An Analysis of Quality Indicators Using Approximated Optimal Distributions in a Three-dimensional Objective Space
Abstract
Although quality indicators play a crucial role in benchmarking evolutionary multi-objective optimization algorithms, their properties are still unclear. One promising approach for understanding quality indicators is the use of the optimal distribution of objective vectors that optimizes each quality indicator. However, it is difficult to obtain the optimal distribution for each quality indicator, especially when its theoretical property is unknown. Thus, optimal distributions for most quality indicators have not been well investigated. To address these issues, first, we propose a problem formulation of finding the optimal distribution for each quality indicator on an arbitrary Pareto front. Then, we approximate the optimal distributions for nine quality indicators using the proposed problem formulation. We analyze the nine quality indicators using their approximated optimal distributions on eight types of Pareto fronts of three-objective problems. Our analysis demonstrates that uniformly-distributed objective vectors over the entire Pareto front are not optimal in many cases. Each quality indicator has its own optimal distribution for each Pareto front. We also examine the consistency among the nine quality indicators.
Index Terms:
Evolutionary multi-objective optimization, quality indicators, optimal distributions of objective vectorsI Introduction
MULTI-OBJECTIVE optimization problems (MOPs) appear in real-world applications. Since no solution can simultaneously optimize multiple objective functions in general, the goal of MOPs is usually to find a Pareto optimal solution preferred by a decision maker [1]. When no information about the decision maker’s preference is available, an “a posteriori” decision making is performed. The decision maker selects a final solution from a non-dominated solution set that approximates the Pareto front in the objective space. An evolutionary multi-objective optimization algorithm (EMOA) is frequently used for the “a posteriori” decision making [2].
In multi-objective optimization, a vector that consists of all objective values of a solution is referred to as an objective vector. In this paper, we are interested in the distribution of objective vectors in the objective space, rather than the distribution of solutions in the solution space. Two terms “objective vector” and “solution” are used synonymously in some previous studies (e.g., [3, 4, 5]). For the sake of clarity, we distinguish the two terms. That is, solutions in the objective space are always referred to as objective vectors in this paper. We also assume that the number of objective vectors is bounded by the population size .
Most quality indicators evaluate the quality of an objective vector set in terms of at least one of the three criteria (the convergence, the uniformity, and the spread) [6, 7, 8, 5]. Although a number of quality indicators have been proposed in the literature, we focus on unary quality indicators that map objective vectors to a real number. Representative quality indicators include hypervolume (HV) [9], the additive -indicator () [7], and inverted generational distance (IGD) [10]. Since the performance of EMOAs is discussed based on the quality of obtained objective vector sets, quality indicators play a central role in benchmarking EMOAs. Although this paper does not address the cardinality of an objective vector set, it does not mean that the cardinality is less important. As pointed out in [5], the cardinality is one of important aspects when the size of the Pareto front is relatively small (e.g., combinatorial MOPs [11]). Since we address only non-dominated objective vectors on the Pareto front of a continuous MOPs in this paper, we do not analyze the cardinality-based quality indicators.
One of the critical issues in quality indicators is that their properties are not always obvious. Thus, some quality indicators are likely to provide misleading information about the quality of objective vector sets. HV is maximized by non-uniform objective vectors when the Pareto front is nonlinear [12]. Although the original generalized spread () for bi-objective problems [13] can evaluate the uniformity of given objective vectors, its extended version for problems with more than two objectives [14] overestimates the uniformity of non-uniform objective vectors in some cases [15, 5].
Since understanding the properties of quality indicators is necessary for the development of EMOAs in the right direction, some analysis studies have been presented in the literature. One of the most promising approaches is the use of the optimal distribution of objective vectors that optimizes a given quality indicator. A distribution of objective vectors is said to be the optimal -distribution if it optimizes a quality indicator [16]. The optimal -distribution can explain which distribution of objective vectors is highly evaluated by each quality indicator. For example, the optimal -distribution for IGD does not contain objective vectors on the edges of the linear Pareto front in some cases [3]. Thus, IGD may overestimate an objective vector set with a poor spread. The optimal -distribution helps an indirect analysis of each quality indicator in this manner.
Although the optimal -distributions for HV and IGD can be obtained on the linear Pareto front of two objective problems [12, 3], it is difficult to obtain the optimal -distributions for other quality indicators in an exact manner, especially problems with more than two objectives. Thus, approximated optimal -distributions are used for the analysis of quality indicators. In general, an approximated optimal -distribution is obtained in an analytical or empirical manner [12, 17, 18, 19, 3]. However, existing analytical and empirical approaches have some limitations. Analytical approaches utilize some specific properties of a quality indicator (e.g., the decomposability of the HV calculation [18]). For this reason, analytical approaches can be applied only to quality indicators whose theoretical properties are clear (e.g., HV for two- and three-objective problems [12, 18] and only for two-objective problems [19]). Empirical approaches translate the problem of finding the optimal -distribution on the Pareto front into a black-box single-objective continuous optimization problem. Then, the optimal -distribution is approximated using a derivative-free optimizer. For example, the optimal -distribution for R2 was approximated by CMA-ES [20] in [17]. Although empirical approaches are more flexible than analytical approaches, empirical approaches have been applied to only a few quality indicators, including HV [12] and R2 [17]. In addition, most previous studies addressed only two-objective problems. This is because it is not obvious how to formulate the problem of finding the optimal -distribution on a multi-objective problem with more than two objectives. For these reasons, the (approximated) optimal -distributions for most quality indicators on problems with more than two objectives have not been well analyzed in the literature.
To address these issues, first, we propose a problem formulation of finding the optimal -distribution for each quality indicator on a Pareto front in an arbitrary-dimensional objective space. Then, we approximate the optimal -distribution for each of the following nine quality indicators on a Pareto front in a three-dimensional objective space: HV, IGD, IGD plus (IGD+) [21], R2, new R2 (NR2) [22], , -energy (SE) [23], , and pure diversity (PD) [24]. We analyze the nine quality indicators using their approximated optimal -distributions on eight types of Pareto fronts.
Our main contributions in this paper are as follows:
-
1.
We propose a general problem formulation of finding the optimal -distribution. In contrast to the existing empirical approaches, the proposed formulation can handle any number of objectives. The proposed formulation is applicable to any types of the Pareto front (under the condition that its front shape function is given). Note that the formulation proposed in [12] and our formulation can be categorized into set-based optimization [25]. Details are discussed in Section IV.
-
2.
We approximate the optimal -distributions for the nine quality indicators on the Pareto fronts of eight problems with three objectives. This is the first study to present the approximated optimal -distributions for NR2, , SE, PD, R2, and for three-objective problems.
-
3.
We analyze the nine quality indicators from the viewpoint of the approximated optimal -distributions. We provide insightful information about the nine quality indicators. For example, PD may overestimate an objective vector set with a small dissimilarity. Our observations are summarized in Section VII.
The rest of this paper is organized as follows. Section II provides some preliminaries. Section III describes related studies. Section IV proposes a problem formulation to search for the optimal distribution of objective vectors. Section V describes the setting of our computational experiments. Section VI shows analysis results. Section VII concludes this paper.
II Preliminaries
II-A Definition of multi-objective optimization problems (MOPs)
We suppose a multi-objective minimization problem in this paper. A continuous MOP is to find a solution that minimizes a given objective function vector . Here, is the -dimensional solution space, and is the -dimensional objective space. Thus, is the number of decision variables, and is the number of objective functions.
A solution is said to dominate iff for all and for at least one index . In addition, is said to weakly dominate iff for all . If is not dominated by any other solutions in , is a Pareto optimal solution. The set of all is the Pareto optimal solution set. The set of all is the Pareto front. The goal of MOPs for the “a posteriori” decision making is to find a non-dominated solution set that approximates the Pareto front in the objective space.
II-B Quality indicators
For the sake of simplicity, we denote the objective vector as , where for . Let be a set of objective vectors, where is the population size.
Let be a set of all possible objective vector sets. A unary quality indicator evaluates the quality of in terms of at least one of the convergence, the uniformity, and the spread. is said to be Pareto-compliant iff the ranking of all objective vector sets in by is consistent with the Pareto dominance relation (for details, see [26]). In this paper, we define the convergence, the uniformity, and the spread as follows. The convergence of means how close objective vectors in are to the Pareto front. The uniformity of means how uniform the distribution of objective vectors in is. The spread of means how well objective vectors in cover the entire Pareto front. As pointed out in [5], the spread is not equal to the extensity, which represents the length of the boundaries of . A combination of the uniformity and the spread is referred to as “diversity” in the evolutionary multi-objective optimization (EMO) community. Fig. S.1 in the supplementary file shows examples of distributions of objective vectors in the three cases on the linear Pareto front with .
Below, we explain the following nine quality indicators used in this paper: HV, IGD, IGD+, R2, NR2, , SE, , and PD. We do not consider convergence-based quality indicators, such as generational distance (GD) [27], which evaluate the quality of an objective vector set in terms only of the convergence. This is because the optimal -distribution for such a quality indicator is obvious. is optimal for convergence-based quality indicators if all elements in are on the Pareto front regardless of their distribution. For the same reason, we do not consider cardinality-based quality indicators, such as overall non-dominated vector generation (ONVG) [28], which evaluate the quality of based on the number of non-dominated solutions. For example, all of , , and in Fig. S.1 are optimal for both GD and ONVG.
Below, is a set of -dimensional reference vectors that approximate the Pareto front in the objective space. The reference point is used for the HV and NR2 calculations. It should be noted that .
II-B1 Hypervolume (HV)
Since HV [9] is the only Pareto-compliant quality indicator known so far [29], HV is one of the most popular quality indicators. The HV value of is the volume of the area that is dominated by objective vectors in and bounded by the reference point as follows:
| (1) |
where the function “” in (1) is the Lebesgue measure. A large HV value indicates that approximates the Pareto front well in terms of both convergence and diversity.
II-B2 Inverted generational distance (IGD)
II-B3 IGD plus (IGD+)
Since IGD is not Pareto compliant, IGD may incorrectly evaluate the quality of that contains non-converged objective vectors [21, 30]. IGD+ [21] addresses the issue in IGD. While IGD is Pareto non-compliant, IGD+ is weakly Pareto compliant. The IGD+ value of is the average distance from each reference vector to its nearest objective vector in the dominated region by [31]. Although the IGD+ value of is calculated using (2), is replaced by the following distance function: . It should be noted that small IGD and IGD+ values are preferable whereas large HV values are preferable.
In addition to IGD+, the averaged Hausdorff distance indicator () [30] addresses the issue in IGD. When all elements in are on the Pareto front and has a large number of uniformly distributed reference vectors over the entire Pareto front (as in our computational experiments in this paper), the value of is equal to the IGD value of in general. Actually, the IGD and values are the same for all of the obtained solution sets in this paper. For this reason, we do not report experimental results for . Of course, the above-mentioned relationship between and IGD does not always hold depending on and .
II-B4 The additive -indicator ()
Here, we describe the unary version of [7]. The value of two objective vectors and is given as follows:
| (3) |
where the value is the minimal shift such that weakly dominates . It should be noted that in (3). evaluates how well approximates the reference vector set as follows:
| (4) |
where the value of in (4) is the minimal shift such that each reference objective vector in is weakly dominated by at least one objective vector in . A small value indicates that the corresponding is a good approximation of the Pareto front in terms of both convergence and diversity.
II-B5 R2
Although three R indicators are proposed in [32], the following R2 indicator is the most widely used one:
| (5) | ||||
| (6) |
where in (5) is a set of weight vectors. For each , for and . In (6), is the weighted Tchebycheff function, and is the ideal point. The -th element of is the minimum value of the -th objective function over the Pareto front. According to [5], R2 with a tuned works well on various problems with . A small R2 value indicates that approximates the Pareto front well in terms of both convergence and diversity.
II-B6 New R2 indicator (NR2)
Although the Pareto compliance of HV is attractive, the computation time for the HV calculation increases exponentially with the number of objectives . To address this issue, the method of approximating the HV value using R2 is proposed in [33]. The following NR2 [22] is an improved version of R2 to obtain a better approximation of the HV value:
| (7) | ||||
| (8) |
where in (8) is a modified version of . If in (8), was set to to avoid division by zero. Similar to HV, NR2 uses the reference point . A large NR2 value indicates that the corresponding has a good HV value. Since NR2 was designed to approximate the HV value, it is expected that their optimal -distributions are similar to each other. However, such an expectation has not been verified in the literature. To address this issue, we examine the approximated optimal -distribution for NR2 in this paper.
II-B7 -energy (SE)
Although SE [23] was not originally proposed in the field of EMO, SE is used as a quality indicator in some studies (e.g., [34]). SE is given as follows:
| (9) |
where is usually set to , and is the norm of . If in (9), we set the SE value of to an infinitely large value to avoid division by zero. A small SE value indicates that has a good uniformity and a good spread.
II-B8 Generalized Spread ()
The original indicator [13] can handle only the two-dimensional objective space. In this paper, we use an extension of with respect to presented in [14]. evaluates the quality of in terms of both uniformity and spread as follows:
| (10) | ||||
| (11) | ||||
| (12) | ||||
| (13) |
where the function in (11) returns the Euclidean distance from to its nearest vector in the set . In (12), is the -th extreme objective vector with the maximum value of the -th objective function in (). In (10), aims to evaluate the spread of , while the other parts aim to evaluate the uniformity of . A small value indicates that has good spread and uniformity.
II-B9 Pure diversity (PD)
PD [24] is an extended version of the Solow-Polasky diversity indicator [35] for multi-objective optimization. The PD value of is based on the dissimilarity of each objective vector to as follows:
| (14) | ||||
| (15) |
where the recommended value of in the norm in (15) is . Most diversity-based quality indicators (including SE and ) evaluate the uniformity of . In contrast, PD evaluates the dissimilarity between objective vectors in .
III Related work
This section describes related work. Analysis of quality indicators can be categorized into two approaches. One is ranking information based approaches. First, multiple objective vector sets are ranked by each quality indicator. Then, the properties of each quality indicator are discussed based on which objective vector set is highly evaluated by the quality indicator. The consistency of multiple quality indicators can also be investigated in this manner. One main drawback of the ranking information based approaches is that only relative information can be obtained.
The other is optimal -distribution based approaches. As explained in Section I, the optimal -distribution provides insightful information about the properties of each quality indicator. One main drawback of the optimal -distribution based approaches is that it is difficult to find the optimal -distributions for quality indicators.
III-A Ranking information based approaches
Okabe et al. [8] analyzed 15 quality indicators using objective vector sets artificially generated on the linear Pareto front and objective vector sets found by EMOAs on the convex Pareto front. The results show that some quality indicators can generate misleading results. Jiang et al. [15] examined six quality indicators using a pair of objective vector sets on the linear, convex, and concave Pareto fronts. The results show that , IGD, and HV are consistent with each other on the convex Pareto front, but IGD is inconsistent with HV on the concave Pareto front. Ravber et al. [36] investigated 11 quality indicators using a chess rating system. They used objective vector sets found by EMOAs on some test problems. The results show the robustness of HV, , and IGD+. However, the results also show that the three quality indicators do not equally evaluate the quality of objective vector sets in terms of the convergence, the uniformity, and the spread.
Wessing and Naujoks [37] analyzed the correlation between HV, R2, and . Their analysis was based on objective vector sets randomly generated on two- and three-objective problems. The results based on Pearson’s correlation coefficient show that HV is highly consistent with R2. Liefooghe and Derbel [38] examined the correlation between six quality indicators. They used objective vector sets found by the random search and NSGA-II [13] on test problems with . The results based on the Kendall rank correlation show that HV is consistent with R2 and R3. In contrast, and its multiplicative version are inconsistent with other quality indicators. Ishibuchi et al. [39] compared IGD+ with IGD on various objective vector sets found by NSGA-II on problems with up to 10 objectives. The results show that IGD+ can evaluate objective vector sets more accurately than IGD in terms of the Pareto compliance. In addition to IGD+ and IGD, three quality indicators (GD, , and D1 [32]) were examined. Bezerra et al. [40] analyzed the relation between IGD+ and IGD on the linear Pareto front. Various objective vector sets were used in their analysis. The results show that IGD and IGD+ are consistent with each other in most cases. The results also show that IGD may favor objective vectors with a poor spread.
III-B Optimal -distribution based approaches
It is difficult to obtain the optimal -distributions in an exact manner. Thus, the optimal -distributions are generally approximated by analytical or empirical methods. For the differences between the two methods, see Section I.
Auger et al. [12] formulated finding the optimal -distribution for HV on two-objective problems as a single-objective continuous optimization problem. Below, we describe its problem formulation in a general manner. Our description significantly differs from the original one.
Let be a set of objective vectors on the Pareto front. Also, let be a real value that determines the first element (i.e., the value of the first objective ) of the -th objective vector () in . All objective vectors in the optimal -distributions must always be on the Pareto front. For this restriction, the position of for specifies that for the second objective . In [12], a front shape function is used to determine the position of for as follows: . For all , is in the range , where and are the lower and upper bounds for . Here, and correspond to the minimum and maximum values of in the Pareto front, respectively. In this manner, the distribution of objective vectors in is determined by a vector .
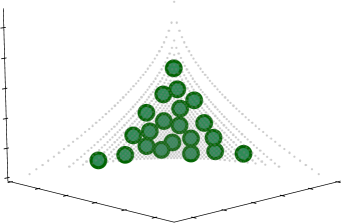
Fig. 1 shows examples of five objective vectors. In Fig. 1, the Pareto front is shown by
| (16) | |||||
| (17) | |||||
| (18) |
where , , and represent the Pareto front shapes of DTLZ1 [41], DTLZ2 [41], and ZDT1 [42], respectively. In Fig. 1, , for , and for and . As shown in Fig. 1, distributions of objective vectors on various Pareto fronts can be examined by changing .
In summary, finding that minimizes a quality indicator is the same as finding that indirectly minimizes as follows:
| (19) |
where is a solution of the problem defined in (19). that needs to be maximized (e.g., HV, NR2, and PD) can be translated as without loss of generality. Any derivative-free optimizer can be used to minimize in (19).



Auger et al. [12] proposed analytical and empirical methods of approximating optimal -distributions for HV. Details of the analytical method for each can be found in the supplementary website of [12] (https://sop.tik.ee.ethz.ch/download/supplementary/testproblems/). The proposed problem-specific local search algorithm in [12] for (19) uses variable-wise perturbation. For each iteration, each is perturbed by a value selected randomly from a normal distribution. Brockhoff et al. [17] applied CMA-ES [20] to (19) to find the optimal -distributions for R2. Their results show that objective vectors in the optimal -distributions for R2 are densely distributed in the center of the Pareto front. They also examined the contribution of each objective vector in the optimal -distribution for R2 to HV (and that for HV to R2).
In contrast to the above-mentioned studies [12, 17], the following studies do not use (19). Bringmann et al. [19] proposed the analytical method for finding the optimal -distributions for on the Pareto front with . The proposed method explicitly exploits the properties of presented in [43]. The results show that the optimal -distributions for on most Pareto fronts with are uniform. Glasmachers [18] proposed a gradient-based analytical method for approximating the optimal -distributions for HV on . For , the proposed method in [18] decomposes the three-dimensional objective space into cuboids. Then, the proposed method in [18] uses the gradient of HV based on the cuboids.
Ishibuchi et al. [4] used SMS-EMOA [44] to approximate the optimal -distributions for HV on Pareto fronts of three-objective problems. SMS-EMOA uses the HV contribution in the steady-state selection. For each iteration, the worst individual in terms of the HV contribution is removed from the last non-domination level. In [4], SMS-EMOA was applied to the DTLZ and inverted-DTLZ problems whose number of distance variables is zero. Then, the influence of the reference vector on the optimal -distributions for HV is examined. Ishibuchi et al. [3] also investigated the optimal -distributions for IGD approximated by a similar approach. The HV contribution-based selection in SMS-EMOA was replaced by the IGD contribution-based selection. The optimal -distributions for HV, IGD, and IGD+ approximated by SMS-EMOA in a similar manner were analyzed in [31]. The results show that the optimal -distributions for IGD are almost uniform in all problems. The results also show that the optimal -distributions for HV and IGD+ are similar in all problems when the reference vector for HV is set appropriately.
IV Proposed formulation
Here, we introduce the proposed problem formulation of finding the optimal -distribution for quality indicators on Pareto fronts for arbitrary number of objectives (). As reviewed in Subsection III-B, some methods of approximating the optimal -distributions have been proposed in the literature. The analytical methods [12, 18, 19] can efficiently approximate the optimal -distributions in a computationally cheap manner. Unfortunately, they can be applied to only quality indicators whose theoretical properties are clear (i.e., HV and ). It is questionable whether the empirical methods using SMS-EMOA [3, 4, 31] can be applied to quality indicators except for HV, IGD, and IGD+. The empirical methods based on the problem formulation in (19) are promising. Although the previous studies [12, 17] addressed only HV and R2, the approaches using (19) can be applied to any quality indicators in principle. However, the problem formulation in (19) can handle only Pareto fronts for . In contrast, the proposed problem formulation can handle Pareto fronts for . We do not claim that the degenerated version of our formulation for is better than the formulation in (19). Note that our formulation for is almost the same as the formulation in (19).
The formulation proposed in [12] for and our formulation for are essentially one of the set-based optimization methods [25]. Test problems constructed by bottom-up approaches (e.g., DTLZ) have two types of decision variables [45]. One is position-related variables that specify the position of an objective vector on the Pareto front. The other is distance-related variables that determine the distance between the objective vector and the Pareto front. Thus, any solutions with only position-related variables are always on the Pareto front in the objective space. The optimal -distribution for a quality indicator can be approximated by a set-based method that finds a set of solutions (not objective vectors) with only position-related variables for minimization of the quality indicator. While we here denote this approach as the solution set-based approach, we denote the formulations proposed in [12] and this paper as the objective vector set-based approach. The main advantage of the objective vector set-based approach is its simplicity. While the solution set-based approach needs to handle both solution and objective spaces, the objective vector set-based approach just needs to handle only the objective space. We can focus only on the objective space in the objective vector set-based approach. This simplicity is beneficial for an analysis of the optimal -distributions as demonstrated in [12].
IV-A Proposed problem formulation
Below, we explain the proposed formulation for general cases. Only a disconnected front shape function explained in Subsection IV-C requires an alternative formulation. For details, see Subsection S.1-D in the supplementary file. Finding the optimal -distribution for a quality indicator on the Pareto front with objectives is formulated as follows:
| minimize | (20) | |||
| subject to |
where is a constraint function for constrained front shape functions (e.g., explained in Subsection IV-C). In contrast to (19), is added to (20). If a given front shape function has no constraint, is eliminated from (20). An objective vector set is a translated version of a solution of this problem in a two-phase manner as follows:
| (21) | ||||
| (22) |
where is a -dimensional vector, and . Any single-objective black-box optimizer can be used to find that minimizes . While the size of is in (19), that is in (21). For all , is in .
The function “” in (22) translates a -dimensional vector into a set that consists of -dimensional vectors. For each , , and . Although is an -dimensional vector, it is not an objective vector. Subsection IV-B explains the translation operator in detail.
After translating into in (22), is further mapped to the objective vector set by a front shape function in (21). For each , an element in corresponds to an objective vector in . All objective values are normalized into in our study by using the ideal point and the nadir point of each as follows: for each . Here, is the maximum value of the -th objective function of the Pareto front. We use the normalization in order to examine the approximated optimal -distributions for the quality indicators without worrying about the influence of differently-scaled objective values. Subsection IV-C specifies how to map to by the front shape function .
IV-B Translation operator
We explain how the translation operator in (22) maps to . First, all elements in are divided into vector groups as , …, . For example, when , , , and , 4 elements in are divided as follows: and . For the sake of simplicity, we denote as for each .
Below, we describe how the -dimensional vector is translated into an -dimensional vector in . To obtain all vectors in , the same operation is repeatedly applied to for each . Each element in is obtained using the Jaszkiewicz’s method of generating random weight vectors [46] as follows:
| (23) | ||||
where in (23). It should be noted that obtained by (23) satisfies the condition . Although the Jaszkiewicz’s method was originally proposed for the weight vector generation in decomposition-based EMOAs, it can be used to translate into in a straightforward manner.
IV-C Front shape function
The proposed formulation can be applied to any Pareto front when its front shape function is available. In other words, the proposed formulation cannot be applied to the Pareto front whose analytical expression (i.e., its front shape function) is unavailable such as WFG3 [47]. Although various front shape functions were presented in the previous study [12], they are only for . We design front shape functions for based on a method of generating uniformly distributed reference vectors in representative test problems (e.g., DTLZ and WFG) presented in [48].
We use eight front shape functions shown in Table I. The name of the original problems and the shape of the Pareto fronts are also shown in Table I. , , and are the most basic front shape functions. , , and are inverted versions of , , and , respectively. It should be noted that an inverted version of the convex Pareto front is concave, and vice versa. has the disconnected and mixed Pareto front. Some parts of the Pareto front of are infeasible due to the constraint. We select to demonstrate that the proposed formulation can handle the constrained Pareto front. In our preliminary experiments, we used the degenerate front shape function whose original problem is DTLZ5. is not a surface but a curve since it is degenerate. Because the shape of is concave, the optimal -distribution on is similar to that for a two-objective problem with . For this reason, we omit .
Due to the paper length limitation, we explain only in this paper. We describe other front shape functions in Section S.1 in the supplementary file. In , the -th element of in is translated into the -th element of in on the concave Pareto front as follows:
| (24) |
where . This translation is based on the method of generating reference vectors in DTLZ2 described in [48]. All objective vectors obtained by (24) satisfy the following relation of the Pareto front of DTLZ2: . In addition to the eight front shape functions in Table I, we believe that it is possible to design other front shape functions using [48] as reference.
V Experimental settings
This section describes experimental settings. We examine the properties of the nine quality indicators using the eight front shape functions in Table I. Although the number of objectives can be arbitrarily specified in the proposed formulation, is set to three in order to visually discuss the distributions of objective vectors. We investigate the optimal -distributions with (, respectively). We select these values so that we can visually discuss the distribution of objective vectors. The distribution of objective vectors with a too large value is unclear. We can also examine the influence of on the optimal -distributions by using the various values.
In the proposed formulation in (20), a black-box optimizer is necessary to find that minimizes a given quality indicator. We use L-SHADE [52], which is an improved version of differential evolution (DE) [53]. L-SHADE was the winner of the IEEE CEC2014 competition on single-objective real-parameter optimization. We used the Java source code of L-SHADE provided by the authors of [52]. The default parameter setting was used for L-SHADE. The maximum number of function evaluations was set to , and 31 independent runs were performed. For the constrained front shape function , we use the death-penalty constraint handling method. This is because objective vector sets are just classified into feasible and infeasible groups as described in Subsection S.1-E in the supplementary file. The fitness value of an infeasible individual is an infinitely large value so that all infeasible individuals cannot survive to the next iteration. We compared L-SHADE to the analytical approach that approximates the optimal -distributions for HV for [12] (see Subsection III-B). We confirmed that L-SHADE can find the approximated optimal -distribution for HV with acceptable quality for . For details, see Section S.3 in the supplementary file.
We implemented the nine quality indicators ourselves, except for HV. The WFG algorithm [54] was used for the HV calculation. We used the source code of the WFG algorithm provided by the authors of [54]. For PD, we carefully translated the Matlab source code provided by the authors of [24] into our implementation in order to speed up the PD calculation. We confirmed that our version and the original version output exactly the same PD value on all the front shape functions used in our study. The source codes used in our experiments can be downloaded from the supplementary website (https://sites.google.com/view/optmudist).
We set the reference vector for HV and NR2 to according to [4]. We set for R2 to . As mentioned in Subsection IV-A, all objective values are in the range for all front shape functions. For R2 and NR2, we generated the weight vector set using simplex-lattice design [55]. For IGD, IGD+, , and , we generated the reference vector set by applying each front shape function to as follows . That is, in order to generate , is used in (21) instead of (the resulting is used as ). For details, see Section S.2 in the supplementary file. The size of and was set to . For and , we set the size of to and , respectively. This is due to the properties of and .





























|






























|

















VI Experimental results
This section analyzes the nine quality indicators using their optimal -distributions approximated by the proposed formulation. Subsection VI-A discusses the optimal -distributions for each quality indicator. Subsection VI-B examines the nine quality indicators using the ranking information. Subsection VI-C analyzes the generality of results for with respect to . Subsection VI-D investigates a unary version of an -nary quality indicator.
VI-A Approximated optimal -distributions for the nine quality indicators
Figs. 4–9 show approximated optimal -distributions with obtained by the proposed approach for the nine quality indicators on the eight Pareto fronts. In Figs. 4–9, , , and axes represent , , and , respectively. Figs. 4–9 show the best objective vector set found by L-SHADE among 31 runs for each quality indicator on each front shape function . Below, we denote the best -distribution for a quality indicator as (e.g., ). Figs. S.3–S.50 in the supplementary file show approximated optimal -distributions with the other values. All reference vectors in are shown in each figure.
For the sake of comparison, Figs. 4–7 (j) show a set of objective vectors generated by simplex-lattice design, denoted as . We generated using the same method as for generating the reference vector set described in Section V. Since the number of objective vectors generated by simplex-lattice design on and cannot be specified arbitrarily due to their characteristics, we do not show in Figs. 9 and 9. can be viewed as an “ideal” objective vector set found by decomposition-based EMOAs (e.g., NSGA-III [49]). Although the distribution of objective vectors in is uniform, is not optimal for all the nine quality indicators (see Subsection VI-B).
Since the distribution of objective vectors in some objective vector sets is not uniform, one may think that the approximated objective vector sets are far from optimal. However, as demonstrated in Subsection VI-B using Table II, some quality indicators do not prefer uniformly distributed objective vectors. For example, as shown in Figs. 4 (j) and (h), clearly has a better uniformity than on . Nevertheless, Table II shows that evaluates as better than (details are discussed later). Such an unintuitive result may be due to a hidden property of each quality indicator. We reemphasize that a theoretical analysis of the optimal -distribution for is difficult. For this reason, the (true and approximated) optimal -distributions for almost all quality indicators have not been investigated on the Pareto front with .
Below, we individually discuss the optimal -distribution for each of the nine quality indicators (, , , , , , , , and ). Although results of HV, IGD, and IGD+ are consistent with the previous studies, some results of other quality indicators provide insightful information. Our findings are summarized in Section VII.
VI-A1
It should be noted that the optimal -distribution for HV significantly depends on the position of the reference vector [4]. Objective vectors in are on the edge and the center of the Pareto front for all the front shape functions, except for and . These observations on the convex Pareto fronts are consistent with the previous studies [12, 15, 4]. When is small, does not contain the extreme objective vectors even for the linear front shape function (e.g., with shown in Fig. S.3 in the supplementary file). As increases, covers the edge of the Pareto front on most front shape functions.
VI-A2
The distribution of objective vectors in is uniform on most front shape functions, even including . However, objective vectors in on all front shape functions are not on the edge of the Pareto front. Thus, IGD may incorrectly evaluate the spread quality of objective vector sets. The poor spread quality of is consistent with the previous studies [3, 31].
VI-A3
Our results are consistent with the results presented in [31]. The distribution of objective vectors in is almost the same as that in on and similar to that in on the other front shape functions. As the value increases, the distributions of objective vectors in and become more similar. For details, see Figs. S.3–S.50 in the supplementary file.
VI-A4
Objective vectors in are densely distributed in the center of the Pareto front for , , and . These results are consistent with the previous study [17] for . However, our results on and are inconsistent with [17]. Only one objective vector in is in the center of the Pareto front for . Almost all objective vectors in are on the edge of the Pareto front. Similarly, all objective vectors in are on the edge of the Pareto front for . When is set to a larger value, contains a few objective vectors on the center of the Pareto front for as shown in Figs. S.3–S.50.
Our inconsistent results on and are mainly due to the inverted triangular Pareto front. The analysis presented in [51] shows that some decomposition-based EMOAs (e.g., MOEA/D and NSGA-III) perform poorly on problems with inverted triangular Pareto fronts. This is because the shape of the distribution of weight vectors used in the decomposition-based EMOAs is different from the shape of the Pareto front. Since R2 uses the weight vector set that is similar to decomposition-based EMOAs, R2 is likely to have a similar issue in decomposition-based EMOAs for .
VI-A5
Since NR2 was designed to approximate the HV value, is very similar to for all front shape functions. Although NR2 is the modified version of R2, is dissimilar to . For example, does not contain any objective vector in the center of the Pareto front for . In contrast, contains some objective vectors in the center of the Pareto front for that is similar to .
VI-A6
As mentioned in Subsection III-B, the optimal -distributions for on were investigated in [19]. However, our results on are inconsistent with [19]. The distribution of objective vectors in is not uniform for all front shape functions (except for ). Thus, our results show that optimal -distributions for depend on the choice of . As pointed out in [5], the value of a given objective vector set depends only on one objective value of one objective vector in . This property of may influence its optimal -distributions on in a complicated manner. An in-depth analysis of the optimal -distributions for on is another future work.
VI-A7
Similar to , the distribution of objective vectors in is uniform for all front shape functions. In contrast, objective vectors in are more widely distributed than those in . For example, while objective vectors in are densely distributed in the center of the Pareto front for , those in cover the whole Pareto front. We can conclude that SE evaluates the quality of objective vector sets in terms of both uniformity and spread.
However, most objective vectors in are on the edge of the Pareto front (especially on ). Even as the value increases, this characteristic can be still found (see Figs. S.3–S.50). Thus, SE may overestimate a set of objective vectors on the edge of the Pareto front.
| HV | 1 | 10 | 3 | 5 | 2 | 7 | 4 | 8 | 9 | 6 |
| IGD | 9 | 1 | 10 | 7 | 8 | 2 | 4 | 6 | 5 | 3 |
| IGD+ | 2 | 9 | 1 | 4 | 3 | 7 | 5 | 8 | 10 | 6 |
| R2 | 2 | 10 | 4 | 1 | 3 | 8 | 5 | 7 | 9 | 6 |
| NR2 | 2 | 10 | 3 | 5 | 1 | 7 | 4 | 8 | 9 | 6 |
| 3 | 5 | 6 | 4 | 2 | 1 | 8 | 9 | 10 | 7 | |
| SE | 7 | 6 | 4 | 3 | 5 | 8 | 1 | 9 | 10 | 2 |
| 9 | 3 | 6 | 4 | 7 | 5 | 2 | 1 | 10 | 8 | |
| PD | 7 | 5 | 8 | 3 | 9 | 2 | 6 | 4 | 1 | 10 |
| Avg. | 4.2 | 5.9 | 4.5 | 3.6 | 4.0 | 4.7 | 3.9 | 6.0 | 7.3 | 5.4 |
VI-A8
Since contains the extreme objective vectors on all , can evaluate the spread quality of objective vector sets. In contrast, the distribution of objective vectors in is far from uniform. Thus, may incorrectly evaluate the uniformity quality of objective vector sets.
uses a pairwise distance between two closest objective vectors. As pointed out in [15], this calculation scheme in can provide misleading results in some cases. This is because does not consider the distance between non-closest objective vectors. In fact, objective vectors in for seem to be connected in a chained manner (e.g., see Fig. 4 (h)). In contrast, SE handles the distance between all pairs of two objective vectors. Thus, SE does not have this issue in . It should be noted that the misleading results by have already been reported in [15, 5]. Thus, this observation is not new. Our contribution here is that we find and analyze on the eight front shape functions. The above-mentioned unintuitive distribution of objective vectors in has not been investigated in the literature.
VI-A9
Unlike the other quality indicators, PD evaluates the dissimilarity between objective vectors. For this reason, the distribution of objective vectors in is not uniform on all front shape functions. This observation is consistent with the property of PD reported in [24, 5]. Also, does not contain all the three extreme objective vectors in most cases.
Interestingly, at least two objective vectors in overlap. Since some objective vectors in completely overlap on and , it looks like that is less than . Thus, PD may overestimate an objective vector set that contains similar objective vectors. Although we calculated the PD value using the translated version of the original source code as explained in Section V, we can obtain exactly the same results even using the original one.
To understand the influence of overlapping objective vectors on PD, we slightly modified one of overlapping objective vectors in on (Fig. 7 (i)). Two resulting objective vector sets are denoted as and . Fig. S.2 in the supplementary file shows the distribution of objective vectors in and on . The distribution of objective vectors in and is more diverse than that in . Nevertheless, and are evaluated as worse than as follows: , , and . Recall that PD is to be maximized.
Our observation may be due to the sensitivity of PD to the order of objective vectors. PD constructs a tree based on objective vectors in an objective vector set . In this procedure, each objective vector is greedily linked to its nearest unreplicated objective vector in lexical order (i.e., from to ). The resulting tree depends on the order of the objective vectors. We arranged the objective vectors in on in reverse order (i.e., from to ). The resulting objective vector set is denoted as . Although and contain exactly the same objective vectors, is evaluated as worse than in terms of PD as follows: . Overlapping objective vectors in may help to construct a larger tree by implicitly exploiting the lexical characteristic of PD.
VI-B Ranking information based analysis
In Subsection VI-A, we analyzed the nine quality indicators using the optimal -distributions. Here, we examine the nine quality indicators using the ranking information.
Table II shows the rankings of the nine approximated optimal -distributions (, …, ) and by each quality indicator on . The average ranking values are reported at the bottom of Table II. Tables S.2–S.6 in the supplementary file show the rankings on , , , , and , respectively. Since cannot be generated on and , the rankings for and are not shown. Note that the quality indicator called “SLD” does not exist. Recall that is generated by simplex-lattice design. Due to the paper length limitation, we mainly explain the results on .
On the one hand, from each row in Table II, we can read the ranking of the ten objective vector sets by the corresponding quality indicator on . For example, HV evaluates and as the best and the worst, respectively. On the other hand, from each column in Table II, we can read the ranking of the corresponding objective vector set by the nine indicators. For example, is ranked at fourth by HV, IGD, and NR2.
The average ranking value of each objective vector set in the bottom row of Table II (i.e., average value of each column) means how highly the corresponding objective vector set is evaluated by all the nine quality indicators. performs the best among the 10 objective vector sets on in terms of the average ranking values. Thus, a good objective vector set with respect to R2 may be highly evaluated by the other quality indicators on . In contrast, performs the worst in terms of the average ranking values. This result indicates that a good objective vector set with respect to PD may be evaluated as inferior to other objective vector sets by the other quality indicators on . These results are useful for selecting a quality indicator used in indicator-based EMOAs. Note that the best objective vector set in terms of the average ranking values depends on the choice of . For example, Table S.4 shows that performs the second worst on .
Each quality indicator evaluates its optimal -distribution as the best. For this reason, all diagonal elements in Table II are “1”. The same results can be found in the rankings on the other front shape functions, except for the ranking of by IGD+ on in Table S.2 and by NR2 on in Table S.5. IGD+ and NR2 evaluate and as the best in Tables S.2 and S.5, respectively. These exceptional results are due to the similarity between IGD and IGD+, and the similarity between HV and NR2.
As in [38], Table III shows the rank-based nonlinear Kendall rank correlation values of the nine quality indicator on . Tables S.7–S.11 in the supplementary file show the values of the nine quality indicator on , , , , and , respectively. The value in Table III represents the similarity of the rankings by two quality indicators and on the 10 objective vector sets (, …, ). The values in Table III are symmetric. The range of the value is . While the non-negative value means that and are consistent with each other, the negative value means that and are inconsistent with each other. For example, Table III shows that HV is inconsistent with IGD (), but HV is consistent with IGD+ ().
| HV | IGD | IGD+ | R2 | NR2 | SE | PD | |||
| HV | 1.00 | -0.60 | 0.82 | 0.78 | 0.96 | 0.33 | 0.24 | -0.24 | -0.42 |
| IGD | -0.60 | 1.00 | -0.69 | -0.56 | -0.56 | -0.02 | -0.02 | 0.20 | 0.20 |
| IGD+ | 0.82 | -0.69 | 1.00 | 0.69 | 0.78 | 0.33 | 0.33 | -0.16 | -0.42 |
| R2 | 0.78 | -0.56 | 0.69 | 1.00 | 0.73 | 0.29 | 0.29 | -0.11 | -0.29 |
| NR2 | 0.96 | -0.56 | 0.78 | 0.73 | 1.00 | 0.38 | 0.29 | -0.20 | -0.47 |
| 0.33 | -0.02 | 0.33 | 0.29 | 0.38 | 1.00 | -0.07 | -0.11 | -0.11 | |
| SE | 0.24 | -0.02 | 0.33 | 0.29 | 0.29 | -0.07 | 1.00 | 0.16 | -0.47 |
| -0.24 | 0.20 | -0.16 | -0.11 | -0.20 | -0.11 | 0.16 | 1.00 | 0.11 | |
| PD | -0.42 | 0.20 | -0.42 | -0.29 | -0.47 | -0.11 | -0.47 | 0.11 | 1.00 |
As seen from Table II, no optimal -distribution is ranked as the best by multiple quality indicators due to the conflicting properties of the nine quality indicators. For example, is ranked as the best by IGD but the worst by HV, R2, and NR2. In contrast, the rankings by HV and NR2 are almost the same on all front shape functions (except for the rankings of and ). In fact, the value of HV and NR2 in Table III is , which indicates HV and NR2 are highly correlated with each other. Although the rankings by IGD and IGD+ are almost the same on the linear Pareto fronts ( and ), they are dissimilar on the non-linear Pareto fronts (, , , and ). The value of IGD and IGD+ in Table III is also on . These results of IGD and IGD+ are consistent with [40, 31].
The simplex lattice-based can be viewed as the optimal objective vector set obtained by decomposition-based EMOAs. Since has a good uniformity, is evaluated as the second best by SE on . In contrast, is evaluated as “poor” by the other quality indicators in most cases (except for the results on in Table S.4). In fact, the distribution of objective vectors in is not identical to optimal -distributions for the nine quality indicators (see Figs. 4–7). The poor results of suggest that decomposition-based EMOAs need an adaptive weight vector method considering the optimal -distributions for a given quality indicator.
VI-C Analysis for
Since it is almost impossible to clearly show the distribution of objective vectors of a problem with in an understandable manner [56, 57], this paper focused on . We reemphasize that our analysis for itself is already an important contribution to the EMO community. Nevertheless, it is interesting to investigate whether the results for can be generalized to the case of .
Since the distribution of objective vectors for is unclear, our analysis here is based on the ranking information as in Subsection VI-B. Tables S.12–S.23 in the supplementary file show the rankings of the nine approximated optimal -distributions (, …, ) with by each quality indicator on six front shape functions (, , , , , and ) with and , respectively. Since with cannot be generated for and , is removed from this experiment. The size of the reference point set was set to for and for . We generated for using the two-layered version of simplex-lattice design [49]. Tables S.24–S.35 in the supplementary file also show the Kendall rank correlation values of the nine quality indicators on the six front shape functions with and , respectively.
Although most results for are consistent with the results for , some exceptional results can be found. is ranked as the best by on and with , and and with . This means that a better approximated optimal -distribution for can be found by optimizing SE. Similarly, is ranked as the best by on with . This may be because of the problem difficulty in finding the optimal -distribution for and . For example, as mentioned in Subsection VI, the value of depends only on one objective value of one objective vector in . As in the Schwefel 2.21 function [58], this property of can incorporate a strong nonseparability between variables in the proposed formulation. In addition, this property can make some areas of the fitness landscape of the proposed formulation plateaus. These problem difficulties become pronounced with the increase of . A landscape analysis of the proposed formulation for each quality indicator is needed for deeper understanding.
Table IV shows the best objective vector sets on each with in terms of the average ranking. We can see that the best objective vector set in terms of the average ranking depends on in addition to the choice of . For example, , , and perform the best on with , , and , respectively. These results indicate the necessity of an adaptive indicator selection mechanism in indicator-based EMOAs (e.g., [34]).
| , | ||||||
| , | ||||||
In addition, the correlation between HV and NR2 becomes weak with the increase of . For example, the values of HV and NR2 on are for , for , and for (see Tables III, S.24, and S.30, respectively). This observation indicates that the approximation performance of NR2 is likely to deteriorate with the increase of .
In summary, the results here show that some results for cannot be always generalized to the case of . Thus, our observations are only for as emphasized in the title of this paper. Further analysis for many-objective problems is need in future research.
VI-D Analysis of a unary version of an -nary indicator
As in , some binary or -nary quality indicators can be converted into their unary versions by using the reference vector set as the compared vector set. However, it is questionable that such a converted unary quality indicator works well. Here, we demonstrate that the proposed formulation can be useful to analyze the unary version of an -nary indicator.
Since a number of -nary quality indicators have been proposed, it is very difficult to investigate all of them. Instead, we selected the diversity comparison indicator (DCI) [59] since it is recommended in [5]. DCI relatively compares objective vector sets , …, . A large DCI value indicates that the corresponding has a good diversity among , …, . We explain DCI in Section S.4 in the supplementary file. For the DCI calculation, we used the source code provided by the authors of [59].
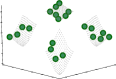
We converted DCI into the unary indicator using the reference vector set . To generate , we used the same method described in Section V. Thus, the DCI value of is obtained by comparing to by DCI. As recommend in [59], we set in DCI to for in this study. Since we want to examine the general property of DCI, we did not finely tune for each . We set to 21. We investigate the influence of the size of on DCI. Below, we denote DCI with and as DCI21 and DCI28, respectively.
Fig. 10 shows the distribution of objective vectors in and on . Figs. S.51–S.55 in the supplementary file show (and ) on , , , , and , respectively. On the one hand, Fig. 10 (a) shows that the objective vectors in are uniformly distributed. Thus, DCI21 is likely to prefer uniformly distributed objective vectors. In fact, and , where is shown in Fig. 4 (j). On the other hand, Fig. 10 (b) shows that the distribution of the objective vectors in is not uniform. This result means that DCI28 does not prefer uniformly distributed objective vectors. Actually, DCI28 evaluates as better than as follows: and .
In summary, we can conclude that it is possible to design a unary version of DCI, but its result is sensitive to the size of . In the unary version of DCI, the size of and should be the same. Otherwise, non-uniformly distributed objective vectors are highly evaluated by DCI (as shown in Fig. 10 (b)).


VII Conclusion
We have analyzed the nine quality indicators using their approximated optimal -distributions for . First, we proposed the problem formulation of finding the optimal -distribution for each quality indicator on Pareto fronts for arbitrary number of objectives (). Then, we approximated the optimal -distributions for the nine quality indicators on the Pareto fronts of eight problems with . We analyzed the nine quality indicators based on the optimal -distribution based approach and the ranking information based approach. We also examined the generality of results for with respect to and a unary version of an -nary indicator.
Our observations for can be summarized as follows:
-
i)
Objective vectors in the approximated optimal -distributions for R2 are biased on the edge of the Pareto front for and . These results for are inconsistent with the results for .
-
ii)
The approximated optimal -distributions for NR2 and HV are similar. NR2 and HV are correlated with each other in terms of the Kendall rank correlation ( on ). Thus, NR2 can substitute for HV.
-
iii)
While the optimal -distributions for for are almost uniform, those for are not uniform even on the linear front.
-
iv)
Although SE can evaluate both uniformity and spread quality of objective vector sets, SE prefers objective vectors that are on the edge of the Pareto front.
-
v)
Since the optimal -distributions for are far from uniform, may incorrectly evaluate the uniformity quality of objective vector sets.
-
vi)
PD may overestimate an objective vector set with a small dissimilarity. PD is also sensitive to the order of objective vectors.
-
vii)
Most quality indicators evaluate objective vectors generated by simplex-lattice design as poor. Thus, decomposition-based EMOAs need an adaptive weight vector method when they try to search for a good objective vector set with respect to each quality indicator.
-
viii)
A unary version of DCI is sensitive to the size of the reference vector set.
We emphasize that the above-mentioned observations on the Pareto front for could not be obtained without searching for the optimal distributions of objective vectors by the proposed problem formulation. As shown in Subsection VI-C, our results for cannot be always generalized to the case of . Further analysis is needed for many-objective problems in future research.
A further analysis of the optimal -distributions for R2 and on the Pareto front for is needed. The undesirable property of PD could be addressed by using an algorithm for finding a minimum spanning tree (e.g., [60]). The problem of finding the optimal -distribution in the proposed problem formulation itself can be viewed as a “real-world” black-box single-objective optimization problem. Although we used L-SHADE in this paper, we believe that benchmarking various single-objective optimizers on the proposed problem formulation is beneficial for both the EMO community and the evolutionary single-objective optimization community.
Acknowledgment
This work was supported by National Natural Science Foundation of China (Grant No. 61876075), the Program for Guangdong Introducing Innovative and Enterpreneurial Teams (Grant No. 2017ZT07X386), Shenzhen Peacock Plan (Grant No. KQTD2016112514355531), the Science and Technology Innovation Committee Foundation of Shenzhen (Grant No. ZDSYS201703031748284), the Program for University Key Laboratory of Guangdong Province (Grant No. 2017KSYS008).
References
- [1] K. Miettinen, Nonlinear Multiobjective Optimization. Springer, 1998.
- [2] K. Deb, Multi-Objective Optimization Using Evolutionary Algorithms. John Wiley & Sons, 2001.
- [3] H. Ishibuchi, R. Imada, Y. Setoguchi, and Y. Nojima, “Reference Point Specification in Inverted Generational Distance for Triangular Linear Pareto Front,” IEEE TEVC, vol. 22, no. 6, pp. 961–975, 2018.
- [4] ——, “How to Specify a Reference Point in Hypervolume Calculation for Fair Performance Comparison,” Evol. Comput., vol. 26, no. 3, 2018.
- [5] M. Li and X. Yao, “Quality Evaluation of Solution Sets in Multiobjective Optimisation: A Survey,” ACM CSUR, vol. 52, no. 2, pp. 26:1–26:38, 2019.
- [6] J. Knowles and D. Corne, “On Metrics for Comparing Nondominated Sets,” in IEEE CEC, 2002, pp. 711–716.
- [7] E. Zitzler, L. Thiele, M. Laumanns, C. M. Fonseca, and V. G. da Fonseca, “Performance assessment of multiobjective optimizers: an analysis and review,” IEEE TEVC, vol. 7, no. 2, pp. 117–132, 2003.
- [8] T. Okabe, Y. Jin, and B. Sendhoff, “A Critical Survey of Performance Indices for Multi-Objective Optimisation,” in IEEE CEC, 2002, pp. 878–885.
- [9] E. Zitzler and L. Thiele, “Multiobjective Optimization Using Evolutionary Algorithms - A Comparative Case Study,” in PPSN, 1998, pp. 292–304.
- [10] C. A. C. Coello and M. R. Sierra, “A Study of the Parallelization of a Coevolutionary Multi-objective Evolutionary Algorithm,” in MICAI, 2004, pp. 688–697.
- [11] H. Ishibuchi and T. Murata, “A multi-objective genetic local search algorithm and its application to flowshop scheduling,” IEEE Trans. SMC, Part C, vol. 28, no. 3, pp. 392–403, 1998.
- [12] A. Auger, J. Bader, D. Brockhoff, and E. Zitzler, “Theory of the hypervolume indicator: optimal -distributions and the choice of the reference point,” in FOGA, 2009, pp. 87–102.
- [13] K. Deb, S. Agrawal, A. Pratap, and T. Meyarivan, “A fast and elitist multiobjective genetic algorithm: NSGA-II,” IEEE TEVC, vol. 6, no. 2, pp. 182–197, 2002.
- [14] Y. Wang, L. Wu, and X. Yuan, “Multi-objective self-adaptive differential evolution with elitist archive and crowding entropy-based diversity measure,” Soft Comput., vol. 14, no. 3, pp. 193–209, 2010.
- [15] S. Jiang, Y. Ong, J. Zhang, and L. Feng, “Consistencies and Contradictions of Performance Metrics in Multiobjective Optimization,” IEEE Trans. Cyber., vol. 44, no. 12, pp. 2391–2404, 2014.
- [16] A. Auger, J. Bader, D. Brockhoff, and E. Zitzler, “Hypervolume-based multiobjective optimization: Theoretical foundations and practical implications,” Theor. Comput. Sci., vol. 425, pp. 75–103, 2012.
- [17] D. Brockhoff, T. Wagner, and H. Trautmann, “On the properties of the R2 indicator,” in GECCO, 2012, pp. 465–472.
- [18] T. Glasmachers, “Optimized Approximation Sets for Low-Dimensional Benchmark Pareto Fronts,” in PPSN, 2014, pp. 569–578.
- [19] K. Bringmann, T. Friedrich, and P. Klitzke, “Efficient computation of two-dimensional solution sets maximizing the epsilon-indicator,” in IEEE CEC, 2015, pp. 970–977.
- [20] N. Hansen and A. Ostermeier, “Completely derandomized self-adaptation in evolution strategies,” Evol. Comput., vol. 9, no. 2, pp. 159–195, 2001.
- [21] H. Ishibuchi, H. Masuda, Y. Tanigaki, and Y. Nojima, “Modified Distance Calculation in Generational Distance and Inverted Generational Distance,” in EMO, 2015, pp. 110–125.
- [22] K. Shang, H. Ishibuchi, M. Zhang, and Y. Liu, “A new R2 indicator for better hypervolume approximation,” in GECCO, 2018, pp. 745–752.
- [23] D. P. Hardin and E. B. Saff, “Discretizing Manifolds via Minimum Energy Points,” Notices of the AMS, vol. 51, no. 10, pp. 1186–1194, 2004.
- [24] H. Wang, Y. Jin, and X. Yao, “Diversity Assessment in Many-Objective Optimization,” IEEE Trans. Cyber., vol. 47, no. 6, pp. 1510–1522, 2017.
- [25] E. Zitzler, L. Thiele, and J. Bader, “On Set-Based Multiobjective Optimization,” IEEE TEVC, vol. 14, no. 1, pp. 58–79, 2010.
- [26] J. Knowles, L. Thiele, and E. Zitzler, “A tutorial on the performance assessment of stochastic multiobjective optimizers,” ETH Zurich, Tech. Rep. TIK-214, 2006.
- [27] D. A. V. Veldhuizen and G. B. Lamont, “Multiobjective Evolutionary Algorithm Research: A History and Analysis,” Air Force Institute of Technology, Tech. Rep. TR-98-03, 1998.
- [28] D. A. V. Veldhuizen, “Multiobjective evolutionary algorithms: Classifications, analyses, and new innovations,” Air University, Tech. Rep. AFIT/DS/ENG/99-01, 1999.
- [29] E. Zitzler, D. Brockhoff, and L. Thiele, “The Hypervolume Indicator Revisited: On the Design of Pareto-compliant Indicators Via Weighted Integration,” in EMO, 2006, pp. 862–876.
- [30] O. Schütze, X. Esquivel, A. Lara, and C. A. C. Coello, “Using the Averaged Hausdorff Distance as a Performance Measure in Evolutionary Multiobjective Optimization,” IEEE TEVC, vol. 16, no. 4, pp. 504–522, 2012.
- [31] H. Ishibuchi, R. Imada, N. Masuyama, and Y. Nojima, “Comparison of Hypervolume, IGD and IGD+ from the Viewpoint of Optimal Distributions of Solutions,” in EMO, 2019, pp. 332–345.
- [32] M. P. Hansen and A. Jaszkiewicz, “Evaluating the quality of approximations to the non-dominated set,” Poznan University of Technology, Tech. Rep. IMM-REP-1998-7, 1998.
- [33] H. Ishibuchi, N. Tsukamoto, Y. Sakane, and Y. Nojima, “Indicator-based evolutionary algorithm with hypervolume approximation by achievement scalarizing functions,” in GECCO, 2010, pp. 527–534.
- [34] J. G. Falcón-Cardona and C. A. C. Coello, “A multi-objective evolutionary hyper-heuristic based on multiple indicator-based density estimators,” in GECCO, 2018, pp. 633–640.
- [35] A. R. Solow and S. Polasky, “Measuring biological diversity,” Environ. Ecol. Stat., vol. 1, no. 2, pp. 95–103, 1994.
- [36] M. Ravber, M. Mernik, and M. Crepinsek, “The impact of Quality Indicators on the rating of Multi-objective Evolutionary Algorithms,” Appl. Soft Comput., vol. 55, pp. 265–275, 2017.
- [37] S. Wessing and B. Naujoks, “Sequential parameter optimization for multi-objective problems,” in IEEE CEC, 2010, pp. 1–8.
- [38] A. Liefooghe and B. Derbel, “A Correlation Analysis of Set Quality Indicator Values in Multiobjective Optimization,” in GECCO, 2016, pp. 581–588.
- [39] H. Ishibuchi, H. Masuda, and Y. Nojima, “A Study on Performance Evaluation Ability of a Modified Inverted Generational Distance Indicator,” in GECCO, 2015, pp. 695–702.
- [40] L. C. T. Bezerra, M. López-Ibáñez, and T. Stützle, “An Empirical Assessment of the Properties of Inverted Generational Distance on Multi- and Many-Objective Optimization,” in EMO, 2017, pp. 31–45.
- [41] K. Deb, L. Thiele, M. Laumanns, and E. Zitzler, “Scalable Test Problems for Evolutionary Multi-Objective Optimization,” in Evolutionary Multiobjective Optimization. Theoretical Advances and Applications. Springer, 2005, pp. 105–145.
- [42] E. Zitzler, K. Deb, and L. Thiele, “Comparison of Multiobjective Evolutionary Algorithms: Empirical Results,” Evol. Comput., vol. 8, no. 2, pp. 173–195, 2000.
- [43] K. Bringmann, T. Friedrich, and P. Klitzke, “Two-dimensional subset selection for hypervolume and epsilon-indicator,” in GECCO, 2014, pp. 589–596.
- [44] N. Beume, B. Naujoks, and M. T. M. Emmerich, “SMS-EMOA: multiobjective selection based on dominated hypervolume,” EJOR, vol. 181, no. 3, pp. 1653–1669, 2007.
- [45] S. Z. Martínez, C. A. C. Coello, H. E. Aguirre, and K. Tanaka, “A Review of Features and Limitations of Existing Scalable Multiobjective Test Suites,” IEEE TEVC, vol. 23, no. 1, pp. 130–142, 2019.
- [46] A. Jaszkiewicz, “On the performance of multiple-objective genetic local search on the knapsack problem - a comparative experiment,” IEEE TEVC, vol. 6, no. 4, pp. 402–412, 2002.
- [47] H. Ishibuchi, H. Masuda, and Y. Nojima, “Pareto Fronts of Many-Objective Degenerate Test Problems,” IEEE TEVC, vol. 20, no. 5, pp. 807–813, 2016.
- [48] Y. Tian, X. Xiang, X. Zhang, R. Cheng, and Y. Jin, “Sampling Reference Points on the Pareto Fronts of Benchmark Multi-Objective Optimization Problems,” in IEEE CEC, 2018, pp. 1–6.
- [49] K. Deb and H. Jain, “An evolutionary many-objective optimization algorithm using reference-point-based nondominated sorting approach, part I: solving problems with box constraints,” IEEE TEVC, vol. 18, no. 4, pp. 577–601, 2014.
- [50] H. Jain and K. Deb, “An evolutionary many-objective optimization algorithm using reference-point based nondominated sorting approach, part II: handling constraints and extending to an adaptive approach,” IEEE TEVC, vol. 18, no. 4, pp. 602–622, 2014.
- [51] H. Ishibuchi, Y. Setoguchi, H. Masuda, and Y. Nojima, “Performance of Decomposition-Based Many-Objective Algorithms Strongly Depends on Pareto Front Shapes,” IEEE TEVC, vol. 21, no. 2, pp. 169–190, 2017.
- [52] R. Tanabe and A. S. Fukunaga, “Improving the search performance of SHADE using linear population size reduction,” in IEEE CEC, 2014, pp. 1658–1665.
- [53] R. Storn and K. Price, “Differential Evolution - A Simple and Efficient Heuristic for Global Optimization over Continuous Spaces,” J. Global Optimiz., vol. 11, no. 4, pp. 341–359, 1997.
- [54] R. L. While, L. Bradstreet, and L. Barone, “A Fast Way of Calculating Exact Hypervolumes,” IEEE TEVC, vol. 16, no. 1, pp. 86–95, 2012.
- [55] I. Das and J. E. Dennis, “Normal-Boundary Intersection: A New Method for Generating the Pareto Surface in Nonlinear Multicriteria Optimization Problems,” SIAM J. Optimiz, vol. 8, no. 3, pp. 631–657, 1998.
- [56] T. Tusar and B. Filipic, “Visualization of Pareto Front Approximations in Evolutionary Multiobjective Optimization: A Critical Review and the Prosection Method,” IEEE TEVC, vol. 19, no. 2, pp. 225–245, 2015.
- [57] M. Li, L. Zhen, and X. Yao, “How to Read Many-Objective Solution Sets in Parallel Coordinates [Educational Forum],” IEEE CIM, vol. 12, no. 4, pp. 88–100, 2017.
- [58] X. Yao, Y. Liu, and G. Lin, “Evolutionary Programming Made Faster,” IEEE TEVC, vol. 3, no. 2, pp. 82–102, 1999.
- [59] M. Li, S. Yang, and X. Liu, “Diversity Comparison of Pareto Front Approximations in Many-Objective Optimization,” IEEE Trans. Cyber., vol. 44, no. 12, pp. 2568–2584, 2014.
- [60] B. Chazelle, “A minimum spanning tree algorithm with Inverse-Ackermann type complexity,” J. ACM, vol. 47, no. 6, pp. 1028–1047, 2000.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/612244fb-d061-4b85-8512-e16631cf0418/x84.png) |
Ryoji Tanabe is a Research Assistant Professor with Department of Computer Science and Engineering, Southern University of Science and Technology, China, from 2017 to 2019. He was a Post-Doctoral Researcher with ISAS/JAXA, Japan, from 2016 to 2017. He received his Ph.D. in Science from The University of Tokyo, Japan, in 2016. His research interests include stochastic single- and multi-objective optimization algorithms, parameter control in evolutionary algorithms, and automatic algorithm configuration. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/612244fb-d061-4b85-8512-e16631cf0418/x85.png) |
Hisao Ishibuchi (M’93-SM’10-F’14) received the B.S. and M.S. degrees in precision mechanics from Kyoto University, Kyoto, Japan, in 1985 and 1987, respectively, and the Ph.D. degree in computer science from Osaka Prefecture University, Sakai, Osaka, Japan, in 1992. He was with Osaka Prefecture University in 1987-2017. Since 2017, he is a Chair Professor at Southern University of Science and Technology, China. His research interests include fuzzy rule-based classifiers, evolutionary multi-objective and many-objective optimization, memetic algorithms, and evolutionary games. Dr. Ishibuchi was the IEEE Computational Intelligence Society (CIS) Vice-President for Technical Activities (2010-2013), an AdCom member of the IEEE CIS (2014-2019), and the Editor-in-Chief of the IEEE COMPUTATIONAL INTELLIGENCE MAGAZINE (2014-2019). |