AIM 2020 Challenge on
Video Temporal Super-Resolution
Abstract
Videos in the real-world contain various dynamics and motions that may look unnaturally discontinuous in time when the recorded frame rate is low. This paper reports the second AIM challenge on Video Temporal Super-Resolution (VTSR), a.k.a. frame interpolation, with a focus on the proposed solutions, results, and analysis. From low-frame-rate (15 fps) videos, the challenge participants are required to submit higher-frame-rate (30 and 60 fps) sequences by estimating temporally intermediate frames. To simulate realistic and challenging dynamics in the real-world, we employ the REDS_VTSR dataset derived from diverse videos captured in a hand-held camera for training and evaluation purposes. There have been 68 registered participants in the competition, and 5 teams (one withdrawn) have competed in the final testing phase. The winning team proposes the enhanced quadratic video interpolation method and achieves state-of-the-art on the VTSR task.
Keywords:
Video Temporal Super-Resolution, Frame Interpolation1 Introduction
††footnotetext: S. Son ([email protected], Seoul National University), J. Lee, S. Nah, R. Timofte, K. M. Lee are the challenge organizers, while the other authors participated in the challenge. Appendix 0.A contains the authors’ teams and affiliations.AIM 2020 webpage: https://data.vision.ee.ethz.ch/cvl/aim20/
Competition webpage: https://competitions.codalab.org/competitions/24584
The growth of broadcasting and streaming services have brought needs for high-fidelity videos in terms of both spatial and temporal resolution. Despite the advances in modern video technologies capable of playing videos in high frame-rates, e.g., 60 or 120 fps, videos tend to be recorded in lower frame-rates due to the recording cost and quality adversaries [25]. First, fast hardware components are required to process and save large numbers of pixels in real-time. For example, memory and storage should be fast enough to handle at least 60 FHD (1920 1080) video frames per second, while the central processor has to encode those images into a compressed sequence. Meanwhile, relatively high compression ratios are required to save massive amounts of pixels into slow storage. Line-skipping may occur at the sensor readout time to compensate for the slow processor. Also, small camera sensors in mobile devices may suffer from high noise due to the short exposure time as the required frame rate goes higher. Such limitations can degrade the quality of recorded videos and make them difficult to be acquired in practice.
To overcome those constraints, video temporal super-resolution (VTSR), or video frame interpolation (VFI), algorithms aim to enhance the temporal smoothness of a given video by interpolating missing frames. For such purpose, several methods [17, 24, 29, 30, 38, 39] have been proposed to reconstruct smooth and realistic sequences from videos of low-frame-rate, which looks discontinuous in the temporal domain. Nevertheless, there also exist several challenges in conventional VTSR methods. First, real-world motions are highly complex and nonlinear, not easy to estimate with simple dynamics. Also, since the algorithm has to process videos of high-quality and high-resolution, efficient approaches are required to handle thousands of frames swiftly in practice.
To facilitate the development of robust and efficient VTSR methods, we have organized AIM 2020 VTSR challenge. In this paper, we report the submitted methods and the benchmark results. Similarly to the last AIM 2019 VTSR challenge [26], participants are required to recover 30 and 60 fps video from low-frame-rate 15 fps input sequences from the REDS_VTSR [26] dataset. 5 teams have submitted the final solution, and the XPixel team won the first-place prize with the Enhanced Quadratic Video Interpolation method. The following sections describe the related works and introduce AIM 2020 Video Temporal Super-Resolution challenge (VTSR) in detail. We also present and discuss the challenge results with the proposed approaches.
2 Related Works
While some approaches synthesize intermediate frames directly [22, 6], most methods embed motion estimation modules into neural network architectures. Roughly, the motion modeling could be categorized into phase, kernel, and flow-based approaches. Several methods try to further improve inference accuracy adaptively to the input.
Phase-based, Kernel-based methods: In an early work of Meyer et al. [24], the temporal change of frames is modeled as phase shifts. The PhaseNet [23] model has utilized steerable pyramid filters for encoding larger dynamics with a phase shift. On the other hand, kernel-based approaches use convolutional kernels to shift the input frames to an intermediate position. The AdaConv [29] model estimates spatially adaptive kernels, and the SepConv [27] improves computational efficiency by factorizing the 2D spatial kernel into 1D kernels.
Flow-based approaches: Meanwhile, optical flow-based piece-wise linear models have grown popular. The DVF [21] and SuperSloMo [17] models estimate optical flow between two input frames and warp them to the target intermediate time. Later, the accuracy of SuperSloMo is improved by training with cycle consistency loss [34]. The TOF [39], CtxSyn [27], and BMBC [32] models additionally apply image synthesis modules on the warped frames to produce the intermediate frame. To interpolate high-resolution videos in fast speed, the IM-Net [33] uses block-level horizontal/vertical motion vectors in multi-scale.
It is essential to handle the occluded area when warping with the optical flow as multiple pixels could overlap in the warped location. Jiang et al. [17] and Yuan et al. [40] estimate occlusion maps to exclude invalid contributions. Additional information is explored, such as depth [1] and scene context [27] to determine proper local warping weights. Niklaus et al. [28] suggests forward warping with the softmax splatting method, while many other approaches use backward warping with sampling.
Several works tried mixed motion representation of kernel-based and flow-based models. The DAIN [1] and MEMC-Net [2] models use both the kernel and optical flow to apply adaptive warping. The AdaCof [18] unifies the combined representation via an adaptive collaboration of flows in a similar formulation as deformable convolution [7]. To enhance the degree of freedom in the representation, the local weight values differ by position.
Despite the success of motion estimation with optical flow, complex motions in the real world are hard to be modeled due to the simplicity of optical flow. Most of the methods using the optical flow between the two frames are limited to locally linear models. To improve the degree of freedom in the motion model, higher-order representations are proposed. Quadratic [38, 19] and cubic [4] motion flow is estimated from multiple input frames. Such higher-order polynomial models could reflect accelerations and nonlinear trajectories. In AIM 2019 Challenge on Video Temporal Super-Resolution, the quadratic video interpolation method [38, 19] achieved the best accuracy.
Refinement methods: On top of the restored frames, some methods try to improve the initial estimation with various techniques. Gui et al. [10] propose a 2-stage estimation method. Initial interpolation is obtained with a structure guide in the first stage and the second stage refines the texture. Choi et al. [5] perform test-time adaptation of the model via meta-learning. Motivated by classical pyramid energy minimization, Zhang et al. [41] propose a recurrent residual pyramid network. Residual displacements are refined via recurrence.





3 AIM 2020 VTSR Challenge
This challenge is one of the AIM 2020 associated challenges on: scene relighting and illumination estimation [8], image extreme inpainting [31], learned image signal processing pipeline [15], rendering realistic bokeh [16], real image super-resolution [37], efficient super-resolution [42], and video extreme super-resolution [9]. Our development phase has started on May 1st, and the test phase is opened on July 10th. Participants are required to prepare and submit their final interpolation results in one week. In AIM 2020 VTSR challenge, there have been a total of 68 participants registered in the CodaLab. 5 teams, including one withdrawn, have submitted their final solution after the test phase.
3.1 Challenge goal
The purpose of the AIM 2020 VTSR challenge is to develop state-of-the-art VTSR algorithms and benchmark various solutions. Participants are required to reconstruct 30 and 60 fps video sequences from 15 fps inputs. We provide 240 training sequences and 30 validation frames from the REDS_VTSR [25] dataset with 60 fps ground-truth videos. The REDS_VTSR dataset is captured by GoPro 6 camera and contains HD-quality (1280 720) videos with 43,200 independent frames for training. At the end of the test phase, we evaluate the submitted methods on disjoint 30 test sequences. Fig. 1 shows a sample test sequence.
3.2 Evaluation metrics
In conventional image restoration problems, PSNR and SSIM between output and ground-truth images are considered standard evaluation metrics. In the AIM 2020 VTSR challenge, we use the PSNR as a primary metric, while SSIM values are also provided. We also require all participants to submit their codes and factsheets at the submission time for the fair competition. We then check consistency between submitted result images and reproduced outputs by challenge organizers to guarantee reproducible methods. Since VTSR models are required to process thousands of frames swiftly in practice, one of the essential factors in the algorithms is their efficiency. Therefore, we measure the runtime of each method in a unified framework to provide a fair comparison. Finally, this year, we have experimentally included a new perceptual metric, LPIPS [43], to assess the visual quality of result images. Similar to the PSNR and SSIM, the reference-based LPIPS metric is also calculated between interpolated and ground-truth frames. However, it is known that the LPIPS shows a better correlation with human perception [43] than the conventional PSNR and SSIM. We describe more details in Section 4.2.
| 15fps 30fps | 15fps 60fps | Runtime | |||
| Team | PSNR↑ | SSIM↑ | PSNR↑ | SSIM↑ | (s/frame) |
| XPixel [20] (Challenge Winner) | 24.78 | 0.7118 | 25.69 | 0.7425 | 12.40 |
| KAIST-VICLAB | 24.69 | 0.7142 | 25.61 | 0.7462 | 1.57 |
| BOE-IOT-AIBD (Reproduced) | 24.49 | 0.7034 | 25.27 | 0.7326 | 1.00 |
| TTI | 23.59 | 0.6720 | 24.36 | 0.6995 | 6.45† |
| BOE-IOT-AIBD (Submission) | 24.40 | 0.6972 | 25.19 | 0.7269 | - |
| Withdrawn team | 24.29 | 0.6977 | 25.05 | 0.7267 | 2.46 |
| SenseSloMo (AIM 2019 Winner) | 24.56 | 0.7065 | 25.47 | 0.7383 | - |
| SepConv [30] | 22.48 | 0.6287 | 23.40 | 0.6631 | - |
| Baseline (overlay) | 19.68 | 0.6384 | 20.39 | 0.6625 | - |















4 Challenge Results
Table 1 shows the overall summary of the proposed methods from the AIM 2020 VTSR challenge. The XPixel team has won the first prize, while the KAIST-VICLAB team follows by small margins. We also provide visual comparisons between the submitted methods. Fig. 2 illustrates how various algorithms perform differently on a given test sequence.
4.1 Result analysis
In this section, we focus on some test examples where the proposed methods show interesting behaviors. First, we pick several cases where different methods show high performance, i.e., PSNR, variance. Such analysis can show an advantage of a specific method over the other approaches. In the first row of Fig. 3, the XPixel team outperforms all the other by a large margin by achieving 32.64dB PSNR. Compared to the other results, it is clear that an accurate reconstruction of the intermediate frame has contributed to high performance. On the other hand, the KAIST-VICLAB and TTI team show noticeable performance in the second and third row of Fig. 3, respectively. In those cases, precise alignments play a critical role in achieving better performance. Specifically, Fig. 3(i) looks perceptually more pleasing than Fig. 3(h) while there is a significant gap between PSNR and SSIM of those interpolated frames. Fig. 3(o) shows over +5dB gain compared to all the other approaches. Although the result frames all look very similar, an accurate alignment algorithm has brought such large gain to the TTI team.
In Fig. 4, we also introduce a case where all of the proposed methods are not able to generate clean output frames. While the submitted models can handle edges and local structures to some extent, they cannot deal with large plain regions and generate unpleasing artifacts. Such limitation shows the difficulty of the VTSR task on real-world videos and implies several rooms to be improved in the following research.
4.2 Perceptual quality of interpolated frames
Recently, there have been rising needs for considering the visual quality of output frames in image restoration tasks. Therefore, we have experimentally included the LPIPS [43] metric to evaluate how the result images are perceptually similar to the ground-truth. Table 2 compares the LPIPS score of the submitted methods. The KAIST-VICLAB team has achieved the best (lowest) LPIPS on both 15 fps 30 fps and 15 fps 60 fps VTSR tasks even they show lower PSNR compared to the XPixel team. However, we have also observed that the perceptual metric has a weakness to be applied to video-related tasks directly. For example, the result from KAIST-VICLAB team in Fig. 3(m) has an LPIPS of 0.100, while the TTI team in Fig. 3(o) shows an LPIPS of 0.158. As the score shows, the LPIPS metric does not consider whether the output frame is accurately aligned with the ground-truth. In other words, an interpolated sequence with a better perceptual score may look less natural, regardless of how each frame looks realistic. In future challenges, it would be interesting to develop a video-specific perceptual metric to overcome the limitation of the LPIPS.
| Task Team | XPixel | KAIST-VICLAB | BOE-IOT-AIBD | TTI |
| 15 fps 30 fps | 0.268 | 0.222 | 0.249 | 0.289 |
| 15 fps 60 fps | 0.214 | 0.181 | 0.230 | 0.253 |
5 Challenge Methods and Teams
This section briefly describes each of the submitted methods in the AIM 2020 VTSR challenge. Teams are sorted by their final ranking. Interestingly, the top three teams (XPixel, KAIST-VICLAB, and BOE-IOT-AIBD) have leveraged the QVI model as a baseline and improved the method by their novel approaches. We briefly describe each method base on the submitted factsheets.
5.1 XPixel
Method. The XPixel team has proposed the Enhanced Quadratic Video Interpolation (EQVI) [20] method. The algorithm is built upon the AIM 2019 VTSR Challenge winning approach, QVI [38, 19], with three main components: rectified quadratic flow prediction (RQFP), residual contextual synthesis network (RCSN), and multi-scale fusion network (MS-Fusion). To ease the overall optimization procedure and verify the performance gain of each component, four-stage training, and fine-tuning strategies are adopted. First, the baseline QVI model is trained with a ScopeFlow [3] flow estimation method instead of the PWC-Net [36]. Then, the model is fine-tuned with an additional residual contextual synthesis network. In the third stage, the rectified quadratic flow prediction is adopted to improve the model with fine-tuning all the modules except the optical flow estimation network. Finally, all the modules are assembled into the multi-scale fusion network and fine-tuned.
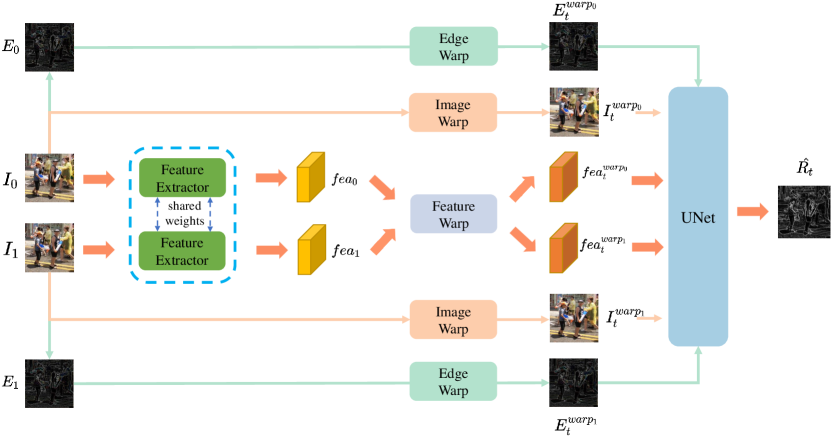
Residual contextual synthesis network. Inspired by [27], a residual contextual synthesis network (RCSN) is designed to warp and exploit the contextual information in high-dimension feature space. Specifically, the layer of the pre-trained ResNet18 [14] is adopted to capture the contextual information of input frame and . Then we apply back warping on the features with to attain pre-warped features. The edge information of and is also extracted and warped to preserve and leverage more structural information. For simplicity, we calculate the gradient of each channel of the input frame as edge information. Afterward, we feed the warped images, edges, and features into a small network to synthesize a residual map . The refined output is obtained by . Fig. 5 shows the overall organization of the network.
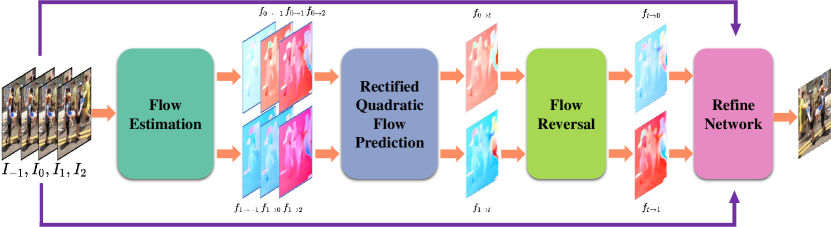
Rectified quadratic flow prediction. Given four input consecutive frames , , and , the goal of video temporal super-resolution is to interpolate an intermediate frame , where . Following the quadratic model [38], a least square estimation method is utilized to improve the accuracy of quadratic frame interpolation further. Unlike the original QVI [38], all four frames (or three equations) are used for the quadratic model. If the motion of the input four frames basically conforms to the uniform acceleration model, the following equations should hold or approximately hold:
| (1) |
where denotes the displacement of the pixel from frame 0 to frame , represents the velocity at frame 0, and is the acceleration of the quadratic motion model. The equations above can be transformed into a matrix form:
| (2) |
where the solution can be derived as . Then, the intermediate flow could be formulated as . When the motion of input four frames approximately fits the quadratic assumption, the LSE solution can make a better estimation of . As the real scenes are usually complex, several simple rules are adopted to discriminate whether the motion satisfies the quadratic assumption. For any pair picked from , and , an acceleration is calculated as:
| (3) |
Theoretically, for quadratic motion, , and should be in the same direction and approximately equal to each other. If the orientation of those accelerations is not consistent, the model will be directly degenerated to the original QVI; otherwise, we adopt the following weight function to fuse the rectified flow and the original quadratic flow according to the proximity of quadratic model:
| (4) |
where , is the axis of symmetry, and is the stretching factor. Empirically, and are set to 5 and 1, respectively. The final and is obtained by:
| (5) |
where lse and ori represent the rectified LSE prediction and original prediction, respectively. Fig. 6 demonstrates how the rectified quadratic flow is estimated.
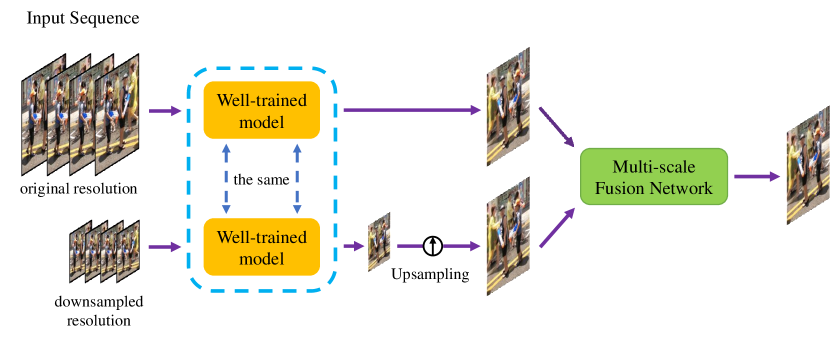
Multi-scale fusion network. Finally, a novel multi-scale fusion network is proposed to capture various motions at a different level and further boost the performance. This fusion network can be regarded as a learnable augmentation process at different resolutions. Once we obtain a well-trained interpolation model from previous stages, we feed the model with one input sequence and its downsampled counterpart. Then a fusion network is trained to predict a pixel-wise weighted map to fuse the results.
| (6) |
where represents the well-trained QVI model, and denote the downsampling and upsampling operations, respectively. Then, the final output interpolated frame is formulated as follows, as illustrated in Fig. 7:
| (7) |
The proposed method is implemented under Python 3.6 and PyTorch 1.2 environments. The training requires about 5 days using 4 RTX 2080 Ti GPUs.
5.2 KAIST-VICLAB
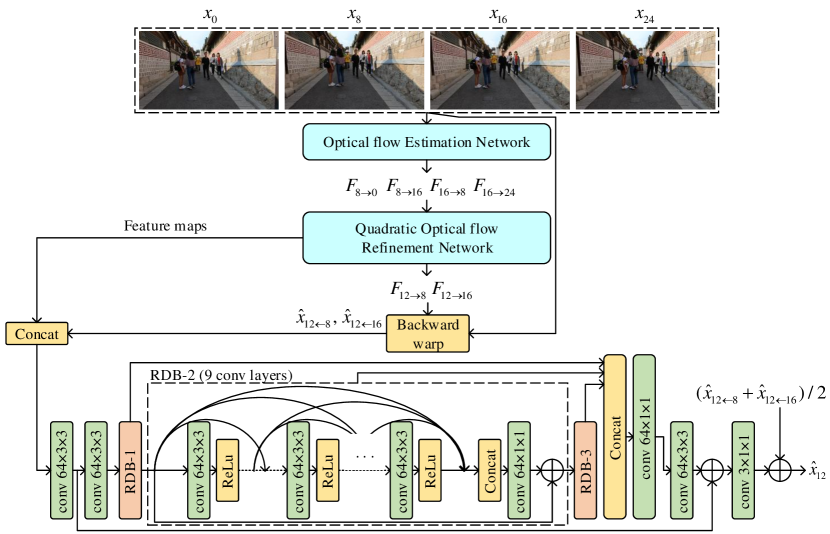
Method. KAIST-VICLAB team proposes the quadratic video frame interpolation with a multi-frame synthesis network. Inspired by the quadratic video interpolation [38] and the context-aware synthesis for video interpolation [27], the proposed approach leverages these types of flow-based method. The REDS_VTSR dataset [26] is composed of high-resolution frames with much more complex motion than typical frame interpolation dataset [39]. Since the optical flow is vulnerable to complex motion or occlusion, the proposed method attempts to handle the vulnerability by a nonlinear synthesis method with more information from neighbor frames. Therefore, the proposed algorithm first estimates the optical flows between the intermediate frame and the neighboring frames using four adjacent frames. The method for estimating the optical flows follows the same method for estimating the optical flows of the intermediate frame by a quadratic method based on the PWC-net [36] in [38]. Unlike the QVI [38] method, the proposed method utilizes all the four neighboring frames for the synthesis network and incorporates a nonlinear synthesis network into the last part of our total network to better adapt to the frames containing complex motion or occlusion.
Details. The proposed model is composed of the residual dense network [44], and the inputs of the synthesis network are not only the feature maps obtained by estimating the optical flows using four neighboring frames, but also the warped neighboring frames. Also, the output of the synthesis network is the corresponding intermediate frame. Motivated by TOFlow [39], the PWC-net for the optical flow estimation is fine-tuned on the REDS_VTSR dataset. More details about the proposed network are illustrated in Fig. 8. The intermediate frames are optimized using the Laplacian loss [27] on three different scales and VGG loss. The method is developed under Python 3.6 and PyTorch 1.4 environments, using one TITAN Xp GPU. The training takes about 3 days.
5.3 BOE-IOT-AIBD
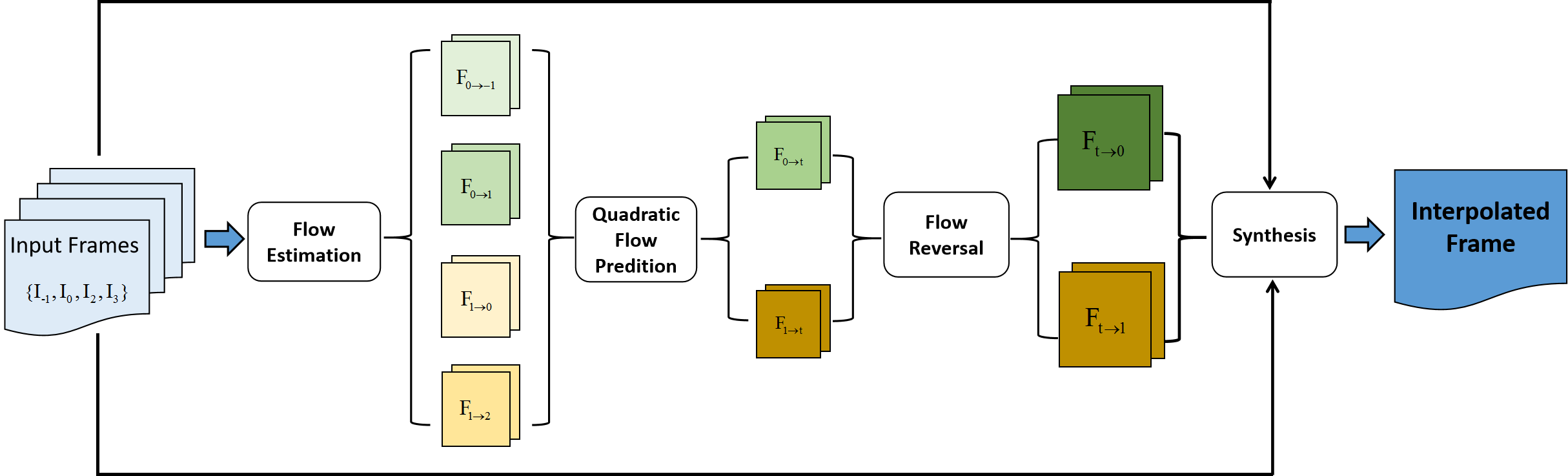
Method. BOE-IOT-AIBD team has proposed the Multi Scale Quadratic Interpolation (MSQI) approach for the VTSR task. The model is trained on the REDS_VTSR dataset [26] of three different scales. At each scale, the proposed MSQI employs PWC-Net [36] to extract optical flows and further refines the flow continuously through three modules: quadratic acceleration, flow reverse, and U-Net [35] refine module. Finally, a synthesis module interpolates the output frame by warping in-between inputs and refined flows. During the inference, a post-processing method is applied to grind the interpolated frame.
Details. Fig. 9 illustrates an overview of the proposed MSQI method. Firstly, the MSQI model has trained on sequences from the REDS_VTSR dataset [26], using lower resolution () and frame rate (15fps) for quick convergence. Then, the model is fine-tuned on sequences of higher resolution (). In the last stage, the MSQI model is trained using full-size images () with a 15fps frame rate. During the inference time, a smoothing function is adopted for post-processing. Also, quantization noise is injected during the training and inference phase. The proposed method also adds the quantization noise to input frames at the inference phase and employs a smooth function to grind the interpolated frame. The method adopts the pre-trained off-the-shelf optical flow algorithm, PWC-Net [36], from the SenseSlowMo [19, 38] model. Compared to the baseline SenseSlowMo [19, 38] architecture, the proposed MSQI converges better and focuses on multiple resolutions. Python 3.7 and PyTorch environments are used on a V100 GPU server with a total of 128GB VRAM.
5.4 TTI
Method. TTI team has proposed a temporal super-resolution method that copes large motions by reducing an input sequence’s spatial resolution. The approach is inspired by STARnet [11] model. With the idea that space and time are related, STARnet jointly optimizes three tasks, i.e., spatial, temporal, and spatio-temporal super-resolution.
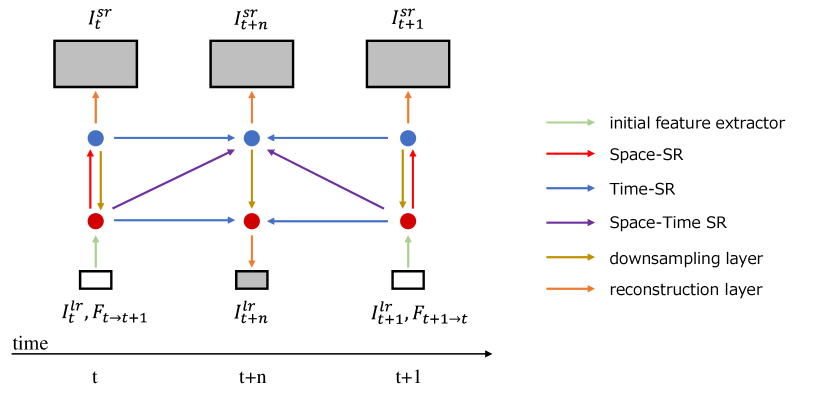
Details. Fig. 10 illustrates the concept of the STARnet. The model takes two LR frames and , with bidirectional dense motion flows of these frames and as input. The output consists of an in-between LR and three SR frames , , and , where denotes the temporal interpolation rate. While the STARnet model can be fine-tuned only for temporal super-resolution as proposed in [11], the TTI team has employed the original spatio-temporal framework. This is because large motions observed in the REDS [25] dataset make it difficult to estimate accurate optical flows, which take an essential role for the VTSR task. Therefore, the optical flows on the LR domain might support VTSR of HR frames in the REDS sequences. In the proposed strategy, two given frames are resized to LR frames and , and then fed into the network shown in Fig. 10 in order to acquire in the original resolution. For temporal super-resolution, is set to . To realize those three temporal interpolation rates with one network, input flow maps and are scaled according to as follows:
| (8) |
where and denote the re-scaled flow maps that are used as input, respectively. For higher accuracy, two changes are made to the original STARnet model. First, a deformable convolution [7] is added at the end of T- and ST-SR networks to explicitly deal with object motions. Second, the PWC-Net [36] is used to get flow maps, which show better performance than the baseline.
During training, each input frame is downscaled by half using bicubic interpolation. Those frames are super-resolved to its original resolution by the S-SR network. The S-SR network, which is based on the DBPN [12] and RBPN [13] models, is pre-trained on the Vimeo-90k dataset [39]. Various data augmentations, such as rotation, flipping, and random cropping, are applied to input and target pairs. All experiments are conducted using Python 3.6 and PyTorch 1.4 on Tesla V100 GPUs.
6 Conclusion
In the AIM 2020 VTSR challenge, 5 teams competed to develop state-of-the-art VTSR methods with the REDS_VTSR dataset. Top 3 methods leverage the quadratic motion modeling [38, 19], demonstrating the importance of accurate motion prediction. The winning team XPixel proposes Enhanced Quadratic Video Interpolation framework, which improves the QVI [38, 19] method with three novel components. Compared to AIM 2019 VTSR challenge [26], there has been a significant PSNR improvement of 0.22dB on the 15 60 fps task over the QVI method [19]. We also compare the submitted methods in a unified framework and provide a detailed analysis with specific example cases. In our future challenge, we will encourage participants to develop 1) More efficient algorithms, 2) Perceptual interpolation methods, 3) Robust models on challenging real-world inputs.
Acknowledgments
We thank all AIM 2020 sponsors: Huawei Technologies Co. Ltd., MediaTek Inc., NVIDIA Corp., Qualcomm Inc., Google, LLC and CVL, ETH Zürich.
Appendix 0.A Teams and affiliations
AIM 2020 team
Title: AIM 2020 Challenge on Video Temporal Super-Resolution
Members:
Sanghyun Son1 ([email protected]),
Jaerin Lee1,
Seungjun Nah1,
Radu Timofte2,
Kyoung Mu Lee1
Affiliations:
1 Department of ECE, ASRI, Seoul National University (SNU), Korea
2 Computer Vision Lab, ETH Zürich, Switzerland
XPixel
Title: Enhanced Quadratic Video Interpolation
Members:
Yihao Liu1,2 ([email protected]),
Liangbin Xie1,2,
Li Siyao3,
Wenxiu Sun3,
Yu Qiao1,
Chao Dong1
Affiliations:
1 Shenzhen Institutes of Advanced Technology, CAS
2 University of Chinese Academy of Sciences
3 SenseTime Research
KAIST-VICLAB
Title: Quadratic Video Frame Interpolation with Multi-frame Synthesis Network
Members:
Woonsung Park1 ([email protected]),
Wonyong Seo1 ([email protected]),
Munchurl Kim1 ([email protected])
Affiliations:
1 Video and Image Computing Lab, Korea Advanced Institute of Science and Technology (KAIST)
BOE-IOT-AIBD
Title: Multi Scale Quadratic Interpolation Method
Members:
Wenhao Zhang1 ([email protected]),
Pablo Navarrete Michelini1
Affiliations:
1 BOE, IOT AIBD, Multi Media Team
TTI
Title: STARnet for Video Frame Interpolation
Members:
Kazutoshi Akita1 ([email protected]),
Norimichi Ukita1
Affiliations:
1 Toyota Technological Institute (TTI)
References
- [1] Bao, W., Lai, W.S., Ma, C., Zhang, X., Gao, Z., Yang, M.H.: Depth-aware video frame interpolation. In: CVPR (2019)
- [2] Bao, W., Lai, W.S., Zhang, X., Gao, Z., Yang, M.H.: Memc-net: Motion estimation and motion compensation driven neural network for video interpolation and enhancement. IEEE TPAMI (2019)
- [3] Bar-Haim, A., Wolf, L.: Scopeflow: Dynamic scene scoping for optical flow. In: CVPR (2020)
- [4] Chi, Z., Nasiri, R.M., Liu, Z., Lu, J., Tang, J., Plataniotis, K.N.: All at once: Temporally adaptive multi-frame interpolation with advanced motion modeling. In: ECCV (2020)
- [5] Choi, M., Choi, J., Baik, S., Kim, T.H., Lee, K.M.: Scene-adaptive video frame interpolation via meta-learning. In: CVPR (2020)
- [6] Choi, M., Kim, H., Han, B., Xu, N., Lee, K.M.: Channel attention is all you need for video frame interpolation. In: AAAI (2020)
- [7] Dai, J., Qi, H., Xiong, Y., Li, Y., Zhang, G., Hu, H., Wei, Y.: Deformable convolutional networks. In: ICCV (2017)
- [8] El Helou, M., Zhou, R., Süsstrunk, S., Timofte, R., et al.: AIM 2020: Scene relighting and illumination estimation challenge. In: ECCV Workshops (2020)
- [9] Fuoli, D., Huang, Z., Gu, S., Timofte, R., et al.: AIM 2020 challenge on video extreme super-resolution: Methods and results. In: ECCV Workshops (2020)
- [10] Gui, S., Wang, C., Chen, Q., Tao, D.: Featureflow: Robust video interpolation via structure-to-texture generation. In: CVPR (2020)
- [11] Haris, M., Shakhnarovich, G., Ukita, N.: Space-time-aware multi-resolution video enhancement. In: CVPR (2020)
- [12] Haris, M., Shakhnarovich, G., Ukita, N.: Deep back-projection networks for super-resolution. In: CVPR (2018)
- [13] Haris, M., Shakhnarovich, G., Ukita, N.: Recurrent back-projection network for video super-resolution. In: CVPR (2019)
- [14] He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: CVPR (2016)
- [15] Ignatov, A., Timofte, R., et al.: AIM 2020 challenge on learned image signal processing pipeline. In: ECCV Workshops (2020)
- [16] Ignatov, A., Timofte, R., et al.: AIM 2020 challenge on rendering realistic bokeh. In: ECCV Workshops (2020)
- [17] Jiang, H., Sun, D., Jampani, V., Yang, M.H., Learned-Miller, E., Kautz, J.: Super SloMo: High quality estimation of multiple intermediate frames for video interpolation. In: CVPR (2018)
- [18] Lee, H., Kim, T., Chung, T.y., Pak, D., Ban, Y., Lee, S.: Adacof: Adaptive collaboration of flows for video frame interpolation. In: CVPR (2020)
- [19] Li, S., Xu, X., Pan, Z., Sun, W.: Quadratic video interpolation for vtsr challenge. In: ICCV Workshops (2019)
- [20] Liu, Y., Xie, L., Siyao, L., Sun, W., Qiao, Y., Dong, C.: Enhanced quadratic video interpolation. In: ECCV Workshops (2020)
- [21] Liu, Z., Yeh, R.A., Tang, X., Liu, Y., Agarwala, A.: Video frame synthesis using deep voxel flow. In: ICCV (2017)
- [22] Long, G., Kneip, L., Alvarez, J.M., Li, H., Zhang, X., Yu, Q.: Learning image matching by simply watching video. In: ECCV (2016)
- [23] Meyer, S., Djelouah, A., McWilliams, B., Sorkine-Hornung, A., Gross, M., Schroers, C.: Phasenet for video frame interpolation. In: CVPR (2018)
- [24] Meyer, S., Wang, O., Zimmer, H., Grosse, M., Sorkine-Hornung, A.: Phase-Based frame interpolation for video. In: CVPR (2015)
- [25] Nah, S., Baik, S., Hong, S., Moon, G., Son, S., Timofte, R., Lee, K.M.: NTIRE 2019 challenges on video deblurring and super-resolution: Dataset and study. In: CVPR Workshops (2019)
- [26] Nah, S., Son, S., Timofte, R., Lee, K.M., et al.: AIM 2019 challenge on video temporal super-resolution: Methods and results. In: ICCV Workshops (2019)
- [27] Niklaus, S., Liu, F.: Context-aware synthesis for video frame interpolation. In: CVPR (2018)
- [28] Niklaus, S., Liu, F.: Softmax splatting for video frame interpolation. In: CVPR (2020)
- [29] Niklaus, S., Mai, L., Liu, F.: Video frame interpolation via adaptive convolution. In: CVPR (2017)
- [30] Niklaus, S., Mai, L., Liu, F.: Video frame interpolation via adaptive separable convolution. In: ICCV (2017)
- [31] Ntavelis, E., Romero, A., Bigdeli, S.A., Timofte, R., et al.: AIM 2020 challenge on image extreme inpainting. In: ECCV Workshops (2020)
- [32] Park, J., Ko, K., Lee, C., Kim, C.S.: Bmbc: Bilateral motion estimation with bilateral cost volume for video interpolation. In: ECCV (2020)
- [33] Peleg, T., Szekely, P., Sabo, D., Sendik, O.: Im-net for high resolution video frame interpolation. In: CVPR (2019)
- [34] Reda, F.A., Sun, D., Dundar, A., Shoeybi, M., Liu, G., Shih, K.J., Tao, A., Kautz, J., Catanzaro, B.: Unsupervised video interpolation using cycle consistency. In: ICCV (2019)
- [35] Ronneberger, O., Fischer, P., Brox, T.: U-net: Convolutional networks for biomedical image segmentation. In: MICCAI (2015)
- [36] Sun, D., Yang, X., Liu, M.Y., Kautz, J.: PWC-Net: CNNs for optical flow using pyramid, warping, and cost volume. In: CVPR (2018)
- [37] Wei, P., Lu, H., Timofte, R., Lin, L., Zuo, W., et al.: AIM 2020 challenge on real image super-resolution. In: ECCV Workshops (2020)
- [38] Xu, X., Siyao, L., Sun, W., Yin, Q., Yang, M.H.: Quadratic video interpolation. In: NeurIPS (2019)
- [39] Xue, T., Chen, B., Wu, J., Wei, D., Freeman, W.T.: Video enhancement with task-oriented flow. IJCV 127(8), 1106–1125 (2019)
- [40] Yuan, L., Chen, Y., Liu, H., Kong, T., Shi, J.: Zoom-in-to-check: Boosting video interpolation via instance-level discrimination. In: CVPR (2019)
- [41] Zhang, H., Zhao, Y., Wang, R.: A flexible recurrent residual pyramid network for video frame interpolation. In: ICCV (2019)
- [42] Zhang, K., Danelljan, M., Li, Y., Timofte, R., et al.: AIM 2020 challenge on efficient super-resolution: Methods and results. In: ECCV Workshops (2020)
- [43] Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: CVPR (2018)
- [44] Zhang, Y., Tian, Y., Kong, Y., Zhong, B., Fu, Y.: Residual dense network for image super-resolution. In: CVPR (2018)