AFed: Algorithmic Fair Federated Learning
Abstract
Federated Learning (FL) has gained significant attention as it facilitates collaborative machine learning among multiple clients without centralizing their data on a server. FL ensures the privacy of participating clients by locally storing their data, which creates new challenges in fairness. Traditional debiasing methods assume centralized access to sensitive information, rendering them impractical for the FL setting. Additionally, FL is more susceptible to fairness issues than centralized machine learning due to the diverse client data sources that may be associated with group information. Therefore, training a fair model in FL without access to client local data is important and challenging. This paper presents AFed, a straightforward yet effective framework for promoting group fairness in FL. The core idea is to circumvent restricted data access by learning the global data distribution. This paper proposes two approaches: AFed-G, which uses a conditional generator trained on the server side, and AFed-GAN, which improves upon AFed-G by training a conditional GAN on the client side. We augment the client data with the generated samples to help remove bias. Our theoretical analysis justifies the proposed methods, and empirical results on multiple real-world datasets demonstrate a substantial improvement in AFed over several baselines.
Index Terms:
Federated learning, fair machine learning, generative model.I Introduction
With the increasing use of machine learning algorithms in critical decision-making areas such as credit evaluation, loan applications, and healthcare, there are concerns about potential bias and discrimination in trained models. For instance, COMPAS, a software used by courts to aid judges in pretrial detention and release decisions, has been found to have a substantial bias against African-Americans when comparing false positive rates of African-American offenders to Caucasian offenders.
As a result, fairness research has gained prominence, with group fairness [18] and individual fairness [13] being two broad classifications for approaches to fairness. We refer to these two concepts as algorithmic fairness because the definition of fairness is expanded in the context of FL, such as accuracy parity [24], good-intent fairness [31, 12]. This paper presents an algorithmic fair FL framework emphasizing group fairness since clients tend to belong to specific demographic groups in FL [20].
Various algorithms have been proposed to train an algorithmic fair model in centralized machine learning [46, 47, 45, 40], including pre-processing, in-processing and post-processing [11]. Although the details differ, all of these algorithms assume centralized access to data. In FL, however, training data is not centrally accessible by either the server or the clients. Therefore, one cannot simply apply centralized fair learning algorithms in FL tasks. This begs the question: How to train an algorithmic fair FL model without centralized access to data?
This problem is challenging due to restricted access and data heterogeneity. FL models are trained on all clients’ local data, with only gradients/model parameters transmitted to the server during each round. Debiasing on the server side is not feasible since the server is prohibited from directly accessing clients’ local data. On the other hand, a single client can’t accurately picture the global distribution due to limited data [29]. Worse yet, data distributions vary between clients [20]. There is no guarantee that the model debiased with local data will generalize to the global distribution. In addition, it has been long observed that fairness conflicts with accuracy [49, 3]. A trivial model that makes constant predictions is perfectly fair but useless.
To address these challenges, we proposed a novel framework named AFed to achieve algorithmic fair FL. AFed aims to learn a fair model satisfying group fairness (e.g., demographic parity [18]) in FL. The core idea is to learn global data distribution and then disseminate that knowledge to all clients to help with local debiasing. To this end, two algorithms are proposed. Our first algorithm, AFed-G, trains a conditional generator to learn clients’ data distribution on the server side. AFed-G enjoys less computation and communication overhead. The second algorithm, AFed-GAN, trains a conditional GAN on the client side, which is more effective in learning data distribution. An auxiliary classification head is designed to help extract informative features that benefit the generator training. The knowledge about global distribution is then shared among all clients to help debiasing the model. We mix the true training data with generated data to debiase the model.
In summary, the contributions of this paper are listed below.
-
•
We tackle the challenge of training a fair model in FL without accessing clients’ data. We bypass the restricted centralized data access by introducing a conditional generator/GAN.
-
•
We design an auxiliary classification head to help extract more informative features, which benefits the conditional generator/GAN training.
-
•
We provide theoretical analysis to justify the robustness of the proposed method. Our empirical results demonstrate substantial improvement of the proposed methods over baselines on several real-world datasets.
II Related works
II-A Fair Machine learning
At a high level, algorithmic fairness notions adopted in centralized machine learning can be categorized as two different families: the statistical notion and individual notion [6]. The statistical notions require specific statistical measures to be comparable across all of these groups [22, 5]. The individual notions aim at fairness between specific pairs of individuals: Give similar predictions to similar individuals [13]. Individual notions offer a meaningful fairness guarantee but need to make significant assumptions, some of which present non-trivial challenges in fairness. We adopt statistical notions, more specifically, demographic parity [18] as fairness metric in this paper.
Debiasing methods can be classified as pre-processing, in-processing, and post-processing, respectively [11]. Pre-processing improves fairness by eliminating bias present in the training dataset. The model is subsequently trained and applied on the modified data [15, 21]. For instance, Kamiran et al. [21] propose reweighting samples in the training dataset to correct for biased treatment. Xu et al. [37] proposed FairGAN, which generates fair data from the original training data and uses the generated data to train the model. In-processing achieves fairness by adding constraints during training. Berk et al. [3] integrated a family of fairness regularizers into the objective function for regression issues. Zhang et al. [42] borrowed the ideal of adversarial training to restrict a model’s bias. The general methodology of post-processing methods is to adjust the decision thresholds of different groups following specific fairness standards [5, 18, 4]. However, existing methods assume centralized access to the data, which is invalid in FL. Each client can only access its own data, and the server does not know the local data distribution. As such, it remains challenging to train a fair model in FL.
II-B Fairness in Federated Learning
Fairness can be defined from different aspects in FL. A body of work focuses on accuracy disparity, i.e., trying to minimize the performance gaps between different clients [24]. A model with a more uniform performance distribution is considered fairer. The goal, in this case, is to address any statistical heterogeneity during the training phase by using techniques like data augmentation [50], client selection [38] and reweighting [19], multi-task learning [35], etc. Another area of focus is good-intent fairness [31], ensuring that the training procedure does not overfit a model to any client at the expense of others. In this instance, the objective is to train a robust model against an unknown testing distribution.
However, these two lines of work don’t address the algorithmic fairness issues in FL. To date, there are limited works about algorithmic fairness in FL. Du et al. [12] formulated a distributed optimization problem with fairness constraints. Gálvez et al. [16] cast fairness as a constraint to an optimization problem. To protect privacy, the constraint problem is optimized based on statistics provided by clients. Chu et al. [8] and Cui et al. [10] took a similar path, imposing fairness constraints on the learning problem. To avoid intruding on the data privacy of any client, the fairness violations are locally calculated by each client. Zhang et al. [43] focused on client selection, using a team Markov game to select clients to ensure fairness. Ezzeldin et al. [14] proposed a fairness-aware aggregation method that amplifies local debiasing by weighting clients whose fairness metric aligns well with the global one. Wang et al. [36] explore the relationship between local group fairness and propose a regularized objective for achieving global fairness. Zeng et al. [41] extend FairBatch [33], a fair training method in centralized machine learning, to FL. In their design, each client shares extra information about the unfairness of its local classifier with the server. Chu et al. [7] propose estimating global fairness violations by aggregating the fairness assessments made locally by each client. They then constrain the model training process based on the global fairness violation.
II-C Discussion of Related Works
Currently, most FL research focuses on accuracy disparity, which is more closely related to data heterogeneity rather than the potentially unfair decisions the model may make. Comparatively, less research has been conducted regarding algorithmic fairness in FL. The difficulty of ensuring algorithmic fair FL stems from the privacy restriction of FL, i.e., the data never leaves the device. In the presence of client-specific data heterogeneity, however, local debiasing may fail to provide acceptable performance for the entire population. Existing works have attempted to circumvent this restriction by providing server statistics or calculating fairness constraints locally. However, they fail to adequately address the non-i.i.d. challenge in FL. For example, in the presence of non-i.i.d. data, the estimated global fairness violation in [7] could be inaccurate. Our approach distinguishes itself from existing methods in two key ways: 1) Alternative methodology: We explore a different direction by leveraging local data augmentation to enhance debiasing efforts; 2) Enhanced practicality: We address the non-i.i.d. challenges inherent in FL when training fair models. Our local data augmentation technique effectively mitigates these non-i.i.d. issues.
III Background
III-A Notations
This research focuses on addressing fairness issues in the context of binary classification tasks to illustrate our method. Note that our methods can be extended to the general multi-class classification problem since we didn’t explicitly require the target label to be binary. Denote as the input space. is the latent feature space with . is the output space, and is the set of all possible sensitive attribute values. The classification model parameterized by consists of two parts: a feature extractor and a classification head , where stands for the probability simplex over . In addition, we train another classification head parameterized by to classify sensitive attribute . In AFed-G, a conditional generator parameterized by is trained at the server side to synthesize fake representations condition on : . In AFed-GAN, we replace with conditional GAN parameterized by . The discriminator is trained to distinguish fake samples from real ones.
III-B Federated Learning
A FL system comprises local clients and a central server. Each client possesses a specific dataset , and the -th data sample is represented as , where is the features, is the ground-true label, and is the sensitive attribute. The amount of data of the -th client is denoted as . The goal of FL is to minimize the empirical risk over the samples of all clients, i.e.,
| (1) |
where is the loss objective of the -th client. Unlike central machine learning, which assumes centralized access to all train data , the client’s training data is never exposed to the server. Only gradients/model parameters are transmitted to the server for aggregation.
At the -th training round, the server randomly selects a set of clients to train the current global model . Selected clients first receive from the server, then train it on their local dataset ,
| (2) |
where denotes the learning rate and is a mini-batch of training data sampled from in the -th iteration. The local training process could run for multiple rounds. After that, the trained model or equivalently gradients is send back to the server for aggregation,
| (3) |
where is the aggregation weight. is used as the initial model for the next training round. This interaction between clients and the server is repeated until a certain criterion (e.g., accuracy) is satisfied.
III-C Fairness
Fairness in FL can be defined in different ways. This paper focuses on algorithmic fairness, especially group fairness, which is measured by the disparities in the algorithm decisions made for different groups determined by sensitive attributes, such as gender, race, etc. Here, we have opted for demographic parity as the fairness metric in this paper.
Definition 1 (Demographic parity [18]).
Demographic parity (DP) requires that a model’s prediction be independent of any sensitive attributes. The positive prediction rate for a demographic group is defined as follows,
| (4) | |||
| (5) |
The task of fair supervised learning is to train a classification model that can accurately label samples while minimizing discrimination. The discrimination level in terms of demographic parity can be measured by the absolute difference in the model’s outcomes between groups
| (6) |
The smaller is, the fairer will be. iif , i.e., demographic parity is achieved.
III-D GAN and Conditional GAN
GAN was first proposed by [17] as a min-max game between the generator and discriminator . The aim is to approximate a target data distribution so that the generated data can’t be separated from the true data by . The objective function of the generator is formed as
| (7) |
where is the real data distribution.
There exist various kinds of generators to generate synthetic data for different purposes. Among these, we chose conditional GAN [30] to generate synthetic data conditional on the given input. The conditional GAN differs from the unconditional GAN by providing the generator and discriminator condition information. The learning objective of conditional GAN is formulated as follows:
| (8) |
The additional information is fed to the generator and the discriminator during training. After convergence, the generator can generate fake data conditional on .




IV Algorithmic Fair Federated Learning
IV-A Motivation Example
The non-i.i.d. nature of local data distributions in a typical FL system presents a significant challenge for local debiasing. Certain groups may dominate a client’s data, while others may have limited representation. To illustrate this challenge, we create a toy FL system with four clients, each with a unique local dataset having different distributions. We generated the data from a mixture of four Gaussian distributions and grouped them based on the attribute into two categories. In this example, 85% of a client’s data is sampled from one Gaussian distribution, while the remaining 15% is evenly distributed across the other three Gaussian distributions.
In this situation, local debiasing is futile because none of the clients completely understand the data distribution across all clients. For example, client 1 has very few samples from group 1 (i.e., ), as shown in Fig. 1(a). Even less is the proportion when all clients’ data is considered. Therefore, it is difficult for client 1 to debias the classification model, given that client 1 has almost no knowledge of group 1. The same issue arises with the other clients. Our theoretical analysis in Section V confirms this. The performance of the local model on the global distribution depends on the quantity and similarity of the data, making it challenging to achieve a fair FL model through local debiasing alone.
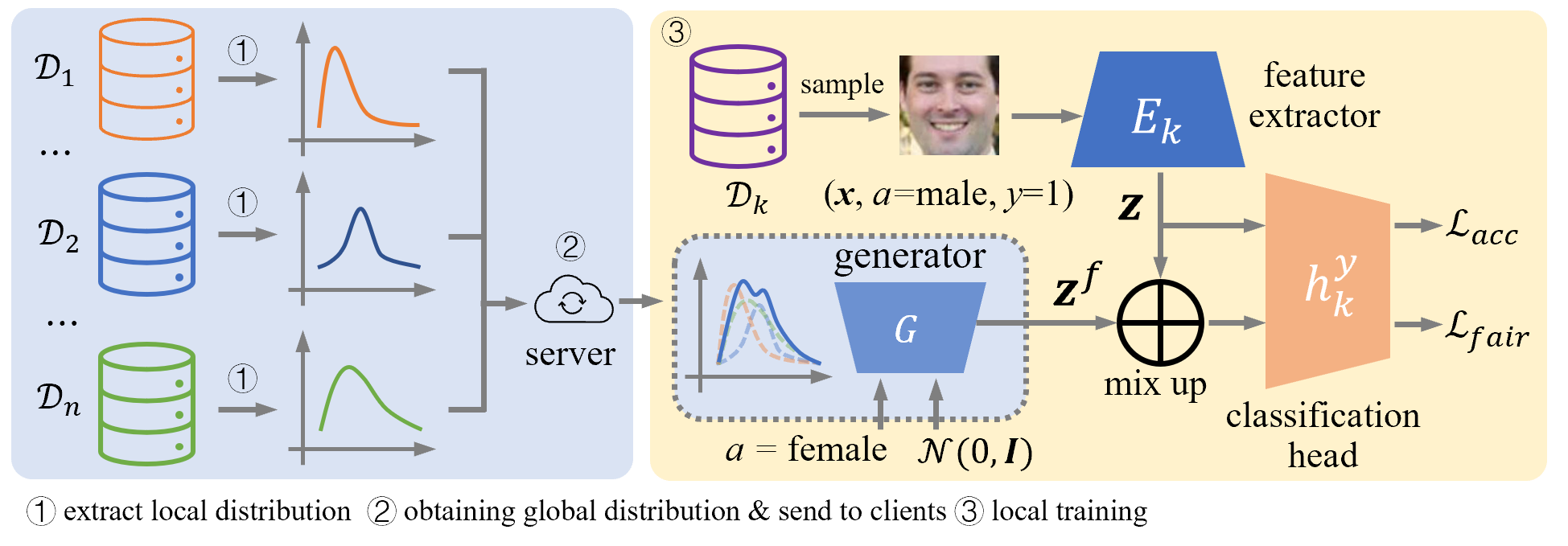
To address this problem, in AFed, a conditional generator/GAN is trained collectively by all clients to extract knowledge about the local data distribution. The result is illustrated in Fig. 2. It can be seen that the generated data has a similar distribution to that of all client data, indicating that the generator was successful in extracting the knowledge about the local data distribution. The extracted knowledge can be shared with all clients to help local debiasing. With the generated sample, clients can access the global data distribution and achieve a more accurate debiasing outcome. Fig. 3 illustrates the approach.


IV-B Overview of AFed
This section details the proposed AFed framework, summarized in Algorithm 1. Fig.3 shows the general description of AFed, which involves two learning tasks. As shown on the left part of Fig.3, the first task is to extract knowledge about local distribution. To this end, we train a conditional generator/GAN to learn clients’ local data distribution. We then aggregate the extracted distributions to form a global distribution embedded in a conditional generator .
In the right part of Fig.3, our second task is to train a fair and accurate model , consisting of a feature extractor and classification head. The accuracy loss is obtained on real samples. To debias the model, the generator produces a corresponding fake latent feature with a different attribute value for each latent feature. We mix the true features with the fake ones and require the model to make consistent predictions on the mixed samples, which gives the fairness loss . Each of these two tasks is discussed in more detail in the following.
IV-C Learning Global Data Distribution
Our first task is to learn the global data distribution. We draw inspiration from the field of knowledge extraction [51, 39]. We extract local data distribution information before aggregating it to form a global distribution. We chose to perform this task in the latent space instead of input space for both privacy and practical concerns. Because 1) sample-specific information is compressed in the latent space, only class-related information is retained; and 2) the latent space is more compact than the input space , making optimization more manageable. Note that the object of this paper is to train an algorithmic fair FL model without accessing client data, which is understudied in the literature. We leave both private and fair FL to our future work.
The feature extractor trained with will only retain the information relevant to . While information about the attribute may be compressed. To address this, we designed an auxiliary classification head that can assist in extracting informative latent features. The benefit of is twofold: first, it provides feedback to the extractor , allowing it to extract more informative latent features; second, embeds the relationships between the latent feature and the sensitive attribute , i.e., . This knowledge is crucial for the server to learn a global data distribution in AFed-G.
For the -th client, the training process of the feature extractor and the classification head is formulated as follows:
| (9) |
where is the cross-entropy loss.
A typical federated learning (FL) system faces the challenge of non-i.i.d. data, where each client possesses a distinct data distribution. As a result, a model that is fair in the local data may be unfair when applied to data sampled from the global data distribution. To address this issue, we propose augmenting local data with generated samples. The key is to capture the global data distribution without violating the privacy constraints of the FL system. To achieve this, we introduce two approaches.
Input: Local dataset .
Parameter: learning rate , and , epoch , , .
Output: , ,
IV-C1 Conditional generator approach
We implement our first method AFed-G based on a conditional generator trained on the server side. Denote the ground-truth global joint distribution , our target is to learn the global conditional distribution , where represents the latent feature. We approximate by finding a distribution that satisfies
| (10) |
where and are the ground-truth prior and posterior distribution of the sensitive attribute , respectively. The target of Eq. 10 is to find a distribution from which we can sample a latent feature conditional on the given value . The sampled should be correlated with the sensitive attribute , i.e., maximizing .
However, is unknown in FL. We estimated it by the sum of local distributions that are embedded in clients’ classification head [51]:
| (11) |
The uploaded models can provide the server with a global view of the data distribution without violating the privacy requirement of FL. Based on the relation of Eq. 11, we approximate Eq. 10 as:
| (12) |
Solving Eq. 12 is difficult, instead, we train a conditional generator to learn the conditional distribution to approximate the solution. The training objective is formulated as follows:
| (13) |
The latent feature generated by the optimal generator should be correctly classified as the pre-defined attribute by all clients’ classification heads . This way, the knowledge about the local data distribution is distilled to and forms a global data distribution.
The conditional generator has demonstrated the ability to extract knowledge about the local data distribution in FL [51]. However, a conditional generator trained with the classification feedback extracts knowledge about the decision boundary. This knowledge does not adequately describe the local data distribution of clients, especially those far from the decision boundary. Thus a conditional generator may fail to provide gains for those samples.
IV-C2 Conditional GAN approach
In our second method, we replace the conditional generator with a conditional GAN parameterized by . Compared to the first method, this incurs computation overhead but can receive more informative feedback from the discriminator. We train the generator and discriminator on the client side and then aggregate them on the server side. For the -th client, the training objective function of is formed as:
| (14) |
where is the target distribution, and are training parameters of the generator and discriminator, respectively. The objective function of is formed as:
| (15) |
After local training, both and are uploaded to the server for aggregation. Algorithm 1 describes the detailed procedure.
IV-D Local Debiasing
The second task is performed on the client side. It aims to train a fair and accurate classifier with the help of . The classification model is trained on both true and mixed samples, and the objective function is defined as
| (16) |
where and are model’s classification loss and fairness violation loss, respectively. controls the trade-off between the model’s accuracy and fairness. A larger indicates a greater emphasis on fairness, while a smaller improves the model’s overall accuracy at the expense of fairness. The empirical loss is obtained on ,
| (17) |
We focus on DP [18] in this work, which requires the prediction to be independent of the sensitive attribute . The straightforward idea is to treat the discrimination level as a regularizer [26], i.e., .
However, in FL, the data is partitioned among all clients, with each holding only a subset of the total. Debiasing with only local data will fail in global data distribution. Thus, we propose augmenting the local dataset with synthetic data. More specifically, for a real sample from the training dataset , the corresponding latent feature is , where is the feature extractor. We generate a fake latent feature with a different sensitive attribute :
| (18) |
where is the noise input. We mix the true feature with the fake one to get an augmented sample [44]:
| (19) |
where , for .
One assumption made in the mixup is that feature linear interpolations can be translated into label linear interpolations. Incorporating this kind of prior knowledge implicitly helps to broaden the model’s training data distribution and, in turn, its ability to make accurate predictions on new data. Similarly, the sensitive attribute of can be assumed as . To ensure fairness, the model’s prediction should be invariant to the interpolation degree and consequently the intermediate value of sensitive attribute [9]:
| (20) |
The penalized optimization problem is now formulated as follows:
| (21) |
By minimizing Eq. 21, we are optimizing the model to, on the one hand, fit the local data distribution of dataset , and on the other hand, regularize the model’s disparate predictions on the mixed distribution of and .


V Analysis
This section presents our analysis. We begin by showing is necessary for the extractor to learn informative features. Then, we analyze the drawbacks of AFed-G. In the third part of this section, we thoroughly analyzed the fairness guarantee of our framework. First, we demonstrate that debiasing with local data is futile. Next, we show that generated samples improve the local model’s fairness performance on global data distribution. Since Rasou et al. [32] have proven the convergence of GAN training in FL with non-i.i.d. data, we omit the convergence analysis of AFed-GAN.
V-A Feature Extractor Analysis
Fig. 4(a) shows the one classification head case. The resultant extractor tends only to retain information pertinent to label and compresses all other information. and are mapped to the same area due to the same label despite having different attribute values . This brings confusion when training conditional GAN in this feature space.
When training conditional GAN, the generated sample should resemble the training data. In other words, the fake samples should be close to the real ones in the feature space. Near , within the area , there are samples with attribute values and . As a result, feeding the generator with attribute value will produce samples similar to group or group , as depicted in Fig. 5(a). The same holds for the group .
To address this, we propose adding an auxiliary classification head to provide more feedback for the extractor as shown in Fig.4(b). With the guidance of and , the extracted features contain information about and . Samples from groups defined by and are mapped to four distinct feature space regions. On this basis, we can train a generator capable of generating samples conditional on .
Fig. 5 shows the results of the single and two classification head cases. The inputs to are sampled from the CelebA dataset. As shown in Fig. 5(a), the generated data fails to match the real data. For , the generated features (purple cross) overlap with the real features with attributes and . As a comparison, Fig. 5(b) demonstrates that the auxiliary feedback signal from significantly improves generator performance. The extracted features are divided into four parts, corresponding to the four groups defined by and . Since the features are well-separated, the GAN can learn the maps from to flawlessly.


V-B Generator Analysis
Our first method AFed-G trains a conditional generator to approximate the using the knowledge embedded in the classification head , i.e. . The second method, AFed-GAN, is more direct. A discriminator guides training to train a conditional GAN to learn the distribution . The former enjoys simplicity (only a generator is added) and can be carried out on the server’s side, which reduces the client’s training and communication load. In comparison, the latter performs better in learning the local data distribution.
Since introduced in [17], numerous researchers have successfully implemented GAN to learn the target distribution [27, 30]. In the context of FL, [32] demonstrates the convergence of GAN training in FL with non-i.i.d. data. Here, we focus on analyzing the shortcomings of the AFed-G approach.
Theorem 1.
Given the optimal classification head , optimizing Eq. 12 is equivalent to
| (22) |
where and are the joint probability distribution of clients’ data. is the conditional entropy of the generated samples.
Proof.
Let’s denote the likelihood of client ’s local data distribution, which is embedded in the classification head . Eq. 12 aims to find the target distribution . Note we lose for simplicity.
∎
Optimizing Eq. 12 comprises three terms. The first minimizes the KL divergence between the conditional generator distribution and the ground-truth joint distribution of clients, which is our target, matching the with . However, the second term maximizes the KL divergence between the marginal generator and target joint distributions . This contradicts our goal and will degrade the generator’s performance by pushing the marginal distribution away from the ground truth distribution. The last term is the conditional entropy of label of data sampled from the generator distribution . Minimizing the last term will decrease the data’s diversity by making generated be classified as with higher confidence, i.e., away from the decision boundary. This is in accordance with our intuition that only the feedback from classification head is available. This is to say, only information related to the decision boundary is provided, and the model will learn to generate ”safe” examples that can be correctly classified by . As a result, the generated data may fail to distribute in the space spanned by real data.
V-C Fairness Analysis
V-C1 Debiasing with local data is ineffective
Our analysis borrows the idea from the field of domain adaptation. Each client’s data is associated with a source domain from which local data is sampled. The goal is to train a model that performs well on the global (or target) domain, which is the ensemble of all source domains .
We first introduce a metric to measure the local and global distribution differences. We use the -divergence [1] to measure the difference between two probabilities,
| (23) |
where is the hypothesis space, is a set of samples which is defined as .
Lemma 1.
[2] Let be a hypothesis space of VC dimension , and are samples of size , sampled from and , respectively. is the -divergence between and and is the empirical distance computed on and . Then for any , with probability at least 1-,
| (24) |
Now we are ready to bound the fairness violation that a hypothesis trained with the local model can have on global data, i.e., . We borrow the idea from the field of domain adaptation. Each client’s data can be viewed as a source domain , and the goal is to train a global model that performs well on the global domain, which is the ensemble of all source domains .
Theorem 2.
[34] Let be a hypothesis space of VC dimension with a ground truth labeling function , is a local model trained on local dataset . Then for any , with probability at least 1- (over the choice of samples), the discrimination level of on is bounded by
| (25) |
where is the subdomain defined by attribute , similar as . is the optimal risk a hypothesis can have on the union of domain and . is the empirical loss of on , similar as .
Proof.
Theorem 2 provides some insights on why local debiasing is ineffective. Consider a client , who can implement some powerful local debiasing method that produces a perfectly fair hypothesis on the local domain . However, this fairness guarantee could fail to generalize to the global domain . Because the -divergence between and (a=0,1) can be huge due to the non-iid fact in FL.
V-C2 Generated samples improve fairness on global distribution
The client can train a model with better fairness generalization performance on the global distribution with the generated samples.
Remark 1.
Denote the client ’s data, which is the augmented by the generated samples drawn from . is the ratio of generated samples over the total samples. The -divergence between local and global data. we have
| (28) |
Proof.
According to the definition, we have
| (29) |
The inequality is due to . Because is trained to generate samples similar to the real samples drawn from the . ∎
Remark 1 shows augmenting the client’s data with generated samples reduces the -divergence. The conclusion of Remark 1 can be generalized to subdomains (). In AFed, a conditional generator is designed to generate samples similar to those drawn from and . Therefore, AFed is able to decrease and in Eq. 25 and consequently induce a smaller discrimination level . In addition, a larger dataset size help close the gap between the empirical estimation and real -divergence as shown in Eq. 24, which in turn helps improve the empirical performance.
V-C3 Mix-up samples improve fairness
One reason for unfairness is the bias that exists in the unbalanced dataset. One way to alleviate this is to balance the dataset through data augmentation. As stated above, a conditional generator is collectively trained by all clients, which can generate fake representations conditional on sensitive value. We further proposed mixing the synthetic data with the real data to improve the quality of synthetic data. The sensitive attribute of the mixed data can be represented as [44]. To ensure the model makes consistent predictions over different demographic groups, we require the model’s prediction on the mixed data to be invariant w.r.t .
Theorem 3.
[9] Let be the mixed sample, and are samples with different sensitive attributes. For any differentiable function , the discrimination level of on two groups and is
| (30) |
Proof.
Let , gives samples from the group and for group
| (31) |
∎
VI Experiments
In this section, we empirically verify the effectiveness of AFed. We compare the performance of our method with several baseline methods on four real-world datasets. After that, we demonstrate the performance gain of auxiliary classification head and the robustness of our method w.r.t different participant ratios.
VI-A Experimental Setup
We conducted experiments on four datasets, including three image datasets (UTKFace [48], FairFace [23], and CelebA [25]) and one tabular dataset (Adult111http://archive.ics.uci.edu/ml/datasets/Adult). In UTKFace and FairFace datasets, we set race as the sensitive attribute when training the model to predict the gender of a given image. For the CelebA dataset, the objective is to determine whether an image contains an object with wavy hair, and the data is split into male and female groups. For the Adult dataset, we aim to determine if a person’s income exceeds 50K with gender as the sensitive attribute.
In our experiments, we preprocessed the dataset to increase the heterogeneity by 1) using the Dirichlet distribution to determine the quantity of data clients hold for the UTKface, Fairface, and Adult datasets; 2) creating multiple sets each containing images of twenty different celebrities from the CelebA dataset, each set is assigned to a different client. In addition, we also exaggerated the imbalance in the data.
VI-A1 Configuration
We implemented the feature extractor using a five-layer convolutional neural network with a kernel size of 3, a stride of 2, and padding of 1. Each layer is followed by a batch normalization layer and a Rectified Linear Unit (ReLU) activation function. The two classification heads are realized by two fully connected layers with a hidden dimension of size 32. The generator and discriminator are implemented using Multi-Layer Perceptrons (MLPs) as [51]. The generator takes a noise vector of 32 dimensions and a one-hot sensitive attribute vector of 2 dimensions as input. The output dimension is the same as that of the feature extractor, which is 64 in our experiments. We use the Adam optimizer to update the feature extractor and two classification heads, as well as the RMSprop optimizer for the generator and discriminator. The learning rate is set to for the classification models and for , and for . The batch size equals the size of the local training dataset.
We simulate five clients, all clients are selected during every global communication round. The training epochs are set to 150, and the local training epochs are set to .
VI-A2 Baseline
To illustrate the effectiveness and superiority of AFed over debiasing methods that are solely based on local data, we select three baselines:
-
•
FedAvg: The canonical training method in FL without any considerations about fairness.
-
•
FedReg: A naive way to learn fair model in FL. We add the fairness regularization term to the loss function to train a fair model on the client side and aggregate them on the server side.
- •
-
•
FairFB [41]: Assigns different weights for each group, and the weight is optimized on the client side and aggregated by the server.
-
•
FedGFT [36]: adapts the local objective function to the fairness regularization and uses strictly local summary statistics to minimize the fairness-penalized empirical loss of the global model.
-
•
CML: We assemble all clients’ data to form a centralized setting. We implement fair mix-up [9] to train a fair model.
VI-B Effectiveness of Proposed Method




Fig. 6 shows the trade-offs between accuracy and on three different datasets. All curves are obtained by altering the hyperparameter in Eq. 16, which controls the trade-off between accuracy and fairness. A smaller means a fairer model. Only controlling is trivial. However, our goal is to train a model that is both fair and accurate, which means we must control unfairness while still achieving acceptable accuracy performance. Therefore, we prioritize curves in the upper left corner over those in the lower right corner.
We present the averaged results across five runs in all experiments to mitigate the impact of randomness. Overall, several key observations can be drawn. 1) Both FairFed-Mix and CML significantly reduce discrimination but suffer from substantial accuracy degradation. As shown in Figure 6(b), these methods reduce by two-thirds, but at the cost of a more than 10% accuracy drop for CML and over 20% for FairFed-Mix. 2) AFed-GAN demonstrates superior performance compared to AFed-G and FairFed-Mix, particularly in the UTKface, Fairface, and CelebA datasets, where it outperforms FairFed-Mix and CML by a large margin. 3) On the Adult dataset, AFed-G achieves comparable results to AFed-GAN, while on more complex image-based tasks where the latent distribution is more diverse, AFed-GAN surpasses AFed-G. 4) Both AFed-G and AFed-GAN achieve higher accuracy than FedAvg, likely due to the generator’s ability to extract and provide clients with valuable information about the global data distribution.








VI-C Comparison between Generator and GAN Approach
Our analysis in Section V indicates the conditional generator in AFed-G surfers lack of diversity problem, which would result in inferior performance to the GAN approach. Our experiment results confirm this finding. As we can see from Fig. 6, for the simple task, i.e., task on the Adult dataset, AFed-GAN and AFed-G demonstrate similar performance. While on complicated tasks, i.e., tasks on UTKface, Fairface and CelebA, AFed-GAN outperforms AFed-G. As decrease, the accuracy gap between AFed-GAN and AFed-G increase.
We contribute this to the sample diversity. One drawback of AFed-G is optimizing Eq. 12 will decrease the diversity of the generated samples. Debiasing with those samples will work at the earlier stage, and as the decreases, the model can make fair predictions on most samples except for some “hard” samples. And, due to the lack of diversity, the AFed-G algorithm fails to generate samples similar to those “hard” samples that contribute to unfairness. As a comparison, AFed-GAN can generate diverse samples, thus, better debiasing performance.
Our claim is supported by Fig.7. It shows the change of w.r.t different . For all four tasks, AFed-G shows an overall higher standard variation than AFed-GAN. This confirms our argument that due to the lack of effective feedback, data generated by AFed-G lacks diversity. Hence, leading to a higher fluctuation in the debiasing result.
VI-D Effects of Auxiliary Classification Head
We remove the auxiliary classification head and rerun the experiment on the UTKface dataset. The results are shown in Fig. 9. The performance of both AFed-GAN and AFed-G drops after removing . This confirms our previous analysis that helps the feature extractor extract more informative representations and keep information about label and attribute . Which consequently benefits the generator training. Nevertheless, our methods outperform baseline methods without an auxiliary classification head.

VI-E Impacts of Participant ratio
In each round of FL, only part of the clients is selected to participate in the current round. To investigate the impact of participant ratio on proposed methods, we performed an additional experiment on the UTKface dataset. We vary participant ratio from 0.2 to 0.8. As we can see from Fig. 8, AFed-GAN consistently outperforms AFed-G and the two baseline methods. Notice that when , AFed-G didn’t show much improvement. In addition, the improvement of AFed-G increased with the increase of .
Training a conditional generator on the server side needs the information related to the decision boundary embedded clients’ classification head . The decision boundary information may be inaccurate when there are only limited clients. As a result, the server fails to train a good generator that can produce fake latent features of high quality (i.e., lie within the decision boundary). On the contrary, the generator in AFed-GAN is free of such problems. As we can see, the performance of AFed-GAN barely changes w.r.t .
VII Conclusion
In this paper, we propose AFed-G and AFed-GAN, two algorithms designed to learn a fair model in FL without centralized access to clients’ data. We first employ a generative model to learn the clients’ data distribution, which is then shared with all clients. Subsequently, each client’s data is augmented with synthetic samples, providing a broader view of the global data distribution. This approach helps derive a more generalized and fair model. Both empirical and theoretical analyses validate the effectiveness of the proposed method. One potential future application of our methods is the case of multiple sensitive attributes, where the data is divided into several groups. Additionally, the proposed framework could be extended to FL scenarios where each client uses a different model architecture, provided they share the same latent feature dimension.
References
- [1] Shai Ben-David et al. “A theory of learning from different domains” In Machine learning 79.1 Springer, 2010, pp. 151–175
- [2] Shai Ben-David, John Blitzer, Koby Crammer and Fernando Pereira “Analysis of representations for domain adaptation” In Advances in neural information processing systems 19, 2006
- [3] Richard Berk et al. “A convex framework for fair regression” In arXiv preprint arXiv:1706.02409, 2017
- [4] Tolga Bolukbasi et al. “Man is to computer programmer as woman is to homemaker? debiasing word embeddings” In Advances in neural information processing systems 29, 2016, pp. 4349–4357
- [5] Toon Calders and Sicco Verwer “Three naive bayes approaches for discrimination-free classification” In Data mining and knowledge discovery 21.2 Springer, 2010, pp. 277–292
- [6] Alexandra Chouldechova and Aaron Roth “The frontiers of fairness in machine learning” In arXiv preprint arXiv:1810.08810, 2018
- [7] Lingyang Chu et al. “FedFair: Training Fair Models In Cross-Silo Federated Learning”, 2021 arXiv: https://arxiv.org/abs/2109.05662
- [8] Lingyang Chu et al. “FedFair: Training Fair Models In Cross-Silo Federated Learning” In ArXiv abs/2109.05662, 2021
- [9] Ching-Yao Chuang and Youssef Mroueh “Fair Mixup: Fairness via Interpolation” In International Conference on Learning Representations, 2020
- [10] Sen Cui et al. “Addressing algorithmic disparity and performance inconsistency in federated learning” In Advances in Neural Information Processing Systems 34, 2021
- [11] Brian d’Alessandro, Cathy O’Neil and Tom LaGatta “Conscientious classification: A data scientist’s guide to discrimination-aware classification” In Big data 5.2 Mary Ann Liebert, Inc. 140 Huguenot Street, 3rd Floor New Rochelle, NY 10801 USA, 2017, pp. 120–134
- [12] Wei Du, Depeng Xu, Xintao Wu and Hanghang Tong “Fairness-aware Agnostic Federated Learning” In Proceedings of the 2021 SIAM International Conference on Data Mining (SDM), 2021, pp. 181–189 SIAM
- [13] Cynthia Dwork et al. “Fairness through awareness” In Proceedings of the 3rd innovations in theoretical computer science conference, 2012, pp. 214–226
- [14] Yahya H Ezzeldin et al. “Fairfed: Enabling group fairness in federated learning” In arXiv preprint arXiv:2110.00857, 2021
- [15] Michael Feldman et al. “Certifying and removing disparate impact” In proceedings of the 21th ACM SIGKDD international conference on knowledge discovery and data mining, 2015, pp. 259–268
- [16] Borja Rodr’iguez G’alvez, Filip Granqvist, Rogier C. Dalen and Matthew Stephen Seigel “Enforcing fairness in private federated learning via the modified method of differential multipliers” In ArXiv abs/2109.08604, 2021
- [17] Ian J Goodfellow et al. “Generative Adversarial Nets” In NIPS, 2014
- [18] Moritz Hardt, Eric Price and Nati Srebro “Equality of opportunity in supervised learning” In Advances in neural information processing systems 29, 2016, pp. 3315–3323
- [19] Wei Huang et al. “Fairness and Accuracy in Federated Learning”, 2020 arXiv:2012.10069 [cs.LG]
- [20] Peter Kairouz et al. “Advances and open problems in federated learning” In arXiv preprint arXiv:1912.04977, 2019
- [21] Faisal Kamiran and Toon Calders “Data preprocessing techniques for classification without discrimination” In Knowledge and information systems 33.1 Springer, 2012, pp. 1–33
- [22] Toshihiro Kamishima, Shotaro Akaho and Jun Sakuma “Fairness-aware Learning through Regularization Approach” In 2011 IEEE 11th International Conference on Data Mining Workshops, 2011, pp. 643–650 DOI: 10.1109/ICDMW.2011.83
- [23] Kimmo Karkkainen and Jungseock Joo “Fairface: Face attribute dataset for balanced race, gender, and age for bias measurement and mitigation” In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2021, pp. 1548–1558
- [24] Tian Li, Maziar Sanjabi, Ahmad Beirami and Virginia Smith “Fair resource allocation in federated learning” In arXiv preprint arXiv:1905.10497, 2019
- [25] Ziwei Liu, Ping Luo, Xiaogang Wang and Xiaoou Tang “Deep Learning Face Attributes in the Wild” In Proceedings of International Conference on Computer Vision (ICCV), 2015
- [26] David Madras, Elliot Creager, Toniann Pitassi and Richard Zemel “Learning adversarially fair and transferable representations” In International Conference on Machine Learning, 2018, pp. 3384–3393 PMLR
- [27] Qi Mao et al. “Mode seeking generative adversarial networks for diverse image synthesis” In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 1429–1437
- [28] Leland McInnes, John Healy and James Melville “Umap: Uniform manifold approximation and projection for dimension reduction” In arXiv preprint arXiv:1802.03426, 2018
- [29] Brendan McMahan et al. “Communication-efficient learning of deep networks from decentralized data” In Artificial intelligence and statistics, 2017, pp. 1273–1282 PMLR
- [30] Mehdi Mirza and Simon Osindero “Conditional generative adversarial nets” In arXiv preprint arXiv:1411.1784, 2014
- [31] Mehryar Mohri, Gary Sivek and Ananda Theertha Suresh “Agnostic federated learning” In International Conference on Machine Learning, 2019, pp. 4615–4625 PMLR
- [32] Mohammad Rasouli, Tao Sun and Ram Rajagopal “FedGAN: Federated Generative Adversarial Networks for Distributed Data”, 2020 arXiv:2006.07228 [cs.LG]
- [33] Yuji Roh, Kangwook Lee, Steven Euijong Whang and Changho Suh “Fairbatch: Batch selection for model fairness” In arXiv preprint arXiv:2012.01696, 2020
- [34] Candice Schumann et al. “Transfer of machine learning fairness across domains” In arXiv preprint arXiv:1906.09688, 2019
- [35] Virginia Smith, Chao-Kai Chiang, Maziar Sanjabi and Ameet S Talwalkar “Federated Multi-Task Learning” In NIPS, 2017
- [36] Ganghua Wang, Ali Payani, Myungjin Lee and Ramana Kompella “Mitigating group bias in federated learning: Beyond local fairness” In arXiv preprint arXiv:2305.09931, 2023
- [37] Depeng Xu, Shuhan Yuan, Lu Zhang and Xintao Wu “Fairgan: Fairness-aware generative adversarial networks” In 2018 IEEE International Conference on Big Data (Big Data), 2018, pp. 570–575 IEEE
- [38] Miao Yang et al. “Federated learning with class imbalance reduction” In arXiv preprint arXiv:2011.11266, 2020
- [39] Jaemin Yoo, Minyong Cho, Taebum Kim and U Kang “Knowledge Extraction with No Observable Data” In Advances in Neural Information Processing Systems 32 Curran Associates, Inc., 2019
- [40] Muhammad Bilal Zafar, Isabel Valera, Manuel Gomez Rogriguez and Krishna P Gummadi “Fairness constraints: Mechanisms for fair classification” In Artificial Intelligence and Statistics, 2017, pp. 962–970 PMLR
- [41] Yuchen Zeng, Hongxu Chen and Kangwook Lee “Improving fairness via federated learning” In arXiv preprint arXiv:2110.15545, 2021
- [42] Brian Hu Zhang, Blake Lemoine and Margaret Mitchell “Mitigating unwanted biases with adversarial learning” In Proceedings of the 2018 AAAI/ACM Conference on AI, Ethics, and Society, 2018, pp. 335–340
- [43] Daniel Yue Zhang, Ziyi Kou and Dong Wang “Fairfl: A fair federated learning approach to reducing demographic bias in privacy-sensitive classification models” In 2020 IEEE International Conference on Big Data (Big Data), 2020, pp. 1051–1060 IEEE
- [44] Hongyi Zhang, Moustapha Cisse, Yann N Dauphin and David Lopez-Paz “mixup: Beyond Empirical Risk Minimization” In International Conference on Learning Representations, 2018
- [45] L Zhang, Y Wu and X Wu “Fairness-aware classification: Criterion convexity and bounds” In AAAI, 2019
- [46] Tao Zhang et al. “Balancing Learning Model Privacy, Fairness, and Accuracy With Early Stopping Criteria” In IEEE Transactions on Neural Networks and Learning Systems IEEE, 2021
- [47] Tao Zhang et al. “Fairness in semi-supervised learning: Unlabeled data help to reduce discrimination” In IEEE Transactions on Knowledge and Data Engineering 34.4 IEEE, 2020, pp. 1763–1774
- [48] Zhifei Zhang, Yang Song and Hairong Qi “Age progression/regression by conditional adversarial autoencoder” In Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 5810–5818
- [49] Han Zhao and Geoffrey J Gordon “Inherent Tradeoffs in Learning Fair Representations” In Journal of Machine Learning Research 23, 2022, pp. 1–26
- [50] Yue Zhao et al. “Federated learning with non-iid data” In arXiv preprint arXiv:1806.00582, 2018
- [51] Zhuangdi Zhu, Junyuan Hong and Jiayu Zhou “Data-free knowledge distillation for heterogeneous federated learning” In International Conference on Machine Learning, 2021, pp. 12878–12889 PMLR
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/d095fde5-7b1d-411a-b7ce-be7ee9f82631/hqc.jpg) |
Huiqiang Chen received the B.E. degree from Hunan University, China, in 2016, M.S. degree form Zhejiang University, China, in 2019, and the Ph.D. degree from the School of Computer Science, University of Technology Sydney, in 2025. His research interests center on trustworthy machine learning and cybersecurity, with a focus on AI security, privacy-preserving techniques, and fairness-aware algorithms in deep neural networks. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/d095fde5-7b1d-411a-b7ce-be7ee9f82631/tqz.jpg) |
Tianqing Zhu received the B.Eng. and M.Eng. degrees from Wuhan University, Wuhan, China, in 2000 and 2004, respectively, and the Ph.D. degree from Deakin University, Sydney, Australia, in 2014. She was a Lecturer with the School of Information Technology, Deakin University, from 2014 to 2018, and an Associate Professor with the University of Technology Sydney, Ultimo, NSW, Australia. She is currently a Professor with the Faculty of Data Science, City University of Macau, Macau, SAR, China. Her research interests include cyber security and privacy in artificial intelligence (AI). |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/d095fde5-7b1d-411a-b7ce-be7ee9f82631/wlz.jpg) |
Wanlei Zhou received the PhD degree in computer science and Engineering from The Australian National University, Canberra, Australia, in 1991 and the DSc degree (a higher Doctorate degree) from Deakin University in 2002. He is currently the vice-rector (Academic Affairs) and dean of the Institute of Data Science, City University of Macau, Macao, China. He has authored or co-authored more than 400 papers in refereed international journals and refereed international conference proceedings, including many articles in IEEE Transactions and journals. His main research interests include security, privacy, and distributed computing. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/d095fde5-7b1d-411a-b7ce-be7ee9f82631/wz.jpg) |
Wei Zhao An internationally renowned scholar, Professor Wei Zhao has served important leadership roles in academia, including, currently the Provost and Chair Professor at the Shenzhen University of Advanced Technology, and previously the eighth Rector (i.e., President) of the University of Macau, the Dean of Science at Rensselaer Polytechnic Institute, the Director for the Division of Computer and Network Systems in the U.S. NSF, the Chief Research Officer (i.e., VPR) at the American University of Sharjah, the Chair of Academic Council at the Shenzhen Institute of Advanced Technology, and the Senior Associate Vice President for Research at Texas A&M University. An IEEE Fellow, Professor Zhao has made significant contributions in cyber-physical systems, distributed computing, real-time systems, computer networks, and cyberspace security. He led the effort to define the research agenda of and to create the very first funding program for cyber-physical systems when he served as the NSF CNS Division Director in 2006. His research group has received numerous awards. Their research results have been adopted in the standard of DOD SAFENET. Professor Zhao was honored with the Lifelong Achievement Award by the Chinese Association of Science and Technology, and the Overseas Achievement Award by the Chinese Computer Federation. He has been conferred honorable doctorates by 12 universities in the world and academician of the International Eurasian Academy of Sciences. |