Analytical bounds on the local Lipschitz constants of affine-ReLU functions
Abstract
In this paper, we determine analytical bounds on the local Lipschitz constants of of affine functions composed with rectified linear units (ReLUs). Affine-ReLU functions represent a widely used layer in deep neural networks, due to the fact that convolution, fully-connected, and normalization functions are all affine, and are often followed by a ReLU activation function. Using an analytical approach, we mathematically determine upper bounds on the local Lipschitz constant of an affine-ReLU function, show how these bounds can be combined to determine a bound on an entire network, and discuss how the bounds can be efficiently computed, even for larger layers and networks. We show several examples by applying our results to AlexNet, as well as several smaller networks based on the MNIST and CIFAR-10 datasets. The results show that our method produces tighter bounds than the standard conservative bound (i.e. the product of the spectral norms of the layers’ linear matrices), especially for small perturbations.
1 Introduction
1.1 Introduction
The huge successes of deep neural networks have been accompanied by the unfavorable property of high sensitivity. As a result, for many networks a small perturbation of the input can produce a huge change in the output [13]. These sensitivity properties are still not completely theoretically understood, and raise significant concerns when applying neural networks to safety-critical and other applications. This establishes a strong motivation to obtain a better theoretical understanding sensitivity.
One of the main tools in analyzing the sensitivity of neural networks is the Lipschitz constant, which is a measure of how much the output of a function can change with respect to changes in the input. Analytically computing the exact Lipschitz constant of neural networks has so far been unattainable due to the complexity and high-dimensionality of most networks. As feedforward neural networks consist of a composition of functions, a conservative upper bound on the Lipschitz constant can be determined by calculating the product of each individual function’s Lipschitz constant [13]. Unfortunately, this method usually results in a very conservative bound.
Calculating or estimating tighter bounds on Lipschitz constants has recently been approached using optimization-based methods [11, 8, 3, 17, 6]. The downside to these approaches is that they usually can only be applied to small networks, and also often have to be relaxed, which invalidates any guarantee on the bound.
In summary, the current state of Lipschitz analysis of neural networks is that the function-by-function approach yields bounds which are too loose, and holistic approaches are too expensive for larger networks. In this paper, we explore a middle ground between these two approaches by analyzing the composite of two functions, the affine-ReLU function, which represents a common layer used in modern neural networks. This function is simple enough to obtain analytical results, but complex enough to provide tighter bounds than the function-by-function analysis. We can also combine the constants between layers to compute a Lipschitz constant for the entire network. Furthermore, our analytical approach leads us to develop intuition behind the structure of neural network layers, and shows how the different components of the layer (e.g. the linear operator, bias, nominal input, and size of the perturbation) contribute to sensitivity.
1.2 Related work
The high sensitivity of deep neural networks has been noted as early as [13]. This work conceived the idea of adversarial examples, which have since become a popular area of research [4]. One tool that has been used to study the sensitivity of networks is the input-output Jacobian [9, 12], which gives a local estimate of sensitivity but generally provides no guarantees.
Lipschitz constants are also a common tool to study sensitivity. Recently, several studies have explored using optimization-based approaches to compute the Lipschitz constant of neural networks. The work of [11] presents two algorithms, AutoLip and SeqLip, to compute the Lipschitz constant. AutoLip reduces to the standard conservative approach, while SeqLip is an optimization which requires a greedy approximation for larger networks. The work of [8] presents a sparse polynomial optimization (LiPopt) method which relies on the network being sparse. To apply this technique to larger networks, the authors have to first prune the network to increase sparsity. A semidefinite programming technique (LipSDP) is used in [3], but in order to apply the results to larger networks, a relaxation must be used which invalidates the guarantee. Another approach is that of [17], in which linear programming is used to estimate Lipschitz constants. Finally, [6] proposes exactly computing the Lipschitz constant using mixed integer programming, which is very expensive and can only be applied to very small networks.
Other work has considered computing Lipschitz constants in the context of adversarial examples [10, 15, 16]. While these works use Lipschitz constants and similar mathematical analysis, their focus is on classification, and it is not clear how or if these techniques can be adapted to provide guaranteed upper Lipschitz bounds for larger networks. Additionally, other work has considered constraining the Lipschitz constant as a means to regularize a network [5, 14, 1]. Finally, we note that in this work we study affine-ReLU functions which are commonly used in neural networks, but we are not aware of any work that has directly analyzed these functions except for [2].
1.3 Contributions
Our main contributions are that develop analytical upper bounds on the local Lipschitz constant of affine-ReLU function. We show how these bounds can be combined to create a bound on an entire feedforward network, and also how we can compute our bounds even for large layers.
1.4 Notation
In this paper, we use non-bold lowercase and capital ( and ) to denote scalars, bold lowercase () to denote vectors, and bold uppercase () to denote matrices. Similarly, we use non-bold to denote scalar-valued functions () and bold to denote vector-valued functions (). We will use inequalities to compare vectors, and say that holds if all corresponding pairs of elements satisfy the inequality. Additionally, unless otherwise specified, we let denote the 2-norm.
2 Affine & ReLU functions
2.1 Affine functions
Affine functions are ubiquitous in deep neural networks, as convolutional, fully-connected, and normalization functions are all affine. An affine function can be written as where , , and . Note that since we are considering neural networks, without loss of generality we can define to be a tensor that has been reshaped into a 1D vector. We note that we can redefine the origin of the domain of an affine function to correspond to any point . More specifically, if we consider the system and nominal input , we can redefine as in which case the affine function becomes . We then redefine the bias as , which gives us the affine function . In this paper, we will use the form to represent an affine function that has been shifted so that the origin is at , and represents a perturbation from .
2.2 Rectified Linear Units (ReLUs)
The rectified linear unit (ReLU) is widely used as an activation function in deep neural networks. The ReLU is simply the elementwise maximum of an input and zero: . The ReLU is piecewise linear, and can therefore be represented by a piecewise linear matrix. To define this matrix, we will first define the following function which indicates if a value is non-negative: . We will define the elementwise version of this function as . By defining as the function which creates a diagonal matrix from a vector, we define the ReLU matrix and ReLU function as follows
| (1) |
Note that is a function of , but to make our notation clear we choose to denote the dependence on using a subscript rather than parentheses.
Note that ReLUs are naturally related to the geometric concept of orthants, which are a higher dimensional generalization of quadrants in and octants in . The -dimensional space has orthants. Furthermore, the matrix can be interpreted as an orthogonal projection matrix, which projects onto a lower-dimensional space of . In for example, will represent a projection onto either the origin (when ), a coordinate axis, a coordinate plane, or all of (when ). Each orthant in corresponds to a linear region of the ReLU function, so since there are orthants there are linear regions.
2.3 Affine-ReLU Functions

We define an affine-ReLU function as a ReLU composed with an affine function. In a neural network, these represent one layer, e.g. a convolution or fully-connected function with a ReLU activation. Using the notation in (1), we can write an affine-ReLU function as
| (2) |
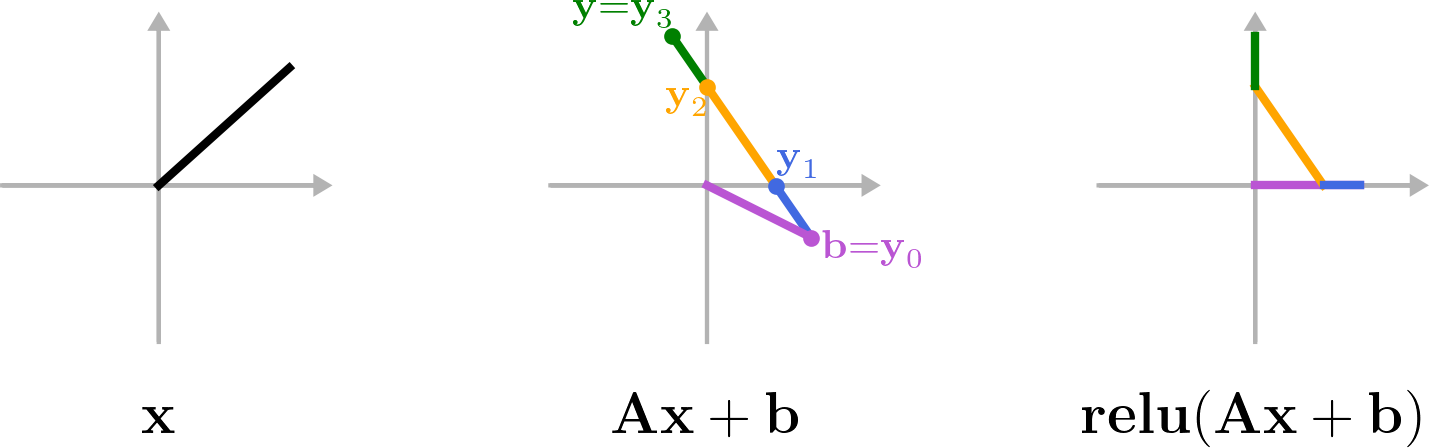
Using Fig. 2 as a reference, we note that the vector will lie in several different orthants of , which are the linear regions of the ReLU function. As a result, can be represented as a sum across the linear regions (i.e. orthants) of the function. For each , there will be some number of linear regions, and we define the points at which transitions between linear regions as for and where and . We also define and so that and . The transition vectors can be determined for a given by determining the value of for which elements of equal zero. With these vectors defined, we note that any vectors and will lie in or at the boundary of the same orthant, and we define as the ReLU matrix corresponding to that orthant. Therefore, we can write the net change of the affine-ReLU function across the orthant adjacent to and as
| (3) |
Next, we define and note that . Noting that the change from the to segment of is (see Fig. 2), we can write the affine-ReLU function as
| (4) |
3 Lipschitz Constants
3.1 Local Lipschitz Constant
We will analyze the sensitivity of the affine-ReLU functions using a Lipschitz constant, which measures how much the output of a function can change with respect to changes in the input. The Lipschitz constant of a function is . Our goal is to analyze the sensitivity of the affine-ReLU function by considering a nominal input and perturbation. As mentioned in Section 2.1, we consider the affine function to be shifted so that the origin corresponds to the nominal input , and corresponds to a perturbation. We define the local Lipschitz constant as a modified version of the standard Lipschitz constant:
| (5) |
The set represents the set of all permissible perturbations. In this paper, we will be most interested in the case that is the Euclidean ball () or the positive part of the Euclidean ball (). See Appendix A.2 for more information. As denotes the domain of affine function (and affine-ReLU function), we will define the range of the affine function similarly as
| (6) |
Applying the local Lipschitz constant to the affine-ReLU function we have
| (7) |
Determining the Lipschitz constant above is a difficult problem due to the piecewise nature of the ReLU. We are not aware of a way to do this computation for high dimensional spaces, which prohibits us from exactly computing the Lipschitz constant. Instead, we will try to come up with a conservative bound. In this paper, we will present several bounds on the Lipschitz constant. The following lemma will serve as a starting point for several of our bounds.
Lemma 1.
Consider the affine function , its domain , and the piecewise representation of the affine-ReLU function in (4). We have the following upper bound on the affine-ReLU function’s local Lipschitz constant: .
The proof is shown in Appendix A.1.
3.2 Naive and intractable upper bounds
We will now approach the task of deriving an analytical upper bound on the local Lipschitz constant of the affine-ReLU function. We start by presenting a standard naive bound.
Proposition 1.
Consider the affine function and its domain . The spectral norm of is an upper bound on the affine-ReLU function’s local Lipschitz constant: .
The proof is shown in Appendix A.1. This is a standard conservative bound that is often used in determining the Lipschitz constants of a full neural network. Next, we will attempt to create a tighter bound. Consider the term in the inequality in Lemma 1. The ReLU matrices are those that correspond to the vectors . So if we can determine all possible ReLU matrices for the vectors in , then we can determine a tighter bound on the Lipschitz constant. We start by defining the matrix as
| (8) |
Proposition 2.
Consider the affine function , its domain , and matrix defined in (8). The spectral norm of is an upper bound on the affine-ReLU function’s local Lipschitz constant: .
Proof.
Consider the inequality in Lemma 1, and note that the ReLU matrices correspond to vectors . So, by definition of , we have for all and all . Since , we have . ∎
While this proposition would provide an upper bound on the Lipschitz constant, in practice it requires determining all possible ReLU matrices corresponding to all vectors . Since has orthants, this method would most likely be intractable except for very small (due to the large number of matrices we would need to compare). As we do not know of a way that avoids computing a large number of spectral norms, this motivates us to look for an even more conservative bound that is more easily computable.
4 Upper bounding regions

4.1 Bounding regions
Our approach in determining a more easily computable bound is based on the idea that we can find a ReLU matrix such that for all . To find this matrix, we will create a coordinate-axis-aligned bounding region around the set (see the left side of Fig. 3 for a diagram). We define the upper bounding vertex of this region as , its associated ReLU matrix as , and the upper bounding region as :
| (9) |
We define , which represents the distance in each coordinate direction from to the border of the bounding region (see Fig. 3). This region will function as a conservative estimate around in regards to the ReLU operation. For information about how and can be computed for various domains , see Appendix A.2.
Recalling the definition of in (1), we note that is a diagonal matrix of 0’s and 1’s. Since the matrix is computed with respect to , it is a reflection of the “most positive” orthant in , and will have a 1 anywhere any matrix for has a 1. The matrix can also be interpreted as the logical disjunction of all matrices for .
4.2 Nested bounding regions
We have described the concept of an upper bounding region , which will lead us to develop an upper bound on the local Lipschitz constant. However, we will be able to develop an even tighter bound by noting that within a bounding region there will be some number of smaller, “nested” bounding regions, each with its own matrix (see the right side of Fig. 3). We then note that the vector can be described using a piecewise representation, in which pieces of closer to are contained in smaller bounding regions. We consider some number of the these bounding regions, which we will index by . We define these bounding regions using scalars where . For a given , we define the affine transformation of as . Furthermore, we define and so that and . We define the scaled bounding region to be the region that bounds for all . As in (9), we define the scaled bounding region as , the bounding vertex as , and its corresponding ReLU matrix as :
| (10) |
Note that the distance from to is for , and the distance from to is for . It will be most sensible to define the scalars to occur at the points for which the scaled region enters positive space for each coordinate, which are the locations at which changes. These values can be found by determining when equals zero for each coordinate. Also, we define the difference in values as for . Lastly, we define the following lemma which we will use later to create our bound.
Lemma 2.
Consider a bounding region and its bounding ReLU matrix . For any two points , the following inequality holds: .
The proof is shown in Appendix A.1.
5 Upper bounds
5.1 Looser and tighter upper bounds
We are now ready to present the main mathematical results of the paper.
Theorem 1.
Consider the affine function , its domain , and its bounding ReLU matrix from (9). The spectral norm of is an upper bound on the affine-ReLU function’s local Lipschitz constant: .
Proof.
From Lemma 1 we have . We note that the matrix corresponds to vectors which are inside the bounding region . Recalling that the ReLU matrices are diagonal matrices with 0’s and 1’s on the diagonal, and will have a 1 anywhere any matrix for has a 1. Therefore the non-zero elements of will be a subset of the non-zero elements of for all and all , which implies for all and all . Since , we have . ∎
Computing this bound for a given domain will be quick if we can quickly compute and . However, we can create an even tighter bound by using the idea of nested regions in Section 4.2.
Theorem 2.
Consider the affine function and its domain . Consider the nested bounding regions , their scale factors and their bounding ReLU matrices as described in Section 4.2. The following is an upper bound on the affine-ReLU function’s local Lipschitz constant: .
5.2 Bounds for Multiple Layers
So far, our analysis has applied to a single affine-ReLU function, which would represents one layer (e.g. convolution-ReLU) of a network. We now describe how these bounds can be combined for multiple layers. First, assume that we have a bound on the size of the perturbation , i.e. . We can rearrange the local Lipschitz constant equation in (5) by moving the denominator to the LHS and applying the bound as follows
| (12) |
Recall that represents the nominal input of the next layer, so represents the perturbation with respect to the next layer. Defining this perturbation as , we have
| (13) |
This gives us a bound on perturbations of the nominal input of the next layer. We can therefore compute the local Lipschitz bounds in an iterative fashion, by propagating the perturbation bounds through each layer of the network. More specifically, if we start with , we can compute the Lipschitz constant of the current layer and then determine the bound for the next layer. We can continue this process for subsequent layers. Using these perturbation bounds, we will consider the domains for each layer of the network to be of the form or when the layer is preceded by a ReLU. Also note that for other types of layers such as max pooling, if we can’t compute a local bound, we can use the global bound, which is what we will do in our simulations.
6 Simulation
6.1 Spectral norm computation
Our results rely on computing the spectral norm for various ReLU matrices . The matrix will correspond to either a convolution or fully-connected function. For larger convolution functions, the matrices are often too large to define explicitly. The only way we can compute for larger layers is by using a power iteration method.
To compute the spectral norm of a matrix , we can note that the largest singular value of is the square root of the largest eigenvalue of . So, we can find the spectral norm of by applying a power iteration to the operator . In our case, and (for various matrices). We can compute the operations corresponding to the , , and matrices in code using convolution to apply , transposed convolution to apply , and zeroing appropriate elements to apply . In all of our simulations, we used 100 iterations, which we verified to be accurate for smaller systems for which an SVD can be computed for comparison.
6.2 Simulations
In our simulations, we compared three different networks: a 7-layer network trained on MNIST, an 8-layer network trained on CIFAR-10, and AlexNet [7] (11-layers, trained on ImageNet). See Appendix A.3 for the exact architectures we used. We trained the MNIST and CIFAR-10 networks ourselves while we used the trained version of AlexNet from Pytorch’s torchvision package. For all of our simulations, we used nominal input images which achieved good classification. However, we noticed that we obtained similar trends using random images. We compared the upper bounds of Proposition 1, Theorem 1, Theorem 2, as well as naive lower bound based on randomly sampling 10,000 perturbation vectors from an -sized sphere. Figure 4 shows the results for different layers of the MNIST network. Figure 5 shows the full-network local Lipschitz constants using the method discussed in Section 5.2. Table 1 shows the computation times.







| network | MNIST net | CIFAR-10 net | AlexNet |
| computation time | 2 sec | 58 sec | 72 min |
The results show that our Lipschitz bounds increase with the size of the perturbation , and approach the spectral norm of for large . For small perturbations, the bound is significantly lower than the naive bound.
7 Conclusion
We have presented the idea of computing upper bounds on the local Lipschitz constant of an affine-ReLU function, which represents one layer of a neural network. We described how these bounds can be combined to determine the Lipschitz constant of a full network, and also how they can be computed in an efficient way, even for large networks. The results show that our bounds are tighter than the naive bounds for a full network, especially for small perturbations.
We believe that the most important direction of future work regarding our method is to more effectively apply it to multiple layers. While we can combine our layer-specific bounds as we have in Fig. 5, it almost certainly leads to an overly conservative bound, especially for deeper networks. We also suspect that our bounds become more conservative for larger perturbations. However, calculating tight Lipschitz bounds for large neural networks is still an open and challenging problem, and we believe our results provide a useful step forward.
8 Broader Impact
We classify this work as basic mathematical analysis that applies to functions commonly used in neural networks. We believe this work could benefit those who are interested in developing more robust algorithms for safety-critical or other applications. It does not seem to us that this research puts anyone at a disadvantage. Additionally, since our bounds are provable, our method should not fail unless it is implemented incorrectly. Finally, we do not believe our method leverages any biases in data.
Acknowledgments and Disclosure of Funding
This work was supported by ONR grant N000141712623.
References
References
- [1] Peter L Bartlett, Dylan J Foster, and Matus J Telgarsky. Spectrally-normalized margin bounds for neural networks. In I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors, Advances in Neural Information Processing Systems 30, pages 6240–6249. Curran Associates, Inc., 2017.
- [2] Sören Dittmer, Emily J. King, and Peter Maass. Singular values for ReLU layers. CoRR, abs/1812.02566, 2018.
- [3] Mahyar Fazlyab, Alexander Robey, Hamed Hassani, Manfred Morari, and George Pappas. Efficient and accurate estimation of Lipschitz constants for deep neural networks. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alché-Buc, E. Fox, and R. Garnett, editors, Advances in Neural Information Processing Systems 32, pages 11427–11438. Curran Associates, Inc., 2019.
- [4] Ian J. Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and harnessing adversarial examples, 2014.
- [5] Henry Gouk, Eibe Frank, Bernhard Pfahringer, and Michael Cree. Regularisation of neural networks by enforcing Lipschitz continuity, 2018.
- [6] Matt Jordan and Alexandros G. Dimakis. Exactly computing the local Lipschitz constant of ReLU networks, 2020.
- [7] Alex Krizhevsky. One weird trick for parallelizing convolutional neural networks. CoRR, abs/1404.5997, 2014.
- [8] Fabian Latorre, Paul Rolland, and Volkan Cevher. Lipschitz constant estimation of neural networks via sparse polynomial optimization. In International Conference on Learning Representations, 2020.
- [9] Roman Novak, Yasaman Bahri, Daniel A. Abolafia, Jeffrey Pennington, and Jascha Sohl-Dickstein. Sensitivity and generalization in neural networks: an empirical study. In International Conference on Learning Representations, 2018.
- [10] Jonathan Peck, Joris Roels, Bart Goossens, and Yvan Saeys. Lower bounds on the robustness to adversarial perturbations. In I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors, Advances in Neural Information Processing Systems 30, pages 804–813. Curran Associates, Inc., 2017.
- [11] Kevin Scaman and Aladin Virmaux. Lipschitz regularity of deep neural networks: analysis and efficient estimation. In S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, editors, Advances in Neural Information Processing Systems 31, pages 3835–3844. Curran Associates, Inc., 2018.
- [12] J. Sokolić, R. Giryes, G. Sapiro, and M. R. D. Rodrigues. Robust large margin deep neural networks. IEEE Transactions on Signal Processing, 65(16):4265–4280, Aug 2017.
- [13] Christian Szegedy, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian Goodfellow, and Rob Fergus. Intriguing properties of neural networks, 2013.
- [14] Dávid Terjék. Adversarial Lipschitz regularization. In International Conference on Learning Representations, 2020.
- [15] Yusuke Tsuzuku, Issei Sato, and Masashi Sugiyama. Lipschitz-margin training: Scalable certification of perturbation invariance for deep neural networks. In S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, editors, Advances in Neural Information Processing Systems 31, pages 6541–6550. Curran Associates, Inc., 2018.
- [16] Tsui-Wei Weng, Huan Zhang, Pin-Yu Chen, Jinfeng Yi, Dong Su, Yupeng Gao, Cho-Jui Hsieh, and Luca Daniel. Evaluating the robustness of neural networks: An extreme value theory approach. In International Conference on Learning Representations, 2018.
- [17] D. Zou, R. Balan, and M. Singh. On Lipschitz bounds of general convolutional neural networks. IEEE Transactions on Information Theory, 66(3):1738–1759, 2020.
Appendix A Appendix
A.1 Proofs
Lemma 1.
Consider the affine function , its domain , and the piecewise representation of the affine-ReLU function in (4). We have the following upper bound on the affine-ReLU function’s local Lipschitz constant: .
Proof.
We can start with (7) and plug in (4):
∎
Proposition 1.
Consider the affine function and its domain . The spectral norm of is an upper bound on the affine-ReLU function’s local Lipschitz constant: .
Proof.
Consider the inequality from Lemma 1: . Note that the ReLU matrix is a diagonal matrix of 0’s and 1’s, so for any , the non-zero elements of will be a subset of the non-zero elements of . Therefore, for all and all , and we can rearrange the inequality from Lemma 1 as follows:
Where in the last step we have used the fact that . ∎
Lemma 2.
Consider a bounding region and its bounding ReLU matrix . For any two points , the following inequality holds: .
Proof.
Since the matrices are diagonal, we can consider this problem on an element-by-element basis, and show that each element of is greater in magnitude than its counterpart in . For a given , let and denote the entry of and , respectively, and let , , and denote the entries of , , and , respectively. We can write the element of as and the corresponding element of as .
Since or imply , there are five possible cases we have to consider, which are shown in the table below.
| case 1 | 0 | 0 | 0 | 0 | 0 |
|---|---|---|---|---|---|
| case 2 | 0 | 0 | 1 | 0 | |
| case 3 | 1 | 0 | 1 | ||
| case 4 | 0 | 1 | 1 | ||
| case 5 | 1 | 1 | 1 |
For cases 1, 2, and 5 it is clear that . For case 3, we note that if and , then and , which means that is a non-positive number that has magnitude equal to or less than the magnitude of . This implies that for case 3. Similar logic can be applied to case 4, except in this case is a non-negative number that has magnitude equal to or greater than the magnitude of . This implies that for case 4.
We showed that for all , each element of is greater in magnitude than the corresponding element in , i.e. . This implies . ∎
Theorem 2.
Consider the affine function and its domain . Consider the nested bounding regions , their scale factors and their bounding ReLU matrices as described in Section 4.2. The following is an upper bound on the affine-ReLU function’s local Lipschitz constant: .
Proof.
First, define the affine transformation of to be . We can write the function as the sum of the differences of the function taken across each segment. For the segment from to , the difference in the affine-ReLU function is . So we can write the total function as
Plugging the equation above into (7), we can write the local Lipschitz constant as
Recalling that and , and that , we know that . So, using Lemma 2 we can rearrange the equation above as follows:
∎
A.2 Bounding region determination for various domains
We have presented the idea of considering an affine function with domain and range . We are interested in determining the axis-aligned bounding region around . We will now show how to tightly compute this region for various domains. Recall from Section 4.1 that we denote the upper bounding vertex of the region as , and define (the distance from to ). We let denote the rows of , and denote the element of . Similarly, we let and denote the elements of and , respectively. Denoting as the standard basis vector, we can write this problem as
We can subtract out the bias term in the maximization above since it is constant. By doing so, our maximization will find instead of . We also define as the maximizing vector:
Domain 1:
Let denote the element of . In this case we have. The quantity will be maximized when the element of with the largest magnitude is given all of the weight. In other words,
Domain 2:
In this case, we are maximizing over all vectors with length less than or equal to . So, the maximum will occur when points in the direction of and has the largest possible magnitude (i.e. ). Note that intuitively this can be thought of as maximizing the dot product of an -sized -sphere with . We have
Note that we have assumed that . If , then it is obvious that any will produce a maximum value of , and the last equation still holds.
Domain 3:
In this case, . So, the quantity is maximized when for positive , and for negative . So, we have
Note that when , the value of does not matter as long as it is in the range . But we define it as zero so that when we consider non-negative domains in the next section, we can simply replace the matrix with its positive part .
Non-negative Domains:
In many cases, due to the affine-ReLU function being preceded by a ReLU, the domain will consist of vectors with non-negative entries. In these cases, the bounding region often becomes smaller (i.e. some or all elements of are smaller). For the 1, 2, or -norms above, we can first decompose the matrix into its positive and negative parts: . Since placing emphasis on a negative element of will always be suboptimal, we can apply the same analysis in Domains 1, 2, and 3, except replace with .
Efficient computation
Note that for large convolutional layers, it is too expensive to represent the entire matrix . In these cases, we can obtain the row of using the transposed convolution operator. More specifically, we create a transposed convolution function with no bias, based on the original convolution function. Then, by noting that if we consider a standard basis vector , the column of (and row of ) is given by . Therefore, by plugging in the standard basis vector to the transposed convolution function, we can obtain , the row of . Note that a vector must first be reshaped into the proper input dimension before plugging it into the transposed convolution function. Furthermore, to reduce computation time in practice, instead of plugging in each standard basis vector one at a time, we plug in a batch of different standard basis vectors to obtain multiple rows of .
A.3 Neural network architectures
We used three neural networks in this paper. The first network is based on the MNIST dataset and we refer to it as “MNIST net”. We constructed MNIST net ourselves and trained it to 99% top-1 test accuracy in 100 epochs. The second network is based on the CIFAR-10 dataset and we refer to it as “CIFAR-10 net”. We constructed CIFAR-10 net ourselves and trained it to 84% top-1 test accuracy in 500 epochs. The third network is the pre-trained implementation of AlexNet from Pytorch’s torchvision package. The following table shows the architectures of MNIST net and CIFAR-10 net.
| MNIST net | CIFAR-10 net |
|---|---|
| conv5-6 | conv3-32 |
| maxpool2 | conv3-32 |
| conv5-16 | maxpool2 |
| maxpool2 | dropout |
| FC-120 | conv3-64 |
| FC-84 | conv3-64 |
| FC-10 | maxpool2 |
| dropout | |
| FC-512 | |
| dropout | |
| FC-10 |