Algorithm xxxx: HiPPIS A High-Order Positivity-Preserving Mapping Software for Structured Meshes
Abstract.
Polynomial interpolation is an important component of many computational problems. In several of these computational problems, failure to preserve positivity when using polynomials to approximate or map data values between meshes can lead to negative unphysical quantities. Currently, most polynomial-based methods for enforcing positivity are based on splines and polynomial rescaling. The spline-based approaches build interpolants that are positive over the intervals in which they are defined and may require solving a minimization problem and/or system of equations. The linear polynomial rescaling methods allow for high-degree polynomials but enforce positivity only at limited locations (e.g., quadrature nodes). This work introduces open-source software (HiPPIS) for high-order data-bounded interpolation (DBI) and positivity-preserving interpolation (PPI) that addresses the limitations of both the spline and polynomial rescaling methods. HiPPIS is suitable for approximating and mapping physical quantities such as mass, density, and concentration between meshes while preserving positivity. This work provides Fortran and Matlab implementations of the DBI and PPI methods, presents an analysis of the mapping error in the context of PDEs, and uses several 1D and 2D numerical examples to demonstrate the benefits and limitations of HiPPIS.
1. Introduction
Mapping data values from one grid to another is a fundamental part of many computational problems. Preserving certain properties such as positivity when interpolating solution values between meshes is important. In many applications (skamrock, ; LIU201982, ; SUBBAREDDY2017827, ; BALSARA20127504, ; Damodar, ; ZHANG2017, ), failure to preserve the positivity of quantities such as mass, density, and concentration results in negative values that are unphysical. These negative values may propagate to other calculations and corrupt other quantities. Many polynomial-based methods have been developed to address these limitations.
Positivity-preserving methods based on linear polynomial rescaling are introduced in (Light, ; ZHANG2017, ; Zhang2012_2, ; LIU201982, ; HU2013169, ). These polynomial rescaling methods are often used in the context of hyperbolic PDEs, in numerical weather prediction (NWP) (Light, ), combustion simulation (LIU201982, ; HU2013169, ), and other applications. These methods introduce rescaling parameters obtained from quadrature weights that are used to linearly rescale the polynomial to ensure positivity at the quadrature nodes and conserve mass. These approaches ensure positivity only at the set of mesh points used for the simulation but do not address the case of mapping data values between different meshes, which is the focus of HiPPIS.
Other approaches for preserving positivity that are based on splines can be found in computer-aided design (CAD), graphics, and visualization (Schmidt1988, ; Schmidt1987, ; HUSSAIN2008446, ; karim2015positivity, ; SARFRAZ199269, ; fritsch1980monotone, ). Several positivity- and monotonicity-preserving cubic splines have been developed. A widely used example of such an approach is the piecewise cubic Hermite interpolation (PCHIP) (fritsch1980monotone, ), which is available as open-source code in (moler2004numerical, ). In addition, quartic and quintic spline-based approaches have been introduced in (HE199451, ; Lux2019ANAF, ; Lux2023, ; hussain2009c2, ; Hussain2018ACR, ). These methods impose some restrictions on the first and second derivatives to ensure monotonicity, positivity, and continuity. For instance, the monotonic quintic spline interpolation (MQSI) methods in (Lux2019ANAF, ) and (Lux2023, ) use the sufficient conditions stated in (Schmidt1988, ) and (doi:10.1137/0915035, ) to check for monotonicity and iteratively adjust the first and second derivative values to enforce monotonicity.
Positivity can also be enforced using ENO-type methods (Damodar, ; berzins2010nonlinear, ; Berzins, ; Ouermi2022, ), which enforce data-boundedness and positivity by adaptively selecting mesh points to build the stencil used to construct the positive interpolant for each interval. ENO-type methods use divided differences to develop a sufficient condition for data-boundedness or positivity that is used to guide the stencil selection process. The software introduced in this work is based on the high-order ENO-type data-bounded interpolation (DBI) and positivity-preserving interpolation (PPI) methods in (Ouermi2022, ). The work in (Ouermi2022, ) provides a positivity-preserving method that uses higher degree polynomials compared to the other ENO-type methods in (Damodar, ; berzins2010nonlinear, ; Berzins, ) and the spline-based methods.
Given that polynomial interpolation is well-established and widely used, several implementations of the different polynomial approximation algorithms are available. For example, FunC by Green et al. (Green2019, ) uses polynomial interpolation with a lookup table for faster approximation of a given function compared to direct evaluation. However, most of these implementations, including FunC, do not preserve data-boundedness and positivity. The implementations available for positivity preservation are based on splines (HE199451, ; fritsch1980monotone, ) and polynomial rescaling (ZHANG2017, ; Light, ). The spline-based approaches often require solving a linear system of equations to ensure continuity and an optimization problem in the case of quartic and quintic splines. These spline approaches are often limited to fifth-order polynomials and can be computationally expensive in cases where solving a global optimization problem is required. A full suite of test problems comparing the DBI and PPI methods against different spline-based methods including PCHIP (fritsch1980monotone, ), MQSI (Lux2019ANAF, ), and shape-preserving splines (SPS) (10.1145/264029.264059, ) has been undertaken by the authors in (arkivtajo, ). The different polynomial rescaling methods allow for polynomial degrees higher than five and are built as part of larger partial differential equation (PDE) solvers (Light, ; ZHANG2017, ). As previously mentioned, the polynomial rescaling approaches guarantee positivity only at a given set of points, not over the entire domain. The present work provides an implementation of a high-order software (HiPPIS) based on (Ouermi2022, ) that guarantees positivity over the entire domain where the interpolant is defined. In addition, this work evaluates the use of HiPPIS in the context of function approximation and mapping between different meshes. This evaluation provides an analysis of the mapping error in the case of PDEs and numerical examples demonstrating the benefits and limitations of HiPPIS.
The remaining parts of the paper are organized as follows: Section 2 presents the background for the mathematical framework required for the DBI and PPI methods. Section 3 provides the algorithms used to build the software, and the descriptions of the different components of HiPPIS. Section 4 provides several 1D and 2D numerical examples, while Section 5 conducts an analysis and evaluation of the mapping error in the context of time-dependent PDEs. A discussion and concluding remarks are presented in Section 6.
2. Mathematical Framework
This section provides a summary and the theoretical background of both the DBI and PPI methods.
2.1. Adaptive Polynomial Construction
Both the DBI and PPI methods rely on the Newton polynomial (doi:10.1137/0912034, ; 10.2307/2004888, ) representation to build interpolants that are positive or bounded by the data values. The ability to adaptively choose stencil points to construct the interpolation, as in ENO methods (HARTEN19973, ), is the key feature employed to develop the data-bounded and positivity-preserving interpolants.
Consider a 1D mesh defined as follows:
| (1) |
where , and is the set of data values associated with the mesh points in Equation (1). The subscripts , , , and , for . The DBI and PPI procedure starts by setting the initial stencil ,
| (2) |
The stencil in Equation (2) is expanded by successively appending a point to the right or left of to form . Once the final stencil is obtained, the interpolant of degree defined on can be written as
| (3) |
where are the Newton basis functions. is the point added to expand the stencil to and can be explicitly expressed as
The divided differences are recursively defined as follows:
The polynomial can be compactly expressed as
| (4) |
in Equation (4) is defined as
| (5) |
where , , and are expressed as follows:
| (6) |
| (7) |
| (8) |
and in Equations (5), (6), and (8) are defined such that and . The positivity-preserving and data-bounded interpolants are obtained by imposing some bounds on , defined as
| (9) |
2.2. Positivity-Preserving and Data-Bounded Interpolation
For a given interval inside a mesh, the DBI and PPI polynomial interpolant is constructed by adaptively selecting points near the target interval to build an interpolation stencil and polynomial that together meet the requirements for positivity or data-boundedness. Requiring positivity alone can lead to large oscillations and extrema that degrade the approximation. Positivity alone does not restrict how much the interpolant is allowed to grow beyond the data values. The large oscillations can be removed with the PCHIP, MQSI, and DBI methods. However, in the case where a given interval has a hidden extremum, PCHIP, MQSI, and DBI will truncate the extremum. As in (berzins2010nonlinear, ; sekora2009extremumpreserving, ), the interval has an extremum when two of the three divided differences , , and of neighboring intervals are of opposite signs. The constrained PPI algorithm addresses these limitations by allowing the constructed interpolant to grow beyond the data values but not produce extrema that are too large.
The positive polynomial interpolant is constrained as follows:
| (10) |
The bounds and in Equation (10) are defined as
| (11) |
The parameters and in Equation (11) are positive, and the data-bounded interpolant is obtained for =. These parameters are chosen according to
| (12) |
and
| (13) |
The positive parameters and , used for intervals with and without extrema, respectively, are introduced to adjust and . This work extends the bounds in (Ouermi2022, ) by introducing the parameter to allow for more flexibility on how to bound the interpolants in cases where an extremum is detected. The choice for the positive parameters and depends on the underlying function and the input data used for the approximation. As both and get smaller, the upper and lower bounds get tighter and the PPI method converges to the DBI method. The choices for and are further discussed in Section 3.2. In Equation (12), the interval has a local maximum if and . Correspondingly, in Equation (13), the interval has a local minimum if and . In both Equations (12) and (13), the type of extremum is ambiguous if , and .
Equation (10) is equivalent to bounding as follows:
| (14) |
where the factors and in Equation (14) are expressed as
-
(1)
:
(15) -
(2)
:
(16)
The DBI method can be recovered from the PPI methods by setting and . For , , and as written in Equations (15), (16), and (4) are not defined. This limitation is addressed by re-writing as
where is expressed as follows:
The summation starts at because the linear term . Let
in this context is defined as
For , the parameters and in Equation (14) are then defined according to
-
(1)
:
(17) -
(2)
:
(18)
For , the data , , , and have the same value (). In this case, the algorithm approximates the function in the interval with a linear interpolant.
The positivity-preserving result in Equation (10) is obtained by successively imposing bounds on the quadratic, cubic, and higher order terms in the expression of defined in Equation (5). The reconstruction procedure begins by considering the linear and quadratic terms from in Equation (5) and imposing the following bounds:
| (19) |
Equation (19) can be reorganized to obtain
Noting that , , and , we obtain
| (20) |
The bounds from Equation (20) are extended to bound the cubic form by requiring that what multiplies must fit into the inequality in Equation (20). Thus, for the cubic case, Equation (20) becomes
When defined in Equation (7) is negative, has a maximum value at and a minimum value at . is then bounded by
When is positive, is substituted by and the inequalities with and vice versa are swapped.
This procedure is continued to quartic and higher order interpolants to produce the recursive expression for the bounds on for the PPI and DBI methods as follows:
| (21a) | |||
| and | |||
| (21b) | |||
and are defined as and for the DBI method, whereas for the PPI method, they are defined as and , respectively. We refer the reader to Theorems 1 and 2 in (Ouermi2022, ) for more details on the mathematical foundation used to build the positivity-preserving software.
3. Algorithms and Software
This section describes the algorithms and different components used in the data-bounded and positivity-preserving software. The software developed in this work provides 1D, 2D, and 3D implementations of the DBI and PPI methods for uniform and nonuniform structured meshes. The 1D implementation is constructed based on the mathematical framework provided in Section 2. The 2D and 3D implementations are obtained via a tensor product of the 1D version.
3.1. Algorithms
The algorithms provide the necessary elements to construct the data-bounded or positive interpolants. Rogerson and Meiburg (rogerson1990numerical, ) showed that the ENO reconstruction can lead to a left- or right-biased stencil that causes stability issues when used to solve hyperbolic equations. Shu (shu1990numerical, ) addressed this limitation by introducing a bias coefficient used to target a preferred stencil. As indicated in (Ouermi2022, ), the left- and right-biased stencil can fail to recover hidden extrema. For a given interval , the left- and right-biased stencil does not include the points or , respectively. Algorithm I addresses these limitations by extending the algorithm in (Ouermi2022, ) to introduce more options for the adaptive stencil selection process described below. In addition to the symmetry-based points selection in (Ouermi2022, ), Algorithm I includes ENO-type and locality-based point selection processes.
At any given step , the next point inserted into can be to the left or right. Let and be the mesh points immediately to the left and right of , respectively.
We define and as follows:
| (22) |
The terms and in Equation 22 correspond to the case where the stencil inserted is to the left and right, respectively. Given , let be the number of points to the left of and the number of points to the right. Algorithm I extends the algorithm in (Ouermi2022, ) by introducing a user-supplied parameter used to guide the procedure for stencil construction. In the cases where adding both (to the left) or (to the right) are valid, the algorithm makes the selection based on the three cases below:
-
•
If (default), the algorithm chooses the point with the smallest divided difference, as in the ENO stencil.
-
•
If , the point to the left of the current stencil is selected if the number of points to the left of is smaller than the number of points to the right. Similarly, the point to the right is selected if the number of points to the right of is smaller than the number of points to the left. When both the number of points to the right and left are the same, the algorithm chooses the point with the smallest .
-
•
If , the algorithm chooses the point that is closest to the starting interval . It is important to prioritize the closest points in cases where the intervals surrounding vary significantly in size. These variations are found in computational problems for which different resolutions are used for different parts of the domain.
Algorithm II describes the 1D DBI and PPI methods built using the mathematical framework in Section 2 and Algorithm I. Algorithm II further extends the constraints in (Ouermi2022, ) by introducing the user-supplied positive parameter that is used to impose upper and lower bounds on the interpolants according to Equations (12) and (13). The positive parameters and are used for intervals without and with an extremum, respectively. The user-supplied parameter is used to choose between the DBI and PPI methods. Algorithm III and Algorithm IV describe the extension from 1D to 2D and 3D, respectively. Both Algorithm III and IV are constructed by successively applying Algorithm II to each dimension. Given that the DBI and PPI methods are nonlinear, the order in which Algorithm II is used can lead to different approximation results. In this paper and in (Ouermi2022, ), the 1D DBI and PPI are first applied to , then the dimension, and finally the dimensions, as indicated in Algorithm III and IV. In Algorithm III and IV, the input and intermediate data values are modified only by Algorithm I, which preserves data-boundedness or positivity. Therefore, the resulting solutions from the 2D and 3D extensions will preserve data-boundedness and positivity. Similar to Algorithm II, the choices of parameters , , and influence the quality of the approximation in Algorithm III and IV. In the 1D, 2D, and 3D cases, the choice for parameters , , and is dependent on the data. In the case of 2D and 3D, applying the 1D PPI method (Algorithm II) along the and/or dimensions may introduce oscillations that could be amplified when applying the 1D PPI in the subsequent dimensions. These oscillations can be significantly reduced with small values for and . The parameters and should be chosen to be small enough such that hidden extrema are recovered without introducing new large oscillations. In Algorithm II and IV, and represent 2D and 3D meshes obtained by taking the tensor product of the 1D mesh along the and dimensions for the 2D mesh, and along the , , and dimensions for the 3D mesh. The square represents or .
Algorithm I
Input: , , , , , , , , , and .
-
(1)
if
-
•
if , then insert a new stencil point to the left;
-
•
else if , then insert a new stencil point to the right;
-
•
else insert a new stencil point to the right if ; otherwise, insert a new point to left;
-
•
-
(2)
if
-
•
if , then insert a new stencil point to the left;
-
•
else if , then insert a new stencil point to the right;
-
•
else insert a new stencil point to the right if ; otherwise, insert a new point to left;
-
•
-
(3)
else
-
•
if , then insert a new stencil point to the left;
-
•
else if , then insert a new stencil point to the right;
-
•
else insert a new stencil point to the right if ; otherwise, insert a new point to left;
-
•
Algorithm II (1D)
Input: , , , , , , and .
Output: .
-
(1)
Select an interval . Let .
-
(2)
If or , then the interval has a hidden local extremum. For the boundary intervals, we assume that the divided differences to the left and right have the same sign.
- (3)
- (4)
-
(5)
Given a stencil ,
-
•
if and , choose the point to add based on Algorithm I
-
•
else if , then insert a new stencil point to the left;
-
•
else if , then insert a new stencil point to the right;
-
•
-
(6)
This process (Steps ) iterates until the halting criterion that the ratio of divided differences lies outside the required bounds stated above or the stencil has points, with being the target degree for the interpolant.
-
(7)
Evaluate the final interpolant (for DBI) or (for PPI) at the output points that are in .
-
(8)
Repeat Steps – for each interval in the input 1D mesh.
Algorithm III (2D)
Input:, , , , , , , and .
Output: .
-
(1)
Interpolate from the mesh to by applying the Algorithm II (1D) along the x dimension for each index along the y direction. More precisely, for each index (), Algorithm II (1D) uses , to interpolate from to . The interpolation solution is saved in
-
(2)
Use the solution from step (1) to interpolate from to the final output mesh by applying the Algorithm II (1D) along the y dimension for each index along the x direction. For each index (), Algorithm II (1D) uses (, ) to interpolate from to . The interpolation final results are saved in
Algorithm IV (3D)
Input:,, , , , , , , , , and .
Output: .
-
(1)
Interpolate from the mesh to by applying the Algorithm II (1D) along the x dimension for each pair . More precisely, for each each pair ( and ), Algorithm II (1D) uses , to interpolate from to . The interpolation solution is saved in
-
(2)
Use the solution from step (1) to interpolate from to by applying the Algorithm II (1D) along the dimension. For each pair ( and ), Algorithm II (1D) uses (, ) to interpolate from to . The interpolation results are saved in .
-
(3)
Use the solution from step (1) to interpolate from to by applying the Algorithm II (1D) along the dimension. For each pair ( and ), Algorithm II (1D) uses (, ) to interpolate from to . The interpolation final results are saved in .
3.2. Software Description
The DBI and PPI software implementation is guided by the algorithms described above. HiPPIS is available at https://github.com/ouermijudicael/HiPPIS. The software can be organized into four major parts: (1) computation of divided differences, (2) calculations of upper and lower bounds for each interval, (3) a stencil construction procedure, and (4) 1D, 2D, and 3D DBI and PPI implementations.
The divided differences are essential to the DBI and PPI methods because they are used in the calculations of and the stencil selection process. The divided differences are computed using the standard recurrence form in Equation (2.1) and stored in a table of dimension where is the maximum polynomial degree for each interpolant. Given that the maximum degree is , it is sufficient to consider the divided differences for the stencil selection process and the construction of the final polynomial interpolant for each interval.
The bounds on each interpolant are obtained from Equation (11), (12), and (13) where the positive parameters and are user-supplied values used to adjust the bounds for the interval with and without extremum, respectively. The adjustment focuses on removing large oscillations as much as possible while still allowing high-degree polynomial interpolants that meet the positivity requirements.
The stencil selection process requires the computation of and , which are both dependent on , , and . The stencil is constructed from by appending a point to the left or right of . When appending to either the right or left meets the requirements for positivity, the software offers three possible options for choosing from both points that can be set by the user. The first and default option () chooses the stencil with the smallest divided difference, similar to the ENO-like approach. The second option () prioritizes the choice that makes the stencil more symmetric around . The third option () chooses the point closest to the starting interval , thus prioritizing locality.
The 1D DBI and PPI methods use (1), (2), and (3) as building blocks to construct the final approximation. Once the final stencil has been selected, the interpolant is built using a Newton polynomial representation and then evaluated at the corresponding output points. The Newton polynomial is used here because its coefficients/divided differences are available. The 2D and 3D implementations successively use the 1D version along each dimension to construct the final approximation on uniform and nonuniform structured meshes.
The interfaces for the 1D, 2D, and 3D DBI and PPI subroutines are designed to be similar to widely used interfaces for polynomial interpolation such as PCHIP, and can be incorporated into larger application codes. The interfaces require
-
•
the input mesh points and the data values associated with those points,
-
•
the maximum polynomial degree to be used for each interpolant,
-
•
the interpolation method to be used (DBI or PPI), and
-
•
the output mesh points.
Listing 1 shows examples of how to use the 1D, 2D, and 3D interfaces for DBI and PPI in HiPPIS. The variables x, y, and z are 1D arrays used to define the input meshes, and xout, yout, and zout are used to define the output meshes. The variables v, v2D, and v3D correspond to the input data values associated with the input meshes. The parameters d and im (1, or 2) are used to indicate the target polynomial degree and the interpolation method to be used. For DBI and PPI, the parameter im is set to 1 and 2, respectively. The parameters , , and are optional parameters that are set to , , and by default, as explained below. The choice of the optional parameters depends on the underlying function and the input data.
In problems for which different resolutions are used for different parts of the computational domain, st=3 is a preferable choice. The algorithm prioritizes the closest points to the starting interval if st=3. This choice is particularly important in regions where the size of the intervals varies significantly. For cases when smoothness is the primary goal, st=1 is a suitable choice. For st=1, the Algorithm I prioritizes smoothness by choosing the points with the smallest divided differences during the stencil construction process. Both the st=1 and st=3 can lead to a left- or right-biased stencil. In these instances, st=2 can be used to remove the bias. For st=2, the algorithm prioritizes a symmetric stencil. The default value of st is set to 3 because the examples in this study indicate that st=3 leads to better approximations compared to st=1 or 2 and locality is often a highly desired property in many computational problems.
The positive parameters and are used to bound the interpolants for the intervals with and without extrema, respectively. The configurations in (Ouermi2022, ) and (arkivtajo, ) correspond to setting the parameters and to the default values of and , respectively. The values of and are chosen such that the lower and upper bounds on each interpolant are relaxed enough to allow for a high-order polynomial that does not introduce undesirable oscillations. For profiles that are prone to oscillation such as the logistic functions, it is important to choose small values for and . For , the approximation leads to large oscillations if and are greater than . For intervals without extrema, it is important to keep small to not introduce new extrema. For the intervals with extrema, needs to be large enough to allow for recovery of hidden extrema but small enough to not cause undesired large oscillations. This is very challenging given that the sizes of the peaks are not known a priori. The default values of are such that the interpolant maximum value is twice . This default value of one is sufficient for the modified Runge and TWP-ICE examples. However, in the case of BOMEX, smaller values of are required to remove undesired oscillations. In practice, it is prudent to start with a small value for and and increase them as needed if the approximation fails to recover hidden extrema or uses low-degree polynomial interpolants.
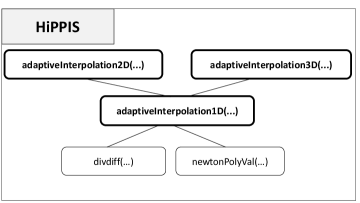
Figure 1 is a diagram of the different components of the main module of HiPPIS. The function divdiff(…) is used to calculate the divided differences needed for Algorithms I and II. Once the final stencil is constructed, the function newtonPolyVal(…) is used to build and evaluate the positive interpolant at the corresponding output points. The major part of the data-boundedness and positivity preservation including Algorithms I and II is in the function adaptiveInterpolation1D(…). This function is used for the 1D approximation or mapping problems and depends on the function divdiff(…) and newtonPolyVal(…). The functions adaptiveIterpolation2D(…) and adaptiveInterpolation3D(…) use adaptiveInterpolation1D(..) to construct the data-bounded or positive polynomial approximations on 2D and 3D structured tensor product meshes, respectively. The interfaces for the 1D, 2D, and 3D interpolations, in bold, require the parameter , which is used to indicate the interpolation method chosen. For the DBI and PPI methods, the parameter is set using 1 and 2, respectively. HiPPIS does not allow for any other choices for the parameter .
4. Numerical Examples for Function Approximation
This section provides 1D and 2D numerical examples used to evaluate the PCHIP, MQSI, DBI, and PPI methods. The results are based on the Fortran implementation of the software. These examples include a subset of the full suite of test problems considered in (arkivtajo, ). The interpolation methods are used to approximate positive functions from provided data values that are obtained by evaluating the 1D and 2D functions on a given set of mesh points. The function approximations in 2D examples use the 2D extension of the DBI and PPI methods described in Algorithm III. The 2D PCHIP and MQSI methods are obtained by successively applying the 1D PCHIP and MQSI algorithms to each dimension, similar to the steps described in Algorithm III. The 1D PCHIP and MQSI are first applied to , then the dimension, and finally the dimension. Similar to 2D and 3D DBI and PPI, the order in which 1D PCHIP or MQSI is applied can lead to different results, as both methods are nonlinear and non-commutative. Using a standard polynomial interpolation to approximate the different functions leads to negative values and oscillations. In this section, the -norms in the tables below are approximated using the trapezoidal rule with, and uniformly spaced points for the 1D and 2D examples, respectively. For the numerical examples in Sections 4.1 - 5.3, the errors from using , and are similar, with leading to slightly smaller errors compared to and . Given that the results are similar, Tables 1 - 8 show errors with the parameter set to . For the BOMEX example, the errors from the three choices are significantly different. Therefore, the results from all three choices are included. More test examples can be found in (arkivtajo, ).
4.1. Example I: Modified Runge Function
This example uses a modified version of the canonical Runge function defined as
| (23) |
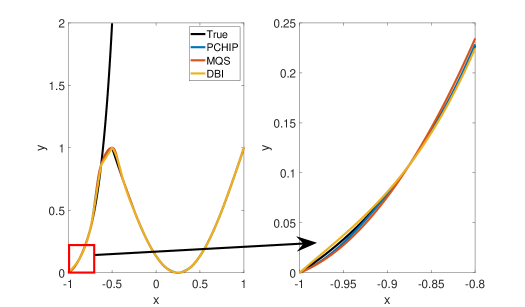
Approximating the modified Runge function in Equation (23) with a global standard polynomial leads to large oscillations. Table 1 shows the -errors norms when using the PCHIP, MQSI, DBI, and PPI methods to approximate . The DBI and PPI methods lead to better approximation results compared to the PCHIP and MQSI methods. The errors from PCHIP and MQSI are comparable. In this example, the algorithms used in MQSI to approximate and adjust the derivatives to enforce monotonicity do not produce more accurate results compared to PCHIP. As the target polynomial degree increases from to , the DBI approximation does not improve significantly compared to the PPI method. The relaxed nature of the PPI method allows for higher degree polynomial interpolants compared to DBI, PCHIP, and MQSI which lead to better approximations.
| PCHIP | MQSI | DBI | PPI | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 17 | 3.99E-2 | 3.63E-2 | 5.10E-2 | 2.91E-2 | 4.61E-2 | 5.10E-2 | 2.91E-2 | 4.61E-2 | ||||
| 33 | 4.52E-3 | 4.32E-3 | 6.31E-3 | 9.57E-3 | 3.05E-3 | 6.31E-3 | 9.57E-3 | 3.05E-3 | ||||
| 65 | 2.79E-3 | 2.67E-3 | 2.44E-3 | 2.49E-3 | 1.33E-3 | 2.44E-3 | 2.49E-3 | 9.92E-4 | ||||
| 129 | 6.23E-4 | 6.71E-4 | 2.22E-4 | 1.21E-4 | 1.05E-4 | 2.22E-4 | 1.21E-4 | 2.43E-5 | ||||
| 257 | 1.17E-4 | 9.89E-5 | 1.51E-5 | 1.15E-5 | 1.07E-5 | 1.51E-5 | 4.68E-6 | 9.89E-8 | ||||
4.2. Example II: 1D Logistic Function
This test case uses a logistic function defined as
| (24) |
This function is a smoothed analytical approximation of the Heaviside step function. The logistic function in Equation (24) is challenging because of the steep gradient at about . Approximating with a standard polynomial interpolation leads to large oscillations to the left and right of the gradient. In addition, the oscillations to the left produce negative values.
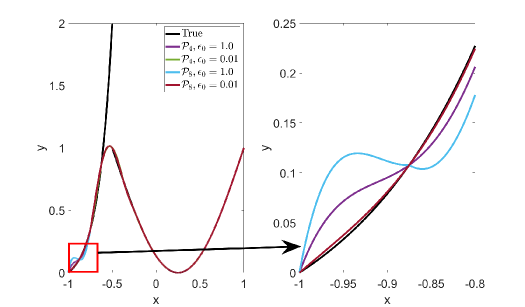
Table 2 shows -error norms when using the PCHIP, MQSI, DBI, and PPI methods to approximate the smoothed logistic function . The MQSI method has larger errors compared to the other methods. In this case, the algorithms employed by MQSI to approximate and adjust derivatives values used to construct the monotonic quintic splines are less accurate than the one used in PCHIP. For a target polynomial degree , the approximation errors using PCHIP, DBI, and PPI are comparable. Increasing the target polynomial degree improves the approximations for DBI and PPI, as shown in Table 2. The errors from both the DBI and PPI methods are similar because the logistic example has no hidden extrema, and the stencils used for both methods are the same, around . The global error is dominated by the local errors in the region with steep gradients around .
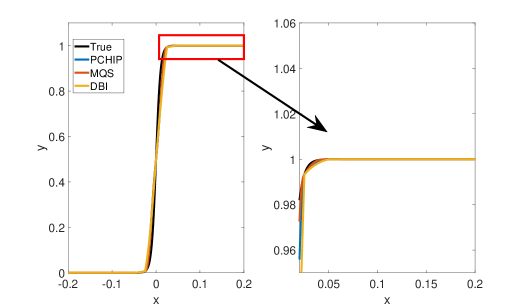
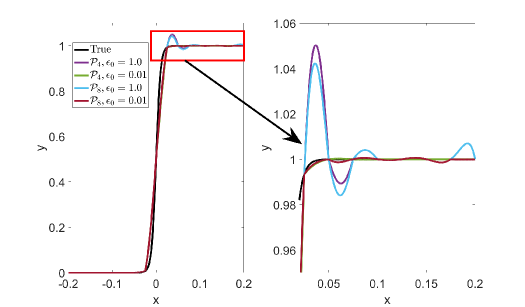
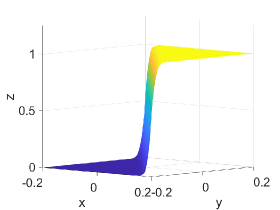
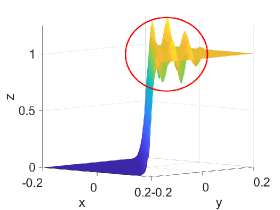
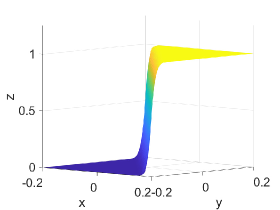
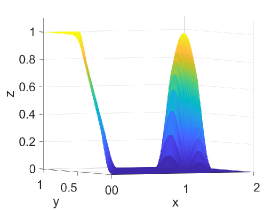
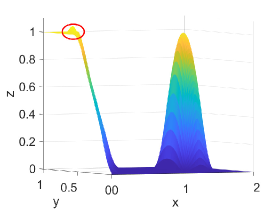
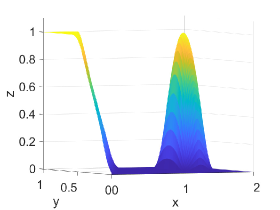
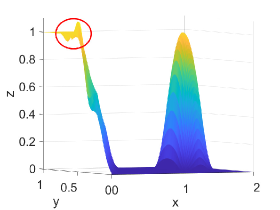
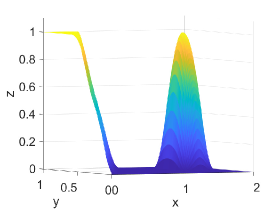
Figure 2 shows approximation plots of using uniformly spaced points with different values of and . The target polynomial degree is set to . For , we observe oscillations, as shown in the right part of Figure 2. As decreases, the oscillations decrease. For , the errors and oscillations are negligible compared to errors in the region with the steep gradient. The oscillations are completely removed for .
| PCHIP | MQSI | DBI | PPI | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 17 | 2.02E-2 | 1.92E-2 | 2.41E-2 | 2.41E-2 | 2.08E-2 | 2.41E-2 | 2.41E-2 | 2.08E-2 | ||||
| 33 | 3.38E-3 | 3.72E-3 | 4.89E-3 | 4.86E-3 | 3.59E-3 | 4.90E-3 | 4.86E-3 | 3.57E-3 | ||||
| 65 | 3.59E-4 | 1.61E-3 | 4.17E-4 | 1.89E-4 | 1.47E-4 | 4.17E-4 | 1.89E-4 | 1.47E-4 | ||||
| 129 | 4.21E-5 | 1.71E-4 | 3.09E-5 | 1.55E-5 | 1.70E-6 | 3.09E-5 | 1.55E-5 | 1.70E-6 | ||||
| 257 | 5.12E-6 | 1.75E-5 | 2.04E-6 | 5.31E-7 | 5.22E-9 | 2.04E-6 | 5.31E-7 | 5.22E-9 | ||||
4.3. Example III: 1D Discontinuous Function
This example uses a modified version of a function introduced by Tadmor and Tanner (Tadmor2002, ) and used by Berzins (Berzins, ) in the context of bounded interpolation methods. The value one is added to the original function in (Tadmor2002, ) to ensure that the function is positive over the interval [-1,1]. The modified function is defined as
| (25) |
Table 3 shows -error norms when using the PCHIP, MQSI, DBI, and PPI methods to approximate the function in Equation (25). Approximating is challenging because is a piecewise function with a discontinuity at . The global error is dominated by the local errors around the discontinuity. The PCHIP, MQSI, DBI, and PPI approximation results are comparable. Increasing the target polynomial degree does not decrease the -error norms. The approximations in the smooth regions improve as we increase the target polynomial degree, but the global error is dominated by the error around the discontinuity. The error around the discontinuity does not decrease with higher polynomial degrees.
Figure 3 shows approximation plots of using uniformly spaced points with different values of . The target polynomial degree is set to . The bottom right part of Figure 3 shows oscillations at the left boundary for . The oscillations are removed for . As expected, all the interpolation methods have difficulties approximating the function around the discontinuity, as shown in Figure 3.
| PCHIP | MQSI | DBI | PPI | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 17 | 1.77E-1 | 1.76E-1 | 1.82E-1 | 1.83E-1 | 1.82E-1 | 1.73E-1 | 1.72E-1 | 1.70E-1 | ||||
| 33 | 1.39E-1 | 1.41E-1 | 1.35E-1 | 1.39E-1 | 1.36E-1 | 1.35E-1 | 1.39E-1 | 1.36E-1 | ||||
| 65 | 1.03E-1 | 1.06E-1 | 9.95E-2 | 1.04E-1 | 1.02E-1 | 9.95E-2 | 1.04E-1 | 1.02E-1 | ||||
| 129 | 7.42E-2 | 7.63E-2 | 7.12E-2 | 7.54E-2 | 7.35E-2 | 7.15E-2 | 7.55E-2 | 7.38E-2 | ||||
| 257 | 5.28E-2 | 5.43E-2 | 5.06E-2 | 5.38E-2 | 5.24E-2 | 5.07E-2 | 5.39E-2 | 5.26E-2 | ||||
4.4. Example IV: 2D Modified Runge Function
This example extends the previously modified 1D Runge function to 2D as follows:
| (26) |
Table 4 shows -error norms when using the PCHIP, MQSI, DBI, and PPI methods to approximate the 2D modified Runge function in Equation (26). In this example, as in Example I, the MQSI and PCHIP methods have comparable errors. The approaches used to approximate the derivatives and construct the quintic splines are not more accurate than the approximation obtained from PCHIP. The DBI and PPI methods with lead to better approximation results compared to the PCHIP and MQSI. As the target polynomial degree increases, the approximation errors from PPI decrease much faster than from DBI. The relaxed nature of the PPI methods allows for higher degree polynomials compared to DBI. The bounds for data-boundedness, which are based on Equation (11) with , are more restrictive than positivity for which and . In addition, the approximation does not lead to oscillations for and
| PCHIP | MQSI | DBI | PPI | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 17 | 1.76E-2 | 1.67E-2 | 2.12E-2 | 9.09E-3 | 1.91E-2 | 2.12E-2 | 9.09E-3 | 1.91E-2 | ||||
| 33 | 2.05E-3 | 2.84E-3 | 2.45E-3 | 4.61E-3 | 1.25E-3 | 2.45E-3 | 4.61E-3 | 1.24E-3 | ||||
| 65 | 1.05E-3 | 8.01E-4 | 8.59E-4 | 9.33E-4 | 4.99E-4 | 8.59E-4 | 9.33E-4 | 3.51E-4 | ||||
| 129 | 2.23E-4 | 2.57E-4 | 7.47E-5 | 4.76E-5 | 4.12E-5 | 7.47E-5 | 4.64E-5 | 7.16E-6 | ||||
| 257 | 4.19E-5 | 3.53E-5 | 5.05E-6 | 4.20E-6 | 3.80E-6 | 5.05E-6 | 1.62E-6 | 2.91E-8 | ||||
4.5. Example V: 2D Logistic Function
The test case extends the 1D logistic (smoothed Heaviside) function from Example II to 2D.
| (27) |
The function is challenging because of the large gradient at . Approximating with a standard polynomial interpolation leads to oscillations and negative values that violate the desired property of positivity.
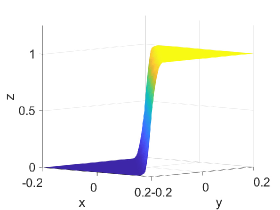
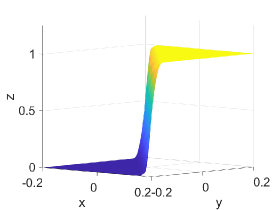
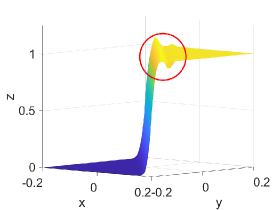
Table 5 shows -error norms when using the PCHIP, MQSI, DBI, and PPI methods to approximate the 2D logistic function defined in Equation (27). The errors from MQSI are larger compared to the other methods. In this example, the approximated derivatives and quintic splines from MQSI are less accurate than the approximations from PCHIP. The DBI and PPI methods lead to better approximation results compared to the PCHIP and MQSI approaches. Increasing the target polynomial degree improves the approximations for DBI and PPI, as shown in Table 5. The global error is dominated by the local around the steep gradients at . For points and above with , , and , the DBI and PPI choose the identical stencils for the intervals around the steep gradient. Therefore, the global error, which is dominated by the local error around the steep gradient, is the same for both DBI and PPI. However, for points with , , and , the DBI and PPI choose different stencils that lead to different errors, as indicated in the row with of Table 5. Figure 4 shows approximation plots of using uniformly spaced points with PCHIP, MQSI, and PPI. The approximations in Figures 4(c) and 4(e) are obtained using PPI with . The PPI method with is used for the approximations in Figures 4(d) and 4(f). The target polynomial degrees for the second and third rows are set to and , respectively. The oscillations increase when going from to with . For , the oscillations are significantly reduced, and the approximation is closer to the target solution.
| PCHIP | MQSI | DBI | PPI | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 17 | 8.07E-3 | 7.12E-3 | 1.05E-2 | 9.79E-3 | 8.18E-3 | 1.05E-2 | 9.77E-3 | 8.61E-3 | ||||
| 33 | 1.26E-3 | 2.62E-3 | 1.67E-3 | 1.36E-3 | 1.06E-3 | 1.64E-3 | 1.30E-3 | 8.87E-4 | ||||
| 65 | 1.44E-4 | 6.35E-4 | 1.58E-4 | 8.84E-5 | 4.89E-5 | 1.58E-4 | 8.84E-5 | 5.01E-5 | ||||
| 129 | 1.63E-5 | 6.51E-5 | 1.13E-5 | 3.07E-6 | 2.64E-7 | 1.13E-5 | 3.07E-6 | 2.64E-7 | ||||
| 257 | 1.94E-6 | 6.74E-6 | 7.29E-7 | 1.02E-7 | 5.39E-10 | 7.29E-7 | 1.02E-7 | 5.39E-10 | ||||
4.6. Example VI: -continuous Surface Function
This example is based on a 2D function used to study positive and monotonic splines (CHAN2001135, ; 10.1007/11537908_20, ). The function is defined as follows:
| (28) |
The function is challenging because it is only -continuous at various locations.
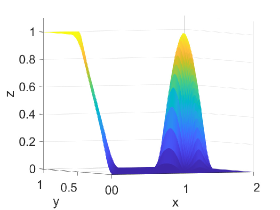
Table 6 shows -error norms when using the PCHIP, MQSI, DBI, and PPI methods to approximate the 2D function defined in Equation (28). The PCHIP, MQSI, DBI, and PPI methods lead to comparable error norms. Increasing the target polynomial degree does not significantly improve the approximation for DBI and PPI, as shown in Table 6. The global error is dominated by the local around the . The approximation for both DBI and PPI can be improved by using an underlying mesh that better captures the -continuity.
Figure 5 shows approximation plots of using uniformly spaced points with PCHIP, MQSI, and PPI. The left and right approximation plots show approximated solutions using the PPI method. For the left plot using PPI, , and for the right plot using PPI, The target polynomial degree is set to and for the second and third rows, respectively. For , the oscillations increase as the target polynomial degree increases from to . The oscillations observed for are removed for small values of and , shown in Figures 5(d) and 5(f).
| PCHIP | MQSI | DBI | PPI | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 17 | 1.91E-2 | 2.19E-2 | 1.72E-2 | 1.69E-2 | 1.63E-2 | 1.72E-2 | 1.68E-2 | 1.59E-2 | ||||
| 33 | 6.92E-3 | 7.44E-3 | 6.16E-3 | 5.81E-3 | 5.88E-3 | 6.16E-3 | 5.80E-3 | 5.87E-3 | ||||
| 65 | 2.47E-3 | 2.45E-3 | 2.24E-3 | 2.14E-3 | 2.11E-3 | 2.24E-3 | 2.14E-3 | 2.11E-3 | ||||
| 129 | 8.99E-4 | 8.69E-4 | 8.21E-4 | 7.77E-4 | 7.63E-4 | 8.20E-4 | 7.77E-4 | 7.63E-4 | ||||
| 257 | 3.23E-4 | 3.04E-4 | 2.97E-4 | 2.81E-4 | 2.76E-4 | 2.96E-4 | 2.81E-4 | 2.76E-4 | ||||
5. Mapping Error Analysis and Examples
This section provides an analysis of the mapping error between two different meshes in the context of time-dependent PDEs when DBI and PPI are employed to interpolate data values between the meshes. In addition to the error analysis, the Runge, tropical warm pool international cloud experiment (TWP-ICE), and Barbados oceanographic and meteorological experiment (BOMEX) examples are used to evaluate the use of the PPI and DBI to map data values between two meshes. The Runge and TWP-ICE examples use meshes that emulate the advection and reaction meshes used in NEPTUNE. These meshes are constructed by linearly scaling the NEPTUNE vertical mesh points to the desired interval for the Runge and TWP-ICE examples. In the BOMEX example, the advection mesh is composed of uniformly spaced points, and the reaction mesh is constructed using the mid-point of each interval from the advection mesh.
5.1. Mapping Error Analysis
In addition to the development and study of the DBI and PPI methods, it is important to provide some insight into the behavior of the mapping error in the context of time-dependent PDEs. An example of a time-dependent problem where a positivity-preserving mapping is required is the US Navy Environmental Prediction System Using the NUMA Core (NEPTUNE) (doyle:NEPTUNE, ). NEPTUNE is a next-generation global NWP system being developed at the Naval Research Laboratory (NRL) and the Naval Postgraduate School (NPS). In NEPTUNE, the physics and dynamics are calculated using different meshes and require mapping the solution values between both meshes. NEPTUNE uses nonuniform structured meshes that have vertical columns with nonuniformly spaced points inside each column. The mapping must preserve positivity for quantities such as density and cloud water mixing ratio. The cloud water mixing ratio is the amount of cloud water in air. At each time step, the dynamics (advection) solutions, which are calculated on the advection mesh, are mapped to the reaction mesh to be used as input for the physics calculations. The physics results are then mapped back to the dynamics to be used as input for the next time step. Enforcing positivity alone may still lead to large oscillations and approximation errors. Using the DBI method will remove the large oscillations but will truncate any hidden extremum and may be too restrictive for high-order accuracy in some cases. For simulations in which different structured meshes are used and mapping is required, the errors from both the DBI and unconstrained PPI will propagate into other calculations and may even cause the simulation to fail. This section provides an analysis of the mapping error when interpolating from one mesh to another and back to the starting mesh. The mapping error is considered within time-dependent PDEs. For example, when interpolating the data values between the advection and reaction mesh in NEPTUNE, a mapping error is introduced in addition to the physics and time integration errors. The error in approximating a function with the Newton polynomial over the interval is
| (29) |
where . Given that and are not known, the local interpolation error in Equation (29) can approximated as follows:
| (30) |
where
The error approximation in Equation (30) is based on the mean value theorem for divided differences, which states that there exist such that
Equation (30) approximates the local interpolation error for each interval when mapping from one set of points to another. To consider a mapping error for interpolating from one mesh to another and back to the starting mesh, let and be the advection and reaction mesh, respectively. In addition, let and be the interpolation operators that map a given set of data values from to and from to , respectively. We consider an advection-reaction problem where the advection part is calculated on and the reaction on . A simple forward Euler time integration is used. Let and be the approximate and the exact solution at time . The dynamics/advection part is written as
| (31) |
and the physics/reaction is expressed as
| (32) |
where . Let be the global space and time error accumulated up to after the advection in Equation (31) and before mapping the solution values to . does not include the mapping errors at . The final solution after applying the operator in Equation (32) is
| (33) |
The true solution at the end of time step and after the mapping from to and back to can be expressed as
| (34) |
where is assumed to be the corresponding “exact” operator for . Subtracting Equation (34) from (33) gives an expression for the true error that can be written as
where is the global space and time error including the mapping errors at . Adding and subtracting yields
Using a Taylor expansion of about and dropping the high-order terms, we can approximate the total errors as
| (35) |
The results in Equation (35) indicate that the total error is dependent on
-
•
the existing global space and time error , which does not include the mapping error at ,
-
•
the mapping error at ,
-
•
a multiplier of the existing global space and time error ,
Mapping data values from to and back to introduces the interpolation errors that degrade the solution if is greater than the existing global space and time error . This problem is resolved when the mapping error is kept smaller than the existing global space and time error. Similar ideas in the context of time dependent differential equations are explored in (doi:10.1137/050622092, ; doi:10.1137/0912031, ; BERZINS1998117, ). The studies in (doi:10.1137/050622092, ) and (doi:10.1137/0912031, ) develop strategies for balancing the space and time error for better error control and improved performance while (BERZINS1998117, ) show that in mesh adaptivity the spatial interpolation error must be controlled and kept smaller than the temporal error.
5.2. 1D Modified Runge Function
This example is based on the modified version of the Runge function defined in Equation (23) and two meshes that emulate the dynamics/advection () and physics/reaction () meshes used in NEPTUNE. No actual PDE is solved in this example. Here, we consider the advection time step of the trivial case where the identity operator is used to represent the advection and reaction. The function is evaluated on advection mesh to create the initial data values. Given that the identity operator is used for both the advection and reaction, these initial data values are mapped to the reaction mesh and back to the starting mesh . Using the identity operator allows for a study of the mapping error without the influence of the advection and reaction.
Table 7 shows -norms of the mapping errors over the grid points for when using the PCHIP, MQSI, DBI, and PPI methods to map the data values from the advection mesh to the reaction mesh and back to the advection mesh. For points, increasing the interpolant degree does not significantly improve the approximation. The global error is dominated by the local error in the regions with steep gradients that are to the left and right of the peak at . The mapping errors can be improved by increasing the resolution and adding more points in the regions with steep gradients. The resolution is increased by adding one or three uniformly spaced points in each interval from the initial profile with 64 points. Increasing the resolution leads to better approximations when mapping data values between both meshes, and the error decreases as we increase the polynomial degree from to . This example demonstrates that in cases with steep gradients, using the PPI method with high-order interpolants may not significantly improve the approximation unless there is sufficient resolution. In order to benefit from the positivity and the high-order interpolants, it is important to be in the regime where the problem has sufficiently many points to observe convergence as the polynomial degree increases. Overall, the PPI method leads to smaller errors compared to the other methods as the resolution and polynomial degree increase.
| PCHIP | MQSI | DBI | PPI | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 64 | 2.92E-03 | 1.93E-03 | 4.93E-03 | 4.78E-04 | 7.12E-05 | 3.99E-03 | 3.13E-04 | 2.85E-05 | ||||
| 127 | 3.81E-04 | 5.57E-04 | 3.58E-03 | 3.81E-04 | 6.50E-05 | 2.85E-03 | 1.02E-04 | 3.65E-06 | ||||
| 253 | 6.71E-05 | 1.48E-04 | 3.41E-03 | 3.69E-04 | 6.49E-05 | 2.46E-03 | 3.50E-05 | 8.62E-07 | ||||
5.3. TWP-ICE Example
This study uses the tropical warm pool international cloud experiment (TWP-ICE) test case from the common community physics package (CCPP) (ccpp-v4, ). The input mesh for the simulation is configured to emulate a vertical column in NEPTUNE. The simulation result at time sec is extracted and scaled, and used to evaluate different interpolation approaches when mapping solution values between advection and reaction meshes. The domain and range are scaled to and , respectively. This study considers the cloud water mixing ratio profile, which represents the amount of cloud water in air. The extracted profile is then fitted using a radial basis function interpolation to construct an analytical function that can be used as the starting point of the mapping evaluation. The radial basis function is based on multiquadrics:
The parameter is approximated using cross validation (fasshauer2007choosing, ). The initial values are obtained by evaluating the analytical function on the advection mesh. These values are then mapped to the reaction mesh and back to the advection mesh.
Table 8 shows norms of the mapping errors for the extracted profile when using the PCHIP, DBI, and PPI methods to map the data values from the advection to physics mesh and back to advection mesh. For , the global error is dominated by the local error at a few points located in the regions with steep gradients. Increasing the polynomial degree does not significantly improve the approximation compared to using PCHIP for . More points are required to better approximate the underlying profile in the regions with steep gradients. The resolutions are increased by adding one and three uniformly spaced points in each interval from the initial mesh points. Table 8 shows that with the increased resolution, the approximation improves as the polynomial degree increases. The number of points used in each region with steep gradients increased as more points were added. This example provides an application example using simulation data from TWP-ICE. In cases of coarse resolution (64 points), the PCHIP and MQSI results are comparable and going to higher degree interpolants doesn’t significantly improve the approximation for DBI and PPI. The approximation improves with higher degree interpolants when the resolution is increased, as shown in Table 8. The results from this experiment suggest that increasing the resolution is needed for the mapping between meshes to benefit from the high-order interpolants from the PPI methods.
| PCHIP | MQSI | DBI | PPI | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 64 | 4.66E-03 | 3.25E-03 | 1.17E-02 | 3.15E-03 | 6.77E-04 | 5.11E-03 | 9.86E-04 | 1.12E-04 | ||||
| 127 | 1.56E-03 | 2.05E-03 | 1.12E-02 | 3.10E-03 | 6.49E-04 | 2.30E-03 | 3.10E-04 | 1.83E-05 | ||||
| 253 | 4.89E-04 | 6.92E-04 | 1.11E-02 | 3.11E-03 | 6.46E-04 | 1.41E-03 | 1.45E-04 | 3.70E-06 | ||||
5.4. BOMEX Example
Here, a maritime shallow convection example based on the 1D Barbados Oceanographic and Meteorological Experiment (BOMEX) (friedman1970essa, ) is used to study the effects of the different interpolation methods in an application. BOMEX is a single-column shallow convection test case used to measure and study changes in temperature, wind, water vapor mixing ratio, rain water mixing ratio, and cloud water mixing ratio. The mixing ratios represent the amount of water vapor, rain water, and cloud water in air. In this simulation, the dynamics/advection is modeled by
where is the state variable that contains the wind, temperature, water vapor mixing ratio, cloud water mixing ratio, and rain water mixing ratio. The dynamics are approximated using fifth-order weighted essentially nonoscillatory (WENO) and third-order Runge-Kutta methods (doi:10.1080/1061856031000104851, ). The physics component of the simulation uses the hybrid eddy-diffusivity mass-flux and free atmospheric turbulence (hybrid EDMF) and Kessler microphysics schemes from (ccpp-v4, ) to alter the results of the dynamics and incorporate the physics properties. The dynamics and physics results are calculated on different meshes. At each time step, the dynamics are calculated on the advection mesh , and the results are interpolated to the reaction mesh for the use of the physics routines. The physics terms are calculated using the reaction mesh , and the results are interpolated back to the advection mesh .
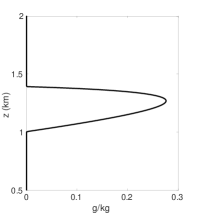
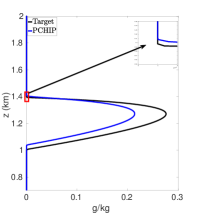
As in (Rotstayn2000, ), let be the cloud water mixing ratio profile in the different experiments. Figures 6(a) - 7(f) show the cloud mixing ratio profile at hours that is used as input for the physics routines. The physics calculations require positive input values for . Figure 6(a) shows the target profile for . This target profile is obtained by using the same mesh for both dynamics and physics calculations where mapping is not required and remains positive during the simulation. In addition, as the temporal and spatial resolution increases, converges to the profile shown in Figure 6(a). Figures 6(b) - 7(f) are used to investigate different interpolation methods for mapping the solution values between meshes in the case where the dynamics and physics are calculated using different meshes.
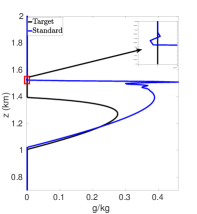
Figure 6(b) shows the cloud mixing ratio profiles for the target and approximated solution at hours. In the case of the approximated solution, a fifth-order standard polynomial interpolation is used when mapping between the advection and reaction meshes. For a given interval , the polynomial interpolant is constructed using the stencil . At the boundary and nearby boundary intervals, the stencil is biased toward the interior of the domain. The results in Figure 6(b) demonstrate that using the standard polynomial interpolation leads to oscillations, negative values, and an overestimation of the peak and total cloud mixing ratio of the profile . Using standard polynomial interpolation leads to an overproduction of the total cloud mixing ratio by . The peak is , which is larger than the target peak .
The negative values in Figure 6(b) can be removed via “clipping”, which is a procedure that consists of removing the negative values by setting them to zero. Figure 6(c) shows the cloud mixing ratio profiles for the target solution and an approximated solution that uses “clipping” to remove the negative values at each time step. The approximated solution uses a standard interpolation to map the data values from one mesh to another. The interpolant for each interval is constructed using the stencil with a fifth-order polynomial. Once the interpolation is completed, “clipping” is used to remove the negative values. Figure 6(c) shows that using “clipping” still allows for oscillations and a positive bias in the prediction of the cloud mixing ratio . The total cloud mixing ratio is times greater than the target solution, and the peak is larger than the target peak .
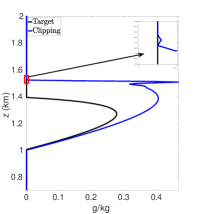
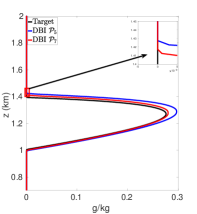
Using PCHIP to map between the advection and reaction meshes eliminates the negative values, removes oscillations, and reduces the positive bias in the cloud mixing ratio prediction compared to the standard interpolation with and without “clipping”. Figure 6(d) shows the target profile and an approximated profile that uses PCHIP for mapping solution values between advection and reaction meshes. The total cloud mixing ratio is now less than the target with a peak . In the BOMEX test case, NEPTUNE, and similar codes, using PCHIP for mapping data values from one mesh to another can degrade the high-order accuracy obtained from the high-order methods used for the dynamics calculations. PCHIP is only third-order whereas the dynamics calculations use a fifth-order method. This limitation can be addressed via high-order DBI and PPI. Here, the MQSI method is not used because it oversmoothes the state variable at each time step and leads to no production of cloud mixing ratio.
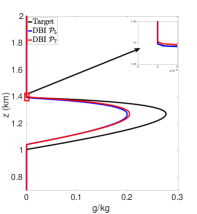
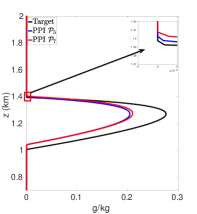
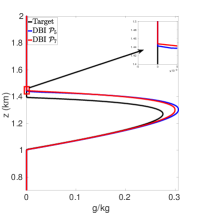
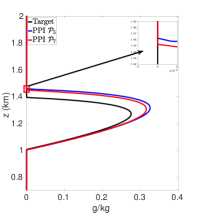
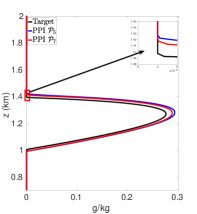
Figures 7(a)-7(f) show cloud mixing ratio profiles for the target and approximated solutions that use the DBI and PPI methods to map the solution values between meshes. The maximum polynomial degree for the DBI and PPI methods is set to and , and the parameters and are both set a value of . For larger values of and , the PPI approach introduces oscillations that lead to positive bias prediction of the cloud mixing ratio. These oscillations are caused by the relaxed nature of the PPI approach, which still allows the interpolants to oscillate while remaining positive. The positive bias and oscillations can be removed using the DBI or PPI method with small values for and . When using the PPI method for mapping, the total amount of the cloud mixing ratio is less than the target for and more than the target for and . Figures 7(a)-7(f) show that using the DBI and PPI methods with to map data values between the advection and reaction meshes eliminates the negative values, removes the oscillations, and significantly reduces the positive bias in the cloud mixing ratio prediction. Using the DBI and PPI methods leads to a better approximation of the peak value of the total cloud mixing ratio compared to using the standard interpolation and PCHIP approaches. The best approximation of the total amount of the cloud mixing ratio is with the DBI method, which is more than the target with a peak of .
In summary, using DBI and PPI methods to map data values between both the advection and reaction meshes produces better approximation results compared to the standard interpolation and PCHIP methods. Tables 9 and 10 provide a summary of the maximum values and the total amount of cloud mixing ratios for each case. The DBI and PPI methods with a target polynomial set to lead to a better approximation of the peak and the total cloud mixing ratios compared to the standard interpolation and PCHIP approaches. The results from Tables 9 and 10 indicate that the DBI method is the most suitable approach to map data values between meshes for the BOMEX test case. This study provided an example demonstrating how to use the DBI and PPI methods for mapping data values between meshes in the context of NWP. The BOMEX example also demonstrated that positivity alone may not be sufficient to remove oscillations in the solution, and the interpolants may need to be constrained to be between the data values for a better approximation.
| Target | STD | Clipping | PCHIP | |
|---|---|---|---|---|
| maximum | 0.28 | 0.46 | 0.46 | 0.21 |
| total | 69.82 | 135.07 | 145.89 | 50.82 |
| Target | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| DBI | |||||||||
| maximum | 0.20 | 0.20 | 0.31 | 0.30 | 0.30 | 0.28 | 0.28 | ||
| total | 45.91 | 47.74 | 87.98 | 86.57 | 82.67 | 75.11 | 69.82 | ||
| PPI | |||||||||
| maximum | 0.20 | 0.21 | 0.33 | 0.32 | 0.29 | 0.29 | 0.28 | ||
| total | 47.87 | 50.09 | 97.60 | 92.54 | 81.44 | 78.85 | 69.82 | ||
6. Discussion and Concluding Remarks
In this work we introduced HiPPIS: a high-order 1D, 2D, and 3D data-bounded and positivity-preserving interpolation software for structured meshes. The software implementation is based on the mathematical framework in Section 2 and the algorithms in Section 3. The software is self-contained and can be incorporated into larger codes that require data-bounded or positivity-preserving interpolation. The interface is designed to be similar to commonly used PCHIP and splines interfaces. The algorithms used in the software extend the DBI and PPI methods introduced in (Ouermi2022, ) by adding more options for the stencil construction process that can be set by the user with the parameter . For a given interval , the algorithm starts with the stencil and successively appends points to the left and/or right of to form the final stencil. The stencil construction is done in accordance with the DBI and PPI conditions outlined in Equations (21a) and (21b). In addition to the different options for the stencil selection process, the software introduces a parameter that can be used to adjust the bounds of the interpolants in the intervals where extrema are detected.
Various 1D and 2D examples are employed to evaluate the use of the DBI and PPI software in different contexts. The results in Section 4 show that for Examples I, II, IV, and V, which are based on underlying smooth functions, the DBI and PPI methods produce more accurate results compared to PCHIP and MQSI. For Example III, and VI which are obtained from discontinuous and -continuous functions, all the methods have comparable errors. Figures 2-5 show that the parameters and can be used to reduce undesired oscillations from the PPI method. We only report the results for because the differences between , , and are negligible for the examples in Section 4.
Section 5 provides an analysis and numerical comparison of the mapping error when the DBI and PPI methods are used to map data values between different meshes. The error analysis in Section 5.1 shows that it is important to keep mapping errors smaller than the already existing global errors from other calculations. Removing negative values and spurious oscillations can help reduce the mapping error.
The results in Tables 7 and 8 show that using small values for parameters and improves the approximation in cases where the input data are coarse. Small values of and further restrict how much the interpolant is allowed to grow beyond the data values. The parameters and are used to adjust the lower and upper bounds on each interpolant according to Equations (12) and (13). The study of the modified Runge example in Section 5.2 and TWP-ICE example in Section 5.3 demonstrated that for a profile with steep gradients or fronts, more points are required to better take advantage of the DBI and PPI algorithm. If there are not sufficiently many points in the regions with steep gradients or fronts, increasing the polynomial degree may not improve the accuracy. The results in Tables 7 and 8 show that once the resolution is sufficiently increased, the approximations improve as the polynomial degree increases.
In the BOMEX test case, prioritizing a symmetry () or locality () leads to better approximations compared to the ENO stencil () using the DBI and PPI methods. Using the ENO stencil () produces significantly less cloud mixing ratio compared to both the prioritizing symmetry and locality. In the BOMEX example with parameters and greater than , the PPI method allows for oscillations that degrade the approximation compared to the DBI and PCHIP approaches. The MQSI method is not used for the BOMEX example because it oversmoothes the different variables at each time step and leads to no production of cloud mixing ratio.
In summary, this work provided (1) a high-order DBI and PPI software for 1D, 2D, and 3D structured meshes; (2) an analysis of the mapping error when using the DBI or PPI to map data values between meshes; and (3) an evaluation of the DBI and PPI methods in the context of function approximation and interpolating data values between different meshes. As this work continues, we plan to investigate different approaches for extending the DBI and PPI methods to unstructured 2D and 3D meshes.
Acknowledgements.
This work has been supported by the US Naval Research Laboratory (559000669), the National Science Foundation (1521748), and the Intel Graphics and Visualization Institute at the University of Utah’s Scientific Computing and Imaging (SCI) Institute (29715).References
- (1) Balsara, D. S. Self-adjusting, positivity preserving high order schemes for hydrodynamics and magnetohydrodynamics. Journal of Computational Physics 231, 22 (2012), 7504–7517.
- (2) Berzins, M. Adaptive polynomial interpolation on evenly spaced meshes. SIAM Review 49, 4 (2007), 604–627.
- (3) Berzins, M. Nonlinear data-bounded polynomial approximations and their applications in eno methods. Numerical Algorithms 55, 2 (2010), 171–189.
- (4) Berzins, M., Capon, P. J., and Jimack, P. K. On spatial adaptivity and interpolation when using the method of lines. Applied Numerical Mathematics 26, 1 (1998), 117–133.
- (5) Chan, E., and Ong, B. Range restricted scattered data interpolation using convex combination of cubic bézier triangles. Journal of Computational and Applied Mathematics 136, 1 (2001), 135 – 147.
- (6) Costantini, P. Algorithm 770: Bvspis–a package for computing boundary-valued shape-preserving interpolating splines. ACM Trans. Math. Softw. 23, 2 (jun 1997), 252–254.
- (7) Fasshauer, G. E., and Zhang, J. G. On choosing “optimal” shape parameters for rbf approximation. Numerical Algorithms 45, 1 (2007), 345–368.
- (8) Firl, G., Carson, L., Harrold, M., Bernardet, L., and Heinzeller, D. Common community physics package single column model (scm), Sept 2020.
- (9) Friedman, H. A., Conrad, G., and McFadden, J. D. Essa research flight facility aircraft participation in the barbados oceanographic and meteorological experiment. Bulletin of the American Meteorological Society 51, 9 (1970), 822–834.
- (10) Fritsch, F. N., and Carlson, R. E. Monotone piecewise cubic interpolation. SIAM Journal on Numerical Analysis 17, 2 (1980), 238–246.
- (11) Goodyer, C. E., and Berzins, M. Adaptive timestepping for elastohydrodynamic lubrication solvers. SIAM Journal on Scientific Computing 28, 2 (2006), 626–650.
- (12) Green, K. R., Bohn, T. A., and Spiteri, R. J. Direct function evaluation versus lookup tables: When to use which? SIAM Journal on Scientific Computing 41, 3 (2019), C194–C218.
- (13) Harten, A., Engquist, B., Osher, S., and Chakravarthy, S. R. Uniformly high order accurate essentially non-oscillatory schemes, iii. Journal of Computational Physics 131, 1 (1997), 3 – 47.
- (14) Heß, W., and Schmidt, J. W. Positive quartic, monotone quintic c2-spline interpolation in one and two dimensions. Journal of Computational and Applied Mathematics 55, 1 (1994), 51 – 67.
- (15) Hu, X. Y., Adams, N. A., and Shu, C.-W. Positivity-preserving method for high-order conservative schemes solving compressible euler equations. Journal of Computational Physics 242 (2013), 169–180.
- (16) Hussain, M., Hussain, M. Z., and Cripps, R. J. C2 rational quintic function. Journal of Prime Research in Mathematics 5 (2009), 115–123.
- (17) Hussain, M. Z., Hussain, M., and Yameen, Z. A C2-continuous rational quintic interpolation scheme for curve data with shape control. Journal of The National Science Foundation of Sri Lanka 46 (2018), 341.
- (18) Hussain, M. Z., and Sarfraz, M. Positivity-preserving interpolation of positive data by rational cubics. Journal of Computational and Applied Mathematics 218, 2 (2008), 446 – 458. The Proceedings of the Twelfth International Congress on Computational and Applied Mathematics.
- (19) James D. Doyle and P. A. Reinecke, K. C. Viner, S. Gabersek, M. Martini, D. D. Flagg, J. Michalakes, D. R. Ryglicki, and F. X. Giraldo. Next generation nwp using a spectral element dynamical core, January 2017.
- (20) Karim, A., Ariffin, S., Voon Pang, K., and Saaban, A. Positivity preserving interpolation using rational bicubic spline. Journal of Applied Mathematics 2015 (2015).
- (21) Krogh, F. T. Efficient algorithms for polynomial interpolation and numerical differentiation. Mathematics of Computation 24, 109 (1970), 185–190.
- (22) Lawson, J., Berzins, M., and Dew, P. M. Balancing space and time errors in the method of lines for parabolic equations. SIAM Journal on Scientific and Statistical Computing 12, 3 (1991), 573–594.
- (23) Light, D., and Durran, D. Preserving nonnegativity in discontinuous galerkin approximations to scalar transport via truncation and mass aware rescaling (tmar). Monthly Weather Review 144, 12 (2016), 4771–4786.
- (24) Liu, H., Gao, Z., Jiang, C., and Lee, C. Numerical study of combustion effects on the development of supersonic turbulent mixing layer flows with weno schemes. Computers and Fluids 189 (2019), 82–93.
- (25) Lux, T., Watson, L. T., Chang, T., and Thacker, W. Algorithm 1031: Mqsi–monotone quintic spline interpolation. ACM Trans. Math. Softw. 49, 1 (mar 2023).
- (26) Lux, T. C. H., Watson, L. T., and Chang, T. H. An algorithm for constructing monotone quintic interpolating splines. In SpringSim ’20: Proceedings of the 2020 Spring Simulation Conference, May 2020 (2019), pp. 1–12.
- (27) Moler, C. B. Numerical computing with MATLAB. SIAM, 2004.
- (28) Ouermi, T. A. J., Kirby, R. M., and Berzins, M. Numerical testing of a new positivity-preserving interpolation algorithm, 2020.
- (29) Ouermi, T. A. J., Kirby, R. M., and Berzins, M. Eno-based high-order data-bounded and constrained positivity-preserving interpolation. Numerical Algorithms (2022).
- (30) Piah, A. R. M., Goodman, T. N. T., and Unsworth, K. Positivity-preserving scattered data interpolation. In Mathematics of Surfaces XI (Berlin, Heidelberg, 2005), R. Martin, H. Bez, and M. Sabin, Eds., Springer Berlin Heidelberg, pp. 336–349.
- (31) Rogerson, A., and Meiburg, E. A numerical study of the convergence properties of eno schemes. Journal of Scientific Computing 5, 2 (1990), 151–167.
- (32) Rotstayn, L. D., Ryan, B. F., and Katzfey, J. J. A scheme for calculation of the liquid fraction in mixed-phase stratiform clouds in large-scale models. Monthly Weather Review 128, 4 (2000), 1070–1088.
- (33) Sahasrabudhe, D., Berzins, M., and Schmidt, J. Node failure resiliency for uintah without checkpointing. Concurrency and Computation: Practice and Experience (2019), e5340.
- (34) Sarfraz, M. A c2 rational cubic spline alternative to the nurbs. Computers and Graphics 16, 1 (1992), 69 – 77.
- (35) Schmidt, J. W., and Heß, W. Positive interpolation with rational quadratic splines. Computing 38, 3 (Sep 1987), 261–267.
- (36) Schmidt, J. W., and Heß, W. Positivity of cubic polynomials on intervals and positive spline interpolation. BIT 28, 2 (feb 1988), 340–352.
- (37) Sekora, M., and Colella, P. Extremum-preserving limiters for muscl and ppm, 2009.
- (38) Shu, C.-W. Numerical experiments on the accuracy of eno and modified eno schemes. Journal of Scientific Computing 5, 2 (1990), 127–149.
- (39) Shu, C.-W. High-order finite difference and finite volume weno schemes and discontinuous galerkin methods for cfd. International Journal of Computational Fluid Dynamics 17, 2 (2003), 107–118.
- (40) Skamarock, W. C., and Weisman, M. L. The impact of positive-definite moisture transport on nwp precipitation forecasts. Monthly Weather Review 137, 1 (2009), 488–494.
- (41) Subbareddy, P. K., Kartha, A., and Candler, G. V. Scalar conservation and boundedness in simulations of compressible flow. Journal of Computational Physics 348 (2017), 827–846.
- (42) Tadmor, E., and Tanner, J. Adaptive mollifiers for high resolution recovery of piecewise smooth data from its spectral information. Foundations of Computational Mathematics 2, 2 (Jan 2002), 155–189.
- (43) Tal-Ezer, H. High degree polynomial interpolation in newton form. SIAM Journal on Scientific and Statistical Computing 12, 3 (1991), 648–667.
- (44) Ulrich, G., and Watson, L. T. Positivity conditions for quartic polynomials. SIAM Journal on Scientific Computing 15, 3 (1994), 528–544.
- (45) Zhang, X. On positivity-preserving high order discontinuous galerkin schemes for compressible navier–stokes equations. Journal of Computational Physics 328 (2017), 301 – 343.
- (46) Zhang, X., and Shu, C.-W. Positivity-preserving high order finite difference weno schemes for compressible euler equations. J. Comput. Phys. 231, 5 (Mar. 2012), 2245–2258.