An Efficient Egocentric Regulator for Continuous Targeting Problems of the Underactuated Quadrotor
Abstract
Flying robots such as the quadrotor could provide an efficient approach for medical treatment or sensor placing of wild animals. In these applications, continuously targeting the moving animal is a crucial requirement. Due to the underactuated characteristics of the quadrotor and the coupled kinematics with the animal, nonlinear optimal tracking approaches, other than smooth feedback control, are required. However, with severe nonlinearities, it would be time-consuming to evaluate control inputs, and real-time tracking may not be achieved with generic optimizers onboard. To tackle this problem, a novel efficient egocentric regulation approach with high computational efficiency is proposed in this paper. Specifically, it directly formulates the optimal tracking problem in an egocentric manner regarding the quadrotor’s body coordinates. Meanwhile, the nonlinearities of the system are peeled off through a mapping of the feedback states as well as control inputs, between the inertial and body coordinates. In this way, the proposed efficient egocentric regulator only requires solving a quadratic performance objective with linear constraints and then generate control inputs analytically. Comparative simulations and mimic biological experiment are carried out to verify the effectiveness and computational efficiency. Results demonstrate that the proposed control approach presents the highest and stablest computational efficiency than generic optimizers on different platforms. Particularly, on a commonly utilized onboard computer, our method can compute the control action in approximately 0.3 ms, which is on the order of 350 times faster than that of generic nonlinear optimizers, establishing a control frequency around 3000 Hz.
Index Terms:
Continuous targeting, efficient egocentric regulator, underactuated quadrotorI Introduction
In the past few years, the quadrotor has demonstrated impressive capabilities for biological researches [1, 2]. A recent work also realized the plants’ health management via autonomous sensor placement [3]. Motivated by those works, the quadrotor equipped with devices such as an anesthesia gun might be able to further apply for wildlife’s health management. With autonomous anesthetizing or sensor placing, it may significantly reduce the danger or labor of human beings when coping with agile and aggressive animals [4].
Different from the case of stationary plants as mentioned in Ref. [3], the moving animal should be continuously targeted before anesthetizing. For such a targeting task, it requires accurate control simultaneously on the position and attitude of the underactuated quadrotor in a continuous-time horizon. Therefore, smooth feedback control [5, 6, 7] is not applicable for such a targeting task, and an effective optimal tracking approach should be formulated. Considering the quadrotor’s underactuated characteristics and its coupled kinematics with the moving animal, optimal control of this continuous targeting problem involves severe nonlinearities. Solving such a nonlinear optimal control problem is commonly time consuming. Therefore computational efficiency is a crucial issue regarding the processing capability of onboard computers commonly adopted by quadrotors.
In previous researches, mainly two similar types of optimal problems are extensively studied, i.e., state-to-state maneuver problem [8, 9, 10, 11] and optimal tracking multiple fixed waypoints problem [12, 13, 14, 15, 16, 17]. For the state-to-state maneuver problem, the computational efficiency is guaranteed since the original problem can be linearizable or the optimal trajectory can be generated offline. For example, in Refs. [8, 9], computationally efficient trajectory generation algorithms, as well as subspace stabilization tracking method, are also proposed to maneuver the quadrotor to a time-varying target point in 6-dimensional state space. As the reported problems can be formulated with quadratic or linear optimizations, the optimal trajectories can be generated fairly fast. In Refs. [10, 11], time-optimal trajectory generation algorithms are designed for landing a quadrotor onto a moving platform. Although the problem is not formulated as a linear-quadratic problem, it assumes that the platform motion can be represented by a function of time. Therefore, the optimal trajectory can be generated offline without the requirement of computational efficiency. On the other hand, for the optimal tracking of multiple fixed waypoints problem [12, 13, 14, 15, 16, 17], it is a fully actuated problem that mainly concerns situations in which an invariable terminal target point or a set of fixed waypoints are given. Since the waypoints can be defined a priori, the optimal trajectory can be either generated online or offline, and the computational efficiency is not the primary concern. Instead, the trajectory tracking performance is more crucial [16, 17].
Given that the targeted animal is moving randomly during the whole targeting process, the waypoints cannot be obtained a priori in this underactuated targeting problem, as the fully actuated multiple fixed waypoints problem does. Meanwhile, the real-time tracking problem in this work cannot be linearized directly ,and the animal motion cannot be obtained a priori, as the state-to-state maneuver problem does. This is because three variables, i.e., the pitch angle, the translational position and vertical position of the quadrotor, are controlled simultaneously with two control inputs, i.e., thrust and pitch to ensure the targeting. Meanwhile, the vertical targeting performance objective is determined by the pitch angle, the translational as well as vertical position simultaneously, whereas the pitch angle and the translational position are coupled with each other again. Worse still is that the coupled kinematics with the moving animal further intensifies the nonlinearities of this optimal control problem. The aforesaid coupled nonlinearities and underactuated characteristics exist in the performance objective and the nonlinear constraints, making such a targeting optimal problem unlinearizable. Hence, it is inherently different from the aforementioned linearizable optimization problems such as those investigated in [8, 9]. Therefore, the optimal tracking methods proposed in these two types of problems are all unapplicable to solve this targeting problem, considering the heavy nonlinearities and computational efficiency simultaneously. Meanwhile, according to our outdoor experiments, generic optimizers also cannot directly solve this problem with sufficient computational efficiency.
To tackle this problem, an efficient egocentric regulator is proposed in this paper. Firstly, regarding the quadrotor’s body coordinates, a virtual mathematical model is established in an egocentric manner. In such a way, the decoupling of the pitch angle with the translational position is achieved and the fully actuated system is then obtained. Based on this transformed model, the nonlinearities of the system are peeled off. Then, it only needs to solve a linear quadratic optimization problem and then generate the virtual control inputs analytically. The peeled-off nonlinear part is compensated through a mapping of the feedback states and the virtual inputs between the virtual body and inertial coordinates. This kind of mapping can directly obtain the analytical real control input, achieving high computational efficiency. Mimic biological simulations and experiments are performed to testify the excellent targeting performance and the computational efficiency. Results demonstrate that the proposed control approach presents the highest and stablest computational efficiency than generic optimizers on different platforms. Particularly, it can compute the control action on the order of 350 times faster than generic optimizers on the onboard computer. In such a case, a control frequency of thousands of hertz can be achieved by the proposed approach on a commonly utilized onboard computer.
The main contributions of this work are: 1) To continuously target a moving animal, an efficient egocentric regulator is first proposed, which can present the highest and stablest computational efficiency than generic optimizers on different platforms. Particularly, on the onboard computer, our method can provide high computational efficiency on the order of 350 times higher than that of generic optimizers; 2) Extensive mimic biological simulations and experiments are first carried out, and the results demonstrate the excellent targeting performance and real-time computational efficiency of the proposed strategy.
The remainder of this paper is organized as follows. Section II presents the system dynamics and the problem formulation. Section III proposes the efficient egocentric regulator. Comparative simulations are implemented in Section IV ,while outdoor experiments are conducted in Section V. Section VI concludes the paper.
II System Dynamics And Problem Formulation
We first present the general dynamic model of the quadrotor in this section. On this basis, the targeting problem is formulated.
II-A Dynamics of quadrotor
The coordinates and free body diagram of the quadrotor are shown in Fig. 1.
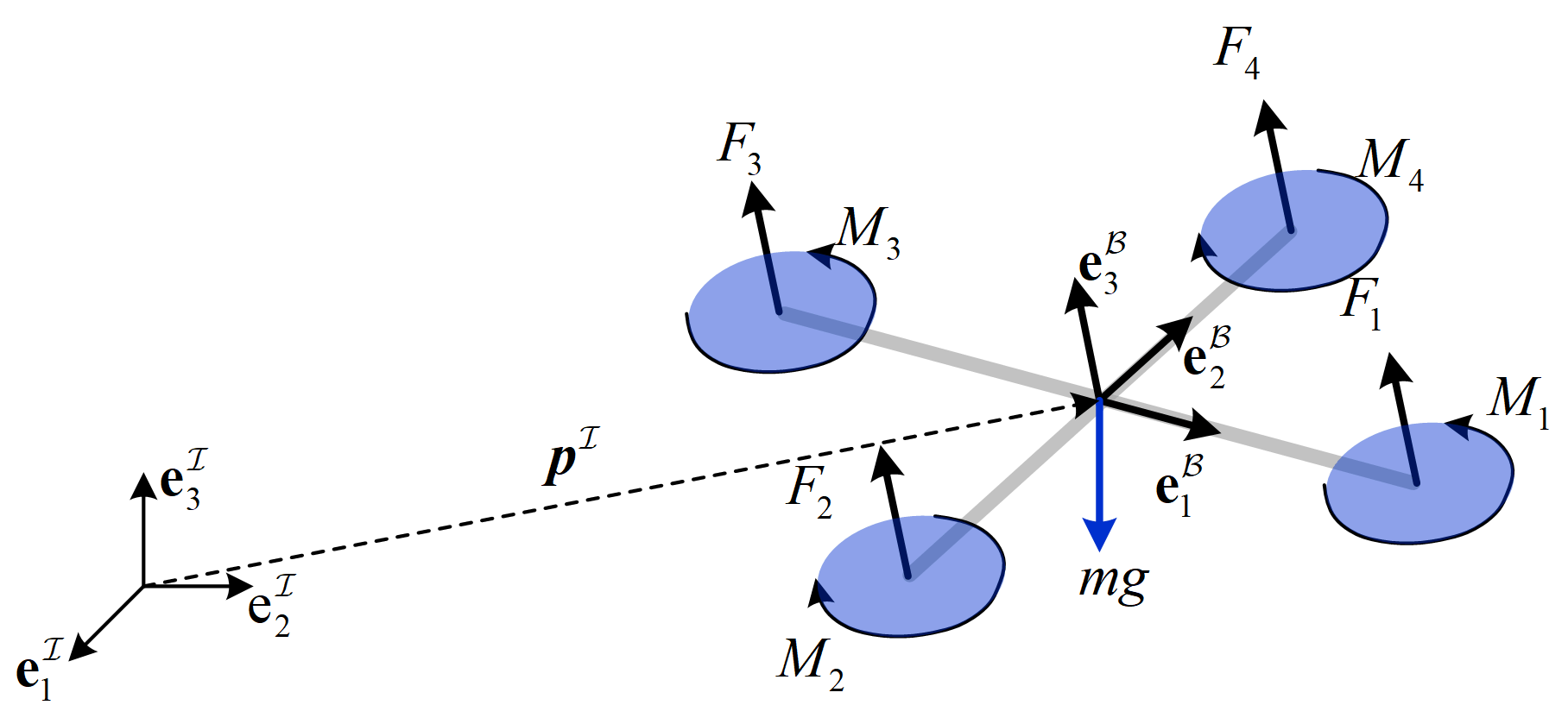
On this basis, the dynamics of the quadrotor is investigated as follows. First, the force and moment generated by four individual rotors are commonly expressed as
| (1) |
where is the length from the rotor to the center of the mass of the quadrotor, and and are the thrust and torque generated by rotor .
In view of Eq.(1), considering air drag effects, the dynamics of the quadrotor with respect to the inertial coordinates can be expressed as [18, 19, 20]
| (2) |
where denotes the position of the quadrotor in inertial coordinates ; is the velocity of the quadrotor in ; is the mass of the quadrotor; is the gravity constant; is the constant matrix to estimate the aerial drag effects in ; is the attitude, which contains three components: pitch roll and yaw ; matrix establishes relationship between attitude velocity and angular velocity ; is the moment of inertia; ; is the transformation matrix from to , which is expressed as
| (3) |
in which .
II-B Problem Formulation
To clarify the formulation of the optimal control strategy designed in this work, three assumptions are imposed as follows.
Assumption 1. The pitch angle and the roll angle of the quadrotor can be set directly without dynamics and delay such that they can be regarded as the control inputs.
Assumption 2. Considering that the yaw angle of the quadrotor can be controlled separately without underactuated characteristics, it can be approximated as zero, i.e., .
Assumption 3. The animal’s velocity is regarded as a constant in each controller updating timestep.
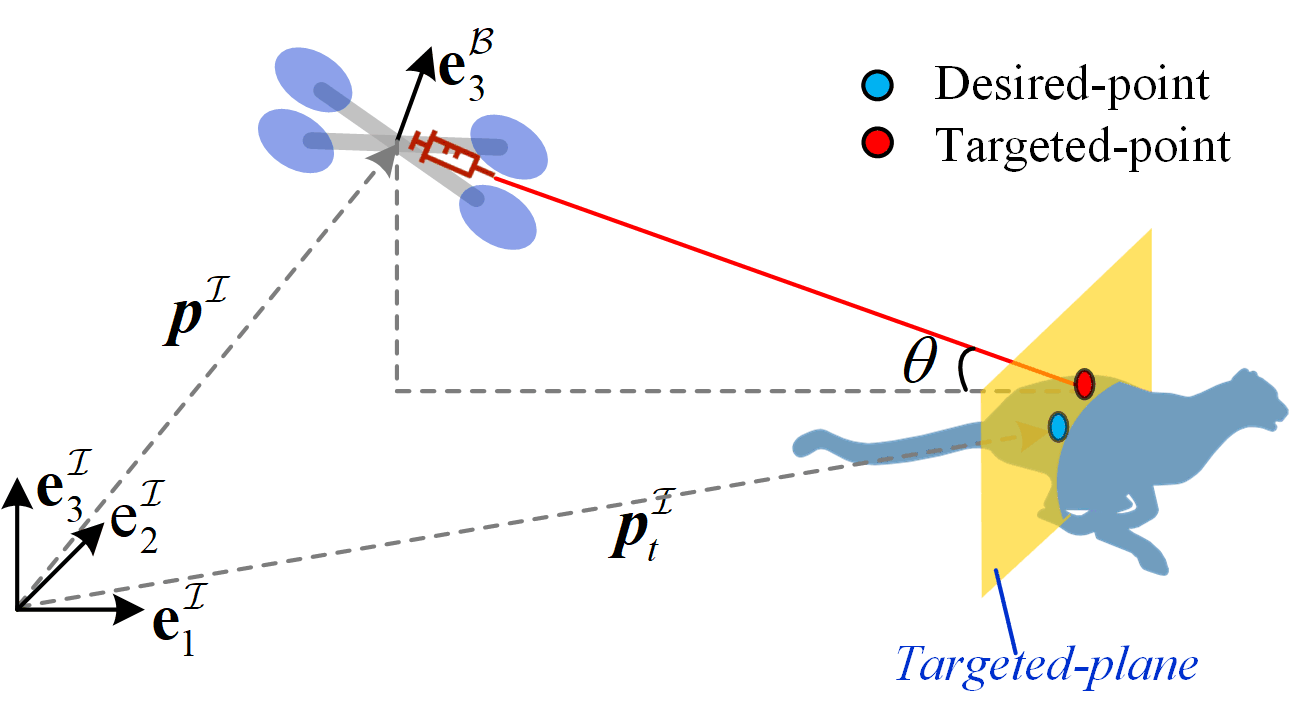
In view of the developed model, the control objective can be described as follows. An optimal control input of the quadrotor is required to design in such a way the quadrotor can continuously target the animal and keep in a safe distance. The targeting problem is illustrated in Fig. 2, where denotes the position of the desired-point in inertial coordinate .
Combining with Assumption 1, we can define the state vector and the control input of the system as:
| (4) |
where denotes the velocity of the desired-point in inertial coordinate . The quadrotor’s velocity is considered as separate states. It is separately introduced to reflect the air drag effect. In this way, the static case and the uniform motion case, where the animal and the quadrotor are both relatively stationary, can be distinguished.
Based on Assumption 2, Assumption 3 and Eq. (2), the dynamics of the targeting process can then be reformulated as follows:
| (5) |
where denotes the -th component of ; , where denotes -th component of .
To facilitate the optimal control, Define as the distance from the center of mass of the quadrotor to the targeted plane, and define , as the distance along between the targeted-point and the desired-point on the targeted plane. For this targeting task, the control objective is to design an optimal control input such that is as close to the safe distance (3 meters in this paper) as possible. At the same time, and control input should be minimized within a finite time horizon . In this way, the considered optimal control problem of the targeting problem can be formulated as the follows:
| (6) | ||||
| s.t. |
where the terminal time is fixed; ; is the initial value of the state vector, which is known a priori; are the positive weights.
From (6), it can be inferred that the pitch angle is coupled with the translational position in the performance objective . Additionally, there exists severe nonlinear characteristics in this optimal control problem, owing to the coupled kinematics with the animal and the inherent nonlinearities of the quadrotor. Hence, this optimal control problem can neither be linearized nor be solved analytically. The general ways of solving a nonlinear optimal control problem is to solve it numerically with generic optimizers. Due to the coupled and nonlinear characteristics, directly solving this nonlinear optimal control problem with generic optimizers is time-consuming and cannot meet the real-time calculation requirements for real system.
III Efficient Egocentric Regulator
To tackle this issue, a novel method called Efficient Egocentric Regulator (EER) with high computational efficiency is proposed in this section, which peels off the nonlinearities from the optimal control problem (6), as shown in Fig. 3.
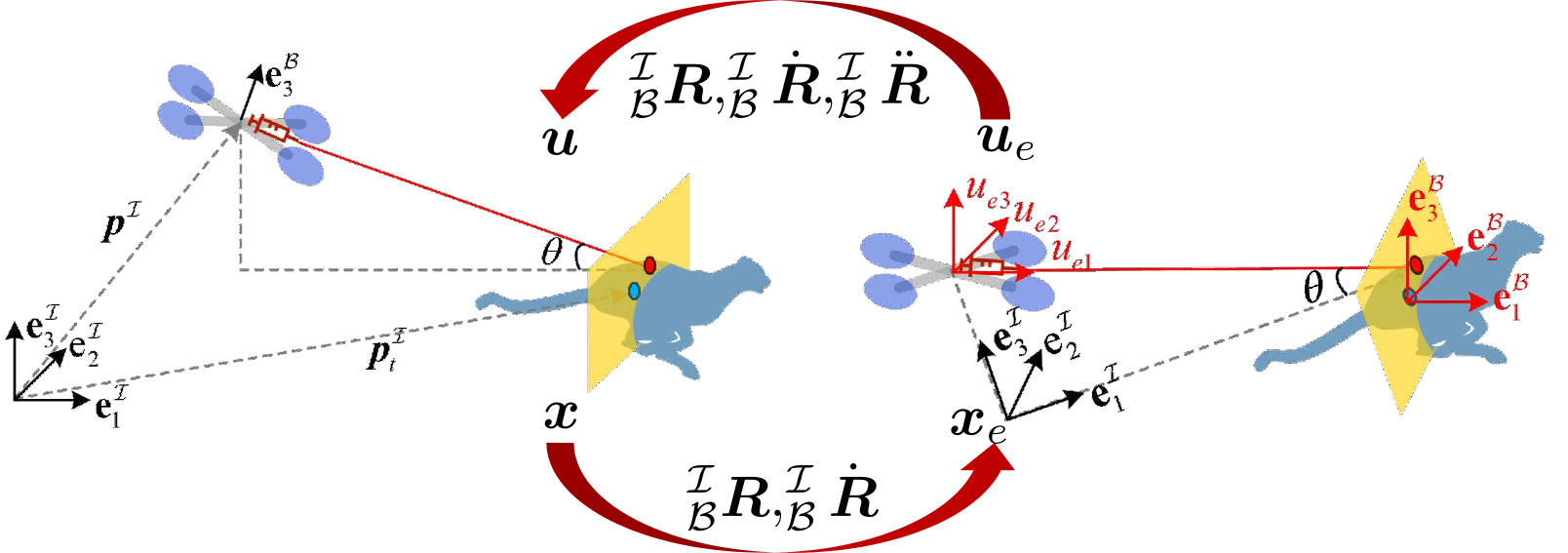
Firstly, a virtual coordinate parallel to the quadrotor’s instantaneous body coordinate is established while taking the desired-point as the origin. Then, the virtual position and the velocity of the quadrotor in virtual coordinate can be defined as . The virtual state and the virtual control input of the considered system in virtual coordinate can be defined as
| (7) |
where is a constant, denoted as the instantaneously desired position of ; , and are the accelerations in virtual coordinate along , .
Theoreom 1. The mapping of the feedback states and control inputs, between the inertial and virtual coordinates can be approximated as
| (8) |
where denotes the first six components of .
Proof.
It can be easily obtained that
| (9) |
where denotes the first three components of . Taking the first and second time derivative of Eq. (LABEL:transform1) gives
| (10) | ||||
Furthermore, it can be assumed that in each controller updating timestep. Substituting this assumption into Eq. (LABEL:transform1) and Eq. (10), one can then prove Theoreom 1. ∎
Theoreom 2. The optimal control input given by the proposed EER in inertial coordinate is
| (11) | ||||
where is the optimal acceleration in inertial coordinate , in which is a control gain matrix.
Proof.
Firstly, based on the definition in Eq. (7), the virtual system model can be established in a egocentric manner as:
| (12) |
with , . Based on this transformed model, the pitch angle is decoupled with the translational position and a fully actuated linear system with three inputs and three outputs is obtained. In addition, the nonlinearities of the system are peeled off and the separated nonlinear part can be compensated through a mapping of the feedback states and control inputs, between the inertial and virtual coordinates.
Then, it only needs to solve a linear quadratic optimization problem. For the targeting task, the goal is to design an optimal controller which minimizes the sum of the targeting error and input energy. Based on the virtual coordinate, a quadratic optimal control problem can be formulated as
| (13) | ||||
where denotes semi-definite diagonal state weighting matrix; is a positive definite diagonal control weighting matrix; is the initial state of . Then, by solving such a linear quadratic optimization problem, the optimal virtual control input can be obtained:
| (14) |
where can be obtained from the mapping given in Eq.(8); , is a positive constant matrix found by solving the continuous time algebraic Riccati equation . As and are constant, can be solved offline. In this work, to be consistent with the cost function given in Eq. (6), in is selected with , and it can be assumed as a constant in each controller updating timestep considering high computational efficiency. In practice, it is also feasible to directly select .
After calculating the optimal virtual control input, combined with Theoreom 1, the desired acceleration in inertial coordinate can be obtained as
| (15) |
Therefore, according to the system dynamics in Eq. (5), the optimal control input in inertial coordinate can be derived analytically as Theoreom 2. ∎
Corollary 1. When , the control of the EER in can be equivalent to a PD controller.
Proof.
According to the definition of , and , the control gain matrix can be rewritten as
| (16) |
where are two diagnoal matrixes.
Based on Eq. (8) and Eq. (15), one can obtain
| (17) | ||||
where denotes the first diagonal element of . Given the near hovering state, i.e., and according to Eq. (3), the optimal accelaration along can be given by
| (18) | ||||
where denote the second diagonal element of and , respectively; are the control gains. Therefore, it can be inferred that the control of the EER in can be equivalent to a PD controller. ∎
Remark 1. From corollary 1, it can be inferred that the position control along can be independent of the proposed EER control and then simplified as an independent PD control. In this case, the state variable can be reduced to 4 dimensions, and the dimensions of other parameters will also be reduced accordingly.
IV Numerical Evaluation
In this section, to verify the effectiveness of this work, numerical simulations are first carried out.
IV-A Generic optimizers
Generally, to directly tackle the optimal control problem in Eq. (6), there are two types of approaches, i.e., the indirect one and the direct one [21]. In this paper, for comparison, two representative methods are selected from each type, that is, the Gauss Pseudospectral Method[21, 22] and the Boundary Value Problem method [23].
IV-A1 Gauss pseudospectral method
Firstly, Legendre-Gauss (LG) points were selected as interpolation nodes and the values of the state and the control variables on LG points are regarded as unknown parameters. On this basis, the state and control trajectories are approximated using Lagrange interpolating polynomials and the system dynamics can be obtained in a discretized manner. Furthermore, the continuous cost function of Eq. (6) is approximated using a Gauss quadrature. Then, the optimal control problem can be transformed into a nonlinear programming problem (NLP). Due to the space limitation, the specific discretization process of the optimal trajectory control problem via GPM is omitted here. Detailed principles of GPM can be found in [21, 22]. The resulting transcribed NLP via GPM can be written as follows:
| (19) | ||||
where is the Gauss weight vector; is the discretized vector, composed of all values of at LG points; Similarly, , denotes the discretized vector of ; is an all-one vector; denotes element-wise square; is the differential approximation matrix; denotes -th component of ; for simplicity, the multiplication of two vectors denotes the Hadamard product , which is the element-wise product.
Thus, the transcribed problem is still a nonlinear programming problem and can be solved using any Non-linear Programming (NLP) solver. The calculated control input will then be sent to the quadrotor to drive the quadrotor to target the moving animal.
IV-A2 Boundary Value Problem
This method transforms the optimal problem into a boundary value problem via the calculus of variations. Then the boundary value problem can be solved (often numerically) for extremal trajectories.
However, due to the severe nonlinearities, this method cannot be directly applied to solve the original optimal control problem in Eq.(6). It should be further assumed that the system is in the near hovering state (), such that . In this case, the optimal problem can be reformulated as
| (20) | ||||
| s.t. |
where ; . Firstly, by applying the Lagrange multiplier method, the augmented performance objective can be constructed as
| (21) |
where is the costate vector. Then, via the calculus of variations, the optimal control input can be generated as
| (22) | ||||
in which denotes -th component of ; and can be calculated by solving the following boundary value problem via well-developed numerical algorithms.
| (23) | ||||
where
, is -th component of .
IV-B Evaluation Environment Setup
The simulation is implemented on a desktop computer with an Intel Core i7-10700 CPU running at 2.9GHz, with 16GB of RAM. It runs on a Linux (Ubuntu 18.04) operating system and is constructed in a physically realistic environment.
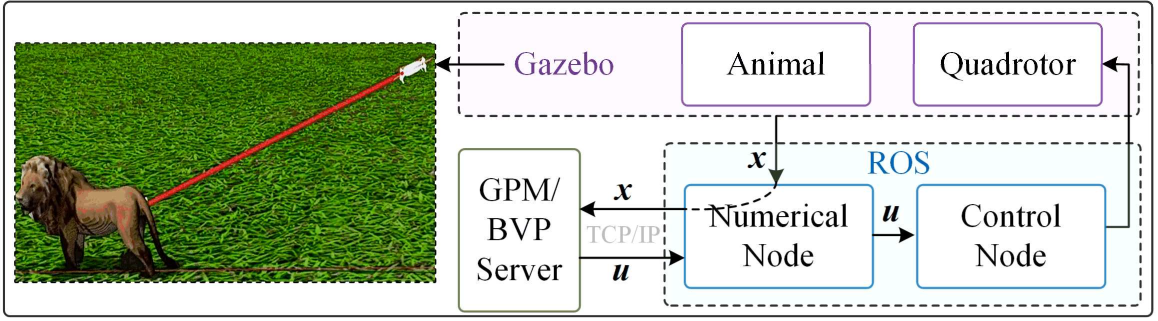
The implemented structure of this simulation environment is illustrated in Fig. 4. The quadrotor and animal dynamics are implemented in the Gazebo environment. The numerical node is utilized to calculate the optimal control input via the received state in Python. The control node is implemented in C++ to calculate the optimal control input and then control the quadrotor at a frequency of 50 Hz. Both control node and numerical node are implemented within the Robot Operating System (ROS).
To further increase the computational efficiency of the generic optimizers, the following three acceleration techniques are adopted.
1) The optimal control computations of generic optimizers are separately running on GPM/BVP server, which is accelerated by Numba 0.51.2 of Python. In such a case, the numerical node of generic optimizers only serves to forward the message and is bridged with GPM/BVP server by TCP/IP.
2) The calculations of the generic optimizers are combined with warm-starting [24], i.e., initializing using the estimate from the previous calculation results.
3) In the following simulations and experiments, to reduce the computing complexity of the generic optimizers, the position of the quadrotor along is separately controlled by PD controller as the proposed EER does.
In all of the following simulation tests, the EER and generic optimizers are implemented as follows:
1) EER: with the trial and error approach, the two weighting matrices in the EER are selected as . The position control gains along are .
2) Generic optimizers: the terminal time is selected as ; the weighting gains are chosen as ; the number of LG points in GPM is chosen as . The position control gains along are the same as the EER. Boundary value problem in BVP and the NLP in GPM are solved with scipy.integrate.solvebvp and scipy.minimize in Python 3.6, respectively.
IV-C Simulation Tests
In this section, two cases are carried out on the desktop computer to investigate the targeting performance and computational efficiency of the designed method.
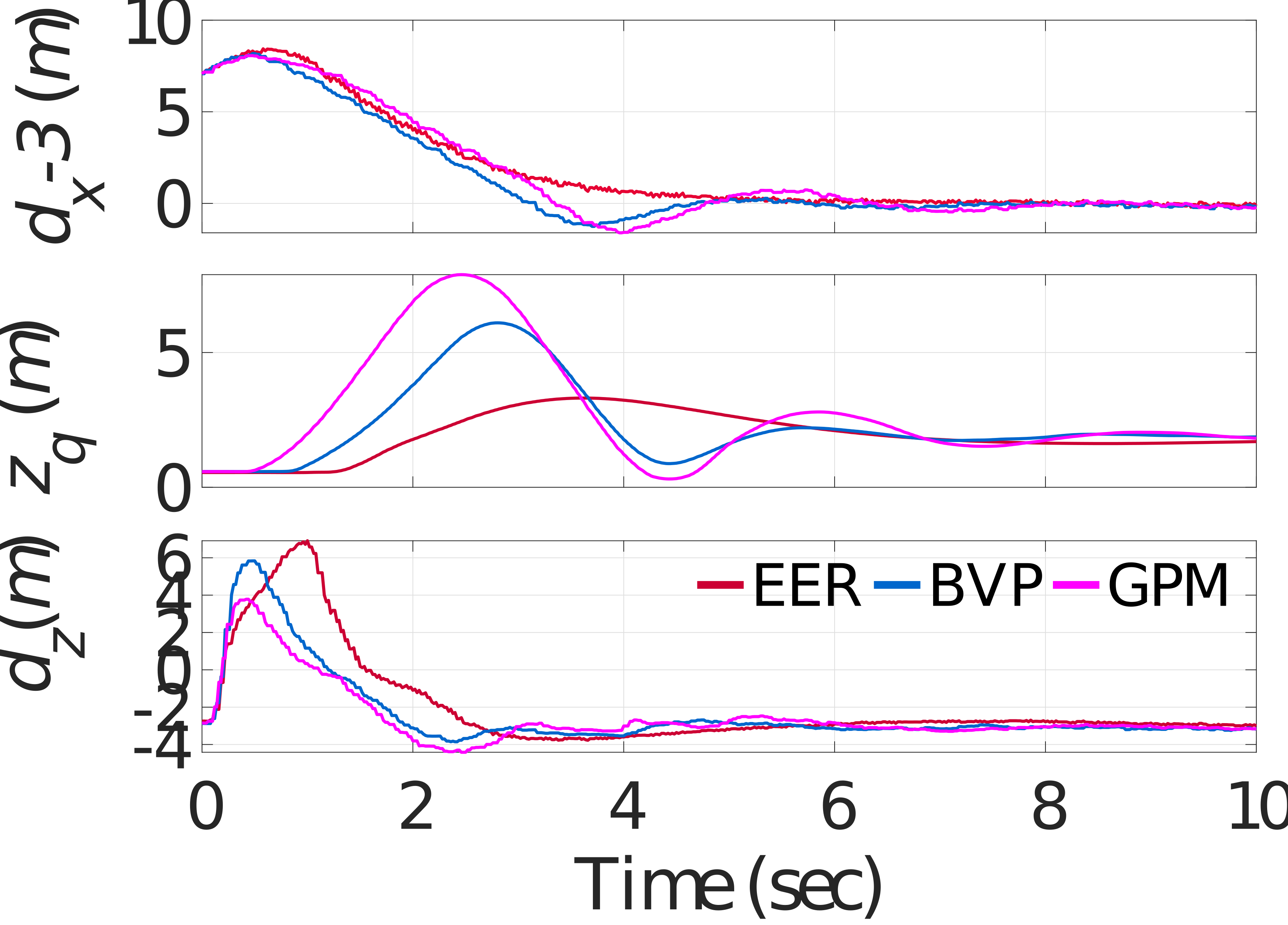
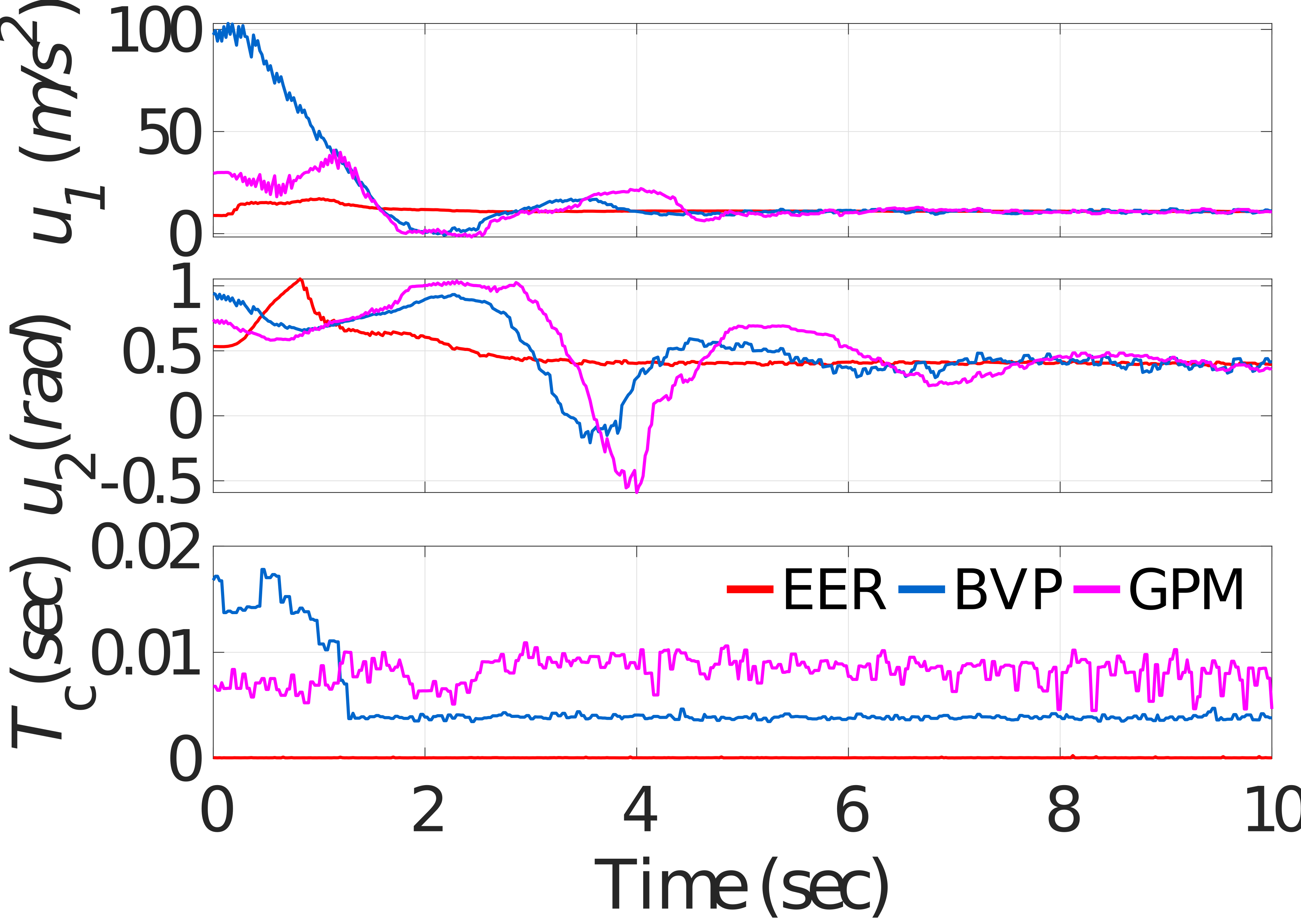
Case 1: A first test is conducted, where the animal is moving along at a constant speed, i.e., , and the height of the targeted-point is 0.61m. At the initial moment, the animal is located at the origin and the quadrotor is hovering at . The comparative targeting results are depicted in Fig. 5, where represents the computation time in each controller updating timestep. Because the positions along of the compared methods are all controlled by the PD controller, there exists little difference in targeting performance between different methods in . Therefore, is omitted in the figure. The average computation times of EER, BVP and GPM are 0.07 ms, 3.88 ms, 8.40 ms, respectively. It can be seen that the computational efficiency of the EER is on the order of 120 times faster than GPM. The result can be interpreted as follows. For the generic optimizers, severe nonlinearities of the considered problem deteriorate the computational efficiency. In contrast, for the EER, the severe nonlinear characteristics is peeled off and only a quadratic optimal control problem is required to be solved. In such a case, the control input is generated analytically, which provides excellent profits for high computational efficiency.
Furthermore, it can also be noted that large overshooting and strong oscillation of appears in generic optimizers. While with the EER, the height of the quadrotor converges relatively smoothly and fast without overshooting. The reasons for this phenomenon lie in two aspects. Firstly, for the EER, thanks to its high computational efficiency, the control action can be updated in real-time and thus presents a smooth characteristic as shown in Fig. 5. In contrast, for generic optimizers, the long computation time leads to the trembling and discontinuity of the control inputs, deteriorating the targeting performance. Secondly, for the generic optimizers, according to Eq. (6), the vertical position of the quadrotor is coupled with the translational position as well as the pitch angle in the performance objective. Therefore, cannot be constrained directly by the performance objective. On the contrary, the pitch angle and the translational position decoupled in the EER. Therefore, the vertical position of the quadrotor can be well constrained by the performance objective in a reasonable range. In this case, no oscillation, smaller overshooting as well as fast convergence appear in when utilizing the proposed EER to target the animal.
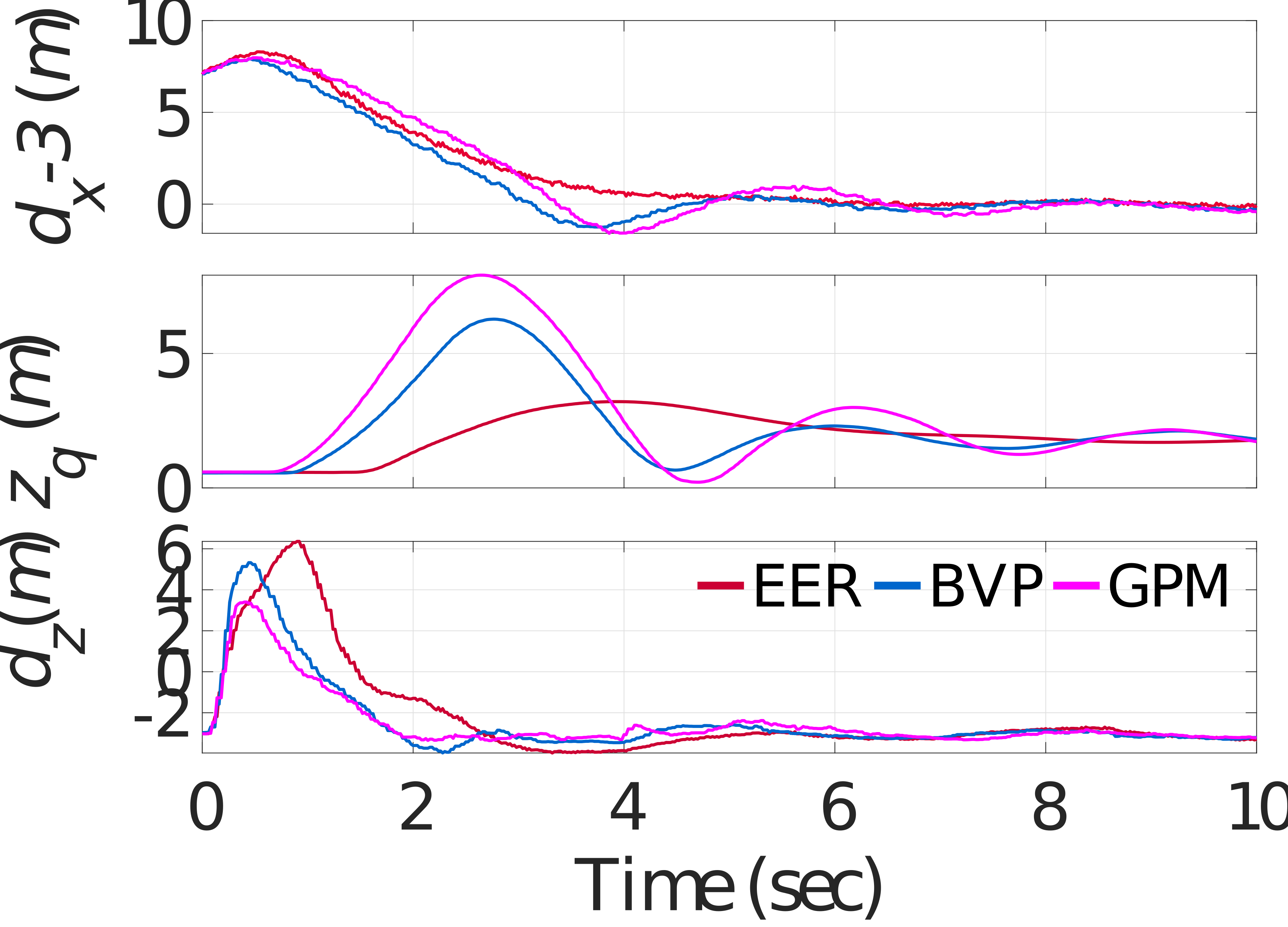
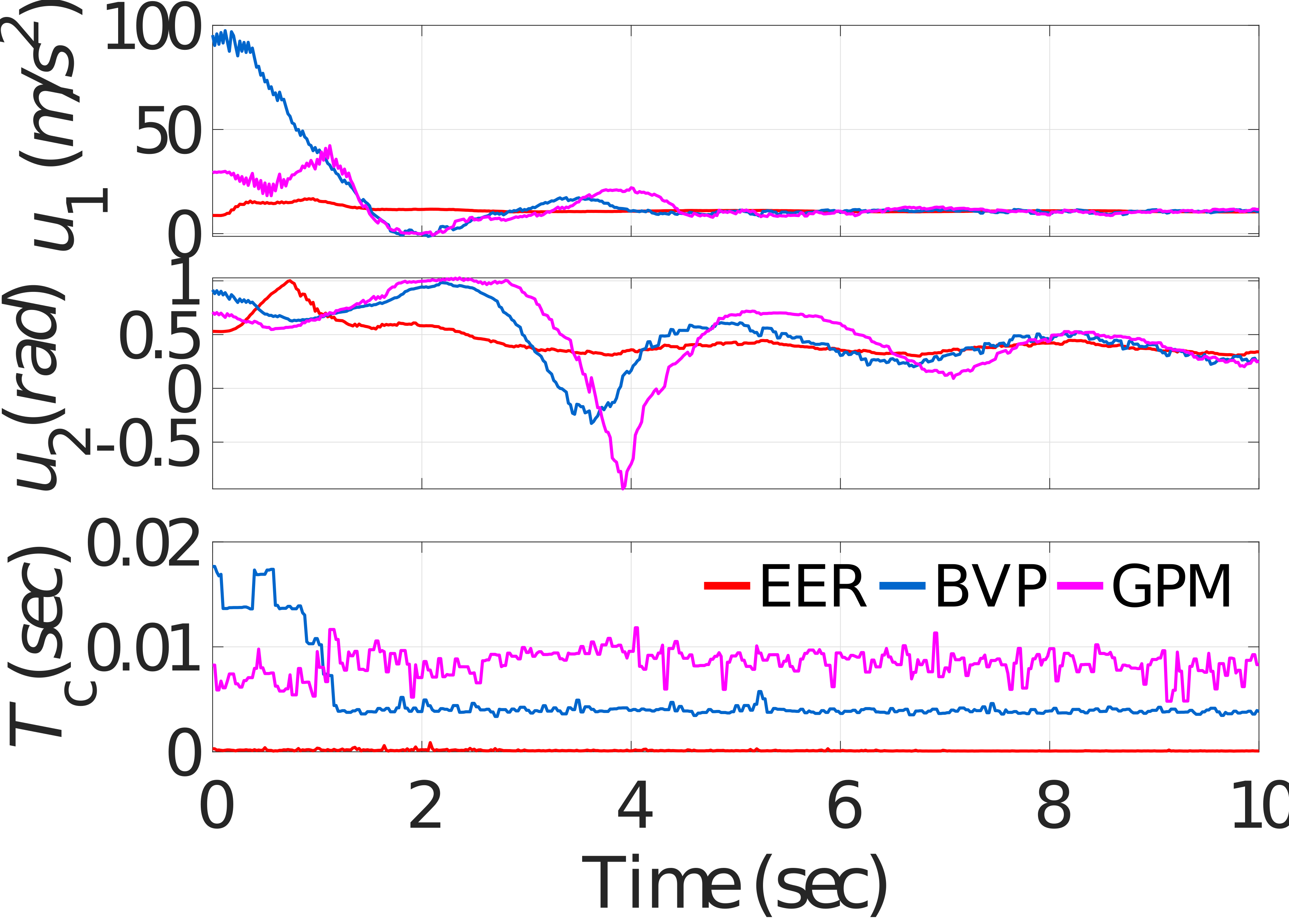
Case 2: The second test is then carried out when the velocity of the animal is time-varying. Specifically, the animal’s speed is sinusoidal at a frequency of 0.5 Hz, ranging from 2.6 to 3. Similar to case 1, the quadrotor is hovering at and the animal is located at the origin initially. The targeting result is illustrated in Fig. 6. In this case, the average computation times of EER, BVP, and GPM are 0.1 ms, 3.95 ms, 8.57 ms, respectively. It can be seen that the computational efficiency of the EER is on the order of 85.7 times faster than GPM. It should be mentioned that the computation time of the same approach under the two cases is slightly different. This fluctuation in computation time is affected by some other parallel tasks executing on the desktop computer.
Additionally, in steady-state, the oscillations of in the generic optimizers are larger than that in case 1. By comparison, for the EER, the vertical position of the quadrotor could also provide comparatively excellent performance. This result can be interpreted as follows. Thanks to the high computational efficiency of the proposed EER, it is reasonable to treat the animal’s velocity as a constant at each controller updating timestep in the system modeling. Therefore, the time-varying characteristic of the animal’s velocity has little effect on targeting performance in the EER. For the generic optimizers, due to the long computation time, assuming the animal velocity as a constant will lead to large modeling errors and worsen the targeting performance when the animal speed is time-varying.
V Experiment
In order to testify the feasibility of EER in practical application, real-time mimic biological experiments are carried out in this section.
V-A Experimental Setup
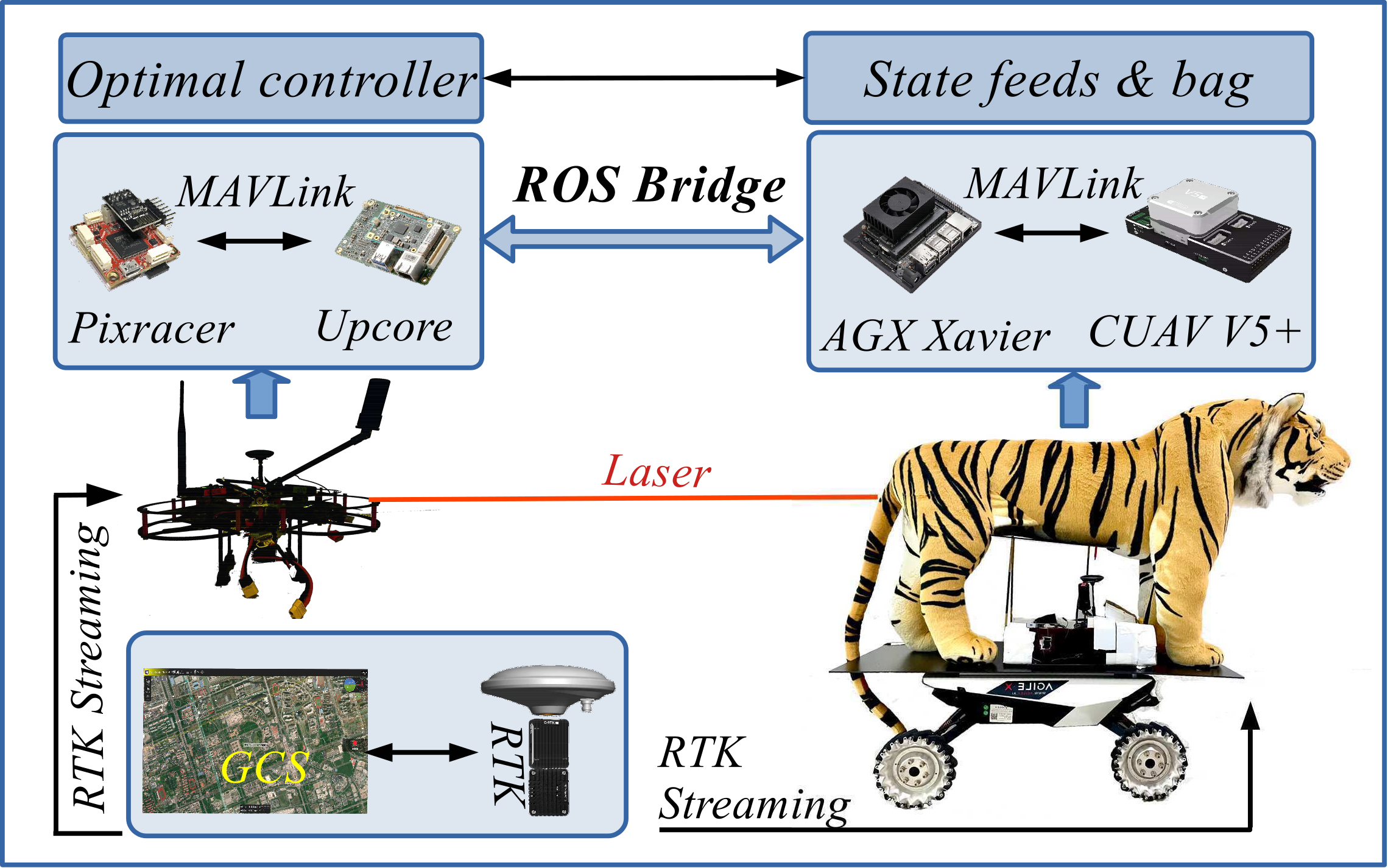
A mimic biological experimental test-bed is developed to verify the developed EER for the targeting task, as shown in Fig. 7. This test-bed consists of a quadrotor, a targeted animal and a Ground Control System (GCS). The airframe is a custom-developed quadrotor that weighs 1.98kg. Its attitude is controlled with an open-source controller Pixracer®, which mainly adopts the cascaded PID control technique. All control methods are implemented in an onboard computer, namely the Up-core®, and it communicates with the Pixracer® by MAVLink. The targeted animal is mounted on a small car, which is controlled by a remote controller.
The position and velocity of the quadrotor, as well as the targeted animal, is estimated by the Real-time Kinematic positioning(RTK). The RTK is a differential GNSS technique which provides centimeter accuracy in the vicinity of a base station. In addition, an LIDAR-Lite v3® is implemented to estimate the altitude of the quadrotor accurately. The quadrotor obtains the position of the targeted animal via a ROS bridge. The detailed implementations of the positioning system of the targeted animal are as follows: 1) The Ground Control System (GCS) first receives the messages from RTK, and then transmits them to CUAV V5+® by radio. 2) Then, the CUAV V5+® accepts the messages, and sends them to the NVIDIA® Jetson AGX Xavier by MAVROS. 3) AGX Xavier publishes the position and velocity of the targeted animal by ROS, and the ROS implemented on the Up-core of the quadrotor can subscribe to the messages.
In all of the following experiments, with a trial and error approach, the two weighting matrices regarding the developed EER are tuned as follows: . The control gains of BVP and GPM are selected as . The selection of the other parameters in optimizations is consistent with the simulation.
V-B Experimental Results
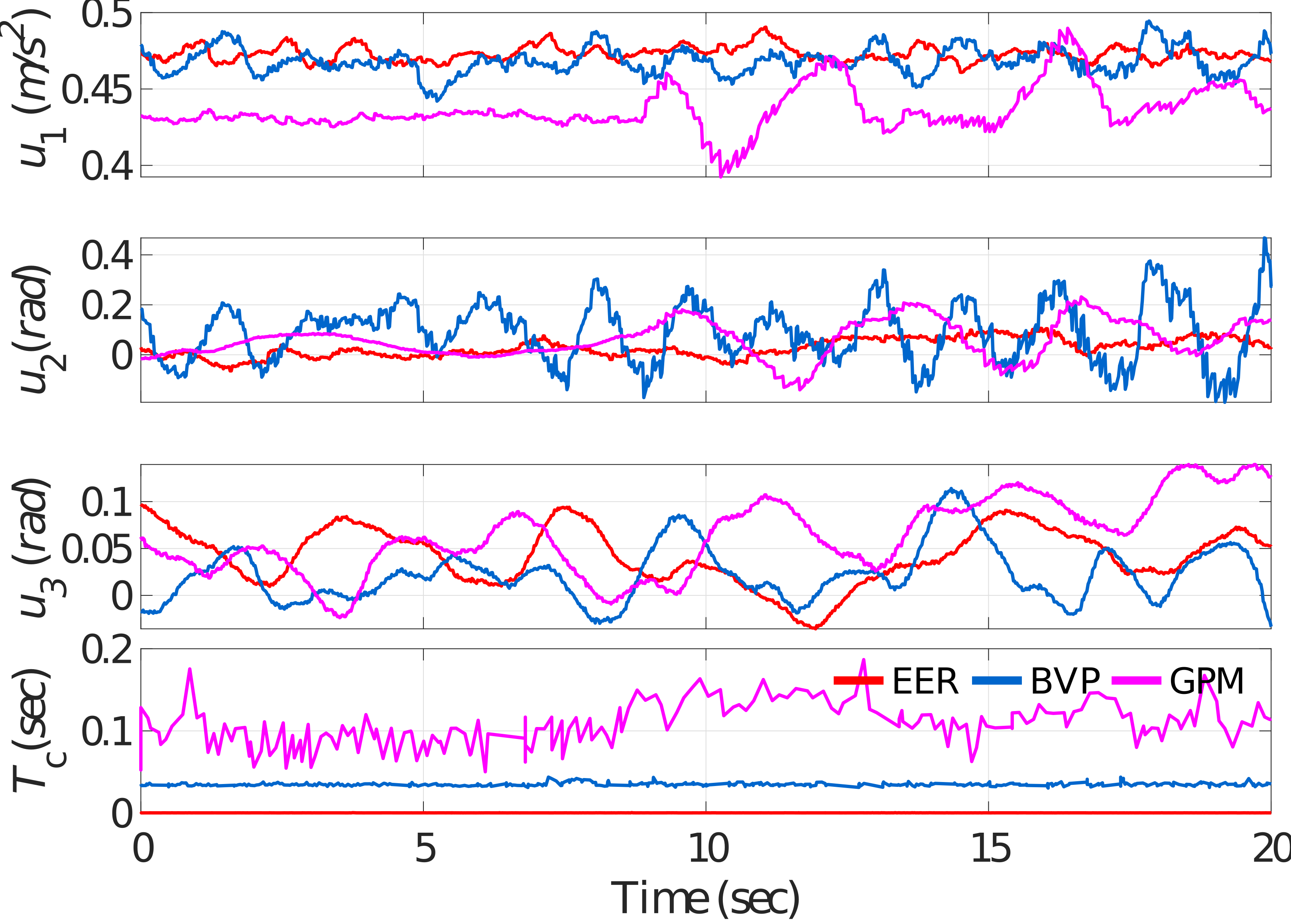
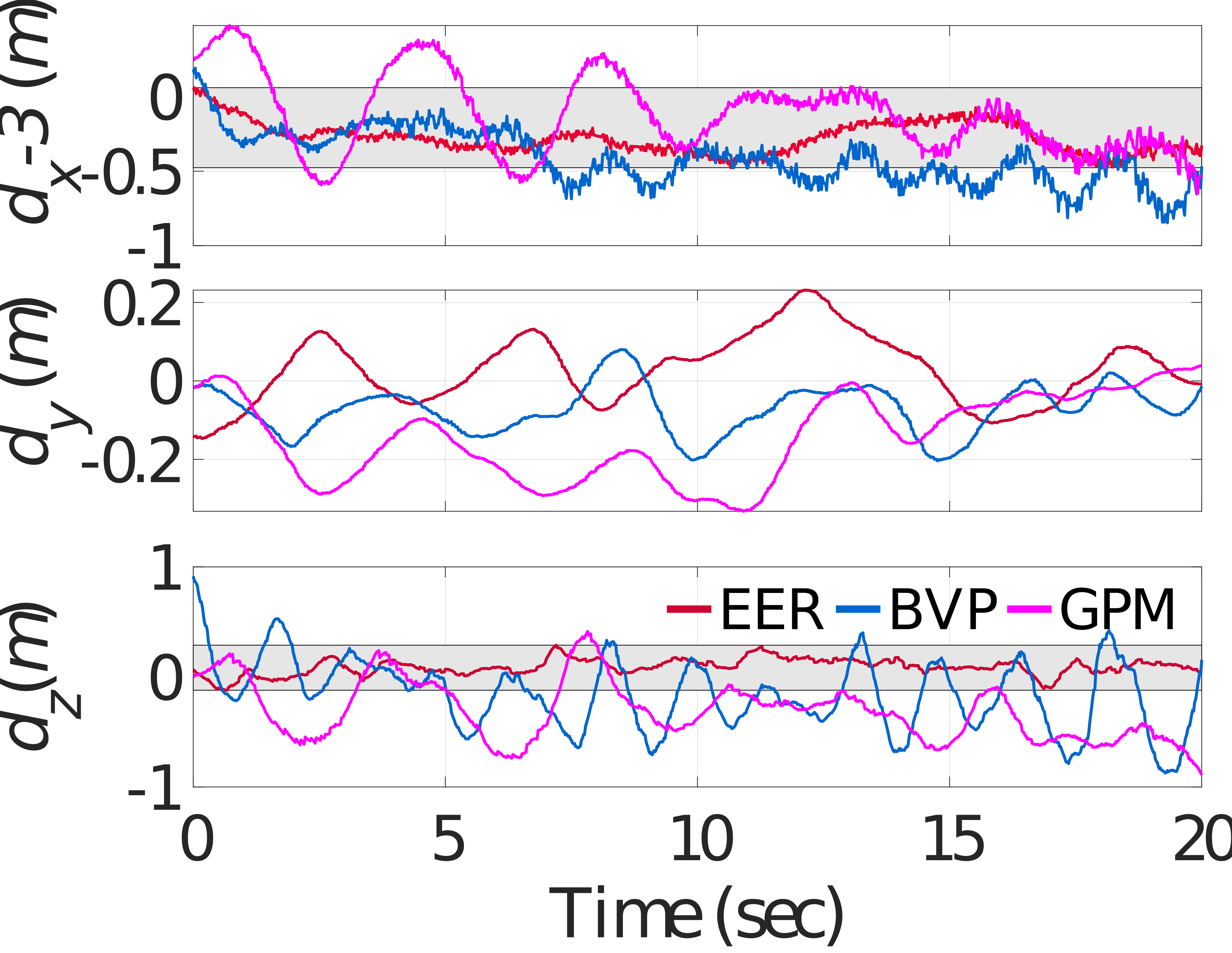
A first test is conducted, where the animal is located at the origin and the quadrotor is hovering at at the initial moment. The height of the desired point is 0.7 m and it then moves along . Its speed increases from 0 to about 1.5 with nearly a uniform acceleration. The comparative targeting results are depicted in Fig. 8 and Fig. 9.
Fig. 8 depicts the control inputs and the computational time of the EER, BVP, and GPM. In this case, the average computation times of EER, BVP, and GPM are 0.27 ms, 38.12 ms, 108.87 ms, respectively. It can be seen that the EER can compute the control action on the order of 400 times faster than GPM on Up Core® at least. Particularly, EER can achieve a control frequency of thousands of hertz. Compared with the simulation, we can find that the computational efficiency of the EER is stabler than the generic optimizers on different platforms. To be specific, the computation time of the EER in the experiment is similar to that in simulation, while the computation time of the BVP and GPM is about tens or even hundreds of milliseconds slower than in simulation.
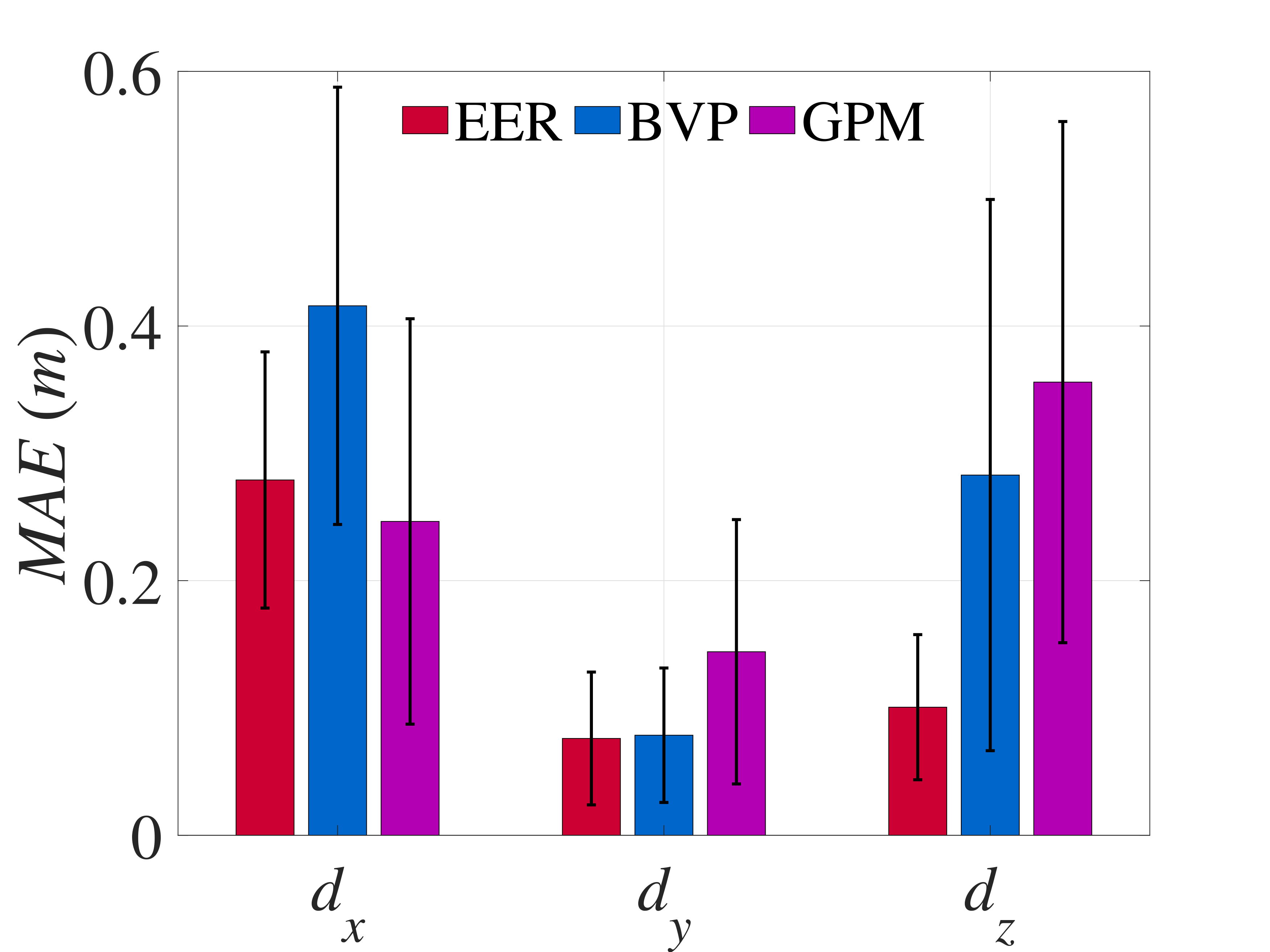
Fig. 9 illustrates the targeting error and the mean absolute error (MAE) of the three compared methods. Compared with the simulation, it can be inferred that in the experiment, the superiority of EER compared to the generic optimizers regarding targeting performance is more obvious. Specifically, the MAE of with EER are smaller than those with the generic optimizers. In addition, regarding , EER presents relatively smaller oscillation than generic optimizers, as shown in Fig. 9(a). This phenomenon can be interpreted as follows. Compared to the Gazebo environment, there exists inherent time delay and various unknown disturbances in the real system, and the processing capability of the onboard computer is not as good as that of the desktop computer in the simulation. Besides, the fluctuation of the animal’s velocity is larger than that of the simulation, leading to a larger modeling error in generic optimizers. In such a case, the computational efficiency in the real experiment is a more crucial issue than that in the simulation. However, due to severe nonlinearities of this optimal problem, generic optimizers cannot solve this problem with sufficient computational efficiency on the onboard computers, leading to a long time delay in the state feedback. Therefore, the targeting performance of the generic optimizers is worse than that of the proposed EER. The above results effectively demonstrate the significance of the computational efficiency for this targeting problem.
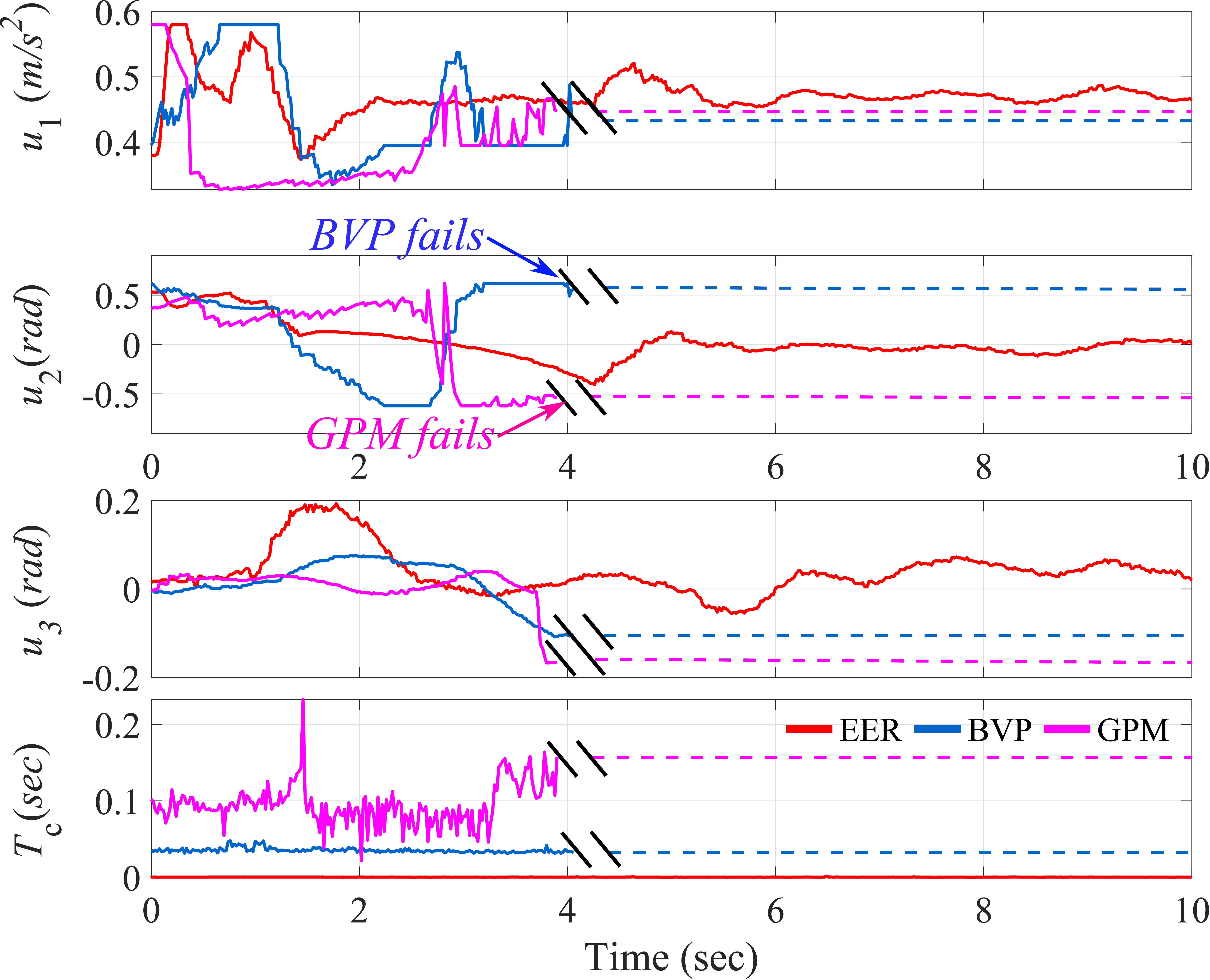
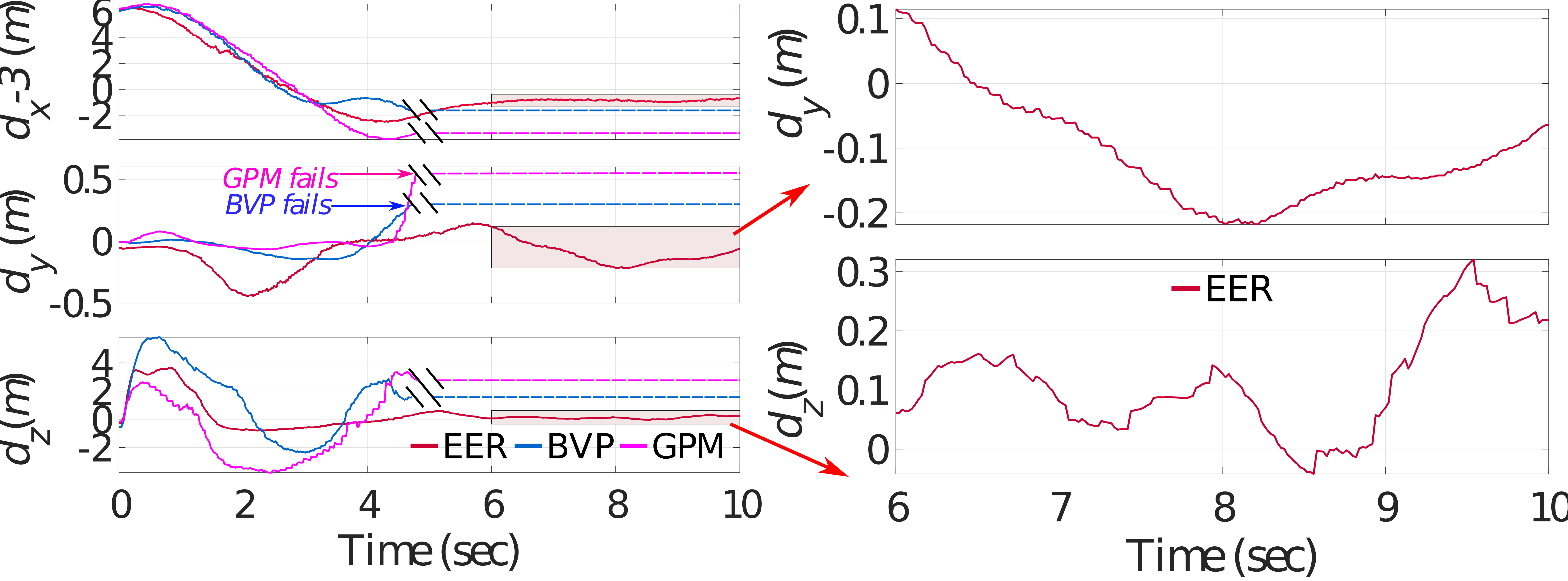
The second test is conducted, where the quadrotor is targeting a moving animal at a long distance. The animal is moving at speed close to 1.0 along and is 9 away from the quadrotor. In the experiment, it can be observed that with the generic optimizers, the quadrotor flies very high and oscillates up and down, finally directly collides the animal or crash into the ground. Fig. 10 and Fig. 11 depict the comparative results, where the double slash denotes the crash time.
In Fig. 10, the control input and computation time of the proposed EER and generic optimizers are illustrated. The average computation time of EER, BVP, and GPM from 0 to 4.60 are 0.29 ms, 35.40 ms, 100.1 ms, respectively. It can be seen that the computational efficiency of the EER is on the order of 345 times faster than GPM. It can be seen that the generic optimizers fail around 4.6 s. This is because the tiger has speed at the initial moment and the initial error is large. Therefore, the targeting task in this case has higher real-time requirements. Due to the low computational efficiency of the generic optimizers, they cannot adjust the targeting error in time and leads to the crash.
Fig. 11 shows the compared targeting error. It should be stated that the targeting performance in and is mainly concerned, so the zoomed views of them are given particularly. Even in such a case, with the EER, the quadrotor quickly catches up with the animal with small oscillation and overshooting. Furthermore, after the system reaches a steady state, the proposed presents excellent targeting performance again. Particularly, the targeting error of is between -0.2 and 0.1, and the targeting error of is between -0.1 and 0.3, which can ensure the completion of the targeting task.
All the aforementioned simulation and experimental results demonstrate that the proposed EER has high computational efficiency either on a powerful desktop computer or an onboard computer and can achieve the best targeting performance than those of the generic optimizers.
VI Conclusion
In this paper, in order to continuously target a moving animal with a highly underactuated quadrotor, an efficient egocentric regulator is proposed. This strategy directly constructs the optimal tracking problem in an egocentric manner with regard to the quadrotor’s body coordinates and peels off the system nonlinearities through a mapping of the feedback states as well as control inputs, between the inertial and body coordinates. In this way, only a quadratic performance objective with linear constraint is required to be solved with an analytic evaluation. To verify the advantages and computational efficiency of the proposed strategy, mimic biological simulations and experiments are first carried out. Results demonstrate that the proposed EER can achieve faster convergence and smaller overshooting than those of the generic optimizers and its computational efficiency is highest and stablest than generic optimizers on different platforms. Particularly, on the onboard computer, the computation time of the EER is about 0.3 ms, which is on the order of 350 times faster than generic nonlinear optimizers and can accomplish a control frequency of thousands of hertz. In view of these convincing results, the development of this work is able to effectively enhance the computational efficiency for continuous targeting problems of quadrotors in practice.
References
- [1] O. M. Cliff, D. L. Saunders, and R. Fitch, “Robotic ecology: Tracking small dynamic animals with an autonomous aerial vehicle,” Science Robotics, vol. 3, no. 23, p. eaat8409, 2018.
- [2] K. Shah, G. Ballard, A. Schmidt, and M. Schwager, “Multidrone aerial surveys of penguin colonies in antarctica,” Science Robotics, vol. 5, p. eabc3000, 2020.
- [3] A. Farinha, R. Zufferey, P. Zheng, S. F. Armanini, and M. Kovac, “Unmanned aerial sensor placement for cluttered environments,” IEEE Robotics and Automation Letters, vol. PP, no. 99, pp. 1–1, 2020.
- [4] J. Dodd, “Zoo animal and wildlife immobilization and anesthesia,” Canadian Veterinary Journal, vol. 51, p. 622, 2010.
- [5] K. Mohammadi, S. Sirouspour, and A. Grivani, “Control of multiple quad-copters with a cable-suspended payload subject to disturbances,” IEEE/ASME Transactions on Mechatronics, vol. 25, no. 4, pp. 1709–1718, 2020.
- [6] V. P. Tran, F. Santoso, M. A. Garratt, and I. R. Petersen, “Adaptive second-order strictly negative imaginary controllers based on the interval type-2 fuzzy self-tuning systems for a hovering quadrotor with uncertainties,” IEEE/ASME Transactions on Mechatronics, vol. 25, no. 1, pp. 11–20, 2020.
- [7] G. Chen, W. Dong, X. Sheng, X. Zhu, and H. Ding, “An active sense and avoid system for flying robots in dynamic environments,” IEEE/ASME Transactions on Mechatronics, vol. 26, no. 2, pp. 668–678, 2021.
- [8] M. W. Mueller, M. Hehn, and R. D’Andrea, “A computationally efficient algorithm for state-to-state quadrocopter trajectory generation and feasibility verification,” in 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, 2013, pp. 3480–3486.
- [9] W. Dong, G. Y. Gu, Y. Ding, X. Zhu, and H. Ding, “Ball juggling with an under-actuated flying robot,” in IEEE/RSJ International Conference on Intelligent Robots & Systems, 2015, pp. 68–73.
- [10] B. T. Hu and S. Mishra, “A time-optimal trajectory generation algorithm for quadrotor landing onto a moving platform,” in 2017 American Control Conference, 2017, pp. 4183–4188.
- [11] B. Hu and S. Mishra, “Time-optimal trajectory generation for landing a quadrotor onto a moving platform,” IEEE/ASME Transactions on Mechatronics, pp. 1–1, 2019.
- [12] C. Richter, A. Bry, and N. Roy, “Polynomial trajectory planning for quadrotor flight,” in International Conference on Robotics and Automation, 2013, pp. 69–88.
- [13] G. M. Hoffmann, S. L. Waslander, and C. J. Tomlin, “Quadrotor helicopter trajectory tracking control,” in 2008 AIAA Guidance, Navigation and Control Conference and Exhibit, 2008, pp. 1–14.
- [14] I. D. Cowling, O. A. Yakimenko, J. F. Whidborne, and A. K. Cooke, “A prototype of an autonomous controller for a quadrotor uav,” in Proceedings of the European Control Conference, 2007, pp. 1–8.
- [15] Y. Bouktir, M. Haddad, and T. Chettibi, “Trajectory planning for a quadrotor helicopter,” 2008, p. 1258–1263.
- [16] R. Sandeepkumar and R. Mohan, “Proceedings of the advances in robotics 2019,” in Flatness-based model predictive control of six degree of freedom fixed-wing UAV, 2019, pp. 1–6.
- [17] M. Greeff and A. P. Schoellig, “Flatness-based model predictive control for quadrotor trajectory tracking,” in 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems, 2018, pp. 6740–6745.
- [18] Z. T. Dydek, A. M. Annaswamy, and E. Lavretsky, “Adaptive control of quadrotor uavs: A design trade study with flight evaluations,” IEEE Transactions on Control Systems Technology, vol. 21, no. 4, pp. 1400–1406, 2013.
- [19] W. Dong, G. Y. Gu, X. Y. Zhu, and H. Ding, “High-performance trajectory tracking control of a quadrotor with disturbance observer,” Sensors and Actuators a-Physical, vol. 211, pp. 67–77, 2014.
- [20] T. Luukkonen, “Modelling and control of quadcopter,” Independent research project in applied mathematics, Espoo, vol. 22, p. 22, 2011.
- [21] D. A. Benson, G. T. Huntington, T. P. Thorvaldsen, and A. V. Rao, “Direct trajectory optimization and costate estimation via an orthogonal collocation method,” Journal of Guidance, Control, and Dynamics, vol. 29, no. 6, pp. 1435–1440, 2006.
- [22] A. V. Rao, D. A. Benson, C. Darby, M. A. Patterson, C. Francolin, I. Sanders, and G. T. Huntington, “Algorithm 902: Gpops, a matlab software for solving multiple-phase optimal control problems using the gauss pseudospectral method,” ACM Transactions on Mathematical Software, vol. 37, no. 2, pp. 1–39, 2010.
- [23] A. Rao, “A survey of numerical methods for optimal control,” Advances in the Astronautical Sciences, vol. 135, 2010.
- [24] Y. Wang and S. Boyd, “Fast model predictive control using online optimization,” IEEE Transactions on Control Systems Technology, vol. 18, pp. 267–278, 2010.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/88d5f516-05e5-47b8-b256-0bc889e693e6/Fig-bio-zyLin.png) |
Ziying Lin received the B.S. degree in mechanical engineering from Nanjing University of Science and Technology, Nanjing, China, in 2019. She is currently a Ph.D. candidate in the School of mechanical and engineering, Shanghai Jiao Tong University, China. Her research focuses on cooperation and control of unmanned system. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/88d5f516-05e5-47b8-b256-0bc889e693e6/Fig-bio-wdong.png) |
Wei Dong received the B.S. degree and Ph.D. degree in mechanical engineering from Shanghai Jiao Tong University, Shanghai, China, in 2009 and 2015, respectively. He is currently an associate professor in the School of Mechanical Engineering, Shanghai Jiao Tong University. His research interests include cooperation, perception and agile control of unmanned system. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/88d5f516-05e5-47b8-b256-0bc889e693e6/Fig-bio-ssLiu.png) |
Sensen Liu received the B.S. degree in mechanical engineering from Tongji University, Shanghai, China, in 2016. He is currently a Ph.D. candidate in the School of mechanical and engineering, Shanghai Jiao Tong University, China.His research focuses on aerial manipulation, gripper design, planning and control of unmanned aerial vehicles manipulation system. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/88d5f516-05e5-47b8-b256-0bc889e693e6/Fig-bio-xjsheng.png) |
Xinjun Sheng received the B.Sc., M.Sc.,and Ph.D. degrees in mechanical engineering from Shanghai Jiao Tong University, Shanghai, China, in 2000, 2003, and 2014, respectively. He is currently a Professor in the School of Mechanical Engineering, Shanghai Jiao Tong University. His current research interests include robotics, and bio-mechatronics. Dr. Sheng is a Member of the IEEERAS, the IEEEEMBS,and the IEEEIES. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/88d5f516-05e5-47b8-b256-0bc889e693e6/Fig-bio-xyzhu.png) |
Xiangyang Zhu received the B.S. degree from the Department of Automatic Control Engineering, Nanjing Institute of Technology, Nanjing, China, in 1985, the M.Phil. degree in instrumentation engineering and the Ph.D. degree in control engineering, both from Southeast Engineering, in 1989 and 1992, respectively. Since June 2002, he has been with the School of Mechanical Engineering, Shanghai Jiao Tong University, Shanghai, China, where he is currently a chair professor and the director of the Robotics Institute. His research interests include robotic manipulation planning, neuro-interfacing and neuro-prosthetics, and soft robotics. Dr. Zhu has received a number of awards including the National Science Fund for Distinguished Young Scholars from NSFC in 2005, and the Cheung Kong Distinguished Professorship from the Ministry of Education in 2007. He is serving on the editorial board of IEEE Transactions on Cybernetics and Journal of Bionic Engineering. |