[1,2]\surZi Xu
1]\orgdivDepartment of Mathematics, College of Sciences, \orgnameShanghai University, \orgaddress\cityShanghai, \postcode200444, \countryP.R.China 2]\orgdivNewtouch Center for Mathematics of Shanghai University, \orgnameShanghai University, \orgaddress\cityShanghai, \postcode200444, \countryP.R.China
An accelerated first-order regularized momentum descent ascent algorithm for stochastic nonconvex-concave minimax problems
Abstract
Stochastic nonconvex minimax problems have attracted wide attention in machine learning, signal processing and many other fields in recent years. In this paper, we propose an accelerated first-order regularized momentum descent ascent algorithm (FORMDA) for solving stochastic nonconvex-concave minimax problems. The iteration complexity of the algorithm is proved to be to obtain an -stationary point, which achieves the best-known complexity bound for single-loop algorithms to solve the stochastic nonconvex-concave minimax problems under the stationarity of the objective function.
keywords:
stochastic nonconvex minimax problem, accelerated momentum projection gradient algorithm, iteration complexity, machine learning1 Introduction
Consider the following stochastic nonconvex-concave minimax optimization problem:
| (1.1) |
where and are nonempty convex and compact sets, is a smooth function, possibly nonconvex in and concave in , is a random variable following an unknown distribution , and denotes the expectation function. We focus on the single-loop first-order algorithms to solve problem (1.1). This problem has attracted increasing attention in machine learning, signal processing, and many other research fields in recent years, e.g., distributed nonconvex optimization Giannakis ; Liao ; Mateos , wireless system Chen20 , statistical learning Abadeh ; Giordano , etc.
There are few existing first-order methods for solving stochastic nonconvex-concave minimax optimization problem. Rafique et al. Rafique proposed a proximally guided stochastic mirror descent method (PG-SMD), which updates and simultaneously, and the iteration complexity has been proved to be to an approximate -stationary point of . Zhang et al. Zhang2022 proposed a SAPD+ which achieves the oracle complexities of for solving deterministic nonconvex-concave minimax problems. Both algorithms are multi-loop algorithms. On the other hand, there are few existing single-loop algorithms for solving stochastic nonconvex-concave minimax problems. Lin et al. Lin2019 proposed a stochastic gradient descent ascent (SGDA) and Bot et al. Bot proposed a stochastic alternating GDA, both of them require stochastic gradient evaluations to obtain an approximate -stationary point of . Boroun et al. Boroun proposed a novel single-loop stochastic primal-dual algorithm with momentum (SPDM) for a special class of nonconvex-concave minimax problems, i.e., the objective function statisfies the Polyak-Łojasiewicz (PL) condition with respect to , and the iteration complexity is proved to be .
There are some exisiting first order methods on solving stochastic nonconvex-strongly concave minimax optimization problems. Lin et al. Lin2019 proposed a stochastic gradient descent ascent (SGDA) which requires stochastic gradient evaluations to get an -stationary point. Luo et al. luo2020stochastic proposed a stochastic recursive gradient descent ascent (SREDA) algorithm, which requires a total number of stochastic gradient evaluations. Huang et al. Huang proposed an accelerated first-order momentum descent ascent (Acc-MDA) method with the total number of stochastic gradient evaluations being .
There are also some zeroth-order methods for stochastic nonconvex-strongly concave minimax optimization problems. Liu et al. Liu proposed a ZO-Min-Max algorithm and it needs function evaluations to obtain -stationary point. Wang et al. Wang proposed a zeroth-order gradient descent multi-step ascent (ZO-GDMSA) algorithm, and the function evaluation complexity of is proved. Luo et al. luo2020stochastic proposed a stochastic recursive gradient descent ascent (SREDA) algorithm, and its function evaluation complexity is . Xu et al. Xu20 proposed a zeroth-order variance reduced gradient descent ascent (ZO-VRGDA) algorithm with function evaluation complexity. Huang et al. Huang proposed an accelerated zeroth-order momentum descent ascent (Acc-ZOMDA) method which owns the function evaluation complexity of .
There are few exisiting methods on solving stochastic nonconvex-nonconcave minimax optimization problems. Yang et al. Yang22 proposed a smoothed GDA algorithm for nonconvex-PL minimax problems with the iteration complexity of . Xu et al. xu22zeroth proposed a zeroth-order variance reduced alternating gradient descent ascent (ZO-VRAGDA) algorithm for solving nonconvex-PL minimax problems, which can obtain the total complexity of . Huang Huang23 proposed two enhanced momentum-based gradient descent ascent methods for nonconvex-PL minimax problems, which owns the iteration complexity of .
In this paper, we propose an accelerated first-order regularized momentum descent ascent algorithm (FORMDA) for solving stochastic nonconvex-concave minimax problems. The iteration complexity of the algorithm is proved to be to obtain an -stationary point.
1.1 Related Works.
We give a brief review on algorithms for solving deterministic minimax optimization problems. There are many existing works on solving convex-concave minimax optimization problems. Since we focus on nonconvex minimax problems, we do not attempt to survey it in this paper and refer to Chen ; Lan2016 ; Mokhtari ; Nemirovski ; Nesterov2007 ; Ou15 ; Ou21 ; Tom ; Zhang22 for more details.
For deterministic nonconvex-concave minimax problem, there are two types of algorithms, i.e., multi-loop algorithms and single-loop algorithms. One intensively studied type is nested-loop algorithms. Various algorithms of this type have been proposed in Rafique ; nouiehed2019solving ; Thek19 ; Kong ; ostrovskii2020efficient . Lin et al. lin2020near proposed a class of accelerated algorithms for smooth nonconvex-concave minimax problems with the complexity bound of which owns the best iteration complexity till now. On the other hand, fewer studies focus on single-loop algorithms for nonconvex-concave minimax problems. One typical method is the gradient descent-ascent (GDA) method, which performs a gradient descent step on and a gradient ascent step on simultaneously at each iteration. Jin et al. Lin2019 proposed a GDmax algorithm with iteration complexity of . Lu et al. Lu proposed a hybrid block successive approximation (HiBSA) algorithm, which can obtain an -stationary point of in iterations. Pan et al. Pan proposed a new alternating gradient projection algorithm for nonconvex-linear minimax problem with the iteration complexity of . Xu et al. Xu proposed a unified single-loop alternating gradient projection (AGP) algorithm for solving nonconvex-(strongly) concave and (strongly) convex-nonconcave minimax problems, which can find an -stationary point with the gradient complexity of . Zhang et al. Zhang proposed a smoothed GDA algorithm which achieves iteration complexity for general nonconvex-concave minimax problems.
Few algorithms have been proposed for solving more general deterministic nonconvex-nonconcave minimax problems. Sanjabi et al. Sanjabi18 proposed a multi-step gradient descent-ascent algorithm which can find an -first order Nash equilibrium in iterations when a one-sided PL condition is satisfied. Yang et al. Yang showed the alternating GDA algorithm converges globally at a linear rate for a subclass of nonconvex-nonconcave objective functions satisfying a two-sided PL inequality. Song et al. SongOptDE proposed an optimistic dual extrapolation (OptDE) method with the iteration complexity of , if a weak solution exists. Hajizadeh et al. Hajizadeh showed that a damped version of extra-gradient method linearly converges to an -stationary point of nonconvex-nonconcave minimax problems that the nonnegative interaction dominance condition is satisfied. Xu et al. xu22zeroth proposed a zeroth-order alternating gradient descent ascent (ZO-AGDA) algorithm for solving NC-PL minimax problem, which can obtain the iteration complexity . For more related results, we refer to Bohm ; cai2022accelerated ; DiakonikolasEG ; Doan ; Grimmer ; Jiang ; Lee .
Notations For vectors, we use to represent the Euclidean norm and its induced matrix norm; denotes the inner product of two vectors of and . We use (or ) to denote the partial derivative of with respect to (or ) at point , respectively. We use the notation to hide only absolute constants which do not depend on any problem parameter, and notation to hide only absolute constants and log factors. A continuously differentiable function is called -smooth if there exists a constant such that for any given ,
A continuously differentiable function is called -strongly convcave if there exists a constant such that for any ,
The paper is organized as follows. In Section 2, an accelerated first-order momentum projection gradient algorithm is proposed for stochastic nonconvex-concave minimax problem, and its iteration complexity is also established. Numerical results are presented in Section 3 to show the efficiency of the proposed algorithm. Some conclusions are made in the last section.
2 An Accelerated First-order Regularized Momentum Descent Ascent Algorithm
In this section, based on the framework of the Acc-MDA algorithm Huang , we propose an accelerated first-order regularized momentum descent ascent algorithm (FORMDA) for solving problem (1.1). At the th iteration of FORMDA, we consider a regularized function of , i.e.,
| (2.1) |
where is a regularization parameter. Compared to the Acc-MDA algorithm, the main difference in the FORMDA algorithm is that instead of , the gradient of , is computed and used at each iteration. More detailedly, at the th iteration, for some given drawn i.i.d. from an unknown distribution, by denoting
| (2.2) |
we compute the gradient of the stochastic function as follows,
| (2.3) | ||||
| (2.4) |
Then, based on and , we compute the variance-reduced stochastic gradient and as shown in (2.5) and (2.6) respectively with and that will be defined later. We update and through alternating stochastic gradient projection with the momentum technique shown in (2.7)-(2.10), which is similar to that in the Acc-MDA algorithm. The proposed FORMDA algorithm is formally stated in Algorithm 1.
Note that FORMDA algorithm differs from the Acc-MDA algorithm proposed in Huang in two ways. On one hand, at each iteration of the FORMDA algorithm, the gradient of , a regularized version of , is computed and used, instead of the gradient of that used in the Acc-MDA algorithm. On the other hand, the FORMDA algorithm is designed to solve general nonconvex-concave minimax problems, whereas the Acc-MDA algorithm can only solve nonconvex-strongly concave minimax problems.
Before we prove the iteration complexity of Algorithm 1, we first give some mild assumptions.
Assumption 2.1.
For any given , has Lipschitz continuous gradients and there exist a constant such that for any , and , we have
Assumption 2.2.
is a nonnegative monotonically decreasing sequence.
If Assumption 2.1 holds, has Lipschitz continuous gradients with constant by Lemma 7 in xu22zeroth . Then, by the definition of and Assumption 2.2, we know that has Lipschitz continuous gradients with constant , where .
Assumption 2.3.
For any given , there exists a constant such that for all and , it has
By Assumption 2.3, we can immediately get that
| (2.11) | ||||
| (2.12) |
We define the stationarity gap as the termination criterion as follows.
Definition 2.1.
For some given and , the stationarity gap for problem (1.1) is defined as
2.1 Complexity analysis.
In this subsection, we prove the iteration complexity of Algorithm 1. When strong concavity of with respect to is absent, is not necessarily unique, and is not necessarily smooth. To address these challenges, we analyze the iteration complexity of FORMDA algorithm by utilizing and , where
| (2.13) | ||||
| (2.14) |
By Lemma 24 in nouiehed2019solving , is -Lipschitz smooth with under the -strong concavity of . Moreover, similar to the proof of Lemma B.2 in lin2020near , we have .
We will begin to analyze the iteration complexity of the FORMDA algorithm, mainly through constructing potential functions to obtain the recursion. Firstly, we estimate an upper bound of , which will be utilized in the subsequent construction of the potential function.
Proof: The optimality condition for implies that and ,
| (2.16) | ||||
| (2.17) |
Setting in (2.16) and in (2.17), adding these two inequalities and using the strong concavity of with respect to , we have
| (2.18) |
By the definition of , the Cauchy-Schwarz inequality and Assumption 2.1, (2.18) implies that
| (2.19) |
Since and Assumption 2.2, (2.19) implies that
The proof is completed.
Next, we provide an estimate of the difference between and .
Lemma 2.2.
Proof: Since that is -smooth with respect to and , we have that
| (2.21) |
Next, we estimate the first three terms in the right hand side of (2.21). By the Cauchy-Schwarz inequality, we get
| (2.22) |
By the Cauchy-Schwarz inequality, we have
| (2.23) |
The optimality condition for in (2.7) implies that and ,
| (2.24) |
Plugging (2.22), (2.23) and (2.24) into (2.21) and using , we get
| (2.25) |
On the other hand, we have
| (2.26) |
We further to estimate the upper bound of the first two terms in the right-hand side of (2.20) in Lemma 2.2.
Lemma 2.3.
Proof: is -strongly concave with respect to , which implies that
| (2.28) |
By Assumption 2.1, has Lipschitz continuous gradient with respect to and then
| (2.29) |
The optimality condition for in (2.9) implies that and ,
| (2.30) |
Plugging (2.1) into (2.1) and combining (2.29), by setting , we have
| (2.31) |
Next, we estimate the first two terms in the right hand side of (2.1). By (2.10), we get
| (2.32) |
(2.32) can be rewritten as
| (2.33) |
By the Cauchy-Schwarz inequality, we have
| (2.34) |
Plugging (2.33), (2.34) into (2.1), and using the fact that , we get
| (2.35) |
By the assumption , , and (2.35), we obtain that
| (2.36) |
By the Cauchy-Schwarz inequality, Lemma 2.1 and (2.8), we have
| (2.37) |
Plugging (2.36) into (2.37), we obtain
| (2.38) |
Since , and , we have .Then, by Assumption 2.2, we get , , , . Thus, we obtain
The proof is completed.
Next, we provide upper bound estimates of and in the following lemma.
Lemma 2.4.
Proof: Note that , , and by the definition of , we have
| (2.41) |
By the fact that , for i.i.d. random variables with zero mean, and (2.11), we have
| (2.42) |
Similarly, we get
The proof is completed.
We now establish an important recursion for the FORMDA algorithm.
Lemma 2.5.
Proof: By the definition of and Lemmas 2.2-2.4, we get
| (2.44) |
The proof is then completed by the definition of and .
Define , where is a given target accuracy. Denote
It can be easily checked that
and if . Next, we provide an upper bound estimate of .
Lemma 2.6.
Proof: By (2.9), the nonexpansive property of the projection operator, we immediately get
| (2.46) |
On the other hand, by (2.7) and the nonexpansive property of the projection operator, we have
| (2.47) |
Combing (2.46), (2.47), using Cauchy-Schwarz inequality and taking the expectation, we complete the proof.
Theorem 2.1.
Proof: By the definition of , and , we have and
Then, by the setting of , we get
Similarly, we also have
By the settings of , we obtain
and
Plugging these inequalities into (2.1), we get
| (2.49) |
It follows from the definition of , (2.6) and (2.1) that ,
| (2.50) |
Denoting , . By summing both sides of (2.1) from to , we obtain
| (2.51) |
Since and , by the definition of and , we get
| (2.52) |
On the other hand, if , then . This inequality together with the definition of then imply that . Therefore, there exists a
such that which completes the proof.
2.2 Nonsmooth Case.
Consider the following stochastic nonsmooth nonconvex-concave minimax optimization problem:
| (2.53) |
where , both and are convex continuous but possibly nonsmooth function.
Denote the proximity operator as . Based on FORMDA Algorithm, we propse an accelerated first-order regularized momentum descent ascent algorithm for nonsmooth minimax problem (FORMDA-NS) by replacing with , with in FORMDA Algorithm. The proposed FORMDA-NS algorithm is formally stated in Algorithm 2.
| (2.54) |
| (2.55) |
| (2.56) | ||||
| (2.57) | ||||
| (2.58) | ||||
| (2.59) |
Before analyzing the convergence of Algorithm 2, we define the stationarity gap as the termination criterion as follows.
Definition 2.2.
For some given and , the stationarity gap for problem (2.53) is defined as
Denote
| (2.60) | ||||
| (2.61) |
By Proposition B.25 in Bertsekas , we have and is -Lipschitz smooth with under the -strong concavity of . Similar to the proof of Section 2.1, we first estimate an upper bound of .
Proof: The optimality condition for implies that and ,
| (2.63) | ||||
| (2.64) |
By , and similar to the proof of Lemma 2.1, we complete the proof.
Next, we prove the iteration complexity of Algorithm 2.
Lemma 2.8.
Proof: The optimality condition for in (2.56) implies that and ,
| (2.66) |
where . Similar to the proof of Lemma 2.2, by replacing (2.24) in Lemma 2.2 with (2.66), we have
| (2.67) |
By the definition of subgradient, we have , then we have
| (2.68) |
Utilizing the convexity of , and , we get
| (2.69) |
The proof is completed by combining (2.67), (2.68) and (2.69).
Lemma 2.9.
Proof: The optimality condition for in (2.58) implies that and ,
| (2.71) |
where , the last inequality holds by . Similar to the proof of Lemma 2.3, by replacing (2.1) in Lemma 2.3 with (2.2), we complete the proof.
Theorem 2.2.
3 Numerical Results
In this section, we compare the numerical performance of the proposed FORMDA algorithm with some existing algorithms for solving two classes of problems. All the numerical tests are implemented in Python 3.9. The first test is run in a laptopwith 2.30GHz processor and the second one is carried out on a RTX 4090 GPU.
Firstly, we consider the following Wasserstein GAN (WGAN) problem Arjovsky ,
where is a normally distributed random variable with mean and variance , and a normally distributed random variable with mean and variance . The optimal solution is .
We compare the numerical performance of the proposed FORMDA algorithm with the SGDA algorithm Lin2019 and the PG-SMD algorithm Rafique for solving the WGAN problem. The batch size is set to be for all three tested algorithms. The parameters in FORMDA are chosen to be , , , , , . All the parameters of the PG-SMD algorithm and the SGDA algorithm are chosen the same as that in Rafique and Lin2019 respectively.

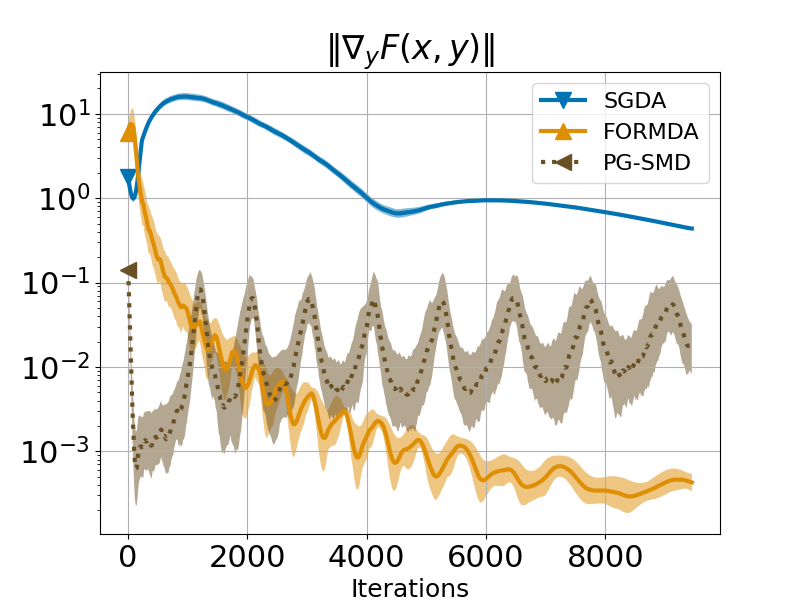

Figure 1 shows the average change in the stochastic gradient norm and the distance from the iteration point to the optimal value point for 5 independent runs of the four test algorithms, and the shaded area around the line indicates the standard deviation. It can be found that the proposed FORMDA algorithm is better than SGDA and close to the performance of PG-SMD.
Secondly, we consider a robust learning problem over multiple domains Qian . Let denote distributions of data. Robust learning over multiple domains is to minimize the maximum of the expected losses over the distributions, it can be formulated as the following stochastic nonconvex-concave minimax problem:
where , is a nonnegative loss function, denotes the network parameters, describes the weights over different tasks and is the simplex, i.e., . We consider two image classification problems with MNIST and CIFAR10 datasets. Our goal is to train a neural network that works on these two completely unrelated problems simultaneously. The quality of the algorithm for solving a robust learning problem over multiple domains is measured by the worst case accuracy over all domains Qian .
We compare the numerical performance of the proposed FORMDA algorithm with SGDA algorithm Lin2019 and PG-SMD algorithm Rafique . We use cross-entropy loss as our loss function and set the batch size in all tasks to be 32. All algorithms were run for 50 epochs. The parameters in FORMDA are chosen to be , , , , , . All the parameters of the PG-SMD algorithm and the SGDA algorithm are chosen the same as that in Rafique and Lin2019 respectively.


Figure 2 shows the testing accuracy on MNIST and CIFAR10 datasets. It can be found that the proposed FORMDA algorithm outperforms SGDA and has similar performance to PG-SMD.
4 Conclusions
In this paper, we propose an accelerated FORMDA algorithm for solving stochastic nonconvex-concave minimax problems. The iteration complexity of the algorithm is proved to be to obtain an -stationary point. It owns the optimal complexity bounds within single-loop algorithms for solving stochastic nonconvex-concave minimax problems till now. Moreover, we can extend the analysis to the scenarios with possibly nonsmooth objective functions, and obtain that the iteration complexity is . Numerical experiments show the efficiency of the proposed algorithm. Whether there is a single-loop algorithm with better complexity for solving this type of problem is still worthy of further research.
Acknowledgments The authors are supported by National Natural Science Foundation of China under the Grant (Nos. 12071279 and 12471294).
Declarations
-
•
Conflict of interest The authors have no relevant financial or non-financial interests to disclose.
-
•
Data availability Data sharing not applicable to this article as no datasets were generated or analyzed during the current study.
References
- (1) Abadeh S S, Esfahani P M M, and Kuhn D. Distributionally robust logistic regression. In NeurIPS, 2015: 1576-1584.
- (2) Arjovsky M, Chintala S, Bottou L. Wasserstein generative adversarial networks. International conference on machine learning. PMLR, 2017: 214-223.
- (3) Bertsekas D P. Nonlinear programming. Journal of the Operational Research Society, 1997, 48(3): 334-334.
- (4) Boroun M, Alizadeh Z, Jalilzadeh A. Accelerated primal-dual scheme for a class of stochastic nonconvex-concave saddle point problems. arXiv preprint arXiv:2303.00211, 2023.
- (5) Bot R I, Böhm A. Alternating proximal-gradient steps for (stochastic) nonconvex-concave minimax problem. SIAM Journal on Optimization, 2023, 33(3): 1884-1913.
- (6) Böhm A. Solving nonconvex-nonconcave min-max problems exhibiting weak minty solutions. arXiv preprint arXiv:2201.12247, 2022.
- (7) Chen Y, Lan G, Ouyang Y. Accelerated schemes for a class of variational inequalities. Mathematical Programming,2017,165(1):113-149.
- (8) Cai Y, Oikonomou A, Zheng W. Accelerated algorithms for monotone inclusions and constrained nonconvex-nonconcave min-max optimization. arXiv preprint arXiv:2206.05248, 2022.
- (9) Chen J, Lau V K N. Convergence analysis of saddle point problems in time varying wireless systems—Control theoretical approach. IEEE Transactions on Signal Processing, 2011, 60(1): 443-452.
- (10) Diakonikolas J, Daskalakis C, Jordan M. Efficient methods for structured nonconvex-nonconcave min-max optimization. International Conference on Artificial Intelligence and Statistics. PMLR, 2021: 2746-2754.
- (11) Doan T. Convergence rates of two-time-scale gradient descent-ascent dynamics for solving nonconvex min-max problems. Learning for Dynamics and Control Conference, PMLR, 2022:192-206.
- (12) Grimmer B, Lu H, Worah P, Mirrokni V. The landscape of the proximal point method for nonconvex-nonconcave minimax optimization.Mathematical Programming, 2023, 201(1-2): 373-407.
- (13) Giannakis G B, Ling Q, Mateos G, Schizas I D, and Zhu H. Decentralized learning for wireless communications and networking. Splitting Methods in Communication, Imaging, Science, and Engineering, Springer, Cham, 2016:461-497.
- (14) Giordano R, Broderick T andJordan M I. Covariances, robustness, and variational bayes. Journal of Machine Learning Research, 19(51), 2018.
- (15) Huang F, Gao S, Pei J, Huang H. Accelerated zeroth-order and first-order momentum methods from mini to minimax optimization. Journal of Machine Learning Research, 2022, 23: 1-70.
- (16) Huang F. Enhanced Adaptive Gradient Algorithms for Nonconvex-PL Minimax Optimization. arXiv preprint arXiv:2303.03984, 2023.
- (17) Hamedani E Y, Aybat N S. A primal-dual algorithm with line search for general convex-concave saddle point problems. SIAM Journal on Optimization, 2021, 31(2): 1299-1329.
- (18) Hajizadeh S, Lu H, Grimmer B. On the linear convergence of extra-gradient methods for nonconvex-nonconcave minimax problems. INFORMS Journal on Optimization, 2023.
- (19) Jiang J, Chen X. Optimality conditions for nonsmooth nonconvex-nonconcave min-max problems and generative adversarial networks. arXiv preprint arXiv:2203.10914, 2022.
- (20) Kong W, Monteiro R D C. An accelerated inexact proximal point method for solving nonconvex-concave min-max problems. SIAM Journal on Optimization, 2021, 31(4): 2558-2585.
- (21) Kingma D P, Ba J. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- (22) Lan G, Monteiro R D C. Iteration-complexity of first-order augmented lagrangian methods for convex programming. Mathematical Programming, 2016,155(1-2):511-547.
- (23) Lin T, Jin C, Jordan M. Near-optimal algorithms for minimax optimization. Conference on Learning Theory, PMLR, 2020:2738-2779.
- (24) Lin H, Mairal J, Harchaoui Z. Catalyst acceleration for first-order convex optimization: from theory to practice. Journal of Machine Learning Research, 2018, 18(212): 1-54.
- (25) Liao W, Hong M, Farmanbar H, and Luo Z Q. Semi-asynchronous routing for large scale hierarchical networks. In Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2015:2894-2898.
- (26) Luo L, Ye H S, Huang Z C, Zhang T. Stochastic recursive gradient descent ascent for stochastic nonconvex-strongly-concave minimax problems. NeurIPS, 2020, 33: 20566-20577.
- (27) Liu S, Lu S, Chen X, et al. Min-max optimization without gradients: Convergence and applications to adversarial ml. arXiv preprint arXiv:1909.13806, 2019.
- (28) Lin T, Jin C, Jordan M. On gradient descent ascent for nonconvex-concave minimax problems. International Conference on Machine Learning, PMLR, 2020:6083-6093.
- (29) Lu S, Tsaknakis I, Hong M, Chen Y. Hybrid block successive approximation for one-sided nonconvex min-max problems: algorithms and applications. IEEE Transactions on Signal Processing, 2020,68:3676-3691.
- (30) Lee S, Kim D. Fast extra gradient methods for smooth structured nonconvex-nonconcave minimax problems. Advances in Neural Information Processing Systems, 2021, 34:22588-22600.
- (31) Mokhtari A, Ozdaglar A, Pattathil S. A unified analysis of extra-gradient and optimistic gradient methods for saddle point problems: Proximal point approach. International Conference on Artificial Intelligence and Statistics. PMLR, 2020: 1497-1507.
- (32) Mateos G, Bazerque J A, and Giannakis G B. Distributed sparse linear regression. IEEE Transactions on Signal Processing, 2010, 58(10):5262-5276.
- (33) Nouiehed M, Sanjabi M, Huang T, Lee J. D. Solving a class of non-convex min-max games using iterative first order methods. Advances in Neural Information Processing Systems, 2019: 14934-14942.
- (34) Nemirovski A. Prox-method with rate of convergence O (1/t) for variational inequalities with Lipschitz continuous monotone operators and smooth convex-concave saddle point problems. SIAM Journal on Optimization, 2004, 15(1): 229-251.
- (35) Nesterov Y. Smooth minimization of non-smooth functions. Mathematical programming, 2005, 103: 127-152.
- (36) Nesterov Y. Dual extrapolation and its applications to solving variational inequalities and related problems. Mathematical Programming, 2007, 109(2): 319-344.
- (37) Ouyang Y, Chen Y, Lan G, Pasiliao Jr E. An accelerated linearized alternating direction method of multipliers. SIAMJournal on Imaging Sciences, 2015, 8(1):644-681.
- (38) Ouyang Y, Xu Y. Lower complexity bounds of first-order methods for convex-concave bilinear saddle-point problems.Mathematical Programming, 2021, 185(1): 1-35.
- (39) Ostrovskii D, Lowy A, Razaviyayn M. Efficient search of first-order nash equilibria in nonconvex-concave smooth min-max problems. SIAM Journal on Optimization, 2021, 31(4): 2508-2538.
- (40) Pan W, Shen J, Xu Z. An efficient algorithm for nonconvex-linear minimax optimization problem and its application in solving weighted maximin dispersion problem. Computational Optimization and Applications, 2021,78(1): 287-306.
- (41) Qian Q, Zhu S, Tang J, Jin R, Sun B, Li H. Robust optimization over multiple domains. Proceedings of the AAAI Conference on Artificial Intelligence, 2019,33(01):4739–4746.
- (42) Rafique H, Liu M, Lin Q, et al. Weakly-convex-concave min-max optimization: provable algorithms and applications in machine learning. Optimization Methods and Software, 2022, 37(3): 1087-1121.
- (43) Sanjabi M, Razaviyayn M, Lee J D. Solving non-convex non-concave min-max games under polyak-Łojasiewicz condition. arXiv preprint arXiv:1812.02878, 2018.
- (44) Song C, Zhou Z, Zhou Y, Jiang Y, Ma Y. Optimistic dual extrapolation for coherent non-monotone variational inequalities. Advances in Neural Information Processing Systems, 2020,33: 14303-14314.
- (45) Shen J, Wang Z, Xu Z. Zeroth-order single-loop algorithms for nonconvex-linear minimax problems. Journal of Global Optimization, doi:10.1007/s10898-022-01169-5, 2022.
- (46) Thekumparampil K K, Jain P, Netrapalli P,Oh S. Efficient algorithms for smooth minimax optimization. Advances inNeural Information Processing Systems, 2019:12680-12691.
- (47) Tominin V, Tominin Y, Borodich E, Kovalev D, Gasnikov A, Dvurechensky P. On accelerated methods for saddle-pointproblems with composite structure. COMPUTER,2023, 15(2): 433-467.
- (48) Tieleman T, Hinton G, et al. Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude. COURSERA: Neural networks for machine learning, 2012, 4(2):26-31.
- (49) Wang Z, Balasubramanian K, Ma S, Razaviyayn M. Zeroth-order algorithms for nonconvex minimax problems with improved complexities. arXiv preprint arXiv:2001.07819, 2020.
- (50) Xu Z, Zhang H, Xu Y, Lan G. A unified single-loop alternating gradient projection algorithm for nonconvex-concave and convex-nonconcave minimax problems. Mathematical Programming, 2023, 201:635-706.
- (51) Xu T, Wang Z, Liang Y, Poor H V. Gradient free minimax optimization: Variance reduction and faster convergence. arXiv preprint arXiv:2006.09361, 2020.
- (52) Xu Z, Wang Z, Shen J, Dai Y. H. Derivative-free alternating projection algorithms for general nonconvex-concave minimax problems. SIAM Journal on Optimization, 34(2):1879-1908, (2024).
- (53) Xu Z, Wang Z Q, Wang J L, Dai Y. H. Zeroth-order alternating gradient descent ascent algorithms for a class of nonconvex-nonconcave minimax problems. Journal of Machine Learning Research, 24(313): 1-25, (2023).
- (54) Yang J, Kiyavash N, He N. Global convergence and variance-reduced optimization for a class of nonconvex-nonconcaveminimax problems.Advances in Neural Information Processing Systems, 2020, 33: 1153-1165.
- (55) Yang J, Orvieto A, Lucchi A, et al. Faster single-loop algorithms for minimax optimization without strong concavity. International Conference on Artificial Intelligence and Statistics. PMLR, 2022: 5485-5517.
- (56) Zhang J, Xiao P, Sun R, Luo Z. A single-loop smoothed gradient descent-ascent algorithm for nonconvex-concave min-max problems. Advances in Neural Information Processing Systems, 2020, 33:7377-7389.
- (57) Zhang G, Wang Y, Lessard L, Grosse R B. Near-optimal local convergence of alternating gradient descent-ascent forminimax optimization. International Conference on Artificial Intelligence and Statistics, PMLR, 2022:7659-7679.
- (58) Zhang X, Aybat N S, Gurbuzbalaban M. Sapd+: An accelerated stochastic method for nonconvex-concave minimax problems. Advances in Neural Information Processing Systems, 2022, 35: 21668-21681.