Adversarial network training using higher-order moments in a modified Wasserstein distance
Abstract
Generative-adversarial networks (GANs) have been used to produce data closely resembling example data in a compressed, latent space that is close to sufficient for reconstruction in the original vector space. The Wasserstein metric has been used as an alternative to binary cross-entropy, producing more numerically stable GANs with greater mode covering behavior. Here, a generalization of the Wasserstein distance, using higher-order moments than the mean, is derived. Training a GAN with this higher-order Wasserstein metric is demonstrated to exhibit superior performance, even when adjusted for slightly higher computational cost. This is illustrated generating synthetic antibody sequences.
1 Introduction
1.1 Generative-adversarial network
The generative-adversarial network (GAN) is a game-theoretic technique for generating values according to a latent distribution estimated on example data .[1] GANs employ a generator, , which maps high-entropy inputs to an immitation datum; these high-entropy inputs effectively determine a location in the latent space and are decoded to produces an immitation datum. GANs also employ a discriminator, , which is used to evaluate the plausibility that a datum is genuine. Generator and discriminator are trained in an adversarial manner, with the goal of reaching an equilibrium where both implicitly encode the distribution of real data in the latent space. If training is successful, (where ) will produce data resembling a row of ; will correspond to the cumulative density in a unimodal latent space where the latent space density projects the empirical distribution of .
1.2 Cross-entropy loss
GANs are typically trained using a cross-entropy loss to optimize the parameters of both and , which measures the expected bits of surprise that samples from a foreground distribution would produce if they had been drawn from a background distribution. The parameters are optimized to minimize the surprise of the Bernoulli distribution given the background distribution (i.e., minimizing the surprise from a background that scores ). The parameters are optimized to minimize the surprise of the Bernoulli distribution given the background distribution with and .
1.3 Wasserstein metric loss
When two distributions are highly dissimilar from one another, their support may be distinct such that cross-entropy becomes numerically unstable. This causes uninformative loss metrics: two distributions with non-overlapping support are quantified identically to two distributions whose supports are non-overlapping and very far from one another. These factors lead to poor training, particularly given that will initially produce noise, which will quite likely have poor overlap with real data in the latent space.
For this reason, Wasserstein distance was proposed to replace cross-entropy.[2] Wasserstein distance is the continuous version of the discrete earth-mover distance, which solves an optimal transport problem measuring the minimal movements in Euclidean distance that could be used to transform one probability density to another. Earth-mover distance is well defined, even when the two distributions have disjoint support. This avoids modal collapse while training.
If earth-mover distance is used to measure the distance between distributions and , then the set of candidate solutions will be functions with domain and where the marginals equal and . Thus, , where is the set of distributions with marginals .
The discrete formulation can be solved combinatorically via LP; however, the continuous formulation, Wasserstein distance, is computed via the Kantorovich-Rubinstein dual[3], which we show below.
The penalty term, here named , can be recreated using an adversarial critic function, , which has a unitless codomain:
is achieved when because can be made s.t., w.l.o.g., at the value where .
Thus,
We can further reorder to : For any function , , and , and so . Thus (i.e., weak duality). Furthermore, if is convex in and concave in , then the minimax principle yields (i.e., strong duality). Because is convex in (here manifest via convexity in ) and concave in (manifest via concave uses of rather then concavity of itself), we have
is achieved by concentrating the mass of where and setting wherever . Thus . This constrains that where , the dual penalty term will become , and so we need only consider s.t. . This is equivalent to constraining s.t. all secants having a maximum slope (i.e., Lipschitz ) yields the weakest penalty, 0:
In WGAN training, our critic functions as , exploiting differences between real and generated sequences. The critic loss function is simply the difference between mean critic values of generated sequences minus mean critic values of real sequences; minimizing this loss will maximize discrimination, with real sequences awarded higher critic scores. With the goal of attaining Lipschitz continuity on , we constrain its parameters , clipping them to small values at the end of each batch step. A small enough will ensure Lipschitz continuity for any finite network. Furthermore, ; therefore, can be chosen rather arbitrarily as long as , because the cone of functional solutions includes all nonnegative scales of functions for which . Choice of will influence the optimal choice of learning rate.
When training , the WGAN attempts to fool the critic and thus maximize the loss used by the critic . Thus, ’s loss is the negative of ’s loss. In practice, does not influence critic values of real data , and so ’s loss needs only be to maximize critic scores of generated sequences.
All expectations are taken via Monte Carlo (i.e., by taking the mean of scores over each batch).
2 Methods
2.1 A WGAN using Wasserstein distance with higher moments
In this manuscript, we propose a modified WGAN, in which we consider other satisfying
Wasserstein distance employs duality via an adversarial that concentrates where (w.l.o.g.) :
This correspond to exploiting deviations in the first moment of under distribution (w.l.o.g.).
Motivated by the method of moments, we consider the first moments, . At WGAN convergence, deviations between and marginals of should not be exploitable at any moment:
We continue using a signed deviation for the first moment (i.e., ), but unsigned deviations for the remaining moments:
Note that is still used in a convex manner, as its outputs are either unconstrained (in ) or within a bounded polytope ; strong duality holds.
The same derivation holds under central moments, which are used in these experiments.
Lipschitz continuity under higher moments of is achieved by decreasing s.t. . In this case, both and the all central moments can be bounded: , and thus . Thus Lipschitz continuity is ensured by the standard Wasserstein derivation.
Since concentrates at deviations between distributions, it should approach a Dirac delta before convergence if ’s training lags the training of ; thus, here we have not investigated using the higher moments informing when training ; is trained using the same Wasserstein loss using . is used to train , which corresponds to replacing standard code
with new code
This formulation allows learning from batches in gestalt. When the number of computed moments equals the batch size , there is sufficient information to recover the entire distribution; furthermore, even relatively few moments can accurately summarize the distribution in practice in a manner reminiscent of the fast multipole method[4, 5].
2.2 Impact on runtime
Considering higher moments at batch size results in a per-batch runtime or if the layer of moments is used to separate the data from critic output. Also, the modified WGAN needs to compute critic scores when training the generator. This increases computation cost.
Fractional moments can be informative and numerically stable; however, in the general case, they require arithmetic on complex numbers and may negatively influence performance.
3 Results
To benchmark WGAN training methodology, we train WGANs to output heavy chain antibody sequences. The overall scheme for this WGAN is heavily inspired by the seminal neural network-based antibody sequence design work of Tileli et al.[6]; furthermore, our model architecture is inspired by the multi-layer convolutional network from that work.
3.1 Experimental setup
3.1.1 Sequence data
Heavy chain sequence examples from from Observed Antibody Space[7, 8] are filtered for outliers based on sequence length and sampled to sequences. Note that sequences are not embedded using a multiple sequence alignment; instead, every sequence is appended with starting and ending characters ^ and $ and then padded with $ so that all sequences have the same length. Sequences are embedded via one-hot embedding.
3.1.2 Critic and generator model architectures
Critic: The critic is constructed of two 2D convolutional layers. For simplicity, 2D convolution is performed with padding such that there is no movement of the kernel over the axis labeling amino acids in the one-hot embedding and the input padded sequence length equals the length of the convolved vector. In this manner, each of the channels of the first 2D convolution essentially passes a PSSM with embedding characters over the sequence. These channels are transposed to view them as a single matrix of one channel with an alternate embedding with characters. This is again nonlinearized with leaky ReLU, and 2D convolved again to produce a single channel output. This is now akin to using a PSSM on -mer motifs (using an alphabet of possible motifs) rather than on amino acids, which is in turn equivalent to inferring an order- Markov model. Padding is performed in the same manner as in the first 2D convolution; the output is a vector of the same length as the original amino acid sequence. This vector is condensed to a single value via feedforward layers: each collection has linear layers that halve the number of nodes followed by leaky ReLU transfer function to allow nonlinearity. Note that 2D convolution here is equivalent to several channels of 1D convolution and can be implemented as such.
Generator: The generator is nearly identical to the critic in reverse. Thinking of the critic and generator as two halves of an autoencoder, inverting the critic’s compression to lower-dimensional latent space, deconvolution would be desired; however, deconvolution is a form of convolution (but with a kernel whose values have been multaplicatively inverted in the frequency domain) as shown by the convolution theorem.[9]
A standard normal noise vector inflates to a vector with length where is the size of the alphabet used for one-hot embedding. A leaky ReLU is used to permit nonlinearity. The vector is then viewed as a matrix matrix and is convolved in 2D to produce channels of output (padding in the 2D convolution matches the approach used in the critic). This output is transposed to be viewed as a single matrix of one channel with an alternate embedding in new characters. Nonlinearity is again induced with leaky ReLU. The matrix is then convolved 2D again with the same padding strategy and channels out and transposed to form a matrix of one channel and characters embedded. This is nonlinearized with leaky ReLU. Note that this matrix is of the same shape as used by the sequence embedding. Softmax is then applied to the character embedding axis, forcing it into an embedding that resembles a one-hot.
All leaky ReLUs have negative slope 0.2. Layers are delimited with dropout 0.1 during training, but not during evaluation.
3.1.3 Evaluation
After each epoch, quality of are evaluated using KL divergence of the categorical distributions of 6-mer sequences given the 6-mer sequence distribution from the heavy chain antibody sequences and sequences sampled from . For numeric stability, KL divergence is computed using a pseudocount of added to values not in the background distribution’s support.
3.1.4 Hyperparameters
Learning rate and batch size are chosen by training a standard WGAN network is trained for several replicates with various learning rates and batch sizes . The learning rate that produced the best 6-mer KL divergence is 0.001. yielded the best 6-mer KL divergence while still maintaining GPU usage with nvidia-smi. These hyperparameters are used for training the WGANs using higher-order moments.
3.1.5 Reproducibility
The random seeds are used for replicate experiments. This includes seeding random, numpy.random, torch, and torch.utils.data.DataLoader. torch.use_deterministic_algorithms(True) is used, along with the accompanying recommended environment variable set by export CUBLAS_WORKSPACE_CONFIG=:4096:8.
3.1.6 Training details
Models are instantiated and trained with pytorch 1.10. A shuffled DataLoader with 8 worker threads and pinned memory is used in training. In each epoch, is trained on each batch and is trained on of batches to avoid adjusting with improper guidance from an uninformed critic.
Adaptive moment estimation (Adam) is used for gradient descent.[10]
Benchmarks are performed on AWS g4dn.8xlarge instance using a single Nvidia T4. Storage IOPS and throughput are maximized.
3.2 Influence of higher moments on WGAN performance
Data are produced using 5 replicate trials of 200 epochs. For fairness, each loss function investigated used every random seed .
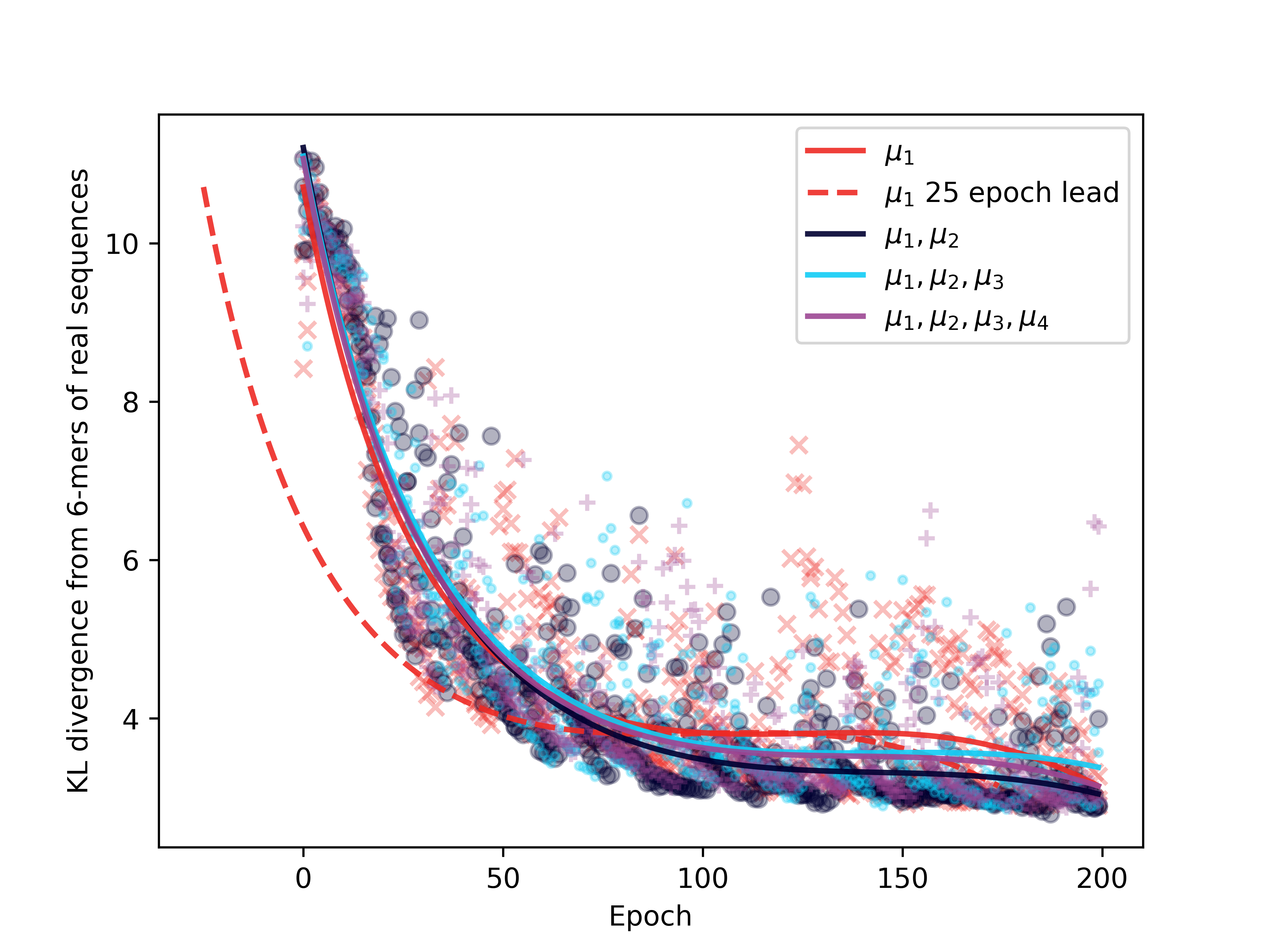
Figure 1 illustrates the relationship between sequence quality produced by at each epoch and the loss function used.
Figure 2 illustrates the relationship between sequence quality produced by and the loss function value for each loss function used. Note that for any , generator loss uses penalty term , and so a small loss function necessarily implies a small loss function using a standard WGAN.
 |
 |
| (a) | (b) |
| Mean runtime (s) | KL & crit. loss | KL & gen. loss | |
|---|---|---|---|
| 1 | 2917.66 | 0.7059 | 0.4169 |
| 2 | 3079.00 | 0.8961 | 0.9257 |
| 3 | 3097.12 | 0.8388 | 0.8722 |
| 4 | 3110.64 | 0.8921 | 0.9205 |
4 Discussion
Figure 1 demonstrates that early in training, the standard WGAN exhibits superior performance; however, later on, using higher moments results in benefit to sequence quality, specifically for the and loss functions. This is shown to be rougly equivalent to gaining a 25 epoch advantage.
Figure 2 and Table 1 demonstrate a greater correspondence between sequence quality and loss functions with higher moments.
Qualitatively, using higher moments incentivizes optimizing batches as a whole. One way that this may manifest is by improving batch diversity of to better match that of , thereby reducing modal collapse. For early epochs, this could explain the slightly poorer performance, as these loss functions will initially be less seeking of a dominant nearby mode.
Interestingly, did not perform as well as and . This could be because training the critic inherently drives toward a high-concentration similar to a Dirac delta. While the first moment is informative and even moments describe spread (variance quantifies spread, excess kurtosis quantifies modality near ), the skew, , informs of direction but in a way that may here be less useful or numerically stable than simply using .
Using higher moments increased runtimes, but not substantially. Training modified WGAN with moments in ’s loss required more runtime than the standard WGAN. At a cost of $2.176 per hour[11], this corresponds to a cost of $1.76 per replicate of the standard WGAN, and less than $0.10 more expensive to train the variant; however, the variant reaches comparable convergence in 75% of the training, and thus would cost roughly $1.63 per replicate. For larger data and more stringent convergence criteria, the exponentially decaying gain in sequence quality by training for further epochs suggests that this 25 epoch advantage demonstrated by the variants would produce benefits far more dramatic. Furthermore, it is likely the benefits illustrated here would be stronger with more replicate experiments.
It is possible that deviations for different moments should receive their own weighting in computing the loss function. In this manner, it may be desirable to perform batch-based discrimination, where each batch is reduced to its constituent moments, and then a critic is computed on the moments of critic values for the batch. Parameters could be learned and clamped during training to ensure .
5 Conclusion
Here we have shown that viewing distributions with several moments rather than only using the first moment, , improves WGAN training. We could also easily train the critic using this strategy.
6 Acknowledgements
Thank you to Ryan Emerson and Randolph Lopez for the scientific discussion, James Harrang for the helpful comments, and to the entire A-Alpha Bio team.
7 Declarations
7.1 Conflicts of interest
O.S. is an employee of A-Alpha Bio and owns stock options in the company.
References
- [1] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. Advances in neural information processing systems, 27, 2014.
- [2] Martin Arjovsky, Soumith Chintala, and Léon Bottou. Wasserstein generative adversarial networks. In International conference on machine learning, pages 214–223. PMLR, 2017.
- [3] John Thickstun. Kantorovich-Rubinstein Duality, 2019.
- [4] Leslie Greengard and Vladimir Rokhlin. A fast algorithm for particle simulations. Journal of computational physics, 73(2):325–348, 1987.
- [5] Julianus Pfeuffer and Oliver Serang. A bounded p-norm approximation of max-convolution for sub-quadratic bayesian inference on additive factors. The Journal of Machine Learning Research, 17(1):1247–1285, 2016.
- [6] Tileli Amimeur, Jeremy M Shaver, Randal R Ketchem, J Alex Taylor, Rutilio H Clark, Josh Smith, Danielle Van Citters, Christine C Siska, Pauline Smidt, Megan Sprague, et al. Designing feature-controlled humanoid antibody discovery libraries using generative adversarial networks. BioRxiv, 2020.
- [7] Aleksandr Kovaltsuk, Jinwoo Leem, Sebastian Kelm, James Snowden, Charlotte M Deane, and Konrad Krawczyk. Observed antibody space: a resource for data mining next-generation sequencing of antibody repertoires. The Journal of Immunology, 201(8):2502–2509, 2018.
- [8] Tobias H Olsen, Fergus Boyles, and Charlotte M Deane. Observed antibody space: A diverse database of cleaned, annotated, and translated unpaired and paired antibody sequences. Protein Science, 31(1):141–146, 2022.
- [9] John G Proakis. Digital signal processing: principles algorithms and applications. Pearson Education, 2001.
- [10] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- [11] Amazon EC2 G4 Instances, 8 2022. Archived at https://web.archive.org/web/20220809081441/https://aws.amazon.com/ec2/instance-types/g4/.