Adaptive lasso and Dantzig selector for spatial point processes intensity estimation
Abstract
Lasso and Dantzig selector are standard procedures able to perform variable selection and estimation simultaneously. This paper is concerned with extending these procedures to spatial point process intensity estimation. We propose adaptive versions of these procedures, develop efficient computational methodologies and derive asymptotic results for a large class of spatial point processes under an original setting where the number of parameters, i.e. the number of spatial covariates considered, increases with the expected number of data points. Both procedures are compared theoretically, in a simulation study, and in a real data example.
keywords:
, and
1 Introduction
Spatial point processes are stochastic processes which model random locations of points in space, such as random locations of trees in a forest, locations of disease cases, earthquake occurrences and crime events [e.g. 2, 8, 13, 23]. To understand the arrangement of points, the intensity function is the standard summary function [2, 13]. When one seeks to describe the probability of observing a point at location in terms of covariates, the most popular model for the intensity function, , is
| (1) |
where, for , , represent spatial covariates measured at location and is a real -dimensional parameter.
The score of the Poisson likelihood, i.e. the likelihood if the underlying process is assumed to be the Poisson process, remains an unbiased estimating equation to estimate even if the point pattern does not arise from a Poisson process [25]. Such a method is well-studied in the literature and extended in several ways to gain efficiency [e.g. 18, 19] when the number of covariates is moderate. Standard results cover the consistency and asymptotic normality of the maximum Poisson likelihood under the increasing domain asymptotic (see e.g. [18] and references therein).
When a large number of covariates is available, variable selection is unavoidable. Performing estimation and selection for spatial point processes intensity models has received a lot of attention. Recent developments consider techniques centered around regularization methods [e.g. 10, 14, 24, 27] such as lasso technique. In particular, [10] consider several composite likelihoods penalized by a large class of convex and non-convex penalty functions and obtain asymptotic results under the increasing domain asymptotic framework.
The Dantzig selector is an alternative procedure to regularization techniques. It was initially proposed for linear models by [7] and subsequently extended to more complex models [e.g. 1, 15, 21]. In particular, [15] generalizes this approach to general estimating equations. One of the main advantages of the Dantzig selector is its implementation which, for linear models, results in a linear programming. Since then, the Dantzig selector and lasso procedures have been compared in different contexts [e.g. 3, 22].
In this paper, we compare lasso and Dantzig selector when they are applied to intensity estimation for spatial point processes. We compare these procedures in the complex asymptotic framework where the number of informative covariates, say and the number of non-informative covariates, say , may increase with the mean number of points. Our asymptotic results are developed under a setting which embraces both increasing domain asymptotic and infill asymptotic which are often considered in the literature (see also Section 2). Such a setting is almost never considered in the spatial point processes literature (see again e.g. [18]).
It is well-known that the Poisson likelihood can be approximated as a quasi-Poisson regression model, see e.g. [2]. For the adaptive lasso procedure, our theoretical contributions can also be seen as extension of work such as [16] which provides asymptotic results for estimators from regularized generalized linear models. However, in our spatial framework, the more standard sample size must be substituted by, here, a mean number of points. Furthermore, observations are no more independent, i.e. our results are valid for a large class of spatial dependent point processes. Note also that [16] assumes .
The theoretical contributions of the present paper are two-fold. First, for the adaptive lasso procedure, the question stems from extending the work by [10] which considers only an increasing domain asymptotic, and assumes and . For the Dantzig selector, our contributions are to extend the standard methodology to spatial point processes, propose an adaptive version and derive theoretical results. This yields different computational and theoretical issues. As revealed by our main result, Theorem 4.1, the adaptive lasso and Dantzig selector procedures share several similarities but also some slight differences. We first prove that both procedures satisfy an oracle property, i.e. methods can correctly select the nonzero coefficients with probability converging to one, and second that the estimators of the nonzero coefficients are asymptotically normal. However, the conditions under which results are valid for the Dantzig selector are slightly more restrictive.
Our conducted simulation study and application to environmental data also demonstrate that both procedures behave similarly.
2 Background and framework
Let be a spatial point process on , . We view as a locally finite random subset of . Let be a compact set of Lebesgue measure which will play the role of the observation domain. A realization of in is thus a set , where and is the observed number of points in . Suppose has intensity function and second-order product density . Campbell theorem states that, for any function or
| (2) |
Based on the first two intensity functions, the pair correlation function is defined by
when both and exist with the convention . The pair correlation function is a measure of departure of the model from the Poisson point process for which . For further background materials on spatial point processes, see for example [2, 23].
For our asymptotic considerations, we assume that a sequence is observed within a sequence of bounded domains . We denote by and the intensity and pair correlation of . With an abuse of notation, we denote by and , the expectation and variance under . we assume that the intensity writes , . We thus let denote the true parameter vector and assume it can be decomposed as . Therefore, , and , where is the number of non-zero coefficients, the number of zero coefficients and the total number of parameters. We underline that it is unknown to us which coefficients are non-zero and which are zero. Thus, we consider a sparse intensity model where in particular and may diverge to infinity as grows.
For any or for the spatial covariates , we use a similar notation, i.e. and , . We let , that is the expected number of points in . By Campbell theorem, we have
Note that is a function of . In this paper, we assume that as . That kind of assumption is very general and embraces the well-known frameworks called increasing domain asymptotics and infill asymptotics. For the increasing domain context, and usually depends on only through . For the infill asymptotics, is assumed to be a bounded domain of and usually , as . In some sense, the parameter plays the role of the sample size in standard inference.
To reduce notation in the following, unless it is ambiguous, we do not index , , , , , with .
3 Methodologies
3.1 Standard methodology
If is a Poisson point process, then, on , admits a density with respect to the unit rate Poisson point process [23]. This yields the log-likelihood function for , which, for the intensity model (1), is proportional to
| (3) |
The gradient of (3) writes
| (4) |
If is not a Poisson point process, Campbell Theorem shows that (4) remains an unbiased estimating equation. Hence, the maximum of (3), still makes sense for non-Poisson models. Such an estimator, which can be viewed as composite likelihood has received a lot of attention in the literature and asymptotic properties are well-established when and is moderate [e.g 18, 19, 25].
We end this section with the definition of the two following matrices
| (5) | ||||
| (6) |
The matrix corresponds to the sensitivity matrix defined by while corresponds to the variance of the estimating equation, i.e. . By passing, we point out that . Let be some matrix, e.g. or . Such a matrix is decomposed as
| (7) |
where (resp. ) is the first (resp. the following ) components of and (resp. , , and ) is the top-left corner (resp. the top-right corner, the bottom-left corner, and the bottom-right corner) of . In what follows, for a squared symmetric matrix , and denote respectively the smallest and largest eigenvalue of . Finally, denotes the Euclidean norm of a vector , while denotes the spectral norm. We remind that the spectral norm is subordinate and that for a symmetric definite positive matrix .
3.2 Adaptive lasso (AL)
When the number of parameters is large, regularization methods allow one to perform both estimation and variable selection simultaneously. When , [10] consider several regularization procedures which consist in adding a convex or non-convex penalty term to (3). The proposed methods are unchanged even when the number of covariates diverges. In particular, the adaptive lasso consists in maximizing
| (8) |
where the real numbers are non-negative tuning parameters. We therefore define the adaptive lasso estimator as
| (9) |
When for , the method reduces to the maximum composite likelihood estimator and when to the standard lasso estimator. If acts as an intercept, meaning that , it is often desired to let this parameter free. This can be done by setting in the second term of (8). Finally, the choice of as a normalization factor in (8) follows the implementation of the adaptive lasso procedure for generalized linear models in the standard software (e.g. R package glmnet [17]).
3.3 Adaptive (linearized) Dantzig selector (ALDS)
When applied to a likelihood [7, 21], the Dantzig selector estimate is obtained by minimizing subject to the infinite norm of the score function bounded by some threshold parameter . In the spatial point process setting, we propose an adaptive version of the Dantzig selector estimate as the solution of the problem
| (10) |
where and where is the estimating equation given by (4). It is worth pointing out for reduces the criterion (10) to , which leads to the maximum composite likelihood estimator. Similarly to the adaptive lasso procedure, the intercept can be let free by setting . However, in the following, we assume, for the ALDS procedure, that for convenience, in order to rewrite (10) in the following matrix form
| (11) |
We claim that the whole methodology and the proofs could be redone without involving the notation and so that Theorem 4.1 remains valid if one does not regularize the intercept term for example.
Due to the nonlinearity of the constraint vector, standard linear programming can no more be used to solve (11). This results in a non-convex optimization problem. In particular the feasible set is non-convex, which makes the method difficult to implement and to analyze from a theoretical point of view. In the context of generalized linear models, [21] consider the iterative reweighted least squares method and define an iterative procedure where at each step of the algorithm the constraint vector corresponds to a linearization of the updated pseudo-score. Such a procedure is not straightforward to extend from (11) and remains complex to analyze from a theoretical point of view. As an alternative, we follow [15, Chapter 3] and propose to linearize the constraint vector by expanding around , an initial estimate of , using a first order Taylor approximation; i.e. we substitute by . Such a linearization enables now the use of standard linear programming. We term adaptive linearized Dantzig selector (ALDS) estimate and denote it by the solution to the optimization problem
| (12) |
Properties of depend on properties of which are made precise in the next section.
4 Asymptotic results
Our main result relies upon the following conditions:
-
(.1)
The intensity function has the log-linear specification given by (1) where .
-
(.2)
is an increasing sequence of real numbers, such that as .
-
(.3)
The covariates satisfy
-
(.4)
The intensity and pair correlation satisfy
-
(.5)
The matrix satisfies
-
(.6)
For any , the following convergence holds in distribution as :
where .
-
(.7)
The initial estimate satisfies and is such that .
-
(.8)
As , we assume that and are such that as
-
(.9)
Let and . We assume that these sequences are such that, as
Condition (.1) specifies the form of intensity models considered in this paper. In particular, note that we do not assume that is an element of a bounded domain of . Condition (.2) specifies our asymptotic framework where we assume to observe in average more and more points in . As already mentioned, this may cover increasing domain type or infill type asymptotics. To our knowledge, only [11] consider a similar asymptotic framework in order to construct information criteria for spatial point process intensity estimation. The context is however very different here as we consider a large number of covariates and we study methodologies (adaptive lasso or Dantzig) which are able to produce a sparse estimate. Condition (.3) is quite standard and is not too restrictive. Note that conditions (.1)-(.3) allow us in Lemma A.2 to prove that in a ‘neighbordhood’ of , , a useful result widely used in our proofs. The last part of Condition (.3) asserts that at any location the covariates are linearly independent. Condition (.3) also implies first that and second that . Condition (.5) is a similar assumption but for the submatrix which corresponds to . Condition (.4) is also natural. Combined with Condition (.3), this implies that . When (and therefore ) and in the increasing domain framework, such an assumption can be satisfied by a large class of spatial point processes such as determinantal point processes, log-Gaussian Cox processes and Neyman-Scott point processes [see 10]. When and in the infill asymptotic framework, these assumptions are also valid for many spatial point processes, as discussed by [11]. Condition (.6) is required to derive the asymptotic normality of . Under a specific framework, such a result has already been obtained for a large class of spatial point processes: by [4, 26] under the increasing domain framework and and [9] when ; by [11] in the infill/increasing domain asymptotics frameworks and .
Condition (.7) is very specific to the ALDS estimate which requires a preliminary estimate of . That condition is not unrealistic as a simple choice for could be the maximum of the composite likelihood function (3), see the remark after Theorem 4.1. Of course, we do not require that produces a sparse estimate.
Condition (.8) reflects the restriction on the number of covariates that can be considered in this study. For the AL estimate, this assumption is very similar to the one required by [16] when is replaced by and where the number of non-zero coefficients is constant.
Condition (.9) contains the main ingredients to derive sparsity properties, consistency and asymptotic normality. We first note that if , then , whereby it is easily deduced that the two conditions on and cannot be satisfied simultaneously even if . This justifies the introduction of an adaptive version of the Dantzig selector and motivates the use of the adaptive lasso. The condition for the adaptive lasso is similar to the one imposed by [16] when is replaced by and in their context. However, we require a slightly stronger condition on than the one required by [16]. In our setting, their assumption would be written as . However, we would have to assume that . Such a condition is not straightforwardly satisfied in our setting since, for instance, the conditions (.2)-(.4) only imply that .
As already mentioned, we do not assume that satisfies any sparsity property. We believe this is the main reason why conditions (.8))-(.9) contain slightly stronger assumptions for the ALDS estimate than for the AL estimate. We now present our main result, whose proof is provided in Appendices B-C.
Theorem 4.1.
Let denote either or . Assume that the conditions (.1)-(.9) hold, then the following properties hold.
-
(i)
exists. Moreover satisfies, .
-
(ii)
Sparsity: as .
-
(iii)
Asymptotic Normality: for any such that
in distribution, where .
To derive the consistency of , a careful look at the proof in Appendix B shows that the condition could be sufficient. The convergence rate, i.e. , is times the convergence rate of the estimator obtained when is constant [see 10, Theorem 1]. It also corresponds to the rate of convergence obtained by [16] for generalized linear models when and when corresponds to the standard sample size. It is worth pointing out that a possible diverging number of non-zero coefficients does not affect the rate of convergence. It does however impose a more restrictive condition on . Still on Theorem 4.1 (i), its proof shows that this result remains valid when for . In other words, the maximum composite likelihood estimator is consistent with the same rate of convergence. Hence a simple choice for the initial estimate defining the ALDS estimate is the maximum of the Poisson likelihood given by (3).
Theorem 4.1 (iii) would be the result one would obtain if . Therefore, the efficiency of and is the same as the estimator of obtained by maximizing (3) based on the sub model knowing that . In other words, when is sufficiently large, both estimators are as efficient as the oracle one.
We end this section with the following remark. Despite the asymptotic properties for and and the conditions under which they are valid, are (almost) identical, the proofs are completely different and rely upon different tools. For , our contribution is to extend the proof by [10] where only the increasing domain framework was considered, i.e. and as and where and . The results for are the first ones available for spatial point processes. To handle this estimator, we first have to study existence and optimal solutions for the primal and dual problems.
5 Computational considerations
To lessen notation, we remove the index in different quantities such as , and . For the practical point of view, we define the number of data points in .
5.1 Berman-Turner approach
Before discussing how AL and ALDS estimates are obtained we first remind the Berman-Turner approximation [2] used to derive the Poisson likelihood estimate (3). The so-called Berman-Turner approximation consists in discretizing the integral term in (3) as
where are points in consisting of the data points and dummy points and where the quadrature weights are non-negative real numbers such that . Using this specific integral discretization, (3) is then approximated by
| (13) |
where and . Equation (13) is formally equivalent to the weighted likelihood function of independent Poisson variables with weights . The method to approximate (4) and (5) follows along similar lines which respectively results in
| (14) |
where . Thus, standard statistical software for generalized linear models can be used to obtain the estimates. This fact is implemented in the R package by ppm function with option method="mpl" [2].
5.2 Adaptive lasso (AL)
First, given a current estimate , (13) is approximated using second order Taylor approximation to apply iteratively reweighted least squares,
| (15) |
where is a constant, and are the new working response values and weights, Second, a penalized weighted least squares problem is obtained by adding penalty term. Therefore, we solve
| (16) |
using the coordinate descent algorithm [17]. The method consists in partially minimizing (16) with respect to given for , , that is
With a few modifications (16) is solved using the R package [17]. More detail about this implementation can be found in [10, Appendix C].
5.3 Adaptive (linearized) Dantzig selector (ALDS)
5.4 Tuning parameter selection
Both AL and ALDS rely on the proper regularization parameters to avoid from unnecessary bias due to too small selection and from large variance due to too large choice, so the selection of becomes an important task. To tune the , we follow [10, 28] and define , where and is the maximum composite likelihood estimate. The weights serve as a prior knowledge to identify the non-zero coefficients since, for a constant , large (resp. small) will force close to zero (resp. infinity) [28],
Our theoretical results are not in line with this stochastic way of setting the regularization parameters but we believe this choice is pertinent in our context. Here is the intuition: let . Using the -consistency of , for non-zero coefficients, while, for zero coefficients, we may conjecture that . Forgetting the , we may conjecture that and . Hence, considering the AL procedure for instance, that would mean that we require to be such that and , which constitutes a non empty condition. For instance, assuming (.8), the sequence satisfies (.9) as soon as , since as
Considering rigorously the stochastic choice for the regularization parameters is left for future research.
The remaining task is to specify . We follow here the literature, mainly [11], and propose to select as the minimum of the Bayesian information criterion, BIC(), for spatial point processes
where is the maximized composite likelihood function, is the number of non-zero elements in and is the number of observed data points.
6 Numerical results
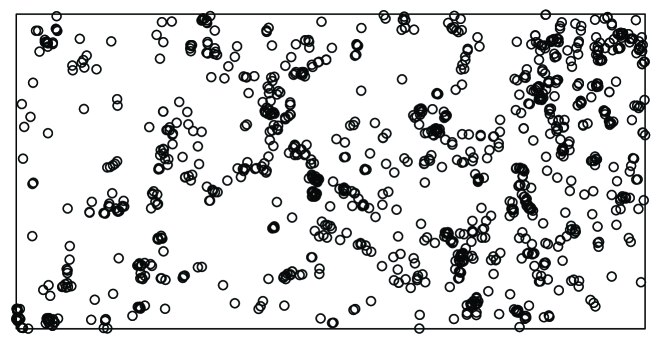
In Sections 6.1-6.2, we compare the AL and ALDS for intensity modeling of a simulated and real data. In particular, the real data example comes from an environmental data where 1146 locations of Acalypha diversifolia trees given by Figure 1 are surveyed in a 50-hectare region () of the tropical forest of Barro Colorado Island (BCI) in central Panama [e.g. 20]. A main question is how this tree species profits from environmental habitats [12, 26] that could be related to the 15 environmental covariates depicted in Figure 2 and their 79 interactions. With a total of 94 covariates, we perform variable selection using the AL and ALDS to determine which covariates should be included in the model. We center and scale the 94 covariates to sort the important covariates according to the magnitudes of . The subset of such covariates are also considered to construct a realistic setting for the simulation studies.
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
6.1 Simulation study
The simulated point patterns are generated from Poisson and Thomas cluster processes with intensity (1). To generate point patterns from Thomas process with intensity (1) [e.g. 10], we first generate a parent point pattern from a stationary Poisson point process with intensity . Given , offspring point patterns are generated from inhomogeneous Poisson point process with intensity
where . The point process is indeed an inhomogeneous Thomas point process with intensity (1). We set and . The smaller the , the more clustered the point patterns, leading to moderate clustering for and highly clustering for .
The covariates used for the simulation experiment are from the BCI data. In addition to the 15 environmental factors depicted by Figure 2, we add interaction between two covariates until we obtain the desired number of covariates or . For each , we consider three mean numbers of points () which increase when the observation domain expands. More precisely, we set that (resp. ) points is generated in (resp. , ). When or is considered, we simply rescale the covariates to fit the desired observation domain. We fix and while the rest are set to zero, so . The parameter acts as intercept and is tuned to control the average number of points.
| TPR | FPR | RMSE | Time | |||||
|---|---|---|---|---|---|---|---|---|
| AL | ALDS | AL | ALDS | AL | ALDS | AL | ALDS | |
| () | ||||||||
| 57 | 57 | 23 | 23 | 2.4 | 2.4 | 0.3 | 0.3 | |
| 7 | 7 | 15 | 15 | 2.9 | 2.9 | 2.0 | 2.0 | |
| 0 | 0 | 8 | 8 | 2.8 | 2.8 | 4.0 | 4.0 | |
| () | ||||||||
| 100 | 100 | 3 | 4 | 0.3 | 0.3 | 0.3 | 0.3 | |
| 97 | 96 | 4 | 5 | 0.5 | 0.5 | 0.8 | 0.6 | |
| 86 | 86 | 8 | 8 | 0.9 | 0.9 | 3.0 | 3.0 | |
| () | ||||||||
| 100 | 100 | 0 | 0 | 0.1 | 0.1 | 0.4 | 0.3 | |
| 100 | 100 | 0 | 0 | 0.1 | 0.1 | 0.9 | 0.9 | |
| 100 | 100 | 0 | 0 | 0.1 | 0.1 | 3.0 | 3.0 | |
| TPR | FPR | RMSE | Time | |||||
|---|---|---|---|---|---|---|---|---|
| AL | ALDS | AL | ALDS | AL | ALDS | AL | ALDS | |
| () | ||||||||
| 59 | 59 | 44 | 44 | 8.2 | 8.2 | 0.3 | 0.3 | |
| 20 | 20 | 30 | 30 | 11.0 | 11.0 | 2.0 | 2.0 | |
| 0 | 0 | 15 | 15 | 8.3 | 8.3 | 4.0 | 4.0 | |
| () | ||||||||
| 91 | 89 | 53 | 47 | 2.6 | 2.2 | 0.3 | 0.3 | |
| 88 | 86 | 48 | 43 | 4.9 | 3.8 | 1.0 | 0.6 | |
| 80 | 80 | 35 | 35 | 7.7 | 7.7 | 5.0 | 5.0 | |
| () | ||||||||
| 100 | 100 | 59 | 43 | 1.0 | 0.8 | 0.9 | 1.0 | |
| 100 | 100 | 56 | 39 | 1.7 | 1.1 | 2.0 | 3.0 | |
| 100 | 100 | 52 | 52 | 3.2 | 3.2 | 8.0 | 8.0 | |
| TPR | FPR | RMSE | Time | |||||
|---|---|---|---|---|---|---|---|---|
| AL | ALDS | AL | ALDS | AL | ALDS | AL | ALDS | |
| () | ||||||||
| 64 | 64 | 72 | 72 | 39.0 | 39.0 | 0.5 | 0.5 | |
| 29 | 29 | 72 | 72 | 130.0 | 130.0 | 6.0 | 6.0 | |
| 0 | 0 | 36 | 36 | 69.0 | 69.0 | 6.0 | 6.0 | |
| () | ||||||||
| 91 | 90 | 66 | 61 | 4.1 | 3.6 | 0.4 | 0.3 | |
| 84 | 80 | 70 | 64 | 13.0 | 10.0 | 2.0 | 0.7 | |
| 80 | 80 | 74 | 74 | 53.0 | 53.0 | 10.0 | 10.0 | |
| () | ||||||||
| 100 | 100 | 66 | 51 | 1.4 | 1.1 | 1.0 | 1.0 | |
| 100 | 100 | 69 | 51 | 2.6 | 1.9 | 3.0 | 4.0 | |
| 100 | 100 | 70 | 70 | 7.1 | 7.1 | 10.0 | 10.0 | |
For each model and setting, we generate 500 independent point patterns and estimate the parameters for each of these using the AL and ALDS procedures. The performances of AL and ALDS estimates are compared in terms of the true positive rate (TPR), false positive rate (FPR), and root-mean squared error (RMSE). We also report the computing time. The TPR (resp. FPR) are the expected fractions of informative (resp. non-informative) covariates included in the selected model, so we would expect to obtain a high (resp. low) TPR (resp. FPR). The RMSE is defined for an estimate by
where is the empirical mean.
Tables 1-3 report results respectively for the Poisson model and the Thomas model with moderate and high clustering. In the situation where point patterns come from Poisson processes, AL and ALDS perform very similarly. In particular, both methods do not work well in a small spatial domain with large . The performances improve significantly as expands even for large . When the point patterns exhibit clustering (Tables 2-3), in general AL and ALDS tend to overfit the intensity model by selecting too many covariates (indicated by higher FPR) which yields higher RMSE. ALDS sometimes performs slightly better in terms of RMSE. Results tend to deteriorate in the high clustering situation but remain very satisfactory: for the three considered models, the TPR (resp. FPR, RMSE) increases (decreases) when grows for given while for given (especially when ), the results remain quite stable when increases. In terms of computing time, no major difference can be observed.
6.2 Application to the forestry dataset
We model the intensity function for the point pattern of the Acalypha diversifolia using (1) depending on 94 environmental described previously. The overall estimates from the AL and ALDS procedures are presented in Table 5. We only report in Table 4 the top 12 important variables.
Among 94 environmental variables, the AL and ALDS respectively selects 32 and 33 important covariates (most of them are similar). We sort the magnitude of to identify the 12 most informative covariates. It turns out that these 12 covariates are similar for both procedures (see Table 4). For the rest of selected covariates, the rankings are slightly different but the magnitudes are very similar (see Table 5).
| Covariates | AL | ALDS |
|---|---|---|
| Ca:N.min | -0.89 | -0.89 |
| K:N.min | 0.58 | 0.53 |
| Al:Mg | -0.51 | -0.47 |
| pH | 0.48 | 0.46 |
| B | -0.46 | -0.43 |
| Ca | 0.45 | 0.42 |
| Al:Fe | 0.38 | 0.39 |
| Fe:K | -0.31 | -0.33 |
| B:P | -0.30 | -0.29 |
| P:Nz | 0.27 | 0.26 |
| Fe | 0.26 | 0.25 |
| Mn | -0.24 | -0.24 |
| Number of selected covariates | 32 | 33 |
7 Discussion
In this paper, we develop the adaptive lasso and Dantzig selector for spatial point processes intensity estimation and provide asymptotic results under an original setting where the number of non-zero and zero coefficients diverge with the mean number of points. We demonstrate that both methods share identical asymptotic properties and perform similarly on simulated and real data. This study supplements previous ones [see e.g. 3] where similar conclusions on linear models and generalized linear models were addressed.
[10] considered extensions of lasso type methods by involving general convex and non-convex penalties. In particular, composite likelihoods penalized by SCAD or MC+ penalty showed interesting properties. To integrate such an idea for the Dantzig selector, we could consider the optimization problem
where is the derivative with respect to of a general penalty function . However, such an interesting extension would make linear programming unusable and theoretical developments more complex to derive. We leave this direction for further study.
Another direction for further study is to derive results for the selection of regularization parameters. As mentioned earlier, a challenging and definitely interesting perspective would be the validity of Theorem 4.1 when we define the regularization parameters in a stochastic way such as .
On a similar topic, [11] studied information criteria such as AIC, BIC, and the composite-versions under similar asymptotic framework for selecting intensity model of spatial point process. These criteria could be extended for tuning parameter selection in the context of regularization methods for spatial point process.
Appendix A Additional notation and auxiliary Lemmas
Lemmas A.1-A.2 are used for the proof of Theorem 4.1 in both cases . Throughout the proofs, the notation or for a random vector and a sequence of real numbers means that and . In the same way for a vector or a squared matrix , the notation and mean that and .
Proof.
Using Campbell Theorems (2), the score vector is unbiased and has variance . By Condition (.3) for any , . Hence, . By definition of (6) and conditions (.2) and (.4), we deduce that . We deduce that . In the same way, and . The result is proved since for any centered real-valued stochastic process with finite variance , . ∎
The next lemma states that in the vicinity of , and have the same behaviour.
Lemma A.2.
Appendix B Proof of Theorem 4.1 when
B.1 Existence of a root- consistent local maximizer
The first result presented hereafter shows that there exists a local maximizer of which is a consistent estimator of .
Proposition B.1.
Note that the conditions on and are actually implied by conditions (.8) and (.9). In the proof of this result and the following ones, the notation stands for a generic constant which may vary from line to line. In particular this constant is independent of , and .
Proof.
Let . We remind the reader that the estimate of is defined as the maximum of the function , given by (8), over . To prove Proposition B.1, we aim at proving that for any given , there exists sufficiently large such that for sufficiently large
| (18) |
Equation (18) will imply that with probability at least , there exists a local maximum in the ball , and therefore a local maximizer such that . We decompose as where
Since is infinitely continuously differentiable and , then using a second-order Taylor expansion there exists such that
where
By condition (.3)
where . Now, for some on the line segment between and
By conditions (.2)-(.3) and Lemma A.2
Hence, for sufficiently large
Regarding the term we have,
We deduce that for large enough, there exists such that whereby we deduce that
By the assumption of Proposition B.1, , whereby we deduce that for sufficiently large
Now for sufficiently large,
for any given since by Lemma A.1.
∎
B.2 Sparsity property for
Lemma B.2.
Proof.
Let . It is sufficient to show that with probability tending to as , for any satisfying , we have for any
| (19) |
B.3 Asymptotic normality for
Proof.
As shown in Proposition B.1, there is a root- consistent local maximizer of , and it can be shown that there exists an estimator in Proposition B.1 that is a root- consistent local maximizer of , which is regarded as a function of , and that satisfies
There exists and such that for
| (22) |
where
Let (resp. ) be the first components (resp. top-left corner) of (resp. ). Let also be the matrix containing . Finally, let the vector
These notation allow us to rewrite (22) as
| (23) |
Let and , then
Now, by condition (.5), and by the definition of , . By conditions (.1)-(.3), there exists some on the line segment between and such that
whereby we deduce from conditions (.1)-(.3) and Lemma A.2 that
The last two results and conditions (.8)-(.9) yield that
These results finally lead to
and finally to the proof of the result using Slutsky’s lemma and condition (.6).
∎
Appendix C Proof of Theorem 4.1 when
C.1 Existence and optimal solutions for the primal and dual problems
For , we let .
Lemma C.1.
There exists a solution to the problem (12).
Proof.
Following [6], we state that (12) is equivalent to
| (24) |
where is an additional parameter vector to be optimized and is the initial estimator. Note that (24) is a linear problem with linear inequality constraints. To prove the existence of ALDS estimates, we need to derive dual problem of (24) and prove that strong duality holds. To derive the dual problem, we first construct the Lagrangian form associated with the problem (24) considering the main arguments by [5, section 5.2]
where is the dual vector (which can be viewed as a Lagrange multiplier).
The dual function is defined by
| (25) | ||||
For any , is a lower bound to the optimality problem (24) (see [5, p.216]). To find the best lower bound comes to solve the dual problem:
Recall that problem (24) is a linear program with linear inequality constraints, so that strong duality holds if the dual problem is feasible [see 5, p.227], that is to say if there exists some such that
Moreover, we remark that
is equivalent to
which is also equivalent to
This comes to the condition that there exists such that
| (26) |
Therefore, the dual problem associated with (24) is
| (27) |
Note that the dual problem (27) can be unequivocally reparameterized in terms of as follows
| (28) |
due to complementary slackness conditions. Now, we derive the following optimality conditions and obtain optimal primal and dual solutions.
We derive the following optimality conditions ensuring the Karush-Kuhn-Tucker (KKT) conditions and thus obtain optimal primal and dual solutions.
Lemma C.2.
Proof.
We start by writing the Karush-Kuhn-Tucker (KKT) conditions for the problem (12):
| (33) | ||||
| (34) | ||||
| (35) | ||||
| (36) | ||||
| (37) | ||||
| (38) | ||||
| (39) | ||||
| (40) | ||||
| (41) | ||||
| (42) | ||||
| (43) | ||||
| (44) |
Let and satisfy (29)-(32). (35) and (36) are obviously satisfied under (29). If one defines and such that and , then and (38) is satisfied.
From the definition of and , we rewrite (32) as
From (36)-(37) each term in the above sum is the sum of two negative terms, whereby we dedude that (41)-(42) necessarily hold. With a similar argument, by using (31), we also deduce that (39)-(40) are also true by setting in particular . And that latter choice implies that (33)-(34) are also satisfied. ∎
C.2 A few auxiliary statements
Before tackling more specifically the proof of Theorem 4.1 for the ALDS estimator, we present a few auxiliary results that will be used.
Proof.
(i) follows from conditions on and .
(ii) follows from conditions (.1)-(.3), (.7) and Lemma A.2. We only prove the assertions for the matrices and . The other cases follow along similar lines. First,
Second, using Taylor expansion, there exists on the segment between and such that whereby we deduce that
(iii) We only have to prove it for . Using Taylor expansion, there exists such that . Using Lemma A.1, (ii) and condition (.7), we obtain
∎
C.3 Sparsity property for
The sparsity property of follows from the following Lemma.
Lemma C.4.
Let and satisfy the following conditions
| (47) | ||||
| (48) | ||||
| (49) | ||||
| (50) |
Then, under the conditions (.1)-(.9), the following two statements hold.
(i)
(ii) With probability tending to 1, and given by (47)-(50) satisfy conditions (29)-(32) and are thus the primal and dual optimal solutions (whence the notation ).
It is worth mentioning that the rate in Lemma C.4 (i) is required to derive the central limit theorem proved in Appendix C.4. That required rate of convergence imposes some stronger restriction on the sequence .
Proof.
(i) Using Taylor expansion, there exists on the line segment between and such that which leads, by noticing that , to
Condition (.3) ensures that . Let where
Regarding the term we have
Condition (.3) ensures that . Using this, Lemma C.3 and Lemma A.1 we obtain
With similar arguments, we have
Condition (.8) ensures that
Now, regarding the last term
And we observe that condition (.9) is sufficient to establish that which proves (i) using again condition (.3) and Lemma A.1.
(ii) We have to show that with probability tending to 1, and given by (47)-(50) satisfy conditions (29)-(32). By (47)-(50),
so, (31) is satisfied. Now, we want to show that (32) holds. We have
where
C.4 Asymptotic normality for
Appendix D Resulting estimates for the BCI dataset
| Int | elev | grad | Al | B | Ca | Cu | Fe | K | Mg | Mn | P | Zn | N | |
| AL | -6.252 | 0 | 0 | 0 | -0.461 | 0.448 | 0 | 0.260 | 0 | 0 | -0.244 | 0 | 0 | 0 |
| ALDS | -6.245 | 0 | 0 | 0 | -0.429 | 0.419 | 0 | 0.245 | 0 | 0 | -0.235 | 0 | 0 | 0 |
| N.min | pH | AlB | AlCa | AlCu | AlFe | AlK | AlMg | AlMn | AlP | AlZn | AlN | AlN.min | AlpH | |
| AL | 0.076 | 0.477 | -0.162 | 0 | 0 | 0.379 | 0 | -0.514 | 0 | -0.022 | 0 | 0.103 | 0 | -0.033 |
| ALDS | 0.077 | 0.464 | -0.221 | 0 | 0 | 0.394 | 0 | -0.471 | 0 | -0.008 | 0 | 0.103 | 0 | 0 |
| BCa | BCu | BFe | BK | BMg | BMn | BP | BZn | BN | BN.min | BpH | CaCu | CaFe | CaK | |
| AL | 0 | 0 | 0.152 | 0 | 0 | 0 | -0.299 | 0 | -0.071 | 0 | 0 | 0 | 0.144 | 0 |
| ALDS | 0 | -0.093 | 0.183 | 0 | 0 | 0 | -0.286 | -0.080 | -0.027 | 0.053 | 0 | 0 | 0.142 | 0 |
| CaMg | CaMn | CaP | CaZn | CaN | CaN.min | CapH | CuFe | CuK | CuMg | CuMn | CuP | CuZn | CuN | |
| AL | -0.155 | 0 | 0.104 | 0 | 0 | -0.888 | 0 | 0 | -0.091 | 0 | 0.134 | 0.148 | 0 | 0 |
| ALDS | -0.125 | 0 | 0.095 | 0 | 0 | -0.890 | 0.042 | 0 | -0.013 | 0 | 0.130 | 0.148 | 0 | 0 |
| CuN.min | CupH | FeK | FeMg | FeMn | FeP | FeZn | FeN | FeN.min | FepH | KMg | KMn | KP | KZn | |
| AL | 0 | 0 | -0.311 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | -0.051 |
| ALDS | 0 | 0 | -0.331 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| KN | KN.min | KpH | MgMn | MgP | MgZn | MgN | MgN.min | MgpH | MnP | MnZn | MnN | MnN.min | MnpH | |
| AL | 0.198 | 0.580 | 0.023 | 0 | 0 | -0.011 | 0 | 0 | 0 | 0 | 0 | -0.050 | 0.107 | 0 |
| ALDS | 0.161 | 0.530 | 0 | -0.003 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | -0.047 | 0.100 | 0 |
| PZn | PN | PN.min | PpH | ZnN | ZnN.min | ZnpH | NN.min | NpH | N.minpH | elevgrad | ||||
| AL | 0 | 0.269 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.054 | 0 | |||
| ALDS | 0 | 0.258 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.054 | 0 |
Acknowledgements
We thank the editor, associate editor, and two reviewers for the constructive comments. The research of J.-F. Coeurjolly is supported by the Natural Sciences and Engineering Research Council of Canada. J.-F. Coeurjolly would like to thank Université du Québec à Montréal for the excellent research conditions he received these last years. The research of A. Choiruddin is supported by the Direktorat Riset, Teknologi, dan Pengabdian Kepada Masyarakat, Direktorat Jenderal Pendidikan Tinggi, Riset, dan Teknologi, Kementerian Pendidikan, Kebudayaan, Riset, dan Teknologi Republik Indonesia. The BCI soils data sets were collected and analyzed by J. Dalling, R. John, K. Harms, R. Stallard and J. Yavitt with support from NSF DEB021104,021115, 0212284,0212818 and OISE 0314581, and STRI Soils Initiative and CTFS and assistance from P. Segre and J. Trani.
References
- [1] {barticle}[author] \bauthor\bsnmAntoniadis, \bfnmAnestis\binitsA., \bauthor\bsnmFryzlewicz, \bfnmPiotr\binitsP. and \bauthor\bsnmLetué, \bfnmFrédérique\binitsF. (\byear2010). \btitleThe Dantzig selector in Cox’s proportional hazards model. \bjournalScandinavian Journal of Statistics \bvolume37 \bpages531–552. \endbibitem
- [2] {bbook}[author] \bauthor\bsnmBaddeley, \bfnmAdrian\binitsA., \bauthor\bsnmRubak, \bfnmEge\binitsE. and \bauthor\bsnmTurner, \bfnmRolf\binitsR. (\byear2015). \btitleSpatial Point Patterns: Methodology and Applications with R. \bpublisherCRC Press. \endbibitem
- [3] {barticle}[author] \bauthor\bsnmBickel, \bfnmPeter J\binitsP. J., \bauthor\bsnmRitov, \bfnmYa’acov\binitsY. and \bauthor\bsnmTsybakov, \bfnmAlexandre B\binitsA. B. (\byear2009). \btitleSimultaneous analysis of lasso and Dantzig selector. \bjournalThe Annals of statistics \bvolume37 \bpages1705–1732. \endbibitem
- [4] {barticle}[author] \bauthor\bsnmBiscio, \bfnmChristophe Ange Napoléon\binitsC. A. N. and \bauthor\bsnmWaagepetersen, \bfnmRasmus P\binitsR. P. (\byear2019). \btitleA general central limit theorem and a subsampling variance estimator for -mixing point processes. \bjournalScandinavian Journal of Statistics \bvolume46 \bpages1168–1190. \endbibitem
- [5] {bbook}[author] \bauthor\bsnmBoyd, \bfnmStephen\binitsS. and \bauthor\bsnmVandenberghe, \bfnmLieven\binitsL. (\byear2004). \btitleConvex optimization. \bpublisherCambridge university press. \endbibitem
- [6] {bunpublished}[author] \bauthor\bsnmCandes, \bfnmEmmanuel\binitsE. and \bauthor\bsnmRomberg, \bfnmJustin\binitsJ. (\byear2005). \btitle-Magic: recovery of Sparse Signals via Convex Programming. \bnotehttp://www.acm.caltech. edu/l1magic/. \endbibitem
- [7] {barticle}[author] \bauthor\bsnmCandes, \bfnmEmmanuel\binitsE. and \bauthor\bsnmTao, \bfnmTerence\binitsT. (\byear2007). \btitleThe Dantzig selector: statistical estimation when is much larger than . \bjournalThe Annals of Statistics \bvolume35 \bpages2313–2351. \endbibitem
- [8] {barticle}[author] \bauthor\bsnmChoiruddin, \bfnmA.\binitsA., \bauthor\bsnmAisah, \bauthor\bsnmTrisnisa, \bfnmF.\binitsF. and \bauthor\bsnmIriawan, \bfnmN.\binitsN. (\byear2021). \btitleQuantifying the effect of geological factors on distribution of earthquake occurrences by inhomogeneous Cox processes. \bjournalPure and Applied Geophysics \bvolume178 \bpages1579–1592. \endbibitem
- [9] {barticle}[author] \bauthor\bsnmChoiruddin, \bfnmAchmad\binitsA., \bauthor\bsnmCoeurjolly, \bfnmJean-François\binitsJ.-F. and \bauthor\bsnmLetué, \bfnmFrédérique\binitsF. (\byear2017). \btitleSpatial point processes intensity estimation with a diverging number of covariates. \bjournalarXiv preprint arXiv:1712.09562. \endbibitem
- [10] {barticle}[author] \bauthor\bsnmChoiruddin, \bfnmAchmad\binitsA., \bauthor\bsnmCoeurjolly, \bfnmJean-François\binitsJ.-F. and \bauthor\bsnmLetue, \bfnmFrédérique\binitsF. (\byear2018). \btitleConvex and non-convex regularization methods for spatial point processes intensity estimation. \bjournalElectronic Journal of Statistics \bvolume12 \bpages1210–1255. \endbibitem
- [11] {barticle}[author] \bauthor\bsnmChoiruddin, \bfnmAchmad\binitsA., \bauthor\bsnmCoeurjolly, \bfnmJean-François\binitsJ.-F. and \bauthor\bsnmWaagepetersen, \bfnmRasmus P\binitsR. P. (\byear2021). \btitleInformation criteria for inhomogeneous spatial point processes. \bjournalAustralian and New Zealand Journal of Statistics \bvolume63 \bpages119–143. \endbibitem
- [12] {barticle}[author] \bauthor\bsnmChoiruddin, \bfnmA.\binitsA., \bauthor\bsnmCuevas-Pacheco, \bfnmF.\binitsF., \bauthor\bsnmCoeurjolly, \bfnmJ. F.\binitsJ. F. and \bauthor\bsnmWaagepetersen, \bfnmR. P.\binitsR. P. (\byear2020). \btitleRegularized estimation for highly multivariate log Gaussian Cox processes. \bjournalStatistics and Computing \bvolume30 \bpages649–662. \endbibitem
- [13] {bincollection}[author] \bauthor\bsnmCoeurjolly, \bfnmJean-François\binitsJ.-F. and \bauthor\bsnmLavancier, \bfnmFrédéric\binitsF. (\byear2019). \btitleUnderstanding spatial point patterns through intensity and conditional intensities. In \bbooktitleStochastic Geometry \bpages45–85. \bpublisherSpringer. \endbibitem
- [14] {barticle}[author] \bauthor\bsnmDaniel, \bfnmJeffrey\binitsJ., \bauthor\bsnmHorrocks, \bfnmJulie\binitsJ. and \bauthor\bsnmUmphrey, \bfnmGary J\binitsG. J. (\byear2018). \btitlePenalized composite likelihoods for inhomogeneous Gibbs point process models. \bjournalComputational Statistics & Data Analysis \bvolume124 \bpages104–116. \endbibitem
- [15] {bphdthesis}[author] \bauthor\bsnmDicker, \bfnmLee\binitsL. (\byear2010). \btitleRegularized regression methods for variable selection and estimation, \btypePhD thesis, \bpublisherHarvard University. \endbibitem
- [16] {barticle}[author] \bauthor\bsnmFan, \bfnmJianqing\binitsJ. and \bauthor\bsnmPeng, \bfnmHeng\binitsH. (\byear2004). \btitleNonconcave penalized likelihood with a diverging number of parameters. \bjournalThe Annals of Statistics \bvolume32 \bpages928–961. \endbibitem
- [17] {barticle}[author] \bauthor\bsnmFriedman, \bfnmJerome\binitsJ., \bauthor\bsnmHastie, \bfnmTrevor\binitsT. and \bauthor\bsnmTibshirani, \bfnmRob\binitsR. (\byear2010). \btitleRegularization paths for generalized linear models via coordinate descent. \bjournalJournal of Statistical Software \bvolume33 \bpages1–22. \endbibitem
- [18] {barticle}[author] \bauthor\bsnmGuan, \bfnmYongtao\binitsY., \bauthor\bsnmJalilian, \bfnmAbdollah\binitsA. and \bauthor\bsnmWaagepetersen, \bfnmRasmus Plenge\binitsR. P. (\byear2015). \btitleQuasi-likelihood for spatial point processes. \bjournalJournal of the Royal Statistical Society: Series B (Statistical Methodology) \bvolume77 \bpages677–697. \endbibitem
- [19] {barticle}[author] \bauthor\bsnmGuan, \bfnmYongtao\binitsY. and \bauthor\bsnmShen, \bfnmYe\binitsY. (\byear2010). \btitleA weighted estimating equation approach for inhomogeneous spatial point processes. \bjournalBiometrika \bvolume97 \bpages867–880. \endbibitem
- [20] {barticle}[author] \bauthor\bsnmHubbell, \bfnmStephen P\binitsS. P., \bauthor\bsnmCondit, \bfnmRichard\binitsR. and \bauthor\bsnmFoster, \bfnmRobin B\binitsR. B. (\byear2005). \btitleBarro Colorado forest census plot data. \bnotehttp://ctfs.si.edu/webatlas/datasets/bci/. \endbibitem
- [21] {barticle}[author] \bauthor\bsnmJames, \bfnmGareth M\binitsG. M. and \bauthor\bsnmRadchenko, \bfnmPeter\binitsP. (\byear2009). \btitleA generalized Dantzig selector with shrinkage tuning. \bjournalBiometrika \bvolume96 \bpages323–337. \endbibitem
- [22] {barticle}[author] \bauthor\bsnmJames, \bfnmGareth M\binitsG. M., \bauthor\bsnmRadchenko, \bfnmPeter\binitsP. and \bauthor\bsnmLv, \bfnmJinchi\binitsJ. (\byear2009). \btitleDASSO: connections between the Dantzig selector and lasso. \bjournalJournal of the Royal Statistical Society: Series B (Statistical Methodology) \bvolume71 \bpages127–142. \endbibitem
- [23] {bbook}[author] \bauthor\bsnmMøller, \bfnmJesper\binitsJ. and \bauthor\bsnmWaagepetersen, \bfnmRasmus Plenge\binitsR. P. (\byear2004). \btitleStatistical inference and simulation for spatial point processes. \bpublisherCRC Press. \endbibitem
- [24] {barticle}[author] \bauthor\bsnmRakshit, \bfnmSuman\binitsS., \bauthor\bsnmMcSwiggan, \bfnmGreg\binitsG., \bauthor\bsnmNair, \bfnmGopalan\binitsG. and \bauthor\bsnmBaddeley, \bfnmAdrian\binitsA. (\byear2021). \btitleVariable selection using penalised likelihoods for point patterns on a linear network. \bjournalAustralian & New Zealand Journal of Statistics \bvolume63 \bpages417–454. \endbibitem
- [25] {barticle}[author] \bauthor\bsnmWaagepetersen, \bfnmRasmus Plenge\binitsR. P. (\byear2007). \btitleAn estimating function approach to inference for inhomogeneous Neyman–Scott processes. \bjournalBiometrics \bvolume63 \bpages252–258. \endbibitem
- [26] {barticle}[author] \bauthor\bsnmWaagepetersen, \bfnmRasmus Plenge\binitsR. P. and \bauthor\bsnmGuan, \bfnmYongtao\binitsY. (\byear2009). \btitleTwo-step estimation for inhomogeneous spatial point processes. \bjournalJournal of the Royal Statistical Society: Series B (Statistical Methodology) \bvolume71 \bpages685–702. \endbibitem
- [27] {barticle}[author] \bauthor\bsnmYue, \bfnmYu Ryan\binitsY. R. and \bauthor\bsnmLoh, \bfnmJi Meng\binitsJ. M. (\byear2015). \btitleVariable selection for inhomogeneous spatial point process models. \bjournalCanadian Journal of Statistics \bvolume43 \bpages288–305. \endbibitem
- [28] {barticle}[author] \bauthor\bsnmZou, \bfnmHui\binitsH. (\byear2006). \btitleThe adaptive lasso and its oracle properties. \bjournalJournal of the American Statistical Association \bvolume101 \bpages1418–1429. \endbibitem