Algorithmic Regularization in Model-free Overparametrized Asymmetric Matrix Factorization
Abstract
We study the asymmetric matrix factorization problem under a natural nonconvex formulation with arbitrary overparametrization. The model-free setting is considered, with minimal assumption on the rank or singular values of the observed matrix, where the global optima provably overfit. We show that vanilla gradient descent with small random initialization sequentially recovers the principal components of the observed matrix. Consequently, when equipped with proper early stopping, gradient descent produces the best low-rank approximation of the observed matrix without explicit regularization. We provide a sharp characterization of the relationship between the approximation error, iteration complexity, initialization size and stepsize. Our complexity bound is almost dimension-free and depends logarithmically on the approximation error, with significantly more lenient requirements on the stepsize and initialization compared to prior work. Our theoretical results provide accurate prediction for the behavior gradient descent, showing good agreement with numerical experiments.
1 Introduction
Let be an arbitrary given matrix. In this paper, we study the following nonconvex objective function for asymmetric matrix factorization
| () |
and the associated vanilla gradient descent dynamic:
| (-) |
where are the factor variables, is a user-specified rank parameter, is the stepsize, and
In many statistical and machine learning settings [FYY20], the observed matrix takes the form where is an unknown low-rank matrix to be estimated, and is the additive error/noise. Gradient descent applied to the objective () is a natural approach for computing an estimate of . Such an estimate can in turn be used as an approximate solution in more complicated nonconvex matrix estimation problems, such as matrix sensing [RFP10], matrix completion [CT10] and even nonlinear problems like the Single Index Model [FYY20]. In fact, the gradient descent procedure (-) is often used, explicitly or implicitly, as a subroutine in more sophisticated algorithms for these problems. As such, characterizing the dynamics of (-) provides deep intuition for more general problems and is considered an important first step for understanding various aspects of (linear) neural networks [DHL18, YD21].
Despite the apparent simplicity of the dynamic (-), our understanding of its behavior remains limited, especially for general settings of and . Results in existing work often only apply to symmetric, exactly low-rank matrices or specific choices of . Many of them impose strong assumption on the initialization , only provides asymptotic analysis, or has order-wise suboptimal error and iteration complexity bounds. We discuss these existing results and the associated challenges in greater details later.
Of particular interest is the overparametrization regime, which is common in modern machine learning paradigms [HCB+19, KBZ+20, TL19]. In the context of the objective (), overparametrization means choosing the rank parameter to be larger than what is statistically necessary, e.g., rank. Doing so, however, necessarily leads to overfitting in general. Indeed, with , any global optimum of () is simply (a full factorization of) itself and overfits the noise/error in , therefore failing to provide a useful estimate for . Moreover, as can be seen from the numerical results in Figure 1, gradient descent (-) with random initialization asymptotically converges to such a global minimum, with a vanishing training error (dashed lines) but a large test error (solid lines).
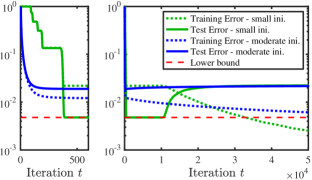
A careful inspection of Figure 1, however, reveals an interesting phenomenon: gradient descent with small random initialization achieves a small (and near optimal) test error before it eventually overfits; on the other hand, this behavior is not observed with moderate initialization. We note that similar phenomena have been empirically observed in many other statistical and machine learning problems, where vanilla gradient descent coupled with small random initialization (SRI) and early stopping (ES) has good generalization performance, even with overparametrization [WGL+20, GMMM20, Pre98, WLZ+21, LMZ18, SS21]. This observation motivates us to theoretically characterize, both qualitatively and quantitatively, the behavior of gradient descent (-) and the algorithmic regularization effect of SRI and ES.
Our results
We relate the dynamics of (-) to the best low-rank approximations of , defined as for Our main results, Theorems 4.1 and 4.2, establish the following:
The iteration (-) with SRI sequentially approaches the principal components of , and proper ES produces the best low-rank approximation of .
Specifically, we show that for each , there exists a (range of) stopping time such that (-) terminated at iteration produces an approximate . Moreover, we provide a sharp characterization of the scaling relationship between the approximation error, iteration complexity, initialization size and stepsize. This quantitative characterization agrees well with numerical experiments.
It is known that under many statistical models where is an observed noisy version of some structured matrix , the matrix with an appropriate is a statistically optimal estimator of [Cha15, FYY20]. Our results thus imply that gradient descent with SRI and ES learns such an optimal estimate, even with overparametrization and no explicit regularization. In fact, our results are more general, applicable to any observed matrix and not tied to the existence of a ground truth .
We emphasize that we do not claim that vanilla gradient descent is a more efficient way for computing for a given than standard numerical procedures (e.g., via singular value decomposition). Rather, our focus is to show, rigorously and quantitatively, that overparametrized gradient descent, a common and fundamental algorithmic paradigm, has an implicit regularization effect characterized by a deep connection to the computation of best low-rank approximation.
Analysis and challenges
Our analysis elucidates the mechanism that gives rise to the algorithmic regularization effect of small initialization and early stopping: starting from a small initial , the singular values of the iterate approach those of at geometrically different rates, hence approximates sequentially (we elaborate in Section 3). While the intuition is simple, a rigorous and sharp analysis is highly non-trivial, due to the following challenges:
(i) Model-free setting. Most existing work assumes that is (exactly or approximately) low-rank with a sufficiently large singular value gap between the -th and -th singular values of [LMZ18, ZKHC21, YD21, FYY20, SS21]. We allow for an arbitrary nonzero and characterize its impact on the stopping time and final error. In this setting, the “signal” may have magnitude arbitrarily close to that of the “noise” even in operator norm.
(ii) Asymmetry. Since the objective () is invariant under the rescaling , the magnitudes of and may be highly imbalanced, in which case the gradient has a large Lipschitz constant. This issue is well recognized to be a primary difficulty in analyzing the gradient dynamics (-) even without overparametrization [DHL18]. Most previous works either restrict to the symmetric positive semidefinite formulation [LMZ18, ZKHC21, SS21, ZFZ21, MF21, DJC+21, Zha21], or add an explicit regularization term of the form [TBS+16, ZL16].
(iii) Trajectory analysis and cold start. As the desired is not a local minimizer of (), our analysis is inherently trajectory-based and initialization-specific.
Random initialization leads to a cold start: the initial iterates are far from and nearly orthogonal to when the dimensions are large. More precisely, assuming the SVD , one may measure the relative signal strength of by
| (1.1) |
which is the ratio between the projections of and to the column/row space of and the projections to the complementary space. Most existing work requires to be larger than a universal constant [FYY20, LMZ18], which does not hold when .111For with i.i.d. standard Gaussian entries, we have w.h.p. for .
(iv) General rank overparametrization. Our result holds for any choice of with . The work in [YD21, MLC21] only considers the exact-parametrization setting . The work [FYY20] assumes the specific choice ; as mentioned in the previous paragraph, the setting with a smaller involves additional challenges due to cold-start.
2 Related work
The literature on gradient descent for matrix factorization is vast; see [CC18, CLC19] for a survey. Most prior work focuses on the exact parametrization setting (where is the target rank or the rank of a ground truth matrix ) and requires an explicit regularizer . More recent work in [DJC+21, DHL18, FYY20, LMZ18, MLC21, MF21, SS21, YD21, ZFZ21, Zha21, ZKHC21], discussed in the last section, studies (overparametrized) matrix factorization and implicit regularization. Below we discuss recent results that are most related to ours.
The work [YD21] also provides recovery guarantees for vanilla gradient descent (-) with random small initialization. Their result only applies to the setting where the matrix has exactly rank and , i.e., with exact parametrization. Moreover, their choice of stepsize is quite conservative and consequently their iteration complexity scales proportionally with dimension . In comparison, we allow for significantly larger stepsizes and establish almost dimension-free iteration complexity bounds.
The work [FYY20] considers a wide range of statistical problems with a symmetric ground truth matrix and shows that can be recovered with near optimal statistical errors using gradient descent for () with replaced by . While one may translate their results to the asymmetric setting via a dilation argument, doing so requires the specific rank parametrization . This restriction allows for a decoupling of the dynamics of different singular values, which is essential to their analysis. While this decoupled setting provides intuition for the general setting (as we elaborate in Section 3), the same analysis no longer applies for other values of , e.g., , for which the decoupling ceases to hold. Moreover, a smaller value of leads to the cold start issue, as discussed in footnote 1.
The work in [CGMR20] studies the deep matrix factorization problem. While on a high level their results deliver a message similar to our work, namely gradient descent sequentially approaches the principal components of , the technical details differ significantly. In particular, they results only apply to symmetric and guarantee recovery of the positive semidefinite part of . Their analysis relies crucially on the assumption , a specific identity initialization scheme and the resulting decoupled dynamics, which do not hold in the general setting as discussed above. A major contribution of our work lies in handling the entanglement of singular values resulted from general overparametrization, asymmetry, and random initialization.
In Section C, we provide additional discussion on related work.
3 Intuitions and the symmetric setting
In this section, we illustrate the behavior of gradient descent with small random initialization in the setting with a symmetric , and explain the challenges for generalizing to asymmetric .
Consider a simple example where , and is a positive semidefinite diagonal matrix that is approximately rank-1, i.e., . We consider the natural symmetric objective and the associated gradient descent dynamic ,222This is equivalent to (-) with initialization . with initialization for some small .
It is easy to see that is diagonal for all , and the -th diagonal element of , denoted by , is updated as
| (3.1) |
Thus, the dynamics of the two eigenvalues decouple and can be analyzed separately. In particular, simple algebra shows that (i) when , increases geometrically by a factor of , i.e., , and (ii) when , converges to geometrically with a factor of , i.e., In a similar fashion, converges to the second eigenvalue . It follows that the gradient descent iterate converges to the observed matrix as goes to infinity.
What makes a difference, however, is that converges at an exponentially slower rate than . In particular, assuming the stepsize is sufficiently small, we can show that is always nonnegative and satisfies . Note that the growth factor is smaller than , the growth factor for . We conclude that
| With small initialization, larger eigenvalues converge (exponentially) faster. | (3.2) |
Thanks to the property (3.2), the gradient descent trajectory approaches the principal components of one by one. In particular, if the initial size is sufficiently small, then (3.2) implies the existence of time window for during which is close to while remains close to its initial value (i.e., close to ). If we terminate at a time within this window, then the gradient descent output satisfies . If we continue the iteration, then eventually grows away from and converges quickly to , yielding .
In Section C, we generalize the above argument to any symmetric positive semi-definite via a diagonalization argument, which shows that approaches sequentially. However, this simple derivation breaks down for general rectangular and , since the dynamics of eigenvalues no longer decouple as in (3.1); rather, they have complicated dependence on each other, as can be seen in the proof of our main theorems. One of the main contributions of our proof is to rigorously establish the property (3.2) despite this complicated dependence.
4 Main results and analysis
In this section, we present our main theorems on the trajectory of gradient descent under small random initialization and early stopping. We also outline the analysis, deferring the full proof to the appendices.
4.1 Main theorems
Recall that is a general rectangular matrix and denote its singular values by . Fix and define the -th condition number . Suppose that the gradient descent dynamic (-) is initialized with , where is a size parameter and have i.i.d. entries. The operator norm is denoted by .
Below we state two theorems under one of the following assumptions:
Assumption A.
The first singular values are distinct, i.e., .
Assumption B.
The -th and -th singular values are distinct, i.e.,
Both theorems are high probability statements (w.r.t. random initialization); we refer to Theorem A.1 in the appendix for the precise value of the probability.
Our first theorem shows that under Assumption A, gradient descent with small random initialization approaches the principal components sequentially.
Theorem 4.1.
Our next, more precise theorem applies under Assumption B and shows that there is in fact a range of iterations at which gradient descent approximates . Note that the first theorem can be derived by applying the second theorem to each
Theorem 4.2.
We highlight that Theorem 4.2 applies to any observed matrix with a nonzero singular value gap ,333Otherwise is not uniquely defined. which can be arbitrarily small; we refer to this as the model-free setting. Moreover, Theorem 4.2 quantifies the relationship between various problem parameters: if has a relative singular value gap , then gradient descent with initialization size and early stopping at iteration outputs up to an error (we ignore logarithmic terms).
We make two remarks regarding the tightness of the above parameter dependence.
- •
-
•
Iteration complexity and stepsize: The number of iterations needed for an error scales as , which is akin to a geometric/linear convergence rate. Moreover, our stepsize and iteration complexity are independent of the dimension (up to log factors), both of which improve upon existing results in [YD21], which requires a significantly smaller stepsize and hence an iteration complexity proportional to . Again, our dimension-independent scaling agrees well with the numerical results in Section 5.
4.2 Proof Sketch for Theorem 4.2
We sketch the main ideas for proving Theorem 4.2 and discuss our main technical innovations. Our proof is inspired by the work [YD21], which studies the setting with low-rank and exact parametrization .
We start by simplifying the problem using the singular value decomposition (SVD) of , where and . By replacing , with , , respectively, we may assume without loss of generality that is diagonal. The distribution of the initial iterate remains the same thanks to the rotational invariance of Gaussian. Hence, the gradient descent update (-) becomes
| (4.2) |
where the subscript indicates the next iterate and will be used throughout the rest of the paper. Let be the upper submatrix of and be the lower submatrix of . Similarly, let be the upper submatrix of and be the lower submatrix of . Also let be the upper left submatrix of and be a diagonal matrix with on the diagonal. The gradient descent update (4.2) induces the following update for the “signal” matrices and the “error” matrices :
| (4.3) |
We may bound the difference as the following:
Hence, it suffices to show that the signal term converges to and the error term remains small. To account for the potential imbalance of and , we introduce the following quantities using the symmetrization idea in [YD21]:
| (4.4) |
(Similarly define based on the -th iterates.) Here is the symmetrized part of the signal terms , and represents the imbalance between them. Since , the quantities and capture how far the signal term is from the true signal . Let be iteration index defined as in Theorem 4.2. Our proof studies three phases of lengths within these iterations, where . The proof consists of three steps:
-
•
Step 1. We use induction on to show that the error term and the imbalance term remain small throughout the iterations.
-
•
Step 2. We characterize the evolution of the smallest singular value . After the first iteration, the value dominates the errors. Then, with more iterations, grows above the threshold , in which case signal term has magnitude close to that of the true signal .
-
•
Step 3. After becomes sufficiently large, we show that decreases geometrically. After more iterations, has the same magnitude as the error terms . Theorem 4.2 then follows by bounding in terms of .
Our analysis of and departs from that in [YD21], which requires the stepsize to depend on both problem dimension and initialization size, resulting in an iteration complexity that has polynomial dependence on the dimension. The better dependence in our Theorem 4.2 is achieved using the following new techniques:
-
1.
Unlike [YD21] which bounds by quantities independent of , we control them using geometrically increasing series, which are tighter and more accurately capture the dynamics of across .
-
2.
Our analysis decouples the choices of the stepsize and initialization size , allowing them to be independent. We do so by making the crucial observation that the desired lower bound on only depends on and the singular value gap . As a result, we can take a very small initialization size (in both theory and experiments), since the iteration complexity depends only logarithmically on . In contrast, the desired lower bound on in [YD21] depends on initialization size , and in turn their stepsize have more stringent dependence on .
-
3.
The analysis in [YD21] cannot be easily generalized to the overparametrized setting, since in this case the error terms no longer decay geometrically when they are within a small neighborhood of zero—to our best knowledge, tightly characterizing this local convergence behavior in the overparametrized setting remains an open problem. We circumvent this difficulty by using a smaller initialization size , which is made possible by the tighter analysis outlined in the last bullet point.
5 Experiments
We present numerical experiments that corroborate our theoretical findings on gradient descent with small initialization and early stopping. In Section 5.1, we provide numerical results that demonstrate the dynamics and algorithmic regularization of gradient descent. In Section 5.2, we numerically verify our theoretical prediction on the scaling relationship between the initialization size, stepsize, iteration complexity and final error.
5.1 Dynamics of gradient descent
We generate a random rank- matrix with and , and run gradient descent (-) with initialization size , stepsize and rank parameter . As shown in Figure 2a, the top singular values of the iterate grow towards those of sequentially at geometrically different rates. Consequently, for each , the iterate is close to the best rank- approximation when and ; early stopping of gradient descent at this time outputs .


In Figure 2b, we compare the convergence rates of gradient descent with small () and moderate () initialization sizes. We see that using a small results in fast convergence to a small error level; moreover, the convergence rate is geometric-like (before saturation), which is consistent with the iteration complexity predicted by Theorem 4.2. Therefore, compared to moderate initialization, small initialization has both computational benefit (in terms of iteration complexity) and a statistical regularization effect (when coupled with early stopping, as demonstrated in Figure 1).




5.2 Parameter dependence
Theorem 4.2 predicts that if has relative singular value gap , then gradient descent outputs with a relative error in iterations when using an initialization size and a stepsize nearly independent of the dimension of . We numerically verify these scaling relationships.
In all experiments, we fix , stepsize and rank parametrization , and generate a matrix with . We vary the dimension , relative singular value gap and condition number , and record the smallest relative error attained within iterations as well as the iteration index at which this error is attained. The results are the averaged over ten runs with randomly generated and shown in Figure 3a-3d.
The results in Figure 3a verify the relation for fixed . We believe the flat part of the curves (for ) is due to numerical precision limits. Figure 3b verifies for fixed . Figure 3c verifies . In all these plots, the the curves for different dimensions overlap, which is consistent with the (near) dimension-independent results in Theorem 4.2. Finally, Figure 3d shows that with a single fixed stepsize , the error is largely independent of the dimension , for different values of . This supports the prediction of Theorem 4.2 that the stepsize can be chosen independently of the dimension.
6 Discussion
In this paper, we characterize the dynamics of overparametrized vanilla gradient descent for asymmetric matrix factorization. We show that with sufficiently small random initialization and proper early stopping, gradient descent produces an iterate arbitrarily close to the best rank- approximation for any so long as the singular values and are distinct. Our theoretical results quantify the dependency between various problem parameters and match well with numerical experiments. Interesting future directions include extension to the matrix sensing/completion problems with asymmetric matrices, as well as understanding and capitalizing on the algorithmic regularization effect of overparametrized gradient descent in more complicated, nonlinear statistical models.
Acknowledgement
Y. Chen is partially supported by National Science Foundation grants CCF-1704828 and CCF-2047910. L. Ding is supported by National Science Foundation grant CCF-2023166.
References
- [CC18] Yudong Chen and Yuejie Chi. Harnessing structures in big data via guaranteed low-rank matrix estimation: Recent theory and fast algorithms via convex and nonconvex optimization. IEEE Signal Processing Magazine, 35(4):14–31, 2018.
- [CGMR20] Hung-Hsu Chou, Carsten Gieshoff, Johannes Maly, and Holger Rauhut. Gradient descent for deep matrix factorization: Dynamics and implicit bias towards low rank. arXiv preprint arXiv:2011.13772, 2020.
- [Cha15] Sourav Chatterjee. Matrix estimation by universal singular value thresholding. The Annals of Statistics, 43(1):177–214, 2015.
- [CLC19] Yuejie Chi, Yue M Lu, and Yuxin Chen. Nonconvex optimization meets low-rank matrix factorization: An overview. IEEE Transactions on Signal Processing, 67(20):5239–5269, 2019.
- [CT10] Emmanuel J Candès and Terence Tao. The power of convex relaxation: Near-optimal matrix completion. IEEE Transactions on Information Theory, 56(5):2053–2080, 2010.
- [DHL18] Simon S Du, Wei Hu, and Jason D Lee. Algorithmic regularization in learning deep homogeneous models: Layers are automatically balanced. arXiv preprint arXiv:1806.00900, 2018.
- [DJC+21] Lijun Ding, Liwei Jiang, Yudong Chen, Qing Qu, and Zhihui Zhu. Rank overspecified robust matrix recovery: Subgradient method and exact recovery. arXiv preprint arXiv:2109.11154, 2021.
- [FYY20] Jianqing Fan, Zhuoran Yang, and Mengxin Yu. Understanding implicit regularization in over-parameterized nonlinear statistical model. arXiv preprint arXiv:2007.08322, 2020.
- [GMMM20] Behrooz Ghorbani, Song Mei, Theodor Misiakiewicz, and Andrea Montanari. When do neural networks outperform kernel methods? Advances in Neural Information Processing Systems, 33:14820–14830, 2020.
- [HCB+19] Yanping Huang, Youlong Cheng, Ankur Bapna, Orhan Firat, Dehao Chen, Mia Chen, HyoukJoong Lee, Jiquan Ngiam, Quoc V Le, Yonghui Wu, et al. Gpipe: Efficient training of giant neural networks using pipeline parallelism. Advances in neural information processing systems, 32:103–112, 2019.
- [KBZ+20] Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, and Neil Houlsby. Big transfer (bit): General visual representation learning. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part V 16, pages 491–507. Springer, 2020.
- [LMZ18] Yuanzhi Li, Tengyu Ma, and Hongyang Zhang. Algorithmic regularization in over-parameterized matrix sensing and neural networks with quadratic activations. In Conference On Learning Theory, pages 2–47. PMLR, 2018.
- [MF21] Jianhao Ma and Salar Fattahi. Sign-RIP: A robust restricted isometry property for low-rank matrix recovery. arXiv preprint arXiv:2102.02969, 2021.
- [MLC21] Cong Ma, Yuanxin Li, and Yuejie Chi. Beyond Procrustes: Balancing-free gradient descent for asymmetric low-rank matrix sensing. IEEE Transactions on Signal Processing, 69:867–877, 2021.
- [Pre98] Lutz Prechelt. Early stopping-but when? In Neural Networks: Tricks of the trade, pages 55–69. Springer, 1998.
- [RFP10] Benjamin Recht, Maryam Fazel, and Pablo A Parrilo. Guaranteed minimum-rank solutions of linear matrix equations via nuclear norm minimization. SIAM review, 52(3):471–501, 2010.
- [RV09] Mark Rudelson and Roman Vershynin. Smallest singular value of a random rectangular matrix. Communications on Pure and Applied Mathematics: A Journal Issued by the Courant Institute of Mathematical Sciences, 62(12):1707–1739, 2009.
- [SS21] Dominik Stöger and Mahdi Soltanolkotabi. Small random initialization is akin to spectral learning: Optimization and generalization guarantees for overparameterized low-rank matrix reconstruction. arXiv preprint arXiv:2106.15013, 2021.
- [TBS+16] Stephen Tu, Ross Boczar, Max Simchowitz, Mahdi Soltanolkotabi, and Ben Recht. Low-rank solutions of linear matrix equations via Procrustes flow. In International Conference on Machine Learning, pages 964–973. PMLR, 2016.
- [TL19] Mingxing Tan and Quoc Le. Efficientnet: Rethinking model scaling for convolutional neural networks. In International Conference on Machine Learning, pages 6105–6114. PMLR, 2019.
- [Wai19] Martin J Wainwright. High-dimensional statistics: A non-asymptotic viewpoint, volume 48. Cambridge University Press, 2019.
- [WGL+20] Blake Woodworth, Suriya Gunasekar, Jason D Lee, Edward Moroshko, Pedro Savarese, Itay Golan, Daniel Soudry, and Nathan Srebro. Kernel and rich regimes in overparametrized models. In Conference on Learning Theory, pages 3635–3673. PMLR, 2020.
- [WLZ+21] Hengkang Wang, Taihui Li, Zhong Zhuang, Tiancong Chen, Hengyue Liang, and Ju Sun. Early stopping for deep image prior. arXiv preprint arXiv:2112.06074, 2021.
- [YD21] Tian Ye and Simon S Du. Global convergence of gradient descent for asymmetric low-rank matrix factorization. arXiv preprint arXiv:2106.14289, 2021.
- [ZFZ21] Jialun Zhang, Salar Fattahi, and Richard Zhang. Preconditioned gradient descent for over-parameterized nonconvex matrix factorization. Advances in Neural Information Processing Systems, 34, 2021.
- [Zha21] Richard Y Zhang. Sharp global guarantees for nonconvex low-rank matrix recovery in the overparameterized regime. arXiv preprint arXiv:2104.10790, 2021.
- [ZKHC21] Jiacheng Zhuo, Jeongyeol Kwon, Nhat Ho, and Constantine Caramanis. On the computational and statistical complexity of over-parameterized matrix sensing. arXiv preprint arXiv:2102.02756, 2021.
- [ZL16] Qinqing Zheng and John Lafferty. Convergence analysis for rectangular matrix completion using Burer-Monteiro factorization and gradient descent. arXiv preprint arXiv:1605.07051, 2016.
Organization of Appendix
Appendix A Proof of Theorem 4.2
For the ease of presentation, we work with (an upper bound) of the singular value ratio , where we recall that is a lower bound of the relative singular value gap. Theorem 4.2 is a simplified version of the following more precise theorem. The numerical constants below are not optimized.
Theorem A.1.
Fix any . Suppose . Pick any such that . Pick any stepsize . For any , pick any initialization size satisfying
and
Define
| (A.1) | ||||
Define . Then we have
| (A.2) |
Moreover, there exists a universal constant such that with probability at least , for all , we have
| (A.3) |
Proof.
The inequality (A.2) follows from the auxiliary Lemma C.9, which can be proved by mechanical though tedious calculation.
Appendix B Induction steps for proving Theorem 4.2
Proposition B.1 (Base Case).
Suppose that and have i.i.d. entries. For any fixed , we take and . Then with probability at least , we have
-
1.
.
-
2.
.
-
3.
.
-
4.
.
-
5.
.
-
6.
.
Proof.
In the sequel, we condition on the high probability event that the conclusion of Proposition B.1 holds. The rest of the analysis is deterministic.
Proposition B.2 (Inductive Step).
Suppose that the stepsize satisfies , the initial size satisfies
and the following holds for all with :
-
1.
.
-
2.
.
-
3.
, if .
-
4.
, if .
-
5.
If , we have and
Then the above items also hold for . Consequently, by Proposition B.1 and induction, they hold for all .
Proof.
Item 3. By (4.3) and the induction hypothesis that , We have
By the same argument, we can show that , whence
By applying the above inequality inductively, we have
Item 4. By induction hypothesis and definition of , we have . On the other hand, by induction hypothesis on Item 5, we have . Therefore, we have and
By the updating formula of in (A.6), we can write
| (B.1) |
where
By and triangle inequality, we have
Similarly, we have . By the bounds above, triangle inequality, and the upper bound on , we have
Combining the above estimates on and , and the assumption on , we see that we can apply Lemma C.10 to and obtain
By the fact that , we have . Hence,
where the last inequality follows from .
Item 5. Note that
where the equality follows from (A.5) and brute force, and the inequality follows from Lemma C.8, Cauchy-Schwarz inequality and definition of . By induction hypothesis, we have and . Moreover, the rank of is at most . Hence,
Furthermore, we have
where the second inequality follows from the induction hypothesis and the last inequality follows from the bound . Combining with Item 4, we have
| (B.2) |
Consider two cases. Case (i): . By (B.2), we have
Hence, Case (ii): . By (B.2), we have
As a result,
For the rest of Item 5, we note that for any ,
where the last inequality follows from the base case that and the assumption that . As a result,
Next, we will show that will increase geometrically until it is at least .
Proposition B.3.
Suppose that the conditions of Proposition B.2 holds. In addition, we assume . Then for any , we have
In particular, for and all , we have .
Proof.
We prove it by induction. Clearly, the inequality holds for . Suppose the result holds for . By the updating formula of in (A.4), we have
| (B.3) |
where Note that
| (B.4) | ||||
where the first inequality follows from Proposition B.2 and triangle inequality, the second inequality from , the third inequality from , and the last inequality from the assumption that . On the other hand,
where the last inequality follows from the assumption that . Combining both bounds on , we have
Therefore, it holds that
where the second inequality follows from Lemma C.7 and the last inequality follows from the assumption that . We consider two cases.
-
1.
. We have
where the last inequality follows from and .
-
2.
Note that
Combining these two cases completes the induction step. ∎
After exceeds , we show that increases to at a slower rate.
Proposition B.4.
Proof.
We prove it by induction. By Proposition B.3, the inequality holds for . Suppose the result holds for . By the same argument of Proposition B.3, (B.3) and (B.4) hold. It follows that
| (B.5) |
Applying Lemma C.7, we have
We consider two cases.
-
1.
. We have
where the last inequality follows from and .
-
2.
We have
Combining the two cases completes the induction step. ∎
After exceeds , we show that decreases geometrically.
Proposition B.5.
Proof.
Recall the updating formula (B.1). By the same argument as the proof of the item 4 in Proposition B.2, for , we have the bound . On the other hand,
By Proposition B.2 and Proposition B.4, we have and . It follows that
hence
As a result, we have
Applying the above inequality inductively, we have
The result follows if we shift the index of by one. The statement for follows from direct calculation and the upper bound on . ∎
Appendix C Auxiliary lemmas and additional literature review
C.1 Auxiliary lemmas
In this section, we state several technical lemmas that are used in the proof of Theorem 4.2. These lemmas are either direct consequence of standard results or follow from simple algebraic calculation.
Lemma C.1 ([RV09, Theorem 1.1]).
Let be an matrix with and i.i.d. Gaussian entries with distribution . Then for every we have with probability at least that
where is a universal constant.
Lemma C.2 ([Wai19, Example 2.32, Exercise 5.14]).
Let be an matrix with i.i.d. Gaussian entries with distribution . Then there exists a universal constant such that
with probability at least .
Lemma C.3 (Initialization Quality).
Suppose that we sample with i.i.d. entries. For any fixed , if we take and , then with probability at least , we have
-
1.
.
-
2.
.
-
3.
.
Proof.
Lemma C.4.
Let be an matrix with . If , then the largest and smallest singular values of are and , respectively.
Proof.
Let be the SVD of . Simple algebra shows that
| (C.1) |
This is exactly the SVD of . Let . Ty taking derivative, is monotone increasing in interval . Since the singular values of are exactly the singular values of mapped by , the result follows. ∎
Lemma C.5.
Let be an matrix such that . Then is invertible and
Proof.
Since , the matrix is well defined and indeed is the inverse of . By continuity, subadditivity and submultiplicativity of operator norm,
| (C.2) |
∎
Lemma C.6.
Let be an matrix and be an matrix. Then
Proof.
For any matrix , the variational expression of -th singular value is
| (C.3) |
Applying this variational result twice, we obtain
| (C.4) | ||||
| (C.5) | ||||
| (C.6) |
∎
Lemma C.7.
Let be an matrix with . Suppose that . Let be a diagonal matrix. Suppose that , , , and Then we have .
Proof.
Lemma C.8.
Let be a real matrix and a symmetric matrix. We have
Proof.
Let the eigenvalue decomposition of be , where is an orthogonal matrix and consists of eigenvalues of . Let , we have
where the last inequality follows from the fact that is positive semi-definite. ∎
Lemma C.9.
Under the assumption of Theorem A.1, we have
Proof.
For simplicity, we omit the flooring and ceiling operations and assume
and
Using the bound
we have
| (C.7) |
| (C.8) |
and
| (C.9) |
We will prove the following three inequalities:
-
1.
;
-
2.
;
-
3.
The result will follow if we add these inequalities together. To prove the above inequalities, we make frequent use of the following two facts from Calculus: (i) For any . (ii) For any and , .
First, we have
where the first inequality follows from fact 2, and the second inequality follows from (C.7). Next, we have
where the first inequality follows from fact 2 and the second inequality follows from (C.8). Finally, we have
where the first inequality follows from fact 1 and the second inequality follows from (C.9). Therefore, the result follows. ∎
Lemma C.10 ([YD21, Lemma 3.3]).
Suppose are two symmetric matrices, , and . Suppose and . Then, for all and , it holds that
C.2 Additional literature review
The literature on gradient descent for matrix factorization is vast; see [CC18, CLC19] for a comprehensive survey of the literature, most of which focuses on the exact parametrization case (where is the target rank or the rank of certain ground truth matrix ) with the regularizer that balances the magnitude of and . Below we review recent progress on overparametrization for matrix factorization without additional regularizers. A summary of the results can be found in Table 1.
| Asymmetric | Range of | Gap | -SVD | Speed | Cold Start | |
|---|---|---|---|---|---|---|
| [LMZ18] | ✗ | 1 | ✓ | fast | ✗ | |
| [ZKHC21] | ✗ | ✗ | n.a. | ✗ | ||
| [SS21] | ✗ | 1 | ✓ | fast | ✓ | |
| [YD21] | ✓ | 1 | ✓ | slow | ✓ | |
| [FYY20] | ✓ | ✗ | n.a. | ✗ | ||
| Our work | ✓ | ✓ | fast | ✓ |
Matrix sensing with positive semidefinite matrices
A majority of existing theoretical work on overparametrization focuses on the matrix sensing problem: (approximately) recovering a positive semidefinite (psd) and rank- ground truth matrix from some linear measurement , where is the noise vector and the linear constraint map satisfies the so-called Restricted Isometry Property [RFP10, Definition 3.1] (when is the identity map, then this problem becomes the matrix factorization problem). These works analyze the gradient descent dynamics applied to the problem . In the noiseless () setting with an exactly rank- , the pioneer work [LMZ18] and subsequent improvement in [SS21] show gradient descent recovers using random small initialization and arbitrary rank overparametrization . In the noisy and approximately rank- setting, the work in [ZKHC21] shows that for arbitrary rank overparametrization, spectral initialization followed by gradient descent approximately recovers with a sublinear rate of convergence. However, their error bound for the gradient descent output with respect to scales with the overparametrization , i.e., the algorithm overfits the noise under overparametrization. In particular, with ( being the dimension of ), this error could be worse than that of the trivial estimator . A similar limitation, that the error and/or sample complexity scales with , also appears in earlier work on landscape analysis [Zha21] as well as the recent work on preconditioned gradient descent [ZFZ21] and subgradient methods [MF21, DJC+21]. Existing results along this line all focus on positive semidefinite ground truth whose eigengap between the -th and -th eigenvalues is significant. In comparison, our results apply to a general asymmetric with arbitrary singular values, and our error bound depends only on the initialization size and stopping time but not .
Matrix factorization and general asymmetric
The work [YD21] also provides recovery guarantees for vanilla gradient descent (-) with random small initialization. Their result only applies to the setting where the matrix has exactly rank and , i.e., with exact parametrization. Moreover, their choice of stepsize is conservative and consequently their iteration complexity scales proportionally with the matrix dimension . In comparison, we allow for significantly larger stepsizes and establish almost dimension-free iteration complexity bounds. To achieve an accuracy, the result in [YD21] requires iterations, while our main theorem only requires iterations. The work in [FYY20] considers a wide range of statistical problems with a symmetric ground truth matrix , and shows that can be recovered with near optimal statistical errors using gradient descent for the objective function () with replaced by . While one may translate their results to the asymmetric setting via a dilation argument, it is feasible to do so only under the specific rank parametrization . This strong restriction on allows for a decoupling of the dynamics of different singular values, which is essential to their analysis. While this decoupled setting provides intuition for the general setting (as we elaborate in Section 3), the same analysis no longer applies for other values of , e.g., , in which case the singular values do not decouple. Moreover, a smaller value of leads to the cold start issue, as discussed in footnote 1.
Deep matrix factorization
The work in [CGMR20] studies the deep matrix factorization problem of factorizing a given matrix into a product of multiple matrices. While on a high level their results deliver a message similar to our work—namely, gradient descent sequentially approaches the principal components of —the technical details differ significantly. In particular, they results only apply to symmetric and guarantee recovery of the positive semidefinite part of . Their analysis relies crucially on the assumption , a specific identity initialization scheme and the resulting decoupled dynamics, which do not hold in the general setting as discussed above. A major contribution of our work lies in handling the entanglement of singular values resulted from general overparametrization, asymmetry, and random initialization.
C.3 The general symmetric setting
In this section, we show that the arguments in Section 3 can be generalized to the setting where the observed matrix is a general symmetric positive semidefinite (p.s.d.) matrix.
In particular, we illustrate the behavior of gradient descent with small random initialization in the setting with (i) , and (ii) is a p.s.d. matrix with eigen decomposition , where . Moreover, we assume that the -th eigengap exists, i.e. for some . The following argument works for any ; for ease of presentation, we assume . We consider the natural objective function and the associated gradient descent dynamic444One can obtain the same dynamic by using the initialization in (-). , with initialization for some small . Let . To understand how approaches , we can equivalently study how approaches . By simple algebra, we have
| (C.10) |
Since is diagonal, it is easy to see see that is diagonal for all , and the -th diagonal element in , denoted by , is updated as
| (C.11) |
Thus, the dynamics of all the eigenvalues decouples and can be analyzed separately. In particularly, simple algebra shows that for , (i) when , increases geometrically by a factor of , i.e., , and (ii) when holds, converges to geometrically because
In summary, the first diagonal elements of will first increase geometrically by a factor of (at least) , and then converge to geometrically by a factor of .
What makes a difference, however, is that for , converges at an exponentially slower rate than the first diagonal elements. In particular, assuming the step size is sufficiently small, for , we can show that is always nonnegative and satisfies
| (C.12) | ||||
Note that the growth factor is smaller than , the growth factor for Consequently, we conclude that larger singular value converges (exponentially) faster. This property implies that approaches sequentially for a positive semidefinite with distinct singular values, since we can repeat the above argument for each