ARMANI: Part-level Garment-Text Alignment for Unified Cross-Modal Fashion Design
Abstract.
Cross-modal fashion image synthesis has emerged as one of the most promising directions in the generation domain due to the vast untapped potential of incorporating multiple modalities and the wide range of fashion image applications. To facilitate accurate generation, cross-modal synthesis methods typically rely on Contrastive Language-Image Pre-training (CLIP) to align textual and garment information. In this work, we argue that simply aligning texture and garment information is not sufficient to capture the semantics of the visual information and therefore propose MaskCLIP. MaskCLIP decomposes the garments into semantic parts, ensuring fine-grained and semantically accurate alignment between the visual and text information. Building on MaskCLIP, we propose ARMANI, a unified cross-modal fashion designer with part-level garment-text alignment. ARMANI discretizes an image into uniform tokens based on a learned cross-modal codebook in its first stage and uses a Transformer to model the distribution of image tokens for a real image given the tokens of the control signals in its second stage. Contrary to prior approaches that also rely on two-stage paradigms, ARMANI introduces textual tokens into the codebook, making it possible for the model to utilize fine-grain semantic information to generate more realistic images. Further, by introducing a cross-modal Transformer, ARMANI is versatile and can accomplish image synthesis from various control signals, such as pure text, sketch images, and partial images. Extensive experiments conducted on our newly collected cross-modal fashion dataset demonstrate that ARMANI generates photo-realistic images in diverse synthesis tasks and outperforms existing state-of-the-art cross-modal image synthesis approaches. Our code is available at https://github.com/Harvey594/ARMANI.
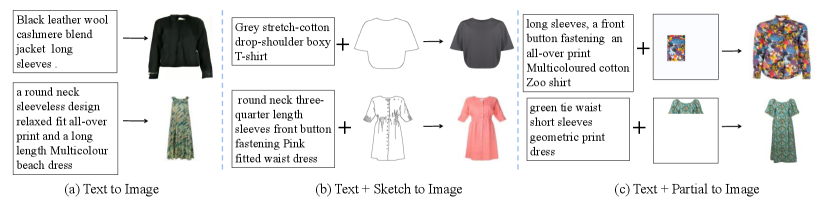
1. Introduction
Cross-modal fashion design, in which a garment image is altered based on control signals from a variety of modalities, such as pure text, sketches, partial images, etc., has the potential to revolutionize the fashion design process. There exist several text-to-image synthesis works (Reed et al., 2016; Dong et al., 2017; Hong et al., 2018; Li et al., 2019b; Zhang et al., 2018a; Yuan and Peng, 2018; Huang et al., 2018; Lao et al., 2019), which can be regarded as early attempts of cross-modal fashion design. However, these methods can only achieve text-guided image synthesis, which greatly limits their practicality. Hence, there is increasing demand for a framework that allows the integration of different control signals from diverse modalities for fashion design. However, designing a unified framework for simultaneously handling cross-modal signals is nontrivial, due to their inherent representation differences.
More specifically, as shown in Fig. 1, a sketch image is a concise image describing the overall outline of an object, while a partial image is an incomplete RGB image with missing regions. Pure text, on the other hand, differs from the two image counterparts and typically describes a particular object’s main characteristics. The representation discrepancy among diverse modalities makes integrating control signals from various modalities difficult for most of the existing cross-modal synthesis works (Xu et al., 2018; Zhang et al., 2018b; Hinz et al., 2019; Li et al., 2020b; Zhang et al., 2021a; Wang et al., 2021), which are usually based on the prevalent generative model, i.e., Generative Adversarial Nets (Reed et al., 2016). Recently, Vision Transformers (Ding et al., 2021; Zhang et al., 2021c; Ramesh et al., 2021; Esser et al., 2021; Zeng et al., 2021; Khan et al., 2021; Jiang et al., 2021; Zhu et al., 2021) have been demonstrated as a feasible paradigm for unified cross-modal image synthesis, where the generated images and the control signals from different modalities are transferred into uniform representations. These methods typically use Vector Quantized Variational AutoEncoders (VQ-VAE) (Oord et al., 2017) in the first stage to learn a codebook of local features for various visual parts in the real images by compressing the input image into a low-resolution discretized feature map and then reconstructing the input image. During the second stage, the tokens of the control signals are then fed into a Transformer-based decoder to predict a token sequence for the synthesized image, where predicted tokens are sampled from the learnable codebook in the first stage. Benefiting from the global expressivity of the Transformer and the uniform representation for various control signals and the generated image, methods like UFC-BERT (Zhang et al., 2021c) can address arbitrary types of cross-modal image synthesis within a single model and generate reasonable results that comply with the control signals in most scenarios.
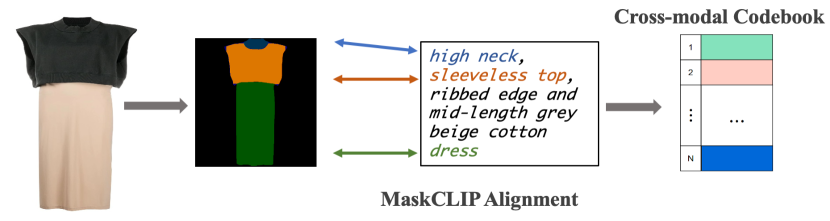
However, the codebook generation mechanism used by the aforementioned two-stage paradigm inevitably leads to an issue that compromises the generalization of the model. Since the codebook is learned by reconstructing images from the training set, the codebook can only contain visual information and represent local features of the various visual parts of the training images. Moreover, when testing, generation according to words that appear less frequently in the training set may not be accurate. For instance, most garment descriptions only provide an overall description and do not contain detailed descriptions of the garment components such as buttons. This again will lead to poor generation results.
The prime reason for this issue is that codes in the codebook only encode the local visual features of the images and neglect the corresponding text information that provides more distinguishing features. This leads to an inferior representation with coarse semantics. To address this, text information with more fine-grain semantics should be considered to enhance codebook expressivity. However, naively aligning visual and text information using Contrastive Language-Image Pre-training (CLIP (Radford et al., 2021)) would be insufficient as it neglects the semantic information of the garment.
In this paper, we therefore propose a pARt-level garMent-text Alignment for uNIfied cross-modal fashion design (ARMANI) to accomplish diverse manipulations according to control signals from different modalities. In contrast to existing two-stage methods, ARMANI divides the first stage (i.e., the codebook learning stage) into two steps. The first step consists of a Mask-level Contrastive Language-Image Pretraining (MaskCLIP) module that decomposes the garments into semantic parts to facilitate fine-grained alignment between the visual information and the text description (illustrated in Fig. 2). In the second step, each code in the learnable codebook is updated by collaboratively considering the visual feature and its most related word embedding, resulting in a text-aware and semantically accurate, cross-modal codebook.
The textual semantics in the cross-modal codebook enable the model to predict more reasonable codes for control signals not seen in the training data. Let us consider the example of ”a T-shirt with a zip”. Despite the lack of a specific code for ”a T-shirt with a zip”, the model can now pay more attention to the textual semantics of the word ”zip” and predict the code by leveraging the word embedding of ”zip” from other zip items such as ”a jacket with a zip”.
Furthermore, to increase the versatility of ARMANI, we design a cross-modal Transformer in the second stage, which simultaneously takes as inputs different types of control signals (i.e., pure text, sketches, partial images) to predict the final token sequence. Further, we propose a semantic loss that leverages our proposed MaskCLIP in both stages of the framework to ensure that the cross-model codebook and cross-modal Transformer are semantically accurate. Finally, we collect a new cross-modal fashion dataset (CM-Fashion) that contains over 500,000 garment images with corresponding textual descriptions. Extensive experiments on our newly collected dataset demonstrate that ARMANI can conduct various fashion manipulation tasks in compliance with diverse control signals (see Fig. 1 and is superior to existing state-of-the-art cross-modal image synthesis works. In summary, our contributions are:
-
•
ARMANI, a novel and versatile framework for cross-modal fashion design that can perform fashion manipulation based on cross-modal control signals and leverages an expressive cross-modal codebook to incorporate the fine-grain text information.
-
•
MaskCLIP, a Mask-level Contrastive Language-Image Pretraining module that learns a semantically accurate alignment between the visual and textual features. MaskCLIP further ensures semantic consistency when training the cross-modal codebook and the cross-modal Transformer.
-
•
CM-Fashion, the largest publicly released cross-modal fashion dataset that both contains high-resolution images from a large variety of garment categories and detailed noise-free text descriptions.
-
•
An extensive evaluation of our proposed ARMANI, which demonstrates its benefits over prior cross-modal approaches.
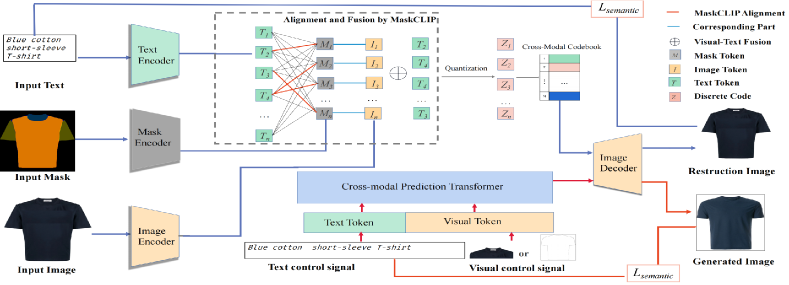
2. RELATED WORK
2.1. Cross-modal Image Synthesis
Recently, a great deal of progress (Xia et al., 2020; Karras et al., 2019; Ramesh et al., 2021; Esser et al., 2021; Zhang et al., 2021c; Li et al., 2019c; Cai et al., 2019; Zhu and Ngo, 2020) has been made on the cross-modal image synthesis task, which aims to generate realistic pictures from various control signals, such as pure text, sketch images, or partial images. Existing methods can be divided into two categories, in which the first category generates images via GAN-based approaches. For instance, TediGAN (Xia et al., 2020) learns a StyleGAN (Karras et al., 2019) inversion module and then computes the visual-linguistic similarity to generate an image from cross-modal inputs. The second category of methods produces images via a two-stage image synthesis framework, where the first stage trains a VQVAE (Oord et al., 2017) to convert an image into a sequence of discrete tokens and convert such a sequence of tokens back into an image. During the second stage, various control signals are used as inputs and a Transformer is trained to capture the distribution of the token sequences. Leveraging this two-stage framework, DALL·E (Ramesh et al., 2021) and Cogview (Ding et al., 2021) generate high-resolution images from text descriptions, while M6-UFC (Zhang et al., 2021c) adopts a BERT-based two-stage framework to unify any number of cross-modal control signals for conditional image synthesis. These methods, however, use discrete tokens without textual information, resulting in sub-optimal generation capabilities. ARMANI addresses this problem by integrating textual information in the first stage, leading to more expressive tokens.
2.2. Cross-Modal Interaction Mechanism
One of the key challenges in cross-modal research is the modeling of the interaction between two modalities, which is mainly addressed by two types of approaches: single-stream and dual-stream models. Single-stream models like VisualBERT (Li et al., 2019a), UNITER (Chen et al., 2020), and ViLT (Kim et al., 2021) directly concatenate the patch-wise and textual embeddings and leverage a Transformer to model interactions, while dual-stream models like ViLBERT (Li et al., 2019a), ALIGN (Jia et al., 2021), UNIMO (Li et al., 2020a), CLIP (Radford et al., 2021), FILIP (Yao et al., 2021), and GLIP (Li et al., 2021) learn separate encoders for the different modalities prior to aligning the modalities, which allows flexible use of different models for different modalities and to address various downstream tasks. Inspired by these dual-stream models, ARMARNI introduces the novel MaskCLIP module to learn the correspondence between the fine-grained features of different modalities.
3. ARMANI
We first briefly discuss the technical details of the two-stage synthesis paradigm, which our model ARMANI (see Fig. 3) inherits. We then introduce the components of our framework in Sec. 3.2-3.4.
3.1. Preparatory: Two-stage Synthesis Framework
The first stage aims to learn a semantically rich codebook and an expressive generator, where the codebook encompasses a variety of visual features from the dataset, while the generator can synthesize realistic images given a collection of codes sampled from the codebook. This is achieved by introducing a Variational Autoencoder (VAE) with a convolutional encoder (E) and a decoder (G) that is trained to conduct image reconstruction. Concretely, the encoder first compresses the input image into a low-resolution feature map . Then, for each spatial position (i,j) of , the vector is quantized into a discrete code by replacing it with the closest entry in the learnable codebook , which can be formulated as:
| (1) |
Finally, the decoder takes as input the discrete feature map and reconstructs the input image,
| (2) |
Thus, once the VAE is fully trained, the codebook and the generator (i.e., decoder) can be obtained.
Given the learned VAE and the codebook, each image in the dataset can be converted into a discrete feature map and further be represented as an index sequence , in which each element represents the entry index in the codebook . In the second stage, a sequence generation model (e.g., Transformer) is then used to model the sequence distribution conditioned on the control signals . More specifically, taking as inputs the control signals and the preceding predicted tokens , the sequence generation model predicts a conditional distribution for the next token . Finally, the predicted index sequence is converted to a discrete feature map and fed into the generator to generate a new image.
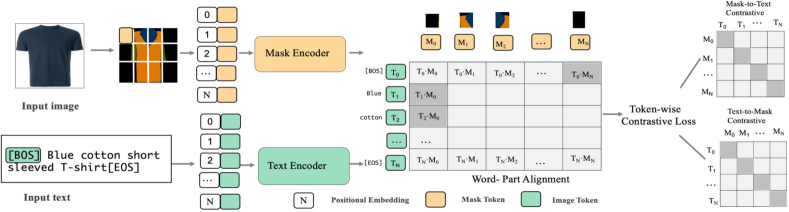
3.2. MaskCLIP: Mask-level Contrastive Language-Image Pretraining
The learnable codebook in the existing two-stage-based methods (Ramesh et al., 2021; Zhang et al., 2021c) struggles to represent visual parts that do not (or only rarely) exist in the training set, largely impairing its expressivity during inference. To address this issue, our ARMANI framework combines each visual code in the codebook with its most relevant word embedding, resulting in a text-aware cross-modal codebook with more distinct semantics.
However, directly combining a visual code with its corresponding word embedding is not trivial, since the visual code and the word embedding are in different feature spaces and the correspondence between these two features is not accessible. To align the visual code and the word embedding and at the same time capture the detailed semantic information of the garment, we propose to leverage the garment segmentation mask, which has been proven useful in vision-language understanding to gain more fine-grained image information (Zhang et al., 2021b; Lu et al., 2019). In particular, ARMANI introduces a Mask-level Contrastive Language-Image Pretraining (MaskCLIP) module to explicitly learn the correspondence between the word embedding and the visual part through the segmentation mask (see Fig. 4). Concretely, during training, given a training batch , a garment segmentation mask is first obtained from the garment image using a mask prediction network to represent the detailed parts of the garment such as button, sleeve, belt, etc. The mask is then encoded as the visual token . Similarly, the text sample is encoded producing the text token . We then compute the similarity between each entry in and all the text tokens and let the largest similarity represent the token-wise similarity between the visual token and the whole text:
| (3) |
The similarity between a mask and a text is then computed as the average over the token-wise similarity for the given mask. Thus, the similarity of to can be formulated as:
| (4) |
where . Similarly, the similarity of to can be formulated as:
| (5) |
where . Based on the definition of the token-wise similarity between the image and the text, the image-to-text token-wise contrastive loss for a training batch and its text-to-image counterpart can be calculated as:
| (6) |
| (7) |
The total loss of our MaskCLIP module can be formulated as:
| (8) |
3.3. Cross-modal Codebook
After training MaskCLIP, we learn the cross-modal codebook by injecting the relevant word embedding into each visual code. More specifically, when learning the codebook, we first get the mask label of the input image and its related text . For each visual part token in , we then obtain its related text token according to the similarity of the mask token and the text tokens, namely,
| (9) |
A cross-modal local feature , which incorporates the visual information as well as the fine-grain text information, can then be obtained by averaging the visual token and its corresponding text token . Finally, all cross-modal features are quantized using Eq. 1, and form the discrete feature map , which is further sent to the generator to reconstruct the input image . In addition, we use the proposed MaskCLIP loss to ensure that the cross-modal codebook captures semantically accurate information by optimizing a symmetric cross entropy loss over the similarities of an image and text embedding batch. This results in the semantic loss
| (10) |
where is the similarity between the MaskCLIP embeddings of its two arguments, is the text description of the picture, and is the mask prediction model.
The total loss in the first stage can thus be formulated as:
| (11) |
where denotes the training losses used in VQ-GAN (Esser et al., 2021).

3.4. Cross-modal Transformer
In contrast to existing cross-modal image synthesis approaches (Esser et al., 2021; Patashnik et al., 2021; Tan et al., 2021; Kenan et al., 2020; Zhang et al., 2021a) which can only accomplish text-to-image synthesis or image-to-image synthesis, our ARMANI framework is a versatile model that can handle diverse control signals within a unified network. The main challenge of such a unified model is how to represent diverse control signals in a uniform way. To address this challenge, ARMANI introduces a cross-modal Transformer to jointly take diverse control signals as input and predict a sequence of discrete tokens that are used to generated the image (see Fig. 3). As opposed to CNN-based approaches, Transformers are capable of handling this task, since data from various modalities (e.g., images, text, audio, etc.) can be transferred into the same representation, the token sequence. Besides, since Transformers predict the next token in an autoregressive manner, according to the previous token sequence or the condition signals, we can easily add a new control signal into the model by prepending the token sequence of the new signal to the input tokens.
Specifically, the control signals in our ARMANI framework are comprised of pure text, sketches, and partial images, in which the pure text is directly obtained from a cross-modal dataset, while sketches and partial images can be obtained by applying the Canny edge detection algorithm (Canny, 1986) and extracting a random crop of the RGB image, respectively.
The control signals are first converted into text and image token sequences, where the text token sequence is obtained directly by a Transformer-based encoder. For the image token sequence, we instead learn a codebook for each type of signal and quantize each signal into a discrete image token sequence. The different token sequences are combined and a special token [SEP] is used to indicate the separation between the modalities. The cross-modal Transformer then predicts the token sequence and feeds it to the image decoder to synthesize the image.
During training, the cross-modal Transformer is trained by maximizing the log-likelihood of the generated token sequence conditioned on various control signals by minimizing the following training loss:
| (12) |
| (13) |
where represents the predicted token sequence while denotes the conditional token sequence. To further ensure that the generated image represents the text, we apply our semantic loss for the token prediction to improve the ability to capture the relation between text and image. Finally, the total loss in the second stage can thus be formulated as:
| (14) |

4. Experiments
Datasets. Fashion design research has been limited by the lack of a high-quality garment dataset, as previous approaches like M6-UFC (Zhang et al., 2021c) have not released their dataset for commercial reasons. Further, existing openly available fashion datasets such as DeepFashion (Liu et al., 2016) lack detailed text descriptions of the garments. We, therefore, collect a new dataset from Farfetch for the task of cross-modal fashion synthesis, which we call CM-Fashion. Specifically, our CM-Fashion dataset contains over 500,000 images from a variety of garment categories (e.g., t-shirts, jackets, dresses, pants, etc.) and includes detailed descriptions. We will release the dataset at https://github.com/Harvey594/ARMANI to facilitate the development of fashion design approaches. CM-Fashion comprises the first open source data set with text descriptions in the field of fashion design and we believe that it will pave the way towards further development of methods tailored towards cross-modal fashion design such as ARMANI. Details of the dataset are provided in the appendix.
Baselines. We verify the effectiveness of ARMANI on three tasks, namely, the Text-to-Image, Text+Sketch-to-Image, and Text+Partial-to-Image tasks. To validate the benefits of ARMANI over existing methods, we compare to three cross-modal synthesis works, namely, TediGAN (Xia et al., 2020), DALL·E (Ramesh et al., 2021), and Cogview (Ding et al., 2021). Since DALL·E (Ramesh et al., 2021) also leverages the two-stage paradigm, we ensure a fair comparison by choosing VQGAN (Esser et al., 2021) instead of VQVAE2 (Razavi et al., 2019) in the first stage and extend their framework to the Text+Sketch-to-Image and Text+Partial-to-Image tasks with a cross-modal Transformer. For TediGAN (Xia et al., 2020), which is a GAN-based approach, we instead use their proposed complex instance-level optimization scheme and use the official implementation of Cogview (Ding et al., 2021).
Implementation Details. Our proposed ARMANI model is implemented using PyTorch and is trained on 8 Tesla V100 GPUs. For the mask prediction network, we use Pointrend of Detecton2 (Wu et al., 2019) as our segmentation network, which is trained on a private dataset consisting of 45,000 labeled images. The final predicted segmentation has 15 labels, each label representing a garment part such as pocket, waistband, buttons, etc. The full label list and corresponding visualizations are provided in the appendix. To facilitate reproducibility, the trained mask prediction model will be released together with the code of ARMANI and the CM-Fashion dataset upon acceptance. During MaskCLIP training, the text and image encoders are the same as the ones used in CLIP (Radford et al., 2021) and consist of a Transformer with 12-layers, 8 attention heads, 512 hidden state size, and a total of 63M parameters. During the first training stage, we convert images of size 256*256 into a sequence of 16*16 codes and set the codebook size to 1024. In the second stage, we use a GPT2-medium (Radford et al., 2019) architecture with 16 attention heads, embedding dimensionality of 1024 and 16 transformer blocks, resulting in 407M parameters. As for the hyper-parameters of the first stage loss , , and are set to 0.9, 0.1, and 2, respectively. Additional implementation details are provided in the appendix.

| Task | Text-to-Image | Text+Sketch-to-image | Text+Partial-to-Image | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Metric | FID | IS | CLIPScore | FID | IS | CLIPScore | FID | IS | CLIPScore | |||
| TediGAN (Xia et al., 2020) | 27.378 | 18.46 | 0.5587 | —— | —— | —— | —— | —— | —— | |||
| Cogview (Ding et al., 2021) | 12.198 | 23.99 | 0.6572 | —— | —— | —— | —— | —— | —— | |||
| DALL·E (Ramesh et al., 2021) | 13.249 | 20.33 | 0.6423 | 12.578 | 24.98 | 0.7028 | 13.287 | 22.99 | 0.6812 | |||
| ARMANI (Ours) | 12.336 | 24.32 | 0.6988 | 11.882 | 25.29 | 0.7433 | 11.741 | 24.03 | 0.7189 | |||
4.1. Visualization of MaskCLIP
In this section, we visualize MaskCLIP’s capability of capturing fine-grained semantically-accurate cross-modal correspondence using the proposed word-part alignment.
Visualization Strategy. The word-part alignment is performed based on the token-wise similarity between the mask patches and the textual tokens. Specifically, for the text, the visual token with the largest similarity to it is considered as its predicted label. Note that one garment part may be tokenized to more than one mask token. For an image and its mask, MaskCLIP predicts the patch that is most relevant to the given text. We highlight the mask patch and the image patch corresponding to the text, while the others are marked in white.
Visualization result. Fig. 6 shows the word-part alignment results for MaskCLIP. The first image shows the correspondence between the text and the mask, and the second image shows the correspondence between the original image and the mask. As can be seen, MaskCLIP accurately predicts the mask token that is most relevant to a given text.
4.2. Comparison With State-Of-The-Art Methods
Qualitative Results. We first present qualitative results for ARMANI in Fig. 5 for all three tasks, before comparing to DALL·E (Ramesh et al., 2021). For the Text-to-Image synthesis task (Fig. 7), ARMANI can synthesize realistic fashion images that comply with the textual description, while DALL·E (Ramesh et al., 2021) generates garment images that comply with the overall content of the textual description, but tends to neglect fine-grained information in the input text. Moreover, DALL·E fails to synthesize precise details such as buttons and small logos (red box in Fig. 7). ARMANI on the other hand is capable of recovering the fine-grain details corresponding to each word in the input text due to the explicit introduction of the text tokens into the codebook and accurate sequence prediction. We observe similar behavior for the other two tasks and provide the qualitative results in the appendix.
Quantitative Results. We apply FID (Heusel et al., 2017) and IS (Salimans et al., 2016) to measure the quality of the synthesized images. Further, we use CLIPScore (Hessel et al., 2021) to measure the relevance of the text to a given image. A higher CLIPScore (Hessel et al., 2021) indicates that the text is more relevant to the image. In addition, we designed a human evaluation to compare the baselines and our generation results. A higher human evaluation score indicates that a larger fraction of participants preferred the results of a given method.111Details on the human evaluation are provided in the appendix. As reported in Table 1, our ARMANI model outperforms the baselines TediGAN (Xia et al., 2020), Cogview (Ding et al., 2021), and DALL·E (Ramesh et al., 2021) in most cases by a large margin, mostly obtaining the lowest FID (Heusel et al., 2017) and IS (Salimans et al., 2016) scores and the highest CLIPScore (Hessel et al., 2021) on the three tasks. Note, here DALL·E (Ramesh et al., 2021) has been extended to the Text+Partial-to-Image and Text+Sketch-to-Image synthesis tasks.
As the corresponding ground truth is not available when generating images based on text conditions, we perform a human evaluation study in order to assess the image quality and its relevance to the text jointly. We observe from Fig. 8 that ARMANI’s results are preferred according to the human evaluation on all the three tasks and we also observe that, compared to the machine evaluation, the human evaluation indicates a larger difference among the models.


4.3. Ablation Study
To validate the effectiveness of the semantically accurate alignment of our proposed MaskCLIP, we perform an ablation study, where we compare ARMANI with a version of ARMANI without the MaskCLIP module. We compare these models on all three tasks and observe that the full ARMANI model obtains higher CLIPscore (Hessel et al., 2021). This illustrates that the generated results are more relevant to the text description, thus validating the effect of MaskCLIP in enabling a semantically accurate cross-modal codebook. To validate the effectiveness of the semantic loss, we perform another ablation study, where we compare ARMANI to two versions of ARMANI, one without the semantic loss in the first stage and one without the semantic loss in the second stage. Again, we compare the CLIPScore (Hessel et al., 2021) for all three tasks and observe that the CLIPScore worsen as we remove the semantic losses, indicating that the semantic loss plays a significant role for the generation. QWe further visualize qualitative results of these ablation studies on the Text-to-Image task in Fig. 9. These results further demonstrate the validity of our method. In particular, we observe that if MaskCLIP alignment is removed, the codebook’s ability to express garment parts will be weakened. While the model can still leverage the garment part information via the semantic loss in the second stage, the generation results are worse. If we instead remove the semantic loss in the first stage, we observe that the information obtained from the MaskCLIP alignment will not be retained in the codebook, again worsening the generation ability for the garment details. Finally, if the semantic loss is removed in the second stage, it will lead to the garment details being ignored in the code sequence prediction of the generated picture and some parts will be ignored and not generated. Additional qualitative results for the other two tasks are provided in the appendix. We further show quantitative results on all three tasks in Table 2 to evaluate the effectiveness of our model components and observe that the absence of each component leads to a decrease in CLIPScore.
| Model Setting | CLIPScore | ||||||
|---|---|---|---|---|---|---|---|
| MaskCLIP | Task 1 | Task 2 | Task 3 | ||||
| ✕ | ✓ | ✓ | 0.6779 | 0.7246 | 0.7003 | ||
| ✓ | ✕ | ✓ | 0.6764 | 0.7151 | 0.7011 | ||
| ✓ | ✓ | ✕ | 0.6617 | 0.7031 | 0.6931 | ||
| ✓ | ✓ | ✓ | 0.6988 | 0.7433 | 0.7189 | ||
5. Conclusion
We proposed a pARt-level garMent-text Alignment for uNIfied cross-modal fashion design (ARMANI) that can leverage multi-modal control signals to accomplish diverse fashion manipulations. Empowered by its elaborately designed MaskCLIP module, which combines visual and textual features in a semantically accurate manner, ARMANI is able to learn a powerful cross-modal codebook and generate fine-grained photo-realistic images guided by text, sketches, or partial images. Experimental results highlight ARMANI’s ability to capture fine-grained semantic information, outperforming previous methods on the cross-model image synthesis task. Finally, we believe that both ARMANI and our newly released dataset CM-Fashion will inspire research on developing versatile cross-modal fashion image synthesis approaches.
Acknowledgements.
This work was supported in part by National Key R&D Program of China under Grant No. 2020AAA0109700, National Natural Science Foundation of China (NSFC) under Grant No. U19A2073, No. 62103454, Guangdong Province Basic and Applied Basic Research (Regional Joint Fund-Key) Grant No.2019B1515120039, No.2019A151 5110680, Guangdong Outstanding Youth Fund (Grant No.2021B1515 020061), the Shenzhen Municipal Basic Research Project for Natural Science Foundation (Grant No.JCYJ20190806143408992), Shenzhen Fundamental Research Program (Project No. JCYJ20190807154211365 ) and CAAI-Huawei MindSpore Open Fund. We thank MindSpore (https://www.mindspore.cn/), which is a new deep learning computing framework, for the partial support of this work.References
- (1)
- Cai et al. (2019) Jinzheng Cai, Zizhao Zhang, Lei Cui, Yefeng Zheng, and Lin Yang. 2019. Towards cross-modal organ translation and segmentation: A cycle-and shape-consistent generative adversarial network. Medical image analysis 52 (2019), 174–184.
- Canny (1986) John Canny. 1986. A computational approach to edge detection. IEEE Transactions on pattern analysis and machine intelligence 6 (1986), 679–698.
- Chen et al. (2020) Yen-Chun Chen, Linjie Li, Licheng Yu, Ahmed El Kholy, Faisal Ahmed, Zhe Gan, Yu Cheng, and Jingjing Liu. 2020. Uniter: Universal image-text representation learning. In European conference on computer vision. Springer, 104–120.
- Ding et al. (2021) Ming Ding, Zhuoyi Yang, Wenyi Hong, Wendi Zheng, Chang Zhou, Da Yin, Junyang Lin, Xu Zou, Zhou Shao, Hongxia Yang, et al. 2021. Cogview: Mastering text-to-image generation via transformers. Advances in Neural Information Processing Systems 34 (2021).
- Dong et al. (2017) Hao Dong, Jingqing Zhang, Douglas McIlwraith, and Yike Guo. 2017. I2t2i: Learning text to image synthesis with textual data augmentation. In 2017 IEEE international conference on image processing (ICIP). IEEE, 2015–2019.
- Esser et al. (2021) Patrick Esser, Robin Rombach, and Bjorn Ommer. 2021. Taming transformers for high-resolution image synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 12873–12883.
- Hessel et al. (2021) Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. 2021. CLIPScore: A reference-free evaluation metric for image captioning. arXiv preprint arXiv:2104.08718 (2021).
- Heusel et al. (2017) Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. 2017. Gans trained by a two time-scale update rule converge to a local nash equilibrium. Advances in neural information processing systems 30 (2017).
- Hinz et al. (2019) Tobias Hinz, Stefan Heinrich, and Stefan Wermter. 2019. Semantic object accuracy for generative text-to-image synthesis. arXiv preprint arXiv:1910.13321 (2019).
- Hong et al. (2018) Seunghoon Hong, Dingdong Yang, Jongwook Choi, and Honglak Lee. 2018. Inferring semantic layout for hierarchical text-to-image synthesis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 7986–7994.
- Huang et al. (2018) He Huang, Philip S Yu, and Changhu Wang. 2018. An introduction to image synthesis with generative adversarial nets. arXiv preprint arXiv:1803.04469 (2018).
- Jia et al. (2021) Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. 2021. Scaling up visual and vision-language representation learning with noisy text supervision. In International Conference on Machine Learning. PMLR, 4904–4916.
- Jiang et al. (2021) Yifan Jiang, Shiyu Chang, and Zhangyang Wang. 2021. Transgan: Two transformers can make one strong gan. arXiv preprint arXiv:2102.07074 1, 3 (2021).
- Karras et al. (2019) Tero Karras, Samuli Laine, and Timo Aila. 2019. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 4401–4410.
- Kenan et al. (2020) E Ak Kenan, Ying Sun, and Joo Hwee Lim. 2020. Learning cross-modal representations for language-based image manipulation. In 2020 IEEE International Conference on Image Processing (ICIP). IEEE, 1601–1605.
- Khan et al. (2021) Salman Khan, Muzammal Naseer, Munawar Hayat, Syed Waqas Zamir, Fahad Shahbaz Khan, and Mubarak Shah. 2021. Transformers in vision: A survey. arXiv preprint arXiv:2101.01169 (2021).
- Kim et al. (2021) Wonjae Kim, Bokyung Son, and Ildoo Kim. 2021. Vilt: Vision-and-language transformer without convolution or region supervision. In International Conference on Machine Learning. PMLR, 5583–5594.
- Lao et al. (2019) Qicheng Lao, Mohammad Havaei, Ahmad Pesaranghader, Francis Dutil, Lisa Di Jorio, and Thomas Fevens. 2019. Dual adversarial inference for text-to-image synthesis. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 7567–7576.
- Li et al. (2020b) Bowen Li, Xiaojuan Qi, Thomas Lukasiewicz, and Philip HS Torr. 2020b. Manigan: Text-guided image manipulation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 7880–7889.
- Li et al. (2019a) Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, and Kai-Wei Chang. 2019a. Visualbert: A simple and performant baseline for vision and language. arXiv preprint arXiv:1908.03557 (2019).
- Li et al. (2021) Liunian Harold Li, Pengchuan Zhang, Haotian Zhang, Jianwei Yang, Chunyuan Li, Yiwu Zhong, Lijuan Wang, Lu Yuan, Lei Zhang, Jenq-Neng Hwang, et al. 2021. Grounded Language-Image Pre-training. arXiv preprint arXiv:2112.03857 (2021).
- Li et al. (2020a) Wei Li, Can Gao, Guocheng Niu, Xinyan Xiao, Hao Liu, Jiachen Liu, Hua Wu, and Haifeng Wang. 2020a. Unimo: Towards unified-modal understanding and generation via cross-modal contrastive learning. arXiv preprint arXiv:2012.15409 (2020).
- Li et al. (2019b) Wenbo Li, Pengchuan Zhang, Lei Zhang, Qiuyuan Huang, Xiaodong He, Siwei Lyu, and Jianfeng Gao. 2019b. Object-driven text-to-image synthesis via adversarial training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 12174–12182.
- Li et al. (2019c) Yunzhu Li, Jun-Yan Zhu, Russ Tedrake, and Antonio Torralba. 2019c. Connecting touch and vision via cross-modal prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 10609–10618.
- Liu et al. (2016) Ziwei Liu, Ping Luo, Shi Qiu, Xiaogang Wang, and Xiaoou Tang. 2016. DeepFashion: Powering Robust Clothes Recognition and Retrieval with Rich Annotations. In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
- Lu et al. (2019) Jiasen Lu, Dhruv Batra, Devi Parikh, and Stefan Lee. 2019. Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. Advances in neural information processing systems 32 (2019).
- Oord et al. (2017) Aaron van den Oord, Oriol Vinyals, and Koray Kavukcuoglu. 2017. Neural discrete representation learning. arXiv preprint arXiv:1711.00937 (2017).
- Patashnik et al. (2021) Or Patashnik, Zongze Wu, Eli Shechtman, Daniel Cohen-Or, and Dani Lischinski. 2021. Styleclip: Text-driven manipulation of stylegan imagery. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 2085–2094.
- Radford et al. (2021) Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. 2021. Learning transferable visual models from natural language supervision. arXiv preprint arXiv:2103.00020 (2021).
- Radford et al. (2019) Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. 2019. Language models are unsupervised multitask learners. OpenAI blog 1, 8 (2019), 9.
- Ramesh et al. (2021) Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea Voss, Alec Radford, Mark Chen, and Ilya Sutskever. 2021. Zero-shot text-to-image generation. arXiv preprint arXiv:2102.12092 (2021).
- Razavi et al. (2019) Ali Razavi, Aaron Van den Oord, and Oriol Vinyals. 2019. Generating diverse high-fidelity images with vq-vae-2. Advances in neural information processing systems 32 (2019).
- Reed et al. (2016) Scott Reed, Zeynep Akata, Xinchen Yan, Lajanugen Logeswaran, Bernt Schiele, and Honglak Lee. 2016. Generative adversarial text to image synthesis. In International Conference on Machine Learning. PMLR, 1060–1069.
- Salimans et al. (2016) Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. 2016. Improved techniques for training gans. Advances in neural information processing systems 29 (2016).
- Tan et al. (2021) Hongchen Tan, Xiuping Liu, Baocai Yin, and Xin Li. 2021. Cross-modal Semantic Matching Generative Adversarial Networks for Text-to-Image Synthesis. IEEE Transactions on Multimedia (2021).
- Wang et al. (2021) Hao Wang, Guosheng Lin, Steven CH Hoi, and Chunyan Miao. 2021. Cycle-Consistent Inverse GAN for Text-to-Image Synthesis. In Proceedings of the 29th ACM International Conference on Multimedia. 630–638.
- Wu et al. (2019) Yuxin Wu, Alexander Kirillov, Francisco Massa, Wan-Yen Lo, and Ross Girshick. 2019. Detectron2. https://github.com/facebookresearch/detectron2.
- Xia et al. (2020) Weihao Xia, Yujiu Yang, Jing-Hao Xue, and Baoyuan Wu. 2020. TediGAN: Text-Guided Diverse Face Image Generation and Manipulation. arXiv preprint arXiv:2012.03308 (2020).
- Xu et al. (2018) Tao Xu, Pengchuan Zhang, Qiuyuan Huang, Han Zhang, Zhe Gan, Xiaolei Huang, and Xiaodong He. 2018. Attngan: Fine-grained text to image generation with attentional generative adversarial networks. In Proceedings of the IEEE conference on computer vision and pattern recognition. 1316–1324.
- Yao et al. (2021) Lewei Yao, Runhui Huang, Lu Hou, Guansong Lu, Minzhe Niu, Hang Xu, Xiaodan Liang, Zhenguo Li, Xin Jiang, and Chunjing Xu. 2021. FILIP: Fine-grained Interactive Language-Image Pre-Training. arXiv:2111.07783 [cs.CV]
- Yuan and Peng (2018) Mingkuan Yuan and Yuxin Peng. 2018. Text-to-image synthesis via symmetrical distillation networks. In Proceedings of the 26th ACM international conference on Multimedia. 1407–1415.
- Zeng et al. (2021) Yanhong Zeng, Huan Yang, Hongyang Chao, Jianbo Wang, and Jianlong Fu. 2021. Improving Visual Quality of Image Synthesis by A Token-based Generator with Transformers. arXiv preprint arXiv:2111.03481 (2021).
- Zhang et al. (2021a) Han Zhang, Jing Yu Koh, Jason Baldridge, Honglak Lee, and Yinfei Yang. 2021a. Cross-modal contrastive learning for text-to-image generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 833–842.
- Zhang et al. (2018b) Han Zhang, Tao Xu, Hongsheng Li, Shaoting Zhang, Xiaogang Wang, Xiaolei Huang, and Dimitris N Metaxas. 2018b. Stackgan++: Realistic image synthesis with stacked generative adversarial networks. IEEE transactions on pattern analysis and machine intelligence 41, 8 (2018), 1947–1962.
- Zhang et al. (2021b) Pengchuan Zhang, Xiujun Li, Xiaowei Hu, Jianwei Yang, Lei Zhang, Lijuan Wang, Yejin Choi, and Jianfeng Gao. 2021b. Vinvl: Revisiting visual representations in vision-language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 5579–5588.
- Zhang et al. (2021c) Zhu Zhang, Jianxin Ma, Chang Zhou, Rui Men, Zhikang Li, Ming Ding, Jie Tang, Jingren Zhou, and Hongxia Yang. 2021c. UFC-BERT: Unifying Multi-Modal Controls for Conditional Image Synthesis. arXiv preprint arXiv:2105.14211 (2021).
- Zhang et al. (2018a) Zizhao Zhang, Yuanpu Xie, and Lin Yang. 2018a. Photographic text-to-image synthesis with a hierarchically-nested adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 6199–6208.
- Zhu and Ngo (2020) Bin Zhu and Chong-Wah Ngo. 2020. CookGAN: Causality based text-to-image synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 5519–5527.
- Zhu et al. (2021) Jianwei Zhu, Zhixin Li, and Huifang Ma. 2021. TT2INet: Text to Photo-realistic Image Synthesis with Transformer as Text Encoder. In 2021 International Joint Conference on Neural Networks (IJCNN). IEEE, 1–8.
Appendix A Dataset Details
The newly collected CM-Fashion dataset consists of garment images and has the following two key properties: 1) CM-Fashion covers most of the regular garment categories, including pants, dresses, jackets, etc. Further, our dataset contains information about gender and target age. Each category has also been divided into garments for men, women, and kids. 2) The images in the CM-Fashion dataset are accompanied by detailed text descriptions and sketches. The sketches are binary pictures that have been obtained via the Canny edge detection algorithm (Canny, 1986). Note, the partial images mentioned in our paper are the result of a random crop (keeping of the original area) and therefore not included explicitly in the dataset. After collecting the raw images, data pre-processing is required to exclude invalid data. We removed images whose text description was either too long (longer than 400 words) or missing, and images that contained more than one garment. Finally, our dataset is divided into a train set containing 468960 images (90%) and a test set with 52108 images (10%). The images in CM-Fashion are crawled from the E-commerce website Farfetch.222https://www.farfetch.cn/uk/


Appendix B Additional Implementation Details
While most of the implementation details have been described in the main paper, we provide the remaining details here. For the mask prediction network, we use PointRend of Detecton2 (Wu et al., 2019) as our segmentation network, to obtain the garment segmentation result. There are 15 different labels for the garment segmentation (see Fig 11). In the training step of MaskClip, the text encoder consists of a Transformer with 12-layers, 8 attention heads, and a hidden state of dimensionality 512. For the image encoder, we use a ViT-B/16 (Kim et al., 2021) and for the implementation of the contrastive loss, following CLIP (Radford et al., 2021). In the first stage, we trained the encoder, the cross-modal codebook, and the decoder for 20 epochs, which took approximately five days on 4 Tesla V100 GPUs with a batchsize of 8. During the second stage, we use the GPT2 [4] architecture. We trained the model for 10 epochs which took almost four days on 4 Tesla V100 GPUs with a batchsize of 8. The learning rate for the first stage was set to , while it was set to for the second stage.
Appendix C Human Evaluation Details
For the human evaluation, we separately design three questionnaires for our ARMANI and the baseline methods, one for each of the investigated settings (Text-to-Image, Text+Sketch-to-Image, and Text+Partial-to- Image tasks). Each questionnaire is composed of 100 tasks, where the results for the different methods are presented in random order and where the volunteers are asked to pick the result that looks most realistic and relevant to the provided information in the task. Before the start of the human evaluation, we first invite five volunteers to accomplish the questionnaires in a serious manner to test the time required to complete the questionnaires. During the evaluation, for a particular questionnaire, we then invite 100 random volunteers, who are asked to spend at least 6 seconds to accomplish each task in the questionnaire.
Appendix D Additional Results
Additional ablation study. We verify that also with single signal inputs such as in the Sketch-to-Image or Partial-to-Image tasks, ARMANI can generate details due to our cross-modal codebook (see Fig. 10)
Visual Comparison to DALL·E on the CM-Fashion Dataset. Fig. 12 displays additional qualitative comparisons of ARMANI and DALL·E (Ramesh et al., 2021) on the CM-Fashion dataset.
Visual Comparison for the ablation study. Fig. 13 displays additional qualitative comparisons of our methods w/o MaskCLIP alignment, w/o semantic loss in the first stage, w/o semantic loss in the second stage, and our full version.
Appendix E Limitation
Limitations of our approach are: (1) Synthesis results are affected by noisy text. Obtaining completely detailed correspondence to the text becomes challenging when generation is conditioned on complicated and noisy text. (2) Our method is more focused on generating part details. More complex visual information, such as textures, are not directly addressed via our method. However, when the codebook size is increased, we observe that texture generation is also improved.

