[2,3]\fnmZongyuan \surGe
1]\orgdivDepartment of Electrical and Computer Systems Engineering, \orgnameMonash University, \orgaddress\cityMelbourne, \countryAustralia
[2]\orgdivAIM for Health Lab, \orgnameMonash University, \orgaddress\cityMelbourne, \countryAustralia
3]\orgdivDepartment of Data Science and AI, \orgnameMonash University, \orgaddress\cityMelbourne, \countryAustralia
4]\orgdivMonash Centre for Health Research and Implementation, \orgnameMonash University, \orgaddress\cityMelbourne, \countryAustralia
5]\orgdivDepartment of Neuroscience, \orgnameMonash University, \orgaddress\cityMelbourne, \countryAustralia
6]\orgdivDepartment of Neurology, \orgnameMonash University, \orgaddress\cityMelbourne, \countryAustralia
Adaptive Transformer Modelling of Density Function for Nonparametric Survival Analysis
Abstract
Survival analysis holds a crucial role across diverse disciplines, such as economics, engineering and healthcare. It empowers researchers to analyze both time-invariant and time-varying data, encompassing phenomena like customer churn, material degradation and various medical outcomes. Given the complexity and heterogeneity of such data, recent endeavors have demonstrated successful integration of deep learning methodologies to address limitations in conventional statistical approaches. However, current methods typically involve cluttered probability distribution function (PDF), have lower sensitivity in censoring prediction, only model static datasets, or only rely on recurrent neural networks for dynamic modelling. In this paper, we propose a novel survival regression method capable of producing high-quality unimodal PDFs without any prior distribution assumption, by optimizing novel Margin-Mean-Variance loss and leveraging the flexibility of Transformer to handle both temporal and non-temporal data, coined UniSurv. Extensive experiments on several datasets demonstrate that UniSurv places a significantly higher emphasis on censoring compared to other methods.
keywords:
Survival analysis, Transformer, Margin-Mean-Variance loss, Deep learning1 Introduction
The primary task of survival analysis is to determine the timing of one or multiple events, which can signify the moment of a mechanical system malfunction, the period of transition from corporate deficit to surplus, the instance of patient fatality or so on, depending on the specific circumstance [19]. Among all scenarios, survival analysis for medical data poses the most severe challenges [1]. Some medical datasets are longitudinal, as exemplified by electronic health records (EHRs), where multiple observations of each patient’s covariates over time are recorded. Survival models must be capable of handling such measurements and learning from their continuous temporal trends. Moreover, observations in longitudinal data are often sparse, necessitating the effective handling of missing values for any reliable survival model, even when the missing rates are exceedingly high [32]. Additionally, censoring represents a fundamental aspect of survival data, referring to cases in which complete information regarding the survival time or event occurrence of a subject is not fully observed or available within the study period [20]. The occurrence of censoring signifies the unknown exact timing of the event, consequently lacking ground truth for comparative learning. This, in turn, poses significant challenges for deep survival learning. Existing deep learning approaches aim at mitigating this issue by typically guaranteeing non-occurrence of events before censoring. Notwithstanding, detailed elucidation pertaining to the temporal aspect of events subsequent to censoring frequently remains inadequately explored.
Developing survival analysis models requires regressing the probability of survival over a defined period. A high-quality estimation of probability distribution is essential for the time-to-event prediction. As the initial category, parametric survival models are capable of generating high-quality probability density function (PDF) or survival curve by predetermining stochastic distribution, however, their precision is contingent upon the validity of all underlying assumptions. In contrast, non-parametric models do not presume any prior distribution of events, but they struggle to accurately predict PDF over extended temporal spans within medical datasets, consequently yielding PDF or survival curve of comparatively lower quality.
To address the challenges in the development of survival models and to mitigate the limitations inherent in existing models, we propose UniSurv, a non-parametric model based on the Transformer architecture. In particular, UniSurv can: 1) generate higher quality PDF resembling normal distribution without any prior probability assumption, and significantly improve accuracy for predicting censoring by integrating novel Margin-Mean-Variance loss; 2) use distinct embedding branches for static and dynamic feature extractions separately; 3) effectively handle cases with high missing rates of longitudinal data and various data modalities. The superiority of the UniSurv is substantiated through empirical evidence obtained from real and synthetic datasets.
2 Literature
Semi- and fully-parametric models heavily rely on the premise of making explicit assumptions about the underlying distribution of event times. They provide a structured framework for understanding the relationship between covariates and the occurrence of events over time. However, the strength of these assumptions results in overly simplistic probability distributions predicted by the models. The lack of flexibility stemming from this oversimplification also renders these models impractical in various scenarios. Cox proportional hazard (CPH) [2] is a prime example in this field. It estimates the hazard function by multiplying a predetermined base hazard function with the learnt representation of features . Subsequent studies [5, 35, 21] have used more sophisticated models to improve the CPH model. However, the oversimplified stochastic process continues to constrain their predictive capabilities, and it is unable to conduct dynamic analysis. Meanwhile, [24] introduced Deep Survival Machines (DSM), which postulates that the survival function is a composition of multiple Weibull and log-normal distributions. The parameters of those distributions are estimated by a multi-layer perceptron (MLP). Besides, [23] illustrated Recurrent DSM (RDSM) by incorporating recurrent neural network (RNN) into DSM, thereby endowing it to process dynamic analysis. Nonetheless, DSM models exhibit suboptimal accuracy in predicting event times. Its loss function frequently becomes divergent during training, contributing to the overfitting problem.
Some recent works have concentrated on static analysis. For example, DeepSurv [13] employs an MLP network to replace the parametric assumptions of the hazard function present in the conventional CPH. This transformation results in a semi-parametric variant of the CPH model. The incorporation of neural networks enhances its flexibility by enabling the model to learn nonlinear relationships more adeptly from covariates. Besides, Deep Cox Mixtures (DCM) [25] encounters the same underlying assumption of proportional hazards, wherein it assumes the presence of latent groups. Employing Variational Autoencoders for clustering, DCM assumes the validity of proportional hazards within each latent group. Moreover, [11] propose an extension of random forest (RF) algorithm, named Random Survival Forest (RSF), which initially breaks through the inherent assumptions of CPH. It computes the risk scores through the generation of Nelson-Aalen estimators within the partitions established by RF. RSF assumes independence among trees in forest, which might not always hold. This assumption can affect its performance, usually when correlations or dependencies exist among survival trees.
Several studies have explored the dynamic analysis field. [17] propose DeepHit for competing risk events as a non-parametric model. The encoder of DeepHit is constructed as a joint MLP, while its decoder employs a series of distinct MLPs to address individual events. This design results in the generation of separate PDFs for each event. [18] further extend it into Dynamic DeepHit (DDH) by replacing the encoder with RNNs followed by an attention mechanism, to process longitudinal data. A primary limitation lies in the arbitrary fluctuations between adjacent predictions within the output layer, resulting in noise present in the final PDFs. This phenomenon becomes particularly pronounced when forecasting over a long-time horizon. Survival SEQ2SEQ (SS2S) [30] addresses this issue and takes advantage of RNN cells in their framework decoder to generate smoother PDFs. However, its approach to handling censoring is overly simplistic, focusing solely on the premise that events should not occur before the censoring time, without addressing any potential implications after it. Another model that shares a similar concern in handling censoring is the Transformer-based Deep Survival Model (TDSM) [9]. This deficiency is evident in the designs of their loss functions. The previous transformer architectures in survival analysis include TDSM and SurvTRACE [36], but none of them have been extended to handle dynamic analysis.
In summary, while most existing methods could perform static analysis, only three of them could handle longitudinal data. Despite all the advancements in these recent works, there is a lack of a universal model which could jointly integrate handling miss data method, process various input formats and produce organized PDFs.
3 Method
In this section, we introduce our formal framework UniSurv, which is a adaptive Transformer-based architecture for survival analysis. We assume that the available survival dataset is subject to right censoring.
3.1 Survival Notation
We denote time-invariant and time-varying covariates by and , probability by , time by , or , PDF by and survival function by . Let’s represent the survival dataset as , where for individual , is the event indicator typically taken from the set without competing risks, and represents the event or censoring time depending on . We omit the explicit dependence on throughout this and the next subsections for simplifying notation.
We assume that time to fit a discrete survival model, where is a discrete random variable, and is each time step with equal interval. The cumulative distribution function (CDF) of can be easily calculated by its PDF as
| (1) |
Having defined the probability that an event has occurred by duration , the survival function can then be estimated as the probability that the survival time is at least . It can also be represented as the complement of CDF as
| (2) |
3.2 Model Description


Fig. 1(a) presents a comprehensive illustration of the UniSurv model. It integrates a novel survival loss design to enable a seamless end-to-end learning procedure. It encompasses dynamic and static extraction components, coupled with a Transformer encoder module culminating in a softmax layer at the output terminal. Besides, Fig. 1(b) depicts the conceptual process of UniSurv during both training and testing stages.
3.2.1 Static and Dynamic Extractions
We integrate the variation of last-observation-carried-forward (LOCF) method to handle missing data. It duplicates the value of the last observation to replace the following missing values until , and the ones that are still missing after LOCF are imputed by mean/mode of all previous points for continuous/binary covariates until , making sure no missing data for all time points [18]. Next, we extract latent representations of time-invariant features and time-varying features by static (-s) and tabular-data-based dynamic (-d1) extraction modules separately. These modules are constructed using MLPs to deal with numerical tabular data. The representation of is replicated times by encompassing as well. For static modelling, these are subsequently transmitted to encoder. For dynamic modelling, these representations are concatenated with the representation of at their respective time points before the transmission. Meanwhile, a convolutional neural network (CNN) variation (-d2) of the image-based dynamic extraction module can be used to address the image-like input formats. As shown in Fig. 1(a), the extracted feature can be shared across a predefined time window in light of the data sparsity.
3.2.2 Transformer Encoder
The core of the encoder module is a Transformer, which treats each patient as a ‘sentence’ and the embedded features as ‘words’ of the sentence. For an input sample, the number of words correspond to the duration , where we predefined and is a hyper-parameter selected based on the longest temporal data of a dataset. The previous concatenated representations pass through a MLP followed by layer normalization to get the embedded features. Following the conventional approach of a Transformer, we utilize the sine-cosine positional embedding [34] as temporal embedding in this work, and add it onto the set of embedded features, whose length is set as the embedding dimension of the Transformer. The Transformer encoder then processes embedded features and produces outputs, each with shape . It is worth noting that the self-attention layers in the encoder is modified to prevent positions from attending to subsequent positions. Specifically, it prohibits each position from attending to subsequent positions, and the attention scores for all illegal connections are masked out by assigning them with [34]. Next, all-time point outputs are fed into an exclusive 2-layer MLP. The first layer is followed by rectified linear unit (ReLU) and layer normalization, with shape of . The second layer, with shape of , is followed by a softmax layer to produce the individual estimated PDF. Further, the estimated survival function can be calculated based on Eq. 2, which ensures its monotonicity is preserved. Moreover, in discrete survival analysis, the mean lifetime can be approximated by the sum of the survival probabilities up to . We could get the estimated mean lifetime by further involving Eq. 2 as
| (3) |
where the employment of the approximately equal symbol in the equation is attributed to the presence of time point . The variance of distribution is computed as
| (4) |
3.3 Loss Function
To robustly estimate the uncensored survival time via distribution learning and generating smooth PDF, we adopt a variation of Mean-Variance loss [26] in UniSurv, which requiring each training sample has a corresponding event time label. However, censoring existing in survival dataset does not have event but censoring time. Using censoring time as the label will be misleading for the model, resulting in prediction bias. To overcome this, we employ the “margin time” concept [8], to assign a “best guess” value to each censored subject based on the non-parametric population Kaplan-Meier (KM) [12] estimator. Given a subject censored at time , its margin event time is calculated by
| (5) |
where is the KM estimation derived from the training dataset. It is worth to mention that during the integration process, we compute it up to in this work, ensuring that remains within the bounds of , which stands in contrast to the approach proposed by [8]. They extend the KM curve infinitely through risky extrapolation beyond observed values.
We denote as the corresponding ground-truth event/censoring time for individual . With the estimated mean lifetime , the Margin-Mean loss can be computed as
| (6) |
where can give high confidence weight with late censor time but low with early censor time. Margin-Mean loss can penalize dissimilarity between estimated mean lifetime and actual event/margin-event time. Besides, the Variance loss is calculated as
| (7) |
which is implemented to regulate the spread of the estimated survival distribution, limiting it to a narrow range within the mean. Considering with Eq. 4, can cause the probabilities at time points farther from to approach . The softmax loss, as known as cross-entropy loss, can be computed as
| (8) |
which is further utilized to aid in early training convergence, as Margin-Mean-Variance loss alone may experience substantial fluctuations [26].
Finally, tailored to address uncensoring, we utilize discordant loss by
| (9) |
which can penalize the randomized discordant pairs for improving model’s pairwise ranking ability. The process is similar to randomized algorithm: random sampling with replacement individual for each confirmed individual , making sure that and the difference between estimated times should not be smaller than the difference between ground truths. can further penalize the discordant pairs because when and are close, the Margin-Mean-Variance loss cannot effectively discriminate discordant pairs and may fall into a local optimum.
The total loss to train UniSurv is the combination of the above four losses as
| (10) |
where , , are weights for the corresponding loss functions.
4 Experiments
In this section, we demonstrate the effectiveness of UniSurv by comparing it with other benchmarks on real and synthetic datasets from static and dynamic settings.
4.1 Datasets
To highlight the right-skewed characteristic of survival data, we utilized three real-world datasets and two long-tailed synthetic datasets.
4.1.1 Static Datasets
The Study to Understand Prognoses Preferences Outcomes and Risks of Treatment (SUPPORT) [14] is a large static survival dataset of seriously ill hospitalized adults. The Molecular Taxonomy of Breast Cancer International Consortium (METABRIC) [3] is a static breast cancer dataset aiming to distinguish its subtypes based on the molecular characteristics. Their pre-processing strategies follow DeepSurv [13].
We also generate a static synthetic dataset (SYNTH-s) of the style of that in [17] but without competing risks. The dataset contains examples drawn from the stochastic process
| (11) |
where is a vector of 4-dimensional variables and . We randomly select patients to be right-censored with random censoring time uniformly drawn from . More details are listed in Tab. 1.
| Dataset | Longitudinal | Uncensored | Censored | Features | Event Time | Censoring Time | |||||
| static | dynamic | min | max | mean | min | max | mean | ||||
| SUPPORT | No | 6036 (68%) | 2837 (32%) | 14 | - | 0 | 65 | 6.85 | 12 | 68 | 35.33 |
| METABRIC | No | 1103 (58%) | 801 (42%) | 9 | - | 0 | 355 | 99.95 | 0 | 337 | 159.55 |
| SYNTH-s | No | 7600 (50%) | 7500 (50%) | 4 | - | 0 | 192 | 22.45 | 0 | 165 | 10.80 |
| MSReactor | Yes | 148 (20%) | 598 (80%) | 8 | 90 | 1 | 68 | 17.54 | 0 | 80 | 45.43 |
| SYNTH-d | Yes | 7462 (49%) | 7638 (51%) | 4 | 20 | 0 | 199 | 57.96 | 0 | 195 | 28.59 |
4.1.2 Dynamic Datasets
On the basis of SYNTH-s, we further generate dynamic synthetic dataset (SYNTH-d) by adding additional dynamic variables following Weibull distribution, and introducing temporal noise disturbances to make them variable over time as
| (12) |
where is a dynamic variable matrix for all time points, is the shape parameter, is the scale parameter, , and and are operations on the temporal dimension. Besides, and are two randomly selected subsets that satisfy , . is then resampled, and the method of introducing censoring cases remains the same as before.
Moreover, MSReactor [22] dataset is a quantifiable, objective collection on cognition via longitudinal computerized test for Multiple Sclerosis (MS), integrating with other 8 static covariates. In each test, patients are instructed to respond as quickly as possible to onscreen stimuli, and their reaction time is recorded in millisecond (ms). The test includes 3 different tasks for testing their psychomotor function, attention and working memory. Each patient undergoes the test a number of times after the diagnosis and prior to the occurrence of the event/censoring (with at least one-month interval between every two adjacent tests). The survival event is characterized by EDSS progression through the six-month disability worsening confirmation rule [10]. Numerous research investigations have indicated that utilizing reaction data could potentially offer a more responsive approach for detecting subclinical cognitive impairment in comparison to current cognitive assessment methods [6, 27, 37].

The longitudinal reaction test will be considered as time-varying covariates. However, due to certain redundancies present in MSReactor, evident through pronounced inter-column associations, the characteristics of adjacent columns exhibit robust correlations, deviating from the conventional tabular data extraction where each column represents highly streamlined information. Without the application of specialized data preprocessing techniques and innovative model architectures, the existing survival models may encounter difficulties in extracting meaningful latent patterns from this data. Therefore, we transform the longitudinal tabular data part into a composite “reaction tensor” after monthly imputation, and utilize the certain module to deal with it. Specifically, each patient has a unique 3-dimensional reaction tensor111More details are illustrated in Appendix A., as shown in Fig. 2. Its Z-axis is corresponding to the 3 different tasks. X-axis is response dimension with fixed length of 30, corresponding to the 30 times the patient needs to finish three tasks separately in each test. Y-axis corresponds to the times patient has undergone tests per month with fixed length from the start time to the end time . The reaction tensor is divided into several smaller tensors along Y-axis by as in Fig. 1(a).
4.2 Evaluation Metrics
We utilize ranking measures such as concordance index (C-index) from lifelines [4] library and mean cumulative area under ROC curve (mAUC) from scikit-survival [29] library, and accuracy measures such as mean absolute error (MAE) as the evaluation metrics for all experiments.
4.2.1 Concordance
C-index [33] is able to estimate ranking ability by comparing relative risks across all pairs in the test set as
| (13) |
where is an indicator function, and if is uncensored and 1 otherwise.
4.2.2 MAE-Uncensored
MAE-Uncensored (MAE-U) can compensate for the inability of C-index to measure the mean absolute value of the estimated risk score. It is computed as
| (14) |
4.2.3 MAE-Hinge
MAE-Hinge (MAE-H) is a one-sided MAE for only censoring cases, opposite with MAE-U for uncensoring only. It considers only if the predicted time is earlier than the censored time as follow
| (15) |
4.2.4 Mean Cumulative Area Under ROC Curve
The area under ROC curve for survival analysis involves treating survival issue as binary classification across various quantiles of event times and defining the sensitivity and specificity as time-dependent measures [16]. The cumulative AUC measures model’s capability of discriminating individuals who fail by a specified () from subjects who fail after this time (). We compute the mAUC by integrating the cumulative AUC over all time range .
4.3 Experimental Setting
We compare with five static benchmarks, including CPH, DeepSurv, DeepHit, DSM and TDSM, and two dynamic benchmarks222We have not compared with SS2S in this study as its code has not been made publicly at the moment., including DDH and RDSM. As static dataset does not have longitudinal covariates, our dynamic extraction module in UniSurv is in non-activation mode named UniSurv-s. For MSReactor, the dynamic extraction module has two variants based on different data representations, tabular data representation named UniSurv-d1 and image-like representation named UniSurv-d2. More implementation and hyperparameter details are in the Appendix B333Code availability: https://github.com/XinZ0419/UniSurv.
For a fair comparison, we use C-index as early stopping criterion for all approaches as it can cover more subjects than MAE. We report the results by using cross-validation, randomly splitting datasets 5 times into training, validation and test sets with ratio 7:1:2. All experiments are implemented in PyTorch 2.0.1 on the same environments with a fixed random seed.
4.4 Benchmarking Results
| Model | SUPPORT | METABRIC | SYNTH-s | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| C-index | MAE-U | MAE-H | mAUC | C-index | MAE-U | MAE-H | mAUC | C-index | MAE-U | MAE-H | mAUC | |
| CPH | ||||||||||||
| DeepSurv | ||||||||||||
| DeepHit | ||||||||||||
| DSM | ||||||||||||
| TDSM | ||||||||||||
| UniSurv-s | ||||||||||||
| UniSurv-s w/o mask | ||||||||||||
Performance comparisons for all datasets are summarized in Tab. 2 and Tab. 3. We bold the best and underline the second best. Besides, the statistical significance is determined by paired t-test between the best results and all others individually.
4.4.1 Static Modelling Results
In terms of C-index, our UniSurv-s secures the first position on SYNTH-s and the second position on both SUPPORT and METABRIC. It also reaches the best mAUC on METABRIC and SYNTH-s and the second best on SUPPORT. DeepSurv shows comparable ranking performance on two real-world datasets. This illustrates that parametric model still hold a slight advantage over non-parametric model, rely on its robust probability distribution assumptions. Meanwhile, the performances of the other four models vary, creating a competitive landscape. This makes it difficult to definitively judge their performance under single ranking metrics.
Meanwhile, our UniSurv performs well in MAE-U and exhibits notably superior performance in the realm of MAE-H, with statistical significance compared to other models. Only DeepSurv in SUPPORT is comparable with ours in both two MAEs. Conversely, the performance of TDSM, while excelling in MAE-U, lags notably behind in MAE-H. This is because the loss design of TDSM leads to overfitting on uncensored data throughout the learning process, failing to capture the fact that most censored samples have longer survival times. Further, the inadequacy of TDSM’s predictions for censoring is also evident by Fig. 3, in which we represent the difference between true censoring time and estimated mean lifetime with red lines for some censoring cases. We show the METABRIC results from TDSM, UniSurv-s and the second-best MAE-U model DeepHit here. The more and longer red lines, the model have less sensitivity of censoring prediction. It can be observed that UniSurv has the capability to provide accurate predictions for the majority of censoring cases. This outcome can be attributed to the incorporation of the MAE-margin concept within the Margin-Mean loss in Eq. 6, as it leverages prior knowledge from the training dataset to effectively “enforce” predicted survival time to exceed the censoring time. On the other hand, DeepHit exhibits significant inefficiency in forecasting longer censoring times. Similar to TDSM, this is also due to the absence of certain constraints within its loss designs beyond the censoring time, which may give rise to a systemic bias in predicting censoring cases.
4.4.2 Dynamic Modelling Results
As depicted in Tab. 3, UniSurv-d1 demonstrates superior performance over two other models for longitudinal datasets, as evidenced by higher values in C-index, mAUC and lower values in two MAEs. However, the performance of these three methods is generally suboptimal, as their C-index values remain below . This occurrence likely arises from the fact that the temporal data in MSReactor diverges from conventional survival tabular data, instead representing a reaction testing approach applied to MS patients. Traditional models struggle to effectively extract meaningful insights from this intricate and redundant information. Notably, when we preprocess the computerized test data into ”reaction tensor” and employ CNN to extract latent features, the performance of UniSurv-d2 surpasses the others with statistically significant improvements. However, this ”tensor” method has not demonstrated effectiveness for SYNTH-d, primarily due to the isotropic distribution of each variable during data generation, resulting in their mutual independence and lack of correlation.

| Model | MSReactor | SYNTH-d | ||||||
|---|---|---|---|---|---|---|---|---|
| C-index | MAE-U | MAE-H | mAUC | C-index | MAE-U | MAE-H | mAUC | |
| DDH | ||||||||
| RDSM | ||||||||
| UniSurv-d1 | ||||||||
| UniSurv-d2 | ||||||||
| UniSurv-d1 w/o mask | ||||||||
| UniSurv-d2 w/o mask | ||||||||
4.4.3 The Implication of Data Distribution

As shown in Fig. 4, all five histograms depict the distribution of survival times skewed towards the early segment of the time horizon, while censoring times tend to cluster in the latter half, especially in SUPPORT, SYNTH-s, MSReactor and SYNTH-d. This leads to survival models facing difficulty in maintaining predictive accuracy over time, as evidenced by the time-dependent AUC (TD-AUC). For example, all the performances of UniSurv-s, DeepHit and DSM, or their dynamic variants (UniSurv-d2, DDH, RDSM) exhibit a consistent decline in TD-AUC as time progresses. However, UniSurv still outperforms others, especially on two dynamic datasets. For METABRIC, due to its relatively low censoring rate and evenly distributed censoring cases, all three models maintain their TD-AUC quite well, with some even showing an upward trend, particularly UniSurv. It affirms that Transformer encoder based on Margin-Mean-Variance loss learning can effectively alleviate the challenges posed by survival datasets characterized by long-tail distributions.

4.5 Importance of Masked Attention Mechanism
In the context of leveraging Transformer for inference, the masking function within the attention mechanism is inherently discretionary, contingent upon whether each output necessitates contributions from all or specific designated inputs. For static survival data, the design of UniSurv does not entail distinctions in latent features at each time point beyond temporal embedding. Hence, there is no risk of information leakage, rendering the masking mechanism inconsequential. For instance, it is not employed in the TDSM. As demonstrated by Tab. 2, the overall performance of UniSurv-s has not been affected by removing masking mechanism from UniSurv-s, and the slight performance fluctuations can be negligible. However, when dealing with dynamic survival data, the missing data problem is inevitable, and imputations following event or censoring times may give rise to potential retro-active prediction concern. Therefore, the masking mechanism becomes imperative in such scenario. In Tab. 3, both UniSurv-d1 and UniSurv-d2 exhibited an equivalent degree of performance decline across two datasets by removing masking, which are evidenced by their ranking ability.
4.6 Comparison of PDF Visualizations
In addition to predictive accuracy, the quality of estimated individual PDF stands as another crucial consideration when comparing non-parametric survival models. The distribution of PDF generated by our UniSurv is specifically governed by Margin-Mean-Variance loss and remains unaffected by variations in distinct extraction modules. In Fig. 5, we present a comparison of the PDF outputs for 5 randomly selected uncensoring cases in MSReactor. We choose to contrast the DDH and UniSurv due to their absence of assumptions regarding the shape of the PDF, whereas RDSM relies on strong assumptions related to the Weibull and log-normal distributions. As described in above sections and shown in Fig. 5, our can penalize dissimilarity between the peak of PDF and the ground truth. Besides, diverging from the disordered PDFs from DDH, can regulate the spread of PDF and limit it into a distinct pattern and organization. In contrast, despite using the same MLP and softmax as the output layer in DDH, the high fluctuations of PDFs can be attributed to the shortcomings in its loss function design.
The unimodal nature of survival PDF offers several advantages. For example, it can better reflect the time-to-event and naturally calibrate the median survival time corresponding to survival curve, such as [31] employed several pre-defined unimodal distributions for survival modelling. However, UniSurv departs from this assumption, achieving the same objective through a distinctive loss design. The current over-concentrated PDF is not optimal, and appropriately adjusting to relax its constraints on the shape will become necessary.






4.7 Ablation Study
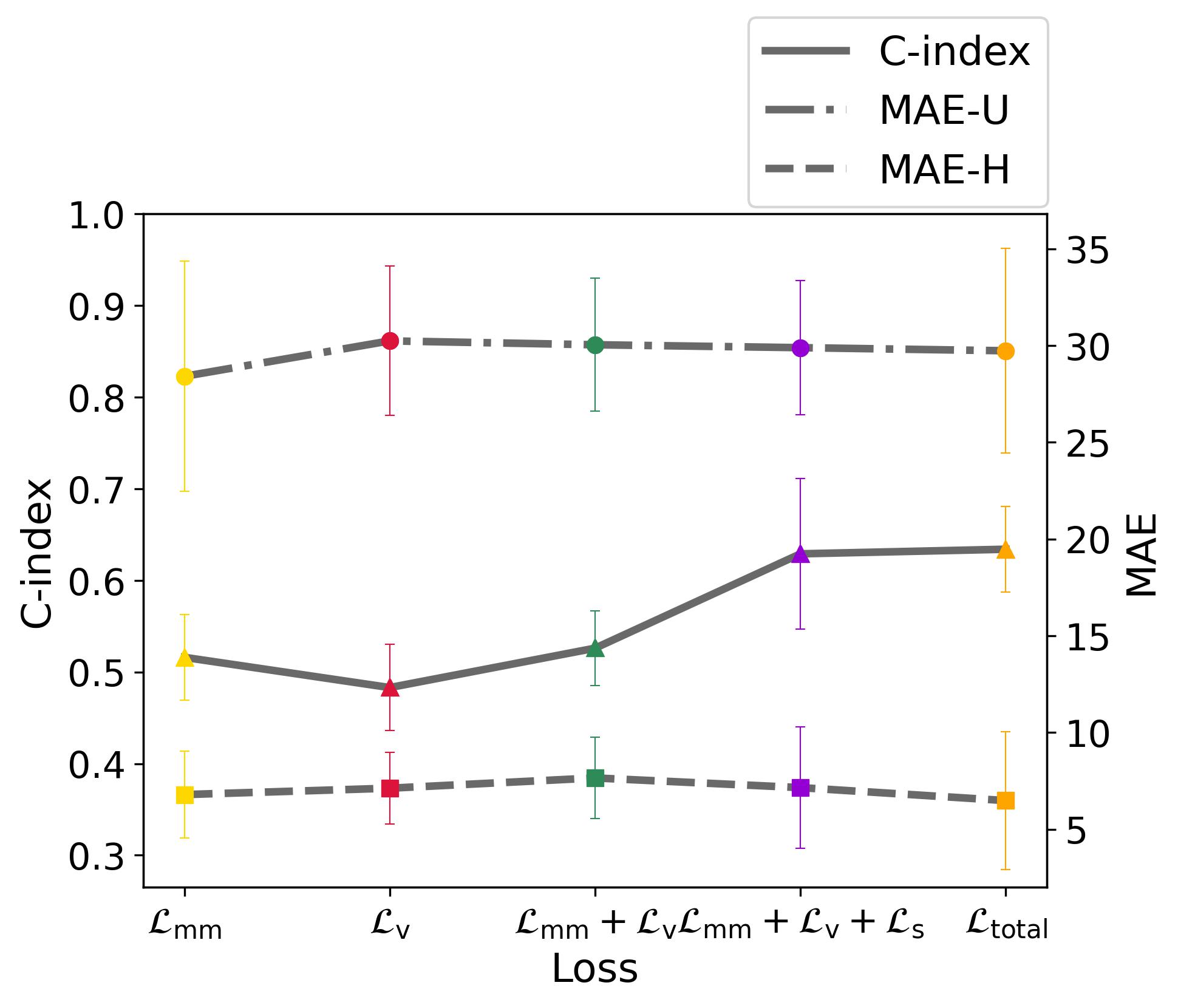
We further conduct an ablation study of losses on MSReactor using UniSurv-d2, to demonstrate the contribution of each loss. In Fig. 6(a), it is evident that an incomplete loss combination sometimes can lead to lower MAE-U or MAE-H, however, this often results in a situation of local optimization, which is reflected in the shape of the PDF. In Fig. 6(f), we compare the PDFs under selected scenarios: only, only and . It is discernible that relying solely on , due to the absence of constraints, tends to produce a probability distribution biased towards uniformity around the ground truth. On the other hand, training solely with generates irregular PDFs and fails to acquire meaningful information. This observation elucidates why these scenarios do not yield the optimal C-index. Besides, the inclusion of can further enhance the performance by mitigating the occurrence of discordant pairs. In addition, incorporating results in faster convergence and significant performance improvement, particularly evident in C-index. However, also leads to a rapid concentration of all probability distributions near the event time, which can result in overly concentrated PDFs and potential calibration issues. As shown in Fig. 6(e), we compared the averaged PDF shape with and without in the combinations presented in Fig. 6(a). The averaged shape is calculated by aligning all PDF peaks using the Dynamic Time Warp [7] technique and then averaging them in normalized horizon. It is apparent that the absence of yields a multimodal, smoother, and more realistic PDF. Hence, the selection of involves a trade-off between the ranking and calibration ability.
4.8 Effectiveness Analysis
4.8.1 Sensitivity of Time Window
Fig. 6(b) shows the effect of . We can observe that when , the model can achieve the highest C-index and lowest MAE-H, which is associated with the progression rate of MS. However, during the same period, MAE-U demonstrates its poorest performance. It is also apparent that the fluctuations in MAE-U and MAE-H exhibit a contrasting pattern. This disparity can be attributed to the disparate distributions of censoring and uncensoring within the MSReactor as in Fig. 4. Meanwhile, this underscores that there exists potential for enhancing the robustness of UniSurv.
4.8.2 Sensitivity of Loss Weights And
As the number of losses increases, finding the optimal weight combination indeed becomes challenging, but grid search can take care of this. The four losses do not need to be standardized to a similar magnitude. The unique characteristics of different datasets can lead to distinct optimal weights for losses. We assessed the sensitivities of and particularly on MSReactor in Fig. 6(c) and Fig. 6(d), and some selected PDFs are shown in Fig. 6(g). The model exhibits robustness when small variations occur in or , as the performance near their optimal values does not exhibit significant degradation. In some cases, two MAEs even perform better. This phenomenon is attributed to the opposing fluctuation trends exhibited by the MAEs, indicating a trade-off made by UniSurv during training. Notably, the C-index appears to be more sensitive to changes in compared to variations in . As the variations in both weights increase, deviations in the PDF gradually emerge, with its peak drifting further away from the actual event time and assuming irregular shapes.
4.8.3 Sensitivity of Larger and Noised Synthetic datasets
To emphasize UniSurv’s reliability for higher dimensionality datasets and its robustness to data noise, we have expanded the number of features for the existing synthetic datasets SYNTH-s and SYNTH-d without altering event or censoring settings, resulting in new SYNTH-sk and SYNTH-dk datasets, where k denotes the dimension of in Eq. 11 and Eq. 12 is increased from to , and the dimension of in Eq. 12 is increased from to . Additionally, we introduced noise to and separately in all datasets. As the results shown in Tab. 4, UniSurv performs well on high-dimensional datasets and exhibits robustness to small levels of noise interference.
| UniSurv-s | UniSurv-d2 | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SYNTH-s | SYNTH-s1 (k=1) | SYNTH-s2 (k=2) | SYNTH-d | SYNTH-d1 (k=1) | SYNTH-d2 (k=2) | |||||||
| C-index | MAE-H | C-index | MAE-H | C-index | MAE-H | C-index | MAE-H | C-index | MAE-H | C-index | MAE-H | |
5 Conclusion And Discussion
In this paper, we propose a non-parametric discrete survival model named UniSurv. Departing from the existing models of utilizing RNN for processing longitudinal data, we employ a Transformer for adeptly handling dynamic analysis. In particular, our survival framework firstly integrates imputation for handling missing data issue, then incorporates different embedding branches for time-varying and time-invariant features extraction. The Transformer encoder takes merged features as input and outputs the individual PDF. We also demonstrated how to process image-like data using variations of modules and how to select a time window based on the progression speed of the disease to share information. This is particularly beneficial in the field of medicine, as obtaining regular time-series medical images in the real world is challenging.
Furthermore, our novel Margin-Mean-Variance loss effectively produces smooth PDF in a unimodal manner, demonstrating clear superiority over other discrete models. Importantly, the proposed loss can be seamlessly embedded into various discrete survival models. Moreover, it significantly enhances prediction accuracy, particularly for patients with extended censoring times. Applying poorly performing models in such scenarios could evidently disrupt physician’s judgments and place unnecessary burdens on both society and healthcare institutions. This constitutes a valuable contribution. Although our current PDF may appear overly concentrated around event times, akin to many models relying on strong probability assumptions, resulting in unconventional survival curves, we intend to further modify the and to relax certain constraints in the future. This adjustment aims to yield a more elegant PDF, characterized by a smoother and less abrupt distribution while maintaining overall performance. Meanwhile, adapting UniSurv to accommodate multiple censoring scenarios, such as left truncation and interval-censored data, presents an interesting direction for future research. Additionally, expanding the scope to include a post-processing statistic for interpreting risk predictions in both static and dynamic analyses of disease progression is necessary. For example, individual explanations of predicted probabilities can be achieved through the generation of SHapley Additive exPlanations (SHAP) [28, 15]. This approach is expected to result in more effective health care.
Acknowledgements
X.Z. receives support from the Australian Government Research Training Program (RTP) Scholarship.
Declarations
Availability of data and materials We are restricted from making MSReactor data available to the public for the moment. All the other data are publicly available.
Competing interests Not applicable.
Ethics approval Not applicable.
Consent for participation Not applicable.
Consent for publication Not applicable.
Appendix A MSReactor
A.1 Missing Details
For each patient, temporal tests were done once around roughly every half-year. The time interval between two adjacent tests range from to months with mean of . The number of yearly follow-ups was from to with mean of tests per patients.
A.2 Min-Max Values Selection of Reaction Tensor Representation
In our proposed innovative reaction tensor representation, as illustrated in Fig. 2, the chosen minimum and maximum values are not directly derived from the original tabular data for MSReactor dataset, but rather determined by threshold selection. Specifically, we sort individual patient’s data for a particular task , and the and percentiles of the sorted values are taken as the minimum and maximum values, denoted as and , respectively. The outliers are automatically set as minimum or maximum values. We use the same strategy in SYNTH-d dataset.
The rationale for adopting this approach stems from the inherent instability of recorded reaction times in such tests, attributed at times to individual patient idiosyncrasies or extraneous environmental interference, rendering these reaction times as outliers in our analysis. Instances of a patient expending time to accommodate their sitting posture, being diverted by ambient noise distractions, or experiencing rapid inadvertent touchscreen interactions, exemplify scenarios capable of inducing aberrations in reaction time.
Appendix B Hyperparameter Information
Tab. 5 shows the hyperparameter spaces and their optimal choices we used in UniSurv-s for SUPPORT, METABRIC and SYNTH-s dataset, and in UniSurv-d2 for SYNTH-d, MSReactor. Clearly, we shrink the architecture of Transformer encoder part, since the survival datasets are much smaller than the standard natural language processing (NLP) or computer vision (CV) datasets, and the number of features is also small. Besides, the selection of is based on the maximum survival/censoring time in the corresponding dataset, and the value of is directly chosen from the factors of for the sake of convenience during training dynamic datasets.
| Hyperparameter | SUPPORT | METABRIC | SYNTH-s | MSReactor | SYNTH-d |
| 80 | 400 | 200 | 95 | 199 | |
| - | - | - | {4, 6, 8, 12, 24, 32} | {4, 5, 8, 25, 40} | |
| {0.01, 0.1, 1, 10} | {0.01, 0.1, 1, 10} | {0.01, 0.1, 1, 10} | {0.01, 0.1, 1, 10} | {0.01, 0.1, 1, 10} | |
| {0.001, 0.01, 0.1, 1} | {0.001, 0.01, 0.1, 1} | {0.001, 0.01, 0.1, 1} | {0.001, 0.01, 0.1, 1} | {0.001, 0.01, 0.1, 1} | |
| {0, 1} | {0, 1} | {0, 1} | {0, 1} | {0, 1} | |
| Epochs | 400 | 200 | 200 | 200 | 200 |
| Batch size | 16 | 16 | {4, 8, 16, 32} | {4, 8, 16, 32} | {4, 8, 16, 32} |
| Dropout rate | 0.1 | 0.1 | {0.0, 0.1, 0.3} | {0.0, 0.1, 0.3} | {0.0, 0.1, 0.3} |
| Number of heads | 4 | 4 | {1, 2, 4, 8} | {1, 2, 4, 8} | {1, 2, 4, 8} |
| Embedding dimension | 512 | 512 | {256, 512} | {256, 512} | {256, 512} |
| Number of attention layers | 4 | 4 | {1, 2, 3, 4} | {1, 2, 3, 4} | {1, 2, 3, 4} |
| Adam optimizer with fixed learning rate | 1e-4 | 1e-4 | {1e-4, 1e-3} | {1e-4, 1e-3} | {1e-4, 1e-3} |
References
- \bibcommenthead
- Collett [2023] Collett D (2023) Modelling survival data in medical research. CRC press
- Cox [1972] Cox DR (1972) Regression models and life-tables. Journal of the Royal Statistical Society: Series B (Methodological) 34(2):187–202
- Curtis et al [2012] Curtis C, Shah SP, Chin SF, et al (2012) The genomic and transcriptomic architecture of 2,000 breast tumours reveals novel subgroups. Nature 486(7403):346–352
- Davidson-Pilon [2019] Davidson-Pilon C (2019) lifelines: survival analysis in python. Journal of Open Source Software 4(40):1317. 10.21105/joss.01317, URL https://doi.org/10.21105/joss.01317
- Faraggi and Simon [1995] Faraggi D, Simon R (1995) A neural network model for survival data. Statistics in medicine 14(1):73–82
- Foong et al [2023] Foong YC, Bridge F, Merlo D, et al (2023) Smartphone monitoring of cognition in people with multiple sclerosis: A systematic review. Multiple Sclerosis and Related Disorders p 104674
- Giorgino [2009] Giorgino T (2009) Computing and visualizing dynamic time warping alignments in r: the dtw package. Journal of statistical Software 31:1–24
- Haider et al [2020] Haider H, Hoehn B, Davis S, et al (2020) Effective ways to build and evaluate individual survival distributions. The Journal of Machine Learning Research 21(1):3289–3351
- Hu et al [2021] Hu S, Fridgeirsson E, van Wingen G, et al (2021) Transformer-based deep survival analysis. In: Survival Prediction-Algorithms, Challenges and Applications, PMLR, pp 132–148
- Hunter et al [2021] Hunter SF, Aburashed RA, Alroughani R, et al (2021) Confirmed 6-month disability improvement and worsening correlate with long-term disability outcomes in alemtuzumab-treated patients with multiple sclerosis: Post hoc analysis of the care-ms studies. Neurology and therapy 10(2):803–818
- Ishwaran et al [2008] Ishwaran H, Kogalur UB, Blackstone EH, et al (2008) Random survival forests. The annals of applied statistics 2(3):841–860
- Kaplan and Meier [1958] Kaplan EL, Meier P (1958) Nonparametric estimation from incomplete observations. Journal of the American statistical association 53(282):457–481
- Katzman et al [2018] Katzman JL, Shaham U, Cloninger A, et al (2018) Deepsurv: personalized treatment recommender system using a cox proportional hazards deep neural network. BMC medical research methodology 18(1):1–12
- Knaus et al [1995] Knaus WA, Harrell FE, Lynn J, et al (1995) The support prognostic model: Objective estimates of survival for seriously ill hospitalized adults. Annals of internal medicine 122(3):191–203
- Krzyziński et al [2023] Krzyziński M, Spytek M, Baniecki H, et al (2023) Survshap (t): time-dependent explanations of machine learning survival models. Knowledge-Based Systems 262:110234
- Lambert and Chevret [2016] Lambert J, Chevret S (2016) Summary measure of discrimination in survival models based on cumulative/dynamic time-dependent roc curves. Statistical methods in medical research 25(5):2088–2102
- Lee et al [2018] Lee C, Zame W, Yoon J, et al (2018) Deephit: A deep learning approach to survival analysis with competing risks. In: Proceedings of the AAAI conference on artificial intelligence
- Lee et al [2019] Lee C, Yoon J, Van Der Schaar M (2019) Dynamic-deephit: A deep learning approach for dynamic survival analysis with competing risks based on longitudinal data. IEEE Transactions on Biomedical Engineering 67(1):122–133
- Lee and Whitmore [2006] Lee MLT, Whitmore G (2006) Threshold regression for survival analysis: Modeling event times by a stochastic process reaching a boundary. Statist Sci 21(1):501–513
- Leung et al [1997] Leung KM, Elashoff RM, Afifi AA (1997) Censoring issues in survival analysis. Annual review of public health 18(1):83–104
- Luck et al [2017] Luck M, Sylvain T, Cardinal H, et al (2017) Deep learning for patient-specific kidney graft survival analysis. arXiv preprint arXiv:170510245
- Merlo et al [2021] Merlo D, Stankovich J, Bai C, et al (2021) Association between cognitive trajectories and disability progression in patients with relapsing-remitting multiple sclerosis. Neurology 97(20):e2020–e2031
- Nagpal et al [2021a] Nagpal C, Jeanselme V, Dubrawski A (2021a) Deep parametric time-to-event regression with time-varying covariates. In: Survival Prediction-Algorithms, Challenges and Applications, PMLR, pp 184–193
- Nagpal et al [2021b] Nagpal C, Li X, Dubrawski A (2021b) Deep survival machines: Fully parametric survival regression and representation learning for censored data with competing risks. IEEE Journal of Biomedical and Health Informatics 25(8):3163–3175
- Nagpal et al [2021c] Nagpal C, Yadlowsky S, Rostamzadeh N, et al (2021c) Deep cox mixtures for survival regression. In: Machine Learning for Healthcare Conference, PMLR, pp 674–708
- Pan et al [2018] Pan H, Han H, Shan S, et al (2018) Mean-variance loss for deep age estimation from a face. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 5285–5294
- Pham et al [2021] Pham L, Harris T, Varosanec M, et al (2021) Smartphone-based symbol-digit modalities test reliably captures brain damage in multiple sclerosis. NPJ digital medicine 4(1):36
- Pieszko et al [2023] Pieszko K, Shanbhag AD, Singh A, et al (2023) Time and event-specific deep learning for personalized risk assessment after cardiac perfusion imaging. npj Digital Medicine 6(1):78
- Pölsterl [2020] Pölsterl S (2020) scikit-survival: A library for time-to-event analysis built on top of scikit-learn. Journal of Machine Learning Research 21(212):1–6. URL http://jmlr.org/papers/v21/20-729.html
- Pourjafari et al [2022] Pourjafari E, Ziaei N, Rezaei MR, et al (2022) Survival seq2seq: A survival model based on sequence to sequence architecture. In: Machine Learning for Healthcare Conference, PMLR, pp 79–100
- Rindt et al [2022] Rindt D, Hu R, Steinsaltz D, et al (2022) Survival regression with proper scoring rules and monotonic neural networks. In: International Conference on Artificial Intelligence and Statistics, PMLR, pp 1190–1205
- Singer and Willett [1991] Singer JD, Willett JB (1991) Modeling the days of our lives: using survival analysis when designing and analyzing longitudinal studies of duration and the timing of events. psychological Bulletin 110(2):268
- Uno et al [2011] Uno H, Cai T, Pencina MJ, et al (2011) On the c-statistics for evaluating overall adequacy of risk prediction procedures with censored survival data. Statistics in medicine 30(10):1105–1117
- Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Advances in neural information processing systems 30
- Vinzamuri and Reddy [2013] Vinzamuri B, Reddy CK (2013) Cox regression with correlation based regularization for electronic health records. In: 2013 IEEE 13th International Conference on Data Mining, IEEE, pp 757–766
- Wang and Sun [2022] Wang Z, Sun J (2022) Survtrace: Transformers for survival analysis with competing events. In: Proceedings of the 13th ACM International Conference on Bioinformatics, Computational Biology and Health Informatics, pp 1–9
- Whitehouse et al [2019] Whitehouse CE, Fisk JD, Bernstein CN, et al (2019) Comorbid anxiety, depression, and cognition in ms and other immune-mediated disorders. Neurology 92(5):e406–e417