Alias-Free Generative Adversarial Networks
Abstract
We observe that despite their hierarchical convolutional nature, the synthesis process of typical generative adversarial networks depends on absolute pixel coordinates in an unhealthy manner. This manifests itself as, e.g., detail appearing to be glued to image coordinates instead of the surfaces of depicted objects. We trace the root cause to careless signal processing that causes aliasing in the generator network. Interpreting all signals in the network as continuous, we derive generally applicable, small architectural changes that guarantee that unwanted information cannot leak into the hierarchical synthesis process. The resulting networks match the FID of StyleGAN2 but differ dramatically in their internal representations, and they are fully equivariant to translation and rotation even at subpixel scales. Our results pave the way for generative models better suited for video and animation.
1 Introduction
The resolution and quality of images produced by generative adversarial networks (GAN) [21] have seen rapid improvement recently [31, 11, 33, 34]. They have been used for a variety of applications, including image editing [49, 55, 43, 22, 39, 3], domain translation [70, 37, 61, 42], and video generation [57, 15, 24]. While several ways of controlling the generative process have been found [8, 29, 10, 42, 25, 2, 7, 48, 6], the foundations of the synthesis process remain only partially understood.
In the real world, details of different scale tend to transform hierarchically. For instance, moving a head causes the nose to move, which in turn moves the skin pores on it. The structure of a typical GAN generator is analogous: coarse, low-resolution features are hierarchically refined by upsampling layers, locally mixed by convolutions, and new detail is introduced through nonlinearities. We observe that despite this superficial similarity, current GAN architectures do not synthesize images in a natural hierarchical manner: the coarse features mainly control the presence of finer features, but not their precise positions. Instead, much of the fine detail appears to be fixed in pixel coordinates. This disturbing “texture sticking” is clearly visible in latent interpolations (see Figure 1 and our accompanying videos on the project page https://nvlabs.github.io/stylegan3), breaking the illusion of a solid and coherent object moving in space. Our goal is an architecture that exhibits a more natural transformation hierarchy, where the exact sub-pixel position of each feature is exclusively inherited from the underlying coarse features.
It turns out that current networks can partially bypass the ideal hierarchical construction by drawing on unintentional positional references available to the intermediate layers through image borders [28, 35, 66], per-pixel noise inputs [33] and positional encodings, and aliasing [5, 69]. Aliasing, despite being a subtle and critical issue [44], has received little attention in the GAN literature. We identify two sources for it: 1) faint after-images of the pixel grid resulting from non-ideal upsampling filters111Consider nearest neighbor upsampling. If we upsample a 44 image to 88, the original pixels will be clearly visible, allowing one to reliably distinguish between even and odd pixels. Since the same is true on all scales, this (leaked) information makes it possible to reconstruct even the absolute pixel coordinates. With better filters such as bilinear or bicubic, the clues get less pronounced, but are nevertheless evident for the generator. such as nearest, bilinear, or strided convolutions, and 2) the pointwise application of nonlinearities such as ReLU [60] or swish [47]. We find that the network has the means and motivation to amplify even the slightest amount of aliasing and combining it over multiple scales allows it to build a basis for texture motifs that are fixed in screen coordinates. This holds for all filters commonly used in deep learning [69, 59], and even high-quality filters used in image processing.
How, then, do we eliminate the unwanted side information and thereby stop the network from using it? While borders can be solved by simply operating on slightly larger images, aliasing is much harder. We begin by noting that aliasing is most naturally treated in the classical Shannon-Nyquist signal processing framework, and switch focus to bandlimited functions on a continuous domain that are merely represented by discrete sample grids. Now, successful elimination of all sources of positional references means that details can be generated equally well regardless of pixel coordinates, which in turn is equivalent to enforcing continuous equivariance to sub-pixel translation (and optionally rotation) in all layers. To achieve this, we describe a comprehensive overhaul of all signal processing aspects of the StyleGAN2 generator [34]. Our contributions include the surprising finding that current upsampling filters are simply not aggressive enough in suppressing aliasing, and that extremely high-quality filters with over 100dB attenuation are required. Further, we present a principled solution to aliasing caused by pointwise nonlinearities [5] by considering their effect in the continuous domain and appropriately low-pass filtering the results. We also show that after the overhaul, a model based on 11 convolutions yields a strong, rotation equivariant generator.
StyleGAN2 Ours
StyleGAN2
latent interpolation
Ours
latent interpolation
Averaged Central




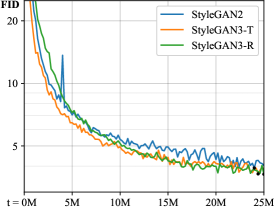
Once aliasing is adequately suppressed to force the model to implement more natural hierarchical refinement, its mode of operation changes drastically: the emergent internal representations now include coordinate systems that allow details to be correctly attached to the underlying surfaces. This promises significant improvements to models that generate video and animation. The new StyleGAN3 generator matches StyleGAN2 in terms of FID [26], while being slightly heavier computationally. Our implementation and pre-trained models are available at https://github.com/NVlabs/stylegan3
Several recent works have studied the lack of translation equivariance in CNNs, mainly in the context of classification [28, 35, 66, 5, 38, 69, 12, 71, 59]. We significantly expand upon the antialiasing measures in this literature and show that doing so induces a fundamentally altered image generation behavior. Group-equivariant CNNs aim to generalize the efficiency benefits of translational weight sharing to, e.g., rotation [16, 65, 63, 62] and scale [64]. Our 11 convolutions can be seen an instance of a continuously -equivariant model [62] that remains compatible with, e.g., channel-wise ReLU nonlinearities and modulation. Dey et al. [17] apply rotation-and-flip equivariant CNNs [16] to GANs and show improved data efficiency. Our work is complementary, and not motivated by efficiency. Recent implicit network [53, 56, 13] based GANs [4, 54] generate each pixel independently via similar 11 convolutions. While equivariant, these models do not help with texture sticking, as they do not use an upsampling hierarchy or implement a shallow non-antialiased one.
2 Equivariance via continuous signal interpretation
To begin our analysis of equivariance in CNNs, we shall first rethink our view of what exactly is the signal that flows through a network. Even though data may be stored as values in a pixel grid, we cannot naïvely hold these values to directly represent the signal. Doing so would prevent us from considering operations as trivial as translating the contents of a feature map by half a pixel.
According to the Nyquist–Shannon sampling theorem [51], a regularly sampled signal can represent any continuous signal containing frequencies between zero and half of the sampling rate. Let us consider a two-dimensional, discretely sampled feature map that consists of a regular grid of Dirac impulses of varying magnitudes, spaced units apart where is the sampling rate. This is analogous to an infinite two-dimensional grid of values.
Given and , the Whittaker–Shannon interpolation formula [51] states that the corresponding continuous representation is obtained by convolving the discretely sampled Dirac grid with an ideal interpolation filter , i.e., , where denotes continuous convolution and using the signal processing convention of defining . has a bandlimit of along the horizontal and vertical dimensions, ensuring that the resulting continuous signal captures all frequencies that can be represented with sampling rate .
Conversion from the continuous to the discrete domain corresponds to sampling the continuous signal at the sampling points of that we define to be offset by half the sample spacing to lie at the “pixel centers”, see Figure 2, left. This can be expressed as a pointwise multiplication with a two-dimensional Dirac comb .
We earmark the unit square in as our canvas for the signal of interest. In there are discrete samples in this region, but the above convolution with means that values of outside the unit square also influence inside it. Thus storing an -pixel feature map is not sufficient; in theory, we would need to store the entire infinite . As a practical solution, we store as a two-dimensional array that covers a region slightly larger than the unit square (Section 3.2).
Having established correspondence between bandlimited, continuous feature maps and discretely sampled feature maps , we can shift our focus away from the usual pixel-centric view of the signal. In the remainder of this paper, we shall interpret as being the actual signal being operated on, and the discretely sampled feature map as merely a convenient encoding for it.

Discrete and continuous representation of network layers
Practical neural networks operate on the discretely sampled feature maps. Consider operation (convolution, nonlinearity, etc.) operating on a discrete feature map: . The feature map has a corresponding continuous counterpart, so we also have a corresponding mapping in the continuous domain: . Now, an operation specified in one domain can be seen to perform a corresponding operation in the other domain:
| (1) |
where denotes pointwise multiplication and and are the input and output sampling rates. Note that in the latter case must not introduce frequency content beyond the output bandlimit .
2.1 Equivariant network layers
Operation is equivariant with respect to a spatial transformation of the 2D plane if it commutes with it in the continuous domain: . We note that when inputs are bandlimited to , an equivariant operation must not generate frequency content above the output bandlimit of , as otherwise no faithful discrete output representation exists.
We focus on two types of equivariance in this paper: translation and rotation. In the case of rotation the spectral constraint is somewhat stricter — rotating an image corresponds to rotating the spectrum, and in order to guarantee the bandlimit in both horizontal and vertical direction, the spectrum must be limited to a disc with radius . This applies to both the initial network input as well as the bandlimiting filters used for downsampling, as will be described later.
We now consider the primitive operations in a typical generator network: convolution, upsampling, downsampling, and nonlinearity. Without loss of generality, we discuss the operations acting on a single feature map: pointwise linear combination of features has no effect on the analysis.
Convolution
Consider a standard convolution with a discrete kernel . We can interpret as living in the same grid as the input feature map, with sampling rate . The discrete-domain operation is simply , and we obtain the corresponding continuous operation from Eq. 1:
| (2) |
due to commutativity of convolution and the fact that discretization followed by convolution with ideal low-pass filter, both with same sampling rate , is an identity operation, i.e., . In other words, the convolution operates by continuously sliding the discretized kernel over the continuous representation of the feature map. This convolution introduces no new frequencies, so the bandlimit requirements for both translation and rotation equivariance are trivially fulfilled.
Convolution also commutes with translation in the continuous domain, and thus the operation is equivariant to translation. For rotation equivariance, the discrete kernel needs to be radially symmetric. We later show in Section 3.2 that trivially symmetric 11 convolution kernels are, despite their simplicity, a viable choice for rotation equivariant generative networks.
Upsampling and downsampling
Ideal upsampling does not modify the continuous representation. Its only purpose is to increase the output sampling rate () to add headroom in the spectrum where subsequent layers may introduce additional content. Translation and rotation equivariance follow directly from upsampling being an identity operation in the continuous domain. With , the discrete operation according to Eq. 1 is . If we choose with integer , this operation can be implemented by first interleaving with zeros to increase its sampling rate and then convolving it with a discretized filter .
In downsampling, we must low-pass filter to remove frequencies above the output bandlimit, so that the signal can be represented faithfully in the coarser discretization. The operation in continuous domain is , where an ideal low-pass filter is simply the corresponding interpolation filter normalized to unit mass. The discrete counterpart is . The latter equality follows from . Similar to upsampling, downsampling by an integer fraction can be implemented with a discrete convolution followed by dropping sample points. Translation equivariance follows automatically from the commutativity of with translation, but for rotation equivariance we must replace with a radially symmetric filter with disc-shaped frequency response. The ideal such filter [9] is given by , where is the first order Bessel function of the first kind.
Nonlinearity
Applying a pointwise nonlinearity in the discrete domain does not commute with fractional translation or rotation. However, in the continuous domain, any pointwise function commutes trivially with geometric transformations and is thus equivariant to translation and rotation. Fulfilling the bandlimit constraint is another question — applying, e.g., ReLU in the continuous domain may introduce arbitrarily high frequencies that cannot be represented in the output.
A natural solution is to eliminate the offending high-frequency content by convolving the continuous result with the ideal low-pass filter . Then, the continuous representation of the nonlinearity becomes and the discrete counterpart is (see Figure 2, right). This discrete operation cannot be realized without temporarily entering the continuous representation. We approximate this by upsampling the signal, applying the nonlinearity in the higher resolution, and downsampling it afterwards. Even though the nonlinearity is still performed in the discrete domain, we have found that only a 2 temporary resolution increase is sufficient for high-quality equivariance. For rotation equivariance, we must use the radially symmetric interpolation filter in the downsampling step, as discussed above.
Note that nonlinearity is the only operation capable of generating novel frequencies in our formulation, and that we can limit the range of these novel frequencies by applying a reconstruction filter with a lower cutoff than before the final discretization operation. This gives us precise control over how much new information is introduced by each layer of a generator network (Section 3.2).
3 Practical application to generator network
We will now apply the theoretical ideas from the previous section in practice, by converting the well-established StyleGAN2 [34] generator to be fully equivariant to translation and rotation. We will introduce the necessary changes step-by-step, evaluating their impact in Figure 3. The discriminator remains unchanged in our experiments.
The StyleGAN2 generator consists of two parts. First, a mapping network transforms an initial, normally distributed latent to an intermediate latent code . Then, a synthesis network starts from a learned 44512 constant and applies a sequence of layers — consisting of convolutions, nonlinearities, upsampling, and per-pixel noise — to produce an output image . The intermediate latent code controls the modulation of the convolution kernels in . The layers follow a rigid 2 upsampling schedule, where two layers are executed at each resolution and the number of feature maps is halved after each upsampling. Additionally, StyleGAN2 employs skip connections, mixing regularization [33], and path length regularization.
| Configuration | FID | EQ-T | EQ-R | |
| a | StyleGAN2 | 5.14 | – | – |
| b | + Fourier features | 4.79 | 16.23 | 10.81 |
| c | + No noise inputs | 4.54 | 15.81 | 10.84 |
| d | + Simplified generator | 5.21 | 19.47 | 10.41 |
| e | + Boundaries & upsampling | 6.02 | 24.62 | 10.97 |
| f | + Filtered nonlinearities | 6.35 | 30.60 | 10.81 |
| g | + Non-critical sampling | 4.78 | 43.90 | 10.84 |
| h | + Transformed Fourier features | 4.64 | 45.20 | 10.61 |
| t | + Flexible layers (StyleGAN3-T) | 4.62 | 63.01 | 13.12 |
| r | + Rotation equiv. (StyleGAN3-R) | 4.50 | 66.65 | 40.48 |
| Parameter | FID | EQ-T | EQ-R | Time | Mem. | |
|---|---|---|---|---|---|---|
| Filter size | 4.72 | 57.49 | 39.70 | 0.84 | 0.99 | |
| * | Filter size | 4.50 | 66.65 | 40.48 | 1.00 | 1.00 |
| Filter size | 4.66 | 65.57 | 42.09 | 1.18 | 1.01 | |
| Upsampling | 4.38 | 39.96 | 36.42 | 0.65 | 0.87 | |
| * | Upsampling | 4.50 | 66.65 | 40.48 | 1.00 | 1.00 |
| Upsampling | 4.57 | 74.21 | 40.97 | 2.31 | 1.62 | |
| Stopband | 4.62 | 51.10 | 29.14 | 0.86 | 0.90 | |
| * | Stopband | 4.50 | 66.65 | 40.48 | 1.00 | 1.00 |
| Stopband | 4.68 | 73.13 | 41.63 | 1.36 | 1.25 |
Our goal is to make every layer of equivariant w.r.t. the continuous signal, so that all finer details transform together with the coarser features of a local neighborhood. If this succeeds, the entire network becomes similarly equivariant. In other words, we aim to make the continuous operation of the synthesis network equivariant w.r.t. transformations (translations and rotations) applied on the continuous input : . To evaluate the impact of various architectural changes and practical approximations, we need a way to measure how well the network implements the equivariances. For translation equivariance, we report the peak signal-to-noise ratio (PSNR) in decibels (dB) between two sets of images, obtained by translating the input and output of the synthesis network by a random amount, resembling the definition by Zhang [69]:
| (3) |
Each pair of images, corresponding to a different random choice of , is sampled at integer pixel locations within their mutually valid region . Color channels are processed independently, and the intended dynamic range of generated images gives . Operator implements spatial translation with 2D offset , here drawn from distribution of integer offsets. We define an analogous metric EQ-R for rotations, with the rotation angles drawn from . Appendix E gives implementation details and our accompanying videos highlight the practical relevance of different dB values.
3.1 Fourier features and baseline simplifications (configs b–d)
To facilitate exact continuous translation and rotation of the input , we replace the learned input constant in StyleGAN2 with Fourier features [56, 66], which also has the advantage of naturally defining a spatially infinite map. We sample the frequencies uniformly within the circular frequency band , matching the original 44 input resolution, and keep them fixed over the course of training. This change (configs a and b in Figure 3, left) slightly improves FID and, crucially, allows us to compute the equivariance metrics without having to approximate the operator . This baseline architecture is far from being equivariant; our accompanying videos show that the output images deteriorate drastically when the input features are translated or rotated from their original position.
Next, we remove the per-pixel noise inputs because they are strongly at odds with our goal of a natural transformation hierarchy, i.e., that the exact sub-pixel position of each feature is exclusively inherited from the underlying coarse features. While this change (config c) is approximately FID-neutral, it fails to improve the equivariance metrics when considered in isolation.
To further simplify the setup, we decrease the mapping network depth as recommended by Karras et al. [32] and disable mixing regularization and path length regularization [34]. Finally, we also eliminate the output skip connections. We hypothesize that their benefit is mostly related to gradient magnitude dynamics during training and address the underlying issue more directly using a simple normalization before each convolution. We track the exponential moving average over all pixels and feature maps during training, and divide the feature maps by . In practice, we bake the division into the convolution weights to improve efficiency. These changes (config d) bring FID back to the level of original StyleGAN2, while leading to a slight improvement in translation equivariance.

(a) Filter design concepts (b) Our alias-free StyleGAN3 generator architecture (c) Flexible layers
3.2 Step-by-step redesign motivated by continuous interpretation
Boundaries and upsampling (config e)
Our theory assumes an infinite spatial extent for the feature maps, which we approximate by maintaining a fixed-size margin around the target canvas, cropping to this extended canvas after each layer. This explicit extension is necessary as border padding is known to leak absolute image coordinates into the internal representations [28, 35, 66]. In practice, we have found a -pixel margin to be enough; further increase has no noticeable effect on the results.
Motivated by our theoretical model, we replace the bilinear 2 upsampling filter with a better approximation of the ideal low-pass filter. We use a windowed filter with a relatively large Kaiser window [41] of size , meaning that each output pixel is affected by 6 input pixels in upsampling and each input pixel affects 6 output pixels in downsampling. Kaiser window is a particularly good choice for our purposes, because it offers explicit control over the transition band and attenuation (Figure 4a). In the remainder of this section, we specify the transition band explicitly and compute the remaining parameters using Kaiser’s original formulas (Appendix C). For now, we choose to employ critical sampling and set the filter cutoff , i.e., exactly at the bandlimit, and transition band half-width . Recall that sampling rate equals the width of the canvas in pixels, given our definitions in Section 2.
The improved handling of boundaries and upsampling (config e) leads to better translation equivariance. However, FID is compromised by 16%, probably because we started to constrain what the feature maps can contain. In a further ablation (Figure 3, right), smaller resampling filters () hurt translation equivariance, while larger filters () mainly increase training time.
Filtered nonlinearities (config f)
Our theoretical treatment of nonlinearities calls for wrapping each leaky ReLU (or any other commonly used non-linearity) between upsampling and downsampling, for some magnification factor . We further note that the order of upsampling and convolution can be switched by virtue of the signal being bandlimited, allowing us to fuse the regular 2 upsampling and a subsequent upsampling related to the nonlinearity into a single upsampling. In practice, we find to be sufficient (Figure 3, right), again improving EQ-T (config f). Implementing the upsample-LReLU-downsample sequence is not efficient using the primitives available in current deep learning frameworks [1, 45], and thus we implement a custom CUDA kernel (Appendix D) that combines these operations (Figure 4b), leading to 10 faster training and considerable memory savings.
Non-critical sampling (config g)
The critical sampling scheme — where filter cutoff is set exactly at the bandlimit — is ideal for many image processing applications as it strikes a good balance between antialiasing and the retention of high-frequency detail [58]. However, our goals are markedly different because aliasing is highly detrimental for the equivariance of the generator. While high-frequency detail is important in the output image and thus in the highest-resolution layers, it is less important in the earlier ones given that their exact resolutions are somewhat arbitrary to begin with.
To suppress aliasing, we can simply lower the cutoff frequency to , which ensures that all alias frequencies (above ) are in the stopband.222Here, and correspond to the output (downsampling) filter of each layer. The input (upsampling) filters are based on the properties of the incoming signal, i.e., the output filter parameters of the previous layer. For example, lowering the cutoff of the blue filter in Figure 4a would move its frequency response left so that the the worst-case attenuation of alias frequencies improves from dB to dB. This oversampling can be seen as a computational cost of better antialiasing, as we now use the same number of samples to express a slower-varying signal than before. In practice, we choose to lower on all layers except the highest-resolution ones, because in the end the generator must be able to produce crisp images to match the training data. As the signals now contain less spatial information, we modify the heuristic used for determining the number of feature maps to be inversely proportional to instead of the sampling rate . These changes (config g) further improve translation equivariance and push FID below the original StyleGAN2.
Transformed Fourier features (config h)
Equivariant generator layers are well suited for modeling unaligned and arbitrarily oriented datasets, because any geometric transformation introduced to the intermediate features will directly carry over to the final image . Due to the limited capability of the layers themselves to introduce global transformations, however, the input features play a crucial role in defining the global orientation of . To let the orientation vary on a per-image basis, the generator should have the ability to transform based on . This motivates us to introduce a learned affine layer that outputs global translation and rotation parameters for the input Fourier features (Figure 4b and Appendix F). The layer is initialized to perform an identity transformation, but learns to use the mechanism over time when beneficial; in config h this improves the FID slightly.
Flexible layer specifications (config t)
Our changes have improved the equivariance quality considerably, but some visible artifacts still remain as our accompanying videos demonstrate. On closer inspection, it turns out that the attenuation of our filters (as defined for config g) is still insufficient for the lowest-resolution layers. These layers tend to have rich frequency content near their bandlimit, which calls for extremely strong attenuation to completely eliminate aliasing.
So far, we have used the rigid sampling rate progression from StyleGAN2, coupled with simplistic choices for filter cutoff and half-width , but this need not be the case; we are free to specialize these parameters on a per-layer basis. In particular, we would like to be high in the lowest-resolution layers to maximize attenuation in the stopband, but low in the highest-resolution layers to allow matching high-frequency details of the training data.
Figure 4c illustrates an example progression of filter parameters in a 14-layer generator with two critically sampled full-resolution layers at the end. The cutoff frequency grows geometrically from in the first layer to in the first critically sampled layer. We choose the minimum acceptable stopband frequency to start at , and it grows geometrically but slower than the cutoff frequency. In our tests, the stopband target at the last layer is , but the progression is halted at the first critically sampled layer. Next, we set the sampling rate for each layer so that it accommodates frequencies up to , rounding up to the next power of two without exceeding the output resolution. Finally, to maximize the attenuation of aliasing frequencies, we set the transition band half-width to , i.e., making it as wide as possible within the limits of the sampling rate, but at least wide enough to reach . The resulting improvement depends on how much slack is left between and ; as an extreme example, the first layer stopband attenuation improves from dB to dB using this scheme.
The new layer specifications again improve translation equivariance (config t), eliminating the remaining artifacts. A further ablation (Figure 3, right) shows that provides an effective way to trade training speed for equivariance quality. Note that the number of layers is now a free parameter that does not directly depend on the output resolution. In fact, we have found that a fixed choice of works consistently across multiple output resolutions and makes other hyperparameters such as learning rate behave more predictably. We use in the remainder of this paper.
Rotation equivariance (config r)
We obtain a rotation equivariant version of the network with two changes. First, we replace the 33 convolutions with 11 on all layers and compensate for the reduced capacity by doubling the number of feature maps. Only the upsampling and downsampling operations spread information between pixels in this config. Second, we replace the -based downsampling filter with a radially symmetric -based one that we construct using the same Kaiser scheme (Appendix C). We do this for all layers except the two critically sampled ones, where it is important to match the potentially non-radial spectrum of the training data. These changes (config r) improve EQ-R without harming FID, even though each layer has 56% fewer trainable parameters.
We also employ an additional stabilization trick in this configuration. Early on in the training, we blur all images the discriminator sees using a Gaussian filter. We start with pixels, which we ramp to zero over the first 200k images. This prevents the discriminator from focusing too heavily on high frequencies early on. Without this trick, config r is prone to early collapses because the generator sometimes learns to produce high frequencies with a small delay, trivializing the discriminator’s task.
4 Results
| Dataset | Config | FID | EQ-T | EQ-R |
|---|---|---|---|---|
| FFHQ-U 70000 img, 10242 Train from scratch | StyleGAN2 | 3.79 | 15.89 | 10.79 |
| StyleGAN3-T (ours) | 3.67 | 61.69 | 13.95 | |
| StyleGAN3-R (ours) | 3.66 | 64.78 | 47.64 | |
| FFHQ 70000 img, 10242 Train from scratch | StyleGAN2 | 2.70 | 13.58 | 10.22 |
| StyleGAN3-T (ours) | 2.79 | 61.21 | 13.82 | |
| StyleGAN3-R (ours) | 3.07 | 64.76 | 46.62 | |
| MetFaces-U 1336 img, 10242 ADA, from FFHQ-U | StyleGAN2 | 18.98 | 18.77 | 13.19 |
| StyleGAN3-T (ours) | 18.75 | 64.11 | 16.63 | |
| StyleGAN3-R (ours) | 18.75 | 66.34 | 48.57 | |
| MetFaces 1336 img, 10242 ADA, from FFHQ | StyleGAN2 | 15.22 | 16.39 | 12.89 |
| StyleGAN3-T (ours) | 15.11 | 65.23 | 16.82 | |
| StyleGAN3-R (ours) | 15.33 | 64.86 | 46.81 | |
| AFHQv2 15803 img, 5122 ADA, from scratch | StyleGAN2 | 4.62 | 13.83 | 11.50 |
| StyleGAN3-T (ours) | 4.04 | 60.15 | 13.51 | |
| StyleGAN3-R (ours) | 4.40 | 64.89 | 40.34 | |
| Beaches 20155 img, 5122 ADA, from scratch | StyleGAN2 | 5.03 | 15.73 | 12.69 |
| StyleGAN3-T (ours) | 4.32 | 59.33 | 15.88 | |
| StyleGAN3-R (ours) | 4.57 | 63.66 | 37.42 |
| Ablation | Translation eq. | + Rotation eq. | ||||
| FID | EQ-T | FID | EQ-T | EQ-R | ||
| * | Main configuration | 4.62 | 63.01 | 4.50 | 66.65 | 40.48 |
| With mixing reg. | 4.60 | 63.48 | 4.67 | 63.59 | 40.90 | |
| With noise inputs | 4.96 | 24.46 | 5.79 | 26.71 | 26.80 | |
| Without flexible layers | 4.64 | 45.20 | 4.65 | 44.74 | 22.52 | |
| Fixed Fourier features | 5.93 | 64.57 | 6.48 | 66.20 | 41.77 | |
| With path length reg. | 5.00 | 68.36 | 5.98 | 71.64 | 42.18 | |
| 0.5 capacity | 7.43 | 63.14 | 6.52 | 63.08 | 39.89 | |
| 1.0 capacity | 4.62 | 63.01 | 4.50 | 66.65 | 40.48 | |
| 2.0 capacity | 3.80 | 66.61 | 4.18 | 70.06 | 42.51 | |
| * | Kaiser filter, | 4.62 | 63.01 | 4.50 | 66.65 | 40.48 |
| Lanczos filter, | 4.69 | 51.93 | 4.44 | 57.70 | 25.25 | |
| Gaussian filter, | 5.91 | 56.89 | 5.73 | 59.53 | 39.43 | |
| G-CNN comparison | FID | EQ-T | EQ-R | Params | Time | |
|---|---|---|---|---|---|---|
| * | StyleGAN3-T (ours) | 4.62 | 63.01 | 13.12 | 23.3M | 1.00 |
| + symmetry [16] | 4.69 | 61.90 | 17.07 | 21.8M | 2.48 | |
| * | StyleGAN3-R (ours) | 4.50 | 66.65 | 40.48 | 15.8M | 1.37 |
Figure 5 gives results for six datasets using StyleGAN2 [34] as well as our alias-free StyleGAN3-T and StyleGAN3-R generators. In addition to the standard FFHQ [33] and Metfaces [32], we created unaligned versions of them. We also created a properly resampled version of AFHQ [14] and collected a new Beaches dataset. Appendix B describes the datasets in detail. The results show that our FID remains competitive with StyleGAN2. StyleGAN3-T and StyleGAN3-R perform equally well in terms of FID, and both show a very high level of translation equivariance. As expected, only the latter provides rotation equivariance. In FFHQ (10241024) the three generators had 30.0M, 22.3M and 15.8M parameters, while the training times were 1106, 1576 (+42%) and 2248 (+103%) GPU hours. Our accompanying videos show side-by-side comparisons with StyleGAN2, demonstrating visually that the texture sticking problem has been solved. The resulting motion is much more natural, better sustaining an illusion that there is a coherent 3D scene being imaged.
Ablations and comparisons
In Section 3.1 we disabled a number of StyleGAN2 features. We can now turn them on one by one to gauge their effect on our generators (Figure 5, right). While mixing regularization can be re-enabled without any ill effects, we also find that styles can be mixed quite reliably even without this explicit regularization (Appendix A). Re-enabling noise inputs or relying on StyleGAN2’s original layer specifications compromises equivariances significantly, and using fixed Fourier features or re-enabling path length regularization harms FID. Path length regularization is in principle at odds with translation equivariance, as it penalizes image changes upon latent space walk and thus encourages texture sticking. We suspect that the counterintuitive improvement in equivariance may come from slightly blurrier generated images, at a cost of poor FID.
In a scaling test we tried changing the number of feature maps, observing that equivariances remain at a high level, but FID suffers considerably when the capacity is halved. Doubling the capacity improves result quality in terms of FID, at the cost of almost 4 training time. Finally, we consider alternatives for our windowed Kaiser filter. Lanczos is competitive in terms of FID, but as a separable filter it compromises rotation equivariance in particular. Gaussian leads to clearly worse FIDs.
We compare StyleGAN3-R to an alternative where the rotation part is implemented using symmetric G-CNN [16, 17] on top of our StyleGAN3-T. This approach provides only modest rotation equivariance while being slower to train. Steerable filters [63] could theoretically provide competitive EQ-R, but the memory and training time requirements proved infeasible with generator networks of this size.
Appendix A demonstrates that the spectral properties of generated images closely match training data, comparing favorably to several earlier architectures.

Internal representations
Figure 6 visualizes typical internal representations from the networks. While in StyleGAN2 all feature maps seem to encode signal magnitudes, in our networks some of the maps take a different role and encode phase information instead. Clearly this is something that is needed when the network synthesizes detail on the surfaces; it needs to invent a coordinate system. In StyleGAN3-R, the emergent positional encoding patterns appear to be somewhat more well-defined. We believe that the existence of a coordinate system that allows precise localization on the surfaces of objects will prove useful in various applications, including advanced image and video editing.
5 Limitations, discussion, and future work
In this work we modified only the generator, but it seems likely that further benefits would be available by making the discriminator equivariant as well. For example, in our FFHQ results the teeth do not move correctly when the head turns, and we suspect that this is caused by the discriminator accidentally preferring to see the front teeth at certain pixel locations. Concurrent work has identified that aliasing is detrimental for such generalization [59].
Our alias-free generator architecture contains implicit assumptions about the nature of the training data, and violating these may cause training difficulties. Let us consider an example. Suppose we have black-and-white cartoons as training data that we (incorrectly) pre-process using point sampling [44], leading to training images where almost all pixels are either black or white and the edges are jagged. This kind of badly aliased training data is difficult for GANs in general, but it is especially at odds with equivariance: on the one hand, we are asking the generator to be able to translate the output smoothly by subpixel amounts, but on the other hand, edges must still remain jagged and pixels only black/white, to remain faithful to the training data. The same issue can also arise with letterboxing of training images, low-quality JPEGs, or retro pixel graphics, where the jagged stair-step edges are a defining feature of the aesthetic. In such cases it may be beneficial for the generator to be aware of the pixel grid.
In future, it might be interesting to re-introduce noise inputs (stochastic variation) in a way that is consistent with hierarchical synthesis. A better path length regularization would encourage neighboring features to move together, not discourage them from moving at all. It might be beneficial to try to extend our approach to equivariance w.r.t. scaling, anisotropic scaling, or even arbitrary homeomorphisms. Finally, it is well known that antialiasing should be done before tone mapping. So far, all GANs — including ours — have operated in the sRGB color space (after tone mapping).
Attention layers in the middle of a generator [68] could likely be dealt with similarly to non-linearities by temporarily switching to higher resolution – although the time complexity of attention layers may make this somewhat challenging in practice. Recent attention-based GANs that start with a tokenizing transformer (e.g., VQGAN [18]) may be at odds with equivariance. Whether it is possible to make them equivariant is an important open question.
Potential negative societal impacts
of (image-producing) GANs include many forms of disinformation, from fake portraits in social media [27] to propaganda videos of world leaders [50]. Our contribution eliminates certain characteristic artifacts from videos, potentially making them more convincing or deceiving, depending on the application. Viable solutions include model watermarking [67] along with large-scale authenticity assessment in major social media sites. This entire project consumed 92 GPU years and 225 MWh of electricity on an in-house cluster of NVIDIA V100s. The new StyleGAN3 generator is only marginally costlier to train or use than that of StyleGAN2.
6 Acknowledgments
We thank David Luebke, Ming-Yu Liu, Koki Nagano, Tuomas Kynkäänniemi, and Timo Viitanen for reviewing early drafts and helpful suggestions. Frédo Durand for early discussions. Tero Kuosmanen for maintaining our compute infrastructure. AFHQ authors for an updated version of their dataset. Getty Images for the training images in the Beaches dataset. We did not receive external funding or additional revenues for this project.
References
- [1] M. Abadi, P. Barham, J. Chen, Z. Chen, A. Davis, J. Dean, M. Devin, S. Ghemawat, G. Irving, M. Isard, M. Kudlur, J. Levenberg, R. Monga, S. Moore, D. G. Murray, B. Steiner, P. Tucker, V. Vasudevan, P. Warden, M. Wicke, Y. Yu, and X. Zheng. TensorFlow: A system for large-scale machine learning. In Proc. 12th USENIX Conference on Operating Systems Design and Implementation, OSDI’16, pages 265–283, 2016.
- [2] R. Abdal, P. Zhu, N. J. Mitra, and P. Wonka. StyleFlow: Attribute-conditioned exploration of StyleGAN-generated images using conditional continuous normalizing flows. ACM Trans. Graph., 40(3), 2021.
- [3] Y. Alaluf, O. Patashnik, and D. Cohen-Or. Only a matter of style: Age transformation using a style-based regression model. CoRR, abs/2102.02754, 2021.
- [4] I. Anokhin, K. Demochkin, T. Khakhulin, G. Sterkin, V. Lempitsky, and D. Korzhenkov. Image generators with conditionally-independent pixel synthesis. In Proc. CVPR, 2021.
- [5] A. Azulay and Y. Weiss. Why do deep convolutional networks generalize so poorly to small image transformations? Journal of Machine Learning Research, 20(184):1–25, 2019.
- [6] D. Bau, A. Andonian, A. Cui, Y. Park, A. Jahanian, A. Oliva, and A. Torralba. Paint by word. CoRR, abs/2103.10951, 2021.
- [7] D. Bau, S. Liu, T. Wang, J.-Y. Zhu, and A. Torralba. Rewriting a deep generative model. In Proc. ECCV, 2020.
- [8] D. Bau, J. Zhu, H. Strobelt, B. Zhou, J. B. Tenenbaum, W. T. Freeman, and A. Torralba. GAN dissection: Visualizing and understanding generative adversarial networks. In Proc. ICLR, 2019.
- [9] R. E. Blahut. Theory of remote image formation. Cambridge University Press, 2004.
- [10] T. Broad, F. F. Leymarie, and M. Grierson. Network bending: Expressive manipulation of deep generative models. In Proc. EvoMUSART, pages 20–36, 2021.
- [11] A. Brock, J. Donahue, and K. Simonyan. Large scale GAN training for high fidelity natural image synthesis. In Proc. ICLR, 2019.
- [12] A. Chaman and I. Dokmanić. Truly shift-invariant convolutional neural networks. In Proc. CVPR, 2021.
- [13] Y. Chen, S. Liu, and X. Wang. Learning continuous image representation with local implicit image function. In Proc. CVPR, 2021.
- [14] Y. Choi, Y. Uh, J. Yoo, and J.-W. Ha. StarGAN v2: Diverse image synthesis for multiple domains. In Proc. CVPR, 2020.
- [15] M. Chu, Y. Xie, J. Mayer, L. Leal-Taixé, and N. Thuerey. Learning temporal coherence via self-supervision for GAN-based video generation. ACM Trans. Graph., 39(4), 2020.
- [16] T. S. Cohen and M. Welling. Group equivariant convolutional networks. In Proc. ICML, 2016.
- [17] N. Dey, A. Chen, and S. Ghafurian. Group equivariant generative adversarial networks. In Proc. ICLR, 2021.
- [18] P. Esser, R. Rombach, and B. Ommer. Taming transformers for high-resolution image synthesis. In Proc. CVPR, 2021.
- [19] R. Gal, D. Cohen, A. Bermano, and D. Cohen-Or. SWAGAN: A style-based wavelet-driven generative model. CoRR, abs/2102.06108, 2021.
- [20] R. Ge, X. Feng, H. Pyla, K. Cameron, and W. Feng. Power measurement tutorial for the Green500 list. https://www.top500.org/green500/resources/tutorials/, Accessed March 1, 2020.
- [21] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio. Generative adversarial networks. In Proc. NIPS, 2014.
- [22] J. Gu, Y. Shen, and B. Zhou. Image processing using multi-code GAN prior. In Proc. CVPR, 2020.
- [23] Gwern. Making anime faces with stylegan. https://www.gwern.net/Faces#stylegan2-ext-modifications, Accessed June 4, 2021.
- [24] Z. Hao, A. Mallya, S. J. Belongie, and M. Liu. GANcraft: Unsupervised 3D neural rendering of minecraft worlds. CoRR, abs/2104.07659, 2021.
- [25] E. Härkönen, A. Hertzmann, J. Lehtinen, and S. Paris. GANSpace: Discovering interpretable GAN controls. In Proc. NeurIPS, 2020.
- [26] M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochreiter. GANs trained by a two time-scale update rule converge to a local Nash equilibrium. In Proc. NIPS, 2017.
- [27] K. Hill and J. White. Designed to deceive: Do these people look real to you? The New York Times, 11 2020.
- [28] M. A. Islam, S. Jia, and N. D. B. Bruce. How much position information do convolutional neural networks encode? In Proc. ICLR, 2020.
- [29] A. Jahanian, L. Chai, and P. Isola. On the "steerability" of generative adversarial networks. In Proc. ICLR, 2020.
- [30] J. F. Kaiser. Nonrecursive digital filter design using the I0-sinh window function. In Proc. 1974 IEEE International Symposium on Circuits & Systems, pages 20–23, 1974.
- [31] T. Karras, T. Aila, S. Laine, and J. Lehtinen. Progressive growing of GANs for improved quality, stability, and variation. In Proc. ICLR, 2018.
- [32] T. Karras, M. Aittala, J. Hellsten, S. Laine, J. Lehtinen, and T. Aila. Training generative adversarial networks with limited data. In Proc. NeurIPS, 2020.
- [33] T. Karras, S. Laine, and T. Aila. A style-based generator architecture for generative adversarial networks. In Proc. CVPR, 2018.
- [34] T. Karras, S. Laine, M. Aittala, J. Hellsten, J. Lehtinen, and T. Aila. Analyzing and improving the image quality of StyleGAN. In Proc. CVPR, 2020.
- [35] O. S. Kayhan and J. C. van Gemert. On translation invariance in CNNs: Convolutional layers can exploit absolute spatial location. In Proc. CVPR, 2020.
- [36] D. P. Kingma and J. Ba. Adam: A method for stochastic optimization. In Proc. ICLR, 2015.
- [37] M. Liu, T. Breuel, and J. Kautz. Unsupervised image-to-image translation networks. In Proc. NIPS, 2017.
- [38] M. Manfredi and Y. Wang. Shift equivariance in object detection. In Proc. ECCV 2020 Workshops, 2020.
- [39] S. Menon, A. Damian, S. Hu, N. Ravi, and C. Rudin. PULSE: Self-supervised photo upsampling via latent space exploration of generative models. In Proc. CVPR, 2020.
- [40] L. Mescheder, A. Geiger, and S. Nowozin. Which training methods for GANs do actually converge? In Proc. ICML, 2018.
- [41] A. V. Oppenheim and R. W. Schafer. Discrete-Time Signal Processing. Prentice Hall Press, USA, 3rd edition, 2009.
- [42] T. Park, M. Liu, T. Wang, and J. Zhu. Semantic image synthesis with spatially-adaptive normalization. In Proc. CVPR, 2019.
- [43] T. Park, J.-Y. Zhu, O. Wang, J. Lu, E. Shechtman, A. A. Efros, and R. Zhang. Swapping autoencoder for deep image manipulation. In Proc. NeurIPS, 2020.
- [44] G. Parmar, R. Zhang, and J. Zhu. On buggy resizing libraries and surprising subtleties in FID calculation. CoRR, abs/2104.11222, 2021.
- [45] A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, A. Desmaison, A. Kopf, E. Yang, Z. DeVito, M. Raison, A. Tejani, S. Chilamkurthy, B. Steiner, L. Fang, J. Bai, and S. Chintala. PyTorch: An imperative style, high-performance deep learning library. In Proc. NeurIPS, 2019.
- [46] O. Patashnik, Z. Wu, E. Shechtman, D. Cohen-Or, and D. Lischinski. StyleCLIP: Text-driven manipulation of StyleGAN imagery. CoRR, abs/2103.17249, 2021.
- [47] P. Ramachandran, B. Zoph, and Q. V. Le. Swish: a self-gated activation function. CoRR, abs/1710.05941, 2017.
- [48] A. Ramesh, M. Pavlov, G. Goh, S. Gray, C. Voss, A. Radford, M. Chen, and I. Sutskever. Zero-shot text-to-image generation. CoRR, abs/2102.12092, 2021.
- [49] E. Richardson, Y. Alaluf, O. Patashnik, Y. Nitzan, Y. Azar, S. Shapiro, and D. Cohen-Or. Encoding in style: A StyleGAN encoder for image-to-image translation. In Proc. CVPR, 2021.
- [50] M. Seymour. Canny AI: Imagine world leaders singing. fxguide, 4 2019.
- [51] C. E. Shannon. Communication in the presence of noise. Proc. Institute of Radio Engineers, 37(1):10–21, 1949.
- [52] Y. Shen and B. Zhou. Closed-form factorization of latent semantics in GANs. In CVPR, 2021.
- [53] V. Sitzmann, J. N. Martel, A. W. Bergman, D. B. Lindell, and G. Wetzstein. Implicit neural representations with periodic activation functions. In Proc. NeurIPS, 2020.
- [54] I. Skorokhodov, S. Ignatyev, and M. Elhoseiny. Adversarial generation of continuous images. In Proc. CVPR, 2021.
- [55] R. Suzuki, M. Koyama, T. Miyato, T. Yonetsuji, and H. Zhu. Spatially controllable image synthesis with internal representation collaging. CoRR, abs/1811.10153, 2019.
- [56] M. Tancik, P. P. Srinivasan, B. Mildenhall, S. Fridovich-Keil, N. Raghavan, U. Singhal, R. Ramamoorthi, J. T. Barron, and R. Ng. Fourier features let networks learn high frequency functions in low dimensional domains. In Proc. NeurIPS, 2020.
- [57] S. Tulyakov, M. Liu, X. Yang, and J. Kautz. MoCoGAN: Decomposing motion and content for video generation. In Proc. CVPR, 2018.
- [58] K. Turkowski. Filters for Common Resampling Tasks, pages 147–165. Academic Press Professional, Inc., USA, 1990.
- [59] C. Vasconcelos, H. Larochelle, V. Dumoulin, R. Romijnders, N. L. Roux, and R. Goroshin. Impact of aliasing on generalization in deep convolutional networks. In ICCV, 2021.
- [60] C. von der Malsburg. Self-organization of orientation sensitive cells in striate cortex. Biological Cybernetics, 14(2):85–100, 1973.
- [61] T. Wang, M. Liu, J. Zhu, A. Tao, J. Kautz, and B. Catanzaro. High-resolution image synthesis and semantic manipulation with conditional GANs. In Proc. CVPR, 2018.
- [62] M. Weiler and G. Cesa. General -equivariant steerable CNNs. In Proc. NeurIPS, 2019.
- [63] M. Weiler, F. A. Hamprecht, and M. Storath. Learning steerable filters for rotation equivariant CNNs. In Proc. CVPR, 2018.
- [64] D. Worrall and M. Welling. Deep scale-spaces: Equivariance over scale. In Proc. NeurIPS, 2019.
- [65] D. E. Worrall, S. J. Garbin, D. Turmukhambetov, and G. J. Brostow. Harmonic networks: Deep translation and rotation equivariance. In Proc. CVPR, 2017.
- [66] R. Xu, X. Wang, K. Chen, B. Zhou, and C. C. Loy. Positional encoding as spatial inductive bias in GANs. In Proc. CVPR, 2021.
- [67] N. Yu, V. Skripniuk, S. Abdelnabi, and M. Fritz. Artificial fingerprinting for generative models: Rooting deepfake attribution in training data. CoRR, abs/2007.08457, 2021.
- [68] H. Zhang, I. Goodfellow, D. Metaxas, and A. Odena. Self-attention generative adversarial networks. In Proc. ICML, 2019.
- [69] R. Zhang. Making convolutional networks shift-invariant again. In Proc. ICML, 2019.
- [70] J.-Y. Zhu, T. Park, P. Isola, and A. A. Efros. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proc. ICCV, 2017.
- [71] X. Zou, F. Xiao, Z. Yu, and Y. J. Lee. Delving deeper into anti-aliasing in ConvNets. In Proc. BMVC, 2020.
Appendices
Appendix A Additional results
Real images from the training set StyleGAN2, FID 3.79


StyleGAN3-T (ours), FID 3.67 StyleGAN3-R (ours), FID 3.66


Real images from the training set StyleGAN2, FID 18.98

StyleGAN3-T (ours), FID 18.75 StyleGAN3-R (ours), FID 18.75


Real images from the training set StyleGAN2, FID 4.62

StyleGAN3-T (ours), FID 4.04 StyleGAN3-R (ours), FID 4.40

Real images from the training set StyleGAN2, FID 5.03

StyleGAN3-T (ours), FID 4.32 StyleGAN3-R (ours), FID 4.57
Uncurated sets of samples for StyleGAN2 (baseline config b with Fourier features) and our alias-free generators StyleGAN3-T and StyleGAN3-R are shown in Figures 7 (FFHQ-U), 8 (MetFaces-U), 9 (AFHQv2), and 10 (Beaches). Truncation trick was not used when generating the images.
StyleGAN2 and our generators yield comparable FIDs in all of these datasets. Visual inspection did not reveal anything surprising in the first three datasets, but in Beaches our new generators seem to generate a somewhat reduced set of possible scene layouts properly. We suspect that this is related to the lack of noise inputs, which forces the generators to waste capacity for what is essentially random number generation [34]. Finding a way to reintroduce noise inputs without breaking equivariances is therefore an important avenue of future work.
The accompanying interpolation videos reveal major differences between StyleGAN2 and StyleGAN3-R. For example, in MetFaces much of details such as brushstrokes or cracked paint seems to be glued to the pixel coordinates in StyleGAN2, whereas with StyleGAN3 all details move together with the depicted model. The same is evident in AFHQv2 with the fur moving credibly in StyleGAN3 interpolations, while mostly sticking to the image coordinates in StyleGAN2. In Beaches we furthermore observe that StyleGAN2 tends to “fade in” details while retaining a mostly fixed viewing position, while StyleGAN3 creates plenty of apparent rotations and movement. The videos use hand-picked seeds to better showcase the relevant effects.
In a further test we created two example cinemagraphs that mimic small-scale head movement and facial animation in FFHQ. The geometric head motion was generated as a random latent space walk along hand-picked directions from GANSpace [25] and SeFa [52]. The changes in expression were realized by applying the “global directions” method of StyleCLIP [46], using the prompts “angry face”, “laughing face”, “kissing face”, “sad face”, “singing face”, and “surprised face”. The differences between StyleGAN2 and StyleGAN3 are again very prominent, with the former displaying jarring sticking of facial hair and skin texture, even under subtle movements.
The equivariance quality videos illustrate the practical relevance of the PSNR numbers in Figures 3 and 5 of the main paper. We observe that for EQ-T numbers over 50 dB indicate high-quality results, and for EQ-R 40 dB look good.
We also provide an animated version of the nonlinearity visualization in Figure 2.

In style mixing [34] two or more independently chosen latent codes are fed into different layers of the generator. Ideally all combinations would produce images that are not obviously broken, and furthermore, it would be desirable that specific layers end up controlling well-defined semantic aspects in the images. StyleGAN uses mixing regularization [34] during training to achieve these goals. We observe that mixing regularization continues to work similarly in StyleGAN3, but we also wanted to know whether it is truly necessary because the regularization is known to be detrimental for many complex and multi-modal datasets [23]. When we disable the regularization, obviously broken images remain rare, based on a visual inspection of a large number of images. The semantically meaningful controls are somewhat compromised, however, as Figure 11 shows.


(a) FFHQ-U at 256256 (b) FFHQ at 10241024 (c) MetFaces at 10241024
Figure 12 compares the convergence of our main configurations (config t and r) against the results of Karras et al. [34, 32]. The overall shape of the curves is similar; introducing translation and rotation equivariance in the generator does not appear to significantly alter the training dynamics.







Following recent works that address signal processing issues in GANs [4, 19], we show average power spectra of the generated and real images in Figure 13. The plots are computed from images that are whitened with the overall training dataset mean and standard deviation. Because FFT interprets the signal as periodic, we eliminate the sharp step edge across the image borders by windowing the pixel values prior to the transform. This eliminates the axis-aligned cross artifact which may obscure meaningful detail in the spectrum. We display the average 2D spectrum as a contour plot, which makes the orientation-dependent falloff apparent, and highlights detail like regularly spaced residuals of upsampling grids, and fixed noise patterns. We also plot 1D slices of the spectrum along the horizontal and diagonal angle without azimuthal integration, so as to not average out the detail. The code for reproducing these steps is included in the public release.
Appendix B Datasets
In this section, we describe the new datasets and list the licenses of all datasets.
B.1 FFHQ-U and MetFaces-U
We built unaligned variants of the existing FFHQ [33] and MetFaces [32] datasets. The originals are available at https://github.com/NVlabs/ffhq-dataset and https://github.com/NVlabs/metfaces-dataset, respectively. The datasets were rebuilt with a modification of the original procedure based on the original code, raw uncropped images, and facial landmark metadata. The code required to reproduce the modified datasets is included in the public release.
We use axis-aligned crop rectangles, and do not rotate them to match the orientation of the face. This retains the natural variation of camera and head tilt angles. Note that the images are still generally upright, i.e., never upside down or at angle. The scale of the rectangle is determined as before. For each image, the crop rectangle is randomly shifted from its original face-centered position, with the horizontal and vertical offset independently drawn from a normal distribution. The standard deviation is chosen as of the crop rectangle dimension. If the crop rectangle falls partially outside the original image boundaries, we keep drawing new random offsets until we find one that does not. This removes the need to pad the images with fictional mirrored content, and we explicitly disabled this feature of the original build script.
Aside from the exact image content, the number of images and other specifications match the original dataset exactly. While FFHQ-U contains identifiable images of persons, it does not introduce new images beyond those already in the original FFHQ.
B.2 AFHQv2
We used an updated version of the AFHQ dataset [14] where the resampling filtering has been improved. The original dataset suffers from pixel-level artifacts caused by inadequate downsampling filters [44]. This caused convergence problems with our models, as the sharp “stair-step” aliasing artifacts are difficult to reproduce without direct access to the pixel grid.
The dataset was rebuilt using the original uncropped images and crop rectangle metadata, using the PIL library implementation of Lanczos resampling as recommended by Parmar et al. [44]. In a minority of cases, the crop rectangles were modified to remove non-isotropic scaling and other unnecessary transformations. A small amount () of images were dropped for technical reasons, leaving a total of images. Aside from this, the specifications of the dataset match the original. We use all images of all the three classes (cats, dogs, and wild animals) as one training dataset.
B.3 Beaches
Beaches is a new dataset of photographs of beaches at resolution 512512. The training images were provided by Getty Images. Beaches is a proprietary dataset that we are licensed to use, but not to redistribute. We are therefore unable to release the full training data or pre-trained models for this dataset.
B.4 Licenses
The FFHQ dataset is available under Creative Commons BY-NC-SA 4.0 license by NVIDIA Corporation, and consist of images published by respective authors under Creative Commons BY 2.0, Creative Commons BY-NC 2.0, Public Domain Mark 1.0, Public Domain CC0 1.0, and U.S. Government Works license.
The MetFaces dataset is available under Creative Commons BY-NC 2.0 license by NVIDIA Corporation, and consists of images available under the Creative Commons Zero (CC0) license by the Metropolitan Museum of Art.
The original AFHQ dataset is available at https://github.com/clovaai/stargan-v2 under Creative Commons BY-NC 4.0 license by NAVER Corporation.
Appendix C Filter details
In this section, we review basic FIR filter design methodology and detail the recipe used to construct the upsampling and downsampling filters in our generator. We start with simple Kaiser filters in one dimension, discussing parameter selection and the necessary modifications needed for upsampling and downsampling. We then proceed to extend the filters to two dimensions and conclude by detailing the alternative filters evaluated in Figure 5, right. Our definitions are consistent with standard signal processing literature (e.g., Oppenheim [41]) as well as widely used software packages (e.g., scipy.signal.firwin).
C.1 Kaiser low-pass filters
In one dimension, the ideal continuous-time low-pass filter with cutoff is given by , where . The ideal filter has infinite attenuation in the stopband, i.e., it completely eliminates all frequencies above . However, its impulse response is also infinite, which makes it impractical for three reasons: implementation efficiency, border artifacts, and ringing caused by long-distance interactions. The most common way to overcome these issues is to limit the spatial extent of the filter using the window method [41]:
| (4) |
where is a window function and is the resulting practical approximation of . Different window functions represent different tradeoffs between the frequency response and spatial extent; the smaller the spatial extent, the weaker the attenuation. In this paper we use the Kaiser window [30], also known as the Kaiser–Bessel window, that provides explicit control over this tradeoff. The Kaiser window is defined as
| (5) |
where is the desired spatial extent, is a free parameter that controls the shape of the window, and is the zeroth-order modified Bessel function of the first kind. Note that the window has discontinuities at ; the value is strictly positive at but zero at .
When operating on discretely sampled signals, it is necessary to discretize the filter as well:
| (6) |
where is the discretized version of and is the sampling rate. The filter is defined at discrete spatial locations, i.e., taps, located units apart and placed symmetrically around zero. Given the values of and , the spatial extent can be expressed as . An odd value of results in a zero-phase filter that preserves the original sample locations, whereas an even value shifts the sample locations by units.
The filters considered in this paper are approximately normalized by construction, i.e., . Nevertheless, we have found it beneficial to explicitly normalize them after discretization. In other words, we strictly enforce by scaling the filter taps to reduce the risk of introducing cumulative scaling errors when the signal is passed through several consecutive layers.
C.2 Selecting window parameters
Kaiser [30] provides convenient empirical formulas to connect the parameters of to the properties of . Given the number of taps and the desired transition band width, the maximum attenuation achievable with is approximated by
| (7) |
where is the attenuation measured in decibels and is the width of the transition band expressed as a fraction of . We choose to define the transition band using half-width , which gives . Given the value of , the optimal choice for the shape parameter is then approximated [30] by
| (8) |
This leaves us with two free parameters: controls the spatial extent while controls the transition band. The choice of these parameters directly influences the resulting attenuation; increasing either parameter yields a higher value for .
C.3 Upsampling and downsampling
When upsampling a signal, i.e., , we are concerned not only the with input sampling rate , but also with the output sampling rate . With an integer upsampling factor , we can think of the upsampling operation as consisting of two steps: we first increase the sampling rate to by interleaving zeros between each input sample by and then low-pass filter the resulting signal to eliminate the alias frequencies above . In order to keep the signal magnitude unchanged, we must also scale the result by with one-dimensional signals, or by with two-dimensional signals. Since the filter now operates under instead of , we must adjust its parameters accordingly:
| (9) |
which gives us the final upsampling filter
| (10) |
Multiplying the number of taps by keeps the spatial extent of the filter unchanged with respect to the input samples, and it also compensates for the reduced attenuation from . Note that if the upsampling factor is even, will be even as well, meaning that shifts the sample locations by . This is the desired behavior — if we consider sample to represent the continuous interval in the input signal, the same interval will be represented by consecutive samples in the output signal. Using a zero-phase upsampling filter, i.e., an odd value for , would break this symmetry, leading to inconsistent behavior with respect to the boundaries. Note that our symmetric interpretation is common in many computer graphics APIs, such as OpenGL, and it is also reflected in our definition of the Dirac comb in Section 2.
Upsampling and downsampling are adjoint operations with respect to each other, disregarding the scaling of the signal magnitude. This means that the above definitions are readily applicable to downsampling as well; to downsample a signal by factor , we first filter it by and then discard the last samples within each group of consecutive samples. The interpretation of all filter parameters, as well as the sample locations, is analogous to the upsampling case.
C.4 Two-dimensional filters
Any one-dimensional filter, including , can be trivially extended to two dimensions by defining the corresponding separable filter
| (11) |
where . has the same cutoff as along the coordinate axes, i.e., and , and its frequency response forms a square shape over the 2D plane, implying that the cutoff frequency along the diagonal is . In practice, a separable filter can be implemented efficiently by first filtering each row of the two-dimensional signal independently with and then doing the same for each column. This makes an ideal choice for all upsampling filters in our generator, as well as the downsampling filters in configs a–t (Figure 3, left).
The fact that the spectrum of is not radially symmetric, i.e., , is problematic considering config r. If we rotate the input feature maps of a given layer, their frequency content will rotate as well. To enforce rotation equivariant behavior, we must ensure that the effective cutoff frequencies remain unchanged by this. The ideal radially symmetric low-pass filter [9] is given by . The function, also known as besinc, sombrero function, or Airy disk, is defined as , where is the first order Bessel function of the first kind. Using the same windowing scheme as before, we define the corresponding practical filter as
| (12) |
Note that even though is radially symmetric, we still treat the window function as separable in order to retain its spectral properties. In config r, we perform all downsampling operations using , except for the last two critically sampled layers where we revert to .
C.5 Alternative filters
In Figure 5, right, we compare the effectiveness of Kaiser filters against two alternatives: Lanczos and Gaussian. These filters are typically defined using prototypical filter kernels and , respectively:
| (13) | ||||
| (14) |
where is the spatial extent of the Lanczos kernel, typically set to 2 or 3, and is the standard deviation of the Gaussian kernel. In Figure 5 of the main paper we set and ; we tested several different values and found these choices to work reasonably well.
The main shortcoming of the prototypical kernels is that they do not provide an explicit way to control the cutoff frequency. In order to enable apples-to-apples comparison, we assume that the kernels have an implicit cutoff frequency at 0.5 and scale their impulse responses to account for the varying :
| (15) |
We limit the computational complexity of the Gaussian filter by enforcing when , with respect to the input sampling rate in the upsampling case. In practice, is already very close to zero in this range, so the effect of this approximation is negligible. Finally, we extend the filters to two dimensions by defining the corresponding separable filters:
| (16) |
Note that is radially symmetric by construction, which makes it ideal for rotation equivariance. , however, has no widely accepted radially symmetric counterpart, so we simply use the same separable filter in config r as well.
Appendix D Custom CUDA kernel for filtered nonlinearity
Implementing the upsample-nonlinearity-downsample sequence is inefficient using the standard primitives available in modern deep learning frameworks. The intermediate feature maps have to be transferred between on-chip and off-chip GPU memory multiple times and retained for the backward pass. This is especially costly because the intermediate steps operate on upsampled, high-resolution data. To overcome this, we implement the entire sequence as a single operation using a custom CUDA kernel. This improves training performance by approximately an order of magnitude thanks to reduced memory traffic, and also decreases GPU memory usage significantly.
The combined kernel consists of four phases: input, upsampling, nonlinearity, and downsampling. The computation is parallelized by subdividing the output feature maps into non-overlapping tiles, and computing one output tile per CUDA thread block. First, in input phase, the corresponding input region is read into on-chip shared memory of the thread block. Note that the input regions for neighboring output tiles will overlap spatially due to the spatial extent of filters.
The execution of up-/downsampling phases depends on whether the corresponding filters are separable or not. For a separable filter, we perform vertical and horizontal 1D convolutions sequentially, whereas a non-separable filter requires a single 2D convolution. All these convolutions and the nonlinearity operate in on-chip shared memory, and only the final output of the downsampling phase is written to off-chip GPU memory.
D.1 Gradient computation
To compute gradients of the combined operation, they need to propagate through each of the phases in reverse order. Fortunately, the combined upsample-nonlinearity-downsample operation is mostly self-adjoint with proper changes in parameters, e.g., swapping the up-/downsampling factors and the associated filters. The only problematic part is the nonlinearity that is performed in the upsampled resolution. A naïve but general solution would be to store the intermediate high-resolution input to the nonlinearity, but the memory consumption would be infeasible for training large models.
Our kernel is specialized to use leaky ReLU as the nonlinearity, which offers a straightforward way to conserve memory: to propagate gradients, it is sufficient to know whether the corresponding input value to nonlinearity was positive or negative. When using 16-bit floating-point datatypes, there is an additional complication because the outputs of the nonlinearity need to be clamped [32], and when this occurs, the corresponding gradients must be zero. Therefore, in the forward pass we store two bits of auxiliary information per value to cover the three possible cases: positive, negative, or clamped. In the backward pass, reading these bits is sufficient for correct gradient computation — no other information from the forward pass is needed.
D.2 Optimizations for common upsampling factors
Let us consider one-dimensional 2 upsampling where the input is (virtually) interleaved with zeros and convolved with an -tap filter where (cf. Equation 9). There are nonzero input values under the -tap kernel, so if each output pixel is computed separately, the convolution requires multiply-add operations per pixel and equally many shared memory load instructions, for a total of instructions per output pixel.333Input of the upsampling is stored in shared memory, but the filter weights can be stored in CUDA constant memory where they can be accessed without a separate load instruction. However, note that the computation of two neighboring output pixels accesses only input pixels in total. By computing two output pixels at a time and avoiding redundant shared memory load instructions, we obtain an average cost of instructions per pixel — close to 25% savings. For 4 upsampling, we can similarly reduce the instruction count by up to 37.5% by computing four output pixels at a time. We apply these optimizations in 2 and 4 upsampling for both separable and non-separable filters.
| upsample 2 | upsample 4 | upsample 2 | ||||||||||
| downsample 2 | downsample 2 | downsample 4 | ||||||||||
| Sep. up | yes | yes | no | no | yes | yes | no | no | yes | yes | no | no |
| Sep. down | yes | no | yes | no | yes | no | yes | no | yes | no | yes | no |
| PyTorch (ms) | 7.88 | 12.40 | 12.68 | 17.12 | 10.07 | 31.51 | 14.96 | 36.33 | 39.35 | 56.73 | 125.83 | 143.15 |
| Ours (ms) | 0.42 | 0.59 | 0.66 | 0.92 | 0.49 | 0.84 | 0.80 | 1.01 | 1.20 | 1.89 | 3.04 | 3.66 |
| Speedup | 19 | 21 | 19 | 19 | 21 | 38 | 19 | 36 | 33 | 30 | 41 | 39 |
Figure 14 benchmarks the performance of our kernel with various up-/downsampling factors and with separable and non-separable filters. In network layers that keep the sampling rate fixed, both factors are 2, whereas layers that increase the sampling rate by a factor of two, 4 upsampling is combined with 2 downsampling. The remaining combination of 2 upsampling and 4 downsampling is needed when computing gradients of the latter case. The speedup over native PyTorch operations varies between 20–40, which yields an overall training speedup of approximately 10.
Appendix E Equivariance metrics
In this section, we describe our equivariance metrics, EQ-T and EQ-R, in detail. We also present additional results using an alternative translation metric, EQ-Tfrac, based on fractional sub-pixel translation.
We express each of our metrics as the peak signal-to-noise ratio (PSNR) between two sets of images, measured in decibels (dB). PSNR is a commonly used metric in image restoration literature. In the typical setting we have two signals, reference and its noisy approximation , defined over discrete domain — usually a two-dimensional pixel grid. The PSNR between and is then defined via the mean squared error (MSE):
| (17) | ||||
| (18) |
where is the average squared difference between matching elements of and . is the expected dynamic range of the reference signal, i.e., . The dynamic range is usually considered to be a global constant, e.g., the range of valid RGB values, as opposed to being dependent on the content of . In our case, and represent desired and actual outputs of the synthesis network, respectively, with a dynamic range of . This implies that . High PSNR values indicate that is close to ; in the extreme case, where , we have dB.
Since we are interested in sets of images, we use a slightly extended definition for MSE that allows and to be defined over an arbitrary, potentially uncountable domain:
| (19) |
E.1 Integer translation
The goal of our integer translation metric, EQ-T, is to measure how closely, on average, the output the synthesis network matches a translated reference image when we translate the input of . In other words,
| (23) |
where is a random intermediate latent code produced by the mapping network, is a random translation offset, enumerates pixel locations in the mutually valid region , is the color channel, and represents the input Fourier features. For integer translations, we sample the translation offsets and from , where is the width of the image in pixels.
In practice, we estimate the expectation in Equation 23 as an average over 50,000 random samples of . For given and , we generate the reference image by running the synthesis network and translating the resulting image by pixels (operator ). We then obtain the approximate result image by translating the input Fourier features by the corresponding amount (operator ), as discussed in Appendix F.1, and running the synthesis network again. The mutually valid region of (translated by ) and (translated by ) is given by
| (24) |
E.2 Fractional translation
| Configuration | FID | EQ-T | EQ-Tfrac | |
| a | StyleGAN2 | 5.14 | – | – |
| b | + Fourier features | 4.79 | 16.23 | 16.28 |
| c | + No noise inputs | 4.54 | 15.81 | 15.84 |
| d | + Simplified generator | 5.21 | 19.47 | 19.57 |
| e | + Boundaries & upsampling | 6.02 | 24.62 | 24.70 |
| f | + Filtered nonlinearities | 6.35 | 30.60 | 30.68 |
| g | + Non-critical sampling | 4.78 | 43.90 | 42.24 |
| h | + Transformed Fourier features | 4.64 | 45.20 | 42.78 |
| t | + Flexible layers (StyleGAN3-T) | 4.62 | 63.01 | 46.40 |
| r | + Rotation equiv. (StyleGAN3-R) | 4.50 | 66.65 | 45.92 |
| Parameter | FID | EQ-T | EQ-Tfrac | |
|---|---|---|---|---|
| Filter size | 4.72 | 57.49 | 44.65 | |
| * | Filter size | 4.50 | 66.65 | 45.92 |
| Filter size | 4.66 | 65.57 | 46.57 | |
| Upsampling | 4.38 | 39.96 | 37.55 | |
| * | Upsampling | 4.50 | 66.65 | 45.92 |
| Upsampling | 4.57 | 74.21 | 46.81 | |
| Stopband | 4.62 | 51.10 | 44.46 | |
| * | Stopband | 4.50 | 66.65 | 45.92 |
| Stopband | 4.68 | 73.13 | 46.27 |
Our translation equivariance metric has the nice property that, for a perfectly equivariant generator, the value of EQ-T converges to dB when the number of samples tends to infinity. However, this comes at the cost of completely ignoring subpixel effects. In fact, it is easy to imagine a generator that is perfectly equivariant to integer translation but fails with subpixel translation; in principle, this is true for any generator whose output is not properly bandlimited, including, e.g., implicit coordinate-based MLPs [4].
To verify that our generators are able to handle subpixel translation, we define an alternative translation equivariance metric, EQ-Tfrac, where the translation offsets and are sampled from a continuous distribution . While the continuous operator readily supports this new definition with fractional offsets, extending the discrete is slightly more tricky.
In practice, we define via standard Lanczos resampling, by filtering the image produced by using the prototypical Lanczos filter (Equation 15) with , evaluated at integer tap locations offset by . We explicitly normalize the resulting discretized filter to enforce the partition of unity property. We also shrink the mutually valid region to account for the spatial extent by redefining
| (25) |
Figure 15 compares the results of the two metrics, EQ-T and EQ-Tfrac, using the same training configurations as Figure 3 in the main paper. The metrics agree reasonably well up until 40 dB, after which the fractional metric starts to saturate; it consistently fails to rise above 50 dB in our tests. This is due to the fact that the definition of subpixel translation is inherently ambiguous. The choice of the resampling filter represents a tradeoff between aliasing, ringing, and retention of high frequencies; there is no reason to assume that the generator would necessarily have to make the same tradeoff as the metric. Based on the results, we conclude that our configs g–r are essentially perfectly equivariant to subpixel translation within the limits of Lanczos resampling’s accuracy. However, due to its inherent limitations, we refrain from choosing EQ-Tfrac as our primary metric.
E.3 Rotation
Measuring equivariance with respect to arbitrary rotations has the same fundamental limitation as our EQ-Tfrac metric: the resampling operation is inherently ambiguous, so we cannot except the results to be perfectly accurate beyond 40 dB. Arbitrary rotations also have the additional complication that the bandlimit of a discretely sampled image is not radially symmetric.
Consider rotating the continuous representation of a discretely sampled image by 45∘. The original frequency content of the image is constrained within the rectangular bandlimit . The frequency content of the rotated image, however, forms a diamond shape that extends all the way to along the main axes but only to along the diagonals. In other words, it simultaneously has too much frequency content, but also too little. This has two implications. First, in order to obtain a valid discretized result image, we have to low-pass filter the image both before and after the rotation to completely eliminate aliasing. Second, even if we are successful in eliminating the aliasing, the rotated image will still lack the highest representable diagonal frequencies. The second point further implies that when computing PSNR, our reference image will inevitably lack some frequencies that are present in the output of . To obtain the correct result, we must eliminate these extraneous frequencies — without modifying the output image in any other way.
Based on the above reasoning, we define our EQ-R metric as follows:
| (29) |
where the random rotation angle is drawn from and operator corresponds to continuous rotation of the input Fourier features by with respect to the center of the canvas . corresponds to high-quality rotation of the reference image, and represents a pseudo-rotation operator that modifies the frequency content of the image as if it had undergone — but without actually rotating it.
The ideal rotation operator is easily defined under our theoretical framework presented in Section 2.1:
| (30) |
In other words, we first convolve the discretely sampled input image with to obtain the corresponding continuous representation. We then rotate this continuous representation using , bandlimit the result by convolving with , and finally extract the corresponding discrete representation by multiplying with . To reduce notational clutter, we omit the subscripts denoting the sampling rate . We can swap the order of the rotation and a convolution in the above formula by rotating the kernel in the opposite direction to compensate:
| (31) |
where represents an ideal “rotation filter” that bandlimits the signal with respect to both the input and the output. Its spectrum is the eight-sided polygonal intersection of the original and the rotated rectangle.
In order to obtain a practical approximation , we must replace with an approximate filter that has finite support. Given such a filter, we get . In practice, we implement this operation using two additional approximations. First, we approximate by an upsampling operation to a higher temporary resolution, using as the upsampling filter and . Second, we approximate by performing a set of bilinear lookups from the temporary high-resolution image.
To obtain , we again utilize the standard Lanczos window with :
| (32) |
where we apply the same rotation-convolution to both the filter and the window function. corresponds the canonical separable Lanczos window, similar to the one used in Equation 15:
| (33) |
We can now define the pseudo-rotation operator as a simple convolution with another filter that resembles :
| (34) |
where the discrete version is obtained from using Equation 6.
Finally, we define the valid region the same way as in Appendix E.2: the set of pixels for which both filter footprints fall within the bounds of the corresponding original images.
Appendix F Implementation details
We implemented our alias-free generator on top of the official PyTorch implementation of StyleGAN2-ADA, available at https://github.com/NVlabs/stylegan2-ada-pytorch. We kept most of the details unchanged, including discriminator architecture [34], weight demodulation [34], equalized learning rate for all trainable parameters [31], minibatch standard deviation layer at the end of the discriminator [31], exponential moving average of generator weights [31], mixed-precision FP16/FP32 training [32], non-saturating logistic loss [21], regularization [40], lazy regularization [34], and Adam optimizer [36] with , , and .
We ran all experiments on NVIDIA DGX-1 with 8 Tesla V100 GPUs using PyTorch 1.7.1, CUDA 11.0, and cuDNN 8.0.5. We computed FID between 50k generated images and all training images using the official pre-trained Inception network, available at http://download.tensorflow.org/models/image/imagenet/inception-2015-12-05.tgz
Our implementation and pre-trained models are available at https://github.com/NVlabs/stylegan3
F.1 Generator architecture
Normalization (configs d–r)
We have observed that eliminating the output skip connections in StyleGAN2 [34] results in uncontrolled drift of signal magnitudes over the generator layers. This does not necessarily lead to lower-quality results, but it generally increases the amount of random variation between training runs and may occasionally lead to numerical issues with mixed-precision training. We eliminate the drift by tracking a long-term exponential moving average of the input signal magnitude on each layer and normalizing the feature maps accordingly. We update the moving average once per training iteration, based on the mean of squares over the entire input tensor, and freeze its value after training. We initialize the moving average to 1 and decay it at a constant rate, resulting in 50% decay per 20k real images shown to the discriminator. With this explicit normalization in place, we have found it beneficial to slightly adjust the dynamic range of the output RGB colors. StyleGAN2 uses and to represent black and white, respectively; we change these values to and starting from config d and, for consistency with the original generator, divide the color channels by 4 afterwards.
Transformed Fourier features (configs h–r)
We enable the orientation of the input features to vary on a per-image basis by introducing an additional affine layer (Figure 4b) and applying a geometric transformation based on its output. The affine layer produces a four-dimensional vector based on . We initialize its weights so that at the beginning, but allow them to change freely over the course of training. To interpret as a geometric transformation, we first normalize its value based on the first two components, i.e., . This makes the transformation independent of the magnitude of , similar to the weight modulation and demodulation [34] on the other layers. We then interpret the first two components as rotation around the center of the canvas , with the rotation angle defined by and . Finally, we interpret the remaining two components as translation by units, so that the translation is performed after the rotation. In practice, we implement the resulting geometric transformation by modifying the phases and two-dimensional frequencies of the Fourier features, which is equivalent to applying the same transformation to the continuous representation of analytically.
Flexible layer specifications
In configs t and r, we define the per-layer filter parameters (Figure 4c) as follows. The cutoff frequency and the minimum acceptable stopband frequency obey geometric progression until the first critically sampled layer:
| (35) |
where is the total number of layers, is the number of critically sampled layers at the end, corresponds to the frequency content of the input Fourier features, and is defined by the output resolution. and are free parameters; we use and in most of our tests. Given the values of and , the sampling rate and transition band half-width are then determined by
| (36) |
The sampling rate is rounded up to the nearest power of two that satisfies , but it is not allowed to exceed the output resolution. The transition band half-width is selected to satisfy either or , whichever yields a higher value.
We consider to represent the output frequency content of layer , for , whereas the input is represented by . Thus, we construct the corresponding upsampling filter according to and and the downsampling filter according to and . The nonlinearity is evaluated at a temporary sampling rate , where is the upsampling parameter discussed in Section 3.2 that we set to 2 in most of our tests.
F.2 Hyperparameters and training configurations
| Parameter | Datasets (Figure 5, left) | Ablations at 256256 | ||||
|---|---|---|---|---|---|---|
| Config | b | t | r | a–c | d–t | r |
| Batch size | 32 | 32 | 32 | 64 | 64 | 64 |
| Moving average | 10k | 10k | 10k | 20k | 20k | 20k |
| Mapping net depth | 8 | 2 | 2 | 8 | 2 | 2 |
| Minibatch stddev | 4 | 4 | 4 | 8 | 4 | 4 |
| G layers | 15/17 | 14 | 14 | 13 | 14 | 14 |
| G capacity: | ||||||
| G capacity: | 512 | 512 | 1024 | 512 | 512 | 1024 |
| G learning rate | 0.0020 | 0.0025 | 0.0025 | 0.0025 | 0.0025 | 0.0025 |
| D learning rate | 0.0020 | 0.0020 | 0.0020 | 0.0025 | 0.0025 | 0.0025 |
| R1 regularization | b | t | r | |
|---|---|---|---|---|
| FFHQ-U | 2562 | 1.0 | 1.0 | 1.0 |
| FFHQ-U | 10242 | 10.0 | 32.8 | 32.8 |
| FFHQ | 10242 | 10.0 | 32.8 | 32.8 |
| MetFaces-U | 10242 | 10.0 | 16.4 | 6.6 |
| MetFaces | 10242 | 5.0 | 6.6 | 3.3 |
| AFHQv2 | 5122 | 5.0 | 8.2 | 16.4 |
| Beaches | 5122 | 2.0 | 4.1 | 12.3 |
We used 8 GPUs for all our training runs and continued the training until the discriminator had seen a total of 25M real images when training from scratch, or 5M images when using transfer learning. Figure 16 shows the hyperparameters used in each experiment. We performed the baseline runs (configs a–c) using the corresponding standard configurations: StyleGAN2 config F [34] for the high-resolution datasets in Figure 5, left, and ADA 256256 baseline config [32] for the ablations in Figure 3 and Figure 5, right.
Many of our hyperparameters, including discriminator capacity and learning rate, batch size, and generator moving average decay, are inherited directly from the baseline configurations, and kept unchanged in all experiments. In configs c and d, we disable noise inputs [33], path length regularization [34], and mixing regularization [33]. In config d, we also decrease the mapping network depth to 2 and set the minibatch standard deviation group size to 4 as recommended in the StyleGAN2-ADA documentation. The introduction of explicit normalization in config d allows us to use the same generator learning rate, 0.0025, for all output resolutions. In Figure 5, right, we show results for path length regularization with weight 0.5 and mixing regularization with probability 0.5.
Augmentation
Since our datasets are horizontally symmetric in nature, we enable dataset -flip augmentation in all our experiments. To prevent the discriminator from overfitting, we enable adaptive discriminator augmentation (ADA) [32] with default settings for MetFaces, MetFaces-U, AFHQv2, and Beaches, but disable it for FFHQ and FFHQ-U. Furthermore, we train MetFaces and MetFaces-U using transfer learning from the corresponding FFHQ or FFHQ-U snapshot with the lowest FID, similar to Karras et al. [32], but start the training from scratch in all other experiments.
Generator capacity
StyleGAN2 defines the number of feature maps on a given layer to be inversely proportional to its resolution, i.e., , where is the output resolution of layer . Parameters and control the overall capacity of the generator; our baseline configurations use and or depending on the output resolution. Since StyleGAN2 can be considered to employ critical sampling on all layers, i.e., , we can equally well define the number of feature maps as . These two definitions are equivalent for configs a–f, but in configs g–r we explicitly set , which necessitates using the latter definition. In config r, we double the value of both and to compensate for the reduced capacity of the 11 convolutions. In Figure 5, right, we sweep the capacity by multiplying both parameters by 0.5, 1.0, and 2.0.
R1 regularization
The optimal choice for the regularization weight is highly dependent on the dataset, necessitating a grid search [34, 32]. For the baseline config b, we tested and selected the value that gave the best FID for each dataset. For our configs t and r, we followed the recommendation of Karras et al. [32] to define , where is the number of output pixels and is the batch size, and performed a grid search over . For the low-resolution ablations, we chose to use a fixed value for simplicity. The resulting values of are shown in Figure 16, right.
Training of config r
In this configuration, we blur all images the discriminator sees in the beginning of the training. This Gaussian blur is executed just before the ADA augmentation. We start with pixels, which we ramp to zero over the first 200k images. This prevents the discriminator from focusing too heavily on high frequencies early on. It seems that in this configuration the generator sometimes learns to produce high frequencies with a small delay, allowing the discriminator to trivially tell training data from the generated images without providing useful feedback to the generator. As such, config r is prone to random training failures in the beginning of the training without this trick. The other configurations do not have this issue.
F.3 G-CNN comparison
In Figure 5, bottom, we compare our config r with config t extended with -symmetric group convolutions [16, 17]. symmetry makes the generator equivariant to 0∘, 90∘, 180∘, and 270∘ rotations, but not to arbitrary rotation angles. In practice, we implement the group convolutions by extending all intermediate activation tensors in the synthesis network with an additional group dimension of size 4 and introducing appropriate redundancy in the convolution weights. We keep the input layer unchanged and introduce the group dimension by replicating each element of four times. Similarly, we eliminate the group dimension after the last layer by computing an average of the four elements. -symmetric group convolutions have 4 as many trainable parameters as the corresponding regular convolutions. To enable an apples-to-apples comparison, we compensate for this increase by halving the values of and , which brings the number of parameters back to the original level.
Appendix G Energy consumption
| Item | Number of | GPU years | Electricity |
| training runs | (Volta) | (MWh) | |
| Early exploration | 233 | 18.02 | 42.45 |
| Project exploration | 1207 | 48.93 | 118.13 |
| Setting up ablations | 297 | 13.30 | 32.48 |
| Per-dataset tuning | 63 | 4.54 | 13.28 |
| Producing results in the paper | 53 | 5.26 | 14.35 |
| StyleGAN3-R at 10241024 | 1 | 0.30 | 0.87 |
| Other runs in the dataset table | 17 | 2.35 | 6.88 |
| Ablation tables | 35 | 2.61 | 6.60 |
| Results intentionally left out | 23 | 1.72 | 3.93 |
| Total | 1876 | 91.77 | 224.62 |
Computation is an essential resource in machine learning projects: its availability and cost, as well as the associated energy consumption, are key factors in both choosing research directions and practical adoption. We provide a detailed breakdown for our entire project in Table 17 in terms of both GPU time and electricity consumption. We report expended computational effort as single-GPU years (Volta class GPU). We used a varying number of NVIDIA DGX-1s for different stages of the project, and converted each run to single-GPU equivalents by simply scaling by the number of GPUs used.
We followed the Green500 power measurements guidelines [20]. The entire project consumed approximately 225 megawatt hours (MWh) of electricity. Approximately 70% of it was used for exploratory runs, where we gradually built the new configurations; first in an unstructured manner and then specifically ironing out the new StyleGAN3-T and StyleGAN3-R configurations. Setting up the intermediate configurations between StyleGAN2 and our generators, as well as, the key parameter ablations was also quite expensive at 15%. Training a single instance of StyleGAN3-R at 10241024 is only slightly more expensive (0.9MWh) than training StyleGAN2 (0.7MWh) [34].