AdvFlow: Inconspicuous Black-box Adversarial Attacks using Normalizing Flows
Abstract
Deep learning classifiers are susceptible to well-crafted, imperceptible variations of their inputs, known as adversarial attacks. In this regard, the study of powerful attack models sheds light on the sources of vulnerability in these classifiers, hopefully leading to more robust ones. In this paper, we introduce AdvFlow: a novel black-box adversarial attack method on image classifiers that exploits the power of normalizing flows to model the density of adversarial examples around a given target image. We see that the proposed method generates adversaries that closely follow the clean data distribution, a property which makes their detection less likely. Also, our experimental results show competitive performance of the proposed approach with some of the existing attack methods on defended classifiers. The code is available at https://github.com/hmdolatabadi/AdvFlow.
1 Introduction
Deep neural networks (DNN) have been successfully applied to a wide variety of machine learning tasks. For instance, trained neural networks can reach human-level accuracy in image classification [46]. However, Szegedy et al., [53] showed that such classifiers can be fooled by adding an imperceptible perturbation to the input image. Since then, there has been extensive research in this area known as adversarial machine learning, trying to design more powerful attacks and devising more robust neural networks. Today, this area encompasses a broader type of data than images, with video [25], graphs [65], text [34], and other types of data classifiers being attacked.
In this regard, the design of stronger adversarial attacks plays a crucial role in understanding the nature of possible real-world threats. The ultimate goal of such studies is to help neural networks become more robust against such adversaries. This line of research is extremely important as even the slightest flaw in some real-world applications of DNNs such as self-driving cars can have severe, irreparable consequences [12].
In general, adversarial attack approaches can be classified into two broad categories: white-box and black-box. In white-box adversarial attacks, the assumption is that the threat model has full access to the target DNN. This way, adversaries can leverage their knowledge about the target model to generate adversarial examples (for instance, by taking the gradient of the neural network). In contrast, black-box attacks assume that they do not know the internal structure of the target model a priori. Instead, they can only query the model about some inputs, and work with the labels or confidence levels associated with them [62]. Thus, black-box attacks seem to be making more realistic assumptions. In the beginning, black-box attacks were mostly thought of as the transferability of white-box adversarial examples to unseen models [42]. Recently, however, there has been more research to attack black-box models directly.
In this paper, we introduce AdvFlow: a black-box adversarial attack that makes use of pre-trained normalizing flows to generate adversarial examples. In particular, we utilize flow-based methods pre-trained on clean data to model the probability distribution of possible adversarial examples around a given image. Then, by exploiting the notion of search gradients from natural evolution strategies (NES) [59, 58], we solve the black-box optimization problem associated with adversarial example generation to adjust this distribution. At the end of this process, we wind up having a data distribution whose realizations are likely to be adversarial. Since this density is constructed on the top of the original data distribution estimated by normalizing flows, we see that the generated perturbations take on the structure of data rather than an additive noise (see Figure 1). This property impedes distinguishing AdvFlow examples from clean data for adversarial example detectors, as they often assume that the adversaries come from a different distribution than the clean data. Moreover, we prove a lemma to conclude that adversarial perturbations generated by the proposed approach can be approximated by a normal distribution with dependent components. We then put our model under test and show its effectiveness in generating adversarial examples with 1) less detectability, 2) higher success rate, 3) lower number of queries, and 4) higher rate of transferability on defended models compared to the similar method of Attack [33].
In summary, we make the following contributions:
-
•
We introduce AdvFlow, a black-box adversarial attack that leverages the power of normalizing flows in modeling data distributions. To the best of our knowledge, this is the first work that explores the use of flow-based models in the design of adversarial attacks.
-
•
We prove a lemma about the adversarial perturbations generated by AdvFlow. As a result of this lemma, we deduce that AdvFlows can generate perturbations with dependent elements, while this is not the case for Attack [33].
-
•
We show the power of the proposed approach in generating adversarial examples that have a similar distribution to the data. As a result, our method is able to mislead adversarial example detectors for they often assume adversaries come from a different distribution than the clean data. We then see the performance of the proposed approach in attacking some of the most recent adversarial training defense techniques.





2 Related Work
In this section, we review some of the most closely related work to our proposed approach. For a complete review of (black-box) adversarial attacks, we refer the interested reader to [62, 3].
Black-box Adversarial Attacks.
In one of the earliest black-box approaches, Chen et al., [5] used the idea of Zeroth Order Optimization and came up with a method called ZOO. In particular, ZOO uses the target neural network queries to build up a zero-order gradient estimator. Then, it utilizes the estimated gradient to minimize a Carlini and Wagner (C&W) loss [4] and find an adversarial image. Later and inspired by [58, 47], Ilyas et al., [22] tried to estimate the DNN gradient using a normally distributed search density. In particular, they estimate the gradient of the classifier with
which only requires querying the black-box model . Having the DNN gradient estimate, Ilyas et al., [22] then take a projected gradient descent (PGD) step to minimize their objective for generating an adversarial example. This idea is further developed in the construction of Attack [33]. Specifically, instead of trying to minimize the adversarial example generation objective directly, they aim to fit a distribution around the clean data so that its realizations are likely to be adversarial (see Section 3.3 for more details). In another piece of work, Ilyas et al., [23] observe that the gradients used in adversarial example generation by PGD exhibit a high correlation both in time and across data. Thus, the number of queries to attack a black-box model can be reduced if one incorporates this prior knowledge about the gradients. To this end, Ilyas et al., [23] uses a bandit-optimization technique to integrate these priors into their attack, resulting in a method called Bandits & Priors. Finally, Simple Black-box Attack (SimBA) [16] is a straightforward, intuitive approach to construct black-box adversarial examples. It is first argued that for any particular direction and step size , either or is going to decrease the probability of detecting the correct class label of the input image . Thus, we are likely to find an adversary by iteratively taking such steps. The vectors are selected from a set of orthonormal candidate vectors . Guo et al., 2019b [16] use Discrete Cosine Transform (DCT) to construct such a set, exploiting the observation that “random noise in low-frequency space is more likely to be adversarial” [15].
Adversarial Attacks using Generative Models.
There has been some prior work that utilizes the power of generative models (mostly generative adversarial networks (GAN)) to model adversarial perturbations and attack DNNs [2, 61, 56, 20]. The target of these models is mainly white-box attacks. They require training of their parameters to produce adversarial perturbations using a cost function that involves taking the gradient of a target network. To adapt themselves to black-box settings, they try to replace this target network with either a distilled version of it [61], or a substitute source model [20]. However, as we will see in Section 3, the flow-based part of our model is only pre-trained on some clean training data using the maximum likelihood objective of Eq. (5). Thus, AdvFlow can be adapted to any target classifier of the same dataset, without the need to train it again. Moreover, while prior work is mainly concerned with generating the adversarial perturbations (for example [55]), here we use the normalizing flows output as the adversarial example directly. In this sense, our work is more similar to [51] that generates unrestricted adversarial examples using GANs in a white-box setting, and falls under functional adversarial attacks [31]. However, besides being black-box, in AdvFlow we restrict the output to be in the vicinity of the original image.
3 Proposed Method
In this section, we propose our attack method. First, we define the problem of black-box adversarial attacks formally. Next, we go over normalizing flows and see how we can train a flow-based model. Then, we review the idea of Natural Evolution Strategies (NES) [59, 58] and Attack [33]. Afterward, we show how normalizing flows can be mixed with NES in the context of black-box adversarial attacks, resulting in a method we call AdvFlow. Finally, we prove a lemma about the nature of the perturbations generated by the proposed approach and show that Attack cannot produce the adversarial perturbations generated by AdvFlow. Our results in Section 4 support this lemma. There, we see that AdvFlow can generate adversarial examples that are less detectable than the ones generated by Attack [33] due to its perturbation structure.
3.1 Problem Statement
Let denote a DNN classifier. Assume that the classifier takes a -dimensional input , and outputs a vector . Each element of the vector indicates the probability of the input belonging to one of the classes that the classifier is trying to distinguish. Furthermore, let denote the correct class label of the data. In other words, if the -th element of the classifier output is larger than the rest, then the input has been correctly classified. Finally, let the well-known Carlini and Wagner (C&W) loss [4] be defined as111 Note that although we are defining our objective function for un-targeted adversarial attacks, it can be easily modified to targeted attacks. To this end, it suffices to replace in Eq. (1) with , where shows the target class output. In this paper, we only consider un-targeted attacks.
| (1) |
where indicates the -th element of the classifier output. In the C&W objective, we always have . The minimum occurs when , which is an indication that our classifier has been fooled. Thus, finding an adversarial example for the input data can be written as [33]:
| (2) |
Here, denotes a set that contains similar data to in an appropriate manner. For example, it is common to define
| (3) |
for image data. In this paper, we define as in Eq. (3) since we deal with the application of our attack on images.
3.2 Flow-based Modeling
Normalizing Flows.
Normalizing flows (NF) [54, 7, 44] are a family of generative models that aim at modeling the probability distribution of a given dataset. To this end, they make use of the well-known change of variables formula. In particular, let denote a random vector with a straightforward, known distribution such as uniform or standard normal. The change of variables formula states that if we apply an invertible and differentiable transformation on to obtain a new random vector , the relationship between their corresponding distributions can be written as:
| (4) |
Here, and denote the probability distributions of and , respectively. Moreover, the multiplicative term on the right-hand side is called the absolute value of the Jacobian determinant. This term accounts for the changes in the volume of due to applying the transformation . Flow-based methods model the transformation using stacked layers of invertible neural networks (INN). They then apply this transformation on a base random vector to model the data density. In this paper, we assume that the base random vector has a standard normal distribution.
Maximum Likelihood Estimation.
To fit the parameters of INNs to the i.i.d. data observations , NFs use the following maximum likelihood objective [44]:
| (5) |
Here, denotes the parameter set of the model and is the density defined in Eq. (4). Note that INNs should be modeled such that they allow for efficient computation of their Jacobian determinant. Otherwise, this issue can impose a severe hindrance in the application of NFs to high-dimensional data given the cubic complexity of determinant computation. For a more detailed review of normalizing flows, we refer the interested reader to [41, 28] and the references within.
Training the Flow-based Models.
We assume that we have access to some training data of the same domain to pre-train our flow-based model. However, at the time of adversarial example generation, we use unseen test data. Note that while in our experiments we use the same training data as the classifier itself, we are not obliged to do so. We observed that our results remain almost the same even if we separate the flow-based model training data from what the classifier is trained on. We argue that using the same training data is valid since our flow-based models do not extract discriminative features, and they are only trained on clean data. This is in contrast to other generative approaches used for adversarial example generation [2, 61, 56, 20]. In Appendix C.5, we empirically show that not only is this statement accurate, but we can get almost the same performance by using similar datasets to the true one.
3.3 Natural Evolution Strategies and Attack
Natural Evolution Strategies (NES).
Our goal is to solve the optimization problem of Eq. (2) in a black-box setting, meaning that we only have access to the inputs and outputs of the classifier . Natural Evolution Strategies (NES) use the idea of search gradients to optimize Eq. (2) [59, 58]. To this end, a so-called search distribution is first defined, and then the expected value of the original objective is optimized under this distribution.
In particular, let denote the search distribution with parameters . Then, in NES we aim to minimize
| (6) |
over as a surrogate for [58]. To minimize Eq. (6) using gradient descent, one needs to compute the Jacobian of with respect to . To this end, NES makes use of the “log-likelihood trick” [58] (see Appendix A.1)
| (7) |
Finally, the parameters of the model are updated using a gradient descent step with learning rate :222Note that this update procedure is not what NES precisely stands for. It is rather a canonical gradient search algorithm as is called by Wierstra et al., [58], which only makes use of a vanilla gradient [59] for evolution strategies. In fact, the natural term in natural evolution strategies represents an update of the form , where is called the natural gradient. Here, the matrix is the Fischer information matrix of the search distribution . However, since NES in the adversarial learning literature [22, 23, 33] points to Eq. (8), we use the same convention here.
| (8) |
Attack.
To find an adversarial example for an input , Attack [33] tries to find a distribution over the set of legitimate adversaries in Eq. (3). Therefore, it models as
| (9) |
where is an isometric normal distribution with mean and standard deviation . Moreover, projects its input back into the set of legitimate adversaries . Li et al., [33] define their model parameters as . Then, they find using grid-search and by the update rule of Eq. (8) exploiting NES.
3.4 Our Approach: AdvFlow
Recently, there has been some effort to detect adversarial examples from clean data. The primary assumption of these methods is often that the adversaries come from a different distribution than the data itself; for instance, see [37, 32, 64]. Thus, to come up with more powerful adversarial attacks, it seems reasonable to construct adversaries that have a similar distribution to the clean data. To this end, we propose AdvFlow: a black-box adversarial attack that seeks to build inconspicuous adversaries by leveraging the power of normalizing flows (NF) in exact likelihood modeling of the data [8].
Let denote a pre-trained, invertible and differentiable NF model on the clean training data. To reach our goal of decreasing the attack’s detectability, we propose using this pre-trained, fixed NF transformation to model the adversaries. In an analogy with Eq. (9), we assume that our adversarial example comes from a distribution that is modeled by
| (10) |
where is a projection rule that keeps the generated examples in the set of legitimate adversaries . By the change of variables formula from Eq. (4), we know that in Eq. (10) is distributed similar to the clean data distribution. The only difference is that the base density is transformed by an affine mapping, i.e., from to . This small adjustment can result in an overall distribution for which the generated samples are likely to be adversarial.
Putting the rule of the lazy statistician [57] together with our attack definition in Eq. (10), we can write down the objective function of Eq. (6) as
| (11) |
As in Attack [33], we will consider to be a hyperparameter.333Indeed, we can also optimize alongside to enhance the attack strength. However, since Attack [33] only optimizes , we also stick with the same setting. Thus, we are only required to minimize with respect to . Using the “log-likelihood trick” of Eq. (7), we can derive the Jacobian of as
| (12) |
This expectation can then be estimated by sampling from a distribution and forming their sample average. Next, we update the parameter by performing a gradient descent step
| (13) |
In the end, we generate our adversarial example by sampling from Eq. (10).
Practical Considerations.
To help our model to start its search from an appropriate point, we first transform the clean data to its latent space representation. Then, we aim to find a small additive latent space perturbation in the form of a normal distribution. Moreover, as suggested in [33], instead of working with directly, we normalize them so that they have zero mean and unit variance to help AdvFlows convergence faster. Finally, among different flow-based models, it is preferable to choose those that have a straightforward inverse, such as [8, 27, 11, 10]. This way, we can efficiently go back and forth between the original data and their base distribution representation. Algorithm 1 in Appendix D.1 summarizes our black-box attack method. Other variations of AdvFlow can also be found in Appendix D. These variations include our solution to high-resolution images and investigation of un-trained AdvFlow.
3.4.1 AdvFlow Interpretation
We can interpret AdvFlow from two different perspectives.
First, there exists a probabilistic view: we use the flow-based model transformation of the original data, and then try to adjust it using an affine transformation on its base distribution. The amount of this change is determined by our urge to minimize the C&W cost of Eq. (1) such that we get the minimum value on average. Thus, if it is successful, we will end up having a distribution whose samples are likely to be adversarial. Meanwhile, since this distribution is initialized with that of clean data, it resembles the clean data density closely.
Second, we can think of AdvFlow as a search over the latent space of flow-based models. We map the clean image to the latent space and then try to search in the vicinity of that point to find an adversarial example. This search is ruled by the objective of Eq. (11). Since our approach exploits a fully invertible, pre-trained flow-based model, we would expect to get an adversarial example that resembles the original image in the structure and look less noisy. This adjustment gives our model the flexibility to produce perturbations that take the structure of clean data into account (see Figure 1).
3.4.2 Uniqueness of AdvFlow Perturbations
In this section, we present a lemma about the nature of perturbations generated by AdvFlow and Attack [33]. As a direct result of this lemma, we can easily deduce that the adversaries generated by AdvFlow can be approximated by a normal distribution whose components are dependent. However, this is not the case for Attack as they always have independent elements. In this sense, we can then rigorously conclude that the AdvFlow perturbations are unique and cannot be generated by Attack. Thus, we cannot expect Attack to be able to generate perturbations that look like the original data. This result can also be generalized to many other attack methods as they often use an additive, independent perturbation. Proofs can be found in Appendix A.2.
Lemma 3.1.
Let be an invertible, differentiable function. For a small perturbation we have
Corollary 3.1.1.
The adversarial perturbations generated by AdvFlow have dependent components. In contrast, Attack perturbation components are independent.
4 Experimental Results
In this section, we present our experimental results. First, we see how the adversarial examples generated by the proposed model can successfully mislead adversarial example detectors. Then, we show the attack success rate and the number of queries required to attack both vanilla and defended models. Finally, we examine the transferability of the generated attacks between defended classifiers. To see the details of the experiments, please refer to Appendix B. Also, more simulation results can be found in Appendices C and D.
For each dataset, we pre-train a flow-based model and fix it across the experiments. To this end, we use a modified version of Real NVP [8] as introduced in [1], the details of which can be found in Appendix B.1. Once trained, we then try to attack target classifiers in a black-box setting using AdvFlow (Algorithm 1).
4.1 Detectability
One approach to defend pre-trained classifiers is to employ adversarial example detectors. This way, a detector is trained and put on top of the classifier. Before feeding inputs to the un-defended classifier, every input has to be checked whether it is adversarial or not. One common assumption among such detectors is that the adversaries come from a different distribution than the clean data [37, 32]. Thus, the performance of these detectors seems to be a suitable measure to quantify the success of our model in generating adversarial examples that have the same distribution as the original data. To this end, we choose LID [37], Mahalanobis [32], and Res-Flow [64] adversarial attack detectors to assess the performance of the proposed approach. We compare our results with Attack [33] that also approaches the black-box adversarial attack from a distributional perspective for a fair comparison. As an ablation study, we also consider the un-trained version of AdvFlows where the weights of the NF models are set randomly. This way, we can observe the effect of the clean data distribution in misleading adversarial example detectors more precisely. We first generate a set of adversarial examples alongside some noisy ones using the test set. Then, we use of the adversarial, noisy, and clean image data to train adversarial attack detectors. Details of our experiments in this section can be found in Appendix B.2.
We report the area under the receiver operating characteristic curve (AUROC) and the detection accuracy for each case in Table 1. As seen, in almost all the cases the selected adversarial detectors struggle to detect the attacks generated by AdvFlow in contrast to Attack. These results support our statement earlier about the distribution of the attacks being more similar to that of data, hence the failure of adversarial example detectors. Also, we see that pre-training the AdvFlow using clean data is crucial in fooling adversarial example detectors.
Finally, Figure 2 shows the relative change in the base distribution of the flow-based model for adversarial examples of Table 1. Interestingly, we see that AdvFlow adversaries are distinctively closer to the clean data compared to Attack [33]. These results highlight the need to reconsider the underlying assumption that adversaries come from a different distribution than the clean data. Also, it can motivate training classifiers that learn data distributions, as our results reveal this is not currently the case.


4.2 Success Rate and Number of Queries
Next, we investigate the performance of the proposed model in attacking vanilla and defended image classifiers. It was shown previously that Attack struggles to break into adversarially trained models more than any other defense [33]. Thus, we select some of the most recent defense techniques that are built upon adversarial training [38]. This selection also helps us in quantifying the attack transferability in our next experiment. Therefore, we select Free [48] and Fast [60] adversarial training, alongside adversarial training with auxiliary rotations [19] as the defense mechanisms that our classifiers employ. Note that these models are the most recent defenses built upon adversarial training. For a brief explanation of each one of these methods, please refer to Appendix B.3. We then train target classifiers on CIFAR-10 [30] and SVHN [40] datasets. The architecture that we use here is the well-known Wide-ResNet-32 [63] with width . We then try to attack these classifiers by generating adversarial examples on the test set. We compare our proposed model with bandits with time and data-dependent priors [23], Attack [33], and SimBA [16]. 444Note that SimBA [16] is originally designed for efficient attacks, and it may not use the entire query quota for small images. Anyways, we included SimBA [16] in the paper as per one of the reviewers’ suggestions. To simulate a realistic environment, we set the maximum number of queries to . Moreover, for Attack and AdvFlow we use a population size of . More details on the defense methods as well as attack hyperparameters can be found in Appendices B.3 and B.4.
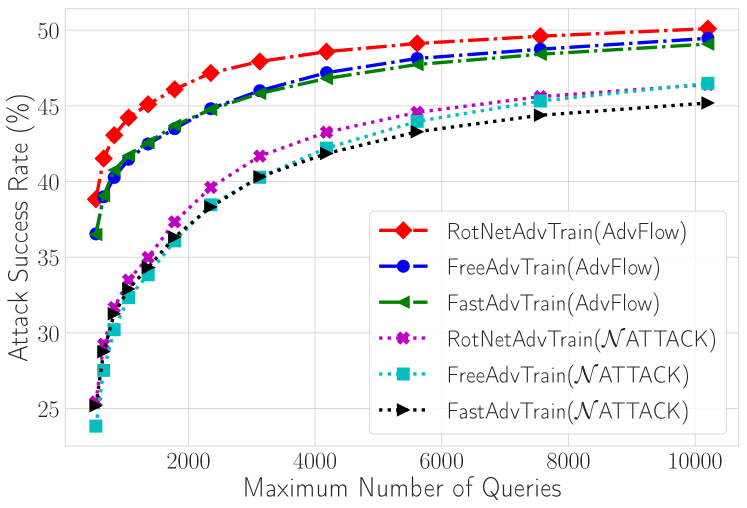
Tables 2 and 3 show the success rate as well as the average and median number of queries required to successfully attack a vanilla/defended classifier. Also, Figure 3 in Appendix C shows the attack success rate for AdvFlow and Attack [33] versus the maximum number of queries for defended models. As can be seen, AdvFlows can improve upon the performance of Attack [33] in all of the defended models in terms of the number of queries and attack success rate. Also, it should be noted that although our performance on vanilla classifiers is worse than Attack [33], we are still generating adversaries that are not easily detectable by adversarial example detectors and come from a similar distribution to the clean data.
| Data | Success Rate(%) | |||||
|---|---|---|---|---|---|---|
| Defense | Acc.(%) | Bandits[23] | Attack [33] | SimBA [16] | AdvFlow | |
| CIFAR-10 | Vanilla [63] | |||||
| FreeAdv [48] | ||||||
| FastAdv [60] | ||||||
| RotNetAdv [19] | ||||||
| SVHN | Vanilla [63] | |||||
| FreeAdv [48] | ||||||
| FastAdv [60] | ||||||
| RotNetAdv [19] | ||||||
| Data | Query Average (Median) on Mutually Successful Attacks | ||||
|---|---|---|---|---|---|
| Defense | Bandits[23] | Attack [33] | SimBA [16] | AdvFlow | |
| CIFAR-10 | Vanilla [63] | ||||
| FreeAdv [48] | |||||
| FastAdv [60] | |||||
| RotNetAdv [19] | |||||
| SVHN | Vanilla [63] | ||||
| FreeAdv [48] | |||||
| FastAdv [60] | |||||
| RotNetAdv [19] | |||||
4.3 Transferability
Finally, we examine the transferability of the generated attacks for each of the classifiers in Table 2. In other words, we generate attacks using a substitute classifier, and then try to attack another target model. The results of this experiment are shown in Figure 4 of Appendix C. As seen, the generated attacks by AdvFlow transfer to other defended models easier than the vanilla one. This observation precisely matches our intuition about the mechanics of AdvFlow. More specifically, we know that in AdvFlow the model is learning a distribution that is more expressive than the one used by Attack. Also, we have seen in Section 3.4.2 that the perturbations generated by AdvFlow have dependent elements in contrast to Attack. As a result, AdvFlow learns to attack classifiers using higher-level features (Figure 1). Thus, since vanilla classifiers use different features for classification than the defended ones, AdvFlows are less transferable from defended models to vanilla ones. In contrast, the expressiveness of AdvFlows enables the attacks to be transferred more successfully between adversarially trained classifiers, and from vanilla to defended ones.
5 Conclusion and Future Directions
In this paper, we introduced AdvFlow: a novel adversarial attack model that utilizes the capacity of normalizing flows in representing data distributions. We saw that the adversarial perturbations generated by the proposed approach can be approximated using normal distributions with dependent components. In this sense, Attack [33] cannot generate such adversaries. As a result, AdvFlows are less conspicuous to adversarial example detectors in contrast to their Attack [33] counterpart. This success is due to AdvFlow being pre-trained on the data distribution, resulting in adversaries that look like the clean data. We also saw the capability of the proposed method in improving the performance of bandits [23], Attack [33], and SimBA [16] on adversarially trained classifiers. This improvement is in terms of both attack success rate and the number of queries.
Flow-based modeling is an active area of research. There are numerous extensions to the current work that can be investigated upon successful expansion of normalizing flow models in their range and power. For example, while Attack [33] and other similar approaches [22, 23] are specifically designed for use on image data, the current work can potentially be expanded to entail other forms of data such as graphs [35, 49]. Also, since normalizing flows can effectively model probability distributions, finding the distribution of well-known perturbations may lead to increasing classifier robustness against adversarial examples. We hope that this work can provide a stepping stone to exploiting such powerful models for adversarial machine learning.
Broader Impact
In this paper, we introduce a novel adversarial attack algorithm called AdvFlow. It uses pre-trained normalizing flows to generate adversarial examples. This study is crucial as it indicates the vulnerability of deep neural network (DNN) classifiers to adversarial attacks.
More precisely, our study reveals that the common assumption made by adversarial example detectors (such as the Mahalanobis detector [32]) that the adversaries come from a different distribution than the data may not be an accurate one. In particular, we show that we can generate adversaries that come from a close distribution to the data, yet they intend to mislead the classifier decision. Thus, we emphasize that adversarial example detectors need to adjust their assumption about the distribution of adversaries before being deployed in real-world situations.
Furthermore, since our adversarial examples are closely related to the data distribution, our method shows that DNN classifiers are not learning to classify the data based on their underlying distribution. Otherwise, they would have resisted the attacks generated by AdvFlow. Thus, it can bring the attention of the machine learning community to training their DNN classifiers in a distributional sense.
All in all, we pinpoint a failure of DNN classifiers to the rest of the community so that they can become familiar with the limitations of the status-quo. This study, and similar ones, could raise awareness among researchers about the real-world pitfalls of DNN classifiers, with the aim of consolidating them against such threats in the future.
Acknowledgments and Disclosure of Funding
We would like to thank the reviewers for their valuable feedback on our work, helping us to improve the final manuscript. We also would like to thank the authors and maintainers of PyTorch [43], NumPy [17], and Matplotlib [21].
This research was undertaken using the LIEF HPC-GPGPU Facility hosted at the University of Melbourne. This Facility was established with the assistance of LIEF Grant LE170100200.
References
- Ardizzone et al., [2019] Ardizzone, L., Lüth, C., Kruse, J., Rother, C., and Köthe, U. (2019). Guided image generation with conditional invertible neural networks. CoRR, abs/1907.02392.
- Baluja and Fischer, [2018] Baluja, S. and Fischer, I. (2018). Learning to attack: Adversarial transformation networks. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence, pages 2687–2695.
- Bhambri et al., [2019] Bhambri, S., Muku, S., Tulasi, A., and Buduru, A. B. (2019). A survey of black-box adversarial attacks on computer vision models. CoRR, abs/1912.01667.
- Carlini and Wagner, [2017] Carlini, N. and Wagner, D. (2017). Towards evaluating the robustness of neural networks. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), pages 39–57.
- Chen et al., [2017] Chen, P.-Y., Zhang, H., Sharma, Y., Yi, J., and Hsieh, C.-J. (2017). ZOO: Zeroth order optimization based black-box attacks to deep neural networks without training substitute models. In Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security, pages 15–26.
- Coleman et al., [2017] Coleman, C., Narayanan, D., Kang, D., Zhao, T., Zhang, J., Nardi, L., Bailis, P., Olukotun, K., Ré, C., and Zaharia, M. (2017). DAWNBench: An end-to-end deep learning benchmark and competition. NeurIPS ML Systems Workshop.
- Dinh et al., [2015] Dinh, L., Krueger, D., and Bengio, Y. (2015). NICE: non-linear independent components estimation. In Workshop Track Proceedings of the 3rd International Conference on Learning Representations (ICLR).
- Dinh et al., [2017] Dinh, L., Sohl-Dickstein, J., and Bengio, S. (2017). Density estimation using real NVP. In Proceedings of the 5th International Conference on Learning Representations (ICLR).
- [9] Dolatabadi, H. M., Erfani, S. M., and Leckie, C. (2020a). Black-box adversarial example generation with normalizing flows. In Second workshop on Invertible Neural Networks, Normalizing Flows, and Explicit Likelihood Models, 37th International Conference on Machine Learning (ICML).
- [10] Dolatabadi, H. M., Erfani, S. M., and Leckie, C. (2020b). Invertible generative modeling using linear rational splines. In Proceedings of the 23rd International Conference on Artificial Intelligence and Statistics (AISTATS), pages 4236–4246.
- Durkan et al., [2019] Durkan, C., Bekasov, A., Murray, I., and Papamakarios, G. (2019). Neural spline flows. In Proceedings of the Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems (NeurIPS), pages 7511–7522.
- Eykholt et al., [2018] Eykholt, K., Evtimov, I., Fernandes, E., Li, B., Rahmati, A., Xiao, C., Prakash, A., Kohno, T., and Song, D. (2018). Robust physical-world attacks on deep learning visual classification. In Proceeding of the 2018 IEEE Conference on Computer Vision and Pattern Recognition CVPR, pages 1625–1634.
- Gidaris et al., [2018] Gidaris, S., Singh, P., and Komodakis, N. (2018). Unsupervised representation learning by predicting image rotations. In Proceedings of the 6th International Conference on Learning Representations (ICLR).
- Goodfellow et al., [2015] Goodfellow, I. J., Shlens, J., and Szegedy, C. (2015). Explaining and harnessing adversarial examples. In Proceedings of the 3rd International Conference on Learning Representations (ICLR).
- [15] Guo, C., Frank, J. S., and Weinberger, K. Q. (2019a). Low frequency adversarial perturbation. In Proceedings of the 35th Conference on Uncertainty in Artificial Intelligence (UAI), page 411.
- [16] Guo, C., Gardner, J. R., You, Y., Wilson, A. G., and Weinberger, K. Q. (2019b). Simple black-box adversarial attacks. In Proceedings of the 36th International Conference on Machine Learning (ICML), pages 2484–2493.
- Harris et al., [2020] Harris, C. R., Millman, K. J., van der Walt, S. J., Gommers, R., Virtanen, P., Cournapeau, D., Wieser, E., Taylor, J., Berg, S., Smith, N. J., Kern, R., Picus, M., Hoyer, S., van Kerkwijk, M. H., Brett, M., Haldane, A., del R’ıo, J. F., Wiebe, M., Peterson, P., G’erard-Marchant, P., Sheppard, K., Reddy, T., Weckesser, W., Abbasi, H., Gohlke, C., and Oliphant, T. E. (2020). Array programming with NumPy. Nature, 585(7825):357–362.
- He et al., [2016] He, K., Zhang, X., Ren, S., and Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 770–778.
- Hendrycks et al., [2019] Hendrycks, D., Mazeika, M., Kadavath, S., and Song, D. (2019). Using self-supervised learning can improve model robustness and uncertainty. In Proceedings of the Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems (NeurIPS), pages 15637–15648.
- Huang and Zhang, [2020] Huang, Z. and Zhang, T. (2020). Black-box adversarial attack with transferable model-based embedding. In Proceedings of the 8th International Conference on Learning Representations (ICLR).
- Hunter, [2007] Hunter, J. D. (2007). Matplotlib: A 2D graphics environment. Computing in Science & Engineering, 9(3):90–95.
- Ilyas et al., [2018] Ilyas, A., Engstrom, L., Athalye, A., and Lin, J. (2018). Black-box adversarial attacks with limited queries and information. In Proceedings of the 35th International Conference on Machine Learning (ICML), pages 2142–2151.
- Ilyas et al., [2019] Ilyas, A., Engstrom, L., and Madry, A. (2019). Prior convictions: Black-box adversarial attacks with bandits and priors. In Proceedings of the 7th International Conference on Learning Representations (ICLR).
- Jacobsen et al., [2018] Jacobsen, J., Smeulders, A. W. M., and Oyallon, E. (2018). i-RevNet: Deep invertible networks. In Proceedings of the 6th International Conference on Learning Representations (ICLR).
- Jiang et al., [2019] Jiang, L., Ma, X., Chen, S., Bailey, J., and Jiang, Y. (2019). Black-box adversarial attacks on video recognition models. In Proceedings of the 27th ACM International Conference on Multimedia, pages 864–872.
- Kingma and Ba, [2015] Kingma, D. P. and Ba, J. (2015). Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations (ICLR).
- Kingma and Dhariwal, [2018] Kingma, D. P. and Dhariwal, P. (2018). Glow: Generative flow with invertible 1x1 convolutions. In Proceedings of the Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems (NeurIPS), pages 10236–10245.
- Kobyzev et al., [2020] Kobyzev, I., Prince, S., and Brubaker, M. A. (2020). Normalizing flows: An introduction and review of current methods. IEEE Transactions on Pattern Analysis and Machine Intelligence.
- Kolter and Madry, [2018] Kolter, Z. and Madry, A. (2018). Adversarial robustness: Theory and practice. https://adversarial-ml-tutorial.org/. Tutorial in the Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems (NeurIPS).
- Krizhevsky and Hinton, [2009] Krizhevsky, A. and Hinton, G. (2009). Learning multiple layers of features from tiny images. Master’s thesis, Department of Computer Science, University of Toronto.
- Laidlaw and Feizi, [2019] Laidlaw, C. and Feizi, S. (2019). Functional adversarial attacks. In Proceedings of the Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems (NeurIPS), pages 10408–10418.
- Lee et al., [2018] Lee, K., Lee, K., Lee, H., and Shin, J. (2018). A simple unified framework for detecting out-of-distribution samples and adversarial attacks. In Proceedings of the Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems (NeurIPS), pages 7167–7177.
- Li et al., [2019] Li, Y., Li, L., Wang, L., Zhang, T., and Gong, B. (2019). NATTACK: learning the distributions of adversarial examples for an improved black-box attack on deep neural networks. In Proceedings of the 36th International Conference on Machine Learning (ICML), pages 3866–3876.
- Liang et al., [2018] Liang, B., Li, H., Su, M., Bian, P., Li, X., and Shi, W. (2018). Deep text classification can be fooled. In Proceedings of the 27th International Joint Conference on Artificial Intelligence (IJCAI), pages 4208–4215.
- Liu et al., [2019] Liu, J., Kumar, A., Ba, J., Kiros, J., and Swersky, K. (2019). Graph normalizing flows. In Proceedings of the Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems (NeurIPS), pages 13556–13566.
- Liu et al., [2015] Liu, Z., Luo, P., Wang, X., and Tang, X. (2015). Deep learning face attributes in the wild. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), pages 3730–3738.
- Ma et al., [2018] Ma, X., Li, B., Wang, Y., Erfani, S. M., Wijewickrema, S. N. R., Schoenebeck, G., Song, D., Houle, M. E., and Bailey, J. (2018). Characterizing adversarial subspaces using local intrinsic dimensionality. In Proceedings of the 6th International Conference on Learning Representations (ICLR).
- Madry et al., [2018] Madry, A., Makelov, A., Schmidt, L., Tsipras, D., and Vladu, A. (2018). Towards deep learning models resistant to adversarial attacks. In Proceedings of the 6th International Conference on Learning Representations (ICLR).
- Moon et al., [2019] Moon, S., An, G., and Song, H. O. (2019). Parsimonious black-box adversarial attacks via efficient combinatorial optimization. In Proceedings of the 36th International Conference on Machine Learning (ICML), pages 4636–4645.
- Netzer et al., [2011] Netzer, Y., Wang, T., Coates, A., Bissacco, A., Wu, B., and Ng, A. Y. (2011). Reading digits in natural images with unsupervised feature learning. In NeurIPS Workshop on Deep Learning and Unsupervised Feature Learning.
- Papamakarios et al., [2019] Papamakarios, G., Nalisnick, E., Rezende, D. J., Mohamed, S., and Lakshminarayanan, B. (2019). Normalizing flows for probabilistic modeling and inference. CoRR, abs/1912.02762.
- Papernot et al., [2016] Papernot, N., McDaniel, P. D., and Goodfellow, I. J. (2016). Transferability in machine learning: from phenomena to black-box attacks using adversarial samples. CoRR, abs/1605.07277.
- Paszke et al., [2017] Paszke, A., Gross, S., Chintala, S., Chanan, G., Yang, E., DeVito, Z., Lin, Z., Desmaison, A., Antiga, L., and Lerer, A. (2017). Automatic differentiation in PyTorch. In NeurIPS Autodiff Workshop.
- Rezende and Mohamed, [2015] Rezende, D. J. and Mohamed, S. (2015). Variational inference with normalizing flows. In Proceedings of the 32nd International Conference on Machine Learning (ICML), pages 1530–1538.
- Rudin et al., [1964] Rudin, W. et al. (1964). Principles of Mathematical Analysis, volume 3. McGraw-Hill New York.
- Russakovsky et al., [2015] Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., Huang, Z., Karpathy, A., Khosla, A., Bernstein, M. S., Berg, A. C., and Li, F. (2015). ImageNet large scale visual recognition challenge. International Journal of Computer Vision, 115(3):211–252.
- Salimans et al., [2017] Salimans, T., Ho, J., Chen, X., and Sutskever, I. (2017). Evolution strategies as a scalable alternative to reinforcement learning. CoRR, abs/1703.03864.
- Shafahi et al., [2019] Shafahi, A., Najibi, M., Ghiasi, A., Xu, Z., Dickerson, J. P., Studer, C., Davis, L. S., Taylor, G., and Goldstein, T. (2019). Adversarial training for free! In Proceedings of the Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems (NeurIPS), pages 3353–3364.
- Shi* et al., [2020] Shi*, C., Xu*, M., Zhu, Z., Zhang, W., Zhang, M., and Tang, J. (2020). Graphaf: a flow-based autoregressive model for molecular graph generation. In Proceedings of the 8th International Conference on Learning Representations (ICLR).
- Simonyan and Zisserman, [2015] Simonyan, K. and Zisserman, A. (2015). Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations (ICLR).
- Song et al., [2018] Song, Y., Shu, R., Kushman, N., and Ermon, S. (2018). Constructing unrestricted adversarial examples with generative models. In Proceedings of the Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems (NeurIPS), pages 8322–8333.
- Szegedy et al., [2016] Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J., and Wojna, Z. (2016). Rethinking the inception architecture for computer vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 2818–2826.
- Szegedy et al., [2014] Szegedy, C., Zaremba, W., Sutskever, I., Bruna, J., Erhan, D., Goodfellow, I. J., and Fergus, R. (2014). Intriguing properties of neural networks. In Proceedings of the 2nd International Conference on Learning Representations (ICLR).
- Tabak and Turner, [2013] Tabak, E. G. and Turner, C. V. (2013). A family of nonparametric density estimation algorithms. Communications on Pure and Applied Mathematics, 66(2):145–164.
- Tu et al., [2019] Tu, C., Ting, P., Chen, P., Liu, S., Zhang, H., Yi, J., Hsieh, C., and Cheng, S. (2019). AutoZOOM: Autoencoder-based zeroth order optimization method for attacking black-box neural networks. In Proceedings of the 33rd AAAI Conference on Artificial Intelligence, pages 742–749.
- Wang and Yu, [2019] Wang, H. and Yu, C. (2019). A direct approach to robust deep learning using adversarial networks. In Proceedings of the 7th International Conference on Learning Representations (ICLR).
- Wasserman, [2013] Wasserman, L. (2013). All of statistics: a concise course in statistical inference. Springer Science & Business Media.
- Wierstra et al., [2014] Wierstra, D., Schaul, T., Glasmachers, T., Sun, Y., Peters, J., and Schmidhuber, J. (2014). Natural evolution strategies. Journal of Machine Learning Research (JMLR), 15(1):949–980.
- Wierstra et al., [2008] Wierstra, D., Schaul, T., Peters, J., and Schmidhuber, J. (2008). Natural evolution strategies. In Proceedings of the 2008 IEEE Congress on Evolutionary Computation (IEEE World Congress on Computational Intelligence), pages 3381–3387.
- Wong et al., [2020] Wong, E., Rice, L., and Kolter, J. Z. (2020). Fast is better than free: Revisiting adversarial training. In Proceedings of the 8th International Conference on Learning Representations (ICLR).
- Xiao et al., [2018] Xiao, C., Li, B., Zhu, J., He, W., Liu, M., and Song, D. (2018). Generating adversarial examples with adversarial networks. In Proceedings of the 27th International Joint Conference on Artificial Intelligence (IJCAI), pages 3905–3911.
- Yuan et al., [2019] Yuan, X., He, P., Zhu, Q., and Li, X. (2019). Adversarial examples: Attacks and defenses for deep learning. IEEE Transactions on Neural Networks and Learning Systems, 30(9):2805–2824.
- Zagoruyko and Komodakis, [2016] Zagoruyko, S. and Komodakis, N. (2016). Wide residual networks. In Proceedings of the British Machine Vision Conference (BMVC).
- Zisselman and Tamar, [2020] Zisselman, E. and Tamar, A. (2020). Deep residual flow for out of distribution detection. In Proceedings of the 2020 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 13991–14000.
- Zügner et al., [2018] Zügner, D., Akbarnejad, A., and Günnemann, S. (2018). Adversarial attacks on neural networks for graph data. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD), pages 2847–2856.
Supplementary Materials
This supplementary document includes the following content to support the material presented in the paper:
-
•
In Section A, we present the “log-likelihood trick" and the proof to our lemma and corollary.
-
•
In Section B, we give the implementation details of our algorithm and experiments. Besides introducing the flow-based model architecture, we present a detailed explanation of classifier architectures and defense mechanisms used to evaluate our method. The set of hyperparameters used in each defense and attack model is also given.
-
•
In Section C, we present an extended version of our simulation results. Moreover, we investigate the effect of the training data on our algorithm’s performance.
-
•
In Section D, we see important extensions to the current work. These extensions include our solution to high-resolution images and un-trained AdvFlow.
Appendix A Mathematical Details
A.1 The Log-likelihood Trick
Here we provide the complete proof of the “log-likelihood trick” as presented in [58]:
A.2 Proofs
Lemma A.1.
Let be an invertible, differentiable function. For a small perturbation we have
Proof.
By the first-order Taylor series for we have
where is the Jacobian matrix of the function . Now, by substituting , and using the inverse function theorem [45], we can write
which gives us the result immediately. ∎
Corollary A.1.1.
The adversarial perturbations generated by AdvFlow have dependent components. In contrast, Attack perturbation components are independent.
Proof.
By Lemma 3.1 we know that
where is distributed according to an isometric normal distribution. For Attack, we have . Thus, it can be shown that . As a result, the random vector will be still normally distributed with a diagonal covariance matrix, and hence, have independent components. In contrast, we know that for an effective flow-based model is not always diagonal. Otherwise, this means that our NF is simply a data-independent affine transformation. For example, in Real NVP [8] which we use, this matrix is a product of lower and upper triangular matrices. Hence, for a normalizing flow model we have non-diagonal . Thus, it will make the random variable normal with correlated (dependent) components. ∎
Appendix B Implementation Details
In this section, we present the implementation details of our algorithm and experiments. Note that all of the experiments were run using a single NVIDIA Tesla V100-SXM2-16GB GPU.
B.1 Normalizing Flows
For the flow-based models used in AdvFlow, we implement Real NVP [8] by using the framework of Ardizzone et al., [1].555github.com/VLL-HD/FrEIA In particular, let denote the input to one layer of a normalizing flow transformation. If we denote the output of this layer by , then the Real NVP transformation between the input and output of this particular layer can be written as:
where is an element-wise multiplication. The functions and are called the scaling and translation functions. Since the invertibility of the transformation does not depend on these functions, they are implemented using ordinary neural networks. To help with the stability of the transformation, Ardizzone et al., [1] suggest using a soft-clamp before passing the output of scaling networks to exponential function. This soft-clamp function is implemented by
where is a hyperparameter that controls the amount of softening. In our experiments, we set . Moreover, at the end of each layer of transformation, we permute the output so that we end up getting different partitions of the data as and . The pattern by which the data is permuted is set at random at the beginning of the training process and kept fixed onwards.
After passing the data through some high-resolution transformations, we downsample it using i-RevNet downsamplers [24]. Specifically, the high-resolution input is downsampled so that each one of them constitutes a different channel of the low-resolution data.
To help the normalizing flow model learn useful features, we use a fixed convolution at the beginning of each low-resolution layer. This adjustment is done with the same spirit as in Glow [27]. However, instead of having a trainable convolution, here we initialize them at the beginning of the training and keep them fixed afterward.
Finally, we used a multi-scale structure [8] to reduce the computational complexity of the flow-based model. Specifically, we pass the input through several layers of invertible transformations constructed using convolutional neural networks as and . Then, we send three-quarters of the data directly to the ultimate output. The rest goes through other rounds of mappings, which use fully-connected networks. This way, one can reduce the computational burden of flow-based models as they keep the data dimension fixed.
For training, we use an Adam [26] optimizer with weight decay . Besides, we set the learning rate according to an exponential scheduler starting from and ending to . Also, to dequantize the image pixels, we add a small Gaussian noise with to the pictures. Table 4 summarizes the hyperparameters and architecture of the flow-based model used in AdvFlow.
| Optimizer | Adam |
| Scheduler | Exponential |
| Initial lr | |
| Final lr | |
| Batch Size | |
| Epochs | |
| Added Noise Std. | |
| Multi-scale Levels | |
| Each Level Network Type | CNN-FC |
| High-res Transformation Blocks | |
| Low-res Transformation Blocks | |
| FC Transformation Blocks | |
| (clamping hyperparameter) | |
| CNN Layers Hidden Channels | |
| FC Layers Internal Width | |
| Activation Function | Leaky ReLU |
| Leaky Slope |
B.2 Adversarial Example Detectors
In this section, we provide the details of the LID [37], Mahalanobis [32], and ResFlow [64] adversarial example detectors. All of the methods use logistic regression as their classifier, and the way that they construct their training and evaluation sets is the same. The only difference among these methods is the way each one extracts their features, which we review below. The training set used to train the logistic regression classifier consists of three types of data: clean, noisy, and adversarial. We take the test portion of each target dataset and add a slight noise to them to make the noisy data. The clean and noisy data are going to be used as the positive samples of the logistic regression. For the adversarial part of the data, we then use a nominated adversarial attack method and generate adversarial examples that are later used as negative samples of the logistic regression. After constructing the entire dataset, of it is used as the logistic regression training set, and the rest for evaluation. Also, the hyperparameters of the detectors are set using nested cross-validation.
LID Detectors.
Ma et al., [37] use the concept of Local Intrinsic Dimensionality (LID) to characterize adversarial subspaces. It is argued that for a data point that resides on some high-dimensional submanifold, its adversarially generated sample is likely to lie outside this submanifold. As such, Ma et al., [37] argue that the intrinsic dimensionality of the adversarial examples in a local neighborhood is going to be higher than the clean or noisy data (see Figure 1 of [37]). Thus, LID can be a good measure for differentiating adversarial examples from clean data. Ma et al., [37] then estimate the LID measure for mini-batches of data using the extreme value theory. To this end, they extract features of the input images using a DNN classifier. They then compute the LID score for all these features across the training and evaluation sets. After extracting these scores for all the data, they train and evaluate the logistic regression classifier as described above. Here, we use the PyTorch implementation of LID detectors given by Lee et al., [32].
Mahalanobis Detectors.
Lee et al., [32] propose an adversarial example detector based on a Mahalanobis distance-based confidence score. To this end, the authors extract features from different hidden layers of a nominated DNN classifier. Assuming that these features are distributed according to class-conditional Gaussian densities, the detector aims at estimating the mean and covariance matrix associated with each one of the features across the training set. These densities are then used to train the logistic regression classifier based on the Mahalanobis distance confidence score between a given image feature and its closest distribution. In this paper, we use the official implementation of the Mahalanobis adversarial example detector available online.666github.com/pokaxpoka/deep_Mahalanobis_detector For more information about these detectors, see [32].
ResFlow Detectors.
Zisselman and Tamar, [64] generalize the Mahalanobis detectors [32] using normalizing flows. It is first argued that modeling the activation distributions as Gaussian densities may not be accurate. To find a better non-Gaussian distribution, Zisselman and Tamar, [64] exploit flow-based models to construct an architecture they call Residual Flow (ResFlow). The same procedure as in the Mahalanobis detectors is then utilized to extract features that are later used to train the logistic regression detectors. We use the official PyTorch implementation of ResFlow available online.777github.com/EvZissel/Residual-Flow Note that in the original paper, ResFlows are only used for out-of-distribution detection. For our purposes, we generalized their implementation to adversarial example detection using the Mahalanobis detector implementation.
B.3 Defense Methods
In this section, we briefly review the defense techniques used in our experiments. We will then present the set of parameters used in the training of each one of the classifiers. Note that we only utilized these methods for the sake of evaluating our attack models, and our results cannot be regarded as a close case-study, or comparison, of the nominated defense methods.
B.3.1 Review of Defense Methods
Adversarial Training.
Adversarial training [38] is a method to train robust classifiers. To achieve robustness, this method tries to incorporate adversarial examples into the training process. In particular, adversarial training aims at minimizing the following objective function for classifier with parameters :
| (14) |
Here, and are the training examples and their associated correct labels. Also, is an appropriate cost function for classifiers, such as the standard cross-entropy loss. The inner maximization objective in Eq. (14) is the cost function used to generate adversarial examples. Thus, we can interpret Eq. (14) as training a model that can predict the labels correctly, even in the presence of additive perturbations. However, finding the exact solution to the inner optimization problem is not straightforward, and in most real-world cases cannot be done efficiently [29]. To circumvent this problem, Madry et al., [38] proposed approximately solving it by using a Projected Gradient Descent algorithm. This method is widely known as adversarial training.
Adversarial Training for Free.
The main disadvantage of adversarial training, as proposed in [38], is that solving the inner optimization problem makes the algorithm much slower than standard classifier training. This problem arises because solving the inner maximization objective requires back-propagating through the DNN. To address this issue, Shafahi et al., [48] exploits a Fast Gradient Sign Method (FGSM) [14] with step-size to compute an approximate solution to the inner maximization objective and then update the DNN parameters. This procedure is repeated times on the same minibatch. Finally, the total number of epochs is divided by a factor of to account for repeated minibatch training. We use the PyTorch code available on the official repository of the free adversarial training to train our classifiers.888github.com/mahyarnajibi/FreeAdversarialTraining
Fast Adversarial Training.
To make adversarial training even faster, Wong et al., [60] came up with a method called “fast" adversarial training. In this approach, they combine FGSM adversarial training with the idea of random initialization to train robust DNN classifiers. To make the proposed algorithm even faster, Wong et al., [60] also utilize several fast training techniques (such as cyclic learning rate and mixed-precision arithmetic) from DAWNBench competition [6]. In this paper, we replace the FGSM adversarial training with PGD. However, we still use the cyclic learning rate and mixed-precision arithmetic. For this method, we used the official PyTorch code available online.999github.com/anonymous-sushi-armadillo
Adversarial Training with Auxiliary Rotations.
Gidaris et al., [13] showed that Convolutional Neural Networks can learn useful image features in an unsupervised fashion by predicting the amount of rotation applied to a given image. Throughout their experiments, they observed that these features can improve classification performance. Motivated by these observations, Hendrycks et al., [19] suggest exploiting the idea of self-supervised feature learning to improve the robustness of classifiers against adversaries. Specifically, it is proposed to train a so-called “head” alongside the original classifier. This auxiliary head takes the penultimate features of the classifier and aims at predicting the amount of rotation applied to an image from four possible angles (, , , or ). It was shown that this simple addition can improve the performance of adversarially trained classifiers. To train our models, we make use of the PyTorch code for adversarial learning with auxiliary rotations available online.101010github.com/hendrycks/ss-ood
B.3.2 Hyperparameters of Defense Methods
| Classifier | Free-1 | Free-2 | Fast-1 | Fast-2 | RotNet-1 | RotNet-2 |
|---|---|---|---|---|---|---|
| Optimizer | SGD | SGD | SGD | SGD | SGD | SGD |
| lr | ||||||
| Momentum | ||||||
| Weight Decay | ||||||
| Nesterov | N | N | N | N | Y | Y |
| Batch Size | ||||||
| Epochs | ||||||
| Inner Optimization | FGSM | FGSM | PGD | PGD | PGD | PGD |
| Step Size | ||||||
| Number of Steps (Repeats) |
| Classifier | Free-1 | Free-2 | Fast-1 | Fast-2 | RotNet-1 | RotNet-2 |
|---|---|---|---|---|---|---|
| Optimizer | SGD | SGD | SGD | SGD | SGD | SGD |
| lr | ||||||
| Momentum | ||||||
| Weight Decay | ||||||
| Nesterov | N | N | N | N | Y | Y |
| Batch Size | ||||||
| Epochs | ||||||
| Inner Optimization | FGSM | FGSM | PGD | PGD | PGD | PGD |
| Step Size | ||||||
| Number of Steps (Repeats) |
B.4 Hyperparameters of Attack Methods
In this part, we present the set of hyperparameters used for each attack method. For Attack [33] and AdvFlow, we tune the hyperparameters on a development set so that they result in the best performance for an un-defended CIFAR-10 classifier. In the case of bandits with time and data-dependent priors [23], we use two sets of hyperparameters tuned for these methods. For the vanilla classifiers we use the hyperparameters set in [23], while for defended classifiers we use those set in [39]. For SimBA [16], we used the hyperparameters set in the official repository. We only changed the stride from to to allow for the correct computation of block reordering. Once set, we keep the hyperparameters fixed throughout the rest of experiments. Tables 7-10 summarize the hyperparameters used for each attack method in our experiments.
| Hyperparameter | Vanilla | Defended |
|---|---|---|
| OCO learning rate | ||
| Image learning rate | ||
| Bandit exploration | ||
| Finite difference probe | ||
| Tile size |
| Hyperparameter | Value |
|---|---|
| (noise std.) | |
| Sample size | |
| Learning rate | |
| Maximum iteration |
| Hyperparameter | Value |
|---|---|
| Freq. Dimensionality | |
| Order | Strided |
| Stride |
| Hyperparameter | Value |
|---|---|
| (noise std.) | |
| Sample size | |
| Learning rate | |
| Maximum iteration |
Appendix C Extended Experimental Results
In this section, we present an extended version of our experimental results.
C.1 Table of Attack Success Rate and Number of Queries
Table 11 presents attack success rate, as well as average and median of the number of queries for AdvFlow alongside bandits [23] and Attack [33]. In each case, we have also shown the clean data accuracy and success rate of the white-box PGD-100 attack for reference. Details of classifier training and defense mechanism can be found in Appendix B.3. As can be seen, when it comes to attacking defended models, AdvFlow can outperform the baselines in both the number of queries and attack success rate.
C.2 Success Rate vs. Number of Queries
C.3 Confusion Matrices of Transferability
Figure 4 shows the transferability rate of generated attacks to various classifiers. Each entry shows the success rate of adversarial examples intended to attack the row-wise classifier in attacking the column-wise classifier. There are a few points worth mentioning regarding these results:
-
•
AdvFlow attacks are more transferable between defended models than vanilla to defended models. We argue that the underlying reason is the fact that AdvFlow learns a higher-level perturbation to attack DNNs. As a result, since vanilla classifiers use different features than the defended ones, they are less adaptable to attack defended classifiers. In contrast, since Attack acts on a pixel level, they are less susceptible to this issue.
-
•
Generally, adversarial examples generated by AdvFlow are more transferable between different architectures than Attack. The same argument as in our previous point applies here.
-
•
Transferability of black-box attacks is not as important as in the white-box setting. The reason is that in the case of black-box attacks, since no assumption is made about the model architecture, we can try to generate new adversarial examples to attack a new target classifier. However, for white-box attacks, transferability is somehow related to their success in attacking previously unseen target networks. Thus, it is essential to have a high rate of transferability if a white-box attack is meant to be deployed in real-world situations where often, we do not have any access to internal nodes of a classifier.
C.4 Samples of Adversarial Examples
Figure 5 shows samples of adversarial examples generated by AdvFlow and Attack [33], intended to attack a vanilla Wide-ResNet-32 [63]. As the images show, AdvFlow can generate adversarial perturbations that often take the shape of the original data. This property makes AdvFlows less detectable to adversarial example detectors. In contrast, it is clear that the perturbations generated by Attack come from a different distribution than the data itself. As a result, they can be detected easily by adversarial example detectors.
| Arch | Data | Attack | PGD-100 | Bandits [23] / Attack [33] / SimBA [16] / AdvFlow (ours) | |||
|---|---|---|---|---|---|---|---|
| Defense | Clean Acc.(%) | Success Rate(%) | Success Rate(%) | Avg. of Queries | Med. of Queries | ||
| WideResNet32 [63] | CIFAR-10 | Vanilla | / / / | / / / | / / / | ||
| FreeAdv [48] | / / / | / / / | / / / | ||||
| FastAdv [60] | / / / | / / / | / / / | ||||
| RotNetAdv [19] | / / / | / / / | / / / | ||||
| SVHN | Vanilla | / / / | / / / | / / / | |||
| FreeAdv [48] | / / / | / / / | / / / | ||||
| FastAdv [60] | / / / | / / / | / / / | ||||
| RotNetAdv [19] | / / / | / / / | / / / | ||||
| ResNet50 [18] | CIFAR-10 | Vanilla | / / / | / / / | / / / | ||
| FreeAdv [48] | / / / | / / / | / / / | ||||
| FastAdv [60] | / / / | / / / | / / / | ||||
| RotNetAdv [19] | / / / | / / / | / / / | ||||
| SVHN | Vanilla | / / / | / / / | / / / | |||
| FreeAdv [48] | / / / | / / / | / / / | ||||
| FastAdv [60] | / / / | / / / | / / / | ||||
| RotNetAdv [19] | / / / | / / / | / / / | ||||









C.5 Training Data and Its Effects
In the closing paragraph of Section 3.1 we discussed that while we are using the same training data as the classifier for our flow-based models, it does not have any effect on the performance of generated adversarial examples. This claim is valid since we did not explicitly use this data to either generate adversarial examples or learn their features by which the classifier intends to distinguish them. To support our claim, we replicate the experiments of Table 2 for the case of CIFAR-10 [30]. This time, however, we select of the test data and pre-train our normalizing flow on them. Then, we evaluate the performance of AdvFlow on the remaining test data. We then report the attack success rate and the average number of queries in Table 12 for this new scenario (Scenario 2) vs. the original case (Scenario 1).
As can be seen, the performance does not change in general. The little differences between the two cases come from the fact that in Scenario 1, we had training data to train our flow-based model, while in Scenario 2 we only trained our model on training data. Also, here we are evaluating AdvFlow performance on test data in contrast to the whole test images used in assessing Scenario 1. Finally, it should be noted that we get even a more balanced relative performance for the fair case where we split the training data between classifier and flow-based model. However, since the performance of the classifier drops in this case, we only report the unfair situation here.
| Data | Success Rate(%) | Avg. (Med.) of Queries | |||
|---|---|---|---|---|---|
| Defense | Scenario 1 | Scenario 2 | Scenario 1 | Scenario 2 | |
| CIFAR-10 | Vanilla | () | () | ||
| FreeAdv | () | () | |||
| FastAdv | () | () | |||
| RotNetAdv | () | () | |||
More interestingly, we observe that in case we train our flow-based model on some similar dataset to the original one, we can still get an acceptable relative performance. More specifically, we train our flow-based model on CIFAR-100 [30] dataset instead of CIFAR-10 [30]. Then, we perform AdvFlow on the test data of CIFAR-10 [30]. We know that despite being visually similar, these two datasets have their differences in terms of classes and samples per class.
Table 13 shows the performance of AdvFlow in this case where it is pre-trained on CIFAR-100 instead of CIFAR-10. As the results indicate, we can achieve a competitive performance despite our model being trained on a slightly different dataset. Furthermore, a few adversarial examples from this model are shown in Figure 6. We see that the perturbations are still more or less taking the shape of the data.
| Test | Success Rate(%) | Avg. (Med.) of Queries | |||
|---|---|---|---|---|---|
| Def/Train Data | CIFAR-10 | CIFAR-100 | CIFAR-10 | CIFAR-100 | |
| CIFAR-10 | Vanilla | () | () | ||
| FreeAdv | () | () | |||
| FastAdv | () | () | |||
| RotNetAdv | () | () | |||

Appendix D AdvFlow and Its Variations
D.1 AdvFlow
Algorithm 1 summarizes the main adversarial attack approach introduced in this paper.
Input: Clean data , true label , pre-trained flow-based model .
Output: Adversarial example
Parameters: noise variance , learning rate , population size , maximum number of queries .
D.2 Greedy AdvFlow [9]
We can modify Algorithm 1 so that it stops upon reaching a data point where it is adversarial. To this end, we only have to actively check whether we have generated a data sample for which the C&W cost of Eq. (1) is zero or not. Besides, instead of using all of the generated samples to update the mean of the latent Gaussian , we can select the top- for which the C&W loss is the lowest. Then, we update the mean by taking the average of these latent space data points. Applying these changes, we get a new algorithm coined Greedy AdvFlow. This approach is given in Algorithm 2.
Input: Clean data , true label , pre-trained flow-based model .
Output: Adversarial example
Parameters: noise variance , voting population , population size , maximum number of queries .
Table 14 shows the performance of the proposed method with respect to AdvFlow. As can be seen, this way we can improve the success rate and number of required queries.
| Data | Success Rate(%) | Avg. (Med.) of Queries | |||
|---|---|---|---|---|---|
| Defense | Greedy AdvFlow | AdvFlow | Greedy AdvFlow | AdvFlow | |
| CIFAR-10 | Vanilla | () | () | ||
| FreeAdv | () | () | |||
| FastAdv | () | () | |||
| RotNetAdv | () | () | |||
| SVHN | Vanilla | () | () | ||
| FreeAdv | () | () | |||
| FastAdv | () | () | |||
| RotNetAdv | () | () | |||
D.3 AdvFlow for High-resolution Images
Despite their ease-of-use in generating low-resolution images, high-resolution image generation with normalizing flows is computationally demanding. This issue is even more pronounced in the case of images with high variabilities, such as the ImageNet [46] dataset, which may require a lot of invertible transformations to model them. To cope with this problem, we propose an adjustment to our AdvFlow algorithm. Instead of generating the image in the high-dimensional space, we first map it to a low-dimension space using bilinear interpolation. Then, we perform the AdvFlow algorithm to generate the set of candidate examples. Next, we compute the adversarial perturbations in the low-dimensional space and map them back to their high-dimensional representation using bilinear upsampling. These perturbations are then added to the original target image, and the rest of the algorithm continues as before. Figure 7 shows the block-diagram of the proposed solution for high-resolution data. Moreover, the updated AdvFlow procedure is summarized in Algorithm 3. Changes are highlighted in red.
Input: Clean data , true label , pre-trained flow-based model .
Output: Adversarial example
Parameters: noise variance , learning rate , population size , maximum number of queries .
To test the performance of the proposed approach, we pre-train a flow-based model on a version of ImageNet [46]. The normalizing flow architecture and training hyperparameters are as shown in Table 4. Furthermore, we use bandits with data-dependent priors [23] and Attack [33] to compare our model against them. For bandits, we use the tuned hyperparameters for ImageNet [46] in the original paper [23]. Also, for Attack [33] and AdvFlow we observe that the hyperparameters in Tables 8 and 10 work best for the vanilla architectures in this dataset. Thus, we kept them as before.
We use the nominated black-box methods to attack a classifier in less than queries. We use pre-trained Inception-v3 [52], ResNet-50 [18], and VGG-16 [50] classifiers available on torchvision as our vanilla target models. Also, a defended ResNet-50 [18] model trained by fast adversarial training [60] with FGSM () is used for evaluation. This model is available online on the official repository of fast adversarial training.111111github.com/anonymous-sushi-armadillo
Table 15 shows our experimental results on the ImageNet [46] dataset. As can be seen, we get similar results to CIFAR-10 [30] and SVHN [40] experiments in Table 2: in case of vanilla architectures, we are performing slightly worse than Attack [33], while in the defended case we improve their performance considerably. It should also be noted again that in all of the cases we are generating adversaries that look like the original data, and come from the same distribution. This property is desirable in confronting adversarial example detectors. Figure 8 depicts a few adversarial examples generated by AdvFlow compared to Attack [33] for a vanilla Inception-v3 [52] DNN classifier. As seen, the AdvFlow perturbations tend to take the shape of the data to reduce the possibility of changing the underlying data distribution. In contrast, Attack perturbations are pixel-level, independent additive noise that cause the adversarial example distribution to become different from that of the data.

























D.4 AdvFlow for People in a Hurry!
Alternatively, one can use the plain structure of AdvFlows for black-box adversarial attacks. To this end, we are only required to initialize the normalizing flow randomly. This way, however, we will be getting random-like perturbations as in Attack [33] since we have not trained the flow-based model. Using this approach, we can surpass the performance of the baselines in vanilla DNNs. In fact, giving away a little bit of performance is the price we pay to force the perturbation to have a data-like structure so that the adversaries have a similar distribution to the data. Table 16 summarizes the performance of randomly initialized AdvFlow in contrast to bandits with data-dependent priors [23] and Attack [33] for vanilla ImageNet [46] classifiers. Also, Figure 9 shows a few adversarial examples generated by randomly initialized AdvFlows in this case.







