Achieving Better Kinship Recognition Through Better Baseline
Abstract
Recognizing blood relations using face images can be seen as an application of face recognition systems with additional restrictions. These restrictions proved to be difficult to deal with, however, recent advancements in face verification show that there is still much to gain using more data and novel ideas. As a result face recognition is a great source domain from which we can transfer the knowledge to get better performance in kinship recognition as a source domain. We present new baseline for automatic kinship recognition task and relatives search based on RetinaFace[1] for face registration and ArcFace[2] face verification model. With the approach described above as the foundation, we constructed a pipeline that achieved state-of-the-art performance on two tracks in the recent Recognizing Families In the Wild Data Challenge.
I INTRODUCTION
Face recognition using neural networks and RGB image data is still on the rise thanks to the abundance of raw data on the Internet, more public data [3, 4, 5], and popular computational frameworks being open source. Algorithms in this field reach new records [6, 7] both in quality and resource consumption which were unimaginable several years before.
Automatic kinship recognition using visual information is very similar to face verification and thanks to growing Families In the Wild (FIW) [8] dataset is getting more attention in the research community [9].
Annual Recognizing Families In the Wild (RFIW) Data Challenge tries to bring the difficult problem closer to have a solution applicable to the real-world tasks. And every year contestants show new approaches based on metric learning [10, 11], ensembling different facial features [12] and the introduction of additional data pre-processing [13]. We decided to take a step back and start with a better baseline model and then gradually apply different approaches to improve performance. To our surprise, basic fine-tuning happened to be enough to achieve better performance than other competitors. In this work we make three main contributions:
-
1.
We propose a new baseline for evaluating kinship recognition methods, which is based on recent advancements in the face recognition field.
-
2.
We designed a pipeline for the fine-tuning face verification models for visual kinship recognition task based on the new baseline.
-
3.
We show that our approach111We encourage you to download our implementation and test it: https://github.com/vuvko/fitw2020 achieves the best performance in Recognizing Families In the Wild Data Challenge (Tracks 1&3).
The rest of this paper is organized as follows: in section II we briefly review existing methods that are useful for our task of kinship recognition and family search, in section III we explain our proposed baseline and pipeline, in section IV we evaluate our approach on RFIW challenge dataset, in section V we conclude our work and discuss further possible improvements.
II RELATED WORK
Our task is to recognize a binary feature (kin, non-kin) given two face images. There are several different approaches we can use to tackle this problem: from hand-crafted features to generative methods for data augmentation. But we will focus on closer work in similar fields.
Convolutional neural networks (CNN) became the backbone in the variety of methods in computer vision tasks. Since the introduction of AlexNet [14] hand-crafted features had been quickly replaced by better and sometimes even faster algorithms based on CNNs.
Face recognition is an example of a fast-moving field in computer vision. The progress is due to novel datasets [3, 5, 4] for training and evaluation, introduction of different architectures and learning methods [15, 16, 17, 2], more data challenges [18, 19] and industrial interest [7]. Similarity with visual kinship recognition tasks makes the face recognition models a good candidate for fine-tuning for our task. And it was shown [9] that better base models can achieve much higher performance than carefully tuned older ones.
Image retrieval also had a success incorporating CNNs. The deep representation from the penultimate layer was shown [20, 21] to be a good feature extractor. Typically methods were tuned for retrieval task with metric learning [22] but classification approach using proxies [23, 24] became a new promising design.
III PROPOSED PIPELINE
In [9] fine-tuned SphereFace [16] was proposed as the best baseline benchmark for our task. However, better algorithms were proposed in recent years. ArcFace [2] achieved better performance in face verification and was widely recognized 222Original implementation: https://github.com/deepinsight/insightface in Github community with several re-implementations easily obtainable in every popular framework. Thus, we tried to use it as a new baseline and foundation for our design.
III-A Extracting Face Embeddings
We could use images from FIW dataset without the special preparations to obtain the image embedding, but facial recognition models work differently based on the different face alignment techniques that were used during their training. Moreover, better face detection and registration further improve model performance [1]. Knowing this, we re-detected faces in the challenge’s dataset and aligned them with landmarks from the RetinaFace [1] detector. At this step, some faces were not detected with the selected confidence threshold and were removed from the training and validation set. For the test set, such images were just resized to fit into the face recognition model. There were a total of images removed from the training set, images from validation, and problematic images that occurred in the test set.
The ArcFace [2] model was used for features extraction. This model was pre-trained on cleaned MS-Celeb-1M [3] dataset 333Clean dataset can be downloaded from https://github.com/deepinsight/insightface/wiki/Dataset-Zoo and has the embedding dimension of 512.
To compare two images and we used cosine distance between their computed embeddings and :
| (1) |
III-B Transfer Learning
The main difference between face and kinship recognition tasks is in the relative distance between different people. While face recognition cares mostly about pictures of the same person being close in embedding space, kinship recognition is trying to achieve a much harder task. In the later different people must be closer to each other than the other groups of people, ideally forming family clusters. The difference in the available labeled data and similarity between the tasks makes face recognition a great source domain for transferring to the kinship recognition domain.
In the previous iterations of RFIW, the metric learning was used as a transfer learning approach and achieved a great performance [10]. However, it requires pairs of images to be carefully sampled to confidently estimate the distribution of all distances in the metric space. Another concern is that it requires a significant amount of time to train the final model. Given the information for each person about their family association, we can construct a family classification problem similar to the recent methods in face recognition [16, 2, 17] and metric learning for image retrieval [23, 24]. With this our loss function looks like:
| (2) |
where is the batch size, is the number of families, is the image embedding of a member of the -th family, is the weight matrix (with denoting it’s -th column) and is the bias from classification layer.
III-C Forming Validation Pairs
In track 1 of RFIW Data Challenge images are divided between families. As the distribution between persons and between families in challenge’s data is non-uniform, we need to be careful with sampling the pairs, as validating model offline is crucial given the limited number of submissions. We sampled positive and negative pairs selected uniformly between all families from the validation set using algorithm 1.
number of image pairs to sample
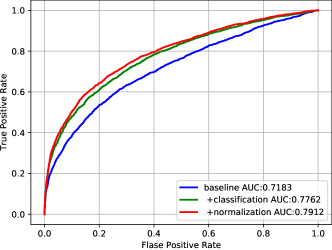
Using this approach validates our model without the issue of popular families that have lots of images. We used AUC ROC metric on the validation pairs (see fig. 1) for choosing the best model for submission Another problem occurs though: as we select uniformly between the families, families with low member count are given higher priority. We chose to resolve this issue with a higher binarization threshold.
III-D Choosing Binarization Threshold
Given a comparison of two image embeddings using cosine distance (1) we need some binarization function to get the needed result. In our case, a simple binarization by threshold was used. The threshold can be chosen based on the trade-off between the false positive rate and the true positive rate. As we had no prior knowledge of how the test pairs were selected we chose target false positive rate based on our three submissions for the final phase.
Given the information about the pair’s possible kind of kinship relation, we could have chosen the threshold for every kind separately. Alas, we could only submit results and some kinds of relations had a low number of pairs to confidently select threshold. We further discuss this in section IV-C.
III-E Using for Retrieval
The retrieval task can be reduced to a series of verification tasks. Every probe image is matched with every gallery image to construct a retrieval matrix (every row contains a retrieval result for the probe image). Our task also has more than one image for every probe person, and we can solve this in different ways. One way is creating an aggregated feature for each probe person. We can do this by averaging all the embeddings from their images. Thus we reduced our task to a single feature per probe and can form a retrieval matrix.
The other way is using all matching results from all images. We need to add aggregation function that would consolidate distances between images to adapt to this. Given a gallery image and a probe person with images we can sort the gallery images using the distance:
| (3) |
Aggregation function should take a vector with an arbitrary number of elements and return a single real number. There are different options for such function but we tested only mean and max in this challenge.
With this approach, we need to compare embeddings for every probe image with every gallery image. It can be difficult to compute with reasonable resources when there is a large number of images per person. There is a variety of approaches [22] for that purpose: from reducing latent space [25, 26] to constructing special structures [27] but in this work we will only show (see IV-D) that getting a mean embedding for a person is comparable with searching using the aggregated function .
IV EXPERIMENTS
| method | MD | MS | SIBS | SS | BB | FD | FS | GFGD | GFGS | GMGD | GMGS | Average |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| pretrained | 0.73 | 0.69 | 0.70 | 0.72 | 0.69 | 0.67 | 0.71 | 0.62 | 0.56 | 0.65 | 0.51 | 0.70 |
| +classification | 0.78 | 0.73 | 0.77 | 0.79 | 0.78 | 0.73 | 0.79 | 0.75 | 0.69 | 0.72 | 0.57 | 0.77 |
| +normalization | 0.78 | 0.74 | 0.77 | 0.80 | 0.80 | 0.75 | 0.81 | 0.78 | 0.69 | 0.76 | 0.58 | 0.78 |
| +different thresholds | 0.78 | 0.74 | 0.77 | 0.80 | 0.80 | 0.75 | 0.81 | 0.78 | 0.69 | 0.76 | 0.60 | 0.78 |
| 2nd place | 0.75 | 0.74 | 0.75 | 0.77 | 0.77 | 0.74 | 0.81 | 0.72 | 0.73 | 0.67 | 0.68 | 0.76 |
| 3rd place | 0.75 | 0.75 | 0.72 | 0.74 | 0.75 | 0.76 | 0.82 | 0.79 | 0.69 | 0.76 | 0.67 | 0.76 |
IV-A Recognizing Families In the Wild Data Challenge
The Recognizing Families In the Wild Data Challenge (RFIW2020) focuses on determining blood relations based on visual facial similarities. For that, it has images from families for training and validation sets. This year there were a total of three tracks: one-to-one kinship verification (track 1), two-to-one kinship verification (track 2), and family search and retrieval (track 3). Our team chose to participate in tracks 1&3 so we will focus only on them.
In track 1 there were pairs for the final testing. Methods were evaluated based on the average accuracy of binary classification (kin, non-kin) over all of the testing pairs. Additional measurements were provided separately for every kinship type.
Track 3 is the image retrieval problem with one family member as a query (or probe) and other family members with distractors as a gallery. There were probe subjects (each with a different number of images) and images in the gallery. Methods were evaluated based on mean average precision (mAP) and rank@k metrics.
IV-B Implementation Details
We used Mxnet [28] for the implementation of our pipeline. For detection and feature extraction insightface python package was used. In particular, retinaface_r50_v1 which is RetinaFace implementation with ResNet50 as the backbone and arcface_r100_v1 which is modified ResNet101 trained with ArcFace loss on cleaned MS-Celeb-1M dataset.
Re-detected and aligned (as described in III-A) faces were given to the feature extractor model to obtain image embeddings. Performance of this approach (pretrained on fig. 1) was used as a baseline to test our hypotheses.
First, we tried to add a simple classification layer and finetune the whole model on the train set with stochastic gradient descent with base learning rate of , momentum , linear warmup for first batches of size , linear cooldown for last batches, multiplying learning rate by on epochs and gradient clipping for epochs. Random color jitter and random lightning with parameter were used for the data augmentation. No random cropping or similar technique was used to not confuse the model that was trained on similar aligned images. After that, we added normalization of the embeddings and retrained the model starting with pre-trained weights. Performance of these two models on our sampled validation pairs (see III-C) can be seen in fig. 1.
IV-C Verification Results
We needed to binarize our predictions to submit for test verification on track 1. We chose threshold such that we had true positive rate (TPR) of on our sampled validation images for our first submission (pretrained in table I). Next submissions were tested with different thresholds and between several strategies, the one that showed the best average performance was to choose the threshold such that the method would have a false positive rate (FPR) of . Other entries in table I are provided with that strategy of choosing the binarization threshold.
We tested the simple fine-tuning using a classification layer (+classification) with a similar approach where the embeddings are normalized to have a unit norm before the classification layer (+normalization). Both on our validation data and test set the second approach was superior. This indicates that consistency with our cosine distance metric that we use for image comparison is crucial for fine-tuning the model for kinship verification.
From comparison table I we can see that our approach performs poorly on grandparents-grandchildren type of kinship because there is a small number of images with this type of relationship in the training set, but we can mitigate this bias through a different threshold for every kind of relationship. Sadly, we could not test this idea due to the lack of time, but we provide a proof of this hypothesis with +different thresholds submission where we improved the performance for grandmother-grandson relationship by lowering binarization threshold.
We should note that though our approach scores first on average it is not by a far margin and mostly due to our great performance on sibling pairs. Having an average accuracy at best, automatic kinship recognition still needs to be improved to be considered for usage in real-world applications. For the reference, the best face verification models perform with FPR around [7].
IV-D Retrieval Results
| method | mAP | Rank@K | Average |
|---|---|---|---|
| pretrained | 0.163 | 0.53 | 0.34 |
| +norm+class | 0.192 | 0.56 | 0.38 |
| +mean aggregation | 0.193 | 0.57 | 0.38 |
| +max aggregation | 0.179 | 0.60 | 0.39 |
| 2nd place | 0.08 | 0.38 | 0.23 |
| 3rd place | 0.08 | 0.36 | 0.23 |
| 4th place | 0.06 | 0.32 | 0.19 |
In track 3 we needed to aggregate several embeddings per probe person to rank gallery images. We used average consolidated embedding for our baseline submission pretrained and compared it to every gallery image using the cosine metric to get a resulting retrieval matrix. The same procedure was used with our best model from track 1 (+norm+class) and we can see that our approach gives improvements not only to the verification task but also to the retrieval. Then we compared this search method with different aggregation functions (see III-E). We can see that averaging embeddings for probe subjects perform worse than searching using all available embeddings with aggregation function but is still comparable. Furthermore, we can see that max aggregation function, which searches for the image from the gallery that is closest to any of the query images, has a higher rank@K metric than mean aggregation but lower mAP.
Table II shows that even the pre-trained ArcFace model performs much better than the other competitors and our pipeline improved this performance even further. But even such great performance is too low for trying to use this pipeline in a real-world scenario.
V CONCLUSIONS AND FUTURE WORKS
In this work we show that using better face verification models is crucial for improving kinship recognition due to more available data. We presented the new baseline for kinship verification and retrieval tasks, which is based on more accurate face recognition model than the previous baseline. Furthermore our designed pipeline for the verification task improved this result and achieved the best performance in the recent challenge.
In future work we plan to provide a more thorough analysis of methods suitable for the automatic kinship recognition task. Different feature extractors and ensembling are the most promising next steps from our perspective.
VI ACKNOWLEDGMENTS
The author would like to thank Nikolai Amiantov, Konstantin Aleshkin, and Anastasia Belikova for the helpful discussion in preparing this publication, all reviewers for their valuable comments, and the competition organizers for the opportunity to show this work.
References
- [1] Jiankang Deng, Jia Guo, Zhou Yuxiang, Jinke Yu, Irene Kotsia, and Stefanos Zafeiriou. Retinaface: Single-stage dense face localisation in the wild. In arxiv, 2019.
- [2] Jiankang Deng, Jia Guo, Xue Niannan, and Stefanos Zafeiriou. Arcface: Additive angular margin loss for deep face recognition. In CVPR, 2019.
- [3] Yandong Guo, Lei Zhang, Yuxiao Hu, Xiaodong He, and Jianfeng Gao. Ms-celeb-1m: A dataset and benchmark for large-scale face recognition. In European conference on computer vision, pages 87–102. Springer, 2016.
- [4] Brianna Maze, Jocelyn Adams, James A Duncan, Nathan Kalka, Tim Miller, Charles Otto, Anil K Jain, W Tyler Niggel, Janet Anderson, Jordan Cheney, et al. Iarpa janus benchmark-c: Face dataset and protocol. In 2018 International Conference on Biometrics (ICB), pages 158–165. IEEE, 2018.
- [5] Qiong Cao, Li Shen, Weidi Xie, Omkar M Parkhi, and Andrew Zisserman. Vggface2: A dataset for recognising faces across pose and age. In 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), pages 67–74. IEEE, 2018.
- [6] Patrick Grother, Mei Ngan, and Kayee Hanaoka. Ongoing face recognition vendor test (FRVT) part 2: Identification. Technical report, November 2018.
- [7] Patrick Grother, Mei Ngan, and Kayee Hanaoka. Face recognition vendor test part 3: Demographic effects. Technical report, December 2019.
- [8] Joseph P Robinson, Ming Shao, Yue Wu, and Yun Fu. Families in the wild (fiw): Large-scale kinship image database and benchmarks. In Proceedings of the 2016 ACM on Multimedia Conference, pages 242–246. ACM, 2016.
- [9] Joseph P Robinson, Ming Shao, Yue Wu, Hongfu Liu, Timothy Gillis, and Yun Fu. Visual kinship recognition of families in the wild. IEEE transactions on pattern analysis and machine intelligence, 40(11):2624–2637, 2018.
- [10] Yong Li, Jiabei Zeng, Jie Zhang, Anbo Dai, Meina Kan, Shiguang Shan, and Xilin Chen. Kinnet: Fine-to-coarse deep metric learning for kinship verification. In Proceedings of the 2017 Workshop on Recognizing Families In the Wild, pages 13–20, 2017.
- [11] Abhilash Nandy and Shanka Subhra Mondal. Kinship verification using deep siamese convolutional neural network. In 2019 14th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2019), pages 1–5. IEEE, 2019.
- [12] Oualid Laiadi, Abdelmalik Ouamane, Abdelhamid Benakcha, Abdelmalik Taleb-Ahmed, and Abdenour Hadid. Kinship verification based deep and tensor features through extreme learning machine. In 2019 14th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2019), pages 1–4. IEEE, 2019.
- [13] Decky Aspandi, Oriol Martinez, and Xavier Binefa. Heatmap-guided balanced deep convolution networks for family classification in the wild. In 2019 14th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2019). IEEE, May 2019.
- [14] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems, pages 1097–1105, 2012.
- [15] Florian Schroff, Dmitry Kalenichenko, and James Philbin. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 815–823, 2015.
- [16] Weiyang Liu, Yandong Wen, Zhiding Yu, Ming Li, Bhiksha Raj, and Le Song. Sphereface: Deep hypersphere embedding for face recognition. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
- [17] Hao Wang, Yitong Wang, Zheng Zhou, Xing Ji, Dihong Gong, Jingchao Zhou, Zhifeng Li, and Wei Liu. Cosface: Large margin cosine loss for deep face recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5265–5274, 2018.
- [18] Ira Kemelmacher-Shlizerman, Steven M Seitz, Daniel Miller, and Evan Brossard. The megaface benchmark: 1 million faces for recognition at scale. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4873–4882, 2016.
- [19] Jiankang Deng, Jia Guo, Debing Zhang, Yafeng Deng, Xiangju Lu, and Song Shi. Lightweight face recognition challenge. In Proceedings of the IEEE International Conference on Computer Vision Workshops, pages 0–0, 2019.
- [20] Jeff Donahue, Yangqing Jia, Oriol Vinyals, Judy Hoffman, Ning Zhang, Eric Tzeng, and Trevor Darrell. Decaf: A deep convolutional activation feature for generic visual recognition. In International conference on machine learning, pages 647–655, 2014.
- [21] Artem Babenko and Victor Lempitsky. Aggregating local deep features for image retrieval. In Proceedings of the IEEE international conference on computer vision, pages 1269–1277, 2015.
- [22] Liang Zheng, Yi Yang, and Qi Tian. Sift meets cnn: A decade survey of instance retrieval. IEEE transactions on pattern analysis and machine intelligence, 40(5):1224–1244, 2017.
- [23] Yair Movshovitz-Attias, Alexander Toshev, Thomas K Leung, Sergey Ioffe, and Saurabh Singh. No fuss distance metric learning using proxies. In Proceedings of the IEEE International Conference on Computer Vision, pages 360–368, 2017.
- [24] Andrew Zhai and Hao-Yu Wu. Classification is a strong baseline for deep metric learning. In British Machine Vision Conference (BMVC), 2019.
- [25] Herve Jegou, Matthijs Douze, and Cordelia Schmid. Product quantization for nearest neighbor search. IEEE transactions on pattern analysis and machine intelligence, 33(1):117–128, 2010.
- [26] Dmitry Baranchuk, Artem Babenko, and Yury Malkov. Revisiting the inverted indices for billion-scale approximate nearest neighbors. In Proceedings of the European Conference on Computer Vision (ECCV), pages 202–216, 2018.
- [27] Yury A Malkov and Dmitry A Yashunin. Efficient and robust approximate nearest neighbor search using hierarchical navigable small world graphs. IEEE transactions on pattern analysis and machine intelligence, 2018.
- [28] Tianqi Chen, Mu Li, Yutian Li, Min Lin, Naiyan Wang, Minjie Wang, Tianjun Xiao, Bing Xu, Chiyuan Zhang, and Zheng Zhang. Mxnet: A flexible and efficient machine learning library for heterogeneous distributed systems. In Neural Information Processing Systems, Workshop on Machine Learning Systems, 2015.