to the workers for a new training round. Yu et al. [21] proposed an asynchronous and hierarchical framework for federated learning which is used for unreliable IoT networks. The authors proposed two levels of asynchronous model aggregation, i.e., at the gateway and cloud server, to reduce the delay of both network and computing devices on the global model since the number of workers is large.
Chen et al. [15] defined a method for asynchronous online federated learning. At each step, this method first uses attention mechanisms to extract the features from the incoming data of each worker and aggregates them to have the feature representation learning on the server. It then uses this feature vector to update the global model. Adapting FedAvg [7], Wu and Wang [16] developed an Asynchronous Federated Learning framework, namely KAFL with two algorithms. The first one is named K-FedAsyn which waits for the first fastest workers that run FedAvg to update the global model. The difference with the original FedAvg is that the average of local models is merged to the global model by a ratio . The second one is named M-Step KAFL, which defines a buffer with a limited size of . Whenever the server receives a local model from a worker, it assigns this local model as the global model, denoted as . When the buffer is full, the average of local models in the buffer is computed and then merged into by a ratio . Wang et al. [17] defined an asynchronous federated learning algorithm, in which a worker can join the training process at any time instant and get the latest version of the global model to train on its local data. The worker computes the difference between the downloaded global model and the local model after its training iteration and sends the difference to the server. The server then uses the Euclidean distance to compute the adaptive learning rate to update the global model based on the information received from the worker. Recently, Zhang et al. [18] developed FedMDS, a framework for semi-asynchronous federated learning. Unlike FedAvg, FedMDS classifies workers into different groups. In each group, the workers synchronously send their local model to the server for aggregation, but the aggregated model of each group is asynchronously updated by the server. Miao et al. [22] recently proposed an asynchronous federated learning algorithm using time-weighted and stale model aggregation. The algorithm sets a duration threshold to classify the workers into online workers or stragglers, then uses the delay to compute the contribution weightage of local models into the global model.
All the above works propose methods for aggregation of the global model at the server but not at the workers, thus raising the issue of obsolete information for the workers. They also do not consider a practical implementation of the framework in which multiple practical implementation requirements need to be addressed.
3 Framework Design and Model Aggregation Algorithms
In this section, we present our proposed framework. We first provide a brief overview of framework architecture. We then describe the aggregation algorithms that the server and the workers use for aggregating and updating models.
3.1 General Framework Architecture
The general architecture of Asyn2F is depicted in Fig. 1. The server side consists of two main components. The Aggregation Strategy component includes various model aggregation algorithms. We aim to design our framework as generic as possible so that it can integrate not only our aggregation algorithm but also other algorithms such as the existing ones. The Worker Manager component manages all the workers of the framework. The Worker Proxy helps the server communicate with the workers via advanced message queuing protocols for exchanging control messages, e.g., notification of a new global model or local model submissions. The Storage Service is a third-party component (i.e., a cloud service) used for storing the local models obtained from the workers and the global model aggregated by the server. On the worker side, we design a Model interface that allows users to implement the model using their preferred libraries. The interface also includes functions for the workers to aggregate a new global model into the local model during the training process. Given a defined model, the training pipeline includes functions to retrieve training data and invoke the model training on computing resources. The training pipeline also includes a monitoring module that reports the performance of the local models as well as the training status to a monitoring dashboard for real-time visualization. Via real-time monitoring, users can control the training process such as stopping the training process at a specific worker or the entire training process at the server when achieving a desired performance.

3.2 Asynchronous Federated Learning Algorithms
3.2.1 Algorithm Overview and Illustration
The training process of a model with Asyn2F is presented in Algorithm 1, which is executed by the main thread at the server. The server initializes a global model, denoted as . The server notifies all the workers joining the training to download the global model and start their training (i.e., execute notify_workers()). As discussed in the framework architecture, let denote the queue that contains the local models of the participating workers. While all the workers execute their local training process, the server waits for local models sent from the workers and keeps checking the aggregation condition (i.e., execute check_aggregation_cond()). If the aggregation condition is satisfied, the server performs model aggregation and produces a new global model, versioned as , . The aggregation can be triggered periodically or based on the size of the queue that contains notifications received from the workers. For instance, the server updates the global model whenever there is a new local model submitted. The server can also update the global model when there are models received from workers (i.e., the case of FedAvg [7]). If we set to the number of workers joining the training process, the training becomes entirely synchronous training in which the server waits for all the workers to submit their local model before doing aggregation.
The training will be terminated once the stopping condition is satisfied. Conventionally, the training is terminated when it reaches a pre-defined number of training epochs. In practice, users may consider the trade-off between the model performance and the training cost (e.g., time or computing resources of the workers). Thus, we incorporate two other different stopping conditions including: (i) maximum training duration, and (ii) desired performance of the model.
The training process is illustrated in Fig. 2. The five workers receive the (initialized) global model (illustrated by light green squares) and start the training process at different time instants. Combined with the heterogeneity in computing resources and the size of training datasets, the workers complete their training epoch and send the local model (represented by pink squares) to the server at different time instants. For instance, Worker 2 finishes its training epoch very early compared to Worker 1 and Worker 3 while Worker 4 spends a longer time to finish its training epoch. Without waiting for the new global model, those workers completing their training epoch early will immediately start a new training epoch with their current local model (e.g., Worker 2 and Worker 3). This significantly reduces the idle time of workers and improves resource utilization. Given that the aggregation condition is satisfied (periodically triggered at time , , and as shown in Fig. 2), the server performs global model aggregation and creates a new version of the global model. The server will then notify all the workers to download the updated global model. In Fig. 2, Worker 1 just finished its training epoch, thus it will take the updated global model and start the next training epoch. Worker 2 and Worker 3 started the subsequent training epoch earlier, thus requiring a local model aggregation to accommodate the updated global model to the local model that is currently being trained. The local model aggregation process is denoted as yellow circles. The local models obtained from the local model aggregation process (denoted as purple circles in Fig. 2) at the workers will also be sent to the server for the next global aggregation. In this way, our framework avoids the problem of obsolete information at the worker that takes a longer time for a training epoch while the global model has been updated many times by the local models obtained from other workers that complete the training faster.

3.2.2 Global Model Aggregation at Server
Given that the aggregation condition is satisfied, the server starts the global model aggregation process shown in Algorithm 2. We assume that the server has the metadata of the private datasets of the workers such as the size and quality of the dataset. Worker has a private dataset , which has its quality denoted by , and the number of data samples is denoted as . It is to be noted that there exist many tools for determining the quality of data and the server can rely on them to request the report of data quality from the workers. Furthermore, metrics for the quality of data are different for different applications. There are many metrics that have been discussed extensively in the literature, such as class overlap, feature relevance, timeliness, completeness, and duplicates explained in detail in [23], which can be used to estimate the quality of data. Technically, the implementation of data evaluation can be diverse [24].
For a local model received from a worker (denoted as for the local model received from worker ), the algorithm computes its contribution to the global model, which depends on the quality of data of the worker, the size of the dataset (i.e., the number of samples), the value of the loss function that is used in the training at the worker and the delay of the local model compared to the global model. The contribution ratio is computed as follows:
| (1) |
where and are the quality and size of the dataset of worker . is the value of the loss function obtained after the training at worker . is the version index of the global model that worker has downloaded and used in its training process, and is the version index of the resulting global model after aggregation as shown in Algorithm 1. Thus, is the version delay at worker in incorporating the newly-released global model in its training. For instance, means that worker has used the latest version of the global model in its training. Thus, the rationale behind Eq. (1) is that if the value of the loss function and the version delay is large, the contribution of the local model obtained from the worker to the global model should be small. This allows the training to avoid the problem of incorporating obsolete local models received from slow workers into the global model that has been updated by other faster workers. The contribution of each local model will be normalized before being used in updating the global model as shown in the last step of Algorithm 2.
It is to be noted that if a fast worker submits multiple versions of its local model, the latest version will be considered for the global model aggregation. As shown in Fig. 2, before time has submitted two versions of its local model. The first one represented by the purple color square is the result of a local aggregation process when the server releases the global model aggregated at time . The second one is the result of the subsequent training epoch without aggregating with any new global model.
3.2.3 Local Model Aggregation at Workers
Given a new version of the global model, the workers use Algorithm 3 to incorporate the global model into their training immediately. In the mini-batch training approach, the training process at the workers takes a batch of data from the dataset and trains the model using stochastic gradient descent. After each batch, the workers check if there is a new version of the global model released by the server. If so, the workers will download the global model and aggregate it into the local model before starting a new batch.
Without loss of generality, we assume that worker is updating the latest global model denoted as where is the version index of the model to the local model that is being trained. has been computed by the server using Algorithm 2 and it is contributed by a number of workers whose average quality of data is . The total number of samples in the datasets of those workers is denoted as and the average loss of the local models contributing to is denoted as . We also assume that the local model that is being trained has been initiated from the global model versioned (). This model has been trained on the private dataset of worker for data batches.
The algorithm computes a weighted parameter to determine the contribution of the latest global model and that of the local model at batch to the new version of the local model. The formula used to compute this parameter is defined in Eq. (2) where is a hyper-parameter that defines the importance of the quality of data or the performance of the models represented by the loss.
| (2) |
The above formula takes into account two important factors which are the quality of data and the model performance represented by the loss. Rationally, the higher the quality of data at worker , the higher the contribution of the current local model () to the updated version. If the loss of the current local model is low, it will also have a higher contribution to the updated version of the local model.
For every parameter (weight) of the model, the algorithm calculates the movement distance and direction between two data batches and between the latest global model and the local model. For instance, between two data batches, the movement distance of weight is calculated as . If is greater than zero, it means that increases from batch to batch and vice versa. Similarly, the movement distance and direction between the latest global version and the local version is calculated as . Given the values of and , weight of the local model at batch (i.e., ) will be updated accordingly. If and have the same sign (i.e., or both the local model and global model move in the same direction), will be updated directly to . Otherwise, is computed based on the contribution from both the global model and the current version of the local model as follows:
| (3) |
where is defined in Eq. (2).
The updated local model returned by Algorithm 3 () continues being trained on the next data batches at worker until completing the training epoch and notifies the server the availability of a new local model.
3.3 Privacy Preservation Analysis
Data privacy is the most important factor that motivates the development of federated learning. We prove that the framework developed in our work protects the data of every worker participating in the training process of a model. We consider a threat model in which there is a total of workers that collude with each other to attack the remaining worker with the objective of learning the data of the victim. During each training epoch, there are two scenarios that can happen to the local model trained by a worker. We analyze the data privacy issue of these two scenarios below.
-
1.
The local model is completely trained with all the data batches of the worker without being aggregated with any version of the global model. For instance, a worker has a small dataset and the training time for each epoch is too short compared to that of other workers. By applying mini-batch gradient descent with private training parameters, it has been proved in [6, 5] that the honest-but-curious server and/or workers have no information on the private dataset of the victim.
-
2.
Local model aggregation has happened during a training epoch, i.e., Algorithm 3 is executed one or several times in a training epoch. Without loss of generality, we assume that the victim worker is at the training epoch. This implies that the dataset of the worker is protected by non-linear equations in previous training epochs. The local model aggregation process presented in Algorithm 3 adds an additional non-linear equation shown in Eq. (3). This further enhances privacy-preserving property, thus protecting the private datasets more securely.
We note that as the local datasets are protected by our training approach, the man-in-the-middle threat model will not affect the privacy-preserving property of our framework. Man-in-the-middle adversaries can sniff the training results (local models) during the exchanges between workers and the server but they cannot infer the data even if the models are transferred in plain text without any encryption techniques. However, this may not happen as network traffic nowadays is usually encrypted with Transport Layer Security (TLS) protocol.
4 Framework Implementation
In this section, we first present the essential requirements of an asynchronous federated learning framework and then we present the technologies and implementation details of our framework, Asyn2F.
4.1 Framework Functional Requirements
We consider a practical context of federated learning such as machine learning marketplace [10] where users whether they are data providers equipped with computing resources for model training or end-users who request models. In this context, the data providers can join the training framework at any time. Their computing resources (the workers) are heterogeneous and may fail in the middle of the training process (e.g., due to network issues or other reasons). We believe that the following requirements are essential for the success of the federated learning framework.
4.1.1 Monitoring Support (R1)
As the workers can join in and leave the federated learning framework at any time, a monitoring dashboard that supports real-time visualization of the model performance and/or loss value of each worker is necessary. Due to asynchronous communications between the server and workers, as well as the different sizes of datasets, a training epoch may take a longer time for a particular worker than the other, this monitoring dashboard should also report to end-users the current status of the workers and the server about training time and joined in/out timestamp. This helps end-users to stop training when the trained model attains a desired performance or stop a worker if the contribution of the local model is no longer needed. This feature is useful especially when model training incurs a cost, e.g., the cost of computing and storage resources, communication cost, and the cost of training data.
4.1.2 Testing Worker (R2)
To provide real-time performance monitoring, a testing worker is needed as the server usually does not have a test dataset. This testing worker can belong to the user who requests the model such that the obtained model attains the desired performance of the requester.
4.1.3 Threshold for Model Exchange (R3)
The communication cost (either time or monetary cost) is a critical problem of federated learning if models are sent back and forth between the server and the workers frequently. To reduce the impact of this problem, the federated learning framework should allow the workers to train the local model independently using their data until reaching a desired performance or a required number of iterations (i.e., epochs), pre-defined as a training parameter. If the local model of a worker attains this threshold, the worker can start exchanging its local model with the server for global aggregation. This is particularly practical, especially for the models that are trained from scratch and normally have low performance in the first few epochs.
4.1.4 Synchronizing Learning Rate among Workers (R4)
Due to the heterogeneity of computing resources and the size of the training dataset of each worker, the training time for an epoch is different among workers. Since the learning rate is decayed depending on the number of epochs performed, the above issue leads to the fact that the local models are trained at the workers with different learning rates. Those local models when aggregated in the global model affect the stability and convergence speed of the global model. To address this issue, the decay function of each worker must be updated according to the number of training epochs of the global model.
4.2 Implementation Details
4.2.1 Sequence Diagram and Communication Messages
As shown in Fig. 1, there are 4 components: server, worker, storage service, and queue in our federated learning framework. In Fig. 3, we present the sequence diagram showing the interaction among components during the entire process of model training. The server starts the training process by creating a bucket on the storage service for model exchange and registers the queue channel to publish/subscribe the messages from/to the workers.

As discussed earlier, the workers can join the platform and start the training process at any time. When a worker joins, it first registers the queue for message publishing/subscribing, and once the queue registration is successful, it sends an init message to the server via the queue. The format of the init message of the worker is presented in Listing 1. With this message, the worker informs the server about its role in the framework (i.e., trainer or tester based on the requirement R2), its hardware configuration, and metadata of the dataset (i.e., size/number of samples, quality of data). When the server receives the init message from a worker, it creates a WorkerProxy instance and responds to the worker with necessary information packaged in a JSON message presented in Listing 2. This message includes the following information: i) storage information; ii) the current version of the global model and threshold for model exchange (based on the requirement R3); and iii) the aggregation strategy at the server. It is to be noted that the developed framework supports not only the model aggregation approach proposed in our work but also other existing approaches such as FedAvg [7] and M-Step KAFL [16].
During the training process, whenever the server completes the aggregation of the local models received from the workers, it uploads the new global model to the storage and notifies all the workers about the availability of a new global model by sending the message shown in Listing 3. The message contains information on the current version of the global model, the average quality of data, and the average loss of the models that were aggregated in the new version of the global model. This information is needed for the workers to perform local aggregation of the global model to the local model as shown in Algorithm 3. Upon receiving this message, all the workers will need to download the new version of the global model, perform local model aggregation, and continue the training process.
Upon completion of a training epoch and the local model attains the performance threshold for contribution to the global model, the worker uploads the local model to the storage server and uses the message shown in Listing 4 to notify the server. This message contains information about the performance and loss of the local model, the version of the global model that has been used for training the local model. It is to be noted that during a training epoch of the local model, multiple versions of the global model could have been used at different local model aggregations. When notifying the server, the worker takes the latest version of the global model that has been downloaded to include in the notification message.
4.2.2 Technologies and Implementation Details
Abstract Class for Model Definition. To support the training of various deep learning models defined by the users of the framework, we define an abstract class, namely Model, which allows users to define their own neural network architecture and implements 3 required methods: get_weight(), set_weight(), and train() - for one mini-batch. An optional method for a tester is also defined, namely evaluate() allowing users to implement the test function based on their performance metrics.
Messaging System for Communications. We used RabbitQM111\urlhttps://www.rabbitmq.com/ in our framework. This avoids the use of socket programming and ephemeral ports, which are usually blocked by security systems, e.g., firewalls. All delivered messages are executed by the routing_key concept of RabbitMQ. Each worker has two connections to the queue. The first one asynchronously subscribes to the queue using its own queue name and the same routing_key to listen to the messages from the server. The second one is used to asynchronously publish messages to the server. Similarly, the server also uses two connections to the queue for receiving/publishing messages from/to workers.
Object Storage. Our framework supports both S3222\urlhttps://aws.amazon.com/s3/ and Minio333\urlhttps://min.io/. In addition to the two main functions that are uploading and downloading models, our framework also supports several additional functions such as the creation of buckets, and deletion of models that are no longer needed. This is useful in the case of S3 as it is chargeable.
Monitoring and Report. To meet requirement R1, the monitoring service is implemented by subscribing to messages from workers, the tester, and the server. From these messages, the service extracts necessary information such as worker_id, timestamp, loss value, and performance based on a pre-defined metric, and pushes them to InfluxDB444\urlhttps://www.influxdata.com/ and uses Grafana555\urlhttps://grafana.com/ to visualize the information in real-time during the training process.
Synchronizing Learning Rate. To meet the requirement R4, the decay function is defined by using the version of the global model. Both information (i.e., version of the global model and learning rate) are included in the message that the server uses to notify the workers (see Listing 3).
Supporting Multiple Model Aggregation Strategies. In our framework, WorkerProxy keeps all the necessary information of a training worker. It also provides an abstract class namely Strategy with an aggregate() method and a train() method. With this abstract class, apart from the aggregation algorithms presented in previous sections, our framework additionally implemented the existing algorithms such as M-Step KAFL [16], AsynFedED [17] or FedAvg [7]. Respectively, the server also implements the aggregate() method for the above techniques. This makes our framework effective for not only asynchronous training techniques but also synchronous ones.
5 Experiments
In this section, we present extensive experiments to demonstrate the effectiveness of our proposed federated learning approach along with the developed training framework. We use 2 datasets for our experiments: CIFAR10 [25] and EMBER [26]. While CIFAR10 is a benchmarking dataset used by many works in the literature, EMBER is a malware dataset used in malware detection applications. It contains the feature vector of 1 million samples including both malware samples and benign samples. Benign samples are actually goodware and sometimes contain sensitive information (e.g., email attachments), thus rarely being shared. For both datasets, we assume that the quality of data is the same when splitting into multiple subsets. Thus, global model aggregation and local model aggregation are mostly based on the loss values. We perform various experimental scenarios, each being described in the below sections with the details of experimental infrastructure, dataset distribution, model architecture, and analysis of results.
We demonstrate the effectiveness of Asyn2F by comparing its performance with existing techniques including FedAvg [7] and M-Step KAFL [16]. With the two applications mentioned above, we use accuracy as a performance metric. We also use the number of training epochs to demonstrate the convergence speed of the global model.
5.1 Peformance with CIFAR10
5.1.1 Experiments with a small-size infrastructure
We set up the experimental infrastructure that is composed of 1 server, 1 testing worker, and 10 training workers. The details of location and computing resources are given in Table I. All the training techniques (Asyn2F, FedAvg, and M-Step KAFL) use the same infrastructure.
Data Preparation. We use both iid and non-iid random methods to split the CIFAR10 dataset into 10 sub-datasets. When using the iid random method, the sub-datasets are created with two 2 scenarios:
-
•
In the first scenario, each sub-dataset is randomly selected from the original dataset by a random ratio from to . This leads to the fact that there is an overlap among 10 sub-datasets, and the total data size of 10 sub-datasets is greater than the original size (i.e., samples).
-
•
In the second scenario, there is no overlap among the 10 sub-datasets. However, we make sure that every dataset should have samples of all the labels.
When using non-iid random method, all the sub-datasets are non-overlapping. The data distribution of one of the experiments is presented in Fig. 4 where the colors represent the labels of the datasets.
| Role | No. Instances | Description |
|---|---|---|
| Storage | 1 | Amazon S3 / CSC - HPC (Finland) |
| Queue | 1 | RabbitMQ of CloudAMQP |
| Server | 1 | CSC - HPC (Finland) |
| Tester | 1 | Google Colab GPU |
| Workers | 3 | 2 GPU Workstations at TTU (Vietnam) |
| 2 | 2 CPU Workstations at TTU (Vietnam) | |
| 5 | Google Colab GPU |


Model architecture and hyper-parameter setting.
We use ResNet18 model [27], implemented in TensorFlow. We use a stochastic gradient descent optimizer with the momentum parameter set to 0.9. We run the experiments with 3 settings of learning rate (LR).
-
•
Fixed learning rate: All the workers use the same learning rate for the entire training set to 0.01.
-
•
Synchronously-decayed learning rate: The learning rate is decayed along the training process by the server using the cosine decay function with an initial value set to 0.1. The updated learning rate is synchronized with all the workers.
-
•
Asynchronously-decayed learning rate: Each worker uses the cosine decay function by its local training steps with an initial value set to 0.1. The updated learning rate is used locally without synchronizing with other workers.
For each training approach, we run the training process for 3 hours. Each worker trains 5 iteration rounds of local data as an epoch. For Asyn2F, the global model aggregation process at the server is triggered when there are three local models received from three different workers (always get the latest version). Whereas, M-Step KAFL waits for three models without differentiating workers. The client selection strategy of FedAvg is all clients, i.e., 10 workers.
Analysis of Results. In Table II, we present the accuracy of the ResNet18 models trained by our training technique and the other two existing techniques. The experimental results show that Asyn2F achieves the best performance compared to the other two existing techniques. The improvement is more significant (up to 2.90%) in the case of non-overlapping and non-iid sub-datasets, which is usually a practical situation where data providers have different (diverse) datasets. Comparing three methods of learning rate setting, we observe that synchronizing the learning rate among workers achieves the best performance. This reflects the requirement (R4) of the training framework discussed in Section 4.1. It is worth mentioning that the existing works (FedAvg and M-Step KAFL) do not address this issue in their work. When integrating their training techniques into our framework, we additionally implement their techniques with the three learning rate setting strategies, thus providing insightful performance comparison.
| Strategy | Asyn2F | M-Step KAFL | FedAvg |
| Overlapping iid sub-datasets | |||
| Fixed LR=0.01 | |||
| Sync.-decayed LR | |||
| Async.-decayed LR | NA | ||
| Non-overlapping iid sub-datasets | |||
| Sync.-decayed LR | |||
| Non-overlapping, non-iid sub-datasets | |||
| Sync.-decayed LR | |||
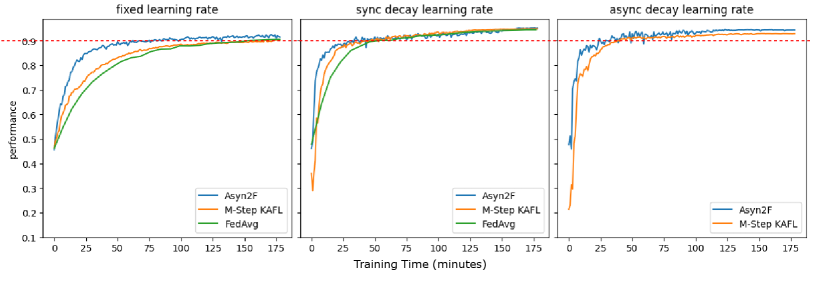

Looking into convergence speed, we present in Fig. 5 and Fig. 6 the performance of the global model obtained by the testing worker over training time in case of overlapping and non-overlapping sub-datasets, respectively. The experimental results show that the global model trained by Asyn2F converges faster compared to the models trained by the other two techniques regardless of the learning rate setting methods. This is explained by the fact that the local model aggregation in Asyn2F enables a faster convergence of local models trained by the workers and avoids the information obsolete issue at the workers. In the long run, all the models will achieve maximum performance (which could not be further improved by any chance). But with a desired performance (e.g., of accuracy), a fast convergence of the model benefits a lot. For instance, the users can stop the training when the global model achieves the desired performance. From the training cost point of view, this could lead to a lower training cost for both time and monetary cost of computing resources, especially in the context of federated learning marketplaces.

A fast convergence of the model also implies a lower communication cost. In Fig. 7, we present the number of training epochs carried out at the workers and the server until the global model achieves of accuracy. The experimental results show that while Asyn2F achieves a faster convergence, all the workers and the server need fewer training epochs compared to M-Step KAFL to converge to the desired performance. This implies that Asyn2F incurs a lower communication cost as the workers and the server need to exchange the obtained models after each training epoch (at the workers) and after each aggregation at the server. The ResNet18 model has a size of MB, which incurs a significant communication cost, especially when we use Amazon S3 as the storage service, which charges monetary cost based on the amount of data uploaded/downloaded from the cloud. It is worth mentioning that the higher the number of models exchanged (stored), the higher the storage cost as well. To reduce the storage cost, those intermediate (local and global) models (obtained prior to the final global model) could be deleted.
It is to be noted that, in Fig. 7, we do not present the number of training epochs of FedAvg, which requires the same number of training epochs for all the workers and the server (10 epochs to attain of accuracy). However, due to the synchronization among workers, the time duration for each training epoch is very long due to the heterogeneity of computing resources of the workers and their dataset. This explains the reason why FedAvg spends a longer time to converge to the stabilized performance of the model. This demonstrates the practicality of our technique and the implemented framework, which can work very well in a heterogeneous infrastructure including both network connectivity and computing resources.
5.1.2 Experiments with larger infrastructures
In this section, we perform the experiments with a larger training infrastructure including heterogeneous workers. The details of the infrastructure are presented in Table III. It is worth mentioning that several workers are running CPU resources, which are much slower than GPU resources when training large deep learning models on large datasets.
| Role | No. Instances | Description |
|---|---|---|
| Storage | 1 | CSC - HPC (Finland) |
| Queue | 1 | RabbitMQ of CloudAMQP |
| Server | 1 | CSC - HPC (Finland) |
| Tester | 1 | Google Colab GPU |
| Workers | 3 | 2 GPU Workstations at TTU (Vietnam) |
| 2 | 2 CPU Workstations at TTU (Vietnam) | |
| 2 | 2 Laptop GPU (Home Network) | |
| 2 | GPU Workstation at SIT (Singapore) | |
| 11 | Google Colab GPU |
Data Preparation: We split the CIFAR10 dataset into 20 sub-datasets with non-iid splitting method. The data size and label distribution of one of the runs are shown in Fig. 8.


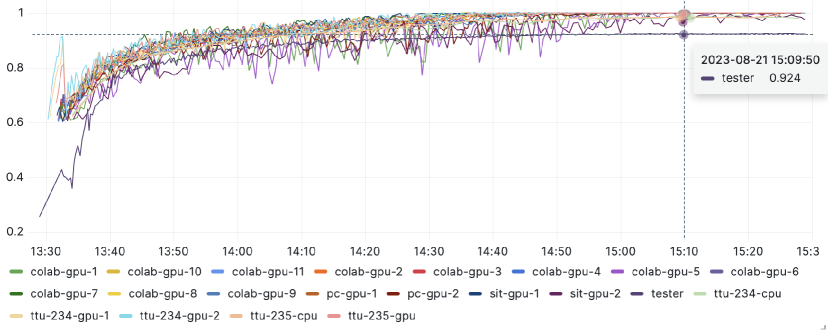
Analysis of Results: As shown in Table IV, we obtain the same performance behavior of the proposed technique and the existing ones. Asyn2F outperforms both M-Step KAFL and FedAvg. Obviously, compared to the case with fewer workers, there is a performance drop due to the scarce distribution of the same number of training data samples to a larger number of workers. In Fig. 9 (captured from the monitoring dashboard of the framework), we present the performance evolution of the local models trained by the workers despite small training datasets. All the local models converge to a stabilized performance thanks to the knowledge obtained from the global model, which is in turn aggregated from other local models. The curve represented by the tester is the performance of the global model that stabilizes after a few hours of training. We also observe an interesting behavior of the framework in this experiment. Due to a large number of training workers and small local training datasets, the workers complete their training epoch very fast, especially the workers with GPU resources. These workers quickly submit their local models to the server for aggregation and continue the next training epoch with the new version of the global model aggregated by the server. The issue of obsolete information does not incur with these workers. Nevertheless, the larger the training framework, the more heterogeneous the workers. Those workers with less powerful computing resources will suffer the consequence of the obsolete information issue, thus significantly benefiting when joining our framework.
It is to be noted that M-Step KAFL needs 10 local models for every global aggregation to achieve an accuracy of . With a fair comparison with 3 local models for every global aggregation, M-Step KAFL achieves an accuracy of only . Further experiments with 7 local models for every global aggregation, M-Step KAFL achieves an accuracy of . This makes M-Step KAFL less practical in a heterogeneous federated learning environment.
| Strategy | Asyn2F | M-Step KAFL | FedAvg |
| Sync.-decayed LR |
5.2 Experiments with EMBER Dataset
5.2.1 Experimental settings
EMBER [26] is a malware dataset including 1 million samples, each being represented by a vector of 2381 feature values. There are 300000 benign samples (labeled as 0), 300000 malicious samples (labeled as 1) and the remaining 400000 samples are undefined. We remove the 400000 undefined samples and use 600000 labeled samples for our experiments. We split the data into 7 sub-datasets using the non-overlapping and non-iid splitting methods. We adopt MalConv model [26], whose detailed parameters are presented in Table V and train it on the training framework with 7 training workers and a tester as shown in Table VI. We note that with only 2381 features representing a sample, the length of the feature vector of the EMBER dataset is much smaller compared to CIFAR10. Even with a deep learning model described in Table V (which is also much smaller than ResNet18 used for CIFAR10), the workers with GPU resources complete a training epoch very fast. This explains why we split the original dataset into only 7 sub-datasets so that the training time of one epoch on a worker will be long enough to demonstrate the heterogeneity of the framework.
| Layer | Parameters |
| Embedding | in_dim=261, out_dim=8 |
| Conv1D | filters=128, kernel_size=15, strides=15, |
| use_bias=True, activation=’relu’, padding=’valid’ | |
| Conv1D | filters=128, kernel_size=15, use_bias=True |
| strides=15, activation=’sigmoid’, padding=’valid’ | |
| Multiply | multiplies (element-wise) layers 2 & 3 |
| GlobalMaxPooling1D | |
| Dense | units=128, activate=’relu’ |
| Dense | units=1, activate=’sigmoid’ |
| Role | No. Instances | Description |
|---|---|---|
| Queue | 1 | RabbitMQ of CloudAMQP |
| Storage | 1 | CSC - HPC (Finland) |
| Server | 1 | CSC - HPC (Finland) |
| Tester | 1 | Google Colab GPU |
| Workers | 3 | 2 CPU Workstations at TTU (Vietnam) |
| 2 | 2 CPU Desktop at TTU (Vietnam) | |
| 1 | 1 GPU Mac M1 (Home - Vietnam) | |
| 1 | Google Colab GPU |
| Strategy | Asyn2F | M-Step KAFL | FedAvg |
|---|---|---|---|
| Fixed LR=0.01 | |||
| Sync.-decayed LR | |||
| Async.-decayed LR | NA |
5.2.2 Analysis of Results
The performance reported in Table VII demonstrates the effectiveness of the training framework as well as the aggregation algorithms. We obtain similar performance behavior as with CIFAR10 such that Asyn2F has a superior performance compared to the existing ones. The results also confirm the fact that synchronizing the decayed learning rate among training workers results in the best performance.
6 Conclusion
In this work, we designed and developed Asyn2F an asynchronous federated learning framework with bidirectional aggregation. The framework addresses the intrinsic characteristics of a distributed computing environment where computing and network resources are heterogeneous combined with diversity in training datasets of data providers. We developed two aggregation algorithms used for the server and the workers, respectively. The global model aggregation algorithm allows the server to aggregate multiple local models to create a new version of the global model. The local model aggregation allows training workers to merge the global model into the local model which is being trained as soon as a new version of the global model is available. This addresses the obsolete information issue and enables a fast convergence of the models. We carried out extensive experiments on a benchmarking dataset (CIFAR10) and a more practical dataset (EMBER) to validate the performance of Asyn2F. The experimental results show the superiority of the proposed framework over the recently developed ones. The framework demonstrates its practicality with the use of cloud services for its implementation, thus overcoming the security restrictions of enterprises or organizations to protect the privacy of their data.
Acknowledgements
The work is supported by Tan Tao University Foundation for Science and Technology Development under Grant No. TTU.RS.22.102.001. The authors wish to acknowledge CSC IT Center for Science, Finland, for cloud resources.
References
- [1] D. Evans, “The Internet of Things: How the Next Evolution of the Internet Is Changing Everything,” Apr. 2011, White Paper, Cisco.
- [2] Q. Xia, W. Ye, Z. Tao, J. Wu, and Q. Li, “A survey of federated learning for edge computing: Research problems and solutions,” High-Confidence Computing, vol. 1, no. 1, p. 100008, 2021.
- [3] EU, “European Union’s General Data Protection Regulation (GDPR) ,” Apr. 2023. [Online]. Available: \urlhttps://gdpr-info.eu/
- [4] Q. Ho et al., “More Effective Distributed ML via a Stale Synchronous Parallel Parameter Server,” in Proc. NIPS’13, Lake Tahoe, Nevada, 2013.
- [5] T.-D. Cao, T. Truong-Huu, H. Tran, and K. Tran, “A federated deep learning framework for privacy preservation and communication efficiency,” Journal of Systems Architecture, vol. 124, 2022.
- [6] L. T. Phong and T. T. Phuong, “Privacy-Preserving Deep Learning via Weight Transmission,” IEEE Transactions on Information Forensics and Security, vol. 14, no. 11, pp. 3003–3015, Nov. 2019.
- [7] H. B. McMahan et al., “Communication-Efficient Learning of Deep Networks from Decentralized Data,” in International Conference on Artificial Intelligence and Statistics, 2017.
- [8] C. Gong, Y. Chen, Y. Lu, T. Li, C. Hao, and D. Chen, “VecQ: Minimal Loss DNN Model Compression With Vectorized Weight Quantization,” IEEE Trans. Comput., vol. 70, no. 5, May 2021.
- [9] A. Kumar, B. Finley, T. Braud, S. Tarkoma, and P. Hui, “Marketplace for AI models,” CoRR, vol. abs/2003.01593, 2020.
- [10] T. Cao, H.-L. Truong, T. Truong-Huu, and M.-T. Nguyen, “Enabling Awareness of Quality of Training and Costs in Federated Machine Learning Marketplaces,” in IEEE UCC 2022, CA, USA, Dec. 2022.
- [11] C. Xie, S. Koyejo, and I. Gupta, “Asynchronous federated optimization,” in 12th Annual Workshop on Optimization for Machine Learning, 2020.
- [12] M. Even, H. Hendrikx, and L. Massoulié, “Asynchronous speedup in decentralized optimization,” in Workshop on Federated Learning: Recent Advances and New Challenges, 2022.
- [13] S. Liu, Q. Chen, and L. You, “Fed2a: Federated learning mechanism in asynchronous and adaptive modes,” Electronics, vol. 11, no. 9, 2022.
- [14] M. S. Assran and M. G. Rabbat, “Asynchronous gradient push,” IEEE Transactions on Automatic Control, vol. 66, no. 1, 2021.
- [15] Y. Chen, Y. Ning, M. Slawski, and H. Rangwala, “Asynchronous Online Federated Learning for Edge Devices with Non-IID Data,” in IEEE Big Data 2020, Los Alamitos, CA, USA, Dec. 2020.
- [16] X. Wu and C. Wang, “KAFL: Achieving High Training Efficiency for Fast-K Asynchronous Federated Learning,” in IEEE ICDCS 2022, Los Alamitos, CA, USA, Jul. 2022, pp. 873–883.
- [17] Q. Wang, Q. Yang, S. He, Z. Shi, and J. Chen, “Asyncfeded: Asynchronous federated learning with euclidean distance based adaptive weight aggregation,” arXiv, 2022, 2205.13797.
- [18] Y. Zhang et al., “FedMDS: An Efficient Model Discrepancy-Aware Semi-Asynchronous Clustered Federated Learning Framework,” IEEE Trans. Parallel Distrib. Syst., vol. 34, no. 03, Mar. 2023.
- [19] X. Lian, W. Zhang, C. Zhang, and J. Liu, “Asynchronous decentralized parallel stochastic gradient descent,” arXiv, 2018, 1710.06952.
- [20] S. Sundhar Ram, A. Nedić, and V. V. Veeravalli, “Asynchronous gossip algorithms for stochastic optimization,” in Proc. of the 48h IEEE Conference on Decision and Control (CDC), 2009, pp. 3581–3586.
- [21] X. Yu et al., “Async-HFL: Efficient and Robust Asynchronous Federated Learning in Hierarchical IoT Networks,” in Proc. ACM/IEEE IoTDI’23, New York, NY, USA, 2023, p. 236–248.
- [22] Y. Miao et al., “Robust Asynchronous Federated Learning with Time-weighted and Stale Model Aggregation,” IEEE Trans Dependable Secure Comput, pp. 1–15, 2023.
- [23] H. Patel et al., “Automatic Assessment of Quality of Your Data for AI,” in 5th Joint Int. Conf. on Data Science and Management of Data, 2022.
- [24] C. Batini et al., “Methodologies for data quality assessment and improvement,” ACM Comput. Surv., vol. 41, no. 3, Jul. 2009.
- [25] A. Krizhevsky, V. Nair, and G. Hinton, “The CIFAR-10 dataset,” 2009.
- [26] H. S. Anderson and P. Roth, “EMBER: An Open Dataset for Training Static PE Malware Machine Learning Models,” arXiv, 2018.
- [27] K. He, X. Zhang, S. Ren, and J. Sun, “Deep Residual Learning for Image Recognition,” in Proc. IEEE CVPR 2026, Las Vegas, NV, USA, June 2016, pp. 770–778.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/1eeeb1a0-f361-42a3-9a45-3d9763bc58f6/Dung_Photo.png) |
Tien-Dung Cao received the Ph.D. in Computer Science from the University of Bordeaux, France in 2010. He is currently Dean of the School of Information Technology, Tan Tao University, Vietnam. His research interests include Machine Learning, Big Data, and Service Engineering. He has served as an academic editor of PLOS ONE journal since 2022. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/1eeeb1a0-f361-42a3-9a45-3d9763bc58f6/ThaoNguyenVuong.png) |
Thao Nguyen Vuong recently completed a Bachelor’s Degree in Computer Science from Tan Tao University. She is now a research intern at Aalto University, Finland. Her current research interests lie in federated learning and automation in machine learning services. She aims to address challenges such as the heterogeneity of training workers in federated systems, including aspects like computational capacity, data distribution, network latency, and availability. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/1eeeb1a0-f361-42a3-9a45-3d9763bc58f6/LeQuangThai.jpg) |
Thai Q. Le recently completed a Bachelor’s Degree in Computer Science from Tan Tao University. He is a passionate programmer who thrives on exploring the uncharted territories of technology. With an insatiable curiosity, he constantly seeks out new and innovative ideas. His research interests include game development which inspires him with new ideas for his work. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/1eeeb1a0-f361-42a3-9a45-3d9763bc58f6/hoang.jpg) |
Hoang V. N. Dao is a software engineer with an insatiable curiosity for technology and a knack for solving complex problems. He recently completed his bachelor’s degree in Computer Science with a specialization in AI from Tan Tao University, Vietnam. His research interests include distributed computing, artificial intelligence, and big data. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/1eeeb1a0-f361-42a3-9a45-3d9763bc58f6/tram.jpg) |
Tram Truong-Huu is an Assistant Professor at the Singapore Institute of Technology (SIT), Infocomm Technology (ICT) Cluster. He is currently holding a joint appointment with the Agency for Science, Technology and Research (A*STAR), Singapore, where he has worked as a computer scientist at the Institute for Infocomm Research (I2R) since May 2019. He received the Ph.D. degree in computer science from the University of Nice - Sophia Antipolis (now Côte d’Azur University), France in December 2010. From January 2011 to June 2012, he held a post-doctoral fellowship at the French National Center for Scientific Research (CNRS), France. He worked at the National University of Singapore as a research fellow from July 2012, then senior research fellow from January 2017. His research interests include software-defined networks, the Internet of Things, and the application of artificial intelligence to cybersecurity. He won the Best Presentation Recognition at IEEE/ACM UCC 2013. He has been a member of the IEEE since 2012 and a Senior Member since 2015. |