Arbitrarily Scalable Environment Generators via Neural Cellular Automata
Abstract
We study the problem of generating arbitrarily large environments to improve the throughput of multi-robot systems. Prior work proposes Quality Diversity (QD) algorithms as an effective method for optimizing the environments of automated warehouses. However, these approaches optimize only relatively small environments, falling short when it comes to replicating real-world warehouse sizes. The challenge arises from the exponential increase in the search space as the environment size increases. Additionally, the previous methods have only been tested with up to 350 robots in simulations, while practical warehouses could host thousands of robots. In this paper, instead of optimizing environments, we propose to optimize Neural Cellular Automata (NCA) environment generators via QD algorithms. We train a collection of NCA generators with QD algorithms in small environments and then generate arbitrarily large environments from the generators at test time. We show that NCA environment generators maintain consistent, regularized patterns regardless of environment size, significantly enhancing the scalability of multi-robot systems in two different domains with up to 2,350 robots. Additionally, we demonstrate that our method scales a single-agent reinforcement learning policy to arbitrarily large environments with similar patterns. We include the source code at https://github.com/lunjohnzhang/warehouse_env_gen_nca_public.
1 Introduction
We study the problem of generating arbitrarily large environments to improve the throughput of multi-robot systems. As a motivating example, consider a multi-robot system for automated warehousing where thousands of robots transport inventory pods in a shared warehouse environment. While numerous works have studied the underlying Multi-Agent Path Finding (MAPF) problem [42] to more effectively coordinate the robots to improve the throughput [4, 6, 8, 24, 27, 29, 31, 35, 46], we can also optimize the throughput by designing novel warehouse environments. A well-optimized environment can alleviate traffic congestion and reduce the travel distances for the robots to fulfill their tasks in the warehouse.
A recent work [51] formulates the environment optimization problem as a Quality Diversity (QD) optimization problem and optimizes the environments by searching for the best allocation of shelf and endpoint locations (where endpoints are locations where the robots can interact with the shelves). It uses a QD algorithm to iteratively generate new environments and then repairs them with a Mixed Integer Linear Programming (MILP) solver to enforce domain-specific constraints, such as the storage capacity and connectivity of the environment. The repaired environments are evaluated with an agent-based simulator [28] that simulates the movements of the robots in the warehouse. Figure 1(a) shows an example optimized environment, which is shown to have much higher throughput and is more scalable than human-designed environments.
However, with the aforementioned method, the search space of the QD algorithm grows exponentially with the size of the environment. To optimize arbitrarily large environments, QD algorithms require a substantial number of runs in both the agent-based simulator and the MILP solver. Each run also takes more time to finish. For example, in the aforementioned work [51], it took up to 24 hours on a 64-core local machine to optimize a warehouse environment of size only 36 33 with 200 robots, which is smaller than many warehouses in reality or warehouse simulations used in the literature. For example, Amazon fulfillment centers are reported to have more than 4,000 robots [2]. Previous research motivated by Amazon sortation centers run simulations in environments of size up to 179 69 with up to 1,000 robots [48, 28].




Therefore, instead of optimizing the environments directly, we propose to train Neural Cellular Automata (NCA) environment generators capable of scaling their generated environments arbitrarily. Cellular automata (CA) [19] are well suited to arbitrary scaling as they incrementally construct environments through local interactions between cells. Each cell observes the state of its neighbors and incorporates that information into changing its own state. NCA [33] represents the state change rules via a neural network that can be trained with any optimization method.
We follow the insight from prior work [10] and use QD algorithms to efficiently train a diverse collection of NCA generators in small environments. We then use the NCA generators to generate arbitrarily large environments with consistent and regularized patterns. In case the generated environments are invalid, we adopt the MILP solver from the previous works [49, 15, 51] to repair the environments. Figure 1(b) shows an example environment with regularized patterns generated by our NCA generator and then repaired by the MILP solver. Figure 1(c) shows a much larger environment generated by the same NCA generator with similar patterns and then repaired by MILP. Similar to previous environment optimization methods [51], we need to run the MILP solver repeatedly on small environments (Figure 1(b)) to train the NCA generator. However, once the NCA generators are trained, we only run the MILP solver once after generating large environments (Figure 1(c)).
We show that our generated environments have competitive or better throughput and scalability compared to the existing methods [51] in small environments. In large environments where the existing methods are not applicable due to computational limits, we show that our generated environments have significantly better throughput and scalability than human-designed environments.
We make the following contributions: (1) instead of directly searching for the best environments, we present a method to train a collection of NCA environment generators on small environments using QD algorithms, (2) we then show that the trained NCA generators can generate environments in arbitrary sizes with consistent regularized patterns, which leads to significantly higher throughput than the baseline environments in two multi-robot systems with large sizes, (3) we additionally demonstrate the general-purpose nature of our method by scaling a single-agent RL policy to arbitrarily large environments with similar patterns, maintaining high success rates.
2 Background and Related Work
2.1 Neural Cellular Automata (NCA)
Cellular automata (CA) [3, 39] originated in the artificial life community as a way to model incremental cell development. A CA consists of grid cells and an update rule for how to change a cell based on the state of its neighbors. Later work [33] showed that these rules could be encoded by a convolutional neural network. By iteratively updating a grid of cells, an NCA is capable of producing complex environments. Figure 6 in Appendix A shows an example NCA environment generation process of 50 iterations from an initial environment shown in Figure 6(a).
Representing the rules of CAs by a neural network facilitates learning useful rules for the cellular automata. Several works have trained NCA generators to generate images [33], textures [36, 32], and 3D structures [43]. Other works have replaced the convolutional network with other model architectures [44, 18]. In the case of environment optimization, the objective is computed from a non-differentiable agent-based simulator. Therefore, we choose derivative-free optimization methods to train the NCA generators for environment optimization.
Prior work [10] shows that derivative-free QD algorithms can efficiently train a diverse collection of NCA video game environment generators. However, our work differs in the following ways: (1) we show how environments generated by NCA generators can scale to arbitrary sizes with similar regularized patterns, (2) in addition to encoding the constraints as part of the objective function of QD algorithms, we also use MILP to enforce the constraints on the generated environments, (3) the objective function of the previous work focus on the reliability, diversity, and validity of the generated environments, while we primarily focus on optimizing throughput, which is a simulated agent-based metric of the multi-robot systems.
2.2 Quality Diversity (QD) Algorithms
Although derivative-free single-objective optimization algorithms such as Covariance Matrix Adaptation Evolutionary Strategy (CMA-ES) [20] have been used to optimize derivative-free objective functions, we are interested in QD algorithms because they generate a diverse collection of solutions, providing users a wider range of options in terms of the diversity measure functions.
Inspired by evolutionary algorithms with diversity optimization [7, 25, 26], QD algorithms simultaneously optimize an objective function and diversify a set of diversity measure functions to generate a diverse collection of high-quality solutions. QD algorithms have many different variants that incorporate different optimization methods, such as model-based approaches [1, 17, 50], Bayesian optimization [23], and gradient descent [11].
MAP-Elites. MAP-Elites [7, 34] constructs a discretized measure space, referred to as archive, from the user-defined diversity measure functions. It tries to find the best solution, referred to as elite, in each discretized cell. The QD-score measures the quality and diversity of the elites by summing the objective values of elites in the archive. MAP-Elites generates new solutions either randomly or by mutating existing elites. It then evaluates the solutions and replaces existing elites in the corresponding cells with superior ones. After a fixed number of iterations, MAP-Elites returns the archive with elites.
CMA-MAE. We select Covariance Matrix Adaptation MAP-Annealing (CMA-MAE) [13, 14] as our QD method for training NCA generators because of its state-of-the-art performance in continuous domains. CMA-MAE extends MAP-Elites by incorporating the self-adaptation mechanisms of CMA-ES [20]. CMA-ES maintains a Gaussian distribution, samples from it for new solutions, evaluates them, and then updates the distribution towards the high-objective region of the search space. CMA-MAE incorporates this mechanism to optimize the QD-score. In addition, CMA-MAE implements an archive updating mechanism to balance exploitation and exploration of the measure space. The mechanism introduces a threshold value to each cell in the archive, which determines whether a new solution should be added. The threshold values are iteratively updated via an archive learning rate, with lower learning rates focusing more on exploitation. Because of the updating mechanism, some high-quality solutions might be thrown away. Therefore, CMA-MAE maintains two archives, an optimization archive implementing the updating mechanism, and a separate result archive that does not use the mechanism and stores the actual elites.
2.3 Automatic Environment Generation and Optimization
Automatic environment generation has emerged in different research communities for various purposes such as generating diverse game content [41], training more robust RL agents [40, 22], and generating novel testing scenarios [1, 12].
In the MAPF community, Zhang et al. [51] have proposed an environment optimization method based on QD algorithms MAP-Elites [7, 34] and Deep Surrogate Assisted Generation of Environments (DSAGE) [1] to improve the throughput of the multi-robot system in automated warehouses. In particular, they represent environments as tiled grids and use QD algorithms to repeatedly propose new warehouse environments by generating random environments or mutating existing environments by randomly replacing the tiles. Then they repair the proposed environments with a MILP solver and evaluate them in an agent-based simulator. The evaluated environments are added to an archive to create a collection of high-throughput environments.
However, since the proposed method directly optimizes warehouse environments, it is difficult to use the method to optimize arbitrarily large environments due to (1) the exponential growth of the search space and (2) the CPU runtime of the MILP solver and the agent-based simulator increase significantly. In comparison, we optimize environment generators instead of directly optimizing environments. In addition, we explicitly take the regularized patterns into consideration which allows us to generate arbitrarily large environments with high throughput.
3 Problem Definition
We define the environments and the corresponding environment optimization problem as follows.
Definition 1 (Environment).
We represent each environment as a 2D four-neighbor grid, where each tile can be one of tile types. is determined by the domains.
Definition 2 (Valid Environment).
An environment is valid iff the assignment of tile types satisfies its domain-specific constraints.
For example, the warehouse environments shown in Figure 1 have (endpoints, workstations, empty spaces, and shelves). One example domain-specific constraint for warehouse environments is that all non-shelf tiles should be connected so that the robots can reach all endpoints.
Definition 3 (Environment Optimization).
Given an objective function and a measure function , where is the space of all possible environments, the environment optimization problem searches for valid environments that maximize the objective function while diversifying the measure function .
4 Methods

We extend previous works [10, 51] to use CMA-MAE to search for a diverse collection of NCA generators with the objective and diversity measures computed from an agent-based simulator that runs domain-specific simulations in generated environments. Figure 2 provides an overview of our method. We start by sampling a batch of parameter vectors from a multivariate Gaussian distribution, which form NCA generators. Each NCA generator then generates one environment from a fixed initial environment, resulting in environments. We then repair the environments using a MILP solver to enforce domain-specific constraints. After getting the repaired environments, we evaluate each of them by running an agent-based simulator for times, each with timesteps, and compute the average objective and measures. We add the evaluated environments and their corresponding NCA generators to both the optimization archive and the result archive. Finally, we update the parameters of the multivariate Gaussian distribution (i.e., and ) and sample a new batch of parameter vectors, starting a new iteration. We run CMA-MAE iteratively with batch size , until the total number of evaluations reaches .
NCA Generator. We define an NCA generator as a function , where is the space of all possible environments, is a fixed initial environment, and is a fixed number of iterations for the NCA generator. is parameterized by . Since both and are fixed, each parameter vector corresponds to an NCA generator, which corresponds to an environment . We discretize the measure space into cells to create an archive and attempt to find the best NCA generator in each cell to optimize the QD-score of the archive.
Our NCA generator is a convolutional neural network (CNN) with the same architecture as the previous work [10] with 3 convolutional layers of kernel size 3 3 followed by ReLU or sigmoid activations. Figure 8 in Section C.1.1 shows the architecture. We represent the 2D tile-based environments as 3D tensors, with each tile as a one-hot encoded vector. Depending on the tile types, our NCA model has about 1,500 3,000 parameters. The input and output of the generator are one-hot environments of the same size, facilitating iterative environment generation by feeding the generator’s output back into it. By using a CNN, we can use the same NCA generator to generate environments of arbitrary sizes.
MILP Repair. The environments generated by the NCA generators might be invalid. Therefore, we follow previous works [49, 15, 51] to repair the invalid environments using a MILP solver. For each unrepaired environment , we find such that (1) the hamming distance between and is minimized, and (2) the domain-specific constraints are satisfied. We introduce the domain-specific constraints in detail in Section 5 and Appendix B.
Objective Functions. We have two objective functions and for the optimization archive and the result archive, respectively. runs an agent-based simulator for times and returns the average throughput. optimizes the weighted sum of and a similarity score between the unrepaired and repaired environments and . Specifically, , where is a hyperparameter that controls the weight between and . We incorporate the similarity score to so that the NCA generators are more inclined to directly generate valid environments with desired regularized patterns, reducing reliance on the MILP solver for pattern generation. We show in Section 6 that incorporating the similarity score to significantly improves the scalability of the environments generated by the NCA generators.
Let be the number of tiles in the environment, the similarity score is computed as:
| (1) |
encodes if the tile type of tile in and are the same. assigns a weight to each tile. As a result, the numerator computes the unnormalized similarity score. is the theoretical upper bound of the unnormalized similarity score of all environments of a domain. Dividing by normalizes the score to the range of 0 to 1. Intuitively, the similarity score quantifies the level of similarity between the unrepaired and repaired environments and , with each tile weighted according to .
Environment Entropy Measure. We want the NCA generators to generate environments with regularized patterns. To quantify these patterns, we introduce environment entropy as a diversity measure, inspired by previous work [30, 16]. We define a tile pattern as one possible arrangement of a 2 2 grid in the environment. Then we count the occurrence of all possible tile patterns in the given environment, forming a tile pattern distribution. The environment entropy is calculated as the entropy of this distribution. In essence, the environment entropy measures the degree of regularization of patterns within a given environment. A lower value of environment entropy indicates a higher degree of pattern regularization. We use environment entropy as a diversity measure to find NCA generators that can generate a broad spectrum of environments of varying patterns.
5 Domains
We perform experiments in three different domains: (1) a multi-agent warehouse domain [28, 51], (2) a multi-agent manufacturing domain, and (3) a single-agent maze domain [16, 5, 1].
Warehouse. The warehouse domain simulates automated warehousing scenarios, where robots transport goods between shelves in the middle and human-operated workstations on the left and right borders. We use two variants of the warehouse domain, namely warehouse (even) and warehouse (uneven). In warehouse (even), all workstations are visited with equal frequency, while in warehouse (uneven), the workstations on the left border are visited 5 times more frequently than those on the right border. We constrain the warehouse environments such that all non-shelf tiles are connected and the number of shelves is to keep consistent storage capability. We use and introduced in Section 4 as the objective functions, and environment entropy as one of the measures. Inspired by previous work [51], we use the number of connected shelf components as the other measure. Figure 1 and Figure 7(a) in Appendix B show example warehouse environments.
Manufacturing. The manufacturing domain simulates automated manufacturing scenarios, where robots go to different kinds of manufacturing workstations in a fixed order to manufacture products. We create this domain to show that our method can generate environments with more tile types for more complex robot tasks. We assume 3 kinds of workstations to which the robots must visit in a fixed order and stay for different time duration. We constrain the manufacturing environments such that all non-workstation tiles are connected and there is at least one workstation of each type. We use and introduced in Section 4 as the objective functions, and the environment entropy and the number of workstations as the measures. The number of workstations can approximate the cost of the manufacturing environment. By diversifying the number of workstations, our method generates a collection of environments with different price points. Figure 5 and Figure 7(b) in Appendix B show example manufacturing environments.
Maze. We conduct additional experiments in the maze domain to show that our method can scale a single-agent reinforcement learning (RL) policy trained in small environments to larger environments with similar patterns. The maze domain does not have domain-specific constraints. We use the same objective and measure functions in the previous work [1]. Specifically, and are both binary functions that return 1 if the environment is solvable and 0 otherwise. The measures are the number of walls and the average path length of the agent over simulations. Figure 5 and Figure 7(c) in Appendix B show example maze environments.
We include more detailed information on the domains in Appendix B.
6 Experimental Evaluation
| Domain | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Warehouse (even) | |||||||||
| Warehouse (uneven) | |||||||||
| Manufacturing | N/A | N/A | |||||||
| Maze | N/A | N/A |
Table 1 summarizes the experiment setup. We train the NCA generators with environments of size and then evaluate them in sizes of both and . In addition, we set the number of NCA iterations for environments of size and for those of size for all domains. is larger than because the NCA generators need more iterations to converge to a stable state while generating environments of size . For the warehouse and manufacturing domains, we use Rolling-Horizon Collision Resolution (RHCR) [28], a state-of-the-art centralized lifelong MAPF planner, in the simulation. We run each simulation for timesteps during training and timesteps during evaluation and stop early in case of congestion, which happens if more than half of the agents take wait actions at the same timestep. For the maze domain, we use a trained ACCEL agent [9] in the simulations. We include more details of the experiment setup, compute resources, and implementation in Appendix C.
6.1 Multi-Agent Domains
Baseline Environments. We consider two types of baseline environments for the multi-agent domains (warehouse and manufacturing), namely those designed by human and those optimized by DSAGE [51], the state-of-the-art environment optimization method. In DSAGE, we use as the objective function for the result archive and with for the surrogate archive. With size , however, it is impractical to run DSAGE due to the computational limit. One single run of MILP repair, for example, could take 8 hours in an environment of size . We use the human-designed warehouse environments from previous work [29, 28, 51]. The manufacturing domain is new, so we create human-designed environments for it.
NCA-generated Environments. We take the best NCA generator from the result archive to generate environments of size and . In the manufacturing domain, we additionally take the best NCA generator that generate an environment of size with a similar number of workstations as the DSAGE-optimized environment. This is to ensure a fair comparison, as we do not constrain the number of workstations, which is correlated with throughput, in the manufacturing domain.
We show more details of the baselines and NCA-generated environments in Appendix D.
6.1.1 Environments of Size
| Size with agents | Size with agents | ||||
| Domain | Algorithm | Success Rate | Throughput | Success Rate | Throughput |
| warehouse (even) | CMA-MAE + NCA () | 100% | 6.79 0.00 | 0% | N/A |
| CMA-MAE + NCA () | 100% | 6.73 0.00 | 0% | N/A | |
| CMA-MAE + NCA () | 100% | 6.74 0.00 | 90% | 16.01 0.00 | |
| DSAGE () | 100% | 6.35 0.00 | N/A | N/A | |
| Human | 0% | N/A | 0% | N/A | |
| warehouse (uneven) | CMA-MAE + NCA () | 100% | 6.89 0.00 | 62% | 12.32 0.00 |
| CMA-MAE + NCA () | 100% | 6.70 0.00 | 8% | 11.56 0.01 | |
| CMA-MAE + NCA () | 100% | 6.82 0.00 | 84% | 12.03 0.00 | |
| DSAGE () | 100% | 6.40 0.00 | N/A | N/A | |
| Human | 0% | N/A | 0% | N/A | |
| Manufacturing | CMA-MAE + NCA (, opt) | 94% | 6.82 0.00 | 100% | 23.11 0.01 |
| CMA-MAE + NCA (, comp DSAGE) | 98% | 6.61 0.00 | N/A | N/A | |
| DSAGE () | 28% | 5.61 0.12 | N/A | N/A | |
| Human | 100% | 5.92 0.00 | 0% | N/A | |





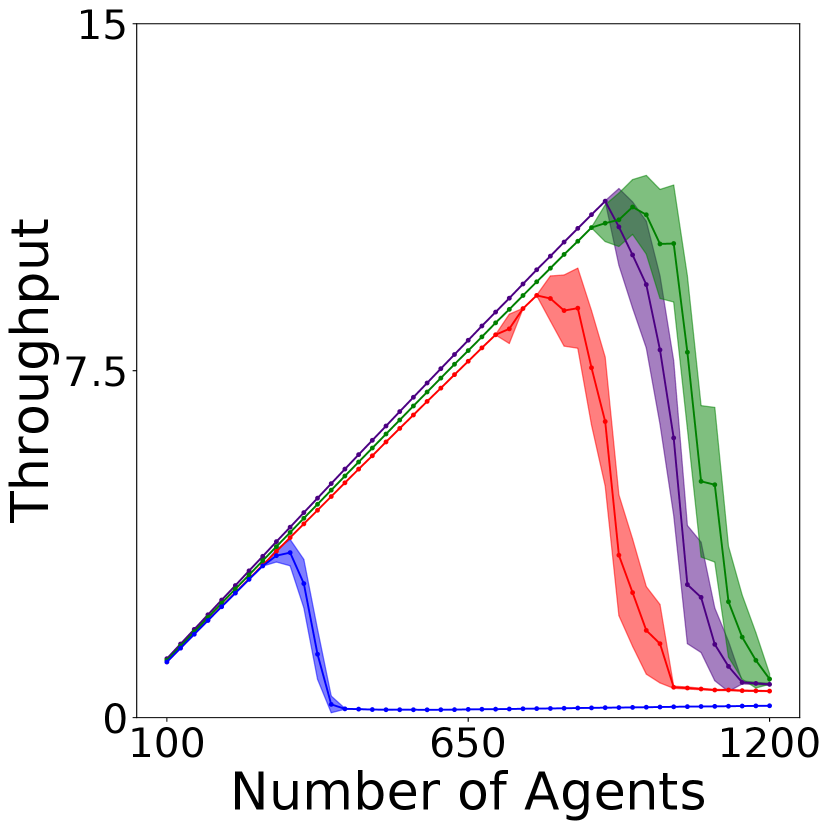

Columns 3 and 4 of Table 2 show the numerical results with agents in the warehouse and manufacturing domains with environment size . All NCA-generated environments have significantly better throughput than the baseline environments. In addition, we observe that larger values have no significant impact on the throughput with agents.
We also analyze the scalability of the environments by running simulations with varying numbers of agents and show the throughput in Figures 3(a), 3(b) and 3(c). In both the warehouse (even) and manufacturing domains, our NCA-generated environments have higher throughput than the baseline environments with an increasingly larger gap with more agents. In the warehouse (uneven) domain, however, the DSAGE-optimized environment displays slightly better scalability than those generated by NCA. This could be due to a need for more traversable tiles near the popular left-side workstations to alleviate congestion, a pattern creation task that poses a significant challenge for NCA generators compared to DSAGE’s direct tile search. In addition, in the manufacturing domain, the optimal NCA generator (green line) creates an environment with top throughput for 200 agents, but it is slightly less scalable than the sub-optimal one used for DSAGE comparison (grey line). We conjecture this is due to the optimizer being caught in a local optimum region due to the complexity of the tasks. On the effect of values, we observe that larger values enhance the scalability of the generated environments in the warehouse (even) domain, as shown in Figure 3(a). We include further discussion of values in Section E.1.
To further understand the gap of throughput among different environments of size with agents, we present additional results on the number of finished tasks over time in Section E.2. All NCA-generated environments maintain a stable number of finished tasks throughout the simulation.
6.1.2 Environments of Size
Columns 5 and 6 of Table 2 compare environments of size with agents. In the warehouse (even) domain, all environments, except for the one generated by CMA-MAE + NCA (), run into congestion. In the warehouse (uneven) domain, CMA-MAE + NCA () also achieves the best success rate, even though it does not have the highest throughput. This shows the benefit of using a larger value with CMA-MAE in creating large and scalable environments.
To further understand the scalability, Figures 3(d), 3(e) and 3(f) show the throughput of the environments with an increasing number of agents. We observe that all our NCA-generated environments are much more scalable than the human-designed ones. In particular, the environments generated by CMA-MAE + NCA () yield the best scalability in all domains. This is because a higher value of makes CMA-MAE focus more on minimizing the disparity between the unrepaired and repaired environments. As a result, the optimized NCA generators are more capable of generating environments with desired regularized patterns directly. On the other hand, a smaller value of makes the algorithm rely more on the MILP solver to generate patterns, introducing more randomness as the MILP solver arbitrarily selects an optimal solution with minimal hamming distance when multiple solutions exist. We show additional results of scaling the same NCA generators to more environment sizes in Section E.3. We also include a more competitive baseline by tiling environments of size to create those of size in Section E.4.
6.2 Scaling Single-Agent RL Policy



In the maze domain, we show that it is possible to scale a single-agent RL policy to larger environments with similar regularized patterns. We use the NCA generator trained from 18 18 maze environments to generate a small 18 18 and a large 66 66 maze environment, shown in Figure 5. Running the ACCEL [9] agent 100 times in these environments results in success rates of 90% and 93%, respectively. The high success rate comes from the fact that the similar local observation space of the RL policy enables the agent to make the correct local decision and eventually arrive at the goal.
For comparison, we generate 100 baseline 66 66 maze environments by restricting the wall counts to be the same and the path lengths to range between 80% to 120% of the one in Figure 5(b), to maintain similar difficulty levels. Figure 15 in Section D.2 shows two example baseline environments. Testing the ACCEL agent in these environments yields an average success rate of 22% (standard error: 3%), significantly lower than that achieved in the NCA-generated environments. This demonstrates the ability of our method to generate arbitrarily large environments with similar patterns in which the trained RL agent performs well.
6.3 NCA Generation Time
| Size with agents | Size with agents | ||||||
| Domain | Algorithm | ||||||
| Warehouse (even) | CMA-MAE () | 0.06 | 2.72 | 0.94 | 0.12 | 228.80 | 0.95 |
| CMA-MAE () | 0.06 | 2.97 | 0.86 | 0.13 | 9278.18 | 0.84 | |
| CMA-MAE () | 0.06 | 2.55 | 0.97 | 0.13 | 19.79 | 0.99 | |
| Warehouse (uneven) | CMA-MAE () | 0.06 | 2.41 | 0.85 | 0.13 | 1,376.62 | 0.85 |
| CMA-MAE () | 0.06 | 2.36 | 0.95 | 0.13 | 26.54 | 0.96 | |
| CMA-MAE () | 0.06 | 13.42 | 0.84 | 0.13 | 15,656.04 | 0.86 | |
| Manufacturing | CMA-MAE (, opt) | 0.07 | 3.04 | 0.17 | 0.18 | 15,746.10 | 0.18 |
We show the total CPU runtime of generating and repairing the environments of sizes and in Table 3. In both sizes, larger similarity scores are correlated with shorter MILP runtime. The similarity scores of the manufacturing environments are significantly lower because we use a larger normalization factor than that in the warehouse domains. Nevertheless, we note that even the longest combined runtime of the NCA generation and MILP repair ( seconds for the manufacturing domain) on the environments of size is significantly shorter than optimizing the environments of that size directly. This reduction in time is attributed to our method, which involves running the MILP repair times with an environment size of while training the NCA generators, and then using the MILP solver only once with size while generating the environments. Our method stands in contrast to the previous direct environment optimization method [51] which requires running the MILP repair with the size of for times.
6.4 On the Benefit of QD Algorithms
QD algorithms can train a diverse collection of NCA generators. In Section E.5, we compare the QD-score and archive coverage of CMA-MAE + NCA and DSAGE. We also benchmark CMA-MAE against MAP-Elites [34, 47] to highlight the benefit of using CMA-MAE in training NCA generators. We observe that CMA-MAE + NCA has the best QD-score and archive coverage in all domains.
Furthermore, QD algorithms can train more scalable NCA generators than single-objective optimizers. In Section E.6 we compare CMA-MAE with a single-objective optimizer CMA-ES [20]. We observe that CMA-MAE is less prone to falling into local optima and thus better NCA generators.
7 Limitations and Future Work
We present a method to train a diverse collection of NCA generators that can generate environments of arbitrary sizes within a range defined by finite compute resources. In small environments of size , our method generates environments that have competitive or better throughput compared to the state-of-the-art environment optimization method [51]. In large environments of size , where existing optimization methods are inapplicable, our generated environments achieve significantly higher throughput and better scalability compared to human-designed environments.
Our work is limited in many ways, yielding many directions for future work. First, our method is only arbitrarily scalable under a range determined by finite compute resources. For example, with the compute resource in Sections C.3 and C.4, the upper bound of the range is about . Although this upper bound is significantly higher than previous environment optimization methods, future work can seek to further increase it. Second, we focus on generating 4-neighbor grid-based environments with an underlying undirected movement graph. Future work can consider generating similar environments with directed movement graphs or irregular-shaped environments. We additionally discuss social impacts of our work in Appendix F.
Acknowledgements
This work used Bridge-2 at Pittsburgh Supercomputing Center (PSC) through allocation CIS220115 from the Advanced Cyberinfrastructure Coordination Ecosystem: Services & Support (ACCESS) program, which is supported by National Science Foundation grants #2138259, #2138286, #2138307, #2137603, and #2138296. In addition, this work was supported by the CMU Manufacturing Futures Institute, made possible by the Richard King Mellon Foundation, and was partially supported by the NSF CAREER Award (#2145077).
References
- Bhatt et al. [2022] Varun Bhatt, Bryon Tjanaka, Matthew Fontaine, and Stefanos Nikolaidis. Deep surrogate assisted generation of environments. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), pages 37762–37777, 2022.
- Brown [2022] Alan S. Brown. How Amazon robots navigate congestion. https://www.amazon.science/latest-news/how-amazon-robots-navigate-congestion, 2022. Accessed: 2023-05-09.
- Chan [2020] Bert Wang-Chak Chan. Lenia and expanded universe. In Proceedings of the Conference on Artificial Life (ALIFE), pages 221–229, 2020.
- Chen et al. [2021] Zhe Chen, Javier Alonso-Mora, Xiaoshan Bai, Daniel D Harabor, and Peter J Stuckey. Integrated task assignment and path planning for capacitated multi-agent pickup and delivery. IEEE Robotics and Automation Letters, 6(3):5816–5823, 2021.
- Chevalier-Boisvert et al. [2018] Maxime Chevalier-Boisvert, Lucas Willems, and Suman Pal. Minimalistic gridworld environment for openai gym. https://github.com/maximecb/gym-minigrid, 2018.
- Contini and Farinelli [2021] Antonello Contini and Alessandro Farinelli. Coordination approaches for multi-item pickup and delivery in logistic scenarios. Robotics and Autonomous Systems, 146:103871, 2021.
- Cully et al. [2015] Antoine Cully, Jeff Clune, Danesh Tarapore, and Jean-Baptiste Mouret. Robots that can adapt like animals. Nature, 521(7553):503–507, 2015.
- Damani et al. [2021] Mehul Damani, Zhiyao Luo, Emerson Wenzel, and Guillaume Sartoretti. PRIMAL2: Pathfinding via reinforcement and imitation multi-agent learning - lifelong. IEEE Robotics and Automation Letters, 6(2):2666–2673, 2021.
- Dennis et al. [2020] Michael Dennis, Natasha Jaques, Eugene Vinitsky, Alexandre Bayen, Stuart Russell, Andrew Critch, and Sergey Levine. Emergent complexity and zero-shot transfer via unsupervised environment design. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), pages 13049–13061, 2020.
- Earle et al. [2022] Sam Earle, Justin Snider, Matthew C. Fontaine, Stefanos Nikolaidis, and Julian Togelius. Illuminating diverse neural cellular automata for level generation. In Proceedings of the Genetic and Evolutionary Computation Conference (GECCO), pages 68–76, 2022.
- Fontaine and Nikolaidis [2021a] Matthew Fontaine and Stefanos Nikolaidis. Differentiable quality diversity. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), pages 10040–10052, 2021.
- Fontaine and Nikolaidis [2021b] Matthew C. Fontaine and Stefanos Nikolaidis. A quality diversity approach to automatically generating human-robot interaction scenarios in shared autonomy. In Proceedings of the Robotics: Science and Systems (RSS), 2021.
- Fontaine and Nikolaidis [2023] Matthew Fontaine and Stefanos Nikolaidis. Covariance matrix adaptation map-annealing. In Proceedings of the Genetic and Evolutionary Computation Conference (GECCO), pages 456–465, 2023.
- Fontaine et al. [2020] Matthew C. Fontaine, Julian Togelius, Stefanos Nikolaidis, and Amy K. Hoover. Covariance matrix adaptation for the rapid illumination of behavior space. In Proceedings of the Genetic and Evolutionary Computation Conference (GECCO), pages 94–102, 2020.
- Fontaine et al. [2021a] Matthew C. Fontaine, Ya-Chuan Hsu, Yulun Zhang, Bryon Tjanaka, and Stefanos Nikolaidis. On the importance of environments in human-robot coordination. In Proceedings of the Robotics: Science and Systems (RSS), 2021.
- Fontaine et al. [2021b] Matthew C. Fontaine, Ruilin Liu, Ahmed Khalifa, Jignesh Modi, Julian Togelius, Amy K. Hoover, and Stefanos Nikolaidis. Illuminating Mario scenes in the latent space of a generative adversarial network. Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), pages 5922–5930, 2021.
- Gaier et al. [2018] Adam Gaier, Alexander Asteroth, and Jean-Baptiste Mouret. Data-efficient design exploration through surrogate-assisted illumination. Evolutionary computation, 26(3):381–410, 2018.
- Gala et al. [2023] Gennaro Gala, Daniele Grattarola, and Erik Quaeghebeur. E(n)-equivariant graph neural cellular automata. ArXiv, abs/2301.10497, 2023.
- Gardner [1970] Martin Gardner. Mathematical games – the fantastic combinations of john conway’s new solitaire game “life”. Scientific American, 223(4):120–123, 1970.
- Hansen [2016] Nikolaus Hansen. The CMA evolution strategy: A tutorial. ArXiv, abs/1604.00772, 2016.
- IBM Corp. [2022] IBM Corp. IBM ILOG CPLEX Optimization Studio. https://www.ibm.com/products/ilog-cplex-optimization-studio, 2022.
- Justesen et al. [2018] Niels Justesen, Ruben Rodriguez Torrado, Philip Bontrager, Ahmed Khalifa, Julian Togelius, and Sebastian Risi. Illuminating generalization in deep reinforcement learning through procedural level generation. In NeurIPS Workshop on Deep Reinforcement Learning, 2018.
- Kent and Branke [2023] Paul Kent and Juergen Branke. Bayesian quality diversity search with interactive illumination. In Proceedings of the Genetic and Evolutionary Computation Conference (GECCO), pages 1019–1026, 2023.
- Kou et al. [2020] Ngai Meng Kou, Cheng Peng, Hang Ma, T. K. Satish Kumar, and Sven Koenig. Idle time optimization for target assignment and path finding in sortation centers. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), pages 9925–9932, 2020.
- Lehman and Stanley [2011a] Joel Lehman and Kenneth O Stanley. Abandoning objectives: Evolution through the search for novelty alone. Evolutionary computation, 19(2):189–223, 2011.
- Lehman and Stanley [2011b] Joel Lehman and Kenneth O. Stanley. Evolving a diversity of virtual creatures through novelty search and local competition. In Proceedings of the Genetic and Evolutionary Computation Conference (GECCO), pages 211–218, 2011.
- Li et al. [2020] Jiaoyang Li, Kexuan Sun, Hang Ma, Ariel Felner, T. K. Satish Kumar, and Sven Koenig. Moving agents in formation in congested environments. In Proceedings of the International Joint Conference on Autonomous Agents and Multiagent Systems (AAMAS), pages 726–734, 2020.
- Li et al. [2021] Jiaoyang Li, Andrew Tinka, Scott Kiesel, Joseph W. Durham, T. K. Satish Kumar, and Sven Koenig. Lifelong multi-agent path finding in large-scale warehouses. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), pages 11272–11281, 2021.
- Liu et al. [2019] Minghua Liu, Hang Ma, Jiaoyang Li, and Sven Koenig. Task and path planning for multi-agent pickup and delivery. In Proceedings of the International Conference on Autonomous Agents and Multi-Agent Systems (AAMAS), pages 1152–1160, 2019.
- Lucas and Volz [2019] Simon M. Lucas and Vanessa Volz. Tile pattern KL-divergence for analysing and evolving game levels. In Proceedings of the Genetic and Evolutionary Computation Conference (GECCO), pages 170–178, 2019.
- Ma et al. [2017] Hang Ma, Jiaoyang Li, T. K. Satish Kumar, and Sven Koenig. Lifelong multi-agent path finding for online pickup and delivery tasks. In Proceedings of the International Conference on Autonomous Agents and Multiagent Systems (AAMAS), pages 837–845, 2017.
- Mordvintsev and Niklasson [2021] Alexander Mordvintsev and Eyvind Niklasson. NCA: Texture generation with ultra-compact neural cellular automata. ArXiv, abs/2111.13545, 2021.
- Mordvintsev et al. [2020] Alexander Mordvintsev, Ettore Randazzo, Eyvind Niklasson, and Michael Levin. Growing neural cellular automata. Distill, 2020.
- Mouret and Clune [2015] Jean-Baptiste Mouret and Jeff Clune. Illuminating search spaces by mapping elites. ArXiv, abs/1504.04909, 2015.
- Nguyen et al. [2017] Van Nguyen, Philipp Obermeier, Tran Cao Son, Torsten Schaub, and William Yeoh. Generalized target assignment and path finding using answer set programming. In Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI), pages 1216–1223, 2017.
- Niklasson et al. [2021] Eyvind Niklasson, Alexander Mordvintsev, Ettore Randazzo, and Michael Levin. Self-organising textures. Distill, 2021.
- Parker-Holder et al. [2022] Jack Parker-Holder, Minqi Jiang, Michael Dennis, Mikayel Samvelyan, Jakob Foerster, Edward Grefenstette, and Tim Rocktäschel. Evolving curricula with regret-based environment design. In Proceedings of the International Conference on Machine Learning (ICML), pages 17473–17498, 2022.
- Paszke et al. [2019] Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Kopf, Edward Yang, Zachary DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. PyTorch: An imperative style, high-performance deep learning library. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), pages 8024–8035, 2019.
- Reinke et al. [2020] Chris Reinke, Mayalen Etcheverry, and Pierre-Yves Oudeyer. Intrinsically motivated discovery of diverse patterns in self-organizing systems. In International Conference on Learning Representations (ICLR), 2020.
- Risi and Togelius [2020] Sebastian Risi and Julian Togelius. Increasing generality in machine learning through procedural content generation. Nature Machine Intelligence, 2:428–436, 2020.
- Shaker et al. [2016] Noor Shaker, Julian Togelius, and Mark J. Nelson. Procedural Content Generation in Games: A Textbook and an Overview of Current Research. Springer, 2016.
- Stern et al. [2019] Roni Stern, Nathan R. Sturtevant, Ariel Felner, Sven Koenig, Hang Ma, Thayne T. Walker, Jiaoyang Li, Dor Atzmon, Liron Cohen, T. K. Satish Kumar, Roman Barták, and Eli Boyarski. Multi-agent pathfinding: Definitions, variants, and benchmarks. In Proceedings of the International Symposium on Combinatorial Search (SoCS), pages 151–159, 2019.
- Sudhakaran et al. [2021] Shyam Sudhakaran, Djordje Grbic, Siyan Li, Adam Katona, Elias Najarro, Claire Glanois, and Sebastian Risi. Growing 3D artefacts and functional machines with neural cellular automata. In Proceedings of the Conference on Artificial Life (ALIFE), page 108, 2021.
- Tesfaldet et al. [2022] Mattie Tesfaldet, Derek Nowrouzezahrai, and Chris Pal. Attention-based neural cellular automata. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), pages 8174–8186, 2022.
- Tjanaka et al. [2023] Bryon Tjanaka, Matthew C. Fontaine, David H. Lee, Yulun Zhang, Nivedit Reddy Balam, Nathaniel Dennler, Sujay S. Garlanka, Nikitas Dimitri Klapsis, and Stefanos Nikolaidis. pyribs: A bare-bones python library for quality diversity optimization. In Proceedings of the Genetic and Evolutionary Computation Conference (GECCO), pages 220–229, 2023.
- Varambally et al. [2022] Sumanth Varambally, Jiaoyang Li, and Sven Koenig. Which MAPF model works best for automated warehousing? In Proceedings of the Symposium on Combinatorial Search (SoCS), pages 190–198, 2022.
- Vassiliades and Mouret [2018] Vassiiis Vassiliades and Jean-Baptiste Mouret. Discovering the elite hypervolume by leveraging interspecies correlation. In Proceedings of the Genetic and Evolutionary Computation Conference (GECCO), pages 149–156, 2018.
- Yu and Wolf [2023] Ge Yu and Michael Wolf. Congestion prediction for large fleets of mobile robots. In Proceedings of the International Conference on Robotics and Automation (ICRA), pages 7642–7649, 2023.
- Zhang et al. [2020] Hejia Zhang, Matthew C. Fontaine, Amy K. Hoover, Julian Togelius, Bistra Dilkina, and Stefanos Nikolaidis. Video game level repair via mixed integer linear programming. In Proceedings of the AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment (AIIDE), pages 151–158, 2020.
- Zhang et al. [2022] Yulun Zhang, Matthew C. Fontaine, Amy K. Hoover, and Stefanos Nikolaidis. Deep surrogate assisted map-elites for automated hearthstone deckbuilding. In Proceedings of the Genetic and Evolutionary Computation Conference (GECCO), pages 158–167, 2022.
- Zhang et al. [2023] Yulun Zhang, Matthew C. Fontaine, Varun Bhatt, Stefanos Nikolaidis, and Jiaoyang Li. Multi-robot coordination and layout design for automated warehousing. In Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI), pages 5503–5511, 2023.
Appendix A NCA Generation Process





Figure 6 shows an example NCA generation process with 50 iterations.



Appendix B Domain Details
B.1 Warehouse
Environment. We use the workstation scenario from previous work [51]. Figure 7(a) shows an example. A warehouse environment has four tile types. Black tiles are shelves for storing goods and also serve as obstacles. Blue tiles are endpoints where the agents park and interact with shelves. White tiles are empty spaces. Pink tiles are workstations where agents interact with human staff. Agents can traverse all non-black tiles. The goal location (= task) of each agent alternates between randomly selected workstations and endpoints. Furthermore, the NCA generator only generates the storage area inside the red box in Figure 7(a), which contains only black, blue, and white tiles. The non-storage area outside the red box is kept unchanged. This is because the locations of the workstations are usually fixed along the borders of the real-world warehouses.
Domain-Specific Constraints. The constraints of the warehouse environment include: (1) all non-black tiles are connected so that the agents can reach all endpoints and workstations, (2) each black tile is adjacent to at least one blue tile and vice versa, ensuring that agents can interact with shelves via endpoints, (3) the number of black tiles is equal to a predefined number ( or in Table 1) so that all generated warehouse environments have the same storage capability, and (4) the non-storage area is kept unchanged. The detailed MILP formulation of the constraints is included in the previous paper [51].
Agent-based Simulator. Following previous work [51], we use Rolling-Horizon Collision Resolution (RHCR) [28], a state-of-the-art lifelong MAPF planner, in our simulations. In lifelong MAPF, agents are constantly assigned new tasks once they finish their previous ones. At every timesteps, RHCR plans collision-free paths for all agents for the next timesteps (). Following the design recommendation from the previous work [28], we use and . We set the initial locations of the agents uniformly at random from the non-shelf tiles. We use two different task assigners, leading to two variations of the warehouse domain. First, we adopt the task assigner from the previous work [51] that assigns the next task (workstation or endpoint) uniformly at random. We refer to this variant as warehouse (even). Second, we extend the previous task assigner by asking it to select the next workstation with uneven probabilities. Specifically, the workstations on the left border are 5 times more likely to be selected than those on the right. The endpoints remain being evenly selected. We refer to this variant as warehouse (uneven), which is more challenging than warehouse (even) because the more frequently visited left border workstations could make the simulation to be congested.
B.2 Manufacturing
Environment. Figure 7(b) shows an example of a manufacturing environment. Each manufacturing environment has five tile types. The blue (endpoint) and white (empty space) tiles are the same as the warehouse environments. The red, green, and yellow tiles represent three types of workstations. Agents can traverse only blue and white tiles. The task of each agent is to go to an endpoint adjacent to a red, green, and yellow workstation in order and stay there for , , and timesteps, respectively. The NCA generator generates the entire environment. Since the manufacturing domain has multiple types of workstations, one of the challenges of generating high-performance manufacturing environments is to find a reasonable ratio of the number of different workstations.
Domain-Specific Constraints. In line with the warehouse domain, we constrain the manufacturing environments such that (1) all blue and white tiles are connected so that the robots can reach all endpoints, (2) each blue tile is adjacent to at least one of red, green, or yellow tiles and vice versa so that the robots can interact with the workstations via endpoints, (3) there is at least one red, one green, and one yellow tile to support the cyclical nature of manufacturing tasks, where a complete cycle involves sequential visits to endpoints next to red, green, and yellow workstations.
Agent-based Simulator. The agent-based simulator is the same as the one used in the warehouse domain except that (1) we ask each agent to stay for , , and timesteps after arriving at their goal endpoints next to red, green, and yellow workstations, respectively, and (2) the task assigner assigns the next task to an endpoint, chosen uniformly at random, near the red, green, and yellow workstations in order.
B.3 Maze
Environment. We use the maze domain from previous works [1, 5, 9, 37]. Figure 7(c) shows an example maze environment. A maze environment has two tile types: wall (gray) and empty space (black). The yellow triangle represents the agent, and the green square is the goal location. We omit the agent and the goal location when generating the environments.
Domain-Specific Constraints. We do not have any domain-specific constraints for the maze domain.
Agent-based Simulator. We use a trained ACCEL agent [9]. The observation space is a 5 5 grid in front of it. The agent can turn left or right in its current tile, move forward to the adjacent tile, or stay in the current tile. We assign the start and goal locations of the agent to the first and last tile of the longest shortest path in the environment. We limit the time horizon to 2 times the number of tiles in the environment, which is 648 for environments of size , and 8,712 for environments of size , respectively. We stop the simulation early if the agent reaches the goal.
Appendix C Experiment Details

C.1 NCA Setup
C.1.1 NCA Generator Architecture
Figure 8 shows the model architecture of the NCA generator. The generator has 3 convolutional layers of kernel size 3, stride 1 and padding 1. The first 2 convolutional layers have 32 output channels and are followed by a ReLU activation. The last layer has 3 output channels and is followed by a sigmoid function. This configuration guarantees that the width, height, and number of channels of the input and output tensors are the same.
C.1.2 Initial Environments


Figure 9 shows the initial environments of size for all domains. They are characterized by a small central block of non-empty-spaces surrounded by empty spaces. The initial environments of size maintains the same central blocks and are surrounded by more expansive empty spaces.
C.1.3 Postprocessing Generated Environments
After generating an environment and before repairing it, we may need to postprocess the environment to prepare for repairing.
Warehouse. In the warehouse domain, we generate a 32 33 and 98 101 storage area and add fixed non-storage area to the left and right side to form an environment of size and , respectively.
Manufacturing. In the manufacturing domain, we directly generate environments of size and .
Maze. In the maze domain, we generate a 16 16 environment and surround it with walls to create a environment. Similarly, we generate a 64 64 environment and surround it with walls to create a environment.
C.2 QD Setup
C.2.1 Objective
Warehouse. We use and in Section 4 as the objective functions. We set for all , meaning that all tiles have the same weight while computing the similarity score.
Manufacturing. We use and in Section 4 as the objective functions. We set as it results in the most scalable environments in the warehouse domain. Suppose denotes the tile of the environment . For the objective functions, we let if is a workstation, and otherwise. Intuitively, we give more rewards to the environments in which workstations are not changed during MILP repair.
Maze. We use the same binary objective from the previous work [1].
Baseline


CMA-MAE with
warehouse (even)



CMA-MAE with
warehouse (uneven)


Baseline

NCA-generated (Repaired)


NCA-generated (Unrepaired)


C.2.2 Archive Dimensions
Warehouse. We use a 100 100 archive for the warehouse domain. We set the range of the connected shelf components to be , following previous work [51], and the range of the environment entropy to be . In DSAGE, we follow previous work to downsample the archive to get a subset of elites [1, 51]. We set the downsampled archive dimension to be , with 50 on the dimension of the number of connected shelf components and 25 on the environment entropy dimension. We use an irregular dimension because DSAGE fails to diversify the environment entropy measure (introduced in Section E.5) and we need to use a higher downsampling resolution on the number of connected shelf components to sample a reasonable number of elites.
Manufacturing. We use a 100 100 archive for the manufacturing domain. We set the range of the number of workstations to be to allow CMA-MAE to explore a wide range of environments with different number of workstations, and the range of the environment entropy to be . We use an irregular 25 10 downsampled archive with higher resolution on the number of workstations for the same reason as the warehouse domain
Maze. Following previous work [1], we use a 256 162 archive. We set the range of the number of walls to be , where 256 is the total number of tiles in the environments of size (excluding the appended walls around the border), and the range of average agent path length to be , where 648 is the time horizon of the agent-based simulation in environments of size .
C.2.3 CMA-MAE
For the warehouse and manufacturing domains, we use an archive learning rate of 0.01, while, for the maze domain, we use 0.5. We use a higher archive learning rate for the maze domain because a higher learning rate promotes CMA-MAE to explore the measure space. Since the binary objective function of the maze domain (introduced in Section 5) can be trivially optimized, we promote CMA-MAE to do more exploration than exploitation in the maze domain. In all domains, the initial batch of solutions is sampled from a multivariate Gaussian distribution with a mean of 0 and a standard deviation of 0.2.
C.3 Compute Resource
We run our experiments on 4 local machines and 2 high performing clusters, namely (1) a local machine with a 16-core AMD Ryzen 9 5950X CPU, 32 GB of RAM, and a Nvidia RTX 3080 GPU, (2) a local machine with a 64-core AMD Ryzen Threadripper 3990X, 192 GB of RAM, and an Nvidia RTX 3090Ti GPU, (3) a local machine with a 64-core AMD Ryzen Threadripper 3990X, 64 GB of RAM, and an Nvidia RTX A6000 GPU, (4) a local machine with a 64-core AMD Ryzen Threadripper 3990X, 64 GB of RAM, and an Nvidia RTX 3090 GPU, (5) a high-performing clusters with a V100 GPU, 200 Xeon CPUs each with 4 GB of RAM, and numerous 32-core AMD EPYC 7513 CPUs, each with up to 248 GB of RAM, (6) a high-performing cluster with a V100 GPU and heterogeneous CPUs. We perform our experiments in different machines because our experiments are not sensitive to runtime and require massive parallelization. We measure all CPU runtimes in machine (1).
Warehouse (even)



Warehouse (uneven)


C.4 Implementation
We implement CMA-MAE with Pyribs [45], the NCA generators in PyTorch [38], and the MILP solver with IBM’s CPLEX library [21] in Python.
Compute Constraint of MILP. In the CPLEX MILP solver, we constrain the maximum number of threads to 1 and 28 for environments of size and , respectively. We set the deterministic runtime limit to be ticks for size and ticks for size in CPLEX. The deterministic runtime limit in CPLEX is a metric that provides a consistent measure on the “effort” made by the MILP solver, measured in “ticks”, a CPLEX abstract unit.
Appendix D Baseline and NCA-generated Environments
D.1 NCA-generated Environments






Warehouse. Figures 10(d), 10(e), 10(f), 10(g), 10(h) and 10(i) show the NCA-generated warehouse environments of size . Figure 12 shows those of size . For the environments of warehouse (even), larger values lead the optimal NCA generators in the result archives to generate environments with clearer patterns. Specifically, with (Figure 10(d)), the environment has a large area of empty spaces at the bottom. With (Figure 10(e)), the area of empty spaces is gone but the distribution of shelves is not even. With (Figure 10(f)), the generated environment is mostly filled with repeated blocks of 1 2 shelves and the space in between the block is filled with endpoints. The trend is similar for environments of size in the warehouse (even) domain (Figures 12(a), 12(b) and 12(c)). With , the generated environment possesses the most regularized pattern.
For the warehouse (uneven) domain, larger values do not always generate clearer patterns. Specifically, with size , the environments generated with (Figure 10(g)) and (Figure 10(i)) have similar patterns. Both environments have fewer shelves on the left part of the environments and cluster more shelves on the right so that the agents have more traversable tiles to resolve conflicts near the more frequently visited workstations on the left border. Such pattern can also be found in size (Figures 12(d) and 12(f)). Notably, however, with size , the environment with has more traversable tiles near the workstations on the left border than that with , resulting in higher success rate as shown in Table 2 of Section 6.
Manufacturing. Figures 11(d) and 11(c) show the NCA-generated environments of size . The one generated by the optimal NCA generator (Figure 11(d)) possesses more regularized patterns than the one used to compare with DSAGE (Figure 11(c)). However, in their corresponding unrepaired environments (Figures 11(e) and 11(f)), the NCA generators only generate empty spaces and endpoints and rely on the MILP solver to put the workstations in the environment. We conjecture that for the manufacturing domain, the number of endpoints is more important than the ratio between different types of workstations because more endpoints allow the agents to perform tasks in parallel around the workstations. Similarly, Figure 13 shows the unrepaired and repaired NCA-generated environments of size . The unrepaired environment (Figure 13(a)) has no workstations at all, while the repaired environment has randomly placed workstations by the MILP solver.
D.2 Baseline Environments
Warehouse. Figure 10(a) shows the human-designed warehouse environment of size for both variants of warehouse domains. It is taken from the previous works [29, 28, 51], where 1 10 blocks of shelves are repeatedly placed, and each shelf is surrounded by two endpoints from the top and bottom of it. We scale this pattern to create the human-designed warehouse environment of size , shown in Figure 14(a). Figures 10(b) and 10(c) shows the DSAGE-optimized warehouse environments of size for warehouse (even) and warehouse (uneven), respectively. Both of them have no clear regularized patterns.
Manufacturing. Figures 11(a) and 14(b) show the human-designed manufacturing environments of size and , respectively. We create the human-designed environment of size (Figure 11(a)) such that (1) the number of workstations mirrors that in the DSAGE-optimized environment so that approximately the same number of agents can operate in parallel around the workstations, and (2) the ratio of different types of stations approximates so that the environment has more workstations that require agents to stay longer.
To create these human-designed environments, we draw insights from some NCA-generated environments. Notably, the warehouse (even) environment with (Figure 10(f)) has the best scalability (shown in Section 6). This informs the design of the human-designed manufacturing environment of size , displayed in Figure 11(a), where we evenly distribute blocks of workstations and position endpoints around each for parallel agents operation.
In the size of , the NCA-generated manufacturing environment (Figure 13(b)) features standalone workstations surrounded by endpoints. We imitate this pattern to create the human-designed manufacturing environment of size , shown in Figure 14(b). Similar to the human-designed environment of size , we additionally let the ratio of different types of workstations to approximate and the total number of workstations are similar.
Given these human-designed manufacturing environments have NCA-inspired designs, we anticipate them to outperform their counterparts in the warehouse domain, compared to the NCA-generated ones.
Maze. Figure 15 shows two example baseline environments using the method described Section 6. Compared to the NCA-generated maze environment of size shown in Figure 5(b), both of them have no clear regularized patterns. Running the ACCEL agent in these two environments for 100 times results in success rates of 0% and 8%, respectively.
Warehouse (even)



Warehouse (uneven)



Appendix E Additional Results
In this section, we include the following additional results: (1) we compare the result archives with different values to discuss the effect of on patterns, (2) we show the number of finished tasks over time in the NCA-generated and baseline environments of size in the warehouse and manufacturing domains, analyzing the occurrence of congestion in these environments, (3) we show the scalability of the trained NCA generators in environment sizes other than and , (4) we compare our method with an additional baseline of tiling environments of size to create those of size , (5) we show the QD-score and archive coverage of CMA-MAE + NCA comparing with MAP-Elites [34, 47] + NCA to demonstrate the advantage of CMA-MAE in terms of training a diverse collection of NCA generators, (6) we show the QD-score and archive coverage of CMA-MAE + NCA comparing with DSAGE with direct tile search [1, 51] to demonstrate the advantage of NCA in terms of generating environments with regularized patterns, and (7) we compare CMA-MAE with a derivative-free single-objective optimizer CMA-ES [20] to demonstrate that optimizing without diversifying measures can more easily lead to local optima.
E.1 On the Effect of on Patterns
Figure 16 shows the result archives of warehouse domains with different values of . We observe that a larger value is correlated with better archive coverage in the low environment entropy area in the archive. Since a lower value of environment entropy corresponds to clearer regularized patterns and thus a possibly more scalable NCA generator, a reasonably large value can give users more freedom in choosing trained NCA generators from the result archive.
E.2 Number of Finished Tasks Over Time
To understand the gap in the performance of the environments in the warehouse and manufacturing domains, we run 100 simulations with agents in all of the environments of size and plot the number of finished tasks at each timestep. We do not stop the simulation even if the agents encounter congestion. Figure 17 shows the number of finished tasks over 5,000 timesteps. All NCA-generated environments maintain a stable number of finished tasks throughout the simulation.








E.3 Scalability in More Environment Sizes






To further demonstrate the scalability of our method, we use trained NCA generators from Section 6 to generate progressively larger environments and run simulations. Figure 18 shows the result. The y-axis illustrates two metrics: maximum mean throughput over 50 simulations (right) and the maximum scalability, defined as the agent count at this maximum (left).
We see an increasing trend for both maximum scalability and maximum mean throughput as the environment size increases. The NCA-generated environments generally scale better than the human-designed ones.
We see two exceptions: the maximum mean throughput in the 6969 warehouse (uneven) environment and both metrics in the 5758 manufacture environment. We can attribute this to the interaction between the MILP and the specific environment generated by the NCA. Since MILP makes numerous changes to the generated environments in these domains, certain combinations of generated environments and MILP random seeds can lead to repaired layouts that create congestion. However, if we encounter such issues in practice, we can either leverage a different NCA generator from the archive or re-run the MILP repair with a different random seed.
E.4 Tiling Environments of size
Due to the similarity incurred in the NCA-generated environments of different sizes, one may argue that tiling small environments can create larger environments with competitive performance as the NCA-generated ones. To test this argument, we add a new baseline. We tile the environments of size , namely Figure 10(f) (warehouse (even)), Figure 10(i) (warehouse (uneven)), and Figure 11(d) (manufacturing) in Section C.1, to create environments of size . We then use MILP to enforce constraints.
We run 50 simulations with agents specified in Table 1. The new baseline achieves a success rate of only 0% and 23% in the warehouse (even) and warehouse (uneven) domains, respectively. Figure 19 displays the tiled environments of size and their tile-usage maps, which show the usage frequency of each tile in the simulation. As shown in Figures 19(b) and 19(d), the agents are congested, resulting in low success rates. In contrast, for the manufacturing domain, the baseline matches our method, with a success rate of 100% and an average throughput of 22.73. This is because the tiling of Figure 11(d), creating Figure 19(e), resembles the NCA-generated patterns in Figure 13(b). Thus, the tiling baseline may be a good method for the manufacturing domain, yet it falls short in the warehouse domains.
E.5 QD Score and Archive Coverage





| Domain | Algorithm | QD-score | Archive Coverage |
|---|---|---|---|
| Maze w/o env entropy | CMA-MAE + NCA | 22,299.00 612.46 | 0.54 0.01 |
| DSAGE | 16,446.60 42.27 | 0.40 0.00 | |
| MAP-Elites + NCA | 12,446.80 2,207.08 | 0.30 0.05 | |
| Maze w/ env entropy | CMA-MAE + NCA | 12,468.20 342.09 | 0.77 0.02 |
| DSAGE | 1,444.20 52.60 | 0.09 0.00 | |
| MAP-Elites + NCA | 9,288.80 590.13 | 0.57 0.04 | |
| Warehouse (even) | CMA-MAE + NCA | 20,366.07 653.46 | 0.33 0.01 |
| DSAGE | 914.60 33.09 | 0.02 0.00 | |
| MAP-Elites + NCA | 6,893.49 1,291.68 | 0.15 0.03 | |
| Warehouse (uneven) | CMA-MAE + NCA | 19,985.23 493.98 | 0.33 0.01 |
| DSAGE | 926.69 23.42 | 0.02 0.00 | |
| MAP-Elites + NCA | 5,906.86 1,027.29 | 0.14 0.02 | |
| Manufacturing | CMA-MAE + NCA | 6,449.56 1,106.83 | 0.18 0.02 |
| DSAGE | 378.33 4.69 | 0.02 0.00 | |
| MAP-Elites + NCA | 2,398.99 422.61 | 0.14 0.02 |
Algorithm:
CMA-MAE + NCA
MAP-Elites + NCA
DSAGE
Warehouse (even)



Warehouse (uneven)



Manufacturing



Maze w/o
env entropy



Maze w/
env entropy


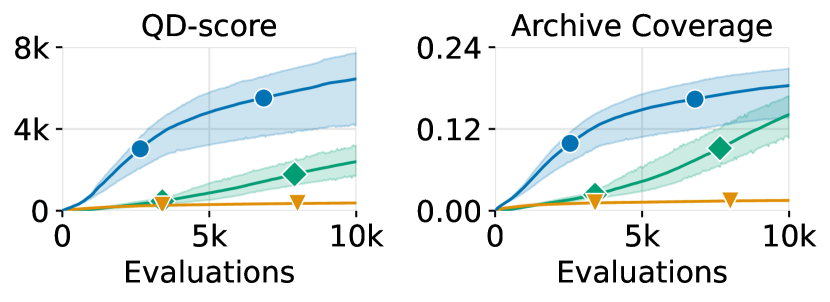
Figure 20 shows the QD-score and the archive coverage over the number of evaluations during training. Table 4 shows the corresponding numerical results. Figure 21 then shows the result archive of one of the runs.
We compare CMA-MAE with MAP-Elites [34] to show the benefit of using CMA-MAE to train NCA. We use the state-of-the-art Iso+LineDD mutation operator [47] on MAP-Elites with and . We also compare CMA-MAE + NCA with DSAGE to demonstrate the benefit of using NCA to generate environments with regularized patterns. In the maze domain, in addition to the combination of diversity measures discussed in Section 5 (number of walls and average agent path length), we run experiments with the environment entropy measure, paired with average agent path length, to demonstrate the effect of the environment entropy measure on the QD-score and archive coverage.
We observe that CMA-MAE achieves the best QD-score and the best archive coverage in all domains, generating solutions with the best quality and diversity. We also observe from the result archives that CMA-MAE covers the largest number of cells. Notably, in all domains, DSAGE fails to diversify environment entropy, covering only the high entropy area of the archives and not exploring the low entropy region. This happens because we directly optimize environments instead of training NCA generators in DSAGE. Without NCA, DSAGE cannot generate candidate environments with low entropy (i.e., with regularized patterns). As a result, despite being high-quality, the DSAGE-optimized environments lack regularized patterns and cannot be scaled to arbitrary sizes.
E.6 Compare CMA-ES with CMA-MAE







| Size with agents | Size with agents | ||||
| Domain | Algorithm | Success Rate | Throughput | Success Rate | Throughput |
| warehouse (even) | CMA-ES + NCA | 100% | 6.51 0.00 | N/A | N/A |
| CMA-MAE + NCA | 100% | 6.74 0.00 | 90% | 16.01 0.00 | |
| warehouse (uneven) | CMA-ES + NCA | 100% | 6.62 0.00 | 0% | N/A |
| CMA-MAE + NCA | 100% | 6.82 0.00 | 84% | 12.03 0.00 | |
| Manufacturing | CMA-ES + NCA | 98% | 6.81 0.01 | N/A | N/A |
| CMA-MAE + NCA | 94% | 6.82 0.00 | 100% | 23.11 0.01 | |


Derivative-free single objective optimizers such as CMA-ES [20] that do not diversify a given set of measures can also be used to train the NCA generators. To demonstrate the effect of diversifying measures on the trained NCA generators, we run CMA-ES in the warehouse and manufacturing domains with and compare the trained NCA generator with those trained by CMA-MAE. Table 5 shows the numerical results, and Figure 22 shows the throughput over different numbers of agents.
With an environment size of , CMA-ES is competitive with CMA-MAE in all domains. In fact, CMA-ES ends up being slightly more scalable than CMA-MAE in the warehouse (uneven) domain with size . However, CMA-MAE is significantly more scalable than CMA-ES with size . In particular, the MILP solver cannot find solutions for warehouse (even) and manufacturing domains of size in the given computational budget (introduced in Section C.4).
Figure 23 shows the unrepaired environments of size in the warehouse (even) and manufacturing domains for CMA-ES. Both environments have a large number of endpoints. As a result, they rely on the MILP solver to both satisfy the domain-specific constraints and generate patterns, which takes a significant amount of time because almost no constraints are satisfied in the unrepaired environments. Given the deviation of the unrepaired environments, CMA-ES fails to optimize the similarity score, converging to a local optima while optimizing only the throughput. In comparison, CMA-MAE is less prone to falling into the deceptive local optima because of the diversity measures.
Appendix F Societal Impact
We propose using QD algorithms to generate arbitrarily large environments that enhance throughput beyond state-of-the-art environment optimization methods and human-designed environments. This is achieved by optimizing a diverse collection of NCA generators. Our method can be applied to generate any multi-robot system as long as an agent-based simulator is available for evaluation. Large companies such as Amazon and Alibaba have deployed multi-robot systems in warehouses to transport packages or inventory pods. Therefore, one real world application of our method is optimizing the layout of the automated warehouses to improve throughput. Since our method is agnostic to the specific agent simulator and only requires metrics such as throughput post-simulation, we can plug-in different simulators and apply our environment generation algorithm. Improving the throughput of their warehouses can present a significant economic impact on the industry.
Our method may have negative impacts. While designing a real-world automated warehouse or manufacturing environment and deploying large-scale multi-robot systems in reality, we shall take into account other factors such as safety measures. In our method, however, we ignore all factors except for the throughput and scalability of the environment. Consequently, while our method can contribute to optimizing operational efficiency, caution should be exercised to ensure that other crucial parameters are not compromised in real-world applications.