An Efficient Split Fine-tuning Framework for Edge and Cloud Collaborative Learning
Abstract
To enable the pre-trained models to be fine-tuned with local data on edge devices without sharing data with the cloud, we design an efficient split fine-tuning (SFT) framework for edge and cloud collaborative learning. We propose three novel techniques in this framework. First, we propose a matrix decomposition-based method to compress the intermediate output of a neural network to reduce the communication volume between the edge device and the cloud server. Second, we eliminate particular links in the model without affecting the convergence performance in fine-tuning. Third, we implement our system atop PyTorch to allow users to easily extend their existing training scripts to enjoy the efficient edge and cloud collaborative learning. Experiments results on 9 NLP datasets show that our framework can reduce the communication traffic by 96 times with little impact on the model accuracy.
Index Terms:
AI System, cloud-edge collaborative training, split learning, matrix decompositionI Introduction
In recent years, pre-trained language models (PLMs) (or called foundation models [1]) [2, 3, 4, 5] have achieved significant breakthroughs in many downstream natural language processing (NLP) applications like text generation [6], language translation [7], etc. Once PLMs are well trained with pre-training, they can be used in many scenarios with fine-tuning, where the model is fine-tuned on task-specific datasets with only several epochs going through the datasets. Compared to training from scratch, fine-tuning on PLMs normally takes much faster time (i.e., several epochs on task-specific datasets) and higher accuracy, so it becomes a common practice in many NLP tasks. For example, top-ranked models on GLUE [8] and SQuAD [9] benchmarks are fine-tuned from PLMs.
On the other hand, with the exponential growth of edge devices (e.g., mobile and Internet of Things, IoT), lots of generated data are privacy sensitive, which could not be shared for training models. The fine-tuning technique is very suitable for local training on edge devices as they can keep their data private to learn a model for local usage. However, due to the low computational resources and the memory limitation of edge devices, keeping all training processes on devices may not be possible or it takes very long training time. To alleviate this problem, split learning (SL) [10] has become a promising distributed learning paradigm to enable resource-constraint edge devices to train deep neural networks (DNNs) with the help of powerful cloud servers without exposing their data to the server [11]. Specifically, SL splits the DNN into two parts (one part is stored on the edge and the other part on the cloud) at a particular layer. Meanwhile, modern DNN training (or fine-tuning) mainly uses stochastic gradient descent (SGD) and its variants (e.g., Adam) with backpropagation [12] to update model parameters iteratively. At each iteration, the training algorithm loads a mini-batch of local data to do the feed-forward computations, and then do backpropagation computations to calculate the gradients to update the model parameters. As the model is split into two parts in SL, the client should send the activation outputs to the server in the feed-forward pass, and the server sends the gradient w.r.t. the activation to the client in the backpropagation pass for updating model parameters locally [10, 13].
However, due to the bandwidth between the edge devices and the server (e.g., 1-1000Mb/s) is typically much smaller than the bandwidth between two servers (e.g., 1-200Gb/s) in a data center, the data exchange of communicating activation outputs and their gradients between the client and the server is very slow. For example, fine-tuning a popular BERTBASE model (around 110 million parameters) [2] on an Nvidia V100 GPU takes 120ms per iteration, while the communication volume per iteration is 340MB which requires 2300ms for communication in SL under a 1000Mb/s connection. It means that the introduced communication cost hinders the advantage of SL in making use of powerful servers for training. While there exist some studies [14, 15, 16] trying to reduce training or fine-tuning costs on edge devices, they fail to address the communication problem in SL.
To this end, in this work, we propose an efficient split fine-tuning framework, SFT. Specifically, we first identify the low-rank property of weight parameters and their gradients in fine-tuning BERT models (§IV-B). Then, we propose a novel compression approach (§III) to reduce the communication cost of exchanging data between the edge device and the cloud server by decomposing a single feed-forward layer into three much smaller feed-forward layers based on matrix decomposition while requiring no extra computation overheads. We implement our framework111Our code is available in https://openi.pcl.ac.cn/Encore/splitfinetuning. atop PyTorch to allow users to easily utilize our SFT with pre-trained models with little impact on model accuracy (§III-E). To show the effectiveness of our SFT, we conduct extensive experiments on GLUE [8] and SQuAD [9] datasets with the pre-trained BERT [2] model. Experimental results show that SFT can reduce 96 communication volume than SL with little impact on the model accuracy.
The rest of the paper is organized as follows. We first introduce some background and related work in Section II. Then we present our proposed system in Section III. After that, we demonstrate the experimental studies in Section IV. We finally conclude the paper in Section V.


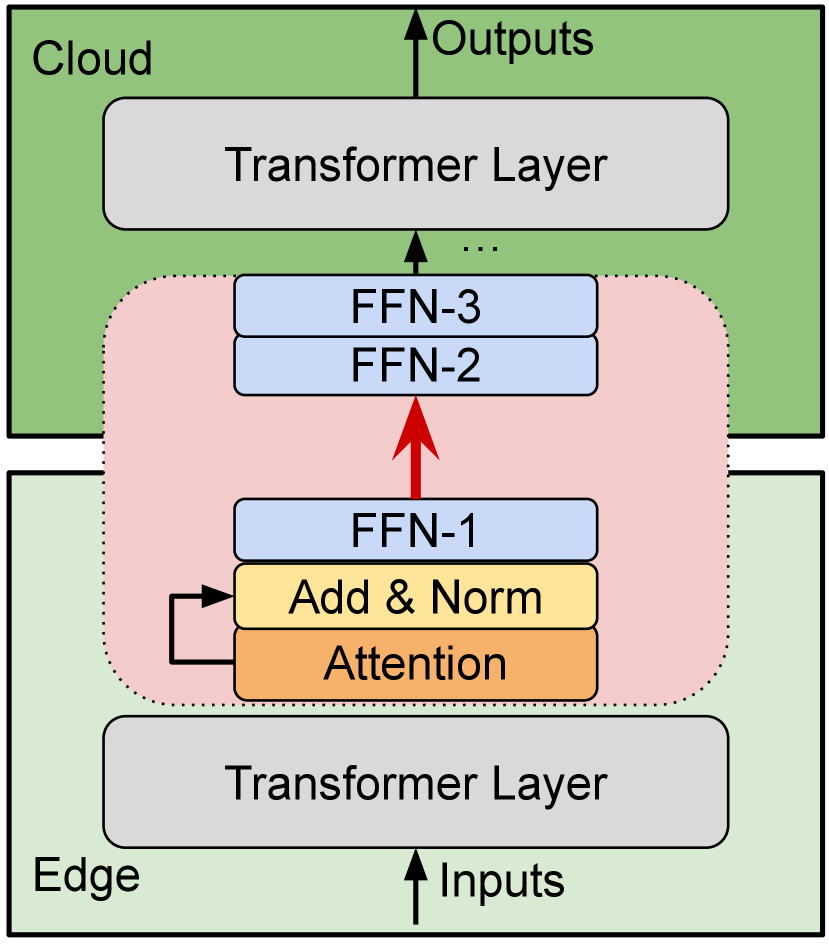
II Background and related Work
II-A The feed-forward layer (FFN) in Transformer
Existing popular PLMs in NLP are mainly built on the Transformer [17] architecture. As shown in Fig. 1(a), a PLM consists of a series of transformer layers (or blocks), each of which contains an attention layer and a feed-forward layer (FFN) with residual connections. Since each layer requires a residual connection (Add & Norm), the input size and the output size of the layer should be identical, which means the shapes of all input and output tensors within the transformer layer or between transformer layers are identical. This is an important feature causing extensive communication traffics in SL for fine-tuning such models. See below for more details.
II-B Split learning
Split learning (SL) [10, 18] has provided an emerging solution for edge and cloud collaborative learning without exposing the private data on the edge while enjoying the powerful computational resources from the cloud servers. As shown in Fig. 1(b), a DNN model is split into two parts at a particular layer. One part (say ) is stored on the edge and the other part (say ) is stored on the cloud. The number of layers on each part may be different, and more layers typically take higher computational costs. Thus, in SL, the data located on the edge is loaded for feed-forward computation on , and its activation output is transferred (upload) to the cloud. We assume the activation output is a tensor with shape , where is the mini-batch size and and are two dimensions of a matrix of the hidden feature representation. Note that and may be the explicit dimensions of the hidden feature as different types of layers (e.g., FFN, attention, etc.) have different structures, but they all can be organized as a matrix. For the transformer-based architecture, as we analyzed in the above subsection, the shape is the same no matter which layer is chosen as the split layer in SL. During the backpropagation pass, the gradient w.r.t. , which is denoted as and has the same shape with , is calculated on the cloud side and transferred to the edge for calculating the gradients w.r.t. the model parameters for updating the model.
It is seen that the computations of training have been partially () offloaded to the server to utilize the powerful server to reduce the training time for edge devices. However, the exchange data (i.e., and ) has a large number of elements, which requires significant communication time at each training iteration and becomes the performance bottleneck. In this work, we will present how to reduce the communicating volume of and without sacrificing model accuracy.
II-C Activation or model compression
Some works in reducing and are activation compression techniques [19, 20, 21, 16, 22]. These studies try to compress the activation outputs for each layer to save computational costs and memory for storing the temporary data in activation, which can be classified as the quantization method and the pruning method with tensor decomposition. Particularly, Evans et al., [20] propose the AC-GC lossy compression algorithm to dynamically compress the activation via quantization and an optimization objective of maximizing the compression ratio while minimizing the accuracy loss. While the quantization technique can maximally reduce the storage of (with 1-bit) by 32 times compared to the 32-bit counterpart, too aggressive compression easily introduces an accuracy loss in model training [20] in practice. The tensor decomposition approaches [14, 16, 21] are to decompose the parameter tensors to small-size approximate tensors, thus reducing the computational and memory costs. Particularly, MPO [14, 16] decomposes an original parameter matrix (say ) into () small matrices (i.e., ). Even though MPO achieves high compression ratios with slight accuracy loss, it requires particular tricks like dimension squeezing and takes extra computational costs for finding the layer with the least reconstruction error, which makes the optimization procedure difficult to be applied in edge and cloud collaborative learning.
III SFT: The Split Fine-tuning Framework
III-A Overview
The architecture overview of our proposed SFT is shown in Fig. 1(c). The key idea is two folds: 1) decomposing the FFN layer into three smaller FFN layers (FFN-1, FFN-2, and FFN-3) after loading the pre-trained parameters, and 2) the residual connection in the original FFN layer is eliminated, but the model convergence is guaranteed. The communication volume between the edge and cloud in the split layer of FFN-1 becomes much smaller than the original FFN output, thus significantly reducing the communication time in collaborative learning. The details are provided as follows.
III-B System architecture
As the high communication cost is caused by the large dimension of and at each iteration, we propose to decompose to multiple small tensors, so that the generated activation output is with small dimensions. Specifically, given a transformer-based model, we first load the pre-trained parameters to the original model architecture. In SFT, we only need to compress the layer that needs to be communicated between the edge and the cloud. According to our observation that decomposition does not affect the model accuracy (§IV-B), the weights in FFN layers in fine-tuning PLMs are mostly low-rank matrices. We choose the FFN layer as the split layer in SL. Formally, for an FFN layer at layer with weight matrix and the input (the output of its previous layer), its output can be represented as
| (1) |
Assuming that SL splits the DNN into two parts at layer , should be communicated from the edge to the cloud in the forward pass, and its gradient should be communicated from the cloud to the edge in the backward pass. Note that in fine-tuning tasks, has been initialized with pre-trained parameters. Our goal is to compress and such that the communication volume is small enough to eliminate the communication bottleneck in SL.
In SFT, we decompose the split layer (i.e., layer ) whose weights are denoted by to three matrices via singular value decomposition (SVD), i.e.,
| (2) |
where , is a diagonal matrix whose diagonal entries are singular values of , and . is the rank of . With the decomposed matrices, Eq. (1) becomes
| (3) |
Let and . Note that is equivalent to constructing an FFN layer whose weight is . Similarly, is equivalent to constructing two FFN layers whose weights are and respectively. Instead of splitting the DNN in the original architecture at layer , SFT splits its decomposed form at . It means that the activation output on the edge side is , which should be communicated to the server side in the forward pass. The corresponding gradient is in the backward pass. Thus, the communication volume is reduced from to , i.e., the communication time is shortened by times theoretically.
Note that SFT decomposes a single FFN layer to three smaller FFN layers after loading the pre-trained parameters but before fine-tuning. The three constructed FFN layers are initialized with the SVD decomposition and they are tuned every iteration in fine-tuning. Due to the low-rank feature of the weight matrix of the FFN layer during fine-tuning, we can choose an extremely small value of without affecting the convergence performance in fine-tuning. In our experiments, setting or can almost preserve the model accuracy (§IV). In summary, SFL can reduce the communication traffic by times over SL.
III-C Algorithm
Input:
The SFT algorithm is shown in Algorithm 1, where some comments illustrate that some code is only executed on the edge and some are only on the cloud. The inputs are the neural network architecture , the split layer , and the number of iterations for fine-tuning. In Algorithm 1, lines 1-3 are splitting the model, loading pre-trained models, and reconstructing the split layer based on SVD. The for loop in lines 4-14 is the training procedure in both the edge and cloud sides. For each iteration, the edge first loads the training data (line 5) and then performs the feed-forward on the first part of the network (line 6), whose results () are sent to the cloud (line 7). After the cloud receives the activation from the client, it performs feed-forward on the second part of the network (line 8), followed by the backward computation with loss (lines 9-10). The gradient () w.r.t. the activation is sent from the cloud to the edge (line 11), followed by back-propagation on the edge side (line 12). After that, the models are updated simultaneously on the edge and the cloud (lines 13-14). Our system enables users with existing training scripts to be able to explore the cloud to fine-tune their models without exposing the data to the server.
III-D Performance analysis
SFL has two main goals: 1) making the low-memory edge device possible for fine-tuning when the edge cannot store the whole model, and 2) enabling edge devices to explore the cloud servers to fine-tune a model more efficiently. The first goal is obviously our advantage using SFT when low-memory devices cannot store the whole model. For the second goal, however, we should consider whether SFT can reduce the overall fine-tuning time. Assume that the original iteration time on the edge to fine-tune a model is denoted by . When we use SFT, the fine-tuning time per iteration is
| (4) |
where is the computation time on the cloud and is the communication time between the edge and the cloud. Thus, SFT can be used if . As the cloud server typically has much higher computational power than the edge device, should become much smaller than . However, should not be too large so that one can enjoy the efficiency of SFT.
and depend on the split layer. A lower split layer indicates that more computational workloads are uploaded to the server for calculation, which would make smaller and larger, and vice visa. As the cloud is much more powerful than the edge, we expect the split layer to be as low as possible, but the lower layer may sacrifice the model accuracy (§IV-B). Therefore, we have a trade-off between accuracy and efficiency in SFT. depends on the rank we used for decomposition. A larger rank makes higher. Therefore, the two parameters (i.e., split layer and rank) should be well-tuned for achieving better end-to-end training performance in SFT. In this work, we do not develop a strategy for tuning them, but we present some observations from the experiments for helping tune them.
III-E Implementation
To enable users to easily use our SFT framework, we implement a distributed optimizer named “SFTOptimizer” atop the PyTorch optimizer to integrate the layer decomposition of the model and the communication between the edge and the cloud. To use SFT, users only need two more lines of code to extend their original training scripts. An example is shown in Listing 1, where lines 2-3 are inserted into the original training code to use SFT.
IV Evaluation
IV-A Experimental settings
Testbed. We use two Nvidia Tesla V100 GPUs in a single node as an emulation environment. One GPU is used to simulate an edge device, and one GPU is used to work as a cloud server.
DNN and datasets. We use the popular language model, BERTBASE [2], which has 12 layers and 110M parameters, as our experimental neural network. The dimension of the split layer is . Its corresponding pre-trained model is downloaded from the well-trained parameters at HuggingFace222https://huggingface.co/bert-base-uncased. We fine-tune the model on 9 datasets from GLUE [8] and SQuAD [9] for different downstream tasks including named entity recognition, textual entailment, co-reference resolution, etc.
IV-B Convergence performance




SFT w/ the residual connection. We first demonstrate the convergence results of the SVD decomposition for replacing the large FFN with three small FFNs for fine-tuning, which shows the low-rank feature of FFN weights. We use SST-2 and QNLI datasets to study the convergence property of our SFT as shown in Fig. 2. Due to the page limit, we do not show the results of other datasets as they have similar patterns. The results show that the weight matrix in the split layer can be decomposed as a rank-1 matrix without sacrificing the model accuracy. In some scenarios, rank-1 decomposition is better than the baseline. For example, decomposing at layers 2 or 3 (11 or 12)333The smaller layer index means the lower layer is much better than the baseline in SST-2 (QNLI). How to determine which layer should be split to achieve the highest efficiency in a given environment is also of importance to explore, and we will leave it as our future work.
SFT w/o the residual connection. Since we also need to eliminate the residual connection in the original transformer layer in SFT, we conduct experiments to verify the convergence performance by eliminating the residual connection and decomposing the FFN with SVD. The results are shown in Fig. 3, which shows that the model accuracy tends to decrease when the split layer is chosen at lower layers. However, it can still preserve the model accuracy when splitting at higher layers. Thus, it is possible to use SFT to enjoy the powerful cloud server to accelerate the fine-tuning tasks for edge devices without sharing the data.
| Algorithm | SST-2 | QNLI | MNLI | QQP | CoLA | RTE | STS-B | MRPC | SQuAD |
|---|---|---|---|---|---|---|---|---|---|
| (67k) | (105k) | (364k) | (91.2k) | (8.5k) | (2.5k) | (7k) | (3.7k) | (88k) | |
| Baseline | 92.54 | 91.24 | 84.56 | 90.73 | 55.3 | 66.06 | 88.38 | 85.33 | 88.25 |
| SFT(l=11,R=8) | 92.43 | 90.98 | 83.98 | 90.93 | 57.13 | 64.25 | 86.46 | 84.81 | 88.33 |
| SFT(l=11,R=16) | 92.31 | 91.22 | 84.33 | 90.75 | 57.35 | 62.09 | 86.78 | 83.47 | 88.75 |
| SFT(l=11,R=32) | 92.77 | 91.04 | 84.27 | 90.99 | 57.87 | 62.81 | 87.46 | 84.23 | 88.56 |
Model accuracy in all datasets. Based on the convergence results in Fig. 3, we use a rank of 8, 16, and 32 for decomposition at layer 11 in SFT (denoted as SFT(l=11,R=8), SFT(l=11,R=12), and SFT(l=11,R=32) respectively). Therefore, the communication cost can be reduced by 768/8=96 times in the chosen BERT model if R=8. The model accuracy of validation sets in all chosen 9 datasets is shown in Table I. The results show that different ranks have little differences and a higher rank does not guarantee a higher accuracy. For example, SFT(l=11,R=8) achieves higher accuracy than SFT(l=11,R=16) on QQP and RTE datasets. In most cases, SFT(l=11,R=8) preserves the model accuracy compared to the baseline. In the particular case of RTE, SFT(l=11,R=8) achieves much lower accuracy than the baseline due to the extremely small size (only around 2,500 training samples) of the dataset. The results show that SFT (using a rank of 8) makes the fine-tuning tasks possible to train in a collaborative learning environment so that the edge does not need to expose the data to the server.
IV-C Estimated iteration performance
To show the end-to-end performance of our SFT compared with SL on the BERTBASE model, we benchmark the time performance on a V100 GPU using SST-2 (other datasets have similar patterns). Let denote the wall-clock time per iteration training the BERTBASE model on a particular using layers of the model. The full 12 layer BERTBASE on SST-2 takes
| (5) |
with a mini-batch size of 32 and a sequence length of 66. Since the 12 layers of BERTBASE have an identical architecture, each layer has the same computational workloads and thus has the same computation time. We can estimate the iteration time of one layer as
| (6) |
Assume that the edge side is a relatively new Nvidia edge device, XAVIER-NX, with 21 TOPs AI performance, and the cloud side is a V100 GPU with 130 TOPs AI performance, which means the cloud server is around 6 times faster than the edge device. Therefore, on a XAVIER-NX GPU, we have
| (7) |
and
| (8) |
The communication traffic with SL is MB, while it is MB with our SFT. Assume that the typical bandwidth between the edge to the cloud is 1000Mbps Ethernet444We also assume the bandwidth can be fully utilized, while it cannot in practice. The main purpose of the emulation is to demonstrate the potential benefits of our SFT in real-world environments, and the performance also varies with different configurations., the communication time of SL and SFT is 2,300ms and 24ms respectively. Thus, the iteration times with local training (on an edge device), with SL (on an edge and a cloud), and with SFT (on an edge and a cloud) are
| (9) |
| (10) |
and
| (11) | ||||
| (12) |
respectively. The results show that the introduced communication time in SL is very high, making it even slower than the local training. Our SFT, on the other hand, can achieve faster training time (14% reduction in the end-to-end training time) by reducing the communication volume between the cloud server and the edge device.
IV-D Discussion
Our experimental results conclude two folds. First, when the edge devices cannot conduct fine-tuning tasks due to their memory constraint, it is possible to enjoy our SFT to fine-tune the model. Second, even if the edge clients can fine-tune the model locally, our SFT can help accelerate the training by exploring the more powerful cloud servers without requiring the data from the edge devices. However, there are still two important problems that should be further studied to make SFT more practical. First, could it be possible to split the layer in the lower layer of the model such that more computational workloads can be offloaded to the server? In our existing results, splitting the lower layer may introduce some accuracy loss. Thus, it is a trade-off between the model accuracy and training efficiency. Enjoying higher training speed may sacrifice some accuracy. Second, as keeping the residual connection can preserve the model accuracy (as shown in Fig. 2) even using rank-1 decomposition, could it be possible to keep the residual connection without introducing significant communication costs between the edge and the cloud? As SFT decomposes the FFN to smaller FFNs which are distributed to the client and server, the residual connection should require the activation data to be transferred between the edge and the cloud, which makes the communication extremely heavy. However, eliminating the residual connection only allows higher layers to be split layers, which means only a small proportion of layers can be uploaded to the server if we want to preserve the model’s accuracy.
V Conclusion
In this work, we proposed an efficient split learning framework for fine-tuning tasks, which is called split fine-tuning (SFT). Specifically, we first observed that model weights are normally low-rank in fine-tuning tasks based on our extensive experiments. Then based on the low-rank feature of fine-tuning, we introduced a novel layer decomposition method using SVD such that we can significantly reduce the communication volume between the edge and the cloud in collaborative learning. We implemented our prototype system atop PyTorch and enable end-users to easily conduct SFT with very little change to their existing training scripts. Extensive experimental results showed that our SFT reduces the communication traffic by 96 times compared to SL with little impact on the model accuracy.
References
- [1] R. Bommasani, D. A. Hudson, E. Adeli, R. Altman, S. Arora, S. von Arx, M. S. Bernstein, J. Bohg, A. Bosselut, E. Brunskill et al., “On the opportunities and risks of foundation models,” arXiv preprint arXiv:2108.07258, 2021.
- [2] J. D. M.-W. C. Kenton and L. K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” in Proceedings of NAACL-HLT, 2019, pp. 4171–4186.
- [3] L. Floridi and M. Chiriatti, “GPT-3: Its nature, scope, limits, and consequences,” Minds and Machines, vol. 30, no. 4, pp. 681–694, 2020.
- [4] D. Narayanan, M. Shoeybi, J. Casper, P. LeGresley, M. Patwary, V. Korthikanti, D. Vainbrand, P. Kashinkunti, J. Bernauer, B. Catanzaro et al., “Efficient large-scale language model training on GPU clusters using megatron-lm,” in Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, 2021, pp. 1–15.
- [5] A. Chowdhery, S. Narang, J. Devlin, M. Bosma, G. Mishra, A. Roberts, P. Barham, H. W. Chung, C. Sutton, S. Gehrmann et al., “Palm: Scaling language modeling with pathways,” in Proceedings of Machine Learning and Systems 2022, MLSys 2022, 2022.
- [6] Y.-C. Chen, Z. Gan, Y. Cheng, J. Liu, and J. Liu, “Distilling knowledge learned in BERT for text generation,” in Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, 2020, pp. 7893–7905.
- [7] D. Adelani, J. Alabi, A. Fan et al., “A few thousand translations go a long way! leveraging pre-trained models for African news translation,” in Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Jul. 2022, pp. 3053–3070.
- [8] A. Wang, A. Singh, J. Michael, F. Hill, O. Levy, and S. R. Bowman, “GLUE: A multi-task benchmark and analysis platform for natural language understanding,” in International Conference on Learning Representations, 2018.
- [9] P. Rajpurkar, J. Zhang, K. Lopyrev, and P. Liang, “SQuAD: 100, 000+ questions for machine comprehension of text,” in EMNLP, 2016.
- [10] P. Vepakomma, O. Gupta, T. Swedish, and R. Raskar, “Split learning for health: Distributed deep learning without sharing raw patient data,” arXiv preprint arXiv:1812.00564, 2018.
- [11] S. Oh, J. Park, P. Vepakomma, S. Baek, R. Raskar, M. Bennis, and S.-L. Kim, “LocFedMix-SL: Localize, federate, and mix for improved scalability, convergence, and latency in split learning,” in Proceedings of the ACM Web Conference 2022, 2022, pp. 3347–3357.
- [12] R. Hecht-Nielsen, “Theory of the backpropagation neural network,” in Neural networks for perception. Elsevier, 1992, pp. 65–93.
- [13] K. Palanisamy, V. Khimani, M. H. Moti, and D. Chatzopoulos, “Spliteasy: A practical approach for training ml models on mobile devices,” in Proceedings of the 22nd International Workshop on Mobile Computing Systems and Applications, 2021, pp. 37–43.
- [14] Z.-F. Gao, S. Cheng, R.-Q. He, Z.-Y. Xie, H.-H. Zhao, Z.-Y. Lu, and T. Xiang, “Compressing deep neural networks by matrix product operators,” Physical Review Research, vol. 2, no. 2, p. 023300, 2020.
- [15] H. Cai, C. Gan, L. Zhu, and S. Han, “Tinytl: Reduce memory, not parameters for efficient on-device learning,” Advances in Neural Information Processing Systems, vol. 33, pp. 11 285–11 297, 2020.
- [16] P. Liu, Z.-F. Gao, W. X. Zhao, Z.-Y. Xie, Z.-Y. Lu, and J.-R. Wen, “Enabling lightweight fine-tuning for pre-trained language model compression based on matrix product operators,” in Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), 2021, pp. 5388–5398.
- [17] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” in Advances in Neural Information Processing Systems, I. Guyon, U. von Luxburg, S. Bengio, H. M. Wallach, R. Fergus, S. V. N. Vishwanathan, and R. Garnett, Eds., 2017, pp. 5998–6008.
- [18] M. G. Poirot, P. Vepakomma, K. Chang, J. Kalpathy-Cramer, R. Gupta, and R. Raskar, “Split learning for collaborative deep learning in healthcare,” arXiv preprint arXiv:1912.12115, 2019.
- [19] G. Georgiadis, “Accelerating convolutional neural networks via activation map compression,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 7085–7095.
- [20] R. D. Evans and T. Aamodt, “AC-GC: Lossy activation compression with guaranteed convergence,” Advances in Neural Information Processing Systems, vol. 34, pp. 27 434–27 448, 2021.
- [21] M. Xia, Z. Zhong, and D. Chen, “Structured pruning learns compact and accurate models,” in Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2022, pp. 1513–1528.
- [22] Y. Xiang, Z. Wu, W. Gong, S. Ding, X. Mo, Y. Liu, S. Wang, P. Liu, Y. Hou, L. Li et al., “Nebula-I: A general framework for collaboratively training deep learning models on low-bandwidth cloud clusters,” arXiv preprint arXiv:2205.09470, 2022.