Anchor-based Multi-view Subspace Clustering with Hierarchical Feature Descent
Abstract
Multi-view clustering has attracted growing attention owing to its capabilities of aggregating information from various sources and its promising horizons in public affairs. Up till now, many advanced approaches have been proposed in recent literature. However, there are several ongoing difficulties to be tackled. One common dilemma occurs while attempting to align the features of different views. Moreover, due to the fact that many existing multi-view clustering algorithms stem from spectral clustering, this results to cubic time complexity w.r.t. the number of dataset. However, we propose Anchor-based Multi-view Subspace Clustering with Hierarchical Feature Descent(MVSC-HFD) to tackle the discrepancy among views through hierarchical feature descent and project to a common subspace( STAGE 1), which reveals dependency of different views. We further reduce the computational complexity to linear time cost through a unified sampling strategy in the common subspace( STAGE 2), followed by anchor-based subspace clustering to learn the bipartite graph collectively( STAGE 3). Extensive experimental results on public benchmark datasets demonstrate that our proposed model consistently outperforms the state-of-the-art techniques. Our code is publicly available at https://github.com/QiyuanOu/MVSC-HFD/tree/main.
keywords:
Multi-view Clustering, multimodal fusion, subspace clustering, anchor graph, Machine Learning\ul
organization=College of Computer, National University of Defense Technology,addressline=ouqiyuan14, zhangpei, [email protected], city=Changsha, postcode=410073, state=Hunan, country=China
organization=Intelligent Game and Decision Lab,[email protected], city=Beijing, postcode=100000, country=China
organization=College of Intelligence Science and Technology, National University of Defense Technology,[email protected], city=Changsha, postcode=410073, state=Hunan, country=China
MVSC-HFD has high adaptability to various dimensions of different views.
Tackle the discrepency among different views.
Reduce multiple views of different dimensions hierarchically to a common subspace.
Uniformly learn anchors in common subspace and construct bipartite graphs.
Low spatial and time consumption which are linear to data size.
1 Introduction
With the advance of information technology, many practical datasets are collected from different channels or provided in different modalities[4, 20, 47, 40]. As a result, multi-view learning has gained increasing attention due to its ability in handling and learning from various source information. Among those learning datasets, the majorities are unlabeled with only features of different views attached to them. Many clustering algorithms have been used in practice in order to discover inherent patterns from these cluttered datasets and also to reveal things that were previously unknown to humans. One common task that multi-view clustering algorithms confront is that in some datasets, different views vary tremendously in dimensions, which will adversely affect the extraction and expression of common representations and data patterns revealed by features from each view[41, 44, 28, 43, 30, 29, 27].
Projecting different views into a common space is a long-term academic issue, e.g., Canonical Correlation Analysis (CCA)[14] and its variants [1, 2] aim to align a pair of views with linear correlation through complex nonlinear transformation. This technique is restricted to the simple case where only two views are provided. In multi-view circumstances, [31] assumes that the high dimensional data emanate from noisy redundancies, which can be eliminated by minimizing norm of the representation. It is a typical phenomenon that, the lower the dimensions of data points are reduced to, the more the information is lost [24, 37]. On the contrary, the higher dimensions we preserve to learn from, the better the resulting representation captures the underlying semantic essence of the data points, although with typically higher computational cost.
Subspace clustering directly bypasses the curse of dimensionality[3] through expressing each data point as a linear combination of other points and minimizing the reconstruction loss to attain the combination coefficient[21, 9]. Recently, subspace clustering has been extended to multi-view circumstances[11, 6, 42, 8, 50], where each view owns a distinct coefficient matrix and a regularization term is used to obtain the joint coefficient matrix, which is then expressed as similarity matrix for downstream spectral clustering and k-means clustering tasks. It is obvious that, as the self-representation matrix has the size of , which is the same as the scale of data points, extremely high computational and spatial cost are imposed on the optimization procedure and the clustering task, which would bring time cost and at least storage cost, respectively. As a typical paradigm for reducing the computational and spatial cost, the anchor scheme is introduced to various clustering models[7, 32, 16, 51, 26, 45]. It is a common practice to carefully choose (mainly adopt k-means clustering as a preliminary scheme) or randomly sample from the original dataset. The above formula bears several drawbacks: a) Results highly rely on the initialization as the anchors are predetermined. Although a preliminary -means clustering on data features can make a favorable selection, the pre-selected anchor points are fixed in the same dimensional space as the original data, so the practicability can be greatly reduced when the nodes are not linearly separable; b) In multi-view learning background, the fundamental problem with most of the frameworks is that both the anchors and the graph reconstruction matrices are view-specific, which ignores the alliance between different views; c) For final spectral clustering step, the fusion step is required to build the global graph based on view-specific graphs. In this circumstance, the fusion method will also extensively affect the clustering result. d) Specifically for [33, 18], which efficiently learn anchors using subspace clustering method, assume that cross-view consistent bipartite graph exists. Accordingly, they deploy dependency among views without tackling the discrepancy of dimensions and features adequately, thus inhibiting a better performance.
To address the aforementioned limitations, we propose a novel approach named Anchor-based Multi-view Subspace Clustering with Hierarchical Feature Descent(MVSC-HFD). Specifically, in our method, we adopt three mechanisms to extract the bipartite graph reconstruction matrix. First, the input data points of different views are reduced to the same dimensional space through hierarchical dimensional projection matrices. Second, we assume that for all views, data points sketch the same structure in this unified dimension, and can be jointly expressed by common subspace, thus reuniting the separate clustering of distinct views into a collectively learned framework. Thirdly, to negotiate between feature preservation and efficiency, we adopt an anchor graph with carefully designed dimensions and the number of anchor points.
Compared with existing methods, our algorithm has the following advantages:
-
1.
High adaptability to various dimensions. Our algorithm can cater to different dimensions of multiple views.
-
2.
Reduce the discrepancy and reveal dependency of different views. Our method can tackle discrepancy among multiple views by hierarchically dimensional descent at different rates into a common subspace for clustering, which increases the effectiveness of the anchors-based clustering scheme.
-
3.
Model integrity and performance gains. Aforementioned variables including weight vector, projection matrix, anchor matrix and bipartite graph are collectively learned throughout the optimization procedure with guaranteed convergence. The extensive experiments show the validity of our proposed method from both accuracy and efficiency.
2 Related Work
In this section, we precede our work with some most relevant work, including non-negative matrix factorization, subspace clustering and multi-view subspace clustering. For clarity, to elaborate on the correlation and inspiration of the preceding work, we use the unified annotations throughout this prologue, which is shown below.
| The number of data clusters. | |
| The number of views. | |
| The number of anchor points. | |
| The depth of hierarchical feature descent. | |
| Dimension of the -th view. | |
| Dimension of the -th layer. | |
| A concatenation of weights. | |
| The data matrix of the -th view. | |
| The -th order identity matrix. | |
| The hierarchical anchor graph of the -th depth. | |
| The partition matrix of consensus embedding. | |
| The unified anchor point representation. | |
| The consensus reconstruction matrix. |
2.1 Non-Negative Matrix Factorization
Non-negative matrix factorization (NMF or NNMF) is a group of algorithms that factorize a matrix into (usually) two matrices and , with the uniform constraint that all these three matrices have the property of non-negativity, which makes the formulation easy to solve whereas endow the practicality of the algorithms in real-world applications such as processing of natural language, audio-visual signal spectrograms or missing data imputation.
| (1) |
where is the data matrix, each column represents a vector of dimension and there are numbers of such vector. and is the number of base vectors. is the representation mapped through the mapping matrix . While keeping the information unchanged as much as possible, NMF aims to simplify high dimensional data to low dimensional mode , in order to estimate the essential structure which represents. Original NMF and Deep-NMF are illustrated in Fig. 1.

2.2 Subspace Clustering
Subspace clustering assumes that the whole dataset can be represented linearly by a fraction of them, which is called subspace. By minimizing the reconstruction loss, the target function acquires a combination coefficient matrix. Considerable advancements have been achieved in uncovering underlying subspaces. Currently, there are two main research directions in subspace clustering: sparse subspace clustering (SSC) [9] and low-rank representation (LRR)[21]. SSC employs sparse representation techniques to cluster a set of multi-subspaces, while LRR utilizes the nuclear norm to impose an approximate low-rank constraint on the reconstruction matrix. Both types of algorithms follow a similar routine: they first reconstruct the data using the original input and then apply spectral clustering on the resulting similarity graph. For a given data matrix with samples and features, the formula for naive single-view subspace clustering is presented below,
| (2) |
where means each element in similarity graph matrix is non-negative, and restricts the diagonal elements to zero, so as to prohibits trivial solution. The term represents a manifold of adequate norms that can serve as regularizers to adjust to various algorithmic application backgrounds. For example, -norm, -norm, nuclear norm, Frobenius norm are corresponding to different properties like sparsity of matrix, sparsity of row space, low-rank matrices, respectively. is a regularization parameter to negotiate between the regularization term and the alignment term( the squared Frobenius norm of reconstruction). The constraint is synonymous with , ensuring that every data point is assigned to at least one subspace. In order to unveil the inherent correlations among data samples, these algorithms incorporate to linearly reconstruct the data points, aligning them with their original counterparts. Hence, is often referred to as a reconstruction coefficient matrix or self-representation matrix. A multitude of relative researches build the similarity matrix as
| (3) |
where is the input non-negative symmetric similarity matrix of the downstream tasks, usually with spectral clustering methods which generate the result of data cluster as follows,
| (4) |
where means the trace of the matrix. is known as the spectral embedding of data matrices, which is then used as the input of the k-means clustering scheme to get the final cluster indicating matrix.
2.3 Multi-view Subspace Clustering
In multi-view circumstances, suppose represents multi-view data matrix with , where means the feature dimension of the -th view and means sample number. Multi-view subspace clustering scheme can be represented below:
| (5) |
where the regularization term endows view-specific anchor graphs with different properties. is the self-representation matrix optimized by minimizing the term , which represents categories of many fusion techniques. The clustering process of existing methods for multi-view subspace clustering is in two stages: - Step 1: Learning the subspace representation and integrating multi-view information at the level of similarity matrix or self-expression matrix by fusing the graphs or self-expression matrices of multiple views (reconstruction matrix) to form a shared similarity matrix [19, 35, 36]. For example, [13] learned shared sparsity by performing Matrix Factorization (MF) of the subspace representations. Unlike obtaining shared self-expressions or shared graphs directly, to better exploit the complementary information and diversity between different views, the work [6, 15] and [39] were performed by Hilbert-Schmidt independence criterion (HSIC) and Markov chain, respectively. Wang et al.[34] introduced an exclusion constraint to learn different subspace representations in each view, which force multiple subspace representations to be sufficiently different from each other, and then added them together directly or adaptively to obtain a uniform graph or self-expression matrix. - In the second step: Clustering, the obtained uniform graph representation is fed into an off-the-shelf clustering model (generally using spectral clustering) to obtain the final clustering results.
Although satisfying clustering performances have been achieved by existing multi-view subspace learning algorithms in many real world applications, the large computational consumption and storage cost by optimizing the reconstruction matrix prohibits the scalability of these methods on large-scale background.
3 Methodology
In the section that follows, we first sketch our motivation and the outline of our proposed method(MVSC-HFD). Then we elaborate on the optimization of the algorithm with proved convergence. Finally, we summarize the algorithmic procedure and analyze the computatioanl complexity of the learning task.
3.1 Motivation
In large-scale data circumstances (either with large data size or with high dimension), the time and space overhead of traditional learning algorithms would be overwhelmingly huge[25]. For high dimensional datasets, it is of much redundancy to directly learn representations from original data samples. Although subspace clustering provides an alternative approach to circumvent high-dimensional feature learning, it still spends high computational and storage costs to construct global similarity graphs between each two elements. And it is obvious that a large proportion of the data does not contribute significantly to the clustering structure. Anchor graph theory[32, 48] proposes that a good clustering structure can be acquired with only a fraction of the sample points by correlating these sample points with the full sets of data. These similarity matrices are also termed as anchor graph or bipartite graph. Nevertheless, existing anchor-based subspace learning methods often use delicately chosen landmarks beforehand, hence the clustering result highly relies upon these pre-specified knowledge, which restricts the scalability of the algorithm. We propose an adaptable clustering algorithm to tackle not only high dimensional data, but also large-scale samples by hierarchically projecting the original data to a low dimensional common subspace, where a set of anchors are learned uniformly to construct the bipartite graph. We demonstrate the overall procedure together with traditional methods in fig. 2.

3.2 The Proposed Formulation
| (6) |
where is the original data matrix of the -th view, with denoting the dimension and denoting the number of data points. The hierarchical dimensional projection matrix (, , in particular) is the projection matrix that performs dimensional reduction. Specifically, data in different views often have different dimensions. So usually are not the same for of different views, which means different dimensional reduction process. Distinctive represents the discrepancy of different views and the serial multiplier aims to reduce the discrepancy. is the unified anchor points in which represents the dimension and stands for the number of the anchor points. This anchor matrix is shared among different views and reveals the dependency. It represents the common features extracted through dimensional projection matrix multiplier . The learnable vector of parameters represents the weights adherent to different views. And the linear constraint of corresponds to the quadratic optimization target, which is a convex optimization problem owing to the inherently non-negative nature of Frobenius norm. represents the consensus bipartite graph amongst different views, which constructs the pairwise relationship between original data samples and delicately learned landmarks. Traditional subspace clustering algorithms utilize the learned bipartite graph to construct the full similarity graph using where and denotes a diagonal matrix with . Afterwards, they perform spectral clustering with the acquired similarity matrix to obtain final clustering results. These give rise to computational consumption and spatial cost. We adopt a different approach by proving an equivalence in right singular matrix of bipartite graph and eigenvectors of the similarity matrix :
| (7) |
where denotes the singular value decomposition(SVD) of the consensus bipartite graph . Therefore, we only need to compute the right singular matrix of for further clustering task (lite -means for example), and this costs .
3.2.1 Optimization Algorithm
The decision variables for the objective function are , and . As a result, we introduce a four-step iterative optimization method to approximate the optimal target mentioned in Eq. (6). In this approach, we keep three variables fixed while optimizing the remaining ones. The specific procedure is derived from the following detailed steps.
Initialization. Our algorithm adopts a straightforward initialization by setting as an matrix with the first block deposited as identity matrix and the rest elements deposited to be . The anchor matrix is initialized as identity matrix w.r.t. its dimension. And is initialized using mean values factorized by view count. The other decision variable is neglected for initializing as it is the first to optimize.
Update with , , and fixed. Given , , and the rest numbers of , the optimization problem in Eq. (6) with respect to becomes:
| (8) |
Where denotes the hierarchical dimensional projection series . The multiplication term refers to the anchor-based subspace reconstruction of -th layer’s representation, and denotes the generalized anchors. Through deduction of matrix Frobenius norm and let , Eq. (3.2.1) can be reformulated as:
| (9) |
Denote the SVD of matrix as and the optimal solution of Eq. (9) is demonstrated as . In this case, is a nonnegative diagonal matrix with each entry representing the singular value of , both and are unitary matrix with orthogonal entries. According to deduction in [23], a closed-form resolution can be found by calculating , where is a function imposed on matrix with each element, which returns if the element is larger than . And it is obvious that in our case, is an identity matrix. Accordingly, the optimal solution can be calculated as:
| (10) |
By following the updating expression in Eq. (10), our algorithm updates in succession.
Update with , and fixed. When and of each view are all prescribed, updating with fixed , which relocates the unified anchor matrix, can be termed as:
| (11) |
Likewise, the deduction for the optimization of the anchor selection variable is similar to Eq. (9), which can be equally written as:
| (12) |
where and .
Corresponding to the updating rule in [23], it is straightforward to obtain the optimal solution for as in Eq. (9). The multiplication of the left and right singular matrices of costs .
Update with , and fixed. Given , the anchors are separately lodged in different anchor spaces of the same dimension and are reunited by the optimized anchor matrix , which is shared amongst views. This subtask of updating is equivalent to the process of constructing the bipartite graph from the anchor space to the original feature space. The optimization problem in Eq. (6) concerning can be written as:
| (13) |
According to the definition of Frobenius norm, we can easily derive Eq. (13) as follows:
| (14) |
where . As the optimisation of the columns in is identical with each other, the optimisation task can be separated into sub-tasks by the identical form as:
| (15) |
for , where the parameter for quadratic term is and the first order polynomial term . These are several QP(quadratic programming) problems with domain constraints. As each column of is an dimensional vector, and there are sub-problems identical to each other, the overall time cost of optimising is .
Update with , and fixed. When variables , and are fixed, the optimization problem in Eq. (6) with regard to the variable automatically learns the coefficients of different views, the procedure is assembled below:
| (16) |
Denote the Frobenius norm of the alignment term as , and the vector refers to the concatenation. By Cauchy-Schwarz inequality, the optimal value of can be directly acquired by
| (17) |
3.3 Algorithmic Discussion
In the section of Algorithmic Discussion, we thoroughly examine the computational complexity of our algorithm and provide a comprehensive review of our methodology.
3.3.1 Convergence Analysis
In our four-step iterative convex optimization process, each updating formula has a closed-form solution and for each iteration, the objective value of the optimization target monotonically decreases while keeping the rest of the decision variables fixed. At the same time, both and are orthogonal matrices, while both and satisfies -sum non-negative constraints, which provides the lower bound of the optimization target. Consequently, the convex objective monotonically decreases with a lower bound, thus guaranteeing the overall convergence of the proposed method MVSC-HFD.
3.3.2 Complexity Analysis
The optimization procedure demonstrated in Algorithm 1 has decomposed the model into four sub-problems with a closed-form solution. For simplicity and practicality, the hierarchical dimensional reduction processes are conducted identically for different views. Subsequently, their layers’ dimensions are the same. In specific, the optimization of in Eq. (10) involves the calculation of and its SVD complexity, which is and , respectively. The multiplication applied to acquire is . In all, suppose the dimension of the last layer is the same as the cluster number and , it needs to update for all views. The optimization of requires time cost to gather the multiplicator and to decompose it. In sum, the overall complexity of our algorithm is , which is scalable for large-scale datasets.
4 Experiments and Analysis
In the section that follows, we conduct a series of experiments to validate the effectiveness of the algorithm using synthetic and real-world datasets and compare our algorithm with state-of-the-art multi-view clustering algorithms. Last but not least, it is worthwhile to explore the mechanism of the algorithm by analyzing the experimental results.
4.1 Datasets Overview and Experimental Settings
4.1.1 A Brief Introduction of Datasets
For in-depth experimental analysis, we conduct a series of tests over 10 real-world datasets, varying in multiple domains. The datasets used in our experiments are WebKB 111http://lig-membres.imag.fr/grimal/data.html, BDGP 222https://www.fruitfly.org/, MSRCV1 [38], Caltech7-2view 333http://www.vision.caltech.edu/Image_Datasets/Caltech101/, NUS-WIDE-10 444https://lms.comp.nus.edu.sg/wp-content/uploads/2019/research/nuswide/NUS-WIDE.html, Caltech101-7 3, Caltech101-20 3, NUS-WIDE 4, SUNRGBD 555https://rgbd.cs.princeton.edu/, YoutubeFace 666https://www.cs.tau.ac.il/ wolf/ytfaces/. These datasets vary in broad ranges of application background. In specific, WebKB is a dataset that includes web pages from computer science departments of various universities and they are categorized into 5 categories (Student, Faculty, Department, Course, Project). The SUNRGBD dataset contains 10335 real RGB-D images of room scenes. The MSRCV1 dataset from Microsoft Research in Cambridge contains 7 classes of images with coarse pixel-wise labeling. In Table 2, we summarize the detailed information of these benchmark datasets.
| Datasets | # Samples | # Views | # Clusters |
|---|---|---|---|
| MSRCV1 | 210 | 6 | 7 |
| WebKB | 265 | 2 | 5 |
| Caltech101-7 | 1474 | 6 | 7 |
| Caltech7-2view | 1474 | 2 | 7 |
| Caltech101-20 | 2386 | 6 | 20 |
| BDGP | 2500 | 3 | 5 |
| NUS-WIDE-10 | 6251 | 5 | 10 |
| NUS-WIDE | 23953 | 5 | 31 |
| SUNRGBD | 10335 | 2 | 45 |
| YoutubeFace | 101499 | 5 | 31 |
4.1.2 Experimental Settings
We use the initialization specified in Algorithm 1. In practice, we simply adopt the number of clusters as the value of the dimension of embedding space and the value of anchor count. For each view, the hierarchical feature descent rate is different according to their original dimensions. However, it is rather practicable as it performs well by directly slicing the dimension to equal sections: . The best depths among of the datasets WebKB, BDGP, MSRCV1, Caltech7-2view, NUS-WIDE-10, Caltech101-7, Caltech101-20, NUS-WIDE 4, SUNRGBD, YoutubeFace are 5, 5, 5, 5, 4, 4, 5, 5, 2, respectively.
To be specific, the experiments are conducted in MATLAB environment on PC with Intel(R) Core(TM) i7-6800K 3.40GHz CPU and 128GB RAM.
4.1.3 Compared Algorithms
We list the information of our compared algorithms as in detail as possible by first giving brief introduction to their distinct mechanism, and analyze the hyper-parameters of each method.
-
1.
Multi-view k-means clustering on big data (RMKM) [5]. This method uses norm to minimize the non-negative matrix factorization form of the cluster indicator matrix in terms of reconstruction of the original data matrix. Its inherent property is similar to the -means clustering method and the -of- coding scheme provides one-step clustering results.
-
2.
Large-scale multi-view subspace clustering in linear time (LM-
VSC) [16]. Under the framework of subspace clustering, this paper intends for clustering of large-scale datasets by using initially selected anchor points to build reconstruction. -
3.
Parameter-free auto-weighted multiple graph learning: a fram-ework for multi-view clustering and semi-supervised classification (AMGL) [22]. A fusion of different graph representations where the weights of each graph of view are automatically learned and assumed to be the optimal combination.
-
4.
Binary Multi-view Clustering (BMVC) [49]. In order to reduce computational complexity and spacial cost, this work proposes to integrate binary representation of all views and consensus binary clustering into a uniform framework by both minimizing these two parts of loss at the same time.
-
5.
Flexible Multi-View Representation Learning for Subspace Clustering (FMR) [17]. After performing clustering on each different view, the best clustering result is flexibly encoded via adopting complementary information of provided views, thus avoiding the partial outcome in the reconstruction stage.
-
6.
Multi-view Subspace Clustering (MVSC) [12]. MVSC proposes to learn subspace representation of different views simultaneously while regularising the separate affinity matrices to a common one to improve clustering consistency among different views.
-
7.
Multi-view clustering: A scalable and parameter-free bipartite graph fusion method (SFMC) [18]. Based on Ky Fan’s Theorem [10], SFMC explores the relationship between Laplacian matrix and graph connectivity, thus proposing a scalable and parameter-free method to interactively fuse the view-specific graphs into a consensus graph with adaptable anchor strategy.
-
8.
Fast parameter-free multi-view subspace clustering with consensus anchor guidance (FPMVS-CAG) [33]. FPMVS-CAG integrates anchor guidance and bipartite graph construction within an optimization framework and learns collaboratively, promoting clustering quality. The algorithm offers linear time complexity, is hyper-parameter-free, and automatically learns an optimal anchor subspace graph.
-
9.
Efficient Multi-view K-means Clustering with Multiple Anchor Graphs (EMKMC) [46]. EMKMC integrates anchor graph-based and -means-based approaches, constructing anchor graphs for each view and utilizing an improved -means strategy for integration. This enables high efficiency, particularly for large-scale high-dimensional multi-view data, while maintaining or surpassing clustering effectiveness compared to other methods.
| RMKM | LMVSC | AMGL | BMVC | FMR | MVSC | SFMC | FPMVS-CAG | EMKMC | proposed | |
|---|---|---|---|---|---|---|---|---|---|---|
| #Parameter | 1 | 2 | 0 | 3 | 2 | 3 | 1 | 0 | 1 |
As shown in Table.3, most of algorithm have more than one hyper-parameters. It is encouraged to use learnable parameters which can adaptively collaborate with the optimization of other decision variables to boost the performance whereas spare the acquisition of prior knowledge. In our method, the learnable vector of parameters represents the weights adherent to different views, and they are optimized in each iteration. However, for the compared algorithm EMKMC, each view has a hyper-parameter, so the number of parameters is equal to the number of views, which we denote by . As a result, the searching space for best parameter is where denotes the size of the candidate set of the hyper-parameter. These unlearnable parameters dramatically increases computation time of EMKMC.
4.2 Comparison With State-of-the-Art Algorithms
In this section, we conduct a comparative analysis between our algorithm and several state-of-the-art MVC algorithms to validate its effectiveness. We evaluate the performance of our algorithm using 9 widely-used methods, considering accuracy (ACC), Normalized Mutual Information (NMI), and purity as evaluation metrics. The results are presented in Table 4. It shows that our findings entail most of the best practices and recommendations that can improve multi-view learning performance.
To illustrate the effectiveness of the anchors, we conduct t-Distributed Stochastic Neighbor Embedding (t-SNE) experiment and mark the anchors with red crosses. Due to space constraints, we show the clustering effect for WebKB, MSRCV1 and Caltech7-2views in Figure 3. We observe that a red cross is located in each cluster, which empirically verifies the effectiveness of the optimization of anchors in the objective function.



| RMKM | LMVSC | AMGL | BMVC | FMR | MVSC | SFMC | FPMVS-CAG | EMKMC | Proposed | |
|---|---|---|---|---|---|---|---|---|---|---|
| ACC | ||||||||||
| WebKB | 0.4151 | \ul0.5472 | 0.2264 | 0.3925 | 0.4943 | 0.4830 | 0.4755 | 0.4830 | 0.4455 | 0.6189 |
| BDGP | 0.4144 | \ul0.4540 | 0.3328 | 0.3292 | 0.3860 | 0.3600 | 0.2012 | 0.3892 | 0.3186 | 0.4796 |
| MSRCV1 | 0.5429 | 0.7905 | 0.7381 | 0.3619 | 0.8381 | 0.4571 | 0.7000 | \ul0.8714 | 0.4027 | 0.8952 |
| Caltech7-2view | 0.4233 | 0.7022 | 0.3867 | 0.4417 | 0.5115 | 0.4423 | 0.6737 | 0.5916 | 0.4453 | \ul0.7008 |
| NUS-WIDE-10 | 0.1992 | 0.2342 | 0.1339 | \ul0.2544 | 0.2492 | 0.1899 | 0.2174 | 0.2464 | 0.1956 | 0.2553 |
| Caltech101-7 | 0.2877 | 0.6248 | 0.3996 | 0.3874 | 0.4552 | 0.5204 | 0.6526 | \ul0.6988 | 0.4632 | 0.7205 |
| Caltech101-20 | 0.3345 | 0.4149 | 0.2993 | 0.4011 | 0.3822 | 0.3651 | \ul0.5256 | 0.5163 | 0.3108 | 0.5298 |
| NUS-WIDE | 0.1336 | 0.1298 | 0.0493 | 0.1461 | - | - | 0.1341 | \ul0.1680 | 0.0940 | 0.1761 |
| SUNRGBD | 0.1836 | 0.1628 | 0.1002 | 0.1538 | - | - | 0.1136 | \ul0.2022 | 0.1164 | 0.2222 |
| YoutubeFace | - | 0.1471 | - | 0.0904 | - | - | - | 0.1359 | 0.0903 | \ul0.1380 |
| NMI | ||||||||||
| WebKB | 0.1068 | 0.3175 | 0.0464 | 0.0960 | 0.1266 | 0.0761 | 0.0476 | 0.1361 | 0.1868 | \ul0.2566 |
| BDGP | 0.2812 | \ul0.2567 | 0.1460 | 0.0848 | 0.1090 | 0.1063 | 0.0032 | 0.1531 | 0.0840 | 0.2450 |
| MSRCV1 | 0.4850 | 0.7123 | 0.7639 | 0.1955 | 0.7330 | 0.3627 | 0.7197 | \ul0.8151 | 0.2946 | 0.8420 |
| Caltech7-2view | 0.4981 | 0.5253 | 0.4252 | 0.4139 | 0.4443 | 0.3268 | 0.5862 | \ul0.5959 | 0.2930 | 0.5989 |
| NUS-WIDE-10 | 0.0789 | 0.1076 | 0.0107 | 0.1531 | \ul0.1169 | 0.0606 | 0.0176 | 0.1088 | 0.0686 | 0.1111 |
| Caltech101-7 | 0.1411 | 0.5345 | 0.4514 | \ul0.5579 | 0.3225 | 0.3823 | 0.5629 | 0.4580 | 0.3007 | 0.4949 |
| Caltech101-20 | 0.0121 | 0.5125 | 0.4920 | 0.5527 | \ul0.5323 | 0.4495 | 0.4942 | 0.4837 | 0.3316 | 0.5169 |
| NUS-WIDE | 0.0016 | 0.1041 | 0.0140 | 0.1510 | - | - | 0.0049 | 0.1228 | 0.0581 | \ul0.1240 |
| SUNRGBD | 0.2343 | \ul0.2321 | 0.1857 | 0.1758 | - | - | 0.0230 | 0.2104 | 0.1158 | 0.2245 |
| YoutubeFace | - | 0.1319 | - | 0.0568 | - | - | - | 0.1039 | 0.0616 | \ul0.1050 |
| Purity | ||||||||||
| WebKB | 0.5321 | 0.6943 | 0.2340 | 0.5208 | 0.5660 | 0.5019 | 0.4830 | 0.5358 | 0.5878 | \ul0.6415 |
| BDGP | \ul0.4576 | 0.4540 | 0.3504 | 0.3592 | 0.3860 | 0.3600 | 0.2016 | 0.4044 | 0.3300 | 0.4852 |
| MSRCV1 | 0.5810 | 0.7905 | 0.8000 | 0.3810 | 0.8381 | 0.4762 | 0.7238 | \ul0.8714 | 0.4304 | 0.8952 |
| Caltech7-2view | 0.8589 | 0.8514 | 0.3962 | 0.7910 | 0.8318 | 0.7802 | \ul0.8636 | 0.8632 | 0.7621 | 0.8711 |
| NUS-WIDE-10 | 0.3172 | 0.3232 | 0.1366 | 0.3745 | \ul0.3620 | 0.2788 | 0.2284 | 0.3120 | 0.3059 | 0.3158 |
| Caltech101-7 | 0.6608 | \ul0.8541 | 0.3996 | 0.8548 | 0.7096 | 0.8033 | 0.8528 | 0.8033 | 0.7689 | 0.8297 |
| Caltech101-20 | 0.3345 | 0.6903 | 0.3215 | 0.7334 | \ul0.7091 | 0.6568 | 0.6249 | 0.6622 | 0.5625 | 0.6811 |
| NUS-WIDE | 0.1336 | 0.2148 | 0.0502 | 0.2622 | - | - | 0.1353 | 0.2238 | 0.1859 | \ul0.2240 |
| SUNRGBD | 0.3771 | \ul0.3536 | 0.1098 | 0.2984 | - | - | 0.1163 | 0.2999 | 0.2470 | 0.3111 |
| YoutubeFace | - | 0.2886 | - | 0.2675 | - | - | - | 0.2743 | 0.2664 | \ul0.2766 |
4.2.1 Running Time Comparison
The running time of compared algorithms on benchmark datasets are shown in Figure 4. Due to the excessive time consumed by some of the algorithms, we use the logarithms of the time as the vertical axis of the coordinate.
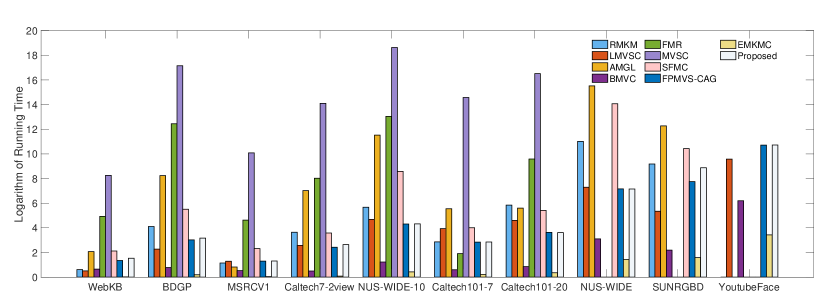
It is worth noticing that for large-scale datasets, namely NUS-WIDE, SUNRGBD and YoutubeFace, some algorithms(FMR, MVSC, SFMC, RMKM) encounter the ’Out-of-Memory’ problem. As a result, the time bars of these methods are omitted in the comparison graph. We observe that the time cost of EMKMC is comparable to ours, but the total runtime cost is still high owing to the aforementioned search space for the best hyper-parameters.
4.2.2 Convergence
As described in the previous sections, our proposed algorithm possesses a theoretical guarantee, ensuring its convergence to a local minimum. Furthermore, to provide empirical evidence of its convergence, we conduct experiments on benchmark datasets. Figure 5 illustrates the evolution of the objective value throughout the experimental process. Notably, the experimental results reveal a consistent and monotonically decreasing trend in the objective values of our algorithm at each iteration. Furthermore, we observe that the algorithm achieves rapid convergence, typically within fewer than 10 iterations. These findings undeniably validate the convergence property of our proposed algorithm.










4.2.3 Parameter Analysis
To demonstrate the impact of varying selections for the number of hierarchical dimension projection matrix, we present the performance variation across distinct layers of with respect to each dataset, as depicted in Figure 6.

4.3 Conclusion
Our work focuses on multi-view clustering and explore ways to increase the effectiveness of anchor-based subspace clustering by tackling the discrepancy and deploying the dependency of different views. We will further investigate whether the number of categories of the datasets can positively affect the accuracy of clustering by providing guidance for the assignation of the number of anchors; and whether it can be beneficial to the heuristic setting of the dimensions of each layer.
References
- Akaho [2006] Akaho, S., 2006. A kernel method for canonical correlation analysis. CoRR abs/cs/0609071.
- Andrew et al. [2013] Andrew, G., Arora, R., Bilmes, J.A., Livescu, K., 2013. Deep canonical correlation analysis, in: Proceedings of the 30th International Conference on Machine Learning, ICML 2013, Atlanta, GA, USA, 16-21 June 2013, JMLR.org. pp. 1247–1255.
- Bellman [1954] Bellman, R., 1954. Some applications of the theory of dynamic programming - A review. Oper. Res. , 275–288.
- Cai et al. [2023] Cai, X., Huang, D., Zhang, G.Y., Wang, C.D., 2023. Seeking commonness and inconsistencies: A jointly smoothed approach to multi-view subspace clustering. Information Fusion 91, 364–375.
- Cai et al. [2013] Cai, X., Nie, F., Huang, H., 2013. Multi-view k-means clustering on big data, in: Twenty-Third International Joint conference on artificial intelligence.
- Cao et al. [2015] Cao, X., Zhang, C., Fu, H., Liu, S., Zhang, H., 2015. Diversity-induced multi-view subspace clustering, in: IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2015, Boston, MA, USA, June 7-12, 2015.
- Chen and Cai [2011] Chen, X., Cai, D., 2011. Large scale spectral clustering with landmark-based representation, in: Twenty-fifth AAAI conference on artificial intelligence.
- Chen et al. [2022] Chen, Z., Lin, P., Chen, Z., Ye, D., Wang, S., 2022. Diversity embedding deep matrix factorization for multi-view clustering. Information Sciences 610, 114–125.
- Elhamifar and Vidal [2013] Elhamifar, E., Vidal, R., 2013. Sparse subspace clustering: Algorithm, theory, and applications. IEEE Trans. Pattern Anal. Mach. Intell. .
- Fan [1949] Fan, K., 1949. On a theorem of weyl concerning eigenvalues of linear transformations i. Proceedings of the National Academy of Sciences 35, 652–655.
- Gao et al. [2015a] Gao, H., Nie, F., Li, X., Huang, H., 2015a. Multi-view subspace clustering, in: 2015 IEEE International Conference on Computer Vision, ICCV 2015, Santiago, Chile, December 7-13, 2015.
- Gao et al. [2015b] Gao, H., Nie, F., Li, X., Huang, H., 2015b. Multi-view subspace clustering, in: Proceedings of the IEEE international conference on computer vision, pp. 4238–4246.
- Guo [2013] Guo, Y., 2013. Convex subspace representation learning from multi-view data, in: Proceedings of the Twenty-Seventh AAAI Conference on Artificial Intelligence, July 14-18, 2013, Bellevue, Washington, USA, AAAI Press.
- Hotelling [1992] Hotelling, H., 1992. Relations between two sets of variates, in: Breakthroughs in statistics. Springer, pp. 162–190.
- Huang et al. [2021] Huang, S., Tsang, I.W., Xu, Z., Lv, J., Liu, Q., 2021. CDD: multi-view subspace clustering via cross-view diversity detection, in: MM ’21: ACM Multimedia Conference, Virtual Event, China, October 20 - 24, 2021, ACM. pp. 2308–2316.
- Kang et al. [2020] Kang, Z., Zhou, W., Zhao, Z., Shao, J., Han, M., Xu, Z., 2020. Large-scale multi-view subspace clustering in linear time, in: Proceedings of the AAAI Conference on Artificial Intelligence, pp. 4412–4419.
- Li et al. [2019] Li, R., Zhang, C., Hu, Q., Zhu, P., Wang, Z., 2019. Flexible multi-view representation learning for subspace clustering., in: IJCAI, pp. 2916–2922.
- Li et al. [2020] Li, X., Zhang, H., Wang, R., Nie, F., 2020. Multi-view clustering: A scalable and parameter-free bipartite graph fusion method. IEEE Transactions on Pattern Analysis and Machine Intelligence .
- Li et al. [2015] Li, Y., Nie, F., Huang, H., Huang, J., 2015. Large-scale multi-view spectral clustering via bipartite graph, in: Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, January 25-30, 2015, AAAI Press. pp. 2750–2756.
- Liang et al. [2022] Liang, W., Liu, X., Zhou, S., Liu, J., Wang, S., Zhu, E., 2022. Robust graph-based multi-view clustering, in: Proceedings of the AAAI Conference on Artificial Intelligence, pp. 7462–7469.
- Liu et al. [2013] Liu, G., Lin, Z., Yan, S., Sun, J., Yu, Y., Ma, Y., 2013. Robust recovery of subspace structures by low-rank representation. IEEE Trans. Pattern Anal. Mach. Intell. .
- Nie et al. [2016] Nie, F., Li, J., Li, X., et al., 2016. Parameter-free auto-weighted multiple graph learning: a framework for multiview clustering and semi-supervised classification., in: IJCAI, pp. 1881–1887.
- Ou et al. [2020] Ou, Q., Wang, S., Zhou, S., Li, M., Guo, X., Zhu, E., 2020. Anchor-based multiview subspace clustering with diversity regularization. IEEE MultiMedia 27, 91–101.
- Qaqish et al. [2017] Qaqish, B.F., O’Brien, J.J., Hibbard, J.C., Clowers, K.J., 2017. Accelerating high-dimensional clustering with lossless data reduction. Bioinform. 33, 2867–2872.
- Shakhnarovich [2005] Shakhnarovich, G., 2005. Learning task-specific similarity. Ph.D. thesis. Massachusetts Institute of Technology, Cambridge, MA, USA.
- Shu et al. [2022] Shu, X., Zhang, X., Gao, Q., Yang, M., Wang, R., Gao, X., 2022. Self-weighted anchor graph learning for multi-view clustering. IEEE Transactions on Multimedia .
- Tang et al. [2023a] Tang, C., Li, Z., Wang, J., Liu, X., Zhang, W., Zhu, E., 2023a. Unified one-step multi-view spectral clustering. IEEE Trans. Knowl. Data Eng. 35, 6449–6460.
- Tang et al. [2023b] Tang, C., Sun, K., Tang, C., Zheng, X., Liu, X., Huang, J., Zhang, W., 2023b. Multi-view subspace clustering via adaptive graph learning and late fusion alignment. Neural Networks 165, 333–343.
- Tang et al. [2022] Tang, C., Zheng, X., Liu, X., Zhang, W., Zhang, J., Xiong, J., Wang, L., 2022. Cross-view locality preserved diversity and consensus learning for multi-view unsupervised feature selection. IEEE Trans. Knowl. Data Eng. 34, 4705–4716.
- Tang et al. [2023c] Tang, C., Zheng, X., Zhang, W., Liu, X., Zhu, X., Zhu, E., 2023c. Unsupervised feature selection via multiple graph fusion and feature weight learning. Sci. China Inf. Sci. 66.
- Wang et al. [2020] Wang, B., Xiao, Y., Li, Z., Wang, X., Chen, X., Fang, D., 2020. Robust self-weighted multi-view projection clustering, in: Proceedings of the AAAI Conference on Artificial Intelligence, pp. 6110–6117.
- Wang et al. [2016] Wang, M., Fu, W., Hao, S., Tao, D., Wu, X., 2016. Scalable semi-supervised learning by efficient anchor graph regularization. IEEE Transactions on Knowledge and Data Engineering 28, 1864–1877.
- Wang et al. [2021] Wang, S., Liu, X., Zhu, X., Zhang, P., Zhang, Y., Gao, F., Zhu, E., 2021. Fast parameter-free multi-view subspace clustering with consensus anchor guidance. IEEE Transactions on Image Processing 31, 556–568.
- Wang et al. [2017] Wang, X., Guo, X., Lei, Z., Zhang, C., Li, S.Z., 2017. Exclusivity-consistency regularized multi-view subspace clustering, in: 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, IEEE Computer Society. pp. 1–9.
- Wang et al. [2015] Wang, Y., Lin, X., Wu, L., Zhang, W., Zhang, Q., Huang, X., 2015. Robust subspace clustering for multi-view data by exploiting correlation consensus. IEEE Trans. Image Process. 24, 3939–3949.
- Wang et al. [2018] Wang, Y., Wu, L., Lin, X., Gao, J., 2018. Multiview spectral clustering via structured low-rank matrix factorization. IEEE Trans. Neural Networks Learn. Syst. 29, 4833–4843.
- Wei et al. [2023] Wei, W., Yue, Q., Feng, K., Cui, J., Liang, J., 2023. Unsupervised dimensionality reduction based on fusing multiple clustering results. IEEE Trans. Knowl. Data Eng. 35, 3211–3223.
- Winn and Jojic [2005] Winn, J., Jojic, N., 2005. Locus: Learning object classes with unsupervised segmentation, in: Tenth IEEE International Conference on Computer Vision (ICCV’05) Volume 1, IEEE. pp. 756–763.
- Xia et al. [2014] Xia, R., Pan, Y., Du, L., Yin, J., 2014. Robust multi-view spectral clustering via low-rank and sparse decomposition, in: Proceedings of the Twenty-Eighth AAAI Conference on Artificial Intelligence, July 27 -31, 2014, AAAI Press. pp. 2149–2155.
- Xu et al. [2013] Xu, C., Tao, D., Xu, C., 2013. A survey on multi-view learning. CoRR abs/1304.5634.
- Yan et al. [2023a] Yan, W., Gu, M., Ren, J., Yue, G., Liu, Z., Xu, J., Lin, W., 2023a. Collaborative structure and feature learning for multi-view clustering. Inf. Fusion 98, 101832.
- Yan et al. [2023b] Yan, W., Gu, M., Ren, J., Yue, G., Liu, Z., Xu, J., Lin, W., 2023b. Collaborative structure and feature learning for multi-view clustering. Information Fusion 98, 101832.
- Yan et al. [2022] Yan, W., Xu, J., Liu, J., Yue, G., Tang, C., 2022. Bipartite graph-based discriminative feature learning for multi-view clustering, in: MM ’22: The 30th ACM International Conference on Multimedia, 2022, ACM. pp. 3403–3411.
- Yan et al. [2023c] Yan, W., Zhang, Y., Lv, C., Tang, C., Yue, G., Liao, L., Lin, W., 2023c. Gcfagg: Global and cross-view feature aggregation for multi-view clustering, in: IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR, 2023, IEEE. pp. 19863–19872.
- Yang et al. [2023] Yang, B., Wu, J., Zhang, X., Lin, Z., Nie, F., Chen, B., 2023. Robust anchor-based multi-view clustering via spectral embedded concept factorization. Neurocomputing .
- Yang et al. [2022a] Yang, B., Zhang, X., Li, Z., Nie, F., Wang, F., 2022a. Efficient multi-view k-means clustering with multiple anchor graphs. IEEE Transactions on Knowledge and Data Engineering .
- Yang et al. [2022b] Yang, B., Zhang, X., Nie, F., Wang, F., 2022b. Fast multiview clustering with spectral embedding. IEEE Transactions on Image Processing 31, 3884–3895.
- Yang et al. [2022c] Yang, H., Gao, Q., Xia, W., Yang, M., Gao, X., 2022c. Multiview spectral clustering with bipartite graph. IEEE Transactions on Image Processing 31, 3591–3605.
- Zhang et al. [2018] Zhang, Z., Liu, L., Shen, F., Shen, H.T., Shao, L., 2018. Binary multi-view clustering. IEEE transactions on pattern analysis and machine intelligence 41, 1774–1782.
- Zhao et al. [2023] Zhao, M., Yang, W., Nie, F., 2023. Auto-weighted orthogonal and nonnegative graph reconstruction for multi-view clustering. Information Sciences 632, 324–339.
- Zhou et al. [2021] Zhou, S., Ou, Q., Liu, X., Wang, S., Liu, L., Wang, S., Zhu, E., Yin, J., Xu, X., 2021. Multiple kernel clustering with compressed subspace alignment. IEEE Transactions on Neural Networks and Learning Systems .