An Evaluation of Standard Statistical Models and LLMs on Time Series Forecasting ††thanks: 979-8-3503-7565-7/24/$31.00 ©2024 IEEE
Abstract
This research examines the use of Large Language Models (LLMs) in predicting time series, with a specific focus on the LLMTIME model. Despite the established effectiveness of LLMs in tasks such as text generation, language translation, and sentiment analysis, this study highlights the key challenges that large language models encounter in the context of time series prediction. We assess the performance of LLMTIME across multiple datasets and introduce classical almost periodic functions as time series to gauge its effectiveness. The empirical results indicate that while large language models can perform well in zero-shot forecasting for certain datasets, their predictive accuracy diminishes notably when confronted with diverse time series data and traditional signals. The primary finding of this study is that the predictive capacity of LLMTIME, similar to other LLMs, significantly deteriorates when dealing with time series data that contain both periodic and trend components, as well as when the signal comprises complex frequency components.
Index Terms:
ARIMA, Large Language Model, Time Series Forecasting, Almost periodic functions.I Introduction
Time series analysis is a highly practical and fundamental issue that holds significant importance in various real-world scenarios [1][2], such as predicting retail sales as discussed by Böse et al. [3], filling in missing data in economic time series according to Friedman [4], identifying anomalies in industrial maintenance per Gao et al. [5], and categorizing time series data from different domains by Ismail Fawaz et al. [6]. Numerous statistical and machine learning techniques have been created over time for time series analysis. Drawing inspiration from the remarkable success seen in natural language processing and computer vision, transformers [22] have been integrated into various tasks involving time series data. Wen et al. [8] demonstrated promising outcomes, particularly in time series forecasting as shown by Lim et al. [9]; Nie et al. [10].
Time series datasets frequently consist of sequences originating from various sources, each potentially characterized by distinct time scales, durations, and sampling frequencies. This diversity poses difficulties in both model training and data processing. Moreover, missing values are common in time series data, necessitating specific approaches to address these gaps to maintain the precision and resilience of the model. Furthermore, prevalent applications of time series forecasting, such as weather prediction or financial analysis, entail making predictions based on observations with limited available information, rendering forecasting a challenging task. Ensuring both accuracy and reliability is complex due to the necessity of handling unknown and unpredictable variables when extrapolating future data, underscoring the importance of estimating uncertainty. Consequently, it is crucial for the model to possess strong generalization capabilities and an effective mechanism for managing uncertainty to adeptly adapt to forthcoming data variations and obstacles.
Currently, large-scale pre-training has emerged as a crucial technique for training extensive neural networks in the domains of vision and text, leading to a significant enhancement in performance [11][12]. Nonetheless, the utilization of pre-training in time series modeling faces certain challenges. Time series data, unlike visual and textual data, lacks well-defined unsupervised targets, posing difficulties in achieving effective pre-training. Moreover, the scarcity of large-scale and coherent pre-trained datasets for time series further hinders the adoption of pre-training in this domain. Consequently, conventional time-series approaches (e.g., ARIMA [13] and linear models [14]) often outperform deep learning methods in widely used benchmarks [15]. With the advent of pre-trained models, many researchers have started to forecast time series by leveraging LLMs, such as the LLMTIME technique [16], illustrating how LLMs naturally bridge the gap between the simplistic biases of traditional methods and the intricate representational learning and generation capabilities of contemporary deep learning. The pre-trained LLMs are applied to tackle the challenge of continuous time series forecasting [33][34]. However, while this method demonstrates comparable performance to traditional processing methods on some datasets, extensive experimentation in this study reveals that the LLMTIME approach lacks the ability for zero-shot time series forecasting and even underperforms compared to the traditional time series method ARIMA when tested on a diverse set of datasets.
II Background
II-A Language Model
A language model is created to determine the probability that a specific sequence of words forms a coherent sentence. For example, let’s consider two instances: Sequence A = never, too, late, to, learn, which clearly constructs a sentence (”never too late to learn.”), and a proficient language model should assign it a high likelihood. Conversely, the word sequence B = ever, zoo, later, too, eat is less probable to create a coherent sentence, and a well-trained language model would assign it a lower probability. The main objectives of language models involve evaluating the probability of a word sequence forming a grammatically correct sentence and forecasting the probability of the next word based on the preceding words. To accomplish these objectives, language models work under the fundamental assumption that the occurrence of a subsequent word is influenced only by the words that come before it. This assumption allows the sentence’s joint probability to be related to the conditional probability of each word in the sequence. Language models are trained on a set of sequences denoted as , where each sequence is depicted as , and each token ( in ) belongs to a vocabulary . Large language models typically function as autoregressive distributions, implying that the probability of each token is dependent solely on the preceding tokens in the sequence, and can be formulated as . In this context, the model parameters are acquired by maximizing the probability of the complete dataset, expressed as .
II-B Large Language Model
LLMs represent a type of artificial intelligence model created to comprehend and produce human language. They undergo training on extensive text datasets and have the capability to carry out various tasks, such as text creation [17, 18, 19], machine translation [20], dialogue systems [21], among others. These models are distinguished by their immense size, encompassing billions of parameters that facilitate their understanding of intricate patterns in language-related data. Typically, these models are constructed on deep learning frameworks, like the transformer architecture [22], which contributes to their remarkable performance across a spectrum of NLP assignments. The development of Bidirectional Encoder Representation Transformers (BERT) [11] and Generative Pre-trained Transformers (GPT) [12] has significantly propelled the NLP domain, ushering in the widespread adoption of pre-training and fine-tuning techniques [23][24]. Extensive datasets are leveraged through task-specific aims and are commonly denoted as unsupervised training (although technically supervised, it lacks human-annotated labels) [25][26]. Subsequently, it is standard procedure to fine-tune the pre-trained model to amplify the utility of the final model for downstream tasks. Noteworthy is the superior performance of these models over earlier deep learning approaches [27], prompting a focus on the meticulous design of pre-training and fine-tuning procedures. Research endeavors have also shifted towards the ultimate objectives of machine learning, pre-training language models as intermediary components of self-directed learning tasks.
II-C Time Series Forecasting Tasks
The various functions associated with time series can be categorized into multiple types, including prediction, anomaly identification, grouping, identification of change points, and segmentation. Prediction and anomaly detection are among the most commonly utilized applications. The task of time prediction involves examining the historical data patterns and trends in time series information to forecast future numerical changes using different time series prediction models. The forecasted future time point can be a singular value or a series of values over a specific time frame. This predictive task is frequently employed to analyze and predict time-dependent data such as stock prices, sales figures, temperature variations, and traffic volume. Given a sequence of values , where the value corresponding to time stamp is , the objective of prediction is to estimate based on .
Traditional time series modeling, such as the ARIMA model, is commonly employed for forecasting time series data. The ARIMA model consists of three key components: the autoregressive model (AR), the differencing process, and the moving average model (MA). Essentially, the ARIMA model leverages historical data to make future predictions. The value of a variable at a specific time is influenced by its past values and previous random occurrences. This implies that the ARIMA model assumes the variable fluctuates around a general time trend, where the trend is shaped by historical values and the fluctuations are influenced by random events within a timeframe. Moreover, the general trend itself may not remain constant. In essence, the ARIMA model aims to uncover hidden patterns within the time series data using autocorrelation and differencing techniques. These patterns are then utilized for future predictions. ARIMA models are adept at capturing both trends and temporary, sudden, or noisy data, making them effective for a wide range of time series forecasting tasks.
If we temporarily set aside the distinction, the ARIMA model can be perceived as a straightforward fusion of the AR model and the MA model. In a formal manner, the equation for the ARIMA model can be represented as:
| (1) | ||||
In the equation provided, represents the time series data under examination, while to denote the coefficients of the autoregressive (AR) model that depict the connection between the present value and the value at the previous time instances. Similarly, to stand for the coefficients of the moving average (MA) model, which elucidate the relationship between the current value and the deviation at the last time points. The term symbolizes the deviation at time , and is a constant term.
II-D LLMTIME
A technique for predicting time series using Large Language Models (like GPT-3) involves converting numerical data into text and generating potential future trends through text predictions. Essentially, this approach converts time series data into a sequence of numbers and interprets time series prediction as forecasting the next token in a textual context, leveraging advanced pre-trained models and probabilistic functions like likelihood evaluation and sampling. The tokens play a crucial role in shaping patterns within tokenized sequences and determining the operations that the language model can comprehend.
Common methods for tokenization, such as Byte Pair Encoding (BPE), often break down a single number into segments that do not correspond directly to the number [28]. For instance, the GPT-3 tagger decomposes the number 42235630 into [422,35,630]. New language models like LLaMA [29] typically treat numbers as a single entity by default. LLMTIME adopts a method where it separates each digit of a number using spaces, tokenizes each digit individually, and uses commas to distinguish between different time steps in a time series. Since decimal points do not add value for a specific precision level, LLMTIME eliminates them during encoding to reduce the length of the context. For example, with a precision of two digits, we preprocess a time series by converting it from
LLMTIME resizes the value to ensure that the rescaled time series value at the -percentile is 1. It refrains from scaling by the maximum value to allow the LLM to observe instances where the quantity of numbers varies, and it mimics this pattern in its results to generate a larger value than it observes. Furthermore, LLMTIME endeavors to incorporate an offset computed from the percentile of the input data and fine-tunes these two parameters in accordance with the verification log-likelihood.
II-E Our Work
Although LLMTIME may perform similarly to the traditional autoregressive model ARIMA on some datasets, its forecasting accuracy is lower than ARIMA when dealing with other datasets such as traditional and artificial signals that exhibit noisy almost periodic patterns. Moreover, as the data values increase over time, the forecasting performance of LLMTIME diminishes noticeably.
III Experiments
The zero-shot forecasting ability of LLMs is assessed by contrasting LLMTIME with well-known time series benchmarks across different baseline time series datasets. The model ’text-davinci-003’ has been discontinued, further details can be found in [30]. Consequently, we exclusively employed the ’gpt-3.5-turbo-instruct’ model for our assessments. In terms of deterministic metrics like MAE, LLMs exhibit inferior performance when compared to conventional forecasting techniques like ARIMA.

III-A Darts
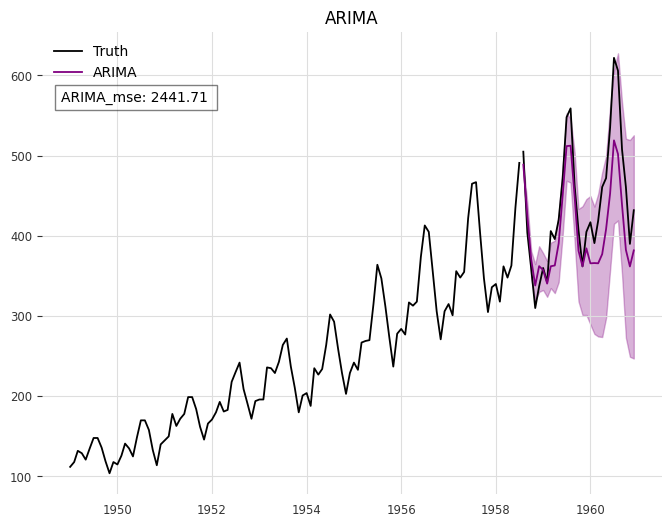
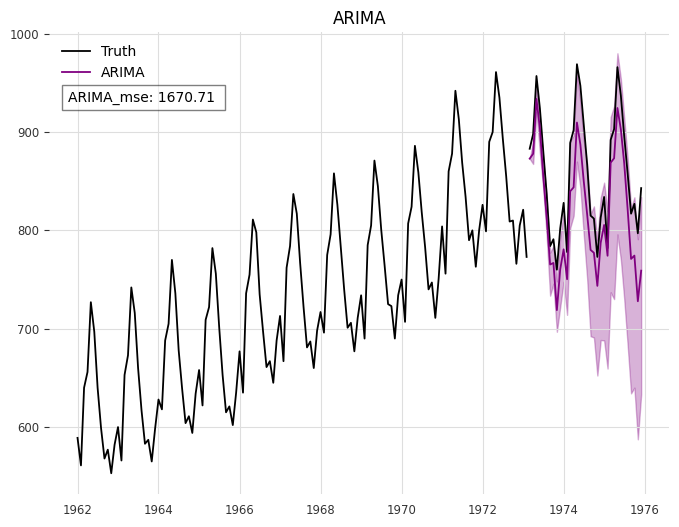
In Darts [31], the darts.datasets module offers a variety of pre-existing time series datasets suitable for showcasing, testing, and experimentation purposes. These datasets typically consist of traditional time series data, with Darts specializing in time series forecasting and boasting a comprehensive forecasting system. We utilized LLMTIME and ARIMA models to conduct forecasting on eight datasets (’AirPassengersDataset’, ’AusBeerDataset’, ’GasRateCO2Dataset’, ’MonthlyMilkDataset’, ’SunspotsDataset’, ’WineDataset’, ’WoolyDataset’, ’HeartRateDataset’) integrated into Darts. A portion of the experimental outcomes is depicted in Fig. 1. The AirPassengersDataset comprises classic airline data, documenting the total monthly count of international air passengers from 1949 to 1960, measured in thousands. All experimental findings are detailed in Appendix V-A.
The experimental results demonstrate that the predictive performance of the LLMTIME approach utilizing GPT-3.5 on the Darts dataset is notably inferior to that of the ARIMA method. It is evident that as the data values increase steadily over time, the forecasting accuracy of LLMTIME diminishes significantly, a pattern observed in other data experiments as well.


III-B Monash
The Monash dataset, referenced as [32], comprises 30 openly accessible datasets and baseline metrics for 12 predictive models. There are various versions of the datasets due to differences in frequency and handling of missing values, resulting in a total of 58 dataset variations. Additionally, the dataset collection includes a diverse range of real-world and competition time series datasets across different domains. Similar to the LLMTIME approach, we assessed GPT-3’s zero-shot performance on the top 10 datasets with the most effective baseline model. A noticeable decline in the LLMTIME forecasting performance is evident in the FredMd dataset, which is a monthly database focused on Macroeconomic Research, as described in Working Paper 2015-012B by Michael W. McCracken and Serena Ng. This database aims to provide a comprehensive monthly macroeconomic dataset to facilitate empirical analysis that leverages ”big data.” (The outcomes are depicted in Fig. 2 for FreMD and CovidDeaths, with additional details in Appendix V-B).




III-C Time series in economics
In this section, we examined time series data related to the economy, specifically focusing on the total exports of six countries over the past few decades. The data was sourced from CEIE [35], a comprehensive database offering economic information on over 213 countries and regions, encompassing macroeconomic indicators, industry-specific economics, and specialized data. Figure 3 illustrates the total export value of the United Kingdom from January 1989 to December 2023, denominated in millions of dollars and plotted against months.
III-D Data generated by noisy almost periodic functions
A range of artificial signals were forecasted, and data was produced by adding noise to the almost periodic function
| (2) |
where the term denotes Gaussian noise with a variance of . The almost periodic function has traditionally been significant in the development of harmonic analysis, leading to the formulation of Wiener’s general harmonic analysis theory (GHA) [2], and subsequently influencing the study of statistics of random processes.
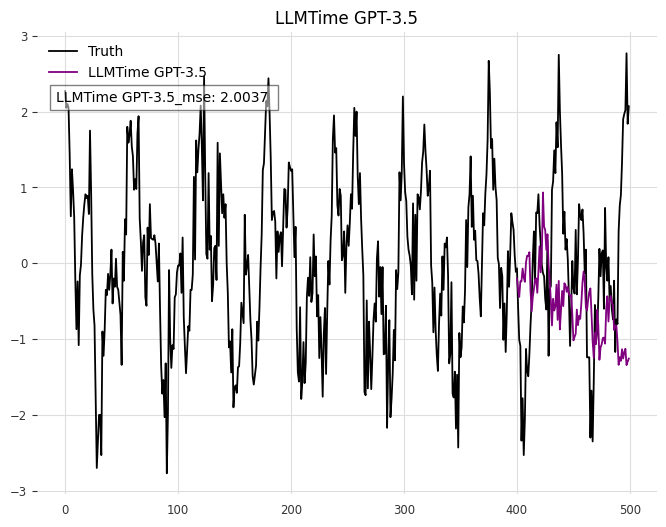
The function (2) corresponds to an almost periodic function. In the field of mathematics, an almost periodic function is characterized by having multiple frequency components that do not share any common factor. Almost periodicity is a feature of dynamical systems that seem to revisit their trajectories in phase space, albeit not precisely. Several experiments were carried out by varying the standard deviations (). The outcomes of certain experiments (=0.1) are depicted in Fig. 4.
Furthermore, we conducted experiments on the four standard deviations of Gaussian noise using LLLTIME and ARIMA methods, and computed their mean square errors to generate Fig. 5.

The comparison of the mean square errors indicates that the forecasts generated by the LLMTIME model generally exhibit higher errors compared to those produced by the ARMIR model. Additionally, the forecasting effectiveness graphs demonstrate that the ARMIR model outperforms the LLMTIME model significantly. For further details on the remaining experimental outcomes, please refer to Appendix V-D.
Furthermore, we examined the sine wave and the combination of sinusoidal and linear functions. The findings indicate that LLMTIME is effective only for time series that exhibit complete periodicity, while it struggles to forecast non-periodic signals. Refer to Fig. 6 for more information.


| DATASETS LLMTIME_MAE ARIMA_MSE | ||
|---|---|---|
| AirPassengers | 10380.56 | 2441.71 |
| AusBeer | 454.15 | 754.21 |
| GasRateCO2 | 32.71 | 8.25 |
| MonthlyMilk | 6023.25 | 1670.71 |
| Sunspots | 1485.97 | 1007.62 |
| Wine | 31683665.37 | 8826996.13 |
| Wooly | 628419.65 | 587217.59 |
| HeartRate | 87.95 | 53.22 |
| Cif2016 | 98009.38 | 3173.05 |
| CovidDeaths | 492338.81 | 10747.88 |
| ElectricityDemand | 983958.23 | 720077.08 |
| FredMd | 11344708.41 | 574689.74 |
| Hospital | 18.79 | 22.57 |
| Nn5Weekly | 1964.31 | 3920.95 |
| PedestrianCounts | 306676.68 | 1082241.58 |
| TourismMonthly | 3033529.57 | 346055.66 |
| TrafficWeekly | 1.28 | 1.31 |
| UsBirths | 1021661.84 | 411167.05 |
| =0∗ | 0.7762 | 0.1997 |
| =0.1 | 0.7811 | 0.0385 |
| =0.2 | 1.1289 | 0.1708 |
| =0.3 | 1.4096 | 1.1824 |
| =0.4 | 2.0037 | 0.5909 |
| ∗The synthetic signal is , | ||
| where denotes the standard deviation of Gaussian noise. | ||
Experimental outcomes obtained from the aforementioned datasets allow us to calculate the Mean Squared Error (MSE) between the predicted outcomes and the actual data. Our analysis indicates that, in most instances, the predictive accuracy of the LLMTIME model is inferior to that of the ARIMA model. Refer to Table I for details.
IV Conclusion
It has been observed that the LLMTIME model encounters difficulties in accurately predicting datasets that contain both trend and cyclical elements, as well as in cases where the signal consists of intricate frequency components. In comparison to the conventional ARIMA time series model, the LLMTIME model is less dependable. Despite the challenges and limitations associated with using LLMs as pre-trained models for time series prediction, there is potential for further investigation in this area. We are eager to explore improved methods for integrating LLMs research into time series forecasting.
Acknowledgment: We thank the referees of this paper for their very helpful comments. The code of this paper is available at: https://github.com/crSEU/llmtime_VS_arima
References
- [1] George E. P. Box , Gwilym M. Jenkins , Gregory C. Reinsel and Greta M. Ljung, Time Series Analysis: Forecasting and Control (5th Edition) John Wiley and Sons Inc., Hoboken, New Jersey, 2015
- [2] Wiener N. Extrapolation, interpolation, and smoothing of stationary time series: with engineering applications[M]. The MIT press, 1949.
- [3] Böse, J.-H., Flunkert, V., Gasthaus, J., Januschowski, T., Lange, D., Salinas, D., Schelter, S., Seeger, M., and Wang, Y. Probabilistic demand forecasting at scale. Proceedings of the VLDB Endowment, 10(12):1694–1705, 2017.
- [4] Friedman, M. The interpolation of time series by related series. J. Amer. Statist. Assoc, 1962.
- [5] Gao, J., Song, X., Wen, Q., Wang, P., Sun, L., and Xu, H. RobustTAD: Robust time series anomaly detection via decomposition and convolutional neural networks. KDD Workshop on Mining and Learning from Time Series (KDD-MileTS’20), 2020.
- [6] Ismail Fawaz, H., Forestier, G., Weber, J., Idoumghar, L., and Muller, P.-A. Deep learning for time series classification: a review. Data Mining and Knowledge Discovery, 33(4):917–963, 2019.
- [7] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser Lukasz, and Polosukhin, I. Attention is all you need. arXiv preprint arXiv:1706.03762, 2017.
- [8] Wen, Q., Zhou, T., Zhang, C., Chen, W., Ma, Z., Yan, J., and Sun, L. Transformers in time series: A survey. In International Joint Conference on Artificial Intelligence(IJCAI), 2023.
- [9] Lim, B., Arık, S. Ö., Loeff, N., and Pfister, T. Temporal fusion transformers for interpretable multi-horizon time series forecasting. International Journal of Forecasting, 2021.
- [10] Nie, Y., Nguyen, N. H., Sinthong, P., and Kalagnanam, J. A time series is worth 64 words: Long-term forecasting with transformers. ArXiv, abs/2211.14730, 2022.
- [11] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. In Jill Burstein, Christy Doran, and Thamar Solorio, editors, Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minneapolis, Minnesota, June 2019. Association for Computational Linguistics.
- [12] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9, 2019.
- [13] George EP Box and Gwilym M Jenkins. Some recent advances in forecasting and control. Journal of the Royal Statistical Society. Series C (Applied Statistics), 17(2):91–109, 1968.
- [14] Ailing Zeng, Muxi Chen, Lei Zhang, and Qiang Xu. Are transformers effective for time series forecasting? arXiv preprint arXiv:2205.13504, 2022.
- [15] Hansika Hewamalage, Klaus Ackermann, and Christoph Bergmeir. Forecast evaluation for data scientists: common pitfalls and best practices. Data Mining and Knowledge Discovery, 37(2): 788–832, 2023.
- [16] Nate Gruver, Marc Anton Finzi, Shikai Qiu, and Andrew Gordon Wilson. Large language models are zero-shot time series forecasters. Advances in Neural Information Processing Systems, 2023.
- [17] Leigang Qu, Shengqiong Wu, Hao Fei, Liqiang Nie, and Tat-Seng Chua. Layoutllm-t2i: Eliciting layout guidance from llm for text-to-image generation. In Proceedings of the 31st ACM International Conference on Multimedia, pages 643–654, 2023.
- [18] Zoie Zhao, Sophie Song, Bridget Duah, Jamie Macbeth, Scott Carter, Monica P Van, Nayeli Suseth Bravo, Matthew Klenk, Kate Sick, and Alexandre LS Filipowicz. More human than human: Llm-generated narratives outperform human-llm interleaved narratives. In Proceedings of the 15th Conference on Creativity and Cognition, pages 368–370, 2023.
- [19] Zhuoyan Li, Hangxiao Zhu, Zhuoran Lu, and Ming Yin. Synthetic data generation with large language models for text classification: Potential and limitations. In Houda Bouamor, Juan Pino, and Kalika Bali, editors, Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 10443–10461, Singapore, December 2023. Association for Computational Linguistics.
- [20] Shoetsu Sato, Jin Sakuma, Naoki Yoshinaga, Masashi Toyoda, and Masaru Kitsuregawa. Vocabulary adaptation for domain adaptation in neural machine translation. In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 4269–4279, 2020.
- [21] Zhi Jing, Yongye Su, Yikun Han, Bo Yuan, Haiyun Xu, Chunjiang Liu, Kehai Chen, and Min Zhang. When large language models meet vector databases: A survey, 2024.
- [22] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In I. Guyon, U. Von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017.
- [23] Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, and Graham Neubig. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. ACM Computing Surveys, 55(9):1–35, 2023.
- [24] Yu Gu, Robert Tinn, Hao Cheng, Michael Lucas, Naoto Usuyama, Xiaodong Liu, Tristan Naumann, Jianfeng Gao, and Hoifung Poon. Domain-specific language model pretraining for biomedical natural language processing. ACM Transactions on Computing for Healthcare (HEALTH), 3(1):1–23, 2021.
- [25] Chongyang Tao, Lili Mou, Dongyan Zhao, and Rui Yan. Ruber: An unsupervised method for automatic evaluation of open-domain dialog systems. In Proceedings of the AAAI conference on artificial intelligence, volume 32, 2018.
- [26] Jiashu Liao, Victor Sanchez, and Tanaya Guha. Self-supervised frontalization and rotation gan with random swap for pose-invariant face recognition. In 2022 IEEE International Conference on Image Processing (ICIP), pages 911–915. IEEE, 2022.
- [27] Kangrui Ruan, Cynthia He, Jiyang Wang, Xiaozhou Joey Zhou, Helian Feng, and Ali Kebarighotbi. S2e: Towards an end-to-end entity resolution solution from acoustic signal. In ICASSP 2024, 2024.
- [28] Tiedong Liu and Bryan Kian Hsiang Low. Goat: Fine-tuned llama outperforms gpt-4 on arithmetic tasks. arXiv preprint arXiv:2305.14201, 2023.
- [29] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
- [30] https://platform.openai.com/docs/deprecations
- [31] Julien Herzen, Francesco Lässig, Samuele Giuliano Piazzetta, Thomas Neuer, Léo Tafti, Guillaume Raille, Tomas Van Pottelbergh, Marek Pasieka, Andrzej Skrodzki, Nicolas Huguenin, et al. Darts: User-friendly modern machine learning for time series. The Journal of Machine Learning Research, 23(1):5442–5447, 2022.
- [32] Rakshitha Godahewa, Christoph Bergmeir, Geoffrey I Webb, Rob J Hyndman, and Pablo Montero-Manso. Monash time series forecasting archive. arXiv preprint arXiv:2105.06643, 2021.
- [33] Tian Zhou, Peisong Niu, Xue Wang, Liang Sun, and Rong Jin. One fits all: Power general time series analysis by pretrained lm. arXiv preprint arXiv:2302.11939, 2023.
- [34] Ming Jin, Shiyu Wang, Lintao Ma, Zhixuan Chu, James Y Zhang, Xiaoming Shi, Pin-Yu Chen, Yuxuan Liang, Yuan-Fang Li, Shirui Pan, et al. 2023. Time-LLM: Time Series Forecasting by Reprogramming Large Language Models. arXiv preprint arXiv:2310.01728 (2023).
- [35] https://www.ceicdata.com/en.
V Appendix
V-A Detailed experimental results of Darts dataset













V-B Detailed experimental results of Monash dataset


















V-C Detailed experimental results of time series in economics










V-D Detailed experimental results of Synthetic dataset