Anonymous Learning via Look-Alike Clustering: A Precise Analysis of Model Generalization
Abstract
While personalized recommendations systems have become increasingly popular, ensuring user data protection remains a top concern in the development of these learning systems. A common approach to enhancing privacy involves training models using anonymous data rather than individual data. In this paper, we explore a natural technique called look-alike clustering, which involves replacing sensitive features of individuals with the cluster’s average values. We provide a precise analysis of how training models using anonymous cluster centers affects their generalization capabilities. We focus on an asymptotic regime where the size of the training set grows in proportion to the features dimension. Our analysis is based on the Convex Gaussian Minimax Theorem (CGMT) and allows us to theoretically understand the role of different model components on the generalization error. In addition, we demonstrate that in certain high-dimensional regimes, training over anonymous cluster centers acts as a regularization and improves generalization error of the trained models. Finally, we corroborate our asymptotic theory with finite-sample numerical experiments where we observe a perfect match when the sample size is only of order of a few hundreds.
1 Introduction
Look-alike modeling in machine learning encompasses a range of techniques that focus on identifying users who possess similar characteristics, behaviors, or preferences to a specific target individual. This approach primarily relies on the principle that individuals with shared attributes are likely to exhibit comparable interests and behaviors. By analyzing the behavior of these look-alike users, look-alike modeling enables accurate predictions for the target user. This technique has been widely used in various domains, including targeted marketing and personalized recommendations, where it plays a crucial role in enhancing user experiences and driving tailored outcomes [SGD15, MWXC16, MWW+16, MRH+11].
In this paper, we use look-alike clustering for a different purpose, namely to anonymize sensitive information of users. Consider a supervised regression setup where the training set contains pairs , for , with denoting the response and representing a high-dimensional vector of features. We consider two groups of features: sensitive features, which contain some personal information about users and should be protected from the leaner, and the non-sensitive features. We assume that that the learner has access to a clustering structure on users, which is non-private information (e.g. based on non-sensitive features or other non-sensitive data set on users).
We propose a look-alike clustering approach, where we anonymize the individuals’ sensitive features by replacing them with the cluster’s average values. Only the anonymized dataset will be shared with the learner who then uses it to train a model. We refer to Figure 1 for an illustration of this approach. Note that the learner never gets access to the individuals’ sensitive features and so this approach is safe from re-identification attacks where the learner is given access to the pool of individuals’ sensitive information (up to permutation) and may use the non-sensitive features to re-identify the users. Also note that since a common representation (average sensitive features) is used for all the users in a cluster, this approach offers -anonymity provided that each cluster is of size at least (minimum size clustering) [weeney2002k].

Minimum size clustering has received an increased attention mainly as a tool for anonymization and when privacy considerations are in place [BKBL07, AFK+05, APF+10]. A particular application is for providing anonymity for user targeting in online advertising with the goal of replacing the use of third-party cookies with a more privacy-respecting entity [EMMZ22]. There are a variety of approximation algorithms for clustering with minimum size constraint [PS07, DHHL17, AKBCF16, SSR21], as well as parallel and dynamic implementation [EMMZ22].
In this paper, we focus on linear regression and derive a precise characterization of model generalization333the ability of the model to generalize to new, unseen data from the same distribution as the training data using the look-alike clustering approach, in the so-called proportional regime where the size of training set grows in proportion to the number of parameters (which for the linear regression is equal to the number of features). The proportional regime has attracted a significant attention as overparametrized models have become greatly prevalent. It allows to understand the effect under/overparametrization in feature-rich models, providing insights to several intriguing phenomena, including double-descent behavior in the generalization error [MM22, DKT22, HJ22].
Our precise asymptotic theory allows us to demystify the effect of different factors on the model generalization under look-alike clustering, such as the role of cluster size, number of clusters, signal-to-noise ratio of the model as well as the strength of sensitive and non-sensitive features. A key tool in our analysis is a powerful extension of Gordon’s Gaussian process inequality [Gor88] known as the Convex Gaussian Minimax Theorem (CGMT), which was developed in [TOH15] and has been used for studying different learning problems; see e.g, [TAH18, DKT22, JS22, HJ22, JSH20].
Initially, it might be presumed that look-alike clustering would hinder model generalization by suppressing sensitive features of individuals, suggesting a possible tradeoff between anonymity (privacy) and model performance. However, our analysis uncovers scenarios in which look-alike clustering actually enhances model generalization! We will develop further insights on these results by arguing that the proposed look-alike clustering can serve as a form of regularization, mitigating model overfitting and consequently improving the model generalization.
Before summarizing our key contributions in this paper, we conclude this section by discussing some of the recent work on the tradeoff between privacy and model generalization at large. An approach to study such potential tradeoff is via the lens of memorization. Modern deep neural networks, with remarkable generalization property, operate in the overparametrized regime where there are more tunable parameters than the number of training samples. Such overparametrized models tend to interpolate the training data and are known to fit well even random labels [ZBH+21, ZBH+20]. Similar phenomenon has been observed in other models, such as random forest [BFLS98], Adaboost [Sch13, WOBM17], and kernel methods [BMM18, LR20]. Beyond label memorization, [BBF+21] studies setting where learning algorithms with near-optimal generalization must encode most of the information about the entire high-dimensional (and high-entropy) covariates of the training examples. Clearly, memorization of training data imposes significant privacy risks when this data contains sensitive personal information, and therefore these results hint to a potential trade-off between privacy protection and model generalization [SS19, FZ20, MBG21]. Lastly, [Fel20] studies settings where data is sampled from a mixture of subpopulations, and shows that label memorization is necessary for achieving near-optimal generalization error, whenever the distribution of subpopulation frequencies is long-tailed. Intuitively, this corresponds to datasets with many small distinct subpopulations. In order to predict more accurately on a subpopulation from which only a very few examples are observed, the learning algorithm needs to memorize the labels of those examples.
1.1 Summary of contributions
We consider a linear regression setting for response variable given feature , and posit a Gaussian Mixture Model on the features to model the clustering structure on the samples.
We focus on the high-dimensional asymptotic regime where the number of training samples , the dimension of sensitive features (), and the dimension of non-sensitive features () grow in proportion ( and , for some constants ). Asymptotic analysis in this particular regime, characterized by a fixed sample size to feature size ratio, has recently garnered significant attention due to its relevance to the regime where modern neural networks operate. This analysis allows for the study of various intriguing phenomena related to both statistical properties (such as double-descent) and the tractability of optimizing the learning process in such networks [MM22, DKT22, HJ22], where the population analysis fails to capture. Let denote the (unanonymized) training set and be the set obtained after replacing the sensitive features with the look-alike representations of clusters. We denote by and the min-norm estimators fit to and , respectively. Under this asymptotic setting:
-
•
We provide a precise characterization of the generalization error of and . Despite the randomness in data generating model, we show that in the high-dimensional asymptotic, the generalization errors of these estimators converge in probability to deterministic limits for which we provide explicit expressions.
-
•
Our characterizations reveal several interesting facts about the generalization of the estimators:
-
For the min-norm estimator we observe significantly different behavior in the underparametrized regime than in the overparametrized regime . Note that in the underparametrized regime, the min-norm estimator coincides with the standard least squares estimator. For the look-alike estimator our analysis identifies the underparametrized regime as and the overparametrized regime as .
-
In the underparametrized regime, our analysis shows that, somewhat surprisingly, the generalization error (for both estimators) does not depend on the number or size of the clusters, nor the scaling of the cluster centers.
-
In the overparametrized regime, our analysis provides a precise understanding of the role of different factors, including the number of clusters, energy of cluster centers, and the alignment of the model with the constellation of cluster centers, on the generalization error.
-
-
•
Using our characterizations, we discuss settings where the look-alike estimator has better generalization than its non-private counterpart . A relevant quantity that shows up in our analysis is the ratio of the norm of the model component on the sensitive features over the noise in the response, which we refer to as signal-to-noise ratio (SNR). Using our theory, we show that if SNR is below a certain threshold, then look-alike estimator has lower generalization error than . This demonstrates scenarios where anonymizing sensitive features via look-alike clustering does ‘not’ hinder model generalization. We give an interpretation for this result, after Theorem 5.1, by arguing that at low-SNR, look-alike clustering acts as a regularization and mitigates overfitting, which consequently improves model generalization.
-
•
In our analysis in the previous parts, we assume that the learner has access to the exact underlying clustering structure on the users, to disentangle the clustering estimation error from look-alike modeling. However, in practice the learner needs to estimate the clustering structure from data. In Section 3.5, we combine our analysis with a perturbation analysis to extend our results to the case of imperfect clustering estimation.
Lastly, we refer to Section 7 for an overview of our proof techniques.
2 Model
We consider a linear regression setting, where we are given i.i.d pairs , where the response is given by
| (2.1) |
We assume that there is a clustering structure on features , , independent from the responses. We model this structure via Gaussian-Mixture model.
Gaussian-Mixture Model (GMM) on features. Each example belong to cluster , with probability . We let with and . The cluster conditional distribution of an example in cluster follows an isotropic Gaussian with mean , namely
| (2.2) |
By scaling the model (2.1), without loss of generality we assume . Writing in the matrix form, we let
| (2.3) |
It is also convenient to encode the cluster membership as one-hot encoded vectors , where is one at entry (with being the cluster of example ) and zero everywhere else. The GMM can then be written as
| (2.4) |
with is a Gaussian matrix with i.i.d entries, and is the matrix obtained by stacking vectors as its column.
Sensitive and non-sensitive features. We assume that some of the features are sensitive for which we have some reservation to share with the learner and some non-sensitive features. Without loss of generality, we write it as , where representing the sensitive features and representing the non-sensitive features. We also decompose the model (2.1) as with and . Likewise, the cluster mean vector is decomposed as . The idea of look-alike clustering is to replace the sensitive features of an example with the center of its cluster . This way, if each cluster is of size at least , then look-alike clustering offers -anonymity.
Our goal in this paper is to precisely characterize the effect of look-alike clustering on model generalization. We focus on the high-dimensional asymptotic regime, where the number of training data , and features sizes grow in proportion.
We formalize the high-dimensional asymptotic setting in the assumption below:
Assumption 1.
We assume that the number of clusters is fixed and focus on the asymptotic regime where at a fixed ratio and .
To study the generalization of a model (performance on unseen data) via the out-of-sample prediction risk defined as , where is generated according to (2.1). Our next lemma characterizes the risk when the feature is drawn from GMM.
Lemma 2.1.
Under the linear response model (2.1) and a GMM for features , the out-of-sample prediction risk of a model is given by
The proof of Lemma 2.1 is deferred to the supplementary.
3 Main results
Consider the minimum norm (min-norm) least squares regression estimator of on defined by
| (3.1) |
where denotes the Moore-Penrose pseudoinverse of . This estimator can also be formulated as
We also define the “look-alike estimator” denoted by , where the sensitive features are first anonymized via look-like modeling, and then the min-norm estimator is computed based on the resulting features. Specifically the sensitive feature of each sample is replaced by the center of its cluster. In our notation, writing , we define the features matrix obtained after look-alike modeling on the sensitive features. The look-alike estimator is then given by
| (3.2) |
Our main result is to provide a precise characterization of the risk of look-alike estimator as well as (non-look-alike) in the asymptotic regime, as described in Assumption 1. We then discuss regimes where look-alike clustering offers better generalization.
As our analysis shows there are two majorly different setting in the behavior of the look-alike estimator:
-
. In words, the sample size is asymptotically larger than , the number of non-sensitive features. This regime is called underparametrized asymptotics.
-
, which is referred to as overparametrized asymptotics.
Our first theorem is on the risk of look-alike estimator in the underparametrized setting. To present our result, we consider the following singular value decomposition for , the matrix of cluster centers restricted to sensitive features:
where .
Theorem 3.1.
(Look-alike estimator, underparametrized regime) Consider the linear response model (2.1), where the features are coming from the GMM (2.4). Also assume that and , for all . Under Assumption 1 with , the out-of-sample prediction risk of look-alike estimator , defined by (3.2), converges in probability,
There are several intriguing observations about this result. In the underparametrized regime:
-
1.
The risk depends on (model component on the sensitive features), only through the norms and . Note that measures the alignment of the model with the left singular vectors of the cluster centers.
-
2.
The cluster structure on the non-sensitive features plays no role in the risk, nor does the model component corresponding to the non-sensitive features.
-
3.
The cluster prior probabilities does not impact the risk.
Remark 3.1.
Specializing the result of Theorem 3.1 to the case of (no cluster structure on the sensitive feature), we obtain that the risk of converges in probability to
in the underparametrized regime . Note that in this case, the look-alike modeling zeros the sensitive features and only regresses the response on the non-sensitive features. Therefore, is a misspecified model (using the terminology of [HMRT22]). It is worth noting that in this case, we recover the result of [HMRT22](Theorem 4) in the underparametrized regime.
We next proceed to the overparametrized setting. For technical convenience, we make some simplifying assumption, however, we believe a similar derivation can be obtained for the general case, albeit with a more involved analysis.
Assumption 2.
Suppose that there is no cluster structure on the non-sensitive features (). Also, assume orthogonal, equal energy centers for the clusters on the sensitive features ( with ).
Our next theorem characterizes the risk of look-alike estimator in the underparametrized regime.
Theorem 3.2.
(Look-alike estimator, overparametrized regime) Consider the linear response model (2.1), where the features are coming from the GMM (2.4). Also assume that , and , for all . Under Assumption 1 with , and Assumption 2, the out-of-sample prediction risk of look-alike estimator , defined by (3.2), converges in probability,
| (3.3) |
where encodes the cluster priors and and are given by the following relations:
Remark 3.2.
When there is no cluster structure on the features (), the look-alike modeling zeros the sensitive features and only regress the response on the non-sensitive features. Therefore, is a misspecified model (using the terminology of [HMRT22]). In this case, the risk of converges to
in the overparametrized regime . This complements the characterization of misspecified model provided in Remark 3.1, and recovers the result of [HMRT22](Theorem 4) in the overparametrized regime.
As discussed in the introduction, one of the focal interest in this work is to understand cases where look-alike modeling improves generalization. In Section 5 we discuss this by comparing the look-alike estimator with the min-norm estimator , given by (3.1) which utilizes the full information on the sensitive features. In order to do that, we next derive a precise characterization of the risk of in the asymptotic setting.
Theorem 3.3.
(min-norm estimator with no look-alike clustering) Consider the linear response model (2.1), where the features are coming from the GMM (2.4). Under Assumption 1, the followings hold for the min-norm estimator given by (3.1):
-
(a)
(underparametrized setting) If , we have
-
(b)
(overparametrized setting) If , under Assumption 2, the prediction risk of converges in probability
(3.4) where and are given by the following relations:
Remark 3.3.
In the special case that there is no cluster structure on the features (), Theorem 3.3 characterizes the risk of min-norm estimator under Gaussian designs, which is analyzed in [HMRT22](Theorem 1) under a more general setting (when the features have i.i.d entries with zero mean, unit variance and finite moment for some ).
Example 3.4.
3.5 Extension to imperfect clustering estimation
In our previous results, we assumed that the underlying cluster memberships of users are known to the learner, so we could concentrate our analysis on the impact of training using anonymous cluster centers. However, in practice, clusters should be estimated from the features and thus includes an estimation error. In our next result, we combine our previous result with a perturbation analysis to bound the risk of the look-alike estimator based on estimated clusters.
Recall matrix from (2.3), whose columns are the cluster centers. Also, recall the matrix whose columns are the one-hot encoding of the cluster memberships. We let and indicate the estimated matrices, with the cluster estimation error rate , where indicates spectral norm. Note that only the cluster estimation error with respect to the sensitive features matters because in the look-alike modeling only those features are anononymized (replaced by the cluster centers).
Proposition 3.4.
Let be the feature matrix after replacing the sensitive features with the estimated cluster centers of users. We also let be the look-alike estimator based on . Note that is the counterpart of given by (3.2). Define the cluster estimation error rate , and suppose that either of the following conditions hold:
-
•
() and .
-
•
() and .
Then,
for some constant depending on the problem parameters.
We refer to the supplementary for the proof of Proposition 3.4 and for the explicit constant .
4 Numerical experiments






In this section, we validate our theory with numerical experiments. We consider GMM with clusters, where the centers of clusters are given by , for , where are of unit -norm. Also the vectors are non-zero only on the first entries, and their restriction to these entries form a random orthogonal constellation. Therefore, defining , we have , with . In this setting there is no cluster structure on the non-sensitive features and the cluster centers on the sensitive features are orthogonal and of same norm.
Recall the decomposition of the model , with the true underlying model (2.1) and , the components corresponding to sensitive and non-sensitive features. We generate to have i.i.d standard normal entries and then normalize it to have . For , we generate , independently and let
where is the projection onto column space of . Therefore, and . Note that quantifies the alignment of the model with the cluster centers, confined to the sensitive features.)
We will vary the values of and in our experiments. We also consider the case of balanced clusters, so the cluster prior probabilities are all equal, , for .
We set the number of cluster , dimension of sensitive features and the dimension of entire features vector . We also set and .
In our experiments, we vary the sample size and plot the risk of and versus . We consider different settings, where we vary , and (noise variance in model (2.1)).
In Figure 2, we report the results. Curves correspond to our asymptotic theory and does to the numerical simulations. (Each dot is obtained by averaging over 20 realizations of that configuration.) As we observe, in all scenarios our theoretical predictions are a perfect match to the empirical performance.
5 When does look-alike clustering improve generalization?
In Section 3, we provided a precise characterization of the risk of look-alike estimator and its counterpart, the min-norm estimator which utilizes the full information on the sensitive features. By virtue of these characterizations, we would like to understand regimes where the look-alike clustering helps with the model generalization, and the role of different problem parameters in achieving this improvement. Notably, since the look-alike estimator offers -anonymity on the sensitive features (with the minimum size of clusters), our discussion here points out instances where data anonymization and model generalization are not in-conflict.
We define the gain of look-alike estimator as follows:
which indicates the gain obtained in generalization via look-alike clustering.
For ease in presentation, we focus on the case of balanced clusters (equal priors ), and consider three cases:
Case 1 (): In this case, both and are in the underparametrized regime and Theorems 3.1 and 3.3 (a) provide simple closed-form characterization of the risks of and , by which we obtain
Define the signal-to-noise ratio . Since , it is easy to see that is decreasing in the SNR. In particular, as SNR, we have , which means the look-alike estimator achieves lower risk compared to . In Figure 3(a) we plot versus SNR, for several values of . Here we set and . As we observe in low SNR, the look-alike estimator has lower risk. Specifically, for each curve there is a threshold for the SNR, below which . Furthermore, this threshold increases with , covering a larger range of SNR where has better generalization.


In Figure 3(b) we report similar curves, where this time and we consider several values of . As we observe, at fixed SNR the gain is increasing in . This is expected since measures the alignment of the underlying model with the (left eigenvectors of) cluster centers and so higher is to advantage of the look-alike estimator which uses the cluster centers instead of individuals’ sensitive features.
Case 2 (): In this case, the look-alike estimator is in the underparametrized regime, while the min-norm is in the overparametrized regime. The following theorem uses the characterizations in Theorem 3.1 and and 3.3 (b), and shows that in the low SNR, the look-alike estimator has a positive gain. It further shows the monotonicity of the gain with respect to different problem parameters.
Theorem 5.1.
Suppose that and , and consider the case of equal cluster priors. The gain is increasing in and , and is decreasing in . Furthermore, under the following condition
| (5.1) |
we have , for all values of other parameters ().
We refer to the appendix for the proof of Theorem 5.1.
An interpretation based on regularization: We next provide an argument to build further insight on the result of Theorem 5.1. Recall the data model (2.1), where substituting from (2.2) and decomposing over sensitive and non-sensitive features we arrive at
Note that . At low SNR, this term is of order of the noise term . Recall that the look-alike clustering approach replaces the sensitive feature by the cluster center , and therefore drops the term from the model during the training process. In other words, look-alike clustering acts as a form of regularization which prevents overfitting to the noisy component , and this will help with the model generalization, together with anonymizing the sensitive features.
In Figure 4(a) we plot versus for several values of . Here, , , , and so condition (5.1) holds. As we observe is positive, decreasing in and also at any fixed , it is increasing in , all of which are consistent with the Theorem 5.1. In Figure 4(b), we plot similar curves where this time and we try several values of . As we see the look-alike estimator has larger gain at larger values of .
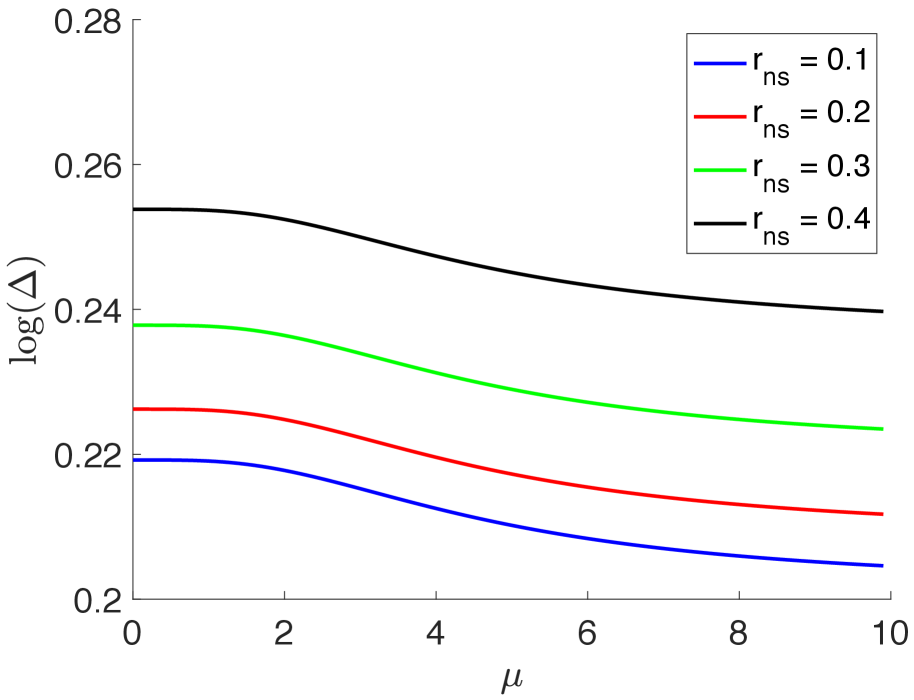



Case 3 (): In this case, both and are in the overparametrized regime. We use Theorems 3.1 and 3.3 (b) to obtain an analytical expression for the gain . Although the form is more complicated in this case, it gives non-trivial insights on the role of different parameters on the gain.
Let us first focus on , the energy of the model on the non-sensitive features. Invoking the equations (3.3) and (3.4) and hiding the terms that do not depend on in constants , we arrive at
Therefore, , indicating a gain for the look-alike estimator over . In Figure 5(a), we plot versus for several values of . As we observe, when is large enough we always have a gain, which is increasing in .
We next consider the effect of SNR = . In Figure 5(b) we plot versus SNR, for several values of . Similar to the underparametrized regime, we observe that in low SNR, the look-alike estimator has better generalization .
6 Beyond linear models
In previous section, we used our theory for linear models to show that at low SNR, look-alike modeling improves model generalization. We also provided an insight for this phenomenon by arguing that look-alike modeling acts as a form of regularization and avoids over-fitting at low SNR regime. In this section we show empirically that this phenomenon also extends to non-linear models.
Consider the following data generative model:
where . We construct the model similar to the setup in Section 4. We set , , , , , , and (number of trials in Binomial distribution).
We vary SNR by changing in the set . The estimators and are obtained by fitting a GLM with logit link function and binomial distribution. We compute the risks of and by averaging over a test set of size . In Figure 6, we plot the gain versus where each data point is by averaging over different realizations of data. As we observe at low SNR, indicating that the look-alike estimator obtains a lower risk than the min-norm estimator.

7 Overview of proof techniques
Our analysis of the generalization error is based on an extension of Gordon’s Gaussian process inequality [Gor88], called Convex-Gaussian Minimax Theorem (CGMT) [TOH15]. Here, we outline the general steps of this framework and refer to the supplementary for complete details and derivations.
Consider the following two Gaussian processes:
where , and , all have i.i.d standard normal entries. Further, is a continuous function, which is convex in the first argument and concave in the second argument.
Given the above two processes, consider the following min-max optimization problems, which are respectively referred to as the Primary Optimization (PO) and the Auxiliary Optimization (AO) problems:
| (7.1) | |||||
| (7.2) |
The main result of CGMT is to connect the above two random optimization problems. As shown in [TOH15](Theorem 3), if and are compact and convex then, for any and ,
An immediate corollary of this result (by choosing ]) is that if the optimal cost of the AO problem concentrates in probability, then the optimal cost of the corresponding PO problem also concentrates, in probability, around the same value. In addition, as shown in part (iii) of [TOH15](Theorem 3), concentration of the optimal solution of the AO problem implies concentration of the optimal solution of the PO around the same value. Therefore, the two optimization are intimately connected and by analyzing the AO problem, which is substantially simpler, one can derive corresponding properties of the PO problem.
The CGMT framework has been used to infer statistical properties of estimators in certain high-dimensional asymptotic regime. The intermediate steps in the CGMT framework can be summarized as follows: First form an PO problem in the form of (7.1) and construct the corresponding AO problem. Second, derive the point-wise limit of the AO objective in terms of a convex-concave optimization problem, over only few scalar variables. This step is called ‘scalarization’. Next, it is possible to establish uniform convergence of the scalarized AO to the (deterministic) min-max optimization problem using convexity conditions. Finally, by analyzing the latter deterministic problem, one can derive the desired asymptotic characterizations.
Acknowledgement
We would like to thank Sugato Basu, Kedar Dhamdhere, Alessandro Epasto, Rezsa Farahani, Asif Islam, Omkar Muralidharan, Dustin Zelle and Peilin Zhong for helpful discussion about this work. We also thank the anonymous reviewers of NeurIPS for their thoughtful comments. This work is supported in part by the NSF CAREER Award DMS-1844481 and the NSF Award DMS-2311024.
References
- [AFK+05] Gagan Aggarwal, Tomas Feder, Krishnaram Kenthapadi, Rajeev Motwani, Rina Panigrahy, Dilys Thomas, and An Zhu, Approximation algorithms for k-anonymity, Journal of Privacy Technology 2005112001 (2005), 400.
- [AKBCF16] Faisal Abu-Khzam, Cristina Bazgan, Katrin Casel, and Henning Fernau, Building clusters with lower-bounded sizes, 27th International Symposium on Algorithms and Computation (ISAAC 2016), Schloss Dagstuhl-Leibniz-Zentrum fuer Informatik, 2016.
- [APF+10] Gagan Aggarwal, Rina Panigrahy, Tomás Feder, Dilys Thomas, Krishnaram Kenthapadi, Samir Khuller, and An Zhu, Achieving anonymity via clustering, ACM Transactions on Algorithms (TALG) 6 (2010), no. 3, 1–19.
- [BBF+21] Gavin Brown, Mark Bun, Vitaly Feldman, Adam Smith, and Kunal Talwar, When is memorization of irrelevant training data necessary for high-accuracy learning?, Proceedings of the 53rd Annual ACM SIGACT Symposium on Theory of Computing, 2021, pp. 123–132.
- [BFLS98] Peter Bartlett, Yoav Freund, Wee Sun Lee, and Robert E Schapire, Boosting the margin: A new explanation for the effectiveness of voting methods, The annals of statistics 26 (1998), no. 5, 1651–1686.
- [BKBL07] Ji-Won Byun, Ashish Kamra, Elisa Bertino, and Ninghui Li, Efficient k-anonymization using clustering techniques, Advances in Databases: Concepts, Systems and Applications: 12th International Conference on Database Systems for Advanced Applications, DASFAA 2007, Bangkok, Thailand, April 9-12, 2007. Proceedings 12, Springer, 2007, pp. 188–200.
- [BMM18] Mikhail Belkin, Siyuan Ma, and Soumik Mandal, To understand deep learning we need to understand kernel learning, International Conference on Machine Learning, PMLR, 2018, pp. 541–549.
- [DHHL17] Hu Ding, Lunjia Hu, Lingxiao Huang, and Jian Li, Capacitated center problems with two-sided bounds and outliers, Algorithms and Data Structures: 15th International Symposium, WADS 2017, St. John’s, NL, Canada, July 31–August 2, 2017, Proceedings 15, Springer, 2017, pp. 325–336.
- [DKT22] Zeyu Deng, Abla Kammoun, and Christos Thrampoulidis, A model of double descent for high-dimensional binary linear classification, Information and Inference: A Journal of the IMA 11 (2022), no. 2, 435–495.
- [EMMZ22] Alessandro Epasto, Mohammad Mahdian, Vahab Mirrokni, and Peilin Zhong, Massively parallel and dynamic algorithms for minimum size clustering, Proceedings of the 2022 Annual ACM-SIAM Symposium on Discrete Algorithms (SODA), SIAM, 2022, pp. 1613–1660.
- [Fel20] Vitaly Feldman, Does learning require memorization? a short tale about a long tail, Proceedings of the 52nd Annual ACM SIGACT Symposium on Theory of Computing, 2020, pp. 954–959.
- [FZ20] Vitaly Feldman and Chiyuan Zhang, What neural networks memorize and why: Discovering the long tail via influence estimation, Advances in Neural Information Processing Systems 33 (2020), 2881–2891.
- [Gor88] Yehoram Gordon, On milman’s inequality and random subspaces which escape through a mesh in , Geometric aspects of functional analysis, Springer, 1988, pp. 84–106.
- [HJ22] Hamed Hassani and Adel Javanmard, The curse of overparametrization in adversarial training: Precise analysis of robust generalization for random features regression, arXiv preprint arXiv:2201.05149 (2022).
- [HMRT22] Trevor Hastie, Andrea Montanari, Saharon Rosset, and Ryan J Tibshirani, Surprises in high-dimensional ridgeless least squares interpolation, The Annals of Statistics 50 (2022), no. 2, 949–986.
- [JS22] Adel Javanmard and Mahdi Soltanolkotabi, Precise statistical analysis of classification accuracies for adversarial training, The Annals of Statistics 50 (2022), no. 4, 2127–2156.
- [JSH20] Adel Javanmard, Mahdi Soltanolkotabi, and Hamed Hassani, Precise tradeoffs in adversarial training for linear regression, Conference on Learning Theory, PMLR, 2020, pp. 2034–2078.
- [LR20] Tengyuan Liang and Alexander Rakhlin, Just interpolate: Kernel “ridgeless” regression can generalize, The Annals of Statistics 48 (2020), no. 3, 1329–1347.
- [MBG21] Mohammad Malekzadeh, Anastasia Borovykh, and Deniz Gündüz, Honest-but-curious nets: Sensitive attributes of private inputs can be secretly coded into the classifiers’ outputs, Proceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security, 2021, pp. 825–844.
- [MM22] Song Mei and Andrea Montanari, The generalization error of random features regression: Precise asymptotics and the double descent curve, Communications on Pure and Applied Mathematics 75 (2022), no. 4, 667–766.
- [MRH+11] Ashish Mangalampalli, Adwait Ratnaparkhi, Andrew O Hatch, Abraham Bagherjeiran, Rajesh Parekh, and Vikram Pudi, A feature-pair-based associative classification approach to look-alike modeling for conversion-oriented user-targeting in tail campaigns, Proceedings of the 20th international conference companion on World wide web, 2011, pp. 85–86.
- [MWW+16] Qiang Ma, Eeshan Wagh, Jiayi Wen, Zhen Xia, Robert Ormandi, and Datong Chen, Score look-alike audiences, 2016 IEEE 16th International Conference on Data Mining Workshops (ICDMW), IEEE, 2016, pp. 647–654.
- [MWXC16] Qiang Ma, Musen Wen, Zhen Xia, and Datong Chen, A sub-linear, massive-scale look-alike audience extension system a massive-scale look-alike audience extension, Workshop on Big Data, Streams and Heterogeneous Source Mining: Algorithms, Systems, Programming Models and Applications, PMLR, 2016, pp. 51–67.
- [PS07] Hyoungmin Park and Kyuseok Shim, Approximate algorithms for k-anonymity, Proceedings of the 2007 ACM SIGMOD international conference on Management of data, 2007, pp. 67–78.
- [Sch13] Robert E Schapire, Explaining adaboost, Empirical inference, Springer, 2013, pp. 37–52.
- [SGD15] Jianqiang Shen, Sahin Cem Geyik, and Ali Dasdan, Effective audience extension in online advertising, Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2015, pp. 2099–2108.
- [SS19] Congzheng Song and Vitaly Shmatikov, Overlearning reveals sensitive attributes, arXiv preprint arXiv:1905.11742 (2019).
- [SSR21] Anik Sarker, Wing-Kin Sung, and M Sohel Rahman, A linear time algorithm for the r-gathering problem on the line, Theoretical Computer Science 866 (2021), 96–106.
- [Ste77] Gilbert W Stewart, On the perturbation of pseudo-inverses, projections and linear least squares problems, SIAM review 19 (1977), no. 4, 634–662.
- [TAH18] Christos Thrampoulidis, Ehsan Abbasi, and Babak Hassibi, Precise error analysis of regularized -estimators in high dimensions, IEEE Transactions on Information Theory 64 (2018), no. 8, 5592–5628.
- [TOH15] Christos Thrampoulidis, Samet Oymak, and Babak Hassibi, Regularized linear regression: A precise analysis of the estimation error, Conference on Learning Theory, 2015, pp. 1683–1709.
- [Tu20] Stephen Tu, On the smallest singular value of non-centered gaussian designs, 2020.
- [WOBM17] Abraham J Wyner, Matthew Olson, Justin Bleich, and David Mease, Explaining the success of adaboost and random forests as interpolating classifiers, The Journal of Machine Learning Research 18 (2017), no. 1, 1558–1590.
- [ZBH+20] Chiyuan Zhang, Samy Bengio, Moritz Hardt, Michael C. Mozer, and Yoram Singer, Identity crisis: Memorization and generalization under extreme overparameterization, International Conference on Learning Representations, 2020.
- [ZBH+21] Chiyuan Zhang, Samy Bengio, Moritz Hardt, Benjamin Recht, and Oriol Vinyals, Understanding deep learning (still) requires rethinking generalization, Communications of the ACM 64 (2021), no. 3, 107–115.
Appendix A Proof of theorems and technical lemmas
A.1 Proof of Lemma 2.1
A.2 Proof of Theorem 3.1 and Theorem 3.2
Recall that the look-alike estimator is defined as the min-norm estimator over the feature matrix , where the look-alike representations are used instead of individual sensitive features; see (3.2).
To analyze risk of , we consider the ridge regression estimator given by
The minimum-norm estimator is given by .
We follow the CGMT framework explained in Section 7. Recall that
and therefore by substituting for , , and , we get
We define the primary optimization loss as follows:
We continue by deriving the auxiliary optimization (AO) problem. By duality, we have
Note that the above is jointly convex in and concave in , and the Gaussian matrix is independent of everything else. Therefore, the AO problem reads:
where and , are independent Gaussian random vectors with i.i.d entries.
We next fix norm of , and maximize over its direction to obtain
where we used that have independent Gaussian entries. Here, has i.i.d entries from . Next, note that the above optimization over has a closed form. Using the identity , with , we get
| (A.1) |
Scalarization of the auxiliary optimization (AO) problem. We next proceed to scalarize the AO problem. Consider the singular value decomposition
with , , , where . Decompose in its projections onto the space spanned by the columns of , and the orthogonal component:
where , , and . Using the shorthand , we write
In addition,
| (A.2) |
Similarly, we define and consider the singular value decomposition
with , , , where . Decomposing in its projections on the orthogonal columns of , and the orthogonal component we write
with , , and . Define . In this notation, we have
Also, . In addition,
Using the above identities in (A.1), we have
| (A.3) |
By the above characterization, minimization over and reduces to minimization over , , , and . Further, these variables are free from each other and can be optimized over separately. For , there is only one term involving this variable and therefore, minimization over it reduces to
For , we note that there are two terms involving this variable, namely and . Since , it is easy to see that the optimal should be in the span of and . In addition,
by the law of large numbers. In words, these two vectors are asymptotically orthogonal. Hence, we can consider the following decomposition of the optimal :
where and denotes the projection of onto the (left) null space of . This brings us to
| (A.4) |
Note that at this stage, the AO problem is reduced to an optimization over scalar variables (, and , ).
Convergence of the auxiliary optimization problem. We next continue to derive the point-wise in-probability limit of the AO problem.
First observe that since and are independent with i.i.d entries, we have
where has i.i.d entries.
Second, by construction , where denotes the number of examples from cluster . Hence,
Next, by using concentration of Lipschitz functions of Gaussian vectors, we obtain
Also, since is bounded and , we get
In addition, concentrates around and , because remains bounded as diverges, and so
Using the above limits, the objective in (A.4) converges in-probability to
| (A.5) |
We are now ready to prove the theorems.
A.2.1 Proof of Theorem 3.1
Using Lemma 2.1, we have
| (A.6) |
Since , we are in the over- determined (a.k.a underparametrized) regime. As , the terms involving become negligible compared to the first term in (A.5) except those that include , as is not present in the first term . Since is increasing, and
the minimum over and is achieved for and . The optimization (A.5) then reduces to
| (A.7) |
The optimal is given by . Also, setting derivative with respect to to zero we obtain the optimal . Next, by setting derivative with respect to we arrive at
Using the optimal variables in (A.6) we obtain the risk of minimum-norm estimator as
Recall that by assumption, and , which completes the proof.
A.2.2 Proof of Theorem 3.2
We continue from (A.5). In the case of , it is easy to see that the derivative of the first term of (A.5), in the active region is decreasing in . With the consideration , minimizing over will push us into the non-active region. Therefore the optimization problem (A.5) reduces to
| subject to | |||
| (A.8) |
By Assumption 2, , , and , (no cluster structure on non-sensitive features and an orthogonal, equal energy cluster centers on the sensitive features). Therefore, by fixing , the optimization problem (A.8) becomes:
| minimize | ||||
| subject to | ||||
| (A.9) | ||||
Since does not appear in the constraint, it is easy to see that its optimal value is given by . Also, note that by decreasing the objective value decreases and also by the constraint on the other variables become more relaxed. Consequently, the optimal value of is . Removing from the objective function, we are left with
| minimize | ||||
| subject to | (A.10) |
Optimal choice of results in the constraint to become equality. Solving for , the optimization reduces to
Setting derivative with respect to to zero, we obtain
| (A.11) |
Setting derivative with respect to to zero and using the previous stationary equation, we get
| (A.12) |
We next square both sides of (A.12) and rearrange the terms to get
which are the same expressions for and given in the theorem statement.
The final step is to write the risk of estimator in terms of , . Invoke equation (A.6), and recall that in the current case, , . Also, as we showed in our derivation, , , by which we arrive at
| (A.13) |
This concludes the proof.
A.3 Proof of Theorem 3.3
We follow the proof strategy used for Theorem 3.1-3.2. Here, we would like to characterize the risk of min-norm estimator . The features matrix has a clustering structure, but the learner is not using that (no look-alike clustering) and is just compute the min-norm estimator for fitting the responses to individual features. Therefore, one can think of this setting as a special case of our previous analysis when there is no sensitive features (so ).
-
By setting and in the result of Theorem 3.1, we get that when ,
-
In this case, we specialize the proof of Theorem 3.2 to the case that . Continuing from (A.8), and removing the terms corresponding to sensitive features, we arrive at
minimize subject to (A.14) We drop the index ‘ns’ as it is not relevant in this case. Also by Assumption 2, , . Therefore, the above optimization can be written as
minimize subject to (A.15) Optimal makes the constraint equality. Solving for , the above optimization can be written as so we have
Setting the derivative with respect to to zero, we get
(A.16) Setting derivative with respect to to zero and using the above equation, we obtain
(A.17) We next square both sides of equation (A.16), and rearrange the terms to get:
Under the simplifying Assumption 2, there is no cluster structure on the non-sensitive features and so . Therefore,
We next proceed to compute the risk of estimator in terms of , . We use equation (A.6), which for the min-norm estimator with no look-alike clustering, reduces to
(A.18) This concludes the proof. Note that in the theorem statement we made the change of variables and , for an easier comparison with the risk of look-alike estimator.)
A.4 Proof of Proposition 3.4
Consider singular value decompositions and . We then can write the estimators and as follows:
We first bound . We write
| (A.19) |
We have
Note that where . In addition,
Therefore by using concentration of Lipschitz functions of Gaussian vectors, we get
This shows that
| (A.20) |
We next use the result of [Ste77, Theorem 3.3], by which we obtain
| (A.21) |
Note that
| (A.22) |
by the assumption of the theorem statement. We next lower bound . Recall that , with having i.i.d entries.
Next suppose that Condition holds true, namely , with . Using the result of [Tu20, Theorem 2.1], we have with probability at least ,
Furthermore,
using the assumption on the estimation error rate . Therefore, using the above bound along with (A.22) in (A.21) we get
Combining the above bound with (A.20), we get
| (A.23) |
We next note that by triangle inequality, the above bound implies that
Therefore, by invoking Lemma 2.1, we obtain the desired result on .
Next suppose that Condition holds, namely with . Using the result of [Tu20, Theorem 2.1] for , we have with probability at least ,
By following a similar argument we prove the claim under Condition .
A.5 Proof of Theorem 5.1
We use Theorem 3.3 (b) to characterize in the regime of . Specializing to the case of balanced cluster priors, the risk depends on only through its norm , and is given by
with
In addition, by Theorem 3.1 we have
Note that in this regime does not depend on . Also, it is easy to verify that is decreasing in . Therefore the gain is decreasing in .
Also observe that is increasing in , while does not depend on . Therefore, the gain is increasing in .
To understand the dependence of on , we write
As we see the numerator is increasing in and denominator is decreasing in , which implies that the gain is increasing in .