An Information-Theoretic Analysis of Nonstationary Bandit Learning
Current Revision: December 2023)
Abstract
In nonstationary bandit learning problems, the decision-maker must continually gather information and adapt their action selection as the latent state of the environment evolves. In each time period, some latent optimal action maximizes expected reward under the environment state. We view the optimal action sequence as a stochastic process, and take an information-theoretic approach to analyze attainable performance. We bound per-period regret in terms of the entropy rate of the optimal action process. The bound applies to a wide array of problems studied in the literature and reflects the problem’s information structure through its information-ratio.
1 Introduction
We study the problem of learning in interactive decision-making. Across a sequence of time periods, a decision-maker selects actions, observes outcomes, and associates these with rewards. They hope to earn high rewards, but this may require investing in gathering information.
Most of the literature studies stationary environments — where the likelihood of outcomes under an action is fixed across time.111An alternative style of result lets the environment change, but tries only to compete with the best fixed action in hindsight. Efficient algorithms limit costs required to converge on optimal behavior. We study the design and analysis of algorithms in nonstationary environments, where converging on optimal behavior is impossible.
In our model, the latent state of the environment in each time period is encoded in a parameter vector. These parameters are unobservable, but evolve according to a known stochastic process. The decision-maker hopes to earn high rewards by adapting their action selection as the environment evolves. This requires continual learning from interaction and striking a judicious balance between exploration and exploitation. Uncertainty about the environment’s state cannot be fully resolved before the state changes and this necessarily manifests in suboptimal decisions. Strong performance is impossible under adversarial forms of nonstationarity but is possible in more benign environments. Why are A/B testing, or recommender systems, widespread and effective even though nonstationarity is a ubiquitous concern? Quantifying the impact different forms of nonstationarity have on decision-quality is, unfortunately, quite subtle.
Our contributions.
We provide a novel information-theoretic analysis that bounds the inherent degradation of decision-quality in dynamic environments. The work can be seen as a very broad generalization of Russo and Van Roy [2016, 2022] from stationary to dynamic environments. To understand our results, it is important to first recognize that the latent state evolution within these environments gives rise to a latent optimal action process. This process identifies an optimal action at each time step, defined as the one that maximizes the expected reward based on the current environment state. Theorem 1 bounds the per-period regret in terms of the entropy rate of this optimal action process. This rate is indicative of the extent to which changes in the environment lead to unpredictable and erratic shifts in the optimal action process. Complementing Theorem 1, Section 5.3 lower bounds regret by the entropy rate of the optimal action process in a family of nonstationarity bandit problems.
Through examples, we illustrate that the entropy rate of the action process may be much lower than the entropy rate of the latent environment states. Subsection 1.1 provides an illustrative example of nonstationarity, drawing inspiration from A/B testing scenarios. This distinction is further explored in the context of news recommendation problems, as detailed in Example 5 and Example 6.
We provide several generalizations of our main result. Section 7 considers problems where the environment evolves very rapidly, so aiming to track the optimal action sequence is futile. The assurances of Theorem 1 become vacuous in this case. Regardless of how erratic the environment is, Theorem 2 shows that it is possible to earn rewards competitive with any weaker benchmark — something we call a satisficing action sequence — whose entropy rate is low.
Section 8 interprets and generalizes the entropy rate through the lens of a communication problem. In this problem, an observer of the latent state aims to transmit useful information to a decision-maker. The decision-maker can implement optimal actions if and only if the observer (optimally) transmits information with bit-rate exceeding the entropy rate of the optimal action process. Theorem 3 replaces the entropy rate in Theorem 1 with a rate-distortion function [Cover and Thomas, 2006], which characterizes the bit-rate required to enable action selection with a given per-period regret.
This abstract theory provides an intriguing link between interactive learning problems and the limits of lossy compression. We do not engage in a full investigation, but provide a few initial connections to existing measures of the severity of nonstationarity. Proposition 2 bounds the entropy rate (and hence the rate-distortion function) in terms the number of switches in the optimal action process, similar to Auer [2002] or Suk and Kpotufe [2022]. Proposition 4 upper bounds the rate distortion in terms of the total-variation in arms’ mean-rewards, following the influential work of Besbes et al. [2015]. Section 9 reviews a duality between stochastic and adversarial models of nonstationarity which shows these information-theoretic techniques can be used to study adversarial models.
Our general bounds also depend on the algorithm’s information ratio. While the problem’s entropy rate (or rate-distortion function) bounds the rate at which the decision-maker must acquire information, the information-ratio bounds the per-period price of acquiring each bit of information. Since its introduction in the study of stationary learning problems in Russo and Van Roy [2016], the information-ratio has been shown to properly capture the complexity of learning in a range of widely studied problems. Recent works link it to generic limits on when efficient learning is possible Lattimore [2022], Foster et al. [2022]. Section 6 details bounds on the information ratio that apply to many of the most important sequential learning problems — ranging from contextual bandits to online matching. Through our analysis, these imply regret bounds in nonstationary variants of these problems.
This work emphasizes understanding of the limits of attainable performance. Thankfully, most results apply to variants of Thompson sampling (TS) [Thompson, 1933], one of the most widely used learning algorithms in practice. In some problems, TS is far from optimal, and better bounds are attained with Information-Directed Sampling [Russo and Van Roy, 2018].
A short conference version of this paper appeared in [Min and Russo, 2023]. In addition to providing a more thorough exposition, this full-length paper provides substantive extensions to that initial work, including the treatment of satisficing in Section 7, the connections with rate-distortion theory in Section 8, and the connections with adversarial analysis in Section 9.
1.1 An illustrative Bayesian model of nonstationarity
Consider a multi-armed bandit environment where two types of nonstationarity coexist – a common variation that affects the performance of all arms, and idiosyncratic variations that affect the performance of individual arms separately. More explicitly, let us assume that the mean reward of arm at time is given by
where and ’s are latent stochastic processes describing common and idiosyncratic disturbances. While deferring the detailed description to Appendix C, we introduce two hyperparameters and in our generative model to control the time scale of these two types of variations.222 We assume that is a zero-mean Gaussian process satisfying so that determines the volatility of the process. Similarly, the volatility of is determined by .

Inspired by real-world A/B tests [Wu et al., 2022], we imagine a two-armed bandit instance involving a common variation that is much more erratic than idiosyncratic variations. Common variations reflect exogenous shocks to user behavior which impacts the reward under all treatment arms. Figure 1 visualizes such an example, a sample path generated with the choice of and . Observe that the optimal action has changed only five times throughout 1,000 periods. Although that the environment itself is highly nonstationary and unpredictable due to the common variation term, the optimal action sequence is relatively stable and predictable since it depends only on the idiosyncratic variations.
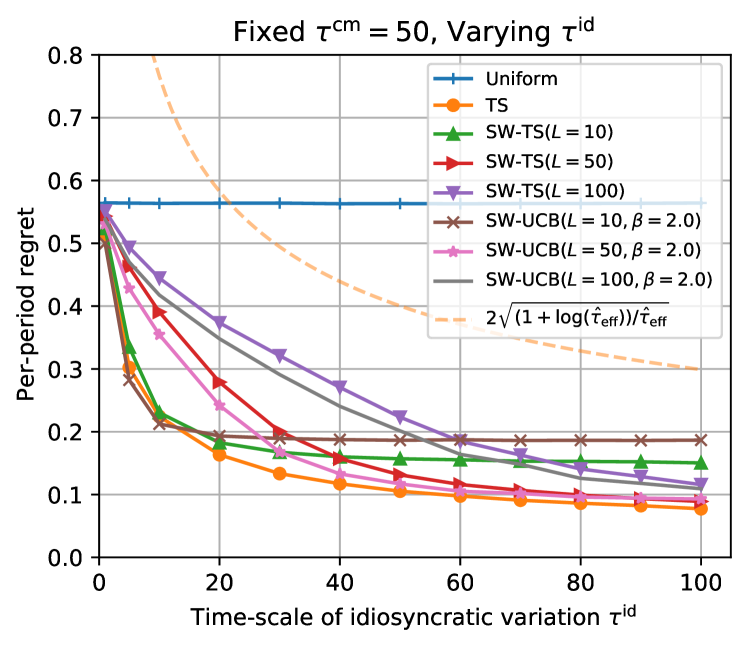
Now we ask — How difficult is this learning task? Which type of nonstationarity determines the difficulty? A quick numerical investigation shows that the problem’s difficulty is mainly determined by the frequency of optimal action switches, rather than volatility of common variation.

See Figure 2, where we report the effect of and on the performance of several bandit algorithms (namely, Thompson sampling with exact posterior sampling,333 In order to perform exact posterior sampling, it exploits the specified nonstationary structure as well as the values of and . and Sliding-Window TS that only uses recent observations; see Appendix C for the details). Remarkably, their performances appear to be sensitive only to but not to , highlighting that nonstationarity driven by common variation is benign to the learner.
We remark that our information-theoretic analyses predict this result. Theorem 1 shows that the complexity of a nonstationary environment can be sufficiently characterized by the entropy rate of the optimal action sequence, which depends only on but not on in this example. Proposition 1 further expresses the entropy rate in terms of effective horizon, which corresponds to in this example. (See Example 7, where we revisit this two-armed bandit problem.)
1.2 Comments on the use of prior knowledge
A substantive discussion of Bayesian, frequentist, and adversarial perspectives on decision-making uncertainty is beyond the scope of this paper. We make two quick observations. First, where does a prior like the one in Figure 1 come from? One answer is that company may run many thousands of A/B tests, and an informed prior may let them transfer experience across tests [Azevedo et al., 2019]. In particular, experience with past tests may let them calibrate , or form hierarchical prior where is also random. Example 5 in Section 2.2.2 illustrates the possibility of estimating prior hyperparameters in a news article recommendation problem. Second, Thompson sampling with a stationary prior is perhaps the most widely used bandit algorithm. One might view the model in Section 1.1 as a more conservative way of applying TS that guards against a certain magnitude of nonstationarity.
1.3 Literature review
We adopt Bayesian viewpoints to describe nonstationary environments: changes in the underlying reward distributions (more generally, changes in outcome distributions) are driven by a stochastic process. Such a viewpoint dates back to the earliest work of Whittle [1988] which introduces the term ‘restless bandits’ and has motivated subsequent work Slivkins and Upfal [2008], Chakrabarti et al. [2008], Jung and Tewari [2019]. On the other hand, since Thompson sampling (TS) has gained its popularity as a Bayesian bandit algorithm, its variants have been proposed for nonstationary settings accordingly: e.g., Dynamic TS [Gupta et al., 2011], Discounted TS [Raj and Kalyani, 2017], Sliding-Window TS [Trovo et al., 2020], TS with Bayesian changepoint detection [Mellor and Shapiro, 2013, Ghatak, 2020]. Although the Bayesian framework can flexibly model various types of nonstationarity, this literature rarely presents performance guarantees that apply to a broad class of models.
To provide broad performance guarantees, our analysis adopts an information-theoretic approach introduced in Russo and Van Roy [2016] and extended in Russo and Van Roy [2022]. While past work applies this framework to analyze learning in stationary environments, we show that it can be gracefully extended to dynamic environments. In this extension, bounds that depend on the entropy of the static optimal action [Russo and Van Roy, 2016] are replaced with the entropy rate of the optimal action process; rate-distortion functions are similarly extended. A strength of this approach is enables one to leverage a wealth of existing bounds on the information-ratio, including for -armed bandits/linear bandits/combinatorial bandits [Russo and Van Roy, 2016], contextual bandits [Neu et al., 2022], logistic bandits [Dong et al., 2019], bandits with graph-based feedback [Liu et al., 2018], convex optimization [Bubeck and Eldan, 2016, Lattimore and Szepesvári, 2020], etc.
Liu et al. [2023] recently proposed an algorithm called Predictive Sampling for nonstationarity bandit learning problems. At a conceptual level, their algorithm is most closely related to our Section 7, in which Thompson sampling style algorithms are modified to explore less aggressively in the face of rapid dynamics. The authors introduce a modified information-ratio and use it to successfully display the benefits of predictive sampling over vanilla Thompson sampling. Our framework does not allow us to study predictive sampling, but enables us to establish a wide array of theoretical guarantees for other algorithms that are not provided in Liu et al. [2023]. We leave a detailed comparison in Appendix B.
Recent work of Chen et al. [2023] develops an algorithm regret analysis for -armed bandit problems when arm means (i.e. the latent states) evolve according to an auto-regressive process. This is a special case of our formulation and a detailed application application of our Theorem 1 or Theorem 3 to such settings would be an interesting avenue for future research. One promising route is to modify the argument in Example 7.
Most existing theoretical studies on nonstationary bandit experiments adopt adversarial viewpoints in the modeling of nonstationarity. Implications of our information-theoretic regret bounds in adversarial environments are discussed in Section 9. These works typically fall into two categories – ‘‘switching environments’’ and ‘‘drifting environments’’.
Switching environments consider a situation where underlying reward distributions change at unknown times (often referred to as changepoints or breakpoints). Denoting the total number of changes over periods by , it was shown that the cumulative regret is achievable: e.g., Exp3.S [Auer et al., 2002, Auer, 2002], Discounted-UCB [Kocsis and Szepesvári, 2006], Sliding-Window UCB [Garivier and Moulines, 2011], and more complicated algorithms that actively detect the changepoints [Auer et al., 2019, Chen et al., 2019]. While those results depend on the number of switches in the underlying environment, the work of Auer [2002] already showed that it is possible to achieve a bound of where only counts the number of switches in identity of the best-arm. More recent studies design algorithms that adapt to an unknown number of switches [Abbasi-Yadkori et al., 2022, Suk and Kpotufe, 2022]. Our most comparable result, which follows from Theorem 1 with Proposition 2, is a bound on the expected cumulative regret of Thompson sampling is , in a wide range of problems beyond -armed bandits (see Section 6.1).
Another stream of work considers drifting environments. Denoting the total variation in the underlying reward distribution by (often referred to as the variation budget), it was shown that the cumulative regret is achievable [Besbes et al., 2014, 2015, Cheung et al., 2019]. Our most comparable result is given in Section 8.3, which recovers the Bayesian analogue of this result by bounding the rate distortion function. In fact, we derive a stronger regret bound that ignores variation that is common across all arms. A recent preprint by Jia et al. [2023] reveals that stronger bounds are possible under the additional smoothness assumptions on environment variations. It is an interesting open question to study whether one can derive similar bounds by bounding the rate-distortion function.
2 Problem Setup
A decision-maker interacts with a changing environment across rounds . In period , the decision-maker selects some action from a finite set , observes an outcome , and associates this with reward that depends on the outcome and action through a known utility function .
There is a function , an i.i.d sequence of disturbances , and a sequence of latent environment states taking values in , such that outcomes are determined as
| (1) |
Write potential outcomes as and potential rewards as . Equation (1) is equivalent to specifying a known probability distribution over outcomes for each choice of action and environment state.
The decision-maker wants to earn high rewards even as the environment evolves, but cannot directly observe the environment state or influence its evolution. Specifically, the decision-maker’s actions are determined by some choice of policy . At time , an action is a function of the observation history and an internal random seed that allows for randomness in action selection. Reflecting that the seed is exogenously determined, assume is jointly independent of the outcome disturbance process and state process . That actions do not influence the environment’s evolution can be written formally through the conditional independence relation .
The decision-maker wants to select a policy that accumulates high rewards as this interaction continues. They know all probability distributions and functions listed above, but are uncertain about how environment states will evolve across time. To perform ‘well’, they need to continually gather information about the latent environment states and carefully balance exploration and exploitation.
Rather than measure the reward a policy generates, it is helpful to measure its regret. We define the -period per-period regret of a policy to be
where the latent optimal action is a function of the latent state satisfying . We further define the regret rate of policy as its limit value,
It measures the (long-run) per-period degradation in performance due to uncertainty about the environment state.
Remark 1.
Our analysis proceeds under the following assumption, which is standard in the literature.
Assumption 1.
There exists such that, conditioned on , is sub-Gaussian with variance proxy .
2.1 ‘Stationary processes’ in ‘nonstationary bandits’
The way the term ‘nonstationarity’ is used in the bandit learning literature could cause confusion as it conflicts with the meaning of ‘stationarity’ in the theory of stochastic process, which we use elsewhere in this paper.
Definition 1.
A stochastic process is (strictly) stationary if for each integer , the random vector has the same distribution for each choice of .
‘Nonstationarity’, as used in the bandit learning literature, means that realizations of the latent state may differ at different time steps. The decision-maker can gather information about the current state of the environment, but it may later change. Nonstationarity of the stochastic process , in the language of probability theory, arises when apriori there are predictable differences between environment states at different timesteps – e.g., if time period is nighttime then rewards tend to be lower than daytime. It is often clearer to model predictable differences like that through contexts, as in Example 4.
2.2 Examples
2.2.1 Modeling a range of interactive decision-making problems
Many interactive decision-making problems can be naturally written as special cases of our general protocol, where actions generate outcomes that are associated with rewards.
Our first example describes a bandit problem with independent arms, where outcomes generate information only about the selected action.
Example 1 (-armed bandit).
Consider a website who can display one among ads at a time and gains one dollar per click. For each ad , the potential outcome/reward is a random variable representing whether the ad is clicked by the visitor if displayed, where represents its click-through-rate. The platform only observes the reward of the displayed ad, so .
Full information online optimization problems fall at the other extreme of -armed bandit problems. There the potential observation does not depend on the chosen action , so purposeful information gathering is unnecessary. The next example was introduced by Cover [1991] and motivates such scenarios.
Example 2 (Log-optimal online portfolios).
Consider a small trader who has no market impact. In period they have wealth which they divide among possible investments. The action is chosen from a feasible set of probability vectors, with denoting the proportion of wealth invested in stock . The observation is where is the end-of-day value of invested in stock at the start of the day and the distribution of is parameterized by . Because the observation consists of publicly available data, and the trader has no market impact, does not depend on the investor’s decision. Define the reward function . Since wealth evolves according to the equation ,
Many problems lie in between these extremes. We give two examples. The first is a matching problem. Many pairs of individuals are matched together and, in addition to the cumulative reward, the decision-maker observes feedback on the quality of outcome from each individual match. This kind of observation structure is sometimes called ‘‘semi-bandit’’ feedback Audibert et al. [2014].
Example 3 (Matching).
Consider an online dating platform with two disjoint sets of individuals and . On each day , the platform suggests a matching of size , with . For each pair , their match quality is given by , where the distribution of is parameterized by . The platform observes the quality of individual matches, , and earns their average, .
Our final example is a contextual bandit problem. Here an action is itself more like a policy — it is a rule for assigning treatments on the basis of an observed context. Observations are richer than in the -armed bandit. The decision-maker sees not only the reward a policy generated but also the context in which it was applied.
Example 4 (Contextual bandit).
Suppose that the website described in Example 1 can now access additional information about each visitor, denoted by . The website observes the contextual information , chooses an ad to display, and then observes whether the user clicks. To represent this task using our general protocol, we let the decision space be the set of mappings from the context space to the set of ads , the decision be a personalized advertising rule, and the observation contains the observed visitor information and the reward from applying the ad . Rewards are drawn according to , where is a parametric click-through-rate model. Assume . This assumption means that advertising decisions cannot influence the future contexts and that parameters of the click-through rate model cannot be inferred passively by observing contexts.
2.2.2 Unconventional models of nonstationarity
Section 1.1 already presented one illustration of a -armed bandit problem with in which arms’ mean-rewards change across time. This section illustrates a very different kind of dynamics that can also be cast as a special case of our framework .
The next example describes a variant of the -armed bandit problem motivated by a news article recommendation problem treated in the seminal work of Chapelle and Li [2011]. We isolate one source of nonstationarity: the periodic replacement of news articles with fresh ones. Each new article is viewed as a draw from a population distribution; experience recommending other articles gives an informed prior on an article’s click-through-rate, but resolving residual uncertainty requires exploration. Because articles are continually refreshed, the system must perpetually balance exploration and exploitation.
Our treatment here is purposefully stylized. A realistic treatment might include features of the released articles which signal its click-through-rate, features of arriving users, time-of-day effects, and more general article lifetime distributions.
Example 5 (News article recommendation).
At each user visit, a news website recommends one out of a small pool of hand-picked news articles. The pool is dynamic – old articles are removed and new articles are added to the pool in an endless manner. An empirical investigation on a dataset from Yahoo news (Yahoo! Front Page User Click Log dataset) shows that, as visualized in Figure 3, the pool size varies between 19 and 25 while one article stays in the candidate pool 17.9 hours in average.

We can formulate this situation with article slots (arms), each of which contains one article at a time. Playing an arm corresponds to recommending the article in slot . The article in a slot gets replaced with a new article at random times; the decision-maker observes that it was replaced but is uncertain about the click-through rate of the new article.
Let denote the vector of click-through rates across article slots, where . The observation at time when playing arm is , where indicates which article slots were updated. If , then almost surely. If , then is drawn independently from the past as
As this process repeats across many articles, the population click-through-rate distribution can be learned from historical data. For purposes of analysis, we simply assume is known.
Assume that is independent across times and arms ; this means that each article’s lifetime follows a Geometric distribution with mean lifetime . (Assume also that is independent of the disturbance process and random seeds ).
3 Thompson sampling
While this paper is primarily focused on the limits of attainable performance, many of our regret bounds apply to Thompson sampling [Thompson, 1933], one of the most popular bandit algorithms. This section explains how to generalize its definition to dynamic environments.
We denote the Thompson sampling policy by and define it by the probability matching property:
| (2) |
which holds for all , . Actions are chosen by sampling from the posterior distribution of the optimal action at the current time period. This aligns with the familiar definition of Thompson sampling in static environments where
Practical implements of TS sampling from the posterior distribution of the optimal action by sampling plausible latent state and picking the action .
How the posterior gradually forgets stale data.
The literature on nonstationary bandit problems often constructs mean-reward estimators that explicitly throw away or discount old data [Kocsis and Szepesvári, 2006, Garivier and Moulines, 2011]. Under Bayesian algorithms like TS, forgetting of stale information happens implicitly through the formation of posterior distributions. To provide intuition, we explain that proper posterior updating resembles an exponential moving average estimator under a simple model of nonstationarity.
Consider -armed bandit with Gaussian noises where each arm’s mean-reward process follows an auto-regressive process with order . That is,
where are i.i.d. innovations in the mean-reward process, are i.i.d. noises in the observations, and is the autoregression coefficient. Assume so that the mean-reward process is stationary.
Algorithm 1 implements Thompson sampling in this environment. It uses a (simple) Kalman filter to obtain the posterior distribution. Past data is ‘‘forgotten’’ at a geometric rate over time, and the algorithm shrinks posterior mean estimates toward (i.e., the prior mean) if few recent observations are available.
| (3) |
| (4) |
4 Information Theoretic Preliminaries
The entropy of a discrete random variable , defined by , measures the uncertainty in its realization. The entropy rate of a stochastic process is the rate at which entropy of the partial realization accumulates as grows.
Definition 2.
The -period entropy rate of a stochastic process , taking values in a discrete set , is
The entropy rate is defined as its limit value:
We provide some useful facts about the entropy rate:
Fact 1.
.
Fact 2.
By chain rule,
If is a stationary stochastic process, then
| (5) |
The form (5) is especially elegant. The entropy rate of a stationary stochastic process is the residual uncertainty in the draw of which cannot be removed by knowing the draw of . Processes that evolve quickly and erratically have high entropy rate. Those that tend to change infrequently (i.e., for most ) or change predictably will have low entropy rate.
The next lemma sharpens this understanding by establishing an upper bound on the entropy rate in terms of the switching frequency.
Lemma 1.
Consider a stochastic process taking values in a finite set . Let be the number of switches in occurring up to time ,
| (6) |
If almost surely for some , the -period entropy rate of is upper bounded as
The proof is provided in Appendix A, which simply counts the number of possible realizations with a restricted number of switches.
The conditional entropy rate and mutual information rate of two stochastic processes are defined similarly. For brevity, we write to denote the random vector .
Definition 3.
Consider a stochastic process , where takes values in a discrete set. The -period conditional entropy rate of given is defined as
and the -period mutual information rate between and is defined as
The conditional entropy rate and mutual information rate are defined as their limit values: i.e., , and .
The mutual information rate represents the average amount of communication happening between two processes, and . This quantity can also be understood as the decrease in the entropy rate of resulting from observing , and trivially it cannot exceed the entropy rate of :
Fact 3.
.
The next fact shows that the mutual information rate can be expressed as the average amount of information that accumulates about in each period, following from the chain rule.
Fact 4.
.
5 Information-Theoretic Analysis of Dynamic Regret
We apply the information theoretic analysis of Russo and Van Roy [2016] and establish upper bounds on the per-period regret, expressed in terms of (1) the algorithm’s information ratio, and (2) the entropy rate of the optimal action process.
5.1 Preview: special cases of our result
We begin by giving a special case of our result. It bounds the regret of Thompson sampling in terms of the reward variance proxy , the number of actions , and the entropy rate of the optimal action process .
Corollary 1.
Under any problem in the scope of our problem formulation,
This result naturally covers a wide range of bandit learning tasks while highlighting that the entropy rate of optimal action process captures the level of degradation due to nonstationarity. Note that it includes as a special case the well-known regret upper bound established for a stationary -armed bandit: when , we have , and thus .
According to (5), the entropy rate is small when the conditional entropy is small. That is, the entropy rate is small if most uncertainty in the optimal action is removed through knowledge of the past optimal actions. Of course, Thompson sampling does not observe the environment states or the corresponding optimal actions, so its dependence on this quantity is somewhat remarkable.
The dependence of regret on the number of actions, , is unavoidable in a problem like the -armed bandit of Example 1. But in other cases, it is undesirable. Our general results depend on the problem’s information structure in a more refined manner. To preview this, we give another corollary of our main result, which holds for problems with full-information feedback (see Example 2 for motivation). In this case, the dependence on the number of actions completely disappears and the bound depends on the variance proxy and the entropy rate. The bound applies to TS and the policy , which chooses in each period .
Corollary 2.
For full information problems, where for each , we have
5.2 Bounds on the entropy rate
Our results highlight that the difficulty arising due to the nonstationarity of the environment is sufficiently characterized by the entropy rate of the optimal action process, denoted by or . We provide some stylized upper bounds on these quantities to aid in their interpretation and to characterize the resulting regret bounds in a comparison with the existing results in the literature.
Bound with the effective time horizon.
In settings where optimal action process is stationary (Definition 1), define . We interpret as the problem’s ‘‘effective time horizon’’, as it captures the average length of time before the identity of the optimal action changes. The effective time horizon is long when the optimal action changes infrequently, so that, intuitively, a decision-maker could continue to exploit the optimal action for a long time if it were identified, achieving a low regret. The next proposition shows that the entropy rate is bounded by the inverse of , regardless of :
Proposition 1.
When the process is stationary,
| (7) |
for every , where
| (8) |
Combining this result with Corollary 1, and the fact that as , we obtain
which closely mirrors familiar regret bounds on the average per-period regret in bandit problems with arms, periods, and i.i.d rewards Bubeck and Cesa-Bianchi [2012], except that the effective time horizon replaces the problem’s raw time horizon.
Example 6 (Revisiting new article recommendation).
In Example 5, the stochastic process is stationary as long as for each article slot . Recall that each article slot is refreshed with probability , independently. As a result,
and . Per-period regret scales with number of article slots that need to be explored and inversely with the lifetime of an article; the latter determines how long information about an article’s click-rate can be exploited before it is no longer relevant.
To attain this result, it is critical that our theory depends on the entropy rate or effective horizon of the optimal action process, rather than the parameter process. The vector of click-through rates changes every periods, since it changes whenever an article is updated. Nevertheless, the optimal action process changes roughy once every periods, on average, since a new article is only optimal of the time.
We now revisit the two-armed bandit example from Section 1.1.
Example 7 (Revisiting example in Section 1.1).
Consider the two-armed bandit example discussed in Section 1.1. The idiosyncratic mean reward process of each arm is a stationary zero-mean Gaussian process such that, for each , for any . By Rice’s formula (Rice, 1944; Barnett and Kedem, 1991, eq. (2)) (also known as the zero-crossing rate formula), we have
Consequently, if ,
Below we give an example where the upper bound in Proposition 1 is nearly exact.
Example 8 (Piecewise stationary environment).
Suppose follows a switching process. With probability there is no change in the optimal action, whereas with probability there is a change-event and is drawn uniformly from among the other arms. Precisely, follows a Markov process with transition dynamics:
for . Then
where we used the approximation . Plugging in and yields,
which matches the upper bound (7).
Bound with the switching rate.
Proposition 1 requires that the optimal action process is stationary, in the sense of Definition 1. We now provide a similar result that removes this restriction. It is stated in terms of the switching rate, which in stationary settings is similar to the inverse of the effective horizon. The added genenerality comes at the expense of replacing the conditional entropy in Proposition 1 with a the crude upper bound .
Proposition 2.
Let be the expected switching rate of the optimal action sequence, defined as
Then,
This results follows from Lemma 1 while slightly generalizing it by bounding the entropy rate with the expected number of switches instead of an almost sure upper bound. Combining this result with Corollary 1 gives a bound
which precisely recovers the well-known results established for switching bandits [Auer et al., 2002, Suk and Kpotufe, 2022, Abbasi-Yadkori et al., 2022]. Although other features of the environment may change erratically, a low regret is achievable if the optimal action switches infrequently.
Bound with the entropy rate of latent state process.
Although it can be illuminating to consider the number of switches or the effective horizon, the entropy rate is a deeper quantity that better captures a problem’s intrinsic difficulty. A simple but useful fact is that the entropy rate of the optimal action process cannot exceed that of the environment’s state process:
Remark 2.
Since the optimal action is completely determined by the latent state , by data processing inequality,
These bounds can be useful when the environment’s nonstationarity has predictable dynamics. The next example illustrates such a situation, in which the entropy rate of the latent state process can be directly quantified.
Example 9 (System with seasonality).
Consider a system that exhibits a strong intraday seasonality. Specifically, suppose that the system’s hourly state (e.g., arrival rate) at time can be modeled as
where is a sequence of i.i.d random variables describing the daily random fluctuation, is a known deterministic sequence describing the intraday pattern, and is a sequence of i.i.d random variables describing the hourly random fluctuation. Then we have
regardless of the state-action relationship. Imagine that the variation within the intraday pattern is large so that the optimal action changes almost every hour (i.e., and ). In this case, the bound like above can be easier to compute and more meaningful than the bounds in Propositions 2 and 1.
5.3 Lower bound
We provide an impossibility result through the next theorem, showing that no algorithm can perform significantly better than the upper bounds provided in Corollary 1 and implied by Proposition 1. Our proof is built by modifying well known lower bound examples for stationary bandits.
Proposition 3.
Let and . There exists a nonstationary bandit problem instance with and , such that
where is a universal constant.
Remark 3.
For the problem instance constructed in the proof, the entropy rate of optimal action process is . This implies that the upper bound established in Corollary 1 is tight up to logarithmic factors, and so is the one established in Theorem 1.
5.4 Main result
The corollaries presented earlier are special cases of a general result that we present now. Define the (maximal) information ratio of an algorithm by,
The per-period information ratio was defined by Russo and Van Roy [2016] and presented in this form by Russo and Van Roy [2022]. It is the ratio between the square of expected regret and the conditional mutual information between the optimal action and the algorithm’s observation. It measures the cost, in terms of the square of expected regret, that the algorithm pays to acquire each bit of information about the optimum.
The next theorem shows that any algorithm’s per-period regret is bounded by the square root of the product of its information ratio and the entropy rate of the optimal action sequence. The result has profound consequences, but follows easily by applying elegant properties of information measures.
Theorem 1.
Under any algorithm ,
Proof.
Use the shorthand notation for regret, for information gain, and for the information ratio at period . Then,
by Cauchy-Schwarz, and
by definition of . We can further bound the information gain. This uses the chain rule, the data processing inequality, and the fact that entropy bounds mutual information:
Combining these results, we obtain
Taking limit yields the bound on regret rate . ∎
Remark 4.
A careful reading of the proof reveals that it is possible to replace the entropy rate with the mutual information rate .
Remark 5.
Following Lattimore and Gyorgy [2021], one can generalize the definition of information ratio,
which immediately yields an inequality, for any .
6 Bounds on the Information Ratio
6.1 Some known bounds on the information ratio
We list some known results about the information ratio. These were originally established for stationary bandit problems but immediately extend to nonstationary settings considered in this paper. Most results apply to Thompson sampling, and essentially all bounds apply to Information-directed sampling, which is designed to minimize the information ratio [Russo and Van Roy, 2018]. The first four results were shown by Russo and Van Roy [2016] under 1.
- Classical bandits.
-
, for bandit tasks with a finite action set (e.g., Example 1).
- Full information.
-
, for problems with full-information feedback (e.g., Example 2).
- Linear bandits.
-
, for linear bandits of dimension (i.e., , , and ).
- Combinatorial bandits.
-
, for combinatorial optimization tasks of selecting items out of items with semi-bandit feedback (e.g., Example 3).
- Contextual bandits.
-
See the below for a new result.
- Logistic bandits.
-
Dong et al. [2019] consider problems where mean-rewards follow a generalized linear model with logistic link function, and bound the information ratio by the dimension of the parameter vector and a new notion they call the ‘fragility dimension.’
- Graph based feedback.
- Sparse linear models.
- Convex cost functions.
6.2 A new bound on the information ratio of contextual bandits
Contextual bandit problems are a special case of our formulation that satisfy the following abstract assumption. Re-read Example 4 to get intuition.
Assumption 2.
There is a set and an integer such that is the set of functions mapping to . The observation at time is the tuple . Define . Assume that for each , , and
Under this assumption, we provide an information ratio bound that depends on the number of arms . It is a massive improvement over Corollary 1, which depends on the number of decision-rules.
Lemma 2.
Under Assumption 2, .
Theorem 1 therefore bounds regret in terms of the entropy rate of the optimal decision rule process , the number of arms , and the reward variance proxy .
Neu et al. [2022] recently highlighted that information-ratio analysis seems not to deal adequately with context, and proposed a substantial modification which considers information gain about model parameters rather than optimal decision-rules. Lemma 2 appears to resolve this open question without changing the information ratio itself. Our bounds scale with the entropy of the optimal decision-rule, instead of the entropy of the true model parameter, as in Neu et al. [2022]. By the data processing inequality, the former is always smaller. Our proof bounds the per-period information ratio, so it can be used to provide finite time regret bounds for stationary contextual bandit problems. Hao et al. [2022] provide an interesting study of variants of Information-directed sampling in contextual bandits with complex information structure. It is not immediately clear how that work relates to Lemma 2 and the information ratio of Thompson sampling.
The next corollary combines the information ratio bound above with the earlier bound of Proposition 1. The bound depends on the number of arms, the dimension of the parameter space, and the effective time horizon. No further structural assumptions (e.g., linearity) are needed. An unfortunate feature of the result is that it applies only to parameter vectors that are quantized at scale . The logarithmic dependence on is omitted in the notation, but displayed in the proof. When outcome distributions are smooth in , we believe this could be removed with careful analysis.
Corollary 3.
Under 2, if is a discretized -dimensional vector, and the optimal policy process is stationary, then
7 Extension 1: Satisficing in the Face of Rapidly Evolving Latent States
In nonstationary learning problems with short effective horizon, the decision-maker is continually uncertain about the latent states and latent optimal action. Algorithms like Thompson sampling explore aggressively in an attempt to resolve this uncertainty. But this effort may be futile, and whatever information they do acquire may have low value since it cannot be exploited for long.
Faced with rapidly evolving environments, smart algorithms should satisfice. As noted by Herbert Simon (Simon [1979], p. 498) when receiving his Nobel Prize, ‘‘decision makers can satisfice either by finding optimum solutions for a simplified world, or by finding satisfactory solutions for a more realistic world.’’ We focus on the latter case, and decision-makers that realistically model a rapidly evolving environment but seek a more stable decision-rule with satisfactory performance.
We introduce a broad generalization of TS that performs probability matching with respect to a latent satisficing action sequence instead of the latent optimal action sequence. Our theory gracefully generalizes to this case, and confirms that the decision-maker can attain rewards competitive with any satisficing action sequence whose entropy rate is low. Whereas earlier results were meaningful only if the optimal action sequence had low entropy rate — effectively an assumption on the environment — this result allows the decision-maker to compete with any low entropy action sequence regardless of the extent of nonstationarity in the true environment. We provide some implementable examples of satisficing action sequences in Section 7.2.
One can view this section as a broad generalization of the ideas in Russo and Van Roy [2022], who explore the connection between satisficing, Thompson sampling, and information theory in stationary environments. It also bears a close conceptual relationship to the work of Liu et al. [2023], which is discussed in detail in Appendix B. In the adversarial bandit literature, the most similar work is that of Auer et al. [2002]. They show a properly tuned exponential weighting algorithm attains low regret relative to any sequence of actions which switches infrequently.
7.1 Satisficing regret: competing with a different benchmark
In our formulation, the latent optimal action process serves as both a benchmark and a learning target. When calculating regret, the rewards a decision maker accrues are compared against the rewards would have accrued, using as a benchmark. When defining TS, we implicitly direct it to resolve uncertainty about the latent optimal action through probability matching, using as a learning target. When the environment evolves rapidly and unpredictably, it is impossible to learn about changes in the latent state quickly enough to exploit them, as does in such cases, the latent optimal action is not a reasonable benchmark or learning target.
We introduce a satisficing action sequence that serves as an alternative benchmark and learning target. We want the optimal action sequence to be a feasible choice of satisficing action sequence, so we must allow to be a function of . The next definition also allows for randomization in the choice. For now, this definition is very abstract, but we give specific examples in Section 7.2.
Definition 4.
A collection of random variables taking values in is a satisficing action sequence if there exists a function and an exogenous random variable (independent of , and ) such that .
Replacing with as a learning target, we modify Thompson sampling so its exploration aims to resolve uncertainty about , which could be much simpler. Satisficing Thompson sampling (STS) [Russo and Van Roy, 2022] with respect to this satisficing action sequence is denoted by . It instantiates the probability matching with respect to so that, under ,
for all and .
Replacing with as a benchmark, we define the regret rate of an action sequence (i.e., some sequence of non-anticipating random variables) with respect to a satisficing action sequence to be
Each policy induces an action sequence , so we can overload notation to write .
Theorem 1 is easily generalized to bound satisficing regret. Define the information ratio with respect to :
| (9) |
It represents the (squared) cost that the algorithm needs to pay in order to acquire one unit of information about the satisficing action sequence .
Replicating the proof of Theorem 1 with respect to yields a bound on regret relative to this alternative benchmark in terms of the information ratio with respect to this alternative benchmark. Intuitively, less information is needed to identify simpler satisficing action sequences, reducing the term in this bound.
Theorem 2.
For any algorithm and satisficing action sequence ,
If the satisficing action sequence satisfies for some function , then
Interpret the mutual information as the rate at which bits about must be communicated in order to implement the changing decision rule . Interpret as the price (in terms of squared regret) that policy pays per bit of information acquired about As made clear in the next remark, satisficing TS controls the price per bit of information regardless of the choice of satisficing action sequence . Theorem 2 therefore offers much stronger guarantees than Theorem 1 as whenever , i.e. whenever the the satisficing action sequence can be implemented while acquiring much less information about the latent states.
Remark 6.
All the upper bounds on listed in Section 6.1 also apply for . Namely, for any satisficing action sequence , the corresponding STS satisfies (a) for bandit tasks with finite action set, (b) for problems with full-information feedback, (c) for linear bandits, (d) for combinatorial bandits, and (e) for contextual bandits.
Therefore it satisfies similar bounds on satisficing regret. For linear bandits,
7.2 Examples of satisficing action sequences
The concept introduced above is quite abstract. Here we introduce three examples. Each aims to construct a satisficing action sequence that is near optimal (i.e., low while requiring limited information about (i.e., low ). As a warmup, we visualize in Figure 4 these examples of satisficing actions; they switch identity infrequently, ensuring they have low entropy, but are nevertheless very nearly optimal.
Our first example is the optimal action sequence among those that switch identity no more than times within periods.
Example 10 (Restricting number of switches).
Define the number of switches in a sequence by , a measure used in (6). Let
be the best action sequence with fewer than switches. Satisficing regret measures the gap between the rewards its actions generate and the true best action sequence with few switches. By Lemma 1, one can bound the accumulated bits of information about this satisficing action sequence as:
Satisficing Thompson sampling can be implemented by at time drawing a sequence
and then picking . This samples an arm according to the posterior probability it is the arm chosen in the true best action sequence with switches. A simple dynamic programming algorithm can be used to solve the optimization problem defining .
The next example also tries to create a more reasonable benchmark that switches less frequently. Here though, we define a satisficing action sequence that switches to a new arm only once an arm’s subotimality exceeds some threshold. This leads to a version of satisficing Thompson sampling that has a simpler implementation.
Example 11 (Ignoring small suboptimality).
Define a sequence of actions as follows:
This sequence of arms switches only when an arm’s suboptimality exceeds a distortion level . The entropy of will depend on the problem, but we will later bound it in problems with ‘‘slow variation’’ as in Besbes et al. [2014]. Algorithm 2 provides an implementation of satisficing Thompson sampling with respect to .
The next example induces satisficing in a very different way. Instead of altering how often the benchmark optimal action can change, it restricts the granularity of information about on which it can depend.
Example 12 (Optimizing with respect to obscured information).
Let
for some function . Since forms a Markov chain, choosing a that reveals limited information about restricts the magnitude of the mutual information .
To implement satisficing TS, one needs to draw from the posterior distribution of . Since where , we can sample from the posterior just as we do in TS: one needs to draw a sample from the posterior distribution of an then pick .
There are two natural strategies for providing obscured information about the latent states . First, one can provide noise corrupted view, like where is mean-zero noise. For stationary problems, this is explored in Russo and Van Roy [2022]. For the -armed nonstationary bandits in Example 1, providing fictitious reward observations , where , is similar to the proposed algorithm in Liu et al. [2023]. The second approach one can take is to reveal some simple summary statistics of .
We describe a simple illustration of the potential benefits of the second approach. Consider a problem with bandit feedback (i.e. ) and Gaussian reward observations; that is,
where is i.i.d Gaussian noise, , and follows a Gaussian process such that .
We construct a variant of satisficing TS that should vastly outperform regular TS when . Choose as
Since , we have , and satisficing TS works as follows.
- Satisficing TS:
-
Sample and pick .
- Regular TS:
-
Sample and pick .
To understand the difference between these algorithms, consider the limiting regimes in which and . In the first case, environment dynamics are so slow that the problems looks like a statationry -armed bandit.
When , the latent states evolve so rapidly and erratically that the problem looks is again equivalent to a stationary problem. Precisely, as , for any ; the process becomes a white noise process, i.e., behaves almost like a sequence of i.i.d. random variables distributed with . The overall problem looks like a stationary -armed Gaussian bandit with prior and i.i.d. noise with law .
Satisficing TS is similar in the and limits; in ether case it attempts to identify the arm with best performance throughout the horizon. But regular TS behaves very differently in these two limits – making its behavior seemingly incoherent. As , regular TS coincides with satisficing TS. But as , the samples maximized by regular TS always have high variance, causing the algorithm to explore in a futile attempt to resolve uncertainty about the white noise process .
8 Extension 2: Generalizing the Entropy Rate with Rate Distortion Theory
Our main result in Theorem 1 bounds regret in a large class of sequential learning problems in terms of the entropy rate of the optimal action process — linking the theory of exploration with the theory of optimal lossless compression. In this section, we replace the dependence of our bounds on the entropy rate with dependence on a rate distortion function, yielding our most general and strongest bounds. The section result is quite abstract, but reveals an intriguing connection between interactive decision-making and compression.
As an application, we bound the rate distortion function for environments in which the reward process has low total variation rate. This recovers regret bounds that are similar to those in the influential work of Besbes et al. [2015], and greatly strengthens what Theorem 1 guarantees under this assumption.
While this section is abstract, the proofs follow easily from attempting to instantiate Theorem 2 with the best possible choice of satisficing action sequence. Like Theorem 2, the results generalize Russo and Van Roy [2022] to nonstationary environments.
8.1 Rate distortion and lossy compression
To derive a rate distortion function, we momentarily ignore the sequential learning problem which is our focus. Consider a simpler communication problem. Imagine that some observer knows the latent states of the environment; their challenge is to encode this knowledge as succinctly as possible and transmit the information to a downstream decision-maker.
As a warmup, Figure 5(a) depicts a more typical problem arising in the theory of optimal communication, in which the goal is to succinctly encode latent states themselves. Assuming the law of the latent states is known, one wants to design a procedure that efficiently communicates information about the realization across a noisy channel. Having observed , the observer transmits some signal to a decoder, which recovers an estimate . The encoder is said to communicate at bit-rate if . While could be very complex, can be encoded in a binary string of length . Shannon proved that lossless communication is possible as while transmitting at any bit-rate exceeding the entropy rate444We use the natural logarithm when defining entropy in this paper. The equivalence between minimal the bit-rate of a binary encoder and the entropy rate requires that log base 2 is used instead. of . If one is willing to tolerate imperfect reconstruction of the latent states, then the bit-rate can be further reduced. Rate distortion theory quantifies the necessary bit-rate to achieve a given recovery loss, e.g. in Figure 5(a).
Figure 5(b) applies similar reasoning to a decision-making problem. Having observed , the observer transmits some signal to a decision-maker, who processes that information and implements the decision . It is possible for the decision-maker to losslessly recover the optimal action process if and only if the encoder communicates at bit-rate exceeding the entropy rate of the optimal action process . Rate distortion theory tells us that the decision-maker can achieve regret-rate lower than some distortion level when the bit-rate exceeds defined as
| (10) |
The function is called the rate-distortion function. It minimizes the information about the latent states required to implement a satisficing action sequence (see Definition 4), over all choices with regret rate less than . For any fixed horizon , one can analogously define
| (11) |
8.2 General regret bounds in terms of the rate distortion function
As discussed in Remark 6, many of the most widely studied online learning problems have the feature that there is a uniform upper bound on the information ratio. While there is a price (in terms of squared regret suffered) for acquiring information, the price-per-bit does not explode regardless of the information one seeks.
For such problems, we can bound the attainable regret-rate of a DM who learns through interaction by solving the kind of lossy compression problem described above. Namely, we bound regret in terms the information ratio and the problem’s rate distortion function. At this point, the proof is a trivial consequence of Theorem 2. But apriori, the possibility of such a result is quite unclear.
Theorem 3.
Suppose that . Then
Similarly, for any finite ,
Proof.
Theorem 2 shows that for any satisficing action sequence and policy ,
Taking the infimum over yields
| (12) |
Taking the infimum over of the right-hand side over satisficing action sequences with , and then minimizing over yields the result. ∎
As in Section 5, we provide some more easily interpreted special cases of our result. The next result is an analogue of Corollary 1 which upper bounds the attainable regret-rate in terms of the number of actions and the rate-distortion function . For brevity, we state the result only for the infinite horizon regret rate.
Corollary 4.
Under any problem in the scope of our formulation,
A dependence on the number of actions can be avoided when it is possible to acquire information about some actions while exploring other actions. Full information problems are an extreme case where information can be acquired without any active exploration. In that case the optimal policy is the rule that chooses in each period . It satisfies the following bound.
Corollary 5.
In full information problems, where for each , we have
8.3 Application to environments with low total variation
One of the leading ways of analyzing nonstationary online optimization problems assumes little about the environment except for a bound on the total variation across time [Besbes et al., 2014, 2015, Cheung et al., 2019]. In this section, we upper bound the rate distortion function in terms of the normalized expected total variation in the suboptimality of an arm:
| (13) |
It is also possible to study the total variation in mean-rewards , as in Besbes et al. [2015]. Figure 1 displays an environment in which total variation of the optimality gap is much smaller, since it ignores variation that is common across all arms.
The next proposition shows it is possible to attain a low regret rate whenever the the total variation of the environment is low. We establish this by bounding the rate distortion function, i.e., the number of bits about the latent environment states that must be communicated in order to implement a near-optimal action sequence. To ease the presentation, we use notation that hides logarithmic factors, but all constants can be found in Section A.9.
Proposition 4.
The rate distortion function is bounded as
If there is a uniform bound on the information ratio , then
From Corollary 4, one can derived bounds for -armed bandits similar to those in Besbes et al. [2015]. One strength of the general result is it can be specialized to a much broader class of important online decision-making problems with bounded information ratio, ranging from combinatorial bandits to contextual bandits.
Proof sketch.
Even if the total variation is small, it is technically possible for the entropy rate of the optimal action process to be very large. This occurs if the optimal action switches identity frequently and unpredictably, but the gap between actions’ performance vanishes.
Thankfully, the satisificing action sequence in Example 11 is near optimal and has low entropy. Recall the definition
This sequence of arms switches only when an arm’s suboptimality exceeds a distortion level . It is immediate that and our proof reveals
Together, these give a constructive bound on the rate distortion function. The remaining claim is Theorem 3. ∎
While we state this result in terms of fundamental limits of performance, it is worth noting that the proof itself implies Algorithm 2 attains regret bounds in terms of the variation budget in the problem types mentioned in Remark 6.
It is also worth mentioning that the entropy rate of the optimal action process could, in general, be large even in problems with low total-variation. This occurs when the optimal action keeps switching identity, but the arms it switches among tend to still be very nearly optimal. The generalization of Theorem 1 to Theorem 3 is essential to this result.
9 Extension 3: Bounds Under Adversarial Nonstationarity
The theoretical literature on nonstationary bandit learning mostly focuses on the limits of attainable performance when faced the true environment, or latent states , can be chosen adversarially. At first glance, our results seem to be very different. We use the language of stochastic processes, rather than game theory, to model the realization of the latent states. Thankfully, these two approaches are, in a sense, dual to one another.
In statistical decision theory, is common to minimax risk by studying Bayesian risk under a least favorable prior distribution. Using this insight, it is possible to deduce bounds on attainable regret in adversarial environments from our bounds on stochastic environments. We illustrate this first when the adversary is constrained to select latent states under which the optimal action switches infrequently [see e.g., Suk and Kpotufe, 2022]. Then, we study when the adversary must pick a sequence under which arm-means have low total-variation, as in Besbes et al. [2015]. We bound the rate-distortion function in terms of the total-variation, and recover adversarial regret bounds as a result.
Our approach builds on Bubeck and Eldan [2016], who leveraged ‘Bayesian’ information ratio analysis to study the fundamental limits of attainable regret of adversarial convex bandits; see also Lattimore and Szepesvári [2019], Lattimore [2020], Lattimore and Gyorgy [2021], Lattimore [2022]. These works study regret relative to the best fixed action in hindsight, wheres we study regret relative to the best changing action sequence — often called ‘‘dynamic regret.’’ In either case, a weakness of this analysis approach is that it is non-constructive. It reveals that certain levels of performance are possible even in adversarial environments, but does not yield concrete algorithms that attain this performance. It would be exciting to synthesize our analysis with recent breakthroughs of Xu and Zeevi [2023], who showed how to derive algorithms for adversarial environments out of information-ratio style analysis.
9.1 A minimax theorem
Define the expected regret rate incurred by a policy under parameter realization by
The Bayesian, or average, regret
produces a scalar performance measure by averaging. Many papers instead study the worst-case regret across a constrained family of possible parameter realizations. The next proposition states that the optimal worst-case regret is the same as the optimal Bayesian regret under a worst-case prior. We state stringent regularity conditions to apply the most basic version of the minimax theorem. Generalizations are possible, but require greater mathematical sophistication.
Proposition 5.
Let be a finite set and take to be the set of probability distributions over . Suppose the range of the outcome function in (1) is a finite set. Then,
proof sketch.
We apply Von-Neumann’s minimax theorem to study a two player game between an experimenter, who chooses and nature, who chooses . A deterministic strategy for nature is a choice of . Take and label the possible choice of nature by . A randomized strategy for nature is a probability mass function .
For the experimenter, we need to make a notational distinction between a possibly randomized strategy and a deterministic one, which we denote by . A deterministic strategy for the experimenter is a mapping from a history of past actions and observations to an action. Let denote the range of , i.e., the set of possible observations. There are at most deterministic policies. Label these . A randomized strategy for the experimenter is a probability mass function .
Define by . By Von-Neuman’s minimax theorem
∎
9.2 Deducing bounds on regret in adversarial environments: environments with few switches
As a corollary of this result, we bound minimax regret when the adversary is constrained to choose a sequence of latent states under which the optimal action changes infrequently. For concreteness, we state the result for linear bandit problems, though similar statements hold for any of the problems with bounded information ratio discusses in Section 6.1.
Corollary 6 (Corollary of Theorem 1 and Proposition 2).
Suppose , rewards follow the linear model , and the range of the reward function is contained in . Under the conditions in Proposition 5, for any ,
where is the switching rate defined in (6).
Proof.
Fix a prior distribution supported on . Theorem 1 yields the bound , where implicitly the information ratio and the entropy rate depend on . We give uniform upper bounds on these quantities.
First, since for any , Lemma 1 implies
Bounded random variables are sub-Gaussian. In particular, since the reward function is contained in , we know the variance proxy is bounded as . From Section 6.1, we know, . Combining these results gives
The claim then follows from Proposition 5. ∎
9.3 Deducing bounds on regret in adversarial environments: environments with low total variation
From the regret bound for stochastic environments in Proposition 4, we can deduce a bound on minimax regret in linear bandits when the adversary is constrained in the rate of total variation in mean rewards [Besbes et al., 2015]. The proof is omitted for brevity.
Corollary 7 (Corollary of Proposition 4).
Suppose , rewards follow the linear model , and rewards are bounded as . Under the conditions in Proposition 5, for any ,
where is the total variation measure used in (13)
10 Conclusion and Open Questions
We have provided a unifying framework to analyze interactive learning in changing environments. The results offer an intriguing measure of the difficulty of learning: the entropy rate of the optimal action process. A strength of the approach is that it applies to nonstationary variants of many of the most important learning problems. Instead of designing algorithms to make the proofs work, most results apply to Thompson sampling (TS), one of the most widely used bandit algorithms, and successfully recover the existing results that are proven individually for each setting with different proof techniques and algorithms.
While our analyses offer new theoretical insights, practical implementation of algorithms in real-world problem involves numerous considerations and challenges that we do not address. Section 3 described a simple setting in which Thompson sampling with proper posterior updating resembles simple exponential moving average estimators. The A/B testing scenario of Section 1.1 and the news recommendation problem in Example 5 reflect there is often natural problem structure that is different from what agnostic exponential moving average estimators capture. To leverage this, it is crucial to properly model the dynamics of the environment and leverage auxiliary data to construct an appropriate prior. Implementing the posterior sampling procedure adds another layer of complexity, given that the exact posterior distribution is often not available in a closed form in for models with complicated dynamics. Modern generative AI techniques (e.g. diffusion models) provide a promising path to enhance both model flexibility and sampling efficiency.
Lastly, we call for a deeper exploration of the connection between learning in dynamic environments and the theory of optimal compression. Section 8 provides intriguing connections to rate-distortion theory, but many questions remain open. One open direction is around information-theoretic lower bounds. For that, we conjecture one needs to construct problem classes in which the uniform upper bound on the information ratio is close to a lower bound. Another open direction is to try to characterize or bound the rate-distortion function in other scenarios. In the information-theory literature, numerous studies have provided theoretical characterizations of rate distortion functions [Cover and Thomas, 2006, Gray, 1971, Blahut, 1972, Derpich and Ostergaard, 2012, Stavrou et al., 2018, 2020]. It is worth investigating whether a synthesis of these existing rate distortion results with our framework can produce meaningful regret bounds, particularly for the nonstationary bandit environments driven by Markov processes such as Brownian motion [Slivkins and Upfal, 2008] or autoregressive processes [Chen et al., 2023]. Furthermore, computational methods for obtaining the rate distortion function and the optimal lossy compression scheme [Blahut, 1972, Jalali and Weissman, 2008, Theis et al., 2017] can be implemented to construct the rate-optimal satisficing action sequence.
References
- Abbasi-Yadkori et al. [2022] Yasin Abbasi-Yadkori, Andras Gyorgy, and Nevena Lazic. A new look at dynamic regret for non-stationary stochastic bandits. arXiv preprint arXiv:2201.06532, 2022.
- Audibert et al. [2014] Jean-Yves Audibert, Sébastien Bubeck, and Gábor Lugosi. Regret in online combinatorial optimization. Mathematics of Operations Research, 39(1):31–45, 2014.
- Auer [2002] Peter Auer. Using confidence bounds for exploitation-exploration trade-offs. Journal of Machine Learning Research, 3:397–422, 2002.
- Auer et al. [2002] Peter Auer, Nicolo Cesa-Bianchi, Yoav Freund, and Robert E. Schapire. The nonstochastic multiarmed bandit problem. SIAM journal on computing, 32(1):48–77, 2002.
- Auer et al. [2019] Peter Auer, Pratik Gajane, and Ronald Ortner. Adaptively tracking the best bandit arm with an unknown number of distribution changes. In Conference on Learning Theory, pages 138–158. PMLR, 2019.
- Azevedo et al. [2019] Eduardo M Azevedo, Alex Deng, José L Montiel Olea, and E Glen Weyl. Empirical Bayes estimation of treatment effects with many A/B tests: An overview. In AEA Papers and Proceedings, volume 109, pages 43–47, 2019.
- Barnett and Kedem [1991] John T Barnett and Benjamin Kedem. Zero-crossing rates of functions of gaussian processes. IEEE Transactions on Information Theory, 37(4):1188–1194, 1991.
- Besbes et al. [2014] Omar Besbes, Yanatan Gur, and Assaf Zeevi. Stochastic multi-armed-bandit problem with non-stationary rewards. Advances in neural information processing systems 27, 2014.
- Besbes et al. [2015] Omar Besbes, Yonatan Gur, and Assaf Zeevi. Non-stationary stochastic optimization. Operations Research, 63(5):1227–1244, 2015.
- Blahut [1972] Richard E. Blahut. Computation of channel capacity and rate-distortion functions. IEEE Transactions on Information Theory, 18(4):460–473, 1972.
- Bubeck and Cesa-Bianchi [2012] Sebastien Bubeck and Nicolo Cesa-Bianchi. Regret analysis of stochastic and nonstochastic multi-armed bandit problems. Foundations and Trends in Machine Learning, 5(1):1–122, 2012.
- Bubeck and Eldan [2016] Sébastien Bubeck and Ronen Eldan. Multi-scale exploration of convex functions and bandit convex optimization. In Conference on Learning Theory, pages 583–589. PMLR, 2016.
- Chakrabarti et al. [2008] Deepayan Chakrabarti, Ravi Kumar, Filip Radlinski, and Eli Upfal. Mortal multi-armed bandits. In Advances in neural information processing systems 21, 2008.
- Chapelle and Li [2011] Olivier Chapelle and Lihong Li. An empirical evaluation of thompson sampling. In Advances in neural information processing systems 24, 2011.
- Chen et al. [2023] Qinyi Chen, Negin Golrezaei, and Djallel Bouneffouf. Non-stationary bandits with auto-regressive temporal dependency. In Thirty-seventh Conference on Neural Information Processing Systems, 2023.
- Chen et al. [2019] Yifang Chen, Chung-Wei Lee, Haipeng Luo, and Chen-Yu Wei. A new algorithm for non-stationary contextual bandits: Efficient, optimal, and parameter-free. In Conference on Learning Theory, pages 696–726. PMLR, 2019.
- Cheung et al. [2019] Wang Chi Cheung, David Simchi-Levi, and Ruihao Zhu. Learning to optimize under non-stationarity. In International Conference on Artificial Intelligence and Statistics, pages 1079–1087. PMLR, 2019.
- Cover [1991] Thomas Cover. Universal portfolios. Mathematical Finance, 1(1):1–29, 1991.
- Cover and Thomas [2006] Thomas M. Cover and Joy A. Thomas. Elements of information theory. John Wiley & Sons, 2006.
- Derpich and Ostergaard [2012] Milan S. Derpich and Jan Ostergaard. Improved upper bounds to the causal quadratic rate-distortion function for gaussian stationary sources. IEEE Transactions on Information Theory, 58(5):3131–3152, 2012.
- Dong et al. [2019] Shi Dong, Tengyu Ma, and Benjamin Van Roy. On the performance of Thompson sampling on logistic bandits. In Conference on Learning Theory, pages 1158–1160, 2019.
- Foster et al. [2022] Dylan J Foster, Alexander Rakhlin, Ayush Sekhari, and Karthik Sridharan. On the complexity of adversarial decision making. In Advances in Neural Information Processing Systems, 2022.
- Garivier and Moulines [2011] Aurélien Garivier and Eric Moulines. On upper-confidence bound policies for switching bandit problems. In International Conference on Algorithmic Learning Theory, pages 174–188. Springer, 2011.
- Ghatak [2020] Gourab Ghatak. A change-detection-based Thompson sampling framework for non-stationary bandits. IEEE Transactions on Computers, 70(10):1670–1676, 2020.
- Gray [1971] Robert M. Gray. Rate distortion functions for finite-state finite-alphabet markov sources. IEEE Transactions on Information Theory, 17(2):127–134, 1971.
- Gupta et al. [2011] Neha Gupta, Ole-Christoffer Granmo, and Ashok Agrawala. Thompson sampling for dynamic multi-armed bandits. In 10th International Conference on Machine Learning and Applications, volume 1, pages 484–489. IEEE, 2011.
- Hao et al. [2021] Botao Hao, Tor Lattimore, and Wei Deng. Information directed sampling for sparse linear bandits. In Advances in Neural Information Processing Systems 34, pages 16738–16750, 2021.
- Hao et al. [2022] Botao Hao, Tor Lattimore, and Chao Qin. Contextual information-directed sampling. In International Conference on Machine Learning, pages 8446–8464. PMLR, 2022.
- Jalali and Weissman [2008] Shirin Jalali and Tsachy Weissman. Rate-distortion via markov chain monte carlo. In 2008 IEEE International Symposium on Information Theory, 2008.
- Jia et al. [2023] Su Jia, Qian Xie, Nathan Kallus, and Peter I Frazier. Smooth non-stationary bandits. arXiv preprint arXiv:2301.12366, 2023.
- Jung and Tewari [2019] Young Hun Jung and Ambuj Tewari. Regret bounds for Thompson sampling in episodic restless bandit problems. In Advances in Neural Information Processing Systems 32, 2019.
- Kocsis and Szepesvári [2006] Levente Kocsis and Csaba Szepesvári. Discounted UCB. In 2nd PASCAL Challenges Workshop, 2006.
- Lattimore [2020] Tor Lattimore. Improved regret for zeroth-order adversarial bandit convex optimisation. Mathematical Statistics and Learning, 2(3):311–334, 2020.
- Lattimore [2022] Tor Lattimore. Minimax regret for partial monitoring: Infinite outcomes and rustichini’s regret. In Conference on Learning Theory, pages 1547–1575. PMLR, 2022.
- Lattimore and Gyorgy [2021] Tor Lattimore and Andras Gyorgy. Mirror descent and the information ratio. In Conference on Learning Theory, pages 2965–2992. PMLR, 2021.
- Lattimore and Szepesvári [2019] Tor Lattimore and Csaba Szepesvári. An information-theoretic approach to minimax regret in partial monitoring. In Conference on Learning Theory, pages 2111–2139. PMLR, 2019.
- Lattimore and Szepesvári [2020] Tor Lattimore and Csaba Szepesvári. Bandit algorithms. Cambridge University Press, 2020.
- Liu et al. [2018] Fang Liu, Swapna Buccapatnam, and Ness Shroff. Information directed sampling for stochastic bandits with graph feedback. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 32, 2018.
- Liu et al. [2023] Yueyang Liu, Benjamin Van Roy, and Kuang Xu. Nonstationary bandit learning via predictive sampling. arXiv preprint arXiv:2205.01970v5, 2023.
- Mellor and Shapiro [2013] Joseph Mellor and Jonathan Shapiro. Thompson sampling in switching environments with Bayesian online change point detection. In Artificial Intelligence and Statistics, pages 442–450. PMLR, 2013.
- Min and Russo [2023] Seungki Min and Daniel Russo. An information-theoretic analysis of nonstationary bandit learning. In International Conference on Machine Learning, pages 24831–24849, 2023.
- Min et al. [2019] Seungki Min, Costis Maglaras, and Ciamac C. Moallemi. Thompson sampling with information relaxation penalties. In Advances in Neural Information Processing Systems 32 (NeurIPS 2019), 2019.
- Neu et al. [2022] Gergely Neu, Julia Olkhovskaya, Matteo Papini, and Ludovic Schwartz. Lifting the information ratio: An information-theoretic analysis of Thompson sampling for contextual bandits. arXiv preprint arXiv:2205.13924, 2022.
- Raj and Kalyani [2017] Vishnu Raj and Sheetal Kalyani. Taming non-stationary bandits: A Bayesian approach. arXiv preprint arXiv:1707.09727, 2017.
- Rice [1944] Stephen O Rice. Mathematical analysis of random noise. The Bell System Technical Journal, 23(3):282–332, 1944.
- Russo and Van Roy [2016] Daniel Russo and Benjamin Van Roy. An information-theoretic analysis of Thompson sampling. Journal of Machine Learning Research, 17(1):1221–1243, 2016.
- Russo and Van Roy [2018] Daniel Russo and Benjamin Van Roy. Learning to optimize via information-directed sampling. Operations Research, 66(1):230–252, 2018.
- Russo and Van Roy [2022] Daniel Russo and Benjamin Van Roy. Satisficing in time-sensitive bandit learning. Mathematics of Operations Research, 47(4):2815–2839, 2022.
- Simon [1979] Herbert A Simon. Rational decision making in business organizations. The American economic review, 69(4):493–513, 1979.
- Slivkins and Upfal [2008] Aleksandrs Slivkins and Eli Upfal. Adapting to a changing environment: the brownian restless bandits. In COLT, pages 343–354, 2008.
- Stavrou et al. [2018] Photios A. Stavrou, Jan Østergaard, and Charalambos D. Charalambous. Zero-delay rate distortion via filtering for vector-valued gaussian sources. IEEE Journal of Selected Topics in Signal Processing, 12(5):841–856, 2018.
- Stavrou et al. [2020] Photios A. Stavrou, Takashi Tanaka, and Sekhar Tatikonda. The time-invariant multidimensional gaussian sequential rate-distortion problem revisited. IEEE Transactions on Automatic Control, 65(5), 2020.
- Suk and Kpotufe [2022] Joe Suk and Samory Kpotufe. Tracking most significant arm switches in bandits. In Conference on Learning Theory, pages 2160–2182. PMLR, 2022.
- Theis et al. [2017] Lucas Theis, Wenzhe Shi, Andrew Cunningham, and Ferenc Huszar. Lossy image compression with compressive autoencoders. In International Conference on Learning Representations (ICLR), 2017.
- Thompson [1933] William R Thompson. On the likelihood that one unknown probability exceeds another in view of the evidence of two samples. Biometrika, 25(3-4):285–294, 1933.
- Trovo et al. [2020] Francesco Trovo, Stefano Paladino, Marcello Restelli, and Nicola Gatti. Sliding-window Thompson sampling for non-stationary settings. Journal of Artificial Intelligence Research, 68:311–364, 2020.
- Whittle [1988] Peter Whittle. Restless bandits: Activity allocation in a changing world. Journal of applied probability, 25:287–298, 1988.
- Wu et al. [2022] Yuhang Wu, Zeyu Zheng, Guangyu Zhang, Zuohua Zhang, and Chu Wang. Non-stationary a/b tests. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 2079–2089, 2022.
- Xu and Zeevi [2023] Yunbei Xu and Assaf Zeevi. Bayesian design principles for frequentist sequential learning. In International Conference on Machine Learning, pages 38768–38800. PMLR, 2023.
Appendix A Proofs
A.1 Proof of Lemma 1
We first bound the number of possible realizations that involve at most switches:555One can imagine a two-dimensional grid of size , represented with coordinates . A feasible switching time configuration corresponds to a path from the lower left corner to the upper right corner that consists of rightward moves and upward moves ; whenever a path makes an upward move, from to , we can mark that a switch occurs at time (if the path makes two or more upward moves in a row, the actual number of switches can be smaller than ). The number of such paths is given by .
Note that for any ,
where the second inequality uses Stirling. Therefore,
By observing , we obtain the desired result.
A.2 Proof of Proposition 1
Let , an indicator of a ‘‘switch’’. Then, and for any ,
With ,
Therefore, we deduce that
A.3 Proof of Proposition 2
We use to denote for shorthand. Let . By Lemma 1,
for any . Since the right hand side is a concave function of , by Jensen’s inequality
On the other hand, we have since . Therefore,
A.4 Proof of Proposition 3
We start with a proof sketch. Our proof is built upon a well-known result established for stationary bandits: there exists a stationary (Bayesian) bandit instance such that any algorithm’s (Bayesian) cumulative regret is lower bounded by where is the length of time horizon.
More specifically, we set and construct a nonstationary environment by concatenating independent -period stationary Gaussian bandit instances, i.e., the mean rewards changes periodically every time steps. In each block (of length ), the best arm has mean reward and the other arms has zero mean reward, where the best arm is drawn from arms uniformly and independently per block. When , no algorithm can identify this best arm within samples, and hence the cumulative regret should increase by per block. Consequently, the per-period regret should be . In our detailed proof, we additionally employ some randomization trick in determination of changepoints in order to ensure that the optimal action sequence is stationary and exactly. Now, we give the formal proof.
Proof.
We will consider Gaussian bandit instances throughout the proof. Without loss of generality, we assume and the noise variances are always one.
We begin by stating a well-known result for the stationary bandits, adopted from Lattimore and Szepesvári [2020, Exercise 15.2]: With , for each , let mean reward vector satisfy . It is shown that, when and , under any algorithm
| (14) |
where is the (frequentist’s) cumulative regret of in a -armed Gaussian bandit instance specified by the time horizon length and mean reward vector (i.e., the reward distribution of arm is ). Considering a uniform distribution over as a prior, we can construct a Bayesian -armed bandit instance of length such that under any algorithm.
Given , set , , and . Let be the random variable such that equals with probability and equals with probability , so that . We construct a stationary renewal process whose inter-renewal time distribution is given by the distribution of . That is, for all , and is drawn from the equilibrium distribution of its excess life time, i.e.,
Since the process is a stationary renewal process,
We now consider a nonstationary Gaussian bandit instance where the mean reward vector is (re-)drawn from uniformly and independently at times . As desired, the effective horizon of this bandit instance matches the target :
Since ,
where the last inequality follows from Equation 14. Since there are at least renewals until time , , and therefore,
Since and , we have . ∎
A.5 Proof of Remark 5
Let , , and . Then, , and we have
where step (a) uses Hölder’s inequality, and step (b) uses .
A.6 Proof of Lemma 2
Recall the definition, where
Our goal is to bound the numerator of in terms of the denominator.
Let denote the conditional expectation operator which conditions on observations prior to time AND the context at time . Similarly, define the probability operation accordingly. Define to be the function that evaluates mutual information when the base measure is .
The law of iterated expectations states that for any real valued random variable , . The definition of conditional mutual information states that for any random variables , ,
| (15) |
Under 2, there exists a function such that
| (16) |
This specifies expected rewards as a function of the parameter and chosen arm, regardless of the specific decision-rule used.
The definition of Thompson sampling is the probability matching property on decision-rules, , for each . It implies the following probability matching property on arms: with .
which holds for each .
With this setup, repeating the analysis in Proposition 3, or Corollary 1, of Russo and Van Roy [2016] implies, immediately, that
| (17) |
(Conditioned on context, one can repeat the same proof to relate regret to information gain about the optimal arm.) Now, we complete the proof:
where step (a) uses (16), step (b) is Jensen’s inequality, step (c) applies (17), step (d) is (15), steps (e) and (f) apply the data processing inequality, step (g) uses the chain-rule of mutual information, step (h) uses that mutual information is non-negative, and step (i) simply recalls that .
A.7 Proof of Corollary 3
If is a discretized dimensional vector, and the optimal policy process is stationary, then, by Proposition 1,
Combining this with Theorem 1 and the information ratio bound in Lemma 2 gives
A.8 Proof of Theorem 2
The proof is almost identical to that of Theorem 1. Let , , and . Then,
and
where the last step uses the fact that since according to Definition 4. Combining these results,
The bound on simply follows by taking limit on both sides.
A.9 Proof of Proposition 4
We state and prove a concrete version of Proposition 4.
Proposition 6 (Concrete version of Proposition 4).
If and , then
and
Proof.
For brevity we define so that .
Fix and consider a satisficing action sequence that gets synchronized to whenever -gap occurs:
It is obvious that since .
Step 1.
Let , and . We first show that by arguing that the total variation must increase at least by whenever the satisficing action switches. Observe that, in every sample path,
where step (a) uses the definition of , step (b) uses the fact that , and step (c) holds since and if then and . By taking expectation on both sides, we obtain .
Step 2.
We further bound by utilizing Proposition 2:
Let and . Since ,
where the last inequality uses for and for .
Step 3.
To simplify notation, let , and . We consider a satisficing action sequence constructed with . By Theorem 3, with ,
where step (a) uses for any , and step (b) uses and . Since , we have
Therefore,
The final claim is obtained by observing that for . ∎
Appendix B Comparison with Liu et al. [2023]
In this section, we provide a detailed comparison between our work and Liu et al. [2023].
Both papers adopt a Bayesian perspective that models the nonstationarity through a stochastic latent parameter process whose law is known to the decision maker. Both papers consider Thompson sampling (TS), which is the rule that employs probability matching with respect to the optimal action sequence . The primary concern in Liu et al. [2023] revolves around the potential shortcomings of TS in rapidly changing environments where learning is hopeless. Our paper considers this shortcoming of TS in Section 7. To tackle this challenge, both studies propose some variants of TS designed to ‘satisfice’, i.e., aim to learn and play a different target other than .
More specifically, Liu et al. [2023] proposes a brilliant algorithm called predictive sampling (PS) that improves over TS by ‘‘deprioritizing acquiring information that quickly loses usefulness’’. Using our notation, PS’s learning target is , the arm that would have been played by a Bayesian decision maker informed of all future rewards but not the latent parameters.666 In its implementation, it generates a fictitious future scenario, and makes an inference on the best arm after simulating the posterior updating procedure with respect to this future scenario. This makes the algorithm to take into account the total amount of information about the current state that the decision maker can potentially accumulate in the future, and hence prevents it from being overly optimistic about the learnability of the target. A similar idea can be found in Min et al. [2019] for the stationary bandit problems with a finite-time horizon. By ignoring the unresolvable uncertainty in the latent states — i.e. that which remains even conditioned on all future reward observations — PS avoids wasteful exploration. We remark that one of our suggested satisificing action sequence designs, Example 12, was motivated from Liu et al. [2023]. But our satisficing TS does not cannot fully generalize PS since we have restricted the learning target to be determined independently from the algorithm’s decisions (see Definition 4), while above depends on the history of observations under the algorithm.
Liu et al. [2023] uses an information-ratio analysis to bound an algorithm’s ‘foresight regret’ in terms of the total possible ‘predictive information.’ Their custom modifications to the information-ratio analysis in Russo and Van Roy [2016] enable an analysis of predictive sampling which seems not to be possible otherwise. By contrast, our analysis does not apply to predictive sampling, but produces a wealth of results that do not follow from Liu et al. [2023]. We elaborate on three main differences in the information-theoretic analysis.
First, Liu et al. [2023] bound a custom suboptimality measure which they call foresight regret, whereas we bound conventional (‘dynamic’) regret. Compared to the conventional regret which we denote by , foresight regret can serve as a tighter benchmark that better quantifies the range of achievable performance, since it is always non-negative while not exceeding the conventional regret. For the same reason, however, their results do not provide upper bounds on the conventional regret , a metric treated in a huge preceding literature. Since our work bounds the conventional regret metric, it enables us to recover results that are comparable to the existing literature; see for instance Section 9.
Second, whereas Liu et al. [2023] introduce a new information ratio, partly specialized to predictive sampling, we use the same information ratio as in Russo and Van Roy [2016] and many subsequent papers. Using the conventional definition of the information ratio enables us to systematically inherit all the upper bounds established for stationary settings (See Sec. 6.1). Liu et al. [2023] provide an upper bound on their modified information ratio for a particular nonstationary environment they termed ‘modulated -armed Bernoulli bandit,’ (this is identical to our Example 5) but more research is required to bound it in other settings.
Finally, due to using a different definitions of the information ratio, our bounds depend on different notions of the maximial cumulative information gain. The corresponding term in our Theorem 1 is simply the entropy rate of the optimal action process (and elsewhere, a mutual information rate). As one of the most fundamental metrics in information theory, numerous techniques can be employed to bound this entropy rate as in Section 5.2. The regret bound in Liu et al. [2023] involves a term which they call cumulative predictive information. They bound this quantity in the special case of modulated -armed bandits (equivalent to Example 5). In that example, their bound on cumulative predictive information is roughly times larger than our bound on the entropy rate of the optimal action process. As a result, Liu et al. [2023] obtain a final regret bound that scales with (see theorem 5 of Liu et al. [2023]) whereas our bound scales with (see Example 6).
Appendix C Numerical Experiment in Detail
We here illustrate the detailed procedure of the numerical experiment conducted in Section 1.1.
Generative model.
We say a stochastic process if follows a multivariate normal distribution satisfying
for any and any . Note that this process is stationary, and given horizon a sample path can be generated by randomly drawing a multivariate normal variable from the distribution specified by and .
As described in Section 1.1, we consider a nonstionary two-arm Gaussian bandit with unit noise variance:
where ’s are i.i.d. noises , is the common variation process , and is arm ’s idiosyncratic variation process .
Note that the optimal action process is completely determined by :
and the optimal action switches more frequently when is small (compare Figure 6 with Figure 1).

Consequently, the problem’s effective horizon , defined in (8), depends only on . To visualize this relationship, we estimate using the sample average of the number of switches occurred over periods (averaged across 100 sample paths), while varying from to . See Figure 7. As expected, is linear in (more specifically, by Rice formula).

Tested bandit algorithms.
Given the generative model described above, we evaluate four algorithms – Thompson sampling (TS), Sliding-Window TS (SW-TS; Trovo et al. [2020]), Sliding-Window Upper-Confidence-Bound (SW-UCB; Garivier and Moulines [2011]), and Uniform.
Thompson sampling (TS) is assumed to know the dynamics of latent state processes as well as the exact values of and (i.e., no model/prior misspecification). More specifically, in each period , draws a random sample of the latent state from its posterior distribution, and then selects the arm . Here, the posterior distribution of given the history is a multivariate normal distribution that can be computed as follows. Given the past action sequence , the (conditional) distribution of is given by
where the pairwise covariances are given by for , for and , and is the identity matrix. Additionally given the reward realizations,
Sliding-Window TS is a simple modification of stationary Thompson sampling such that behaves as if the environment is stationary but discards all observations revealed before periods ago. More specifically, in each period , with window length draws a random sample of mean rewards from where
and then selects the arm . Here, is a control parameter determining the degree of adaptivity.
Similarly, Sliding-Window UCB implements a simple modification of UCB such that computes UCB indices defined as
and then selects the arm . Here, is a control parameter determining the degree of adaptivity, and is a control parameter determining the degree of exploration.
Uniform is a naïve benchmark policy that always selects one of two arms uniformly at random. One can easily show that in our setup, regardless of the choice of and .
Simulation results.
Given a sample path specified by , we measure the (pathwise) Cesàro average regret of an action sequence as
Given an environment specified by , we estimate the per-period regret of an algorithm using sample paths:
where is the sample path (that is shared by all algorithms) and is the action sequence taken by along this sample path. In all experiments, we use and .
We first report convergence of instantaneous regret in Figure 8: we observe that quickly converges to a constant after some initial transient periods, numerically verifying the conjecture made in Remark 1. While not reported here, we also observe that the Cesàro average converges to the same limit value as in every sample path, suggesting the ergodicity of the entire system.
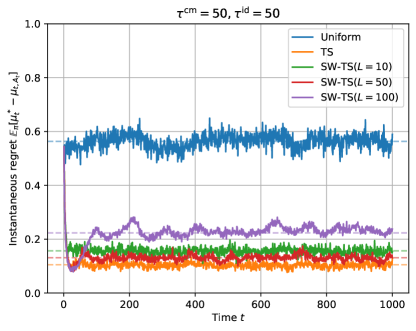
We next examine the effect of and on the performance of algorithms, and provide the detailed simulation results that complement Figure 2 of Section 1.1. While varying and , we measure the per-period regret of algorithms according to the procedure described above. We observe from Figure 9 that for every algorithm its performance is mainly determined by , independent of , numerically confirming our main claim – the difficulty of problem can be sufficiently characterized by the entropy rate of optimal action sequence, , which depends only on . We additionally visualize the upper bound on TS’s regret that our analysis predicts (Example 7). We also observe that TS performs best across all settings, perhaps because TS exploits the prior knowledge about nonstationarity of the environment, whereas SW-TS or SW-UCB performs well when the window length roughly matches .