An Information-Theoretic Framework for Out-of-Distribution Generalization
with Applications to
Stochastic Gradient Langevin Dynamics
Abstract
We study the Out-of-Distribution (OOD) generalization in machine learning and propose a general framework that establishes information-theoretic generalization bounds. Our framework interpolates freely between Integral Probability Metric (IPM) and -divergence, which naturally recovers some known results (including Wasserstein- and KL-bounds), as well as yields new generalization bounds. Additionally, we show that our framework admits an optimal transport interpretation. When evaluated in two concrete examples, the proposed bounds either strictly improve upon existing bounds in some cases or match the best existing OOD generalization bounds. Moreover, by focusing on -divergence and combining it with the Conditional Mutual Information (CMI) methods, we derive a family of CMI-based generalization bounds, which include the state-of-the-art ICIMI bound as a special instance. Finally, leveraging these findings, we analyze the generalization of the Stochastic Gradient Langevin Dynamics (SGLD) algorithm, showing that our derived generalization bounds outperform existing information-theoretic generalization bounds in certain scenarios.
Index Terms:
Generalization, Out-of-Distribution, -Divergence, Integral Probability Metric (IPM), Stochastic Gradient Langevin Dynamics (SGLD)I Introduction
In machine learning, generalization is the ability of a model to make accurate predictions on unseen data during training. How to analyze and improve the generalization of models are the core subjects of machine learning. In the past decades, a series of mathematical tools have been invented or applied to bound the generalization gap, i.e., the difference between testing and training performance of a model, such as the VC dimension [2], Rademacher complexity [3], covering numbers [4], algorithmic stability [5], and PAC Bayes [6]. Recently, there have been attempts to bound the generalization gap using information-theoretic tools. The idea is to regard the learning algorithm as a communication channel that maps the input set of samples to the output hypothesis (model weights) . In the pioneering work [7, 8], the generalization gap is bounded by the Mutual Information (MI) between and , which reflects the intuition that a learning algorithm generalizes well if the learned model weights leaks little information about the training samples. However, the generalization bound becomes vacuous whenever the MI term is infinite. The remedy is to replace the MI term with other smaller quantities to reflect the information that leaks to , and this has been fulfilled by two orthogonal works, exploiting the Individual Mutual Information (IMI) [9] and the Conditional Mutual Information (CMI) [10], respectively. Specifically, the IMI method bounds the generalization gap using the mutual information between and each individual training datum , rather than the MI between and the set of whole samples. In certain scenarios, we have infinite MI term but finite IMI term, and thus the resulting IMI bound significantly enhances the MI bound [9]. Meanwhile, the CMI method studies the generalization through a set of super-samples (also known as ghost samples), a pair of independent and identically distributed (i.i.d.) copies and , and then uses a Rademacher random variable to choose or as the -th training datum. The resulting generalization bound is captured by the CMI between and the samples’ identity , conditioned on the super-samples. Since then, a line of work [11, 12, 13, 14, 15, 16, 17] has been proposed to tighten information-theoretic generalization bounds, and as a remarkable application, these information-theoretic methods have been employed to study the generalization performance of learning algorithms, e.g., the Langevin dynamics and its variants.
In practice, it is often the case that the training data suffer from selection biases and data distribution shifts with time, e.g., in continual learning, causing the distribution of test data differs from the training distribution. This motivates researchers to study the Out-of-Distribution (OOD) generalization. It is common practice to extract invariant features to improve the OOD performance [18], and an OOD generalization theory was established in [19] via the perspective of invariant features. As a sub-field of OOD generalization, the domain adaptation was systematically studied in [20, 21, 22, 23]. In the information-theoretic regime, the mismatch between the training and the testing distributions yields an additional penalty term to the OOD generalization bounds, and such penalty can be measured by either the Kullback–Leibler (KL) divergence [24, 25, 26] or the total variation (TV) as well as the Wasserstein distances [24, 26]. In this paper, we establish a universal framework for the OOD generalization analysis, which interpolates between the Integral Probability Metric (IPM) and the -divergence. Our OOD generalization bounds include most existing bounds as special cases and are shown to strictly improve upon existing bounds in some cases. The framework is expressed in terms of individual datum and thus can be regarded as a natural extension of the classical IMI method. Meanwhile, we demonstrate that part of these results can be adapted to the CMI settings, which gives rise to an extension and improvement of the cutting-edge ICIMI method to its -divergence variants. Finally, we demonstrate that our findings lead to several improved generalization bounds of the Stochastic Gradient Langevin Dynamics (SGLD) algorithm. To this end, we notice that the common way to derive generalization bounds for SGLD, as what IMI and CMI methods did, is to leverage the chain rule of the KL divergence. However, such approaches are inapplicable to our methods in general, simply because the chain rule does not hold for general -divergence. The remedy is to exploit the subaddivity of the -divergence, which leads to an asymptotically tighter generalization bound for SGLD.
I-A Related Works
Information-theoretic generalization bounds have been established in the previous work [24] and [26], under the context of transfer learning and domain adaptation, respectively. The KL-bounds are derived in [25] utilizing the rate-distortion theory. If we ignore the minor difference of models in the generalization bounds, their results can be regarded as natural corollaries of our framework. Moreover, [27] also studied the generalization bounds using -divergence, but it only considered the in-distribution case, and the results are given in the high-probability form. Furthermore, both [28] and our work uses the convex analysis (Legendre-Fenchel dual) to study the generalization. However, our work restricts the dependence measure to -divergence or IPM. In contrast, [28] did not designate the specific form of the dependence measure, but relied on the strong convexity of the dependence measure. This assumption does not hold for IPM and some of the -divergence. Besides, [28] did not consider the OOD generalization as well. In the final writing phase of this paper, we noticed two independent works [29, 30] that use a similar technique to perform the generalization analysis. In particular, [29] derived PAC-Bayes bounds based on the -divergence, which can be regarded as a high-probability counterpart of our paper. [30] focused on the domain adaptation problem using -divergence, and thus their models and methods are partially covered by this paper. Readers are referred to [30] for more specific results under the context of domain adaptation. Additionally, [31] studied the generalization error at a high level through the method of gaps, a technique for deriving the closed-form generalization error in terms of information-theoretic measures. The -divergence was also employed to regularize the empirical risk minimization algorithm, as explored in [32] and the references therein.
I-B Contributions
-
1.
We develop a theoretical framework for establishing information-theoretic generalization bounds in the OOD scenarios, which allows us to interpolate freely between IPM and -divergence. In addition to reproducing existing results, such as the generalization bounds based on the Wasserstein distance [24, 26] and the KL divergence [24, 26, 25], our framework also derives new generalization bounds. Notably, our OOD generalization bounds can be applied to in-distribution cases by simply setting the testing distribution equal to the training distribution.
-
2.
Our framework is designed to work with the CMI methods for bounded loss functions, and extends the state-of-the-art CMI-based result, known as the Individually Conditional Individual Mutual Information (ICIMI) bound, to a range of -divergence-based ICIMI bound. This enables us to properly select the function to derive tighter generalization bounds compared to the standard ICIMI bound.
-
3.
We leverage above results to analyze the generalization of the SGLD algorithm for bounded and Lipschitz loss functions. First, we improve upon an existing SGLD generalization bound in [9] by introducing an additional domination term and extending it to the OOD setting. Next, we employ the squared Hellinger divergence and ICIMI methods to derive an alternative bound, highlighting its advantages under the assumption of without-replacement sampling. Finally, we relax this without-replacement sampling assumption to an asymptotic condition, showing that the resulting generalization bound is tighter than existing information-theoretic bounds for SGLD in the asymptotic regime.
I-C Notation and Organization
We denote the set of real numbers and the set of non-negative real numbers by and , respectively. Sets, random variables, and their realizations are respectively represented in Calligraphic fonts (e.g., ), uppercase letters (e.g., ), and lowercase letters (e.g., ). Let be the set of probability distributions over set and be the set of measurable functions over . Given , we write if is singular to and if is absolutely continuous w.r.t. . We write as the Radon-Nikodym derivative.
The rest of this paper is organized as follows. Section II introduces the problem formulation and some technical preliminaries. In Section III, we propose a general theorem on OOD generalization bounds and illustrate its optimal transport interpretation. Examples and special cases of the general theorem, including both known generalization bounds and new results, are given in Section IV. In Section V, we restate and improve the CMI methods for bounding the generalization gap, and the result is applied to the generalization analysis of the SGLD algorithm in Section VI. Finally, the paper is concluded in Section VII.
II Problem Formulation
In this section, we introduce our problem formulation and some preliminaries.
II-A Problem Formulation
Denote by the hypothesis space and the space of data (i.e., input and output pairs). We assume training data are i.i.d. following the distribution . Let be the loss function. From the Bayesian perspective, our target is to learn a posterior distribution of hypotheses over , based on the observed data sampled from , such that the expected loss is minimized. Specifically, we assume the prior distribution of hypotheses is known at the beginning of the learning. Upon observing samples, , a learning algorithm outputs one through a process like Empirical Risk Minimization (ERM) [33]. The learning algorithm is either deterministic (e.g., gradient descent with fixed hyperparameters) or stochastic (e.g., stochastic gradient descent). Thus, the learning algorithm can be characterized by a probability kernel 111Given , is a probability measure over ., and its output is regarded as one sample from the posterior distribution .
In this paper, we consider the OOD generalization setting where the training distribution differs from the testing distribution . Given a set of samples and the algorithm’s output , the incurred generalization gap is
| (1) |
Finally, we define the generalization gap of the learning algorithm by taking expectation w.r.t. and , i.e.,
| (2) |
where the expectation is w.r.t. the joint distribution of , given by . An alternative approach to defining the generalization gap is to replace the empirical loss in (2) with the population loss w.r.t. the training distribution , i.e.,
| (3) |
where denotes the marginal distribution of . By convention, we refer to (2) as the Population-Empirical (PE) generalization gap and refer to (3) as the Population-Population (PP) generalization gap. In the next two sections, we focus on bounding both the PP and the PE generalization gap using information-theoretic tools.
II-B Preliminaries
Definition 1 (-Divergence [34]).
Let be a convex function satisfying . Given two distributions , decompose , where and . The -divergence between and is defined by
| (4) |
where . If is super-linear, i.e., , then the -divergence has the form of
| (5) |
Definition 2 (Generalized Cumulant Generating Function (CGF) [35, 36]).
Let be defined as above and be a measurable function. The generalized cumulant generating function of w.r.t. and is defined by
| (6) |
where represents the Legendre-Fenchel dual of , as
| (7) |
Remark 1.
Taking in the -divergence yields the KL divergence222Here we choose to be standard, i.e., .. A direct calculation shows . The infimum is achieved at and thus . This means degenerates to the classical cumulant generating function of .
If we refer to as a fixed reference distribution and regard as a function of distribution , then the -divergence and the generalized CGF form a pair of Legendre-Fenchel dual, as clarified in Lemma 1.
Lemma 1 (Variational Representation of -Divergence [34]).
| (8) |
where the supreme can be either taken over
-
1.
the set of all simple functions, or
-
2.
, the set of all measurable functions, or
-
3.
, the set of all -almost-surely bounded functions.
In particular, we recover the Donsker-Varadhan variational representation of KL divergence by combining Remark 2 and Lemma 1:
| (9) |
Definition 3 (-Integral Probability Metric [37]).
Let be a subset of measurable functions, then the -Integral Probability Metric (IPM) between and is defined by
| (10) |
Examples of -IPM include -Wasserstein distance, Dudley metric, and maximum mean discrepancy. In general, if is a Polish space with metric , then the -Wasserstein distance between and is defined through
| (11) |
where is the set of couplings of and . For the special case , the Wasserstein distance can be expressed as IPM due to the Kantorovich-Rubinstein Duality
| (12) |
where is the Lipschitz norm of .
III Main Results
In this section, we first propose an inequality regarding the generalization gap in Subsection III-A, which leads to one of our main results, a general theorem on the generalization bounds in Subsection III-B. Finally, we show the theorem admits an optimal transport interpretation in Subsection III-C.
III-A An Inequality on the Generalization Gap
In this subsection, we show the generalization gap can be bounded from above using the -IPM, -divergence, and the generalized CGF. For simplicity, we denote by and . Moreover, we define the (negative) re-centered loss function as
Proposition 1.
Let be a class of measurable functions and assume . Then for arbitrary probability distributions and arbitrary positive real numbers , , we have
| (13) |
Proof of Proposition 13.
If is the Legendre dual of some functional , then we have
| (14) |
for all and , the dual space of . Let be a fixed reference distribution, be a probability distribution, and be a measurable function. Combining the above fact with Lemma 1 yields the following Fenchel-Young inequality:
| (15) |
As a consequence, we have
| (16) | ||||
| (17) | ||||
| (18) | ||||
| (19) | ||||
Here, inequality (18) follows from (15) and inequality (19) follows since , and the last equality follows by Definition 10. ∎
III-B A Theorem for OOD Generalization
It is common that the generalized CGF does not admit an analytical expression, resulting in the lack of closed-form expression in Proposition 13. This problem can be remedied by finding a convex upper bound of , as clarified in Theorem 20. Section IV provides many cases where is quadratic and Theorem 20 can be further simplified.
Theorem 1.
Let and . If there exists a continuous convex function satisfying and for all . Then we have
| (20) |
where denotes the Legendre dual of and denotes the generalized inverse of .
Remark 2.
Technically we can replace with and prove an upper bound of by a similar argument. This result together with Theorem 20 can be regarded as an extension of the previous result [9, Theorem 2]. Specifically, the extensions are two-fold. First, [9] only considered the KL-divergence while our result interpolates freely between IPM and -divergence. Second, [9] only considered the in-distribution generalization while our result applies to the OOD generalization, including the case where the training distribution is not absolutely continuous w.r.t. the testing distribution.
Proof of Theorem 20.
We first invoke a key lemma.
Lemma 2 (Lemma 2.4 in [38]).
Let be a convex and continuously differentiable function defined on the interval , where . Assume that and for every , let be the Legendre dual of . Then the generalized inverse of , defined by , can also be written as
| (21) |
In general, compared with checking , it is more direct to check that for some . If so, we can choose333Note that , it is the set consists of s.t. both and belong to . . If we further assume that is symmetric, i.e., , then we have and thus
| (24) |
The following corollary says whenever inserting (24) into generalization bounds (20), the coefficient 2 can be removed under certain conditions.
Corollary 1.
Suppose and be symmetric. Let be the distribution of the algorithmic output and be a class of distributions whose marginal distribution on is , then we have
| (25) |
III-C An Optimal Transport Interpretation of Theorem 20
Intuitively, a learning algorithm generalizes well in the OOD setting if the following two conditions hold simultaneously: 1. The training distribution is close to the testing distribution . 2. The posterior distribution is close to the prior distribution . The second condition can be interpreted as the “algorithmic stability” and has been studied by a line of work [39, 40]. The two conditions together imply that the learning algorithm generalizes well if is close to . The right-hand side of (20) can be regarded as a characterization of the “closeness” between and . Moreover, inspired by [35], we provide an optimal transport interpretation to the generalization bound (20). Consider the task of moving (or reshaping) a pile of dirt whose shape is characterized by distribution , to another pile of dirt whose shape is characterized by . Decompose the task into two phases as follows. During the first phase, we move to and this yields an -divergence-type transport cost , which is a monotonously increasing transformation of (see Lemma 21). During the second phase, we move to and this yields an IPM-type transport cost . The total cost is the sum of the two-phased costs and is optimized over all intermediate distributions .
In particular, we can say more if both and are super-linear. By assumption, the -divergence is given by (5) and we have . This implies we require to ensure the cost is finite. In other words, is a “continuous deformation” of and cannot assign mass outside the support of . On the other hand, if we decompose into , where and , then all the mass of is transported during the second phase.
IV Special Cases and Examples
In this section, we demonstrate how a series of generalization bounds, including both PP-type and PE-type, can be derived through Theorem 20 and its Corollary 25. For simplicity, we defer all the proofs in this section to the Appendix B.
IV-A Population-Empirical Generalization Bounds
This subsection bounds the PE generalization gap defined in (2). In particular, the PE bounds can be divided into two classes: the IPM-type bounds and the -divergence-type bounds.
IV-A1 IPM-Type Bounds
From the Bayes perspective, is the prior distribution of the hypothesis and thus is fixed at the beginning. Technically, however, the derived generalization bounds hold for arbitrary and we can optimize over to further tighten the generalization bounds. In particular, set , , and let be the set of -Lipschitz functions. Applying Corollary 25 establishes the Wasserstein distance generalization bound.
Corollary 2 (Wasserstein Distance Bounds for Lipschitz Loss Functions).
If the loss function is -Lipschitz, i.e., is -Lipschitz on for all and -Lipschitz on for all , then we have
| (27) |
Set , , and . Applying Corollary 25 establishes the total variation generalization bound.
Corollary 3 (Total Variation Bounds for Bounded Loss Function).
If the loss function is uniformly bounded: , for all and , then
| (28) | ||||
| (29) |
IV-A2 -Divergence-Type Bounds
Set and . For -sub-Gaussian loss functions, we can choose and thus . This recovers the KL-divergence generalization bound [25, 24, 26].
Corollary 4 (KL Bounds for sub-Gaussian Loss Functions).
If the loss function is -sub-Gaussian for all , we have
| (30) |
where is the mutual information between and .
If the loss function is -sub-gamma, we can choose , , and thus . In particular, the sub-Gaussian case corresponds to .
Corollary 5 (KL Bounds for sub-gamma Loss Functions).
If the loss function is -sub-gamma for all , we have
| (31) |
Setting and , we establish the -divergence bound.
Corollary 6 ( Bounds).
If the variance for all , we have
| (32) |
In particular, by the chain rule of -divergence, we have
| (33) |
In the remaining part of this subsection, we focus on the bounded loss function. Thanks to Theorem 20, we need a convex upper bound of the generalized CGF . The following lemma says that is quadratic if satisfies certain conditions.
Lemma 3 (Corollary 92 in[36]).
Suppose the loss function , is strictly convex and twice differentiable on its domain, thrice differentiable at 1, and
| (34) |
for all . Then , where .
In Table I, we summarize some common -divergence and check whether condition (34) is satisfied. As a result of Lemma 3, we have the following corollary.
Corollary 7.
| -Divergence | Condition (34) holds? | |
|---|---|---|
| -Divergence | Only for | |
| -Divergence | Yes | |
| KL-Divergence | Yes | |
| Squared Hellinger | Yes | |
| Reversed KL | Yes | |
| Jensen-Shannon(with parameter ) | Yes | |
| Le Cam | Yes |
-
1
All in Table I are set to be standard, i.e., .
-
2
Both the -divergence and the squared Hellinger divergence are -divergence, up to a multiplicative constant. In particular, we have and . The -Jensen-Shannon divergence has the form of , where and . The classical Jensen-Shannon divergence corresponds to .
| KL | ||||
| Reversed KL | JS | Le Cam | ||
We end this subsection with some remarks. First, since Corollary 3 also considers the bounded loss function, it is natural to ask whether we can compare (28) and (35). The answer is affirmative and we always have
| (36) |
This Pinsker-type inequality is given by [36]. Thus the bound in (28) is always tighter than that in (35). Secondly, as previously mentioned, we optimize to tighten the bounds. In some examples, e.g., the KL-bound, the optimal is achieved at , but it is not always the case, e.g., the -bound. Lastly, all the results derived in this subsection encompass the in-distribution generalization as a special case, by simply setting . If we further set , then we establish a series of in-distribution generalization bounds by simply replacing with , the -mutual information between and .
IV-B Population-Population Generalization Bounds
By setting , , and , Theorem 20 specializes to a family of -divergence-type PP generalization bounds. See Appendix B-E for proof.
Corollary 8 (PP Generalization Bounds).
Let be defined in Theorem 20. If , then we have
| (37) |
By Corollary 37, each -divergence-type PE bound provided in Section IV-A2 possesses a PP generalization bound counterpart, with replaced by . In particular, under the KL case, we recover the results in [26, Theorem 4.1] if the loss function is -sub-Gaussian:
| (38) |
where the absolute value comes from the symmetry of the sub-Gaussian distribution. The remaining PP generalization bounds are summarized in Table III.
| Assumptions | PP Generalization Bounds |
|---|---|
| is -sub-gamma | |
| , | |
Remark 3.
Corollary 37 coincides with the previous result [36], which studies the optimal bounds between -divergences and IPMs. Specifically, authors in [36] proved if and only if . In our context, is replaced with and thus . Thus, Corollary 37 can be regarded as an application of the general result [36] in the OOD setting.
IV-C Examples
In this subsection, we examine the above results in the context of two simple “learning” problems. We demonstrate that our new -bound surpasses the existing KL-bound in the first example, and the recovered TV-bound achieves the best in the second example.
IV-C1 Estimating the Gaussian Mean
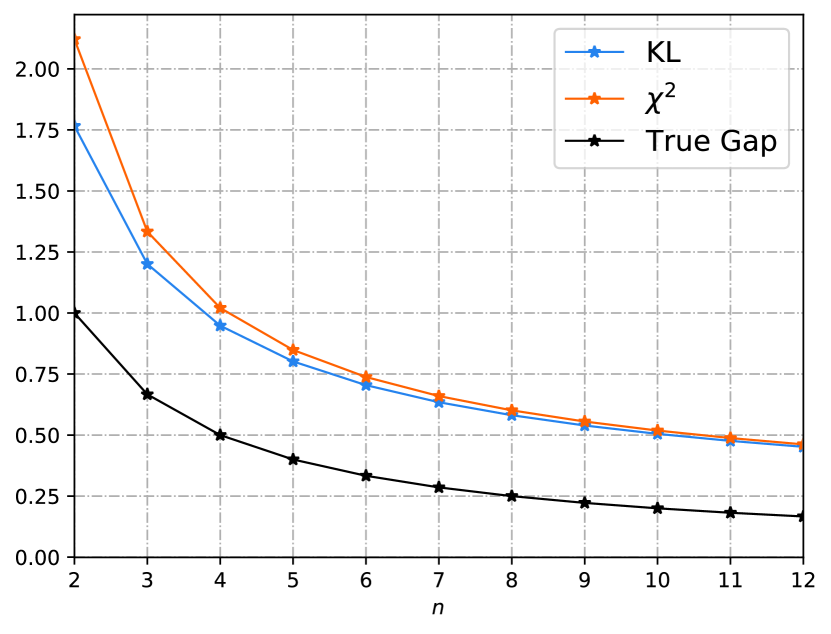
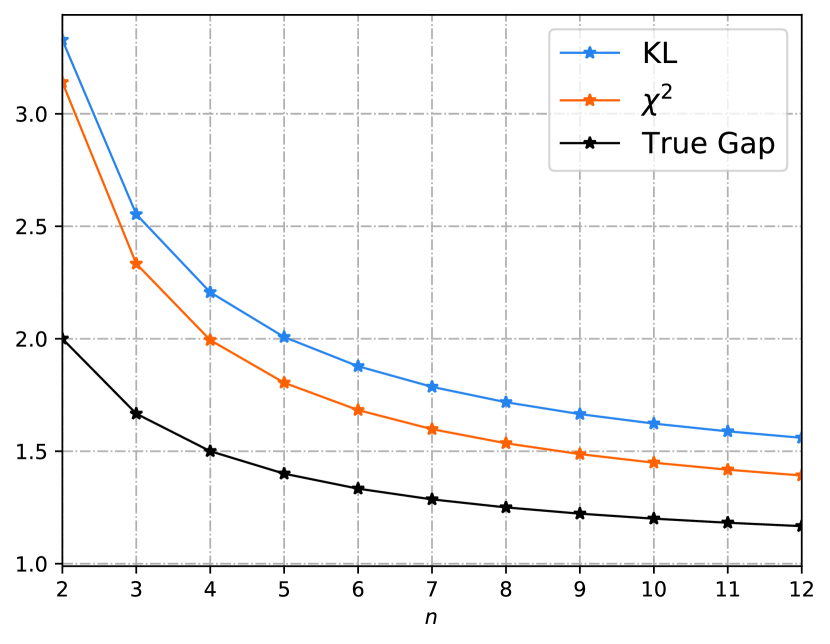
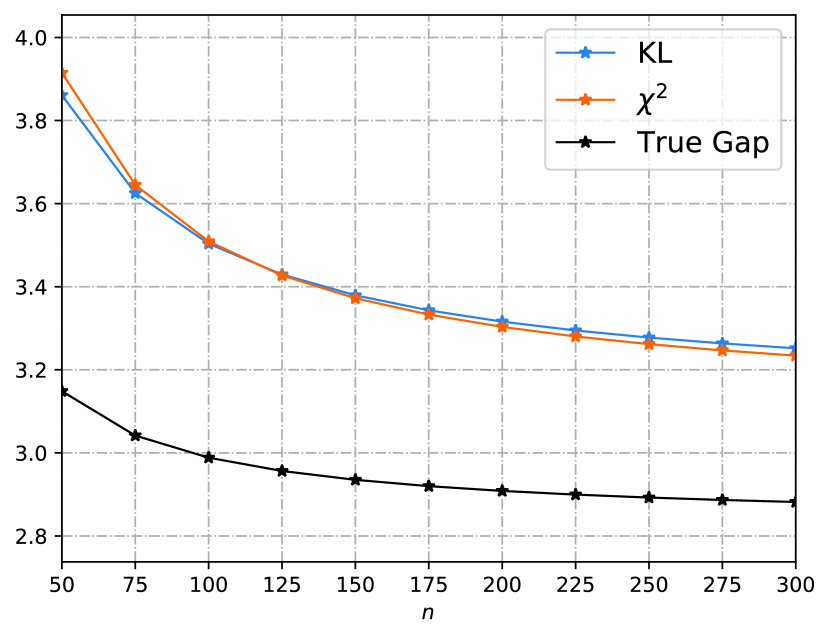
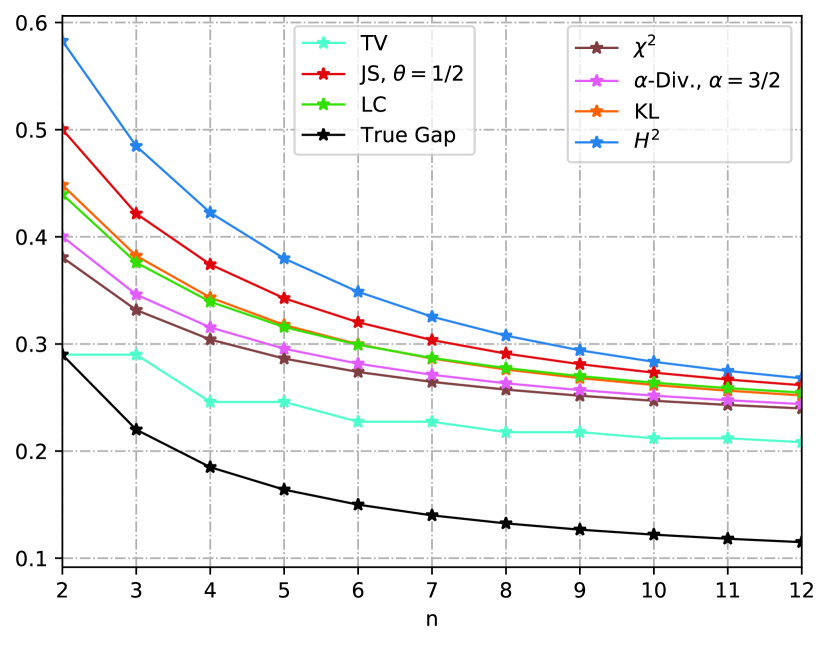
Consider the task of estimating the mean of Gaussian random variables. We assume the training sample comes from the distribution , and the testing distribution is . We define the loss function as , then the ERM algorithm yields the estimation . Under the above settings, the loss function is sub-Gaussian with parameter , and thus Corollary 4 and Corollary 33 apply. The known KL-bounds and the newly derived -bounds are compared in Fig. 1(a) and Fig. 1(b), where we set . In Fig. 1(a) the two bounds are compared under the in-distribution setting, i.e., and . A rigorous analysis in Appendix B-F shows that both - and KL-bound decay at the rate , while the true generalization gap decays at the rate . This additional square root comes from the term in Theorem 20. Moreover, the KL-bound has the form of while the -bound has the form of . Thus the KL-bound is tighter than the -bound and they are asymptotically equivalent as . On the other hand, we compare the OOD case in Fig. 1(b), where we set and . We observe that the -bound is tighter than the KL-bound at the very beginning. In Fig. 1(c), we fix the “covariance error”, i.e., , and extend this example to -dimension with . We observe that the -bound is tighter as is sufficiently large, and more samples are needed in the higher dimensional case for the -bound to surpass the KL-bound. Mathematically, by comparing the -bound (32) and the KL-bound (30), we conclude that the -bound will be tighter than the KL-bound whenever since the variance of a random variable is no more than its sub-Gaussian parameter. See Appendix B-F for more details.
IV-C2 Estimating the Bernoulli Mean
Consider the previous example where the Gaussian distribution is replaced with the Bernoulli distribution. We assume the training samples are generated from the distribution and the test data follows . Again we define the loss function as and choose the estimation .
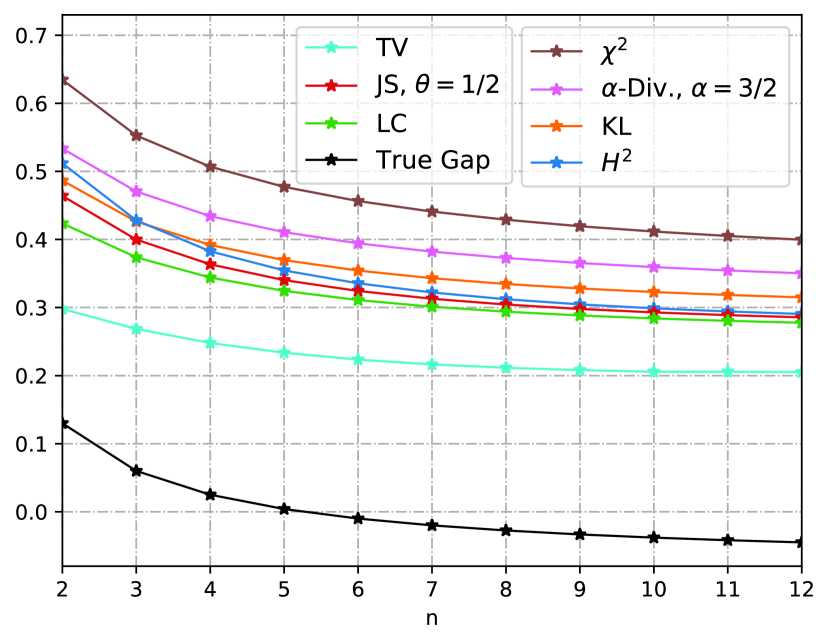
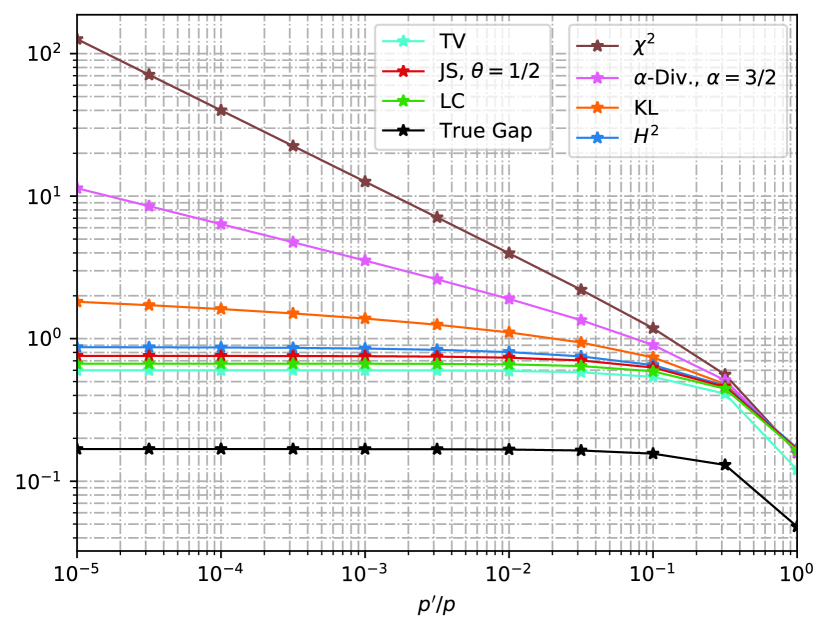
Under the above settings, the loss function is bounded with . If we define the Hamming distance over and , then the total variation bound coincides with the Wasserstein distance bound. In Fig. 2(a), we set and , and we see that the squared Hellinger, Jensen-Shannon, and Le Cam bounds are tighter than the KL-bound. On the contrary, - and -divergence bounds are tighter than the KL-bound as in Fig. 2(b), where we set and . But all these -divergence-type generalization bounds are looser than the total variation bound, as illustrated by (36). Additionally, there exists an approximately monotone relationship between -divergence, -divergence (), KL-divergence, and the squared Hellinger divergence. This is because all these bounds are -divergence type, with KL-divergence corresponds to 444Strictly speaking, , the Rényi--divergence with , and is a -transformation of the -divergence.. Moreover, we observe that the Le Cam divergence is always tighter than the Jensen-Shannon divergence. This is because the generator of Le Cam is smaller than that of Jensen-Shannon, and they share the same coefficient . Finally, we consider the extreme case in Fig. 2(c), where , , and we allow decays to . When is sufficiently small, the KL-bound (along with -divergence () and -bound) is larger than and thus becomes vacuous. In contrast, the squared Hellinger, Jensen-Shannon, Le Cam, and total variation bounds do not suffer from such a problem. See Appendix B-F for derivations.
V The CMI Method and its Improvement
In this section, we study the OOD generalization for bounded loss function using the CMI methods. We first recall some CMI results in Subsection V-A and then improve the state-of-the-art result in Subsection V-B using -divergence. Unless otherwise stated, we assume that .
V-A An Overview of CMI-based In-Distribution Generalization Bounds
Instead of using the training samples generated from distribution , the CMI method generates a set of super-samples from the distribution , where consists of a positive sample and a negative sample . When performing training, the CMI framework randomly chooses or as the -th training data with the help of a Rademacher random variable , i.e., takes or with equal probability 1/2. Specifically, we choose if and choose otherwise.
Based on the above construction, [10] established the first in-distribution CMI generalization bound using the mutual information between the output hypothesis and the identifier conditioned on the super-samples ,
| (39) |
Here we use to denote the expected in-distribution generalization gap by setting . The CMI bound can be improved by combining the ‘individual’ technique in [9]. In particular, the Conditionally Individual Mutual Information (CIMI) bound [11] is achieved by individualizing only on the data identifier ,
| (40) |
and the Individually Conditional Individual Mutual Information (ICIMI) bound [15] is achieved by individualizing on both and the super-sample ,
| (41) |
It is natural to ask which of these generalization bounds is tighter. If we only consider the mutual information term in these generalization bounds, it follows that , and [15]. This is mathematically written as
-
1.
.
-
2.
.
When it comes to the generalization bound, it was proved in [11] that the CIMI bound is tighter than the CMI bound. Thus it follows that the ICIMI bound achieves the best among those CMI-based bounds. However, the ICIMI bound is not necessarily better than the IMI bound. Since a bounded random variable is -sub-Gaussian, the IMI bound reduces to
| (42) |
for bounded loss function . As a consequence, the ICIMI bound is tighter than the IMI bound only if , which does not necessarily hold in general.
V-B f-ICIMI Generalization Bounds
We note that all the above generalization bounds were established for the in-distribution case. When extending to the OOD cases, however, the idea of conditioning on super-samples does not work anymore, since the disagreement between training distribution and test distribution breaks the symmetry of the expected generalization gap. To tackle this problem, we decompose the OOD generalization gap as
| (43) | ||||
| (44) |
Here the outer expectation is taken w.r.t. the joint distribution of and . The first term of (44) is the PP generalization gap and thus can be bounded using total variation or using by Corollary 37. The second term of (44) is the in-distribution generalization gap and thus can be bounded by a series of CMI-based methods as introduced above. In particular, by combining the -divergence with the ICIMI method, we have the following improved generalization bound. The proof is postponed to the end of this subsection.
Theorem 2 (-ICIMI Generalization Bound).
Let the loss function and be an generator of some -divergence satisfying the condition in Lemma 3. Then, we have
| (45) | ||||
| (46) |
In the above, denotes the -mutual information and denotes the disintegrated -mutual information, i.e., .
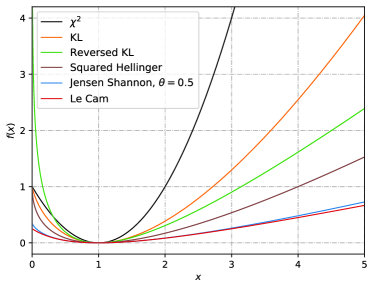
For the in-distribution case, we recover the ICIMI bound by setting , the generator of KL-divergence. Meanwhile, there may exist other leading to a tighter generalization bound (45) or (46). This is equivalent to finding that satisfies the condition . Nonetheless, the existence of such is nontrivial, since there is a trade-off between and , see Fig. 3. On the one hand, the -mutual information is essentially an expectation of the function , hence a “steep” (like the generator of KL- or -divergence) would yield a larger term. On the other hand, the reflects the curvature of the graph of at the point , hence a steep also result a larger term. Similarly, for those “flat” (like the generator of Jensen Shannon- or squared Hellinger divergence), both the -mutual information and the curvature would become smaller. This makes selecting to maximize the quotient a nontrivial task. However, Theorem 2 provides more options beyond the KL divergence, allowing us to identify a better choice in certain scenarios, which we will discuss in the next section.
Proof of the Theorem 2.
By the decomposition (44), it suffices to consider the expected in-distribution generalization gap, which can be rewritten as
| (47) | ||||
| (48) |
Choose and we have . By assumption , we have , and thus the Lemma 3 follows that
| (49) |
As a consequence, we have
| (50) | ||||
| (51) | ||||
| (52) |
where the last inequality follows by Jensen’s inequality. ∎
VI Applications to the SGLD Algorithm
In this section, we demonstrate an application of preceding results to the stochastic gradient Langevin dynamics (SGLD) algorithm [41]. SGLD is a learning algorithm that combines the stochastic gradient descent (SGD), a Robbins–Monro optimization algorithm [42], and Langevin dynamics, a mathematical extension of molecular dynamics models. Essentially, each iteration of SGLD is an SGD update with added isotropic Gaussian noise. The noise enables SGLD to escape local minima and asymptotically converge to global minima for sufficiently regular non-convex loss functions. The wide application of SGLD in machine learning has prompted a series of study on its generalization performance [9, 15, 13, 11, 14]. The remaining part of this section is organized as follows. After a brief introduction to the SGLD in VI-A, we exhibit improved SGLD generalization bounds in the following three subsections. Motivated by the observation in IV-C that TV-based bound achieves the tightest one, we establish a refined SGLD generalization bound in VI-B and show its advantages whenever the Lipschitz constant of the loss function is large. Next, we turn to apply the CMI methods to SGLD. In VI-C, an -ICIMI type generalization bound for SGLD is established on the basis of squared Hellinger divergence. Due to the nature of the chain rule of the squared Hellinger divergence, this generalization bound is superior under the without-replacement sampling scheme, and may become worse whenever replacement is allowed. The latter problem is remedied in VI-D, where we utilize a new technique, the sub-additivity of the -divergence, to establish an asymptotically tighter generalization bound for SGLD.
VI-A Stochastic Gradient Langevin Dynamics
The SGLD algorithm starts with an initialization and iteratively updates through a noisy and stochastic gradient descent process. Mathematically, we write
| (53) |
where is the standard Gaussian random vector and is the scale parameter. In the standard SGLD setting, we have where denotes the inverse temperature. Additionally, specifies which data is employed for calculating the gradient within the -th iteration (i.e., if is taken), and finally the algorithm outputs after iterations. We say is a sample path, which is randomly generated from some process like random sampling over with replacement. Let be the set of steps that is taken for updating . Then, is a deterministic function of the sample path and we write by .
The generalization of the SGLD algorithm was also studied by [9, 15], which we will discuss later. Other generalization analyses of the non-stochastic Langevin dynamic and the mini-batch SGLD are discussed in [13, 11, 14], where they use a data-dependent estimation on the prior distribution and their results are incomparable to ours.
VI-B Generalization Bounds on SGLD for Bounded and Lipschitz Loss Functions
Authors in [9] utilized IMI to proved that, if the loss function is -sub-Gaussian and -Lipschitz, the in-distribution generalization gap of the SGLD algorithm can be bounded by
| (54) |
When the loss function is bounded in , one can simply replace the in (54) with . However, as we see in IV-C, the total variation achieves tighter bound than the KL-based one. Thus, the above result may be further improved. To this end, we invoke Corollary 3 and obtain the following result under the OOD setting. The proof is postponed to Appendix C-A.
Theorem 3.
Let be the output of the SGLD algorithm as defined in (53). Suppose the loss function is -Lipschitz and bounded in . We have
| (55) |
The generalization bound (55) consists of two parts. The first part, , captures the distribution shift and can further be bounded using -divergence between and . The remaining part of (55) captures the in-distribution generalization gap of the SGLD algorithm. In particular, we notice that the first term inside the coincides with the previous result (54). This is also a direct consequence of the Pinsker inequality, as shown in Appendix C-A. In contrast, the second term inside the follows from the Bretagnolle-Huber inequality [43], an exponential KL upper bound on the total variation.
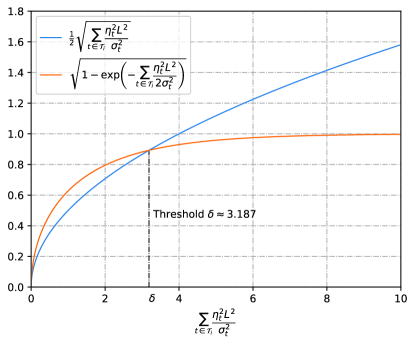
We compare the two terms inside the in Fig. 4, where the x-axis is set to . Since the parameters and depend only on the SGLD algorithm, we keep them fixed and only consider the effect of the Lipschitz constant of the loss function. From Fig. 4, we conclude that, if is small enough such that , then the Pinsker-type term is tighter. Here is the unique non-zero solution of the equation , and we have . Here, with a little abuse of notation, denotes the principal branch of the Lambert function. On the other hand, if is sufficiently large such that , the Pinsker-type term begins to diverge and the newly added term helps establish a tighter generalization bound.
VI-C SGLD using Without-Replacement Sampling Method
In the subsequent two subsections, we turn to the CMI methods for the SGLD. The following theorem is a consequence of combining the -ICIMI bound (Theorem 2) with the squared Hellinger divergence. The proof is postponed to Appendix C-B.
Theorem 4.
Let be the output of the SGLD algorithm as defined in (53). Suppose the loss function is -Lipschitz and bounded in . We have
| (56) |
To compare it with other in-distribution results, it suffices to consider the case so that the first TV term becomes 0. By writing the summation as , we see that the term is outside the square root as in (56), while the term is inside the square root as in (54) and (55). By the inequality , the generalization bound (56) is larger than that of (54) and (55) in general. However, Theorem 56 shows its benefit if the SGLD is performed using the without-replacement sampling scheme, i.e., each data is exactly applied once for updating . Under this setting, becomes a singleton and the summation term vanishes. Thus, under the without-replacement sampling scheme, the generalization bound in Theorem 56 is strictly superior than the previous result (54). This is a direct consequence of the inequality when .
VI-D SGLD with Asymptotic Assumption
As discussed in the previous subsection, the term of Theorem 56 locates outside the square root, mostly causing a larger generalization bound if the replacement is allowed in sampling. Technically, this is a consequence of applying the chain rule of the squared Hellinger divergence in Theorem 56. Although the chain rule is a common technique applied in a series of KL-based SGLD generalization bounds, it does not perform well when other -divergence is involved (at least for the squared Hellinger divergence). In this subsection, we drop the chain rule and utilize the sub-additivity of the squared Hellinger divergence. With the new technique at hand, we are able to move the term inside the square root and derive an asymptotically tighter generalization bound for the SGLD.
We begin with an intuitive observation. As the number of training data goes to infinity, the algorithm output is asymptotically independent of an individual sample. Under the CMI model, this translates that the conditional probability of (identity of the -th training sample), given the super-sample and some history outputs of the learning algorithm, should asymptotically converge to its marginal distribution , where is a Dirac delta distribution located at . The following assumption assumes there exists some function that captures the above convergence behavior. Recall that is the total number of training samples.
Assumption 1.
, where is some deterministic function satisfying .
Remark 4.
One can imagine as a polynomial for some , but we do not add such restrictions. Additionally, one special case is the without-replacement sampling as discussed in the previous subsection. Since is exactly applied for updating at the -th iteration, is independent of , and thus and .
Theorem 5.
Remark 5.
Again, by the inequality , the generalization bound (57) is asymptotically tighter than the IMI bound (54) (with ). Additionally, [15] also derived an ICIMI-based bound for the SGLD algorithm. But it relies on a precise estimation of the posterior probability of (that is, in our proof), which is computationally intractable. In the worst case, the ICIMI-bound can be twice larger than the IMI-bound. In contrast, the generalization bound in Theorem 57 is independent of the specific value of but relies on its asymptotic behavior captured by some function , causing a error on the generalization bound. We conjecture that can be polynomial (e.g., ) under certain sampling or training schemes, so that (57) can decay fast. We leave the study on function for future work.
The remaining part of this section focuses on proving the Theorem 57. As mentioned before, we exploit the sub-additivity, rather than the chain rule, of the -divergence. We start with its definition.
Definition 4 (Sub-additivity of divergence [44]).
Let be a directed acyclic graph that defines a Bayes network. We say a divergence is sub-additive if, for all probability distributions and over the Bayes network, we have
| (58) |
where denotes the vertex of and denotes the set of parents of .
Many -divergences are sub-additive, but here we only need the sub-additivity of the squared Hellinger divergence.
Lemma 4 (Theorem 2 of [44]).
The squared Hellinger divergence (c.f. Table I) is sub-additive on Bayes networks.
Combining the sub-additivity with SGLD yields the following useful lemma. The underlying reason why the sub-additivity can be applied to SGLD is that one can construct a Bayes network from the trajectory of SGLD. The proof is deferred to Appendix C-C.
Lemma 5 (Sub-additivity of Conditional -Mutual Information).
Let be a sub-additive -divergence, and be the trajectory generated by the SGLD algorithm under some fixed sample path . Again, let and respectively be the data identifier and super-sample, as illustrated in the CMI model. We have
| (59) |
where denotes the uniform distribution over the set .
Now we are ready to prove the main result, i.e., Theorem 57, of this subsection.
Proof of Theorem 57.
By Theorem 2, we have
| (60) | ||||
| (61) | ||||
| (62) |
where the last inequality follows by Lemma 5. Let . By Assumption 1 we can write
| (63) |
It follows that is Gaussian and is a Gaussian mixture model (c.f. (145) and (146) in Appendix C-B). We have
| (64) | ||||
| (65) | ||||
| (66) |
In what follows, we set and thus , but we still use the -notation for those expressions holding for arbitrary -divergence. Plugging (64) and (66) into (62) yields
| (67) | |||
| (68) | |||
| (69) | |||
| (70) | |||
| (71) | |||
| (72) |
In the above, inequality (67) follows since the -divergence is jointly (and thus separately) convex, and (68) follows by the definition of -divergence. We derive (69) since . To derive (70), we use
| (73a) | ||||
| (73b) | ||||
| (73c) | ||||
| (73d) | ||||
where these equations come from (63) and the fact that . Expression (71) follows by Lemma 11 in Appendix C-B since , and the last inequality (72) follows by (155) in Appendix C-B.
VII Conclusions
This paper proposes an information-theoretic framework for analyzing OOD generalization, which seamlessly interpolates between IPM and -divergence, reproduces known results as well as yields new generalization bounds. Next, the framework is integrated with the CMI methods, resulting in a class of -ICIMI bounds, among which includes the state-of-the-art ICIMI bound. These results separately give a natural extension and improvement to the IMI methods as well as the CMI methods. Lastly, we demonstrate their applications by proving generalization bounds for the SGLD algorithm, under the premise that the loss function is both bounded and Lipschitz. Although these results are derived under the OOD case, they also demonstrate the benefits for the in-distribution case. In particular, the study gives special attention to two specific scenarios: SGLD employing without-replacement sampling and SGLD with asymptotic posterior probability. Compared with the traditional chain-rule based methods, our approaches also shed light on the alternative way to study the generalization of SGLD algorithms through the subadditivity of -divergence.
Appendix A Proof of Section III
A-A Proof of Proposition 13
We provide an alternative proof of Proposition 13, demonstrating its relationship with -divergence [35]. We start with its definition.
Definition 5 (-Divergence [35]).
Let be a probability space. Suppose and , be the convex function that induces the -divergence. The -divergence between distribution and is defined by
| (74) |
The -divergence admits an upper bound, which interpolates between -IPM and -divergence.
Lemma 6.
([35, Theorem 8])
| (75) |
Now we are ready to prove Proposition 13.
A-B Tightness of the Proposition 13
The following proposition says that the equality in Proposition 13 can be achieved under certain conditions.
Proposition 2.
Remark 6.
Under the case of KL-divergence (see Remark 2), we have and thus . Therefore, the optimal has the form of
| (82) |
This means that the optimal is achieved exactly at the Gibbs posterior distribution, with acting as the inverse temperature.
Proof of Proposition 2.
By assumption 1, we have , and thus Proposition 13 becomes
| (83) |
As a consequence, it suffices to prove
| (84) |
under the conditions that
| (85a) | |||
| (85b) | |||
where , , and . If it is the case, then Proposition 2 follows by setting , , , , and . To see (84) holds, we need the following lemma.
Lemma 7.
([35, Lemma 48])
| (86) |
Then the subsequent argument is very similar to that of [35, Theorem 82]. We have
| (87) | |||
| (88) | |||
| (89) | |||
| (90) | |||
| (91) | |||
| (92) |
In the above, equality (89) follows by (85a), equality (90) follows by Lemma 86, inequality (91) follows by Definition 7, and equality (92) follows by Lemma 1 and equality (14). Therefore, all the inequalities above achieve equality. This proves (84). ∎
Appendix B Proofs in Section IV
B-A Proof of Corollary 27
B-B Proof of Corollary 3
Proof.
By assumption we have and thus
| (97) | ||||
| (98) | ||||
| (99) |
In the above, inequality (97) follows by Corollary 25, equality (98) follows by the translation invariance of IPM, and equality (99) follows by the variational representation of total variation:
| (100) |
Thus we proved (28). Then (29) follows by the chain rule of total variation. The general form of the chain rule of total variation is given by
| (101) |
∎
B-C Proof of Corollaries 4 and 31
Proof.
It suffices to prove Corollary 4 and then Corollary 31 follows by a similar argument. By Theorem 20, we have
| (102) | ||||
| (103) |
where the equality follows from the chain rule of KL divergence. Taking infimum over yields (30), which is due to the following lemma.
Lemma 8 (Theorem 4.1 in [34]).
Suppose is a pair of random variables with marginal distribution and let be an arbitrary distribution of . If , then
| (104) |
By the non-negativity of KL divergence, the infimum is achieved at and thus . ∎
B-D Proof of Corollary 33
B-E Proof of Corollary 37
B-F Derivation of Estimating the Gaussian and Bernoulli Means
To calculate the generalization bounds, we need the distribution and . All the following results are given in the general -dimensional case, where we let the training distribution be and the testing distribution be .
We can check that both and are joint Gaussian. Write the random vector as , then and are given by
| (113) | |||
| (118) |
The KL divergence between and is given by
| (119) |
where (resp., ) denotes the mean vector of (resp., ), and (resp., ) denotes the covariance matrix of (resp., ). The divergence between and is given by
| (120) |
Finally, the true generalization gap is given by
| (121) |
As for the example of estimating Bernoulli examples, a direct calculation shows
| (122) |
| (123) |
The distribution is the product of and the binomial distribution with parameter . Then the -divergence can be directly calculated by definition. Finally, the true generalization gap is given by
| (124) |
Appendix C Proofs in Section VI
C-A Proof of Theorem 55
The following lemma will be useful to the proof, which is implicitly included in [9].
Lemma 9.
Suppose the loss function is -Lipschitz, then,
| (125) |
Proof of Theorem 55.
Invoking Corollary 3 and it suffices to bound the in-distribution term . Let the sample path be fixed, we have
| (126) | ||||
| (127) | ||||
| (128) | ||||
| (129) | ||||
| (130) | ||||
| (131) | ||||
| (132) |
In the above, inequalities (126) and (128) follow by Jensen’s inequality, combined with the fact that the functions and are both concave. Inequality (127) follows by the Bretagnolle-Huber inequality. To achieve inequality (130), we use the inequality and the fact that function is monotonously increasing. Equality (131) follows by the chain rule of mutual information, and the last inequality follows by Lemma 125 and the fact that is independent of given if .
On the other hand, we use Pinsker’s inequality to yield
| (133) | ||||
| (134) | ||||
| (135) |
where the last inequality follows by a similar argument from (129) to (132). Therefore, the term is dominated by the minimum of (132) and (135). Plug this result into Corollary 3, and the proof is completed by taking expectation w.r.t. the sample path . ∎
C-B Proof of Theorem 56
For the proof of Theorem 56, the following lemmas will be useful.
Lemma 10 (Chain Rule of Hellinger Distance).
Let and be two probability distributions on the random vector . Then,
| (136) |
Lemma 11 (Squared Hellinger Divergence between two Gaussian Distribution).
Let and be two multivariate Gaussian distributions. Then the squared Hellinger divergence of and can be written as
| (137) |
Proof Sketch.
It follows from the Gaussian integral and the equality . The last two equalities follow by the Woodbury matrix identity . Then the Lemma 11 follows by direct calculation. ∎
Lemma 12.
Suppose the gradient of loss function is -Lipschitz, i.e., . Then, we have
| (138) |
Proof.
Since and are independent and identically distributed conditioned on , we have
| (139) | ||||
| (140) | ||||
| (141) |
where we remove the superscript and subscript of for simplicity. The last inequality follows since the variance of a bounded random variable is no more than . ∎
Now we are ready to prove the main result of this subsection.
Proof of Theorem 56.
By Theorem 2, we have
| (142) | ||||
| (143) | ||||
| (144) |
where the last inequality follows by Lemma 10. As a consequence, it is sufficient to bound the term. Let , i.e., takes 1 with probability and takes with probability , given and . On the other hand, we have
| (145) |
and thus is mixture Gaussian, expressed by
| (146) |
Keep in mind that is a function of and , and the Gaussian components and are also parameterized by and . We drop these dependencies from the notation for abbreviation. Plugging (145) and (146) into (144) yields
| (147) | ||||
| (148) | ||||
| (149) | ||||
| (150) |
To obtain the first two inequalities, we use the fact that the -divergence is jointly convex w.r.t. its arguments, and thus separately convex. To obtain the last inequality, we use the fundamental inequality to eliminate . Now, we choose to be the squared Hellinger divergence. By Lemma 11, we have
| (151) | ||||
| (152) |
and thus
| (153) | ||||
| (154) | ||||
| (155) |
To obtain the second inequality we use the concavity of the function , and to obtain the last inequality we use Lemma 12 and the fact that is monotonously increasing. Plugging (155) into (144) yields
| (156) | ||||
which is the desired result. ∎
C-C Proof of Lemma 5
Proof of Lemma 5.
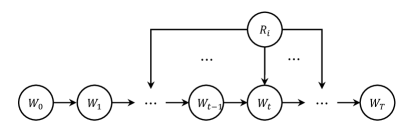
Let the super-sample be fixed. The SGLD optimization trajectory induces a Bayes network , as illustrated in Fig. 5, where only is considered. Since is sub-additive, we have
| (157) | ||||
| (158) |
for all distributions and over . Now define as the joint distribution of and induced by the SGLD algorithm, i.e.,
| (159) | ||||
| (160) |
and define as the product of marginal distribution of and , i.e.,
| (161) | ||||
| (162) |
By induction over , one can prove that and have the same marginal distribution at each vertex in the graph , i.e., , , and . Therefore, we have
| (163a) | ||||
| (163b) | ||||
| (163c) | ||||
| (163d) | ||||
Add all terms together and use the fact that , we have
| (164) |
Keep in mind that (164) is established based on the condition . Thus, the desired result (59) follows by taking expectation over . ∎
References
- [1] W. Liu, G. Yu, L. Wang, and R. Liao, “An information-theoretic framework for out-of-distribution generalization,” arXiv preprint arXiv:2403.19895, 2024.
- [2] V. Vapnik and A. Y. Chervonenkis, “On the uniform convergence of relative frequencies of events to their probabilities,” Theory of Probability & Its Applications, vol. 16, no. 2, pp. 264–280, 1971.
- [3] P. L. Bartlett and S. Mendelson, “Rademacher and gaussian complexities: Risk bounds and structural results,” Journal of Machine Learning Research, vol. 3, no. Nov, pp. 463–482, 2002.
- [4] D. Pollard, Convergence of stochastic processes. David Pollard, 1984.
- [5] O. Bousquet and A. Elisseeff, “Stability and generalization,” The Journal of Machine Learning Research, vol. 2, pp. 499–526, 2002.
- [6] D. A. McAllester, “Some pac-bayesian theorems,” in Proceedings of the eleventh annual conference on Computational learning theory, 1998, pp. 230–234.
- [7] D. Russo and J. Zou, “Controlling bias in adaptive data analysis using information theory,” in Artificial Intelligence and Statistics. PMLR, 2016, pp. 1232–1240.
- [8] A. Xu and M. Raginsky, “Information-theoretic analysis of generalization capability of learning algorithms,” Advances in Neural Information Processing Systems, vol. 30, 2017.
- [9] Y. Bu, S. Zou, and V. V. Veeravalli, “Tightening mutual information-based bounds on generalization error,” IEEE Journal on Selected Areas in Information Theory, vol. 1, no. 1, pp. 121–130, 2020.
- [10] T. Steinke and L. Zakynthinou, “Reasoning about generalization via conditional mutual information,” in Conference on Learning Theory. PMLR, 2020, pp. 3437–3452.
- [11] M. Haghifam, J. Negrea, A. Khisti, D. M. Roy, and G. K. Dziugaite, “Sharpened generalization bounds based on conditional mutual information and an application to noisy, iterative algorithms,” Advances in Neural Information Processing Systems, vol. 33, pp. 9925–9935, 2020.
- [12] F. Hellström and G. Durisi, “Generalization bounds via information density and conditional information density,” IEEE Journal on Selected Areas in Information Theory, vol. 1, no. 3, pp. 824–839, 2020.
- [13] J. Negrea, M. Haghifam, G. K. Dziugaite, A. Khisti, and D. M. Roy, “Information-theoretic generalization bounds for sgld via data-dependent estimates,” Advances in Neural Information Processing Systems, vol. 32, 2019.
- [14] B. Rodríguez-Gálvez, G. Bassi, R. Thobaben, and M. Skoglund, “On random subset generalization error bounds and the stochastic gradient langevin dynamics algorithm,” in 2020 IEEE Information Theory Workshop (ITW). IEEE, 2021, pp. 1–5.
- [15] R. Zhou, C. Tian, and T. Liu, “Individually conditional individual mutual information bound on generalization error,” IEEE Transactions on Information Theory, vol. 68, no. 5, pp. 3304–3316, 2022.
- [16] G. Aminian, S. Masiha, L. Toni, and M. R. Rodrigues, “Learning algorithm generalization error bounds via auxiliary distributions,” arXiv preprint arXiv:2210.00483, 2022.
- [17] Y. Chu and M. Raginsky, “A unified framework for information-theoretic generalization bounds,” Advances in Neural Information Processing Systems, vol. 36, 2024.
- [18] M. Arjovsky, L. Bottou, I. Gulrajani, and D. Lopez-Paz, “Invariant risk minimization,” arXiv preprint arXiv:1907.02893, 2019.
- [19] H. Ye, C. Xie, T. Cai, R. Li, Z. Li, and L. Wang, “Towards a theoretical framework of out-of-distribution generalization,” Advances in Neural Information Processing Systems, vol. 34, pp. 23 519–23 531, 2021.
- [20] S. Ben-David, J. Blitzer, K. Crammer, and F. Pereira, “Analysis of representations for domain adaptation,” Advances in neural information processing systems, vol. 19, 2006.
- [21] S. Ben-David, J. Blitzer, K. Crammer, A. Kulesza, F. Pereira, and J. W. Vaughan, “A theory of learning from different domains,” Machine learning, vol. 79, pp. 151–175, 2010.
- [22] M. Sugiyama, S. Nakajima, H. Kashima, P. Buenau, and M. Kawanabe, “Direct importance estimation with model selection and its application to covariate shift adaptation,” Advances in neural information processing systems, vol. 20, 2007.
- [23] Y. Mansour, M. Mohri, and A. Rostamizadeh, “Multiple source adaptation and the rényi divergence,” arXiv preprint arXiv:1205.2628, 2012.
- [24] X. Wu, J. H. Manton, U. Aickelin, and J. Zhu, “Information-theoretic analysis for transfer learning,” in 2020 IEEE International Symposium on Information Theory (ISIT). IEEE, 2020, pp. 2819–2824.
- [25] M. S. Masiha, A. Gohari, M. H. Yassaee, and M. R. Aref, “Learning under distribution mismatch and model misspecification,” in 2021 IEEE International Symposium on Information Theory (ISIT). IEEE, 2021, pp. 2912–2917.
- [26] Z. Wang and Y. Mao, “Information-theoretic analysis of unsupervised domain adaptation,” arXiv preprint arXiv:2210.00706, 2022.
- [27] A. R. Esposito, M. Gastpar, and I. Issa, “Generalization error bounds via Rényi-, -divergences and maximal leakage,” IEEE Transactions on Information Theory, vol. 67, no. 8, pp. 4986–5004, 2021.
- [28] G. Lugosi and G. Neu, “Generalization bounds via convex analysis,” in Conference on Learning Theory. PMLR, 2022, pp. 3524–3546.
- [29] P. Viallard, M. Haddouche, U. Şimşekli, and B. Guedj, “Tighter generalisation bounds via interpolation,” arXiv preprint arXiv:2402.05101, 2024.
- [30] Z. Wang and Y. Mao, “On -divergence principled domain adaptation: An improved framework,” arXiv preprint arXiv:2402.01887, 2024.
- [31] S. M. Perlaza and X. Zou, “The generalization error of machine learning algorithms,” arXiv preprint arXiv:2411.12030, 2024.
- [32] F. Daunas, I. Esnaola, S. M. Perlaza, and H. V. Poor, “Equivalence of the empirical risk minimization to regularization on the family of f-divergences,” arXiv preprint arXiv:2402.00501, 2024.
- [33] V. Vapnik, “Principles of risk minimization for learning theory,” Advances in neural information processing systems, vol. 4, 1991.
- [34] Y. Polyanskiy and Y. Wu, “Information theory: From coding to learning,” Book draft, 2022.
- [35] J. Birrell, P. Dupuis, M. A. Katsoulakis, Y. Pantazis, and L. Rey-Bellet, “-divergences: Interpolating between -divergences and integral probability metrics,” Journal of machine learning research, vol. 23, no. 39, pp. 1–70, 2022.
- [36] R. Agrawal and T. Horel, “Optimal bounds between -divergences and integral probability metrics,” The Journal of Machine Learning Research, vol. 22, no. 1, pp. 5662–5720, 2021.
- [37] A. Müller, “Integral probability metrics and their generating classes of functions,” Advances in applied probability, vol. 29, no. 2, pp. 429–443, 1997.
- [38] S. Boucheron, G. Lugosi, and P. Massart, “Concentration inequalities: A nonasymptotic theory of independence. univ. press,” 2013.
- [39] M. Raginsky, A. Rakhlin, M. Tsao, Y. Wu, and A. Xu, “Information-theoretic analysis of stability and bias of learning algorithms,” in 2016 IEEE Information Theory Workshop (ITW). IEEE, 2016, pp. 26–30.
- [40] V. Feldman and T. Steinke, “Calibrating noise to variance in adaptive data analysis,” in Conference On Learning Theory. PMLR, 2018, pp. 535–544.
- [41] M. Welling and Y. W. Teh, “Bayesian learning via stochastic gradient langevin dynamics,” in Proceedings of the 28th international conference on machine learning (ICML-11). Citeseer, 2011, pp. 681–688.
- [42] H. Robbins and S. Monro, “A stochastic approximation method,” The annals of mathematical statistics, pp. 400–407, 1951.
- [43] J. Bretagnolle and C. Huber, “Estimation des densités: risque minimax,” Zeitschrift für Wahrscheinlichkeitstheorie und verwandte Gebiete, vol. 47, pp. 119–137, 1979.
- [44] M. Ding, C. Daskalakis, and S. Feizi, “Gans with conditional independence graphs: On subadditivity of probability divergences,” in International Conference on Artificial Intelligence and Statistics. PMLR, 2021, pp. 3709–3717.