Are Word Embedding Methods Stable and Should We Care About It?
Abstract.
A representation learning method is considered stable if it consistently generates similar representation of the given data across multiple runs. Word Embedding Methods (WEMs) are a class of representation learning methods that generate dense vector representation for each word in the given text data. The central idea of this paper is to explore the stability measurement of WEMs using intrinsic evaluation based on word similarity. We experiment with three popular WEMs: Word2Vec, GloVe, and fastText. For stability measurement, we investigate the effect of five parameters involved in training these models. We perform experiments using four real-world datasets from different domains: Wikipedia, News, Song lyrics, and European parliament proceedings. We also observe the effect of WEM stability on three downstream tasks: Clustering, POS tagging, and Fairness evaluation. Our experiments indicate that amongst the three WEMs, fastText is the most stable, followed by GloVe and Word2Vec.
1. Introduction
Word Embedding Methods (WEMs) are based on the idea that contextual information alone constitutes a feasible representation of linguistic terms. For each word in the vocabulary, these methods learn dense and low-dimensional vector representations, also referred as embeddings . These embeddings are observed to capture various semantic properties of words. In distributional semantics, vector space models are being used since the 1990s to capture contextual features. Some of the influential early models include the Latent Semantic Analysis (Deerwester et al., 1990) and Latent Dirichlet Allocation (Blei et al., 2003). But the popularization and utilization of word embeddings in natural language processing (NLP) tasks can be attributed to Mikolov and others who created Word2Vec (Mikolov et al., 2013). Two other popular WEMs are GloVe (Pennington et al., 2014) and fastText (Bojanowski et al., 2017).
The quick answer to the questions in the title of this paper is: WEMs are not stable and we should care about it. Given a text corpus and a WEM , we can train multiple sets of word embeddings by varying different parameters related to and . Each such set corresponds to an embedding space. Consider a word and two embedding spaces and . The representation or embedding of in respective spaces be and . We can evaluate the stability of representation of across and by comparing various properties of and . The overall stability of WEM over corpus can be computed as an aggregate over the vocabulary of . Several benchmarks such as WordSim-353 (Finkelstein et al., 2002) and MEN (Bruni et al., 2014) exist for evaluating the quality of word embeddings. The former contains 353-word pairs while the latter contains 3000-word pairs. However, evaluating models using these tests gives only a partial representation of the model performance. In this work, rather than focusing on only a small subset of words, we focus on evaluating the stability of each word in the vocabulary.
Stability evaluation of WEMs has received a lot of attention in the recent past (Antoniak and Mimno, 2018; Dridi et al., 2018; Chugh et al., 2018; Levy et al., 2015; Wendlandt et al., 2018; Lee and Sun, 2021). Such evaluation is crucial because word embeddings are widely used today for a variety of NLP tasks such as sentiment analysis (Tang et al., 2014; Li et al., 2017), named entity recognition (Lample et al., 2016; Seok et al., 2016) and part-of-speech (POS) tagging (Wendlandt et al., 2018; Wang et al., 2015). However, WEMs are sensitive to a number of factors including the size of the corpus, seeds for random number generations and other algorithmic parameters like number of vector dimensions, size of context window and number of training epochs. This leads to a question: what if the WEMs themselves are not stable? This could have implications for downstream tasks.
| WEM Stability factor | Previous Work | Our Work |
|---|---|---|
| Datasets used (no. of tokens) |
Wikipedia (1.5B) (Levy
et al., 2015)
NYT(58M) and Europarl (61M)(Wendlandt et al., 2018) Brown, Project Gutenberg and Reuters (10k each)(Chugh et al., 2018) US Federal Courts of Appeals (38k), NYT (22k) and Reddit (26k)(Antoniak and Mimno, 2018) NIPS between 2007 and 2012 (2M)(Dridi et al., 2018) Ohsumed dataset (34M)(Lee and Sun, 2021) Google N-gram cor-pus: English Fiction(4.8B) and German(0.7B)(Hellrich and Hahn, 2016b) BNC and ACL An-thology Reference corpus(Pierrejean and Tanguy, 2018) |
Wikipedia, News-Crawl (2007), Lyrics and Europarl (50M each) |
| Methods studied | Word2Vec (Wendlandt et al., 2018; Chugh et al., 2018; Dridi et al., 2018; Lee and Sun, 2021; Pierrejean and Tanguy, 2018), GloVe (Levy et al., 2015; Wendlandt et al., 2018; Antoniak and Mimno, 2018), PPMI (Levy et al., 2015; Wendlandt et al., 2018; Antoniak and Mimno, 2018), SGNS (Levy et al., 2015; Antoniak and Mimno, 2018; Hellrich and Hahn, 2016b), SVD (Levy et al., 2015), LSA (Antoniak and Mimno, 2018), SGHS (Hellrich and Hahn, 2016b) | Word2Vec, GloVe and fastText |
| *Number of nearest neighbors |
Reliability while considering different nearest neighbors is very similar for all languages and time spans and WEMs considered (Hellrich and Hahn, 2016b)
A few nearest neighbors are enough for stability evaluation (Wendlandt et al., 2018) |
Stability of fastText reduces slightly with increase in the number of nearest neighbors. |
| Word frequency |
Medium frequency words have the lowest reliability (Hellrich and Hahn, 2016b)
Frequency is not a major factor in stability (Wendlandt et al., 2018) Words having a low and high frequency range have a tendency to display more variation. Medium frequency words show more stability (Pierrejean and Tanguy, 2018) Frequency does not directly affect the stability of medical word embeddings (Lee and Sun, 2021) |
All word groups(low, medium, and high frequency) show high variance in word stability.
A single WEM need not produce the most stable embedding for each word in the vocabulary |
| Number of vector dimension |
Embedding size is a causal factor and varies across corpora (Chugh
et al., 2018)
Stability increases considerably as the dimensionality increases, but it diminishes or becomes slightly invariant after 200 dimensions (Dridi et al., 2018) |
Stability improves with increase in the vector dimensions. But the improvement plateaus after 300 dimensions |
| Number of training epochs |
Reliability increases for each subsequent epoch under negative sampling. SGHS has higher reliability than SGNS when trained on 1 epoch while there’s no difference in terms of accuracy (Hellrich and Hahn, 2016b)
|
Stability of GloVe reduces with the number of training epochs. Effect on fastText is negligible. Stability of Word2Vec improves significantly with the number of training epochs. |
| Context window size |
Larger context window size leads to better accuracy of word representations.but, it shows a diminishing return after a certain point (Dridi
et al., 2018)
Increase in context window size gives varied results for WEMs (Pierrejean and Tanguy, 2018) |
Stability of fastText reduces slightly with increase in the context window size. Stability of Word2Vec reduces with increase in the context window size. GloVe stability increases slightly with increase in the context window size. Higher values of context window size have negligible effect on WEM stability. |
| Downstream Tasks | Word similarity (Levy et al., 2015; Wendlandt et al., 2018), Word analogy (Levy et al., 2015; Dridi et al., 2018), POS tagging (Wendlandt et al., 2018) | Word Clustering, POS Tagging and Fairness Evaluation |
We explore the stability evaluation of three popular WEMs: Word2Vec, GloVe, and fastText. For a word , we compute the stability of representing across and in terms of number of shared nearest neighbors that and have. Newman-Griffis and Fosler-Lussier (Newman-Griffis and Fosler-Lussier, 2017) have shown that nearest neighbor information alone is sufficient to capture most of the performance benefits of word embeddings. Our findings and comparison with existing stability evaluation studies is summarized in the Table 1. This work makes three specific contributions. First, we evaluate stability of WEMs on diverse real-world datasets. Second, we study the effect of multiple parameters on WEMs stability. Third, we analyze the effect of WEMs instability on three downstream applications.
Rest of the paper is organized as follows. Our experiment set up is described in Section 2. Our results on stability evaluation are discussed in Section 3. Effect on downstream tasks are analyzed in Section 4. Related work is covered in Section 5. Finally we conclude and discuss future work in Section 6.
2. Experiment Set Up
This section describes the datasets used, training methodology, and stability measurement. All code and datasets for our work are publicly available on the Web for reproducibility111https://github.com/AnganaB/Stability-of-WEMs.
2.1. Datasets
We performed experiments using four publicly available real-world datasets. Please refer to Table 2 for the statistics about the datasets. These datasets represent diverse styles of natural language usage. Online collaborative writing style is covered in our Wikipedia (Sample) dataset222https://dumps.wikimedia.org/enwiki/. It contains a subset of English Wikipedia articles from October 2017 Wikipedia dump. News articles are covered in the NewsCrawl(2007) dataset333http://www.statmt.org/wmt16/translation-task.html. We have used the News Crawl articles for the year 2007. The Lyrics dataset represents creative writing style444Datasets from (Barman et al., 2019) and(Fell and Sporleder, 2014). It contains over 400K English songs of around 7.2K artists from the period 1938 to 2016. Formal parliamentary communication is covered in our Europarl (Sample) dataset555http://www.statmt.org/wmt16/translation-task.html. It includes the English version of the proceedings of Bulgarian, Czech, Slovak, Slovene, Romanian and Polish parliaments. Our Lyrics dataset had around fifty million tokens. We sampled other datasets to match the size of our Lyrics dataset. We have deliberately chosen these diverse corpora that vary in corpus parameters like size of vocabulary and topics to assess our models with realistic examples. We have pre-processed these corpora by tokenizing sentences and removing non-alphabetic characters and converting all characters to lower cases. We have also removed the stop words by using the stop words corpora of NLTK 666http://www.nltk.org/. We have also considered a minimum word occurrence of five and removed all words that appear less than five times in a corpus.
| Dataset | Vocab Size | No. of Tokens |
|---|---|---|
| Wikipedia (Sample) | 216,580 | 46,359,850 |
| News Crawl (2007) | 116,401 | 45,149,886 |
| Lyrics | 85,378 | 49,127,358 |
| Europarl (Sample) | 41,674 | 41,330,440 |
2.2. Training
Evaluating all the WEMs that are currently available is beyond the scope of this work. We focused on three popular WEMs: Word2Vec, GloVe, and fastText. For Word2Vec, we used the Continuous Bag of Words (CBOW) variant from the Gensim 777https://github.com/RaRe-Technologies/gensim/tree/develop/gensim/ Python library to train our models. For the fastText, we used both the original fastText 888https://github.com/facebookresearch/fastText library and its Gensim version. The original fastText library does not provide the option for setting a random seed value, which is provided by the Gensim version. We trained the GloVe models using the original GloVe code 999https://github.com/stanfordnlp/GloVe with a slight modification to input random seed as a parameter. For all the models trained on all the three WEMs, we experimented with the vector dimensions, iterations, and window size, keeping all other parameters at default settings. For all the experiments on a corpus, we measured stability across five randomized embedding spaces trained with an algorithm and took the average among them. We used the same random seeds for all the WEMs.
2.3. Stability Evaluation
Consider a dataset with vocabulary of size . A WEM is used to learn word representations in an embeddings space using the dataset . Let and be two such embedding spaces. These two embedding spaces correspond to two distinct executions of WEM over the dataset . These two executions of can differ from each other in terms of one or multiple parameters. We evaluate the stability of across and as follows
| (1) |
Stability of each word in the vocabulary is computed as follows
| (2) |
represents the set of top nearest neighbors of word in the embedding space . These nearest neighbors are computed using the cosine similarity between the word embeddings. Existing stability evaluation studies use the similar method for stability computation.
3. Results
This section describes our experimental results on stability evaluation. We have experimented with five parameters that can affect the stability evaluation. For each such parameter,we will present results here only for one dataset due to the space limitation. However, we have observed similar trends across all four datasets. These additional experimental results are available along with our code.
3.1. Number of Nearest Neighbors



The word stability computation formula in the Section 2.3 involves a parameter . It indicates the number of nearest neighbors considered for stability evaluation. If the value of is set close to one then it is too restrictive and we expect the stability value for WEMs to be low. As we increase the value of , we expect the stability to increase. However, with very high value of , the stability evaluation will be meaningless. For example, in the extreme case of , stability of any WEM will be hundred percent.
Please refer to Figure 1. This figure shows the variation in the stability of WEMs with respect to the value of .We can observe that for Word2Vec and GloVe, the stability increases with increase in the value of . However, it plateaus after . This observation correlates with existing sability evaluation studies(Wendlandt et al., 2018). In contrast, we observe unexpected behavior for the fastText. With increase in the value of , its stability actually reduces slightly. This indicates that fastText maintains the top nearest neighbors across the embedding spaces. However, fastText fails to maintain the stability for the lower ranked nearest neighbors. Still, fastText is the most stable WEM amongst the three.
3.2. Word Frequency
Consider a dataset with the vocabulary of size . To observe the effect of word frequency on word stability, we divide the vocabulary into five groups of equal size (). Based on the word frequency, these groups are named as : Very Low Frequency (), Low Frequency (), Medium Frequency (), High Frequency (), and Very High Frequency (). Each group accounts for twenty percent of the words ranked by frequency. For example, the group will have the top twenty percent most frequent words from and the group will have the bottom twenty percent frequent words from .
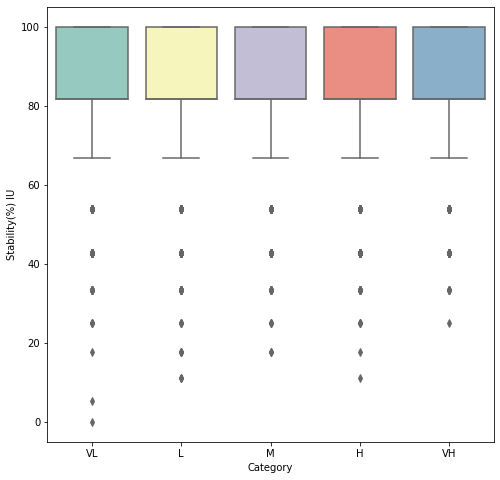
Please refer to Figures 2, 3 4. These figures show the boxplot for word stability when words are grouped based on frequency as described before. Previous studies have reported that stability of a word group increases with increase in the average frequency of the group (Wendlandt et al., 2018). Which means that as we move from group to group, the average or median word stability should increase. Our experimental results correlate with the existing studies. However, Wendlandt et al also report low variance in word stability for low as well as high frequency word groups (Wendlandt et al., 2018). They report high variance in word stability only for medium frequency word groups. In contrast, we observe that all word groups have high variance in word stability.
We can also observe from Figure 5 that the stability of a word varies with word embedding methods used. The words in Figure 5(a) were randomly picked from the Wikipedia (sample) corpus and these words have different frequencies ranging from 7 occurrences for ”lieutenant” to 174163 for ”one”. To generalize this observation to the whole vocabulary, we computed the stability of each word using three WEMs. For each word , now we had three stability values. For the word , we chose the WEM with highest stability value amongst the three values. We observed that out of all words, each WEM was chosen for the following percentage of words: fastText (63%), GloVe (24%), and Word2Vec (13%). This implies that fastText is in general a more stable WEM. However, a particular WEM need not be the most stable method for each word in the vocabulary.















3.3. Number of Vector Dimensions
One of the design choices with word embeddings is the number of dimensions. Lower number of dimensions reduce the computation but they might fail to represent all semantic relations. On the other hand, higher number of dimensions increase the computation while providing better semantic representation. Here we explore this design choice from the stability point of view. Figure 6 shows variation in stability with respect to the number of dimensions for word embeddings. For each WEM, we are comparing stability between two embedding spaces with the same dimensionality. These two embedding spaces differ from each other only in terms of the initial random seeds. For example, two embedding spaces of 300 dimensioanlity that are trained using fastText, have stability of eighty percent. As expected, the stability improves with increase in the number of dimensions. However, the improvement plateaus after 300 dimensions for all WEMs. Stability of fastText is higher than GloVe and Word2Vec for all dimension sizes. Stability of GloVe is lower for lower dimensions but increases rapidly till dimension 300. After dimension 300, the stability of GloVe becomes comparable to fastText. Stability for Word2Vec is the lowest compared to the other WEMs. We would recommend users to train their models using a vector dimension of around 300 for optimal stability.








Please refer to Figure 7. Here we are computing stability between embedding spaces of different dimensionality. For each WEM, consider two embedding spaces and . Let and represent dimensionality of the respective embedding spaces. We set to 100. We vary from 50 to 800. We can observe that for all WEMs, stability values peaks when is 100. It is expected as at , we are comparing embedding spaces of the same dimensionality. For , as we move away from 100, the stability decreases. This indicates that as we change the dimensionality of embedding spaces, the underlying captured semantics also change. The decrease in stability is rapid for lower number of dimensions. Probable reason for this rapid decrease is that we lose a lot of semantic information as we move to the lower number of dimensions. However, stability reduction is not that rapid as we move towards higher dimensions. We can observe only slight reduction in stability from dimension size 300 to 800. With higher dimensions, we do capture new semantic information. However, with higher dimension size, the rate of growth of semantic information also slows down. This might be a probable reason for slow reduction in stability for higher dimension size.
3.4. Number of Training Epochs
While training the word embeddings, another design parameter is the number of training epochs. Ideally, we will expect the word embeddings to stabilize with increase in the number of training epochs. Figure 8 shows trends in the stability with variation in the number of training epochs. Given a particular number of training epochs on the X-axis, we are computing stability between two embeddings spaces that are trained for the same number of epochs. However, these embedding spaces differ in the random initial seeds. We can observe that variations in the stability of fasText are minimal. For Word2Vec, the stability improves significantly with increase in the training epochs. GloVe shows a rather interesting trend. The stability sharply increases as we increase the number of training epochs from 1 to 5. After that, stability starts falling significantly with further increase in the number of training epochs. This appears to contradict the intuition that increasing the number of training epochs will increase the stability. Furthermore, fastText performs better than both GloVe and Word2Vec for all the datasets. Stability of Word2Vec is inferior compared to the other two WEMs. However, its stability approaches that of GloVe with increase in the training epochs. Even after 30 training epochs, stability of Word2Vc and GloVe is below 60%. This indicates that choice of initial seed matters for these two WEMs. In contrast, stability of fastText hovers around 90%, indicating that choice of initial seed is insignificant.




We also wanted to quantify the changes in word embeddings across successive epochs. Please refer to Figure 9. For a given WEM, we are comparing two embedding spaces amd . Both these embedding spaces are identical to each other except for the number of training epochs. Let and be the number of training epochs for respective embedding spaces. X-axis in the Figure 9 represents . We set . For example, using fastText as the WEM when we compare and with and , the stability is close to 60%. Even in this scenario, fastText is the most stable WEM. It indicates that word embeddings in fastText do not change significantly across successive iterations. So we can terminate the training of fastText after a few training epochs. In contrast, Word2Vec and GloVe have significantly lower stability across successive iterations. The stability value for this experiment does not reach close to 100% for any of the WEMs. This indicates that even with high number of training epochs, top ten nearest neighbors for many words do not stabilize.




3.5. Effect of Context Window Size on Stability
The intuition behind any WEM is to generate the representation for a word by learning from its context. The context is limited only to the sentence that the word belongs to. Size of the context window is also a design parameter while training the word embeddings. Figure 10 shows variation in WEM stability with respect to the context window size. For fastText, there is slight reduction in stability. Word2Vec and GloVe show contrasting behavior.After the context window size of ten, these is not significant change in the stability value for any WEM. This is expected as long sentences are rare in real-world datasets that we have considered. Even for this experiment, fastText turns out to be the most stable WEM.




4. Effect of Stability on Downstream tasks
In the previous section, we have analyzed various factors affecting the WEM stability. None of the WEMs are completely stable. Word embeddings are used for various downstream tasks. These embeddings typically serve as initial input for various task specific algorithms and machine learning models. The question we want to ask is: What is the effect of WEM instability on downstream tasks? For our experiments, we have shortlisted three tasks to cover multiple paradigms. First is an unsupervised learning task of word clustering using SNND algorithm. Second is a supervised learning task of POS tagging using a Deep Learning model. Third is a fairness evaluation task involving subjective human opinions.

4.1. Word Clustering
There is a vast variety of clustering algorithms available in the literature. Out of these algorithms we have chosen Shared Nearest Neighbor Density Based Clustering (SNND) algorithm (Ertöz et al., 2003) for the following two reasons. First, SNND is a well known robust clustering algorithm for high-dimensional data. Second, this algorithm clusters data based on the shared top K-nearest neighbors (KNN). This intuition of clustering correlates with our stability measurement.

SNND is a combination of two influential clustering algorithms: Jarvis-Patrick (Jarvis and Patrick, 1973) and DBScan (Ester et al., 1996). In the first step, SNND builds a graph representation of data using the concepts from Jarvis-Patrick algorithm. Then it clusters this graph using concepts from DBScan algorithm. SNND begins by building KNN list for each data point. Similarity between any two data points is the extent of overlap between their KNN lists. Next step is to build the SNN-Graph. In this graph, each data point is a vertex and two vertices have an edge if their similarity is above a predefined threshold . A vertex is labelled as core if its degree is above another predefined threshold . A vertex is labelled as noise if it is not core and it is not connected to any other core point. The remaining vertices are labelled as non-core. All core vertices are initially considered as a separate clusters. In the merging phase, two clusters are merged if at least one core point from each cluster is connected with each other in the SNN-graph. This iterative step is repeated till no more clusters can be merged. Noise vertices are removed from clustering. For each non-core vertex, the cluster having the strongest link with it is chosen.
| Test no. | Target Words | Attribute Words | fastText | GloVe | Word2Vec | CA | IAT |
| 1 | flowers vs insects | pleasant vs unpleasant | 1.17,1.15 | 1.37,1.25 | 0.93,0.79 | 1.5 | 1.35 |
| 2 | instruments vs weapons | pleasant vs unpleasant | 1.64,1.65 | 1.49,1.45 | 1.68,1.62 | 1.53 | 1.66 |
| 3 | european american vs african american names | pleasant vs unpleasant | 0.36,0.35 | 0.39,0.40 | 0.64,0.59 | 1.41 | 1.17 |
| 4 | male vs female names | pleasant vs unpleasant | 1.895,1.893 | 1.80,1.74 | 1.77,1.75 | 1.81 | 0.72 |
| 5 | maths vs arts | male vs female names | 0.86,0.84 | 1.10,1.16 | 0.49,0.25 | 1.06 | 0.82 |
| 6 | science vs arts | male vs female names | 1.09,1.08 | 1.28,1.22 | 0.42,0.29 | 1.24 | 1.47 |
| 7 | mental disease vs physical disease | temporary vs permanent | 0.94,0.93 | 1.43,1.34 | 1.4,1.2 | 1.38 | 1.01 |
| 8 | young people vs old people names | pleasant vs unpleasant | 0.83,0.80 | 1.16,0.87 | 0.06,0.04 | 1.21 | 1.42 |
We experimented with all three WEMs on the Wikipedia (Sample) dataset to evaluate the effect of WEM instability on SNND clustering. Using each WEM, we train embedding spaces: to . These embedding spaces differ only in the random initial seeds. Corresponding to each embedding space, we obtain the clusterings to . We compute the agreement of these clusterings as the percentage of edges from that are preserved across all clusterings. Please refer to Figure 11. This figure shows the variation in the clustering agreement while varying the value of from one to ten. As we increase the value of , the clustering agreement decreases. However, this decrease plateaus for higher values of . This indicates that even with the inherent instability of WEMs, resulting clustering always preserves significant majority of the edges. Here again, we observe that fastText results in the highest clustering agreement.
4.2. Part-Of-Speech Tagging
For POS tagging, we combine a number of corpora using the NLTK library. These include treebank (consists of 5% of Penn Treebank), Brown, CONLL (Conference on Computational Natural Language Learning) 2000, 2002 and 2007. The total corpora size consists of 2.5 million tokens. We have split the data into train, validation and test sets in the ratio 70:15:15.
While performing the POS tagging task, our goal is not to replicate the state of the art. We want to analyze the effect of WEM instability on the task. Like the previous stability studies (Wendlandt et al., 2018), we chose a simple a bidirectional LSTM model (Chollet, 2015). It has 50 dimensional hidden vectors and the outputs are passed through a softmax layer. Similar to the clustering task, we trained embedding spaces to using each of the WEMs. The model requires vector representation of words as input. While considering embedding spaces to generate the vector representation of a word, we simply compute the average of embeddings across all embedding spaces. This averaging strategy across multiple embedding spaces is shown to be effective in the literature (Coates and Bollegala, 2018). Please refer to the Figure 12. This figure shows variation in the POS tagging accuracy score with respect to the number of embedding spaces considered. Initially, the accuracy fluctuates with increase in the number of embedding spaces. However, after crossing seven embedding spaces, the accuracy increases and then it plateaus. Here the instability of WEMs actually benefits the task. If the WEMs were stable and provided similar input across multiple embedding spaces then we will not see any improvement in the accuracy score. However, the increase in the accuracy score indicates that diferent embedding spaces provide complementary information to the model.
4.3. Fairness Evaluation Task
Human actions reflect various biases in our thinking. For example, musical instruments might seem inspiring and weapons might seem harmful to some people. Implicit Association Test (IAT) is designed to measure such biases with human subjects (Greenwald et al., 1998). The Word Embedding Association Test (WEAT) is proposed by Caliskan et al.(Caliskan et al., 2017). The WEAT test is an improvisation over the IAT test such that biases can be measured directly from the word embeddings in the absence of humans subjects. This test computes the similarity between words using cosine similarity. Fairness evaluation task involves measuring biases in the the given set of word embeddings using the WEAT test. We selected this test for our experiments because its intuition of cosine based similarity correlates with our stability evaluation method.
The WEAT test takes in sets of target and attribute words. Target words refer to the set of words which denote a particular group based on a specific criterion such as instrument names (guitar, flute)and weapons (gun, sword). Attribute words refer to the set of words which denote the characteristics such as pleasant words (inspiring, creative) and unpleasant words (dangerous, harmful). Given two sets of target words and two sets of attribute words, the WEAT test checks if the null hypothesis holds. That is, if the word embeddings are unbiased then the similarity of the two sets of target words with the attribute words should be almost same. If the result value for the WEAT test is close to zero then it indicates the absence of bias. Please refer to Table 3. It lists eight target and attribute word set tests that we borrowed from Caliskan et al. (Caliskan et al., 2017). The column reports the bias measurement results from Greenwal et al. using the human subjects (Greenwald et al., 1998). The column reports the results from Caliskan et al. They trained their word embeddings using a large scale crawl of the Web.
| Paper | Algorithms | Stability factors | Datasets (number of tokens) | Results |
| Levy et al.(Levy et al., 2015), 2015 | PPMI matrix, SVD factorization, SGNS, and GloVe |
Preprocessing parameters: Dynamic Window Size, Subsampling and Deleting Rare Words
Association Metric parameters: Shifted PMI, Context Disribution Smoothing Postprocessing parameters: Addition of context vectors, Eigenvalue weighting, Vector normalization |
Wikipedia - Aug 2013 dump (1.5B) |
No global advantage to any single approach
Careful hyperparameter tuning can outweigh the importance of adding more data SGNS outperforms GloVe in every task For both SGNS and GloVe, adding context vectors variant can result in substantial gains |
| Hellrich and Hahn(Hellrich and Hahn, 2016b), 2016 | SGNS and SGHS | Neighborhood size, Word Frequency, Word Ambiguity and Number of Training Epochs | Google N-gram corpus: English Fiction (4.8B) and German (0.7B) |
Both accuracy and reliability are higher for SGNS than for SGHS for all tested combinations of languages and time spans, if 10 training epochs are used
If only one training epoch is used: little difference in accuracy between SGNS and SGHS, but SGHS is clearly better in terms of reliability |
| Wendlandt et al.(Wendlandt et al., 2018), 2018 | Word2Vec, GloVe and PPMI |
Word properties: Primary and Secondary POS, no of syllables in a word, no of different POS present
Training Data properties: Raw frequency in embedding spaces and their difference, vocabulary size of embedding spaces and their difference, percentage overlap between embedding spaces, curriculum learning, training position in embedding spaces and their difference Algorithm properties: embedding dimensions of embedding spaces and their difference |
NYT (58M) and Europarl (61M) |
Curriculum learning is important
POS highly affects stability GloVe is the most stable algorithm overall Frequency is not a major factor for stability |
| Chugh et al.(Chugh et al., 2018) , 2018 | Word2Vec | Embedding dimension and Frequency | Brown (10k), Project Gutenberg (10k) and Reuters (10k) |
Stability of high-frequency words increases and then stabilizes to a lower value. Stability of mid- and low-frequency words initially declines and increases to a stable value
Embedding size is a causal factor and varies across corpora |
| Antoniak and Mimno(Antoniak and Mimno, 2018), 2018 | LSA, SGNS, GloVe, PPMI | Corpus parameters: Order and presence of documents, Size of corpus and length of documents | U.S. Federal Courts of Appeals (38k), NYT (22k) and Reddit (26k) |
Nearest-neighbor distances are highly sensitive
to small changes in the training corpus
All techniques are not sensitive to document order All techniques are sensitive to the presence of specific documents Variability initially increases with the number of models trained |
| Dridi et al.(Dridi et al., 2018), 2018 | Word2Vec (Skipgram) | Vector dimension, Window context and Vocabulary size | NIPS (Neural Information Processing System) between 2007 and 2012 (2M) |
Accuracy of Word2Vec increases with increasing corpora size
Stability increases considerably as the dimensionality increases, but after reaching some point, it diminishes or becomes slightly invariant |
We ran the WEAT test on the three WEMs and used the Wikipedia (Sample) dataset for experimentation. For each WEM, we trained three sets of word embeddings. Using each set of word embeddigs, we ran the WEAT test. In Table 3, three columns for the WEMs report stability results for each method. These three columns contain two values each. These two values correspond to the maximum and minimum value obtained for a test using the given WEM across multiple embedding spaces. For example, consider the WEAT results for test number 1 (flowers vs insects) using the fastText WEM. Corresponding to three embedding spaces, we obtained three different result values. In the table, we list the maximum and minimum of these three values: and . Ideally, our results should be close to the columns and . However, we have trained our word embeddings on much smaller dataset as compared to the dataset used by Caliskan et al. That is the reason why quality of our results does not match well with and . But our goal is not to demonstrate the quality of output. We aim to measure the stability of the results and compare it with the stability of the WEMs used. Till now, we have observed that fastText is the most stable WEM amongst the three methods. As a consequence, WEAT results for fastText have the highest stability. There is very little difference in the maximum and minimum values in the column. WEAT results for Word2Vec are the least stable. This is expected as we have observed that Word2Vec is the least stable method among the three methods considered in this paper.
5. Related Work
There has been a growing interest among researchers to explore the stability of the word embedding techniques. Wendlandt and others (Wendlandt et al., 2018) showed how various factors contribute to the stability of word embeddings including frequency of words. They also analyzed the effects of stability on downstream tasks. Chugh and others (Chugh et al., 2018) presented the impact of dimension size and frequency of words on the consistency of a word embedding model using Word2Vec. Pierrejean and Tanguy (Pierrejean and Tanguy, 2018) explored the variations between different word embeddings models trained using Word2Vec. Their study shows that variation is influenced by parameters of a training algorithm. These parameters influence the geometry of word vectors and their context vectors (Mimno and Thompson, 2017), thereby causing variations. Hellrich and Hahn (Hellrich and Hahn, 2016b) assess the reliability of word embeddings for both modern and historical English and German and provided insights about optimal parameters for negative sampling method of Word2Vec and the number of iterations to train for. They also showed that negative sampling outperforms hierarchical softmax in terms of reliability (Hellrich and Hahn, 2016a). Furthermore, stability is also affected by document properties as shown by Antoniak and Mimno (Antoniak and Mimno, 2018). Their study shows that smaller corpora are much more affected due to these effects. Related work is summarized in Table 4.
6. Conclusion and Future Work
In this work, we have shown that WEMs are not completely stable. Out of three three WEMs studied, fastText is the most stable and Word2Vec is the least stable method. We also observed the effect of WEMs instability on three downstream tasks. While training word embeddings, one needs to carefully analyze the effect of various design choices on the stability of word embeddings. In future, we need a deeper analysis and theoretical explanation for various stability trends observed in this paper.
References
- (1)
- Antoniak and Mimno (2018) Maria Antoniak and David Mimno. 2018. Evaluating the stability of embedding-based word similarities. Transactions of the Association for Computational Linguistics 6 (2018), 107–119.
- Barman et al. (2019) Manash Pratim Barman, Kavish Dahekar, Abhinav Anshuman, and Amit Awekar. 2019. It’s only Words and Words Are All I Have. In Advances in Information Retrieval, Leif Azzopardi, Benno Stein, Norbert Fuhr, Philipp Mayr, Claudia Hauff, and Djoerd Hiemstra (Eds.). Springer International Publishing, Cham, 30–36.
- Blei et al. (2003) David M Blei, Andrew Y Ng, and Michael I Jordan. 2003. Latent dirichlet allocation. Journal of machine Learning research 3, Jan (2003), 993–1022.
- Bojanowski et al. (2017) Piotr Bojanowski, Edouard Grave, Armand Joulin, and Tomas Mikolov. 2017. Enriching Word Vectors with Subword Information. Transactions of the Association for Computational Linguistics 5 (2017), 135–146.
- Bruni et al. (2014) Elia Bruni, Nam-Khanh Tran, and Marco Baroni. 2014. Multimodal distributional semantics. Journal of Artificial Intelligence Research 49 (2014), 1–47.
- Caliskan et al. (2017) Aylin Caliskan, Joanna J Bryson, and Arvind Narayanan. 2017. Semantics derived automatically from language corpora contain human-like biases. Science 356, 6334 (2017), 183–186.
- Chollet (2015) François Chollet. 2015. Bidirectional layer wrapper Keras. https://keras.io/api/layers/recurrent_layers/bidirectional/.
- Chugh et al. (2018) Mansi Chugh, Peter A. Whigham, and Grant Dick. 2018. Stability of Word Embeddings Using Word2Vec. In AI 2018: Advances in Artificial Intelligence, Tanja Mitrovic, Bing Xue, and Xiaodong Li (Eds.). Springer International Publishing, Cham, 812–818.
- Coates and Bollegala (2018) Joshua Coates and Danushka Bollegala. 2018. Frustratingly Easy Meta-Embedding – Computing Meta-Embeddings by Averaging Source Word Embeddings. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers). Association for Computational Linguistics, New Orleans, Louisiana, 194–198. https://doi.org/10.18653/v1/N18-2031
- Deerwester et al. (1990) Scott Deerwester, Susan T Dumais, George W Furnas, Thomas K Landauer, and Richard Harshman. 1990. Indexing by latent semantic analysis. Journal of the American society for information science 41, 6 (1990), 391–407.
- Dridi et al. (2018) Amna Dridi, Mohamed Medhat Gaber, R. Muhammad Atif Azad, and Jagdev Bhogal. 2018. k-NN Embedding Stability for word2vec Hyper-Parametrisation in Scientific Text. In Discovery Science, Larisa Soldatova, Joaquin Vanschoren, George Papadopoulos, and Michelangelo Ceci (Eds.). Springer International Publishing, Cham, 328–343.
- Ertöz et al. (2003) Levent Ertöz, Michael Steinbach, and Vipin Kumar. 2003. Finding Clusters of Different Sizes, Shapes, and Densities in Noisy, High Dimensional Data. SDM, San Francisco, USA, 47–58. https://doi.org/10.1137/1.9781611972733.5 arXiv:https://epubs.siam.org/doi/pdf/10.1137/1.9781611972733.5
- Ester et al. (1996) Martin Ester, Hans-Peter Kriegel, Jörg Sander, and Xiaowei Xu. 1996. A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining (Portland, Oregon) (KDD’96). AAAI Press, New York, 226–231.
- Fell and Sporleder (2014) Michael Fell and Caroline Sporleder. 2014. Lyrics-based Analysis and Classification of Music. In Proceedings of COLING 2014, the 25th International Conference on Computational Linguistics: Technical Papers. Dublin City University and Association for Computational Linguistics, Dublin, Ireland, 620–631. https://www.aclweb.org/anthology/C14-1059
- Finkelstein et al. (2002) Lev Finkelstein, Evgeniy Gabrilovich, Yossi Matias, Ehud Rivlin, Zach Solan, Gadi Wolfman, and Eytan Ruppin. 2002. Placing search in context: The concept revisited. ACM Transactions on information systems 20, 1 (2002), 116–131.
- Greenwald et al. (1998) Greenwald, Anthony G., McGhee, Debbie E., Schwartz, and Jordan L. K. 1998. Measuring individual differences in implicit cognition: The implicit association test. Journal of Personality and Social Psychology 74(6) (1998), 1464–1480.
- Hellrich and Hahn (2016a) Johannes Hellrich and Udo Hahn. 2016a. An Assessment of Experimental Protocols for Tracing Changes in Word Semantics Relative to Accuracy and Reliability. In Proceedings of the 10th SIGHUM Workshop on Language Technology for Cultural Heritage, Social Sciences, and Humanities. Association for Computational Linguistics, Berlin, Germany, 111–117. https://doi.org/10.18653/v1/W16-2114
- Hellrich and Hahn (2016b) Johannes Hellrich and Udo Hahn. 2016b. Bad Company—Neighborhoods in Neural Embedding Spaces Considered Harmful. In Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers. The COLING 2016 Organizing Committee, Osaka, Japan, 2785–2796. https://www.aclweb.org/anthology/C16-1262
- Jarvis and Patrick (1973) R. A. Jarvis and E. A. Patrick. 1973. Clustering Using a Similarity Measure Based on Shared Near Neighbors. IEEE Trans. Comput. C-22, 11 (Nov 1973), 1025–1034. https://doi.org/10.1109/T-C.1973.223640
- Lample et al. (2016) Guillaume Lample, Miguel Ballesteros, Sandeep Subramanian, Kazuya Kawakami, and Chris Dyer. 2016. Neural Architectures for Named Entity Recognition. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Association for Computational Linguistics, San Diego, California, 260–270. https://doi.org/10.18653/v1/N16-1030
- Lee and Sun (2021) Grace E. Lee and Aixin Sun. 2021. Understanding the stability of medical concept embeddings. Journal of the Association for Information Science and Technology 72, 3 (2021), 346–356. https://doi.org/10.1002/asi.24411 arXiv:https://asistdl.onlinelibrary.wiley.com/doi/pdf/10.1002/asi.24411
- Levy et al. (2015) Omer Levy, Yoav Goldberg, and Ido Dagan. 2015. Improving distributional similarity with lessons learned from word embeddings. Transactions of the Association for Computational Linguistics 3 (2015), 211–225.
- Li et al. (2017) Yang Li, Quan Pan, Tao Yang, Suhang Wang, Jiliang Tang, and Erik Cambria. 2017. Learning word representations for sentiment analysis. Cognitive Computation 9, 6 (2017), 843–851.
- Mikolov et al. (2013) Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg Corrado, and Jeffrey Dean. 2013. Distributed Representations of Words and Phrases and Their Compositionality. In Proceedings of the 26th International Conference on Neural Information Processing Systems - Volume 2 (Lake Tahoe, Nevada) (NIPS’13). Curran Associates Inc., Red Hook, NY, USA, 3111–3119.
- Mimno and Thompson (2017) David Mimno and Laure Thompson. 2017. The strange geometry of skip-gram with negative sampling. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Copenhagen, Denmark, 2873–2878. https://doi.org/10.18653/v1/D17-1308
- Newman-Griffis and Fosler-Lussier (2017) Denis Newman-Griffis and Eric Fosler-Lussier. 2017. Second-Order Word Embeddings from Nearest Neighbor Topological Features. arXiv e-prints arXiv:1705.08488, arXiv:1705.08488, Article arXiv:1705.08488 (May 2017), arXiv:1705.08488 pages. arXiv:1705.08488 [cs.CL]
- Pennington et al. (2014) Jeffrey Pennington, Richard Socher, and Christopher Manning. 2014. GloVe: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP). Association for Computational Linguistics, Doha, Qatar, 1532–1543. https://doi.org/10.3115/v1/D14-1162
- Pierrejean and Tanguy (2018) Bénédicte Pierrejean and Ludovic Tanguy. 2018. Towards Qualitative Word Embeddings Evaluation: Measuring Neighbors Variation. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Student Research Workshop. Association for Computational Linguistics, New Orleans, Louisiana, USA, 32–39. https://doi.org/10.18653/v1/N18-4005
- Seok et al. (2016) Miran Seok, Hye-Jeong Song, Chan-Young Park, Jong-Dae Kim, and Yu-Seop Kim. 2016. Named entity recognition using word embedding as a feature. International Journal of Software Engineering and Its Applications 10, 2 (2016), 93–104.
- Tang et al. (2014) Duyu Tang, Furu Wei, Nan Yang, Ming Zhou, Ting Liu, and Bing Qin. 2014. Learning Sentiment-Specific Word Embedding for Twitter Sentiment Classification. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, Baltimore, Maryland, 1555–1565. https://doi.org/10.3115/v1/P14-1146
- Wang et al. (2015) Peilu Wang, Yao Qian, Frank K Soong, Lei He, and Hai Zhao. 2015. A unified tagging solution: Bidirectional lstm recurrent neural network with word embedding. arXiv preprint arXiv:1511.00215 arXiv preprint arXiv:1511.00215, arXiv preprint arXiv:1511.00215 (2015), arXiv preprint arXiv:1511.00215.
- Wendlandt et al. (2018) Laura Wendlandt, Jonathan K. Kummerfeld, and Rada Mihalcea. 2018. Factors Influencing the Surprising Instability of Word Embeddings. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers). Association for Computational Linguistics, New Orleans, Louisiana, 2092–2102. https://doi.org/10.18653/v1/N18-1190