AdaTerm: Adaptive T-Distribution Estimated Robust Moments for Noise-Robust Stochastic Gradient Optimization
Abstract
With the increasing practicality of deep learning applications, practitioners are inevitably faced with datasets corrupted by noise from various sources such as measurement errors, mislabeling, and estimated surrogate inputs/outputs that can adversely impact the optimization results. It is a common practice to improve the optimization algorithm’s robustness to noise, since this algorithm is ultimately in charge of updating the network parameters. Previous studies revealed that the first-order moment used in Adam-like stochastic gradient descent optimizers can be modified based on the Student’s t-distribution. While this modification led to noise-resistant updates, the other associated statistics remained unchanged, resulting in inconsistencies in the assumed models. In this paper, we propose AdaTerm, a novel approach that incorporates the Student’s t-distribution to derive not only the first-order moment but also all the associated statistics. This provides a unified treatment of the optimization process, offering a comprehensive framework under the statistical model of the t-distribution for the first time. The proposed approach offers several advantages over previously proposed approaches, including reduced hyperparameters and improved robustness and adaptability. AdaTerm achieves this by considering the interdependence of gradient dimensions. In particular, upon detection, AdaTerm excludes aberrant gradients from the update process and enhances its robustness for subsequent updates. Conversely, it performs normal parameter updates when the gradients are statistically valid, allowing for flexibility in adapting its robustness. This noise-adaptive behavior contributes to AdaTerm’s exceptional learning performance, as demonstrated through various optimization problems with different and/or unknown noise ratios. Furthermore, we introduce a new technique for deriving a theoretical regret bound without relying on AMSGrad, providing a valuable contribution to the field.
keywords:
Robust optimization , Stochastic gradient descent , Deep neural networks , Student’s t-distribution[label1]organization=Nara Institute of Science and Technology, city=Nara, country=Japan \affiliation[label2]organization=National Institute of Informatics/The Graduate University for Advanced Studies, SOKENDAI, city=Tokyo, country=Japan
1 Introduction
Deep learning [1] has emerged as a highly successful technology in recent years. A significant factor contributing to its success is the widespread adoption of stochastic gradient descent (SGD) algorithms [2] for optimizing deep neural networks. These algorithms utilize first-order gradients computed through the back-propagation technique to update the network parameters, thereby addressing the optimization problem at hand. Therefore, in tandem with the advancement of diverse network architectures such as residual networks [3], various SGD-based optimizers have been pursued that can effectively and reliably optimize these networks. The most representative optimizer is Adam [4], and diverse variants with their respective features have been proposed (see the survey for details in [5, 6]). Among these, RAdam [7] and AdaBelief [8] have illustrated the state-of-the-art (SOTA) learning performance, to the best of our knowledge.
One notable feature of SGD optimizers is their robustness to gradient noise that generally results from the use of noisy datasets containing sensory and mislabeling errors [9, 10]. Moreover, optimization problems that require the use of estimated inputs and/or outputs, such as long-term dynamics learning [11, 12], reinforcement learning (RL) [13], and agents trained using distillation from a trained teacher(s) [14, 15], also suffer from the noise caused by the estimation errors. This feature becomes particularly crucial in robot learning tasks, where the available datasets may be limited in size, augmenting the adverse effects of noise. Additionally, empirical evidence from [16] and [17] has demonstrated that both Adam and SGD exhibit heavy-tailed gradients’ noise, even in the absence of input/output noise.
To address such noise and robustly conduct efficient gradient updates, previous studies have proposed the detection and exclusion of the aberrant gradients affected by noise. In particular, recognizing that the conventional exponential moving average (EMA) momentum used in recent Adam-like optimizers is sensitive to noise owing to its association with a Gaussian distribution, [18] and [19] introduced a novel momentum algorithm called t-momentum that is derived from the Student’s t-distribution. However, the t-momentum approach lacks a unified derivation of all its algorithm components, as described in section 3, leading to certain limitations in its application.
This paper presents a novel Adaptive T-distribution estimated robust moments algorithm, AdaTerm444Code available at https://github.com/kbys-t/adaterm, that addresses the limitations of previous approaches by offering a unified derivation of all the distribution parameters based on their gradients for an online maximum likelihood estimation of the Student’s t-distribution. AdaTerm introduces adaptive step sizes, transforming the gradient-based update of the statistics into an interpolation mechanism between past statistics values and the update amounts. Such adaptive step sizes allow smoothness parameters to be common for all the involved statistics. This is enabled by AdaTerm’s comprehensive integration of the diagonal Student’s t-distribution, allowing the scale estimator to involve every entry and avoiding the independent estimation of scale entries for each variable as in the diagonal Gaussian distribution. In addition, AdaTerm appropriately approximates the gradient of the degrees-of-freedom in the multi-dimensional case based on the behavior observed in the one-dimensional case (since it has been reported that the degrees-of-freedom was unintuitively small in multiple dimensions; see details in [20]).
In order to provide a theoretical basis for the convergence of optimization algorithms, including the proposed AdaTerm, the derivation of a regret bound is required. However, since the introduction of AMSGrad [21], the literature has assumed its usage, even for optimizers that do not practically employ AMSGrad. To address this theoretical and practical contradiction, this paper introduces a new approach for deriving a regret bound without relying on the usage of AMSGrad. This approach can be applied to other optimizers as well, providing a more consistent framework for analyzing the convergence properties of various algorithms. This allows for a more accurate theoretical understanding of the convergence behavior of optimizers, including the proposed AdaTerm.
To summarize, this study presents four-fold contributions:
-
1.
Unified derivation of a novel SGD algorithm that is adaptively robust to noise;
-
2.
Alleviation of the difficulty of tuning multiple hyper-parameters for each statistic (, and ) through replacement with a common and unique smoothness parameter for all the distribution parameters;
-
3.
Theoretical proof of the regret bound without incorporating AMSGrad;
-
4.
Numerical verification of efficacy in major test functions and typical problems such as classification problems with mislabeling, long-term prediction problems, reinforcement learning, and policy distillation.
In the final verification, we compared not only AdaBelief and RAdam as the state-of-the-art algorithms but also t-Adam variants developed in another related study.
2 Problem statement
2.1 Optimization problem
Here, we briefly define the optimization (or minimization, without loss of generality) problem to be solved using either of the SGD optimizers. Suppose that certain input data and output data are generated according to the problem-specific (stochastic) rule, . Accordingly, the problem-specific minimization target, , is given as follows:
| (1) |
where denotes the loss function for each data, and denotes the mapping function (e.g., from to ) with the parameter set that is optimized through this minimization (e.g., network weights and biases).
The above expectation operation can be approximated by the Monte Carlo method. In other words, consider a dataset containing pairs of , , constructed according to the problem-specific rule. Based on , the above minimization target is replaced as follows:
| (2) |
where denotes the size of dataset ( in this case).
2.2 SGD optimizer
To solve the above optimization problem, we can compute the gradient with respect to , , and use gradient descent to obtain the (sub)optimal that (locally) minimizes . However, if is large, the above gradient computation would be infeasible due to the limitation of computational resources. Therefore, the SGD optimizer [2] extracts a subset (also known as mini batch) at each update step , , and updates from to as follows:
| (3) | ||||
| (4) |
where denotes the learning rate, and represents a function used to modify to improve the learning performance. In other words, each SGD-based optimizer have their own .
For example, in the case of Adam [4], the most popular optimizer in recent years, has three hyper-parameters, , , and , and is defined by:
| (5) |
where
| (6) | ||||
| (7) |
where is the element-wise square. A simple interpretation of the aforementioned Adam optimization algorithm is as follows: since fluctuates depending on the sampling method of , the first-order moment smoothens with the past gradients to stabilize the update, and the second-order moment scales , according to the problem, to increase the generality without tuning .
If the problem setting described in section 2.1 is satisfied, we can stably acquire one of the local solutions through one of the SGD optimizers, although their respective regret bounds may be different [21, 22]. However, in real problems, development of datasets that follow the problem-specific rules exactly (i.e., is generated from ) is difficult. In other words, when dealing with real problems, mostly inaccurate datasets , contaminated by improper estimated values, mislabeling errors, etc., are available.
3 Previous work
The ubiquity of imperfect data in practical settings combined with the inherent noisiness of the stochastic gradient has encouraged the propositions of more robust and efficient machine learning algorithms against noisy or heavy-tailed datasets. All these methods can be divided into two main approaches, ranging from methods that produce robust estimates of the loss function, to methods based on the detection and attenuation of incorrect gradient updates [23, 24, 25, 26]. Each approach has its own pros and cons, as summarized in Table 1.
| Approach | ||
|---|---|---|
| Robust Loss Estimation | Robust Gradient Descent | |
| Pros | Robustness independent of batch size | Widely applicable |
| Cons | Usually problem specific | Robustness dependent of batch size and outliers repartition |
| Usually requires the use of all the available data | Relies on only estimates of true gradient | |
| Can be both unstable and costly in high dimensions | ||
As mentioned in the Introduction, we proceed with the latter approach in this study, in view of its wide applicability in machine learning applications. In particular, we extend the concepts pertaining to the use of the Student’s t-distribution as a statistical model that was first proposed by [18] for the gradients of the optimization process. To explicitly highlight the difference between the previous studies (i.e. [18] and [19]) and our current study, we review the previous methods in this section.
3.1 The t-momentum
3.1.1 Overview
Given a variable (e.g. or ), the popular EMA-based momentum underlying the most recent optimization algorithms is defined by , as described in eqs. (6) and (7). This arises from the Gaussian distribution by solving the following equation [18]:
| (8) |
where is the diagonal Gaussian distribution with mean and variance , and is a fixed number of samples (corresponding to the most recent observations) defined by .
Based on this observation, the classical EMA-based momentum (now regarded as the Gaussian-momentum), was replaced by the t-momentum, , obtained by solving the following equation:
| (9) |
where is the diagonal Student’s t-distribution with mean , diagonal scale , and degrees-of-freedom . Subsequently, based on the requirement of a fixed number of samples and the Gaussian limit (as ), the sum was replaced by a decaying sum , where with denoting the -th element of the vector . Note that both eqs. (8) and (9) originate from the maximum log-likelihood (MLL) formulation and provide analytical solutions to the mean estimator.
3.1.2 Limitations of the t-momentum
Nonetheless, in the previous studies, the second-order moment is still based on the regular EMA, i.e., , where is a function of the squared gradient (e.g. for Adam [4] in eq. (7) and for AdaBelief [8]). This is in contrast to its usage in the computation of , which falsely assumes that is also derived from the MLL of the Student’s t-distribution, resulting in the unnatural blending of two statistical models.
Although one could also integrate the t-momentum with the second-order moment, this would require the computation of two “variances”, one for the gradient and the other for the squared gradient function , increasing the overall complexity of the algorithm. Another strategy would be to derive the MLL analytical solution corresponding to the scale of the t-distribution, i.e., , similar to the mean estimator. However, we found this approach to be unstable in practice, as also mentioned in H, and it can result in NaN errors on tasks such as the long-term prediction task.
Finally, the degrees-of-freedom is treated as a hyper-parameter and kept constant throughout the optimization process. This is likely because the MLL formulation of the Student’s t-distribution provides no analytic solution to the degrees-of-freedom estimator. This issue can be connected to the high non-linearity of the distribution with respect to . To alleviate this limitation, the subsequent work [19] proposed the application of the direct incremental degrees-of-freedom estimation algorithm developed by [27] to automatically update the degrees-of-freedom, as discussed below.
3.2 The At-momentum
3.2.1 Overview
As stated, in [19], the authors suggested circumventing the difficulties related to the MLL degrees-of-freedom by adopting a different approach and employing an alternative estimation method that do not require the use of the MLL framework. Indeed, the algorithm developed by Aeschliman et al. [27] and employed in the At-momentum is based on an approximation of and . Specifically, given a -dimensional variable following a Student’s t-distribution with scale , where is a constant and the identity matrix, we have the following results:
where and are the digamma and trigamma functions, respectively, and is the -norm (or Euclidean norm). By setting , the degrees-of-freedom can be estimated by solving the following equation:
Since this equation cannot be solved directly, an approximation of the trigamma function, , is used on the left side and the estimator for the degrees-of-freedom is expressed as follows:
| (10) | ||||
| (11) |
In the previous work [19], the incremental version of this estimator obtained by replacing the arithmetic mean and variance of by EMAs with , was employed to derive the At-momentum.
3.2.2 Limitations of At-momentum
Notably, the direct incremental degrees-of-freedom estimation algorithm was originally developed to utilize specific estimation methods for the location and scale parameters. This again introduces false assumptions, as the degrees-of-freedom estimator assumes that the mean and scale are based on the principles developed by Aeschliman et al. in [27], while they are given as the MLL of Student’s t-distribution and Gaussian distribution, respectively. In the experiment section below, we show that this inconsistency causes insufficient adaptability of the robustness to noise.
3.3 Contributions
| t-momentum | At-momentum | AdaTerm | ||
| Parameters’ origins | Student’s t MLL | Student’s t MLL | Student’s t MLL | |
| Gaussian MLL | Gaussian MLL | Student’s t MLL | ||
| Fixed | Aeschliman et al. [27] | Student’s t MLL | ||
| MLL solution | Analytic | Analytic | Sequential w/ custom step sizes | |
| Decay factors | , | , , |
As explained in the previous paragraphs, the discrepancy in statistical model between the first- and second-order moments and the introduction of a different framework to estimate the degrees-of-freedom creates a chain of equations with different assumptions pertaining to how their defining parameters are obtained. This afflicts the optimization algorithm with certain limitations (e.g. limited robustness and limited adaptability).
In this study, we tackle this lack of unified approach by estimating all the parameters through the unified MLL estimation of the t-distribution. In the previous study, the Student’s t-based EMA of the first-order moment was derived by relying on the analytic solution of the MLL (i.e., by setting the gradient of the log-likelihood to zero and solving explicitly). However, this approach is ill-suited for obtaining the scale and the degrees-of-freedom owing to its practical inefficiency and the absence of a closed-form solution, respectively.
To meet the unification requirement, we propose replacing MLL’s direct solution of the previous studies with a sequential solution based on a gradient ascent algorithm for all the parameters of the Student’s t-model. This new approach has two main advantages: (i) it allows the derivation of an update rule for the degrees-of-freedom that has no close-form solution when one attempts to set its gradient to zero; and (ii) it allows for the use of customized step-sizes that stabilize the components of the algorithm, avoiding the instability of the analytic solution to the scale estimator (i.e., apparition of NaN values, as mentioned in Appendix H). Based on the properties of the t-distribution and the success of the EMA approach for well-behaved datasets, we derive suitable adaptive step sizes to allow for smooth updates. In addition, additional modifications ensure that the algorithm still recovers the EMA in the Gaussian limit and does not violate the positiveness of both the scale and the degrees-of-freedom parameters. As another byproduct of this unified approach, we are able to employ one single decay factor for all the parameters, eliminating the requirement for the usual two distinct decay factors ( and ).
The differences between our algorithm and the previous studies are summarized in Table 2, and the details of the derivation are given in the next section.
4 Derivation of AdaTerm
4.1 The Student’s t-distribution statistical model
To robustly estimate the true average gradient from the disturbed gradients, we model the distribution of these gradients by the Student’s t-distribution, which has a heavy tail and is robust to outliers (as shown in Fig. 1), referring to the related work [18]. Notably, as further motivation for this statistical model, empirical evidence in [16] has shown that the norm of the gradient noise in SGD has heavy tails and [28] revealed that in the continuous-time analysis, the gradient exhibits a stationary distribution following Student’s t-like distributions.

Specifically, in the present study, is assumed to be generated from a -dimensional diagonal Student’s t-distribution, characterized by three types of parameters: a location parameter ; a scale parameter ; and a degrees-of-freedom parameter . That is,
| (12) |
where denotes the gamma function. Following the related work [18] and PyTorch’s implementation [29], AdaTerm is in practice applied to the weight matrix and the bias of each neural network layer separately. Therefore, here corresponds to the dimension size of each subset of parameters (weight or bias of the layer).
4.2 Gradients for the maximum log-likelihood
To derive AdaTerm, let us consider the MLL problem, , to estimate the parameters , , and that can adequately model the most recent observed loss function gradients .
To simplify the notation, the following variables are defined.
When is defined to be proportional to , as in the literature [18], corresponds to the proportionality coefficient. Note that it is not necessary to follow the literature [18] for setting the degrees-of-freedom as . Nonetheless, this procedure is important to provide the same level of robustness to the respective subsets of parameters, regardless of their respective size.
Based on these, the log-likelihood gradients with respect to , , and can respectively be derived as follows:
| (13) | ||||
| (14) | ||||
| (15) |
where the gradients with respect to and are transformed so that the response to outliers can be intuitively analyzed by . denotes the digamma function.
In the previous approach, the gradients would be set to zero to find a direct analytical solution. We instead employ a gradient ascent update rule to solve this MLL problem. Next, we discuss how the adaptive step sizes and the update rule for each one of the parameters are derived to develop the AdaTerm algorithm.
4.3 Online maximum likelihood updates with adaptive step sizes

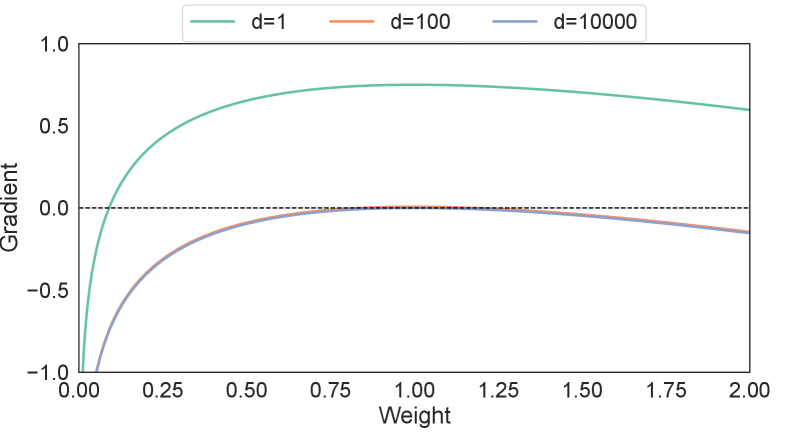
As shown in Fig. 2, the Student’s t-distribution exhibits the property that when , it reverts to a Gaussian distribution. Similarly, when (i.e. ), the AdaTerm optimizer should also yield a non-robust Gaussian optimization algorithm.
Following the success of the EMA scheme in outlier-free optimization, we specifically choose the adaptive step sizes, such that in the Gaussian limit (i.e., when ), the gradient ascent updates of the mean and scale parameters revert to the simple EMA updates given by eq. (6) and eq. (7).
4.3.1 The first-order moment
Since the location parameter can take any value in real space, we can perform unconstrained gradient-based updates without any restriction. The gradient ascent equation is therefore expressed as follows:
| (16) |
where is the update step size to be defined. Because we expect an EMA-like update rule similar to eq. (6), can also be written as:
where is the interpolation factor (or decay factor) satisfying and for . Based on identification with the gradient ascent equation, we can set
Using the second constraint on , i.e., , and the fact that for , we can write the following proposition:
Let be an arbitrary function of such that ; accordingly, satisfies the previous proposition.
To identify a suitable function for our optimizer, we can utilize the first constraint on , i.e., . By replacing the expression for into the expression for , this constraint can be rewritten as follows:
| (17) |
This implies that any function satisfying and will result in a valid step size . In this paper, we consider the simplest version among these functions for which is not a constant, i.e., , where (since by definition).
Based on this, the adaptive step size is expressed as follows:
| (18) |
and the update rule for the first-order moment becomes
| (19) |
where .
4.3.2 Central second-order moment
Similarly, the gradient ascent update rule for the scale parameter is expressed as follows:
| (20) |
where is the update step size, and . Again, we restrict ourselves to an EMA-like update rule similar to eq. (7):
where must satisfy the same constraints as , i.e., and for . The simplicity of this second constraint despite the presence of is because we already have . This leaves only , as found in the Gaussian-based EMA for the variance. Therefore, the derivations for and follow almost exactly the same procedure as performed above for and :
Again, we can use the lowest bound for , i.e., , and set . This results in the following step size:
| (21) |
and the corresponding update rule:
| (22) |
where .
A closer look at this update rule reveals that although for , , the value of can still be negative for . This implies that the update shown above can potentially lead the scale parameter into a negative region during the learning process. This is undesirable since is only defined in the positive real space. There are many ways to satisfy this positive constraint, e.g., reparameterization or the mirror descent (MD) strategies [30]. However, to preserve the EMA-like interpolation directly on the parameter , we simply employ the projected gradient method. Specifically, we use a simple gradient clipping method [31], where we place a lower bound on
| (23) |
where . Such a gradient upper bound is disadvantageous in that it can cause the algorithm to overestimate the scale parameter . In this case, when is larger than the exact value, and becomes smaller and larger, respectively; in other words, the robustness to noise may be impaired. However, this drawback is attenuated by the fact that the scaled learning rate (similar to that of Adam in eq. (5)) is inversely proportional to , rendering the effect of noise insignificant. We also argue that the slow decrease of permitted by the gradient clipping strategy is advantageous in preventing excessive robustness, compared with the case where is analytically estimated (see details in H).
Finally, since , we adopt one common notation for both as . Note that the past work uses the discounted sum of , , by storing it in memory; however, in AdaTerm, is used instead, saving memory.
4.3.3 Degrees-of-freedom
Simplifying the gradient
Compared with and , the update rule of is considerably more delicate to handle. In particular, when the positive constraint on is violated by a simple gradient ascent update cannot be identified. This is mainly due to the digamma function . Hence, the first step is to eliminate it from the problem. In this study, we use the upper and lower bounds of to find the upper bound of the gradient with respect to . Specifically, the upper and lower bounds of are expressed as follows:
implying that we can define an upper-bound for as .
Fig. 3 shows the curves traced by the two equations as a function of , for different values of (given that for our application with typically ). As can be seen, for large values of , which is generally the case for neural networks (NN), the defined upper-bound tightens. For (which can occur for the NN biases), the gap evaluated in the range , is at most and occurs when .

Although the use of an upper bound can impair the noise robustness in theory (as in the case of ), the relative small gap shown in Fig. 3 hardly impairs this in practice. Therefore, the following upper bound for eq. (15) can be defined:
| (24) |
where .
Tackling the curse of dimensionality
The overestimated gradient of the previous paragraph is simple and its behavior is easy to analyze. Notably, the behavior of the overestimated gradient is considerably affected by , as shown in Fig. 4 with (i.e. ). As can be seen, when , the gradient with respect to is negative only when is exceedingly small, corresponding to an extremely large deviation . In this case, the negative gradient effectively decreases to exclude the noisy gradients of the network’s parameters . Conversely, for small deviations , the gradient in (24) becomes positive and is increased to suppress the robustness and easily update the parameters.
Unfavorably, with , which is common for a NN’s weights matrix, the gradient of eq. (24) is always negative and almost zero even when , implying that can only decrease. The same phenomenon occurs even for , whose curve is practically indistinguishable from the curve of . Such a pessimistic behavior is consistent with the non-intuitive behavior of the multivariate Student’s t-distribution reported in the literature [20]. This problem has also been empirically confirmed in [19], where the excessive robustness is forcibly suppressed by correcting the obtained (approximated) estimate by multiplying it with .
To alleviate this problem, we further consider an upper bound, where is replaced by . This choice is further supported by the fact that does not appear directly in any of the other MLL gradients, implying that directly dealing with the gradient with respect to is more natural. The above modifications are summarized below.
| (25) |
Where the second line is obtained by using . This new upper bound can be interpreted as an approximation of the multivariate distribution by a univariate distribution and allows the degrees-of-freedom to increase even for large dimensions when is small (i.e., is large). Although it is possible to model the distribution as a univariate distribution from the beginning of the derivation [32], the robustness may be degraded, since it would capture the average without focusing on the amount of deviation along each axis.
Update rule
Based on this upper bound, we now proceed to the derivation of a suitable update rule for the robustness parameter . We draw similarities with the update rules obtained previously for and and set our goal to an EMA-like equation with an adaptive smoothness parameter , where . We aim for the following update rule:
| (26) |
where is some function of . To derive such an equation, we focus first on and particularly on determining the maximum value of , .
We begin by noticing that is a convex function over with a minimum value at . The maximum value is therefore determined when is the largest () or smallest (). The largest value has already been derived as ; however, the smallest value cannot exactly be given since when . Therefore, instead of the exact minimum value, we employ the tiny value of float that is the closest to zero numerically (in the case of float32, ). In summary, the maximum , , can be defined as follows:
| (27) |
If we design the step size with , we can obtain an interpolation update rule for similar to and . However, although the minimum value of is expected to be positive, an excessive robustness could inhibit the learning process. Thus, it is desirable that the user retain a certain level of control on the extent of robustness the algorithm is allowed to achieve. Therefore, our final step is to transform with a user-specified minimum value, , and the deviation, , automatically controlled by the algorithm. With this transformation, the appropriate step size satisfies the following:
| (28) |
where the right side of the second equality is obtained from eq. (26) by replacing with and using . Substituting by its expression from eq. (25) and using , the following equalities are obtained:
| (29) |
From this, we can derive
| (30) | ||||
| (31) |
along with the update rule for :
Finally, by adding to both sides, we can directly obtain the update rule for .
| (32) | ||||
| (33) | ||||
| (34) |
Note that the minimum value of is given by , such that is always satisfied. This process also prevents from becoming and stopping the update of .
4.4 Algorithm
Finally, the update amount of the optimization parameters for AdaTerm is expressed as follows:
| (35) |
Unlike Adam [4], the small amount usually added to the denominator, , is removed, since in our implementation.
The pseudo-code of AdaTerm555AdaTerm’s t-momentum requires scale estimation and would incur a higher cost if integrated into the pure SGD algorithm. Therefore, we omit it in this study and only consider a variant of the Adam algorithm. is summarized in Alg. 1. The regret bound is also analyzed based on a novel approach different from the literature [21] in A, through combination of the approach proposed by [22], with a novel method based on the Lemma A.1, to eliminate the AMSGrad assumption from the regret analysis.
4.5 Behavior analysis
4.5.1 Convergence analysis
Our convergence proof adopts the approach highlighted in [22]. As such, we start by enunciating the same assumptions:
Assumption 4.1.
Necessary assumptions:
-
1.
is a compact convex set
-
2.
is a convex lower semicontinuous (lsc) function
-
3.
has a bounded diameter, i.e. , and
Following the convergence result, the proof of which can be found in A, the following holds true:
Theorem 4.2.
Let be the value of at time step and let , . Under Assumption 4.1, and with , , AdaTerm achieves a regret , such that
| (36) | ||||
Corollary 4.3 (Non-robust case regret bound).
If , then . Then, the regret becomes:
| (37) | ||||
Note the similarity between this regret bound and the one derived by [21] and by [8] using AMSGrad. In particular, this regret can be bounded by , and thus, the regret is upper-bounded by a minimum of . This leads to the worst-case dependence of the regret on to remain , although AMSGrad is not used.
We emphasize that this approach to the regret bound is not specific to AdaTerm but can be used to bound the regret of other moment-based optimizers, including Adam and AdaBelief.
4.5.2 Qualitative robustness behavior analysis
In AdaTerm, the robustness to noise is qualitatively expressed differently from the previous studies [18, 19], owing to the following two factors.
First, is now updated robustly depending on , ensuring that the observation of aberrant gradients would not cause a sudden increase in the scale parameter and inadvertently loosen the threshold for other aberrant update directions in the next and subsequent steps. In addition, the update of the scale is expected to self-coordinate among the axes, by virtue of the inter-dependency between all of the parameters when estimating the scale.
Indeed, in a diagonal Gaussian distribution, the scale for each axis can and is estimated independently; however, in a diagonal Student’s t-distribution, each entry of the scale also depends on the previous value of the other entries, leading to a coordinated update of the scales. This inter-dependency exists thanks to the Mahalanobis distance metric and its intervention in the weight computation .
Specifically, as illustrated in Fig. 5, if an anomaly is detected only along a particular axis (e.g., points red and green in Fig. 5), the corresponding entry of the vector becomes larger, causing the associated entry of to increase. This in turn would mitigate the anomaly detection of the next step (i.e., a gradient far from the current location estimate would be attributed a higher weight , since the squared Mahalanobis distance will be overall smaller). Conversely, if anomalies are detected on most of the axes (e.g., violet point in Fig. 5), will become smaller () and either prevent any further increase in or cause it to decrease. This would prompt the algorithm to treat a larger number of the further gradients as anomalies ( becomes overall larger, implying is smaller) as described above. Such adaptive and coordinated behavior would yield stable updates even if is smaller than the conventional (set to be in most optimizers).

Secondly, as illustrated in Fig. 6, the robustness indicator is increased when the deviation is small (i.e., when the observed gradient is not an aberrant value). Indeed, in this case, becomes larger and becomes positive. However, the increased speed will be limited by , owing to its inclusion in the step size . In contrast, if an aberrant value is observed, and decreases, such that becomes negative.

An intuitive visualization of the described behavior obtained by the AdaTerm equations for and can also be found in B.
Overall, although the robustness-tuning mechanism replaces the MLL gradient by the upper bounds, it still behaves conservatively and can be expected to retain its excellent robustness to noise, as illustrated in Fig. 7.

As a final remark, if , the robustness is lost by design, and AdaTerm essentially matches a slightly different version of AdaBelief exhibiting performance difference as a result of the simplification of the hyper-parameters () and the variance computation mechanism (AdaBelief estimates , whereas AdaTerm estimates , which is the usual variance estimator). Therefore, in problems where AdaBelief would be effective, AdaTerm would perform effectively as well.
5 Simulation benchmarks
Before solving more practical problems, we analyze the behavior of AdaTerm through minimization of typical test functions, focusing mainly on the adaptiveness of the robustness parameter and the convergence profile.
To evaluate its adaptiveness, in all simulations and experiments, the initial in At-Adam is set to be the same value used in t-Adam. Furthermore, although many SGD-based optimization algorithms are available, in this study, we focus on comparing AdaTerm against the two related works (t-momentum-based Adam - t-Adam [18] - and At-momentum-based Adam - At-Adam [19] -)666Employed implementation can be found at https://github.com/Mahoumaru/t-momentum and include only the results from Adam [4], AdaBelief [8], and RAdam [23] as references for non-robust optimization.
5.1 Analysis based on test functions


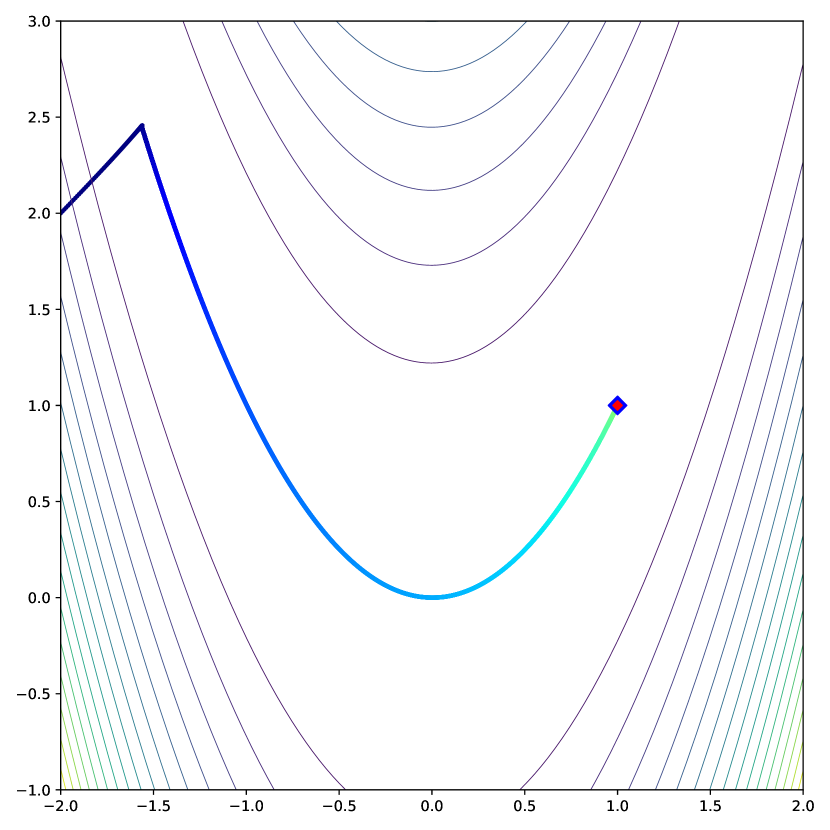
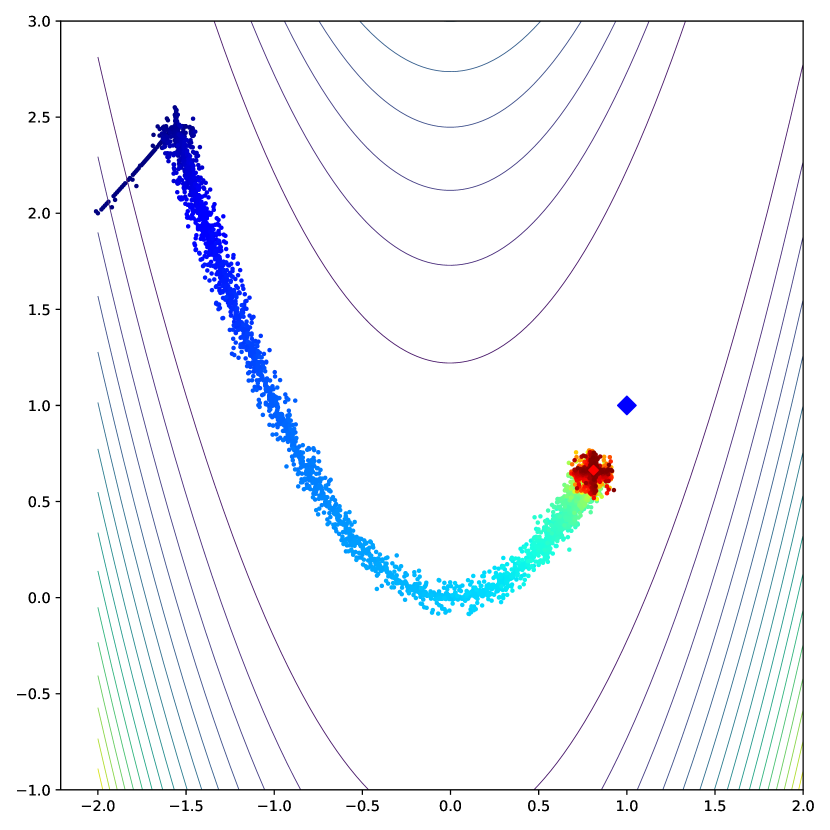
In this task, our aim is to determine the minimum point of a two-dimensional potential field (benchmark function) by relying on the field gradients. To analyze the robustness of the optimization algorithms, a uniformly distributed noise () is added at a specified ratio to the point coordinates. The results are summarized in Figs. 8 and 9 (details are in C).
Fig. 8 shows the error norm from the analytically-optimal point, revealing that AdaTerm’s convergence accuracy on the McCormick function was not effective in the lower noise ratio, probably due to the large learning rate. However, on the other fields, AdaTerm was able to maintain the standard update performance while mitigating the adverse effects of the added noise.
The performance of Adam [4] significantly degraded when noise was introduced, indicating its sensitivity to noise. On the Michalewicz function, At-Adam [19] attributes the steep gradients near the optimal value to noise and tends to exclude them; thus, the optimal solution is not obtained. This result implies that the automatic mechanism for tuning employed by At-Adam has insufficient robustness adaptability to noise.
Indeed, the final plotted in Fig. 9 shows that the robustness parameter converges to a nearly constant value with At-Adam, independently of the noise ratio. In contrast, in AdaTerm, the degrees-of-freedom is inversely proportional to the noise ratio; thus, the typical behavior of increase in under minimal noise and decrease under the condition of a high noise ratio is observed.
5.2 Robustness on regression task
Problem settings
Following the same process as in [18], we consider the problem of fitting a ground truth function given noisy observations with expressed as:
| (38) |
where designates a Student’s t-distribution with degrees-of-freedom , location , and scale ; is a Bernoulli distribution with the ratio as its parameter. trials with different random seeds are conducted for each noise ratio and each optimization method, using pairs sampled as observations and split into batches of size . This batch size is chosen arbitrarily as being neither exceedingly large nor exceedingly small with respect to the full dataset size.
The model used is a fully connected neural network with linear layers, each composed of neurons, equipped with an ReLU activation function [33] for all the hidden layers. The training and the test loss functions are the mean squared error (MSE) applied on and , respectively, where is the network’s estimate given .
Result
The test loss against the noise ratio is plotted in Fig. 10. As can be observed, AdaTerm performed even more robustly than t-Adam and At-Adam and was able to maintain its prediction loss almost constant across all values of noise ratio. The effect of batch size on the learning performance is also studied and can be found in F.

6 Experiments
6.1 Configurations of practical problems
After verifying the optimization efficiency and robustness on certain test functions and a regression task with artificial noise, we now investigate four practical benchmark problems to evaluate the performance of the proposed algorithm, AdaTerm. Details of the setups (e.g., network architectures) can be found in D.
For each method, 24 trials are conducted with different random seeds, and the mean and standard deviation of the scores for the respective benchmarks are evaluated. All the test results after learning can be found in Table 3. An ablation test was also conducted for AdaTerm, as summarized in E.
6.1.1 Classification of mislabeled CIFAR-100
The first problem is an image classification problem with the CIFAR-100 dataset. As artificial noise, a proportion of the labels (0 % and 10 %) of the training data was randomized to differ from the true labels. As a simple data augmentation during the training process, random horizontal flip is introduced along with four paddings.
The loss function is the cross-entropy. To stabilize the learning performance, we utilize the label smoothing technique [34], a regularization tool for deep neural networks. It involves the generation of “soft” labels by applying a weighted average between a uniform distribution and the “hard” labels. In our experiments, the degree of smoothing is set to 20%, in reference to the literature [35].
6.1.2 Long-term prediction of robot locomotion
The second problem is a motion-prediction problem. The dataset used was sourced from the literature [36]. It contains 150 trajectories as training data, 25 trajectories as validation data, and 25 trajectories as test data, all collected from a hexapod locomotion task with 18 observed joint angles and 18 reference joint angles. An agent continually predicts the states within the given time interval (1 and 30 steps) from the initial true state and the subsequent predicted states. Therefore, the predicted states used as inputs deviate from the true states and become noise in the learning process.
For the loss function, instead of the commonly used mean squared error (MSE), we employ the negative log likelihood (NLL) of the predictive distribution, allowing the scale difference of each state to be considered internally. The NLL is computed at each prediction step, and their sum is used as the loss function. Because of the high cost of back-propagation through time (BPTT) over the entire trajectory, truncated BPTT (30 steps on average) [37, 38] is employed.
6.1.3 Reinforcement learning on Pybullet simulator
The third problem is RL performed on the Pybullet simulation engine using OpenAI Gym [39, 40] environments. The tasks to be solved are Hopper and Ant, both of which require an agent to move as straight as possible on a flat terrain. As mentioned before, RL relies on estimated values in behalf of the absence of true target signals. This can easily introduce noise in the training.
The implemented RL algorithm is an actor-critic algorithm based on the literature [41]. The agent only learns after each episode using an experience replay. This experience replay samples 128 batches after each episode, and its buffer size is set to be sufficiently small (at 10,000) to reveal the influence of noise.
6.1.4 Policy distillation by behavioral cloning
The fourth problem is policy distillation [14]; a method used to replicate the policy of a given RL agent by training a smaller and computationally more efficient network to perform at the expert level. Three policies for Ant properly trained on the RL problem above were considered as experts, and 10 trajectories of state-action pairs were collected for each policy. We also collected, as non-expert (or amateur) demonstrations, three trajectories from one policy that fell into a local solution. In the dataset constructed with these trajectories, not only the amateur trajectories but also the expert trajectories could be non-optimal in certain situations, thereby leading to noise.
The loss function is the negative log likelihood of the policy according to behavioral cloning [42], which is the simplest imitation learning method. In addition, a weight decay is added to prevent the small networks (i.e., the distillation target) from over-fitting particular behaviors.
6.2 Analysis of results of practical problems
| Classification | Distillation | Prediction | RL | |||||
|---|---|---|---|---|---|---|---|---|
| Accuracy | The sum of rewards | MSE at final prediction | The sum of rewards | |||||
| Methods | 0 % | 10 % | w/o amateur | w/ amateur | 1 step | 30 steps | Hopper | Ant |
| Adam | 0.7205 | 0.6811 | 1686.94 | 1401.01 | 0.0321 | 1.1591 | 1539.06 | 863.31 |
| (4.33e-3) | (4.93e-3) | (2.34e+2) | (2.39e+2) | (4.48e-4) | (1.04e-1) | (5.64e+2) | (4.01e+2) | |
| AdaBelief | 0.7227 | 0.6799 | 1731.51 | 1344.23 | 0.0320 | 1.2410 | 1152.10 | 692.68 |
| (5.56e-3) | (3.94e-3) | (1.88e+2) | (2.75e+2) | (5.67e-4) | (1.34e-1) | (5.48e+2) | (1.17e+2) | |
| RAdam | 0.7192 | 0.6797 | 1574.13 | 1258.10 | 0.0328 | 1.1218 | 1373.85 | 871.23 |
| (4.28e-3) | (3.41e-3) | (2.86e+2) | (2.70e+2) | (3.55e-4) | (1.36e-1) | (7.55e+2) | (3.57e+2) | |
| t-Adam | 0.7174 | 0.6803 | 1586.99 | 1347.29 | 0.0320 | 1.1048 | 1634.20 | 2272.58 |
| (5.67e-3) | (3.10e-3) | (2.06e+2) | (2.11e+2) | (4.09e-4) | (2.66e-1) | (4.52e+2) | (3.20e+2) | |
| At-Adam | 0.7178 | 0.6811 | 1611.23 | 1347.51 | 0.0319 | 1.1075 | 1523.37 | 2213.75 |
| (4.21e-3) | (4.03e-3) | (2.25e+2) | (2.67e+2) | (3.14e-4) | (1.97e-1) | (5.48e+2) | (2.31e+2) | |
| AdaTerm | 0.7315 | 0.6815 | 1770.17 | 1411.02 | 0.0335 | 1.0016 | 1550.25 | 2021.37 |
| (Ours) | (3.66e-3) | (4.46e-3) | (2.17e+2) | (1.92e+2) | (3.09e-4) | (2.31e-1) | (5.88e+2) | (3.87e+2) |
To analyze the experimental results, we divide the four tasks into two cases depending on the composition of the dataset and the origin of the inaccuracies:
-
1.
In the first class of problems, the corrupted dataset is such that it can be partitioned into two subsets of accurate and noisy observations, i.e. where is the noisy subset.
-
2.
In the second class, the corruption extends to the entire dataset, either due to a stationary noise distribution or a dynamic noise distribution.
6.2.1 Case 1 Tasks:
This first case comprises of the classification and distillation tasks. In the classification task, the subset data (0% or 10%) with randomized labels constitutes the corrupted subset , and in the distillation task, corresponds to the amateur demonstrations. This subdivision holds even though what we consider to be the uncorrupted data may contain noise (CIFAR-100 contains general images that are prone to imperfections, and similarly, the RL expert policies are stochastic) because these corruptions are not as problematic as the ones mentioned previously.
In these types of tasks, adaptiveness is primordial because the proportion of is typically unknown in advance. As can be seen in the left part of Table 3, the non-robust optimizers (Adam, AdaBelief and RAdam) outperform the fixed-robustness t-Adam and the low-adaptive-capability At-Adam when the proportion of is small (0% and w/o amateur). Furthermore, although At-Adam exhibits a low level of adaptiveness, the adaptiveness nevertheless results in a better performance compared to t-Adam. In contrast, when the proportion of increases (10% and w/ amateur), the robust optimizers lead in terms of average performance. Notably, At-Adam still outperforms t-Adam, which uses the most robust version of the algorithm with its degrees-of-freedom fixed at . Finally, we observe that AdaTerm’s adaptive ability allows it to outperform both the other non-robust and robust optimizers under all dataset conditions considered. Its better performance over non-robust optimizers even without corruption can be attributed to the natural imperfections mentioned earlier, implying that a small level of robustness () is still desirable during the optimization process even in the absence of notable corruption.
6.2.2 Case 2 Tasks:
The prediction and RL tasks constitute the second case. Indeed, the estimators and approximators used in these types of tasks are a constant source of noise and corruptions. Although such noise can be suspected to be stronger in the earlier stages of learning, their prevalence may necessitate an optimizer that maintains its a constant robustness.
This preference can be observed on the right side of Table 3. Indeed, the robust optimizers lead by performance, achieving the lowest prediction errors in the 1-step and 30-step prediction and the highest scores in the Hopper and Ant environments.
Although the single-step prediction task is a relatively simple supervised learning approach that does not necessitate a high robustness to noise, the performance of AdaTerm is the worst among all algorithms. We postulate that, similar to the error norm of the McCormick function in Fig. 8, the exceedingly high learning rate caused by contributes to the performance degradation. In contrast, in the 30-step prediction task, only AdaTerm succeeds in achieving a MSE of approximately . As a consequence of the inaccurate estimated inputs, particularly in the earlier stages of learning, this task challenges the ability of the optimization algorithm to ignore aberrant gradient update directions. However, as learning progresses, the accuracy of the estimated inputs improves, and the noise robustness gradually becomes less critical.
For the RL tasks, although AdaTerm did not exhibit the best performance, we can confirm its usefulness from two facts: (i) it demonstrated the second-best performance in Hopper task, and (ii) Ant task was only successful with noise-robust optimizers. This particular task highlights a common drawback of adaptive methods compared with methods based on the right assumption (whether or not robustness will be needed in the considered problem). The inferior performance of the non-robust optimizers indicate the prevalence of noise in RL tasks. Therefore, t-Adam unsurprisingly exhibits the best performance in such situation where robustness is critical. t-Adam was followed closely by At-Adam in the Ant task (clearly, from the results of the non-robust algorithms, the most challenging in terms of noisiness) thanks to its low adaptiveness (similarly to Fig. 9), enabling it to maintain its robustness level close to that of At-Adam during the learning process. Regardless, it was outperformed by AdaTerm (and Adam) on the Hopper.
In summary, the experiments show that AdaTerm interpolates between or prevails over the performance of non-robust and robust optimizers when encountering practical and noisy problems.
7 Discussion
The above experiments and simulations demonstrated the robustness and adaptability improvement of AdaTerm compared with the related works. However, we discuss its limitations below.
7.1 Performance and drawbacks of AdaTerm
As can be seen in Fig. 8 and on the right part of Table 3, there is a drawback of using AdaTerm on a noise-free optimization problems when compared with a non-robust optimizer, such as Adam, and similarly on full-noise problems compared with a fixed-robust optimizer, such as t-Adam. These results show that in the absence of noise (respectively in the presence of abundant noise), employing an optimization method that assumes the absence of aberrant data points (respectively the presence of worst-case noisy data) from the beginning can afford better results on noise-free (respectively on extremely noisy) problems. This is to be expected from an adaptive method such as AdaTerm, which inevitably requires a non-zero adaptation time to converge to a non-robust behavior or may relax its robustness during the learning process before hitting an extremely noisy set of gradients necessitating a fixed high robustness.
Nevertheless, the overall results indicate that the drawback or penalty incurred from using the AdaTerm algorithm instead of Adam or AdaBelief in the case of noise-free applications or t-Adam in the case of high-noise applications is not a significant problem when considering its ability to adapt to different unknown noise ratios. This is particularly why algorithms are equipped with adaptive parameters.
When encountering a potentially noise-free problem, AdaTerm allows setting a large initial value for the degrees-of-freedom and during the course of the training process, the algorithm will decide if the dataset is indeed noise-free and adapt in consequence. Similarly, if there is uncertainty pertaining to the noisiness of the task at hand, the practitioner can directly execute the algorithm and let it automatically adapt to the problem. Such freedom is only possible thanks to the adaptive capability of AdaTerm as clearly displayed in Fig. 9, and the resulting performance is guaranteed to be sub-optimal with respect to the true nature of the problem.
7.2 Gap between theoretical and experimental convergence analysis
Although Theorem 4.2 provides a theoretical upper bound on the regret achieved by AdaTerm; as a typical approach to convergence analysis, it completely eludes the robustness factor introduced by AdaTerm. In particular, Corollary 4.3 provides a more effective bound compared with Theorem 4.2 that is in contrast to the practical application (as displayed in the ablation study of E). This implies a gap between the theoretical and experimental analyses and is anchored on the fact that the theoretical bound relies on .
As a remedy to this shortcoming of the regret analysis, we have employed (in section 4.5.2) an intuitive analysis of the robustness factor based on the behavior of the different components of our algorithm. Although this qualitative analysis possesses a weak theoretical convergence value, the experimental analysis against different noise settings shows that AdaTerm is not only robust but also efficient as an optimization algorithm. Nevertheless, we acknowledge the requirement for a stronger theoretical analysis that considers the noisiness of the gradients, while allowing for a theoretical comparison between the robustness and efficiency of different optimizers.
7.3 Normalization of gradient
By considering the gradients to be generated from Student’s t-distribution, AdaTerm normalizes the gradients (more precisely, its first-order moment) using the estimated scale, instead of the second-order moment. This is similar to the normalization of AdaBelief, as mentioned before. However, as shown in G, the normalization with the second-order moment can exhibit better performances in certain circumstances.
Since the second-order moment is larger than the scale, the normalization by the second-order moment renders the update conservative, while the one by the scale is expected to break through the stagnation of updates. While both characteristics are important, the answer to the question “which one is desirable?” remains situation-dependent. Therefore, we need to pursue the theory concerning this point and introduce a mechanism to adaptively switch the use of both normalization approach according to the required characteristics.
8 Conclusion
In this study, we presented AdaTerm, an optimizer adaptively robust to noise and outliers for deep learning. AdaTerm models the stochastic gradients generated during training using a multivariate diagonal Student’s t-distribution. Accordingly, the distribution parameters are optimized through the surrogated maximum log-likelihood estimation. Optimization of test functions reveals that AdaTerm can adjust its robustness to noise in accordance with the impact of noise. Through the four typical benchmarks, we confirmed that the robustness to noise and the learning performance of AdaTerm are comparable to or better than those of conventional optimizers. In addition, we derived the new regret bound for the Adam-like optimizers without incorporating AMSGrad.
This study focused on computing the moments of the t-distribution; however, in recent years, the importance of integration with raw SGD (i.e., decay of scaling in Adam-like optimizers) has been confirmed [43, 17]. Therefore, we will investigate a natural integration of AdaTerm and the raw SGD by reviewing that may enable the normalization to be constant. In addition, as mentioned in the discussion, a new framework for analyzing optimization algorithms both in terms of robustness and efficiency (such that they can be compared)is required. One such analysis was performed by [44] on SGD; however, its extension to momentum-based optimizers and its ability to allow theoretical comparison across different algorithms remain limited. Therefore, we will seek a similar but better approach in the future, e.g. via trajectory analysis [45], that can be applied to analyze the robustness and efficiency of different optimization algorithms, including AdaTerm. Finally, latent feature analysis methods [46] have attracted extensive attention in recent years. The use of AdaTerm in such approaches is therefore an interesting field of study that we will investigate in the future.
Acknowledgements
This work was supported by JSPS KAKENHI, Grant-in-Aid for Scientific Research (B), Grant Number JP20H04265.
References
- [1] Y. LeCun, Y. Bengio, G. Hinton, Deep learning, Nature 521 (7553) (2015) 436–444.
- [2] H. Robbins, S. Monro, A stochastic approximation method, The Annals of Mathematical Statistics (1951) 400–407.
- [3] K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, in: IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 770–778.
- [4] D. P. Kingma, J. Ba, Adam: A method for stochastic optimization, arXiv preprint arXiv:1412.6980 (2014).
- [5] S. Sun, Z. Cao, H. Zhu, J. Zhao, A survey of optimization methods from a machine learning perspective, IEEE Transactions on Cybernetics 50 (8) (2019) 3668–3681.
- [6] R. M. Schmidt, F. Schneider, P. Hennig, Descending through a crowded valley-benchmarking deep learning optimizers, in: International Conference on Machine Learning, PMLR, 2021, pp. 9367–9376.
- [7] L. Liu, H. Jiang, P. He, W. Chen, X. Liu, J. Gao, J. Han, On the variance of the adaptive learning rate and beyond, arXiv preprint arXiv:1908.03265 (2019).
- [8] J. Zhuang, T. Tang, Y. Ding, S. C. Tatikonda, N. Dvornek, X. Papademetris, J. Duncan, Adabelief optimizer: Adapting stepsizes by the belief in observed gradients, Advances in Neural Information Processing Systems 33 (2020) 18795–18806.
- [9] K. Mirylenka, G. Giannakopoulos, L. M. Do, T. Palpanas, On classifier behavior in the presence of mislabeling noise, Data Mining and Knowledge Discovery 31 (2017) 661–701.
- [10] M. Suchi, T. Patten, D. Fischinger, M. Vincze, Easylabel: A semi-automatic pixel-wise object annotation tool for creating robotic rgb-d datasets, in: International Conference on Robotics and Automation, IEEE, 2019, pp. 6678–6684.
- [11] R. T. Chen, Y. Rubanova, J. Bettencourt, D. Duvenaud, Neural ordinary differential equations, Vol. 31, 2018, pp. 6572–6583.
- [12] M. Kishida, M. Ogura, Y. Yoshida, T. Wadayama, Deep learning-based average consensus, IEEE Access 8 (2020) 142404–142412.
- [13] R. S. Sutton, A. G. Barto, Reinforcement learning: An introduction, MIT press, 2018.
- [14] A. A. Rusu, S. G. Colmenarejo, C. Gulcehre, G. Desjardins, J. Kirkpatrick, R. Pascanu, V. Mnih, K. Kavukcuoglu, R. Hadsell, Policy distillation, arXiv preprint arXiv:1511.06295 (2015).
- [15] J. Gou, B. Yu, S. J. Maybank, D. Tao, Knowledge distillation: A survey, International Journal of Computer Vision 129 (6) (2021) 1789–1819.
- [16] U. Simsekli, L. Sagun, M. Gurbuzbalaban, A tail-index analysis of stochastic gradient noise in deep neural networks, in: International Conference on Machine Learning, PMLR, 2019, pp. 5827–5837.
- [17] P. Zhou, J. Feng, C. Ma, C. Xiong, S. C. H. Hoi, et al., Towards theoretically understanding why sgd generalizes better than adam in deep learning, Advances in Neural Information Processing Systems 33 (2020) 21285–21296.
- [18] W. E. L. Ilboudo, T. Kobayashi, K. Sugimoto, Robust stochastic gradient descent with student-t distribution based first-order momentum, IEEE Transactions on Neural Networks and Learning Systems 33 (3) (2020) 1324–1337.
- [19] W. E. L. Ilboudo, T. Kobayashi, K. Sugimoto, Adaptive t-momentum-based optimization for unknown ratio of outliers in amateur data in imitation learning, in: IEEE/RSJ International Conference on Intelligent Robots and Systems, IEEE, 2021, pp. 7851–7857.
- [20] C. Ley, A. Neven, The value at the mode in multivariate distributions: a curiosity or not?, arXiv preprint arXiv:1211.1174 (2012).
- [21] S. J. Reddi, S. Kale, S. Kumar, On the convergence of adam and beyond, arXiv preprint arXiv:1904.09237 (2019).
- [22] A. Alacaoglu, Y. Malitsky, P. Mertikopoulos, V. Cevher, A new regret analysis for adam-type algorithms, in: International Conference on Machine Learning, PMLR, 2020, pp. 202–210.
- [23] C. Gulcehre, J. Sotelo, M. Moczulski, Y. Bengio, A robust adaptive stochastic gradient method for deep learning, in: International Joint Conference on Neural Networks, IEEE, 2017, pp. 125–132.
- [24] M. J. Holland, K. Ikeda, Efficient learning with robust gradient descent, Machine Learning 108 (8) (2019) 1523–1560.
- [25] A. Prasad, A. S. Suggala, S. Balakrishnan, P. Ravikumar, Robust estimation via robust gradient estimation, Journal of the Royal Statistical Society: Series B (Statistical Methodology) 82 (3) (2020) 601–627.
- [26] K.-S. Kim, Y.-S. Choi, Hyadamc: A new adam-based hybrid optimization algorithm for convolution neural networks, Sensors 21 (12) (2021) 4054.
- [27] C. Aeschliman, J. Park, A. C. Kak, A novel parameter estimation algorithm for the multivariate t-distribution and its application to computer vision, in: European Conference on Computer Vision, Springer, 2010, pp. 594–607.
- [28] L. Ziyin, K. Liu, T. Mori, M. Ueda, Strength of minibatch noise in sgd, arXiv preprint arXiv:2102.05375 (2021).
- [29] A. Paszke, S. Gross, S. Chintala, G. Chanan, E. Yang, Z. DeVito, Z. Lin, A. Desmaison, L. Antiga, A. Lerer, Automatic differentiation in pytorch, in: Advances in Neural Information Processing Systems Workshop, 2017.
- [30] A. Beck, M. Teboulle, Mirror descent and nonlinear projected subgradient methods for convex optimization, Operations Research Letters 31 (3) (2003) 167–175.
- [31] E. Gorbunov, M. Danilova, A. Gasnikov, Stochastic optimization with heavy-tailed noise via accelerated gradient clipping, Advances in Neural Information Processing Systems 33 (2020) 15042–15053.
- [32] T. Kobayashi, W. E. L. Ilboudo, t-soft update of target network for deep reinforcement learning, Neural Networks 136 (2021) 63–71.
- [33] W. Shang, K. Sohn, D. Almeida, H. Lee, Understanding and improving convolutional neural networks via concatenated rectified linear units, in: International Conference on Machine Learning, PMLR, 2016, pp. 2217–2225.
- [34] C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, Z. Wojna, Rethinking the inception architecture for computer vision, in: IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 2818–2826.
- [35] M. Lukasik, S. Bhojanapalli, A. Menon, S. Kumar, Does label smoothing mitigate label noise?, in: International Conference on Machine Learning, PMLR, 2020, pp. 6448–6458.
- [36] T. Kobayashi, q-vae for disentangled representation learning and latent dynamical systems, IEEE Robotics and Automation Letters 5 (4) (2020) 5669–5676.
- [37] G. Puskorius, L. Feldkamp, Truncated backpropagation through time and kalman filter training for neurocontrol, in: IEEE International Conference on Neural Networks, Vol. 4, IEEE, 1994, pp. 2488–2493.
- [38] C. Tallec, Y. Ollivier, Unbiasing truncated backpropagation through time, arXiv preprint arXiv:1705.08209 (2017).
- [39] G. Brockman, V. Cheung, L. Pettersson, J. Schneider, J. Schulman, J. Tang, W. Zaremba, Openai gym, arXiv preprint arXiv:1606.01540 (2016).
- [40] E. Coumans, Y. Bai, Pybullet, a python module for physics simulation for games, robotics and machine learning, GitHub repository (2016).
- [41] T. Kobayashi, Proximal policy optimization with adaptive threshold for symmetric relative density ratio, Results in Control and Optimization 10 (2023) 100192.
- [42] M. Bain, C. Sammut, A framework for behavioural cloning., in: Machine Intelligence 15, 1995, pp. 103–129.
- [43] L. Luo, Y. Xiong, Y. Liu, X. Sun, Adaptive gradient methods with dynamic bound of learning rate, arXiv preprint arXiv:1902.09843 (2019).
- [44] K. Scaman, C. Malherbe, Robustness analysis of non-convex stochastic gradient descent using biased expectations, Advances in Neural Information Processing Systems 33 (2020) 16377–16387.
- [45] M. Sandler, A. Zhmoginov, M. Vladymyrov, N. Miller, Training trajectories, mini-batch losses and the curious role of the learning rate, arXiv preprint arXiv:2301.02312 (2023).
- [46] X. Luo, Y. Yuan, S. Chen, N. Zeng, Z. Wang, Position-transitional particle swarm optimization-incorporated latent factor analysis, IEEE Transactions on Knowledge and Data Engineering 34 (8) (2020) 3958–3970.
- [47] J. Chung, C. Gulcehre, K. Cho, Y. Bengio, Empirical evaluation of gated recurrent neural networks on sequence modeling, arXiv preprint arXiv:1412.3555 (2014).
- [48] J. L. Ba, J. R. Kiros, G. E. Hinton, Layer normalization, arXiv preprint arXiv:1607.06450 (2016).
- [49] J. Xu, X. Sun, Z. Zhang, G. Zhao, J. Lin, Understanding and improving layer normalization, Advances in Neural Information Processing Systems 32 (2019) 4381–4391.
- [50] S. Elfwing, E. Uchibe, K. Doya, Sigmoid-weighted linear units for neural network function approximation in reinforcement learning, Neural Networks 107 (2018) 3–11.
- [51] T. Kobayashi, Student-t policy in reinforcement learning to acquire global optimum of robot control, Applied Intelligence 49 (12) (2019) 4335–4347.
- [52] T. De Ryck, S. Lanthaler, S. Mishra, On the approximation of functions by tanh neural networks, Neural Networks 143 (2021) 732–750.
- [53] C. Lee, K. Cho, W. Kang, Directional analysis of stochastic gradient descent via von mises-fisher distributions in deep learning, arXiv preprint arXiv:1810.00150 (2018).
- [54] N. S. Keskar, D. Mudigere, J. Nocedal, M. Smelyanskiy, P. T. P. Tang, On large-batch training for deep learning: Generalization gap and sharp minima, arXiv preprint arXiv:1609.04836 (2016).
Appendix A Proof of regret bounds
Below is the proof and the detailed analysis of the AdaTerm algorithm. Following the literature, we ignore the bias correction term. We also consider a scheduled learning rate and the non-expansive weighted projection operator . The use of the projection operator is not necessary for deriving the upper bound; in fact, no projection is used in Algorithm 1. Regardless, it provides a more general setting, and therefore, following the literature, we consider its potential use in our proof.
A.1 Preliminary
We start by stating intermediary results that we shall use later to bound the regret.
Lemma A.1 (Peter?Paul inequality or Young’s inequality with and exponent 2).
and we have that .
From which we obtain the following results:
Corollary A.2 (Partial bound of ).
Let , and be the sequence of moment, variance and iterates produced by AdaTerm with a scheduled learning rate . Then, we have:
| (39) |
Proof.
This follows from the application of Lemma A.1 with the identification:
Combined with the fact that , . ∎
A.2 Introduction
Let and be the first- and second-order moments produced by AdaTerm, then:
| (40) |
From the definition of , we can derive the following:
| (41) |
which leads to:
| (42) | ||||
| (43) |
We therefore have that:
| (44) | ||||
| (45) | ||||
| (46) | ||||
| (47) |
A.3 Bound of
Using Corollary A.2, we have that:
| (48) |
A.4 Bound of
With and by using , we have:
Then, by applying Holder’s inequality, followed by the use of the projection operator where , since , we obtain:
The non-expansive property of the operator allows the following:
Finally, by restoring and using , we have:
| (49) |
A.5 Bound of
where the last line is obtained by applying Corollary A.2 on time step t-1. Finally, using the telescoping sum over the first two terms in with the particularity of , combined with , we arrive at the following relation:
| (50) |
A.6 Bound of
Applying Lemma A.1 with and , , we get:
| (51) |
A.7 Bound of
With , we have:
Finally, using Cauchy-Schwartz’s inequality (without the squares) with and , and with , we get:
| (52) |
where where .
A.8 Bound of the regret
With
the bound of the regret is obtained by combining the upper bounds of , and and through a straightforward factorization:
| (53) | ||||
Appendix B Visualization of the key elements of AdaTerm
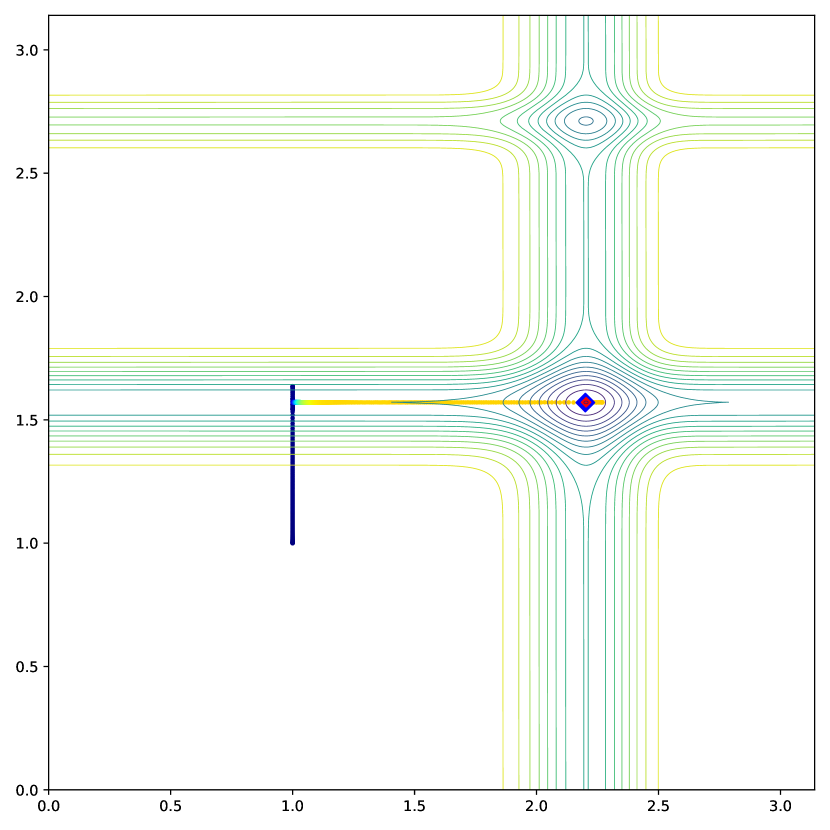
Figures 11 and 12 show the visual description of the interpolation factor and of the gradient ascent increment for the robustness parameter , respectively. As can be seen in Fig. 11, for small deviations , , and conversely, when is large, to alleviate the influence of the aberrant gradient on both and . Similarly, Fig. 12 shows how the degrees-of-freedom is incremented based on the value of . The blue region corresponds to a region where is larger than the current robustness value , leading to an increase in . Conversely, the orange region, corresponding to large , prompts a decrease in the value of because is negative.


Appendix C Details of test functions
The following test functions were tested: were Rosenbrock with a valley, McCormick with a plate, and Michalewicz with steep drops, as defined below.
| (54) |
Using the gradients of , can be optimized to minimize . The initial values of were fixed to , , and , respectively. The noise added to for computing the gradients was sampled from the uniform distribution with range . The probability of noise was set to six conditions: %.
The following optimizers were tested: Adam, At-Adam with adaptive , and the proposed AdaTerm. AdaBelief [8], similar to AdaTerm with , was also tested but excluded from Fig. 8 and 9 owing to its similarity to Adam. The learning rate was set to , which is higher than that for typical network updates; however, other hyper-parameters were left at their default settings. The update was performed 15000 times, and the error norm between the final and the analytically-optimal point was computed. To evaluate the statistics, 100 trials were run using different random seeds.
Trajectories of the convergence process are illustrated in Fig. 13–15. Note that the color of each point indicates the elapsed time, changing from blue to red. AdaTerm was less likely to update in the incorrect direction caused by noise than the others, indicating stable updating. In addition, we observe higher update speed of AdaTerm compared to others. This is probably because could rapidly adapt to small gradients in the saddle area, although this caused an overshoot around the optimal point in Fig. 14(c), resulting in the larger error norm than the others in Fig. 8.
A remarkable result was obtained for Michalewicz function (see Fig. 15(c)). Specifically, AdaTerm initially moved only in the -direction, as in AdaBelief, and subsequently paused at steep gradients in the -direction. This is because the steep gradients toward the optimum were considered as noise in certain cases. In fact, with the elapse of time, AdaTerm judged the steep gradients as non-noise. Gradually, as increased, the update was resumed, finally reaching the optimal point. Furthermore, At-Adam was unable to adapt to the steep gradients, and the point moved to avoid the optimal point (see Fig. 15(b)). However, when noise was added, the steep gradients started to be utilized with the aid of the noise, and the optimal point was finally reached.





















Appendix D Learning setups
The models for learning the four benchmark problems are implemented using PyTorch [29] with the respective setups, as summarized in Table 4. The parameters that are not listed in the table are basically set at the recommended default values. Note that the learning rate for RL was smaller than the ones for the other problems to avoid being trapped in local solutions before effective samples are collected. In addition, the batch size was set to 32, such that the noise is more likely to affect the gradients. However, for the classification problem only, the batch size was increased to 256, which is within the general range, in response to the large learning time cost of this task.
For the classification problem, ResNet18 [3] was employed as the network model. The official PyTorch implementation was employed; however, to account for the size difference of the input image, the first layer of convolution was changed to 1 with a kernel size of 3 and a stride of 1; furthermore, the subsequent MaxPool layer was excluded.
For the prediction problem, a gated recurrent unit (GRU) [47] was employed for constructing a network model consisting of two serial hidden layers, with each including 128 GRU units. The output layer generates the means and standard deviations of the multivariate diagonal Gaussian distribution used to sample the predicted state. Note that, since extending the number of prediction steps delays the learning process, we set the number of epochs to 100 for single-step prediction and 300 for 30-step prediction.
For the RL problem, five fully-connected layers with 100 neurons for each were implemented as hidden layers. Each activation function was an unlearned LayerNorm [48, 49] and Swish function [50]. The output is a multivariate diagonal Student’s t-distribution used to improve the efficiency of the exploration [51].
For the policy distillation problem, two fully-connected layers with only 32 neurons for each were implemented as the hidden layers. This structure is clearly smaller than that for the RL problem described above. The only activation function used for the different layers is the Tanh function, with reference to the fact that this design has been reported to have sufficient expressive capability [52]. The output layer generates the means and standard deviations of the multivariate diagonal Gaussian distribution used to capture the stochastic teacher policy.
| Parameter | Classification | Prediction | RL | Distillation |
|---|---|---|---|---|
| Learning rate | 1e-3 | 1e-3 | 1e-4 | 1e-3 |
| Batch size | 256 | 32 | 32 | 32 |
| #Epoch | 100 | 100/300 | 2000 | 200 |
| Label smoothing | 0.2 | - | - | - |
| Truncation | - | 30 | - | - |
| #Batch/#Replay buffer | - | - | 128/1e+4 | - |
| Weight decay | - | - | - | 1e-4 |
Appendix E Ablation study
For the ablation test of AdaTerm, we test the following three conditions: , called no adaptiveness; , called no robustness; and , called large init. All other conditions are the same as the experiments in the main text.
The test results are summarized in Table 5. As expected, the cases with no adaptiveness outperformed the cases with no robustness for the problems with high noise effects, and vice versa. As observed from the results of the 30-step prediction and the policy distillation, the optimal solution may lie somewhere in the middle rather than at the two extremes, and the normal AdaTerm has been successful in finding it. In the case where is increased and the noise robustness is inferior at the beginning of training, the performance was worse than the normal case where and the noise robustness is maximized at the beginning, except for the classification problem. This tendency suggests that even if is adjusted to gain the appropriate noise robustness after optimization without considering the effects of noise, the performance would be prone to local solution traps. For the classification problem only, the size of the network architecture was larger than that for the other problems, and its redundancy allowed the classifier to escape from the local solutions. In such a case, using more gradients from the beginning resulted in performance improvement.
| Classification | Prediction | RL | Distillation | |||||
|---|---|---|---|---|---|---|---|---|
| Accuracy | MSE at final prediction | The sum of rewards | The sum of rewards | |||||
| Method | 0 % | 10 % | 1 step | 30 steps | Hopper | Ant | w/o amateur | w/ amateur |
| AdaTerm | 0.7315 | 0.6815 | 0.0335 | 1.0016 | 1550.25 | 2021.37 | 1770.17 | 1411.02 |
| (3.66e-3) | (4.46e-3) | (3.09e-4) | (2.31e-1) | (5.88e+2) | (3.87e+2) | (2.17e+2) | (1.92e+2) | |
| No adaptiveness | 0.7330 | 0.6840 | 0.0336 | 1.0718 | 496.75 | 2192.21 | 1701.63 | 1437.18 |
| (3.20e-3) | (4.20e-3) | (4.30e-4) | (2.75e-1) | (6.19e+2) | (4.18e+2) | (2.32e+2) | (2.26e+2) | |
| No robustness | 0.7330 | 0.6810 | 0.0328 | 1.2553 | 1666.30 | 1412.93 | 1625.05 | 1403.92 |
| (3.20e-3) | (3.80e-3) | (4.14e-4) | (2.09e-1) | (6.57e+2) | (6.52e+2) | (2.61e+2) | (2.56e+2) | |
| Large init | 0.7350 | 0.6830 | 0.0332 | 1.2966 | 1750.63 | 1902.63 | 1655.40 | 1442.24 |
| (3.50e-3) | (3.90e-3) | (4.47e-4) | (2.36e-1) | (5.47e+2) | (3.87e+2) | (1.71e+2) | (2.84e+2) | |
| t-AdaBelief | 0.7231 | 0.6827 | 0.0318 | 1.1517 | 1104.87 | 2185.45 | 1639.93 | 1303.19 |
| (4.23e-3) | (4.02e-3) | (4.42e-4) | (1.17e-1) | (4.48e+2) | (4.83e+2) | (3.19e+2) | (2.58e+2) | |
| At-AdaBelief | 0.7223 | 0.6815 | 0.0318 | 1.1306 | 1214.47 | 2196.84 | 1671.65 | 1325.70 |
| (4.50e-3) | (3.46e-3) | (5.02e-4) | (1.17e-1) | (3.77e+2) | (2.29e+2) | (3.32e+2) | (2.72e+2) | |
Appendix F Analysis of the batch size’s effect on robustness
As previously proven [53], the batch size has an impact on the stochastic gradient’s noise strength. Furthermore, larger batch sizes would aid mitigating the effect of corrupted data points by drowning them in a majority of good points inside the mini batch. However, in typical machine learning tasks, given a certain dataset, an increase in the batch size also implies a decrease in the number of updates (and therefore also a decrease in the number of gradients observed). It has also been reported that the large batch size degrades generalization performance [54]. To replicate such trade-off effect and to study its influence on robustness, we use the regression task where the number of samples is fixed at and subsequently split into batches of different sizes .
The results show that for all optimizers in noiseless scenarios, the performance degrades when increasing the batch size, consistent with the results of previous studies, although this is more pronounced for AdaTerm and (A)t-Adam. Specifically, the performance of the robust optimizers degraded as the batch size increased, as expected, since the detection of the effect of aberrant points inside a majority of good points is difficult. Nevertheless, this majority of good points could not mitigate the effect of noise, as can be confirmed in the fact that the non-robust Adam and AdaBelief remained sensitive to noise.




Appendix G AdaTerm variants
Our main proposed algorithm is given in Alg. 1. However, we consider and study two alternative variants as described below.
G.1 Updates with uncentered second-order moment
The derived AdaTerm equations use the estimate of the centered second-order moment, i.e., , in the update based on the same logic outlined in [8]. However, the Adam algorithm employs an estimate of the uncentered second-order moment, i.e., . Therefore, we also consider a gradient descent update based on the uncentered estimated moment.
| (55) |
Here, we approximately use the relationship, . Note that, in that case, is always satisfied, which would yield more conservative learning.
G.2 Adaptive bias correction term
The bias correction term has its origin in the first proposal of Adam [4], where the authors derive the bias term as follows:
| (56) |
and they interpret it as the term needed to correct the bias caused by initializing the EMA with zeros.
Another interpretation (that does not require considering the expectation of the EMA) is to view this term as the normalization term in a weighted average. Indeed, given , the weighted sum of with respect to the weights is expressed as follows:
If , then to obtain the proper weighted average, a correction is required as follows:
In the case of the EMA, the weights are given by:
| (57) |
The bias correction term of Adam can therefore be seen as a correction required for a proper weighted average. We observe that the bias correction term at time step , , corresponds to the EMA of :
corresponds to the fact that EMA is initialized at . If instead, , then .
In AdaTerm, the EMA is expressed as follows:
| (58) |
Since linearly enters in the expression of , the bias correction of Adam can also be used in AdaTerm, as expressed in eq. 35. However, following the weighted average interpretation, a different correction term can be obtained as follows:
| (59) |
This correction term is adaptive, and in the Gaussian limit, it will be the same as the Adam/Adabelief term in eq. (56). Using this adaptive correction term, a slightly modified AdaTerm is used:
| (60) |
G.3 Comparison
As can be observed in Table 6, the adaptive bias correction is a complete downgrade compared with the vanilla bias correction. However, the uncentered version of AdaTerm outperforms the main algorithm in certain cases and proves to have a certain merit that deserves to be further investigated, as mentioned in the conclusion section above.
| Classification | Prediction | RL | Distillation | |||||
|---|---|---|---|---|---|---|---|---|
| Accuracy | MSE at final prediction | The sum of rewards | The sum of rewards | |||||
| Method | 0 % | 10 % | 1 step | 30 steps | Hopper | Ant | w/o amateur | w/ amateur |
| AdaTerm | 0.7315 | 0.6815 | 0.0335 | 1.0016 | 1550.25 | 2021.37 | 1770.17 | 1411.02 |
| (Ours) | (3.66e-3) | (4.46e-3) | (3.09e-4) | (2.31e-1) | (5.88e+2) | (3.87e+2) | (2.17e+2) | (1.92e+2) |
| AdaTerm | 0.7309 | 0.6815 | 0.0338 | 0.9085 | 1688.59 | 2113.81 | 1649.53 | 1372.08 |
| (Uncentered) | (2.60e-3) | (4.77e-3) | (5.23e-4) | (1.21e-1) | (5.42e+2) | (4.01e+2) | (2.48e+2) | (2.48e+2) |
| AdaTerm | 0.7294 | 0.6810 | 0.0336 | 1.0342 | 1595.10 | 2017.69 | 1672.71 | 1400.88 |
| (AdaBias) | (4.26e-3) | (3.13e-3) | (4.65e-4) | (2.53e-1) | (6.45e+2) | (3.21e+2) | (2.50e+2) | (2.45e+2) |
| AdaTerm | 0.7299 | 0.6800 | 0.0336 | 1.1310 | 1552.83 | 1960.78 | 1624.56 | 1302.55 |
| (Uncentered + AdaBias) | (3.70e-3) | (3.76e-3) | (4.31e-4) | (6.43e-1) | (6.72e+2) | (3.74e+2) | (2.21e+2) | (2.47e+2) |
Appendix H Alternative update rule
The gradient ascent update rule for the scale parameter is expressed as follows:
| (61) | ||||
| (62) | ||||
| (63) |
where is the update step size, and . To preserve a limiting Gaussian model, we require that for , , since we already have . Therefore, we have the following:
| (64) |
Since , it is no longer necessary to have as a function of . In particular, we can directly set . However, in practice, this can lead to instabilities and NaN values. Therefore, we instead use , resulting in the following update rule:
| (65) | ||||
| (66) |
where is added to avoid the zero value problem. Since and are both positive, the gradient ascent rule never violates the constraint.
This version of AdaTerm is called AdaTerm2 in the results below, where we can observe that on the simple regression task, it performs on par with our main algorithm but performs less efficiently on the prediction task. Notably, we can see signs of its instability in the -step prediction task around epoch .





