Achieving Linear Speedup with Partial Worker Participation in Non-IID Federated Learning
Abstract
Federated learning (FL) is a distributed machine learning architecture that leverages a large number of workers to jointly learn a model with decentralized data. FL has received increasing attention in recent years thanks to its data privacy protection, communication efficiency and a linear speedup for convergence in training (i.e., convergence performance increases linearly with respect to the number of workers). However, existing studies on linear speedup for convergence are only limited to the assumptions of i.i.d. datasets across workers and/or full worker participation, both of which rarely hold in practice. So far, it remains an open question whether or not the linear speedup for convergence is achievable under non-i.i.d. datasets with partial worker participation in FL. In this paper, we show that the answer is affirmative. Specifically, we show that the federated averaging (FedAvg) algorithm (with two-sided learning rates) on non-i.i.d. datasets in non-convex settings achieves a convergence rate for full worker participation and a convergence rate for partial worker participation, where is the number of local steps, is the number of total communication rounds, is the total worker number and is the worker number in one communication round if for partial worker participation. Our results also reveal that the local steps in FL could help the convergence and show that the maximum number of local steps can be improved to in full worker participation. We conduct extensive experiments on MNIST and CIFAR-10 to verify our theoretical results.
1 Introduction
Federated Learning (FL) is a distributed machine learning paradigm that leverages a large number of workers to collaboratively learn a model with decentralized data under the coordination of a centralized server. Formally, the goal of FL is to solve an optimization problem, which can be decomposed as:
where is the local (non-convex) loss function associated with a local data distribution and is the number of workers. FL allows a large number of workers (such as edge devices) to participate flexibly without sharing data, which helps protect data privacy. However, it also introduces two unique challenges unseen in traditional distributed learning algorithms that are used typically for large data centers:
-
•
Non-independent-identically-distributed (non-i.i.d.) datasets across workers (data heterogeneity): In conventional distributed learning in data centers, the distribution for each worker’s local dataset can usually be assumed to be i.i.d., i.e., . Unfortunately, this assumption rarely holds for FL since data are generated locally at the workers based on their circumstances, i.e., , for . It will be seen later that the non-i.i.d assumption imposes significant challenges in algorithm design for FL and their performance analysis.
-
•
Time-varying partial worker participation (systems non-stationarity): With the flexibility for workers’ participation in many scenarios (particularly in mobile edge computing), workers may randomly join or leave the FL system at will, thus rendering the active worker set stochastic and time-varying across communication rounds. Hence, it is often infeasible to wait for all workers’ responses as in traditional distributed learning, since inactive workers or stragglers will significantly slow down the whole training process. As a result, only a subset of the workers may be chosen by the server in each communication round, i.e., partial worker participation.
In recent years, the Federated Averaging method (FedAvg) and its variants (McMahan et al., 2016; Li et al., 2018; Hsu et al., 2019; Karimireddy et al., 2019; Wang et al., 2019a) have emerged as a prevailing approach for FL. Similar to the traditional distributed learning, FedAvg leverages local computation at each worker and employs a centralized parameter server to aggregate and update the model parameters. The unique feature of FedAvg is that each worker runs multiple local stochastic gradient descent (SGD) steps rather than just one step as in traditional distributed learning between two consecutive communication rounds. For i.i.d. datasets and the full worker participation setting, Stich (2018) and Yu et al. (2019b) proposed two variants of FedAvg that achieve a convergence rate of with a bounded gradient assumption for both strongly convex and non-convex problems, where is the number of workers, is the local update steps, and is the total communication rounds. Wang & Joshi (2018) and Stich & Karimireddy (2019) further proposed improved FedAvg algorithms to achieve an convergence rate without bounded gradient assumption. Notably, for a sufficiently large , the above rates become 111This rate also matches the convergence rate order of parallel SGD in conventional distributed learning., which implies a linear speedup with respect to the number of workers.222To attain accuracy for an algorithm, it needs to take steps with a convergence rate , while needing steps if the convergence rate is (the hidden constant in Big-O is the same). In this sense, one achieves a linear speedup with respect to the number of workers. This linear speedup is highly desirable for an FL algorithm because the algorithm is able to effectively leverage the massive parallelism in a large FL system. However, with non-i.i.d. datasets and partial worker participation in FL, a fundamental open question arises: Can we still achieve the same linear speedup for convergence, i.e., , with non-i.i.d. datasets and under either full or partial worker participation?
In this paper, we show the answer to the above question is affirmative. Specifically, we show that a generalized FedAvg with two-sided learning rates achieves linear convergence speedup with non-i.i.d. datasets and under full/partial worker participation. We highlight our contributions as follows:
-
•
For non-convex problems, we show that the convergence rate of the FedAvg algorithm on non-i.i.d. dataset are and for full and partial worker participation, respectively, where is the size of the partially participating worker set. This indicates that our proposed algorithm achieves a linear speedup for convergence rate for a sufficiently large . When reduced to the i.i.d. case, our convergence rate is , which is also better than previous works. We summarize the convergence rate comparisons for both i.i.d. and non-i.i.d. cases in Table 1. It is worth noting that our proof does not require the bounded gradient assumption. We note that the SCAFFOLD algorithm (Karimireddy et al., 2019) also achieves the linear speedup but extra variance reduction operations are required, which lead to higher communication costs and implementation complexity. By contrast, we do not have such extra requirements in this paper.
-
•
In order to achieve a linear speedup, i.e., a convergence rate , we show that the number of local updates can be as large as , which improves the result previously shown in Yu et al. (2019a) and Karimireddy et al. (2019). As shown later in the communication complexity comparison in Table 1, a larger number of local steps implies relatively fewer communication rounds, thus less communication overhead. Interestingly, our results also indicate that the number of local updates does not hurt but rather help the convergence with a proper learning rates choice in full worker participation. This overcomes the limitation as suggested in Li et al. (2019b) that local SGD steps might slow down the convergence ( for strongly convex case). This result also reveals new insights on the relationship between the number of local steps and learning rate.
Notation. In this paper, we let be the total number of workers and be the set of active workers for the -th communication round with size for some . 333 For simplicity and ease of presentation in this paper, we let . We note that this is not a restrictive condition and our proofs and results still hold for , which can be easily satisfied in practice. We use to denote the number of local steps per communication round at each worker. We let be the number of total communication rounds. In addition, we use boldface to denote matrices/vectors. We let represent the parameter of -th local step in the -th worker after the -th communication. We use to denote the -norm. For a natural number , we use to represent the set .
The rest of the paper is organized as follows. In Section 2, we review the literature to put our work in comparative perspectives. Section 3 presents the convergence analysis for our proposed algorithm. Section 4 discusses the implication of the convergence rate analysis. Section 5 presents numerical results and Section 6 concludes this paper. Due to space limitation, the details of all proofs and some experiments are provided in the supplementary material.
2 Related work
[t] Dataset Algorithm6 Convexity7 Partial Convergence Communication Worker Rate complexity IID Stich1 SC Yu1 NC Wang NC Stich2 NC This paper NC ✓ NON-IID Khaled 1 C Yu22 NC Li SC ✓ Karimireddy 3 NC ✓ Karimireddy 4 NC ✓ This paper5 NC ✔
-
1
Full gradients are used for each worker.
-
2
Local momentum is used at each worker.
-
3
A FedAvg algorithm with two-sided learning rates. . () for full (partial) worker participation.
-
4
The SCAFFOLD algorithm in Karimireddy et al. (2019) for non-convex case.
-
5
The convergence rate becomes under partial worker participation.
- 6
-
7
Shorthand notation for convexity: SC: Strongly Convex, C: Convex, and NC: Non-Convex.
The federated averaging (FedAvg) algorithm was first proposed by McMahan et al. (2016) for FL as a heuristic to improve communication efficiency and data privacy. Since then, this work has sparked many follow-ups that focus on FL with i.i.d. datasets and full worker participation (also known as LocalSGD (Stich, 2018; Yu et al., 2019b; Wang & Joshi, 2018; Stich & Karimireddy, 2019; Lin et al., 2018; Khaled et al., 2019a; Zhou & Cong, 2017)). Under these two assumptions, most of the theoretical works can achieve a linear speedup for convergence, i.e., for a sufficiently large , matching the rate of the parallel SGD. In addition, LocalSGD is empirically shown to be communication-efficient and enjoys better generalization performance (Lin et al., 2018). For a comprehensive introduction to FL, we refer readers to Li et al. (2019a) and Kairouz et al. (2019).
For non-i.i.d. datasets, many works (Sattler et al., 2019; Zhao et al., 2018; Li et al., 2018; Wang et al., 2019a; Karimireddy et al., 2019; Huang et al., 2018; Jeong et al., 2018) heuristically demonstrated the performance of FedAvg and its variants. On convergence rate with full worker participation, many works (Stich et al., 2018; Yu et al., 2019a; Wang & Joshi, 2018; Karimireddy et al., 2019; Reddi et al., 2020) can achieve linear speedup, but their convergence rate bounds could be improved as shown in this paper. On convergence rate with partial worker participation, Li et al. (2019b) showed that the original FedAvg can achieve for strongly convex functions, which suggests that local SGD steps slow down the convergence in the original FedAvg. Karimireddy et al. (2019) analyzed a generalized FedAvg with two-sided learning rates under strongly convex, convex and non-convex cases. However, as shown in Table 1, none of them indicates that linear speedup is achievable with non-i.i.d. datasets under partial worker participation. Note that the SCAFFOLD algorithm (Karimireddy et al., 2019) can achieve linear speedup but extra variance reduction operations are required, which lead to higher communication costs and implementation complexity. In this paper, we show that this linear speedup can be achieved without any extra requirements. For more detailed comparisons and other algorithmic variants in FL and decentralized settings, we refer readers to Kairouz et al. (2019).
3 Linear Speedup of the Generalized FedAvg with Two-Sided Learning Rates for Non-IID Datasets
In this paper, we consider a FedAvg algorithm with two-sided learning rates as shown in Algorithm 1, which is generalized from previous works (Karimireddy et al., 2019; Reddi et al., 2020). Here, workers perform multiple SGD steps using a worker optimizer to minimize the local loss on its own dataset, while the server aggregates and updates the global model using another gradient-based server optimizer based on the returned parameters. Specifically, between two consecutive communication rounds, each worker performs SGD steps with the worker’s local learning rate . We assume an unbiased estimator in each step, which is denoted by , where is a random local data sample for -th steps after -th communication round at worker . Then, each worker sends the accumulative parameter difference to the server. On the server side, the server aggregates all available -values and updates the model parameters with a global learning rate . The FedAvg algorithm with two-sided learning rates provides a natural way to decouple the learning of workers and server, thus utilizing different learning rate schedules for workers and the server. The original FedAvg can be viewed as a special case of this framework with server-side learning rate being one.
In what follows, we show that a linear speedup for convergence is achievable by the generalized FedAvg for non-convex functions on non-i.i.d. datasets. We first state our assumptions as follows.
Assumption 1.
(-Lipschitz Continuous Gradient) There exists a constant , such that .
Assumption 2.
(Unbiased Local Gradient Estimator) Let be a random local data sample in the -th step at the -th worker. The local gradient estimator is unbiased, i.e., , , where the expectation is over all local datasets samples.
Assumption 3.
(Bounded Local and Global Variance)
There exist two constants and , such that the variance of each local gradient estimator is bounded by
, ,
and the global variability of the local gradient of the cost function is bounded by
, .
The first two assumptions are standard in non-convex optimization (Ghadimi & Lan, 2013; Bottou et al., 2018). For Assumption 3, the bounded local variance is also a standard assumption. We use a universal bound to quantify the heterogeneity of the non-i.i.d. datasets among different workers. In particular, corresponds to i.i.d. datasets. This assumption is also used in other works for FL under non-i.i.d. datasets (Reddi et al., 2020; Yu et al., 2019b; Wang et al., 2019b) as well as in decentralized optimization (Kairouz et al., 2019). It is worth noting that we do not require a bounded gradient assumption, which is often assumed in FL optimization analysis.
3.1 Convergence analysis for full worker participation
In this subsection, we first analyze the convergence rate of the generalized FedAvg with two-sided learning rates under full worker participation, for which we have the following result:
Theorem 1.
Remark 1.
The convergence bound contains two parts: a vanishing term as increases and a constant term whose size depends on the problem instance parameters and is independent of . The vanishing term’s decay rate matches that of the typical SGD methods.
Remark 2.
The first part of (i.e., ) is due to the local stochastic gradients at each worker, which shrinks at rate as increases. The cumulative variance of the local steps contributes to the second term in (i.e., , which is independent of and largely affected by the data heterogeneity. To make the second part small, an inverse relationship between the local learning rate and local steps should be satisfied, i.e., . Specifically, note that the global and local variances are quadratically and linearly amplified by . This requires a sufficiently small to offset the variance between two successive communication rounds to make the second term in small. This is consistent with the observation in strongly convex FL that a decaying learning rate is needed for FL to converge under non-i.i.d. datasets even if full gradients used in each worker (Li et al., 2019b). However, we note that our explicit inverse relationship between and in the above is new. Intuitively, the local steps with a sufficiently small can be viewed as one SGD step with a large learning rate.
With Theorem 1, we immediately have the following convergence rate for the generalized FedAvg algorithm with a proper choice of two-sided learning rates:
Corollary 1.
Let and . The convergence rate of the generalized FedAvg algorithm under full worker participation is .
Remark 3.
The generalized FedAvg algorithm with two-sided learning rates can achieve a linear speedup for non-i.i.d. datasets, i.e., a convergence rate as long as . Although many works have achieved this convergence rate asymptotically, we improve the maximum number of local steps to , which is significantly better than the state-of-art bounds such as shown in (Karimireddy et al., 2019; Yu et al., 2019a; Kairouz et al., 2019). Note that a larger number of local steps implies relatively fewer communication rounds, thus less communication overhead. See also the communication complexity comparison in Table 1. For example, when and (as used in (Kairouz et al., 2019)), the local steps in our algorithm is . However, means that no extra local steps can be taken to reduce communication costs.
Remark 4.
When degenerated to the i.i.d. case (), the convergence rate becomes , which has a better first term in the bound compared with previous work as shown in Table 1.
3.2 Convergence analysis for partial worker participation
Partial worker participation in each communication round may be more practical than full worker participation due to many physical limitations of FL in practice (e.g., excessive delays because of too many devices to poll, malfunctioning devices, etc.). Partial worker participation can also accelerate the training by neglecting stragglers. We consider two sampling strategies proposed by Li et al. (2018) and Li et al. (2019b). Let be the participating worker index set at communication round with , , for some . is randomly and independently selected either with replacement (Strategy 1) or without replacement (Strategy 2) sequentially according to the sampling probabilities . For each member in , we pick a worker from the entire set uniformly at random with probability . That is, selection likelihood for anyone worker is . Then we have the following results:
Theorem 2.
Under Assumptions 1–3 with partial worker participation, the sequence of outputs generated by Algorithm 1 with constant learning rates and satisfies:
where , , and the expectation is over the local dataset samples among workers.
For sampling Strategy 1, let and be chosen as such that , and . It then holds that:
For sampling Strategy 2, let and be chosen as such that , and . It then holds that:
From Theorem 2, we immediately have the following convergence rate for the generalized FedAvg algorithm with a proper choice of two-sided learning rates:
Corollary 2.
Let and . The convergence rate of the generalized FedAvg algorithm under partial worker participation and both sampling strategies are:
Remark 5.
The convergence rate bound for partial worker participation has the same structure but with a larger variance term. This implies that the partial worker participation through the uniform sampling does not result in fundamental changes in convergence (in order sense) except for an amplified variance due to fewer workers participating and random sampling. The intuition is that the uniform sampling (with/without replacement) for worker selection yields a good approximation of the entire worker distribution in expectation, which reduces the risk of distribution deviation due to the partial worker participation. As shown in Section 5, the distribution deviation due to fewer worker participation could render the training unstable, especially in highly non-i.i.d. cases.
Remark 6.
The generalized FedAvg with partial worker participation under non-i.i.d. datasets can still achieve a linear speedup with proper learning rate settings as shown in Corollary 2. In addition, when degenerated to i.i.d. case (), the convergence rate becomes .
Remark 7.
Here, we let only for ease of presentation and better readability. We note that this is not a restrictive condition. We can show that can be relaxed to and the same convergence rate still holds. In fact, our full proof in Appendix A.2 is for .
4 Discussion
In light of above results, in what follows, we discuss several insights from the convergence analysis:
Convergence Rate: We show that the generalized FedAvg algorithm with two-sided learning rates can achieve a linear speedup, i.e., an convergence rate with a proper choice of hyper-parameters. Thus, it works well in large FL systems, where massive parallelism can be leveraged to accelerate training. The key challenge in convergence analysis stems from the different local loss functions (also called “model drift” in the literature) among workers due to the non-i.i.d. datasets and local steps. As shown above, we obtain a convergence bound for the generalized FedAvg method containing a vanishing term and a constant term (the constant term is similar to that of SGD). In contrast, the constant term in SGD is only due to the local variance. Note that, similar to SGD, the iterations do not diminish the constant term. The local variance (randomness of stochastic gradients), global variability (non-i.i.d. datasets), and the number of local steps (amplification factor) all contribute to the constant term, but the total global variability in local steps dominates the term. When the local learning rate is set to an inverse relationship with respect to the number of local steps , the constant term is controllable. An intuitive explanation is that the small local steps can be approximately viewed as one large step in conventional SGD. So this speedup and the more allowed local steps can be largely attributed to the two-sided learning rates setting.
Number of Local Steps: Besides the result that the maximum number of local steps is improved to , we also show that the local steps could help the convergence with the proper hyper-parameter choices, which supports previous numerical results (McMahan et al., 2016; Stich, 2018; Lin et al., 2018) and is verified in different models with different non-i.i.d. degree datasets in Section 5. However, there are other results showing the local steps slow down the convergence (Li et al., 2019b). We believe that whether local steps help or hurt the convergence in FL worths further investigations.
Number of Workers: We show that the convergence rate improves substantially as the the number of workers in each communication round increases. This is consistent with the results for i.i.d. cases in Stich (2018). For i.i.d. datasets, more workers means more data samples and thus less variance and better performance. For non-i.i.d. datasets, having more workers implies that the distribution of the sampled workers is a better approximation for the distribution of all workers. This is also empirically observed in Section 5. On the other hand, the sampling strategy plays an important role in non-i.i.d. case as well. Here, we adopt the uniform sampling (with/without replacement) to enlist workers to participate in FL. Intuitively, the distribution of the sampled workers’ collective datasets under uniform sampling yields a good approximation of the overall data distribution in expectation.
Note that, in this paper, we assume that every worker is available to participate once being enlisted. However, this may not always be feasible. In practice, the workers need to be in certain states in order to be able to participate in FL (e.g., in charging or idle states, etc. (Eichner et al., 2019)). Therefore, care must be taken in sampling and enlisting workers in practice. We believe that the joint design of sampling schemes and the generalized FedAvg algorithm will have a significant impact on the convergence, which needs further investigations.
5 Numerical Results
We perform extensive experiments to verify our theoretical results. We use three models: logistic regression (LR), a fully-connected neural network with two hidden layers (2NN) and a convolution neural network (CNN) with the non-i.i.d. version of MNIST (LeCun et al., 1998) and one ResNet model with CIFAR-10 (Krizhevsky et al., 2009). Due to space limitation, we relegate some experimental results in the supplementary material.




(a) Impact of non-i.i.d. datasets.

(b) Impact of worker number.

(c) Impact of local steps
In this section, we elaborate the results under non-i.i.d. MNIST datasets for the 2NN. We distribute the MNIST dataset among workers randomly and evenly in a digit-based manner such that the local dataset for each worker contains only a certain class of digits. The number of digits in each worker’s dataset represents the non-i.i.d. degree. For , each worker has training/testing samples with ten digits from to , which is essentially an i.i.d. case. For , each worker has samples only associated with one digit, which leads to highly non-i.i.d. datasets among workers. For partial worker participation, we set the number of workers in each communication round.
Impact of non-i.i.d. datasets: As shown in Figure 1(a), for the 2NN model with full worker participation, the top-row figures are for training loss versus communication round and the bottom-row are for test accuracy versus communication round. We can see that the generalized FedAvg algorithm converges under non-i.i.d. datasets with a proper learning rate choice in both cases. For five digits () in each worker’s dataset with full (partial) worker participation in Figure 1(a), the generalized FedAvg algorithm achieves a convergence speed comparable to that of the i.i.d. case (). Another key observation is that non-i.i.d. datasets slow down the convergence under the same learning rate settings for both cases. The higher the non-i.i.d. degree, the slower the convergence speed. As the non-i.i.d. degree increases (from case to case ), it is obvious that the training loss is increasing and test accuracy is decreasing. This trend is more obvious from the zigzagging curves for partial worker participation. These two observations can also be verified for other models as shown in the supplementary material, which confirms our theoretical analysis.
Impact of worker number: As shown in Figure 1(b), we compare the training loss and test accuracy between full worker participation and partial worker participation with the same hyper-parameters. Compared with full worker participation, partial worker participation introduces another source of randomness, which leads to zigzagging convergence curves and slower convergence. This problem is more prominent for highly non-i.i.d. datasets. For full worker participation, it can neutralize the the system heterogeneity in each communication round. However, it might not be able to neutralize the gaps among different workers for partial worker participation. That is, the datasets’ distribution does not approximate the overall distribution well. Specifically, it is not unlikely that the digits in these datasets among all active workers are only a proper subset of the total 10 digits in the original MNIST dataset, especially with highly non-i.i.d. datasets. This trend is also obvious for complex models and complicated datasets as shown in the supplementary material. The sampling strategy here is random sampling with equal probability without replacement. In practice, however, the actual sampling of the workers in FL could be more complex, which requires further investigations.
Impact of local steps: One open question of FL is that whether the local steps help the convergence or not. In Figure 1(c), we show that the local steps could help the convergence for both full and partial worker participation. These results verify our theoretical analysis. However, Li et al. (2019b) showed that the local steps may hurt the convergence, which was demonstrated under unbalanced non-i.i.d. MNIST datasets. We believe that this may be due to the combined effect of unbalanced datasets and local steps rather than just the use of local steps only.
| Dataset | IID or Non-IID | Worker selected | Model | SCAFFOLD | This paper | ||||
| # of Round | Communication cost (MB) | Wall-clock time (s) | # of Round | Communication cost (MB) | Wall-clock time (s) | ||||
| MNIST | IID | Logistic | 3 | 0.36 | 0.32 | 3 | 0.18 | 0.22 | |
| 2NN | 3 | 9.12 | 0.88 | 3 | 4.56 | 0.56 | |||
| CNN | 3 | 26.64 | 2.23 | 3 | 13.32 | 1.57 | |||
| Logistic | 5 | 0.60 | 0.53 | 5 | 0.30 | 0.42 | |||
| 2NN | 5 | 15.20 | 1.51 | 8 | 12.16 | 1.49 | |||
| CNN | 1 | 8.88 | 0.79 | 1 | 4.44 | 0.50 | |||
| Non-IID | Logistic | 14 | 1.68 | 1.48 | 14 | 0.84 | 1.16 | ||
| 2NN | 14 | 42.55 | 4.23 | 14 | 21.28 | 2.46 | |||
| CNN | 14 | 124.34 | 11.12 | 10 | 44.41 | 4.92 | |||
| Logistic | 7 | 0.84 | 0.72 | 11 | 0.66 | 0.91 | |||
| 2NN | 7 | 21.28 | 2.11 | 17 | 25.84 | 3.16 | |||
| CNN | 17 | 150.98 | 13.50 | 7 | 31.08 | 3.51 | |||
| CIFAR-10 | IID | Resnet18 | 56 | 9548.07 | 583.24 | 44 | 3751.03 | 256.63 | |
| Non-IID | Resnet18 | 52 | 8866.06 | 539.50 | 61 | 5200.29 | 358.22 | ||
-
1
Bandwidth = 20MB/s.
Comparison with SCAFFOLD: Lastly, we compare with the SCAFFOLD algorithm (Karimireddy et al., 2019) since it also achieves the same linear speedup effect under non-i.i.d. datasets. We compare communication rounds, total communication load, and estimated wall-clock time under the same settings to achieve certain test accuracy, and the results are reported in Table 2. The non-i.i.d. dataset is and the i.i.d. dataset is . The learning rates are , and number of local steps is epochs. We set the target accuracy for MNIST and for CIFAR-10. Note that the total training time contains two parts: i) the computation time for training the local model at each worker and ii) the communication time for information exchanges between the workers and the server. We assume the bandwidth MB/s for both uplink and downlink connections. For MNIST datasets, we can see that our algorithm is similar to or outperforms SCAFFOLD. This is because the numbers of communication rounds of both algorithms are relatively small for such simple tasks. For non-i.i.d. CIFAR-10, the SCAFFOLD algorithm takes slightly fewer number of communication rounds than our FedAvg algorithm to achieve thanks to its variance reduction. However, it takes more than 1.5 times of communication cost and wall-clock time compared to those of our FedAvg algorithm. Due to space limitation, we relegate the results of time proportions for computation and communication to Appendix B (see Figure 7).
6 Conclusions and future work
In this paper, we analyzed the convergence of a generlized FedAvg algorithm with two-sided learning rates on non-i.i.d. datasets for general non-convex optimization. We proved that the generalized FedAvg algorithm achieves a linear speedup for convergence under full and partial worker participation. We showed that the local steps in FL could help the convergence and we improve the maximum number of local steps to . While our work sheds light on theoretical understanding of FL, it also opens the doors to many new interesting questions in FL, such as how to sample optimally in partial worker participation, and how to deal with active participant sets that are both time-varying and size-varying across communication rounds. We hope that the insights and proof techniques in this paper can pave the way for many new research directions in the aforementioned areas.
Acknowledgements
This work is supported in part by NSF grants CAREER CNS-1943226, CIF-2110252, ECCS-1818791, CCF-1934884, ONR grant ONR N00014-17-1-2417, and a Google Faculty Research Award.
References
- Bottou et al. (2018) Léon Bottou, Frank E Curtis, and Jorge Nocedal. Optimization methods for large-scale machine learning. Siam Review, 60(2):223–311, 2018.
- Eichner et al. (2019) Hubert Eichner, Tomer Koren, H Brendan McMahan, Nathan Srebro, and Kunal Talwar. Semi-cyclic stochastic gradient descent. arXiv preprint arXiv:1904.10120, 2019.
- Ghadimi & Lan (2013) Saeed Ghadimi and Guanghui Lan. Stochastic first-and zeroth-order methods for nonconvex stochastic programming. SIAM Journal on Optimization, 23(4):2341–2368, 2013.
- Hsu et al. (2019) Tzu-Ming Harry Hsu, Hang Qi, and Matthew Brown. Measuring the effects of non-identical data distribution for federated visual classification. arXiv preprint arXiv:1909.06335, 2019.
- Huang et al. (2018) Li Huang, Yifeng Yin, Zeng Fu, Shifa Zhang, Hao Deng, and Dianbo Liu. Loadaboost: Loss-based adaboost federated machine learning on medical data. arXiv preprint arXiv:1811.12629, 2018.
- Jeong et al. (2018) Eunjeong Jeong, Seungeun Oh, Hyesung Kim, Jihong Park, Mehdi Bennis, and Seong-Lyun Kim. Communication-efficient on-device machine learning: Federated distillation and augmentation under non-iid private data. arXiv preprint arXiv:1811.11479, 2018.
- Kairouz et al. (2019) Peter Kairouz, H Brendan McMahan, Brendan Avent, Aurélien Bellet, Mehdi Bennis, Arjun Nitin Bhagoji, Keith Bonawitz, Zachary Charles, Graham Cormode, Rachel Cummings, et al. Advances and open problems in federated learning. arXiv preprint arXiv:1912.04977, 2019.
- Karimireddy et al. (2019) Sai Praneeth Karimireddy, Satyen Kale, Mehryar Mohri, Sashank J Reddi, Sebastian U Stich, and Ananda Theertha Suresh. Scaffold: Stochastic controlled averaging for on-device federated learning. arXiv preprint arXiv:1910.06378, 2019.
- Khaled et al. (2019a) Ahmed Khaled, Konstantin Mishchenko, and Peter Richtárik. Better communication complexity for local sgd. arXiv preprint arXiv:1909.04746, 2019a.
- Khaled et al. (2019b) Ahmed Khaled, Konstantin Mishchenko, and Peter Richtárik. First analysis of local gd on heterogeneous data. arXiv preprint arXiv:1909.04715, 2019b.
- Krizhevsky et al. (2009) Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009.
- LeCun et al. (1998) Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11):2278–2324, 1998.
- Li et al. (2018) Tian Li, Anit Kumar Sahu, Manzil Zaheer, Maziar Sanjabi, Ameet Talwalkar, and Virginia Smith. Federated optimization in heterogeneous networks. arXiv preprint arXiv:1812.06127, 2018.
- Li et al. (2019a) Tian Li, Anit Kumar Sahu, Ameet Talwalkar, and Virginia Smith. Federated learning: Challenges, methods, and future directions. arXiv preprint arXiv:1908.07873, 2019a.
- Li et al. (2019b) Xiang Li, Kaixuan Huang, Wenhao Yang, Shusen Wang, and Zhihua Zhang. On the convergence of fedavg on non-iid data. arXiv preprint arXiv:1907.02189, 2019b.
- Lin et al. (2018) Tao Lin, Sebastian U Stich, Kumar Kshitij Patel, and Martin Jaggi. Don’t use large mini-batches, use local sgd. arXiv preprint arXiv:1808.07217, 2018.
- McMahan et al. (2016) H Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, et al. Communication-efficient learning of deep networks from decentralized data. arXiv preprint arXiv:1602.05629, 2016.
- Reddi et al. (2020) Sashank Reddi, Zachary Charles, Manzil Zaheer, Zachary Garrett, Keith Rush, Jakub Konecny, Sanjiv Kumar, and H Brendan McMahan. Adaptive federated optimization. arXiv preprint arXiv:2003.00295, 2020.
- Sattler et al. (2019) Felix Sattler, Simon Wiedemann, Klaus-Robert Müller, and Wojciech Samek. Robust and communication-efficient federated learning from non-iid data. IEEE transactions on neural networks and learning systems, 2019.
- Stich (2018) Sebastian U Stich. Local sgd converges fast and communicates little. arXiv preprint arXiv:1805.09767, 2018.
- Stich & Karimireddy (2019) Sebastian U Stich and Sai Praneeth Karimireddy. The error-feedback framework: Better rates for sgd with delayed gradients and compressed communication. arXiv preprint arXiv:1909.05350, 2019.
- Stich et al. (2018) Sebastian U Stich, Jean-Baptiste Cordonnier, and Martin Jaggi. Sparsified sgd with memory. In Advances in Neural Information Processing Systems, pp. 4447–4458, 2018.
- Wang & Joshi (2018) Jianyu Wang and Gauri Joshi. Cooperative sgd: A unified framework for the design and analysis of communication-efficient sgd algorithms. arXiv preprint arXiv:1808.07576, 2018.
- Wang et al. (2019a) Jianyu Wang, Vinayak Tantia, Nicolas Ballas, and Michael Rabbat. Slowmo: Improving communication-efficient distributed sgd with slow momentum. arXiv preprint arXiv:1910.00643, 2019a.
- Wang et al. (2019b) Shiqiang Wang, Tiffany Tuor, Theodoros Salonidis, Kin K Leung, Christian Makaya, Ting He, and Kevin Chan. Adaptive federated learning in resource constrained edge computing systems. IEEE Journal on Selected Areas in Communications, 37(6):1205–1221, 2019b.
- Yu et al. (2019a) Hao Yu, Rong Jin, and Sen Yang. On the linear speedup analysis of communication efficient momentum sgd for distributed non-convex optimization. arXiv preprint arXiv:1905.03817, 2019a.
- Yu et al. (2019b) Hao Yu, Sen Yang, and Shenghuo Zhu. Parallel restarted sgd with faster convergence and less communication: Demystifying why model averaging works for deep learning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pp. 5693–5700, 2019b.
- Zhao et al. (2018) Yue Zhao, Meng Li, Liangzhen Lai, Naveen Suda, Damon Civin, and Vikas Chandra. Federated learning with non-iid data. arXiv preprint arXiv:1806.00582, 2018.
- Zhou & Cong (2017) Fan Zhou and Guojing Cong. On the convergence properties of a -step averaging stochastic gradient descent algorithm for nonconvex optimization. arXiv preprint arXiv:1708.01012, 2017.
Appendix A Appendix I: Proofs
In this section, we give the proofs in detail for full and partial worker participation in Section A.1 and Section A.2, respectively.
A.1 Proof of Theorem 1
See 1
Proof.
For convenience, we define . Under full device participation (i.e., ), it is clear that .
Due to the smoothness in Assumption 1, taking expectation of over the randomness at communication round , we have:
| (1) |
Note that the term in (1) can be bounded as follows:
| (2) |
where follows from that for and , is due to that , is due to Assumption 1 and follows from Lemma 2.
The term in (1) can be bounded as:
| (3) |
where follows from the fact that and is due to the bounded variance assumption in Assumption 3 and the fact that if s are independent with zero mean and .
Substituting the inequalities in (2) of and (3) of into inequality (1), we have:
where follows from if , holds because there exists a constant satisfying if .
Rearranging and summing from , we have:
which implies,
where . This completes the proof. ∎
A.2 Proof of Theorem 2
See 2
Proof.
Let be defined the same as in the proof of Theorem 1. Under partial device participation, note that (recall that , , and ). The randomness for partial worker participation contains two parts: the random sampling and the stochastic gradient. We still use to represent the expectation with respect to both types of randomness.
Due to the smoothness assumption in Assumption 1, taking expectation of over the randomness at communication round t:
| (4) |
The term in (4) can be bounded as follows: Since due to Lemma 1 for both sampling strategies, we have the same bound as in inequality 2 for :
| (5) |
For strategy 1: We can bound in (4) as follows.
Note is an index set (multiset) for independent sampling (equal probability) with replacement in which some elements may have the same value. Suppose .
where follows from the fact that and is due to the bounded variance assumption 3 and .
By letting , we have:
where is due to the independent sampling with replacement.
So we can bound as follows.
| (6) |
| (8) |
where follows from if , is due to inequality (7) and holds since there exists a constant such that if .
Note that the requirement of can be relaxed to . With workers in -th communication round, 8 is
That is, the same convergence rate can be guaranteed if at least workers in each communication round (no need to be exactly ).
Rearranging and summing from , we have the convergence for partial device participation with sampling strategy 1 as follows:
where and is a constant.
For strategy 2: Under the strategy of independent sampling with equal probability without replacement. We bound as follows.
| (9) |
where is due to the fact that if s are independent with zero mean, is independent random variable with mean zero, and . is due to bounded variance assumption in Assumption 3
Then we bound as follows.
By letting , we have:
It then follows that
where and are due to the fact that follows from the fact that and . Therefore, we have
where follows from the fact that , and is due to the fact that if .
Then we have
| (10) |
where holds because there exists a constant satisfying if .
Note that the requirement of can be relaxed to . With workers in -th communication round, 10 is
That is, the same convergence rate can be guaranteed if at least workers in each communication round (no need to be exactly ).
Rearranging and summing from , we have the convergence for partial device participation with sampling strategy 2 as follows:
where and is a constant. This completes the proof. ∎
A.2.1 Key Lemmas
Lemma 1 (Unbiased Sampling).
For strategies 1 and 2, the estimator is unbiased, i.e.,
Proof of Lemma 1.
Let with size .
Both for sampling strategies 1 and 2, each sampling distribution is identical.
Then we have:
A.3 Auxiliary Lemmas
Lemma 2 (Lemma 4 in Reddi et al. (2020)).
For any step-size satisfying , we can have the following results:
Proof.
In order for this paper to be self-contained, we restate the proof of Lemma 4 in (Reddi et al., 2020) here.
For any worker and , we have:
Unrolling the recursion, we get:
This completes the proof. ∎
Appendix B Appendix II: Experiments
We provide the full detail of the experiments. We uses non-i.i.d. versions for MNIST and CIFAR-10, which are described as follows:
B.1 MNIST
We study image classification of handwritten digits 0-9 in MNIST and modify the MNIST dataset to a non-i.i.d. version.
To impose statistical heterogeneity, we split the data based on the digits () they contain in their dataset. We distribute the data to workers such that each worker contains only a certain class of digits with the same number of training/test samples. For example, for , each worker only has training/testing samples with one digit, which causes heterogeneity among different workers. For , each worker has samples with 10 digits, which is essentially i.i.d. case. In this way, we can use the digits in worker’s local dataset to represent the non-i.i.d. degree qualitatively. In each communication round, 100 workers run epochs locally in parallel and then the server samples workers for aggregation and update. We make a grid-search experiments for the hyper-parameters as shown in Table 3.
| Server Learning Rate | |
| Client Learning Rate | |
| Local Epochs | |
| Clients Partition Number | |
| Non-i.i.d. Degree |
We run three models: multinomial logistic regression, fully-connected network with two hidden layers (2NN) (two 200 neurons hidden layers with ReLU followed by an output layer), convolutional neural network (CNN), as shown in Table 4. The results are shown in Figures 2, 3 and 4.
| Layer Type | Size |
| Convolution + ReLu | |
| Max Pooling | |
| Convolution + ReLu | |
| Max Pooling | |
| Fully Connected + ReLU | |
| Fully Connected |

(a) LR

(b) 2NN

(c) CNN

(a) LR

(b) 2NN

(c) CNN

(a) LR

(b) 2NN

(c) CNN
B.2 CIFAR-10
Unless stated otherwise, we use the following default parameter setting: the server learning rate and client learning rate are set to and , respectively. The local epochs is set to . The total number of clients is set to 100, and the clients partition number is set to . We use the same strategy to distribute the data over clients as suggested in McMahan et al. (2016). For the i.i.d. setting, we evenly partition all the training data among all clients, i.e., each client observes 500 data; for the non-i.i.d. setting, we first sort the training data by label, then divide all the training data into 200 shards of size 250, and randomly assign two shards to each client. For the CIFAR-10 dataset, we train our classifier with the ResNet model. The results are shown in Figure 5 and Figure 6.



B.3 Discussion
Impact of non-i.i.d. datasets: Figure 2 shows the results of training loss (top) and test accuracy (bottom) for three models under different non-i.i.d. datasets with full and partial worker participation on MNIST. We can see that the FedAvg algorithm converges under non-i.i.d. datasets with a proper learning rate choice in these cases. We believe that the major challenge in FL is the non-i.i.d. datasets. For these datasets with a lower degree of non-i.i.d., the FedAvg algorithm can achieve a good result compared with the i.i.d. case. For example, when the local dataset in each worker has five digits () with full (partial) worker participation, the FedAvg algorithm achieves a convergence speed comparable with that of the i.i.d. case (). This result can be observed in Figure 2 for all three models. As the degree of non-i.i.d. datasets increases, its negative impact on the convergence is becoming more obvious. The higher the degree of non-i.i.d., the slower the convergence speed. As the non-i.i.d. degree increases (from case to case ), it is obvious that the training loss is increasing and test accuracy is decreasing. For these with high degree of non-i.i.d., the convergence curves oscillate and are highly unstable. This trend is more obvious for complex models such for CNN in Figure 2(c).
Impact of worker number: For full worker participation, the server can have an accurate estimation of the system heterogeneity after receiving the updates for all workers and neutralize this heterogeneity in each communication round. However, partial worker participation introduces another source of randomness, which leads to zigzagging convergence curves and slower convergence. In each communication round, the server can only receive a subset of workers based on the sampling strategy. So the server could only have a coarse estimation of the system heterogeneity and might not be able to neutralize the heterogeneity among different workers for partial worker participation. This problem is more prominent for highly non-i.i.d. datasets. It is not unlikely that the digits in these datasets among all active workers are only a proper subset of the total digits in the original MNIST dataset, especially with highly non-i.i.d. datasets. For example, for with workers in each communication round, it is highly likely that the datasets formed by these ten workers only includes certain small number of digits (say, or ) rather than total digits. But for , it is the opposite, that is, the digits in these datasets among these workers are highly likely to be . So in each communication round, the server can mitigate system heterogeneity since it covers the training samples with all digits. This trend is more obvious for complex models and datasets given the dramatic drop of test accuracy in the result of CIFAR-10 in Figure 5.
The sample strategy here is random sampling with equal probability without replacement. In practice, the workers need to be in certain states in order to be able to participate in FL (e.g., in charging or idle states, etc.(Eichner et al., 2019)). Therefore, care must be taken in sampling and enlisting workers in practice. We believe that the joint design of sampling schemes, number of workers and the FedAvg algorithm will have a significant impact on the convergence, which needs further investigations.
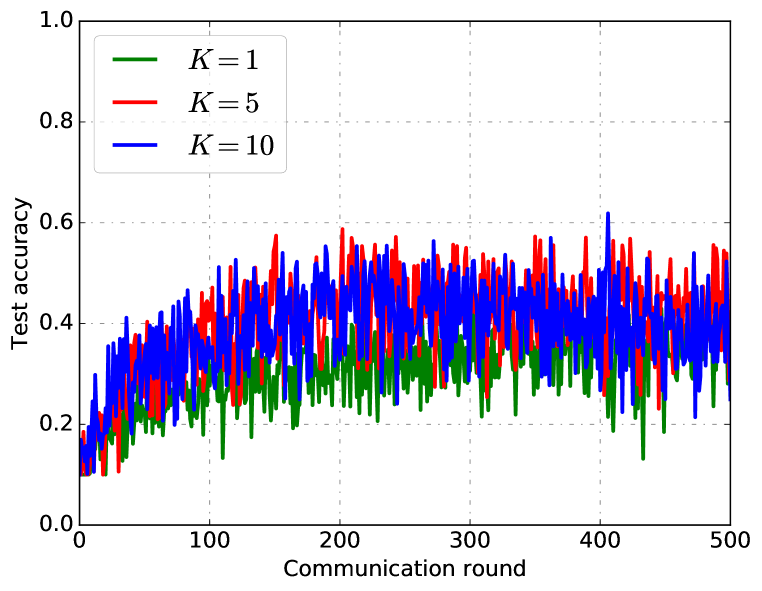
Impact of local steps: Figure 3 and Figure 4 shows the results of training loss (top) and test accuracy (bottom) for three models under different local steps with full and partial worker participation respectively. Figure 6 shows the impact of local steps in CIFAR-10. One open question of FL is that whether the local steps help the convergence or not. Li et al. (2019b) showed a convergence rate , i.e., the local steps may hurt the convergence for full and partial worker participation. In this two figures, we can see that local steps could help the convergence for both full and partial worker participation. However, it only has a slight effect on the convergence compared to the effects of non-i.i.d. datasets and number of workers.
Comparison with SCAFFOLD: We compare SCAFFOLD (Karimireddy et al., 2019) with the generalized FedAVg algorithm in this paper in terms of communication rounds, total communication overloads and estimated wall-clock time to achieve certain test accuracy in Table 2. We run the experiments using the same GPU (NVIDIA V100) to ensure the same conditions. Here, we give a specific comparison for these two algorithms under exact condition. Note that we divide the total training time to two parts: the computation time when the worker trains the local model and the communication time when information exchanges between the worker and server. We only compare the computation time and communication time with a fixed bandwidth for both uploading and downloading connections. As shown in Figure 7, to achieve , SCAFFOLD performs less communication round due to the variance reduction techniques. That is, it spends less time on computation. However, it needs to communicates as twice as the FedAvg since the control variate to perform variance reduction in each worker needs to update in each round. In this way, the communication time would be largely prolonged.
