ADMM for Nonsmooth Composite Optimization under Orthogonality Constraints
Abstract
We consider a class of structured, nonconvex, nonsmooth optimization problems under orthogonality constraints, where the objectives combine a smooth function, a nonsmooth concave function, and a nonsmooth weakly convex function. This class of problems finds diverse applications in statistical learning and data science. Existing methods for addressing these problems often fail to exploit the specific structure of orthogonality constraints, struggle with nonsmooth functions, or result in suboptimal oracle complexity. We propose OADMM, an Alternating Direction Method of Multipliers (ADMM) designed to solve this class of problems using efficient proximal linearized strategies. Two specific variants of OADMM are explored: one based on Euclidean Projection (OADMM-EP) and the other on Riemannian Retraction (OADMM-RR). Under mild assumptions, we prove that OADMM converges to a critical point of the problem with an ergodic convergence rate of . Additionally, we establish a super-exponential convergence rate or polynomial convergence rate for OADMM, depending on the specific setting, under the Kurdyka-Lojasiewicz (KL) inequality. To the best of our knowledge, this is the first non-ergodic convergence result for this class of nonconvex nonsmooth optimization problems. Numerical experiments demonstrate that the proposed algorithm achieves state-of-the-art performance.
Keywords: Orthogonality Constraints; Nonconvex Optimization; Nonsmooth Composite Optimization; ADMM; Convergence Analysis
1 Introduction
This paper focuses on the following nonsmooth composite optimization problem under orthogonality constraints (‘’ means define):
| (1) |
Here, , is a linear mapping of , and is a identity matrix. For conciseness, the orthogonality constraints in Problem (1) is rewritten as , with representing the Stiefel manifold in the literature Edelman et al. (1998); Absil et al. (2008b).
We impose the following assumptions on Problem (1) throughout this paper. (-i) is -smooth, satisfying holds for all . This implies: (cf. Lemma 1.2.3 in Nesterov (2003)). We also assume that demonstrates -Lipschitz continuity, with for all . The convexity of is not assumed. (-ii) The function is convex, proper, and -Lipschitz continuous, though it is not necessarily smooth. (-iii) The function is proper, lower semicontinuous, -Lipschitz continuous, and potentially nonsmooth. Also, it is weakly convexity with constant , which implies that the function is convex for all . (-iv) The proximal operator, , can be computed efficiently and exactly for any given and .
Problem (1) represents an optimization framework that plays a crucial role in a variety of statistical learning and data science models. These models include sparse Principal Component Analysis (PCA) Journée et al. (2010); Lu & Zhang (2012), deep neural networks Cho & Lee (2017); Xie et al. (2017); Bansal et al. (2018); Cogswell et al. (2016); Huang & Gao (2023), orthogonal nonnegative matrix factorization Jiang et al. (2022), range-based independent component analysis Selvan et al. (2015), and dictionary learning Zhai et al. (2020).
1.1 Related Work
Optimization under Orthogonality Constraints. Solving Problem (1) is challenging due to the computationally expensive and non-convex orthogonality constraints. Existing methods can be divided into three classes. (i) Geodesic-like methods Edelman et al. (1998); Abrudan et al. (2008); Absil et al. (2008b); Jiang & Dai (2015). These methods involve calculating geodesics by solving ordinary differential equations, which can introduce significant computational complexity. To mitigate this, geodesic-like methods iteratively compute the geodesic logarithm using simple linear algebra calculations. Efficient constraint-preserving update schemes have been integrated with the Barzilai-Borwein (BB) stepsize strategy Wen & Yin (2013); Jiang & Dai (2015) for minimizing smooth functions under orthogonality constraints. (ii) Projection and retractions methods Absil et al. (2008b); Golub & Van Loan (2013). These methods maintain orthogonality constraints through projection or retraction. They reduce the objective value by using its current Euclidean gradient direction or Riemannian tangent direction, followed by an orthogonal projection operation. This projection can be computed using polar decomposition or singular value decomposition, or approximated with QR factorization. (iii) Multiplier correction methods Gao et al. (2018; 2019); Xiao et al. (2022). Leveraging the insight that the Lagrangian multiplier associated with the orthogonality constraint is symmetric and has an explicit closed-form expression at the first-order optimality condition, these methods tackle an alternative unconstrained nonlinear objective minimization problem, rather than the original smooth function under orthogonality constraints.
Optimization with Nonsmooth Objectives. Another challenge in addressing Problem (1) stems from the nonsmooth nature of the objective function. Existing methods for tackling this challenge fall into three main categories. (i) Subgradient methods Ferreira & Oliveira (1998); Hwang et al. (2015); Li et al. (2021). Subgradient methods, analogous to gradient descent methods, can incorporate various geodesic-like and projection-like techniques. However, they often exhibit slower convergence rates compared to other approaches. (ii) Proximal gradient methods Chen et al. (2020). These methods use a semi-smooth Newton approach to solve a strongly convex minimization problem over the tangent space, finding a descent direction while preserving the orthogonality constraint through a retraction operation. (iii) Operator splitting methods Lai & Osher (2014); Chen et al. (2016); Zhang et al. (2020b). These methods introduce linear constraints to break down the original problem into simpler subproblems that can be solved separately and exactly. Among these, ADMM is a promising solution for Problem (1) due to its capability to handle nonsmooth objectives and nonconvex constraints separately and alternately. Several ADMM-like algorithms have been proposed for solving nonconvex problems Bo & Nguyen (2020); Bo et al. (2019); Wang et al. (2019); Li & Pong (2015); He & Yuan (2012); Yuan (2024); Zhang et al. (2020b), but these methods fail to exploit the specific structure of orthogonality constraints or cannot be adapted to solve Problem (1). (iv) Other methods. OBCD Yuan (2023) has been proposed to solve a specific class of our problems, while the exact augmented Lagrangian method ManIAL was introduced in Deng et al. (2024).
Detailed Discussions on Operator Splitting Methods. We list some popular variants of operator splitting methods for tackling Problem (1). Initially, two natural splitting strategies are used in the literature:
| (2) | |||
| (3) |
(a) Smoothing Proximal Gradient Methods (SPGM, Beck & Rosset (2023); Böhm & Wright (2021)) incorporate a penalty (or smoothing) parameter to penalize the squared error in the constraints, resulting in the subsequent minimization problem Beck & Rosset (2023); Böhm & Wright (2021); Chen (2012): . During each iteration, SPGM employs proximal gradient strategies to alternatively minimize w.r.t. and . (b) Splitting Orthogonality Constraints Methods (SOCM, Lai & Osher (2014)) use the following iteration scheme: , , and , where is a fixed penalty constant, and is the multiplier associated with the constraint at iteration . (c) Similarly, Manifold ADMM (MADMM, Kovnatsky et al. (2016)) iterates as follows: , , and , where is the multiplier associated with the constraint at iteration . (d) Like MADMM, Riemannian ADMM (RADMM, Li et al. (2022)) operates using the first splitting strategy in Equation (2). In contrast, it employs a Riemannian retraction strategy to solve the -subproblem and a Moreau envelope smoothing strategy to solve the -subproblem.
Contributions. We compare existing methods for solving Problem (1) in Table 1, and our main contributions are summarized as follows. (i) We introduce OADMM, a specialized ADMM designed for structured nonsmooth composite optimization problems under orthogonality constraints in Problem (1). Two specific variants of OADMM are explored: one based on Euclidean Projection (OADMM-EP) and the other on Riemannian Retraction (OADMM-EP). Notably, while many existing works primarily address cases where and is convex, our approach considers a more general setting where is weakly convex and is convex. (ii) OADMM could demonstrate fast convergence by incorporating Nesterov’s extrapolation Nesterov (2003) into OADMM-EP and a Monotone Barzilai-Borwein (MBB) stepsize strategy Wen & Yin (2013) into OADMM-RR to potentially accelerate primal convergence. Both variants also employ an over-relaxation strategy to enhance dual convergence Gonçalves et al. (2017); Yang et al. (2017); Li et al. (2016). (iii) By introducing a novel Lyapunov function, we establish the convergence of OADMM to critical points of Problem (1) within an oracle complexity of , matching the best-known results to date Beck & Rosset (2023); Böhm & Wright (2021). This is achieved through a decreasing step size for updating primal and dual variables. In contrast, RADMM employs a small constant step size for such updates, resulting in a sub-optimal oracle complexity of Li et al. (2022). (iv) We establish a super-exponential convergence rate or polynomial convergence rate for OADMM, depending on the specific setting, under the Kurdyka-Lojasiewicz (KL) inequality, providing the first non-ergodic convergence result for this class of non-convex nonsmooth optimization problems.
| Reference | Notable Features | Complexity | Conv. Rate | ||
| SOCM Lai & Osher (2014) | convex | empty | , | unknown | unknown |
| MADMM Kovnatsky et al. (2016) | convex | empty | , | unknown | unknown |
| RSG Li et al. (2021) | weakly convex | empty | – | unknown | |
| ManPG Chen et al. (2020) | empty | hard subproblem | unknown | ||
| OBCD Yuan (2023) | separable | empty | hard subproblem | unknown | |
| RADMM Li et al. (2022) | convex | empty | , | unknown | |
| ManIAL Deng et al. (2024) | convex | empty | inexact subproblem | unknown | |
| SPGM Beck & Rosset (2023) | convex | empty | – | unknown | |
| OADMM-EP[ours] | weakly convex | convex | , | ||
| OADMM-RR[ours] | weakly convex | convex | , MBB | or |
2 Technical Preliminaries
This section provides some technical preliminaries on Moreau envelopes for weakly convex functions and manifold optimization.
Notations. We define . We use to denote the adjoin operator of with for all and . We define . We use to denote the indicator function of orthogonality constants. Further notations, technical preliminaries, and relevant lemmas are detailed in Appendix Section A.
2.1 Moreau Envelopes for Weakly Convex Functions
We provide the following useful definition.
Definition 2.1.
For a proper convex, and Lipschitz continuous function , the Moreau envelope of with the parameter is given by .
We show some useful properties of Moreau envelope for weakly convex functions.
Lemma 2.2.
Let to be a proper, -weakly convex, and lower semicontinuous function. Assume . We have the following results Böhm & Wright (2021). (a) The function is -Lipschitz continuous. (b) The function is continuously differentiable with gradient for all , where . This gradient is -Lipschitz continuous. In particular, when , the condition ensures that is -smooth and -weakly convex.
Lemma 2.3.
(Proof in Appendix B.1) Assume , and fixing . We have: .
Lemma 2.4.
(Proof in Appendix B.2) Assume , and fixing . We have: .
Lemma 2.5.
(Proof in Appendix B.3) Assume that is -weakly convex, , . Consider the following strongly convex optimization problem: , which is equivalent to: . We have: (a) , where . (b) . (c) .
2.2 Manifold Optimization
We define the -stationary point of Problem (1) as follows.
Definition 2.7.
The proposed algorithm is an iterative procedure. After shifting the current iterate in the search direction, it may no longer reside on . Therefore, we must retract the point onto to form the next iterate. The following definition is useful in this context.
Definition 2.8.
A retraction on is a smooth map Absil et al. (2008a): with and satisfying , and for any .
Remark 2.9.
The following lemma concerning the retraction operator is useful for our subsequent analysis.
Lemma 2.10.
(Boumal et al. (2019)) Let and . There exists positive constants such that , and .
Furthermore, we present the following three insightful lemmas.
Lemma 2.11.
(Proof in Appendix B.4) Let and , we have .
Lemma 2.12.
(Proof in Appendix B.5) Let , , and . We define . It follows that: (a) . (b) .
Lemma 2.13.
(Proof in Appendix B.6) Consider the following optimization problem: , where is differentiable. For all , we have: .
3 The Proposed OADMM Algorithm
This section provides the proposed OADMM algorithm for solving Problem (1), featuring two variants, one is based on Euclidean Projection (OADMM-EP) and the other on Riemannian Retraction (OADMM-RR).
Using the Moreau envelope smoothing technique, we consider the following optimization problem:
| (4) |
where , and is the Moreau Envelope of . Importantly, is -smooth when , according to Lemma 2.2. It is worth noting that similar smoothing techniques have been used in the design of augmented Lagrangian methods Zeng et al. (2022), and minimax optimization Zhang et al. (2020a), and ADMMs Li et al. (2022). We define the augmented Lagrangian function of Problem (4) as follows:
| (5) |
Here, is the dual variable for the equality constraint, is the smoothing parameter linked to the function , is the penalty parameter associated with the equality constraint, and is the indicator function of the set .
In simple terms, OADMM updates are performed by minimizing the augmented Lagrangian function over the primal variables at each iteration, while keeping all other primal and dual variables fixed. The dual variables are updated using gradient ascent on the dual problem.
For updating the primal variable , we use different strategies, resulting in distinct variants of OADMM. We first observe that the function is -smooth w.r.t. , where . In OADMM-EP, we adopt a proximal linearized method based on Euclidean projection Lai & Osher (2014), while in OADMM-RR, we apply line-search methods on the Stiefel manifold Liu et al. (2016).
We detail iteration steps of OADMM in Algorithm 1, and have the following remarks.
- (a)
-
(b)
To accelerate primal convergence in OADMM-EP, we incorporate a Nesterov extrapolation strategy with parameter .
-
(c)
To enhance primal convergence in OADMM-RR, we use a Monotone Barzilai-Borwein (MBB) strategy Wen & Yin (2013) with a dynamically adjusted parameter to capture the problem’s curvature 111Following Wen & Yin (2013), one can set or , where and , with being the Riemannian gradient.. The parameters represent the decay rate and sufficient decrease parameter, commonly used in line search procedures Chen et al. (2020).
-
(d)
The -subproblem is solved as: , where , and is the using singular value decomposition of .
-
(e)
The -subproblem can be solved using the result from Lemma 2.5.
-
(f)
For practical implementation, we recommend the following default parameters: , , , , , , , .
4 Oracle Complexity
This section details the oracle complexity of Algorithm 1.
We define , , , , .
We define the potential function (or Lyapunov function) for all , as follows:
| (6) | |||||
where , , and .
Additionally, we define:
| (9) |
We have the following useful lemma, derived using the first-order optimality condition of .
Lemma 4.1.
(Proof in Section C.1, Bounding Dual using Primal) We have: (a) . (b) .
Remark 4.2.
Here, for OADMM-RR, we set , resulting in for all . (i) With the choice , we have: , and .
Lemma 4.3.
(Proof in Appendix C.2) (a) It holds that . (b) There exists constant such that .
The subsequent lemma demonstrates that the sequence is always lower bounded.
Lemma 4.4.
(Proof in Section C.3) For all , there exists constants such that , , , and .
The following lemma is useful for our subsequent analysis, applicable to both OADMM-EP and OADMM-RR.
Lemma 4.5.
(Proof in Appendix C.4, Sufficient Decrease for Variables We have .
In the remaining content of this section, we provide separate analyses for OADMM-EP and OADMM-RR.
4.1 Analysis for OADMM-EP
Using the optimality condition of , we derive the following lemma.
Lemma 4.6.
(Proof in Appendix C.5, Sufficient Decrease for Variable ) We define , where . We have .
Lemma 4.7.
(Proof in Appendix C.6) We have: (a) . (b) .
Finally, we have the following theorem regarding the oracle complexity of OADMM-EP.
Theorem 4.8.
(Proof in Appendix C.7) Let . We have: . In other words, there exists such that: , provided that .
4.2 Analysis for OADMM-RR
Using the properties of the line search procedure for updating the variable , we deduce the following lemma.
Lemma 4.10.
(Proof in Appendix C.8, Sufficient Decrease for Variable ) We define , where . We have: (a) For any , if is large enough such that , then the condition of the line search procedure is satisfied. (b) It follows that: . Here, is a constant that , are defined in Lemma 2.10, and are defined in Algorithm 1.
Remark 4.11.
By Lemma 4.10(a), since is a universal constant and decreases exponentially, the line search procedure of OADMM-RR will terminate in time.
Lemma 4.12.
(Proof in Appendix C.9) We have: (a) . (b) .
Finally, we derive the following theorem on the oracle complexity of OADMM-RR.
Theorem 4.13.
(Proof in Appendix C.10) Let . We have: . In other words, there exists such that: , provided that .
5 Convergence Rate
This section provides convergence rate of OADMM-EP and OADMM-RR. Our analyses are based on a non-convex analysis tool called KL inequality Attouch et al. (2010); Bolte et al. (2014); Li & Lin (2015); Li et al. (2023).
We define the Lyapunov function as: , where we let for OADMM-RR. We define , , , and . Thus, we have . We denote as a limiting point of Algorithm 1.
We make the following additional assumptions.
Assumption 5.1.
(Kurdyka-Łojasiewicz Inequality Attouch et al. (2010)). Consider a semi-algebraic function w.r.t. for all , where is in the effective domain of . There exist , , a neighborhood of , and a continuous and concave desingularization function with and such that, for all satisfying , it holds that: . Here, .
Assumption 5.2.
The function is -smooth such that holds for all and .
Remark 5.3.
Semi-algebraic functions, including real polynomial functions, finite combinations, and indicator functions of semi-algebraic sets, commonly exhibit the KL property and find extensive use in applications Attouch et al. (2010).
We present the following lemma regarding subgradient bounds for each iteration.
Lemma 5.4.
(Proof in Section D.1, Subgradient Bounds) (a) For OADMM-EP, there exists a constant such that: . (b) For OADMM-RR, there exists a constant such that: .
Remark 5.5.
Lemma 5.4 significantly differs from prior work that used a constant penalty due to the crucial role played by the increasing penalty.
The following theorem establishes a finite length property of OADMM.
Theorem 5.6.
(Proof in Section D.2, A Finite Length Property) We define . We define , where is the desingularization function defined in Assumption 5.1. (a) We have the following recursive inequality for both OADMM-EP and OADMM-RR: , where , and is defined in Lemma 5.4. (b) It holds that . The sequence has the finite length property that .
Remark 5.7.
We prove a lemma demonstrating that the convergence of is sufficient to establish the convergence of .
Lemma 5.8.
(Proof in Section D.3) We define . For both OADMM-EP and OADMM-RR, we have: (a) There exists a constant such that . (b) We have , where .
Finally, we establish the convergence rate of OADMM with exploiting the KL exponent .
Theorem 5.9.
(Proof in Section D.4, Convergence Rate) We fix . There exists such that for all , we have:
-
(a)
If , then we have , where .
-
(b)
If , then we have: , where .
Remark 5.10.
(i) To the best of our knowledge, Theorem 5.9 represents the first non-ergodic convergence rate for solving this class of nonconvex and nonsmooth problem in Problem (1). It is worth noting that the work of Li et al. (2023) establishes a non-ergodic convergence rate for subgradient methods with diminishing stepsizes by further exploring the KL exponent. (ii) Under the KL inequality assumption, with the desingularizing function chosen in the form of with , OADMM converges with a super-exponential rate when , and converges with a polynomial convergence rate when for the gap . Notably, super-exponential convergence is faster than polynomial convergence. (iii) Our result generalizes the classical findings of Attouch et al. (2010); Bolte et al. (2014), which characterize the convergence rate of proximal gradient methods for a specific class of nonconvex composite optimization problems.
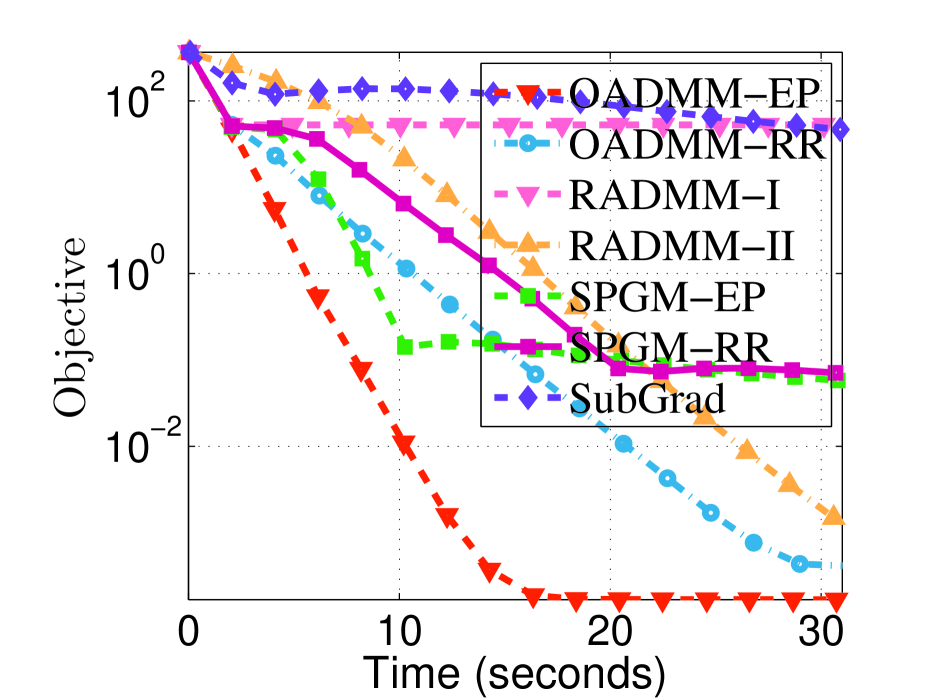
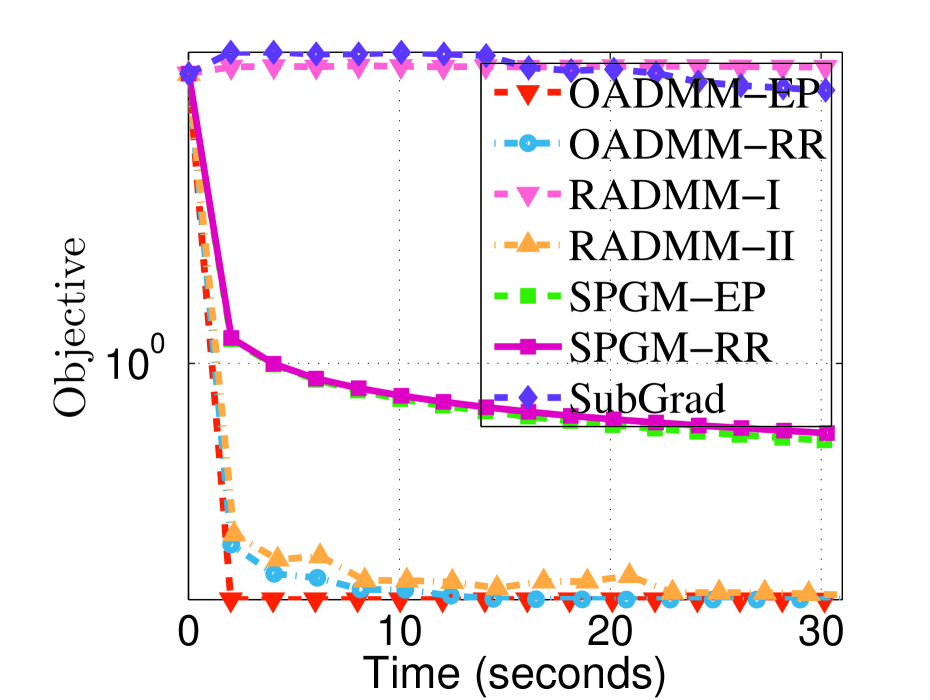
6 Applications and Numerical Experiments
In this section, we assess the effectiveness of the proposed algorithm OADMM on the sparse PCA problem by comparing it against existing non-convex, non-smooth optimization algorithms.
Application to Sparse PCA. Sparse PCA is a method to produce modified principal components with sparse loadings, which helps reduce model complexity and increase model interpretation Chen et al. (2016). It can be formulated as:
where is the data matrix, is the number of data points, and is the norm the the largest (in magnitude) elements of the matrix . Here, we consider the DC -largest- function Gotoh et al. (2018) to induce sparsity in the solution. One advantage of this model is that when is sufficient large, we have , leading to a -sparsity solution .
Compared Methods. We compare OADMM-EP and OADMM-RR against four state-of-the-art optimization algorithms: (i) RADMM: ADMM using Riemannian retraction with fixed and small stepsizes Li et al. (2022), tested with two different penalty parameters , leading to two variants: RADMM-I and RADMM-II. (ii) SPGM-EP: Smoothing Proximal Gradient Method using Euclidean projection Böhm & Wright (2021). (iii) SPGM-EP: SPGM utilizing Riemannian retraction Beck & Rosset (2023). (iv) Sub-Grad: Subgradient methods with Euclidean projection Davis & Drusvyatskiy (2019); Li et al. (2021).
Experiment Settings. All methods are implemented in MATLAB on an Intel 2.6 GHz CPU with 64 GB RAM. For all retraction-based methods, we use only polar decomposition-based retraction. We evaluate different regularization parameters . For OADMM, default parameters are used, with and corresponding values for each . For simplicity, we omit the Barzilai-Borwein strategy and instead use a fixed constant for all iterations. All algorithms start with a common initial solution , generated from a standard normal distribution. Our code for reproducing the experiments is available in the supplemental material.
Experiment Results. We report the objective values for different methods with varying parameters . The experimental results presented in Figures 1 and 2 reveal the following insights: (i) Sub-Grad essentially fails to solve this problem, as the subgradient is inaccurately estimated when the solution is sparse. (ii) SPGM-EP and SPGM-RR, which rely on a variable smoothing strategy, exhibit slower performance than the multiplier-based variable splitting method. This observation aligns with the commonly accepted notion that primal-dual methods are generally more robust and faster than primal-only methods. (iii) The proposed OADMM-EP and OADMM-RR demonstrate similar results and generally achieve lower objective function values than the other methods.
7 Conclusions
This paper introduces OADMM, an Alternating Direction Method of Multipliers (ADMM) tailored for solving structured nonsmooth composite optimization problems under orthogonality constraints. OADMM integrates either a Nesterov extrapolation strategy or a Monotone Barzilai-Borwein (MBB) stepsize strategy to potentially accelerate primal convergence, complemented by an over-relaxation stepsize strategy for rapid dual convergence. We adjust the penalty and smoothing parameters at a controlled rate. Additionally, we develop a novel Lyapunov function to rigorously analyze the oracle complexity of OADMM and establish the first non-ergodic convergence rate for this method. Finally, numerical experiments show that our OADMM achieves state-of-the-art performance.














References
- Abrudan et al. (2008) Traian E Abrudan, Jan Eriksson, and Visa Koivunen. Steepest descent algorithms for optimization under unitary matrix constraint. IEEE Transactions on Signal Processing, 56(3):1134–1147, 2008.
- Absil & Malick (2012) P-A Absil and Jérôme Malick. Projection-like retractions on matrix manifolds. SIAM Journal on Optimization, 22(1):135–158, 2012.
- Absil et al. (2008a) P-A Absil, Robert Mahony, and Rodolphe Sepulchre. Optimization algorithms on matrix manifolds. Princeton University Press, 2008a.
- Absil et al. (2008b) Pierre-Antoine Absil, Robert E. Mahony, and Rodolphe Sepulchre. Optimization Algorithms on Matrix Manifolds. Princeton University Press, 2008b.
- Attouch et al. (2010) Hedy Attouch, Jérôme Bolte, Patrick Redont, and Antoine Soubeyran. Proximal alternating minimization and projection methods for nonconvex problems: An approach based on the kurdyka-lojasiewicz inequality. Mathematics of Operations Research, 35(2):438–457, 2010.
- Bansal et al. (2018) Nitin Bansal, Xiaohan Chen, and Zhangyang Wang. Can we gain more from orthogonality regularizations in training deep networks? Advances in Neural Information Processing Systems, 31, 2018.
- Beck & Rosset (2023) Amir Beck and Israel Rosset. A dynamic smoothing technique for a class of nonsmooth optimization problems on manifolds. SIAM Journal on Optimization, 33(3):1473–1493, 2023.
- Bo & Nguyen (2020) Radu Ioan Bo and Dang-Khoa Nguyen. The proximal alternating direction method of multipliers in the nonconvex setting: convergence analysis and rates. Mathematics of Operations Research, 45(2):682–712, 2020.
- Bo et al. (2019) Radu Ioan Bo, Erno Robert Csetnek, and Dang-Khoa Nguyen. A proximal minimization algorithm for structured nonconvex and nonsmooth problems. SIAM Journal on Optimization, 29(2):1300–1328, 2019. doi: 10.1137/18M1190689.
- Böhm & Wright (2021) Axel Böhm and Stephen J. Wright. Variable smoothing for weakly convex composite functions. Journal of Optimization Theory and Applications, 188(3):628–649, 2021.
- Bolte et al. (2014) Jérôme Bolte, Shoham Sabach, and Marc Teboulle. Proximal alternating linearized minimization for nonconvex and nonsmooth problems. Mathematical Programming, 146(1-2):459–494, 2014.
- Boumal et al. (2019) Nicolas Boumal, Pierre-Antoine Absil, and Coralia Cartis. Global rates of convergence for nonconvex optimization on manifolds. IMA Journal of Numerical Analysis, 39(1):1–33, 2019.
- Chen et al. (2020) Shixiang Chen, Shiqian Ma, Anthony Man-Cho So, and Tong Zhang. Proximal gradient method for nonsmooth optimization over the stiefel manifold. SIAM Journal on Optimization, 30(1):210–239, 2020.
- Chen et al. (2016) Weiqiang Chen, Hui Ji, and Yanfei You. An augmented lagrangian method for -regularized optimization problems with orthogonality constraints. SIAM Journal on Scientific Computing, 38(4):B570–B592, 2016.
- Chen (2012) Xiaojun Chen. Smoothing methods for nonsmooth, nonconvex minimization. Mathematical programming, 134(1):71–99, 2012.
- Cho & Lee (2017) Minhyung Cho and Jaehyung Lee. Riemannian approach to batch normalization. Advances in Neural Information Processing Systems, 30, 2017.
- Cogswell et al. (2016) Michael Cogswell, Faruk Ahmed, Ross B. Girshick, Larry Zitnick, and Dhruv Batra. Reducing overfitting in deep networks by decorrelating representations. In Yoshua Bengio and Yann LeCun (eds.), International Conference on Learning Representations (ICLR), 2016.
- Davis & Drusvyatskiy (2019) Damek Davis and Dmitriy Drusvyatskiy. Stochastic model-based minimization of weakly convex functions. SIAM Journal on Optimization, 29(1):207–239, 2019.
- Deng et al. (2024) Kangkang Deng, Jiang Hu, and Zaiwen Wen. Oracle complexity of augmented lagrangian methods for nonsmooth manifold optimization. arXiv preprint arXiv:2404.05121, 2024.
- Drusvyatskiy & Paquette (2019) Dmitriy Drusvyatskiy and Courtney Paquette. Efficiency of minimizing compositions of convex functions and smooth maps. Mathematical Programming, 178:503–558, 2019.
- Edelman et al. (1998) Alan Edelman, Tomás A. Arias, and Steven Thomas Smith. The geometry of algorithms with orthogonality constraints. SIAM Journal on Matrix Analysis and Applications, 20(2):303–353, 1998.
- Ferreira & Oliveira (1998) OP Ferreira and PR1622188 Oliveira. Subgradient algorithm on riemannian manifolds. Journal of Optimization Theory and Applications, 97:93–104, 1998.
- Gao et al. (2018) Bin Gao, Xin Liu, Xiaojun Chen, and Ya-xiang Yuan. A new first-order algorithmic framework for optimization problems with orthogonality constraints. SIAM Journal on Optimization, 28(1):302–332, 2018.
- Gao et al. (2019) Bin Gao, Xin Liu, and Ya-xiang Yuan. Parallelizable algorithms for optimization problems with orthogonality constraints. SIAM Journal on Scientific Computing, 41(3):A1949–A1983, 2019.
- Golub & Van Loan (2013) Gene H Golub and Charles F Van Loan. Matrix computations. 2013.
- Gonçalves et al. (2017) Max LN Gonçalves, Jefferson G Melo, and Renato DC Monteiro. Convergence rate bounds for a proximal admm with over-relaxation stepsize parameter for solving nonconvex linearly constrained problems. arXiv preprint arXiv:1702.01850, 2017.
- Gotoh et al. (2018) Jun-ya Gotoh, Akiko Takeda, and Katsuya Tono. Dc formulations and algorithms for sparse optimization problems. Mathematical Programming, 169(1):141–176, 2018.
- He & Yuan (2012) Bingsheng He and Xiaoming Yuan. On the o(1/n) convergence rate of the douglas–rachford alternating direction method. SIAM Journal on Numerical Analysis, 50(2):700–709, 2012.
- Huang & Gao (2023) Feihu Huang and Shangqian Gao. Gradient descent ascent for minimax problems on riemannian manifolds. IEEE Trans. Pattern Anal. Mach. Intell., 45(7):8466–8476, 2023.
- Hwang et al. (2015) Seong Jae Hwang, Maxwell D. Collins, Sathya N. Ravi, Vamsi K. Ithapu, Nagesh Adluru, Sterling C. Johnson, and Vikas Singh. A projection free method for generalized eigenvalue problem with a nonsmooth regularizer. In IEEE International Conference on Computer Vision (ICCV), pp. 1841–1849, 2015.
- Jiang & Dai (2015) Bo Jiang and Yu-Hong Dai. A framework of constraint preserving update schemes for optimization on stiefel manifold. Mathematical Programming, 153(2):535–575, 2015.
- Jiang et al. (2022) Bo Jiang, Xiang Meng, Zaiwen Wen, and Xiaojun Chen. An exact penalty approach for optimization with nonnegative orthogonality constraints. Mathematical Programming, pp. 1–43, 2022.
- Journée et al. (2010) Michel Journée, Yurii Nesterov, Peter Richtárik, and Rodolphe Sepulchre. Generalized power method for sparse principal component analysis. Journal of Machine Learning Research, 11(2):517–553, 2010.
- Kovnatsky et al. (2016) Artiom Kovnatsky, Klaus Glashoff, and Michael M Bronstein. Madmm: a generic algorithm for non-smooth optimization on manifolds. In The European Conference on Computer Vision (ECCV), pp. 680–696. Springer, 2016.
- Lai & Osher (2014) Rongjie Lai and Stanley Osher. A splitting method for orthogonality constrained problems. Journal of Scientific Computing, 58(2):431–449, 2014.
- Li & Pong (2015) Guoyin Li and Ting Kei Pong. Global convergence of splitting methods for nonconvex composite optimization. SIAM Journal on Optimization, 25(4):2434–2460, 2015.
- Li & Lin (2015) Huan Li and Zhouchen Lin. Accelerated proximal gradient methods for nonconvex programming. Advances in neural information processing systems, 28, 2015.
- Li et al. (2022) Jiaxiang Li, Shiqian Ma, and Tejes Srivastava. A riemannian admm. arXiv preprint arXiv:2211.02163, 2022.
- Li et al. (2016) Min Li, Defeng Sun, and Kim-Chuan Toh. A majorized admm with indefinite proximal terms for linearly constrained convex composite optimization. SIAM Journal on Optimization, 26(2):922–950, 2016.
- Li et al. (2021) Xiao Li, Shixiang Chen, Zengde Deng, Qing Qu, Zhihui Zhu, and Anthony Man-Cho So. Weakly convex optimization over stiefel manifold using riemannian subgradient-type methods. SIAM Journal on Optimization, 31(3):1605–1634, 2021.
- Li et al. (2023) Xiao Li, Andre Milzarek, and Junwen Qiu. Convergence of random reshuffling under the kurdyka–łojasiewicz inequality. SIAM Journal on Optimization, 33(2):1092–1120, 2023.
- Liu et al. (2016) Huikang Liu, Weijie Wu, and Anthony Man-Cho So. Quadratic optimization with orthogonality constraints: Explicit lojasiewicz exponent and linear convergence of line-search methods. In International Conference on Machine Learning (ICML), pp. 1158–1167, 2016.
- Lu & Zhang (2012) Zhaosong Lu and Yong Zhang. An augmented lagrangian approach for sparse principal component analysis. Mathematical Programming, 135(1-2):149–193, 2012.
- Mordukhovich (2006) Boris S. Mordukhovich. Variational analysis and generalized differentiation i: Basic theory. Berlin Springer, 330, 2006.
- Nesterov (2003) Y. E. Nesterov. Introductory lectures on convex optimization: a basic course, volume 87 of Applied Optimization. Kluwer Academic Publishers, 2003.
- Rockafellar & Wets. (2009) R. Tyrrell Rockafellar and Roger J-B. Wets. Variational analysis. Springer Science & Business Media, 317, 2009.
- Selvan et al. (2015) S Easter Selvan, S Thomas George, and R Balakrishnan. Range-based ica using a nonsmooth quasi-newton optimizer for electroencephalographic source localization in focal epilepsy. Neural computation, 27(3):628–671, 2015.
- Wang et al. (2019) Yu Wang, Wotao Yin, and Jinshan Zeng. Global convergence of admm in nonconvex nonsmooth optimization. Journal of Scientific Computing, 78(1):29–63, 2019.
- Wen & Yin (2013) Zaiwen Wen and Wotao Yin. A feasible method for optimization with orthogonality constraints. Mathematical Programming, 142(1):397–434, 2013.
- Xiao et al. (2022) Nachuan Xiao, Xin Liu, and Ya-Xiang Yuan. A class of smooth exact penalty function methods for optimization problems with orthogonality constraints. Optimization Methods and Software, 37(4):1205–1241, 2022.
- Xie et al. (2017) Di Xie, Jiang Xiong, and Shiliang Pu. All you need is beyond a good init: Exploring better solution for training extremely deep convolutional neural networks with orthonormality and modulation. In IEEE Conference on Computer Vision and Pattern Recognition, pp. 6176–6185, 2017.
- Yang et al. (2017) Lei Yang, Ting Kei Pong, and Xiaojun Chen. Alternating direction method of multipliers for a class of nonconvex and nonsmooth problems with applications to background/foreground extraction. SIAM Journal on Imaging Sciences, 10(1):74–110, 2017.
- Yuan (2023) Ganzhao Yuan. A block coordinate descent method for nonsmooth composite optimization under orthogonality constraints. arXiv preprint arXiv:2304.03641, 2023.
- Yuan (2024) Ganzhao Yuan. Admm for nonconvex optimization under minimal continuity assumption. arXiv preprint, 2024.
- Zeng et al. (2022) Jinshan Zeng, Wotao Yin, and Ding-Xuan Zhou. Moreau envelope augmented lagrangian method for nonconvex optimization with linear constraints. Journal of Scientific Computing, 91(2):61, 2022.
- Zhai et al. (2020) Yuexiang Zhai, Zitong Yang, Zhenyu Liao, John Wright, and Yi Ma. Complete dictionary learning via l4-norm maximization over the orthogonal group. Journal of Machine Learning Research, 21(165):1–68, 2020.
- Zhang et al. (2020a) Jiawei Zhang, Peijun Xiao, Ruoyu Sun, and Zhi-Quan Luo. A single-loop smoothed gradient descent-ascent algorithm for nonconvex-concave min-max problems. In Hugo Larochelle, Marc’Aurelio Ranzato, Raia Hadsell, Maria-Florina Balcan, and Hsuan-Tien Lin (eds.), Advances in Neural Information Processing Systems, 2020a.
- Zhang et al. (2020b) Junyu Zhang, Shiqian Ma, and Shuzhong Zhang. Primal-dual optimization algorithms over riemannian manifolds: an iteration complexity analysis. Mathematical Programming, 184(1):445–490, 2020b.
Appendix
The appendix is organized as follows.
Appendix A provides notations, technical preliminaries, and relevant lemmas.
Appendix E presents additional experiments details and results.
Appendix A Notations, Technical Preliminaries, and Relevant Lemmas
A.1 Notations
In this paper, lowercase boldface letters signify vectors, while uppercase letters denote real-valued matrices. The following notations are utilized throughout this paper.
-
•
:
-
•
: Euclidean norm:
-
•
: the transpose of the matrix
-
•
: A zero matrix of size ; the subscript is omitted sometimes
-
•
: , Identity matrix
-
•
: Orthogonality constraint set (a.k.a., Stiefel manifold: .
-
•
: the Matrix is symmetric positive semidefinite (or definite)
-
•
: Sum of the elements on the main diagonal :
-
•
: Operator/Spectral norm: the largest singular value of
-
•
: Frobenius norm:
-
•
: Absolute sum of the elements in with
-
•
: norm the the largest (in magnitude) elements of the matrix
-
•
: (limiting) Euclidean subdifferential of at
-
•
: Orthogonal projection of with
-
•
: the distance between two sets with
-
•
: .
-
•
: the smoothness parameter of the function w.r.t. .
-
•
: Indicator function of with if and otherwise .
We employ the following parameters in Algorithm 1.
-
•
: proximal parameter
-
•
: correlation coefficient between and , such that
-
•
: over-relaxation parameter with
-
•
: Nesterov extrapolation parameter with
-
•
: search descent parameter with
-
•
: decay rate parameter in the line search procedure with
-
•
: sufficient decrease parameter in the line search procedure with
-
•
: exponent parameter used in the penalty update rule with
-
•
: growth factor parameter used in the penalty update rule with
A.2 Technical Preliminaries
Non-convex Non-smooth Optimization. Given the potential non-convexity and non-smoothness of the function , we introduce tools from non-smooth analysis Mordukhovich (2006); Rockafellar & Wets. (2009). The domain of any extended real-valued function is defined as . At , the Fréchet subdifferential of is defined as , while the limiting subdifferential of at is denoted as . The gradient of at in the Euclidean space is denoted as . The following relations hold among , , and : (i) . (ii) If the function is convex, and represent the classical subdifferential for convex functions, i.e., . (iii) If the function is differentiable, then .
Optimization with Orthogonality Constraints. We introduce some prior knowledge of optimization involving orthogonality constraints Absil et al. (2008b). The nearest orthogonality matrix to any arbitrary matrix is determined as , where represents the singular value decomposition of . We use to denote the limiting normal cone to at , thus defined as . Moreover, the tangent and normal space to at are respectively denoted as and . We have: and , where for and .
Weakly Convex Functions. The function is weakly convex if there exists a constant such that is convex; the smallest such is termed the modulus of weak convexity. Weakly convex functions encompass a diverse range, including convex functions, differentiable functions with Lipschitz continuous gradient, and compositions of convex, Lipschitz-continuous functions with -smooth mappings having Lipschitz continuous Jacobians Drusvyatskiy & Paquette (2019).
A.3 Relevant Lemmas
Lemma A.1.
Let , and be any constant. We have: .
Proof.
We have: . ∎
Lemma A.2.
Assume , and is an integer. We have: .
Proof.
Part (a). When , the conclusion of this lemma is clearly satisfied.
Part (b). Now, we assume and . First, using the convexity of , we obtain . It remains to prove that for all . Second, we derive the following chain of inequalities: .
∎
Lemma A.3.
Let , where , , . For all , we have: .
Proof.
We derive: , where step ① uses ; step ② uses for all when ; step ③ uses Lemma A.2; step ④ uses the fact that for all .
∎
Lemma A.4.
Assume , where , and . We have: .
Proof.
We have: , where the inequality holds due to the convexity of .
∎
Lemma A.5.
Assume that , where , , and is a non-negative sequence. We have: for all .
Proof.
Using basic induction, we have the following results:
Therefore, we obtain: , where step ① uses , and the summation formula of geometric sequences that .
∎
Lemma A.6.
Assume , where , and . We have:
(a) .
(b) .
(c) .
Proof.
Part (a). We have: , where step ① uses ; step ② uses .
Part (b). We have: , where step ① uses ; step ② uses the triangle inequality and .
Part (c). We have: , where step ① uses the triangle inequality; step ② uses Claim (a) of this lemma.
∎
Lemma A.7.
Let , and . We have:
Proof.
First, we obtain:
| (10) | |||||
where step ① uses the triangle inequality; step ② uses , and .
Second, we have:
| (11) | |||||
where step ① uses the triangle inequality; step ② uses , and .
Finally, we derive:
where step ① uses for all Absil et al. (2008a); step ② uses the triangle inequality; step ③ uses Inequalities (10) and (11).
∎
Lemma A.8.
We let . We define . We have for all .
Proof.
We assume .
First, we show that . Recall that it holds: and . Given the function is a decreasing function on , we have .
Second, we show that for all . We have , and , implying that the function is concave on . Noticing , we conclude that .
Third, we show that is an increasing function. We have: , where step ① uses for all ; step ② uses for all ; step ③ uses .
Finally, we have: , where step ① uses the fact that is an increasing function; step ② uses for all .
∎
Lemma A.9.
Assume . We have: .
Proof.
We define and .
Using the integral test for convergence, we obtain: .
Part (a). We first consider the lower bound. We obtain: , where step ① uses ; step ② uses Lemma A.8.
Part (b). We now consider the upper bound. We have: , where step ① uses .
∎
Lemma A.10.
Assume and , where are two nonnegative sequences. For all , we have: .
Proof.
We define . We let .
First, for any , we have:
| (12) |
where step ① uses for all .
Second, we obtain:
| (13) | |||||
Here, step ① uses and ; step ② uses the fact that for all ; step ③ uses the fact that for all .
Assume the parameter is sufficiently small that . Telescoping Inequality (13) over from to , we obtain:
where step ① uses ; step ② uses . This leads to:
step ① uses the fact that and when ; step ② uses Inequalities (12). Letting , we conclude this lemma.
∎
Lemma A.11.
Assume , where is a constant, and is a nonnegative increasing sequence. If is an even number, we have: .
Proof.
We have: , where step ① uses the fact that is increasing.
∎
Lemma A.12.
Assume that , and , where is a positive constant, and are two nonnegative sequences. Assume that is increasing. We have: .
Proof.
We define .
Given , we have , leading to:
| (14) |
Part (a). When is an even number, we have:
where step ① uses Inequality (14); step ② uses for all and ; step ③ uses for all , and for all ; step ④ uses for all and ; step ⑤ uses Lemma A.11 with .
Part (b). When is an odd number, analogous strategies result in the same complexity outcome.
∎
Lemma A.13.
Assume that , and , where are positive constants, and are two nonnegative sequences. Assume that is increasing. We have: .
Proof.
We let be any constant. We define , where .
We consider two cases for .
Case (1). . We define . We derive:
where step ① uses ; step ② uses ; step ③ uses the fact that is a nonnegative and increasing function that for all ; step ④ uses the fact that ; step ⑤ uses the definition of . This leads to:
| (15) |
Case (2). . We have:
| (16) | |||||
where step ① uses the definition of ; step ② uses the fact that if , then for any exponent . We further derive:
| (17) | |||||
where step ① uses Inequality (16); step ② uses and for all .
We now focus on Inequality (18).
Part (a). When is an even number, telescoping Inequality (18) over , we have:
where step ① use Lemma A.11. This leads to:
Part (b). When is an odd number, analogous strategies result in the same complexity outcome.
∎
Appendix B Proofs for Section 2
B.1 Proof of Lemma 2.3
Proof.
Assume , and fixing .
We define , and .
We define , and .
By the optimality of and , we obtain:
| (19) | |||||
| (20) |
Part (a). We now prove that . For any and , we have:
where step ① uses the definition of and ; step ② uses weakly convexity of ; step ③ uses the optimality of and in Equations (19) and (20); step ④ uses ; step ⑤ uses .
Part (b). We now prove that . For any and , we have:
where step ① uses the definition of and ; step ② uses the weakly convexity of ; step ③ uses the optimality of and in Equations (19) and (20); step ④ uses and ; step ⑤ uses ; step ⑥ uses , , and .
∎
B.2 Proof of Lemma 2.4
Proof.
Assume , and fixing .
Using the result in Lemma 2.2, we establish that the gradient of w.r.t can be computed as:
The gradient of the mapping w.r.t. the variable can be computed as: . We further obtain:
Here, step ① uses the optimality of that: . Therefore, for all , we have:
Letting and , we have: .
∎
B.3 Proof of Lemma 2.5
Proof.
We consider the following optimization problem:
| (21) |
Given being -weakly convex and , Problem (21) becomes strongly convex and has a unique optimal solution, which leads to the following equivalent problem:
We have the following first-order optimality conditions for :
| (22) | |||||
| (23) |
Part (a). We have the following results:
| (24) | |||||
where step ① uses Equality (23); step ② uses Equality (22) that . The inclusion in (24) implies that:
Part (c). In view of Equation (23), we have: , leading to: .
∎
B.4 Proofs for Lemma 2.11
Proof.
We let and . We define .
We derive the following results:
where step ① uses for all Absil et al. (2008a); step ② uses the fact that for all ; step ③ uses the definition of ; step ④ uses the symmetric properties of the matrix .
∎
B.5 Proof of Lemma 2.12
Proof.
We let , , and .
We define , and .
First, we have the following equalities:
| (25) | |||||
where step ① uses .
Second, we derive the following equalities:
| (26) | |||||
where step ① uses and ; step ② uses .
Third, we have:
| (27) |
where step ① uses ; step ② uses the fact that the matrix only contains eigenvalues that are or .
Part (a-i). We now prove that . We discuss two cases. Case (i): . We have:
where step ① uses Inequalities (25) and (26); step ② uses for all , and for all .
Case (ii): . We have:
where step ① uses Inequalities (25) and (26); step ② uses for all , and Inequality(27). Therefore, we conclude that: .
Part (a-ii). We now prove that . We consider two cases. Case (i): . We have:
where step ① uses Inequalities (25) and (26); step ② uses , and Inequality (27).
Case (ii): . We have:
where step ① uses Inequality (26); step ② uses for all , and the fact that for all . Therefore, we conclude that: .
Part (b-i). We now prove that . We consider two cases. Case (i): . We have:
where step ① uses Inequality (26); step ② uses for all , and Inequality (27).
Case (ii): . We have:
where step ① uses Inequalities (25) and (26); step ② uses for all , and the fact that for all . Therefore, we conclude that .
Part (b-ii). We now prove that . We consider two cases. Case (i): . We have:
where step ① uses Inequality (26); step ② uses for all , and the fact that for all .
Case (ii): . We have:
where step ① uses Inequalities (25) and (26); step ② uses for all , and Inequality (27). Therefore, we conclude that: .
∎
B.6 Proof of Lemma 2.13
Proof.
Recall that the following first-order optimality conditions are equivalent for all :
| (28) |
Therefore, we derive the following results:
where step ① uses Formulation (28); step ② uses for all Absil et al. (2008a); step ③ uses the norm inequality , and fact that the matrix only contains eigenvalues that are or .
∎
Appendix C Proofs for Section 4
C.1 Proof of Lemma 4.1
Proof.
We define .
We define , and .
Part (a-i). Using the first-order optimality condition of in Algorithm 1, for all , we have:
| (29) | |||||
where step ① uses ; step ② uses .
Part (a-ii). We obtain:
where step ① uses the result in Lemma 2.5 that ; step ② uses , as shown in Algorithm 1; step ③ uses ; step ④ uses .
Part (b). First, we derive:
| (30) | |||||
where step ① uses ; step ② uses the fact that the function is -smooth w.r.t. that: ; step ③ uses the fact that which holds due to Lemma 2.4, and the equality .
Second, we have from Equality (29):
Combining these two equalities yields:
Applying Lemma A.4 with , , , and , we have:
where step ① uses the definitions of ; step ② uses Inequality (30), and the inequality for all ; step ③ uses Lemma A.3 that for all ;
∎
C.2 Proof of Lemma 4.3
Proof.
Part (a). We have:
where step ① uses ; step ② uses for all ; step ③ uses and .
Part (b). It holds with and .
∎
C.3 Proof of Lemma 4.4
Proof.
We define , , , where .
We let , where is the optimal solution of Problem (1).
Part (a). Given , we have: .
Part (b). We show that . For all , we have:
step ① uses the triangle inequality; step ② uses , as shown in Lemma 4.1(a); step ③ uses -Lipschitz continuity of . Applying Lemma A.5 with , , and , we have:
Part (c). We show that . For all , we have:
where step ① uses the triangle inequality, , and ; step ② uses , and .
Part (d). We show that . For all , we have:
where step ① uses the definition of and the positivity of ; step ② uses the -Lipschitz continuity of , ensuring , with the specific choice of ; step ③ uses , which has been shown in Lemma 2.3; step ④ uses , , for all ; , and .
∎
C.4 Proof of Lemma 4.5
Proof.
We define .
We define .
We define , where we use .
Part (a). We focus on the sufficient decrease for variables . First, we have:
| (31) |
where step ① uses the Pythagoras Relation that for all ; step ② uses ; step ③ uses , as shown in Lemma 4.1(a); step ④ uses the fact that the function is -weakly convex w.r.t , and . Furthermore, we have:
| (32) |
where step ① uses the definition of ; step ② uses Inequality (C.4); step ③ uses Lemma 2.3 that for all .
Part (b). We focus on the sufficient decrease for variables . We have:
| (33) |
where step ① uses the definition of ; step ② uses ; step ③ uses ; step ④ uses the upper bound for as shown in Lemma 4.1(b); step ⑤ uses .
∎
C.5 Proof of Lemma 4.6
Proof.
We define .
We let .
We define .
We define , and .
First, using the optimality condition of , we have:
| (34) |
Second, we have:
| (35) |
where step ① uses the -smoothness of and convexity of ;
Third, we derive:
| (36) | |||||
where step ① uses the norm inequality; step ② uses the -smoothness of ; step ③ uses ; step ④ uses for all and .
Summing Inequalities (34),(36), and (C.5), we obtain:
where step ① uses ; step ② uses Lemma A.1 with , and ; step ③ uses the fact that , which is implied by ; step ④ uses Lemma 4.3 that ; step ⑤ uses .
∎
C.6 Proof of Lemma 4.7
Proof.
We define: ,
We define .
Part (a). Using Lemma 4.5, we have:
| (37) | |||||
Using Lemma 4.6, we have:
Adding these two inequalities together and using the definition of , we have:
Part (b). Telescoping this inequality over from 1 to , we have:
| (38) |
where step ① uses . Furthermore, we have:
| (39) |
where step ① uses for all . Combining Inequalities (38) and (39), we have: .
∎
C.7 Proof of Theorem 4.8
Proof.
We define .
We define .
We define .
We first derive the following inequalities:
| (40) |
where step ① uses the definitions of ; step ② uses the triangle inequality; step ③ uses the fact that is -smooth, , , and , as shown in Lemma A.6.
We derive the following inequalities:
where step ① uses the optimality of that:
step ② uses the result of Lemma A.7 by applying
step ③ uses Inequality (C.7), and the fact that .
Finally, we derive:
where step ① uses the definition of ; step ② uses , as shown in Lemma 4.1; step ③ uses ; step ④ uses the choice and Lemma 4.7(b).
∎
C.8 Proof of Lemma 4.10
Proof.
We define .
We let .
We define .
Part (a). Initially, we show that is always bounded for with . We have:
where step ① uses ; step ② uses the triangle inequality; step ③ uses , , , , , ; step ④ uses .
We derive the following inequalities:
| (41) |
where step ① uses the definitions of ; step ② uses the fact that the function is convex and the function is -smooth w.r.t. ; step ③ uses ; step ④ uses the Cauchy-Schwarz Inequality, , and Lemma 2.12(a) that ; step ⑤ uses Lemma 2.10 with given that and ; step ⑥ uses ; step ⑦ uses , , and ; step ⑧ uses the fact that is sufficiently small such that:
| (42) |
Given Inequality (C.8) coincides with the condition of the line search procedure, we complete the proof.
Part (b). We derive the following inequalities:
where step ① uses Inequality (C.8); step ② uses Lemma 2.12(b) that ; step ③ uses the definition ; step ④ uses , and the following inequality:
which can be implied by the stopping criteria of the line search procedure.
∎
C.9 Proof of Lemma 4.12
C.10 Proof of Theorem 4.13
Proof.
We define .
We define , and .
We let .
First, we obtain:
where step ① uses the definition , as shown in Algorithm 1; step ② uses ; step ③ uses the fact that for all Absil et al. (2008a). This leads to:
where step ① uses the triangle inequality; step ② uses Lemma 2.11 that for all .
Finally, we derive:
where step ① uses the definition of ; step ② uses , as shown in Lemma 4.1; step ③ uses ; step ④ uses the choice and Lemma 4.7(b).
∎
Appendix D Proofs for Section 5
D.1 Proof of Lemma 5.4
We begin by presenting the following four useful lemmas.
Lemma D.1.
For both OADMM-EP and OADMM-RR, we have:
| (44) |
where , , , . Here, .
Proof.
We define the Lyapunov function as: .
Using this definition, we can promptly derive the conclusion of the lemma.
∎
Lemma D.2.
Proof.
First, we obtain:
| (46) |
where step ① uses the optimality of for OADMM-EP that:
| (47) |
step ② uses the triangle inequality, the -Lipschitz continuity of for all ; the -Lipschitz continuity of , and the upper bound of as shown in Lemma A.6(c); step ③ uses the upper bound of , and .
Part (a). We bound the term . We have:
where step ① uses the definition of in Lemma D.1; step ② uses the triangle inequality, , and ; step ③ uses Inequality (D.2).
Part (b). We bound the term . We have:
| (48) |
where step ① uses the definition of in Lemma D.1; step ② uses .
Part (c). We bound the term . We have:
where step ① uses the definition of in Lemma D.1; step ② uses the fact that , as shown in Lemma 4.1; step ③ uses , and .
Part (d). We bound the term . We have: .
Part (e). Combining the upper bounds for the terms , we finish the proof of this lemma. ∎
Lemma D.3.
Proof.
We define .
We define , we have: .
First, given , we obtain:
| (49) | |||||
where step ① uses Lemma 2.13; step ② uses the definitions of as in Algorithm 1; step ③ uses , as shown in Lemma 2.12(b).
Part (a). We bound the term . We have:
where step ① uses with the choice for OADMM-RR; step ② uses the triangle inequality and ; step ② uses Inequality (49).
Part (b). We bound the term . Given , we conclude that .
Part (c). We bound the terms and . Considering that the same strategies for updating are employed, their bounds in OADMM-RR are identical to those in OADMM-ER.
Part (d). Combining the upper bounds for the terms , we finish the proof of this lemma.
∎
Now, we proceed to prove the main result of this lemma.
Lemma D.4.
(Subgradient Bounds) (a) For OADMM-EP, there exists a constant such that: . (b) For OADMM-RR, there exists a constant such that: . Here, .
D.2 Proof of Theorem 5.6
Proof.
We define .
Firstly, using Assumption 5.1, we have:
| (50) |
Secondly, given the desingularization function is concave, for any , we have: . Applying the inequality above with and , we have:
| (51) | |||||
Third, we derive the following inequalities for OADMM-EP:
| (52) | |||||
where step ① uses ; step ② uses Lemma 4.7; step ③ uses Inequality (51); step ④ uses Inequality (50); step ⑤ uses Lemma 5.4. We further derive the following inequalities:
| (53) | |||||
where step ① uses the norm inequality that for any ; step ② uses Inequality (52).
Fourth, we derive the following inequalities for OADMM-RR:
| (54) | |||||
where step ① uses Lemma 4.12; step ② uses Inequality (51); step ③ uses Inequality (50); step ④ uses Lemma 5.4. We further derive the following inequalities:
| (55) | |||||
where step ① uses the norm inequality that for any ; step ② uses Inequality (54).
Part (a). Given Inequalities (53) and (55), we establish the following unified inequality applicable to both OADMM-EP and OADMM-RR:
| (56) |
Part (b). Considering Inequality (56) and applying Lemma A.10 with , we have:
Letting , we have: .
∎
D.3 Proof of Lemma 5.8
Proof.
We define .
Part (a-i). For OADMM-EP, we have for all : , where step ① use the triangle inequality.
Part (a-ii). For OADMM-RR, we have: , where step ① uses the update rule of ; step ② uses Lemma 2.10; step ③ uses Lemma 2.12(c); step ④ uses the definition of ; step ⑤ uses , and the fact that . Furthermore, we derive for all : .
Part (b). We define , where . Using the definition of , we derive:
where step ① uses , as shown in Theorem 5.6(b); step ② uses the definitions that , , and ; step ③ uses , leading to ; step ④ uses Assumption 5.1 that ; step ⑤ uses for both OADMM-EP and OADMM-RR, as shown in Lemma 5.4; step ⑥ uses the fact that , which implies:
∎
D.4 Proof of Theorem 5.9
Proof.
Using Lemma 5.8(b), we have:
| (57) |
We consider two cases for Inequality (57).
Part (a). . We define , where is a fixed constant.
We define . We define .
Furthermore, We derive:
where step ① uses and ; step ② uses the definition of ; step ③ uses Lemma A.9 that: for all .
Applying Lemma Lemma A.12 with , we have:
Part (b). . We define , and .
We define , where , and .
Notably, we have: for all .
For all , we have from Inequality (57):
where step ① uses the the definition of ; step ② uses the fact that if and ; step ③ uses and . We further obtain:
Applying Lemma A.13 with , we have:
Part (c). Finally, using the fact as shown in Lemma D.3(b), we finish the proof of this theorem.
∎
Appendix E Additional Experiments Details and Results
Datasets. In our experiments, we utilize several datasets comprising both randomly generated and publicly available real-world data. These datasets are structured as data matrices . They are denoted as follows: ‘mnist--’, ‘TDT2--’, ‘sector--’, and ‘randn--’, where generates a standard Gaussian random matrix of size . The construction of involves randomly selecting examples and dimensions from the original real-world dataset, sourced from http://www.cad.zju.edu.cn/home/dengcai/Data/TextData.html and https://www.csie.ntu.edu.tw/~cjlin/libsvm/. Subsequently, we normalize each column of to possess a unit norm and center the data by subtracting the mean, denoted as .
Additional experiment Results. We present additional experimental results in Figures 4, 4, and 5. The figures demonstrate that the proposed OADMM method generally outperforms the other methods, with OADMM-EP surpassing OADMM-RR. These results reinforce our previous conclusions.























