Approximate Order-Preserving Pattern Mining for Time Series
Abstract
The order-preserving pattern mining can be regarded as discovering frequent trends in time series, since the same order-preserving pattern has the same relative order which can represent a trend. However, in the case where data noise is present, the relative orders of many meaningful patterns are usually similar rather than the same. To mine similar relative orders in time series, this paper addresses an approximate order-preserving pattern (AOP) mining method based on (-) distance to effectively measure the similarity, and proposes an algorithm called AOP-Miner to mine AOPs according to global and local approximation parameters. AOP-Miner adopts a pattern fusion strategy to generate candidate patterns generation and employs the screening strategy to calculate the supports of candidate patterns. Experimental results validate that AOP-Miner outperforms other competitive methods and can find more similar trends in time series.
keywords:
sequential pattern mining , time series , order-preserving pattern , (-) distance , approximate pattern mining1 Introduction
Sequential pattern mining [1] is an important knowledge enhanced search method [2] that has attracted great attention in recent years [3, 4]. With the rapid development of network information technology, and in the era of big data, sequential pattern mining is becoming increasingly important and necessary. Due to its high efficiency and strong interpretability, it has been widely used in many applications, such as virus similarity analysis [5], outlier sequence discovery [7, 8], spatial co-location pattern discovery [9, 10], and patient shock prediction [11].
As a common and important form of data, time series [12, 13] have been applied in numerous fields such as multi-variate time series forecasting [14, 15, 16, 17], stock prices prediction [18], and the analysis of EEG records [19]. Unlike character sequences, a time series is a numerical sequence of data arranged in chronological order, which contains a large amount of regular information [20, 21]. To obtain valuable information, researchers have proposed many methods for the analysis of time series, such as three-way sequential pattern mining [22, 23, 24], neural network method [25, 26], and transformer method [27].
However, for some applications, the trend of a time series may be more meaningful than its actual values. For example, in stock analysis, the trends shown by stocks are more worth studying than the actual prices. In temperature prediction, a change in temperature is more meaningful than the actual value of the temperature. As a new sequential pattern mining method, order-preserving pattern mining was proposed [28], which does not need to transform a time series into a character sequence to mine representative trends. This mining method can mine the most frequent subsequences with the same relative orders from a time series and ensure the continuity of the time series. The potentially changing laws of the time series can therefore be discovered, which can help users to better analyze and predict the time series data.
The existing order-preserving pattern mining algorithm can only mine identical, short, order-preserving patterns [28, 29]. Obviously, identical trends are only found in a situation where data noise is not allowed . More importantly, shorter patterns contain less information. However, if we allow for some data noise, we can find longer order-preserving patterns with similar trends. For example, the order-preserving patterns of (4,1,3,2,5,6) and (5,2,3,1,4,6) are not the same, they have a high level of similarity with the order-preserving pattern , since compared with p, the local error for each position satisfies , and the global error satisfies . Hence, the order-preserving pattern p occurs twice in s and meets the minimum support threshold. The order-preserving pattern is therefore a frequent approximate order-preserving pattern (AOP).
Inspired by (,)-approximate pattern matching [30, 31] and with the aim of overcoming the drawbacks of exact order-preserving pattern mining, this paper presents an AOP mining method based on the (-) distance to effectively measure the similarity, and proposes the AOP-Miner algorithm for mining AOPs. The contributions of this paper are as follows.
-
1.
To mine some longer order-preserving patterns with similar trends, we focus on AOP mining in which the local error does not exceed and the overall error does not exceed .
-
2.
We propose the AOP-Miner algorithm, which has two key steps: candidate pattern generation and pattern support calculation. AOP-Miner adopts a pattern fusion strategy to generate candidate patterns and employs screening and pruning strategies to calculate the support.
-
3.
A large set of experimental results from real time series datasets is presented to verify that AOP-Miner yields better performance than alternative methods, and can find longer order-preserving patterns with similar trends.
The rest of this paper is arranged as follows. Section 2 summarizes related work. Section 3 gives the relevant definition of AOP mining. Section 4 proposes the AOP-Miner algorithm and analyzes its time and space complexities. Section 5 verifies the performance of the AOP-Miner algorithm. Section 6 presents the conclusions of this paper.
2 RELATED WORK
A current research hotspot is the use of sequential pattern mining with the aim of quickly finding patterns that meet the specific needs of users. Various types of mining methods have been derived for different problems, such as gap constraint mining [32, 33, 34], negative sequence mining [35, 36], rule mining [37], high utility mining [38, 39, 40, 41], and contrast pattern mining [42, 43]. Sequential pattern mining methods can be categorized in many ways, such as different types of mining data.
Based on the different types of mining data used, sequential pattern mining can be divided into classical sequential and time series pattern mining. Classical sequential pattern mining [44] is mainly used for discrete sequences such as transaction datasets, webpage click-streams, DNA sequences, and gene sequences. A time series is a numerical sequence composed of continuously changing values. Due to the high dimensionality and continuity of time series data, it is very difficult to mine time series directly. It is therefore necessary to discretize the original numerical information into data in other domains through a series of transformations before performing mining. For example, the SAX algorithm [45] was proposed to symbolize the time series, allowing various classical methods to be used to analyze the time series. However, this transformation will introduce new noise, since the essence of the process is to re-represent the time series, thus making it different from the original time series.
To effectively analyze the trends in time series data, many methods were proposed to measure the distances of two time series, such as Euclidean distance and dynamic time warping (DTW) [46, 47]. Among them, DTW is a famous method, since it can effectively handle shrink, scaling, and noise injection. However, the DTW method is difficult to handle and find the same relative order in time series. For example, the DTW of two time series (13,11,18,23) and (16,12,19,25) is not zero, which means that they are different. However, the two time series have the same relative order (2,1,3,4), since 13 is the second lowest value in (13,11,18,23), 11 is the lowest, 18 is the third lowest, and 23 is the largest. To overcome this shortage, a simple method named order preserving pattern matching method was proposed ref41, in which the rank of each element in the sequence is adopted to represent the time series. This method can effectively find the same relative order in the time series which can be regarded as patterns. Inspired by order-preserving pattern matching, order-preserving pattern mining was proposed with the aim of mining frequently occurring trends from time series data [28, 29] to help users analyze and predict trends in time series which can be used in disease spread analysis, temperature change analysis, and user behavior analysis. The abovementioned researches are based on exact matching, which can only mine frequent patterns with the same trends.
However, in the presence of data noise, it is necessary to use approximate pattern matching. For example, Paw et al. [49] proposed the use of a matching accuracy based on the Hamming distance to measure similarity. If two strings have the same relative order after deleting up to k elements in the same positions, the matching is successful; however, the matching results for this problem are biased as the local similarity between the subsequence and the pattern cannot be measured. Mendivelso et al. [30] proposed a similarity measurement method based on the (-) distance to address this problem, and used local-global constraints to improve the accuracy of matching [50]. All these methods are based on approximate order-preserving pattern matching.
Since current methods do not allow for data noise and only mine frequent patterns with identical trends, there is a need for a method of discovering frequent patterns with similar trends. Inspired by order-preserving pattern mining [28, 29] and approximate order-preserving pattern matching [30], we investigate AOP mining and propose AOP-Miner to effectively mine frequent AOPs. The differences between the OPP-Miner method [28] and AOP-Miner are as follows. OPP-Miner focuses on mining exact order-preserving patterns, which do not allow for data noise, while the approach in this paper is devoted to mining AOPs in a sequence with data noise. More importantly, OPP-Miner employs the order-preserving pattern matching method to calculate the support for each pattern, which requires repeated scanning of the whole sequence in the dataset. In contrast, AOP-Miner can effectively use the results of subpatterns to calculate the supports of superpatterns, an approach that can avoid the need for repeated scanning of the whole sequence.
3 Definitions
Definition 1.
A time series s composed of n values can be expressed as s = (1 i n), where is called an element.
Definition 2.
The rank of element in pattern with length (1 ) is rankp() = 1+ , where means that there are elements in p smaller than .
Definition 3.
A relative order of pattern p with length m is an order-preserving pattern, represented by ).
Example 1.
Suppose we have a pattern p = (12,15,10,13). Since element 12 is the second smallest in pattern p, its rank rankp(12) = 2. Similarly, element 15 is the largest in pattern p. Hence, rankp(15) = 4. The order-preserving pattern of p is then r(p) = (2,4,1,3).
Definition 4.
Given two time series p and q with length m, their order-preserving patterns are rankp() rankp() rankp() and rankp()rankp() rankp(), respectively. The distance for p and q is the maximum value of the relative order, which is (p,q) = rankp(-rankp(. The distance is the sum of the relative order, which is (p,q) =rankp-rankp(.
Definition 5.
Suppose we have an order-preserving pattern p with length m and a subsequence I = in the time series s (1 ). If the order-preserving pattern r(I) and pattern p satisfy the (-) distance constraint, i.e. (p,I) and (p,I) , then I is a (-) occurrence of p in s, where and are two given, non-negative integers. To represent the occurrence concisely, in this paper, we use the first position of I to represent the occurrence.
Definition 6.
The number of (-) occurrences of p in s is called the support, and is denoted by sup(p,s). If the number of (-) occurrences of p in s is not less than the minimum support threshold (minsup) (i.e., sup(p,s) minsup), then p is a frequent (-) order-preserving pattern.
Example 2.
Suppose we have , p = (2,1,4,3), and s = (12,15,10,13,11,18,23,9,26,20,13,16,12,19,25,20). All (-) occurrences of p in s are as follows. For a time sub-series = (13,11,18,23) in s, the order-preserving r() is (2,1,3,4). r() and p satisfy (-) order-preserving matching, since 2-2 = 0 , 1-1 = 0 , 4-3 = 1 , 3-4 = 1 , and . Therefore, is a (-) occurrence of p in s. Similarly, there are three other (-) occurrences of p in s, which are = (23,9,26,20), = (16,12,19,25), and = (12,19,25,20).
Definition 7.
Our problem (AOP mining) is to find all frequent (-) order-preserving patterns (AOPs).
Example 3.
Suppose we have a time series s = (12,15,10,13,11,18,23,9,26,20,13,16,12,19,25,20), = 1, = 2, and minsup = 4. Our aim is to mine all frequent AOPs. From Example 3, we know that (2,1,4,3) is a frequent AOP. Similarly, we know that all frequent AOPs are (1,2),(2,1),(1,2,3),(1,3,2),(2,1,3),(2,3,1),(3,1,2),(3,2,1),(1,2,3,4), (2,1,4,3), and (2,3,1,4).
It is worth noting that if = = 0, then AOP mining can be seen as classical order-preserving pattern mining. Hence, AOP mining is a more general problem.
4 AOP-Miner
In AOP mining, there are two main steps: candidate pattern generation and calculation of the candidate pattern support. In Section 4.1, we introduce the candidate pattern generation strategy. Section 4.2 proposes the candidate pattern support calculation strategy, and Section 4.3 presents AOP-Miner.
4.1 Candidate pattern generation
4.1.1 Enumeration strategy
An enumeration strategy is a strategy that lists all possible situations one by one. Suppose pattern p is a frequent AOP with length m (1 ). With an enumeration strategy, we will add a value at the end of p. There are therefore m+1 possible relative order. Hence, a pattern can generate m+1 candidate patterns. An illustrative example is given below.
Example 4.
Suppose we have two frequent patterns with length three, {(1,3,2),(2,1,3)}. There are four candidate patterns based on the pattern (1,3,2). For example, if the newly added element is smaller than the original three elements, then the candidate pattern (2,4,3,1) is generated. In a similar way, the patterns (1,4,3,2), (1,4,2,3), and (1,3,2,4) are generated. Since each pattern can generate four candidate patterns, two frequent patterns can generate eight candidate patterns. The results are shown in Table 1.
| Candidate patterns with length four | |
| (1,3,2) | (2,4,3,1), (1,4,3,2), (1,4,2,3), (1,3,2,4) |
| (2,1,3) | (3,2,4,1), (3,1,4,2), (2,1,4,3), (2,1,3,4) |
Obviously, the higher the number of candidate patterns, the slower the mining speed. In the next subsection, we will introduce our pattern fusion strategy, which can effectively reduce the number of candidate patterns.
4.1.2 Pattern fusion strategy
The pattern fusion strategy was proposed in [28], which uses the two concepts of order-preserving prefix and suffix subpatterns described as follows.
Definition 8.
Suppose we have a pattern . After removing the last element , the remaining subpattern is the prefix subpattern of pattern p. Its order-preserving prefix subpattern is the order-preserving pattern of the prefix subpattern, and is denoted as prefixorder(p). Similarly, after removing the first element , the remaining subpattern is the suffix subpattern of pattern p, and its order-preserving suffix subpattern is the order-preserving pattern of the suffix subpattern, denoted as suffixorder(p).
Definition 9.
Pattern fusion: Suppose there are two patterns and with length m. If suffixorder(p) = prefixorder(q), then we can generate one or two superpatterns with length m+1 by pattern fusion of p and q, i.e., t = p q or t,k = p q There are three possible cases:
Case 1: . In this case, a superpattern t is generated. First, we let . We then compare () with . If , then . Otherwise, .
Case 2: . In this case, two superpatterns t and k are generated. For pattern , let . We then compare with . If , then . Otherwise, . For pattern , we let . We then compare with . If , then . Otherwise, .
Case 3: . In this case, a superpattern t is generated. First, let . We then compare with . If , then . Otherwise, .
Example 5.
Suppose we have an order-preserving pattern which can join with patterns and , since suffix(p) , prefix(q), prefix(r) , and their order-preserving patterns are suffixorder(p) = prefixorder(q) = prefixorder(r) .
For patterns p and r, suffixorder(p) = prefixorder(r) and , which satisfies Case 2. Hence, p and r can generate two patterns t and k with length four. We know that and , as shown in Fig. 1.

We know that suffixorder(p) = prefixorder(q) and , which indicates Case 3. Hence, . We then compare , and with . Since , and are less than , . Hence, , as shown in Fig. 2.

Example 6.
We use the same frequent pattern set as in Example 4 to generate candidate patterns with length four using a pattern fusion strategy.
From Example 5, we know that (1,3,2) (2,1,3) generates (1,3,2,4). Similarly, we know that (2,1,3) (1,3,2) generates (3,1,4,2) and (2,1,4,3). The results are shown in Table 2.
| Candidate patterns with length four | |
| (1,3,2) | (1,3,2,4) |
| (2,1,3) | (3,1,4,2), (2,1,4,3) |
By comparing Tables 1 and 2, we can see that the enumeration strategy generates eight candidate patterns with length four, while the pattern fusion strategy generates only three candidate patterns. Examples 4 and 6 show that the pattern fusion strategy outperforms the enumeration strategy, since the pattern fusion strategy can effectively reduce the number of candidate patterns, thereby improving the mining efficiency of the algorithm.
4.2 Support calculation
4.2.1 segtreeBA and bitBA
To the best of our knowledge, only the segtreeBA and bitBA algorithms [30] have been developed for calculating the support of a (-) order-preserving pattern. To calculate the support of an order-preserving pattern, these two algorithms need to scan all possible candidate occurrences. Example 7 illustrates the principle of operation of these two algorithms.
Example 7.
Given a time series s = (12,15,10,13,11,18,23, 9,26,20,13,16,12,19,25,20), minsup = 4, = 1, = 2, we can use the segtreeBA and bitBA algorithms to find the candidate occurrences of pattern (2,3,1,5,4).
The segtreeBA and bitBA algorithms scan the time series from the beginning to the end to enumerate all candidate occurrences one by one [30]. For example, the first candidate occurrence is 1, and its corresponding subsequence is (12,15,10,13,11). There are 12 candidate occurrences, since the lengths of s and the pattern are 16 and 5, respectively, and 16-5+1 = 12. Thus, the last candidate occurrence is 12 and its corresponding subsequence is (16,12,19,25,20).
To calculate the support of a candidate pattern, both algorithms need to scan the database and compare each candidate occurrence with the pattern to determine whether it meets the approximate matching criterion. The database is therefore scanned multiple times, which greatly increases the calculation time. To solve this problem, we propose the Alar algorithm, which can quickly calculate the support of the candidate pattern without repeatedly scanning the database.
4.2.2 Alar algorithm
In this section, we describe the Alar algorithm, which finds all frequent AOPs with length +1 using the results for all frequent AOPs with length . The Alar algorithm applies two key strategies to reduce the support calculation: a screening strategy to find the candidate occurrences of a superpattern based on the occurrences of subpatterns, and a pruning strategy to further reduce the number of candidate patterns. The principles of operation of these two strategies are as follows.
In the pattern fusion strategy, each candidate pattern is generated by joining two frequent (-) preserving patterns, i.e., t = p q. Thus, we know that if is an occurrence of pattern t, then prefixorder() must be an occurrence of pattern p and suffixorder(+1) must be an occurrence of pattern q. Hence, if is an occurrence of pattern p and +1 is an occurrence of pattern q, then may be an occurrence of pattern t. Otherwise, is not an occurrence of pattern t. We can then develop the following screening strategy.
Screening strategy: If is an occurrence of pattern p, but +1 is not an occurrence of pattern q, then is not an occurrence of pattern t. Similarly, if -1 is not an occurrence of pattern p, but is an occurrence of pattern q, then -1 is not an occurrence of pattern t.
Theorem 1.
The screening strategy is correct.
Proof.
Proof. The proof is by contradiction. We assume that is an occurrence of pattern t, and is an occurrence of pattern p, but that +1 is not an occurrence of pattern q. Hence, +1 is an occurrence of pattern q, since is an occurrence of pattern t. This contradicts the fact that +1 is not an occurrence of pattern q. Similarly, we know that if -1 is not an occurrence of pattern p, then -1 is not an occurrence of pattern t. ∎
We use this screening strategy to effectively screen out feasible candidate occurrences. All occurrences of p and q are stored in arrays and , respectively. Example 8 illustrates the principle of this strategy.
Example 8.
We use the same data as in Example 3, where (2,3,1,4) and (2,1,4,3) are two frequent patterns of length four. We know that (2,3,1,4) (2,1,4,3) can generate the candidate pattern (2,3,1,5,4).
For a length-four frequent pattern (2,3,1,4), there are four occurrences in s: {1,3,6,11}, which are stored in an array . The corresponding subsequences are (), (), (), and (), and all of these subsequences are occurrences of pattern (2,3,1,4) with and . Similarly, there are four occurrences of pattern (2,1,4,3) in s: {4,7,12,13}, which are stored in . Table 3 shows the occurrences in Example 8.
| Frequent pattern | Occurrences with and |
| (2,3,1,4) | {1,3,6,11} |
| (2,1,4,3) | {4,7,12,13} |
We now generate the candidate occurrences of pattern (2,3,1,5,4) based on the occurrences of (2,3,1,4) and (2,1,4,3). From Table 3, we know that 1 is an occurrence of (2,3,1,4), but 2 is not an occurrence of (2,1,4,3). Thus, 1 cannot be a candidate occurrence of (2,3,1,5,4) according to the screening strategy. Since 3 is an occurrence of (2,3,1,4) and 4 is an occurrence of (2,1,4,3), 3 can be a candidate occurrence of (2,3,1,5,4) according to the screening strategy. Similarly, we know that both 6 and 11 can be candidate occurrences. Hence, the corresponding subsequences of the candidate occurrences are (10,13,11,18,23), (18,23,9,26,20), and (13,16,12,19,25).
We can see that after applying the screening strategy, there are only three candidate occurrences, far fewer than in Example 7. The lower the number of candidate occurrences, the higher the efficiency of the algorithm.
To further improve the efficiency, we also propose a pruning strategy to reduce the number of candidate patterns.
Pruning strategy: If the number of candidate occurrences of a pattern is less than the threshold minsup, then the pattern can be pruned.
Theorem 2.
The pruning strategy is correct.
Proof.
Obviously, the support of a pattern is not greater than the number of candidate occurrences, if the number of candidate occurrences of one pattern is less than minsup. Hence, the pattern cannot be an AOP and can be pruned. ∎
Example 9.
We use the same data as in Example 8. We know that pattern (2,3,1,5,4) has three candidate occurrences, which is less than . Hence, pattern (2,3,1,5,4) can be pruned.
The principle of the Alar algorithm is as follows. Alar judges whether any two frequent patterns p and q with length m can be fused. If yes, then Alar generates the candidate patterns according to Definition 9, and determines whether or not the candidate patterns are frequent using the Checking algorithm. The Alar algorithm is shown in Algorithm 1.
Input: frequent patterns , s, , , m
Output: frequent patterns and their corresponding occurrence arrays
The Checking algorithm adopts the screening strategy to find candidate occurrences and applies the pruning strategy to decrease the number of candidate patterns. Finally, it uses the Matching algorithm to calculate the support of the candidate pattern. The Checking algorithm is shown in Algorithm 2.
Input:
superpattern t, occurrence arrays and , s, , and minsup
Output:
frequent pattern t and its corresponding occurrence array
The Matching algorithm uses the definitions to calculate the support and is shown in Algorithm 3.
Input:
, t, s, , , minsup
Output:
occurrence array
4.3 AOP-Miner algorithm
Pseudocode for AOP-Miner is given in Algorithm 4.
Input:
time sequence dataset s, local constraint , global constraint , minimum support threshold minsup
Output:
frequent (-) order-preserving pattern set
The AOP-Miner algorithm uses three key steps to mine all frequent AOPs.
Step 1: The supports of candidate patterns (1,2) and (2,1) are calculated and frequent patterns are stored in .
Step 2: The Alar algorithm is applied to mine frequent AOPs with length using frequent AOPs with length .
Step 3: Step 2 is iterated until no new AOPs are found.
5 Experimental results and performance analysis
In this section, we evaluate the performance of AOP-Miner. Section 5.1 explains the experimental environment and the datasets used, and Section 5.2 introduces the baseline methods. Section 5.3 verifies the performance of each strategy in AOP-Miner.
5.1 Dataset
The experimental running environment was an Intel(R)Core(TM)i7-6560U processor, 2.20 GHZ CPU with 16 GB memory, Windows 10, a 64-bit operating system, and the program development environment was VS2017.
We used eight real-time series datasets to conduct our experiments, including oil, stock, air temperature,and air quality data. Oil datasets are the closing price of 1WTI crude oil and London Brent crude oil, which can be downloaded at http://www.fansmale.com/index.html. Stock datasets are the closing price of the Russell 2000 index and Nasdaq index, which can be downloaded at https://www.yahoo.com. The air temperature datasets are the average of the air temperature of Shunyi, Huairou, Changping and Tiantan, which can be downloaded at https://archive.ics.uci.edu/ml/datasets.php. The air quality datasets is the PM2.5 values of Beijing city which can be found at https://tianqi.2345.com. A description of each dataset is given in Table 4.
| Dataset | Name | Type | Length |
| SDB1 | 1WTI (2000.07.26-2020.02.26) | Oil | 4,996 |
| SDB2 | London Brent (2000.09.04-2020.02.26) | Oil | 5,000 |
| SDB3 | Russell 2000 (1987.9.10-2019.12.27) | Stock | 8,141 |
| SDB4 | Nasdaq (1971.3.1-2019.10.31) | Stock | 12,279 |
| SDB5 | PRSA_Data_Shunyi (2015.1.1-2017.2.28) | Air quality | 18,960 |
| SDB6 | PRSA_Data_Huairu (2015.1.1-2017.2.28) | Air quality | 18,960 |
| SDB7 | PRSA_Data_Changping (2013.3.1-2017.2.28) | Air temperature | 35,064 |
| SDB8 | PRSA_Data_Tiantan (2013.3.1-2017.2.28) | Air temperature | 35,064 |
5.2 Baseline methods
To evaluate the performance of AOP-Miner, four alternative algorithms were proposed and a competitive algorithm was selected. The operation of each of these algorithms is described below.
1. seg-em-Miner and bit-em-Miner [30]: To validate the efficiency of the candidate pattern generation and support calculation, we developed seg-em-Miner and bit-em-Miner, which used an enumeration strategy to generate the candidate patterns and the segtreeBA and bitBA algorithms to calculate the support, respectively.
2. em-Miner: To verify the performance of our pattern fusion strategy, we developed the em-Miner algorithm, which used the enumeration strategy to generate the candidate patterns. The support calculation method in em-Miner is the same as that of AOP-Miner .
3. Nopruning-Miner: To validate the performance of our pruning strategy, we developed Nopruning-Miner, which adopted a pattern joining strategy to generate the candidate patterns and applied the screening strategy to calculate the support.
5.3 Performance of each strategy
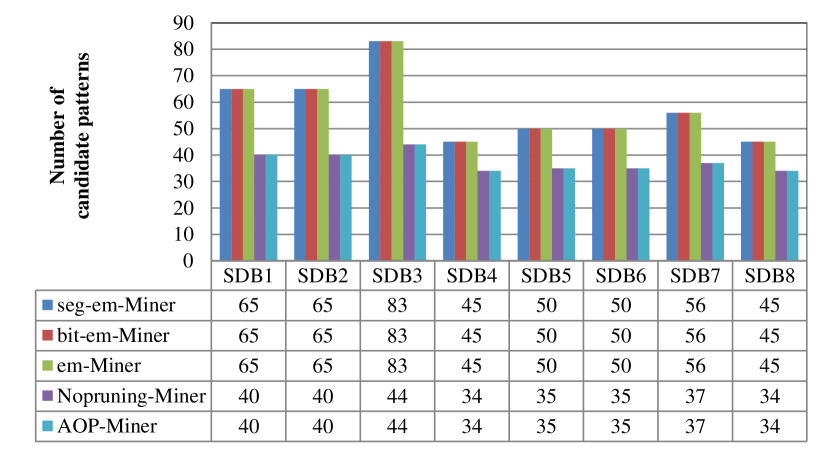
To verify the mining efficiency of each strategy in AOP-Miner, we assessed four competitive algorithms: seg-em-Miner, bit-em-Miner, em-Miner, and Nopruning-Miner. Eight datasets were selected (SDB1 to SDB8). The experimental parameters were = 2 and = 4. Since the lengths of the datasets were different, to mine reasonable number of patterns, minsup was set to 1000, 1000, 1600, 4000, 4000, 4000, 12000, and 12000 for SDB1–SDB8, respectively. These algorithms were able to find 15, 15, 18, 11, 12, 12, 13, and 11 AOPs from SDB1–SDB8, respectively. Comparisons of the number of candidate patterns and running time are shown in Figs. 3 and 4.

The results give rise to the following observations.
(1) AOP-Miner runs faster than em-Miner, thus verifying the efficiency of the pattern fusion strategy. The two algorithms were able to find the same number of patterns on all datasets. Moreover, from Fig. 4, we see that em-Miner took 9.75s for SDB1, while AOP-Miner took 4.26s. Similar results can be found for all other datasets. The reason for this is as follows. Although AOP-Miner and em-Miner adopt the same support calculation method, they use different methods to generate the candidate patterns. AOP-Miner runs faster than em-Miner, meaning that the pattern fusion strategy outperforms the enumeration strategy, since the enumeration strategy generates more candidate patterns. For example, from Fig. 3, we see that em-Miner generates 65 candidate patterns, while AOP-Miner generates 40. The more the candidate patterns, the slower the algorithm runs. Hence, AOP-Miner outperforms em-Miner.
(2) AOP-Miner runs faster than Nopruning-Miner, thus verifying the effectiveness of the pruning strategy. From Fig. 3, we know that the two algorithms generate 44 candidate patterns on SDB3. However, the running time for Nopruning-Miner is 8.54s, while that of AOP-Miner is 8.43s. Similar effects can be found for the other datasets. We know that Nopruning-Miner is the same as AOP-Miner except for the pruning strategy. As Example 9 shows, the pruning strategy can avoid redundant support calculations, and hence, AOP-Miner outperforms Nopruning-Miner.
(3) AOP-Miner runs faster than seg-em-Miner and bit-em-Miner, which further validates the efficiency of both the pattern fusion strategy and the screening and pruning strategies for calculating the supports. From Fig. 3, we know that seg-em-Miner and bit-em-Miner generate 45 candidate patterns on SDB4, while AOP-Miner generates 34 ones. Moreover, the running time of seg-em-Miner and bit-em-Miner are 23.4s and 14.26s, respectively, while that of AOP-Miner is 9.26s. Similar results can be found for all other datasets. The reason for this is that AOP-Miner employs more effective candidate pattern generation and support calculation methods, and therefore outperforms seg-em-Miner and bit-em-Miner.
In conclusion, AOP-Miner has better performance than competitive algorithms.
6 Conclusion
To mine order-preserving patterns in a flexible way, we have proposed the use of AOP mining and have developed the AOP-Miner algorithm. This algorithm can not only mine patterns with identical trends but also patterns with similar trends. Users can set the level of similarity using the parameters and to measure the local and global similarities, respectively. For candidate pattern generation, AOP-Miner uses a pattern fusion strategy that significantly reduces the number of candidate patterns. To calculate the pattern support, AOP-Miner employs a screening strategy to find the candidate occurrences of a superpattern based on the occurrences of subpatterns, and adopts a pruning strategy to further reduce the number of candidate patterns. These screening and pruning strategies can greatly lower the number of pattern matches, and significantly improve the mining performance. Experimental results on real-time series datasets indicate that AOP-Miner is an efficient AOP mining algorithm.
Inspired by OPP mining [28] and (,)-approximate order-preserving pattern matching [30], this paper investigates approximate order-preserving pattern mining based on (,)-distances. However, there are many similarity measurement methods, such as DTW [46]. DTW method can effectively handles shrink, scaling, and noise injection, while (,)-distances cannot. Hence, the research of approximate order-preserving pattern mining based on DTW distance is worth investigating.
References
- [1] P. Fournier-Viger, W. Gan, Y. Wu, M. Nouioua, W. Song, T. Truong, H. Duong, ”Pattern mining: Current challenges and opportunities”, in PMDB, 2022, 34-49.
- [2] X. Wu, X. Zhu, M. Wu, ”The evolution of search: Three computing paradigms”, ACM Transactions on Management Information Systems (TMIS), vol. 13, no.2, pp. 20, 2022.
- [3] G. Atluri, A. Karpatne, V. Kumar, ”Spatio-temporal data mining: A survey of problems and methods”, ACM Computing Surveys (CSUR), vol. 51, no.4, pp. 1-41, 2018.
- [4] Y. Wu, X. Wang, Y. Li, L. Guo, Z. Li, J. Zhang, X. Wu, ”OWSP-Miner: Self-adaptive one-off weak-gap strong pattern mining”, ACM Transactions on Management Information Systems, vol. 13, no. 3, pp. 25, 2022.
- [5] Y. Li, S. Zhang, L. Guo, J. Liu, Y. Wu, X. Wu, ”NetNMSP: Nonoverlapping maximal sequential pattern mining”, Applied Intelligence, vol. 52, no.9, pp, 9861-9884, 2022.
- [6] Y. Wu, C. Zhu, Y. Li, L. Guo, X. Wu, ”NetNCSP: Nonoverlapping closed sequential pattern mining”, Knowledge-Based Systems, vol. 196, 105812, 2020.
- [7] T. Wang, L. Duan, G. Dong, Z. Bao, ”Efficient mining of outlying sequence patterns for analyzing outlierness of sequence data”, ACM Transactions on Knowledge Discovery from Data, vol. 14, no. 5, pp. 62, 2020.
- [8] D. Samariya, J. Ma, ”A new dimensionality-unbiased score for efficient and effective outlying aspect mining”, Data Science and Engineering, vol. 7, no. 2, pp. 120-135, 2022.
- [9] L. Wang, X. Bao, L. Zhou, ”Redundancy reduction for prevalent co-location patterns”, IEEE Transactions on Knowledge and Data Engineering, vol. 30, no. 1, pp. 142-155, 2018.
- [10] L. Wang, Y. Fang, L. Zhou, ”Preference-based spatial co-location pattern mining”, Series Title: Big Data Management. Springer Singapore, 2022, https://doi.org/10.1007/978-981-16-7566-9
- [11] S. Ghosh, J. Li, L. Cao, K. Ramamohanarao, ”Septic shock prediction for ICU patients via coupled HMM walking on sequential contrast patterns”, Journal of Biomedical Informatics, vol. 66, pp. 19-31, 2017.
- [12] P. Senin, J. Lin, X. Wang, T. Oates, S. Gandhi, A. P. Boedihardjo, C. Chen, S. Frankenstein, ”Grammarviz 3.0: Interactive discovery of variable-length time series patterns”, ACM Transactions on Knowledge Discovery from Data (TKDD), vol. 12, no. 1, pp. 1-28, 2018.
- [13] C. C. M. Yeh, Y. Zheng, J. Wang, H. Chen, Z. Zhuang, W. Zhang, E Keogh, ”Error-bounded approximate time series joins using compact dictionary representations of time series”, Proceedings of the 2022 SIAM International Conference on Data Mining (SDM), 2022, pp. 181-189.
- [14] J. Zuo, K. Zeitouni, Y. Taher, ”SMATE: Semi-supervised spatio-temporal representation learning on multivariate time series”, in ICDM, 2021, pp. 1565-1570.
- [15] J. Deng, X. Chen, R. Jiang, X. Song, I. W. Tsang. ”ST-Norm: Spatial and temporal normalization for multi-variate time series forecasting”, Proceedings of ACM SIGKDD, 2021, pp. 269-278.
- [16] Y. Gao, J. Lin. ”Discovering subdimensional motifs of different lengths in large-scale multivariate time series”. ICDM, 2019, pp. 220-229.
- [17] Z. Li, J. He, H. Liu, X. Du, ”Combining global and sequential patterns for multivariate time series forecasting”, In 2020 IEEE International Conference on Big Data (Big Data), 2020, pp. 180-187.
- [18] I. R. Parray, S. S. Khurana, M. Kumar, A. A. Altalbe, ”Time series data analysis of stock price movement using machine learning techniques”, Soft Computing, vol. 24, no. 21, pp. 16509-16517, 2020.
- [19] C. Dai, J. Wu, D. Pi, S. I. Becker, L. Cui, Q. Zhang, B. Johnson. ”Brain EEG time-series clustering using maximum-weight clique”. IEEE Transactions on Cybernetics, vol. 52, no. 1, pp. 357-371, 2022.
- [20] N. Alghamdi, L. Zhang, H. Zhang, E. A. Rundensteiner, M. Y. Eltabakh, ”ChainLink: Indexing big time series data for long subsequence matching”, IEEE 36th International Conference on Data Engineering (ICDE), 2020, pp. 529-540.
- [21] S. Agrawal, M. Steinbach, D. Boley, S. Chatterjee, G. Atluri, A. T. Dang, S. Liess, V. Kumar, ”Mining novel multivariate relationships in time series data using correlation networks”, IEEE Transactions on Knowledge and Data Engineering, vol. 32, no. 9, pp. 1798-1811, 2019.
- [22] Y. Wu, Z. Yuan, Y. Li, L. Guo, P. Fournier-Viger, X. Wu, ”NWP-Miner: Nonoverlapping weak-gap sequential pattern mining”, Information Sciences, vol. 588, pp. 124-141, 2022.
- [23] F. Min, Z. Zhang, W. Zhai, R. Shen, ”Frequent pattern discovery with tri-partition alphabets”. Information Sciences, vol. 507, pp. 715-732, 2020.
- [24] Y. Wu, L. Luo, Y. Li, L. Guo, P. Fournier-Viger, X. Zhu, X. Wu, ”NTP-Miner: Nonoverlapping three-way sequential pattern mining”, ACM Transactions on Knowledge Discovery from Data, vol. 16, no.3, pp. 51, 2022.
- [25] Y. Lin, I. Koprinska, M. Rana, ”SSDNet: State space decomposition neural network for time series forecasting”, in ICDM, 2021, pp. 370-378.
- [26] A. Deng, B. Hooi, ”Graph neural network-based anomaly detection in multivariate time series”, Proceedings of the AAAI Conference on Artificial Intelligence, vol. 35, no. 5, pp. 4027-4035, 2021.
- [27] H. Zhou, S. Zhang, J. Peng, S. Zhang, J. Li, H. Xiong, W. Zhang, ”Informer: Beyond efficient transformer for long sequence time-series forecasting”, Proceedings of AAAI, 2021.
- [28] Y. Wu, Q. Hu, Y. Li, L. Guo, X. Zhu, X. Wu, ”OPP-Miner: Order-preserving sequential pattern mining for time series”, IEEE Transactions on Cybernetics, 2022, DOI: 10.1109/TCYB.2022.3169327
- [29] Y. Wu, X. Zhao, Y. Li, L. Guo, X. Zhu, P. Fournier-Viger, X. Wu, ”OPR-Miner: Order-preserving rule mining for time series”, IEEE Transactions on Knowledge and Data Engineering, 10.1109/TKDE.2022.3224963
- [30] J. Mendivelso, R. Niquefa, Y. Pinzón, G. Hernández, ”New algorithms for -order preserving matching”, Ingeniería, vol. 23, no.2, pp. 190-202, 2018.
- [31] Y. Li, L. Yu, J. Liu, L. Guo, Y. Wu, X. Wu, ”NetDPO: (delta, gamma)-approximate pattern matching with gap constraints under one-off condition”, Applied Intelligence, 2022, DOI: 10.1007/s10489-021-03000-2
- [32] Y. Wu, Y. Tong, X. Zhu, X. Wu, ”NOSEP: Nonoverlapping sequence pattern mining with gap constraints”, IEEE Transactions on Cybernetics, vol. 48, no.10, pp. 2809-2822, 2018.
- [33] Y. Wu, L. Wang, J. Ren, W. Ding, X. Wu, ”Mining sequential patterns with periodic wildcard gaps”, Applied Intelligence, vol. 41, no. 1, pp. 99-116, 2014.
- [34] Y. Wang, Y. Wu, Y. Li, F. Yao, P. Fournier-Viger, X. Wu, ”Self-adaptive nonoverlapping sequential pattern mining”, Applied Intelligence, vol. 52, no. 6, pp. 6646-6661, 2022.
- [35] X. Dong, Y. Gong, L. Cao, ”e-RNSP: An efficient method for mining repetition negative sequential patterns”, IEEE Transactions on Cybernetics, vol. 50, no. 5, pp. 2084-2096, 2018.
- [36] Y. Wu, M. Chen, Y. Li, J. Liu, Z. Li, J. Li, X. Wu, ”ONP-Miner: One-off negative sequential pattern mining”, ACM Transactions on Knowledge Discovery in Data. doi: 10.1145/3549940. 2022.
- [37] Y. Chen, P. Fournier-Viger, F. Nouioua, Y. Wu, ”Sequence prediction using partially-ordered episode rules”, ICDM (Workshops), 2021, pp. 574-580.
- [38] M. M. Hossain, Y. Wu, P. Fournier-Viger, Z. Li, L. Guo, Y. Li, ”HSNP-Miner: High utility self-adaptive nonoverlapping pattern mining”, ICBK, 2021, pp. 70-77.
- [39] W. Song, L. Liu, C. Huang, Generalized maximal utility for mining high average-utility itemsets, Knowledge and Information Systems 63 (2021) 2947-2967.
- [40] Y. Wu, M. Geng, Y. Li, L. Guo, Z. Li, P. Fournier-Viger, X. Zhu, X. Wu, ”HANP-Miner: High average utility nonoverlapping sequential pattern mining”, Knowledge-Based Systems, vol. 229, pp. 107361, 2021.
- [41] Y. Wu, R. Lei, Y. Li, L. Guo, X. Wu, ”HAOP-Miner: Self-adaptive high-average utility one-off sequential pattern mining”, Expert Systems with Applications 184 (2021) 115449.
- [42] R. Mercer, S. Alaee, A. Abdoli, N. S. Senobari, S. Singh, A. Murillo, E. Keogh, ”Matrix Profile XXIII: Contrast Profile: A novel time series primitive that allows real world classification”, 2021 IEEE International Conference on Data Mining (ICDM). IEEE, 2021, pp. 1240-1245.
- [43] Y. Wu, Y. Wang, Y. Li, X. Zhu, X. Wu, ”Top-k self-adaptive contrast sequential pattern mining”, IEEE Transactions on Cybernetics, 2021, DOI: 10.1109/TCYB.2021.3082114.
- [44] T. C. Truong, H. V. Duong, B. Le, P. Fournier-Viger. ”EHAUSM: An efficient algorithm for high average utility sequence mining”, Information Sciences, vol. 515, pp. 302-323, 2020.
- [45] E. Keogh, J. Lin, A. Fu. ”Hot SAX: Efficiently finding the most unusual time series subsequence”, Fifth IEEE International Conference on Data Mining (ICDM’05). 2005, pp. 8.
- [46] E. Keogh, C. A. Ratanamahatana, ”Exact indexing of dynamic time warping”, Knowledge and Information Systems, vol. 7, no. 3, pp. 358-386, 2005.
- [47] D. J. Berndt, J. Clifford, ”Using dynamic time warping to find patterns in time series”, KDD workshop, vol. 10, no. 16, pp. 359-370, 1994.
- [48] J. Kim, P. Eades, R. Fleischer, S. H. Hong, C. S. Iliopoulos, k. Park, T. Tokuyama, ”Order-preserving matching”, Theoretical Computer Science, vol. 525, pp. 68-79, 2014.
- [49] P. Gawrychowski, P. Uznański. ”Order-preserving pattern matching with k mismatches”, Theoretical Computer Science, vol. 638, pp. 136-144, 2016.
- [50] Y. Wu, J. Fan, Y. Li, L. Guo, X. Wu, ”NetDAP: (delta, gamma)-Approximate pattern matching with length constraints”, Applied Intelligence, vol. 50, no. 11, pp. 4094-4116, 2020.