AN EffICEINT ALGRITHM FOR HIGH-DIMENSIONAL INTEGRATIONHUICONG ZHONG AND XIAOBING FENG
An efficient implementation algorithm for quasi-Monte Carlo approximations of high-dimensional integrals
Abstract
In this paper, we develop and test a fast numerical algorithm, called MDI-LR, for efficient implementation of quasi-Monte Carlo lattice rules for computing -dimensional integrals of a given function. It is based on the idea of converting and improving the underlying lattice rule into a tensor product rule by an affine transformation, and adopting the multilevel dimension iteration approach which computes the function evaluations (at the integration points) in the tensor product multi-summation in cluster and iterates along each (transformed) coordinate direction so that a lot of computations can be reused. The proposed algorithm also eliminates the need for storing integration points and computing function values independently at each point. Extensive numerical experiments are presented to gauge the performance of the algorithm MDI-LR and to compare it with standard implementation of quasi-Monte Carlo lattice rules. It is also showed numerically that the algorithm MDI-LR can achieve a computational complexity of order or better, where represents the number of points in each (transformed) coordinate direction and standard for the dimension. Thus, the algorithm MDI-LR effectively overcomes the curse of dimensionality and revitalizes QMC lattice rules for high-dimensional integration.
keywords:
Lattice rule(LR), multilevel dimension iteration (MDI), Monte Carlo methods, Quasi-Monte Carlo(QMC) method, high-dimensional integration.65D30, 65D40, 65C05, 65N99
1 Introduction
Numerical integration is an essential tool and building block in many scientific and engineering fields which requires to evaluate or estimate integrals of given (explicitly or implicitly) functions, which becomes very challenging in high dimensions due to the so-called curse of the conditionality (CoD). They are seen in evaluating quantities of stochastic interests, solving high-dimensional partial differential equations, or computing value functions of an option of a basket of securities. The goal of this paper is to develop and test an efficient algorithm based on quasi-Monte Carlo methods for evaluating the -dimensional integral
| (1.1) |
for a given function and .
Classical numerical integration methods, such as tensor product and sparse grid methods [17, 18] as well as Monte Carlo(MC) methods [19, 20] require the evaluation of a function at a set of integration points. The computational complexity of the first two types of methods grows exponentially with the dimension in the problem (i.e.., the CoD), which limits their practical usage. Monte Carlo (MC) methods are often the default methods for high dimensional integration problems due to their ability of handling complicated functions and mitigating the CoD. We recall that the MC method approximates the integral by randomly sampling points within the integration domain and averaging their function values. The classical MC method has the form
| (1.2) |
where denotes independent and uniformly distributed random samples in the integration domain . The expected error for the MC method is proportional to , where stands for the variance of . If is square-integrable then the expected error in (1.2) has the order (note that the convergence rate is independent of the dimension ). Evidently, the MC method is simple and easy to implement, making them a popular choice for many applications. However, the MC method is slow to converge, especially for high-dimensional problems, and the accuracy of the approximation depends on the number of random samples. One way to improve the convergence rate of the Monte Carlo method is to use quasi-Monte Carlo methods.
Quasi-Monte Carlo (QMC) methods [3, 21] employ integration techniques that use point sets with better distribution properties than random sampling. Similar to the MC method, the QMC method also has the general form (1.2), but unlike the MC method, the integration points are chosen deterministically and methodically. The deterministic nature of the QMC method could lead to guaranteed error bounds and that the convergence rate could be faster than the order of the MC method for sufficiently smooth functions. QMC error bounds are typically given in the form of Koksma-Hlawka-type inequalities as follows:
| (1.3) |
where is a (positive) discrepancy function which measures the non-uniformity of the point set and is a (positive) functional which measures the variability of . Error bounds of this type separate the dependence on the cubature points from the dependence on the integrand. The QMC point sets with discrepancy of order or better are collectively known as low-discrepancy point sets [22].
One of the most popular QMC methods is the lattice rule, whose integration points are chosen to have a lattice structure, low-discrepancy, and better distribution properties than random sampling [1, 2, 4], hence, resulting in a more accurate method with faster convergence rate. However, traditional lattice rules still have limitations when applied to high-dimensional problems. Good lattice rules almost always involve searching (cf. [23, 24]), the cost of an exhaustive search (for fixed) grows exponentially with the dimension . Moreover, like the MC method, the number integration points required to achieve a reasonable accuracy also increases exponentially with the dimension (i.e., the CoD phenomenon), which makes the method computationally infeasible for very high-dimensional integration problems.
To overcome the limitations of QMC lattice rules, we first propose an improved QMC lattice rule based on a change of variables and reformulate it as a tensor product rule in the transformed coordinates. We then develop an efficient implementation algorithm, called MDI-LR, by adapting the multilevel dimension iteration (MDI) idea first proposed by the authors in [11], for the improved QMC lattice rule. The proposed MDI-LR algorithm optimizes the function evaluations at integration points by clustering them and sharing computations via a symbolic-function based dimension/coordinate iteration procedure. This MDI-LR algorithm significantly reduces the computational complexity of the QMC lattice rule from an exponential growth in dimension to a polynomial order , where denotes the number of integration points in each (transformed) coordinate direction. Thus, the MDI-LR effectively overcomes the CoD and revitalizes QMC lattice rules for high-dimensional integration.
The remainder of this paper is organized as follows. In Section 2, we first briefly review the rank-one lattice rule and its properties. In Section 4, we introduce a reformulation of this lattice rule and proposed a tensor product generalization based on an affine transformation. In Section 3 , we introduce our MDI-LR algorithm for efficiently implementing the proposed lattice rule based a multilevel dimension iteration idea. In Section 5, we present extensive numerical experiments to test the performance of the proposed MDI-LR algorithm and compare its performance with the original lattice rule and the improved lattice rule with standard implementation. The numerical experiments show that the MDI-LR algorithm is much faster and more efficient in medium and high-dimensional cases. In Section 6, we numerically examine the impact of parameters appeared in MDI-LR algorithm, including the choice of the generating vector for the lattice rule. In Section 7, we present a detail numerical study of the computational complexity for the MDI-LR algorithm. This is done by using regression techniques to discover the relationship between CPU time and dimension . Finally, the paper is concluded with a summary given in Section 8.
2 Preliminaries
In this section, we first briefly recall some basic materials about Quasi-Monte Carlo (QMC) lattice rules for evaluating integrals (1.1) and their properties, they will set stage for us to introduce our fast implementation algorithm in the later sections.
2.1 Quasi-Monte Carlo lattice rules
Lattice rules are a class of Quasi Monte Carlo (QMC) methods which were first introduced by Korobov in [1] to approximate (1.1) with periodic integrand . A lattice rule is an equal-weight cubature rule whose cubature points are those points of an integration lattice that lie in the half-open unit cube . Every lattice point set includes the origin. The projection of the lattice points onto each coordinate axis are equally spaced. Essentially, the integral is approximated in each coordinate direction by a rectangle rule (or a trapezoidal rule if the integrand is periodic). The simplest lattice rules are called rank-one lattice rules, they use a lattice point set generated by multiples of a single generator vector, which are defined as follows.
Definition 2.1 (rank-one lattice rule).
An n-point rank-one lattice rule in -dimensions, also known as the method of good lattice points, is a QMC method with cubature points
| (2.1) |
where , known as the generating vector, is a -dimensional integer vector having no factor in common with n, and the braces operator takes the fractional part of the input vector.
Every lattice rule can be written as a multiple sum involving one or more generating vectors. The minimal number of generating vectors required to generate a lattice rule is known as the rank of the rule. Besides rank-one lattice rules which have only one generating vector, there are also lattice rules having rank up to .
is said to have an absolutely convergent Fourier series expansion if
| (2.2) |
where the Fourier coefficient is defined as
The following theorem gives two characterizations for the error of the lattice rules (cf. [2, Theorem 1] and [3, Theorem 5.2]).
Theorem 2.2.
Let denote a lattice rule (not necessarily rank-one) and let denote the associated integration lattice. If has an absolutely convergent Fourier series (2.2), then
| (2.3) |
where is the dual lattice associated with .
Theorem 2.3.
Let denote a rank-one lattice rule with a generating vector . If has an absolutely convergent Fourier series (2.2), then
| (2.4) |
It follows from (2.4) that the least upper bound of the error for the class of functions whose Fourier coefficients satisfy (where and ) is given by
| (2.5) |
Let
| (2.6) |
For fixed and , a good lattice point is so chosen to make as small as possible. It ws proved by Niederreiter in [7, 8, Theorem 2.11] that for a prime (or a prime power) there exists a lattice point such that
| (2.7) |
This was done by proving that has the following expansion:
| (2.8) | ||||
where
| (2.9) | ||||
| (2.10) |
As expected, the performance of a lattice rule depends heavily on the choice of the generating vector . For large and , an exhaustive search to find such a generating vector by minimizing some desired error criterion is practically impossible. Below we list a few common strategies for constructing lattice generating vectors.
We end this subsection by stating some well-known error estimate results. To the end, we need to introduce some notations. The worst-case error of a QMC rule using the point set in a normed space (with the norm ) is
By linearity, for any function , we have
For a given (shift) vector , we define the shifted lattice . For any QMC lattice rule with the lattice point set , let denote the corresponding shifted QMC lattice rule over the lattice . Then, for any integrand , it follows from the definition of the worst-case error that
Define the quantity
which denotes the shift-averaged worst-case error. The following bound for the root-mean-square error was derived in [3, Section 5.2]:
where the expectation is taken over the random shift which is uniformly distributed over . The shift-averaged worst-case error is often used as quality measure for randomly shifted QMC rules. For any given point set , the averaging argument guarantees the existence of at least one shift for which
| (2.11) |
In the case of rank-one QMC lattice rule with the generating vector , we use and to denote and . It was proved in [3, Lemma 5.5] that, for any rank-one QMC lattice rule, has an explicit formula as quoted in the following theorem.
Theorem 2.4.
The shift-averaged worst-case error for a rank-one QMC attice rule in the weighted anchored or unanchored Sobolev space (see Remark 2.5 below for the definitions) is given by
| (2.12) | ||||
where for the anchored Sobolev space and for unanchored Sobolev space. are weights.
Remark 2.5.
(1) We recall that for general given weights , the inner product of the weighted anchored Sobolev space is defined by
| (2.13) |
where the sum is over all subsets , including the empty set, while for the symbol denotes the set of components of with , and denotes the vector obtained by replacing the components of for by which is called the ‘anchor’ value. The partial derivative denotes the mixed first partial derivative with respect to the components of .
(2) The inner product for the weighted unanchored Sobolev space is defined by
| (2.14) | ||||
where stands for the vector consisting of the remaining components of the -dimensional vector that are not in .
2.2 Examples of good rank-one lattice rules
The first example is the Fibonacci lattice, we refer the reader to [3] for the details.
Example 2.6 (Fibonacci lattice).
Let and , where and are consecutive Fibonacci numbers. Then the resulting two-dimensional lattice set generated by is called a Fibonacci lattice.
Fibonacci lattices in 2-d have a certain optimality property, but there is no obvious generalization to higher dimensions that retains the optimality property (cf. [3] ).
Example 2.7 (Korobov lattice).
Let be an integer satisfying and and
Then the resulting -dimensional lattice set generated by is called a Korobov lattice.
It is easy to see that there are (at most) choices for the Korobov parameter , which leads to (at most) choices for the generating vector . Thus it is feasible in practice to search through the (at most) choices and take the one that fulfills the desired error criterion such as the one that minimizes , and (2.8) allows to be computed in operations (cf. [4]).
The last example is called the CBC lattice which is based on the component-by-component construction (cf. [9]).
Example 2.8 (CBC lattice).
Let . Given and weights as in in (2.12), define generating vector component-wise as follows.
-
(i)
Set .
-
(ii)
With held fixed, choose from to minimize in -d.
-
(iii)
With held fixed, choose from to minimize in -d.
-
(iv)
repeat the above process until all are determined.
With general weights , the cost of the CBC algorithm is prohibitively expensive, thus in practice some special structure is always adopted, among them, product weights, order-dependent weights, finite-order weights, and POD (product and order-dependent) weights are commonly used. In each of the steps of the CBC algorithm, the search space has cardinality . Then the overall search space for the CBC algorithm is reduced to a size of order (cf. [10, page 11]). Hence, this provides a feasible way of constructing a generating vector .
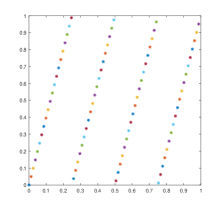
Figure 1 shows a two-dimensional lattice with 81 points, the corresponding generating vectors are (1, 2), (1, 4) and (1, 7) respectively. Figure 2 shows a three-dimensional lattice with 81 points, and the corresponding generating vectors are respectively (1, 2, 4), (1, 4, 16) and (1, 7, 49).





3 Reformulation of lattice rules
Clearly, the lattice point set of each QMC lattice rule has some pattern or structure. Indeed, one main goal of this section is precisely to describe the pattern. We show that a lattice rule almost has a tensor product reformulation viewed in an appropriately transformed coordinate space via an affine transformation. This discovery allows us to introduce a tensor product rule as an improvement to the original QMC lattice rule. More importantly, the reformulation lays an important jump pad for us to develop an efficient and fast implementation algorithm (or solver), called the MDI-LR algorithm, based on the idea of multilevel dimension iteration [11], for evaluating the QMC lattice rule (1.2).
3.1 Construction of affine coordinate transformations
From Figure 1-2, we see that the distribution of lattice points are on lines/planes which are not parallel to the coordinate axes/planes, however, those lines/planes are parallel to each other, this observation suggests that they can be made to parallel to the coordinate axes/planes via affine transformations. Below we prove that is indeed the case and explicitly construct such an affine transformation for a given QMC lattice rule.
Theorem 3.1.
Let and for denote the rank-one QMC lattice rule point set. Define
| (3.1) |
Notice that and . Then form a Cartesian grid in the new coordinate system, where defines as taking the absolute value of each component in the vector .
Proof 3.2.
By the definition of , we have . A direct computation yields
| (3.7) |
Recall that and denote respectively the fractional and integer parts of the number . Because
then
and
| (3.8) |
It is easy to check that
| (3.9) |
On the other hand, let
where
| (3.10) |
and represents the least common multiple.
For any , we have . Since , then . For in the set described by (3.8), , we get
| (3.11) |
Let , it follows that there exists an such that , resulting in . In the same way, . Therefore, we conclude that , that is, the transformed lattice points have the Cartesian product structure.
Lemma 3.3.
Let for denote the Korobov lattice point set, that is , and . Then satisfies the conclusion of Theorem 3.1. Moreover, if , then the number of points in each direction of the lattice set is the same, that is, .
Proof 3.4.
For in the set described by (3.12), let , it follows that there exists an such that , resulting in . Similarly, . Therefore, we conclude that , Obviously, the transformed lattice points have the Cartesian product structure. Moreover, if , then
Hence, . The proof is complete.

Left graph of Figure 3 shows a 2-d example of 81-point rank-one lattice with the generating vector . Right graph displays transformed lattice under the affine coordinate transformation from to itself, where
| (3.13) |

Figure 4 demonstrates a specific example in 3-d. The left graph is a 161-point rank-one lattice with generating vector . The right one shows the transformed points under the affine coordinate transformation from to itself, where
| (3.14) |
3.2 Improved lattice rules
From Figures 3 and 4 we see that the transformed lattice point sets do not exactly form tensor product grids because many lines miss one point. By adding those “missing” points which can be done systematically, we easily make them become tensor product grids in the transformed coordinate system. Since more integration points are added to the QMC lattice rule, the resulting quadrature rule is expected to be more accurate (which is supported by our numerical tests), hence, it is an improvement to the original QMC lattice rule. We also note that those added points would correspond to ghost points in the original coordinates.
Definition 3.5 (Improved QMC lattice rule).
Let and be a rank-one lattice point set and for some and (which uniquely determine an affine transformation). Suppose there exists points so that together the points form a tensor product grid in the transformed coordinate system, then the QMC lattice rule obtained by using those sampling points is called an improved QMC lattice rule, and denoted by .
Figure 5 shows a 81-point (i.e., ) 2-d rank-one lattice with the generating vector , the transformed lattice (middle), and the improved tensor product grid (right). Three points are added on the top, so for this example.

4 The MDI-LR algorithm
Since an improved rank-one lattice is a tensor product grid in the transformed coordinate system and its corresponding quasi-Monte Carlo (QMC) rule is a tensor product rule with equal weight . This tensor product improvement allows us to apply the multilevel dimension iteration (MDI) approach, which was proposed by the authors in [11], for a fast implementation of the original QMC lattice rule, especially in the high dimension case. The resulting algorithm will be called the MDI-LR algorithm throughout this paper,
4.1 Formulation of the MDI-LR algorithm
To formulate our MDI-LR algorithm, we first recall the MDI idea/algorithm in simple terms (cf. [11]).
For a tensor product rule, we need to compute a multi-summation with variable limits
which involves function evaluations for the given function if one uses the conventional approach by computing function value at each point independently, that inevitably leads to the curse of dimensionality (CoD). To make computation feasible in high dimensions, it is imperative to save the computational cost by evaluating the summation more efficiently.
The main idea of the MDI approach proposed in [11] is to compute those function values in cluster (not independently) and to compute the summation layer-by-layer based on a dimension iteration with help of symbolic computation. To the end, we write
| (4.1) |
where is fixed and
MDI approach recursively generates a sequence of symbolic functions , each function has fewer arguments than its predecessor (because the dimension is reduced by at each iteration). As already mentioned above, the MDI approach explores the lattice structure of the tensor product integration point set, instead of evaluating function values at all integration points independently, it evaluates them in cluster and iteratively along -coordinate directions, the function evaluation at any integration point is not completed until the last step of the algorithm is executed. In some sense, the implementation strategy of the MDI approach is to trade large space complexity for low time complexity. That being said, however, the price to be paid by the MDI approach for the speedy evaluation of the multi-summation is that those symbolic function needs to be saved during the iteration process, which often takes up more computer memory.
For example, consider 2-d function and let . In the standard approach, to compute the function value at an integration point , one needs to compute three multiplications , and , and two additions. To compute function values, it requires a total of multiplications and additions. On the other hand, the first for-loop of the MDI approach generates which requires evaluations of (symbolic computations) and evaluations of , as well as additions. The second for-loop generates which requires evaluations of and evaluations of , as well as additions. After the second for-loop completes, we obtain the summation value. The computation complexity of the MDI approach consists of a total of multiplications and additions, which is much cheaper than the standard approach. In fact, the speedup is even more dramatic in higher dimensions.
It is easy to see that the MDI approach can not be applied to the QMC rule (1.2) because it is not in a multi-summation form. However, we have showed in Section 3 that this obstacle can be overcome by a simple affine coordinate transformation (i.e., change of variables) and adding a few integration points.
Let denote the affine transformation, then the integral (1.1) is equivalent to
| (4.2) |
where stands for the determinant of and
Then, our improved QMC rank-one lattice rule for (1.2) in the -coordinate system takes the form
| (4.3) |
Let
Clearly, it is a multi-summation with variable limits. Thus, we can apply the MDI approach to compute it efficiently. Before doing that, we first need to extend the MDI algorithm, Algorithm 2.3 of [11], to the case of variable limits. We name the extend algorithm as MDI, which is defined as follows.
Inputs:
Output:
.
Where denotes the natural embedding from to by deleting the first components of vectors in , and
| (4.4) |
Remark 4.1.
-
(a)
Algorithm 1 recursively generates a sequence of symbolic functions , each function has fewer arguments than its predecessor.
-
(b)
Since , when , we simply use the underlying low dimensional QMC quadrature rules. As done in [11], we name those low dimensional algorithms as 2d-MDI and 3d-MDI, and introduce the following conventions.
-
–
If , set MDI, which is computed by using the underlying 1-d QMC quadrature rule.
-
–
If , set MDI 2d-MDI.
-
–
If , set MDI 3d-MDI.
We note that when , the parameter becomes a dummy variable and can be given any value.
-
–
-
(c)
We also note that the MDI algorithm in [11] has an additional parameter which selects the 1-d quadrature rule. However, such a choice is not needed here because the underlying QMC rule is used as the 1-d quadrature rule.
We are now ready to define our MDI-LR algorithm, which is denoted by MDI-LR, by using the above MDI algorithm to evaluate in (4.3).
Noting that here we set , that is, the dimension is reduced by at each dimension iteration, this is because the numerical tests of [11] shows that when the MDI algorithm is more efficient than when . Also, the upper limit vector depends on the choice of the underlying QMC rule. In Lemma 3.3 we showed that when and , then , that is, the number of integration points is the same in each (transformed) coordinate direction.
5 Numerical performance tests
In this section, we present extensive and purposely designed numerical experiments to gauge the performance of the proposed MDI-LR algorithm and to demonstrate its superiority over the standard implementations of the QMC lattice rule (SLR) and the improved lattice rule (Imp-LR) for computing high dimensional integrals. All our numerical experiments are done in Matlab on a desktop PC with Intel(R) Xeon(R) Gold 6226R CPU 2.90GHz and 32GB RAM.
5.1 Two and three-dimensional tests
We first test our MDI-LR on simple 2- and 3-d examples and to compare its performance (in terms of the CPU time) with the SLR and Imp-LR methods .
Test 1. Let and consider the following 2-d integrands:
| (5.1) |
Table 1 and 2 present the computational results (errors and CPU times) of the SLR, Imp-LR and MDI-LR method for approximating and , respectively. Recall that the Imp-LR is obtained by adding some integration points on the boundary of the domain in the transformed coordinates, and the MDI-LR algorithm provides a fast implementation of the Imp-LR using the MDI approach. From Table 1 and 2, we observe that all three methods require very little CPU time. The difference is almost negligible although the SLR is faster than the other two methods. Moreover, the Imp-LR and MDI-LR methods use function values at some additional sampling points on the boundary, which leads to higher accuracy compared to the SLR method as we predicated earlier.
| SLR(Standard LR) | Imp-LR(Improved LR) | MDI-LR | ||||
| Total nodes () | Relative error | CPU time | Relative error | CPU time | Relative error | CPU time |
| 101 | 0.0422 | 0.0423 | 0.0877 | |||
| 501 | 0.0567 | 0.0547 | 0.3230 | |||
| 1001 | 0.0610 | 0.0657 | 0.5147 | |||
| 5001 | 0.0755 | 0.0754 | 1.6242 | |||
| 10001 | 0.0922 | 0.0921 | 3.9471 | |||
| 40001 | 0.1782 | 0.1787 | 7.0408 | |||
| SLR(Standard LR) | Imp-LR(Improved LR) | MDI-LR | ||||
| Total nodes () | Relative error | CPU time | Relative error | CPU time | Relative error | CPU time |
| 101 | 0.0415 | 0.0410 | 0.0980 | |||
| 501 | 0.0539 | 0.0546 | 0.3498 | |||
| 1001 | 0.0647 | 0.0653 | 0.5028 | |||
| 5001 | 0.0723 | 0.0733 | 1.7212 | |||
| 10001 | 0.0965 | 0.0945 | 3.4528 | |||
| 40001 | 0.1386 | 0.1399 | 6.1104 | |||
Test 2. Let and we consider the following 3-d integrands:
| (5.2) |
Tables 3 and 4 present the simulation results (errors and CPU time) of the SLR, Imp-LR, and MDI-LR methods for computing and in Test 2. We observe that the SLR method requires less CPU time in both simulations. The advantage of the MDI-LR method in accelerating the computation does not materialize in low dimensions as seen in Test 1. Once again, the Imp-LR and MDI-LR have higher accuracy compared to the SLR method because they use additional sampling points on the boundary of the transformed domain.
| SLR(Standard LR) | Imp-LR(Improved LR) | MDI-LR | ||||
| Total nodes () | Relative error | CPU time | Relative error | CPU time | Relative error | CPU time |
| 101 | 0.0574 | 0.0588 | 0.0877 | |||
| 1001 | 0.0634 | 0.0654 | 0.2684 | |||
| 10001 | 0.0833 | 0.0877 | 0.6322 | |||
| 100001 | 0.1500 | 0.1499 | 2.5866 | |||
| 1000001 | 1.0589 | 1.0587 | 14.737 | |||
| 10000001 | 9.8969 | 10.280 | 91.897 | |||
| SLR(Standard LR) | Imp-LR(Improved LR) | MDI-LR | ||||
| Total nodes () | Relative error | CPU time | Relative error | CPU time | Relative error | CPU time |
| 101 | 0.0580 | 0.0554 | 0.1366 | |||
| 1001 | 0.0628 | 0.0649 | 0.3804 | |||
| 10001 | 0.0820 | 0.0828 | 1.1032 | |||
| 100001 | 0.1443 | 0.1557 | 4.8794 | |||
| 1000001 | 1.1163 | 1.2104 | 20.305 | |||
| 10000001 | 10.207 | 10.427 | 101.22 | |||
5.2 High-dimensional tests
Since the MDI-LR method is designed for computing high-dimensional integrals, its performance for is more important and anticipated, which is indeed the main task of this subsection. First, we test and compare the performance (in terms of CPU time) of the SLR, Imp-LR, and MDI-LR methods for computing high-dimensional integrals as the number of lattice points grows due to the dimension increases. Then, we also test the performance of the SLR and MDI-LR methods for computing high-dimensional integrals when the number of lattice points increases slowly in the dimension .
Test 3. Let for and consider the following Gaussian integrand:
| (5.3) |
where stands for the Euclidean norm of the vector .
Table 5 shows the relative errors and CPU times of SLR, Imp-LR, and MDI-LR methods for approximating the Gaussian integral . The simulation results indicate that SLR and Imp-LR methods are more efficient when , but they struggle to compute integrals when as the number of lattice points increases exponentially in the dimension. However, this is not a problem for the MDI-LR method, which can compute this high-dimensional integral easily. Moreover, the MDI-LR method improves the accuracy of the original QMC rule significantly by adding some integration points on the boundary of the transformed domain.
| SLR(Standard LR) Total Nodes() | Imp-LR(Improved LR) Total Nodes() | MDI-LR Total Nodes() | ||||
| Dimension () | Relative error | CPU time | Relative error | CPU time | Relative error | CPU time |
| 2 | 0.0622 | 0.0637 | 0.1335 | |||
| 4 | 0.1068 | 0.1206 | 0.5780 | |||
| 6 | 1.2450 | 1.2745 | 1.2890 | |||
| 8 | 124.91 | 126.85 | 1.4083 | |||
| 10 | 13084 | 13255 | 3.1418 | |||
| 11 | 132927 | 141665 | 3.8265 | |||
| 12 | failed | failed | failed | failed | 4.5919 | |
| SLR | MDI-LR | |||||
| Dimension () | Total nodes () | value | Relative error | CPU time | Relative error | CPU time |
| 2 | 1+ | 31 | 0.0369 | 0.432905 | ||
| 6 | 1+ | 10 | 1.2450 | 0.790102 | ||
| 10 | 1+ | 4 | 1.2453 | 0.582487 | ||
| 14 | 1+ | 4 | 144.759 | 0.536131 | ||
| 18 | 1+ | 3 | 1649.59 | 0.774606 | ||
| 22 | 1+ | 3 | 18694.04 | 0.702708 | ||
| 26 | 1+ | 3 | 217381.41 | 0.866122 | ||
| 30 | 1+ | 3 | 269850.87 | 1.045107 | ||
Table 6 shows the relative errors and CPU times of the SLR and MDI-LR methods for computing when the number of lattice points increase slowly in the dimension . As the dimension increases, the CPU time required by the SLR method also increases sharply (see Figure 6). When approximating the Gaussian integral of about 30 dimensions with lattice points, the SLR method requires hours to obtain a result with relatively low accuracy. In contrast, the MDI-LR method only takes about one second to obtain a more accurate value, this demonstrates that the acceleration effect of the MDI-LR method is quite dramatic.


It is well known that it is difficult to obtain high-accuracy approximations in high dimensions because the number of integration points required is enormous. A natural question is whether the MDI-LR method can handle very high (i.e., ) dimensional integration with reasonable accuracy. First, we note that the answer is machine dependent, as expected. Next, we present a test on the computer at our disposal to provide a positive answer to this question
Test 4. Let and consider the following integrands:
| (5.4) |
We use the algorithm MDI-LR to compute and with parameters , and an increasing sequence of . The computed results are presented in Table 7. The simulation is stopped at because it is already in the very high dimension regime. These tests demonstrate the efficacy and potential of the MDI-LR method in efficiently computing high-dimensional integrals. However, we note that in terms of efficiency and accuracy, the MDI-LR method underperforms its two companion methods, namely, MDI-TP [11] and MDI-SG [12] methods. The main reason for the underperformance is that the original lattice rule is unable to provide high-accuracy integral approximations and the MDI-LR is only a fast implementation algorithm (i.e., solver) for the original lattice rule. Nevertheless, the lattice rule has its own advantages, such as allowing flexible integration points and giving better results for periodic integrands.
| Nodes() | Nodes() | |||||
| Dimension () | value | Relative error | CPU time(s) | value | Relative error | CPU time(s) |
| 10 | 8 | 0.4329063 | 20 | 0.9851172 | ||
| 100 | 8 | 71.253076 | 20 | 11.1203255 | ||
| 300 | 8 | 1856.91018 | 20 | 37.0903112 | ||
| 500 | 8 | 8076.92429 | 20 | 65.9497657 | ||
| 700 | 8 | 20969.96162 | 20 | 108.989057 | ||
| 900 | 8 | 47870.50843 | 20 | 157.487672 | ||
| 1000 | 8 | 69991.88017 | 20 | 189.132615 | ||
6 Influence of parameters
The original MDI algorithm involves three crucial input parameters: , , and . The parameter determines the one-dimensional basis value quadrature rule, while sets the step size in the multidimensional iteration, and represents the number of integration points in each coordinate direction. The algorithm MDI-LR is similar to the original MDI, but uses the QMC rank-one lattice rule with generating vector , so the parameter is muted. Here we focus on the Korobov approach in constructing the generating vector , which is defined as . Moreover, the improved tensor product rule (in the transformed coordinate system) implemented by the algorithm Imp-LR has a variable upper limits in the summation (cf. (4.3)), hence, is now replaced by which is determined by the underlying QMC lattice rule. Furthermore, as explained earlier, we set due to our experience in [11]. As a result, the only parameter to select is . Below, we first test the influence of the Korobov parameter on the efficiency of the algorithm MDI-LR and then test dependence of its performance on and .
6.1 Influence of parameter
In this subsection, we investigate the impact of the generating vector in the algorithm MDI-LR . We note that similar methods can be constructed using other .
Test 5. Let and consider the following integrands:
We compare the performance of the algorithm MDI-LR with different Korobov parameters while holding other parameters unchanged when computing , , and .


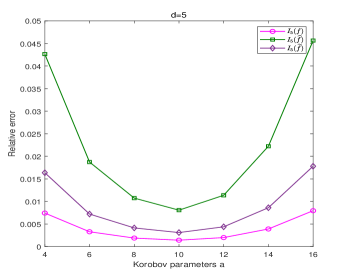

Figure 7 shows the computed results for and , respectively. We observe that the algorithm MDI-LR with different parameters has different accuracy and the effect could be significant. These results indicate that the algorithm is most efficient when , where and represents the total number of integral points. This is because when a smaller is used, although fewer integration points need to be evaluated in each coordinate direction in the first dimension iterations, since the total number of integral points is the same, the amount of computation will increase dramatically. When using a larger , more integration points need to be used in each coordinate direction in the first dimension iterations. Only when the integration points are equally distributed to each coordinate direction, the efficiency of the algorithm MDI-LR can be optimized. A total of points are shown in Figure 8. When , only iterations in the -direction are needed, but iterations in the -direction must performed, hence, a total of iterations in the two directions are required. On the other hand, when , a total of iterations in the two directions are required. It is easy to check that the least total of iterations occurs when . The difference in accuracy is obvious, because the different leads to different generating vector , which in turn results in different integration points. We note that it was already well studied in the literature on how to choose to achieve the highest accuracy (cf. []).

6.2 Influence of parameter
In the previous section, we know that the algorithm is most efficient when , where represents the number of integration points in each direction. This section aims to investigate the impact of on the MDI-LR algorithm. For this purpose, we conduct tests by setting and and .
Test 6. Let , , and be the same as in Test 5.
Table 8, 9, and 10 present a performance comparison for algorithm MDI-LR with and , respectively. We note that the quality of the computed results also depend on types of the integrands. As expected, more integration points must be used to achieve a good accuracy for very oscillatory and fast growth integrands.
| N(n) | Korobov parameter | Relative error | CPU time(s) | Relative error | CPU time(s) |
| 4() | 4 | 0.1456465 | 0.3336161 | ||
| 6() | 6 | 0.1911801 | 0.5690320 | ||
| 8 () | 8 | 0.3373442 | 0.9552591 | ||
| 10 () | 10 | 0.3884146 | 1.9385378 | ||
| 12() | 12 | 0.6545521 | 3.5639475 | ||
| 14() | 14 | 0.7224777 | 6.0036393 | ||
| 16() | 16 | 1.0909097 | 8.4313528 | ||
| N(n) | Korobov parameter | Relative error | CPU time(s) | Relative error | CPU time(s) |
| 4() | 4 | 0.1323887 | 0.2775234 | ||
| 6() | 6 | 0.1955847 | 0.4267706 | ||
| 8 () | 8 | 0.2689113 | 0.5697773 | ||
| 10 () | 10 | 0.3227299 | 0.7828456 | ||
| 12() | 12 | 0.4056192 | 0.9228344 | ||
| 14() | 14 | 0.4940739 | 1.0968489 | ||
| 16() | 16 | 0.6079693 | 1.2933549 | ||
| N(n) | Korobov parameter | Relative error | CPU time(s) | Relative error | CPU time(s) |
| 4() | 4 | 0.1254485 | 0.2460844 | ||
| 6() | 6 | 0.1802281 | 0.3613987 | ||
| 8 () | 8 | 0.2114595 | 0.4414383 | ||
| 10 () | 10 | 0.2748469 | 0.4892808 | ||
| 12() | 12 | 0.3092816 | 0.5859328 | ||
| 14() | 14 | 0.3602077 | 0.6783681 | ||
| 16() | 16 | 0.4157161 | 0.7819849 | ||
7 Computational complexity
7.1 The relationship between the CPU time and
In this subsection, we examine the relationship between CPU time and the parameter and using a regression technique based on test data.
| Integrand | Fitting function | R-square | |||
| N | 1 | 5 | 0.9687 | ||
| N | 1 | 5 | 0.9920 | ||
| N | 1 | 5 | 0.9946 | ||
| N | 1 | 10 | 0.9968 | ||
| N | 1 | 10 | 0.9984 | ||
| N | 1 | 10 | 0.9901 |
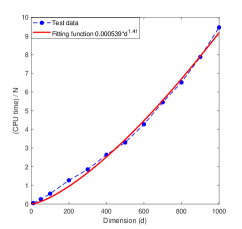
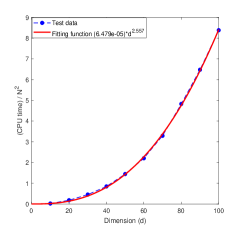
Figures 9 and 10 show CPU time as a function of obtained by the least squares regression with the fitted function given in Table 11. All results show that CPU time grows in proportion to .






7.2 The relationship between the CPU time and the dimension
In this subsection, we exploit the computational complexity (in terms of CPU time as a function of ) using the least squares regression on numerical test data.
Test 7. Let , we consider the following five integrands:
Figure 11 displays the the CPU time as functions of obtained by the least square regression whose analytical expressions are given in Table 12. We note that the parameters of the algorithm MDI-LR only affect the coefficients of the fitted function, not the power of the polynomials. These results show that the CPU time required by the proposed algorithm MDI-LR grows at most with polynomial order .
| Integrand | Fitting function | -square | |||
| 8 | 8 | 1 | 0.9973 | ||
| 10 | 10 | 1 | 0.9995 | ||
| 20 | 20 | 1 | 0.9978 | ||
| 10 | 10 | 1 | 0.9983 | ||
| 14 | 14 | 1 | 0.9987 | ||
| 20 | 20 | 1 | 0.9964 | ||
| 8 | 8 | 1 | 0.9983 | ||
| 10 | 10 | 1 | 0.9986 | ||
| 14 | 14 | 1 | 0.9972 | ||
| 10 | 10 | 1 | 0.9988 | ||
| 20 | 20 | 1 | 0.9974 | ||
| 10 | 10 | 1 | 0.9996 | ||
| 14 | 14 | 1 | 0.9993 | ||
| 10 | 10 | 1 | 0.9983 | ||
| 20 | 20 | 1 | 0.9998 |
We assess the quality of the fitted curves using the -square criterion in Matlab, defined by -, where is a test data output, is the predicted value, and is the mean of . As shown in Table 12, the -square values of all fitted functions are close to , indicating their high accuracy. These results support the observation that the CPU time grows no more than cubically with the dimension . Combined with the results of Test 6 in Section 7.1, we conclude that the computational cost of the proposed MDI-LR algorithm scales at most polynomially in the order of .
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/4c2be377-0640-469a-94cc-3a6c28ec5ad7/x23.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/4c2be377-0640-469a-94cc-3a6c28ec5ad7/x24.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/4c2be377-0640-469a-94cc-3a6c28ec5ad7/x25.png)










8 Conclusions
In this paper, we introduced an efficient and fast algorithm MDI-LR for implementing QMC lattice rules for high-dimensional numerical integration. It is based on the idea of converting and extending them into tensor product rules by affine transformations, and adopting the multilevel dimension iteration approach which computes the function evaluations (at the integration points) in the multi-summation in cluster and iterates along each (transformed) coordinate direction so that a lot of computations can be reused. Based on numerical simulation results, it was concluded that the computational complexity of the algorithm MDI-LR (in terms of CPU time) grows at most cubically in the dimension and has an overall growth rate , which suggests that the proposed algorithm MDI-LR can effectively mitigate the curse of dimensionality in high-dimensional numerical integration, making the QMC lattice rule not only competitive but also practically useful for high dimension numerical integration. Extensive numerical tests were provided to guage the performance of the algorithm MDI-LR and to compare its performance with the standard QMC lattice rules. Extensions to general Monte Carlo methods and applications of the proposed MDI-LR algorithm for solving high-dimensional PDEs will be explored and reported in a forthcoming work.
References
- [1] N. M. Korobov, The approximate computation of multiple integrals, Dokl. Akad. Nauk SSSR, 1959, 124:1207–1210. In Russian.
- [2] I. H. Sloan, S. Joe, Lattice methods for multiple integration, Oxford University Press, 1994.
- [3] J. Dick, F. Y. Kuo, and I. H. Sloan, High-dimensional integration: the quasi-Monte Carlo way, Acta Numer, 22:133–288, 2013.
- [4] X. Wang, I. H. Sloan, and J. Dick, On Korobov lattice rules in weighted spaces, SIAM journal on numerical analysis, 2004, 42(4): 1760-1779.
- [5] N. M. Korobov, Properties and calculation of optimal coefficients,Doklady Akademii Nauk. Russian Academy of Sciences, 1960, 132(5): 1009-1012.
- [6] H. Niederreiter, A. Winterhof, Applied number theory, Cham: Springer, 2015.
- [7] H. Niederreiter, Quasi-Monte Carlo methods and pseudo-random numbers,Bulletin of the American mathematical society, 1978, 957-1041.
- [8] H. Niederreiter, Existence of good lattice points in the sense of Hlawka,Monatshefte für Mathematik, 1978, 86(3): 203-219.
- [9] I. H. Sloan, A. Reztsov Component-by-component construction of good lattice rules, Mathematics of Computation, 2002, 71(237): 263-273.
- [10] P.Kritzer, H. Niederreiter, F. Pillichshammer Ian Sloan and Lattice Rules,Contemporary Computational Mathematics-A Celebration of the 80th Birthday of Ian Sloan, 2018: 741-769.
- [11] X. Feng and H. Zhong, A fast multilevel dimension iteration algorithm for high dimensional numerical integration. preprint.
- [12] H. Zhong and X. Feng , An Efficient and fast Sparse Grid algorithm for high dimensional numerical integration. preprint.
- [13] Paul Bratley, Bennett Fox, Harald Niederreiter, Implementation and Tests of Low Discrepancy Sequences, ACM Transactions on Modeling and Computer Simulation, Volume 2, Number 3, July 1992, pages 195-213.
- [14] Henri Faure, Good permutations for extreme discrepancy, Journal of Number Theory, Volume 42, 1992, pages 47-56.
- [15] Ilya Sobol, Uniformly Distributed Sequences with an Additional Uniform Property, USSR Computational Mathematics and Mathematical Physics, Volume 16, 1977, pages 236-242.
- [16] H. Niederreiter, Low-discrepancy and low-dispersion sequences, Journal of Number Theory, Volume 30, 1988, pages 51-70.
- [17] H.-J. Bungartz and M. Griebel, Sparse grids, Acta Numer., 13:147–269, 2014.
- [18] T. Gerstner and M. Griebel, Numerical integration using sparse grids, Numerical algorithms, 18(3): 209–232, 1998.
- [19] R. E. Caflisch, Monte Carlo and quasi-Monte Carlo methods, Acta Numer., 7:1–49, 1998.
- [20] Y. Ogata, A Monte Carlo method for high dimensional integration, Numer. Math., 55:137–157, 1989.
- [21] F. Y. Kuo, C. Schwab, and I. H. Sloan, Quasi-Monte Carlo methods for high-dimensional integration: the standard (weighted Hilbert space) setting and beyond, ANZIAM J., 53:1–37, 2011.
- [22] H. Niederreiter, Random number generation and quasi-Monte Carlo methods, Society for Industrial and Applied Mathematics, 1992.
- [23] S. Haber, Experiments on optimal coefficients, Applications of number theory to numerical analysis. Academic Press, 1972: 11-37.
- [24] A. R. Krommer,C. W.Ueberhuber, Computational integration, Society for Industrial and Applied Mathematics, 1998.