An empirical evaluation of Tree Kernels for Bug Detection in large-scale software systems
Abstract
Just in time (JIT) defect prediction prevents the defects from being introduced into the software system by predicting them at commit check-in time. This paper finds defects in newly committed source code by matching the newly committed changes with prior buggy commits of the software. It employs the structural representation of source code, and tree kernel based similarity detection to detect buggy changes. A new source code change is converted into an abstract syntax tree format and is then compared with the abstract syntax trees extracted from known buggy commits. To compute the similarity between two trees, we used subtree kernel (STK), subset tree kernel (SSTK), and partial tree kernel (PTK). The newly committed changes are then classified based on their similarity with existing changes. We conducted two case studies to evaluate our approach; one on BigCloneBench benchmark and the second on Technical Debt data set. We also compare our JIT approach with NiCad clone detector which serves as the baseline in this paper. The results based on F-score, Accuracy, MRR, Precision@k, and Top-K show that tree kernels are an an effective alternate to clone detectors for bug prevention in large software systems.
Index Terms:
Just-in-time, Defect Prediction, Tree Kernels, Similarity Detectionidentification
I Introduction
Defect identification and removal is a costly maintenance activity. The later a defect is identified in the software development life cycle, the higher its impact and cost. To identify bugs early on, Just-in-time (JIT) defect prediction [kamei2012large] is used and it can identify risky changes at commit check-in time. The recent works on JIT defect identification employed regression models [commitguru], clone detection [clever], and software naturalness [yan2020JIT]. In this paper, we detect buggy changes using historical project data and identifying new source code changes that looks similar to the past buggy changes. We represent the source code changes in the form of an abstract syntax tree, and compute similarity between trees by employing tree kernels. Tree kernels [treekernels2001] are a well known method for computing similarity over trees without explicitly computing the feature vectors of trees. Of the several well-known tree kernel methods, we rely upon Subtree kernel [STK], Subset tree kernel [STK], and Partial tree kernel [PTK]. We use similarity between past and recent changes as a measure to detect and prevent buggy changes from reaching the central repository. For evaluation, we use two data sets, the first one is the latest version of BigCloneBench [svajlenko2015] which is a clone detection benchmark containing 8.5 million clones from 43 distinct functionalities. The second is a Technical Debt data set [TDD] containing labeled commits from 33 java projects from Apache foundation. The key contributions of this paper include:
-
•
an approach to prevent buggy changes from being committed to the central repository
-
•
an evaluation of three tree kernels; Subset tree kernel, Partial tree kernel and Subtree kernel for the source code similarity detection
-
•
an empirical evaluation to measure and JIT defect identification performance of tree kernels
[Hareem says: Explain motivation for using Tree kernels]
II Background and Related Work
In this section, we review source code representation, code similarity detection, tree kernels, and bug detection studies.
Source Code Representation
Source code can be represented as raw text, or at an abstract level in the form of a tree or graph. In this paper, we use abstract syntax tree (AST) which is a a tree-based data-structure to represent the syntactic structure of source code [AST2005understanding]. An AST consists of several nodes where each node represents a program construct such as a variable, an if-else condition, or a logical operator. The nodes are connected from top to bottom in a way that each node has a parent node from which the child node descends. ASTs are at a higher level of abstraction than the actual program. They represent the essential structure of code, while omitting certain syntactic redundancies such as punctuation or parentheses. Due to these properties they provide an intermediate code representation [cui2010code] which is suitable for various tasks such as clone detection or code similarity detection [baxter1998clone].
Code Similarity Detection
Two fragments of code which are identical or highly similar are called clones. Primarily, the clones are divided into four types;
-
•
Type-1: Identical code fragments that only differ by whitespaces or comments.
-
•
Type-2: Syntactically identical code fragments that differ by identifier names, data types or literal values.
-
•
Type-3: Code fragments that have been modified due to the addition or deletion of statements.
-
•
Type-4: Code fragments that semantically perform the same computation with little syntactic similarity. These are also called semantic clones.
Clone detection techniques leverage the syntactic and structural details of the code along with a source code similarity measure to detect clones. A reliable source code similarity measure is fundamental to many other software engineering tasks as well, including but not limited to plagiarism detection, code recommendation [holmes2005], and bug detection [bugdetect1]. Early approaches used metrics as a measure of similarity but were not very effective. A number of tools have been developed since then for detecting similarity, each exploiting a different intermediate representation, and similarity measure.
Textual approaches compare string sequences e.g. comments and identifiers, returning code fragments as clones when there is a high similarity between the identifiers and comments. One famous string similarity method is the longest common subsequence (LCS) which is adopted by the NiCad clone detector [nicad2008]. To normalise textual differences between source code, the lexical approaches split the program into token, and abstract various aspects of source code, such as identifiers and variable names. Different similarity measures such as suffix trees, string alignment, Jaccard similarity can be applied to streams of tokens. A few examples of well-known tools include JPlag [jplag] and MOSS [MOSS] for plagiarism detection, whereas CCFinder [ccfinder2002], CP-Miner [cpminer2006], and SourcererCC [sourcerercc] for clone detection. Tree-based approaches focus on measuring structural similarity between two pieces of code while ignoring lexical differences through the use of Abstract Syntax Trees. Structural similarity involves comparing subtrees, or characteristic vectors approximating the structure of ASTs. Tools belonging to this category are CloneDR [clonedr1999], and Deckard [deckard2007] which use Euclidean distance and Locality sensitive hashing. Graph-based approaches [surveyCD] use Program Dependency graphs or Control Flow graphs to capture the structure and the semantics of a program. Both trees and graphs similarity suffers from a high computational complexity.
Kernel Methods
In this paper, we exploit the potential of tree kernels, which is a prominent method for comparing structured data, to determine similarity between code fragments. Tree kernels [moschitti2006making] measure similarity between a pair of trees by projecting data to a higher dimension feature space, where actual points need not be known but the dot product has to be known. The definition of a new Tree Kernel for a given problem requires specifying a set of features and a kernel function to compare trees in terms of their features.
Between two trees T1 and T2, a kernel K(T1, T2) can be represented as an inner product between two vectors:
| (1) |
Each tree T can be represented as a vector as follows, where hi(T) is the number of occurrences of the ith subtree in T.
| (2) |
The Subtree kernel [STKoptimal] is a convolution kernel that evaluates the number of common subtrees between two given trees, where a subtree is defined as a node and all its children, excluding terminals. In Subset tree kernel [STKoptimal], which evaluates the subset-trees, single nodes are not considered as trees. It further assumes that leaves need not be terminals i.e., the leaves can be associated with non-terminal symbols. As a result, there are more subset trees than subtrees for a given sentence. While computing subset trees, a node is either considered with either all of its children or none of them. This means that the descendancy can be incomplete in depth, but no partial productions are allowed. The Partial tree kernel [PTK] is a convolution kernel that considers partial trees shared between two trees i.e. nodes and their partial descendency. Figure 1 shows the subtrees, subset trees, and partial trees for the following source code line.




Code Search and Recommendation
Code recommenders and code search engines also use similarity detection, whereby an input query is analyzed in its context, and the relevant code snippets are recommended to the developer. Most code search approaches are based on information retrieval (IR). Lu et al. [lu2015] used query expansion with synonyms obtained from WordNet and then performed keyword matching of method signatures whereas others [Codehow, zhang2017] expanded text query with matched APIs. Gu et al. [deepCS] argued that text and code are heterogenous so there needs to be a high-level semantic mapping between the two. Their CODEnn model embeds code snippets and textual descriptions into a unified vector representation, and retrieves code snippets based on those vectors. Liu et al. [codematcher] proposed Code Matcher which was a simplified version of CODEnn based on IR. Lancer [lancer] used a Library-Sensitive Language Model (LSLM) and a BERT model to analyze the intent of incomplete code written by the developer, and recommends snippets relevant to the analyzed code in real-time. FaCOY [facoy] finds semantic clones of the query code by employing query alternation. It expands the query tokens by including more tokens that may also be relevant in implementing the functional behavior of the queried code. FaCoY works better than Lancer in that it can detect Type-4 clones as well whereas Lancer was not evaluated on them. Aroma [aroma] is another state-of-the-art tool for code recommendation via structural code search. It outperforms conventional approaches based on featurization and TFIDF 111https://radimrehurek.com/gensim/models/tfidfmodel.html.
Defect Detection and Prevention
Defect detection helps developers produce higher quality code by preventing defects early on. Defects in source code are commonly detected based on the historical information such as change histories or software quality metrics [commitguru, clever]. Many defect prediction approaches relate past defects with source code or process metrics to learn a model that can predict future defects [buggyorclean]. On the other hand, there are static analysis based bug-finders [findbugs, bugmemories] that use predefined rules to detect coding style bugs such as buffer overflows or infinite recursive loops. FindBugs [findbugs] is a static tool that flags common programming errors inferred from the syntactic and semantic properties of source code. Due to the repetitive nature of source code [hindle2012], statistical language models can be used to capture the style that a project is supposed to use. Ray et al. [ray2016] showed that language models can spot defective code as effectively as static analysis tools like FindBugs. Campbell et al. [campbell2014syntax, santos2018syntax] also used n-gram language models to detect syntax error locations in Java code. One method of detecting new bugs in the software is to compare new code to known cases of buggy code [clever]. Interestingly, project specific bugs mined from the version control histories are largely distinct from bugs found by static analysis tools, making code-to-code tools complementary to the other tools and techniques. Kim et al. [bugmemories] found that a static analysis tool (PMD) and their tool (BugMem) found largely exclusive bug sets. BugMem [bugmemories] uses the version control history of large software projects to mine patterns for locating project-specific bugs. DynaMine [dynamine] uses data mining techniques to mine application-specific errors from project revision histories. Clever [clever] uses clone detection to improve the detection accuracy of risky changes identified by code and process metrics. DeepBugs[deepbugs] detects incorrect code by reasoning about identifier names, and training a binary classifier on correct and incorrect examples. Yan et al. [yan2020JIT] use several change level features and software naturalness with the N-gram model to localize buggy changes. Their framework ranks buggy changes in order of their suspiciousness. Li et al. [Li2019] proposed an attention-based approach that combines local context and global context using AST paths and program dependency graphs respectively. The approach assigns more weight to the buggy paths and then classifies the code snippet by aggregating different path-based code representations into a single vector.
III Methodology
In this section, we explain how we collect the past buggy and clean changes, and later use them to identify defects introduced into a commit during check-in. Figure 2 provides an overview of our methodology. Our approach begins with extracting method-level source code changes during commit check-in time. The changes are then converted into an abstract syntax tree format and compared with the past changes from the project, using tree kernels. If a newly committed change matches with a buggy change in the existing corpora, it is flagged as risky. The developer can further analyze the risky change to identify the exact defect.

III-A Extracting buggy and fixing commits:
As a first step, we built a corpus of bug-inducing and bug-fixing changes. A change corresponds to one or more lines of code that were modified in a commit. In this paper, we work at method-level changes, which may be obtained from the project history using SZZ algorithm [szz2005, szz2006]. The algorithm works in two steps. In the first step, it identifies the bug-fixing commit using the information available in the version control system and the issue tracking system. The algorithm identifies a commit as bug-fixing if it refers to an issue labeled as fixed in the issue tracking system. In the second step, the algorithm identifies bug-inducing commits using diff and annotate/blame functionality. The diff identifies lines that have been changed between a bug-fixing commit and its previous commit i.e. changes that fix the bug. The annotate/blame functionality identifies the commit that modified those lines in the past. SZZ flags the changes as buggy if the commit was made before filing the issue in the issue tracker. Once SZZ algorithm completes its execution, we have all the buggy and fixing commits for the project.
III-B Processing commits to extract methods:
The source code changes introduced by a commit are spread across one or multiple files. Each changed file has a number of hunks, i.e. a continuous group of lines, that were added, modified, or deleted from a commit [bugmemories]. A hunk may be a partial or a complete block of code and a file can have multiple hunks. Manny tree-based structural analysis techniques such as Nicad clone detector (that we use as baseline) require complete java code. Parsing incomplete code is a challenging task itself because of missing context. Therefore, we refer to the actual GitHub commit to extract complete method bodies of methods that were modified by a buggy or a fixing commit. These are referred hereafter as modified methods. We then wrap the modified methods in a dummy class definition to facilitate parsing.
III-C Generating Abstract Syntax Trees by parsing the modified methods:
We transform the modified methods into an abstract syntax tree (AST). An AST is a structured representation of the source code but at a slightly higher abstraction level. Each modified method was converted into an AST using the GumTree library222https://github.com/GumTreeDiff/gumtree. Gumtree [falleri2014fine] is a source code parsing and differencing library that computes fine-grained edit scripts and presents them in a tree format. Here we only use Gumtree to generate ASTs corresponding to each change. Listing 1 shows an example code snippet, and its corresponding AST is shown in listing 2 in s-expression format. The ASTs of all modified methods were stored into an s-expression format for later use.
III-D Classifying incoming changes:
When a developer commits a change, we obtain the complete body of methods that are part of the change. The newly extracted method-level changes are then classified in two steps. First, we do a quick search of the existing source code corpus to retrieve any candidate matches. Second we do a pairwise comparison between the ASTs of candidate matches and the newly modified method. We then classify the new method by assigning it the label of its top match.
Selecting candidate matches
To make the classification of a new change scalable and efficient, we built an inverted index of the past method-level changes per project. For the purpose of indexing we used Elastic Search333https://www.elastic.co/elasticsearch/, which is a real-time full-text search engine built on top of Apache Lucene library444https://lucene.apache.org/. Each indexed document contains the raw source code of a method that was part of either a buggy or a fixing change. The document also contains metadata information such as commit hash, file name, method name, and timestamp. The Elastic Search index is based on a custom shingle analyzer 555The min_shingle_size=2 and a max_shingle_size=3., and an edge_ngram analyzer with standard tokenizer666The min_gram=1 and the max_gram=20.. For each method-level change extracted from an incoming commit, we query the Elastic Search index to find the top 100 most similar method-level changes from the indexed corpus. We do so with Elastic Search’s more_like_this query which utilizes the source code frequencies to find changes that match an incoming change. The documents retrieved by Elastic Search are called candidate matches. Thus by using Elastic Search we avoid comparing each incoming change with all historical changes, but instead reduce the number of comparisons to only 100 candidates.
Computing tree kernel similarity between ASTs
Finally, an incoming change is classified by detecting its similarity with the candidate matches retrieved from Elastic Search. However, at this stage, instead of comparing the source code we compare their abstract syntax trees. Prior work has used statistical language models [yan2020JIT] or clone detection techniques [nicad2008] [ccfinder2002] for similarity detection. However, we resort to tree kernel methods which measure similarity between a pair of trees. KeLP777https://github.com/SAG-KeLP/kelp-full is a java based framework that provides the implementation of kernel functions over strings, trees and graph [filice2017kelp]. We use the implementation of tree kernel methods provided by KeLP to compute similarity between an incoming change and the candidate changes. The output of KeLP is a sorted list of past changes that match an incoming change we are classifying. The majority label of Top-K changes is then assigned to the new change.
IV Evaluation and Results
The success of our approach depends on retrieving a code change from the past that looks similar to the newly committed source code change. Therefore, we evaluate our approach in two parts and on two different data sets. In the first part, we determine how well tree kernels perform in detecting similar code (clones), whereas in the second part, we determine the bug detection performance of our approach while preserving the time-order of commits. For the first part, we use BigCloneBench benchmark whereas, for the second part, we use Technical Debt data set. Lastly, we compare our results with the results of NiCad clone detector which is used as a comparison baseline in this work.
IV-A Benchmark data sets:
As mentioned earlier, we carry out two evaluations in this work. First, we evaluate the effectiveness of tree kernels in detecting similar code, and second the bug detection performance of tree kernels.
IV-A1 Benchmark for Code Similarity Detection
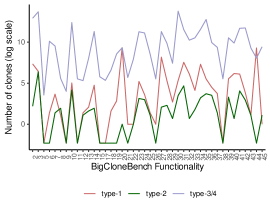
Our approach is similar to code similarity or code clone detection in several aspects, hence, we begin by evaluating the performance of tree kernels on a clone detection benchmark called BigCloneBench [svajlenko2015]. BigCloneBench contains 8.5 million human labeled clones which are mined from the IJadataset 2.0 repository [ija]. IJadataset repository contains 25,000 subject systems spanning 365 MLOC. The clones are divided into 43 distinct functionalities and further based on their types, see Figure 3. Clone pairs that have minor syntactic variations are classified into Type-1 and Type-2, whereas Type-3 and Type-4 are semantic clones. The later two are further divided into sub-categories based on their syntactic similarity values. Very Strongly Type-3 clones range from [0.9, 1.0], Strongly Type-3 from [0.7, 0.9], Moderately Type-3 from [0.5, 0.7], and Weakly Type-3 and 4 range from [0.0, 0.5]. The benchmark also contains false clone pairs, also divided by the functionalities. In total, we have 8,584,153 true positive clones and 279,032 false positive clones constituting 39,951 unique methods altogether. The breakdown per of functionality is shown in Figure 4. More details about the data set are available in [thesis2018]. The BigCloneBench was developed for the evaluation of clone detectors. Although, running clone detectors for the entire IJadataset may not be scalable according to the benchmark authors, but, subsets of the data may be used for evaluation [svajlenko2015].
Evaluation Measures: Our evaluation is based on several binary relevance measures, which are frequently used in prior works [wen2016locus, yan2020JIT, facoy]. Precision@k computes the percentage of relevant responses in the TopK results. It is measured as follows:
| (3) |
Mean Average Precision (MAP) is suitable for evaluating an approach that produces multiple responses against each query, ordered by their probability of correctness. For a set of queries, MAP considers the average precision (AP) scores of each query q as shown in Eq. 4.
| (4) |

IV-A2 Benchmark for Bug Detection
The second part of our evaluation is based on the Technical Debt data set [TDD] which contains labeled commits of 33 java projects from Apache Foundation888We only use 29 projects that have sufficient data for evaluation. The excluded projects are commons-beanutils, commons-configuration, commons-daemon, and commons-ognl.. The data set is available both as an SQLite database and as CSV files. For each project, the data set contains:
-
•
a list of all commits obtained from project’s Github repository.
-
•
a list of all issues obtained from the project’s Jira issue tracker.
-
•
a list of refactorings applied to each commit, such as moving or renaming of classes or packages.
-
•
a list of code quality related issues per commit, such as code smells.
-
•
a list of changes that induced and fixed bug i.e., bug-inducing and bug-fixing commits.
Instead of curating our own data for evaluation, we preferred using the Technical Debt data set because SZZ implementations are prone to implementation errors. However, the authors of this data set manually validated their algorithm hence using their data set allowed us to avoid some of the threats to validity of our study. Lastly, just like any other benchmark, using this benchmark facilitates an easy comparison of future research work to ours.
Evaluation Measures: For the Technical Debt data set experiment, we used TopK, F-score, Accuracy, and Mean Reciprocal Rank. TopK refers to the percentage of changes for which at least one correct result is ranked within the TopK positions in the sorted list of results. We set TopK value for a given change to 1, if the change is correctly classified by looking at the top K results only; otherwise, we set the TopK value to 0. Given a set of Q buggy changes in a project P, its TopK accuracy is calculated as follows:
| (5) |
F-score is the harmonic mean of precision and recall where precision is the ratio of TP values to the sum of TP and FP values. Recall is ratio of TP values to sum of TP and FN values. F-score is calculated as follows:
| (6) |
Accuracy is calculated as ratio of sum of TP and TN values to the total number of values.
| (7) |
Mean Reciprocal Rank (MRR) is a rank-based measure and is used in evaluations where the user is looking for the best match. For a set of queries, MRR averages the reciprocal rank of the first relevant result returned against a query q.
| (8) |
IV-B Research Question Results
RQ1: Can we use a tree kernel based approach to identify inter-project code clones from the BigCloneBench benchmark?
Motivation: The goal of this question is to find out if tree kernels can effectively detect code clones of a query clone in an inter-project setting i.e., code implemented across different real-world projects. The code may be syntactically dissimilar while implementing similar functionality. Our evaluation mimics the real-world settings where a buggy commit resembles a past commit implementing similar functionality.
Approach: To answer this research question, we ran three experiments on all BigCloneBench functionalities. The benchmark authors consider individual functionalities, or a random selection of clones from each of the functionalities to be reasonable subsets for achieving high confidence for a tool. In our evaluation, we included all the true and false positive clones of a functionality. These clones are referred subsequently as candidate clones.
For each candidate clone q, we compute its similarity with the remaining candidate clones using tree kernel methods implemented in KeLP library. These include Subtree kernel, Subset tree kernel, and Partial tree kernel. The matches found by KeLP are ranked based on their similarity with the query clone q. The ranked list may also contain false positives. To confirm if a detected match is a true or a false positive, the matches found between candidate clones are compared against the reference clones i.e., the ground truth.
To determine the number of candidate clones which are correctly matched by KeLP i.e., they are true clones of a given query, we measure Precision@k. Practically, Precision@k measures the usefulness of TopK results for developers. However, the metric fails to take into account positions of relevant clones among the TopK [evalmethod]. As a result, it treats all the errors equally. Also, for a query with fewer relevant results than k, even a perfect system will have a score less than .
Results: Table LABEL:table:precisionK shows Precision@k per BigCloneBench functionality where K is 10 which means we consider top-10 results where they exist. As shown in the table the tree kernel based similarity detection approach achieves a good precision for most of the functionalities. The median values are mostly high, but the mean is slightly lower. There is not a clear winner among the tree kernels though. In almost half of the cases PTK preforms better than the other two tree kernels, and for the remaining SSTK performs better. STK generally performs worse than the other two.
Table LABEL:table:ptk_map, shows the MAP per functionality using the three tree kernel methods. The MAP values range from 0.02 for Create Encryption Key Files functionality to 0.99 for Fibonacci. If a relevant clone never gets retrieved, we assume the precision corresponding to that to be zero. The MAP for Fibonacci is highest, because, for this functionality there are no false positives in the actual data. One may also observe that functionalities that have a smaller number of false positives, have a higher MAP compared to functionalities that have many false positive candidate clones e.g. Setup SGV Event Handler. The reason is that if a given clone has a high similarity with many false positive clones, the true positive clones might be pushed farther in the list, leading to a lower MAP. An ideal similarity detection algorithm should rank the false positives lower than the true positives. Since MAP gives more weight to errors that happen high up in the lists, therefore, such an algorithm will achiever high MAP values. Obtaining a higher MAP perfectly aligns with our goal as developers trying to find bugs in their commits would like to see the similar buggy commits (from the past) high up in the results. The MAP per functionality is generally high for many BigCloneBench functionalities leading to reasonable median (see Table II). The results show that tree-kernel based similarity detection was mostly able to retrieve relevant clones against candidate queries.
| Description | ID | SSTK | PTK | STK |
| Download from Web | 2 | 20 | 20 | 10 |
| Secure hash | 3 | 50 | 60 | 30 |
| Unzip | 5 | 60 | 60 | 60 |
| Connect to the FTP server | 6 | 80 | 90 | 80 |
| Sorts an array | 7 | 40 | 80 | 20 |
| Setup SGV | 8 | 50 | 35 | 50 |
| Setup SGV Event Handler | 9 | 40 | 30 | 30 |
| DB update and rollback | 10 | 80 | 80 | 80 |
| Initialize java project | 11 | 100 | 100 | 100 |
| Get Prime Factors | 12 | 80 | 80 | 60 |
| Shuffle array in place | 13 | 50 | 60 | 40 |
| Binary search | 14 | 20 | 50 | 0 |
| create font | 15 | 80 | 80 | 80 |
| Create Encryption Key Files | 17 | 10 | 0 | 10 |
| Play sound | 18 | 40 | 50 | 30 |
| Take Screenshot to File | 19 | 30 | 40 | 20 |
| Fibonacci | 20 | 100 | 100 | 100 |
| XMPP send message | 21 | 70 | 60 | 50 |
| Encrypt To File | 22 | 40 | 40 | 30 |
| Resize Array | 23 | 80 | 100 | 80 |
| Open URL in System Browser | 24 | 90 | 90 | 80 |
| Open file in Desktop | 25 | 40 | 40 | 40 |
| GCD | 26 | 0 | 30 | 0 |
| Call Method Using Reflection | 27 | 100 | 100 | 70 |
| Parse XML to DOM | 28 | 80 | 90 | 40 |
| Convert Date String Format | 29 | 20 | 30 | 20 |
| Zip Files | 30 | 0 | 90 | 80 |
| File Dialog | 31 | 100 | 100 | 100 |
| Send E-Mail | 32 | 100 | 100 | 100 |
| CRC32 File Checksum | 33 | 90 | 90 | 90 |
| Execute External Process | 34 | 100 | 100 | 100 |
| Instantiate Using Reflection | 35 | 100 | 100 | 100 |
| Connect to Database | 36 | 100 | 100 | 100 |
| Load File into Byte Array | 37 | 10 | 40 | 10 |
| Get MAC Address String | 38 | 100 | 90 | 100 |
| Delete Folder and Contents | 39 | 50 | 80 | 30 |
| Parse CSV File | 40 | 90 | 100 | 80 |
| Transpose Matrix | 41 | 90 | 100 | 80 |
| Extract Matches Using Reg | 42 | 100 | 100 | 100 |
| Copy Directory | 43 | 30 | 80 | 30 |
| Test Palindrome | 44 | 100 | 100 | 100 |
| Write PDF File | 45 | 80 | 80 | 70 |
| Min | Q1 | Median | Mean | Q3 | Max | |
|---|---|---|---|---|---|---|
| PTK | 0.03 | 0.29 | 0.58 | 0.55 | 0.84 | 0.99 |
| STK | 0.02 | 0.23 | 0.54 | 0.51 | 0.83 | 0.99 |
| SSTK | 0.02 | 0.25 | 0.57 | 0.53 | 0.84 | 0.99 |
RQ2: What is the effectiveness of tree kernels in finding intra-project clones?
Motivation: The goal of this question is to find out if tree kernels can effectively detect relevant clones for a query clone in an intra-project setting.
Approach:
Results:
RQ3: What is the effectiveness of tree kernels in finding clones of different types from the BigCloneBench benchmark?
Motivation:The goal of this question is to find out how well a tree kernel based approach performs in detecting different types of clones such as Type-1, Type-2, and Type-3 across projects.
Approach:
Results:
RQ4: Can we use a tree kernel based approach to detect buggy source code changes in a software system?
Motivation: The goal of this question is to find out if a tree kernel based approach can correctly classify an incoming source code change into either buggy or fixing.
Approach:
Results: