Analysis of Evolutionary Algorithms on Fitness Function with Time-linkage Property
Abstract
In real-world applications, many optimization problems have the time-linkage property, that is, the objective function value relies on the current solution as well as the historical solutions. Although the rigorous theoretical analysis on evolutionary algorithms has rapidly developed in recent two decades, it remains an open problem to theoretically understand the behaviors of evolutionary algorithms on time-linkage problems. This paper takes the first step to rigorously analyze evolutionary algorithms for time-linkage functions. Based on the basic OneMax function, we propose a time-linkage function where the first bit value of the last time step is integrated but has a different preference from the current first bit. We prove that with probability , randomized local search and EA cannot find the optimum, and with probability , EA is able to reach the optimum.
Index Terms:
Evolutionary algorithms, time-linkage, convergence, running time analysis.I Introduction
Evolutionary Algorithms (EAs), one category of stochastic optimization algorithms that are inspired by Darwinian principle and natural selection, have been widely utilized in real-world applications. Although EAs are simple and efficient to use, the theoretical understandings on the working principles and complexity of EAs are much more complicated and far behind the practical usage due to the difficulty of mathematical analysis caused by their stochastic and iterative process.
In order to fundamentally understand EAs and ultimately design efficient algorithms in practice, researchers begin the rigorous analysis on functions with simple and clear structure, majorly like pseudo-Boolean function and classic combinatorial optimization problem, like in the theory books [1, 2, 3, 4, 5]. Despite the increasing attention and insightful theoretical analyses in recent decades, there remain many important open areas that haven’t been considered in the evolutionary theory community.
One important open issue is about the time-linkage problem. Time-linkage problem, firstly introduced by Bosman [6] into the evolutionary computation community, is the optimization problem where the objective function to be optimized relies not only on the solutions of the current time but also the historical ones. In other words, the current decisions also influence the future. There are plenty of applications with time-linkage property. We just list the dynamic vehicle routing with time-varying locations to visit [6] as a slightly detailed example. Suppose that the locations are clustered. Then the current vehicle serving some locations in one cluster is more efficient to serve other locations in the same cluster instead of serving the currently available locations when the locations oscillate among different clusters in future times. Besides, the efficiency of the current vehicle routing would influence the quality of the service, which further influences the future orders, that is, future locations to visit. In a word, the current routing and the impact of it in the future together determine the income of this company. The readers could also refer to the survey in [7] to see more than real-world applications, like an optimal watering scheduling to improve the quality of the crops along with the weather change [8].
The time-linkage optimization problems can be tackled offline or online according to different situations. If the problem pursues an overall solution with sufficient time budget and time-linkage dynamics can be integrated into a static objective function, then the problem can be solved offline. However, in the theoretical understanding on the static problem [1, 2, 3, 4, 5], no static benchmark function in the evolutionary theory community is time-linkage.
Another situation that the real-world applications often encounter is that the solution must be solved online as the time goes by. This time-linkage online problem belongs to dynamic optimization problem [7]. As pointed out in [7], the whole evolutionary community, not only the evolutionary theory community, is lack of research on these real-world problems. The dynamic problem analyzed so far in the theory community majorly includes Dynamic OneMax [9], Magnitude and Balance [10], Maze [11], Bi-stable problem [12], dynamic linear function [13], and dynamic BinVal function [14] for dynamic pseudo-Boolean function, and dynamic combinatorial problems including single-destination shortest path problem [15], makespan scheduling [16], vertex cover problem [17], subset selection [18], graph coloring [19], etc. However, there is no theoretical analysis on dynamic time-linkage fitness function, even no dynamic time-linkage pseudo-Boolean function is proposed for the theoretical analysis.
The main contributions of this paper can be summarized as follows. This paper conducts the first step towards the understanding of EAs on the time-linkage function. When solving a time-linkage problem by EAs in an offline mode, the first thing faced by the practitioners to utilize EAs is how they encode the solution. There are obviously two straightforward encoding ways. Take the objective function relying on solutions of two time steps as an example. One way is to merely ignore the time-linkage dependency by solving a non-time-linkage function with double problem size. The other way is to consider the time-linkage dependency, encode the solution with the original problem size, but store the solutions generated in the previous time steps for the fitness evaluation. When solving the time-linkage problem in an online mode, the engineers need to know before they conduct the experiments whether the algorithm they use can solve the problem or not. Hence, in this paper, we design a time-linkage toy function based on OneMax to shed some light on these questions. This function, called OneMax where is the dimension size, is the sum of two components, one is OneMax fitness of the current -dimensional solution, the other one is the value of the first dimension in the previous solution but multiplying minus dimension size. The design of this function considers the situation when the current solution prefers a different value from the previous solution, which could better show the influence of different encodings. Also, it could be the core element of some dynamic time-linkage functions and used in the situation that each time step we only optimize the current state of the online problem in a limited time, so that the analysis of this function could also show some insights to the undiscovered theory for the dynamic time-linkage function.
For our results, this paper analyzes the theoretical behaviors of randomized local search (RLS) and two most common benchmark EAs, EA and EA, on OneMax. We will show that with probability , RLS and EA cannot find the optimum of OneMax (Theorem 7) while the not small population size in EA can help it reach the optimum with probability (Theorem 15). We also show that conditional on an event with probability , the expected runtime for EA is (Theorem 16).
The remainder of this paper is organized as following. In Section II, we introduce the motivation and details about the designed OneMax. Section III shows the theoretical results of RLS and EA on OneMax, and our theoretical results of EA are shown in Section IV. Our conclusion is summarized in Section V.
II OneMax Function
II-A OneMax Function
For the first time-linkage problem for theoretical analysis, we expect the function to be simple and with clear structure. OneMax, which counts the total ones in a bit string, is considered as one of the simplest pseudo-Boolean functions, and is a well-understood benchmark in the evolutionary theory community on static problems. Choosing it as a base function to add the time-linkage property could facilitate the theoretical understanding on the time-linkage property. Hence, the time-linkage function we will discuss in this paper is based on OneMax. In OneMax function, each dimension has the same importance and the same preference for having a dimension value . We would like to show the difference, or more aggressively show the difficulty that the time-linkage property will cause, which could better help us understand the behavior of EAs on time-linkage problems. Therefore, we will introduce the solutions of the previous steps but with different importance and preference. For simplicity of analysis, we only introduce one dimension, let’s say the first dimension, value of the last time step into the objective function but with the weight of , where is the dimension size. Other weights could also be interesting, but for the first time-linkage benchmark, we just take to show the possible difficulty caused by the time-linkage property. More precisely, this function is defined by
| (1) |
for two consecutive and . Clearly, (1) consists of two components, OneMax component relying on the current individual, and the drawing-back component determined by the first bit value of the previous individual. If our goal is to maximize (1), it is not difficult to see that the optimum is unique and the maximum value is reached if and only if . Hence, we integrate and call (1) OneMax function.
The maximization of the proposed OneMax function specializes the maximization of the more general time-linkage pseudo-Boolean problems defined by
| (2) |
for consecutive where and could be infinite. OneMax function could be regarded as a specialization with , , and . We acknowledge that more complicated models are more interesting and practical, like with , with more than one bit value and with other weight values for the historical solutions, etc., but current specialization facilitates the establishment of the first theoretical analysis for the time-linkage problems, and our future work will focus on the analyses of more complicated models.
II-B Some Notes
Time-linkage optimization problem can be solved offline or online due to different situations. In the following, we follow the main terminology from [6], the first paper that used the term “time-linkage” and introduced it into the evolutionary computation community.
II-B1 Offline mode
Solving the general time-linkage problem defined above in an offline mode means that we could evaluate all possible before determine the final solution for the problem . In this case, the optimum is defined differently when we use different representations. Obviously, there are two straightforward kinds of representations. One is ignoring the time-linkage fact and encoding into an -bit string as one solution, and the optimum is a search point with dimensions. We denote this optimum as . Since the problem is transferred to a traditional non-time-linkage problem, it is not of interest of our topic.
The other kind of representation is considering the time-linkage property and encoding , into an -bit string, , and storing other historical solutions for objective function evaluation. In this case, the optimum is a search point with dimensions taking the same values as the last bit values of , the optimum in the first kind of representation, condition on the stored solutions taking the same values as the corresponding bit values of . For the considered OneMax function, we encode an -bit string as one solution and store the previous result for objective function evaluation, and the optimum is the current search point with all 1s condition on that the stored previous first bit has value 0. This representation is more interesting to us since now and OneMax function are truly time-linkage functions and we could figure out how EAs react to the time-linkage property. Hence, the later sections only consider this representation when solving the OneMax function in an offline mode is analyzed.
II-B2 Online mode
As in [6, Section 2], the online mode means that we regard it as a dynamic optimization problem, and that the process continues only when the decision on the current solution is made, that is, solutions cannot be evaluated for any time and we can only evaluate the quality of the historical and the present solutions. More precisely, at present time , we can evaluate
where we note that could dynamically change and could be different from in (2) when the process ends at , since the impact of the historical solutions could change when time goes by. Usually, for the online mode, the overall optimum within the whole time period as in the offline mode cannot be reached once some non-optimal solution is made in one time step. Hence, our goal is to obtain the function value as larger as possible before the end of the time period, or more specifically, to obtain some function value above one certain threshold. We notice the similarity to the discounted total reward in the reinforcement learning [20, Chapter 3]. However, as pointed in [6, Section 1], the online dynamic time-linkage problem is fundamentally different since in each time the decisions themselves are needed to be optimized and can only be made once, while in reinforcement learning the policies are the solutions and the decisions during the process serve to help determine a good policy.
Back to the OneMax, the function itself is not suitable to be solved in an online mode since it only contains the previous time step and the current step. However, we could still relate OneMax function to online dynamic optimization problems, via regarding it as one piece of the objective function that considers the overall results during a given time period and each time step we only optimize the current piece. For example, we consider the following dynamic problem
| (3) |
where , for and the initial and are given. For (3), our goal is to find the solution at some time step when its function value is greater than . Since the previous elements in time steps can contribute at most value, the goal can be transferred to find the time step when the component of the current and the last step, that is, OneMax, has the value of . Thus if we take the strategy for online optimization that we optimize the present each time as discussed in [6, Section 3], that is, for the current time , we optimize with knowing , then the problem can be functionally regarded as maximizing OneMax function with -bit string encoding as time goes by. Hence, we could reuse the optimum of OneMax function in the offline mode as our goal for solving (3) in an online mode, and call it “optimum” for this online mode with no confusion.
In summary, considering the OneMax problem, we note that for the representation encoding -bit string in an offline manner and for optimizing present in an online dynamic manner, the algorithm used for these two situations are the same but with different backgrounds and descriptions of the operators. The details will be discussed when they are mentioned in Sections III and IV.
III RLS and EA Cannot Find the Optimum
III-A RLS and EA Utilized for OneMax
EA is the simplest EA that is frequently analyzed as a benchmark algorithm in the evolutionary theory community, and randomized local search (RLS) can be regarded as the simplification of EA and thus a pre-step towards the theoretical understanding of EA. Both algorithms are only with one individual in their population. Their difference is on the mutation. In each generation, EA employs the bit-wise mutation on the individual, that is, each bit is independently flipped with probability , where is the problem size, while RLS employs the one-bit mutation, that is, only one bit among bits is uniformly and randomly chosen to be flipped. For both algorithms, the generated offspring will replace its parent as long as it has at least the same fitness as its parent.
The general RLS and EA are utilized for non-time-linkage function, and they do not consider how we choose the individual representation and do not consider the requirement to make a decision in a short time. We need some small modifications on RLS and EA to handle the time-linkage OneMax function. The first issue, the representation choice, only happens when the problem is solved in an offline mode. As mentioned in Section II-B, for the two representation options, we only consider the one that encodes the current solution and stores the previous solution for fitness evaluation. In this encoding, we set that only offspring with better or equivalent fitness could affect the further fitness, hoping the optimization process to learn or approach to the situations which are suitable for the time-linkage property. Algorithm 1 shows our modified EA and RLS for solving OneMax, and we shall still use the name EA and RLS in this paper with no confusion. In this case, the optimum of OneMax is the as the current solution with the stored first bit value of the last generation being . Practically, some termination criterion is utilized in the algorithms when the practical requirement is met. Since we aim at theoretically analyzing the time to reach the optimum, we do not set the termination criterion here.
The second issue, the requirement to make a decision in a short time, happens when the problem is solved in an online mode. Detailedly, consider the problem (3) we discussed in Section II-B that in each time step we just optimize the present. If the time to make the decision is not so small that EA or RLS can solve the -dimension problem (OneMax function), then we could obtain in each time step . Obviously, in this case, the sequence of we obtained will lead to a fitness less than for any time step , and thus we cannot achieve our goal and this case is not interesting. Hence, we assume the time to make the decision is small so that we cannot solve -dimensional OneMax function, and we can just expect to find some result with better or equivalent fitness value each time step. That is, we utilize EA or RLS to solve OneMax function, and the evolution process can go on only if some offspring with better or equivalent fitness appears. In this case, we can reuse Algorithm 1, but to note that the generation step need not to be the same as the time step of the fitness function since EA or RLS may need more than one generation to obtain an offspring with better or equivalent fitness for one time step.
In a word, no matter utilizing EA and RLS to solve OneMax offline or online, in the theoretical analysis, we only consider Algorithm 1 and the optimum is the current search point with all 1s condition on that the stored previous first bit has value 0, without mentioning the solving mode and regardless of the explanations of the different backgrounds.
III-B Convergence Analysis of RLS and EA on OneMax
This subsection will show that with high probability RLS and EA cannot find the optimum of OneMax. Obviously, OneMax has two goals to achieve, one is to find all 1s in the current string, and the other is to find the optimal pattern in the first bit that the current first bit value goes to 1 when the previous first bit value is 0. The two goals are somehow contradictory, so that only one individual in the population of RLS and EA will cause poor fault tolerance. Detailedly, as we will show in Theorem 7, with high probability, one of twos goal will be achieved before the optimum is found, but the population cannot be further improved.
Since this paper frequently utilizes different variants of Chernoff bounds, to make it self-contained, we put them from [21, 22] into Lemma 1. Besides, before establishing our main result, with the hope that it might be beneficial for further research, we also discuss in Lemma 2 the probability estimate of the event that the increase number of ones from one parent individual to its offspring is under the condition that the increase number of ones is positive in one iteration of EA, given the parent individual has zeros.
Lemma 1 ([21, 22]).
Let be independent random variables. Let .
-
(a)
If takes values in , then for all , .
-
(b)
If takes values in an interval of length , then for all ,
-
(c)
If follows the geometric distribution with success probability for all , then for all , for all ,
Lemma 2.
Suppose . is generated by independently flipping each bit of with probability . Let be the number of zeros in , and let denote the number of ones in and for the number of ones in . Then
Proof.
Since
and , we have
For , it is easy to see that
For , since
and
we have
With
the lemma is proved. ∎
Now we show the behavior for RLS and EA optimizing OneMax function. The outline to establish our main theorem (Theorem 7) is shown in Figure 1. First, Lemma 3 shows two cases once one of them happens before the optimum is reached, both RLS and EA cannot find the optimum in arbitrary further generations. Then for the non-trivial behaviors for three different initial states, Lemma 4, Lemma 5, and Lemma 6 respectively show that the algorithm will get stuck in one of the two cases. In the following, all proofs don’t specifically distinguish RLS and EA due to their similarity, and discuss each algorithm independently only when they have different behaviors. We start with one definition that will be frequently used in our proofs.
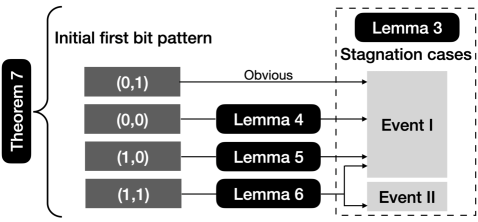
Lemma 3.
Consider using EA (RLS) to optimize -dimensional OneMax function. Let be the solution sequence generated by the algorithm. Let
-
•
Event I: There is a such that and ,
-
•
Event II: There is a such that .
Then if at a certain generation among the solution sequence, Event I or Event II happens, then EA (RLS) can not find the optimum of OneMax in an arbitrary long runtime afterwards.
Proof.
Consider the case when Event I happens, then . In this case, the current fitness . For every possible , the mutation outcome of , since , we know regardless of the values of other bits in . Hence, cannot enter in the -th generation, that is, any progress achieved in the OneMax component of OneMax function (any bit value changing from to from the -nd to the -th bit position) cannot pass on to the next generation. Besides, , then holds for all . That is, RLS or EA gets stuck in this case.
Consider the case when Event II happens, that is, . In this case, the current fitness . Similar to the above case, since , all possible mutation outcome along with will have fitness less than or equal to . Hence, only when happens, can enter into the next generation, which means . Therefore, RLS or EA will get stuck in this case. ∎
Lemma 4.
Consider using EA (RLS) to optimize -dimensional OneMax function. Assume that at the first generation, and . Then with probability at least , Event I will happen at one certain generation after this initial state.
Proof.
Consider the subsequent process once the number of -bits among bit positions of the current individual, becomes less than for any given constant . Note that if the first bit value changes from to before the number of -bits decreases to , Event I already happens. Hence, we just consider the case that the current first bit value is still at the first time when the number of the remaining -bits decreases to . Let denote the number of -bits of the current individual. We conduct the proof of this lemma based on the following two facts.
-
•
Among increase steps (the fitness has an absolute increase), a single increase step increases the fitness by with conditional probability at least . For RLS, due to its one-bit mutation, the amount of fitness increase can only be for a single increase step. For EA, Lemma 2 directly shows this fact.
-
•
Under the condition that one step increases the fitness by , with conditional probability at least , the first bit changes its value from to . It is obvious for RLS. For EA, suppose that the number of bits changing from to in this step is , then the probability that the first bit contributes one is for .
Note that there are increase steps before the remaining positions become all s if each increase step increases the fitness by . Then with the above two facts, it is easy to see that the probability that one individual with the first bit pattern is generated before remaining positions all have bit value is at least
We could just set and obtain the probability lower bound as . ∎
Lemma 5.
Consider using EA (RLS) to optimize -dimensional OneMax function. Assume that at the first generation, and . Then with probability at least , Event I will happen at one certain generation after this initial state.
Proof.
Since , we know that any offspring will have better fitness than the current individual, and will surely enter into the next generation. Then with probability , the first bit value in the next generation becomes , that is, Event I happens. Otherwise, with probability , it turns to the above discussed situation. Hence, in this situation, the probability that eventually Event I happens is at lea st
Lemma 6.
Consider using EA (RLS) to optimize -dimensional OneMax function. Assume that at the first generation, and . Then with probability at least , Event I or Event II will happen at one certain generation after this initial state.
Proof.
For , since in each iteration only one bit can be flipped for RLS, once the first bit is flipped from to , the fitness of the offspring will be less than its parent and the offspring cannot enter into the next generation. Hence, for RLS, the individual will be eventually evolved to for some . That is, Event II happens.
For EA, similar to the situation, we consider the subsequent process once the number of -bits among bit positions of the current individual, becomes less than for some constant , and let denote the number of -bits of the current individual. If the first bit value changes from to before the number of -bits decreases to , we turn to the situation. Otherwise, we will show that in the subsequent generations, with probability at least , the pattern will be maintained after the remaining bits reach the optimal . Consider the condition that the first bit value stays at s and let be the number of time that all bit positions have bit value under this condition. Note that under this condition, one certain bit position in does not change to in generations is at most . Then a union bound shows
Noting that the probability that the offspring with the first bit value changing from to can enter into next generation is at most , we can obtain the probability that Event II happens within generations is at least
Further taking , together with the probability of Event I when the first bit pattern changes to before the number of zeros decreases to , we have Event I or Event II will happen with probability at least . ∎
Theorem 7.
Let . Then with probability at least , EA (RLS) cannot find the optimum of the -dimensional OneMax function.
Proof.
For the uniformly and randomly generated -st generation, we have . The Chernoff inequality in Lemma 1(b) gives that . Hence, with probability at least , holds, that is, bit positions have at least zeros. Thus, neither Event II nor Event II happens at the first generation. We consider this initial status in the following.
Recall that from Lemma 3, Event I and Event II are two stagnation situations. For the first bit values and of the randomly generated two individuals and , there are four situations, or . If , Event I already happens. Respectively from Lemma 4, Lemma 5, and Lemma 6, we could know that with probability at least , Event I or Event II will happen in the certain generations after the initial first bit pattern and .
Overall, together with the probability of , we have the probability for getting stuck is at least
where the last inequality uses when . ∎
One key reason causing the difficulty for (1+1) EA and RLS is that there is only one individual in the population. As we can see in the proof, once the algorithm finds the optimal pattern in the first bit, the progress in OneMax component cannot pass on to the next generation, and once the current OneMax component finds the optimum before the first bit optimal pattern, the optimal first bit pattern cannot be obtained further. In EAs, for some cases, the large population size does not help [23], but the population could also have many benefits for ensuring the performance [24, 25, 26, 27]. Similarly, we would like to know whether introducing population with not small size will improve the fault tolerance to overcome the first difficulty, and help to overcome the second difficulty since individual has worse fitness so that it is easy to be eliminated in the selection. The details will be shown in Section IV.
The above analyses are conducted for the offline mode. For the online mode on problem (3), as discussed in Sections II-B and III-A, we assume the time to make the decision that could change the fitness function value is so small that we can just expect one solution with a better or equivalent fitness value at each time step. Hence, when we reuse Algorithm 1, the time of the fitness function increases to once the algorithm witnesses the generation where the generated satisfies . It is not difficult to see that and are usually different as Algorithm 1 may need more than one generation to generate such . Hence, from Theorem 7, we could also obtain that with probability at least , EA or RLS in our discussed online mode cannot find the solution at some time step when the function value of problem (3) is greater than .
IV EA Can Find the Optimum
IV-A EA Utilized for OneMax
EA is a commonly used benchmark algorithm for evolutionary theory analysis, which maintains a parent population of size comparing with EA that has population size . In the mutation operator, one parent is uniformly and randomly selected from the parent population, and the bit-wise mutation is employed on this parent individual and generates its offspring. Then the selection operator will uniformly remove one individual with the worse fitness value from the union individual set of the population and the offspring.
Similar to EA discussed in Section III, the general EA is utilized for non-time-linkage function, and some small modifications are required for solving time-linkage problems. For solving OneMax function in an offline mode, we just consider the representation that each individual in the population just encodes the current solution and stores the previous solution for the fitness evaluation. Similar to RLS and EA, only offspring with better or equivalent fitness could affect the further fitness, hoping the optimization process to learn the preference of the time-linkage property. Algorithm 2 shows how EA solves the time-linkage function that relies on two consecutive time steps. With no confusion, we shall still call this algorithm EA. Also note that we do not set the termination criterion in the algorithm statement, as we aim at theoretically analyzing the time to reach the optimum, that is, to generate condition on that its parent has the first bit value in Algorithm 2.
We do not consider using EA to solve OneMax function in an online mode. If the decision must be made in a short time period as we discussed in Section III-A, since different individuals in the parent population has their own evolving histories and different time fronts, the better offspring generated in one step cannot be regarded as the decision of the next step for the individuals in the parent population other than its own parent. If we have enough budget before time step changes, similar to the discussion in Section III-A, we will have the fitness less than 1 for any time step since for each time step . Also, it is not interesting for us. Hence, the following analysis only considers EA (Algorithm 2) solving OneMax function in the offline mode.
IV-B Convergence Analysis of EA on OneMax
In Section III, we show the two cases happening before the optimum is reached that cause the stagnation of EA and RLS for the OneMax. One is that the first bit pattern is reached, and the other is that the current individual has the value one in all its bits with the previous first bit value as . The single individual in the population of EA or RLS results in the poor tolerance to the incorrect trial of the algorithm. This subsection will show that the introduction of population can increase the tolerance to the incorrect trial, and thus overcome the stagnation. That is, we will show that EA can find the optimum of OneMax with high probability. In order to give an intuitive feeling about the reason why the population can help for solving OneMax, we briefly and not-so-rigorously discuss it before establishing a rigorous analysis.
Corresponding to two stagnation cases for EA or RLS, EA can get stuck when all individuals have the first bit value as no matter the previous first bit value as the first case or the previous first bit value as the second case. As discussed in Section III, we know that the individual with previous first bit value as has no fitness advantage against the one with previous first bit value as . Due to the selection operator, the one with previous first bit value will be early replaced by the offspring with good fitness. As the process goes by, more detailedly in linear time of the population size in expectation, all individuals with the previous first bit value will die out, and the offspring with its parent first bit value cannot enter into the population. That is, the second case cannot take over the whole population to cause the stagnation.
As for the first case that the pattern individuals takes over the population, we focus on the evolving process of the best pattern individual, which is fertile, similar to the runtime analysis of original EA in [28]. The best pattern individuals can be incorrectly replaced only by the pattern individual with better or the same fitness and only when all individuals with worse fitness than the best pattern individual are replaced. With a sufficient large population size, like as the problem size, with high probability, the better pattern individuals cannot take over the whole population and the pattern individuals with the same fitness as the best pattern individual cannot replace all best individuals when the population doesn’t have any individual with worse fitness than the best individual. That is, the first case with high probability will not happen for EA. In a word, the population in EA increases the tolerance to the incorrect trial.
Now we start our rigorous analysis. As we could infer from the above description, the difficulty of the theoretical analysis lies on the combining discussion of the inter-generation dependencies (the time-linkage among two generations) and the inner-generation dependencies (such as the selection operator). One way to handle these complicated stochastic dependencies could be the mean-field analysis, that is, mathematically analysis on a designed simplified algorithm that discards some dependencies and together with an experimental verification on the similarity between the simplified algorithm and the original one. It has been already introduced for the evolutionary computation theory [29]. However, the mean-field analysis is not totally mathematically rigorous. Hence, we don’t utilize it here and analyze directly on the original algorithm. Maybe the mean-field analysis could help in more complicated algorithm and time-linkage problem, and we also hope our analysis could provide some other inspiration for the future theory work on the time-linkage problem.
For clarity, we put some calculations as lemmas in the following.
Lemma 8.
Let , and . Define the functions and by
then and are monotonically decreasing.
Proof.
Since , and for any and ,
we know is monotonically decreasing.
Similarly, since , and for any and ,
we know is monotonically decreasing. ∎
Lemma 9.
Let . Define the function by , then is monotonically decreasing.
Proof.
Consider . For any and , we have
Then, , and hence , are monotonically decreasing. ∎
Lemma 10.
Let . Then .
Proof.
Consider . Then for ,
Hence, is monotonically decreasing for . Since , we have for . Noting that , we have and hence for . ∎
Now we show our results that EA can find the optimum of OneMax function with high probability. We start with some definitions that will be frequently used in our proofs.
Definition 11.
Consider using EA with population size to optimize -dimensional OneMax function. is the population at the -th generation, and for the -th generation. Let be the best fitness among all individuals with the first bit pattern. For ,
-
•
it is called a temporarily undefeated individual if and .
-
•
it is called a current front individual if and .
-
•
it is called an interior individual if it is neither a temporarily undefeated individual nor a current front individual.
The most difficult case is when all and are replaced, which happens after linear time of the population size as in the proof of Theorem 15. Lemmas 12 to 14 discuss the behavior in this case. Lemma 12 will show that when the population is large enough, with high probability, there are at most accumulative temporarily undefeated individuals before the current front individuals have only 1 zero.
Lemma 12.
Given any . For , consider using EA with population size to optimize -dimensional OneMax function. Assume that
-
•
the current front individuals have less than zeros;
-
•
all individuals are with the or pattern.
Then with probability at least , there are at most accumulative temporarily undefeated individuals generated before the current front individuals only have 1 zero.
Proof.
Consider the case when the current front individuals have at least 2 zeros. For the current population, let denote the number of zeros in one current front individual, then . Let denote the set of the individuals that have number of zeros. Obviously, is the set of the best individuals. Let represent the event that the best fitness of the population increases in one generation, and the event that one offspring with better fitness than the current best fitness is generated in one generation. Then we have
and
Firstly, we discuss what happens under the condition that the parent is not from individuals. Let represent the event that one of individuals generates a offspring with better fitness than the current best fitness in one generation. Since
we know
| (4) |
where the last inequality uses .
Secondly, we consider the case when the parent is selected from individuals, that it, event happens. With Lemma 8, we know
We discuss in two cases considering and for any given constant . From the assumption in this lemma, we know . Then for , we have
For ,
Hence, we have for , since when is large. Together with , we know
| (5) |
Hence, from (4) and (5), we obtain
Then if we consider the subprocess that merely consists of event and , we have . Let be the number of iterations that happens in the subprocess before occurs times, then . It is not difficult to see that is stochastically dominated by the sum of geometric variables with success probability . Hence, with the Chernoff bound for the sum of geometric variables in Lemma 1(c), we have that for any positive constant ,
When and , we know
Hence, we know that with probability at least , there are at most possible accumulative temporarily undefeated individuals before occurs times. Now take , then . With , from Lemma 10, we know and thus (5) hold. Noting that reducing the number of zeros in one current front individuals to 1 requires at most occurrence times of , this lemma is proved. ∎
Lemma 13 will show that with high probability, the current front individuals will get accumulated to before all interior individuals have the same number of zeros as the current front individuals.
Lemma 13.
Let . Consider using EA with population size to optimize -dimensional OneMax function.
-
•
Assume that
-
–
there are at most accumulative temporarily undefeated individuals before the current front individuals only have 1 zero;
-
–
all individuals are with the or pattern;
-
–
-
•
Consider the phase starting from the first time when the current front individuals have zeros, and ending with the first time when one pattern individual with less than zeros is generated for , or ending with the first time when one pattern individual with all ones is generated for .
Then with probability at least , the current front individuals will increase by more than if the current phase doesn’t end before all individuals have at most zeros.
Proof.
Same as the notation in the proof of Lemma 12, denotes the set of the individuals that have number of zeros. We now analyze the change of until all other individuals have at most zeros, if possible, during the phase. Let represent the event that one pattern individual with zeros is generated in one generation, and the event that one pattern individual with zeros is generated in one generation. Then we have
and
where we define for . Assume that the parent is not from individuals. Let represent the event that one of individuals generates a offspring with zeros in one generation. Due to the definition of , when exist, we have , and then . Since
we know
| (6) |
Now we calculate , the probability that one of individual generates a offspring with zeros in one generation, as
| (7) |
where the second inequality follows from Lemma 8 and the last inequality follows from Lemma 9 and . With for , we have
| (8) |
Hence, from (6) and (8), we obtain
Then if we consider the subprocess that merely consists of event and , we have . Recalling the definition of the phase we consider, it is not difficult to see that at the initial generation of this phase, there is only one front individual with number of zeros, and not difficult to see that all individuals with zeros, if exist, are temporarily undefeated individuals of the previous phase. Noting the assumption that there are at most accumulative temporarily undefeated individuals before , we know there are at least individuals that have more than zeros for the current phase. Hence, it requires at least number of steps of the subprocess to replace these individuals with more than zeros. Let be the number of times that happens in steps of the subprocess, then
where the last inequality uses for . The Chernoff inequality in Lemma 1(a) gives that . That is, with probability at least , will increase by more than if current phase does not end before all individuals have at most zeros. ∎
Lemma 14 shows that with high probability, it cannot happen that all current front individuals are replaced by the pattern individuals.
Lemma 14.
Let . Consider using EA with population size to optimize -dimensional OneMax function. Considered the same assumptions and phase as in Lemma 13. Further assume that at one generation of the current phase, there are current front individuals with zeros, and all interior individuals has zeros. Then with probability at least , the current phase ends before decreases to 0.
Proof.
Let denote the event that the current phase ends, that is, a offspring with at most zeros when or a offspring with 0 zero when is generated. Then
Then .
Let denote the event that a offspring with zeros is generated and one individual is replaced. Suppose that the total number of the individuals with zeros is . Then
Hence,
where the last inequality uses . Then
Then the probability that happens times but does not happen is at most , and this lemma is proved. ∎
Now the main result follows.
Theorem 15.
Given any . Let . Then with probability at least , EA with population size can find the optimum of OneMax.
Proof.
Similar to two situations in Lemma 3 that could possibly result in the stagnation of EA and RLS, the only two possible cases that could result in the stagnation of EA are listed in the following.
-
•
Event I’: There is a such that for all , and .
-
•
Event II’: There is a such that for all , .
For the uniformly and randomly generated and , we know that the expected number of the or first bit patterns, that is, the expected cardinality of the set or , is . Via the Chernoff inequality in Lemma 1(b), we know that with probability at most , at most individuals have the pattern or . Under this condition, the expected number of the pattern is at least in the whole population. The Chernoff inequality in Lemma 1(a) also gives that under the condition that at most individuals have the pattern or , with probability at least , there are at least individuals with the pattern for the initial population. Since for any , the Chernoff inequality in Lemma 1(b) on the initial population gives that . Via a union bound, we know
Hence, noting from , it is easy to see that with probability at least
the initial population has at most individuals with the pattern or , at least individuals with the pattern , and at the first generation. Thus, in the following, we just consider this kind of initial population.
We first show that after generations, the individuals with the first bit pattern or will be replaced and will not survive in any further generation, thus Event II’ cannot happen. Since , we know the current front individual has fitness more than . Note that all or pattern individuals have fitness at most . Then any offspring copied from one pattern individual, which has the pattern and the same fitness as its parent, will surely enter into the generation and replace some individual with the or pattern. Since there is at least individuals with the pattern , we know that for each generation, with probability at least , one individual with the or pattern will be replaced. Hence, the expected time to replace all individuals with the pattern or is at most since there are at most individuals with the pattern or . Also it is not difficult to see any offspring with the or pattern cannot be selected into the next generation for a population only with the or pattern. Later, only the and first bit pattern can survive in the further evolution.
Now we consider Event I’ after the first time when all or pattern individuals are replaced. From Lemma 12, we know that before , with probability at least , there are at most accumulative temporarily undefeated individuals. From Lemma 13 among all possible , we know that if the optimum is not found before all individuals with at least zeros are replaced, with probability at least , there are at least number of individuals with . Then for the case in Lemma 14 and considering all possible , we know with probability at least , the optimum is found.
Overall, the probability that EA can find the optimum of OneMax is at least
where the last inequality uses . ∎
In Theorem 15, we require that the population size . One may ask about the behavior when . We note in the proof of Lemma 12, the upper bound for the expected number of accumulative temporarily undefeated individuals is . If , we are not able to ensure that the accumulative temporarily undefeated individuals do not take over the population in our current proof, hence, we require .
Comparing with EA, since individual, corresponding to Event II in EA, has no fitness advantage against the one with previous first bit value as , it is easy to be replaced by the offspring with previous first bit value in a population. Thus, this stagnation case cannot take over the whole population to cause the stagnation of EA. The possible stagnation case that the pattern individuals take over the population, corresponding to Event I in EA, will not happen with a high probability because with a sufficient large, , population size as the problem size, with a high probability, the pattern can be maintained until the optimum is reached, that is, the population in EA increases the tolerance to the incorrect pattern trial.
IV-C Runtime Analysis of EA on OneMax
Theorem 15 only shows the probability that EA can reach the optimum. One further question is about its runtime. Here, we give some comments on the runtime complexity. For the runtime of EA on the original OneMax function, Witt [28] shows the upper bound of the expected runtime is based on the current best individuals’ replicas and fitness increasing. Analogously, for EA on OneMax function, we could consider the expected time when the number of the current front individuals with zeros reaches , that is, , and the expected time when a pattern offspring with less zeros is generated for or when one pattern individual with all ones is generated for conditional on that there are current front individuals with zeros. From Lemma 12, with probability at least , there are at most possible accumulative temporarily undefeated individuals before the current front individuals have only 1 zero. Hence, in each generation before the current front individuals have only 1 zero, it always holds that at least half of individuals of the whole population are current front individuals and interior individuals. Hence, we could just discuss the population containing no temporarily undefeated individual and twice the upper bound of the expected time to reach the optimum as that for the true process. The pattern offspring with zeros will not influence the evolving process of the current front individuals we focus on until all interior individuals have zeros. Recalling Lemma 13, we know that with probability at least , if the current phase does not end before all individuals have at most zeros. Hence, we just need to focus on the case when , that is, .
We discuss the expected length of the phase defined in Lemma 13. When , we consider the event that one replica of an individual can enter into the next generation. When the population contains interior individual(s) with more than zeros, the probability is . When all interior individuals have zeros, we require to be less than . Let denote the total number of the individuals with zeros, and we know the probability of event that one replica of an individual can enter into the next generation is . Note that the probability of event that an individual generates a pattern offspring with zeros that successfully enters into the next generation is at most . Then
where the antepenultimate inequality uses and the penultimate inequality uses . Hence, . Considering the process merely consisting of and , let be the number that happens before happens times. Then . It is not difficult to see that stochastically dominates the sum of geometric variables with success probability . Hence, with the Chernoff bound for the sum of geometric variables in Lemma 1(c), we have that
where the second inequality uses the fact for and the fact for , and the penultimate inequality uses . Since , we know with probability at least , could go above .
When goes above , we consider the event that the current phase ends. Recalling the proof in Lemma 14, we know that with probability at least , happens once before happens times, thus, before goes below .
In summary, in each phase, with probability at least , the current front individuals could increase its number to more than , and will remain above afterwards. Hence, together with the runtime analysis of the original EA on OneMax in [28], we have the runtime result for EA on OneMax in the following theorem, and know that comparing with OneMax function, the cost majorly lies on the success probability for EA solving the time-linkage OneMax, and the asymptotic complexity remains the same for the case when EA is able to find the optimum.
Theorem 16.
Given any . Let . Consider using EA with population size to solve the OneMax function. Consider the same phase in Lemma 13. Let denote the event that
-
•
the first generation has at most individuals with the or first bit pattern, at least individuals with the pattern, and has all individuals with less than zeros;
-
•
there are at most accumulative temporarily undefeated individuals before the current front individuals only have 1 zero;
-
•
the number of the current front individual with zeros can accumulate to and stay above if the current phase does not end.
Then event occurring with probability at least , and conditional on , the expected runtime is .
Recalling that the expected runtime of EA on OneMax is [28], which is for . Since is required for the convergence on OneMax in Section IV-B, Theorem 16 shows the expected runtime for OneMax is if we choose , which is the same complexity as for OneMax with . To this degree, comparing EA solving the time-linkage OneMax with the original OneMax function, we may say the cost majorly lies on convergence probability, not the asymptotic complexity.
V Conclusion and Future Work
In recent decades, rigorous theoretical analyses on EAs has progressed significantly. However, despite that many real-world applications have the time-linkage property, that is, the objective function relies on more than one time-step solutions, the theoretical analysis on the fitness function with time-linkage property remains an open problem.
This paper took the first step into this open area. We designed the time-linkage problem OneMax, which considers an opposite preference of the first bit value of the previous time step into the basic OneMax function. Via this problem, we showed that EAs with a population can prevent some stagnation in some deceptive situations caused by the time-linkage property. More specifically, we proved that the simple RLS and EA cannot reach the optimum of OneMax with probability but EA can find the optimum with probability.
The time-linkage OneMax problem is simple. Only the immediate previous generation and the first bit value of the historical solutions matter for the fitness function. Our future work should consider more complicated algorithms, e.g., with crossover, on more general time-linkage pseudo-Boolean functions, e.g., with more than one bit value and other weight values for the historical solutions, and problems with practical backgrounds.
Acknowledgement
We thank Liyao Gao for his participation and discussion on the EA part during his summer intern.
References
- [1] F. Neumann and C. Witt, Bioinspired Computation in Combinatorial Optimization – Algorithms and Their Computational Complexity. Springer, Berlin, Heidelberg, 2010.
- [2] A. Auger and B. Doerr, Theory of Randomized Search Heuristics: Foundations and Recent Developments. World Scientific, 2011.
- [3] T. Jansen, Analyzing Evolutionary Algorithms: The Computer Science Perspective. Springer Science & Business Media, 2013.
- [4] Z.-H. Zhou, Y. Yu, and C. Qian, Evolutionary Learning: Advances in Theories and Algorithms. Springer, 2019.
- [5] B. Doerr and F. Neumann, Theory of Evolutionary Computation: Recent Developments in Discrete Optimization. Springer Nature, 2020.
- [6] P. A. N. Bosman, “Learning, anticipation and time-deception in evolutionary online dynamic optimization,” in Genetic and Evolutionary Computation Conference, GECCO 2005, Workshop Proceedings. ACM, 2005, pp. 39–47.
- [7] T. T. Nguyen, “Continuous dynamic optimisation using evolutionary algorithms,” Ph.D. dissertation, University of Birmingham, 2011.
- [8] T. Morimoto, Y. Ouchi, M. Shimizu, and M. Baloch, “Dynamic optimization of watering satsuma mandarin using neural networks and genetic algorithms,” Agricultural water management, vol. 93, no. 1-2, pp. 1–10, 2007.
- [9] S. Droste, “Analysis of the (1+1) EA for a dynamically changing onemax-variant,” in Congress on Evolutionary Computation, CEC 2002, vol. 1. IEEE, 2002, pp. 55–60.
- [10] P. Rohlfshagen, P. K. Lehre, and X. Yao, “Dynamic evolutionary optimisation: an analysis of frequency and magnitude of change,” in Genetic and Evolutionary Computation Conference, GECCO 2009. ACM, 2009, pp. 1713–1720.
- [11] T. Kötzing and H. Molter, “ACO beats EA on a dynamic pseudo-boolean function,” in International Conference on Parallel Problem Solving from Nature, PPSN 2012. Springer, 2012, pp. 113–122.
- [12] T. Jansen and C. Zarges, “Analysis of randomised search heuristics for dynamic optimisation,” Evolutionary Computation, vol. 23, no. 4, pp. 513–541, 2015.
- [13] J. Lengler and U. Schaller, “The (1+1)-EA on noisy linear functions with random positive weights,” in IEEE Symposium Series on Computational Intelligence, SSCI 2018. IEEE, 2018, pp. 712–719.
- [14] J. Lengler and J. Meier, “Large population sizes and crossover help in dynamic environments,” arXiv preprint arXiv:2004.09949, 2020.
- [15] A. Lissovoi and C. Witt, “Runtime analysis of ant colony optimization on dynamic shortest path problems,” Theoretical Computer Science, vol. 561, pp. 73–85, 2015.
- [16] F. Neumann and C. Witt, “On the runtime of randomized local search and simple evolutionary algorithms for dynamic makespan scheduling,” in International Joint Conference on Artificial Intelligence, IJCAI 2015. AAAI Press, 2015, pp. 3742–3748.
- [17] M. Pourhassan, W. Gao, and F. Neumann, “Maintaining 2-approximations for the dynamic vertex cover problem using evolutionary algorithms,” in Genetic and Evolutionary Computation Conference, GECCO 2015. ACM, 2015, pp. 903–910.
- [18] V. Roostapour, A. Neumann, F. Neumann, and T. Friedrich, “Pareto optimization for subset selection with dynamic cost constraints,” in AAAI Conference on Artificial Intelligence, AAAI 2019, 2019, pp. 2354–2361.
- [19] J. Bossek, F. Neumann, P. Peng, and D. Sudholt, “Runtime analysis of randomized search heuristics for dynamic graph coloring,” in Genetic and Evolutionary Computation Conference, GECCO 2019. ACM, 2019, pp. 1443–1451.
- [20] R. S. Sutton and A. G. Barto, Reinforcement Learning: An Introduction, 2nd ed. MIT Press, 2018.
- [21] B. Doerr, “Analyzing randomized search heuristics: Tools from probability theory,” in Theory of Randomized Search Heuristics: Foundations and Recent Developments. World Scientific, 2011, pp. 1–20.
- [22] ——, “Probabilistic tools for the analysis of randomized optimization heuristics,” in Theory of Evolutionary Computation: Recent Developments in Discrete Optimization, B. Doerr and F. Neumann, Eds. Springer, 2020, pp. 1–87.
- [23] T. Chen, K. Tang, G. Chen, and X. Yao, “A large population size can be unhelpful in evolutionary algorithms,” Theoretical Computer Science, vol. 436, pp. 54–70, 2012.
- [24] J. He and X. Yao, “From an individual to a population: An analysis of the first hitting time of population-based evolutionary algorithms,” IEEE Transactions on Evolutionary Computation, vol. 6, no. 5, pp. 495–511, 2002.
- [25] D.-C. Dang, T. Jansen, and P. K. Lehre, “Populations can be essential in tracking dynamic optima,” Algorithmica, vol. 78, no. 2, pp. 660–680, 2017.
- [26] D. Corus and P. S. Oliveto, “On the benefits of populations for the exploitation speed of standard steady-state genetic algorithms,” in Genetic and Evolutionary Computation Conference, GECCO 2019. ACM, 2019, pp. 1452–1460.
- [27] D. Sudholt, “The benefits of population diversity in evolutionary algorithms: A survey of rigorous runtime analyses,” in Theory of Evolutionary Computation: Recent Developments in Discrete Optimization, B. Doerr and F. Neumann, Eds. Springer, 2020, pp. 359–404.
- [28] C. Witt, “Runtime analysis of the (+1) EA on simple pseudo-boolean functions,” Evolutionary Computation, vol. 14, no. 1, pp. 65–86, 2006.
- [29] B. Doerr and W. Zheng, “Working principles of binary differential evolution,” Theoretical Computer Science, vol. 801, pp. 110–142, 2020.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/88d56f5a-a4eb-4fae-8437-5ab705c49257/Weijie.jpg) |
Weijie Zheng received Bachelor Degree (July 2013) in Mathematics and Applied Mathematics from Harbin Institute of Technology, Harbin, Heilongjiang, China, and Doctoral Degree (October 2018) in Computer Science and Technology from Tsinghua University, Beijing, China. He is now a postdoctoral researcher in the Department of Computer Science and Engineering at Southern University of Science and Technology, Shenzhen, Guangdong, China, and in the School of Computer Science and Technology, University of Science and Technology of China, Hefei, Anhui, China. His current research majorly focuses on the theoretical analysis and design of evolutionary algorithms, especially binary differential evolution and estimation-of-distribution algorithms. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/88d56f5a-a4eb-4fae-8437-5ab705c49257/Huanhuan.jpg) |
Huanhuan Chen received the B.Sc. degree from the University of Science and Technology of China (USTC), Hefei, China, in 2004, and the Ph.D. degree in computer science from the University of Birmingham, Birmingham, U.K., in 2008. He is currently a Full Professor with the School of Computer Science and Technology, USTC. His current research interests include neural networks, Bayesian inference, and evolutionary computation. Dr. Chen was a recipient of the 2015 International Neural Network Society Young Investigator Award, the 2012 IEEE Computational Intelligence Society Outstanding Ph.D. Dissertation Award, the IEEE TRANSACTIONS ON NEURAL NETWORKS Outstanding Paper Award, and the 2009 British Computer Society Distinguished Dissertations Award. He is an Associate Editor of the IEEE TRANSACTIONS ON NEURAL NETWORKS AND LEARNING SYSTEMS and the IEEE TRANSACTIONS ON EMERGING TOPICS IN COMPUTATIONAL INTELLIGENCE. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/88d56f5a-a4eb-4fae-8437-5ab705c49257/Xin.jpg) |
Xin Yao obtained his Ph.D. in 1990 from the University of Science and Technology of China (USTC), MSc in 1985 from North China Institute of Computing Technologies and BSc in 1982 from USTC. He is a Chair Professor of Computer Science at the Southern University of Science and Technology, Shenzhen, China, and a part-time Professor of Computer Science at the University of Birmingham, UK. He is an IEEE Fellow and was a Distinguished Lecturer of the IEEE Computational Intelligence Society (CIS). He was the President (2014-15) of IEEE CIS and the Editor-in-Chief (2003-08) of IEEE Transactions on Evolutionary Computation. His major research interests include evolutionary computation, ensemble learning, and their applications to software engineering. His work won the 2001 IEEE Donald G. Fink Prize Paper Award; 2010, 2016 and 2017 IEEE Transactions on Evolutionary Computation Outstanding Paper Awards; 2011 IEEE Transactions on Neural Networks Outstanding Paper Award; and many other best paper awards at conferences. He received a prestigious Royal Society Wolfson Research Merit Award in 2012, the IEEE CIS Evolutionary Computation Pioneer Award in 2013 and the 2020 IEEE Frank Rosenblatt Award. |