An Efficient and Exact Algorithm for Locally -Clique Densest Subgraph Discovery
Abstract.
Detecting locally, non-overlapping, near-clique densest subgraphs is a crucial problem for community search in social networks. As a vertex may be involved in multiple overlapped local cliques, detecting locally densest sub-structures considering -clique density, i.e., locally -clique densest subgraph (LCDS) attracts great interests. This paper investigates the LCDS detection problem and proposes an efficient and exact algorithm to list the top- non-overlapping, locally -clique dense, and compact subgraphs. We in particular jointly consider -clique compact number and LCDS and design a new “Iterative Propose-Prune-and-Verify” pipeline (IPPV) for top- LCDS detection. (1) In the proposal part, we derive initial bounds for -clique compact numbers; prove the validity, and extend a convex programming method to tighten the bounds for proposing LCDS candidates without missing any. (2) Then a tentative graph decomposition method is proposed to solve the challenging case where a clique spans multiple subgraphs in graph decomposition. (3) To deal with the verification difficulty, both a basic and a fast verification method are proposed, where the fast method constructs a smaller-scale flow network to improve efficiency while preserving the verification correctness. The verified LCDSes are returned, while the candidates that remained unsure reenter the IPPV pipeline. (4) We further extend the proposed methods to locally more general pattern densest subgraph detection problems. We prove the exactness and low complexity of the proposed algorithm. Extensive experiments on real datasets show the effectiveness and high efficiency of IPPV.
1. Introduction
Finding dense subgraphs can uncover highly connected and cohesive structures in graphs, making it an effective tool for understanding complex systems. The discovery of dense subgraphs and communities has numerous applications in diverse fields including social networks (Chen and Saad, 2012; Tsourakakis et al., 2013; Gibson et al., 2005), web analysis (Gionis et al., 2013; Angel et al., 2012), graph databases (Jin et al., 2009; Zhao and Tung, 2012), and biology (Saha et al., 2010; Li et al., 2022). In these applications, the identification of near-clique subgraphs holds significant importance, as it relaxes the requirement of complete connectivity within cliques and allows for a certain degree of sparsity or missing connections while still maintaining a high level of connectivity.
Given the importance of detecting large near-clique subgraphs (Tsourakakis, 2015), the -clique densest subgraph (CDS) problem that finds near-cliques formed by overlapping cliques has attracted great research attention (Tsourakakis, 2015; Mitzenmacher et al., 2015; Fang et al., 2019; Sun et al., 2020). This is due to the fact that a vertex is generally involved in multiple overlapping cliques, such as a person may be involved in cliques as family members, office mates, etc (Palla et al., 2005). By finding the subgraph with the highest density of -cliques, CDS uncovers the highly-connected component that exhibits strong internal interactions (Benson et al., 2016; Spirin and Mirny, 2003; Liu et al., 2018). Whereas, in the context of the real world, the discovery of a single CDS offers limited insights. Listing the top- CDSes is desired, but due to the substantial overlap inherent in -cliques (Wang et al., 2013; Yuan et al., 2015), the vanilla top- CDSes may refer to the same dense region, still providing limited structural insights.
Therefore, detecting the top- non-overlapping, locally maximal, dense, and compact, i.e., locally -clique densest subgraphs (LCDS) attracts great interest. For example, Figure 1 shows the relationships between a subset of characters in “Harry Potter”. The top- and top- LCDSes are the blue and green subgraphs, respectively. The top- LCDS is a family named Weasley, and the top- LCDS is an organization named Death Eaters, which indicate the potential of LCDS discovery for mining diverse dense communities.

However, no efficient and exact algorithm is known for detecting LCDS yet. The closest work to LCDS discovery is the locally densest subgraph (LDS) discovery (Qin et al., 2015), which is a special case of LCDS with . But LDS only considers the density of edges, and it is challenging to generalize the techniques to arbitrary . Firstly, the -clique compactness is harder to evaluate, because the number of -cliques can be several orders of magnitude more than the number of edges. Secondly, an -clique spans over vertices, making the subgraph division more difficult. Thirdly, verification of LCDS is more complex than verifying LDS since the clique density and clique compactness are harder to evaluate and verify.
To address the above difficulties, we jointly consider the -clique compact number estimation and LCDS detection, so as to design a new iterative propose-prune-and-verify (IPPV) pipeline. IPPV is composed of the following iterative steps: (1) estimate bounds of -clique compact number to propose LCDS candidates efficiently; (2) use the bounds to prune vertices that are definitely not in any LCDS to narrow the candidate set; (3) use verification algorithm to ensure the exactness of IPPV for extracting LCDS; (4) remained candidates reenter the above steps until the top- LCDSes are found. To the best of our knowledge, this paper is the first to explore the LCDS detection. The key contributions of IPPV are as follows:
-
(1)
The initial -clique compact number bounds are proposed based on the structures of graphs, and we show that a convex programming, which provides -clique diminishingly dense decomposition, can be extended to tighten the bounds.
-
(2)
We propose a tentative graph decomposition method to deal with the case when a clique is spanning multiple subgraphs to generate correct decomposition proposals.
-
(3)
Efficient verification is the critical part since the verification is complex for verifying both the -clique density and -clique compactness. We propose a novel fast verification algorithm by carefully constructing a size-reduced flow network and using the maximum flow algorithm. We prove the correctness and efficiency of the proposed fast verification algorithm.
-
(4)
At last, we further extend the iterative propose-prune-and-verify pipeline to detect locally general pattern densest subgraphs. More than six patterns are investigated, showing the potential of detecting locally more general pattern densest subgraphs.
We theoretically verify the exactness and efficiency of the proposed algorithm and conduct extensive experiments with different quality measures on large real datasets to evaluate the algorithm.
2. related work
2.1. Densest Subgraph
The algorithms to the densest subgraph (DS) problem can be classified into two categories: exact algorithms and approximation algorithms. The DS problem can be solved in polynomial time by exact methods based on maximum flow, linear programming, or convex optimization. Picard et al. (Picard and Queyranne, 1982) and Goldberg (Goldberg, 1984) first introduced the maximum-flow-based exact algorithm for the densest subgraph problem. Charikar (Charikar, 2000) proposed an LP-based exact algorithm for the DS problem. The convex-optimization-based exact algorithm is proposed by Danisch et al. (Danisch et al., 2017) and can handle graphs containing tens of billions of edges. Fang et al. (Fang et al., 2019) improved the efficiency of the flow-based exact algorithm by locating the densest subgraph in a specific -core. Exact algorithms cannot scale well to large graphs, so a large number of works on faster approximation algorithms for the DS problem are also presented.
Charikar (Charikar, 2000) proposed a 2-approximation algorithm for the DS problem, which is known as the greedy peeling algorithm. Proving that the -core is a 2-approximation solution to the DS problem, Fang et al. (Fang
et al., 2019) improved the greedy peeling algorithm based on -core. Inspired by the multiplicative weights update method, Boob et al. (Boob et al., 2019) designed an iterative version of the greedy peeling algorithm. Based on the MapReduce model, Bahmani et al. (Bahmani
et al., 2012) proposed an -approximation algorithm, where . Based on the dual of Charikar’s LP relaxation, Harb et al. (Harb
et al., 2022) presented a new iterative algorithm for the DS problem. Chekuri et al. (Chekuri
et al., 2022) proposed a flow-based approximation algorithm for the DS problem.
The DS problem has various variants focusing on different aspects and different types of graphs. Two recent surveys (Lanciano et al., 2023; Luo
et al., 2023) detail different variations of the DS problem and their applications to different types of graphs, such as directed graphs (Charikar, 2000), labeled graphs (Fazzone et al., 2022), and uncertain graphs (Zou, 2013).
2.2. -clique Densest Subgraph
Tsourakakis (Tsourakakis, 2015) defined the notion of -clique density and introduced the -clique densest subgraph (CDS) problem. Mitzenmacher et al. (Mitzenmacher et al., 2015) presented a sampling scheme called the densest subgraph sparsifier, yielding a randomized algorithm that produces a well-approximate solution to the CDS problem. Fang et al. (Fang et al., 2019) proposed more efficient exact and approximation algorithms for the CDS problem. Sun et al. (Sun et al., 2020) aimed at developing near-optimal and exact algorithms for the CDS problem on large real-world graphs. They modified the Frank-Wolfe algorithm for CDS to their algorithm kClist++ and proved the effectiveness of the proposed algorithm.
2.3. Locally Densest Subgraph
The locally densest subgraph (LDS) problem is a variant of the densest subgraph (DS) problem. Qin et al. (Qin et al., 2015) proposed a method to discover the top- representative locally densest subgraphs of a graph. The method involves defining a parameter-free definition of an LDS, showing that the set of LDSes in a graph can be computed in polynomial time, and proposing three novel pruning strategies to reduce the search space of the algorithm. Trung et al. (Trung et al., 2023) observed the hierarchical structure of maximal -compact subgraphs and presented verification-free approaches to improve the efficiency of finding top- LDSes. Ma et al. (Ma et al., 2022) proposed a convex-programming-based algorithm called LDScvx to the LDS problem by introducing the concept of the compact number and using the relations of compactness to the LDS problem and a specific convex program. Capitalizing on previous results (Qin et al., 2015), Samusevich et al. (Samusevich et al., 2016) studied the local triangle densest subgraph (LTDS) problem, which extended the LDS model to triangle-based density. It’s worth noting that, in essence, LDS is a special instance of LCDS when ; LTDS is a special instance of LCDS when .
3. Preliminaries
Given an undirected graph , we use to denote an -clique with vertices and edges. is the collection of -cliques of . denotes the -clique density of , , and is the -clique degree of , i.e., the number of -cliques containing . Given a subset , is the subgraph induced by , and . Table 1 summarizes the main notations used in this paper.
| Notation | Definition |
|---|---|
| a graph with vertex set and edge set | |
| the subgraph induced by | |
| the collection of all -cliques of | |
| an -clique ( is vertex set, is edge set) | |
| the -clique density of , | |
| the -clique compact number of vertex | |
| the -clique degree of vertex in | |
| an upper bound of in | |
| a lower bound of in | |
| the convex programming of for -clique densest subgraph | |
| the weights distributed from -cliques to vertices | |
| the weights received by each vertex |
A densest subgraph in a local region not only means that such a subgraph is not included in any other denser subgraph, but also requires the inner density to be compact and evenly distributed. Qin et al. (Qin et al., 2015) proposed the concept of -compact, which gives a reasonable definition of locally densest subgraph. A graph is -compact when removing any subset from removes at least edges. Considering the -clique density in a graph, we define an -clique -compact graph as:
Definition 0 (-clique -compact).
A graph is -clique -compact if is connected, and removing any subset of vertices will result in the removal of at least -cliques in , where is a non-negative real number.
If is -clique -compact, then the -clique degree of each vertex in is at least , because removing any vertex will remove at least -cliques. Besides, the -clique density of an -clique -compact graph is at least . For any , an -clique -compact graph is also an -clique -compact graph, so we define the -clique compactness of a graph as the largest such that is -clique -compact. A subgraph of is a maximal -clique -compact subgraph if none of the supergraphs of is -clique -compact.
Proposition 1.
If a graph has -clique density , then the -clique compactness of the graph is at most , i.e., .
Proof.
Suppose the compactness of is higher than , then removing all vertices in will result in the removal of more than -cliques, which means that the -clique density of must be higher than , and contradicts the fact that the -clique density of is . ∎
Proposition 1 clarifies that the -clique compactness of a graph cannot be greater than . We are then interested in finding the locally -clique dense and compact subgraph in . We formally define a locally -clique densest subgraph as follows.
Definition 0 (Locally -clique densest subgraph (LCDS)).
A subgraph of is a locally -clique densest subgraph of if the following two conditions hold:
-
1.
is an -clique -compact subgraph;
-
2.
There does not exist a supergraph of (), such that is also -clique -compact.
Proposition 2 (Disjoint property).
Suppose and are two LCDSes in , we have .
Proof.
Without loss of generality, we assume . We prove the proposition by contradiction. Suppose . According to the definition of LCDS, . Since and are two LCDSes, the graph induced by is a connected -clique - compact graph which is larger than . This contradicts the fact that is an LCDS. ∎
Proposition 2 proves that all LCDSes in a graph are pairwise disjoint. Therefore, the number of LCDSes of is bounded by , and the LCDSes can be used to identify all the non-overlapping -clique dense regions of a graph.
Most applications in the real world usually require finding the top- dense regions of a graph (Qin et al., 2015), so we focus on finding the top- LCDSes with the largest densities. When is large enough, all LCDSes can be found. We formulate the problem as follows.
Definition 0 (Locally -clique densest subgraph Problem (LCDS Problem)).
Given a graph , an integer , and an integer , the locally -clique densest subgraph problem is to compute the top- LCDSes ranked by the -clique density in .
Figure 2 shows an example of the LCDS. We use ,, and to represent , , and . When , the top- LCDS is , which has a 3-clique density of , since there are thirteen 3-cliques in it. The top- and top- LCDSes are and . They both have a 4-clique density of .

Note that an edge in a graph is a 2-clique; therefore, the intensively studied LDS problem (Qin et al., 2015; Ma et al., 2022) can be seen as an instance of the LCDS problem when . Similarly, the LTDS problem (Samusevich et al., 2016) is exactly the LCDS problem. Therefore, the LCDS problem studied in this paper provides a more general framework, and we boldly infer that our method can be generalized from -clique to general patterns, which means that we can give an algorithmic framework to solve a wider range of locally pattern densest problems.
4. LCDS Discovery
In this section, we focus on the design of an LCDS discovery algorithm. According to the concept of -clique compactness, each subgraph of a graph has its own compactness. However, a vertex may be contained in various subgraphs with different compactness. Therefore, we introduce the concept of -clique compact number for each vertex in a graph.
Definition 0 (-clique compact number).
Given a graph , for each vertex , the -clique compact number of is the largest such that is contained in an -clique -compact subgraph of , denoted by .
In the following theorem, we prove the relationship between the LCDS and the -clique compact numbers of vertices within it.
Theorem 2.
Given an LCDS in , for each vertex , the -clique compact number of is equal to the -clique density of , i.e., .
Proof.
As is a maximal -clique -compact subgraph, for each , there exists no other subgraph containing such that is an -clique -compact subgraph with . We prove the claim by contradiction. Suppose is an -clique -compact subgraph with and , we have . First, , because is a maximal -clique -compact subgraph and . If we remove from , the number of -cliques removed is . This contradicts that is -clique -compact. Hence, is the -clique compact number of all vertices in . ∎
Based on Theorem 2, once we get the -clique compact number of each vertex in , we can arrange the vertices in descending order based on the -clique compact number and then check whether the vertices with the same -clique compact number satisfy the definition of LCDS to obtain top- LCDSes. For example, in Figure 2, we list the -clique compact numbers of all vertices of . It is obvious that and are both LCDSes.
However, computing the -clique compact numbers directly is difficult. So we jointly consider -clique compact number and LCDS to design a new “iterative propose-prune-and-verify” pipeline for top- LCDS detection, which is called IPPV. In the proposal part, the true LCDSes are allowed to be encapsulated in the proposed candidates, but without missing true LCDSes. Proper graph decomposition methods should be designed, since a clique may span multiple subgraphs to be decomposed. In the verification part, each correct LCDS should be outputted, and LCDS candidates that can be further pruned should be indicated.

Figure 3 gives the flow diagram of IPPV. It has four main parts: 1) calculate the initial bounds of the -clique compact numbers of vertices; 2) iteratively propose all LCDS candidates (generating approximate -clique compact numbers; decomposing the graph tentatively; grouping vertices and tightening bounds); 3) prune invalid vertices; 4) verify the locally densest property of all candidates to find top- LCDSes, and we, in particular, propose a basic algorithm and a fast algorithm for verification. As a general algorithm framework, all blue parts are extensions of existing methods, while all orange parts are our proof and innovation for this problem.
4.1. Initial -clique Compact Number Bounds
In order to derive LCDS candidates, we first give initial upper and lower bounds of -clique compact number . Specifically, we denote and as the upper and lower bound of in . We use -core(Fang et al., 2019), which is a cohesive subgraph model, to compute the initial bounds.
Definition 0 (-core).
Given a graph , the -core is the largest subgraph of , in which the -clique degree of each vertex is at least . The -clique-core number of a vertex , denoted by , is the highest of -core containing .
Proposition 3.
-clique compact number has the following relations to the -clique-core number .
-
(1)
A -core subgraph is -clique -compact. Thus, for any , can be assigned as ;
-
(2)
If is an LCDS of , for all , . Thus, for any , can be assigned as .
Proof.
Any vertex in a -core subgraph is contained in at least -cliques. By removal of any subset from the -core, at least -cliques would be removed. For any , there is an -clique -compact subgraph of that contains , then is a lower bound of . The second relation can be obtained from the fact that an LCDS in a graph is a (,)-core subgraph of . For any , if an LCDS contains , then is an upper bound of . ∎
4.2. Candidate LCDS Proposal
The initial upper and lower bounds for -clique compact numbers from -clique-core numbers are relatively loose. In this section, we focus on how to tighten the bounds and propose LCDS candidates.
4.2.1. Overall Algorithm for Candidate LCDS Proposal
The overall candidate LCDS proposal algorithm is given in Algorithm 2. Approximate -clique compact number is calculated via SEQ-kClist++ (Line 1); the preliminary partition of and recalculated values are obtained via TentativeGD (Line 2); tighter upper and lower bounds for -clique compact numbers and the further partition of (stable -clique group) are calculated via DeriveSG (Line 3). The sub-procedures introduce each of the above functions (Lines 5-33).
4.2.2. Generate Approximate -clique Compact Number
Inspired by a classical convex programming (Danisch et al., 2017; Ma et al., 2022), we propose a convex programming for finding the diminishingly--clique-dense decomposition, and prove that the optimal solution of our convex programming is exactly the -clique compact number of a graph .
Intuitively, the aim of CP() is that each -clique tries to distribute its unit weight among its vertices such that the sum of the weight received by the vertices are as even as possible. We use to represent the weight assigned to from -clique and to denote the sum of the weights assigned to from -cliques that contain . This intuition suggests that we can consider the objective function: , in which , for all . The convex programming is:
where the domain is:
Here, we demonstrate that the -clique compact numbers can be derived from the optimal solution of CP().
Theorem 4.
Let be an optimal solution to CP(). Then, , , i.e., each in is exactly the -clique compact number of .
Proof.
For any vertex , let , , , . denotes the vertices that are contained by -cliques that including vertices both in and . We prove is an -clique -compact subgraph. First, removing from will result in the removal of cliques in . We know that for all , and . Otherwise, if there exists such that , there exists . We can reduce by and increase by , and the objective function be decreased by , which contradicts the optimality of . Similarly, we can prove that for all , and . Therefore, . is exactly the number of -cliques to be removed when removing from . Meanwhile, for any ,we have that , which means removing any from will result in the removal of at least -cliques. Therefore, is an -clique -compact subgraph. Analogously, we can prove that for any other subset containing , is an -clique -compact subgraph, where , by contradiction. Therefore, is the largest such that is contained in an -clique -compact subgraph of , which is exactly the -clique compact number of . ∎

Consider the convex programming CP() for in Figure 2, we use as an example, shown in Figure 4. The -clique compact number of is 2, and the optimal solution value is also 2. It is clear that for each , is exactly .
Theorem 5.
The locally -clique densest subgraph problem can be solved in polynomial time for any given positive integer .
Proof.
However, CP() is a problem with equality constraints and variables. The time complexity of the classical polynomial-time solution of CP() is (Goldfarb and Liu, 1991), which requires long running time. Therefore, exactly attaining the is difficult, so we use the approximate solution of CP() to tighten the -clique compact bounds. Frank-Wolfe-based (FW-based) algorithm is efficient for finding approximate solutions to CP() (Ma et al., 2022). However, FW-based algorithm for -clique densest requires a large amount of memory. SEQ-kClist++(Sun et al., 2020) is better for approximately calculating for each -clique , , as well as for each vertex . All are initialized to (Line 6). stores the sum over all ’s such that contains (Line 7). At each iteration, and are modified simultaneously as follows. For each -clique , we find the minimum among , and new values for the and the are computed as convex combinations (Lines 8-12).
4.2.3. Tentative Graph Decomposition
After getting approximate , we can derive a graph decomposition from the given ().
Proposition 4.
Given an LCDS in , , if and , we have .
Considering vertices adjacent to but not in in Figure 2, such as and , their -clique compact numbers fulfill Proposition 4: , . Proposition 4 is helpful for choosing LCDSes from all subgraphs.
We then propose TentativeGD to generate tentative graph decomposition for proposing LCDS. The vertices in are sorted based on values descendingly (Line 15). The initial partition of the graph is extracted based on the descending order (Lines 16-17). For each , if the clique is contained in multiple vertex sets, the vertex set with the largest set index will be recorded as , and the value of will be redistributed to vertices in (Lines 18-22). In other words, for the convenience of partition, the value of straddling multiple vertex sets is redistributed to a vertex set with the lowest value. Finally, the values of all vertices in are recalculated (Line 23).
4.2.4. Stable -clique Group Derivation
After getting the initial bounds of -clique compact numbers in InitializeBd and a preliminary partition of the graph in TentativeGD, we consider obtaining tighter bounds of -clique compact numbers and a further partition of the graph, to calculate LCDS candidates. Inspired by two concepts, stable subset (Danisch et al., 2017) and stable group (Ma et al., 2022), for solving the -clique densest subgraph problem, we propose the definition of the stable -clique group.
Definition 0 (stable -clique group).
Given a feasible solution to CP(), a stable -clique group with respect to is a non-empty vertex group satisfying the following conditions:
-
(1)
For any , or ;
-
(2)
For any , if , ;
-
(3)
For any , if , .

The concept of stable -clique subset is related to stable -clique group , and the relationship between stable -clique subset and stable -clique group can be shown in Figure 5 with . All stable -clique groups are disjoint, and a stable -clique subset is the union of the previous stable -clique subset and the first stable -clique group outside this previous stable -clique subset. Either or can form a consecutive subsequence of the whole sequence, and we only use the stable -clique group in our algorithm.
Theorem 7.
Given a feasible solution to CP() and a stable -clique group with respect to , for all , we have that .
Proof.
According to Theorem 4, for all . Suppose there exists a vertex such that . Since , correspondingly, there must exist another vertex , . The difference between and means that there exists containing both and , . Since is a stable -clique group, according to the third condition in Definition 6, . There exists , we can increase by and decrease by to decrease the value of the objective function. This contradicts that is the optimal solution to CP(). By the same token, for all . ∎
Based on Theorem 7, the stable -clique groups can give tighter bounds of -clique compact numbers, so we propose DeriveSG algorithm to derive the stable -clique groups, which are our LCDS candidates. In DeriveSG, the subsets in are checked one by one; if the subset is a stable -clique group, it will be pushed into the set of stable -clique groups ; otherwise, in the next iteration, the current subset will be merged with the next subset (Lines 26–28). Then, the upper and lower bounds of -clique compact numbers are updated based on Theorem 7 (Lines 29–32).
4.3. Pruning for Candidate LCDS Derivation
We prove that the following proposition can help to prune invalid vertices that are certainly not contained by any LCDS.
Proposition 5.
For any , is not contained by any LCDS in if either of the following two conditions is satisfied.
-
(1)
If there exists , such that , is invalid;
-
(2)
Let denote the graph after pruning all invalid vertices in condition (1). is the upper bound of in . For any in , if , is invalid.
Proof.
First, we prove condition (1). For any , , if , then . According to Proposition 4, is not contained in LCDS, i.e., is invalid.
For condition (2), means that to form an -clique -compact subgraph containing , some already pruned vertices are needed. So using the vertices in only cannot form an -clique -compact subgraph containing . Therefore, cannot be contained by any LCDS in , i.e., is invalid. ∎
According to Proposition 5, we design Pruning Rule to prune invalid vertices by condition (1) and condition (2). An example can be seen in Figure 2 with . and can be pruned, because for edge , ; for edge , . Analogously, the vertices , , , , and are also pruned by condition (1).
We denote the graph after pruning by . Some vertices in become invalid vertices, because any LCDS in containing these vertices needs to include some already pruned vertices, which can not form an LCDS in . Therefore, we utilize condition (2). Based on Proposition 3, for any vertex , provides an upper bound of . For example, after and are pruned, the upper bounds of -clique compact numbers of and in graph are . So and are pruned using condition (2).
We propose Prune algorithm shown in Algorithm 3. is replicated to for pruning (Line 1). Condition (1) is used to remove invalid vertices in (Lines 2-3); after computing the -clique core numbers for all vertices in (Line 4), condition (2) is applied to further remove invalid vertices in (Lines 5-7). Finally, the LCDS candidates are updated from the intersection of -clique stable groups and the unpruned vertex sets (Line 8).
4.4. LCDS Verification
Since candidate LCDSes are obtained approximately, we need to confirm whether the candidates are LCDSes.
Proposition 6.
An LCDS must satisfy the following properties:
-
(1)
Any subgraph of an LCDS cannot be denser than itself;
-
(2)
An LCDS itself is compact, and any supergraph of an LCDS cannot be more compact than itself.
Proof.
(2) of Proposition 6 can be directly obtained from the definition of LCDS. We prove (1) by contradiction. Suppose that there is a subgraph in an LCDS , , such that . By removal of the set from , we remove -cliques. Note that , which contradicts the fact that is an LCDS, i.e. -clique -compact. ∎
We need to verify: 1) whether a candidate LCDS is self-densest and 2) whether is a maximal -clique -compact subgraph in . We use IsDensest (Sun et al., 2020) algorithm to check whether a candidate LCDS is self-densest. In this section, we focus on the verification of the second property, to verify whether is a connected component of maximal -clique -compact subgraphs in . We design a basic verification algorithm, and we further propose a fast algorithm by reducing the scale of the flow network. The correctness of both algorithms is proved.
4.4.1. Basic Verification Algorithm
Given an LCDS candidate , we propose an innovative flow network to derive maximal -clique -compact subgraph in . If is a connected component of , is indeed maximal -clique -compact subgraph and an LCDS in ; otherwise, is not an LCDS. The flow network is shown in Figure 6. The vertex set of is . The arc set of is given as follows. For each -clique , we add incoming arcs of capacity from the vertices which form , and outgoing arcs of capacity of to the same set of vertices. For each vertex , we add an incoming arc of capacity from the source vertex , and an outgoing arc of capacity to the sink vertex . Given a parameter , we prove that the flow network in DeriveCompact can be used to derive maximal -clique -compact subgraphs in according to Theorem 8.

Theorem 8.
If contains maximal -clique -compact subgraphs, then the result returned by DeriveCompact () is the set of all maximal -clique -compact subgraphs in .
Proof.
Based on Proposition 2, two LCDSes are disjoint. We use to represent the union of all maximal -clique -compact subgraphs in . denotes the subgraph returned by DeriveCompact (), which is the largest subgraph in with maximum (Goldberg, 1984)(Fang et al., 2019). We prove that and are the same. First, we prove that is a subgraph of by contradiction. Suppose a connected component of is not -clique -compact, then there exists a subset such that removing from will result in removing less -cliques than , then . We have . Therefore, replacing by its subgraph in will enlarge the value of , which contradicts the condition that has the maximum . Second, we prove that is a subgraph of by contradiction. Suppose is not a subgraph of , according to the result before, we have . There exists a subset and . Removing from will result in removing at least -cliques, then . We have , so enlarging to will not decrease the value of , which contradicts the condition that has the maximum . Therefore, the theorem is proved. ∎
In Algorithm 4, we first derive all connected components of the -clique -compact subgraph in by DeriveCompact (Line 2). If is a connected component of , the algorithm returns True (Line 3). In DeriveCompact, all the instances of -clique is collected (Line 5). To build a flow network , a vertex set is created, and vertices in are linked by directed edges with different capacities (Lines 6-19). Then, the minimum cut is computed (Line 20).
4.4.2. Fast Verification Algorithm
Although the basic verification algorithm can successfully verify whether a given subset is LCDS, the scale of the flow network in algorithm 4 is large, and the running time is long in large-scale graphs. We prove that the verification can be done by verifying only the subgraph and the vertices around the subgraph , which is denoted by . Since is much smaller than , checking the minimum cut in is much more efficient. Considering the complexity of the overlap of cliques, we propose a fast verification algorithm by constructing a smaller flow network based on . Based on the fact that only the -cliques at the boundary of affect -clique compact numbers in compared to the -clique compact numbers in , we use a set to record these -cliques. For each , the number of vertices that are contained in both and is . The flow network is shown in Figure 7. The vertex set of is . We add the boundary -clique set into to ensure that the results of solving the flow network of are precisely consistent with that of . The arc set of is given as follows. The arcs for vertices and -cliques in are the same as the former flow network. For each , we add incoming arcs of capacity from the vertices that both in and , and outgoing arcs of capacity of to the same set of vertices.

In Algorithm 5, the -clique density of is assigned to (Line 1). Then, a breadth-first search is performed. is used to store the vertices to be traversed (Line 4). The first vertex from is popped out (Line 6), and all -cliques containing are iterated (Lines 7-25). For each that is not in , if any vertex in satisfying , will not affect the -clique compact number of (Lines 9-13); if any vertex is in any outputted LCDS, False is assigned to VerifyLCDS (Lines 17-18); the number of vertices in satisfying is recorded and is added into (Lines 19-25). All neighbors of are iterated (Lines 26-30). For each neighbor that is not in , if , False is assigned to VerifyLCDS (Line 28). If , will be added into and (Line 30). If VerifyLCDS is False, a subgraph induced by and peripheral -cliques in are used to compute all -clique -compact subgraphs in via min-cut (Line 32). Finally, True is returned if is maximal -clique -compact; otherwise, the algorithm returns False (Line 33). The flow network here is much smaller.
Theorem 9.
Given a graph and a self-densest subgraph , is an LCDS of if and only if the fast LCDS verification algorithm returns True.
Proof.
On the one hand, if is an LCDS of , is still an LCDS in , because only the -cliques in might increase the -clique compact numbers in compared to the -clique compact numbers in . Otherwise, there exists a vertex with -cliques in contained in the maximal -clique -compact subgraph containing , and we can construct a larger -clique -compact subgraph in by adding vertices with connected to , which contradicts that is an LCDS. On the other hand, if is not an LCDS of , we will find a larger -clique -compact subgraph containing in . Therefore, is not an LCDS in , and the algorithm returns False. Therefore, the algorithm returns True only when is an LCDS of . ∎
4.5. The LCDS Discovery Algorithm (IPPV)
Combining all the algorithms above, we derive the LCDS discovery algorithm, called the IPPV algorithm shown in Algorithm 6. An empty stack is initialized, and is assigned to (Line 1). The bounds of -clique compact numbers are initialized via InitializeBd (Line 2). LCDS candidates are derived via ProposeCL and Prune (Line 4-5). Next, the LCDS candidates in are reversely pushed into , and the first LCDS candidate in , the one with the highest value, is popped out (Lines 6-7). The LCDS candidate is verified by IsDensest (Line 8) and VerifyLCDS (line 9). If is an LCDS, it will be outputted, and is decreased by 1 (Line 10). If is not an LCDS but is self-densest, is updated as the top LCDS candidate from (Line 12). Then, is assigned to for the next iteration (Line 13). The above process is repeated until top- LCDSes are found (line 3) or the stack is empty (Line 11). Our algorithms can also be extended to find all LCDSes.
Theorem 10.
The LCDS discovery algorithm IPPV is an exact algorithm, i.e., it can output all LCDSes correctly.
Proof.
According to Theorem 7, the set of LCDS candidates proposed by IPPV is a superset of all LCDSes with tight bounds of -clique compact number. Based on Proposition 5, the pruning part only prunes vertices that are not in any LCDS and guarantees that the vertices in any LCDS will not be pruned. Theorem 8 and Theorem 9 state that the verification part verifies whether a candidate is exactly an LCDS without misjudgment. And all candidates are repeated through the above bound updating, pruning, and verification operations until LCDSes are outputted. Since the set of LCDS candidates are arranged in descending order, the outputted LCDSes must be the top- LCDSes. Therefore, the proposed algorithm is an exact algorithm to output the top- LCDSes. ∎
Complexity Analysis. We use to denote the number of iterations that SEQ-kClist++ needs. Each iteration of SEQ-kClist++ costs . We use to represent the total number of LCDS candidates, . Each iteration of verifying an LCDS candidate costs . is the number of times IsDensest and VerifyLCDS are called. The time complexity of max-flow computation, which is for IsDensest and VerifyLCDS when Dinic Algorithm is Applied. The time complexity of IPPV is . As , the time complexity of IPPV is . The memory complexity is . Note that the time complexity of the classical exact solution of only computing -clique compact number is (Goldfarb and Liu, 1991), which is much greater than that of our algorithm.
5. LPDS Discovery
A pattern (also known as a motif) (Wuchty et al., 2003; Leskovec et al., 2006; Hu et al., 2019) is a small connected subgraph that appears frequently in a larger graph, which can be considered as a basic module. Figure 8 shows all kinds of patterns with four vertices: -pattern, ,-pattern.
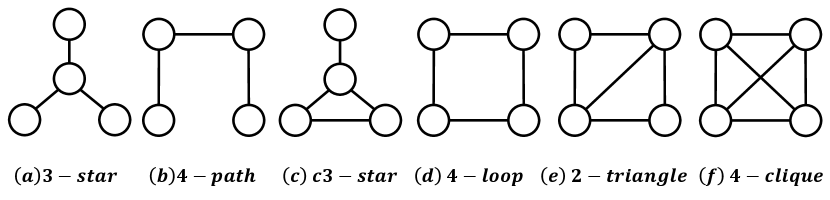
We further show that the algorithm for the locally -clique densest subgraph discovery problem can be extended to solve the locally general pattern densest subgraph discovery problem, which contributes to a deeper understanding of the organizational principles and functional modules within complex networks.
5.1. Densest Supermodular Set Decomposition
In this section, we discuss the feasability of extending the -clique problem to a general pattern problem. The convex programming of -clique can be further generalized to the convex programming of supermodular sets, so that the convex programming for the general pattern densest subgraph problem and the corresponding compact number can be derived. A function is said to be supermodular if . Harb et al. (Harb et al., 2022) proposed the densest supermodular subset (DSS) problem: given a normalized, nonnegative monotone supermodular function , return that maximizes . According to our observation, when and , the DSS problem is the DS and CDS problem, respectively. When represents the number of a particular pattern in a graph, the problem is the densest problem of the proposed pattern. The convex program(Harb et al., 2022) for the densest supermodular set decomposition is subject to: .
With supermodularity, there is a property that each graph has a unique nested diminishingly decomposition for each type of density. The analysis of the generalization of CDS problem to DSS problem has triggered our thinking on the solution of locally general pattern densest problem.
5.2. Locally General Pattern Densest Subgraph Problem
Given an undirected graph , denotes a particular kind of pattern with vertices and is the collection of the -patterns of . denotes the -pattern density of . is the -pattern degree of , i.e., the number of -patterns containing . A graph is -pattern -compact if is connected, and removing any subset of vertices will result in the removal of at least -patterns in . We can formally define a locally -pattern densest subgraph as follows.
Definition 0 (Locally -pattern densest subgraph (LPDS)).
A subgraph of is an LPDS of if is -pattern -compact, and there does not exist a supergraph of (), such that is also -pattern -compact.
Similarly, we formulate the locally -pattern densest subgraph problem as follows.
Definition 0 (Locally -pattern densest subgraph Problem (LPDS Problem)).
Given a graph , an integer , a pattern and an integer , the LPDS problem is to compute the top- LPDSes ranked by the -pattern density in .









Here, we utilize our “iterative propose-prune-and-verify” pipeline to solve the LPDS problem. To apply the -pattern subgraph, there are some differences between Algorithm 6 and Algorithm 7 in the algorithmic details. In Algorithm 7, we need to count -pattern graphs for Seq-kClist++ algorithm and derive candidate LPDS algorithm. In pruning part, the computation of -pattern graph cores is different for diverse kinds of patterns. Unlike -clique, there may be more than one -pattern on a graph with vertices. In verification part, the methods for reducing the size of subgraph to compute the min-cut need small adjustments for different patterns. In general, the process of extending our algorithm to general patterns is concise and clear. In addition, our method may also support expressive graph models as directed graph, attributed graph, etc. These graph models also have meaningful patterns, such as directed closed loop in directed graph. The difficulty of generalizing IPPV to different graph models is related to the properties of the models.
6. Experiments
6.1. Experimental Setup
The datasets we use are undirected real-world graphs (Leskovec and Krevl, 2014; Rossi and Ahmed, 2015), including social networks, biological networks, web graphs, and collaboration networks. All datasets are listed in Table 2.
We compare the performances of the following algorithms:
IPPV : the top- LCDS discovery algorithm proposed by us.
LTDS (Samusevich
et al., 2016) : the top- LTDS discovery algorithm based on the maximum-flow, which solves the LCDS problem with .
LDSflow (Qin
et al., 2015) : the top- LDS discovery algorithm based on the maximum-flow, which solves the LCDS problem with .
Greedy : the top- CDS discovery algorithm based on KClist++ (Sun
et al., 2020) using greedy approach. It has no guarantee on the locally densest property.
| Name | Abbr. | ||||
|---|---|---|---|---|---|
| soc-hamsterster | HA | 2,426 | 16,630 | 53,251 | 298,013 |
| CA-GrQc | GQ | 5,242 | 14,484 | 48,260 | 2,215,500 |
| fb-pages-politician | PP | 5,908 | 41,706 | 174,632 | 2,002,250 |
| fb-pages-company | PC | 14,113 | 52,126 | 56,005 | 207,829 |
| web-webbase-2001 | WB | 16,062 | 25,593 | 21,115 | 382,674 |
| CA-CondMat | CM | 23,133 | 93,439 | 173,361 | 511,088 |
| soc-epinions | EP | 26,588 | 100,120 | 159,700 | 521,106 |
| Email-Enron | EN | 36,692 | 183,831 | 727,044 | 5,809,356 |
| loc-gowalla | GW | 196,591 | 950,327 | 2,273,138 | 14,570,875 |
| DBLP | DB | 317,080 | 1,049,866 | 2,224,385 | 262,663,639 |
| Amazon | AM | 334,863 | 925,872 | 667,129 | 61,551 |
| soc-youtube | YT | 495,957 | 1,936,748 | 2,443,886 | 5,306,643 |
| soc-lastfm | LF | 1,191,805 | 4,519,330 | 3,946,207 | 10,404,656 |
| soc-flixster | FX | 2,523,386 | 7,918,801 | 7,897,122 | 96,315,278 |
| soc-wiki-talk | WT | 2,394,385 | 4,659,565 | 9,203,519 | 382,777,822 |
All algorithms are implemented in C++ and compiled by g++ compiler at -O3 optimization level. All experiments are evaluated on a machine with Intel(R) Xeon(R) CPU 3.20GHz processor and 128GB memory, with Ubuntu operating system. Algorithms running for more than 48 hours are forcibly terminated.
6.2. Efficiency under Parameter Variations
In this section, we summarize the influence of different parameter changes on the running time.
6.2.1. Efficiency improvement by fast verification algorithm
We use VerifyLCDS(basic) to represent the IPPV algorithm with Algorithm 4 and VerifyLCDS(fast) to represent the IPPV algorithm with Algorithm 5. Their running times are compared in Figure 9. The fast verification algorithm with a smaller flow network is much faster than basic verification method. Especially as increases, the efficiency gap between the two algorithms becomes more apparent. We also compare the running time of the two verification algorithms in the total running time in Figure 10. The acceleration effect of the fast algorithm is obvious. The results demonstrate the importance and benefit of optimizing the verification algorithm.
6.2.2. Running time trends with varying
Parameter has a more pronounced impact on the running time of the algorithm than . The experiments in Figure 9 indicate a direct relationship, where an increase in corresponds to a proportional increase in execution time. This trend is consistently observed across different datasets, which strengthens the premise that is an important factor in computational complexity. The running time of both algorithms increases significantly for incremental values of . The only deviation is observed in the Email-Enron dataset, where the running time remains relatively static despite changes in , due to the fact that the total number of LCDSes in this dataset is smaller than .
6.2.3. Running time trends with varying
We took to compare the impact of on the running time. The results are shown in Figure 9. When , the running time is generally longer. The reason is that when , the number of -cliques is larger, as shown in Table 2. On Amazon, the running time is shorter when , because the number of -cliques is smaller. The running time is proportional to the number of -cliques with different .
6.2.4. Influence of structural property
We discuss how the density property () of graph datasets influences the efficiency of IPPV. As shown in Figure 11, we select four datasets and randomly sample edges of these datasets in different proportions. According to the outputs from these synthetically generated graphs, the running time increases as the density of datasets increases. The reason is that when density is higher, the number of -cliques increases, lengthening the total running time.

6.3. Efficiency v.s. Existing Algorithms
Since LDSflow (Qin et al., 2015) outputs LCDSes with , and LTDS (Samusevich et al., 2016) outputs LCDSes with , we compare IPPV with them by setting and respectively.
6.3.1. Efficiency: IPPV v.s. LDSflow
We set , to observe the running time of the two algorithms. The results are shown in Figure 12. We compare IPPV with LDSflow on eight datasets, and IPPV has efficiency improvements on all the datasets. The bottleneck of LDSflow is the loose upper and lower bounds.

6.3.2. Efficiency: IPPV v.s. LTDS
We set and in experiments and the results are shown in Table 3. IPPV and LTDS are compared on all the datasets. There are significant efficiency improvements on all datasets. The main bottleneck of LTDS is the time-consuming verification part, and the reason is that the upper and lower bounds of LTDS are not as tight as that of IPPV, so there will be more failures in the verification part. The running time of our algorithm is closely related to the size of the graph and the number of -cliques. A rise in the number of -cliques can cause an increase in running time.
| Dataset | IPPV (h=3) | LTDS | Speedup |
|---|---|---|---|
| soc-hamsterster | 7.50(s) | 46.54 | 6.20 |
| CA-GrQc | 0.38 | 18.97 | 49.92 |
| fb-pages-politician | 32.32 | 436.30 | 13.50 |
| fb-pages-company | 2.56 | 51.48 | 20.11 |
| web-webbase-2001 | 0.14 | 12.20 | 87.14 |
| CA-CondMat | 21.63 | 541.63 | 25.04 |
| soc-epinions | 82.54 | 558.91 | 6.77 |
| Email-Enron | 1369.84 | 2253.14 | 1.64 |
| loc-gowalla | 5095.63 | 68216.14 | 13.39 |
| DBLP | 360.49 | 4888.93 | 13.56 |
| Amazon | 1118.08 | 1308.53 | 1.17 |
| soc-youtube | 9070.89 | 42821.99 | 4.72 |
| soc-lastfm | 11223.13 | 172, 800 | 15.40 |
| soc-flixster | 3018.62 | 172, 800 | 57.24 |
| soc-wiki-talk | 57382.42 | 172, 800 | 3.011 |
6.4. Characteristics of the Detected LCDSes
We adopt different quality measures to show the characteristics of the detected LCDSes, and then we compare our detected LCDSes with those detected by the Greedy algorithm.
6.4.1. Visualization of LCDSes with varying
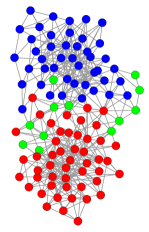
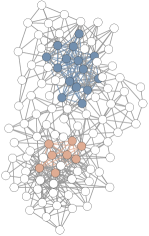
We use a network of books about US politics which were sold by Amazon (Krebs, 2004) to visualize the characteristics of detected LCDSes with varying . The vertices represent different books. Figure 13(a) shows the books fall into neutral(green), liberal(blue), and conservative(red) categories. The edges represent frequent co-purchasing of books by the same buyers, which indicate “customers who bought this book also bought the other books” on Amazon. Figure 13(b)-Figure 13(e) visualize the detected LCDSes with varying . The set of steelblue vertices is the top- LCDS, and the set of orange vertices if exists, is the top- LCDS. The vertices in the dataset have clear attributes, which is convenient for us to measure whether IPPV has the ability to mine diverse communities. As visualized by the results, LCDSes with larger are closer to a clique. Besides, when is larger, LCDSes can find multiple dense communities in different categories. LCDSes contain both liberal and conservative book communities, whereas LDSes (i.e., LCDSes) only contain liberal book community. The results show the potential of IPPV to mine diverse categorical communities.



6.4.2. Edge density of LCDSes with varying
We compare the average edge density () of top- LCDSes for varying in Table 4. When is larger, LCDSes generally have higher edge density. This is aligned with our general purpose.
| Average Edge Density | Average Diameter | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| dataset | =2 | =3 | =5 | =7 | =9 | =2 | =3 | =5 | =7 | =9 |
| PC | 0.752 | 0.858 | 0.891 | 0.894 | 0.957 | 2.00 | 2.00 | 2.00 | 2.00 | 2.00 |
| HA | 0.805 | 0.869 | 0.987 | 0.982 | 0.995 | 1.80 | 1.60 | 1.20 | 1.40 | 1.40 |
| PP | 0.709 | 0.685 | 0.696 | 0.729 | 0.827 | 2.20 | 2.00 | 2.00 | 2.00 | 2.00 |
| CM | 0.984 | 0.984 | 0.986 | 0.986 | 0.986 | 1.20 | 1.20 | 1.40 | 1.40 | 1.40 |
| EP | 0.487 | 0.724 | 0.799 | 0.770 | 0.755 | 2.60 | 1.80 | 1.80 | 1.67 | 2.00 |
| WB | 0.987 | 0.987 | 0.997 | 0.997 | 0.997 | 1.40 | 1.40 | 1.20 | 1.20 | 1.20 |
| GQ | 0.972 | 0.972 | 0.972 | 0.975 | OOM | 1.60 | 1.60 | 1.60 | 1.60 | OOM |
6.4.3. Diameter of LCDSes with varying
We list the average diameter (the longest distance of all pairs of nodes in a graph) of top- LCDSes of different in Table 4. It is obvious that the diameters of the subgraphs produced by LCDS () do not exceed . Coupled with the edge density results, while LCDS can find subgraphs with relatively higher edge density compared to LDS, the diameters of the subgraphs found by LCDS are as small as those found by LDS. This suggests that LCDSes are cohesive, and the nodes within LCDSes are highly interconnected.

6.4.4. Size and -clique density of subgraphs: IPPV vs Greedy
Next, we compare the LCDSes detected by IPPV and the -clique densest subgraphs found by the Greedy algorithm. We select on two datasets, and the results are shown in Figure 14. First, the results of the two algorithms overlap to a certain extent, among which the top- CDS is the same because the first LCDS must be the -clique densest subgraph in the whole graph. Second, there is a certain difference between the returned subgraphs of the Greedy algorithm and IPPV. For example, in CA-CondMat (=3), the -clique density of the second output subgraph is 51 for IPPV, and 78 for Greedy, but the returned subgraphs of Greedy is adjacent to the first output subgraph without the guarantee of the locally densest property. Therefore, the Greedy algorithm cannot solve the LCDS problem well. The two algorithms totally overlap if and only if the top- -clique densest subgraph belongs to different regions occasionally.
6.5. Clustering Coefficient of Different
Since near clique is an important criterion for evaluating dense subgraphs, we evaluate how LCDSes of different are close to the clique structure. In graph theory, clustering coefficient is a measure of the degree to which vertices in a graph tend to cluster together, which is a direct measure to the degree of near clique. For each vertex , which has neighbors (), the clustering coefficient of is . We compare the average of all the LCDSes of different in Table 5.
| Average Clustering Coefficient | |||||
|---|---|---|---|---|---|
| dataset | =2 | =3 | =5 | =7 | =9 |
| fb-pages-company | 0.582 | 0.852 | 0.895 | 0.915 | 0.930 |
| soc-hamsterster | 0.480 | 0.910 | 0.990 | 0.984 | 0.995 |
| fb-pages-politician | 0.583 | 0.683 | 0.776 | 0.798 | 0.835 |
| CA-CondMat | 0.567 | 0.977 | 0.992 | 0.992 | 0.991 |
| soc-epinions | 0.231 | 0.722 | 0.701 | 0.705 | 0.773 |
| web-webbase-2001 | 0.831 | 0.884 | 0.989 | 0.992 | 0.979 |
| CA-GrQc | 0.533 | 0.975 | 0.982 | 0.985 | OOM |
According to the results shown in Table 5, when is larger, the average is generally larger, showing the LCDSes with larger are closer to clique. In addition, there is a big difference between and (LCDS is LDS), which shows that LDS is less dense than other LCDS. Our algorithm is important for finding near-clique subgraphs, which cannot be replaced by LDS.
6.6. Memory Overheads
We compare the memory utilization for the IPPV and LTDS algorithms across all datasets (, ). Figure 15 illustrates a clear correlation between memory usage and dataset size. IPPV strategically reduces the size of candidate subgraphs through a pruning mechanism prior to evaluating self-compactness. The verifying part often dominates the memory consumption.

6.7. The Number of Iterations
To choose the optimal number of iterations of SEQ-kClist++, we set different on the IPPV algorithm. We select , as shown in Figure 16. The experiment on eight datasets shows that the optimal performance is between and iterations. In our experiments, we choose .

6.8. Case Study of LPDS
We utilize the same real dataset (Krebs, 2004) to experimentally illustrate the LPDS problem. For each pattern depicted in Figure 8, we compute the results of LPDS. In Figure 17, the set of steelblue vertices is the top- LPDS, and the set of orange vertices if exists, is the top- LPDS of the pattern . It is evident that the LPDS corresponding to various patterns exhibit differences in terms of the number of LPDS, the number of vertices, and the position of vertices. To delve deeper into graph analysis, tasks such as community clustering can be extended to explore the LPDS subgraph.






7. CONCLUSION
In this paper, we study how to discover locally -clique densest subgraphs in a graph , i.e., the LCDS problem. We present IPPV, an iterative propose-prune-and-verify pipeline for top- LCDS detection. The -clique compact number bounds and graph decomposition method which help to derive LCDS candidates efficiently are proposed. A new optimized verification algorithm is designed, and its correctness is proved. The extension of our algorithm to solve the locally general pattern densest subgraph problem is feasible and promising. Extensive experiments on real datasets show the high efficiency and scalability of our proposed algorithm. When is large in large-scale graphs, there is still room for further optimizing IPPV. We will continue to optimize the algorithm and further explore the LPDS problem in our future work.
Acknowledgements.
Dr. Wang is supported in part by the National Natural Science Foundation of China Grant No. 61972404, Public Computing Cloud, Renmin University of China, and the Blockchain Lab. School of Information, Renmin University of China. Dr. Li is supported in part by the National Natural Science Foundation of China Grant No.12071478. The authors are grateful to Professor Lijun Chang for his help with the revision of this paper. The authors would like to thank the anonymous reviewers and shepherd for providing constructive feedback and valuable suggestions.References
- (1)
- Angel et al. (2012) Albert Angel, Nick Koudas, Nikos Sarkas, Divesh Srivastava, Michael Svendsen, and Srikanta Tirthapura. 2012. Dense subgraph maintenance under streaming edge weight updates for real-time story identification. The VLDB Journal 23 (2012), 175–199. https://api.semanticscholar.org/CorpusID:2185310
- Bahmani et al. (2012) Bahman Bahmani, Ravi Kumar, and Sergei Vassilvitskii. 2012. Densest Subgraph in Streaming and MapReduce. ArXiv abs/1201.6567 (2012).
- Benson et al. (2016) Austin R. Benson, David F. Gleich, and Jure Leskovec. 2016. Higher-order organization of complex networks. Science 353 (2016), 163 – 166. https://api.semanticscholar.org/CorpusID:3635447
- Boob et al. (2019) Digvijay Boob, Yu Gao, Richard Peng, Saurabh Sawlani, Charalampos E. Tsourakakis, Di Wang, and Junxing Wang. 2019. Flowless: Extracting Densest Subgraphs Without Flow Computations. Proceedings of The Web Conference 2020 (2019).
- Boyd and Vandenberghe (2010) Stephen P. Boyd and Lieven Vandenberghe. 2010. Convex Optimization. IEEE Trans. Automat. Control 51 (2010), 1859–1859. https://api.semanticscholar.org/CorpusID:37925315
- Charikar (2000) Moses Charikar. 2000. Greedy approximation algorithms for finding dense components in a graph. In International Workshop on Approximation Algorithms for Combinatorial Optimization.
- Chekuri et al. (2022) Chandra Chekuri, Kent Quanrud, and Manuel R. Torres. 2022. Densest Subgraph: Supermodularity, Iterative Peeling, and Flow. In ACM-SIAM Symposium on Discrete Algorithms.
- Chen and Saad (2012) Jie Chen and Yousef Saad. 2012. Dense Subgraph Extraction with Application to Community Detection. IEEE Transactions on Knowledge and Data Engineering 24 (2012), 1216–1230. https://api.semanticscholar.org/CorpusID:11360561
- Danisch et al. (2017) Maximilien Danisch, T-H. Hubert Chan, and Mauro Sozio. 2017. Large Scale Density-friendly Graph Decomposition via Convex Programming. Proceedings of the 26th International Conference on World Wide Web (2017).
- Fang et al. (2019) Yixiang Fang, Kaiqiang Yu, Reynold Cheng, Laks V. S. Lakshmanan, and Xuemin Lin. 2019. Efficient Algorithms for Densest Subgraph Discovery. Proc. VLDB Endow. 12 (2019), 1719–1732.
- Fazzone et al. (2022) Adriano Fazzone, Tommaso Lanciano, Riccardo Denni, Charalampos E Tsourakakis, and Francesco Bonchi. 2022. Discovering polarization niches via dense subgraphs with attractors and repulsers. Proceedings of the VLDB Endowment 15, 13 (2022), 3883–3896.
- Gibson et al. (2005) David Gibson, Ravi Kumar, and Andrew Tomkins. 2005. Discovering Large Dense Subgraphs in Massive Graphs. In Very Large Data Bases Conference. https://api.semanticscholar.org/CorpusID:120822
- Gionis et al. (2013) A. Gionis, Flavio Paiva Junqueira, Vincent Leroy, Marco Serafini, and Ingmar Weber. 2013. Piggybacking on Social Networks. Proc. VLDB Endow. 6 (2013), 409–420. https://api.semanticscholar.org/CorpusID:2240241
- Goldberg (1984) Andrew V. Goldberg. 1984. Finding a Maximum Density Subgraph. In Technical report,University of California, Berkeley.
- Goldfarb and Liu (1991) Donald Goldfarb and Shucheng Liu. 1991. An O(n3L) primal interior point algorithm for convex quadratic programming. Mathematical Programming 49 (1991), 325–340. https://api.semanticscholar.org/CorpusID:29420601
- Harb et al. (2022) Elfarouk Harb, Kent Quanrud, and Chandra Chekuri. 2022. Faster and Scalable Algorithms for Densest Subgraph and Decomposition. In Neural Information Processing Systems.
- Hu et al. (2019) Jiafeng Hu, Reynold Cheng, Kevin Chen-Chuan Chang, Aravind Sankar, Yixiang Fang, and Brian Yee Hong Lam. 2019. Discovering Maximal Motif Cliques in Large Heterogeneous Information Networks. 2019 IEEE 35th International Conference on Data Engineering (ICDE) (2019), 746–757. https://api.semanticscholar.org/CorpusID:174819659
- Jin et al. (2009) Ruoming Jin, Yang Xiang, Ning Ruan, and David Fuhry. 2009. 3-HOP: a high-compression indexing scheme for reachability query. Proceedings of the 2009 ACM SIGMOD International Conference on Management of data (2009). https://api.semanticscholar.org/CorpusID:7625491
- Krebs (2004) Valdis Krebs. 2004. Books about US politics. Unpublished. http://www.orgnet.com/
- Lanciano et al. (2023) Tommaso Lanciano, Atsushi Miyauchi, Adriano Fazzone, and Francesco Bonchi. 2023. A survey on the densest subgraph problem and its variants. arXiv preprint arXiv:2303.14467 (2023).
- Leskovec and Krevl (2014) Jure Leskovec and Andrej Krevl. 2014. SNAP Datasets: Stanford Large Network Dataset Collection. http://snap.stanford.edu/data.
- Leskovec et al. (2006) Jure Leskovec, Ajit Singh, and Jon M. Kleinberg. 2006. Patterns of Influence in a Recommendation Network. In Pacific-Asia Conference on Knowledge Discovery and Data Mining. https://api.semanticscholar.org/CorpusID:332896
- Li et al. (2022) Ruiming Li, Jung-Yu Lee, Jinn-Moon Yang, and Tatsuya Akutsu. 2022. Densest subgraph-based methods for protein-protein interaction hot spot prediction. BMC Bioinformatics 23 (2022).
- Liu et al. (2018) Yike Liu, Tara Safavi, Abhilash Dighe, and Danai Koutra. 2018. Graph summarization methods and applications: A survey. ACM computing surveys (CSUR) 51, 3 (2018), 1–34.
- Luo et al. (2023) Wensheng Luo, Chenhao Ma, Yixiang Fang, and Laks VS Lakshman. 2023. A Survey of Densest Subgraph Discovery on Large Graphs. arXiv preprint arXiv:2306.07927 (2023).
- Ma et al. (2022) Chenhao Ma, Reynold Cheng, Laks VS Lakshmanan, and Xiaolin Han. 2022. Finding locally densest subgraphs: a convex programming approach. Proceedings of the VLDB Endowment 15, 11 (2022), 2719–2732.
- Mitzenmacher et al. (2015) Michael Mitzenmacher, Jakub W. Pachocki, Richard Peng, Charalampos E. Tsourakakis, and Shen Chen Xu. 2015. Scalable Large Near-Clique Detection in Large-Scale Networks via Sampling. Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (2015).
- Palla et al. (2005) Gergely Palla, Imre Derényi, Illés J. Farkas, and Tamás Vicsek. 2005. Uncovering the overlapping community structure of complex networks in nature and society. Nature 435 (2005), 814–818. https://api.semanticscholar.org/CorpusID:3250746
- Picard and Queyranne (1982) Jean-Claude Picard and Maurice Queyranne. 1982. A network flow solution to some nonlinear 0-1 programming problems, with applications to graph theory. Networks 12 (1982), 141–159.
- Qin et al. (2015) Lu Qin, Rong-Hua Li, Lijun Chang, and Chengqi Zhang. 2015. Locally densest subgraph discovery. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 965–974.
- Rossi and Ahmed (2015) Ryan A. Rossi and Nesreen K. Ahmed. 2015. The Network Data Repository with Interactive Graph Analytics and Visualization. In AAAI. https://networkrepository.com
- Saha et al. (2010) Barna Saha, Allison Hoch, Samir Khuller, Louiqa Raschid, and Xiao-Ning Zhang. 2010. Dense Subgraphs with Restrictions and Applications to Gene Annotation Graphs. In Annual International Conference on Research in Computational Molecular Biology. https://api.semanticscholar.org/CorpusID:11280177
- Samusevich et al. (2016) Raman Samusevich, Maximilien Danisch, and Mauro Sozio. 2016. Local triangle-densest subgraphs. In 2016 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM). IEEE, 33–40.
- Spirin and Mirny (2003) Victor Spirin and Leonid A. Mirny. 2003. Protein complexes and functional modules in molecular networks. Proceedings of the National Academy of Sciences of the United States of America 100 (2003), 12123 – 12128. https://api.semanticscholar.org/CorpusID:136093
- Sun et al. (2020) Bintao Sun, Maximilien Danisch, TH Hubert Chan, and Mauro Sozio. 2020. Kclist++: A simple algorithm for finding k-clique densest subgraphs in large graphs. Proceedings of the VLDB Endowment (PVLDB) (2020).
- Trung et al. (2023) Tran Ba Trung, Lijun Chang, Nguyen Tien Long, Kai Yao, and Huynh Thi Thanh Binh. 2023. Verification-Free Approaches to Efficient Locally Densest Subgraph Discovery. 2023 IEEE 39th International Conference on Data Engineering (ICDE) (2023), 1–13. https://api.semanticscholar.org/CorpusID:260171546
- Tsourakakis (2015) Charalampos Tsourakakis. 2015. The k-clique densest subgraph problem. In Proceedings of the 24th international conference on world wide web. 1122–1132.
- Tsourakakis et al. (2013) Charalampos E. Tsourakakis, Francesco Bonchi, A. Gionis, Francesco Gullo, and Maria A. Tsiarli. 2013. Denser than the densest subgraph: extracting optimal quasi-cliques with quality guarantees. Proceedings of the 19th ACM SIGKDD international conference on Knowledge discovery and data mining (2013). https://api.semanticscholar.org/CorpusID:213308
- Wang et al. (2013) Jia Wang, James Cheng, and Ada Wai-Chee Fu. 2013. Redundancy-aware maximal cliques. Proceedings of the 19th ACM SIGKDD international conference on Knowledge discovery and data mining (2013). https://api.semanticscholar.org/CorpusID:16494932
- Wuchty et al. (2003) Stefan Wuchty, Zoltán N. Oltvai, and A L Barabasi. 2003. Evolutionary conservation of motif constituents in the yeast protein interaction network. Nature Genetics 35 (2003), 176–179. https://api.semanticscholar.org/CorpusID:1627007
- Yuan et al. (2015) Long Yuan, Lu Qin, Xuemin Lin, Lijun Chang, and W. Zhang. 2015. Diversified top-k clique search. The VLDB Journal 25 (2015), 171–196. https://api.semanticscholar.org/CorpusID:15668109
- Zhao and Tung (2012) Feng Zhao and Anthony Kum Hoe Tung. 2012. Large Scale Cohesive Subgraphs Discovery for Social Network Visual Analysis. Proc. VLDB Endow. 6 (2012), 85–96. https://api.semanticscholar.org/CorpusID:12588941
- Zou (2013) Zhaonian Zou. 2013. Polynomial-time algorithm for finding densest subgraphs in uncertain graphs. In Proceedings of MLG Workshop.