AEIOU: A Unified Defense Framework against NSFW Prompts in Text-to-Image Models
Abstract
As text-to-image (T2I) models continue to advance and gain widespread adoption, their associated safety issues are becoming increasingly prominent. Malicious users often exploit these models to generate Not-Safe-for-Work (NSFW) images using harmful or adversarial prompts, highlighting the critical need for robust safeguards to ensure the integrity and compliance of model outputs. Current internal safeguards frequently degrade image quality, while external detection methods often suffer from low accuracy and inefficiency.
In this paper, we introduce AEIOU, a defense framework that is Adaptable, Efficient, Interpretable, Optimizable, and Unified against NSFW prompts in T2I models. AEIOU extracts NSFW features from the hidden states of the model’s text encoder, utilizing the separable nature of these features to detect NSFW prompts. The detection process is efficient, requiring minimal inference time. AEIOU also offers real-time interpretation of results and supports optimization through data augmentation techniques. The framework is versatile, accommodating various T2I architectures. Our extensive experiments show that AEIOU significantly outperforms both commercial and open-source moderation tools, achieving over 95% accuracy across all datasets and improving efficiency by at least tenfold. It effectively counters adaptive attacks and excels in few-shot and multi-label scenarios.
Disclaimer: This article includes potentially disturbing Not-Safe-for-Work (NSFW) text and images. We provide these examples to illustrate how harmful prompts can lead T2I models to generate NSFW content. Unsafe images have been masked or blurred, but reader discretion is advised.
1 Introduction
Recent advancements in text-to-image (T2I) models, such as Stable Diffusion [1], DALL·E 3 [2], and Flux [3], have demonstrated remarkable capabilities in generating high-quality images. However, the widespread use of these models raises significant ethical concerns, particularly in the generation of Not-Safe-for-Work (NSFW) content, including sexual, violent, hateful, and other harmful images. Recent studies [4, 5, 6] reveal that users can easily produce NSFW images using malicious prompts, known as NSFW prompts. Consequently, effectively defending against NSFW prompts becomes a crucial challenge.
Current defenses against NSFW prompts fall into two main categories: internal and external safeguards [7]. Internal safeguards involve altering the semantics of generated images through model editing and inference guidance. Model editing [8, 9, 10] entails fine-tuning or adjusting the model to reduce its capability to produce NSFW images. These methods often demand extensive training and may compromise image quality. Inference guidance [11, 12], on the other hand, modifies predicted noise or conditional embeddings during inference. It is training-free but still tends to affect image quality.
The primary external safeguard is content moderation, which involves reviewing prompts [13, 14], conditional embeddings [15, 16], and generated images [17, 4, 18]. These methods prevent the generation of NSFW content without degrading image quality. However, prompt-based moderation often employs a target-model-agnostic classifier, which can misalign with the T2I model and result in errors in borderline cases. Embedding-based moderation utilizes conditional embeddings of the T2I model to ensure alignment, but it overlooks deep semantics in the text encoder’s attention heads, leading to low detection accuracy. Image-based moderation is more effective but requires post-generation detection, making it less efficient. Additionally, moderation tools typically require large datasets to train large models, resulting in slow inference speeds and difficulties in updating.
In addition, several common issues persist across both internal and external approaches. First, they are frequently vulnerable to adversarial attacks [19, 5]. Second, most methods are specifically designed for the Stable Diffusion v1 model [20], raising concerns about their applicability to other architectures. Third, these methods lack transparent interpretations for both the generation and detection processes, complicating user understanding of the assessments’ rationales.
To address the aforementioned issues, this paper introduces AEIOU, an Adaptable, Efficient, Interpretable, Optimizable and Unified defense framework against NSFW prompts in T2I models. Since current adversarial attacks on T2I models primarily target the text encoder [5, 19], as a countermeasure, our defense framework also focuses on the text encoder. Specifically, we analyze the distribution of the text encoder’s hidden states within the feature space, revealing that NSFW prompts present explicit NSFW semantics across various layers and attention heads. Previous research [21] indicates that hidden states of text encoders can be separated into embeddings for different concepts. Building on this, we analyze the general features of NSFW prompts to identify directions within various attention heads that encapsulate NSFW semantics, termed the NSFW features of the attention heads. By assessing the magnitude of the input prompt’s hidden state components along these NSFW features, we can effectively detect potential NSFW prompts.
To verify whether NSFW features genuinely represent NSFW semantics and help users understand why a prompt triggers the defense mechanism, we develop an interpretability framework based on detection. Our approach considers both textual and image perspectives. On the textual side, we identify NSFW tokens within prompts by leveraging the NSFW features in each attention head. On the image side, we iteratively remove harmful semantics from the hidden states to produce relatively benign embeddings. By generating images from these modified embeddings, we can observe the progressive eradication of NSFW semantics.
Overall, AEIOU overcomes the deficiencies of previous defense methods, demonstrating not only high accuracy but also exhibiting the following five characteristics:
(1) Adaptable. By analyzing attention heads within the text encoder to specifically capture NSFW features, AEIOU can adapt to any transformer-based text encoder, allowing application across various T2I model architectures.
(2) Efficient. AEIOU operates without complex models for detection, requiring minimal time for both training and inference, ensuring high efficiency.
(3) Interpretable. The inference process of AEIOU does not involve black-box models; instead, it relies on comparisons with NSFW features. The results can be visualized and interpreted across text and image modalities, offering both process and outcome interpretability.
(4) Optimizable. By assigning greater weight to the red-teaming data, we can achieve effective data augmentation for AEIOU using only a few samples, simplifying its updating processes.
(5) Unified. AEIOU integrates training, inference, interpretation, and further optimization into a unified framework, avoiding isolated processes.
Experiment results indicate that AEIOU exhibits strong defense capabilities across various text encoders in different T2I models. It surpasses four commercial models, two open-source models, and a state-of-the-art model designed explicitly for NSFW prompt detection in both effectiveness and efficiency. Furthermore, AEIOU achieves excellent results with minimal data for training and optimization, and it effectively defends against unknown adversarial and adaptive attacks. Additionally, our interpretative approach accurately identifies NSFW tokens and effectively removes NSFW semantics while preserving benign information within the embeddings.
Contributions. In summary, we make the following contributions in this paper.
(1) We investigate the emergence of NSFW semantics within the text encoder and identify the general NSFW features that represent NSFW semantics in each attention head.
(2) Based on the insights above, we leverage NSFW features for NSFW prompts detection within T2I models, demonstrating high effectiveness, strong adaptability, excellent optimization ability, and superior efficiency.
(3) We develop a robust interpretative approach to interpret our detection method, enabling interpretation across text and image modalities.
(4) We integrate the aforementioned techniques into a unified framework and conduct extensive experiments. The results demonstrate that AEIOU outperforms four commercial, two open-source, and one state-of-the-art model.
2 Related Work
2.1 Adversarial Attacks against T2I Models
T2I models are extensively used in various applications [22, 1, 2, 23, 24, 25, 26]. Despite their strengths, they are susceptible to adversarial attacks that modify prompts to sneak past defenses and produce NSFW content like pornography, violence, or politically sensitive imagery [19, 5, 27, 28, 29].
Present adversarial attack methods are mainly divided into white-box and black-box approaches. White-box methods primarily utilize the model’s text encoder to optimize the prompt, ensuring that the generated prompt semantically aligns closely with a target prompt containing explicit NSFW information, even without sensitive words [19]. In contrast, black-box methods perturb the prompt to find alternative tokens that can replace sensitive words [5, 30]. These methods often utilize reinforcement learning or assistance from large language models to accelerate the search process. In addition, some attack strategies target T2I models with removed concepts [27, 28]. These strategies demonstrate that T2I models can still generate NSFW images even after removing NSFW concepts.
Current adversarial methods have proven highly effective. Consequently, it is crucial to develop robust defense mechanisms to counter these attack strategies and ensure the safe and responsible use of T2I models.
2.2 Defensive Methods against Attacks
Existing defense methods against attacks in T2I models fall into two categories: internal and external safeguards [7].
Internal safeguards aim to disable the model’s ability to generate NSFW images by fine-tuning the model itself. They can be divided into model editing and inference guidance. Model editing methods [8, 9, 10, 31, 32, 33, 34] aim to modify the internal parameters by training. However, these methods typically require prolonged training periods, and parameter modifications can impact the quality of the generated images. Moreover, most methods focus solely on safety against malicious prompts while ignoring the adversarial prompts. In contrast, inference guidance methods [11, 12] focus on modifying internal features during the inference stage. Unlike model editing methods, they are tuning-free and plug-in, which can be easily inserted into any model. However, these methods also fail to account for adversarial prompts, making them susceptible to targeted attacks.
External safeguards aim to filter out potential malicious samples by examining intermediate variables during the generation process. Current detection methods focus on prompts, conditional embeddings, or generated images. Image-based moderation [17, 4, 18] entails reviewing the generated images to identify NSFW samples. They incur significant inference costs since images must be generated before assessment. Prompt-based moderation [13, 35, 36, 14, 37] screens input prompts to identify those likely to generate NSFW images. Given their lower cost, they are widely used by online services like Midjourney [38] and Leonardo.Ai [39]. Nonetheless, these methods generally lack targeted defenses against adversarial attacks, making them susceptible to circumvention. Embedding-based moderation [16, 15] examines the conditional embeddings to filter out malicious samples. While this approach offers some resistance to adversarial attacks, it relies on large-scale models for classification, resulting in high costs. Additionally, it also suffers from low accuracy and remains vulnerable to adaptive attacks.
2.3 Interpretation on the CLIP Model
As the most widely used text encoder in T2I models, the CLIP model [40] is a significant focus of adversarial attack research. Recent studies [21, 41, 42, 43] have investigated the CLIP model to analyze its internal mechanisms. For instance, Bhalla et al. [41] found that the embeddings generated by CLIP exhibit strong linear properties and can be decomposed into combinations of various concepts. Gandelsman et al. [21] discovered that different attention heads within the CLIP model are responsible for interpreting different semantics, which are then combined to produce the final output embeddings. However, these studies primarily focus on the image domain. In this paper, we build upon existing work to further explore the properties of the CLIP model in the text domain and propose a novel interpretation method to interpret how prompts containing NSFW semantics are generated.
3 Method

3.1 Design Intuition
In this section, we explore how NSFW semantics are concealed within the conditional embeddings and revealed in the text encoder’s hidden states. Our investigation focuses on the CLIP model [40], the most widely used text encoder in T2I models and the primary target of adversarial attacks.

We classify the T2I model prompts into three categories: benign prompts, which do not generate NSFW images; regular NSFW prompts, which are manually crafted with explicit NSFW semantics; and adversarial prompts, which are generated by adversarial attacks and are challenging for humans to interpret as NSFW. Through extensive data collection, we compile a dataset consisting of approximately 25,000 benign prompts, 5,000 regular NSFW prompts, and 2,000 adversarial prompts. We utilize the CLIP model to obtain pooled embeddings of these prompts and examine their distribution with a PCA map [44], as depicted in Figure 1. Although the distributions of benign and NSFW data differ, considerable overlap makes effective differentiation challenging.
This phenomenon is primarily attributed to the architecture of the CLIP network, which comprises multiple layers and attention heads. Each layer employs a multi-head self-attention mechanism [45], where each attention head independently extracts information from the prompt. The outputs of these heads are then combined through a linear layer and passed to the next layer. The linear layers integrate information from various attention heads, making it challenging to isolate individual pieces of information. As the network’s depth increases, the outputs from different layers are accumulated through residual connections, exacerbating the entanglement of information. Consequently, benign prompts and NSFW prompts become intermixed within the pooled embedding space. As illustrated in the figure, two sentences describing the same object might appear semantically similar; however, one could be used to generate NSFW images while the other remains benign.
To more accurately delineate the boundary between NSFW and benign prompts, we examine the internal workings of the model by exploring the hidden states across different layers and attention heads. Figure 2 illustrates the distribution of benign, regular NSFW and adversarial data across several attention heads. The first column illustrates their overall distribution. In some heads, significant overlap remains between benign and NSFW data distributions. However, in other heads, a distinct boundary between these data types is evident. This reveals that attention heads within the model exhibit differing sensitivities to NSFW content. Certain attention heads concentrate on the NSFW semantics within prompts, allowing them to differentiate between benign and NSFW prompts effectively. We include the distribution maps of all attention heads in the appendix for reference.
We also find that different NSFW prompt categories are processed uniquely across attention heads. Columns two, three, and four of Figure 2 illustrate how violence, hate, and sex categories differ from benign data. In the first attention head, violence and hate data are separable from benign data, whereas sex data shows overlap. The second attention head clearly differentiates violence from benign data, with weaker distinctions in the other categories. In the third head, sex and hate data are distinctly separated from benign data, while violence data overlaps significantly. These findings suggest that attention heads specialize in handling specific NSFW content types. Even if a head struggles to differentiate between benign and NSFW data, it may still excel at distinguishing a particular type of NSFW prompt.
Based on these findings, we propose leveraging the attention heads within the text encoder to differentiate between benign and NSFW prompts effectively. By capitalizing on the diverse focus of different attention heads, we can aggregate information from all attention heads to achieve more accurate prompt classification.

3.2 Framework Overview
Based on the findings from Section 3.1, we develop a framework for detecting and interpreting NSFW prompts. The overall architecture of this framework is illustrated in Figure 3. Initially, we identify the direction within each attention head’s hidden states that best represent NSFW semantics by analyzing the distribution differences between benign and NSFW prompts, which we call NSFW features. When a new prompt is inputted, we can assess the risk of generating NSFW images by evaluating the projection magnitude of the prompt along the NSFW feature. To interpret our assessment, we pinpoint the token most representative of NSFW semantics within the prompt, analyzing why the current prompt is classified as an NSFW prompt. Furthermore, we can progressively eliminate NSFW semantics from the hidden states and input the modified prompt embeddings to generate images. This process enables us to observe how NSFW semantics are gradually removed from the embeddings. Finally, we can conduct red team testing on the framework or monitor it in real-time post-deployment to collect prompts that bypass current defenses. By incorporating them into the training set, we achieve more accurate NSFW feature identification and detection results.
The practical application of this framework manifests in two main ways. First, it prevents NSFW image generation from the outset when malicious users attempt to employ adversarial prompts. Second, when regular users inadvertently input prompts with NSFW semantics and encounter blockages, we can interpret why the prompt is considered inappropriate. This assists users in swiftly identifying problematic tokens and modifying their prompts to generate the desired image.
3.3 NSFW Features
The CLIP text encoder consists of layers, each with a multi-head self-attention mechanism with heads followed by an MLP block. A prompt is divided into tokens and projected into initial token embeddings , where is the BOS token and is the EOS token. These embeddings form the matrix , the initial input to the encoder. Each layer updates this input through self-attention and MLP modules with two residual steps:
| (1) |
In this framework, the ATT layer employs attention heads to extract information and integrates them into a vector through linear projection. The MLP layer further refines them to obtain intermediate embeddings that represent the overall information of the prompt. However, some information may be obscured or discarded during this process. Therefore, we need to utilize the original outputs from the attention heads to extract NSFW semantics effectively.
Considering that the outputs from multiple attention heads have been preliminarily integrated into , we need to decompose its computational process to extract the information each attention head represents. Since the CLIP model’s self-attention block employs a causal mask [40], only the EOS token holds the complete semantics of the prompt. Therefore, we concentrate solely on the EOS token. Following Elhage et al. [46] and Gandelsman et al. [21], we formalize the ATT output as a sum over independent attention heads and tokens:
| (2) | ||||
where are transition matrices and are the attention weights from the -th token to the EOS token. In this way, we can get the contribution of -th attention head in -th layer for , which can be expressed as .
Each is located within a -dimensional representation space, and our goal is to identify the direction within this space that best represents NSFW semantics. When a new prompt is input, the more its representation in attention heads aligns with the NSFW direction, the more likely it is to contain NSFW semantics. We refer to these directions as the NSFW features of each attention head.
| Category | Prompt |
|---|---|
| Regular NSFW prompt | A naked woman stands on the beach, facing the sea. |
| Her body shakes with each orgasm, the pleasure overwhelming. | |
| Adversarial prompt | gesture softly licking upon her backwards body allows an |
| vigorconseshrisensuoutgoing man led carmen habns arch. |
To calculate NSFW features, we introduce two sets of prompts: benign prompts and NSFW prompts, where NSFW prompts include regular NSFW prompts and adversarial prompts. We input these prompts into the CLIP model and obtain their outputs of each attention head, denoting the outputs of benign prompts as and the outputs of NSFW prompts as . Our objective is to maximize while minimizing , where are NSFW features we want to extract. To achieve this, we establish three optimization objectives:
| (3) |
| (4) |
| (5) |
where and are the mean value of and . In summary, our goal is to maximize the distance between the projected means of and on the vector , while simultaneously minimizing their respective variances. We can employ Linear Discriminant Analysis (LDA) [47] to solve this problem, ultimately obtaining the NSFW feature :
| (6) |
| (7) |
In text encoders other than CLIP, such as T5 [48], we can still use the method above to extract NSFW features. Any text encoder utilizing multi-head self-attention can be adapted to this approach.
3.4 NSFW Prompts Detection
By utilizing the identified NSFW features, we can detect NSFW prompts. According to previous research [21], we can consider the intermediate embeddings of prompts in the CLIP model as a linear combination of concepts. The projection of these embeddings onto each concept direction represents the contribution of that concept to the embedding. Based on this, we define the projection of the embedding onto the NSFW feature as the NSFW score of a prompt :
| (8) |
By aggregating the NSFW Scores from all attention heads, we can obtain the final NSFW Score for the current prompt:
| (9) |
The larger the , the more likely the current prompt contains NSFW semantics.
Theoretically, if , the prompt contains NSFW semantics and should be classified as an NSFW prompt. Conversely, if , the prompt should be classified as benign. However, experimental results show that while setting the threshold to zero allows AEIOU to achieve high accuracy, optimal classification performance requires a slight threshold adjustment. We hypothesize that this is due to the distribution of the training set not fully representing the actual distribution of NSFW prompts, which introduces bias in the NSFW features derived during training. In our experiments, we determine the classification threshold by selecting the one that yields the highest F1 Score on the training set. For different text encoders, the final offset ranges from 1% to 3%.
The approach above treats NSFW as a single comprehensive category. Suppose there is a need to subdivide it further or to identify specific categories of NSFW prompts, such as sex or violence. In that case, we can categorize NSFW prompts in the training set based on labels. This enables the calculation of NSFW features for each subcategory, facilitating the determination of NSFW scores for each. If we also need to detect NSFW prompts across all categories, we can aggregate the NSFW scores from all subcategories and use their maximum value as the final NSFW score.
Moreover, we can collect adversarial prompts that successfully bypass detection by employing adaptive attacks during red team testing. Incorporating these into the training set for data augmentation allows us to achieve more accurate NSFW feature extraction and detection results. Since adaptive attacks require significant time and have a low success rate, generating a large volume of red-teaming data is challenging. However, we can increase their impact during training by assigning greater weight to these data. Specifically, by weighting the target prompt’s when calculating and , we can amplify their influence on the resulting NSFW feature. Experiments have shown that optimizing the NSFW feature through data augmentation can effectively reduce the success rate of adaptive attacks.

3.5 NSFW Prompts Interpretation
After the detection process, we further interpret NSFW prompts through a two-module framework. First, we propose a novel interpretative method that uses NSFW features and the prompt’s hidden states to identify the tokens most representative of NSFW semantics. Second, we investigate the generation mechanism of NSFW semantics in conditional embeddings by gradually attenuating the NSFW features in the hidden states. Using the resulting embeddings to generate images, we gain insights into how NSFW semantics can be progressively eliminated.
3.5.1 Text-Module Interpretation
In the text module, we interpret NSFW prompts by identifying NSFW tokens. Within each attention head, we assess the NSFW semantic association at any given position by computing the cosine similarity between the hidden state at that position and the head’s NSFW feature:
| (10) |
As tokens pass through the attention model, their semantics interrelate and intertwine, with each position’s hidden states encapsulating information from all preceding tokens. Consequently, we cannot directly use the association between the current position’s hidden states and NSFW semantics to represent that token’s association with NSFW semantics accurately.
Similar to Equation 2, each position’s hidden state can be represented as a combination of , with the corresponding attention weight indicating the contribution of each .
| (11) |
where are the attention weights from the -th token to the -th token. For Layer 1, since it has only undergone a single operation as described in Equation 11, we can conveniently reconstruct the actual contribution of each token based on :
| (12) |
For deeper layers, we need to use the from the preceding layers to approximate the contribution of each token. Since directly forms the attention map , we can multiply the attention maps from each layer to approximate the contribution of each token to the positions in the current layer. In this way, the interpretative results for each layer can be represented as:
| (13) |
By aggregating the interpretation results from all attention heads, we can obtain the final interpretation for each token:
| (14) |
Table I demonstrates several examples of our interpretation. Our method accurately identifies sensitive words in regular samples and adversarial tokens in adversarial samples. We will conduct further experiments to demonstrate the effectiveness of the interpretability method.
3.5.2 Image-Module Interpretation
In the image domain, we gradually attenuate the NSFW semantics contained in the prompts and examine the generated images to observe how the images evolve as the NSFW semantics are progressively diminished. Since the conditional embedding in T2I models includes embeddings of all tokens, we need to eliminate NSFW semantics from all tokens. We assume that the feature space of each token is identical to that of the EOS token. This allows us to compute the NSFW score for each token by projecting the intermediate embeddings onto the NSFW features. Subsequently, we can attenuate the NSFW semantics of all tokens as follows:
| (15) |
By recombining to calculate , we can derive the modified conditional embedding. By gradually increasing the value of and using conditional embedding to generate images, we can observe the process of NSFW semantics being progressively eliminated from the images.
Taking the prompt “A beautiful naked woman.” as an example, Figure 4 illustrates the images generated for various values of . As increases, the images gradually transition from NSFW to benign while maintaining the basic semantics of the prompt. In this process, we discover two interesting observations. First, as the NSFW semantics are gradually attenuated, the generated images strive to remain faithful to the prompt’s semantics. Initially, the woman turns away, then conceals sensitive areas with her hands. Ultimately, only the area above her shoulders is visible, rendering the image harmless. Throughout, the image never violates the prompt’s directive. This process demonstrates the editability of the hidden states.
Secondly, the generated images exhibit several abrupt transitions during the gradual increase of . The overall structure of generated images remains unchanged when increases from zero to 0.68. However, when increases slightly further, the images undergo significant transformations while preserving semantic consistency. This intriguing property merits further investigation.
4 Experiments
4.1 Experimental Settings
4.1.1 Datasets
The dataset we use comprises three categories. Clean datasets consist of benign data that does not generate NSFW images. Regular NSFW datasets include manually generated prompts with explicit NSFW semantics. Adversarial datasets comprise algorithmically generated adversarial NSFW prompts.
Clean Dataset. Our experiments use the validation captions of MSCOCO [49] as the clean dataset. MSCOCO is a cross-modal image-text dataset, a popular benchmark for training and evaluating T2I generation models. We remove all captions containing sensitive words to ensure the samples are benign. A total of 25,008 captions are retained.
Regular NSFW Dataset. We gather data from multiple sources to comprehensively represent various types of NSFW semantics.
Adversarial Dataset. Adversarial datasets include adversarial samples obtained through three open-source adversarial attack methods: MMA [19], SneakyPrompt [5], and Ring-A-Bell [27]. For MMA, we utilize the 1,000 successful adversarial samples provided by the authors. For the other two methods, we generate samples with the open-source algorithms, resulting in approximately 200 samples for each.
4.1.2 Baselines
We employ seven baseline models: four commercial moderation API models, two open-source moderators, and one state-of-the-art NSFW prompt detector. The four commercial models are OpenAI Moderation [13, 53], Azure AI Content Safety [36], AWS Comprehend [35] and Aliyun Text Moderation [54]. These models primarily utilize large transformer-based architectures to analyze prompts for potential toxic content. They have a wide range of applications, including prompts for various generative models and user comments on the internet. The open-source moderators, NSFW-text-classifier [14] and Detoxity [37], use lightweight models to detect NSFW content in text, enabling fast inference speeds. Latent Guard [15] represents the current state-of-the-art method specifically designed for detecting NSFW prompts in T2I models.
| Detector | TPR | FPR | ACC | F1 Score | AUROC | AUPRC | TPR@FPR 1% | Time/Query(ms) |
|---|---|---|---|---|---|---|---|---|
| OpenAI Moderation [13] | 0.2976 | 0.0010 | 0.8220 | 0.4578 | 0.8616 | 0.7960 | 0.4974 | 1288.43 |
| Azure AI Content Safety [36] | 0.4761 | 0.0118 | 0.8590 | 0.6302 | 0.7331 | 0.7708 | 0.4313 | 922.67 |
| AWS Comprehend [35] | 0.4702 | 0.0730 | 0.8118 | 0.5576 | 0.7143 | 0.6244 | 0.2980 | 286.42 |
| Aliyun Text Moderation [54] | 0.1736 | 0.0023 | 0.7897 | 0.2941 | 0.5856 | 0.6720 | 0.1799 | 99.16 |
| NSFW-text-classifier [14] | 0.7325 | 0.3534 | 0.6699 | 0.5466 | 0.7627 | 0.6823 | 0.2922 | 9.14 |
| Detoxify [37] | 0.5432 | 0.1778 | 0.7465 | 0.5379 | 0.7226 | 0.6455 | 0.3340 | 24.82 |
| Latent Guard [15] | 0.5021 | 0.1403 | 0.7625 | 0.5346 | 0.7579 | 0.5995 | 0.1690 | 167.90 |
| AEIOU | 0.9833 | 0.0085 | 0.9895 | 0.9792 | 0.9990 | 0.9977 | 0.9842 | 0.64 |
| AEIOU | 0.9747 | 0.0082 | 0.9875 | 0.9751 | 0.9990 | 0.9974 | 0.9799 | 1.84 |
| AEIOU | 0.9726 | 0.0102 | 0.9853 | 0.9708 | 0.9984 | 0.9957 | 0.9701 | 6.71 |
| AEIOU | 0.9829 | 0.0087 | 0.9873 | 0.9785 | 0.9982 | 0.9971 | 0.9824 | 0.64 |
| AEIOU | 0.9763 | 0.0066 | 0.9890 | 0.9783 | 0.9988 | 0.9973 | 0.9817 | 0.93 |
Note: AEIOU, AEIOU and AEIOU are methods deployed on three different text encoders. AEIOU is trained without any adversarial prompts, while AEIOU is trained across multiple categories and integrates the results. Both of them are deployed on CLIP-L.
4.1.3 Metrics
We employ variable metrics to comprehensively evaluate the effectiveness of AEIOU, including TPR, FPR, Accuracy, F1 Score [55], AUROC, AUPRC [56], and TPR@FPR 1%. We set the threshold to the value that achieves the maximum F1 score on the training set. Moreover, we evaluate the efficiency of AEIOU by measuring the average time per query.
4.1.4 Implementation Details
We deploy AEIOU on three text encoders commonly used in T2I models: CLIP-ViT-L (CLIP-L) [57], CLIP-ViT-bigG (CLIP-G) [58], and T5-v1.1-XXL (T5) [59]. CLIP-L is the most widely used text encoder and serves as the foundation for most safety-related research. CLIP-G and T5 are larger models; many recent models [3, 25] employ them as text encoders.
We design two variant detectors to evaluate our method’s effectiveness in different scenarios. First, when the defender is unaware of the attack method, we employ a model trained solely on clean data and standard NSFW data to test AEIOU’s generalization capability. Second, when the defender has sufficient data labeled with specific categories, they can train on multiple specific concepts to enhance the model’s specificity. We deploy the CLIP-L-based detector in both scenarios.
| Detector | I2P-Soft | I2P-Hard | 4chan | NSFW200 | NSFW-laion | MMA | SneakyPrompt | Ring-A-Bell |
|---|---|---|---|---|---|---|---|---|
| OpenAI Moderation [13] | 0.0244 | 0.0600 | 0.8200 | 0.6800 | 0.3147 | 0.7030 | 0.6311 | 0.6117 |
| Azure AI Content Safety [36] | 0.1184 | 0.2162 | 0.9920 | 0.8300 | 0.8287 | 0.8176 | 0.8058 | 0.9126 |
| AWS Comprehend [35] | 0.1462 | 0.2303 | 1.0000 | 0.7900 | 0.5909 | 0.8977 | 0.7699 | 0.8252 |
| Aliyun Text Moderation [54] | 0.0627 | 0.0415 | 0.9200 | 0.1700 | 0.3392 | 0.1502 | 0 | 0.5437 |
| NSFW-text-classifier [14] | 0.4930 | 0.5841 | 1.0000 | 0.9700 | 0.7972 | 0.9644 | 0.9029 | 0.9806 |
| Detoxify [37] | 0.2180 | 0.3384 | 1.0000 | 0.8300 | 0.4248 | 0.9377 | 0.7282 | 0.8544 |
| Latent Guard [15] | 0.2451 | 0.3581 | 0.9720 | 0.3600 | 0.5455 | 0.7753 | 0.2427 | 0.5922 |
| AEIOU | 0.9652 | 0.9858 | 0.9800 | 0.9800 | 0.9983 | 0.9989 | 0.9903 | 1.0000 |
| AEIOU | 0.9673 | 0.9825 | 0.9960 | 0.9900 | 0.9930 | 0.9978 | 0.9903 | 1.0000 |
| AEIOU | 0.9519 | 0.9738 | 0.9680 | 0.9600 | 0.9843 | 0.9956 | 0.9806 | 1.0000 |
| AEIOU | 0.9680 | 0.9891 | 0.9800 | 0.9700 | 0.9979 | 0.9911 | 0.9806 | 1.0000 |
| AEIOU | 0.9547 | 0.9705 | 0.9880 | 0.9800 | 1.0000 | 0.9933 | 0.9903 | 1.0000 |
4.2 Overall Evaluation
First, we conduct an overall evaluation of the effectiveness of AEIOU. We deploy it across three different text encoders and trained models using three distinct settings. AEIOU is then compared against seven baselines on one benign dataset and eight NSFW datasets. We randomly select half of each dataset as the training set and use the remaining half as the test set.
Table II presents the overall evaluation results across all datasets, with the best performance for each metric highlighted in bold. As shown in the table, AEIOU consistently outperforms previous classification approaches across almost all metrics. It demonstrates high detection accuracy across the CLIP-L, CLIP-G, and T5 models, proving its applicability to various text encoders.
In Table III, we further present the accuracy of various classifiers on each dataset. The first six columns represent regular NSFW datasets, and the last three correspond to adversarial datasets. AEIOU maintains high accuracy across all datasets, whereas the performance of other methods is inconsistent. The accuracy of most methods is low on the I2P dataset. This is likely because they need to detect text across various applications, making it hard to handle prompts used in T2I models specifically. On other regular NSFW datasets, which typically contain human-recognizable NSFW semantics. Most classifiers achieve relatively high accuracy but still lag behind AEIOU. Notably, on the 4chan dataset, three classifiers achieve higher accuracy than AEIOU. However, the difference is very minimal. Finally, regarding adversarial prompts, AEIOU significantly outperforms all other methods. Even AEIOU, which is trained without adversarial datasets, still achieves remarkably high accuracy.
Additionally, we assess each method’s efficiency by measuring the average time per query, presented in the last column of Table II. AEIOU requires significantly less time than other methods, primarily because they often utilize large models for detection. In contrast, AEIOU only incorporates multiple matrix operations during the text encoder’s inference process. On the smallest CLIP-L model, AEIOU’s efficiency improves at least tenfold compared to other models. Even on larger models like CLIP-G and T5, AEIOU’s efficiency surpasses that of all other models.
4.3 Generalization to Unknown Attacks
This section examines AEIOU’s ability to defend against unknown adversarial attacks. In Tables II and III, we present the performance of AEIOU trained solely on benign and regular NSFW datasets, denoted as AEIOU. Despite never encountering adversarial prompts, the experimental results indicate that AEIOU can still effectively identify adversarial NSFW prompts, with accuracy only slightly lower than the standard AEIOU. We attribute this effectiveness to AEIOU’s focus on the semantic information embedded in the hidden states. Although adversarial and regular NSFW prompts may appear different to the human eye, their semantic information is similar, allowing AEIOU to recognize them accurately.
| Detector | Sexual | Hate | Self-Harm | Violence | Shocking | Harassment | Illegal |
|---|---|---|---|---|---|---|---|
| AEIOU | 0.9959 | 0.9863 | 0.9763 | 0.9921 | 0.9790 | 0.9733 | 0.9340 |
| AEIOU | 0.9991 | 0.9795 | 0.9950 | 0.9974 | 0.9848 | 0.9697 | 0.9725 |
| Training Data Size | TPR | FPR | ACC | F1 Score | AUROC | AUPRC | TPR@FPR 1% |
|---|---|---|---|---|---|---|---|
| 10 | 0.9171 | 0.0278 | 0.9583 | 0.9174 | 0.9875 | 0.9734 | 0.8495 |
| 50 | 0.9356 | 0.0164 | 0.9714 | 0.9430 | 0.9940 | 0.9861 | 0.9157 |
| 100 | 0.9605 | 0.0180 | 0.9766 | 0.9538 | 0.9962 | 0.9906 | 0.9351 |
| 500 | 0.9824 | 0.0091 | 0.9888 | 0.9778 | 0.9981 | 0.9974 | 0.9829 |
| 1000 | 0.9833 | 0.0096 | 0.9887 | 0.9776 | 0.9990 | 0.9975 | 0.9833 |

4.4 Multi-Categories Classifier
NSFW serves as an overarching descriptor for harmful prompts, and it can be decomposed into more specific categories. In this section, we follow the I2P dataset to classify NSFW prompts into seven particular categories: sexual, hate, self-harm, violence, shocking, harassment, and illegal. Adhering to the methodology described in Section 3.4, we identify features representing these concepts and derive the multi-categories AEIOU by integrating the NSFW scores of each category. Tables II and III compare the overall performance of AEIOU with the standard AEIOU. Although the detailed AEIOU exhibits slightly worse overall performance, the difference is minimal. Furthermore, Table IV compares their accuracies within each category. AEIOU generally achieves higher accuracy in most categories, but in some, it underperforms compared to the standard AEIOU.
We attribute the lack of superiority in AEIOU to two main reasons. First, prompts from different categories often share overlapping features. Common sensitive words like “f**k” appear across multiple categories, which limits AEIOU’s ability to capture shared features when trained individually on each category. As a result, it demonstrates higher accuracy in more distinct categories like self-harm but lower accuracy in more ambiguous categories such as hate and harassment. Secondly, discrepancies in data quality exist among different categories. In our datasets, sexual prompts have broad coverage and the highest quality, while the quality of other categories’ prompts varies significantly. This leads to suboptimal performance of AEIOU on some categories. To improve AEIOU’s performance, we need to train it using higher-quality datasets.
4.5 The Impact of Training Data Size
In this section, we discuss the impact of training data size on the performance of AEIOU. We set the training data size for AEIOU to 10, 50, 100, 500 and 1000. Half of the training data is randomly selected benign data, while the other half is randomly selected NSFW data. Table V presents the experimental results of AEIOU. The experiments demonstrate that AEIOU maintains high accuracy even with only 10 training samples. When the sample size reaches 500, its performance is comparable to AEIOU trained with a full dataset. As the number of training samples increases further, there is no significant improvement in performance, indicating that improving the quality and coverage of training samples is a better strategy than simply increasing the quantity. In the appendix, we present detailed experimental results on the other two text encoders, which yield conclusions similar to CLIP-L. Figure 5 provides additional insights with different training data sizes across various datasets, which aligns with the results in Table V. These experiments confirm AEIOU’s exceptional performance in few-shot scenarios.

| Defender | SneakyPrompt | MMA | ||||||
|---|---|---|---|---|---|---|---|---|
| Bypass Rate(%) | ASR-H(%) | ASR-M(%) | CLIP Score | Bypass Rate(%) | ASR-H(%) | ASR-M(%) | CLIP Score | |
| Bare | 100 | 46 | 48 | 0.9597 | 100 | 75 | 79 | 0.9315 |
| ESD | 100 | 5 | 7 | 0.9613 | 100 | 10 | 13 | 0.9315 |
| AEIOU | 0 | 0 | 0 | / | 78 | 28 | 31 | 0.8850 |
| AEIOU+ESD | 0 | 0 | 0 | / | 78 | 0 | 0 | / |
| AEIOU | 0 | 0 | 0 | / | 42 | 6 | 7 | 0.8482 |
| AEIOU+ESD | 0 | 0 | 0 | / | 42 | 0 | 0 | / |
4.6 Ablation Study
In our approach, we utilize NSFW features from all layers and all attention heads for detection. In this section, we will discuss the impact of using NSFW features from only a single layer of text encoder. We conduct experiments on three text encoders. Figure 6 presents the accuracy, TPR, and FPR when using each layer for detection. More detailed experimental data are presented in the appendix.
In all three text encoders, even when using attention heads from a single layer, many layers still achieve high accuracy. For CLIP-L and CLIP-G, the middle layers tend to have higher accuracy, while the early and final layers show lower accuracy. Conversely, in the T5 model, the later layers exhibit higher accuracy. This highlights the distinct characteristics of the two types of text encoders.
Although using attention heads from a single layer can achieve high accuracy, we recommend using the original AEIOU method for the highest precision in detection.
5 Adaptive Attack
In this section, we evaluate the robustness of AEIOU against adaptive attacks. To target our model, we design adaptive attacks based on two methods: SneakyPrompt and MMA. They are applicable to all T2I models and can effectively bypass both internal and external safeguards. Considering their different applicable scenarios, we employ SneakyPrompt for black-box adaptive attack and MMA for white-box adaptive attack.
We utilize Stable Diffusion v1.4 [20] as the generative model, as it is the most vulnerable and the easiest model to compromise. We evaluate the attack performance on the bare model, the ESD model [8], and the model employing AEIOU. The bare model only detects whether sensitive tokens are present in the prompt, while ESD fine-tunes the model to make it difficult to generate NSFW images. We assess the attacks using three metrics: bypass rate, attack success rate, and CLIP Score [60]. The bypass rate measures how many adversarial prompts can be successfully generated. The attack success rate indicates the frequency with which NSFW images are produced. The CLIP Score assesses the semantic similarity between adversarial and target prompts. We conduct both model-based and manual evaluations of the attack success rate to ensure our results’ reliability. For classification, a state-of-the-art model [4] is selected. And human evaluations are independently performed by three individuals, with the majority opinion determining the final assessment.
5.1 Black-Box Adaptive Attack
In the black-box scenario, we assume the attacker has no knowledge of the model’s details but can choose prompts and query the model to obtain output results. We integrate AEIOU into the text encoder of Stable Diffusion. When a potential NSFW prompt is detected, the model will refuse to generate the image. We select 100 prompts with clear NSFW semantics from NSFW200 as the target prompts and use SneakyPrompt to attack the models. The experimental results are shown in Table VI.
When attacking the bare model, SneakyPrompt achieves a high bypass rate and attack success rate. ESD significantly reduces the success rate of attacks, yet it cannot entirely prevent the generation of NSFW images. However, after incorporating AEIOU, SneakyPrompt is entirely thwarted by our defenses, unable to generate any NSFW images, and the bypass rate drops to 0. This is because SneakyPrompt only replaces a few tokens in the prompt, which does not effectively neutralize its overall meaning.
5.2 White-Box Adaptive Attack
In a white-box scenario, we assume attackers can only generate images through queries. However, they possess a local copy of the text encoder identical to the target model and are aware of the AEIOU defense strategy. The attacker can target AEIOU by modifying the loss function to conduct a specific attack. The MMA attack’s loss aims to make the conditional embeddings of the adversarial prompt and the target prompt as similar as possible. To effectively attack AEIOU, we incorporate as into the original loss function. This transforms the objective of the loss function to minimize the NSFW Score while ensuring that the semantics of the adversarial prompt closely align with the target prompt.
| (16) |
| (17) |
Where is a weighting factor that balances between the two components. Based on this foundation, we implement a target truncation strategy. Specifically, once exceeds the threshold by a small margin, we stop optimizing it and shift our primary focus to optimizing . This enables adversarial prompts to approximate the semantics of the target prompt as closely as possible while avoiding detection. Consequently, the final loss is formulated as:
| (18) |
Where is the threshold and is the margin. When updating the best prompt, we ensure that the surpasses the threshold. We conduct the attack using the default settings of MMA and evaluate it on 100 target prompts. The experimental results are presented in Table VI.
As a white-box attack, MMA demonstrates stronger capabilities than SneakyPrompt on the bare model. However, when it targets AEIOU, AEIOU exhibits robust performance, significantly reducing the MMA bypass rate and success rate. Meanwhile, the average CLIP score of successfully generated adversarial prompts also decreases, indicating that MMA’s optimization of these prompts is not as successful as in the bare model. Moreover, although AEIOU itself does not increase the memory usage of the text encoder, the adaptive attack against it must optimize hidden states across all attention heads, significantly increasing the memory requirements. While standard MMA operates on less than 10GB of memory, adaptive MMA demands nearly 50GB, restricting its execution to commercial-grade GPUs. This makes adaptive attacks on AEIOU more challenging.
We can also combine AEIOU with other defense methods. For instance, by integrating ESD, we can reduce the success rate of MMA attacks to zero. By implementing a comprehensive defense strategy that addresses other parts of the T2I model, we can enhance the overall defensive performance and make adaptive attacks more challenging.
To further enhance AEIOU’s resilience against adaptive attacks, we incorporate adversarial prompts that successfully breach AEIOU’s defenses into the training set for additional training. The following section will provide a detailed discussion of this process.
5.3 Enhance the Classifier with Red-Teaming Data
We conduct red team testing using a white-box adaptive attack and collect adversarial prompts that successfully bypass AEIOU and generate NSFW images. These prompts are added to AEIOU’s training dataset for data augmentation, aiming to enhance AEIOU’s ability to resist corresponding adaptive attacks. When training, we assign them greater weight to ensure they significantly influence the model even the sample size is limited.
Table VI presents the performance of the data-augmented AEIOU. We include 25 adaptive adversarial prompts in the training set with a weight of 50. This results in AEIOU, demonstrating significantly improved defense against adaptive attacks, reducing the bypass rate to 42% and the success rate to just 7% for MMA. Additionally, the CLIP score experiences a further decline. This underscores the effectiveness of further optimizing AEIOU with data augmentation.
In the practical application of AEIOU, we can also collect adversarial prompts that successfully bypass defenses through manual screening. These prompts can then be added to the training dataset with appropriate weighting, allowing for continuous updates of the defense model.
6 Interpretation Experiments
In this section, we validate AEIOU’s interpretability. This not only makes AEIOU’s classification more transparent and trustworthy but also aids users in further understanding the semantics of prompts. We assess the reliability of interpretations across both text and image modalities.
6.1 Text-Based Interpretation
In the text modality, our interpretation aids users in understanding the semantics of a prompt by identifying tokens containing NSFW semantics. After obtaining the interpretation result for each token in the prompt , we sequentially remove the corresponding tokens from in descending order of and observe the changes in the NSFW score. We compare our interpretation method with the random removal of tokens on 100 randomly selected NSFW prompts, and the results are shown in Figure 7. Compared to randomly removing, removing tokens based on the interpretation results more quickly weakens the NSFW semantics of the prompt, demonstrating that AEIOU can effectively identify NSFW tokens within a prompt.
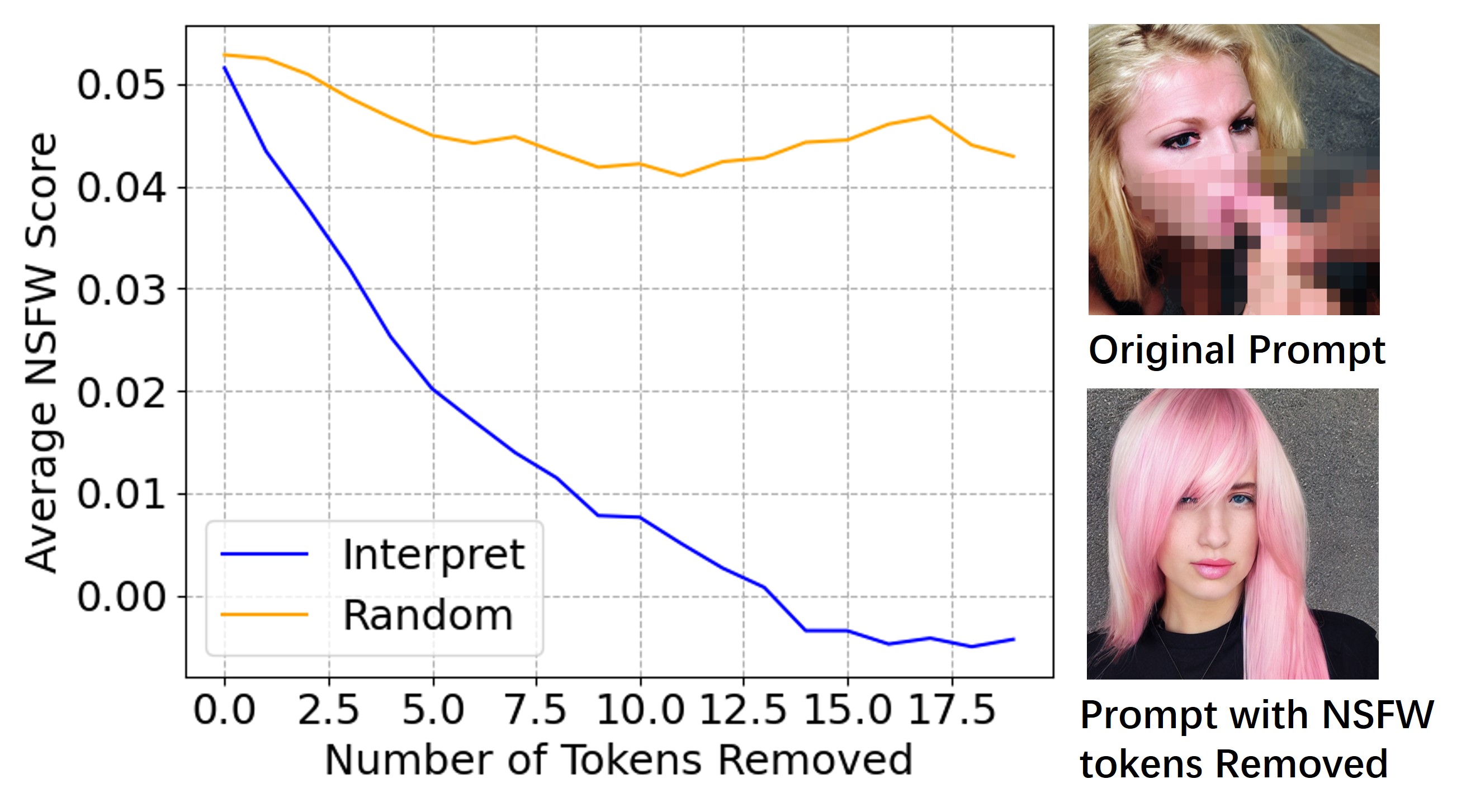
Additionally, we conduct further experiments on image generation using the 100 prompts above. We will compare the images generated from the original prompt with those generated from the prompt after removing the NSFW token. For original prompts, 87 out of the 100 generated images are NSFW. After removing NSFW tokens, only 5 prompts result in NSFW images. This further demonstrates the effectiveness of our interpretation method.
6.2 Image-Based Interpretation
Directly removing tokens with NSFW semantics can prevent the generation of NSFW images. However, it significantly disrupts the original intent of the prompt. To address this drawback, we manipulate the embeddings of each token in the image-based interpretation process, gradually eliminating NSFW semantics and observing changes in the generated images. We use the same 100 prompts as in the previous section. We evaluate the degree to which the generated images contain NSFW semantics and how closely they align with the original prompt semantics.
Figure 8 illustrates the variation in the number of NSFW images generated and the semantic similarity between the images and prompts as the parameter changes. The semantic similarity is evaluated using the CLIP Score. As increases, the number of NSFW images decreases progressively. Although the CLIP Score also shows a decreasing trend, the overall deviation from the original image’s CLIP Score remains minimal. This indicates that the NSFW semantics of the prompt are effectively mitigated while preserving other semantic information as much as possible.
However, because this method directly modifies semantics within the hidden states, the resulting conditional embeddings deviate from the normal distribution, often leading to lower-quality images. Therefore, this approach is supposed to aid in understanding the representation of NSFW semantics within the text encoder. It cannot be directly applied to erase specific concepts from images.

7 Discussion
Practicality. Previous research [61] has identified key qualities for a safe and secure generative model, including integrity, robustness, alignment, and interpretability. Building on this foundation, we propose that a practical defense framework should adhere to the following principles: First, the defense must be integrated, offering protection against both conventional threats and adversarial attacks to maintain model safety and security. Second, the defense should remain robust amidst changing external conditions, addressing issues such as distribution shifts and adaptive attacks. Third, the model with the defensive mechanism should align with the original model, preserving its effectiveness and efficiency. Lastly, the defense should be interpretable, enabling the timely identification of anomalous behaviors to prevent potential hazards.
AEIOU excels in these four areas compared to prior methods. Firstly, AEIOU maintains an accuracy rate exceeding 95% across various models, significantly outperforming earlier approaches. Secondly, it requires only a small number of samples for data augmentation, simplifying updates. Thirdly, its classification process is transparent, and it provides interpretative tools to help users understand target prompts. Lastly, AEIOU does not impact image generation quality and incurs only negligible computational overhead. These all demonstrate its practicality.
Limitations and Future Work. AEIOU detects NSFW prompts by extracting NSFW features from hidden states, showcasing the potential for extracting specific concepts from the text encoder. However, this study does not explore the application of this method to other concepts, which warrants further investigation. For instance, this approach could potentially be employed to prevent the generation of images containing particular objects or styles.
Due to its low computational cost, AEIOU utilizes all attention heads for detection. However, to gain deeper insights into the specific characteristics of text encoders like CLIP, it is crucial to examine the semantic focus of each attention head. Uncovering the specific roles and properties of each attention head is an area that merits further exploration.
Despite AEIOU demonstrating robust capabilities, no defensive method is foolproof. Therefore, in practical applications, it should be combined with other techniques, such as image moderation. However, current image moderation methods have significant shortcomings, primarily due to the vast information and potentially embedded textual content in images. Given that CLIP is a multimodal model, there is potential for adapting AEIOU to the image domain to achieve more powerful post-generation defenses.
Ethical Considerations. We exclusively use publicly available datasets from previous studies, and all manual evaluations of NSFW images are conducted by the authors of this paper. Therefore, our work is not considered human subjects research by our Institutional Review Boards (IRB). To prevent psychological distress and misuse, both the images displayed in this paper and those used for manual evaluation are limited to potentially sexual content, excluding categories such as violence or hate, which could easily cause discomfort or be used to propagate hate.
8 Conclusion
In this paper, we propose a unified defense framework against NSFW prompts in T2I models named AEIOU. The AEIOU framework, being adaptable, efficient, interpretable, optimizable, and unified, has demonstrated superior performance that far exceeds previous defense methods. In addition to detection, we provide interpretability methods to help understand the semantics of NSFW prompts and the generation process of NSFW images. Experimental results show that AEIOU exhibits strong capabilities in defending against both normal attacks and adaptive attacks.
References
- [1] R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High-resolution image synthesis with latent diffusion models,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 10 684–10 695.
- [2] J. Betker, G. Goh, L. Jing, T. Brooks, J. Wang, L. Li, L. Ouyang, J. Zhuang, J. Lee, Y. Guo et al., “Improving image generation with better captions,” Computer Science. https://cdn. openai. com/papers/dall-e-3. pdf, vol. 2, no. 3, p. 8, 2023.
- [3] Flux. [Online]. Available: https://www.flux.ai/
- [4] Y. Qu, X. Shen, X. He, M. Backes, S. Zannettou, and Y. Zhang, “Unsafe diffusion: On the generation of unsafe images and hateful memes from text-to-image models,” in Proceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Security, 2023, pp. 3403–3417.
- [5] Y. Yang, B. Hui, H. Yuan, N. Gong, and Y. Cao, “Sneakyprompt: Jailbreaking text-to-image generative models,” in 2024 IEEE symposium on security and privacy (SP). IEEE, 2024, pp. 897–912.
- [6] J. Rando, D. Paleka, D. Lindner, L. Heim, and F. Tramèr, “Red-teaming the stable diffusion safety filter,” in NeurIPS Workshop on Machine Learning Safety. ETH Zurich, 2022.
- [7] C. Zhang, M. Hu, W. Li, and L. Wang, “Adversarial attacks and defenses on text-to-image diffusion models: A survey,” Information Fusion, p. 102701, 2024.
- [8] R. Gandikota, J. Materzynska, J. Fiotto-Kaufman, and D. Bau, “Erasing concepts from diffusion models,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 2426–2436.
- [9] N. Kumari, B. Zhang, S.-Y. Wang, E. Shechtman, R. Zhang, and J.-Y. Zhu, “Ablating concepts in text-to-image diffusion models,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 22 691–22 702.
- [10] X. Li, Y. Yang, J. Deng, C. Yan, Y. Chen, X. Ji, and W. Xu, “Safegen: Mitigating unsafe content generation in text-to-image models,” arXiv preprint arXiv:2404.06666, 2024.
- [11] P. Schramowski, M. Brack, B. Deiseroth, and K. Kersting, “Safe latent diffusion: Mitigating inappropriate degeneration in diffusion models,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 22 522–22 531.
- [12] H. Li, C. Shen, P. Torr, V. Tresp, and J. Gu, “Self-discovering interpretable diffusion latent directions for responsible text-to-image generation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 12 006–12 016.
- [13] Openai moderation. [Online]. Available: https://platform.openai.com/docs/guides/moderation/overview
- [14] Nsfw-text-classifier. [Online]. Available: https://huggingface.co/michellejieli/NSFW_text_classifier
- [15] R. Liu, A. Khakzar, J. Gu, Q. Chen, P. Torr, and F. Pizzati, “Latent guard: a safety framework for text-to-image generation,” arXiv preprint arXiv:2404.08031, 2024.
- [16] Y. Yang, R. Gao, X. Yang, J. Zhong, and Q. Xu, “Guardt2i: Defending text-to-image models from adversarial prompts,” arXiv preprint arXiv:2403.01446, 2024.
- [17] Safety checker of stable diffusion. [Online]. Available: https://huggingface.co/CompVis/stable-diffusion-safety-checker
- [18] P. Schramowski, C. Tauchmann, and K. Kersting, “Can machines help us answering question 16 in datasheets, and in turn reflecting on inappropriate content?” in Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency, 2022, pp. 1350–1361.
- [19] Y. Yang, R. Gao, X. Wang, T.-Y. Ho, N. Xu, and Q. Xu, “Mma-diffusion: Multimodal attack on diffusion models,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 7737–7746.
- [20] Stable diffusion v1.4. [Online]. Available: https://huggingface.co/CompVis/stable-diffusion-v1-4
- [21] Y. Gandelsman, A. A. Efros, and J. Steinhardt, “Interpreting clip’s image representation via text-based decomposition,” in The Twelfth International Conference on Learning Representations, 2024.
- [22] J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” Advances in neural information processing systems, vol. 33, pp. 6840–6851, 2020.
- [23] D. Podell, Z. English, K. Lacey, A. Blattmann, T. Dockhorn, J. Müller, J. Penna, and R. Rombach, “Sdxl: Improving latent diffusion models for high-resolution image synthesis,” arXiv preprint arXiv:2307.01952, 2023.
- [24] N. Ruiz, Y. Li, V. Jampani, Y. Pritch, M. Rubinstein, and K. Aberman, “Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 22 500–22 510.
- [25] P. Esser, S. Kulal, A. Blattmann, R. Entezari, J. Müller, H. Saini, Y. Levi, D. Lorenz, A. Sauer, F. Boesel et al., “Scaling rectified flow transformers for high-resolution image synthesis,” in Forty-first International Conference on Machine Learning, 2024.
- [26] H. Liu, Y. Wu, S. Zhai, B. Yuan, and N. Zhang, “Riatig: Reliable and imperceptible adversarial text-to-image generation with natural prompts,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 20 585–20 594.
- [27] Y.-L. Tsai, C.-Y. Hsu, C. Xie, C.-H. Lin, J.-Y. Chen, B. Li, P.-Y. Chen, C.-M. Yu, and C.-Y. Huang, “Ring-a-bell! how reliable are concept removal methods for diffusion models?” arXiv preprint arXiv:2310.10012, 2023.
- [28] Z.-Y. Chin, C.-M. Jiang, C.-C. Huang, P.-Y. Chen, and W.-C. Chiu, “Prompting4debugging: Red-teaming text-to-image diffusion models by finding problematic prompts,” arXiv preprint arXiv:2309.06135, 2023.
- [29] Y. Deng and H. Chen, “Divide-and-conquer attack: Harnessing the power of llm to bypass the censorship of text-to-image generation model,” arXiv preprint arXiv:2312.07130, 2023.
- [30] Z. Ba, J. Zhong, J. Lei, P. Cheng, Q. Wang, Z. Qin, Z. Wang, and K. Ren, “Surrogateprompt: Bypassing the safety filter of text-to-image models via substitution,” arXiv preprint arXiv:2309.14122, 2023.
- [31] S. Poppi, T. Poppi, F. Cocchi, M. Cornia, L. Baraldi, R. Cucchiara et al., “Safe-clip: Removing nsfw concepts from vision-and-language models,” in Proceedings of the European Conference on Computer Vision, 2024.
- [32] A. Heng and H. Soh, “Selective amnesia: A continual learning approach to forgetting in deep generative models,” Advances in Neural Information Processing Systems, vol. 36, 2024.
- [33] H. Orgad, B. Kawar, and Y. Belinkov, “Editing implicit assumptions in text-to-image diffusion models,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 7053–7061.
- [34] Y. Wu, S. Zhou, M. Yang, L. Wang, W. Zhu, H. Chang, X. Zhou, and X. Yang, “Unlearning concepts in diffusion model via concept domain correction and concept preserving gradient,” arXiv preprint arXiv:2405.15304, 2024.
- [35] Aws comprehend. [Online]. Available: https://docs.aws.amazon.com/comprehend/latest/dg/what-is.html
- [36] Azure ai content safety. [Online]. Available: https://azure.microsoft.com/en-us/products/ai-services/ai-content-safety
- [37] Detoxify. [Online]. Available: https://github.com/unitaryai/detoxify
- [38] Midjourney. [Online]. Available: https://midjourney.com/
- [39] Leonardo.ai. [Online]. Available: https://leonardo.ai/
- [40] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark et al., “Learning transferable visual models from natural language supervision,” in International conference on machine learning. PMLR, 2021, pp. 8748–8763.
- [41] U. Bhalla, A. Oesterling, S. Srinivas, F. P. Calmon, and H. Lakkaraju, “Interpreting clip with sparse linear concept embeddings (splice),” arXiv preprint arXiv:2402.10376, 2024.
- [42] C. Zhao, K. Wang, X. Zeng, R. Zhao, and A. B. Chan, “Gradient-based visual explanation for transformer-based clip,” in International Conference on Machine Learning. PMLR, 2024, pp. 61 072–61 091.
- [43] E. Aflalo, M. Du, S.-Y. Tseng, Y. Liu, C. Wu, N. Duan, and V. Lal, “Vl-interpret: An interactive visualization tool for interpreting vision-language transformers,” in Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition, 2022, pp. 21 406–21 415.
- [44] H. Abdi and L. J. Williams, “Principal component analysis,” Wiley interdisciplinary reviews: computational statistics, vol. 2, no. 4, pp. 433–459, 2010.
- [45] A. Vaswani, “Attention is all you need,” Advances in Neural Information Processing Systems, 2017.
- [46] N. Elhage, N. Nanda, C. Olsson, T. Henighan, N. Joseph, B. Mann, A. Askell, Y. Bai, A. Chen, T. Conerly et al., “A mathematical framework for transformer circuits,” Transformer Circuits Thread, vol. 1, no. 1, p. 12, 2021.
- [47] S. Balakrishnama and A. Ganapathiraju, “Linear discriminant analysis-a brief tutorial,” Institute for Signal and information Processing, vol. 18, no. 1998, pp. 1–8, 1998.
- [48] C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y. Zhou, W. Li, and P. J. Liu, “Exploring the limits of transfer learning with a unified text-to-text transformer,” Journal of machine learning research, vol. 21, no. 140, pp. 1–67, 2020.
- [49] T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, and C. L. Zitnick, “Microsoft coco: Common objects in context,” in Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13. Springer, 2014, pp. 740–755.
- [50] Lexica. [Online]. Available: https://lexica.art/
- [51] 4chan. [Online]. Available: https://www.4chan.org/
- [52] C. Schuhmann, R. Beaumont, R. Vencu, C. Gordon, R. Wightman, M. Cherti, T. Coombes, A. Katta, C. Mullis, M. Wortsman et al., “Laion-5b: An open large-scale dataset for training next generation image-text models,” Advances in Neural Information Processing Systems, vol. 35, pp. 25 278–25 294, 2022.
- [53] T. Markov, C. Zhang, S. Agarwal, F. E. Nekoul, T. Lee, S. Adler, A. Jiang, and L. Weng, “A holistic approach to undesired content detection in the real world,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 37, no. 12, 2023, pp. 15 009–15 018.
- [54] Aliyun text moderation. [Online]. Available: https://help.aliyun.com/document_detail/2642717.html
- [55] D. Powers, “Evaluation: From precision, recall and f-measure to roc, informedness, markedness & correlation,” Journal of Machine Learning Technologies, vol. 2, no. 1, pp. 37–63, 2011.
- [56] T. Fawcett, “An introduction to roc analysis,” Pattern recognition letters, vol. 27, no. 8, pp. 861–874, 2006.
- [57] clip-vit-large-patch14. [Online]. Available: https://huggingface.co/openai/clip-vit-large-patch14
- [58] Clip-vit-bigg-14-laion2b-39b-b160k. [Online]. Available: https://huggingface.co/laion/CLIP-ViT-bigG-14-laion2B-39B-b160k
- [59] t5-v1_1-xxl. [Online]. Available: https://huggingface.co/google/t5-v1_1-xxl
- [60] J. Hessel, A. Holtzman, M. Forbes, R. L. Bras, and Y. Choi, “Clipscore: A reference-free evaluation metric for image captioning,” arXiv preprint arXiv:2104.08718, 2021.
- [61] X. Qi, Y. Huang, Y. Zeng, E. Debenedetti, J. Geiping, L. He, K. Huang, U. Madhushani, V. Sehwag, W. Shi et al., “Ai risk management should incorporate both safety and security,” arXiv preprint arXiv:2405.19524, 2024.
.1 PCA Maps of All Attention Heads

.2 More Results of Training Data Size
| Training Data Size | TPR | FPR | ACC | F1 Score | AUROC | AUPRC | TPR@FPR 1% |
|---|---|---|---|---|---|---|---|
| 10 | 0.9041 | 0.0260 | 0.9563 | 0.9126 | 0.9881 | 0.9732 | 0.8347 |
| 50 | 0.9347 | 0.0066 | 0.9786 | 0.9565 | 0.9978 | 0.9941 | 0.9561 |
| 100 | 0.9733 | 0.0098 | 0.9859 | 0.9721 | 0.9986 | 0.9963 | 0.9733 |
| 500 | 0.9763 | 0.0089 | 0.9874 | 0.9750 | 0.9989 | 0.9971 | 0.9769 |
| 1000 | 0.9719 | 0.0068 | 0.9878 | 0.9758 | 0.9990 | 0.9975 | 0.9797 |
| Training Data Size | TPR | FPR | ACC | F1 Score | AUROC | AUPRC | TPR@FPR 1% |
|---|---|---|---|---|---|---|---|
| 10 | 0.8155 | 0.0703 | 0.9008 | 0.8058 | 0.9443 | 0.9003 | 0.6138 |
| 50 | 0.9598 | 0.0337 | 0.9647 | 0.9320 | 0.9945 | 0.9867 | 0.9041 |
| 100 | 0.9557 | 0.0142 | 0.9782 | 0.9568 | 0.9970 | 0.9924 | 0.9367 |
| 500 | 0.9747 | 0.0135 | 0.9835 | 0.9676 | 0.9983 | 0.9954 | 0.9678 |
| 1000 | 0.9744 | 0.0112 | 0.9852 | 0.9708 | 0.9985 | 0.9959 | 0.9694 |
.3 More Results of Ablation Study
| Layer | TPR | FPR | ACC | F1 Score | AUROC | AUPRC | TPR@FPR 1% |
|---|---|---|---|---|---|---|---|
| 1 | 1.0000 | 0.9723 | 0.2730 | 0.4097 | 0.9831 | 0.9581 | 0.7328 |
| 2 | 0.9982 | 0.4935 | 0.6305 | 0.5768 | 0.9852 | 0.9645 | 0.7835 |
| 3 | 0.9989 | 0.5949 | 0.5549 | 0.5310 | 0.9870 | 0.9692 | 0.8148 |
| 4 | 0.9813 | 0.1049 | 0.9168 | 0.8561 | 0.9906 | 0.9773 | 0.8383 |
| 5 | 0.9571 | 0.0411 | 0.9585 | 0.9208 | 0.9923 | 0.9810 | 0.8598 |
| 6 | 0.9861 | 0.0824 | 0.9348 | 0.8842 | 0.9940 | 0.9852 | 0.8984 |
| 7 | 0.9559 | 0.0251 | 0.9701 | 0.9416 | 0.9947 | 0.9871 | 0.9135 |
| 8 | 0.9653 | 0.0332 | 0.9664 | 0.9355 | 0.9945 | 0.9872 | 0.9103 |
| 9 | 0.9906 | 0.0983 | 0.9241 | 0.8682 | 0.9953 | 0.9887 | 0.9230 |
| 10 | 0.9619 | 0.0166 | 0.9780 | 0.9566 | 0.9968 | 0.9918 | 0.9393 |
| 11 | 0.9187 | 0.0079 | 0.9736 | 0.9460 | 0.9961 | 0.9901 | 0.9317 |
| 12 | 0.8605 | 0.0031 | 0.9625 | 0.9205 | 0.9968 | 0.9917 | 0.9374 |
| 13 | 0.8888 | 0.0034 | 0.9694 | 0.9361 | 0.9975 | 0.9934 | 0.9459 |
| 14 | 0.9381 | 0.0090 | 0.9776 | 0.9549 | 0.9971 | 0.9925 | 0.9402 |
| 15 | 0.9731 | 0.0210 | 0.9775 | 0.9562 | 0.9972 | 0.9929 | 0.9482 |
| 16 | 0.9358 | 0.0067 | 0.9788 | 0.9570 | 0.9977 | 0.9937 | 0.9573 |
| 17 | 0.9646 | 0.0163 | 0.9789 | 0.9584 | 0.9969 | 0.9918 | 0.9402 |
| 18 | 0.9708 | 0.0176 | 0.9795 | 0.9598 | 0.9972 | 0.9924 | 0.9431 |
| 19 | 0.9635 | 0.0143 | 0.9801 | 0.9606 | 0.9973 | 0.9929 | 0.9511 |
| 20 | 0.9639 | 0.0180 | 0.9775 | 0.9557 | 0.9967 | 0.9916 | 0.9381 |
| 21 | 0.9555 | 0.0179 | 0.9754 | 0.9514 | 0.9965 | 0.9905 | 0.9324 |
| 22 | 0.9694 | 0.0250 | 0.9736 | 0.9488 | 0.9963 | 0.9901 | 0.9240 |
| 23 | 0.9769 | 0.0359 | 0.9673 | 0.9378 | 0.9959 | 0.9888 | 0.9123 |
| 24 | 0.9726 | 0.0207 | 0.9776 | 0.9563 | 0.9971 | 0.9925 | 0.9438 |
| Layer | TPR | FPR | ACC | F1 Score | AUROC | AUPRC | TPR@FPR 1% |
|---|---|---|---|---|---|---|---|
| 1 | 0.8580 | 0.0055 | 0.9601 | 0.9156 | 0.9914 | 0.9814 | 0.8860 |
| 2 | 0.6221 | 0.0000 | 0.9046 | 0.7670 | 0.9965 | 0.9923 | 0.9523 |
| 3 | 0.8646 | 0.0006 | 0.9654 | 0.9265 | 0.9979 | 0.9953 | 0.9733 |
| 4 | 0.8223 | 0.0007 | 0.9547 | 0.9015 | 0.9977 | 0.9949 | 0.9719 |
| 5 | 0.9201 | 0.0025 | 0.9779 | 0.9546 | 0.9978 | 0.9950 | 0.9710 |
| 6 | 0.9299 | 0.0030 | 0.9801 | 0.9592 | 0.9980 | 0.9955 | 0.9710 |
| 7 | 0.9452 | 0.0049 | 0.9825 | 0.9647 | 0.9979 | 0.9952 | 0.9678 |
| 8 | 0.9472 | 0.0063 | 0.9820 | 0.9636 | 0.9975 | 0.9939 | 0.9651 |
| 9 | 0.9169 | 0.0023 | 0.9773 | 0.9532 | 0.9981 | 0.9954 | 0.9715 |
| 10 | 0.9548 | 0.0069 | 0.9834 | 0.9667 | 0.9979 | 0.9949 | 0.9678 |
| 11 | 0.9644 | 0.0225 | 0.9742 | 0.9496 | 0.9958 | 0.9893 | 0.9258 |
| 12 | 0.8497 | 0.0040 | 0.9591 | 0.9129 | 0.9940 | 0.9856 | 0.9039 |
| Layer | TPR | FPR | ACC | F1 Score | AUROC | AUPRC | TPR@FPR 1% |
|---|---|---|---|---|---|---|---|
| 1 | 0.9873 | 0.4277 | 0.6889 | 0.6409 | 0.9747 | 0.9571 | 0.7752 |
| 2 | 0.8819 | 0.0388 | 0.9389 | 0.8903 | 0.9780 | 0.9601 | 0.7696 |
| 3 | 0.9484 | 0.0389 | 0.9575 | 0.9261 | 0.9895 | 0.9812 | 0.8969 |
| 4 | 0.7610 | 0.0022 | 0.9313 | 0.8616 | 0.9869 | 0.9767 | 0.8629 |
| 5 | 0.8246 | 0.0022 | 0.9491 | 0.9011 | 0.9943 | 0.9891 | 0.9285 |
| 6 | 0.7750 | 0.0014 | 0.9358 | 0.8715 | 0.9922 | 0.9851 | 0.8977 |
| 7 | 0.7512 | 0.0006 | 0.9297 | 0.8572 | 0.9944 | 0.9895 | 0.9252 |
| 8 | 0.6460 | 0.0002 | 0.9003 | 0.7847 | 0.9937 | 0.9878 | 0.9166 |
| 9 | 0.6608 | 0.0003 | 0.9044 | 0.7954 | 0.9931 | 0.9865 | 0.9067 |
| 10 | 0.6563 | 0.0002 | 0.9032 | 0.7922 | 0.9931 | 0.9864 | 0.9047 |
| 11 | 0.8272 | 0.0032 | 0.9491 | 0.9014 | 0.9929 | 0.9860 | 0.8961 |
| 12 | 0.8188 | 0.0011 | 0.9483 | 0.8990 | 0.9946 | 0.9902 | 0.9299 |
| 13 | 0.8666 | 0.0037 | 0.9598 | 0.9239 | 0.9954 | 0.9907 | 0.9270 |
| 14 | 0.7846 | 0.0014 | 0.9385 | 0.8776 | 0.9935 | 0.9878 | 0.9227 |
| 15 | 0.9061 | 0.0051 | 0.9699 | 0.9443 | 0.9948 | 0.9906 | 0.9399 |
| 16 | 0.9625 | 0.0187 | 0.9760 | 0.9576 | 0.9948 | 0.9908 | 0.9365 |
| 17 | 0.8793 | 0.0046 | 0.9628 | 0.9300 | 0.9940 | 0.9890 | 0.9235 |
| 18 | 0.8162 | 0.0178 | 0.9355 | 0.8768 | 0.9808 | 0.9613 | 0.7379 |
| 19 | 0.9334 | 0.0095 | 0.9744 | 0.9535 | 0.9948 | 0.9903 | 0.9346 |
| 20 | 0.8387 | 0.0020 | 0.9532 | 0.9097 | 0.9946 | 0.9900 | 0.9320 |
| 21 | 0.8145 | 0.0014 | 0.9468 | 0.8960 | 0.9940 | 0.9889 | 0.9293 |
| 22 | 0.8131 | 0.0023 | 0.9458 | 0.8940 | 0.9944 | 0.9891 | 0.9162 |
| 23 | 0.8949 | 0.0055 | 0.9665 | 0.9375 | 0.9944 | 0.9893 | 0.9346 |
| 24 | 0.9457 | 0.0155 | 0.9736 | 0.9527 | 0.9940 | 0.9884 | 0.9252 |
| 25 | 0.8563 | 0.0037 | 0.9570 | 0.9179 | 0.9940 | 0.9882 | 0.9213 |
| 26 | 0.5157 | 0.0031 | 0.8616 | 0.6769 | 0.9873 | 0.9690 | 0.7483 |
| 27 | 0.9297 | 0.0140 | 0.9702 | 0.9460 | 0.9940 | 0.9874 | 0.9092 |
| 28 | 0.7557 | 0.0014 | 0.9303 | 0.8590 | 0.9944 | 0.9886 | 0.9190 |
| 29 | 0.8971 | 0.0115 | 0.9628 | 0.9313 | 0.9929 | 0.9852 | 0.8766 |
| 30 | 0.5235 | 0.0296 | 0.8448 | 0.6547 | 0.9124 | 0.8260 | 0.3167 |
| 31 | 0.8635 | 0.0034 | 0.9592 | 0.9224 | 0.9939 | 0.9889 | 0.9289 |
| 32 | 0.7670 | 0.0067 | 0.9297 | 0.8598 | 0.9877 | 0.9753 | 0.8159 |