An ocular biomechanics environment for reinforcement learning
Abstract
Reinforcement learning has been applied to human movement through physiologically-based biomechanical models to add insights into the neural control of these movements; it is also useful in the design of prosthetics and robotics. In this paper, we extend the use of reinforcement learning into controlling an ocular biomechanical system to perform saccades, which is one of the fastest eye movement systems. We describe an ocular environment and an agent trained using Deep Deterministic Policy Gradients method to perform saccades. The agent was able to match the desired eye position with a mean deviation angle of . The proposed framework is a first step towards using the capabilities of deep reinforcement learning to enhance our understanding of ocular biomechanics.
keywords:
Ocular Biomechanics, eye movement, reinforcement learning, saccades, neural networks1 Introduction
Eye movement is one of the most complex, and the fastest movement that our body performs (Leigh and Zee, 2015); the different eye movement systems are tightly coupled with mental, cognitive and psychological states of the individual (Wong, 2008; Iskander et al., 2018a). One of the most studied eye movement systems is saccade, which shifts the gaze direction to a new point of interest rapidly (Gilchrist, 2011). Simulating the neural control of the muscles that could efficiently achieve eye movement through biomechanical simulation and analysis is an essential tool for studying different eye movement systems in normal and pathological cases Iskander et al. (2018c, d).
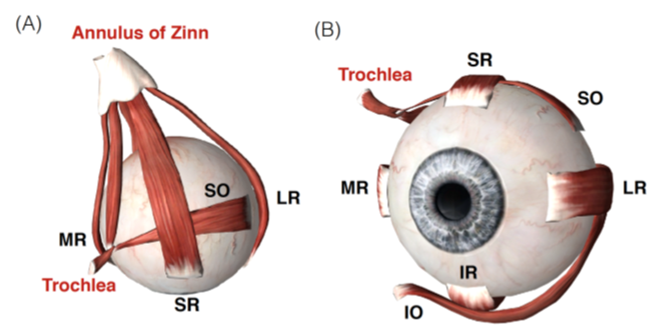
The horizontal, vertical and torsional eye movements are created through the activation of six extraocular muscles (EOM), Fig. LABEL:sub@fig:muscles Iskander et al. (2018c). The action/name of each of the six EOM are described in Table 1. To move the eye to the right, the right LR and the left MR are activated (agonists) while the right MR and left LR are inhibited (antagonists) (Sherrington, 1893; Hering et al., 1977). The opposite happens for leftward eye movement. To move the eye vertically, the SR, IR, SO and IO muscles are activated/inhibited (Purves et al., 2001; Scudder et al., 2002; Sparks, 2002). Next, we will introduce the concept of reinforcement learning as it will be used to control an ocular biomechanical system.
Reinforcement learning (RL) is a form of artificial intelligence that is different and fundamentally more difficult than supervised learning. According to Sutton and Barto (Sutton and Barto, 2018), RL is learning how to map a situation into an action such that a numerical reward is maximised. In the case of biomechanical studies, the situations is the biomechanical model state (), and the actions is the muscle excitation signals (), where as the numerical reward () reflects the desired movement. And, thus the RL agent learns to map each state into an efficient action that maximises the reward. In addition, we have a policy () which defines the strategy the agent uses, Fig. LABEL:sub@fig:model. The policy is the mapping from the to . As the agent proceeds in the training phase, evolves to produce the highest cumulative reward over time. The DRL training takes place in episodes. Each episode is a trial that allows the agent to explore the environment and to receive a reward based on how good or bad its behaviour was. The cumulative reward throughout an episode determines effectiveness of the training. RL has been used to model neural control of movements such as walking, running and standing (Hossny and Iskander, 2020; Kidziński et al., 2018a, b, 2020).

| Muscle | Primary | Secondary | Tertiary |
|---|---|---|---|
| Lateral Rectus (LR) | Abduction | - | - |
| Medial Rectus (MR) | Addution | - | - |
| Superior Rectus (SR) | Supraduction | Incycloduction | Adduction |
| Inferior Rectus (IR) | Infraduction | Excycloduction | Adduction |
| Superior Oblique (SO) | Incycloduction | Infraduction | Abduction |
| Inferior Oblique (IO) | Excycloduction | Supraduction | Abduction |
In the following, we present an ocular biomechanics simulation environment suitable for RL; and we train an agent to control the ocular biomechanics system by producing adequate muscle excitation signals to perform saccades.
2 Methods
The DRL environment used is made up of five components, as follows, the (1) neuro-musculoskeletal model; (2) the continuous state vector, that is produced from the environment; (3) the continuous action vector (muscle excitation signal), used to activate the neuro-musculoskeletal model; (4) the reward function to be maximise; and finally (5) the training mechanism used, which includes the actor and critic neural networks used.
2.1 Ocular Biomechanics Environment
The proposed DRL environment is based on OpenAI (Brockman et al., 2016), OpenSim (Kidziński et al., 2018a; Seth et al., 2018) and ocular biomechanics (Iskander et al., 2018d, 2019, b). The neuro-musculoskeletal model, Fig.1b, consist of a skull and two eyes; the skull has no degrees-of-freedom (DoFs). Each eye has six extraocular muscles which rotated the eye around three axis , , and . The model uses Millard muscle model (Millard et al., 2013) for the muscles.
2.2 The state vector, action vector and reward function
The state() vector includes 27 values, as follows:
-
1.
The 3D position of the object of interest;
-
2.
the 3D direction of gaze of each eye (point of gaze, POG);
-
3.
the 3D orientation of each eye; and
-
4.
the activation of the 12 muscles.
All measured values are in radians and meters.
The action () includes 12 values, in the range [0,1]. They represent the 12 extraocular muscles excitation signals (Millard et al., 2013; Thelen, 2003). The step size of the environment is 0.01 s, i.e. a step every 10 ms.
The reward function is defined as:
| (1) |
where and is the distance between the object of interest and the direction of gaze of each eye (R and L), is the distance between the POG of the two eyes, is the difference in the vertical position of both eyes, is a binary value that indicated whether crossed eyes occurred or not. Crossed eyes is measured by the horizontal position of the eye POG, where the right eye POG should lie to the right of the left eye POG. Finally, , , , , and are weights whose values are 16,16,32,64 and 64, respectively. The objective is that the reward should approach zero.
2.2.1 Training Methodology
The state and action vectors are continuous, therefore Deep Deterministic Policy Gradients (DDPG) is used. DDPG is an off-policy, actor-critic algorithm for continuous observation and action spaces (Lillicrap et al., 2015). Actor-critic based RL uses two modules, an actor and a critic. The actor learns a policy that maps the current state into an action, while the critic assesses the anticipated reward based on the current observation and the actor’s action. DDPG, also, uses an experience replay buffer, to store previous experiences. The experience replay buffer is used randomly to train the actor and critic neural networks; that is why it is categorised as off-policy (Konda and Tsitsiklis, 2000; Silver et al., 2014; Lillicrap et al., 2015). Testing was done on two phases. First, we tested each milestone policy (actor network), by using it to run 10 episodes (100 step each). A video of the process is in the supplementary material. At the start of each episode, the target object of interest is located at (, , ) = (1,0,0), which is centrally in front of the two eyes. Then, the object is randomly moved by (, +, +) where and range between [-0.16, 0.16] and [-0.32, 0.32], respectively. In the second testing phase, we used the policy (actor network) achieved in the final milestone. The test defined nine positions for the object of interest. The nine positions create a 3x3 grid with points at 0.1 m distance from the initial position in and directions. For each position, 50 episodes were performed, each containing 100 steps.
2.2.2 RL Agent Network Structure
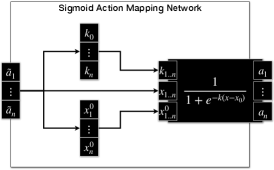
The actor and critic neural networks has 4 layers. All layers, except the final layer, utilise Rectified Linear Unit (ReLU) as the activation function. The final layer, in the actor, is an action mapping network, whereas the final layer, in the critic, receive no activation (Linear). In order to provide fine tuning over the produced excitation signals, action mapping network is added to the actor, to infer the parameters of the sigmoid function () for each muscle independently (Hossny and Iskander, 2020; Hossny et al., 2020), Fig.LABEL:sub@fig:actmap_sigmoid and Fig.LABEL:sub@fig:eomctrl. The sigmoid activation function is,
| (2) |
where controls the steepness of the curve and controls the minimum value as dictated by the intercept with the y-axis.
The actor and the critic neural networks have separate Adam optimisers (Kingma and Ba, 2014). Training took 10000 episodes (100 step each). The batch size used is 64 and the learning rate of 0.001 is used.
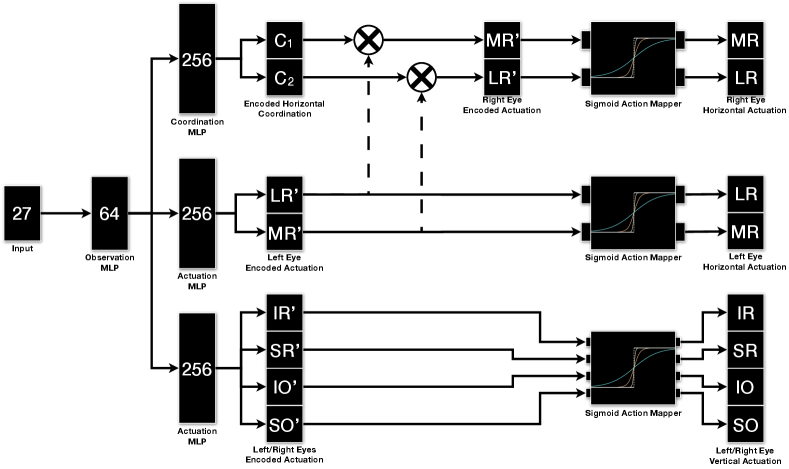
We adapted a model specific neural network architecture. This allowed us to enforce the LR/MR muscle coordination between the left and the right eyes, where the right LR and the left MR are innervated similarly and the same for the right MR and the left LR (Wong, 2008; Purves et al., 2001). In addition, since the LR and MR muscles have different properties (Iskander et al., 2018d), we added a coordination neural network that infers two constants, and , to allow for fine tuning between left LR and right MR as follows;
| (3) | |||||
| (4) |
In the case of the SR, IR, SO and IO muscles, the left and the right eye used excitation signals inferred from the same neural network.
3 Results
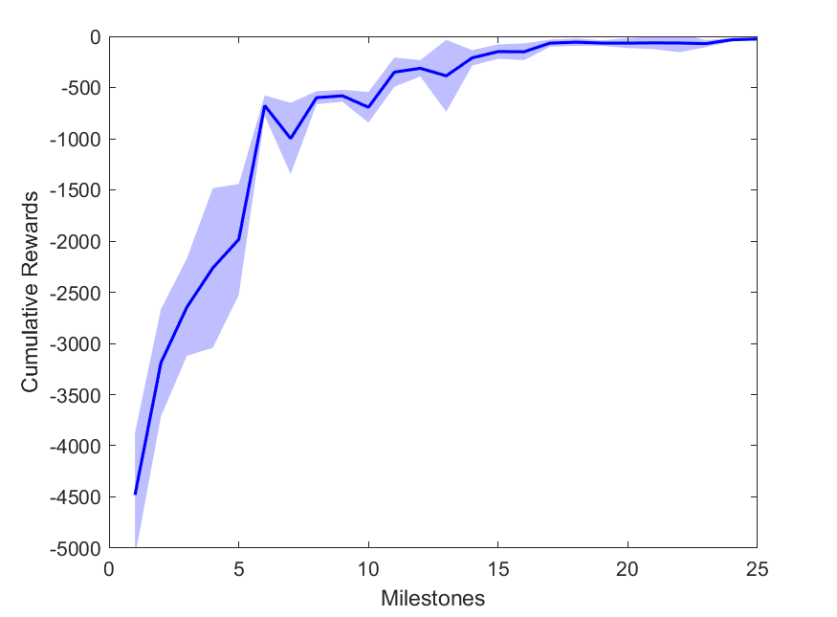
During training, the agent achieved 26 milestones to reach the final trained state. Each milestone defined an increase in the cumulative reward and thus, a better policy () was achieved, Fig. LABEL:sub@fig:milestone_reward.
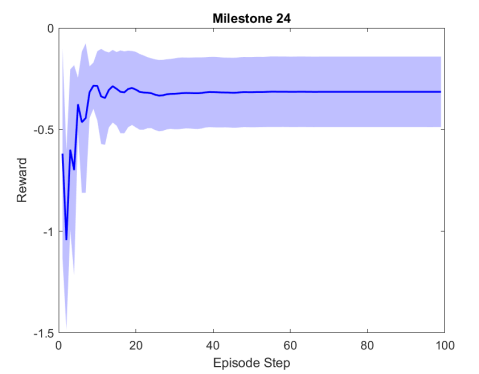
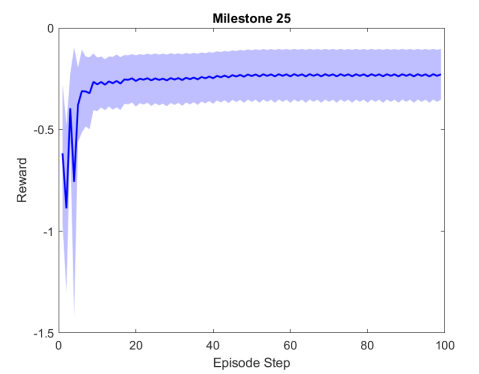
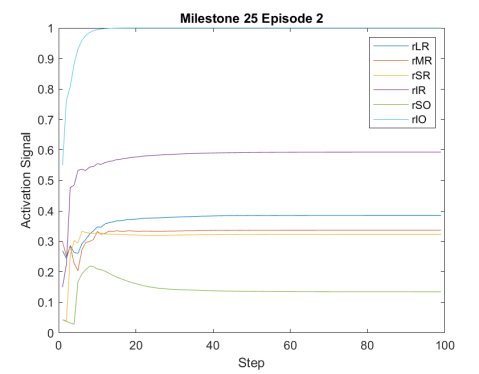
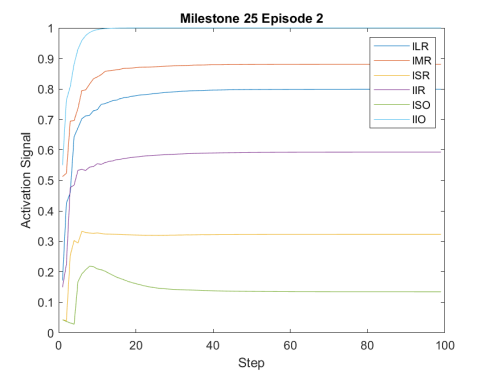
Figure 2 shows the results of the first testing phase done on each milestone. Figure LABEL:sub@fig:milestone_reward shows the cumulative reward achieved at each milestone. As the training proceeded, the cumulative reward improved and approached zero which is the optimal reward value. Figures LABEL:sub@fig:M24 and LABEL:sub@fig:M25 show the rewards achieved at each step for the last two milestones. Figures LABEL:sub@fig:RA and LABEL:sub@fig:RL shows the muscle activation signal of the right and left eye, respectively during the episode number 2 of the last milestone. The object of interest was displaced by =0.1231 and =-0.1112. For the eyes to follow this object, both eyes has to be elevated; the right eye has to be adducted; and the left eye abducted. Figures LABEL:sub@fig:RA and LABEL:sub@fig:RL shows high activation of IO which causes elevation and abduction of the eye in contrast to SO which has a decreasing activation as it is an agonist muscle.
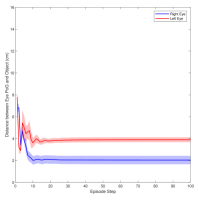
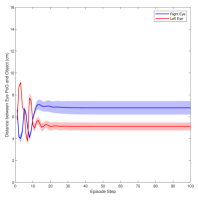
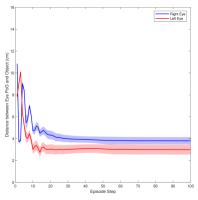
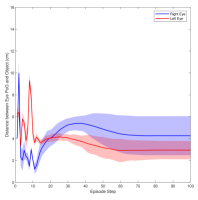
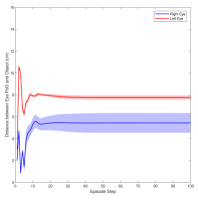
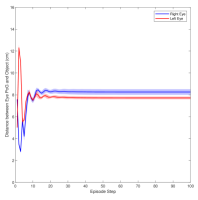
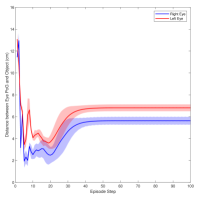
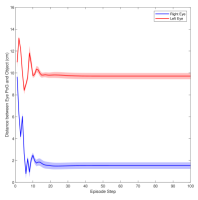
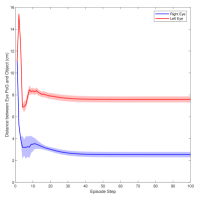
Figure 3 shows the muscle activation signals resulting from the second testing phase, each figure shows the mean activation of each muscle and the shaded part shows the standard deviation. Table 2 shows mean, maximum, minimum, and standard deviation of the distance between the right/left PoG and the object of interest for each object displacement case. The mean distance was approximately cm, which is approximately equivalent to a deviation angle of , respectively, since the object is 1 m away (x-direction). The statistics were calculated after removing the first 20 steps, equivalent to seconds. Figure 4 shows the change in the distance for the right and left eye over time.
| dy,dz | R Mean | L Mean | R Max | L Max | R Min | L Min | R Std Deviation | L Std Deviation |
|---|---|---|---|---|---|---|---|---|
| 0, 0 | 5.4 | 7.7 | 7 | 8.2 | 3.6 | 7.3 | 0.8 | 0.2 |
| 0, 0.1 | 8.2 | 7.7 | 8.6 | 8.1 | 7.6 | 7.5 | 0.2 | 0.12 |
| 0, -0.1 | 4.6 | 3.2 | 6.4 | 4.9 | 1.4 | 0.4 | 1.5 | 0.9 |
| 0.1, 0 | 6.8 | 5.1 | 7.5 | 5.7 | 5.4 | 4.4 | 0.6 | 0.3 |
| 0.1, 0.1 | 3.8 | 3 | 5.1 | 3.9 | 3.2 | 1.9 | 0.3 | 0.4 |
| 0.1, -0.1 | 2 | 3.9 | 2.8 | 4.3 | 1.4 | 3.4 | 0.4 | 0.2 |
| -0.1, 0 | 1.5 | 9.7 | 2.2 | 10.3 | 1.2 | 9.2 | 0.3 | 0.3 |
| -0.1, 0.1 | 2.6 | 7.6 | 3.4 | 8.6 | 2.1 | 7 | 0.2 | 0.3 |
| -0.1, -0.1 | 5.3 | 6.5 | 6.3 | 7.4 | 0.7 | 2.6 | 0.9 | 0.9 |
| Overall | 4.5 | 6.1 | 8.6 | 10.3 | 0.7 | 0.45 | 2.2 | 2.2 |









4 Discussion
In this paper, we presented an ocular environment that could be used in reinforcement learning. The environment was used to train a DRL agent to learn to move the eyes and fixate on a static object at different positions with a mean deviation angle, approximately . It is noted that normal eyes are not stationary even at fixations but exhibits movement of small amplitude around the region of interest (Leigh and Zee, 2015). The DRL agent exhibited a similar behaviour; this is reflected in the shaded parts, presenting standard deviation, in Fig. 3 and Fig. 4.
The DRL agent adapted a model specific neural network that worked on capturing the EOM coordinated activation, Fig. LABEL:sub@fig:eomctrl. The main objective of the training was to drive the eyes to stabilise at or around the object of interest. Therefore, the agent tried to make use of all the muscles to get to the objective. The only constraint imposed was the inverse relationship between the right and left horizontal muscles (LR and MR) and the similarity between the other muscles of the left and right eyes.
The presented framework has its limitations too. As discussed, the agents main target was to maximise the reward; so it made optimal use of all muscles, without consideration of minimal effort or coordination between agonist and antagonist muscles (Wong, 2008), as it was not accounted for in the reward. The forces of the extraocular muscles are very small compared to the forces exerted by other skeletal muscles in the upper and lower limbs and consequently the metabolic cost is balanced by the benefits of having rapid and accurate fixations (Iskander et al., 2018d; Gilchrist, 2011; Leigh and Zee, 2015; Iskander et al., 2018c).
From Fig. 3, the agent relied on using the IO extensively which has a primary action of excyclotorsion and a secondary and tertiary action of elevation and abduction, respectively (Wong, 2008), Table 1. In contrast, LR and MR are used solely for abduction and adduction, respectively. Therefore, to compensate the high activation of IO, the IR was in most cases activated to compensate for the elevation caused by the IO.
From Figures 2 and 3, we can see that the agent was aspiring to achieve the best results; and it used most of the muscles all the time to achieve that objective. Although this may not be physiologically sound, it is a first step towards training a DRL agent for ocular motility. The next stage of this research will focus on fine tuning the actor and critic neural networks to achieve better results comparable to the ocular control theories established (Robinson et al., 1975; Jürgens et al., 1981; Scudder et al., 2002; Sparks, 2002). The environment can be also modified to simulate neck movement and thus, simulate vestibulo-ocular reflex and also, eye-hand coordination. Numerous scenarios can be simulated, from normal to pathological scenarios, and then analysis can be followed which will highlight how different control strategies can be used to perform improved eye movements. The DRL agent training can also be aligned with paediatrics research in ocular development.
Conflict of Interest Declaration
None
References
- Brockman et al. (2016) Brockman, G., Cheung, V., Pettersson, L., Schneider, J., Schulman, J., Tang, J., Zaremba, W., 2016. OpenAI Gym. arXiv preprint arXiv:1606.01540 .
- Gilchrist (2011) Gilchrist, I., 2011. Saccades, in: The Oxford handbook of eye movements.
- Hering et al. (1977) Hering, E., Bridgeman, B., Stark, L., 1977. The theory of binocular vision. Springer.
- Hossny and Iskander (2020) Hossny, M., Iskander, J., 2020. Just don’t fall: An ai agent’s learning journey towards posture stabilisation. AI 1, 286–298.
- Hossny et al. (2020) Hossny, M., Iskander, J., Attia, M., Saleh, K., 2020. Refined continuous control of ddpg actors via parametrised activation. arXiv:2006.02818 [cs.LG] arXiv:2006.02818.
- Iskander et al. (2018a) Iskander, J., Hanoun, S., Hettiarachchi, I., Hossny, M., Saleh, K., Zhou, H., Nahavandi, S., Bhatti, A., 2018a. Eye behaviour as a hazard perception measure, in: Systems Conference (SysCon), 2018 Annual IEEE International, IEEE. pp. 1–6.
- Iskander et al. (2018b) Iskander, J., Hossny, M., Nahavandi, S., 2018b. Biomechanical analysis of eye movement in virtual environments: A validation study, in: 2018 IEEE International Conference on Systems, Man, and Cybernetics (SMC), IEEE. pp. 3498–3503.
- Iskander et al. (2018c) Iskander, J., Hossny, M., Nahavandi, S., 2018c. A review on ocular biomechanic models for assessing visual fatigue in virtual reality. IEEE Access 6, 19345–19361. doi:10.1109/ACCESS.2018.2815663.
- Iskander et al. (2019) Iskander, J., Hossny, M., Nahavandi, S., 2019. Using biomechanics to investigate the effect of VR on eye vergence system. Applied Ergonomics 81, 102883. doi:10.1016/j.apergo.2019.102883.
- Iskander et al. (2018d) Iskander, J., Hossny, M., Nahavandi, S., Del Porto, L., 2018d. An ocular biomechanic model for dynamic simulation of different eye movements. Journal of biomechanics 71, 208–216.
- Jürgens et al. (1981) Jürgens, R., Becker, W., Kornhuber, H., 1981. Natural and drug-induced variations of velocity and duration of human saccadic eye movements: evidence for a control of the neural pulse generator by local feedback. Biological cybernetics 39, 87–96.
- Kidziński et al. (2018a) Kidziński, Ł., Mohanty, S.P., Ong, C.F., Hicks, J.L., Carroll, S.F., Levine, S., Salathé, M., Delp, S.L., 2018a. Learning to run challenge: Synthesizing physiologically accurate motion using deep reinforcement learning, in: The NIPS’17 Competition: Building Intelligent Systems. Springer, pp. 101–120.
- Kidziński et al. (2018b) Kidziński, Ł., Mohanty, S.P., Ong, C.F., Huang, Z., Zhou, S., Pechenko, A., Stelmaszczyk, A., Jarosik, P., Pavlov, M., Kolesnikov, S., et al., 2018b. Learning to run challenge solutions: Adapting reinforcement learning methods for neuromusculoskeletal environments, in: The NIPS’17 Competition: Building Intelligent Systems. Springer, pp. 121–153.
- Kidziński et al. (2020) Kidziński, Ł., Ong, C., Mohanty, S.P., Hicks, J., Carroll, S., Zhou, B., Zeng, H., Wang, F., Lian, R., Tian, H., et al., 2020. Artificial intelligence for prosthetics: Challenge solutions, in: The NeurIPS’18 Competition. Springer, pp. 69–128.
- Kingma and Ba (2014) Kingma, D.P., Ba, J., 2014. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 .
- Konda and Tsitsiklis (2000) Konda, V.R., Tsitsiklis, J.N., 2000. Actor-critic algorithms, in: Advances in neural information processing systems, pp. 1008–1014.
- Leigh and Zee (2015) Leigh, R.J., Zee, D.S., 2015. The neurology of eye movements. volume 90. Oxford University Press, USA.
- Lillicrap et al. (2015) Lillicrap, T.P., Hunt, J.J., Pritzel, A., Heess, N., Erez, T., Tassa, Y., Silver, D., Wierstra, D., 2015. Continuous control with deep reinforcement learning. arXiv preprint arXiv:1509.02971 .
- Millard et al. (2013) Millard, M., Uchida, T., Seth, A., Delp, S.L., 2013. Flexing computational muscle: modeling and simulation of musculotendon dynamics. Journal of biomechanical engineering 135, 021005.
- Purves et al. (2001) Purves, D., Augustine, G., Fitzpatrick, D., Katz, L., LaMantia, A., McNamara, J., Williams, S., 2001. Neural control of saccadic eye movements. Neuroscience. Sutherland (MA): Sinauer Associates .
- Robinson et al. (1975) Robinson, D., Lennerstrand, G., Bach-y Rita, P., 1975. Basic mechanisms of ocular motility and their clinical implications. Pergamon. volume 24.
- Scudder et al. (2002) Scudder, C.A., Kaneko, C.R., Fuchs, A.F., 2002. The brainstem burst generator for saccadic eye movements. Experimental brain research 142, 439–462.
- Seth et al. (2018) Seth, A., Hicks, J.L., Uchida, T.K., Habib, A., Dembia, C.L., Dunne, J.J., Ong, C.F., DeMers, M.S., Rajagopal, A., Millard, M., et al., 2018. Opensim: Simulating musculoskeletal dynamics and neuromuscular control to study human and animal movement. PLoS computational biology 14, e1006223.
- Sherrington (1893) Sherrington, C.S., 1893. Ii. note on the knee-jerk and the correlation of action of antagonistic muscles. Proceedings of the Royal Society of London 52, 556–564.
- Silver et al. (2014) Silver, D., Lever, G., Heess, N., Degris, T., Wierstra, D., Riedmiller, M., 2014. Deterministic policy gradient algorithms, in: International Conference on Machine Learning, pp. 387–395.
- Sparks (2002) Sparks, D.L., 2002. The brainstem control of saccadic eye movements. Nature Reviews Neuroscience 3, 952–964.
- Sutton and Barto (2018) Sutton, R.S., Barto, A.G., 2018. Introduction to reinforcement learning, 2nd ed. MIT press Cambridge.
- Thelen (2003) Thelen, D.G., 2003. Adjustment of muscle mechanics model parameters to simulate dynamic contractions in older adults. Journal of biomechanical engineering 125, 70–77.
- Von Noorden and Campos (2002) Von Noorden, G.K., Campos, E.C., 2002. Binocular vision and ocular motility. Mosby.
- Wong (2008) Wong, A.M.F., 2008. Eye movement disorders. Oxford University Press.