Analysis of COVID-19 in Japan with Extended SEIR model and ensemble Kalman filter
Abstract
We introduce an extended SEIR infectious disease model with data assimilation for the study of the spread of COVID-19. In this framework, undetected asymptomatic and pre-symptomatic cases are taken into account, and the impact of their uncertain proportion is fully investigated. The standard SEIR model does not consider these populations, while their role in the propagation of the disease is acknowledged. An ensemble Kalman filter is implemented to assimilate reliable observations of three compartments in the model. The system tracks the evolution of the effective reproduction number and estimates the unobservable subpopulations. The analysis is carried out for three main prefectures of Japan and for the entire population of Japan. For these four populations, our estimated effective reproduction numbers are more stable than the corresponding ones estimated by a different method (Toyokeizai). We also perform sensitivity tests for different values of some uncertain medical parameters, like the relative infectivity of symptomatic / asymptomatic cases. The regional analysis results suggest the decreasing efficiency of the states of emergency.
- a)
Data Assimilation Research Team, RIKEN Center for Computational Science (R-CCS), Kobe, Japan
- b)
Graduate School of Mathematics, Nagoya University, Nagoya, Japan
- c)
Prediction Science Laboratory, RIKEN Cluster for Pioneering Research, Kobe, Japan
- d)
RIKEN interdisciplinary Theoretical and Mathematical Sciences Program (iTHEMS), Kobe, Japan
E-mails: [email protected], [email protected],
[email protected]
keywords: COVID-19, data assimilation, ensemble Kalman filter, extended SEIR model
Mathematics Subject Classification: 92-08, 92C60
1 Introduction
The outbreak of coronavirus 2019 (COVID-19) had a huge impact on human society, and its devastating effects are still present more than 18 months after its official acknowledgment. One of the specific characteristics of this disease increases the difficulties for any scientific research based on infectious disease models, namely the existence of asymptomatic cases. Their existence, but also their potential infectiousness, blur the full picture of the disease spreading inside the society [41]. The simultaneous existence of mild symptomatic cases, which often remain undocumented, also generates an additional challenge for any epidemiological investigations. For example, one study discussing the potential fraction of undocumented cases at the beginning of the outbreak ends up with a ratio of undocumented infections [23].
There exists now a huge literature related to COVID-19, but only a small number of papers are using techniques of data assimilation, as we shall do. For that reason, we present only a few references closely related to our investigations. To get a better understanding of the spread of COVID-19, some studies start with a specially designed infectious disease model with appropriate structures. Those elaborated models may accurately describe the process in reality but they also bring more uncertainties and unknown parameters. For example in [1], a variables model is adopted with each variable representing a subpopulation. The structure related to asymptomatic, pre-symptomatic, detected, and undetected cases are all properly described by the structure. However, the inference is done with only observations of compartments among all variables. Another example is [9], where an extended SEIR model with age-classes is used to estimate the posterior distribution of parameters and make short period predictions. The distribution of mild, severe and fatal cases for each age class is introduced as pre-defined parameters. Also, a matrix which describes the relative transmissions between each pair of age groups is predefined.
Despite these elaborated models, most of the investigations are still performed on the common infectious disease models, namely the SIR and SEIR models. Such models are easier to implement and contain less parameters, but they also sacrifice some details of the process. For example the SEIR model is used to study the dynamical behavior of COVID-19 outbreaks at the regional level in [13], and the SIR model was used to track the effective reproduction number for countries in [2]. A slightly more elaborated model is also introduced in [27], namely the SITR model with T standing for under treatment, for inferring infection numbers and parameters values.
For dealing with real data, one of the recent tools employed for the study of infectious diseases is data assimilation. The techniques developed for data assimilation have the ability to optimally meld dynamical systems with noisy and imperfect observations. They also provide forecasts and estimations of parameters and variables [34]. As examples of investigations studying the details of the implementation of these techniques to epidemic models, let us mention [25] and [33]. The previously cited work [1] also uses statistical data assimilation for identifying the measurements required for getting accurate states and parameters estimations. Finally, in [14] an ensemble Kalman filter is adopted to forecast the COVID-19 pandemic in Saudi Arabia with an extended SEIR model including vaccination.
Let us now present our research. First, we construct an extended SEIR model which takes into account one of the main specificities of COVID-19: the simultaneous existence of an asymptomatic / pre-symptomatic population and of a symptomatic population. These two infected populations have different characteristics which are encoded with different parameters. The model is also constructed such that it can be fed with the data of only three compartments, namely the Hospitalized (or treated) population, the Recovered population, and the Deceased population, naturally identified by the letters , , and , respectively. Note that the population or are coming from the population , and these three populations are considered as fully recorded by health services. Except for the first couple of weeks at the beginning of the epidemic, these data are also considered as the most reliable ones. With this model and these data, our main aim is to provide information about the effective reproduction number and about the population of asymptomatic / pre-symptomatic or undetected symptomatic, with uncertainty ranges. For these investigations, we shall also mainly concentrate on the population of Tokyo, but provide additional analysis with two additional prefectures (Osaka and Kanagawa) and with the entire population of Japan. Let us mention that targeting a specific population gives the opportunity to rely on local parameters and to use information provided by local medical research or health services. We also emphasize that for data assimilation, we use the ensemble transform Kalman filter [17] which is efficient compared with the standard extended Kalman filter.
As a result of our investigations we get an effective reproduction number for the four populations mentioned before, as well as a time dependent estimate for the number of asymptomatic / pre-symptomatic in these four populations. A comparison between our estimated effective reproduction number and the same statistic provided by Toyokeizai [39] shows the reliability of our strategy. As an asset of our approach, we test the sensitivity of our model and its outcomes to the values of uncertain parameters borrowed from the literature. These experiment’s results show a robust performance of the strategy used in our investigations. Another clear result from our computation of the effective reproduction number is the decay of the effectiveness of the states of emergency as their number increases. This effect is clearly visible independently for the three prefectures and for the entire country. Note that a similar effect is also visible in the use of public transportation, see for example [26]. Other outcomes of our investigation are gathered in Sections 4 and 5.
Let us finally describe the structure of this paper. In Section 2, we recall the standard SIR and SEIR models, and introduce the extended SEIR model. We also provide information for the computation of the effective reproduction number, and discuss the constant parameter values and the observations. In Section 3, we explain the technical details of ensemble transform Kalman filter. Readers familiar with data assimilation and Kalman filters can skip this section without any loss for the application to infectious diseases. In Section 4, background information about the experiments, and subsequently technical information, are provided. The main results of our investigations are also presented in this section. The discussion and the comparisons between the different populations are provided in Section 5. We finally prepare the ground for future projects.
2 Extended SEIR model
In this section, we recall a few information on the SIR and SEIR models, and introduce the extended SEIR model. We also discuss medical parameters, and provide some explanations about the observations.
2.1 The SIR and SEIR models
The SIR model is a deterministic epidemic model expressed by a system of differential equations. Its construction is based on Kermack–McKendrick theory, and it describes the transmission process of an infectious disease. A given population of size is divided into three mutually exclusive sub-populations call compartments: the susceptible hosts , the infectious hosts , and the recovered hosts . For any given time , , , and describe the number of individuals in each respective compartment, and they satisfy . Individuals in compartment can be infected by individuals in compartment through direct contact. Once a successful contact happens, the infected individual leaves compartment and becomes a member of compartment . The number of newly infected individuals per unit time is given by , where the parameter is called the transmission coefficient. Similarly, once a patient recovers, this person leaves compartment and goes to compartment immediately. The transfer between and is controlled by the recovery rate . The transfer rate, namely the number of transfer individuals per unit time, is given by .
Figure 2.1 shows the process of the SIR model, and the following differential system describes its dynamic:
| (1) | ||||
Note that the system (1) assumes a permanent immunity once recovered. In other words, no individual can be infected a second time. The model also assumes a constant total population: there is no inflow to the system, or outflow from the system.
The SEIR model is very similar to the previous model, but with an additional compartment between the compartments and . The individuals in are exposed, namely they have been contaminated, but they are not infectious yet. The time spent in corresponds to the incubation period, before becoming infectious. The transfer rate from to is given by .
Figure 2.1 shows the process of the SEIR model, and the following differential system describes its dynamic:
2.2 The extended SEIR model
The extended SEIR model has been developed based on some specific features of the COVID-19 epidemic, as described now. In early 2020, health services already noticed that some infected individuals, who did not show any symptom, could spread the disease. These persons correspond either to asymptomatic hosts or to pre-symptomatic hosts. In the first cohort, people will never show any symptom, while the second cohort corresponds to individuals who will show some symptoms subsequently. Clearly, asymptomatic hosts and pre-symptomatic hosts are difficult to be identified by health services, even though they play an important role in the spread of the disease. Symptomatic individuals are also infectious, but they can be more easily identified precisely because of their symptoms. Thus, if symptomatic individuals correspond to the compartment of the above SIR or SEIR models, then there is no compartment left for the asymptomatic or the pre-symptomatic individuals.
The existence of COVID-19 infectious spreaders who do not show (yet or at all) any symptom already brings a lot of uncertainties to health services. In addition, whenever the symptoms are relatively mild, some symptomatic individuals do hesitate to report the health service [31, p. 11]. As a consequence, daily new cases are under-reported. Combining this effect with some delayed information, some inaccurate tests (especially in the first phase of the epidemic), and other reasons that we are not aware of, it turns out that that the reported data are not very accurate. In such a situation one needs to use proper strategies to analyse the observation data.
In order to meet the special features of COVID-19, we separate the compartment of the SEIR model into two compartments and . These compartments correspond to asymptomatic / pre-symptomatic and to symptomatic states, respectively. Both and can infect . As shown in Figure 2.2, the transmission processes related to and to have transmission coefficients and respectively. Once an individual in gets infected, this person becomes a member of , and then moves to when it becomes infectious. In , part of these individuals (the asymptomatic) will never generate any symptoms. They will thus spend some time in , and then recover. The corresponding compartment is denoted by . In contrast, the other part of individuals in will develop symptoms, and then move to . In , a majority of individuals will be identified by health services, but as mentioned above a minority will recover without being identified by any health services. Compartment corresponds to those recovered individuals who have not been registered. The identified persons in will then move to the compartment , which corresponds to hospitalized or treated patients. The ones staying at home but under medical control, or the ones isolated in a hotel, are all included in the compartment . Finally, the patients in will recover, and thus move to the compartment , or will decease and end up in the compartment . As for the SIR or SEIR models, we assume a permanent immunity, which means that there is no flow from , , or to . Also, the total number of individual is constant, namely at all time one has
| (2) |
Based on the Figure 2.2 and on the explanations provided above, the differential system of the extended SEIR model reads:
| (3) | ||||||
where and are some medical parameters. Note that some of them are time dependent.
2.3 The reproduction number
The basic reproduction number, denoted by , can be interpreted as the average number of secondary cases generated by on primary case in a susceptible population. It is commonly admitted that is a threshold value, as explained below. We also refer to [8, 16] for more explanations and more precise statements.
To study for different models, a general definition of the basic reproduction number is introduced based on the notion of disease free equilibrium (DFE). In a DFE the population remains in the absence of disease. For example, in the SIR or SEIR models, it means that while in the extended SEIR model it means that . In this context, the basic reproduction number can be defined as the number of new infections produced by a typical infectious individual in a population at a DFE. The main feature of is that it corresponds to a threshold parameter, namely if , the DFE is locally asymptotically stable, while if , the DFE is unstable and an outbreak is possible.
The precise expression for is clearly model dependent, but numerous examples are available in the literature. For example, let us consider a general compartmental disease transmission model. Such models are represented by a system of ordinary differential equations, and under natural assumptions it can be shown that these models have a DFE, see [8]. In this reference, the precise expression for is then provided for some classes of models, and the extended SEIR model meets the assumptions of the staged progression model, as presented in [8, Sec. 4.3]. For the extended SEIR model, the expression for then reads:
| (4) |
where and are the initial transmission coefficients at time .
To understand the above expression, observe that corresponds to the fraction of individuals of going to the compartment , while and define the average times an infected individual spends in compartments and respectively. Thus, each term on the R.H.S. of (4) represents the number of new infections generated by an infectious individual during the time spent in the compartments and .
In contrast, the definition of the effective reproduction number at time is much more delicate. The various challenges and possible errors have recently been discussed in [15], to which we refer for a thorough discussion. In our setting, we shall keep the interpretation of as the average number of secondary cases generated by one primary case. This approach is possible because the transmission coefficients at time are available in our approach, and therefore one can compute with (4) and the corresponding and at time . Additional information on will be provided in Section 5.
2.4 The medical parameters
It clearly appears in Figure 2.2 and in the corresponding system (2.2) that several parameters control the flows between the compartments. The values of these parameters may result in very different behaviors of the model. We refer for example to [22, Sec. 1.4] and to [4, Chap. 2] for general discussions of model behaviors and the role of parameters. In our setting, some parameters are easy to evaluate, as for example the recovery rate or the death rate , but others are difficult to estimate, as for example the transmission coefficients and . Let us also stress that some parameters depend on location. Since our experiment is based on data from Japan, see Section 4, the medical parameters are chosen accordingly. For that reason, we use research or survey results specific to Japan, or even more precisely to specific prefectures in Japan.
In Table 1 we list the estimated values of some parameters for the extended SEIR model, and provide the sources of information. Several parameters in the table have the form of the product of a percentage and the inverse of a time length. A similar setting for the construction of the parameters can be found for example in [9, 21]. For and , the percentage parts should sum up to . For the parameters and , some information can be found in the surveys [31, 37] and the health services website [38]. For parameter and , instead of using constant value estimated by health services, we shall use the observation data to estimate their values on a daily basis. The details will be discussed in Section 4.
Let us stress that the value assigned to some of these parameters has evolved during the last 12 months. For example, the ratio of asymptomatic individuals was thought to be very high at the beginning of the epidemic (up to ), but some recent research [3, 5, 32] have revised this ratio to to . Our knowledge about the length of infectious periods has also evolved, and the possible values are spread over a rather long interval. In Table 1 we list some mean values, but in the simulations additional uncertainties are implemented. Since pre-symptomatic patients become infected before the appearance of symptoms, the incubation period (encoded in ) has been shorten a little bit, and the last 2 days of this incubation period have been moved to .
One very delicate question is the relation between and , namely between the transmission coefficient for asymptomatic / pre-symptomatic and the transmission coefficient for symptomatic. For our investigations, we shall rely on the result of the systematic review [3] which asserts that the relative risk of asymptomatic transmission is lower than that for symptomatic transmission. As a consequence, we shall fix
| (5) |
This factor is slightly smaller but of a comparable scale compared to earlier investigations, see for example [5].
(r,1cm,1.2cm)[2pt]c—c—c—l—c—c—c—c—c—c—c—c—
parameter & estimation source remark
[7] incubation period, not contagious
\pbox6cm
[3, 7] \pbox15cmproportion of pre-symptomatic
\pbox6cm ( 2020/5/31)
(2020/6/1 ) [31, 24] \pbox15cmproportion of detected symptomatic
\pbox6cm
[3, 32] \pbox15cmproportion of asymptomatic
[31, 37] \pbox15cmproportion of undetected symptomatic
\pbox15cmcomputed by
observations [39] discussed in Section 4
\pbox15cmcomputed by
observations [39] discussed in Section 4
2.5 The observations
As introduced in Section 1, one of the aims of this study is to estimate the unknown parameters and , and the unobservable compartments and . Because of relation (5), it is clear that for the parameters only has to be evaluated. The method that we are going to introduce in Section 3 requires observations of some compartments in the extended SEIR model. In Figure 2.2, we highlight the three compartments with observations in yellow, namely , and . The data corresponding to these compartments may not be perfect, and for the analysis based on these data we shall take some uncertainties into consideration. More precisely, some random noise will be added to the observations.
For our experiment, we shall firstly and mainly use the data about Tokyo, with a total population (approximate mean of the population of 2020 and 2021). Subsequently, other prefectures in Japan are also considered. As already mentioned, the compartment corresponds to the identified individuals either hospitalized or treated at home or in a hotel. On the other hand, and describe the accumulated number of recovered and deceased individuals. The information about these three compartments are very easy to find for Tokyo, but also for any region in Japan. One can check for example the website of Ministry of Health, Labour and Welfare, prefecture’s websites or some mass communication companies’ websites to get more details. The information is provided on a daily basis. Note however, that these records were not very accurate at the beginning of the outbreak. This was caused by the delay of reports, but also by some changes in the policy for the collect of information. Our analysis will take this source of uncertainties into consideration.
3 Ensemble Transform Kalman filter
In this section, we introduce the main tool employed in the study, namely the ensemble Kalman filter. The analysis of parameter values and unobservable compartments is performed based on it.
The method Ensemble Transform Kalman Filter (ETKF) used in this paper has been introduced and developed in [6, 17]. It is based on the Ensemble Kalman Filter [10, 11, 12], but it provides analyses in a more efficient way.
Let us consider a discrete time state space model given for any time by
| (6) | ||||
| (7) |
where is an -dimensional state vector and an -dimensional observational vector, is the operator which defines the dynamics of the state, is an operator corresponding to the observation model, and provides the observation error. All these vectors or operators are explicitly dependent. The vector represents the state of the dynamical system, while is called the noisy observation, both at time . The observation error follows a normal distribution , where is an observation error covariance matrix. In this framework, the general question is: given a list of noisy, unbiased observations , how can one find the best estimates for ?
Under the assumption of unbiased Gaussian observation error and of Gaussian initial distributions, one can consider the maximum likelihood approach. For time , the likelihood of is proportional to
| (8) |
where the superscript denotes the transpose of a vector or of a matrix. Clearly, maximizing (8) can be transformed into a minimization problem. More precisely, by using equation (6), one first defines the cost function
| (9) |
Then, one ends up in looking for a list of estimates of which minimize (9).
When the operators and are linear, they can be represented by matrices, denoted also by and . In such a situation, and with our assumption of Gaussian observation error, the linear model leads to the propagation of Gaussian distributions for the states. More precisely, assume that at some time , there is a prior estimate of the state with its covariance estimate (also called the background error covariance). Then the Kalman filter [19, 20] provides an optimal solution to minimize the variance of its uncertainty. For this reason, it is known as the minimum variance estimator. Formally, the prior estimate is updated by using the information of the observation at time as follows [18, Eq. (1), (2), (8) & (10)] :
| (10) | ||||
| (11) | ||||
| (12) | ||||
| (13) |
where is called the Kalman gain, the analysis, and its estimated covariance. With the analysis, one can use the forecast model (6) to evolve the analysis and get the prior estimate and the covariance at the next time step.
When the operators and are nonlinear, the Kalman filter is not applicable in its original form, but a simple extension with linear approximation is known to be effective. The straightforward nonlinear extension of the Kalman filter is known as the extended Kalman filter (EKF). In this case, and in equation (10) to (13) are replaced by their linear approximations respectively. For low dimensional models, the cost of EKF is low. However, when the model complexity and the state dimension increases, one may consider the ensemble Kalman filter. In this case, an ensemble of model states is used to estimate the covariance matrices. Namely, let be an ensemble of estimates of the model states at time . By letting this ensemble evolve according to the model (6), one gets the forecast or background ensemble at time , where
The mean of the ensemble can be used as the most probable estimate of the state, with its covariance estimated by the sample covariance of the ensemble:
where is an matrix with the column .
The next step is to update the forecast ensemble mean and its covariance by using the information of the observation . The updated ensemble mean is denoted by and its covariance by . To get them, one first needs to determine an analysis ensemble . Similar to the background ensemble, the mean and covariance of the analysis ensemble are given by
| (14) | ||||
| (15) |
In our application the operator is linear, so that is given by a matrix. In this case and for ETKF, the computations can be written as follows [18, Eq. (15)(17)] :
| (16) | ||||
| (17) | ||||
| (18) |
where the matrix is called the analysis error covariance in ensemble space. For (18), the background perturbation is transformed into the analysis perturbation with the weight . By adding to each column of , one gets the analysis ensemble that satisfies (14). Note that the ETKF is a deterministic filter since no randomly perturbed observations are used in the computation [40], and it is also a square-root filter because its takes the power of the matrix [36].
To avoid a variance underestimation, caused for example by the limited ensemble size, an artificial inflation of the ensemble spread is usually applied. In [18], several ways to perform the variance inflation are discussed. In our study, we apply multiplicative inflation and additive inflation. For multiplicative inflation, the background error covariance is multiplied by a tunable factor before the analysis. The multiplicative inflation can be thought as a procedure to increase the influence of the current observations on the analysis. For additive inflation, since the extended SEIR model is a conserved closed system, it is then applied by adding a random vector to the background ensemble. The random vector can be sampled from the normal distribution with mean 0 and some covariance matrix. This covariance matrix is assumed to be proportional to the background error covariance by a tunable parameter [18].
For the current study with a low dimensional model, we could use EKF or EnKF. However, by considering the possibility of increasing the model complexity in future, we opted for ETKF with 50 ensemble members.
4 Experiments
In this section, we explain the design of the experiments and illustrate the outcomes by using observations from Tokyo Metropolis. These observations (, , and ) are obtained from the website [39]. Discussions and comparisons with other prefectures are provided in the subsequent section. As mentioned in Section 2.5, health officials started providing data from February 2020 but they included some uncertainties caused by delay or by policy changes. Our experiments start with the observations from March , 2020, when the record of data became more systematic.
4.1 The experiments, using data from Tokyo
For the state space model mentioned in Section 3, the dynamical system (6) is described by the differential system (2.2). To estimate the parameter , we use the augmented state by adding one more equation to the system (2.2), assuming persistence for . Namely, will stay at the same value during the time integration process, and will be updated during the analysis step of the data assimilation. In other words, if has a correlation with the observations, will be updated together with the other states. In system (2.2), the unit of time represents one day. Thus, the one day forecast from day is obtained by integrating the system (2.2) on with the initial values equal to the analysis on day . To avoid negative values in the analysis step, all the compartments are transformed to scale with base . The lower case will be used for these new variables, as for example , and the corresponding equation becomes . The DA analysis update directly applies to the -transformed values.
Now the forecast value of is a -dimensional vector
| (19) |
Note that the compartment is not explicitly included since it can be deduced from the conservation relation (2). Before performing the DA analysis update, the above vector has to be projected to the observation space by the observation system (7). In our setting, the operator introduced in (7) is defined by the projection which sends the forecast vector (19) on , namely on the three compartments with observations.
To initiate the experiments, initial values for all compartments and parameters have to be provided. When these initial values are far away from the observations, the system goes through an unreasonable transition period. To avoid or reduce the unreasonable transition, preliminary experiments were performed for determining suitable initial values. Namely, we run the system for a few days, starting with a few individuals in some compartments and a presumed value for . Different values of were tested, until values comparable to the data of the compartments on day zero (March , 2020) were obtained. The corresponding values for the different compartments were then chosen as initial conditions. However, independent normal distributed random errors are also added to create 50 ensemble members . Note that each member is a -dimensional vector containing the initial conditions for the compartments and for the parameter .
The ensemble on day zero are then integrated by the model (2.2) for one day and the ETKF will update the one day forecast by using the observations. The procedure of the experiments is shown in Figure 4.1.
As mentioned in Section 2.4, parameters and are estimated by assimilating the observations. Consider equation in model (2.2). Since the time is discrete, we can rewrite this relation as which leads to
| (20) |
Similar computation can be generated for also, namely,
| (21) |
The daily values of both parameters are shown in Figure 5. For the implementation of these parameters for the computation of the -day forecast, we have used a slightly smoothed version obtained by a -day convolution with the symmetric weights . The effect is to decrease the amplitude of the weekly oscillations.


For the integration process, we have also included some uncertainties to all parameters: to the ones presented in Table 1, but also to the values of the parameters , . Thus, the -day forecast is obtained with the parameters of the previous day, each of them perturbed by a normal distribution , where corresponds to the value of this parameter. These perturbations are independent and randomly generated for each -day forecast.
The last initial setting for data assimilation is the observation error covariance matrix . We assume that the covariance of the errors between different observations is zero, namely, the matrix is diagonal. Since we observe three states, is a diagonal matrix. Clearly, the bigger the variance, the weaker contribution the corresponding observation will make to the update.
For simplicity, we assume that the observation error covariance is independent of time. The diagonal elements are chosen as for any time , representing the observation error variance: Namely, for one has as CI and as CI. Considering that all the observations have been transformed into scale, that is, the observations in original scale are distributed in as CI and as CI.
Before showing the analysis result, a scatter plot of the values of and of for the different ensemble members on a certain day is provided in Figure 6. Indeed, for the parameter estimation, one assumption is the linear relation between the ensemble of parameters and the ensemble of compartments with observations. As shown in Figure 6, a positive correlation is observed between and . Thus we can use the observation of for the estimation of .

In Figure 7 we finally provide the analysis value for from March 2020 to the middle of October 2021. The black curve represents the mean value of the ensemble. The two shaded regions represent the CI (dark orange) and CI (light orange). The analysis value of is computed by using together with the information contained in (4) and in (5). The red curve shows the provided by Toyokeizai.net for reference. The grey shaded regions represent the periods of state of emergency in Tokyo. Note that the jump at the end of May 2020 is due to an abrupt change in the value of as indicated in Table 1. Additional discussions about this graph will be provided in the subsequent section.

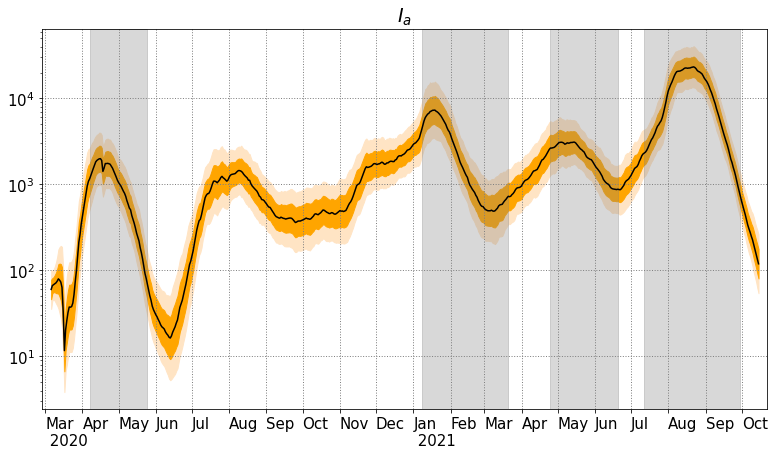
The analysis results for the compartments , , , , , with confidence intervals are also presented in Figure 8. For compartments , , , the red dots represent the observations of Tokyo. For all pictures, the -axis is in scale.





4.2 Technical discussion, using data from Tokyo
In Figure 7, one first notices that the similarity between the analysis and the reference provided by Toyokeizai.net. The Toyokeizai on day is computed by the following formula:
where the average generation time is assumed to be 5 days and the reporting interval is assumed to be 7 days. The formula is a simplified version of a maximum likelihood estimation for the effective reproduction number provided by H. Nishiura [28]. Note that this formula is based on the daily confirmed cases, which experiences quick changes everyday. On the other hand, the analysis and its confidence interval is computed by formula (4) which involve the analysis ensemble of and . The average over the ensemble member provides a smoother evolution of , which is certainly closer to a true statistic’s evolution. Note that a third approach for the computation of is available in [35]: it involves an agent-based model together with a particle filter.
In Figure 8, we show the analysis mean of compartments , , with the CI (dark orange) and CI (light orange), and the same results for compartments , and with the daily observations represented by red dots. One notes that the analyses of , , fit the observations appropriately except at the beginning of the observation period. This may be related to the initial guess and the model imperfections.

As mentioned in Section 2.4, the ratio between and is fixed at based on the information provided by the literature. Since this ratio is quite uncertain, we performed similar investigations with different ratios varying from to . For with and , we run the experiments independently (always with the data from Tokyo) and the analysis mean of are shown in Figure 9. The patterns of each are similar, especially after May , 2020. However, at the beginning of the outbreak and during the first state of emergency, all the analysis value of experience quick changes but with different speed. In Figure 10 we also provide the analysis mean of the different compartments, since they also depend on the ratio between and . The same conclusion is obtained: except for the first three months, the possible ratio do not generate any noticeable difference.



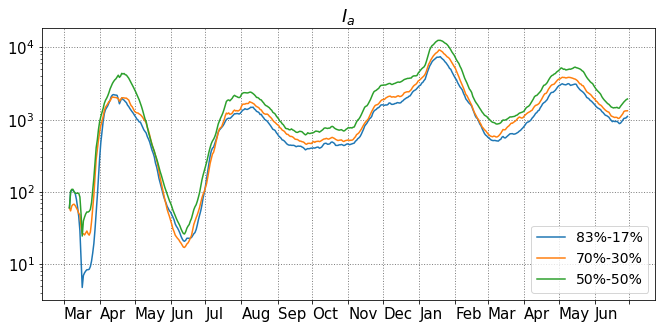
In Section 4.1, the error covariance matrix is defined as a diagonal matrix where is the identity matrix. We also run a sensitivity test for different choices of the covariance matrix, and checked if it has an effect on the analysis results. We choose equals to with , , , , and . For these investigations the ratio between and is fixed as . In Figure 11(a), the analysis means are provided, and they are clearly close to each other except at the beginning stage of the outbreak. The different spreads are shown in Figure 11(b), and one notices that the spread increases with the , but for larger than , the increase is less clear. We also show the analysis mean of compartments , , , , and in Figure 12(a). Again, the analysis results of these compartments with different observation error covariance are quite close to each other. In Figure 12(b), the spread is computed by the standard deviation of ensemble members of the transformed compartments. The relations of spread are quite clear for the three compartments with observations, and there are some overlaps for spread of , and , but in general the spread increases with .


As shown in Table 1, the proportion of symptomatic and asymptomatic used in our investigation is and , respectively. These values were determined based on sources mentioned in Section 2.4. However, since asymptomatic cases are very difficult to detect, and since we can not be fully confident in the above ratio, a sensitivity test is necessary. To do this, we choose two different combinations which are and , and and , and keep the observation error covariance matrix at and . Compared to the previous settings, in these two scenarios more people become asymptomatic and recover without showing any symptoms, as illustrated in Figure 13(a). On the other hand, the three curves for are close to each others, but the one corresponding to only of symptomatic is slightly higher than the other two, see Figure 13(b). In order to understand this, let us recall that the relation between the transmission coefficients and is set to be , it means that the asymptomatic cases are less infectious than the symptomatic and symptomatic cases. Thus, when more people do not show any symptoms, the transmission coefficient has to be bigger to create enough cases to fit the observations. As a consequence, will also be bigger.

5 Discussion, comparisons, and future projects
Let us start by a few easy observations about the results obtained in the previous section.
The analysis values of quickly decrease during the first state of emergency, and this parameter is lower than around the middle of May 2020. This indicates that the disease has started to die out. During the second state of emergency, analysis values of had a much slower decay, but nevertheless in early February 2021, successfully drops below . However it starts to increase from March while the state of emergency had not been released. In the third state of emergency, the analysis had the slowest decay, compared to the previous two states of emergency. During the first several weeks of the fourth state of emergency, the effective reproduction number continued increasing, even at a faster speed. It is only after the end of the first week of August that a decay finally took place.
For , and , one finds that the three values increase at the beginning of the first state of emergency, then they slow down and change the direction to decrease. Similar behaviors can be observed in the second state of emergency, and the values start to increase around the middle of March 2021 while the starts yo increase at the beginning of March. There is clearly a delay between the changes of and their effect on the three compartments , and .
Let us now provide a comparison with two different regions from Japan, namely Osaka and Kanagawa, and also provide the analysis for Japan as a whole. The experiments for Osaka, Kanagawa, and Japan start from March 2020, March 2020, March 2020 respectively. The observed compartments of these regions are the same as those for Tokyo, namely , and . The way to determine the initial setting is the same as that for Tokyo and we use the same setting for the parameters which have been presented in Table 1. The daily values for the parameter and for each region are also computed by using (20) and (21). The ratio between and is , and the observation error covariance matrix is assumed to be .



In Figure 14 we provide the analysis values of with CI and CI for each region. The additional red curves are again given by Toyokeizai.net. The grey shaded regions mark the respective periods of state of emergency. Though each region declared some states of emergency at different periods of time, they all have the common feature that the recent declarations are less efficient than the first ones. In Figure 15, 16, and 17, we provide the analysis results for compartments , , , , and for each region.
In Figure 18, the three analysis curves for Tokyo, Osaka and Kanagawa are drawn simultaneously. The analysis for Japan is represented by red dots. One observes that the general trends for each region are similar, but some delays are also visible. For example in early April 2020, in Tokyo reached the first peak then started to decline, while in Kanagawa reached the first peak in the middle of April, and then start to decline. Subsequently, these two regions are quite correlated, but Osaka has a slightly independent behavior, both in the summer 2020 and in April 2021.
Based on these observations, one can suspect that the movement of populations might be related to the evolution of for regions which are close to each other. The study of the effect of movements can be carried out by constructing a proper model with multi-populations connected to each others. Some parameters may be tuned, for example for simulating movement restriction’s policies. Such simulations could be useful for public health officials or for local governments to understand and estimate different disease-control strategies. We plan to work in this direction in the future.




Acknowledgement
S. R. is supported by the grant Topological invariants through scattering theory and noncommutative geometry from Nagoya University, and by JSPS Grant-in-Aid for scientific research C no 18K03328 & 21K03292, and on leave of absence from Univ. Lyon, Université Claude Bernard Lyon 1, CNRS UMR 5208, Institut Camille Jordan, 43 blvd. du 11 novembre 1918, F-69622 Villeurbanne cedex, France.
References
- [1] E. Armstrong, M. Runge, J. Gerardin, Identifying the measurements required to estimate rates of COVID-19 transmission, infection, and detection, using variational data assimilation, Infectious Disease Modelling 6, 133–147, 2021.
- [2] F. Arroyo-Marioli, F. Bullano, S. Kucinskas, C. Rondón-Moreno, Tracking R of COVID-19: A new real-time estimation using the Kalman filter, PLoS ONE 16(1): e0244474, 2021.
- [3] O. Byambasuren, M. Cardona, K. Bell, J. Clark, M.-L. McLaws, P. Glasziou, Estimating the extent of asymptomatic COVID-19 and its potential for community transmission: systematic review and meta-analysis, J. Association of Medical Microbiology and Infectious Disease Canada 5 Issue 4, 223–234, 2020.
- [4] F. Brauer, P.v.d. Driessche, J. Wu, Mathematical epidemiology, Lecture Notes in Mathematics 1945, Springer, 2008.
- [5] D. Buitrago-Garcia, D. Egli-Gany, M.J. Counotte, S. Hossmann, H. Imeri, A.M. Ipekci, et al., Occurrence and transmission potential of asymptomatic and presymptomatic SARS-CoV-2 infections: A living systematic review and meta-analysis, PLoS Med 17(9): e1003346, 2020.
- [6] C.H. Bishop, B.J. Etherton, S.J. Majumdar, Adaptive sampling with the ensemble transform Kalman filter. Part I: Theoretical aspects, Mon. Wea. Rev. 129, 420–436, 2001.
- [7] C. McAloon, A. Collins, K. Hunt, et al., Incubation period of COVID-19: a rapid systematic review and meta-analysis of observational research, BMJ Open 10:e039652, 2020.
- [8] P.v.d. Driessche, J. Watmough, Reproduction numbers and sub-threshold endemic equilibria for compartmental models of disease transmission, Mathematical Biosciences 180, 29–48, 2002.
- [9] G. Evensen, J. Amezcua, M. Bocquet, A. Carrassi, A. Farchi, A. Fowler, P. L. Houtekamer, C. K. Jones, R. J. de Moraes, M. Pulido, C. Sampson, F. C. Vossepoel, An international initiative of predicting the SARS-CoV-2 pandemic using ensemble data assimilation, Foundations of Data Science, American Institute of Mathematical Sciences, 2020.
- [10] G. Evensen, Sequential data assimilation with a nonlinear quasigeostrophic model using Monte Carlo methods to forecast error statistics, J. Geophys. Res. 99, 10143–10162, 1994.
- [11] G. Evensen, The ensemble Kalman filter: Theoretical formulation and practical implementation, Ocean Dynam. 53, 343–367, 2003.
- [12] G. Evensen, Data Assimilation: The Ensemble Kalman Filter, Springer, 2006.
- [13] R. Engbert, M.M. Rabe, R. Kliegl, S. Reich, Sequential Data Assimilation of the Stochastic SEIR Epidemic Model for Regional COVID-19 Dynamics, Bulletin of Mathematical Biology 83:1, 2021.
- [14] R. Ghostine, M. Gharamti, S. Hassrouny, I. Hoteit, An Extended SEIR Model with Vaccination for Forecasting the COVID-19 Pandemic in Saudi Arabia Using an Ensemble Kalman Filter, Mathematics 9, 636. 2021.
- [15] K.M. Gostic, L. McGough , E.B. Baskerville, S. Abbott, K. Joshi, C. Tedijanto, et al., Practical considerations for measuring the effective reproductive number, , PLoS Comput Biol 16 No. 12, e1008409, 21 pages, 2020.
- [16] H.W. Hethcote, The mathematics of infectious diseases, SIAM Rev. 42 No. 4, 599–653, 2000.
- [17] B.R. Hunt, E.J. Kostelich, I. Szunyogh, Efficient data assimilation for spatiotemporal chaos: a local ensemble transform Kalman filter, Physica D. 230, 112–126, 2007.
- [18] P.L. Houtekamer, F. Zhang, Review of the Ensemble Kalman filter for atmospheric data assimilation, Mon. Wea. Rev. 144, 4489–4532, 2016.
- [19] R.E. Kalman, A new approach to linear filtering and prediction problems, Trans. ASME Ser. D: J. Basic Eng. 82, 35–45, 1960.
- [20] R.E. Kalman, R.S. Bucy, New results in linear filtering and prediction theory, Trans. ASME Ser. D: J. Basic Eng. 83, 95–108, 1961.
- [21] T. Kuniya, H. Inaba, Possible effects of mixed prevention strategy for COVID-19 epidemic: massive testing, quarantine and social distancing, AIMS Public Health 7 No 3, 490–503, 2020.
- [22] M. Li, An Introduction to Mathematical Modeling of Infectious Diseases, Mathematics of Planet Earth 2, Springer 2018.
- [23] R. Li, et al., Substantial undocumented infection facilitates the rapid dissemination of novel coronavirus (SARS-CoV-2), Science 368, 489–493, 2020.
- [24] m3: https://www.m3.com/open/iryoIshin/article/849820/
- [25] L. Mitchell, A. Arnold, Analyzing the effects of observation function selection in ensemble Kalman filtering for epidemic models, Mathematical Biosciences 339, 2021.
- [26] MLIT: https://www.mlit.go.jp/tetudo/tetudo_fr1_000062.html
- [27] P. Nadler, S. Wang, R. Arcucci, X. Yang, Y. Guo, An epidemiological modelling approach for COVID-19 via data assimilation, European Journal of Epidemiology 35, 749–761, 2020.
- [28] H. Nishiura: https://github.com/contactmodel/COVID19-Japan-Reff
- [29] E. Ott, B.R. Hunt, I. Szunyogh, M. Corazza, E. Kalnay, D.J. Patil, J.A. Yorke, A.V. Zimin, E.J. Kostelich, Exploiting local low dimensionality of the atmospheric dynamics for efficient ensemble Kalman filtering, Preprint: https://arxiv.org/abs/physics/0203058v3.
- [30] E. Ott, B.R. Hunt, I. Szunyogh, A.V. Zimin, E.J. Kostelich, M. Corazza, E. Kalnay, D.J. Patil, J.A. Yorke, A local ensemble Kalman filter for atmospheric data assimilation, Tellus A 56, 415–428, 2004.
- [31] Osaka prefecture government, Citizens awareness and behavior change of measures against COVID-19, http://www.pref.osaka.lg.jp/hodo/attach/hodo-40479_4.pdf
- [32] A.M. Pollock, J. Lancaster, Asymptomatic transmission of covid-19, BMJ 371:m4851, 2020.
- [33] T.C. Rebollo, D. Coronil, Predictive data assimilation through Reduced Order Modeling for epidemics with data uncertainty, Preprint: https://arxiv.org/abs/2004.12341.
- [34] C. J. Rhodes, T. D. Hollingsworth, Variational data assimilation with epidemic models, Journal of Theoretical Biology 258, 591–602, 2009.
- [35] C. Sun, S. Richard, T. Miyoshi, Agent-based model and data assimilation: Analysis of COVID-19 in Tokyo, Preprint: https://arxiv.org/abs/2109.00258.
- [36] M.K. Tippett, J.L. Anderson, C.H. Bishop, T.M. Hamill, J.S. Whitaker, Ensemble square-root filters, Mon. Wea. Rev. 131, 1485–1490, 2003.
- [37] Bureau of social welfare and public health, About death cases due to COVID-19 in Tokyo, https://www.fukushihoken.metro.tokyo.lg.jp
- [38] Tokyo metropolitan government, COVID-19 The information website, https://stopcovid19.metro.tokyo.lg.jp.
- [39] Toyokeizai, Coronavirus disease (COVID-19) situation report in Japan, https://toyokeizai.net/sp/visual/tko/covid19/en.html.
- [40] J.S. Whitaker, T.M. Hamill, Ensemble data assimilation without perturbed observations, Mon. Wea. Rev. 130, 1913–1924, 2002.
- [41] World Health Organization: https://www.who.int/.