Amercing: An Intuitive, Elegant and Effective Constraint for Dynamic Time Warping
Abstract
Dynamic Time Warping (), and its constrained () and weighted () variants, are time series distances with a wide range of applications. They minimize the cost of non-linear alignments between series. and have been introduced because is too permissive in its alignments. However, uses a crude step function, allowing unconstrained flexibility within the window, and none beyond it. ’s multiplicative weight is relative to the distances between aligned points along a warped path, rather than being a direct function of the amount of warping that is introduced. In this paper, we introduce Amerced Dynamic Time Warping (), a new, intuitive, variant that penalizes the act of warping by a fixed additive cost. Like and , constrains the amount of warping. However, it avoids both abrupt discontinuities in the amount of warping allowed and the limitations of a multiplicative penalty. We formally introduce , prove some of its properties, and discuss its parameterization. We show on a simple example how it can be parameterized to achieve an intuitive outcome, and demonstrate its usefulness on a standard time series classification benchmark. We provide a demonstration application in C++ [1].
keywords:
Time Series, Dynamic Time Warping, Elastic Distance1 Introduction
Dynamic Time Warping () is a distance measure for time series. First developed for speech recognition [2, 3], it has been adopted across a broad spectrum of applications including gesture recognition [4], signature verification [5], shape matching [6], road surface monitoring [7], neuroscience [8] and medical diagnosis [9].
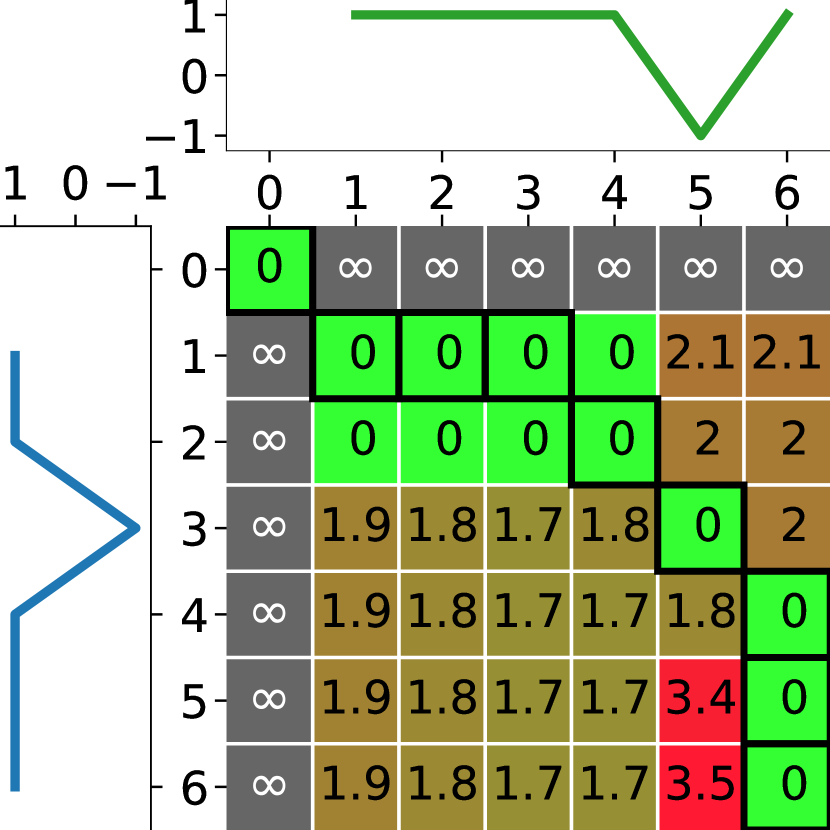
DTW sums pairwise-distances between aligned points in two series. To allow for similar events that unfold at different rates, provides elasticity in which points are aligned. However, it is well understood that can be too flexible in the alignments it allows. We illustrate this with respect to three series shown in Figure 1.



A natural expectation for any time series distance function is that . However, . While this may be appropriate for some tasks, where all that matters is that these sequences all contain five 1s and one -1, it is inappropriate for others.
Two variants have been developed to constrain ’s flexibility, Constrained ( [2, 3], see Section 2.2) and Weighted ( [10], see Section 2.3). constrains the alignments from warping by more than a window, . Within the window, any warping is allowed, and none beyond it. Depending on , there are three possibilities for how might assess our example:
-
1.
For , .
-
2.
(see Figure 3)
-
3.
.
applies a multiplicative penalty to alignments that increases the more the alignment is warped. However, because the penalty is multiplicative, the perfectly matched elements in our example still lead to (see Figure 4).
None of , or can be parameterized to obtain the natural expectation that .
In this paper, we present Amerced DTW (), an intuitive, elegant and effective variant of that applies a tunable additive penalty for warping an alignment. To align the in with the in , it is necessary to warp the alignments by 1 step, incurring a cost of . A further compensatory warping step is required to bring the two end points back into alignment, incurring another cost of . Thus, the total cost of aligning the two series is . Aligning the in with the in requires warping by two steps, incurring a penalty of , with a further penalty required to realign the end points, resulting in . Thus, can be parameterized to be in line with natural expectations for our example, or to allow the flexibility to treat the three series as equivalent if that is appropriate for an application:
-
1.
For (see Figure 5), . We have because the path will not be warped if the resulting cost of is cheaper than 4 warping penalties.
-
2.
For , , because the penalty for warping is greater than the cost of not warping.
-
3.
For , , because there is no penalty for warping.
We show that this approach is not only intuitive, it often provides superior outcomes in practice.
2 Background and related Work
is a foundational technique for a wide range of time series data analysis tasks, including similarity search [11], regression [12], clustering [13], anomaly and outlier detection [14], motif discovery [15], forecasting [16], and subspace projection [17].
In this paper, for ease of exposition, we only consider univariate time series, although extends directly to the multivariate case. We denote series by the capital letters , and . The letter denotes the length of the series. Subscripting (e.g. ) is used to disambiguate between the length of different series. The elements with are the elements of the series , drawn from a domain (e.g. real numbers).
We assess on time series classification tasks. Given a training set of labeled time series , time series classification learns a classifier which is then assessed with respect to classifying an evaluation set of labeled time series.
2.1 Dynamic Time Warping and Variants
Dynamic Time Warping () [2, 3] handles alignment of series with distortion and disparate lengths. An alignment between two series and is made of tuples representing the point-to-point alignments of with . A warping path is an alignment with the following properties:
-
1.
Series extremities are aligned with each other, i.e.
-
2.
It is continuous, i.e.
-
3.
It is monotonic, i.e.
Given a cost function , finds a warping path minimizing the cumulative sum of :
| (1) |
In this paper, following common practice in time series classification, we use the squared L2 norm as the cost function for all distances.
can be computed on a 0-indexed cost matrix . A cell represents the minimal cumulative cost of aligning the first points of with the first points of . It follows that
The cost matrix is defined by a set of recursive equations (2). The first two equations (2a) and (2b) defines the border conditions. The third one (2c) computes the cost of a cell by adding the cost of aligning with , given by , to the cost of its smallest predecessors. Figure 2 shows examples of cost matrices.
| (2a) | ||||
| (2b) | ||||
| (2c) | ||||
An efficient implementation technique [18] allows and its variants, including , to be computed with an space complexity, and a pruned time complexity; the worst case scenario can usually be avoided.



2.2 Constrained DTW
In Constrained DTW (), the warping path is strictly restricted to a subarea of the cost matrix. Different constraints, with different subarea “shapes”, exist [3, 19]. We focus on the popular Sakoe-Chiba band [3], also known as a warping window (or window for short). The window is a parameter controlling how far the warping path can deviate from the diagonal. Given a cost matrix , a line index and a column index , we constrain by . A window of forces the warping path to be on the diagonal, while a window of is equivalent to (no constraint). For example with , the warping path can only step one cell away from each side of the diagonal (Figure 3).



An effective window increases the usefulness of over by preventing spurious alignments. For example, nearest neighbor classification using as the distance measure (NN-) is significantly more accurate than nearest neighbor classification using (NN-, see Section 5). is also faster to compute than , as cells of the cost matrix beyond the window are ignored. However, the window is a parameter that must be learned. The Sakoe-Chiba band is part of the original definition of and the defacto default constraint for (e.g. in [20, 21, 22]).
One of the issues that must be addressed in any application of is how to select an appropriate value for . A method deployed when the UCR benchmark archive was first established has become the defacto default method for time series classification [23]. This method applies leave-one-out cross validation to nearest neighbor classification over the training data for all . The best value of is selected, with respect to the performance measure of interest (typically the lowest error).
2.3 Weighted DTW
Weighted Dynamic Time Warping () [10] penalizes phase difference between two points. An alignment cost of a cell is weighted according to its distance to the diagonal, . In other words, relies on a (3a) function to define a new cost function (3b). A large weight decreases the chances of a cell to be on an optimal path. The weight factor parameter controls the penalization, and usually lies within – [10]. Figure 4 shows several cost matrices.
| (3a) | ||||
| (3b) | ||||
applies a penalty to every pair of aligned points that are off the diagonal. Hence, the longer the off diagonal path is, the greater the penalty. Thus, it favors many small deviations from the diagonal over fewer longer deviations.


is also confronted with the problem of selecting an appropriate value for its parameter, . We use the method employed in the Elastic Ensemble [20], and modeled on the defacto method for parameterizing . This method applies leave-one-out cross validation to nearest neighbor classification over the training data for all .
2.4 Squared Euclidean Distance
One simple distance measure is to simply sum the cost of aligning successive points in the two series. This is equivalent to with , and is only defined for same length series. When the cost function for aligning two points and is , this distance measure is known as the Squared Euclidean Distance:
| (4) |
3 Amerced Dynamic Time Warping
Amerced Dynamic Time Warping () provides a new, intuitive, elegant, and effective mechanism for constraining the alignments within the framework. It achieves this by the introduction of a novel constraint, amercing — the application of a simple additive penalty every time an alignment is warped ( changes). This addresses the following problems:
-
1.
can be too flexible in its alignments;
-
2.
uses a crude step function — any flexibility is allowed within the window and none beyond it;
-
3.
applies a multiplicative weight, and hence promotes large degrees of warping if they lead to low cost alignments — the penalty incurred for warping is dependent on the costs of the warped alignments. Further, as the penalty is paid for every off-diagonal alignment (where ), penalizes off diagonal paths for their length, rather than for the number of times they adjust the alignment 111By adjust the alignment we mean having successive alignments and such that ..
3.1 Formal definition of ADTW
Given two times series and , a cost function , and an amercing penalty (see Section 4), finds a warping path minimizing the cumulative sum of amerced costs:
| (5) |
where indicates that the amercing penalty is only applied if a step from to is not an increment on both series, i.e. it is not the case that and . can be computed on a cost matrix (6) with
has the same border conditions as (equations (6a) and (6b)). The other matrix cells are computed recursively, amercing the off diagonal alignments by the penalty (6c). Methods for choosing are discussed Section 4.
| (6a) | ||||
| (6b) | ||||
| (6c) | ||||



3.2 Properties of ADTW
is monotonic with respect to .
| (7) |
Proof.
For any warping path that minimizes (5) under , the same path will result in an equivalent or lower score for . Hence the minimum score for a warping path under cannot exceed the minimum score under . ∎
| (8) |
If ,
| (9) |
Proof.
With , any off diagonal alignment will receive an infinite penalty. Hence the minimal cost warping path must follow the diagonal. ∎
When ,
| (10) |
This observation provides useful and intuitive bounds for the measure.
is symmetric with respect to the order of the arguments.
| (11) |
Proof.
If we consider the cost matrix, such as illustrated in Figure 5, swapping for has the effect of flipping the matrix on the diagonal. This does not affect the cost of the minimal path. ∎
That a distance measure should satisfy this symmetry is intuitive, as it does not seem appropriate that the order of the arguments to a distance function should affect its value. This symmetry also holds for the other variants of .
is symmetric with respect to the order in which the series are processed. With , we have:
| (12) |
Proof.
For any warping path , there is a matching . As these warping paths both contain the same alignments, the cost terms will be the same. As , the amercing penalty terms will also be identical. ∎
This symmetry is also intuitive, as it does not seem appropriate that the direction from which one calculates a distance measure should affect its value. Neither nor has this symmetry when . This is because both measures apply constraints relative to the diagonal, which is different depending on whether one traces it from the top left or the bottom right of the cost matrix. Unlike , is well defined when . If then is undefined.
4 Parameterization
As shown Section 3.2, can be parameterized so as to range from being as flexible as , to being as constrained as . If the situation requires a large amount of warping, a small penalty should be used. Reciprocally, a large penalty helps to avoid warping. Hence, must be tuned for the task at hand, ideally using expert knowledge. Without the latter, one has to fallback on some automated approach. In this paper, we evaluate on a classification benchmark (Section 5) due to its clearly defined objective evaluation measures. Our automated parameter selection method has been designed to work in this context. It remains an important topic for future investigation on how to best parameterize ADTW in other scenarios.
The penalty range is continuous, and hence cannot be exhaustively assessed unless the objective function is convex with respect to , or there are other properties that can be exploited for efficient complete search. Instead, we use a similar method to the defacto standard for parameterizing and . To this end we define a range from small to large penalties. We select from this range the one that achieves the lowest error when used as the distance measure for nearest neighbor classification, as assessed through leave-one-out cross validation (LOOCV) on the training set.
This leads to a major issue with an additive penalty such as : its scale. A small penalty in a given context may be huge in another one, as the impact of the penalty depends on the magnitude of the costs at each step along a warping path. Hence, we must find a reasonable way to determine the scale of penalties. We achieved this by defining a maximal penalty , and multiplying it by a ratio (13). Our penalty range is now . This leads to two questions: how to define , and how to sample .
| (13) |
Let us first consider two series and . As , taking does ensure that . Indeed, taking one single warping step costs as much as the full diagonal. In turn, this ensures that we do not need to test any other value beyond . However, we need to have a single penalty for all series from , so we sample random pairs of series, and set to their average , .
We now have to find the best — we use a detour to better explain it. Intuitively, represents the cost of steps along the diagonal, and we can define an average step cost . In turn, we have
| (14) |
where . As remains a large penalty, we need to start sampling at value below . Without expert knowledge, our best guess is to start at several order of magnitudes lower. Simplifying equation (14) back to equation (13), must be small enough to account for both , and the magnitude of . Then, successive must gradually increase toward . If several “best” are found, we take the median value.
As leave-one-out cross validation is time consuming, and to ensure a fair comparison with the methods for parameterizing and , we limit the search to a hundred values [20, 24]. The formula for fulfills our requirements, covering a range from to 1 and favoring smaller penalties, which tend to be more useful than large ones, as any sufficiently large penalty confines the warping path to the diagonal.
5 Experiments
Due to its clearly defined objective evaluation measures, we evaluate against other distances on a classification benchmark, using the UCR archive [23] in its 128 dataset versions. We retained 112 datasets after filtering out those with series of variable length, containing missing data, or having only one training exemplar per class (leading to spurious results under LOOCV). The distances are used in nearest neighbor classifiers. The archive provides default train and test splits. For each dataset, the parameters , and are learned on the training data following the methods described Sections 2 and 4. We report the accuracy obtained on the test split. Our results are available online [1].
Following Demsar [25], we compare classifiers using the Wilcoxon signed-rank test. The result can be graphically presented in mean-rank diagrams (Figures 6 and 9), where classifiers not significantly different (at a significance level, adjusted with the Holm correction for multiple testing) are lined by a horizontal bar. A rank closer to 1 indicates a more accurate classifier.
We compare against , , and . Figure 6 summarizes the outcome of this comparison. It shows that attains a significantly better rank on accuracy than any other measure.

Mean rank diagrams are useful to summarize relative performance, but do not tell the full story — a classifier consistently outperforming another would be deemed as significantly better ranked, even if the actual gain is minimal. Accuracy scatter plots (see figures 7 and 8) allow to visualize how a classifier performs relatively to another one. The space is divided by a diagonal representing equal accuracy, and each dot represents a dataset. Points close to the diagonal indicates comparable accuracy between classifiers; conversely, points far away indicates different accuracies.
Figure 7 shows the accuracy scatter plot of against other distances. Points above the diagonal indicate datasets where is more accurate, and conversely below it. We also indicate the numbers of ties and wins per classifiers, and the resulting Wilcoxon score. is almost always more accurate than and — usually substantially so, and the majority of points remain well above the diagonal for and , albeit by a smaller margin. We note a point well below the diagonal in Figures 7(a) and 7(c). This it the “Rock” dataset, for which our parameterization process fails to select a high enough penalty. Although has the capacity to behave like if appropriately parameterized, our parameterization process fails to achieve this for “Rock.” Effective parameterization remains an open problem.




We also compare against a hypothetical classifier, a classifier that uses the most accurate among all competitors. Such a classifier is not feasible to obtain in practice as it is not possible to be certain which classifier will obtain the lowest error on previously unseen test data. The accuracy scatter plots against the hypothetical classifier are shown in Figure 8. A Wilcoxon signed-rank test assesses as significantly more accurate at a significance level than (). These results suggest that is a good default choice of variant.

Finally, we present a sensitivity analysis for the exponent used to tune . Figure 9 shows the effect of using different values for exponent when sampling the ratio under LOOCV at train time. All exponents above lead to comparable results. While leads to the best results on the benchmark, we have no theoretical grounds on which to prefer it and in other applications we have examined, slightly higher values lead to slightly greater accuracy.

6 Conclusions
is a popular time series distance measure that allows flexibility in the series alignments [2, 3]. However, it can be too flexible for some applications, and two main forms of constraint have been developed to limit the alignments. Windows provide a strict limit on the distance over which points may be aligned [3, 19]. Multiplicative weights penalize all off diagonal points proportionally to their distance from the diagonal and the cost of their alignment [10].
However, windows introduce an abrupt discontinuity. Within the window there is unconstrained flexibility and beyond it there is none. Multiplicative weights allow large warping at little cost if the aligned points have low cost. Further, they penalize the length of an off-diagonal path rather than the number of times the path deviates from the diagonal. Whats more, neither windows nor multiplicative weights are symmetric with respect to reversing the series (they do not guarantee when ).
Amerced DTW introduces a tunable additive weight that produces a smooth range of distance measures such that is monotonic with respect to , , and . It is symmetric with respect to the order of the parameters and reversing the series, irrespective of whether the series share the same length. It has the intuitive property of penalizing the number of times a path deviates from simply aligning successive points in each series, rather than penalizing the length of the paths following such a deviation.
Our experiments indicate that when is employed for nearest neighbor classification on the widely used UCR benchmark, it results in more accurate classification significantly more often than any other variant.
The application of in the many other types of task to which is often applied remains a productive direction for future investigation. These include similarity search [11], regression [12], clustering [13], anomaly and outlier detection [14], motif discovery [15], forecasting [16], and subspace projection [17]. One issue that will need to be addressed in each of these domains is how best to tune the amercing penalty , especially if a task does not have objective criteria by which utility may be judged. We hope that will prove as effective in these other applications as it has proved to be in classification. A C++ implementation of is available at [1].
Acknowledgments
This work was supported by the Australian Research Council award DP210100072. We would like to thank the maintainers and contributors for providing the UCR Archive, and Hassan Fawaz for the critical diagram drawing code [26]. We are also grateful to Eamonn Keogh, Chang Wei Tan, and Mahsa Salehi for insightful comments on an early draft.
References
- [1] M. Herrmann, Nn1 adtw demonstration application and results, https://github.com/HerrmannM/paper-2021-ADTW (2021).
- [2] H. Sakoe, S. Chiba, Recognition of continuously spoken words based on time-normalization by dynamic programming, Journal of the Acoustical Society of Japan 27 (9) (1971) 483–490.
- [3] H. Sakoe, S. Chiba, Dynamic programming algorithm optimization for spoken word recognition, IEEE Transactions on Acoustics, Speech, and Signal Processing 26 (1) (1978) 43–49. doi:10.1109/TASSP.1978.1163055.
- [4] H. Cheng, Z. Dai, Z. Liu, Y. Zhao, An image-to-class dynamic time warping approach for both 3d static and trajectory hand gesture recognition, Pattern Recognition 55 (2016) 137–147.
- [5] M. Okawa, Online signature verification using single-template matching with time-series averaging and gradient boosting, Pattern Recognition 112 (2021) 107699.
- [6] Z. Yasseen, A. Verroust-Blondet, A. Nasri, Shape matching by part alignment using extended chordal axis transform, Pattern Recognition 57 (2016) 115–135.
- [7] G. Singh, D. Bansal, S. Sofat, N. Aggarwal, Smart patrolling: An efficient road surface monitoring using smartphone sensors and crowdsourcing, Pervasive and Mobile Computing 40 (2017) 71–88.
- [8] Y. Cao, N. Rakhilin, P. H. Gordon, X. Shen, E. C. Kan, A real-time spike classification method based on dynamic time warping for extracellular enteric neural recording with large waveform variability, Journal of Neuroscience Methods 261 (2016) 97–109.
- [9] R. Varatharajan, G. Manogaran, M. K. Priyan, R. Sundarasekar, Wearable sensor devices for early detection of alzheimer disease using dynamic time warping algorithm, Cluster Computing 21 (1) (2018) 681–690.
- [10] Y.-S. Jeong, M. K. Jeong, O. A. Omitaomu, Weighted dynamic time warping for time series classification, Pattern Recognition 44 (9) (2011) 2231–2240. doi:10.1016/j.patcog.2010.09.022.
- [11] T. Rakthanmanon, B. Campana, A. Mueen, G. Batista, B. Westover, Q. Zhu, J. Zakaria, E. Keogh, Searching and mining trillions of time series subsequences under dynamic time warping, in: Proc. 18th ACM SIGKDD Int. Conf. Knowledge Discovery and Data Mining, 2012, pp. 262–270.
- [12] C. W. Tan, C. Bergmeir, F. Petitjean, G. I. Webb, Time series extrinsic regression, Data Mining and Knowledge Discovery 35 (3) (2021) 1032–1060. doi:10.1007/s10618-021-00745-9.
- [13] F. Petitjean, A. Ketterlin, P. Gançarski, A global averaging method for dynamic time warping, with applications to clustering, Pattern Recognition 44 (3) (2011) 678–693.
- [14] D. M. Diab, B. AsSadhan, H. Binsalleeh, S. Lambotharan, K. G. Kyriakopoulos, I. Ghafir, Anomaly detection using dynamic time warping, in: 2019 IEEE International Conference on Computational Science and Engineering (CSE) and IEEE International Conference on Embedded and Ubiquitous Computing (EUC), IEEE, 2019, pp. 193–198.
- [15] S. Alaee, R. Mercer, K. Kamgar, E. Keogh, Time series motifs discovery under DTW allows more robust discovery of conserved structure, Data Mining and Knowledge Discovery 35 (3) (2021) 863–910.
- [16] K. Bandara, H. Hewamalage, Y.-H. Liu, Y. Kang, C. Bergmeir, Improving the accuracy of global forecasting models using time series data augmentation, Pattern Recognition 120 (2021) 108148.
- [17] H. Deng, W. Chen, Q. Shen, A. J. Ma, P. C. Yuen, G. Feng, Invariant subspace learning for time series data based on dynamic time warping distance, Pattern Recognition 102 (2020) 107210. doi:https://doi.org/10.1016/j.patcog.2020.107210.
-
[18]
M. Herrmann, G. I. Webb,
Early abandoning and
pruning for elastic distances including dynamic time warping, Data Mining
and Knowledge Discovery 35 (6) (2021) 2577–2601.
doi:10.1007/s10618-021-00782-4.
URL https://doi.org/10.1007/s10618-021-00782-4 - [19] F. Itakura, Minimum prediction residual principle applied to speech recognition, IEEE Transactions on Acoustics, Speech, and Signal Processing 23 (1) (1975) 67–72. doi:10.1109/TASSP.1975.1162641.
- [20] J. Lines, A. Bagnall, Time series classification with ensembles of elastic distance measures, Data Mining and Knowledge Discovery 29 (3) (2015) 565–592. doi:10.1007/s10618-014-0361-2.
- [21] B. Lucas, A. Shifaz, C. Pelletier, L. O’Neill, N. Zaidi, B. Goethals, F. Petitjean, G. I. Webb, Proximity Forest: An effective and scalable distance-based classifier for time series, Data Mining and Knowledge Discovery 33 (3) (2019) 607–635. doi:10.1007/s10618-019-00617-3.
- [22] A. Shifaz, C. Pelletier, F. Petitjean, G. I. Webb, TS-CHIEF: A scalable and accurate forest algorithm for time series classification, Data Mining and Knowledge Discovery 34 (3) (2020) 742–775. doi:10.1007/s10618-020-00679-8.
- [23] H. A. Dau, A. Bagnall, K. Kamgar, C.-C. M. Yeh, Y. Zhu, S. Gharghabi, C. A. Ratanamahatana, E. Keogh, The UCR Time Series Archive, arXiv:1810.07758 [cs, stat] (Sep. 2019). arXiv:1810.07758.
- [24] C. W. Tan, F. Petitjean, G. I. Webb, FastEE: Fast Ensembles of Elastic Distances for time series classification, Data Mining and Knowledge Discovery 34 (1) (2020) 231–272. doi:10.1007/s10618-019-00663-x.
- [25] J. Demšar, Statistical Comparisons of Classifiers over Multiple Data Sets, Journal of Machine Learning Research 7 (2006) 1–30.
- [26] H. Ismail Fawaz, Critical difference diagram with Wilcoxon-Holm post-hoc analysis, https://github.com/hfawaz/cd-diagram (2019).