∎
College of Science, National University of Defense Technology, Changsha, 410073, Hunan, China.
Anderson acceleration of derivative-free projection methods for constrained monotone nonlinear equations
Abstract
The derivative-free projection method (DFPM) is an efficient algorithm for solving monotone nonlinear equations. As problems grow larger, there is a strong demand for speeding up the convergence of DFPM. This paper considers the application of Anderson acceleration (AA) to DFPM for constrained monotone nonlinear equations. By employing a nonstationary relaxation parameter and interleaving with slight modifications in each iteration, a globally convergent variant of AA for DFPM named as AA-DFPM is proposed. Further, the linear convergence rate is proved under some mild assumptions. Experiments on both mathematical examples and a real-world application show encouraging results of AA-DFPM and confirm the suitability of AA for accelerating DFPM in solving optimization problems.
Keywords:
Anderson acceleration Derivative-free projection method Monotone nonlinear equations ConvergenceMSC:
65K05 90C56 68U101 Introduction
In this paper, we focus on solving the following monotone nonlinear equations with convex constraint:
| (1) |
where is a continuous and monotone mapping, and is a closed convex set. The monotonicity of the mapping means that
The systems of nonlinear equations have numerous applications, such as chemical equilibrium systems MM87 , split feasibility problems QX05 and neural networks CZ14 . Further, some concrete application models in real world are monotone. For instance, compressed sensing is firstly formulated for a convex quadratic programming, and then for an equivalent monotone nonlinear equations XWH11 . Regularized decentralized logistic regression also can be expressed as monotone nonlinear equations JYTH22 . As observation techniques advance, observed date size expands, and the requirement for resolution of results increases, the scale of nonlinear equations enlarges accordingly.
Various iterative methods for solving (1) include Newton method SWQ02 , trust-region algorithm QTL04 , Levenberg-Marquardt method YJM23 , etc. Although these methods perform well theoretically and numerically, they have difficulties in dealing with large-scale equations due to the computation of Jacobian matrix or its approximation. In contrast, on the basis of the hyperplane projection technique for monotone equations SS98 and the first-order optimization methods for unconstrained optimization, many derivative-free projection methods (DFPM) have sprung up [10-20] for convex-constrained monotone nonlinear equations, whose computational cost in each iteration is only to calculate function values.
The search direction and line search procedure are crucial for DFPM, and different constructions of theirs correspond to different variants of DFPM. Benefiting from the simple structure and low storage capacity of conjugate gradient methods (CGM), the conjugate gradient projection methods (CGPM) based on the design of search direction in CGM provide a class of competitive algorithms, for instance, CGPM LF19 ; LLXWT22 , spectral CGPM IKRPA22 ; WSLZ23 , three-term CGPM YJJLW21 ; WA22 ; MJJYH23 . Meanwhile, different determination of line search procedure may obtain different convergence properties. Some line search procedures have been proposed for DFPM in solving constrained monotone nonlinear equations (see YJJLW21 ; ZZ06 ; OL18 ; AK15 ; LL11 for instance). Although there have been many studies on the DFPM for solving problem (1), almost all of these existing studies focus on specific algorithms. Only a few papers have discussed unified studies on this class of methods partially (see OL23 ; GM23 ), which motivate us to center on a general framework of DFPM and its convergence analysis.
In order to construct more efficient numerical algorithms, a promising strategy that has recently emerged in a number of fields is to embed acceleration techniques in the underlying algorithms. Anderson acceleration (AA) was originally designed for integral equations Anderson65 and is now a very popular acceleration method for fixed-point schemes. AA can be viewed as an extension of the momentum methods, such as inertial acceleration Alvarez00 and Nesterov acceleration Nesterov83 . The idea differs from theirs in maintaining information of previous steps rather than just two last iterates, and update iteration as a linear combination of the information with dynamic weights. Some studies have explored the connection between AA and other classical methods, which also facilitates the understanding of AA. For linear problems, Walker and Ni WN11 showed that AA is related to the well-known generalized minimal residual algorithm (GMRES SS86 ). Potra and Engler PE13 demonstrated the equivalence between GMRES and AA with any mixing parameters under full-memory (i.e., in Algorithm 2). For nonlinear cases, AA is also closely related to the nonlinear GMRES WHS21 . Fang and Saad FS09 identified the relationship between AA and the multi-secant quasi-Newton methods.
Although AA often exhibits superior numerical performance in speeding up fixed-point computations with countless applications, such as reinforcement learning WCHZZQ23 , numerical methods for PDE SRX19 and seismic inversion Yang21 , it is known to only converge locally in theory TK15 ; MJ20 . The convergence analysis of most, if not all, existing methods requires additional assumptions. More recent result in Bian and Chen BC22 proved that AA for is q-linear convergent with a smaller q-factor than existing q-factors for the composite max fixed-point problem, where functions are Lipschitz continuously differentiable. Rebholz and Xiao RX23 investigated the effect of AA on superlinear and sublinear convergence of various fixed-point iteration, with the operator satisfying certain properties. Garner et al. GLZ23 proved that AA improves the root-linear convergence factor over fixed-point iteration when the operator is linear and symmetric or is nonlinear but has a symmetric Jacobian at the solution.
The efficient procedure of AA in solving wide applications further motivates us to investigate this technique to DFPM for solving problem (1). Our main goal in this paper is hence to provide a globally convergent AA of general DFPM without any further assumptions other than monotonicity. Clearly, the work is an extension of recent inertial DFPM in IKRPA22 ; WSLZ23 ; MJJYH23 due to utilizing more information than just last two iterates. The main contributions of this paper are outlined below:
An accelerated version of DFPM combined with AA (AA-DFPM) is proposed to solve convex-constrained monotone nonlinear equations. Fully exploiting the optimization problem structure, several modifications are considered to the acceleration algorithm. To the best of our knowledge, this is the first application of AA in DFPM.
A self-contained proof for the global convergence of AA-DFPM is given with no additional assumptions apart from monotonicity on the nonlinear mapping. We further discuss the convergence rate under some standard assumptions.
The numerical experiments on large-scale constrained nonlinear equations and decentralized logistic regression demonstrate that AA-DFPM outperforms the corresponding DFPM in terms of efficiency and robustness.
The paper is organized as follows. In Section 2, we start by outlining the unified algorithmic framework of DFPM and its convergence results. Based on DFPM with the convergence gained, in Section 3, we further introduce AA and extend the acceleration technique to DFPM. The convergence analysis of AA-DFPM is established under some mild assumptions in Section 4. We report the numerical results of AA-DFPM on large-scale constrained nonlinear equations and a machine learning problem in Section 5. The conclusion is given in Section 6.
Notation. Throughout the paper, we denote by be the Euclidean norm on and . For a closed convex set , denotes the distance from an iterate to and the projection operator . Furthermore, it has the nonexpensive property:
2 Derivative-free projection method
In this section, we review a comprehensive framework of DFPM and recollect its theoretical results. Throughout the paper, we assume that the solution set of problem (1) is nonempty.
2.1 General framework of DFPM
The core of DFPM is the hyperplane projection technique SS98 . It projects the current iterate onto a hyperplane constructed based on the monotonicity of the mapping, which separates the current iterate from the solution effectively. In general, for a given current iterate , a search direction is computed first, then a stepsize is calculated by a line search to satisfy
where . By the monotonicity of , we have
Thus the hyperplane
strictly separates the current iterate from any solution . Projecting first onto the separating hyperplane then onto the feasible set , . Separation arguments show that decreases monotonically with the increase of , which essentially ensures the global convergence of DFPM.
From the above process, the determination of and plays a crucial role in DFPM. Different choices of direction or stepsize lead to different variants of DFPM. Competitive DFPM includes conjugate gradient projection method LF19 , spectral conjugate gradient projection method IKRPA22 , three-term conjugate gradient projection method WA22 . We concentrate on a unified framework for DFPM in Algorithm 1.
| (2) |
| (3) |
| (4) |
| (5) |
Algorithm 1 is a special case of Algorithm UAF OL23 that adopts the line search scheme VI. We focus on this scenario since it is representative of DFPM. Several general characters of the framework are analyzed as follows.
Search direction . The conditions (2) and (3) for are to guarantee the global convergence. If is the gradient of a function , then (2) indicates that is a sufficient descent direction for at . Further, condition (2) implies that the line search procedure (4) is well-defined. Condition (3) means that the magnitude of should be proportional to the magnitude of . The way to obtain satisfying (2) and (3) depends on the particular instance of the framework. For example, the directions in IKRPA22 ; WSLZ23 ; WA22 ; MJJYH23 ; AK15 all satisfy these conditions. Three specific examples are presented in Section 5.
Line search procedure. Note that in right-hand of (4) can be replace by other procedures, for instance in OL18 . Here we only focus on this case since it is a adaptive line search procedure recently proposed by Yin et al. YJJLW21 and is widely used to compute a stepsize WSLZ23 ; MJJYH23 . More specifically, if , then , and thus it reduces to the procedure in ZZ06 ; If and is large enough, then , and thus it reduces to the procedure in LL11 . The projection technique in (4) prevents the right-hand side of (4) from being too small or too large, which effectively reduces the computational cost of Step 3.
2.2 Global convergence
We present two simple results to show the global convergence of Algorithm 1. Based on (2) and (3), the proofs are similar to those of the results in corresponding literature, so we omit them here.
Lemma 1
3 Anderson acceleration for DFPM
Having seen the convergence for the underlying algorithm, we proceed to show how Anderson acceleration (AA) may translate to improved the convergence behavior for DFPM.
3.1 Anderson acceleration
AA is an efficient acceleration method for fixed-point iteration . The key idea of AA is to form a new extrapolation point by using the past iterates. To generate a better estimation , it searches for a point that has smallest residual within the subspace spanned by the most recent iterates. Let and , AA seeks to find a vector of coefficients such that
However, it is hard to find for a general nonlinear mapping . AA uses
where
with to perform an approximation. While is computed, the next iterate of AA is then generated by the following mixing
A formal algorithmic description of AA with the window of length is given by Algorithm 2.
In each iteration in Algorithm 2, AA incorporates useful information from previous iterates by an affine combination, where the coefficient is computed as the solution of a least squares problem, rather than expending evaluation directly at current iterate. The window size indicates how many history iterates will be used in the algorithm and its value is typically no larger than 10 in practice. If , AA reduces to the fixed-point iteration. When is a constant independent of , Algorithm 2 is referred to as stationary AA. Many works (see WN11 ; TK15 ; MJ20 ; BC22 ) take to simplify the analysis. Here we consider a nonstationary case, and the expression of is given in (9).
3.2 Acceleration algorithm
Based on the convergence result in Section 2, we incorporate AA into DFPM and give the resulting algorithm, named AA-DFPM, in Algorithm 3. Note that DFPM may not a fixed-point iteration for due to the direction may involve other parameters. However, since AA is a sequence acceleration technique, we expect DFPM to gain a speedup as long as it is convergent.
| (6) |
Some implementation techniques in the algorithm bear further comment. We thus introduce and discuss the following four aspects.
Feasibility of accelerated iterate. As illustrated in Algorithm 2, AA computes the accelerated iterate via an affine combination of previous iterates, the accelerated point may violate the constraint unless its feasible set is affine. Considering that the feasible set in problem (1) is closed convex and the previous iterates be generated by Algorithm 1 are all in , we set , in Algorithm 3 (line 3 of Step 5) to obtain a reliable accelerated iterate. This means that the accelerated iterate here is computed by a convex combination of previous iterates.
Computation of coefficient . The residual matrix in the least squares problem of AA can be rank-deficient, then ill-conditioning may occur in computing . Here a Tikhonov regularizationSDB16 be added to the problem to obtain a reliable . In this case, combining with the above implementation, the least squares problem is a standard quadratic programming problem that can be solved by the MATLAB command “quadprog”.
Guarantee of convergence. As aforementioned, since AA is known to only converge locally, some globalization mechanisms are required to use it in practice, such as adaptive regularization OTMD23 , restart checking HV19 and safeguarding step OPYZD20 . Following ZOB20 , we introduce a safeguard checking (line 5 of Step 5 in Algorithm 3) to ensure the global convergence, thus
| (7) |
Calculation of . Define the following averages with the solution to the least square problem in Step 5 of Algorithm 3,
Then (6) becomes
| (8) |
The relaxation parameter is generally determined heuristically. Many discussions choose , thereby simplifying the expression to facilitate theoretical analysis. Little attention has been paid to nonstationary case . As Anderson wished in his comment Anderson19 , we design a dynamic factor
| (9) |
The adaptive idea is derived from the inertial-based algorithms MJJYH23 ; CMY14 . Then for all , we have , which implies that
| (10) |
4 Convergence analysis
We temporarily assume for simplicity that a solution of (1) is not found in finite steps. We first present the following lemma to help us complete the proof.
Lemma 2
Polyak1987 Let and be two sequences of nonnegative real numbers satisfying and . Then the sequence is convergent as .
We can now get the convergence results for AA-DFPM.
Lemma 3
Let sequence be generated by Algorithm 3. Then for any , (i) the sequence is convergent; (ii) .
Proof Depending on whether the sequence processes AA or not, we partition the proof into two cases accordingly.
Case I: The iteration does not pass the checking. (i.e. original iteration)
(i) It follows from the monotonicity of and (4) that
| (11) | ||||
By the nonexpensive property of , for any given we have
| (12) |
This shows that sequence is nonincreasing and convergent.
(ii) The above result implies is bounded. This, together with the continuity of and (3), shows that is bounded, further implies is bounded, as well as . Suppose , and sum (12) for , we have
where . This implies .
Case II: The iteration passes the checking. (i.e. acceleration iteration)
(i) From (8), we have
and
| (13) |
Similar to the proof of (12), we get
| (14) |
which means that . Hence
Using Lemma 2 with and as well as (7) and (10), the sequence is convergent.
(ii) The above result implies the boundedness of , further, as well as . Then there exists a constant such that , and
| (15) |
By employing (13), the definition of the checking (line 5 of Step 5 in Algorithm 3) and , we have
| (16) |
Therefore, we get
Adding above inequality for , in view of the boundedness of and (10), it follows that
where is a bound of . This implies . ∎
Based on Lemma 3, we prove the global convergence theorem for AA-DFPM.
Proof Assume that , then there exists a constant such that
| (17) |
Further, from (2) and Cauchy-Schwarz inequality, we have
This together with Lemma 3 (ii) implies
| (18) |
In view of the boundedness of and , there exist two subsequences and such that
Again, it follows from (2) that
Letting in the inequality above, and by the continuity of and (17), we get
| (19) |
Similarly, it follows from (4) that
Letting in the inequality above, taking into account (18) and the continuity of , we conclude that , which contradicts (19). Thus,
| (20) |
By the boundedness of and the continuity of as well as (20), the sequence has an accumulation point such that . By and the closeness of , we have , further . Combining with the convergence of (Lemma 3 (i)), one knows that the whole sequence converges to . ∎
By Theorem 4.1, we can assume that as . Under mild assumptions below, we further illustrate the linear convergence rate of AA-DFPM.
Assumption 4.1
The mapping is Lipschitz continuous on , i.e., there exists a positive constant such that,
| (21) |
The Lipschitz continuity assumption on helps us to provide a uniform lower bound of the stepsize . Based on (2), (3) and (21), the proof is similar to that of Lemma 3.4 in WSLZ23 , so we omit it here.
Assumption 4.2
For the limit of , suppose that there exist two positive constants and such that,
| (23) |
where the neighborhood .
The local error bound Assumption 4.2 is usually used to prove the convergence rate of DFPM in solving (1) (see LF19 ; WSLZ23 ; MJJYH23 ; OL18 for instance). Now we estimate the asymptotic rate of convergence of the iteration, for sufficiently large . The sequence in the proof of the following theorems refers to the acceleration iteration. The convergence rate of the original iteration is identical to Theorem 4.5 in OL23 .
Theorem 4.2
Proof Let be the closest solution to , i.e., . Recall (14) that
| (24) |
From (21), (3) and , it follows from that
| (25) |
where . Again, from (2), (22) and (23), we have
| (26) |
Combining with (24)-(26), we obtain
This, together with and , shows that
| (27) |
Hence
The proof is completed. ∎
Let . Theorem 4.2 further implies the asymptotic convergence rate of sequence .
Corollary 1
Suppose that Assumptions 4.1 and 4.2 hold, the sequence is generated by Algorithm 3. Then the three following claims hold.
(i) If , then ;
(ii) If , then ;
(iii) If , then the sequence converges Q-linearly to 0, i.e.,
This result is consistent with the convergence rate of the inertial-type DFPM WSLZ23 ; MJJYH23 . We further investigate the convergence rate of sequence if the mapping is strongly monotone with modulus , i.e.,
Theorem 4.3
proof By the Cauchy-Schwarz inequality and the strong monotonicity of , it has
Together with (2) and (22), we have
| (28) |
Similar to the proof of (25), it follows that
| (29) |
where . Combining (14) with (28) and (29) implies
Also similar to the proof of (27), we obtain
Thus
The proof is completed. ∎
Let . We can also get the asymptotic convergence rate of sequence from Theorem 4.3.
5 Numerical experiments and applications
In this section, we demonstrate the effectiveness of AA-DFPM through experiments on constrained nonlinear equations as well as a real-world problem of machine learning. All tests are conducted in MATLAB R2016b on a 64-bit Lenovo laptop with Intel(R) Core(TM) i7-6700HQ CPU (2.60 GHz), 16.00 GB RAM and Windows 10 OS. Throughout the numerical experiments, three search directions are chosen as follows:
1) Spectral conjugate gradient projection (SCGP) method WSLZ23
| (30) |
where
and , , , . From Lemma 3.1 in WSLZ23 , direction (30) satisfies conditions (2) and (3).
2) Hybrid three-term conjugate gradient projection (HTTCGP) method YJJLW21
| (31) |
where
with parameters and . From Lemma 2 in YJJLW21 , direction (31) satisfies conditions (2) and (3).
3) Modified spectral three-term conjugate gradient method AF23 (Considering that the direction was originally designed for a conjugate gradient method for solving unconstrained problems, here we have adapted it slightly to accommodate DFPM, named MSTTCGP.)
| (32) |
where
in which and . From Corollary 3.1 in AF23 , it follows that (32) satisfies condition (2). We prove that (32) satisfies condition (3). To proceed, by the definitions of parameters , and , we get
for and , and
for and . Thus .
All related parameters of SCGP, HTTCGP and MSTTCGP are the same as their originals. In addition, we set the line search and the projection parameters , , , , , for MSTTCGP. We use AA-SCGP, AA-HTTCGP and AA-MSTTCGP to denote their Anderson acceleration variant with the AA parameters , , and . During the implementation, the stopping criterion in all algorithms is as , or the number of iterations exceed 2,000.
5.1 Large-scale nonlinear equations
We first test these algorithms on the standard constrained nonlinear equations with different dimensions. To assess the effectiveness of these algorithms objectively, we conduct tests for each problem using initial points randomly generated from the interval . The numerical results, obtained from running each test 10 times with each algorithm, are presented in Table 1, where “ P(n)////” stand for test problems (problem dimensions), average number of iterations, average number of evaluations of , average CPU time in seconds, average final value of when the program is stopped, respectively. The following test Problems 1-4 are respectively selected as the same as Problems 1, 3, 5 and 7 in WSLZ23 . The convex constraints of these problems are and the mapping is defined as
Problem 1.
Problem 2.
Problem 3.
Problem 4.

| P(n) | MSTTCGP | AA-MSTTCGP | HTTCGP | AA-HTTCGP | SCGP | AA-SCGP |
| /// | /// | /// | /// | /// | /// | |
| 1(10000) | 38.4/113.8/0.051/5.27e-07 | 5.0/23.0/0.048/0.00e+00 | 11.0/29.1/0.015/3.17e-07 | 4.0/14.0/0.029/0.00e+00 | 14.0/29.0/0.020/6.56e-07 | 9.0/29.0/0.053/0.00e+00 |
| 1(30000) | 44.8/135.0/0.135/5.78e-07 | 9.1/32.9/0.077/0.00e+00 | 8.8/22.7/0.024/3.37e-07 | 7.0/22.0/0.056/0.00e+00 | 15.0/31.0/0.038/3.34e-07 | 9.0/29.0/0.076/0.00e+00 |
| 1(50000) | 43.6/131.2/0.216/6.38e-07 | 9.7/30.7/0.104/0.00e+00 | 11.8/31.0/0.051/4.13e-07 | 7.0/22.0/0.078/0.00e+00 | 15.0/31.0/0.068/4.31e-07 | 3.0/9.0/0.033/0.00e+00 |
| 1(80000) | 42.7/128.4/0.298/4.62e-07 | 12.2/39.3/0.195/0.00e+00 | 10.9/28.7/0.076/3.93e-07 | 7.0/21.0/0.114/1.99e-09 | 15.0/31.0/0.100/5.45e-07 | 3.0/9.0/0.040/0.00e+00 |
| 1(100000) | 40.6/125.4/0.358/5.48e-07 | 13.1/39.9/0.250/0.00e+00 | 11.8/31.3/0.094/2.44e-07 | 7.0/21.0/0.139/8.52e-10 | 15.0/31.0/0.123/6.08e-07 | 5.0/13.0/0.092/0.00e+00 |
| 1(120000) | 45.4/138.5/0.501/4.22e-07 | 13.1/39.4/0.275/0.00e+00 | 11.0/28.3/0.110/2.60e-07 | 7.0/21.0/0.159/3.46e-10 | 15.0/31.0/0.144/6.67e-07 | 5.0/13.0/0.111/0.00e+00 |
| 1(150000) | 47.3/142.4/0.750/6.23e-07 | 13.0/39.0/0.352/0.00e+00 | 11.6/30.7/0.178/3.79e-07 | 7.0/21.0/0.198/4.15e-14 | 15.0/31.0/0.247/7.47e-07 | 5.7/14.4/0.165/0.00e+00 |
| 1(180000) | 44.2/130.6/0.802/5.02e-07 | 12.4/37.2/0.398/0.00e+00 | 12.7/33.7/0.230/3.19e-07 | 7.0/21.0/0.243/2.76e-11 | 15.0/31.0/0.280/8.17e-07 | 12.0/27.0/0.452/0.00e+00 |
| 1(200000) | 46.0/137.9/0.924/4.91e-07 | 12.0/36.0/0.429/0.00e+00 | 11.2/29.2/0.223/3.85e-07 | 7.0/21.0/0.272/6.60e-15 | 15.0/31.0/0.327/8.61e-07 | 12.0/27.0/0.481/0.00e+00 |
| 1(250000) | 44.1/132.7/1.124/5.09e-07 | 12.0/36.0/0.514/0.00e+00 | 11.0/28.5/0.267/2.31e-07 | 7.0/21.0/0.324/2.58e-14 | 15.0/31.0/0.396/9.63e-07 | 12.0/27.0/0.581/0.00e+00 |
| 2(10000) | 25.3/81.8/0.024/3.10e-07 | 8.8/30.3/0.051/0.00e+00 | 10.9/29.7/0.009/5.77e-07 | 7.2/19.4/0.040/0.00e+00 | 14.0/29.0/0.012/3.22e-07 | 8.0/19.0/0.045/0.00e+00 |
| 2(30000) | 28.4/91.6/0.049/6.15e-07 | 9.2/31.4/0.064/0.00e+00 | 10.0/27.0/0.016/0.00e+00 | 7.3/18.6/0.047/2.98e-07 | 14.0/29.0/0.022/5.61e-07 | 7.0/17.0/0.050/0.00e+00 |
| 2(50000) | 24.4/82.0/0.067/3.42e-07 | 14.2/49.1/0.136/0.00e+00 | 10.0/27.0/0.024/0.00e+00 | 3.0/10.0/0.022/0.00e+00 | 14.0/29.0/0.032/7.23e-07 | 7.0/17.0/0.060/0.00e+00 |
| 2(80000) | 21.1/71.0/0.091/3.96e-07 | 11.6/46.5/0.157/0.00e+00 | 10.0/27.0/0.037/0.00e+00 | 3.0/10.0/0.028/0.00e+00 | 14.0/29.0/0.050/9.14e-07 | 7.0/17.0/0.085/0.00e+00 |
| 2(100000) | 29.3/99.5/0.162/2.19e-07 | 13.1/43.9/0.216/0.00e+00 | 10.0/27.0/0.049/0.00e+00 | 3.0/10.0/0.038/0.00e+000 | 15.0/31.0/0.069/3.09e-07 | 7.0/17.0/0.108/0.00e+00 |
| 2(120000) | 23.5/80.1/0.159/1.49e-07 | 9.6/37.4/0.183/0.00e+00 | 10.0/27.0/0.057/0.00e+00 | 3.0/10.0/0.043/0.00e+00 | 15.0/31.0/0.083/3.38e-07 | 7.0/17.0/0.119/0.00e+00 |
| 2(150000) | 27.2/87.5/0.339/2.94e-07 | 12.7/46.4/0.366/0.00e+00 | 10.0/27.0/0.118/0.00e+00 | 5.0/16.0/0.125/0.00e+00 | 15.0/31.0/0.184/3.79e-07 | 7.0/17.0/0.192/0.00e+00 |
| 2(180000) | 32.0/103.2/0.475/4.15e-07 | 11.5/40.9/0.380/0.00e+00 | 10.0/27.0/0.140/0.00e+00 | 5.0/16.0/0.147/0.00e+00 | 15.0/31.0/0.220/4.15e-07 | 7.0/17.0/0.222/0.00e+00 |
| 2(200000) | 32.2/105.2/0.530/4.73e-07 | 11.8/40.4/0.428/0.00e+00 | 10.0/27.0/0.153/0.00e+00 | 5.0/16.0/0.159/0.00e+00 | 15.0/31.0/0.241/4.37e-07 | 7.0/17.0/0.244/0.00e+00 |
| 2(250000) | 32.7/108.2/0.676/4.19e-07 | 14.2/48.3/0.631/2.44e-08 | 10.0/27.0/0.190/0.00e+00 | 5.0/16.0/0.194/0.00e+00 | 15.0/31.0/0.293/4.89e-07 | 7.0/17.0/0.293/0.00e+00 |
| 3(10000) | 17.4/69.0/0.030/6.67e-08 | 6.0/31.0/0.040/0.00e+00 | 12.0/40.7/0.018/1.78e-07 | 6.0/25.0/0.038/3.70e-14 | 20.0/61.0/0.030/7.03e-07 | 5.0/19.0/0.030/0.00e+00 |
| 3(30000) | 17.6/69.5/0.066/7.75e-08 | 6.0/30.0/0.057/0.00e+00 | 12.0/40.4/0.041/1.56e-07 | 5.0/21.0/0.044/9.24e-10 | 21.0/64.0/0.075/4.90e-07 | 8.0/28.0/0.075/0.00e+00 |
| 3(50000) | 17.8/70.8/0.109/2.09e-15 | 6.0/30.0/0.078/0.00e+00 | 12.0/40.5/0.058/1.63e-07 | 10.8/43.1/0.145/2.04e-08 | 21.0/64.0/0.111/6.30e-07 | 6.0/30.0/0.087/0.00e+00 |
| 3(80000) | 18.8/74.4/0.177/1.63e-07 | 6.0/30.0/0.106/0.00e+00 | 12.0/40.2/0.087/2.42e-07 | 10.2/41.8/0.192/3.18e-08 | 21.0/64.0/0.167/7.99e-07 | 6.0/30.0/0.122/0.00e+00 |
| 3(100000) | 12.2/49.5/0.141/8.46e-08 | 6.0/30.0/0.126/0.00e+00 | 12.0/40.4/0.112/2.69e-07 | 8.0/34.2/0.184/0.00e+00 | 21.0/64.0/0.200/8.91e-07 | 6.0/30.0/0.152/0.00e+00 |
| 3(120000) | 23.9/97.1/0.333/1.73e-07 | 6.0/30.0/0.153/0.00e+00 | 12.0/40.0/0.137/3.26e-07 | 7.5/32.2/0.193/0.00e+00 | 21.0/64.0/0.255/9.76e-07 | 6.0/30.0/0.175/0.00e+00 |
| 3(150000) | 16.1/64.8/0.344/8.86e-08 | 6.0/30.0/0.211/0.00e+00 | 12.0/40.3/0.210/3.02e-07 | 7.4/31.7/0.261/6.99e-09 | 22.0/67.6/0.421/5.59e-07 | 6.0/30.0/0.242/0.00e+00 |
| 3(180000) | 15.0/61.2/0.359/4.86e-08 | 6.0/30.0/0.245/0.00e+00 | 12.0/40.2/0.254/3.68e-07 | 7.5/31.7/0.303/0.00e+00 | 22.0/67.7/0.491/5.19e-07 | 7.0/33.0/0.334/0.00e+00 |
| 3(200000) | 17.4/70.2/0.464/9.00e-08 | 6.0/30.0/0.268/0.00e+00 | 12.0/40.0/0.288/3.76e-07 | 7.8/32.8/0.325/1.72e-11 | 22.0/68.2/0.567/5.97e-07 | 7.0/33.0/0.350/0.00e+00 |
| 3(250000) | 16.1/63.3/0.538/1.60e-08 | 6.0/30.0/0.355/0.00e+00 | 12.0/40.1/0.349/4.54e-07 | 9.8/40.6/0.531/0.00e+00 | 22.0/67.7/0.694/6.13e-07 | 4.0/16.0/0.214/0.00e+00 |
| 4(10000) | 8.5/27.5/0.006/4.99e-07 | 2.0/11.4/0.006/0.00e+00 | 7.0/18.0/0.004/2.62e-07 | 2.4/9.1/0.008/0.00e+00 | 2.0/5.0/0.003/0.00e+00 | 1.0/5.0/0.002/0.00e+00 |
| 4(30000) | 10.2/31.7/0.010/4.81e-07 | 2.0/12.6/0.008/0.00e+00 | 7.0/18.0/0.007/4.50e-07 | 6.0/18.0/0.035/3.36e-09 | 2.0/5.0/0.005/0.00e+00 | 1.0/5.0/0.002/0.00e+00 |
| 4(50000) | 11.3/35.1/0.016/4.08e-07 | 2.0/12.2/0.010/0.00e+00 | 7.0/18.0/0.009/5.61e-07 | 6.0/18.0/0.042/2.95e-10 | 2.0/5.0/0.007/0.00e+00 | 1.0/5.0/0.003/0.00e+00 |
| 4(80000) | 12.1/37.7/0.027/4.03e-07 | 2.0/11.4/0.015/0.00e+00 | 7.0/18.0/0.015/7.25e-07 | 6.0/18.0/0.054/2.96e-10 | 2.0/5.0/0.011/0.00e+00 | 1.0/5.0/0.005/0.00e+00 |
| 4(100000) | 12.6/39.1/0.035/5.64e-07 | 2.0/12.2/0.019/0.00e+00 | 7.0/18.0/0.019/8.38e-07 | 6.0/18.0/0.068/2.87e-10 | 2.0/5.0/0.014/0.00e+00 | 1.0/5.0/0.007/0.00e+00 |
| 4(120000) | 12.8/40.4/0.045/5.24e-07 | 2.0/12.6/0.024/0.00e+00 | 7.0/18.0/0.023/9.00e-07 | 6.0/18.0/0.079/2.81e-10 | 2.0/5.0/0.017/0.00e+00 | 1.0/5.0/0.009/0.00e+00 |
| 4(150000) | 11.8/37.3/0.089/4.04e-07 | 2.0/11.8/0.037/0.00e+00 | 7.6/19.8/0.055/5.14e-07 | 6.0/18.0/0.116/5.67e-10 | 2.0/5.0/0.030/0.00e+00 | 1.0/5.0/0.017/0.00e+00 |
| 4(180000) | 12.5/38.3/0.110/3.37e-07 | 2.0/12.2/0.046/0.00e+00 | 8.0/21.0/0.070/2.25e-07 | 6.0/18.0/0.140/7.78e-10 | 2.0/5.0/0.036/0.00e+00 | 1.0/5.0/0.020/0.00e+00 |
| 4(200000) | 13.0/40.9/0.128/2.93e-07 | 2.0/12.6/0.049/0.00e+00 | 8.0/21.0/0.074/2.34e-07 | 6.0/18.0/0.146/9.32e-10 | 2.0/5.0/0.040/0.00e+00 | 1.0/5.0/0.023/0.00e+00 |
| 4(250000) | 13.7/44.2/0.173/3.57e-07 | 2.0/12.2/0.060/0.00e+00 | 8.0/21.0/0.093/2.64e-07 | 6.0/18.0/0.178/1.03e-09 | 2.0/5.0/0.050/0.00e+00 | 1.0/5.0/0.027/0.00e+00 |
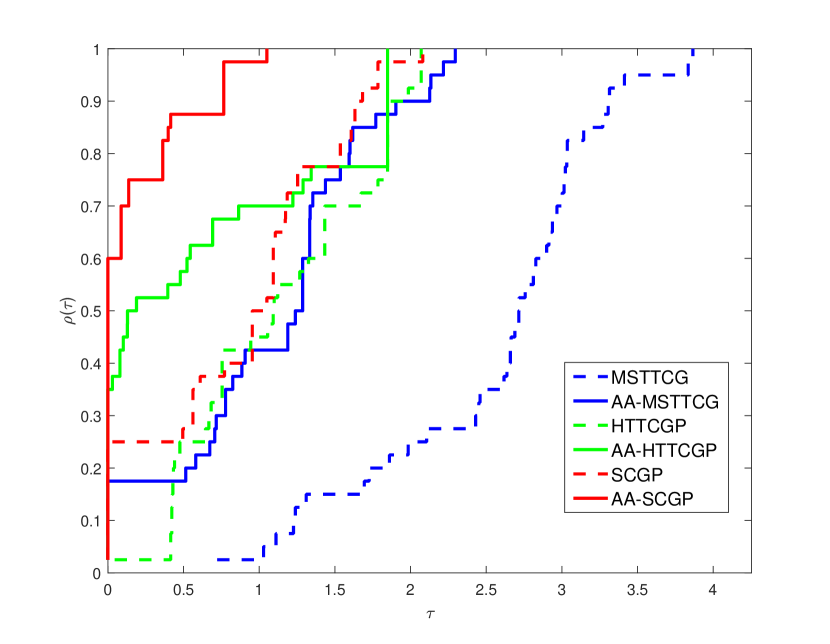
Moreover, we use the performance profiles DM02 to visually compare the performance of these methods, as illustrated in Figures 1(a) and 1(b), which intuitively describe and , respectively. Recall that in the performance profile, efficiency and robustness can be evaluated at the left and right extremes of the graphic, respectively. In a word, the higher the curve, the better the method. It is very clear from Figure 1 that the acceleration process is efficient in its purpose of accelerating DFPM. Table 1 shows that the AA variants of three DFPM are all superior (in terms of , and ) to their originals for these chosen set of test problems, which also confirms the encouraging capability of AA for DFPM. In contrast, deteriorates in certain tests as a result of AA having to solve an extra optimization problem in each iteration. These results motivated us to further apply AA-DFPM to real-world problems.
5.2 Regularized decentralized logistic regression
We consider a real-world application, regularized decentralized logistic regression:
| (33) |
where is a regularization parameter, represents the logistic loss function, and the data pairs are taken from a given data set or distribution. It is easy to know that the objective function is strongly convex Luo21 . Hence is a unique optimal solution to (33) if and only if it is a root of the following monotone nonlinear equations JYTH22 ,
| (34) |
Thus we can apply AA-DFPM to solve the above problem. Considering that problem (34) is unconstrained, we can dispense with the nonnegative constraints in the least squares problem in Algorithm 3 (line 3 of Step 5), let , so the least squares problem can be reformulated as
| (35) |
Our implementation solves above problem using QR decomposition. The QR decomposition of problem (35) at iteration can be efficiently obtained from that of at iteration in GVL96 .
We exclusively focus on AA-SCGP, the top-performing method in our initial experiments, and compare it with two DFPM incorporating inertial acceleration: MITTCGP MJJYH23 and IHCGPM3 JYTH22 . The involved parameters for both MITTCGP and IHCGPM3 are set to their defaults, while the parameters used in AA-SCGP are taken from the experiment in last subsection. The regularization parameter is fixed at and the test instances are sourced from the LIBSVM data sets CL11 . Statistics of the test instances 111Datasets available at https://www.csie.ntu.edu.tw/cjlin/libsvmtools/datasets/. used are listed in Table 2. The termination criterion of all three algorithms is the same as the first experiment.
| Data sets | Data points | Variables | IHCGPM3 | MITTCGP | AA-SCGP |
|---|---|---|---|---|---|
| /// | /// | ()/// | |||
| fourclass_scale | 862 | 2 | 107.6/323.8/0.017/9.60e-07 | 246.6/740.4/0.038/9.82e-07 | 11.4(10.0)/23.8/0.011/2.18e-07 |
| liver-disorders | 145 | 5 | 492.2/1520.6/0.023/9.93e-07 | 1362.6/4136.8/0.065/9.98e-07 | 760.0(462.4)/2086.4/0.088/7.70e-07 |
| phishing | 11055 | 68 | 561.8/1685.6/14.016/9.93e-07 | 1394.0/4182.6/34.768/9.97e-07 | 565.0(243.4)/1131.0/13.651/5.14e-07 |
| w4a | 7366 | 300 | 584.6/1754.8/2.815/9.92e-07 | 1461.4/4384.4/7.050/9.97e-07 | 628.0(309.0)/1257.2/3.104/9.11e-07 |
| w5a | 9888 | 300 | 584.0/1752.6/3.714/9.95e-07 | 1459.8/4380.0/9.226/9.98e-07 | 520.0(87.0)/1041.0/3.039/9.53e-07 |
| w6a | 17188 | 300 | 584.4/1753.0/8.294/9.95e-07 | 1460.2/4381.6/20.713/9.96e-07 | 757.2(575.8)/1515.4/12.007/7.83e-07 |
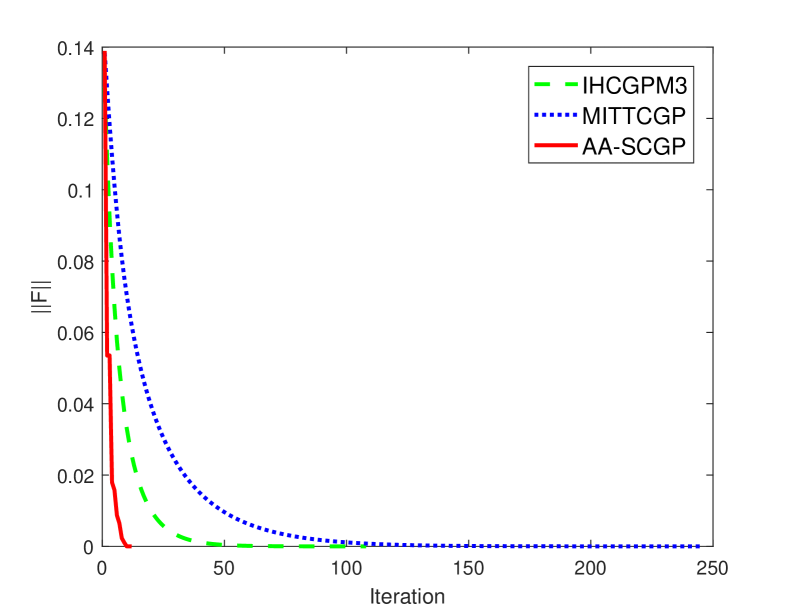
Figure 2 displays the results of four test instances solved by three methods with a fixed initial point . One can observe that our method outperforms the others. Specifically, for different categories of data sets, AA-SCGP performs better in the case that has fewer data points and variables . The reason for this could be that data set “fourclass_scale” has been scaled to [-1,1]. For similar data sets “w5a” and “w6a”, AA-SCGP exhibits faster convergence for a bigger . Similarly, we use the MATLAB script “2*(rand(n,1)-0.5)” to generate the random initial point and run the same test 5 times for each test instance. Table 2 presents the average computational results, with the additional term denoting average number of AA. The results indicate that the quality of solutions obtained by AA-SCGP consistently outperforms those generated by IHCGPM3 and MITTCGP. For most test instances, AA-SCGP outperforms the other two inertial algorithms in terms of and . This benefits from the fact that AA-SCGP accelerates frequently during its iteration, in which the proportion of AA is 55.6%. These facts further illustrate that DFPM integrated with Anderson acceleration is valid and promising.



6 Conclusions
In this paper, we developed a novel algorithm of using Anderson acceleration (AA) for derivative-free projection method (DFPM) in solving convex-constrained monotone nonlinear equations. First, we reviewed the convergence of a general framework for DFPM, and then explored how AA can still be exploited with DFPM though it may not a fixed-point iteration. As a result, an acceleration algorithm (AA-DFPM) with slight modifications is proposed, and the global convergence of AA-DFPM is obtained with no additional assumptions. The convergence rate is further established based on some suitable conditions. The results on both preliminary numerical experiments and applications demonstrate the superior performance. As a future research, we plan to investigate a novel DFPM for general nonlinear equations without the monotonicity. We also intend to explore a simplified AA whose coefficient is easy to calculate, even for large window size.
Acknowledgements.
This work was supported by the National Key Research and Development Program (2020YFA0713504) and the National Natural Science Foundation of China (61977065).References
- (1) Meintjes, K., Morgan, A.P.: A methodology for solving chemical equilibrium systems. Appl. Math. Comput. 2(4), 333-361 (1987)
- (2) Qu, B., Xiu, N.H.: A note on the CQ algorithm for the split feasibility problem. Inverse Probl. 21(5), 1655-1665 (2005)
- (3) Chorowski, J., Zurada, J.M.: Learning understandable neural networks with nonnegative weight constraints. IEEE Trans. Neural Netw. Learn. Syst. 26(1), 62-69 (2014)
- (4) Xiao, Y.H., Wang, Q.Y., Hu, Q.J.: Non-smooth equations based method for -norm problems with applications to compressed sensing. Nonlinear. Anal. 74(11), 3570-3577 (2011)
- (5) Jian, J.B., Yin, J.H., Tang, C.M., Han, D.L.; A family of inertial derivative-free projection methods for constrained nonlinear pseudo-monotone equations with applications. Comp. Appl. Math. 41, 309 (2022)
- (6) Sun, D.F., Womersley, R.S., Qi, H.D.: A feasible semismooth asymptotically Newton method for mixed complementarity problems. Math. Program. 94(1), 167-187 (2002)
- (7) Qi, L.Q., Tong, X.J., Li, D.H.: Active-set projected trust-region algorithm for boxconstrained nonsmooth equations. J. Optim. Theory Appl. 120(3), 601-625 (2004)
- (8) Yin, J.H., Jian, J.B., Ma, G.D.: A modified inexact Levenberg-Marquardt method with the descent property for solving nonlinear equations. Comput. Optim. Appl. 87, 289-322 (2023)
- (9) Solodov, M.V., Svaiter, B.F.: A globally convergent inexact Newton method for systems of monotone equations. In: Fukushima, M., Qi. L. (eds.): Reformulation: Nonsmooth, Piecewise Smooth, Semisooth and Smoothing Methods, pp. 355-369. Kluwer, Dordrecht (1998)
- (10) Liu, J.K., Feng, Y.M.: A derivative-free iterative method for nonlinear monotone equations with convex constraints. Numer. Algorithms 82, 245-262 (2019)
- (11) Liu, J.K., Lu, Z.L., Xu, J.L., Wu, S., Tu, Z.W., An efficient projection-based algorithm without Lipschitz continuity for large-scale nonlinear pseudo-monotone equations. J. Comput. Appl. Math. 403, 113822 (2022)
- (12) Ibrahim, A.H., Kumam, P., Rapajić, S., Papp, Z., Abubakar, A.B.: Approximation methods with inertial term for large-scale nonlinear monotone equations. Appl. Numer. Math. 181, 417-435 (2022)
- (13) Wu, X.Y., Shao, H., Liu, P.J., Zhuo, Y.: An inertial spectral CG projection method based on the memoryless BFGS update. J. Optim. Theory Appl. 198, 1130-1155 (2023)
- (14) Yin, J.H., Jian, J.B., Jiang, X.Z., Liu, M.X., Wang, L.Z.: A hybrid three-term conjugate gradient projection method for constrained nonlinear monotone equations with applications. Numer. Algorithms 88(1), 389-418(2021)
- (15) Waziri, M.Y., Ahmed, K.: Two descent Dai-Yuan conjugate gradient methods for systems of monotone nonlinear equations. J. Sci. Comput. 90, 1-53 (2022)
- (16) Ma, G.D., Jin, J.C., Jian, J.B., Yin, J.H., Han, D.L.: A modified inertial three-term conjugate gradient projection method for constrained nonlinear equations with applications in compressed sensing. Numer. Algorithms 92, 1621-1653 (2023)
- (17) Zhang, L., Zhou, W.J.: Spectral gradient projection method for solving nonlinear monotone equations. J. Comput. Appl. Math. 196, 478-484 (2006)
- (18) Ou, Y.G.; Li, J.Y.: A new derivative-free SCG-type projection method for nonlinear monotone equations with convex constraints. J. Appl. Math. Comput. 56, 195-216 (2018)
- (19) Amini, K., Kamandi, A.: A new line search strategy for finding separating hyperplane in projection-based methods. Numer. Algorithms 70, 559-570 (2015)
- (20) Li, Q.N., Li, D.H.: A class of derivative-free methods for large-scale nonlinear monotone equations. IMA J. Numer. Anal. 31(4), 1625-1635 (2011)
- (21) Ou, Y.G., Li, L.: A unified convergence analysis of the derivative-free projection-based method for constrained nonlinear monotone equations. Numer. Algorithms 93(4), 1639-1660 (2023)
- (22) Goncalves, M.L.N., Menezes, T.C.: A framework for convex-constrained monotone nonlinear equations and its special cases. Comp. Appl. Math. 42, 306 (2023)
- (23) Anderson, D.G.; Iterative procedures for nonlinear integral equations. J. Assoc. Comput. Mach. 12 547-560 (1965)
- (24) Alvarez, F.: On the minimizing property of a second order dissipative system in Hilbert spaces. SIAM J. Control Optim. 38(4), 1102-1119 (2000)
- (25) Nesterov, Y.: A method of solving a convex programming problem with convergence rate . Soviet Math. Dokl. 27, 372-376 (1983)
- (26) Walker, H.F., Ni, P.: Anderson acceleration for fixed-point iterations. SIAM J. Numer. Anal. 49(4), 1715-1735 (2011)
- (27) Saad, Y., Schultz, M.H.: Gmres: A generalized minimal residual algorithm for solving nonsymmetric linear systems. SIAM J. Sci. Stat. Comput. 7(3), 856-869 (1986)
- (28) Potra, F.A., Engler, H.: A characterization of the behavior of the Anderson acceleration on linear problems. Linear Algebra Appl. 438(3), 1002-1011 (2013)
- (29) Wang, D.W., He, Y.H., Sterck, H.D.: On the asymptotic linear convergence speed of Anderson acceleration applied to ADMM. J. Sci. Comput. 88(2), 38 (2021)
- (30) Fang, H.R., Saad, Y.: Two classes of multisecant methods for nonlinear acceleration. Numer. Linear Algebra Appl. 16(3), 197-221 (2009)
- (31) Wang, S.Y., Chen, W.Y., Huang, L.W., Zhang, F., Zhao, Z.T., Qu, H.: Regularization-adapted Anderson acceleration for multi-agent reinforcement learning, Knowl.-Based Syst. 275, 110709 (2023)
- (32) Pollock, S., Rebholz, L.G., Xiao, M.Y.: Anderson-accelerated convergence of Picard iterations for incompressible Navier-Stokes equations. SIAM J. Numer. Anal. 57, 615-637 (2019)
- (33) Yang, Y.N.: Anderson acceleration for seismic inversion. Geophysics 86(1), R99-R108 (2021)
- (34) Toth, A., Kelley, C.: Convergence analysis for Anderson acceleration. SIAM J. Numer. Anal. 53, 805-819 (2015)
- (35) Mai, V., Johansson, M.: Anderson acceleration of proximal gradient methods. In Int. Conf. Mach. Learn., PMLR, 6620-6629 (2020)
- (36) Bian, W., Chen, X.J.: Anderson acceleration for nonsmooth fixed point problems. SIAM J. Numer. Anal. 60(5), 2565-2591 (2022)
- (37) Rebholz, L.G., Xiao, M.Y.: The effect of Anderson acceleration on superlinear and sublinear convergence. J. Sci. Comput. 96(2), 34 (2023)
- (38) Garner, C., Lerman, G., Zhang, T.: Improved convergence rates of Anderson acceleration for a large class of fixed-point iterations. arXiv preprint arXiv: 2311.02490 (2023).
- (39) Cai, X.J., Gu, G.Y., He, B.S.: On the convergence rate of the projection and contraction methods for variational inequalities with Lipschitz continuous monotone operators. Comput. Optim. Appl. 57(2), 339-363 (2014)
- (40) Polyak, B.T.: Introduction to Optimization, Optimization Software, Inc. Publications Division, New York (1987).
- (41) Scieur, D., d’Aspremont, A., Bach, F.: Regularized nonlinear acceleration. In Adv. Neural Inf. Process. Syst. 712-720 (2016)
- (42) Ouyang, W.Q., Tao, J., Milzarek, A., Deng, B.L.: Nonmonotone globalization for Anderson Acceleration via adaptive regularization. J. Sci. Comput. 96, 5 (2023)
- (43) Henderson, N.C., Varadhan, R.: Damped Anderson acceleration with restarts and monotonicity control for accelerating EM and EM-like algorithms. J. Comput. Graph. Stat. 28, 834-846 (2019)
- (44) Ouyang, W.Q., Peng, Y., Yao, Y.X., Zhang, J.Y., Deng, B.L.: Anderson acceleration for nonconvex ADMM based on Douglas-Rachford splitting. Comput. Graph. Forum 39, 221-239 (2020)
- (45) Zhang, J.Y., O’Donoghue, B., Boyd, S.: Globally convergent type-I Anderson acceleration for nonsmooth fixed-point iterations. SIAM J. Optim. 30(4), 3170-3197 (2020)
- (46) Anderson, D.G.M.: Comments on “Anderson Acceleration, Mixing and Extrapolation”. Numer. Algorithms 80, 135-234 (2019)
- (47) Chen, C.H., Ma, S.Q., Yang, J.F.: A general inertial proximal point algorithm for mixed variational inequality problem. SIAM J. Optim. 25, 2120-2142 (2014)
- (48) Amini, K., Faramarzi, P.: Global convergence of a modified spectral three-term CG algorithm for nonconvex unconstrained optimization problems. J. Comput. Appl. Math. 417, 114630 (2023)
- (49) Dolan, E.D., Moré, J.J.: Benchmarking optimization software with performance profiles. Math. Program. 91(2), 201-213 (2002)
- (50) Luo, H.: Accelerated primal-dual methods for linearly constrained convex optimization problems. arXiv preprint arXiv: 2109.12604 (2021).
- (51) Golub, G.H., Van Loan, C.: Matrix Computations, 3rd ed., The Johns Hopkins University Press, Baltimore, MD, (1996)
- (52) Chang, C.C., Lin, C.J.: LIBSVM: a library for support vector machines. ACM Trans. Intell. Syst. Technol. 2(3), 1-27 (2011)