capbtabboxtable[][\FBwidth]
Analog Gated Recurrent Neural Network for Detecting Chewing Events
Abstract
We present a novel gated recurrent neural network to detect when a person is chewing on food. We implemented the neural network as a custom analog integrated circuit in a 0.18 m CMOS technology. The neural network was trained on hours of data collected from a contact microphone that was mounted on volunteers’ mastoid bones. When tested on hours of previously-unseen data, the neural network identified chewing events at a -second time resolution. It achieved a recall of and an F1-score of while consuming W of power. A system for detecting whole eating episodes—like meals and snacks—that is based on the novel analog neural network consumes an estimated W of power.
Index Terms:
Eating detection, wearable devices, analog LSTM, neural networks.I Introduction
Monitoring food intake and eating habits are important for managing and understanding obesity, diabetes and eating disorders [1, 2, 3]. Because self-reporting is unreliable, many wearable devices have been proposed to automatically monitor and record individuals’ dietary habits [4, 5, 6]. The challenge is that if these devices are too bulky (generally due to a large battery), or if they require frequent charging, then they intrude on the user’s normal daily activities and are thus prone to poor user adherence and acceptance [7, 8, 9, 10].
We recently addressed this problem with a long short-term memory (LSTM) neural network for eating detection that is implementable on a low-power microcontroller [11, 12]. However, our previous approach relied on a power-consumptive analog-to-digital converter (ADC). It also required the microcontroller unit (MCU) to unnecessarily spend power to process irrelevant (i.e. non-eating related) data.
Analog LSTM neural networks have been proposed as a way to eliminate the ADC and also to minimize the microcontroller’s processing of irrelevant data. Unfortunately, the state-of-the-art analog LSTMs [13, 14, 15, 16, 17] are implemented with operational amplifiers (opamps), current/voltage converters, Hadamard multiplications and internal ADCs and digital-to-analog converters (DACs). These peripheral components represent a significant amount of overhead cost in terms of power consumption, which diminishes the benefits of an analog LSTM (see Table I).
In this paper, we introduce a power-efficient analog neural network that contains no DACs, ADCs, opamps or Hadamard multiplications. Our novel approach is based on a current-mode adaptive filter, and it eliminates over of the power requirements of a more conventional solution.
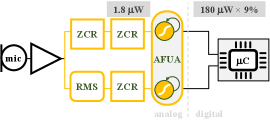
II Eating Detection System
Figure 1 shows our proposed Adaptive Filter Unit for Analog (AFUA) long short-term memory as part of a signal processing system for detecting eating episodes. The input to the system is produced by a contact microphone that is mounted on the user’s mastoid bone. Features are extracted from the contact microphone signal and input to the AFUA neural network, which infers whether or not the user is chewing. The AFUA’s output is a one-hot encoding (()=chewing; ()=not chewing) of the predicted class label. Finally, a microcontroller processes the predicted class labels and groups the chewing events into discrete eating episodes, like a meal, or a snack [4, 5]. Following is a detailed description of the feature extraction and neural network components of the system.
| Circuit | Neuron Type | Power Consumption Overhead (%) | |||||
| ADC | DAC | Buffer | Opamp, V/I | Total | |||
| This work | AFUA | 0 | 0 | 3 | 0 | 3 | |
| [18] | GRU | 0 | 0 | 32 | 0 | 32 | |
| [16] | LSTM | 12 | 25 | 1 | 30 | 68 | |
| [17] | LSTM | 3 | 17 | 8 | 1 | 29 | |
II-A Feature Extraction
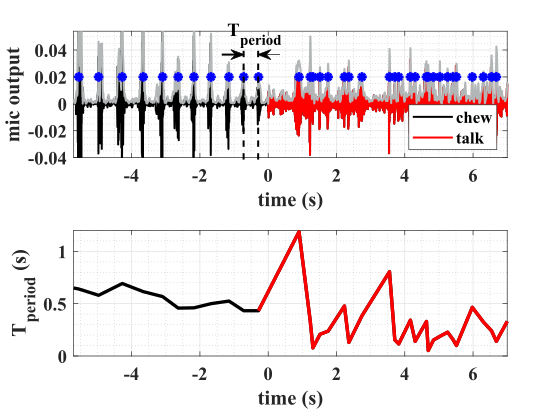
As demonstrated in Fig. 2, chewing is characterized by quasi-periodic bursts of large amplitude, low frequency signals that can be measured by a contact microphone or accelerometer that is mounted on the head [11, 5]. We can use the root mean square (RMS) and the zero-crossing rate (ZCR) to capture the signal’s amplitude and frequency, respectively. A second ZCR operation applied to the RMS and the initial ZCR will produce information about the signal’s periodicity. We implement the ZCR and RMS blocks based on the well-known rectifying current mirror. The details of the ZCR and RMS design may be found in [19, 20].
II-B AFUA Neural Network
Fundamentally, an LSTM is a neuron that selectively retains, updates or erases its memory of input data [21]. The gated recurrent unit (GRU) is a simplified version of the classical LSTM, and it is described with the following set of equations [22]:
| (1) | |||||
| (2) | |||||
| (3) | |||||
| (4) |
where is the input, is the hidden state, is the candidate state, is the reset gate and is the update gate. Also, and are learnable weight matrices.
To implement the GRU in an efficient analog integrated circuit that contains no DACs, ADcs, operational amplifiers or multipliers, we can transform Eqn. (1)-(4) as follows. The function of Eqn. (2) gives a range of , and the extrema of this range reveals the basic mechanism of the update equation, Eqn. (4). For , the update equation is . For , the update equation becomes . Without loss of generality, we can replace with (this merely inverts the logic of the update gate, and inverts the sign of the and weight matrices). So, replacing and rearranging the update equation gives us
| (5) |
which is simply a first-order low pass filter with a continuous-time form of
| (6) |
where , the time step of the discrete-time system. The gating mechanics of the continuous- versus discrete-time update equations are equivalent, modulo the inverted logic: For , Eqn. (6) is a low-pass filter with an infinitely large time constant, and does not change (this is equivalent to in discrete time). For , Eqn. (6) is a low-pass filter with a time constant of . Since the time step is small relative to the GRU’s dynamics, a time constant of produces (equivalent to in discrete time).
Various studies have found the reset gate unnecessary with slow-changing signals, and also for event detection [12]. Both these scenarios describe our eating detection application, so we can discard the reset gate.
Finally, if we translate the origins [23] of both and to , then we can replace the with a saturating function that has a range of . Such a saturating function can easily be implemented in analog circuitry, by taking advantage of the unidirectional nature of a transistor’s drain-source current. We replace both the and the with the following saturating function,
| (7) |
translate the origin and discard the reset gate to arrive at the Adaptive Filter Unit for Analog LSTM (AFUA):
| (8) | |||||
| (9) | |||||
| (10) |
where is the j’th element of the vector. Also, is the input, is the hidden state and is the candidate state. The variable is the nominal time constant, while controls the state update rate in Eqn. (10). , , , are learnable weight matrices, while , are learnable bias vectors. The AFUA resembles the eGRU [12], which we previously showed can be used for cough detection and keyword spotting. But while the eGRU is a conventional digital, discrete-time neural network, the AFUA is a continuous-time system, implementable as an analog integrated circuit.
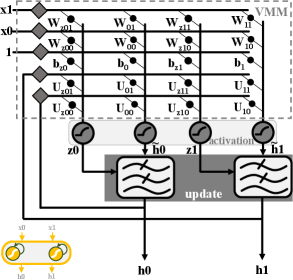
III AFUA circuit implementation
Figure 3 shows the high-level block diagram of the AFUA neural network. It comprises two AFUA cells (with corresponding hidden states and ), and it accepts two inputs, and . Unlike previous LSTMs [13, 14, 15, 16, 17], the AFUA network contains no digital-to-analog converters, analog-to-digital converters, operational amplifiers or four-quadrant multipliers. Avoiding these power-consumptive components is what makes the AFUA implementation so efficient. Following are the circuit implementation details of the AFUA.
III-A Dimensionalization
III-B Activation Function
The Eqn. (7) function is implemented as the current-starved current mirror shown in Fig. 4. Kirchhoff’s Current Law applied to the source of transistor M3 gives
| (11) |
The transistors are all sized equally, meaning that, from Kirchhoff’s Voltage Law, the gate source voltage of transistor M3 is
| (12) |
where we have assumed that the body effect in M2 and Mb is negligible. If we operate the transistors in the subthreshold region, then Eqn. (12) implies
| (13) |
Combining Eqns. (11) and (13) gives us
| (14) |
Now, the current flowing through a diode-connected nMOS is unidirectional, meaning , and we can write
| (15) |
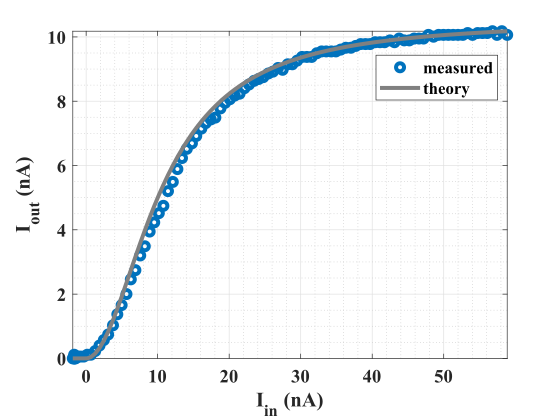
which is a dimensionalized analog of Eqn. (7). The measurement results in Fig. 5 illustrate the nonlinear, saturating behavior of this activation function.
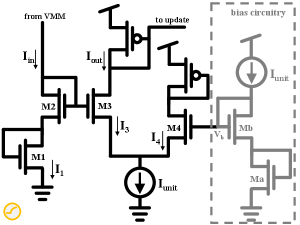
III-C State Update
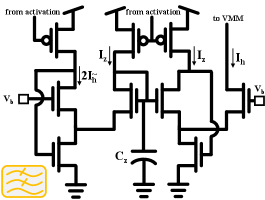
The AFUA state update, Eqn. (10), is implemented as the adaptive filter shown in Fig. 6. The currents , and represent the hidden state , the candidate state and the update gate, , respectively. From the translinear loop principle, the Fig. 6 circuit’s dynamics can be written as [26, 24]
| (16) |
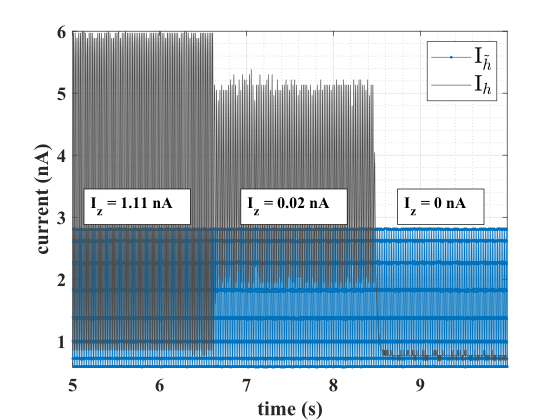
where is the body-effect coefficient and is the thermal voltage [27]. Just as does for in Eqn. (10), controls the update speed of (see Fig. 7).
III-D Vector Matrix Multiplication
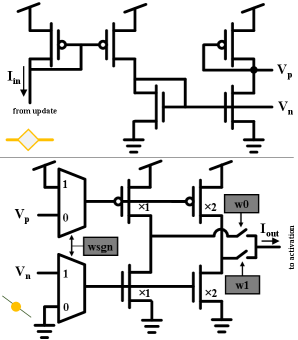
Figure 8 depicts the components of our vector-matrix multiplication (VMM) block. These are the soma and synapse circuits that are common in the analog neuromorphic literature [28]. Crucially, the soma-synapse architecture is current-in, current-out. This means that, unlike other approaches for implementing GRU and LSTM networks [14, 15, 16], the VMM does not need power-consumptive operational amplifiers to convert signals between the current and voltage domains.
IV Circuit Analysis
IV-A Current Consumption
Since the activation function, Eqn. (7), has a range of , the and variables are likewise limited to . Also, from Eqn. (10), spans . This means that all update gate and candidate state currents have a maximum value of , while the hidden state currents have a maximum value of . With this information, we can calculate upper-bounds on the current consumption of each circuit component.
IV-A1 Activation Function
Not counting the input current that is supplied by the VMM, Fig. 4 shows that the only current consumed by the activation function block is the differential-pair tail current of . There are two activation functions per AFUA cell (one each for and ). So, for an -unit AFUA layer, the activation function blocks draw a total current of .
IV-A2 State Update
The total current flowing through the four branches of the state update circuit (Fig. 6) is , which has a worst-case value of . For our -unit AFUA network, the state update circuits consume at most .
IV-A3 VMM soma
The soma is a current-mode buffer that drives a differential signal onto each row of the VMM (see Fig. 8). For the somas on the input and bias rows, the maximum current consumption is . The somas driving the hidden state rows consume at most each. So, with inputs, hidden states and one bias row, the somas will consume a maximum total current of .
IV-A4 VMM core
As depicted in Fig. 8, each multiplier element in the VMM core comprises a number of current sources that are switched on or off, depending on the values of the weight bits. At worst, all current sources are switched on, in which case the VMM elements that process state variables each consume , while those that process input variables or biases each consume . The maximum current draw of each VMM column for an -input AFUA layer with hidden states is therefore . There are columns, to give a total maximum VMM core current consumption of .
IV-A5 Total Current Consumption
From the previous subsections, we conclude that the worst-case total current consumption of an -input AFUA layer with hidden states is
| (17) |
where ‘core’ includes the activation function, VMM core and state update current consumption. The VMM soma is peripheral to the AFUA’s operation and represents overhead cost. For instance, a -input, -unit AFUA layer would spend of its power budget as overhead.
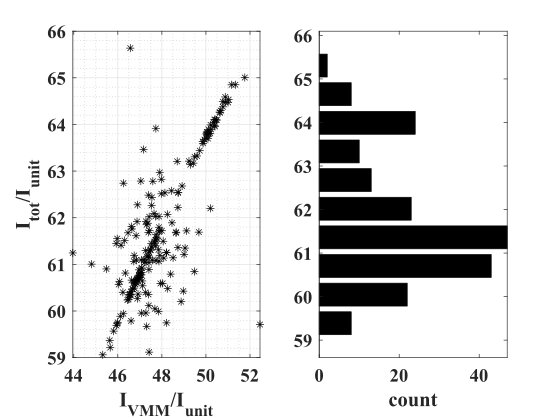
Empirically, we found that the average current consumption of some of the AFUA blocks is significantly lower than their estimated worst-case values. In particular, the VMM consumes only on average (see Fig. 9). This leads to an average AFUA total current consumption of . The specific choice of depends on the desired operating speed, as we discuss in the following subsection.
IV-B Estimated Power Efficiency
The power efficiency of neural networks is conventionally measured in operations per Watt. But this metric does not apply directly to a system like the AFUA, since it executes all of its operations continuously and simultaneously. However, we can estimate the AFUA’s power efficiency by considering the performance of an equivalent discrete time system.
To arrive at the discrete-form AFUA unit, we first replace the state variables of Eqns. (8), (9) and (10) with their discrete-time counterparts. This includes the discretization , where is the sampling period. Then, we set to produce the following expression.
| (18) |
Recall that are matrices, are vectors and are scalars, meaning that each discretized AFUA unit executes multiply operations per time step. Also, there are divisions due to the two activation functions (see Eqn. (7)). Not counting additions and subtractions, each discretized AFUA unit executes operations per time step, to make for a total of operations/step performed by the network. Assuming the sampling period of ms used in our previous eating detection systems [6, 11], this implies the AFUA performs the equivalent of operations per second.
Now, setting ms requires a unit current of
| (19) |
where fF is the integrating capacitor of the translinear loop filter, mV at room temperature and . This gives pA. With a total current consumption of , a voltage supply of V and K operations per second, the AFUA’s equivalent operations per Watt is TOps/W.
IV-C Mismatch
Due to random variations in doping and geometry, transistors that are nominally identical will exhibit mismatch when fabricated in a physical ASIC. To understand the effect of mismatch and other non-idealities on the AFUA neural network’s performance, we performed Monte Carlo analyses with foundry-provided manufacturing and test data. The Monte Carlo analyses included mismatch and process variation, as well as power supply voltage and temperature corners of and , respectively.
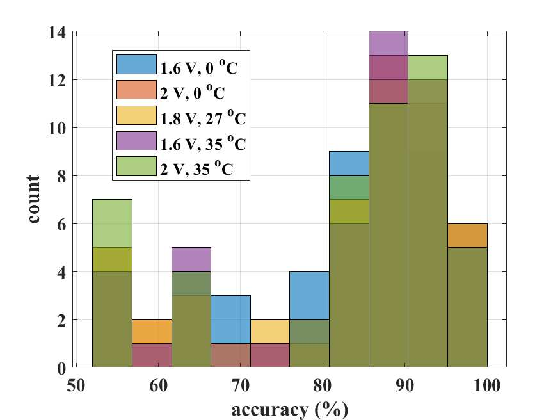
Figure 10 shows the variation in classification accuracy for Monte Carlo runs of one implementation of the AFUA neural network. The median accuracy across all runs is . Most of the variation in accuracy is due to mismatch, and the AFUA neural network is largely robust to temperature, voltage and process variation. The neural network is also unaffected by circuit noise (this is a direct result of the network’s ability to generalize). To mitigate the effect of mismatch, we can use larger transistors [29], calibrate the network’s learning algorithm for each individual chip [28], or incorporate mismatch data into a fault-tolerant learning algorithm [30].
V Experimental Methods
V-A Data Collection
Training and testing data was collected from study volunteers in a laboratory setting. All aspects of the study protocol were reviewed and approved by the Dartmouth College Institutional Review Board (Committee for the Protection of Human Subjects-Dartmouth; Protocol Number: 00030005).
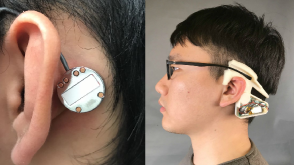
The data used for this study was previously collected in a controlled laboratory setting from 20 participants (8 females, 12 males; aged 21-30) that were instructed to perform both eating and non-eating-related activities. During these activities, a contact microphone (see Fig. 11) was secured behind the ear with a headband, to measure any acoustic signals present at the tip of the mastoid bone [31]. The output of the contact microphone was digitized and stored using a 20 kSa/s, 24-bit data acquisition device (DAQ).
Participants were asked to eat a variety of foods—including carrots, protein bars, crackers, canned fruit, instant food, and yogurt—for at least 2 minutes per food type. This resulted in a 4 hour total eating dataset. Non-eating activities included talking and silence for 5 minutes each and then coughing, laughing, drinking water, sniffling, and deep breathing for 24 seconds each. This resulted in 4 hours total of non-eating data. Each activity occurred separately and was classified based on activity type as eating or non-eating.
We down-sampled the DAQ data to Hz and applied a high pass filter with a Hz cutoff frequency to attenuate noise. We segmented the positive class data (chewing), and negative class data (not chewing) into -second windows with no overlap. The positive and negative class data were labelled with the one-hot encoding and , respectively. Finally, we extracted the ZCR-RMS and ZCR-ZCR features of the windows to produce -dimensional input vectors to be processed by the AFUA network.
V-B Neural Network Training
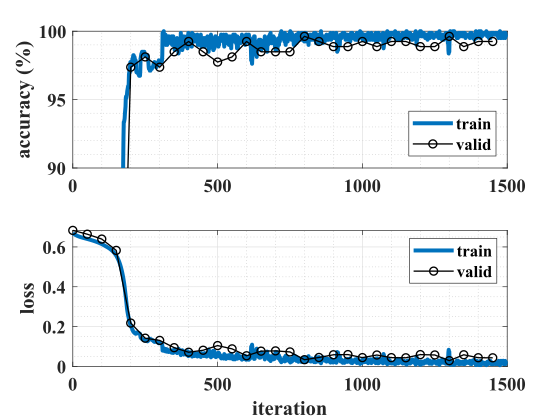
For training, the AFUA neural network was implemented in Python, using a custom layer defined by the discretized system of Eqn. (18). Chip-specific parameters were extracted for each neuron and incorporated into the custom layers. The AFUA network was trained and validated on the laboratory data (train/valid/test split: ) using the TensorFlow Keras v2.0 package. Training was performed with the adam optimizer [32] and a weighted binary cross-entropy loss function to learn full-precision weights.
Python training was followed by a quantization step that converted the full-precision weights to signed -bit values (). An alternative approach would have been to directly incorporate the quantization process into the network’s computational graph [12]. However, we found that such an approach only slows down training with no improvement in our network’s classification performance.
V-C Chip Measurements
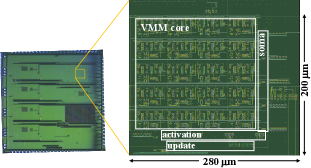
The AFUA was implemented, fabricated and tested as an integrated circuit in a standard m mixed-signal CMOS process with a V power supply. To simplify the measurement process and associated instrumentation, the ASIC I/O infrastructure includes current buffers that scale input currents by and that multiply output currents by .
The AFUA neural network was programmed by storing the -bit version of each learned weight onto its corresponding on-chip register in the VMM array.
The network was then evaluated on the test dataset. Specifically, each -second long window of -dimensional feature vectors from the test dataset was dimensionalized and scaled to and input to the ASIC with an arbitrary waveform generator. We set nA with an off-chip resistor. According to Eqn. (19), this creates a time constant of s, allowing for faster-than-real-time chip measurements—an important consideration, given the large amount of test data to be processed.
Output currents , were each measured from the voltage drop across an off-chip sense resistor. The ASIC’s steady-state response was then taken as the classification decision. An output value of means that the circuit classified the input as eating, while corresponds to non-eating. From these measurements, we calculated the algorithm’s test accuracy, loss, precision, recall, and F1-score.
VI Results and Discussion
| Window Size (s) | Accuracy | F1-Score | Precision | Recall | Power (mW) | |
|---|---|---|---|---|---|---|
| This work | 24 | 0.94 | 0.94 | 0.96 | 0.91 | 0.019 |
| FitByte [33] | 5 | - | - | 0.83 | 0.94 | 105 |
| TinyEats [11] | 4 | 0.95 | 0.95 | 0.95 | 0.95 | 40 |
| Auracle [31] | 3 | 0.91 | - | 0.95 | 0.87 | offline |
| EarBit [4] | 35 | 0.90 | 0.91 | 0.87 | 0.96 | offline |
| AXL [5] | 20 | - | 0.91 | 0.87 | 0.95 | offline |
VI-A Classification Performance
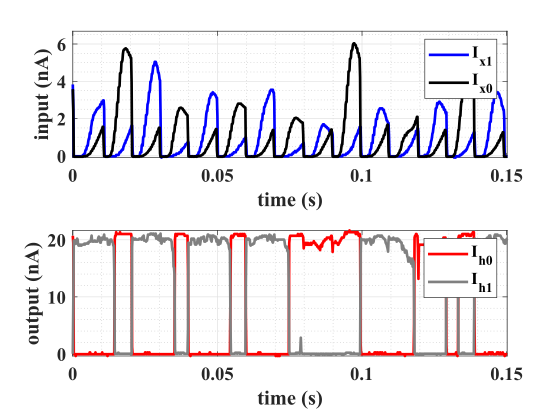
Figure 14 shows the AFUA chip’s typical response to input data. The input currents represent the ZCR-RMS and ZCR-ZCR features extracted from the contact microphone signal. Inputting a stream of patterns produces output currents , which represent the hidden states of the AFUA network.
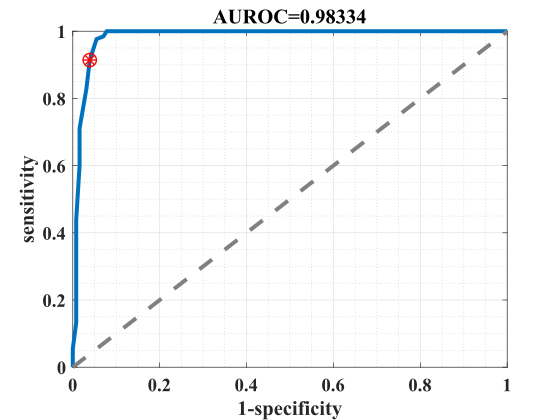
According to our encoding scheme, means that the circuit classified the input as chewing, while corresponds to a prediction of not chewing. But the presence of noise and circuit non-ideality produces some ambiguity in the encoding: some AFUA output patterns can be interpreted as either chewing or not chewing, depending on the choice of threshold used to distinguish between A and . Figure 15 is the receiver operating curve (ROC) produced by varying this threshold current. The highlighted point on the ROC is a representative operating point, where the classifier produced a sensitivity of and a specificity of . This corresponds to a false alarm rate of specificity.
VI-B System-level Considerations
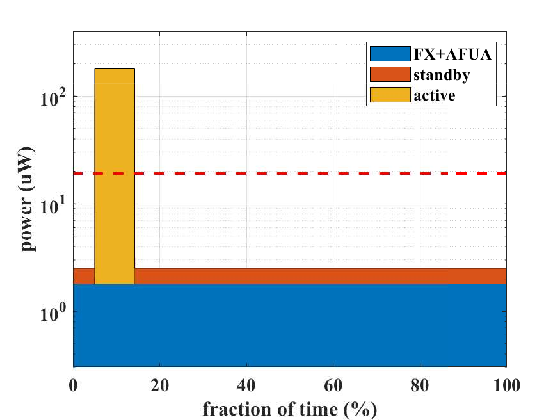
In this section, we consider the impact of using the AFUA neural network in a complete eating event detection system. To process a Hz signal, the ZCR and RMS feature extraction blocks consume a total of W [19]. Also, the AFUA network consumes W, assuming nA. Finally, a microcontroller from the MSP430x series (Texas Instruments Inc., Dallas, TX) running at MHz consumes W when active and W when in standby mode [34].
The feature extraction and AFUA circuitry are always on, while the microcontroller remains in standby mode until a potential chewing event is detected. The fraction of time the microcontroller is in the active mode depends on how often the user eats, as well as the sensitivity and specificity of the AFUA network. Assuming the user spends of the day eating [35], then, using the classifier operating point highlighted in Fig. 15, the fraction of time that the microcontroller is active is
| active | (20) | ||||
So, the microcontroller consumes an average of W. As Fig. 16 shows, the average power consumption of the complete AFUA-based eating detection system is W. If we attempted to implement the system with a front-end ADC (12-bit, 500 Sa/s [6, 36]) followed by a digital LSTM [37, 38], then the ADC alone would consume over W of power [39].
Table II compares our work to other recent eating detection solutions. The different approaches all yield generally the same level of classification accuracy, but our work differs in one critical aspect: while others depend on offline processing, or on tens of milliWatts of power to operate, our approach only requires an estimated W.
VII Conclusion
We have introduced the AFUA—an adaptive filter unit for analog long short-term memory—as part of an eating event detection system. Measurement results of the AFUA implemented in a 0.18 m CMOS technology showed that it can identify chewing events at a 24-second time resolution with a recall of 91 and an F1-score of 94, while consuming W of power. The AFUA precludes the need for an analog-to-digital converter, and it also prevents a downstream microcontroller from unnecessarily processing irrelevant data. If a signal processing system were built around the AFUA for detecting eating episodes (that is, meals and snacks), then the whole system would consume less than W of power. This opens up the possibility of unobtrusive, batteryless wearable devices that can be used for long-term monitoring of dietary habits.
VIII Acknowledgments
This work was supported in part by the U.S. National Science Foundation, under award numbers CNS-1565269 and CNS-1835983. The views and conclusions contained in this document are those of the authors and do not necessarily represent the official policies, either expressed or implied, of the sponsors.
References
- [1] Ki Soo Kang “Nutritional counseling for obese children with obesity-related metabolic abnormalities in Korea” In Pediatric gastroenterology, hepatology & nutrition 20.2 The Korean Society of Pediatric Gastroenterology, HepatologyNutrition, 2017, pp. 71–78
- [2] Laura M O’Connor et al. “Dietary dairy product intake and incident type 2 diabetes: a prospective study using dietary data from a 7-day food diary” In Diabetologia 57.5 Springer, 2014, pp. 909–917
- [3] Robert Turton et al. “To go or not to go: A proof of concept study testing food-specific inhibition training for women with eating and weight disorders” In European Eating Disorders Review 26.1 Wiley Online Library, 2018, pp. 11–21
- [4] Abdelkareem Bedri et al. “EarBit: using wearable sensors to detect eating episodes in unconstrained environments” In Proceedings of the ACM on interactive, mobile, wearable and ubiquitous technologies 1.3 ACM New York, NY, USA, 2017, pp. 1–20
- [5] Muhammad Farooq and Edward Sazonov “Accelerometer-based detection of food intake in free-living individuals” In IEEE sensors journal 18.9 IEEE, 2018, pp. 3752–3758
- [6] Shengjie Bi et al. “Auracle: Detecting eating episodes with an ear-mounted sensor” In Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies 2.3 ACM New York, NY, USA, 2018, pp. 1–27
- [7] Ana Isabel Canhoto and Sabrina Arp “Exploring the factors that support adoption and sustained use of health and fitness wearables” In Journal of Marketing Management 33.1-2 Taylor & Francis, 2017, pp. 32–60
- [8] Yiwen Gao, He Li and Yan Luo “An empirical study of wearable technology acceptance in healthcare” In Industrial Management & Data Systems Emerald Group Publishing Limited, 2015
- [9] Lucy E Dunne et al. “The social comfort of wearable technology and gestural interaction” In 2014 36th annual international conference of the IEEE engineering in medicine and biology society, 2014, pp. 4159–4162 IEEE
- [10] Brian K Hensel, George Demiris and Karen L Courtney “Defining obtrusiveness in home telehealth technologies: A conceptual framework” In Journal of the American Medical Informatics Association 13.4 BMJ Group BMA House, Tavistock Square, London, WC1H 9JR, 2006, pp. 428–431
- [11] Maria T Nyamukuru and Kofi M Odame “Tiny Eats: Eating Detection on a Microcontroller” In 2020 IEEE Second Workshop on Machine Learning on Edge in Sensor Systems (SenSys-ML), 2020, pp. 19–23 IEEE
- [12] Justice Amoh and Kofi M Odame “An optimized recurrent unit for ultra-low-power keyword spotting” In Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies 3.2 ACM New York, NY, USA, 2019, pp. 1–17
- [13] Ian D Jordan and Il Memming Park “Birhythmic analog circuit maze: a nonlinear neurostimulation testbed” In Entropy 22.5 Multidisciplinary Digital Publishing Institute, 2020, pp. 537
- [14] Kazybek Adam, Kamilya Smagulova and Alex Pappachen James “Memristive LSTM network hardware architecture for time-series predictive modeling problems” In 2018 IEEE Asia Pacific Conference on Circuits and Systems (APCCAS), 2018, pp. 459–462 IEEE
- [15] Olga Krestinskaya, Khaled Nabil Salama and Alex Pappachen James “Learning in memristive neural network architectures using analog backpropagation circuits” In IEEE Transactions on Circuits and Systems I: Regular Papers 66.2 IEEE, 2018, pp. 719–732
- [16] Jianhui Han et al. “ERA-LSTM: An efficient ReRAM-based architecture for long short-term memory” In IEEE Transactions on Parallel and Distributed Systems 31.6 IEEE, 2019, pp. 1328–1342
- [17] Zhou Zhao, Ashok Srivastava, Lu Peng and Qing Chen “Long short-term memory network design for analog computing” In ACM Journal on Emerging Technologies in Computing Systems (JETC) 15.1 ACM New York, NY, USA, 2019, pp. 1–27
- [18] Qin Li et al. “NS-FDN: Near-Sensor Processing Architecture of Feature-Configurable Distributed Network for Beyond-Real-Time Always-on Keyword Spotting” In IEEE Transactions on Circuits and Systems I: Regular Papers IEEE, 2021
- [19] Michael W Baker, Serhii Zhak and Rahul Sarpeshkar “A micropower envelope detector for audio applications [hearing aid applications]” In Proceedings of the 2003 International Symposium on Circuits and Systems, 2003. ISCAS’03. 5, 2003, pp. V–V IEEE
- [20] R Sarpeshkar et al. “An analog bionic ear processor with zero-crossing detection” In ISSCC. 2005 IEEE International Digest of Technical Papers. Solid-State Circuits Conference, 2005., 2005, pp. 78–79 IEEE
- [21] Sepp Hochreiter and Jürgen Schmidhuber “Long short-term memory” In Neural computation 9.8 MIT Press, 1997, pp. 1735–1780
- [22] Kyunghyun Cho et al. “Learning phrase representations using RNN encoder-decoder for statistical machine translation” In arXiv preprint arXiv:1406.1078, 2014
- [23] Steven H Strogatz “Nonlinear dynamics and chaos: with applications to physics, biology, chemistry, and engineering” CRC press, 2018
- [24] K.M. Odame and B.A. Minch “The translinear principle: a general framework for implementing chaotic oscillators” In International Journal of Bifurcation and Chaos 15.08 World Scientific, 2005, pp. 2559–2568
- [25] Kofi Odame and Bradley Minch “Implementing the Lorenz oscillator with translinear elements” In Analog Integrated Circuits and Signal Processing 59.1 Springer, 2009, pp. 31–41
- [26] J Mulder, WA Serdijn, AC Van der Woerd and AHM Van Roermund “Dynamic translinear RMS-DC converter” In Electronics letters 32.22 IET, 1996, pp. 2067–2068
- [27] Christian C. Enz, François Krummenacher and Eric A. Vittoz “An analytical MOS transistor model valid in all regions of operation and dedicated to low-voltage and low-current applications” In Analog Integr. Circuits Signal Process. 8.1 Hingham, MA, USA: Kluwer Academic Publishers, 1995, pp. 83–114 DOI: http://dx.doi.org/10.1007/BF01239381
- [28] Jonathan Binas et al. “Precise deep neural network computation on imprecise low-power analog hardware” In arXiv preprint arXiv:1606.07786, 2016
- [29] Marcel JM Pelgrom, Aad CJ Duinmaijer and Anton PG Welbers “Matching properties of MOS transistors” In IEEE Journal of solid-state circuits 24.5 IEEE, 1989, pp. 1433–1439
- [30] AS Orgenci, G Dundar and S Balkur “Fault-tolerant training of neural networks in the presence of MOS transistor mismatches” In IEEE Transactions on Circuits and Systems II: Analog and Digital Signal Processing 48.3 IEEE, 2001, pp. 272–281
- [31] Shengjie Bi et al. “Toward a wearable sensor for eating detection” In Proceedings of the 2017 Workshop on Wearable Systems and Applications, 2017, pp. 17–22
- [32] Diederik P Kingma and Jimmy Ba “Adam: A method for stochastic optimization” In arXiv preprint arXiv:1412.6980, 2014
- [33] Abdelkareem Bedri et al. “Fitbyte: Automatic diet monitoring in unconstrained situations using multimodal sensing on eyeglasses” In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, 2020, pp. 1–12
- [34] “MSP430FR596x, MSP430FR594x Mixed-Signal Microcontrollers datasheet” (Rev. G), 2018 Texas Instruments
- [35] Jim P Stimpson, Brent A Langellier and Fernando A Wilson “Peer Reviewed: Time Spent Eating, by Immigrant Status, Race/Ethnicity, and Length of Residence in the United States” In Preventing Chronic Disease 17 Centers for Disease ControlPrevention, 2020
- [36] Texas Instruments “CC2640R2F Datasheet”, 2020
- [37] Dongjoo Shin, Jinmook Lee, Jinsu Lee and Hoi-Jun Yoo “14.2 DNPU: An 8.1 TOPS/W reconfigurable CNN-RNN processor for general-purpose deep neural networks” In 2017 IEEE International Solid-State Circuits Conference (ISSCC), 2017, pp. 240–241 IEEE
- [38] Juan Sebastian P Giraldo and Marian Verhelst “Laika: A 5uW programmable LSTM accelerator for always-on keyword spotting in 65nm CMOS” In ESSCIRC 2018-IEEE 44th European Solid State Circuits Conference (ESSCIRC), 2018, pp. 166–169 IEEE
- [39] Texas Instruments “ADS1000-Q1 Datasheet”, 2015