Adaptive Distributed Observer-based Model
Predictive Control for Multi-agent Formation
with Resilience to Communication Link Faults
Abstract
In order to address the nonlinear multi-agent formation tracking control problem with input constraints and unknown communication faults, a novel adaptive distributed observer-based distributed model predictive control method is developed in this paper. This design employs adaptive distributed observers in local control systems to estimate the leader’s state, dynamics, and relative positioning with respect to the leader. Utilizing the estimated data as local references, the original formation tracking control problem can be decomposed into several fully localized tracking control problems, which can be efficiently solved by the local predictive controller. Through the incorporation of adaptive distributed observers, this proposed design not only enhances the resilience of distributed formation tracking against communication faults but also simplifies the distributed model predictive control formulation.
Model predictive control; Unmanned aerial vehicles; Adaptive control; Fault-tolerant; Multi-agent system
1 Introduction
Multi-agent systems (MASs), distinguished by decentralized task allocation, distributed mission execution, and self-organization, have drawn increasing attention across diverse fields due to their broad spectrum of applications. Moreover, the study of formation control, which involves controlling the positions and orientations of agents to attain a particular geometric configuration with respect to a leader, has emerged as a prominent research topic [1]. While numerous studies have been made in the field of formation control [2], it is worth noting that many investigations do not account for input constraints and control optimality. However, the incorporation of input constraints is imperative for an accurate formulation of real-world problems. The inclusion of optimality is also essential to fully exploit available control resources while satisfying input constraints.
An appealing framework for formation control is distributed model predictive control (DMPC). DMPC inherits the advantages of centralized model predictive control (MPC), including systematic handling of hard constraints, optimized control performance, inherent robustness, and the ability to cope with nonlinear multi-variable systems [3]. In addition, the distributed implementation fashion of DMPC effectively distributes the computation workload, further enhancing its appeal and practicality [4]. Numerous DMPC methods for MASs have been proposed, as summarized in review papers such as [5, 6]. However, existing DMPC results may encounter limitations when tackling the distinctive challenges posed by multi-UAV formation problems. First of all, the computation resources of onboard microcontrollers are limited, while the proposed DMPC methods with terminal constraints demand a sufficiently long prediction horizon and, thereby, a large computation amount to ensure feasibility. Secondly, the majority of DMPC methods are tailored to address the cooperative regulation problem that drives all agents toward a prior-known set point [7, 8]. These methods underlie an implicit assumption regarding the communication graph that each agent in the system is directly linked to the leader. Such an assumption is not true in the context of formation control, where the leader’s information is often only available to a portion of the followers. A notable exception, proposed in [9], does not require globally known leader information but is only applicable to multi-vehicle platoon scenarios for tracking a constant-speed leader. There also exists a contradiction between the high communication workload of DMPC and the limited bandwidth of wireless communication networks employed in multi-UAV systems. To attain global stability and feasibility of local optimization problems, it is essential for each distributed optimizer to have access to its neighbors’ most up-to-date optimized control sequences over the prediction horizon [7]. As a result, DMPC usually entails a substantial amount of information exchange, iteratively [10, 11, 12] or sequentially [13, 14]. Moreover, the distributed predictive controller, which involves predictions for both itself and its neighbors, not only needs to receive information from its neighbors but also needs to identify the source of that information.
A significant challenge that remains inadequately addressed in current DMPC studies is maintaining control performance in the presence of communication faults. The communication network plays a crucial role in enabling interactions and facilitating cooperative behaviors among agents. However, the inclusion of communication networks introduces additional vulnerabilities to the control system, particularly when facing unexpected events such as cyber-attacks and channel fading. Communication faults between agents can pose major threats to multi-agent control systems, potentially deteriorating control performance or even overall system stability. Attacks and fading within communication networks can be modeled as uncertainties in the communication links. Recent studies in [15, 16, 17] explore the consensus of MASs with stochastic uncertain communication networks. In [18, 19], deterministic network uncertainties are examined within the context of MASs with single integrator agents. In [20], a distributed state observer-based adaptive control protocol is designed to address the leader-follower consensus for linear MASs with communication link faults. This study demonstrates that the distributed leader state observer network is resilient to communication link faults. However, it requires that all following agents know the leader dynamics. As an extension of this result, [21] proposes adaptive distributed leader state/dynamics observers and control protocols, offering a completely distributed solution for synchronizing linear MASs with time-varying edge weights without the need for global knowledge of the leader dynamics. Most existing research on resilience cooperative control in the presence of communication uncertainties is directed towards unconstrained MASs with linear dynamics. Moreover, to the best of our knowledge, fully distributed control for formation tracking under communication link faults has not yet received significant research attention.
Motivated by the aforementioned investigations, this paper develops a novel adaptive distributed observer-based DMPC method for nonlinear MASs in the presence of input constraints and communication link faults. To achieve the formation tracking objective without relying on global access to the leader’s information, adaptive distributed observers are developed for all local control systems, estimating online the leader’s state, dynamics, and the desired relative position with respect to the leader. With information estimated by these observers, distributed MPC controllers are independently developed to manipulate each agent toward a predetermined formation relative to the estimated leader while adhering to input constraints. The asymptotic convergence of the observation process is demonstrated, which in turn proves the closed-loop control performance of the overall system. To validate the efficacy of the proposed design, simulations are conducted using both a numerical example and a practical 5-UAV system. The key contributions of this research work include:
-
•
In contrast to prior works such as [18, 19, 20, 21] that focus on the consensus problem in unconstrained, linear MASs, this study explores the formation tracking control problem in MASs with both input constraints and nonlinear dynamics. Adaptive distributed observers are utilized not only to estimate the leader’s state and dynamics but also the desired formation displacements of each agent relative to the leader. With the estimated real-time information as the reference, MPC is employed for the local controller design to achieve optimized control performance subject to the input constraints.
-
•
By locally estimating tracking references through corresponding adaptive observers, the distributed formation tracking control task can be decoupled into several fully distributed tracking control problems at the local level. This facilitates the development of local controllers. Therefore, the integration of adaptive observers can significantly reduce the complexity of the distributed MPC formulation compared to other designs proposed in [7, 22, 23, 24, 25].
The remainder of this paper is structured as follows: Section 2 provides the mathematical formulation of the control problem and objective; Section 3 elaborates on the distributed control design, presenting the adaptive observer and the MPC-based controller; Section 4 conducts the closed-loop analysis, evaluating the convergence of the estimation and the stability of the control system; Section 5 offers two simulation examples to validate the effectiveness of the proposed design; Finally, Section 6 summarizes this paper.
Notations used in this paper are listed as follows. and denote the set of rational numbers and the set of positive rational numbers, respectively. is the set of -dimensional real column vectors, while is the set of real matrices. represents the transpose of . represents the standard Euclidean norm of and is the weighed squared norm of . and represent the minimal and maximal eigenvalues of matrix , respectively. A diagonal matrix with being the diagonal elements is denoted by , while a diagonal matrix with the elements of vector on the diagonal is denoted by . A diagonal matrix whose diagonal contains blocks of matrices ,,, is denoted by . The notation is used to denote the Kronecker product.
2 Problem Formulation
This section outlines the mathematical formulation of the control problem to tackle: multi-agent formation tracking control in the presence of communication faults. Firstly, we detail the dynamics models of individual agents and the virtual leader and describe their intercommunication through a directed weighted graph. Subsequently, the modeling of communication faults is presented. Finally, we introduce leader-follower tracking errors to formulate the control objective for formation tracking.
2.1 Multi-agent System
Consider a multi-agent system comprising followers and one virtual leader. The dynamics of both followers and the leader are detailed below, while their interactions are modeled using a weighted directed graph.
2.1.1 Follower Dynamics
The dynamics of the th follower can be described by the following higher-order MIMO nonlinear model:
| (6) |
where is the system state vector with each segment for ; and are the control input and system output, respectively; is a vector function, and is a square matrix function. To ensure that the system’s behavior is predictable and well-behave around the origin, the following assumption is necessary and commonly employed
Assumption 1
Al entries of and are sufficiently smooth and locally Lipschitz function of and satisfy and .
2.1.2 Communication Graph
The communication among these followers can be described using a directed weighted graph. Such graph can be represented by . In this representation, is the set of nodes, with each node corresponding to a follower agent. is the set of edges and means there is a communication link from agent to agent . Associated with this graph are two critical matrices. The adjacency matrix is defined such that if and otherwise. The Laplacian matrix is defined with capturing the in-degree of node and for .
2.1.3 Leader Dynamics and Connectivity
In addition to the follower agents, the system includes a virtual leader whose role is to guide the overall behavior of the MAS. The dynamics of this virtual leader can be governed by:
| (7) |
where represents the state vector of the leader; denotes the system dynamics matrix.
Remark 1
It is imperative that the leader’s state vector is of equivalent dimensionality to the followers’ dynamics, ensuring it can serve as a reference for the followers’ outputs. For instance, the th segment of serves as the reference for of follower .
Note that the state vector and the dynamics matrix of the leader are only accessible to certain followers. The leader can be labeled as node , and the connections from this leader to the followers, labeled , can be defined by a set of pinning edges . An edge indicates that follower has direct access to the leader’s state and dynamics. Additionally, we introduce a pinning matrix , where if and otherwise. This matrix effectively quantifies the influence of the leader on each follower.
2.2 Input Constraints and Communication Faults
In this work, we address both the input constraints of individual follower agents and unknown faults that may occur within the communication network. These considerations are crucial for ensuring the robustness and reliability of the system under various operational conditions. The mathematical models that incorporate these elements are provided below.
2.2.1 Input Constraints
Considering the limitations on excitable control actions, the control input of the th follower is restricted to a nonempty compact convex set, as defined by
| (8) |
where and .
2.2.2 Communication Faults
Communication faults can be modeled as time-varying uncertainties affecting the graph edges [20]:
| (9a) | ||||
| (9b) | ||||
where and are the idea weights of general and pinning edges, and and denote corrupted weights caused by communication faults. This fault model covers the following types of communication faults:
-
•
Channel manipulation attack: The unknown corrupted weights and are capable of modeling a range of cyber attacks. The unknown corrupted weights and can simulate various cyber attacks. These attacks involve infiltrating communication channels and manipulating the shared information between vehicles.
-
•
Fading channel: The corrupted communication weights can also represent the effect of a fading channel, resulting in a decrease in the values of the communication weights.
Remark 2
The existence of and introduces time-variation and uncertainty into the weights of the communication links. Consequently, in the event of communication link failures as specified in (9), both the Laplacian matrix and the pinning matrix of the directed graph undergo modifications. Specifically, the Laplacian matrix is redefined as , where for the diagonal elements, and for off-diagonal elements with . Similarly, the pinning matrix is revised to .
Assumption 2
The communication link faults and in the directed graph, as well as their derivatives, are bounded. In addition, the signs of and are the same to that of and .
Remark 3
Assumption 2, as also utilized in [15, 20], ensures the boundedness of communication faults and maintains the invariance of the network structure despite these faults. The modeling of communication link faults in (9) under Assumption 2 can cover various types of communication faults and cyber attacks with bounded derivatives, such as bias attacks and fading channels.
2.3 Formation Tracking Control Objective
Having modeled the MAS, taking into account input constraints and communication faults, we now proceed to formulate the formation tracking control objective. Formation refers to a specific spatial shape maintained by the followers, which is typically defined prior to executing any formation control. To delineate a formation task, we assign each follower in the system a specific formation displacement relative to the virtual leader, denoted as for . Furthermore, let represent the collective state vector of all the followers. The state of the leader is extended correspondingly as . Then, a global formation tracking error can be defined
| (10) |
where is the collective formation displacement vector.
Assumption 3
To define a practical formation task, the displacement vector , which encodes the desired offset between and , is structured as . A default assumption is that should be at least -times differentiable, and the th derivative, , is considered to be zero.
Remark 4
Given the previously defined directed communication topology, the knowledge of the leader’s state and dynamics, as well as the desired formation displacement information, is not required to be globally known across the MAS. Only agents directly connected to the virtual leader have access to the real-time values of and the respective . Agents that do not have a direct communication link with the virtual leader are only required to store and transmit the displacement vector relative to their out-neighbors, defined as , along with their state measurement , to their designated out-neighbor node via the communication links.
The control objective of this study is to develop a distributed control strategy that utilizes solely locally available neighborhood information for effective formation tracking of a MAS composed of followers (6) and a virtual leader (7). The primary goal is to ensure that the global formation error not only converges to, but also remains within a small region near the origin. To ensure such formation tracking control objective is achievable, the following assumption of the graph topology holds throughout this paper.
Assumption 4
In the directed graph , each node is either part of a spanning tree with the root node connected to the virtual leader or a standalone node directly connected to the virtual leader.
Remark 5
The above assumption ensures that there is either direct or indirect connectivity between each follower and the leader, providing a directed path from the leader to all the followers. This network structure is critical for achieving synchronized behaviors among the agents, enabling the distributed control strategies to eliminate the formation error across the system effectively.
Lemma 1
[1] Let be the directed graph for followers, labeled as agents or followers to . Let be the nonsymmetric Laplacian matrix associated with the directed graph . Suppose that in addition to the followers, there exists a leader, labeled as agent , whose connection to the followers can be described by a pinning matrix , where if the th follower can receive information from the leader and otherwise. Let . Then, all eigenvalues of have positive real parts if and only if in the directed graph the leader has directed paths to all followers.
3 Distributed Control Design
In this section, we present the design of an adaptive distributed MPC framework for addressing the formation tracking control problem with input constraints and communication faults. This framework integrates state observers with MPC controllers via a distributed structure. As illustrated in Figure 1, each follower’s local control system operates independently and relies exclusively on locally available information, consisting of an adaptive observer for estimating the leader information with resilience to communication link faults and an MPC-based controller for determining optimal formation tracking control actions online based on the local estimation of leader’s state, dynamics matrix and desired displacement vector. Let us clarify and elaborate on each component in the subsequent subsections.
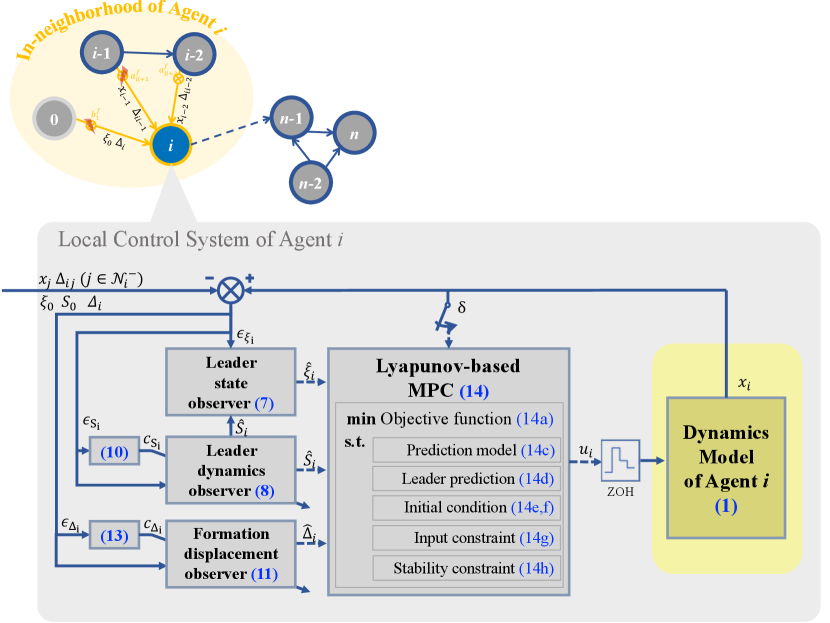
3.1 Adaptive Leader Observer
Given the limitations on the availability of direct, real-time access to the state and dynamics of the virtual leader among all followers in the network, it becomes essential to develop an adaptive distributed observer within each local control system. This observer is responsible for estimating the leader’s information and the formation displacement, which are critical components for effective formation tracking controller design.
The locally estimated leader state for follower is denoted as . We can then define a leader state estimation error as
| (11) |
which is available for the local control system of follower . The distributed adaptive leader state observer is then designed as
| (12) |
where is a user-designed positive observation gain.
In (12), is the estimate of the leader’s dynamics matrix , updated following the following estimating law
| (13) |
where is the local estimation error for , defined as
| (14) |
In (13), satisfying , is updated by
| (15) |
with being the vector form of the matrix . The operation rearranges the matrix segments into a column vector.
Similarly, let denote the estimate of the desired formation displacement . Its estimating law is
| (16) |
where is the local estimation errors for , defined as
| (17) |
with being the desired relative displacement between follower and . In (16), satisfies and follows the following adaptive law:
| (18) |
3.2 MPC-based Formation Tracking Controller
With the local estimation of the leader’s state , the leader’s dynamics matrix , and the desired formation displacement vector , we can move on to the development of the formation tracking controller.
By applying model predictive control, a finite-horizon constrained optimization problem for a forward-looking prediction horizon is solved at each control update instant. The optimization solution is then implemented to the plant system recedingly, under a sampled-and-hold manner for execution. The control update instant sequence is , where represents the sampling period.
At the time instant , the MPC optimization problem is formulated as
| (19a) | ||||
| with | ||||
| (19b) | ||||
| subject to | ||||
| (19g) | ||||
| (19h) | ||||
| (19i) | ||||
| (19j) | ||||
| (19k) | ||||
| (19l) | ||||
where , and the internal variables are denoted by a superscript to distinguish them from the actual system signals. In the optimization problem (19), constraint (19g) serves as the prediction model to predict the future evolution of the follower itself, while (19h) is to predict the leader’s behavior by making use of estimated by the observer. Constraints (19i) and (19j) specify the initial conditions of the prediction models (19g) and (19h) , respectively. Compliance with the input constraint is ensured by (19k). The Lyapunov-based stability constraint (19l) is designed to enforce the decay of the Lyapunov function at the current instant .
Lemma 2
There always exists a feasible solution to the optimization problem (19), constructed as
| (20a) | ||||
| (20b) | ||||
| (20c) | ||||
| (20d) | ||||
for . In (20a), is a saturation function defined as written as
| (21) |
with
in which ; , and being the th element of , and . is the control input saturation degree indicator, and it is clear that all of its diagonal elements vary between . in (20d) is the discontinuous portion of the feasible input, where is the lower bound of satisfying
| (22) |
The user-defined positive parameter is chosen appropriately such that
| (23) |
Proof 3.1.
Due to the inclusion of the saturation function, the control profile constructed in (20) naturally satisfies the input constraint (19k). Substituting into the right half of the inequality in (19l) gives
| (24) |
Recalling inequality (22), it can be obtained that . Further with (23), we can have that
| (25) |
which satisfies the Lyapunov-based stability constraint (19l). Therefore, it can be concluded that is a feasible solution to the optimization problem (19).
Given the feasibility of the optimization problem (19), an optimal control profile for can always be found by solving it at . The found optimal solution is then implemented in a receding horizon manner. In this regard, is applied to the th follower until the next measurement is available, so the actual control command for is
| (26) |
When the new measurement is updated at , the optimization problem (19) will be solved again with replaced by , and a new optimal control profile for will be found. In turn, the newly found optimal control profile updates the actual control command for .
4 Closed-loop Stability Analysis
Given that the local control system includes two decoupled components—an adaptive observer and an MPC-based controller—we can perform the closed-loop stability analysis in a two-step manner. This approach allows us to access the stability contributions of the observer and the controller separately. In this section, we first examine the closed-loop performance of the adaptive observer network to prove that global estimation errors converge asymptotically. Subsequently, we evaluate the MPC-based controller, verifying its ability to maintain system stability and formation tracking control performance based on the observer’s estimations.
4.1 Convergence of Estimation
First of all, let us focus on the estimation performance of the observers. We start by denoting collective vectors of , and for as , and . Then, we can define the following collective estimation errors:
| (28) | ||||
| (29) | ||||
| (30) |
We can also define a vector form of the leader matrix estimation error as
| (31) |
By recalling the adaptive distributed observer design in (12), (13), and (16), we can have the dynamics of these global estimation errors as follows
| (32) | ||||
| (33) | ||||
| (34) | ||||
| (35) |
where , , , , , , .
We introduce a new notation, , to represent the superposition of the Laplacian matrix and the pinning matrix. This notation allows us to elucidate the relationships between global estimation errors and collective local estimation errors in the presence of communication link faults, as demonstrated below:
| (36) | ||||
| (37) | ||||
| (38) | ||||
| (39) |
Subsequently, we can derive the dynamics of the local estimation errors, which are outlined below
| (40) | ||||
| (41) | ||||
| (42) | ||||
| (43) |
Having derived the dynamics of the error, we can then move on to formulate the first theorem regarding the convergence of distributed adaptive estimation. Before proceeding, however, it is essential to establish several foundational lemmas. These lemmas are building blocks for the proof of the main theorem.
Proof 4.1.
Lemma 4
Proof 4.2.
Now, we present our first main result of the closed-loop analysis by the following theorem.
Theorem 1
Suppose that Assumptions 2 and 4 hold. Consider the -agent system with the virtual leader (7), interconnected via the weighted directed graph . Implement the leader dynamics (7), the distributed leader state observer (12), the leader dynamics observer (13) and the formation displacement observer (16) for . If the leader state observer gain for are selected such that the following condition is satisfied
| (54) |
where with , , , , , and , then all signals within the observer network are globally bounded. Moreover, all the estimated errors, , , and , asymptotically converge to the origin.
Proof 4.3.
To prove the convergence of the observer network, we divide the proof into three parts. Firstly, in Part 1 and Part 2, the convergence of the displacement estimation error and the dynamics matrix estimation error are proven, respectively. Finally, in Part 3, we can prove that the leader state estimation error asymptotically converges to the origin.
Part 1: To demonstrate the convergence of the formation displacement estimation error, we begin by examining its corresponding local estimation error . A Lyapunov function candidate can be selected as follows
| (55) |
where is a positive constant to be determined later; is defined in Lemma 4.
Taking the time derivative of gives
| (56) |
Applying Young’s inequality, one has
| (58a) | |||
| (58b) | |||
| (58c) | |||
| (58d) | |||
We define , , and . Then, substituting the above inequalities into yields
| (59) |
where . There exists a bounded constant satisfying such that
| (60) |
which implies that all signals in the developed observer including , and are globally bounded under communication link faults.
To get the convergence of , we solve (60) as
| (61) |
With the fact that and , one has
| (62) |
or equivalently
| (63) |
This demonstrates that is bounded. By applying Barbalat’s Lemma, we establish that converges to zero. Furthermore, according to Lemma 3, it can be deduced that the estimation error also globally converges to zero, even in scenarios involving communication link faults.
Part 2: Similarly, the leader state estimation error convergence can be proven. We firstly select a candidate Lyapunov function as
| (64) |
Following the same procedure, the derivative of can be bounded by
| (65) |
with appropriately chosen such that .
We can further have that
| (66) |
This implies that is bounded. Applying Barbalat’s Lemma, we can conclude that converges to zero. Furthermore, based on Lemma 3, it can be concluded that the estimation errors , , and also converge to zero.
Part 3: Finally, to demonstrate the stability and convergence of the leader state estimation, we select the following candidate for a Lyapunov function:
| (67) |
We define as a new variable that converges to zero given the convergence of . Applying Young’s inequality, one has
| (70a) | ||||
| (70b) | ||||
| (70c) | ||||
| (70d) | ||||
| (70e) | ||||
Given the boundedness of , we can define new constants and , and recall the definitions of , , . Substituting the above inequalities into yields
| (71) |
where .
Therefore, when the user-designated gains for are appropriately chosen to satisfy the stability condition (71), a positive constant must exist such that . As a result, one has
| (72) |
which means that the dynamics of is robust input-to-state stable with as a disturbances input. Integrating the above inequalities over gives
| (73) |
which further yields
| (74) |
From Part 2, we have proven the convergence of , which also implies the convergence of to zero. Hence, it can be concluded that is bounded. From the above inequality, we can prove the boundedness of . By using Barbalat’s Lemma, can be proven to converge to zero as well. From Lemma 3, it can be obtained that also asymptotically converges to the origin.
4.2 Stability of Control
Following the establishment of the asymptotic convergence of the estimation errors as demonstrated in Theorem 1, we can now present our second main result of this paper, which summarizes the convergence of the system’s actual state to the locally estimated leader state under the proposed Lyapunov-based MPC framework.
We start by defining a sliding mode tracking control error for the follower as
| (75) |
Then, the following Lyapunov function candidate for follower can be considered
| (76) |
Differentiating along the closed-loop dynamics yields
| (77) |
Recalling the inequality (3.2), adding and subtracting the right-hand side of it to and from (4.2), we can rewrite over the interval as follows:
| (78) |
By invoking Lipschitz continuity and under Assumption 1, there must exist positive Lipschitz constants , and such that
| (79a) | ||||
| (79b) | ||||
| We also have positive constants and satisfying | ||||
| (79c) | ||||
| (79d) | ||||
By substituting (79) into (4.2), we have that
| (80) |
where and .
We define a collective sliding mode tracking control error as , and Theorem 2 below encapsulates the second main result of this paper
Theorem 2
Suppose Assumptions 1-4 hold. Consider the MASs with followers (6) and a virtual leader 7 in closed loop under the developed adaptive distributed observer-based Lyapunov-based MPC framework with the leader observer (12)-(16) and the MPC problem (19). If and the following stability condition is satisfied by choosing appropriate control gains for ,
| (81) |
where , , and , then, the sliding mode error of the closed-loop system is always bounded and ultimately converges to .
Proof 4.4.
A global Lyapunov function for the entire MAS can be selected as
| (82) |
Recalling (80), we can obtain that
| (83) |
where , and .
From the definition of , we further have
| (84) |
If the condition (81) is satisfied, then it can be derived that for all and for . Therefore, it implies that converges to without leaving the stability region as approaches
Based on Theorem 2, we can conclude that the state variable converges towards . Given the previously validated asymptotic convergence of to and to in Theorem 1, we can conclusively demonstrate the ultimate boundedness and convergence of the global formation tracking error , as defined in (10). This conclusion is drawn by combining the results from both Theorem 1 and Theorem 2.
Remark 6
It is crucial to recognize that the analytical convergence error arises from the sampled-and-hold implementation of the employed MPC. The asymptotically stable nature of the distributed observer network does not compromise the ultimate accuracy of formation tracking by providing sufficiently accurate estimations to the controller.
5 Simulation Study
Simulation studies on two different examples are carried out to evaluate the performance of the proposed method in achieving formation tracking control under input constraints and communication link faults. This section provides the simulation results and
5.1 Example 1: A Numerical Multi-agent System
We first consider a numerical example—a nonlinear MAS with 3 followers and a leader node . The followers can be described by third-order nonlinear systems as follows
| (85e) | |||
| (85j) | |||
| (85o) | |||
with the input constraint defined as
| (86) |
for . The initial conditions of the 3 followers are , , .


Let the dynamics of the leader node be
| (90) |
with .
In simulations, the desired formation displacement vectors of the 3 followers with respect to the leader are set as , , , . Time-varying edge weights, including the adjacency matrix and pinning gains, are designed to mimic faults in the communication network. In particular, the adjacency matrix and the pinning matrix are
| (94) | ||||
| (98) |
where is a random signal chosen from the interval .
The control parameters are selected following the obtained stability conditions. The sampling period for updating the control actions is set as s. The leader state observation gains are chosen as . In the definition of the sliding mode tracking error, and . The control gains are . In the MPC problems, the prediction horizon is 0.8s, and .
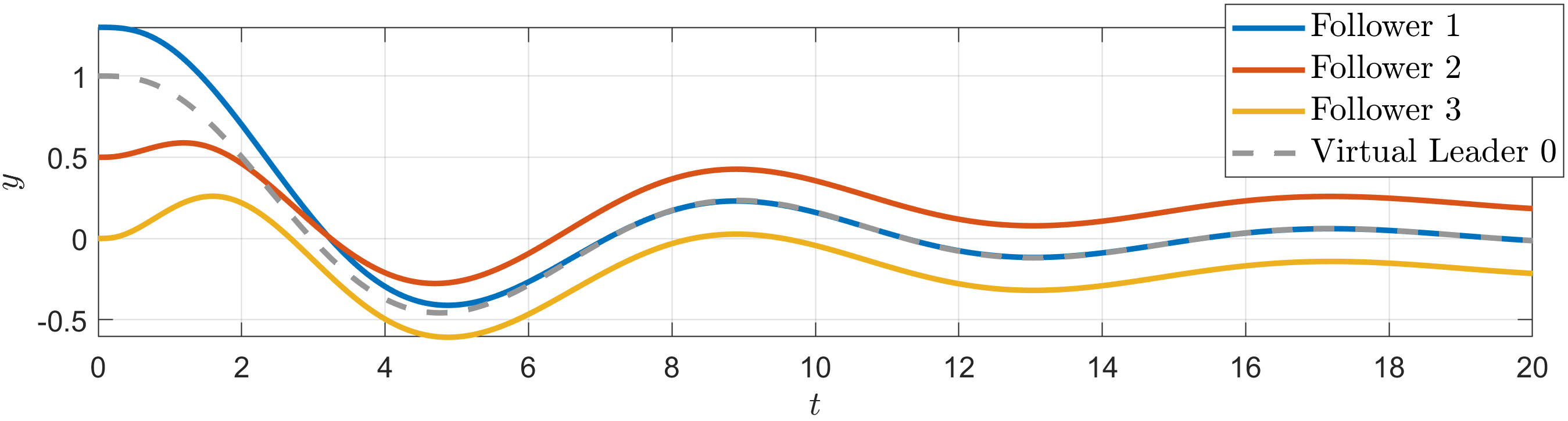
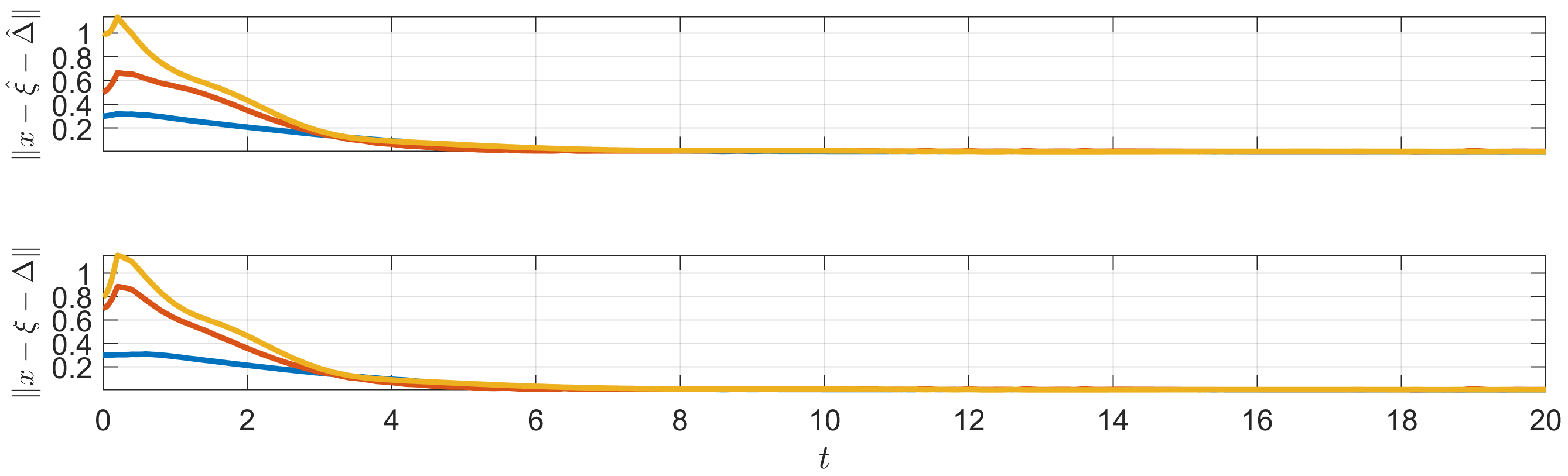
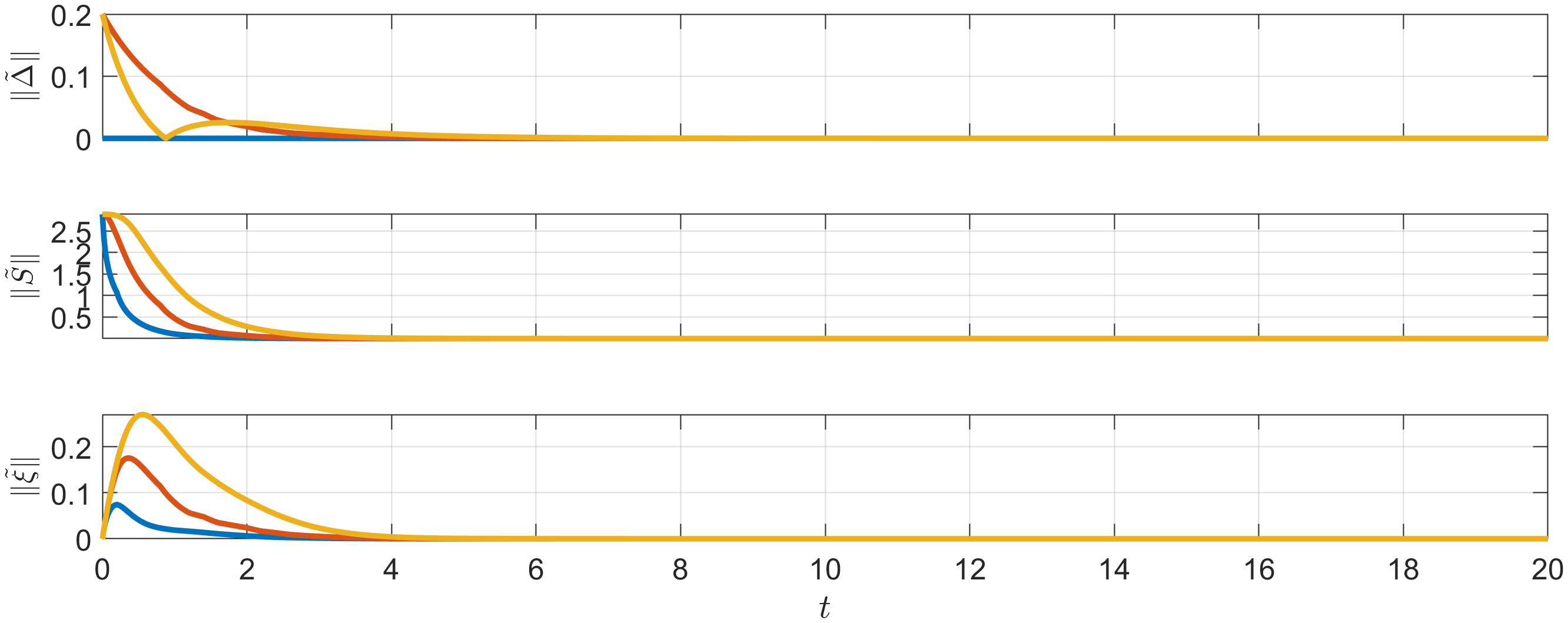
The time-varying communication fault parameters introduced to the network are depicted in Figure 2. The simulation results, as shown in Figures 3-6, illustrate the responses of the three followers with solid lines in blue, orange, and yellow, while the virtual leader’s responses are represented with gray dashed lines. Specifically, Figure 3 illustrates the output trajectories of the followers, demonstrating that the formation tracking objective has been successfully achieved. The norms of the tracking errors, relative to both the estimated and actual leader states, are displayed in Figure 4. Additionally, Figure 5 presents the estimation errors of the relative position displacement, the leader’s dynamics, and the leader state. Figure 6 illustrates the control commands applied to the followers, showing that the input constraint (86) is satisfied.
5.2 Example 2: A Multi-UAV System
Next, we consider applying the proposed adaptive distributed control strategy to the outer-loop translation control of a group of UAVs. The networked UAV system comprises 5 UAVs, with their translational motions described by
| (99c) | |||
where ; and kg; and are position and velocity vectors of the 5 UAVs; and are control inputs of the translational subsystem, representing the desired rotation angles and the total thrust force, respectively. The control inputs suffer from the following input constraints:
| (100) | ||||
| (101) |
The initial positions of the 5 UAVs are , , , , . Their initial linear velocities are all zero.
Let the dynamics of the leader node be
| (102) |
with .
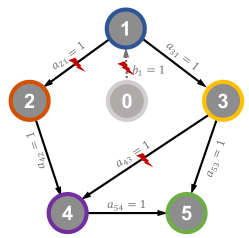
The prescribed formation geometric shape and directed communication graph of the 5-UAV systems are illustrated in Figure 7. The desired displacement vectors of the followers with respect to the leader are set as , , , , . Time-varying edge weights, including the adjacency matrix and pinning gains, are designed to mimic faults in the communication network. In particular, the adjacency matrix and the pinning matrix are
| (103) | ||||
| (104) |
where is a random signal chosen from the interval . The time-varying fault communication parameters added to the network are illustrated in Figure 2.
The control parameters are selected following the previously established stability conditions. The sampling period for updating the control actions is set as s. The leader state observation gains are chosen as . In the definition of the sliding mode tracking error, . The control gains are . In the MPC problems, the prediction horizon is 0.8s, and .
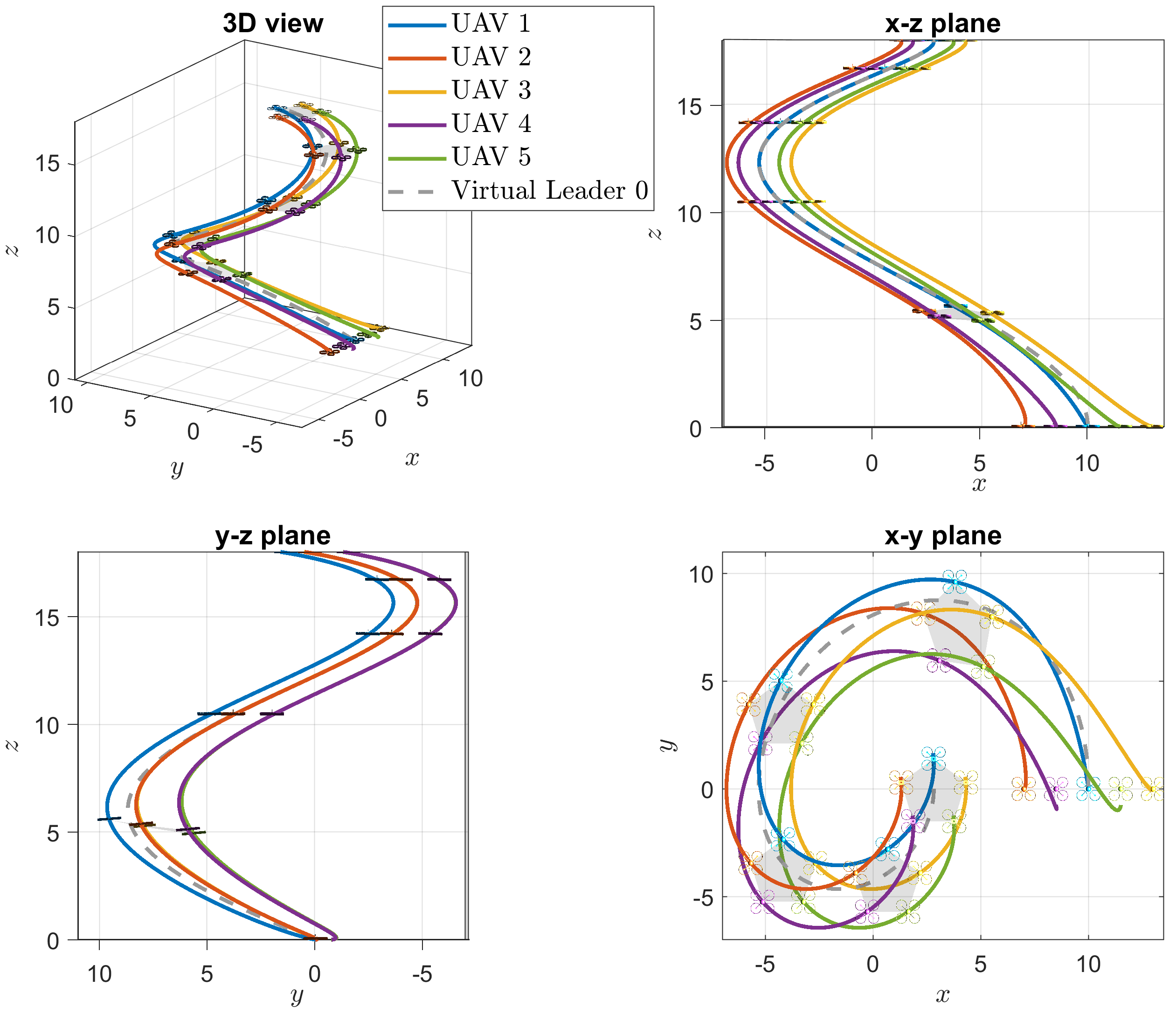
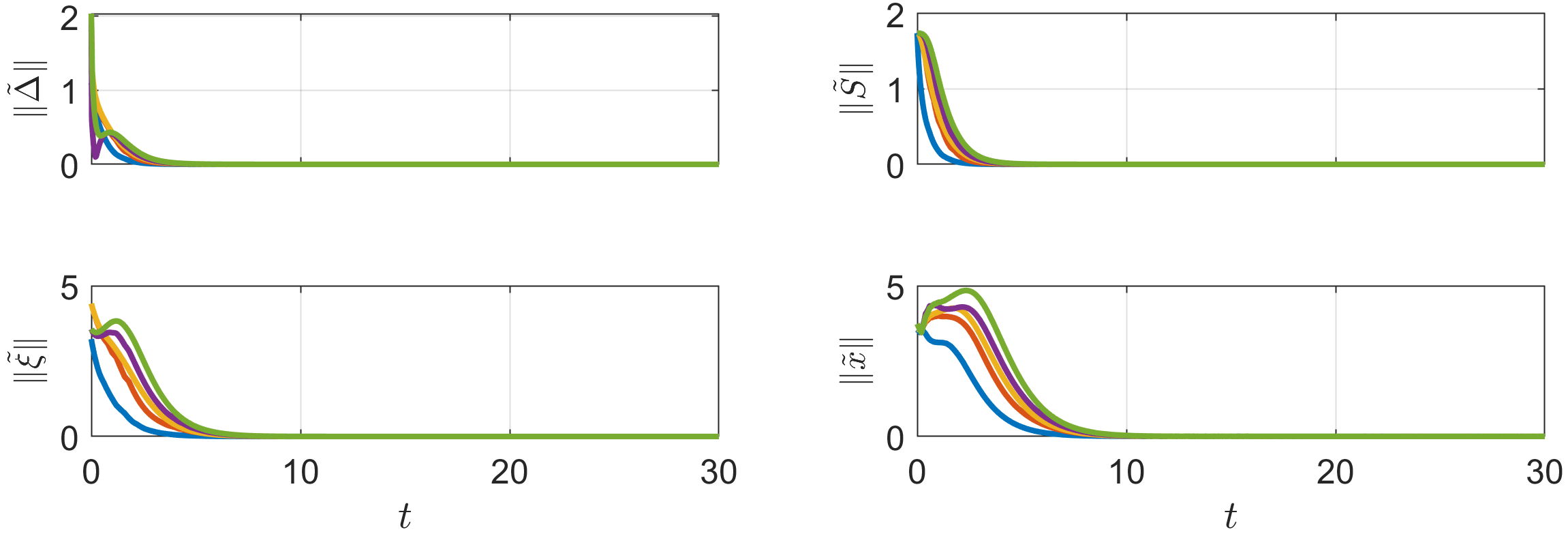
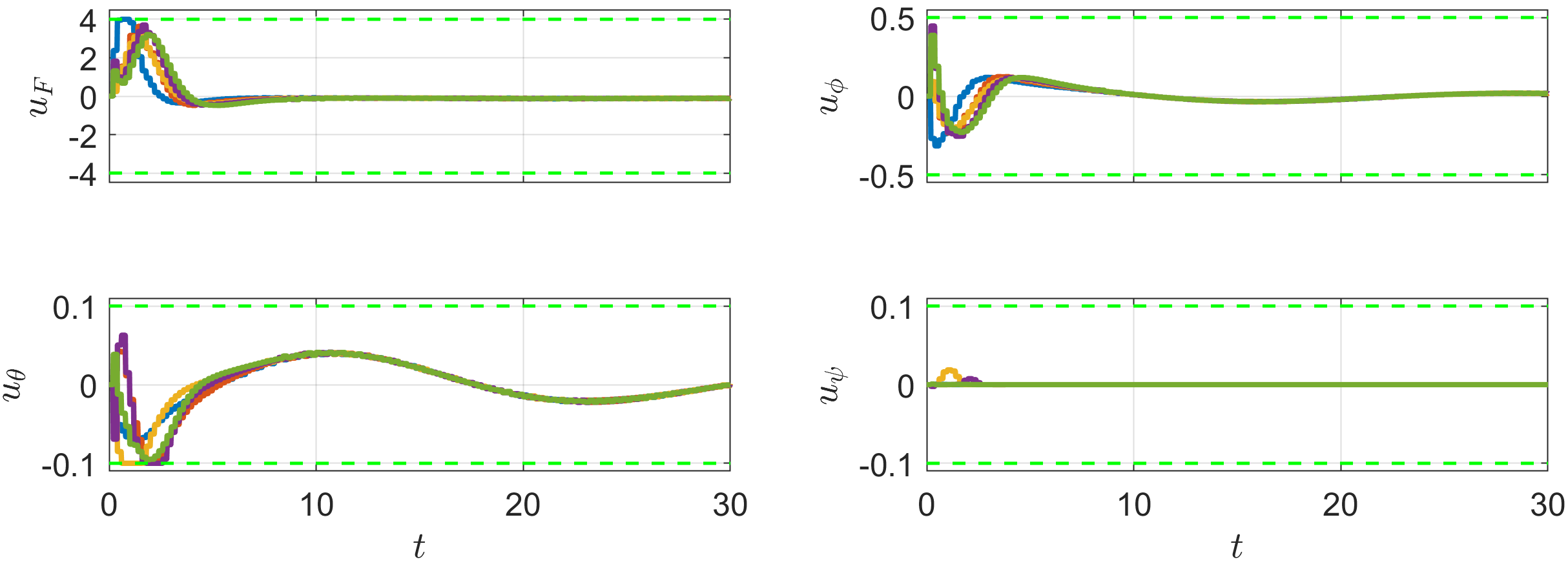
The simulation results are illustrated in Figures 9-11, where the responses of the 5 UAVs are depicted with solid lines in blue, orange, yellow, purple, and green, and the virtual leader’s responses are depicted with gray dashed lines. Figure 9 illustrates the formation tracking performance of the 5-UAV system in 3D and three-plane views. The norms of the estimation and tracking errors of the 5 UAVs are displayed in Figure 10, respectively. Figure 11 shows the control commands of the 5 UAVs. It can be seen that their input constraints are all satisfied.
6 Conclusions
A novel adaptive distributed observer-based DMPC method has been introduced in this paper, which is developed for nonlinear multi-agent formation tracking with input constraints and unknown communication faults. The method utilizes adaptive distributed observers in each local control system to estimate the state, dynamics, and relative position of the leader, enabling each agent to independently achieve formation tracking without direct access to the leader’s information. The designed distributed MPC controllers use the estimated information to manipulate agents into a predefined formation while respecting input constraints. This research employs adaptive observers to reduce the complexity in the DMPC design, allowing for effective local controller formulation and resilient distributed formation tracking.
References
- [1] W. Ren and Y. Cao, Distributed Coordination of Multi-Agent Networks: Emergent Problems, Models, and Issues. Springer, 2011, vol. 1.
- [2] J. Qin, Q. Ma, Y. Shi, and L. Wang, “Recent advances in consensus of multi-agent systems: A brief survey,” IEEE Transactions on Industrial Electronics, vol. 64, no. 6, pp. 4972–4983, 2016.
- [3] Y. Shi and K. Zhang, “Advanced model predictive control framework for autonomous intelligent mechatronic systems: A tutorial overview and perspectives,” Annual Reviews in Control, vol. 52, pp. 170–196, 2021.
- [4] T. Keviczky, F. Borrelli, and G. J. Balas, “A study on decentralized receding horizon control for decoupled systems,” in Proceedings of the 2004 American Control Conference, vol. 6, Boston, MA, USA, May 2004, pp. 4921–4926.
- [5] P. D. Christofides, R. Scattolini, D. M. de la Pena, and J. Liu, “Distributed model predictive control: A tutorial review and future research directions,” Computers & Chemical Engineering, vol. 51, pp. 21–41, 2013.
- [6] R. R. Negenborn and J. M. Maestre, “Distributed model predictive control: An overview and roadmap of future research opportunities,” IEEE Control Systems Magazine, vol. 34, no. 4, pp. 87–97, 2014.
- [7] W. B. Dunbar and R. M. Murray, “Distributed receding horizon control for multi-vehicle formation stabilization,” Automatica, vol. 42, no. 4, pp. 549–558, 2006.
- [8] H. Li and Y. Shi, “Robust distributed model predictive control of constrained continuous-time nonlinear systems: A robustness constraint approach,” IEEE Transactions on Automatic Control, vol. 59, no. 6, pp. 1673–1678, 2013.
- [9] Y. Zheng, S. E. Li, K. Li, F. Borrelli, and J. K. Hedrick, “Distributed model predictive control for heterogeneous vehicle platoons under unidirectional topologies,” IEEE Transactions on Control Systems Technology, vol. 25, no. 3, pp. 899–910, 2016.
- [10] M. Mercangöz and F. J. Doyle III, “Distributed model predictive control of an experimental four-tank system,” Journal of Process Control, vol. 17, no. 3, pp. 297–308, 2007.
- [11] B. T. Stewart, A. N. Venkat, J. B. Rawlings, S. J. Wright, and G. Pannocchia, “Cooperative distributed model predictive control,” Systems & Control Letters, vol. 59, no. 8, pp. 460–469, 2010.
- [12] A. N. Venkat, J. B. Rawlings, and S. J. Wright, “Stability and optimality of distributed model predictive control,” in Proceedings of the 44th IEEE Conference on Decision and Control, Seville, Spain, Dec. 2005, pp. 6680–6685.
- [13] A. Richards and J. How, “A decentralized algorithm for robust constrained model predictive control,” in Proceedings of the 2004 American Control Conference, vol. 5, Boston, MA, USA, Jun. 2004, pp. 4261–4266.
- [14] A. Richards and J. P. How, “Robust distributed model predictive control,” International Journal of Control, vol. 80, no. 9, pp. 1517–1531, 2007.
- [15] Z. Li and J. Chen, “Robust consensus for multi-agent systems communicating over stochastic uncertain networks,” SIAM Journal on Control and Optimization, vol. 57, no. 5, pp. 3553–3570, 2019.
- [16] T. Li, F. Wu, and J.-F. Zhang, “Multi-agent consensus with relative-state-dependent measurement noises,” IEEE Transactions on Automatic Control, vol. 59, no. 9, pp. 2463–2468, 2014.
- [17] X. Ma and N. Elia, “Mean square performance and robust yet fragile nature of torus networked average consensus,” IEEE Transactions on Control of Network Systems, vol. 2, no. 3, pp. 216–225, 2015.
- [18] J. Wang and N. Elia, “Consensus over networks with dynamic channels,” International Journal of Systems, Control and Communications, vol. 2, no. 1-3, pp. 275–297, 2010.
- [19] D. Zelazo and M. Bürger, “On the robustness of uncertain consensus networks,” IEEE Transactions on Control of Network Systems, vol. 4, no. 2, pp. 170–178, 2015.
- [20] C. Chen, K. Xie, F. L. Lewis, S. Xie, and R. Fierro, “Adaptive synchronization of multi-agent systems with resilience to communication link faults,” Automatica, vol. 111, p. 108636, 2020.
- [21] Q. Yang, Y. Lyu, X. Li, C. Chen, and F. L. Lewis, “Adaptive distributed synchronization of heterogeneous multi-agent systems over directed graphs with time-varying edge weights,” Journal of the Franklin Institute, vol. 358, no. 4, pp. 2434–2452, 2021.
- [22] W. B. Dunbar, “Distributed receding horizon control of dynamically coupled nonlinear systems,” IEEE Transactions on Automatic Control, vol. 52, no. 7, pp. 1249–1263, 2007.
- [23] H. Wei, C. Liu, and Y. Shi, “A robust distributed MPC framework for multi-agent consensus with communication delays,” IEEE Transactions on Automatic Control, 2024.
- [24] H. Wei, Q. Sun, J. Chen, and Y. Shi, “Robust distributed model predictive platooning control for heterogeneous autonomous surface vehicles,” Control Engineering Practice, vol. 107, p. 104655, 2021.
- [25] H. Wei, C. Shen, and Y. Shi, “Distributed Lyapunov-based model predictive formation tracking control for autonomous underwater vehicles subject to disturbances,” IEEE Transactions on Systems, Man, and Cybernetics: Systems, vol. 51, no. 8, pp. 5198–5208, 2019.