AeroVerse: UAV-Agent Benchmark Suite for Simulating, Pre-training, Finetuning, and Evaluating Aerospace Embodied World Models
Abstract
Aerospace embodied intelligence aims to empower unmanned aerial vehicles (UAVs) and other aerospace platforms to achieve autonomous perception, cognition, and action, as well as egocentric active interaction with humans and the environment. The aerospace embodied world model serves as an effective means to realize the autonomous intelligence of UAVs and represents a necessary pathway toward aerospace embodied intelligence. However, existing embodied world models primarily focus on ground-level intelligent agents in indoor scenarios, while research on UAV intelligent agents remains unexplored. To address this gap, we develop AeroSimulator, a simulation platform that encompasses realistic urban scenes for UAV flight simulation. Additionally, we construct the first large-scale real-world image-text pre-training dataset, AerialAgent-Ego10k, featuring urban drones from a first-person perspective. We also create a virtual image-text-pose alignment dataset, CyberAgent-Ego500k, to facilitate the pre-training of the aerospace embodied world model. For the first time, we clearly define downstream tasks, i.e., aerospace embodied scene awareness, spatial reasoning, navigational exploration, task planning, and motion decision, and construct corresponding instruction datasets, i.e., SkyAgent-Scene3k, SkyAgent-Reason3k, SkyAgent-Nav3k and SkyAgent-Plan3k, and SkyAgent-Act3k, for fine-tuning the aerospace embodiment world model. Simultaneously, we develop SkyAgent-Eval, the downstream task evaluation metrics based on GPT-4, to comprehensively, flexibly, and objectively assess the results, revealing the potential and limitations of 2D3D visual language models in UAV-agent tasks. Furthermore, we integrate over 2D3D visual-language models, pre-training datasets, finetuning datasets, more than evaluation metrics, and a simulator into the benchmark suite, i.e., AeroVerse, which will be released to the community to promote exploration and development of aerospace embodied intelligence.
Index Terms:
Aerospace Embodied Intelligence, Aerospace Embodied World Model, UAV-Agent, Visual-Language Model.I Introduction
Drones have a wide range of applications, including mountainous photovoltaic inspection, river trash detection, pedestrian traffic monitoring at intersections, electric power inspection, and forest fire rescue [1]. However, these applications often depend on manual remote control of the drones. For instance, in UAV mountain photovoltaic inspections, it is necessary to deploy professional operators who spend several hours each day inspecting multiple stations. This practice can easily lead to operator fatigue, resulting in component defects and missed inspections. Therefore, there is an urgent need for UAVs equipped with autonomous intelligence to reduce costs and enhance efficiency.
Aerospace embodied intelligence refers to the specialized application of embodied intelligence within the aerospace sector, focusing on empowering unmanned platforms such as satellites, drones, and aircraft to autonomously integrate perception, cognition, and action. This integration aims to facilitate egocentric active interactions with both humans and the physical environment. Over the past year, visual-language models that encode world knowledge have rapidly advanced, driven by a wealth of high-fidelity simulators and datasets[2, 3, 4, 5, 6, 7], thereby presenting new opportunities for embodied intelligence. Numerous embodied world models[8, 9, 10, 11, 12, 13, 14, 15], have emerged, significantly enhancing the capabilities of embodied agents in perceiving their surroundings and planning tasks. Consequently, this article posits that the development of an aerospace embodied world model is a crucial strategy for achieving autonomous intelligent agents for drones and represents a necessary pathway toward advancing aerospace embodied intelligence.

However, these embodied world models primarily focus on indoor scenarios (e.g., robotic arms) or ground-based agents in outdoor environments (e.g., unmanned vehicles) [8, 9, 10, 11, 12]. There has been limited exploration of UAV embodied agents, particularly in the context of aerospace embodied world models that facilitate UAV autonomy, which is significantly constrained by the development of UAV embodied datasets. In contrast to indoor embodied intelligence datasets [9, 8], several key challenges arise in the construction of UAV embodied intelligence datasets:
Lack of Definition of UAV Embodied Tasks. In recent years, research on ground-oriented agents has gained significant attention, leading to clearer definitions of downstream tasks such as indoor/outdoor navigation[3, 5], command following[2], and embodied question answering. However, UAV agents must comprehend the intrinsic correlations of four-dimensional space-time and perform actions under conditions of scene randomization and local observability of the environment. This involves aspects such as awareness, cognition, planning, and decision-making. The diversity and interdependence of these downstream tasks result in a lack of clarity in the task definitions for aerial-embodied agents.
Difficulty in UAV 3D Data Acquisition. The widespread use of LiDAR technology in mobile smart devices has facilitated the easy acquisition of indoor 3D data, leading to substantial accumulation. In contrast, obtaining outdoor 3D data necessitates specialized equipment, such as drones, which presents a higher barrier to entry. Furthermore, outdoor 3D data acquisition requires skilled professionals to operate drones and collect extensive point cloud data over larger areas.
High Cost of UAV Embodied Data Collection. UAVs possess a greater range of motion compared to ground agents (e.g., indoor sweeping robots), allowing for a high degree of freedom in three-dimensional space. They can operate over extensive areas (ranging from dozens to hundreds of square kilometers) and navigate complex environments characterized by irregularly distributed obstacles, e.g., buildings and trees. Consequently, this necessitates extensive training for annotators to effectively conduct data collection for UAV agents.
Therefore, our paper, for the first time, explicitly defines five downstream tasks for UAV-embodied agents, highlighting directions for further exploration in this field, as follows:
-
•
Aerospace Embodied Scene Awareness: UAV-agent perceives the surrounding 3D environment from a first-person perspective to enhance scene understanding.
-
•
Aerospace Embodied Spatial Reasoning: The UAV agent models the spatial relationships between objects within a 3D scene, enabling reasoning about the relationships among these objects.
-
•
Aerospace Embodied Navigational Exploration: The UAV agent comprehends navigation commands and navigates to the destination while describing the environment.
-
•
Aerospace Embodied Task Planning: UAV-agent generates detailed, landmark-level long-range path planning scenarios to reach the destination.
-
•
Aerospace Embodied Motion Decision: The UAV agent provides a complete sequence of actions from the starting point to the destination, thereby realizing an end-to-end closed loop of the scene awareness, path planning, and action decision-making.
As illustrated in Figure 1, we address the gap in the UAV-agent dataset and enhance the training of aerospace embodied world models by constructing the first large-scale virtual-reality pre-training dataset alongside a high-quality instruction dataset. Specifically, the first-person, high-resolution real-world pre-training dataset of high-altitude drones, AerialAgent-Ego10k, is derived from the UrbanBIS dataset. Additionally, we develop the aligned pre-training dataset, CyberAgent-Ego500k, which includes perspective images, scene text descriptions, and drone attitudes. Furthermore, we create five downstream task instruction datasets: SkyAgent-Scene3k, SkyAgent-Reason3k, SkyAgent-Nav3k and SkyAgent-Plan3k, and SkyAgent-Act3k. These datasets are constructed using our established simulation platform, AeroSimulator, which employs Unreal Engine 4, the Microsoft AirSim drone simulator[16], and the 3D UrbanScene virtual city dataset[17]. This encompasses four real-world urban scenarios, i.e., Shanghai, Shenzhen, School, and Residence, with a coverage area ranging from to . AerialAgent-Ego10k is utilized to enhance the model’s ability to comprehend real urban scenes. CyberAgent-Ego500k is designed for virtual alignment pre-training of visual-language-posture for the Aerospace Embodied World Model, aiming to improve the model’s fundamental generalization capacity in simulated environments. This dataset contains 500K aligned UAV postures, first-person view images, and text descriptions, collected from four 3D urban environments. The collection principle prioritizes images featuring complex scenes, including buildings, roads, and trees. Furthermore, the downstream task instruction datasets are compiled by ten trained professional annotators who operated the UAV in a 3D urban environment for data acquisition and annotation. This process took a total of eight months and underwent rigorous quality checks to ensure the accuracy and reliability of the data, making it ideal for fine-tuning and evaluating the performance of downstream tasks.
Furthermore, we develop a range of scientific automated evaluations, i.e., SkyAgent-Eval, for downstream tasks. Previous advancements have introduced various rubrics for text generation tasks, including BLUE [18], SPICE[19]. These methods assess text quality from relatively fixed and limited perspectives, such as semantic similarity and word matching, which can impede their customization and adaptability for evaluating downstream tasks involving UAV agents. Moreover, most existing methods depend on probabilistic statistics and do not align with human preferences. In contrast, large language models [20, 21, 22], trained using reinforcement learning with human feedback (RLHF)[23], generate responses that more accurately reflect human values and preferences. This makes them a viable alternative for evaluating text generation while mitigating the high costs associated with human evaluation[24]. Therefore, by leveraging the multifaceted capabilities of large language models, we propose an automated evaluation approach based on GPT-4 [20] for three types of downstream tasks, specifically LLM-Judge-Scene, LLM-Judge-ReasonNav, and LLM-Judge-Plan. This approach employs few-shot instruction and context learning to cater to the customized evaluation needs of various downstream tasks, thus facilitating a more comprehensive and objective assessment of their performance.
In summary, The contributions can be summarized as follows:
(1) We construct the first large-scale real-world image-text pre-training dataset, AerialAgent-Ego10k, utilizing urban UAVs as the primary viewpoint. Additionally, we develop the virtual image-text-posture alignment dataset, CyberAgent-Ego500k, to pre-train the aerospace embodied world model, thereby enhancing the UAV agent’s ability to adapt to both real and virtual environments.
(2) For the first time, we clearly define five aerospace embodied downstream tasks: scene awareness, spatial reasoning, navigational exploration, task planning, and motion decision-making. To support the fine-tuning of the aerospace embodied world model, we create five corresponding instruction datasets, i.e., SkyAgent-Scene3k, SkyAgent-Reason3k, SkyAgent-Nav3k and SkyAgent-Plan3k, and SkyAgent-Act3k, which facilitates the realization of an end-to-end closed-loop of perception, cognition, and action for UAV agents.
(3) We develop a series of automated evaluation methods, i.e., SkyAgent-Eval, based on GPT-4 for the downstream tasks. These methods assess the results comprehensively, flexibly, and objectively, providing quantitative scores and corresponding explanations for task evaluations, thereby enhancing the credibility of the evaluation outcomes.
(4) Extensive experiments are conducted using ten mainstream baselines to analyze their performance on the downstream instruction datasets. The experimental results reveal the potential and limitations of 2D3D visual-language models in UAV-agent tasks, underscoring the necessity of constructing an aerospace embodied world model.
(5) We design over 2D3D visual-language models, pre-training datasets, downstream task instruction datasets, and evaluation metrics, as well as a simulator featuring urban scenarios, into a benchmark suite, AeroVerse, which will be released to the community to advance the field of aerospace embodied agents.
II Related Work
II-A 3D Visual-Language Datasets
The three-dimensional (3D) world encompasses not only horizontal and vertical dimensions but also depth, providing richer information than two-dimensional (2D) images. Depth accurately reflects fundamental aspects of the real world and enhances the ability of embodied agents to learn from and understand their 3D environment. Furthermore, textual annotations accompanying 3D visual-language datasets assist embodied agents in perceiving their surroundings and conducting spatial reasoning. However, challenges in creating 3D datasets have led to a scarcity of such resources, with only a limited number of datasets publicly available to date. For instance, the ScanQA dataset comprises unique Q&A pairs, accompanied by 3D object localization annotations for indoor 3D scenes [25]. The ScanRefer dataset contains distinct Q&A pairs for indoor 3D scenes [26]. The ScanNet dataset includes indoor scenes featuring a total of object categories [27].
In contrast to the aforementioned 3D visual-language datasets that focus on indoor environments, we have pioneered the development of a constructed 3D dataset that emphasizes large-scale urban scenes. This dataset encompasses areas ranging from () to () square meters and includes four representative urban environments, i.e., Shenzhen, Shanghai, Residence, and School. We select flying vehicles, specifically unmanned aerial vehicles (UAVs), as the agents due to their greater degree of freedom.
II-B Embodied Intelligence Datasets
The embodied world model serves as an effective approach for empowering embodied agents to interact with their environments, autonomously plan, make decisions, act, and perform tasks similar to human capabilities. Most existing embodied world models concentrate on mobile robots in indoor settings. For example, in the embodied question-and-answer task, Abhishek et al. introduce the EQA dataset, which consists of question-and-answer pairs across indoor rooms [28]. In the domain of embodied task planning, Mohit et al. present the ALFRED dataset, which includes commands and image-action pairs [29]. Additionally, in the realm of embodied navigation tasks, Anderson et al. propose the R2R dataset, which comprises navigation instructions with an average length of words [30].
In contrast, we explicitly define five types of embodied downstream tasks for UAV agents for the first time, each characterized by distinctive features. Taking embodied navigational exploration as an example, we require the agent not only to follow instructions to navigate to a designated destination but also to describe object attributes, such as the color, shape, and height of the building’s floors. Furthermore, we construct five instruction datasets for downstream tasks, namely SkyAgent-Scene3k, SkyAgent-Reason3k, SkyAgent-Nav3k and SkyAgent-Plan3k, and SkyAgent-Act3k. Additionally, we establish a 3D urban simulator, i.e., AeroSimulator, for training UAV agents and collecting data, significantly narrowing the gap between the agents and the real physical environment, thereby facilitating a smoother transition to real-world scenarios.
III Task Formulation


To facilitate the closed-loop training of perception, cognition, and action in UAV agents and to endow them with autonomous capabilities, this paper categorizes the downstream tasks into five distinct categories, as illustrated in Figure 2. It clearly defines the concepts associated with these tasks, standardizes the input and output formats, and offers innovative perspectives for further research on aerospace embodied intelligence in the context of UAVs.
Aerospace Embodied Scene Awareness. Given the current state of drone intelligent agents, specifically their position in three-dimensional space, drones describe surrounding environmental elements, such as buildings, in a panoramic manner (covering four directions: front, back, left, and right). This capability is essential for the cognitive processes and actions of intelligent agents. Traditional environmental perception tasks generally involve inputting environmental images, extracting features from these images, and generating corresponding descriptions. In contrast, the objective of this task is to enhance the ability of UAV agents to perceive their environment and articulate 3D scenes based on their location coordinates.
Input: Multi-perspective 2D images of the city’s 3D scene, including , depth map , multi-perspective camera pose , and the current attitude of the drone in the environment.
Output: Scene element description of UAV agent in four directions, i.e., front, back, left, right,
Aerospace Embodied Spatial Reasoning. Based on the current location and three-dimensional environment, the drone agent infers the object’s orientation relationships, action trajectories, and counterfactual scenarios within the scene, guided by specific questions. The objective is to enhance the agent’s understanding of the 3D spatial scene graph, which is a fundamental task of embodied cognition. Traditional spatial reasoning tasks primarily focus on recognizing spatial relationships between objects in a single 2D image, characterized by simplistic scenes and a limited number of objects. In contrast, this task emphasizes reasoning about relationships, intentions, counterfactuals, and other dimensions within three-dimensional space, which is inherently more complex and aligns more closely with human logical reasoning.
Input: Multi-perspective 2D images of urban 3D scenes, including , depth map , multi-perspective camera pose , current drone pose in the environment, question .
Output: The answer to the question, i.e.,
Aerospace Embodied Navigational Exploration. Given the UAV agent’s initial position and its long-range, multi-stage navigation instructions, the agent is required to autonomously explore a large urban environment and answer questions related to object characteristics, such as the shape and color of buildings. This capability directly supports applications like object search and tracking in urban settings where building obstructions exist. Unlike traditional navigation tasks that rely solely on navigation instructions and do not include question-answering functions, this task necessitates that the agent not only autonomously navigate and explore its surroundings according to the provided instructions but also respond to inquiries based on the information it collects.
Input: Multi-perspective 2D images of urban 3D scenes with , depth map , multi-perspective camera pose , current drone pose in the environment , navigation command , .
Output: The answer to the question, i.e.,
Aerospace Embodied Task Planning. By specifying the initial position and the anticipated endpoint for the UAV intelligent agent, the agent integrates the 3D environment to generate a detailed, step-by-step path planning process. This process requires the identification of distinct landmarks at each stage, which serves as the core task in UAV embodied cognition. Current path planning methods for indoor environments primarily focus on coarse-grained paths within a single room. In contrast, this task addresses large-scale urban scenes, where the starting and ending points may be separated by several city blocks. During maneuvers such as turning, moving straight, and ascending, the agent will identify observable landmark-level objects to enhance the accuracy of the path planning.
Input: Multi-perspective 2D images of urban 3D scenes, including , depth map , multi-perspective camera pose , as well as the current attitude of the drone, , and target pose .
Output: Step-by-step path plans and intermediate pose , i.e.,
Aerospace Embodied Motion Decision. The intelligent drone agent operates in real-time, guided by its initial position and target endpoint. It dynamically interacts with its environment and adjusts its action strategy based on the outcomes of each movement and the historical sequence of actions. This iterative process continues until it reaches the endpoint. Unlike traditional decision-making tasks, this approach positions the drone as the agent, making decisions informed by first-person environmental observations at each navigation node. It encompasses a nearly complete end-to-end closed-loop of task chains, including perception, reasoning, planning, and action, representing the ultimate objective for drone agents.
Input: Multi-perspective 2D images of urban 3D scenes, including , depth map , multi-perspective camera pose , position , , from to -, and target pose .
Output: Action at time , i.e.,
IV Simulation Platform
Simulator. To simulate a realistic drone flight scenario, we utilize Unreal Engine to load urban environments and select AirSim[16] for constructing the drone model. This enables us to develop a simulator, named AeroSimulator, capable of facilitating multiple action spaces for the drone, as illustrated in Figure 3. Adhering to the real-to-sim-to-real paradigm, we select four representative scenes from the high-quality UrbanScene3D dataset[17] created by Lin et al.: Shenzhen, Shanghai, School, and Residence, all derived from 3D reconstructions of actual physical locations. Furthermore, the simulator accommodates various lighting conditions (day, evening, night, etc.), seasonal variations (spring, summer, autumn, winter), and climatic modes (sunny, cloudy, light snow, etc.), thereby enhancing the transferability of the trained drone agent to real-world applications. Within the simulator, the drone can continuously navigate the urban environment we have loaded, capturing data visually through an integrated RGB, depth, and object segmentation cameras, which output corresponding first-person perspective images in real time.
Scenes. To bridge the gap between transferring drone intelligent agents from simulated environments to real-world scenarios, we utilize UrbanScene3D[17], a large-scale data platform specifically designed for urban scene perception and reconstruction. This platform comprises over 128,000 high-resolution images captured from various cities. The selected 3D scenes from four cities, as illustrated in Figure 3, feature detailed architectural elements, including office buildings, shopping centers, residential complexes, bus stations, and subway entrances and exits. Additionally, these scenes encompass specific street details such as lanes, sidewalks, crossroads, traffic signals, and road markings, along with other urban features like streetlights, signs, trees, shrubs, and lawns. These attributes facilitate the exploration of diverse urban environments by drone intelligent agents. Among the cities, Shanghai presents the most extensive urban scene, featuring objects and covering an area of hectares. This extensive environment is advantageous for training UAV agents in long-distance navigation and path planning. In contrast, the urban scene in Shenzhen is relatively compact, covering an area of hectares with only objects; however, it enhances the spatial reasoning capabilities of drone intelligent agents in smaller settings. Furthermore, the campus area, which spans hectares and contains objects, and the residential zone, covering hectares with objects, focus on localized environments characterized by dense buildings and obstacles such as trees and equipment. This concentration improves scene understanding and decision-making skills, including obstacle avoidance.
Observations. In the simulator, the drone is generated using AirSim, which features five built-in cameras: forward, backward, left, right, and overhead views. Each camera operates in three modes:
RGB Camera. Captures RGB images with a resolution of , saved in PNG format.
Depth Camera. Produces depth images based on the positional information between the camera and the object, maintaining the same resolution as the RGB camera and also saved in PNG format. In this experiment, when the distance exceeds 500 meters, the image appears entirely white; for distances below 500 meters, varying shades of black are displayed according to proximity.
Object Segmentation Camera. Retrieves the object segmentation map, segmenting the image into different colors based on object types—gray for buildings, green for trees, and red for vehicles. The resolution of the segmentation image matches that of the RGB camera and is saved in PNG format.
Actions. The simulator supports drone intelligent agents in altering their position (x, y, z coordinates), direction (pitch, yaw, roll), and speed, while also enabling more complex maneuvers through acceleration adjustments and the application of force vectors. To facilitate the training of UAV agents, we have preliminarily identified the eight most common low-level actions for drones: forward, left turn, right turn, ascend, descend, left shift, right shift, and stop. To balance the frequency of actions during the trajectory with the actual movement of the drone in an outdoor environment, the “forward movement” action propels the drone continuously for meters in the current direction, while the “left movement” and “right movement” actions shift the drone continuously for meter in their respective directions. The left and right rotation actions enable horizontal rotation by degrees, and the ascending and descending actions allow vertical movement for meter.
V Dataset Suite

To address the shortage of large-scale training data for UAV agents, facilitate the training of aerospace embodied word models, and further advance research in aerospace embodied intelligence, we engage ten trained experts who dedicated eight months to developing a comprehensive dataset suite that encompasses two pre-training datasets and five downstream task instruction fine-tuning datasets.
V-A AerialAgent-Ego10k
Multi-Resolution UAV First-Person View City Images. The first-person view images of real cities captured by drones are derived from the UrbanBIS dataset, which is collected using aerial photogrammetry and encompasses a wide array of urban scenes. Specifically, the UrbanBIS dataset[31] comprises TB of aerial photographs from six actual locations: Qingdao, Wuhu, Longhua, Yuehai, Lihu, and Yingrenshi, covering a significant urban area of km² and including buildings, with a total of aerial photogrammetry images. We have requested images from the authors for the regions of Lihu, Longhua, Yingrenshi, and Yuehai, with resolutions of , , , and , respectively, yielding a total of images. From this dataset, we randomly selected images to serve as first-person view representations of real cities captured by drones.
Fine-grained Multi-attribute First-view Text Generation. To generate high-quality environmental descriptions, we utilize LLaVA-1.5-13B[32] to produce detailed accounts of surrounding buildings, roads, trees, and other scenery from first-person perspective images captured by a drone, as illustrated in Figure 4 left (a). To standardize the format of the environmental descriptions generated by LLaVA-1.5-13B[32], we employ specific prompts that emphasize the quantity, appearance, and shape of the buildings in the images, particularly focusing on the spatial relationships among the objects. This approach enhances the spatial reasoning capabilities of the drone agent. Furthermore, we specify that the sky should not be described, as this scene is relatively uniform and appears consistent from various perspectives of the drone, providing insufficient information. Consequently, the generated descriptions ensure a degree of diversity, accuracy, and detail.
Diverse Data Distribution. We perform a quantitative statistical analysis on AerialAgent-Ego10k. Figure 4 (b) and (c) illustrate the probability density functions (PDFs) of text vocabulary length and text sentence length, respectively, both exhibiting a shape akin to a normal distribution. This finding supports the rationality of the text distribution. The maximum length for image descriptions is words, with an average length of words. The maximum number of sentences in image descriptions is , with an average of sentences per image. Both the number of sentences and text lengths exceed those of most existing visual-language datasets. Figure 4 (d) reveals that the dataset contains a total of sentences and words, of which are unique.
V-B CyberAgent-Ego500k
Image Acquisition. We require trained drone pilots to operate drones in four virtual cityscapes: Shenzhen, School, Residence, and Shanghai. The flight range encompasses the entirety of these city scenes, with dense sampling conducted in areas characterized by a high density of objects, such as buildings. To prevent the drones from encountering obstacles, a selection of drone poses is recorded at random. Based on these poses, a total of first-person perspective images, each with a resolution of pixels, are generated within the virtual cityscapes. From this collection, images are randomly selected to construct the image-text-pose dataset.
First-Person Image-Text-Pose Generation. As illustrated on the right side of Figure 4 (a), the dataset construction method aligns with that of AerialAgent-10k and exhibits the following three characteristics:
Drone First-Person Images in Multi-City Scenes. Collected from 3D simulators in Shanghai (large areas), Shenzhen (multiple blocks), campuses (featuring numerous obstacles such as trees), and residential areas (characterized by dense buildings and narrow pathways), this approach aims to minimize the gap between simulated and real-world environments.
Multi-Attribute First-Person Text Descriptions. The generated text descriptions provide comprehensive information regarding the attributes of objects in the drone’s first-person images, including appearance, quantity, shape, absolute position, and relative position. Notably, the spatial relationships among objects are crucial for enhancing the spatial reasoning capabilities of the drone agent.
Image-Text-Pose Alignment. In addition to the images and their corresponding text descriptions, this method incorporates the drone’s attitude (position and orientation) in 3D space. The objective is to integrate the drone’s spatial positioning into the aerospace-embodied world model, thereby enhancing the drone’s self-centered scene understanding capabilities.
Dataset statistics. Figure 4 (b), (c), and (d) in the right block present detailed statistical results for the CyberAgent-500k dataset. The maximum length of the image descriptions is words, with an average length of words. Furthermore, the maximum number of sentences per image description is , with an average of sentences. The dataset contains a total of sentences and words, including unique words. These statistical results indicate that this dataset surpasses most existing visual-language datasets in terms of scale, text length, sentence count, and the alignment of drone poses.
V-C SkyAgent-Scene3k

Dataset Construction. We require the annotator to control the drone to navigate within the 3D virtual city scene, select its current posture, and describe the surrounding environment from four perspectives: front, back, left, and right. The description format is fixed as follows: “front object description , right object description , back object description , left object description ”. The object description should include the elements “quantifier + color + specific description + shape + object”, as illustrated in Figure 5 (a). To ensure data quality, we conduct rigorous inspections, requiring different annotators performing the same task to cross-check their work, followed by cross-checking between annotators from different cities. In summary, SkyAgent-Scene3k possesses the following characteristics:
Diversified Object Types and Instructions. The primary objects include buildings, roads, trees, and grasslands within urban areas. Additionally, we have developed over 20 distinct instructions, as illustrated in Figure 5 (e), to enhance the generalization capabilities of task understanding.
Multi-Directional and Multi-Attribute Environment Description. Focusing on the drone intelligent agent, descriptions of both close-range and long-range scenes are provided from four perspectives: front, back, left, and right. Buildings are characterized by their height, appearance, and color, while roads are described based on the number of lanes, intersections, and directional extensions.
Multi-Perspective 2D Images, Depth Maps, Camera Poses, Drone Poses, and Scene Description Alignment. Multi-perspective images, depth maps, and camera poses of urban landscapes facilitate the reconstruction of a three-dimensional representation of the entire city, assisting drone agents in understanding the spatial relationships between objects and enhancing their perception of three-dimensional scenes.
Dataset statistics. Figure 5 (b), (c), and (d) illustrate the distribution of description lengths, the number of sentences, and statistical information regarding scene descriptions. As shown in Figure 5 (b), the lengths of the descriptions range from to words. Generally, longer descriptions suggest a more complex scene with a greater number of environmental elements that require articulation. Figure 5 (c) indicates that most descriptions consist of four sentences, as we instruct annotators to depict each scene from four perspectives: front, back, left, and right. Descriptions containing 13 sentences occur when annotators consolidate multiple perspectives into a single sentence. In total, this dataset comprises words and distinct word types.
V-D SkyAgent-Reason3k

Dataset Construction. To enhance the cognitive reasoning abilities of UAV agents in three-dimensional urban environments, we require annotators to navigate the 3D city scene, adopt specific postures to pause, establish targeted spatial positions, and create question-and-answer pairs regarding various features encountered by the UAV, including buildings, roads, trees, and grasslands. Specifically, inquiries pertaining to buildings should focus on attributes such as height, appearance, and color, while questions related to roads should address the number of lanes, intersections, and direction of extension. As illustrated in Figure 6 (a), each question in this dataset must be answered accurately through spatial reasoning in conjunction with the three-dimensional environment. This process can be further categorized into six distinct modes of reasoning.
-
•
Color Reasoning. This reasoning process involves prompting the drone’s intelligent agent to identify and inquire about the colors of specific objects encountered as it approaches a designated spatial location. This necessitates the agent’s ability to recognize colors based on the identified targets.
-
•
Count Reasoning. Requires the intelligent agent to compute the number of specific objects encountered while following short-range instructions.
-
•
Shape Reasoning. This reasoning necessitates that the drone’s intelligent agent describes the specific shapes of the objects it encounters upon arriving at the designated target area.
-
•
Object Reasoning. Requires UAV intelligent agents to enumerate the buildings and other objects they encounter while navigating to a specific spatial location.
-
•
Predictive Reasoning. Upon satisfying certain preconditions, the drone must predict potential objects and actions it may encounter.
-
•
Counterfactual Reasoning: This reasoning involves presenting a hypothesis to the drone agent that contradicts established facts, requiring the agent to respond to the hypothesis.
Dataset Statistics. Figure 6 (b) illustrates that the length distribution of questions ranges from to words, significantly surpassing the statistics of questions found in existing VQA datasets in terms of both coverage and length. Figure 6 (c) indicates that the length of answers varies from to words, with the majority consisting of to words, thereby allowing the drone agent to deliver concise responses. Figures 6 (d) and (e) present statistical analyses of the questions and answers, respectively. The results reveal that, although the word count of the questions is approximately three times greater than that of the answers ( vs. ), the vocabulary diversity is actually lower in the questions than in the answers ( vs. ). This discrepancy underscores the potential for drone intelligent agents to enhance their vocabulary in responses.
V-E SkyAgent-Nav3k
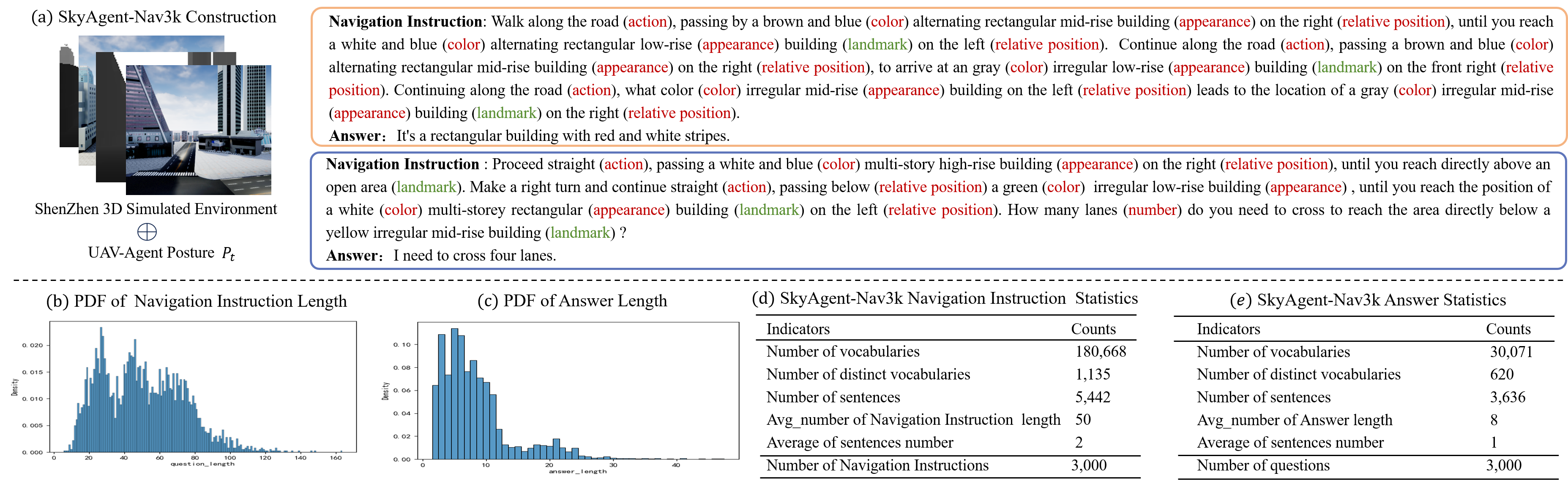
Dataset Construction. We require annotators to control drones to fly specific distances within an urban environment, annotate the textual descriptions of the flight paths, record the starting and ending positions, and design a set of question-and-answer pairs primarily addressing whether actions such as flying straight, turning left, or turning right will occur, as well as the types of buildings, intersections, and lanes encountered. Additionally, manual cross-validation is employed to ensure the quality of the annotations. Two specific examples are illustrated in Figure 7 (a), from which the following characteristics of the dataset can be derived:
Refined Object Attribute Description and Navigation Instructions. The navigation instructions provide comprehensive descriptions of the object, detailing its appearance, quantity, shape, color, and relative position to the drone’s intelligent agent. This ensures the uniqueness of the object in the instructions and minimizes the error recognition rate.
Long-Range Navigation Path Guided by Multiple Landmarks. The navigation instructions encompass extended paths that necessitate multiple consecutive spatial inferences by drones to traverse various blocks within the city. Furthermore, the instructions include specific descriptions of landmarks that can assist the drone’s intelligent agent in adjusting its actions.
Navigation-Based Scene Exploration. In addition to requiring the drone to adhere to language instructions for navigating to a designated location, this dataset also compels the drone agent to articulate environmental information regarding the destination, such as the color and shape of buildings.
Dataset Statistics. From Figure 7 (b), it is evident that the length of navigation instructions predominantly ranges from to 80, exhibiting a relatively even distribution, with a few instances exceeding , which surpasses most existing navigation datasets. Longer navigation instructions can enhance drones’ long-range spatial reasoning abilities. Figure 7 (c) indicates that the lengths of answers primarily fall between and , facilitating drone agents in succinctly describing objects to be explored. Figures 7 (d) and (e) present statistical analyses of the navigation instructions and answers, revealing average lengths of and , respectively, with an average of sentences for navigation instructions and 1 sentence for answers. This variance arises because navigation commands encompass both long-distance, multi-step instructions and attribute queries regarding unknown objects.
V-F SkyAgent-Plan3k

Dataset Construction. We require drone pilots to identify the starting and ending points prior to operating the drone. After flying for a specified duration, they should select a position that serves as the midpoint of the trajectory and provide a description of the route from the previous trajectory to the current location. To generate high-quality route descriptions, we ask drone pilots to choose the optimal path based on their experience. Furthermore, we require professional annotators to provide detailed descriptions of sub-routes in specific scenarios, such as making turns, navigating intersections, or passing by five buildings in a single direction. Figure 8 (a) illustrates an example of path planning, demonstrating the following characteristics:
Refined Self-Centered Object Description. The drone agent provides a distinctive and identifiable description of objects based on color, shape, height, and structure, employing a first-person perspective. The objects include buildings, pathways, trees, and grasslands that sequentially appear on both the left and right sides.
Multi-Perspective Object Localization. In three-dimensional urban environments, the UAV agent accurately locates instance-level objects, such as buildings, by establishing spatial relationships relative to itself, thereby enhancing the precision of object localization.
Landmark-Guided Path Planning. Prior to executing maneuvers such as turning or proceeding straight, the UAV intelligent agent identifies a landmark as a reference point, thereby improving the accuracy of path planning.
Dataset Statistics. Figure 8 (b) presents several instructions for the drone agent concerning path planning, each requiring the agent to avoid obstacles while navigating from the starting point to the endpoint. Figure 8 (c) illustrates that the planned lengths range significantly from to and predominantly follow a normal distribution. Figure 8 (d) indicates that the majority of the dataset consists of planning for five sub-paths. This requirement is designed to enhance planning complexity, necessitating the drone to perform at least five actions and navigate over five objects, thereby improving its capability to plan for longer distances. Figure 8 (e) reveals that the average length of the plans is , which is generally higher than the task planning lengths observed in most indoor scenarios.
V-G SkyAgent-Act3k

Dataset Construction. This task involves recording the dense motion sequence and orientation of the drone, with a particular emphasis on its flight path. Consequently, we restrict the drone’s flight altitude to within 30 meters. The drone pilot is required to select both the starting and ending points, maneuver the drone to depart from the starting location, and leverage their experience to choose an appropriate route to reach the destination. This process allows us to capture the starting point, ending point, drone orientation, and action sequence. To ensure a high-quality path of reasonable length, we instruct drone pilots to avoid choosing arbitrary routes, such as unnecessary detours. Additionally, the need for drone pilots to survey their surroundings to ascertain their position and determine the next destination may lead to excess motion. We mitigate this excess motion through post-processing to achieve a smoother trajectory. Figure 9 (a) illustrates a series of drone action decisions, which exhibit the following characteristics:
Starting and Ending Points Beyond Visual Range: To enhance the long-range autonomous action control capability of UAV intelligent agent in large-scale urban environments, there must be a minimum of ten buildings situated between the starting and ending points, with these buildings not aligned on the same straight line. This necessitates that the UAV intelligent agent execute at least one turn.
Professional Path Selection: Upon determining the starting and ending points, the drone pilot selects the optimal flight route based on experience, while ensuring that the flight altitude does not exceed 30 meters. The route selection must avoid collisions with surrounding objects and unnecessary turns and detours.
Smooth Action Sequence: The drone pilot consciously avoids sharp turns, emergency stops, and abrupt maneuvers when performing turns, ascents, and other actions during flight, striving to ensure smooth transitions in the drone’s movements.
Dataset Statistics. Figure 9 (b) presents several examples of motion decision-making instructions, illustrating that these instructions primarily convey the requirement for the drone to navigate obstacles safely, quickly, and autonomously from the starting point to the endpoint. Figure 9 (c) indicates that the lengths of motion sequences in the dataset predominantly range from 50 to 150, significantly exceeding the action lengths of intelligent agents in existing indoor scenarios. Figure 9 (d) illustrates the distribution of various actions, revealing that “MOVE-FORWARD” is considerably more prevalent than other actions. This observation is entirely logical, as the process of flying from the starting point to the endpoint involves primarily forward flight, with turns, ascents, and other maneuvers required to avoid obstacles and detours. The average length of the action sequences depicted in Figure 9 (e) is , further emphasizing that our dataset focuses on long-distance drone flights in large-scale urban environments. This distinction marks the primary difference between this dataset and those associated with existing indoor scene datasets.
VI Experiments
VI-A Baselines
Baselines Selection. Due to the current scarcity of research on aerospace-embodied world models, we evaluate several mainstream and representative 3D and 2D visual-language models. This assessment aims to explore their potential and limitations concerning the proposed aerospace-embodied downstream task datasets, thereby providing a preliminary foundation for future researchers in the field of aerospace-embodied intelligence. While there are more 2D visual-language models available that are generally more mature, we focus on LLaVA[33], MiniGPT4[34], and BLIP2[35], categorizing them into and models based on parameter scales. Given the limited availability of open-source 3D visual-language models, we select only the 3D-LLM[9] as our research focus.

Baselines Modification. Among the selected baseline models, the 3D visual-language model can be applied to most of the defined downstream tasks; however, the 2D visual-language model cannot be directly utilized for testing due to a mismatch in input formats, as illustrated in Figure 10. Consequently, we modify the inputs and outputs of these models to align with the downstream tasks, as detailed below. Notably, Aerospace Embodied Motion Decision represents the culmination of aerospace embodied tasks, achieving a closed loop of perception, cognition, and action for the UAV agent. Adjusting existing visual-language models presents challenges, and we will continue to explore this area in future.
Aerospace Embodied Scene Awareness. This task involves utilizing the location and environmental data captured by the drone as input to generate scene descriptions of the surrounding environment from multiple perspectives. However, the 2D visual-language model is inherently limited to processing images and does not directly account for environmental features. To mitigate this limitation during testing, we modify the 2D visual-language model by providing it with four images captured from the drone’s perspectives: front, back, left, and right. After generating captions for these images using descriptive prompts, we concatenate the four captions to produce the output for environmental observation, as illustrated in Figure 10 (a).
Aerospace Embodied Spatial Reasoning. This task also requires the integration of 3D features; thus, we modify the 2D visual-language model during testing by adjusting the input to include both the observation image and the question presented directly in front of the drone’s position. By reasoning and responding to questions based on this image, we generate spatial reasoning answers, as illustrated in Figure 10 (b).
Aerospace Embodied Navigational Exploration. As illustrated in Figure 10 (c), the input consists of multiple images and questions along the drone’s flight path. After generating captions for each image, the questions are answered based on the concatenated captions, ultimately yielding the solution for the drone’s navigation exploration.
Aerospace Embodied Task Planning. As illustrated in Figure 10 (d), we modify the input to encompass multiple images depicting the drone’s flight path, in addition to the endpoint image. Initially, a caption for the endpoint image will be generated, followed by the formulation of a question directed at the drone’s intelligent agent, inquiring about the navigation method to reach the specified location. Subsequently, the answer for the drone’s path planning will be derived based on the caption of the concatenated flight path images.
VI-B Evaluation Metrics
Traditional Metrics. Common indicators include BLEU-1, BLEU-2, BLEU-3, and BLEU-4[36]. Compare the degree of overlap between the n-grams in the candidate translation and the reference translation. It is commonly used for evaluating translation quality and can be divided into multiple evaluation indicators based on n-grams.
CIDEr[37] is an evaluation metric used to assess image description tasks. Its main idea is to treat each sentence as a document, then calculate its n-gram TF-IDF vector, and use cosine similarity to measure the semantic consistency between candidate sentences and reference sentences.
SPICE [19] utilizes graph-based semantic representations to encode objects, attributes, and relationships within descriptions. Initially, it parses both the description under evaluation and the reference description into a syntactic dependency tree using a Probabilistic Context-Free Grammar (PCFG) dependency parser.
GPT4-based Metrics. GPT-4[20] has achieved significant success in aligning with human preferences. Consequently, we introduce an automated evaluation method based on GPT-4 for tasks related to aerospace embodied scene awareness, spatial reasoning, navigational exploration, and path planning. This method aims to produce evaluation results that closely resemble human assessments. By designing various prompt templates, we can effectively address different evaluation concerns.
LLM-Judge-Scene. Aerospace Embodied Scene Awareness requires the intelligent drone agent to describe the scene from multiple perspectives. Therefore, the design of the evaluation method must consider both the level of detail in the descriptions and their relevance to the specified direction. To achieve this, we have developed a prompt template for GPT-4 that separately scores the granularity of the descriptions and the accuracy of each directional response.
LLM-Judge-ReasonNav. The prompt language is aligned with that of llm-judge[24], enabling GPT-4 to analyze the correlation and utility between AI assistant responses and reference answers. This process aims to objectively identify and correct errors to the greatest extent possible, provide explanations, and ultimately assign scores.
LLM-Judge-Plan. Certain key actions in the plan, such as left and right turns, are critical, particularly concerning their sequence. Additionally, accurately describing the path requires noting significant buildings and landmarks along the route. To enhance the effectiveness of GPT-4 in scoring the generated responses, we have directed it to focus on two aspects: (a) the degree of alignment between the key action sequence and the reference answer, and (b) the accuracy of the descriptions of the buildings along the route, including their order and direction of passage.
VII Results
VII-A Quantitative Analysis
| City | ShangHai | ShenZhen | Campus | Residence | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Models | BLEU | SPICE | SCENE | BLEU | SPICE | SCENE | BLEU | SPICE | SCENE | BLEU | SPICE | SCENE |
| 3d-llm[9] | 0.0346 | 0.0162 | 0.1660 | 0.0283 | 0.0117 | 0.1156 | 0.0429 | 0.0197 | 0.1511 | 0.0335 | 0.0105 | 0.1378 |
| gpt-4-vision-preview[20] | 0.1200 | 0.0884 | 0.6840 | 0.1039 | 0.0924 | 0.6909 | 0.1035 | 0.0901 | 0.6511 | 0.1246 | 0.0999 | 0.7444 |
| gpt-4o[20] | 0.1539 | 0.1114 | 0.6800 | 0.1532 | 0.1277 | 0.7178 | 0.1237 | 0.1175 | 0.6977 | 0.1606 | 0.1225 | 0.7089 |
| blip2-flan-t5-xxl[35] | 0.1954 | 0.0860 | 0.4041 | 0.1932 | 0.0956 | 0.4333 | 0.2151 | 0.0906 | 0.4318 | 0.2593 | 0.1307 | 0.5089 |
| blip2-opt-6.7b[35] | 0.1968 | 0.0814 | 0.4201 | 0.2279 | 0.0836 | 0.4289 | 0.2140 | 0.0906 | 0.4533 | 0.2558 | 0.1102 | 0.4778 |
| instructblip-flan-t5-xxl[38] | 0.2118 | 0.0808 | 0.4908 | 0.1972 | 0.0852 | 0.4689 | 0.2149 | 0.0969 | 0.5067 | 0.2536 | 0.1202 | 0.5400 |
| instructblip-vicuna-7b[38] | 0.2239 | 0.0787 | 0.4911 | 0.2102 | 0.0835 | 0.5022 | 0.2109 | 0.0867 | 0.4889 | 0.2729 | 0.1193 | 0.5511 |
| instructblip-vicuna-13b[38] | 0.2185 | 0.0810 | 0.4752 | 0.2176 | 0.0852 | 0.4533 | 0.2161 | 0.0832 | 0.4556 | 0.2715 | 0.1084 | 0.5644 |
| llama-adapter-v2-7B[39] | 0.0843 | 0.0512 | 0.5236 | 0.0741 | 0.0546 | 0.5067 | 0.0730 | 0.0584 | 0.5378 | 0.0981 | 0.0715 | 0.5778 |
| llava-v1.5-vicuna-7b[32] | 0.0746 | 0.0469 | 0.5000 | 0.0639 | 0.0515 | 0.5364 | 0.0590 | 0.0533 | 0.5133 | 0.0790 | 0.0645 | 0.5933 |
| llava-v1.5-vicuna-13b[32] | 0.0731 | 0.0468 | 0.5314 | 0.0643 | 0.0545 | 0.5727 | 0.0604 | 0.0505 | 0.5511 | 0.0754 | 0.0673 | 0.6067 |
| llava-v1.6-vicuna-7b[32] | 0.0483 | 0.0019 | 0.4823 | 0.0423 | 0.0025 | 0.5289 | 0.0387 | 0.0036 | 0.5178 | 0.0545 | 0.0148 | 0.5778 |
| llava-v1.6-vicuna-13b[32] | 0.0484 | 0.0039 | 0.5010 | 0.0417 | 0.0024 | 0.5364 | 0.0395 | 0.0047 | 0.4738 | 0.0525 | 0.0057 | 0.5489 |
| minigpt4[34] | 0.0969 | 0.0613 | 0.5592 | 0.0824 | 0.0584 | 0.5467 | 0.0787 | 0.0605 | 0.4607 | 0.0801 | 0.0624 | 0.4489 |
| mplug[40][40] | 0.0605 | 0.0450 | 0.5626 | 0.0520 | 0.0490 | 0.5533 | 0.0522 | 0.0489 | 0.5585 | 0.0680 | 0.0582 | 0.5400 |
| mplug2[41] | 0.0928 | 0.0502 | 0.5276 | 0.0825 | 0.0590 | 0.5796 | 0.0675 | 0.0447 | 0.5705 | 0.1020 | 0.0714 | 0.5614 |
| qwen-lv-7b[42] | 0.2305 | 0.0946 | 0.4780 | 0.2417 | 0.1136 | 0.5133 | 0.2206 | 0.0946 | 0.4467 | 0.2682 | 0.1057 | 0.4733 |
| City | ShangHai | ShenZhen | Campus | Residence | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Models | BLEU | SPICE | REA | BLEU | SPICE | REA | BLEU | SPICE | REA | BLEU | SPICE | REA |
| 3d-llm[9] | 0.1310 | 0.1008 | 0.3180 | 0.1839 | 0.1305 | 0.3133 | 0.0532 | 0.0373 | 0.1778 | 0.0792 | 0.009 | 0.2889 |
| gpt-4-vision-preview[20] | 0.0696 | 0.0701 | 0.3680 | 0.0830 | 0.1233 | 0.4578 | 0.0261 | 0.0154 | 0.3600 | 0.0917 | 0.1064 | 0.2822 |
| gpt-4o[20] | 0.1498 | 0.1710 | 0.493 | 0.1809 | 0.2034 | 0.4733 | 0.0558 | 0.0608 | 0.4467 | 0.3213 | 0.3750 | 0.4844 |
| blip2-flan-t5-xxl[35] | 0.0661 | 0.0863 | 0.3387 | 0.0867 | 0.1252 | 0.2756 | 0.0174 | 0.0089 | 0.1978 | 0.0868 | 0.0677 | 0.3844 |
| blip2-opt-6.7b[35] | 0.0508 | 0.0685 | 0.2023 | 0.0452 | 0.0804 | 0.1444 | 0.0533 | 0.0405 | 0.2089 | 0.0548 | 0.1619 | 0.2156 |
| instructblip-flan-t5-xxl[38] | 0.0966 | 0.1207 | 0.3590 | 0.1351 | 0.1725 | 0.2556 | 0.0354 | 0.0296 | 0.2133 | 0.1261 | 0.0857 | 0.3800 |
| instructblip-vicuna-7b[38] | 0.0254 | 0.0393 | 0.2630 | 0.0207 | 0.0493 | 0.2244 | 0.0480 | 0.0649 | 0.2978 | 0.0865 | 0.1088 | 0.2667 |
| instructblip-vicuna-13b[38] | 0.0158 | 0.0116 | 0.3620 | 0.0260 | 0.0278 | 0.2867 | 0.0041 | 0 | 0.1978 | 0.0002 | 0 | 0.2800 |
| llama-adapter-v2-7B[39] | 0.1582 | 0.1792 | 0.3430 | 0.1720 | 0.2164 | 0.3822 | 0.0721 | 0.0702 | 0.2422 | 0.3137 | 0.4432 | 0.5068 |
| llava-v1.5-vicuna-7b[32] | 0.1054 | 0.1269 | 0.3380 | 0.1190 | 0.1587 | 0.3046 | 0.0422 | 0.0412 | 0.4000 | 0.2339 | 0.3033 | 0.3667 |
| llava-v1.5-vicuna-13b[32] | 0.1235 | 0.1386 | 0.3760 | 0.1205 | 0.1837 | 0.3489 | 0.0509 | 0.0473 | 0.3911 | 0.2159 | 0.2779 | 0.3600 |
| llava-v1.6-vicuna-7b[32] | 0.0653 | 0.0887 | 0.3020 | 0.1016 | 0.1517 | 0.3444 | 0.0214 | 0.0196 | 0.3046 | 0.1123 | 0.1417 | 0.2733 |
| llava-v1.6-vicuna-13b[32] | 0.0680 | 0.0969 | 0.3490 | 0.0731 | 0.1176 | 0.3178 | 0.0250 | 0.0275 | 03378 | 0.106 | 0.164 | 0.3556 |
| minigpt4[34] | 0.1307 | 0.1714 | 0.3930 | 0.1211 | 0.1895 | 0.260 | 0.0288 | 0.0306 | 0.3022 | 0.1784 | 0.2266 | 0.3556 |
| mplug[40] | 0.1277 | 0.1436 | 0.313 | 0.1551 | 0.1932 | 0.3133 | 0.0659 | 0.0770 | 0.3711 | 0.2356 | 0.3148 | 0.3156 |
| mplug2[41] | 0.1375 | 0.1303 | 0.373 | 0.1468 | 0.1444 | 0.3288 | 0.0649 | 0.0520 | 0.3800 | 0.2668 | 0.238 | 0.4222 |
| qwen-lv-7b[42] | 0.1310 | 0.1590 | 0.305 | 0.1475 | 0.1878 | 0.2932 | 0.0873 | 0.0719 | 0.6244 | 0.2432 | 0.3324 | 0.3796 |
| City | ShangHai | ShenZhen | Campus | Residence | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Models | BLEU | SPICE | NAV | BLEU | SPICE | NAV | BLEU | SPICE | NAV | BLEU | SPICE | NAV |
| 3d-llm[9] | 0.108 | 0.0312 | 0.2808 | 0.0851 | 0.0081 | 0.2171 | 0.1263 | 0.0 | 0.292 | 0.0609 | 0.0425 | 0.2135 |
| gpt-4-vision-preview[20] | 0.1277 | 0.1871 | 0.3263 | 0.1193 | 0.1514 | 0.3643 | 0.049 | 0.0529 | 0.3320 | 0.0718 | 0.0836 | 0.3392 |
| gpt-4o[20] | 0.2343 | 0.2861 | 0.4741 | 0.2137 | 0.2004 | 0.3714 | 0.1349 | 0.1289 | 0.5960 | 0.1473 | 0.1684 | 0.4519 |
| blip2-flan-t5-xxl[35] | 0.080 | 0.0611 | 0.383 | 0.0686 | 0.0671 | 0.3357 | 0.0788 | 0.064 | 0.4100 | 0.1024 | 0.0433 | 0.2789 |
| blip2-opt-6.7b[35] | 0.0245 | 0.0228 | 0.1400 | 0.0092 | 0.004 | 0.1333 | 0.0221 | 0.018 | 0.1939 | 0.0358 | 0.0335 | 0.1789 |
| instructblip-flan-t5-xxl[38] | 0.0345 | 0.0248 | 0.3430 | 0.0324 | 0.0427 | 0.2845 | 0.0207 | 0.0367 | 0.4720 | 0.0637 | 0.0213 | 0.3462 |
| instructblip-vicuna-7b[38] | 0.1844 | 0.2168 | 0.2350 | 0.1812 | 0.1576 | 0.2231 | 0.1187 | 0.09 | 0.1674 | 0.1364 | 0.155 | 0.2000 |
| instructblip-vicuna-13b[38] | 0.1917 | 0.2146 | 0.2855 | 0.1952 | 0.1874 | 0.3175 | 0.1245 | 0.1028 | 0.2800 | 0.1508 | 0.1963 | 0.2765 |
| llama-adapter-v2-7B[39] | 0.2324 | 0.2692 | 0.3829 | 0.2067 | 0.1976 | 0.3000 | 0.1366 | 0.1191 | 0.4348 | 0.1789 | 0.194 | 0.3217 |
| llava-v1.5-vicuna-7b[32] | 0.1868 | 0.229 | 0.3688 | 0.1461 | 0.1575 | 0.2786 | 0.0727 | 0.0762 | 0.4660 | 0.1297 | 0.1274 | 0.3500 |
| llava-v1.5-vicuna-13b[32] | 0.1809 | 0.218 | 0.3309 | 0.1701 | 0.1821 | 0.3500 | 0.0971 | 0.099 | 0.4490 | 0.142 | 0.1532 | 0.3173 |
| llava-v1.6-vicuna-7b[32] | 0.1372 | 0.1977 | 0.3242 | 0.1171 | 0.1397 | 0.3571 | 0.0786 | 0.0936 | 0.3939 | 0.075 | 0.0977 | 0.2962 |
| llava-v1.6-vicuna-13b[32] | 0.1251 | 0.1743 | 0.3503 | 0.1099 | 0.1439 | 0.2952 | 0.0607 | 0.060 | 0.4020 | 0.0761 | 0.1002 | 0.2865 |
| minigpt4[34] | 0.2199 | 0.2969 | 0.4080 | 0.1896 | 0.1978 | 0.3310 | 0.1188 | 0.120 | 0.5660 | 0.1374 | 0.1805 | 0.3750 |
| mplug[40] | 0.1971 | 0.2485 | 0.3882 | 0.1712 | 0.1729 | 0.2833 | 0.0773 | 0.0842 | 0.3960 | 0.0963 | 0.1248 | 0.3000 |
| mplug2[41] | 0.2127 | 0.2081 | 0.4121 | 0.1881 | 0.1411 | 0.3643 | 0.1125 | 0.0935 | 0.4900 | 0.1474 | 0.1349 | 0.3404 |
| qwen-lv-7b[42] | 0.1772 | 0.2152 | 0.3505 | 0.1941 | 0.1837 | 0.3857 | 0.1267 | 0.1278 | 0.5225 | 0.1496 | 0.1128 | 0.3827 |
| City | ShangHai | ShenZhen | Campus | Residence | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Models | BLEU | SPICE | PLAN | BLEU | SPICE | PLAN | BLEU | SPICE | PLAN | BLEU | SPICE | PLAN |
| 3d-llm[9] | 0.0002 | 0.0019 | 0.1440 | 0.0014 | 0.0027 | 0.1000 | 0.0023 | 0.0021 | 0.1400 | 0.0 | 0.0 | 0.1044 |
| gpt-4-vision-preview[20] | 0.1073 | 0.0457 | 0.4520 | 0.1269 | 0.0497 | 0.4067 | 0.1231 | 0.0426 | 0.3711 | 0.1168 | 0.0445 | 0.3867 |
| gpt-4o[20] | 0.1064 | 0.0512 | 0.5290 | 0.1152 | 0.0520 | 0.5077 | 0.1167 | 0.0503 | 0.4750 | 0.1183 | 0.0483 | 0.5178 |
| blip2-flan-t5-xxl[35] | 0.0001 | 0.0566 | 0.2000 | 0.0001 | 0.0408 | 0.1844 | 0.0016 | 0.0537 | 0.2200 | 0.0024 | 0.0482 | 0.1956 |
| blip2-opt-6.7b[35] | 0.0 | 0.0002 | 0.1000 | 0.0 | 0.0 | 0.1000 | 0.0 | 0.0 | 0.1000 | 0.0 | 0.0026 | 0.1044 |
| instructblip-flan-t5-xxl[38] | 0.0004 | 0.0579 | 0.2356 | 0.0003 | 0.0423 | 0.1875 | 0.0095 | 0.0458 | 0.2733 | 0.0014 | 0.072 | 0.2667 |
| instructblip-vicuna-7b[38] | 0.0015 | 0.0068 | 0.1386 | 0.0004 | 0.0323 | 0.1546 | 0.0074 | 0.0121 | 0.1667 | 0.0018 | 0.0186 | 0.1625 |
| instructblip-vicuna-13b[38] | 0.0012 | 0.0114 | 0.1610 | 0.0034 | 0.0218 | 0.1579 | 0.0063 | 0.0046 | 0.1452 | 0.0007 | 0.0151 | 0.1667 |
| llama-adapter-v2-7B[39] | 0.0349 | 0.0216 | 0.1905 | 0.0003 | 0.0 | 0.1500 | 0.1138 | 0.0381 | 0.2444 | 0.0838 | 0.0195 | 0.1800 |
| llava-v1.5-vicuna-7b[32] | 0.1324 | 0.0339 | 0.3212 | 0.1654 | 0.0357 | 0.3289 | 0.1662 | 0.0376 | 0.3267 | 0.1603 | 0.0414 | 0.3111 |
| llava-v1.5-vicuna-13b[32] | 0.1375 | 0.0355 | 0.3640 | 0.1612 | 0.038 | 0.3200 | 0.1622 | 0.0448 | 0.3600 | 0.1489 | 0.0497 | 0.3022 |
| llava-v1.6-vicuna-7b[32] | 0.1420 | 0.0406 | 03590 | 0.1697 | 0.044 | 0.044 | 0.1442 | 0.0382 | 0.3727 | 0.1618 | 0.042 | 0.3533 |
| llava-v1.6-vicuna-13b[32] | 0.1246 | 0.0399 | 0.3250 | 0.1388 | 0.0391 | 0.3089 | 0.1378 | 0.034 | 0.3067 | 0.1535 | 0.0452 | 0.3400 |
| minigpt4[34] | 0.1288 | 0.0403 | 0.2770 | 0.1396 | 0.0451 | 0.2511 | 0.1689 | 0.0425 | 0.2511 | 0.1585 | 0.0451 | 0.2622 |
| mplug[40] | 0.1368 | 0.0368 | 0.3020 | 0.1661 | 0.0397 | 0.3136 | 0.1607 | 0.0393 | 0.3400 | 0.1786 | 0.0409 | 0.3244 |
| mplug2[41] | 0.1426 | 0.0343 | 0.3230 | 0.1687 | 0.0392 | 0.3378 | 0.1674 | 0.0379 | 03114 | 0.1673 | 0.0442 | 0.2978 |
| qwen-lv-7b[42] | 0.1574 | 0.0541 | 0.2850 | 0.1536 | 0.0506 | 0.2956 | 0.1218 | 0.0310 | 0.2800 | 0.1001 | 0.0375 | 0.2178 |


As presented in Tables I, II, III, and IV, we summarize the overall performance of visual-language models across four UAV downstream tasks within the AeroVerse benchmark. Despite significant advancements in both 2D and 3D visual-language models (VLMs) in recent years, these models continue to encounter challenges with UAV-embodied tasks, including the GPT-4 series. Among the four tasks, existing visual-language models achieve relatively high scores only on SkyAgent-Scene3k, while their performance on the other tasks declines markedly. Overall, gpt-4-vision-review and gpt-4o consistently outperform other models. We will subsequently provide a detailed analysis of the various embodied tasks.
Results on SkyAgent-Scene3k. In evaluating this task, we utilize BLEU, SPICE, and LLM-JUDGE-SCENE to assess the model’s performance in terms of vocabulary richness, semantic accuracy, and human preference. The Qwen-lv-7b model [42] demonstrates strong performance on BLEU, leading in each urban scene, indicating its closer alignment with the reference vocabulary. Overall, the model achieving the highest score in SPICE is gpt-4o, which highlights its advantages in semantic matching. According to the results from LLM-JUDGE-SCENE, the outputs from gpt-4-vision-review and gpt-4o show greater consistency with human preferences.
Results on SkyAgent-Reason3k. For evaluating, we utilize LLM-JUDGE-REASON to assess human preferences. Three models emerge as prominent in this context, i.e., two open-source models, llama-adapter-v2-7B [39] and qwen-lv-7b [42], along with one closed-source model, gpt-4o. A horizontal comparison among the gpt-4 series reveals that gpt-4o demonstrates superior capabilities in first-person spatial reasoning and question-answering tasks.
Results on SkyAgent-Nav3k. Similar to the evaluation metric with SkyAgent-Reason3k, we employ LLM-JUDGE-NAV to assess human preferences. In this task, gpt-4o demonstrate particularly strong performance, ranking at the top across most urban scenarios and evaluation metrics, including vocabulary level, semantic level, and human preference. In the residential area scenario, the response from llama-adapter-v2-7B [39] exhibit greater alignment with the correct answer at the lexical level compared to other models.
Results on SkyAgent-Plan3k. In evaluating this task, we utilize LLM-JUDGE-PLAN to assess human preferences. The performance of many models in this task is notably poor, with several indicators yielding a score of . This deficiency arises from the necessity of acquiring a comprehensive range of environmental characteristics for planning long-distance paths. The 3D-LLM struggled to address our inquiries due to its limited generalization capabilities. Although we provide initial-view maps of the true path to the 2D-LLM as environmental information, either through image captions or multi-image input, this information remains incomplete. Notably, gpt-4o ranked first in assessing human preferences across all cities.
VII-B Qualitative Analysis


From Figure 11, although the 3D-LLM [9] encodes the 3D environment and perceives its surroundings, it demonstrates limited generalization due to insufficient training on outdoor 3D urban data. When confronted with a 3D urban scene, the output of 3D-LLM[9] resembles a description of an indoor environment, leading to significant hallucinations. The findings indicate that the performance of these 2D visual-language models surpasses that of 3D-LLM [9]. This superiority can be attributed to the greater number of training image-text pairs available for the 2D visual-language models, which enhances their generalization capabilities. Furthermore, they deliver more accurate descriptions based on egocentric view images of urban settings. However, instances of hallucinations persist, such as the erroneous description of a fire hydrant in front of a building with windows in instructblip-vicuna-7b [38], despite the absence of a fire hydrant in the image. Similarly, llama-adapter-v2-7B [39] inaccurately describes an individual walking in the distance, even though no person is present in the image.
In the example illustrated in the left of Figure 12, the 3D visual-language model demonstrates the capability to perform short-term spatial reasoning based on its current posture and the 3D characteristics of the city to address questions. In contrast, the 2D visual-language model can derive answers solely from a single view image, which provides limited information. The results from this example indicate that the answer to the question is not present in the image. The building visible on the right reveals only a corner of the red roof in the bottom right of the image. This situation elucidates why 2D visual-language models, such as gpt-4o [20], instructblip-vicuna-7b [38], and qwen-lv-7b [42], frequently reference red buildings or state their inability to provide a definitive answer. Conversely, the input of the 3D-LLM [9] encompasses a more comprehensive and complex representation of urban features, leading to a correct and logical conclusion.
In the example illustrated in the right of Figure 12, the model is tasked with following specific instructions to explore a distance before addressing subsequent questions. Due to the limitations of the 2D LLM, we derive its response to this question based on the parameters outlined in Section VI-A, effectively simplifying the complexity of the question. The answer provided by the 3D-LLM [9] is incorrect, as its input incorporates more complex 3D features. Currently, GPT-4-vision-preview and GPT-4o rank among the most advanced visual-language models, with GPT-4o demonstrating a slight advantage in addressing questions related to first-person view images. Instructblip-vicuna-7b [38] and llama-adapter-v2-7B [39] exhibit relatively weaker instruction-following capabilities, resulting in their inadequate responses to our inquiries. The responses from open-source 2D visual-language models, including blip2-flan-t5-xxl [35], llava-v1.6-vicuna-7b [32], and Mplug2 [41], are generally consistent with the gold standard, indicating their strong spatial reasoning and instruction-following abilities.
As illustrated in Figure 13, each model exhibits distinct responses to this task. The 3D-LLM’s capability for indoor task planning does not generalize effectively to urban environments, resulting in answers that are inconsistent with our queries and resembling 3D scene captions instead. To address the limitations of the 2D visual-language model, we derive its response to this question based on the parameters outlined in Section VI-A. The Blip2-flan-t5-xxl model [35] fails to accurately represent the flight path as per our instructions, instead providing an interpretation similar to image captioning, which indicates a relatively poor ability to adhere to directives. In contrast, both gpt-4o and gpt-4-vision-review [20] deliver the most detailed and comprehensive analyses of the initial views along the trajectory. The Instructblip-vicuna-7b [38], llava-v1.6-vicuna-7b [32], Mplug2 [41], and llama-adapter-v2-7B [39] models do not describe the flight path in accordance with the timeline; instead, they provide a summary of the trajectory.
VII-C Discussion
Scene Generalization Ability. To investigate the generalization ability of various models across different embodied scenes, we assessed the performance of all models on four tasks corresponding to their respective scenes and compared the average BLEU scores across these tasks, as illustrated in Figure 14 (a). In the campus scene, the dense buildings and numerous obstacles, such as trees, generally lead to poor performance from all models. Conversely, in the residential area, which is smaller and contains fewer objects, all models demonstrate improved performance. Among the models, qwen-lv-7b exhibits the best overall performance, achieving the highest scores in all four scenarios, closely followed by gpt-4o. In contrast, 3d-llm faces greater challenges due to the input being a three-dimensional scene rather than a modified image, resulting in subpar performance in each scenario.
Task Generalization Ability. To investigate the generalization ability of various models across different embodied tasks, we evaluate the performance of all models in four scenarios based on the tasks, comparing the average BLEU scores as depicted in Figure 14 (b). The results indicate that InstructBLIP and BLIP2 excel in Task , which exclusively assesses the models’ captioning capabilities. In contrast, the Llava, MiniGPT, and MPLUG series models demonstrate superior performance in Task , which necessitates the integration, comprehension, and response to information.
The Impact of Scaling Law. To examine the influence of model size on performance in embodied tasks, we selected three pairs of models with billion and billion parameters, comparing the average BLEU scores across the four scenarios within the four tasks, as illustrated in Figure 14 (c). The data reveal that while minor differences in performance arise due to varying model parameters, an increase in the number of parameters does not necessarily correlate with improved performance.
VIII Conclusion
To address the existing research gap in the aerospace embodied world model and to empower UAV intelligent agents with end-to-end autonomous perception, cognition, and action capabilities, we have developed a comprehensive benchmark suite named AeroVerse. This suite integrates simulation, pre-training, fine-tuning, and evaluation processes. Specifically, we establish a simulation platform, AeroSimulator, which encompasses four realistic urban scenarios tailored for the flight simulation of UAV intelligent agents. Furthermore, we introduce the first image-text pre-training dataset, AerialAgent-Ego10k, utilizing real drone footage captured from a first-person perspective, along with the virtual image-text-pose alignment dataset, CyberAgent-Ego500k, to facilitate the pre-training of aerospace embodied world models. To enhance the autonomous capabilities of UAV intelligent agents, we delineate five downstream tasks for the first time: 3D scene awareness, spatial reasoning, navigational exploration, task planning, and motion decision-making. In line with these tasks, we construct five instruction fine-tuning datasets: SkyAgent-Scene3k, SkyAgent-Reason3k, SkyAgent-Nav3k, SkyAgent-Plan3k, and SkyAgent-Act3k. Additionally, we develop a downstream task evaluation method called SkyAgent-Eval, based on GPT-4, which reveals the potential and limitations of 2D/3D visual-language models in aerospace embodied tasks.
In the future, we plan to expand the simulation cities to include locations such as New York and to extend the scenarios to encompass forests, mountains, and other outdoor environments. We will continue to accumulate training datasets and refine the downstream tasks for UAV agents to complete the training of the aerospace embodied world model. This will subsequently promote applications in areas such as river garbage detection, power inspection, and forest fire rescue, thereby unlocking the application value of aerospace embodied intelligence.
References
- [1] DJI, “Dji drone solutions for inspection and infrastructure construction in the oil and gas industry,” Website, 2022. [Online]. Available: https://enterprise.dji.com/cn/oil-and-gas.
- [2] M. Shridhar, J. Thomason, D. Gordon, Y. Bisk, W. Han, R. Mottaghi, L. Zettlemoyer, and D. Fox, “Alfred: A benchmark for interpreting grounded instructions for everyday tasks,” 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 10 737–10 746, 2019. [Online]. Available: https://api.semanticscholar.org/CorpusID:208617407
- [3] A. Ku, P. Anderson, R. Patel, E. Ie, and J. Baldridge, “Room-across-room: Multilingual vision-and-language navigation with dense spatiotemporal grounding,” in Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), B. Webber, T. Cohn, Y. He, and Y. Liu, Eds. Online: Association for Computational Linguistics, Nov. 2020, pp. 4392–4412. [Online]. Available: https://aclanthology.org/2020.emnlp-main.356
- [4] C. Li, F. Xia, R. Mart’in-Mart’in, M. Lingelbach, S. Srivastava, B. Shen, K. Vainio, C. Gokmen, G. Dharan, T. Jain, A. Kurenkov, K. Liu, H. Gweon, J. Wu, L. Fei-Fei, and S. Savarese, “igibson 2.0: Object-centric simulation for robot learning of everyday household tasks,” ArXiv, vol. abs/2108.03272, 2021. [Online]. Available: https://api.semanticscholar.org/CorpusID:236957210
- [5] Y. Qi, Q. Wu, P. Anderson, X. E. Wang, W. Y. Wang, C. Shen, and A. van den Hengel, “Reverie: Remote embodied visual referring expression in real indoor environments,” 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 9979–9988, 2019. [Online]. Available: https://api.semanticscholar.org/CorpusID:214264259
- [6] B. Shen, F. Xia, C. Li, R. Mart’in-Mart’in, L. J. Fan, G. Wang, S. Buch, C. P. D’Arpino, S. Srivastava, L. P. Tchapmi, M. E. Tchapmi, K. Vainio, L. Fei-Fei, and S. Savarese, “igibson 1.0: A simulation environment for interactive tasks in large realistic scenes,” 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 7520–7527, 2020. [Online]. Available: https://api.semanticscholar.org/CorpusID:227347434
- [7] F. Xia, B. W. Shen, C. Li, P. Kasimbeg, M. E. Tchapmi, A. Toshev, R. Martín-Martín, and S. Savarese, “Interactive gibson benchmark: A benchmark for interactive navigation in cluttered environments,” IEEE Robotics and Automation Letters, vol. 5, pp. 713–720, 2019. [Online]. Available: https://api.semanticscholar.org/CorpusID:210931408
- [8] J. Huang, S. Yong, X. Ma, X. Linghu, P. Li, Y. Wang, Q. Li, S.-C. Zhu, B. Jia, and S. Huang, “An embodied generalist agent in 3d world,” in Proceedings of the International Conference on Machine Learning (ICML), 2024.
- [9] Y. Hong, H. Zhen, P. Chen, S. Zheng, Y. Du, Z. Chen, and C. Gan, “3d-llm: Injecting the 3d world into large language models,” ArXiv, vol. abs/2307.12981, 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:260356619
- [10] D. Driess, F. Xia, M. S. M. Sajjadi, and et al, “Palm-e: An embodied multimodal language model,” in International Conference on Machine Learning, 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:257364842
- [11] A. Brohan, N. Brown, J. Carbajal, and et al, “Rt-2: Vision-language-action models transfer web knowledge to robotic control,” ArXiv, vol. abs/2307.15818, 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:260293142
- [12] Y. Mu, Q. Zhang, M. Hu, W. Wang, M. Ding, J. Jin, B. Wang, J. Dai, Y. Qiao, and P. Luo, “Embodiedgpt: Vision-language pre-training via embodied chain of thought,” ArXiv, vol. abs/2305.15021, 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:258865718
- [13] Y. Zeng, X. Zhang, H. Li, J. Wang, J. Zhang, and W. Zhou, “X22-vlm: All-in-one pre-trained model for vision-language tasks,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 5, pp. 3156–3168, 2024.
- [14] A. J. Wang, P. Zhou, M. Z. Shou, and S. Yan, “Enhancing visual grounding in vision-language pre-training with position-guided text prompts,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 5, pp. 3406–3421, 2024.
- [15] J. Zhang, J. Huang, S. Jin, and S. Lu, “Vision-language models for vision tasks: A survey,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 8, pp. 5625–5644, 2024.
- [16] S. Shah, D. Dey, C. Lovett, and A. Kapoor, “Airsim: High-fidelity visual and physical simulation for autonomous vehicles,” in Field and Service Robotics, 2017. [Online]. Available: https://arxiv.org/abs/1705.05065
- [17] Y. Liu, F. Xue, and H. Huang, “Urbanscene3d: A large scale urban scene dataset and simulator,” ArXiv, vol. abs/2107.04286, 2021. [Online]. Available: https://api.semanticscholar.org/CorpusID:235790599
- [18] K. Papineni, S. Roukos, T. Ward, and W.-J. Zhu, “Bleu: a method for automatic evaluation of machine translation,” in Annual Meeting of the Association for Computational Linguistics, 2002. [Online]. Available: https://api.semanticscholar.org/CorpusID:11080756
- [19] P. Anderson, B. Fernando, M. Johnson, and S. Gould, “Spice: Semantic propositional image caption evaluation,” ArXiv, vol. abs/1607.08822, 2016. [Online]. Available: https://api.semanticscholar.org/CorpusID:11933981
- [20] OpenAI, “Gpt-4 technical report,” 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:257532815
- [21] H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozière, N. Goyal, E. Hambro, F. Azhar, A. Rodriguez, A. Joulin, E. Grave, and G. Lample, “Llama: Open and efficient foundation language models,” ArXiv, vol. abs/2302.13971, 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:257219404
- [22] J. Bai, S. Bai, Y. Chu, Z. Cui, and et al, “Qwen technical report,” ArXiv, vol. abs/2309.16609, 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:263134555
- [23] N. Lambert, L. Castricato, L. von Werra, and A. Havrilla, “Illustrating reinforcement learning from human feedback (rlhf),” Hugging Face Blog, 2022, https://huggingface.co/blog/rlhf.
- [24] L. Zheng, W.-L. Chiang, Y. Sheng, S. Zhuang, Z. Wu, Y. Zhuang, Z. Lin, Z. Li, D. Li, E. P. Xing, H. Zhang, J. Gonzalez, and I. Stoica, “Judging llm-as-a-judge with mt-bench and chatbot arena,” ArXiv, vol. abs/2306.05685, 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:259129398
- [25] D. Azuma, T. Miyanishi, S. Kurita, and M. Kawanabe, “Scanqa: 3d question answering for spatial scene understanding,” 2021.
- [26] D. Z. Chen, A. X. Chang, and M. Niener, “Scanrefer: 3d object localization in rgb-d scans using natural language,” in European Conference on Computer Vision, 2020.
- [27] J. Tubiana, D. Schneidman-Duhovny, and H. Wolfson, “Scannet: An interpretable geometric deep learning model for structure-based protein binding site prediction,” Cold Spring Harbor Laboratory, 2021.
- [28] A. Das, S. Datta, G. Gkioxari, S. Lee, D. Parikh, and D. Batra, “Embodied question answering,” IEEE, 2018.
- [29] M. Shridhar, J. Thomason, D. Gordon, Y. Bisk, W. Han, R. Mottaghi, L. Zettlemoyer, and D. Fox, “Alfred: A benchmark for interpreting grounded instructions for everyday tasks,” 2019.
- [30] P. Anderson, Q. Wu, D. Teney, J. Bruce, and A. V. D. Hengel, “Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments,” in 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
- [31] G. Yang, F. Xue, Q. Zhang, K. Xie, C.-W. Fu, and H. Huang, “Urbanbis: a large-scale benchmark for fine-grained urban building instance segmentation,” ACM SIGGRAPH 2023 Conference Proceedings, 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:258480220
- [32] H. Liu, C. Li, Y. Li, and Y. J. Lee, “Improved baselines with visual instruction tuning,” ArXiv, vol. abs/2310.03744, 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:263672058
- [33] H. Liu, C. Li, Q. Wu, and Y. J. Lee, “Visual instruction tuning,” ArXiv, vol. abs/2304.08485, 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:258179774
- [34] D. Zhu, J. Chen, X. Shen, X. Li, and M. Elhoseiny, “Minigpt-4: Enhancing vision-language understanding with advanced large language models,” ArXiv, vol. abs/2304.10592, 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:258291930
- [35] J. Li, D. Li, S. Savarese, and S. C. H. Hoi, “Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models,” in International Conference on Machine Learning, 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:256390509
- [36] S. Roukos, K. Papineni, T. Ward, and W. J. Zhu, “Bleu: a method for automatic evaluation of machine translation,” in 40th Annual Meeting of the Association for Computational Linguistics:(CD:CD-CNF-0517), 2002.
- [37] R. Vedantam, C. L. Zitnick, and D. Parikh, “Cider: Consensus-based image description evaluation,” 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 4566–4575, 2014. [Online]. Available: https://api.semanticscholar.org/CorpusID:9026666
- [38] W. Dai, J. Li, D. Li, A. M. H. Tiong, J. Zhao, W. Wang, B. A. Li, P. Fung, and S. C. H. Hoi, “Instructblip: Towards general-purpose vision-language models with instruction tuning,” ArXiv, vol. abs/2305.06500, 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:258615266
- [39] P. Gao, J. Han, R. Zhang, Z. Lin, S. Geng, A. Zhou, W. Zhang, P. Lu, C. He, X. Yue, H. Li, and Y. J. Qiao, “Llama-adapter v2: Parameter-efficient visual instruction model,” ArXiv, vol. abs/2304.15010, 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:258418343
- [40] Q. Ye, H. Xu, G. Xu, J. Ye, M. Yan, Y. Zhou, J. Wang, A. Hu, P. Shi, Y. Shi, C. Li, Y. Xu, H. Chen, J. Tian, Q. Qi, J. Zhang, and F. Huang, “mplug-owl: Modularization empowers large language models with multimodality,” ArXiv, vol. abs/2304.14178, 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:258352455
- [41] Q. Ye, H. Xu, J. Ye, M. Yan, A. Hu, H. Liu, Q. Qian, J. Zhang, F. Huang, and J. Zhou, “mplug-owl2: Revolutionizing multi-modal large language model with modality collaboration,” ArXiv, vol. abs/2311.04257, 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:265050943
- [42] J. Bai, S. Bai, S. Yang, S. Wang, S. Tan, P. Wang, J. Lin, C. Zhou, and J. Zhou, “Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond,” 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:261101015
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/332b7a54-a7e4-4e35-b56b-17a191eb0be1/yaofanglong.jpg) |
Fanglong Yao received the B.Sc. degree from Inner Mongolia University, Hohhot, China, in 2017, and the Ph.D. degree from the Aerospace Information Research Institute, Chinese Academy of Sciences, Beijing, China, in 2022. He is currently a Post-Doctoral Researcher and assistant professor with the Aerospace Information Research Institute, Chinese Academy of Sciences. His research interests include cognitive intelligence, embodied intelligence, and swarm intelligence, concentrating on multi-agent learning, multimodal fusion, 3D scene understanding and spatiotemporal data analysis. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/332b7a54-a7e4-4e35-b56b-17a191eb0be1/yueyuanchang.jpg) |
Yuanchang Yue received the B.Sc. degree from jiangnan University, wuxi, China, in 2022. He is currently a master’s student with the Aerospace Information Research Institute, Chinese Academy of Sciences. His research interests include embodied intelligence, and task planning. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/332b7a54-a7e4-4e35-b56b-17a191eb0be1/liuyouzhi.jpg) |
Youzhi Liu received the B.Sc. degree from Hunan University, changsha, China, in 2022. He is currently a Ph.D student with the Aerospace Information Research Institute, Chinese Academy of Sciences. His research interests include embodied intelligence, and visual language navigation. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/332b7a54-a7e4-4e35-b56b-17a191eb0be1/sunxian.png) |
Xian Sun received the B.Sc. degree from the Beijing University of Aeronautics and Astronautics, Beijing, China, in 2004, and the M.Sc. and Ph.D. degrees from the Institute of Electronics, Chinese Academy of Sciences, Beijing, in 2009. He is a Professor with the Aerospace Information Research Institute, Chinese Academy of Sciences, Beijing, China. His research interests include computer vision, geospatial data mining, and remote sensing image understanding. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/332b7a54-a7e4-4e35-b56b-17a191eb0be1/fukun.jpg) |
Kun Fu received the B.Sc., M.Sc., and Ph.D. degrees from the National University of Defense Technology, Changsha, China, in 1995, 1999, and 2002, respectively. He is a Professor with the Aerospace Information Research Institute, Chinese Academy of Sciences, Beijing, China. His research interests include computer vision, remote sensing image understanding, geospatial data mining, and visualization. |