Accelerating variational quantum Monte Carlo using the variational quantum eigensolver
Abstract
Variational Monte Carlo (VMC) methods are used to sample classically from distributions corresponding to quantum states which have an efficient classical description. VMC methods are based on performing a number of steps of a Markov chain starting with samples from a simple initial distribution. Here we propose replacing this initial distribution with samples produced using a quantum computer, for example using the variational quantum eigensolver (VQE). We show that, based on the use of initial distributions generated by numerical simulations and by experiments on quantum hardware, convergence to the target distribution can be accelerated compared with classical samples; the energy can be reduced compared with the energy of the state produced by VQE; and VQE states produced by small quantum computers can be used to accelerate large instances of VMC. Quantum-enhanced VMC makes minimal requirements of the quantum computer and offers the prospect of accelerating classical methods using noisy samples from near-term quantum computers which are not yet able to accurately represent ground states of complex quantum systems.
The variational quantum eigensolver (VQE) is a quantum algorithm which attempts to produce the ground state of a quantum system by minimising the energy of states of a particular form (“variational ansatz”) peruzzo14 . The hope is that by optimising over a wider family of states than are accessible to classical methods, one can produce more accurate approximations to ground states. VQE may be more suitable for near-term quantum computers than some other quantum algorithms, because it uses low-depth quantum circuits which are optimised to make best use of the hardware. However, current quantum hardware is as yet unable to run VQE on instances beyond the capacity of classical exact diagonalisation.
In the period before VQE or other algorithms are able to produce ground states accurately directly, it is of interest to develop ways in which VQE can improve – and be improved by – existing classical methods. Here we consider the case of variational Monte Carlo (VMC) methods sorella05 ; yokoyama87 ; giamarchi91 ; carleo17 . These methods allow the calculation of properties of quantum states that are too large to represent directly on a classical computer, but which nevertheless have an efficient classical description, in the sense that any given amplitude of the state can be computed efficiently (up to an overall normalisation constant).
The intent behind VMC is to approximate the true ground state of a quantum system with such a classically efficient state , and then to compute properties of in the hope that these give insight into properties of . Although, from empirical and complexity-theoretic arguments, it is not expected that all quantum ground states have an efficient description of this form, in some cases VMC methods have nevertheless been very effective yokoyama87 ; giamarchi91 ; carleo17 .
Here we propose an approach which we call quantum-enhanced variational Monte Carlo (QEVMC), which is based on using samples produced by VQE – or some other quantum algorithm – as input to VMC. We show using numerical simulations and experimental data from a quantum computer that this hybrid approach can be advantageous, in three respects:
-
1.
Convergence to the target distribution can be accelerated using VQE samples, compared with a standard classically samplable initial distribution;
-
2.
VMC can reduce the energy compared with the energy of the original VQE state;
-
3.
VQE samples generated on a small quantum computer can be used within VMC to accelerate convergence for systems beyond the quantum computer’s capacity.
We validate these three points for two well-studied proof-of-principle systems: the Fermi-Hubbard model using the Gutzwiller wavefunction gutzwiller63 , and the Ising model with transverse field using the neural network quantum state ansatz carleo17 .
The first point above addresses a practical issue faced by VMC: convergence to the target distribution can be slow choo20 ; zhao21 , which is a particular challenge given the inherently sequential nature of the MCMC process. One reason for slow convergence is that the initial distribution in VMC may be far from the target distribution. VQE is expected to be able to produce initial distributions which are closer to the target distribution, by better representing the desired quantum correlations.
Regarding the second point above, note that in a situation where VMC improves the VQE energy, we could instead have used a classical approach throughout to achieve this improved energy, without the need for the quantum computer. Thus, improving the VQE energy using VMC as a goal in itself seems to be primarily of theoretical, rather than practical, interest. However, connecting to the first point, using the quantum computer could speed up convergence to this target energy, and hence make a previously infeasible VMC procedure feasible.
| Method | Type of Hamiltonian | Needs only offline access | Type of access needed | Converges to true ground state |
|---|---|---|---|---|
| Quantum-enhanced MCMC layden22 | Classical | ✗ | Sampling | ✓ |
| QC-QMC huggins22 ; wan23 | Quantum | ✓ | Estimating overlaps | ✓ |
| CQA/QAEE xu22 | Quantum | ✗ | Estimating overlaps | ✓ |
| QC-FCIQMC zhang22 | Quantum | ✗ | Estimating elements of a Hamiltonian | ✓ |
| VQNHE zhang22a | Quantum | ✗ | Sampling (rel. error) | ✗ |
| NEM bennewitz22 | Quantum | ✓ | Sampling | ✗ |
| Data-enhanced VMC czischek22 ; moss23 | Experimental | ✓ | Sampling | ✗ |
| Quantum-enhanced VMC | Quantum | ✓ | Sampling | ✗ |
A crucial advantage of QEVMC is that it can be implemented using a very simple protocol. A set of VQE samples, once generated, are stored and used to generate a distribution which can be sampled from at the start of the VMC procedure; there is no need to interact with the quantum computer after this point. In addition, we expect QEVMC to be resilient to errors in the quantum state. For example, in the simple case where the final state produced by VQE is a mixed state , where is the intended final state and is the maximally mixed state, the use of VMC on is equivalent to using as input, except for an fraction of the samples, where the uniform distribution is used. The final output of QEVMC should therefore gracefully interpolate between the output generated with a perfect input state, and the output generated with the classical uniform distribution as input.
It is even possible that in some cases, a small amount of noise could be beneficial to QEVMC, as it could reduce the distance between the initial distribution generated by VQE and the target distribution.
.1 Related work
Quite a number of recent works have explored ways in which near-term quantum algorithms could accelerate classical approaches for finding low-energy states of quantum (or classical) systems based on Monte Carlo methods. For a very recent survey, see mazzola23 . We summarise these and how they compare with QEVMC in Table 1.
A standard approach for sampling from a desired probability distribution is the Markov chain Monte Carlo method known as the Metropolis-Hastings algorithm. This algorithm produces samples from a desired probability distribution by repeatedly sampling from a proposal distribution that depends on the current state, and accepting or rejecting the sample based on a certain rule. Layden et al. layden22 propose replacing these samples with quantum samples, where for some symmetric unitary . Based on numerical and experimental results, and theoretical intuition, they argue that this should lead to an algorithm which mixes more rapidly to the target distribution than classical proposals. Layden et al. apply their algorithm to producing samples from the Boltzmann distribution of classical Ising models. Attractive aspects of their approach are that it requires relatively simple quantum circuits and should be quite robust to errors experienced by the quantum computer. However, their method requires many rounds of communication with the quantum computer, as each new step of the algorithm requires to be applied to a different computational basis state. By contrast, the method proposed here relies only on the use of one set of samples from the quantum computer, which can even be produced “offline” in advance.
A central concept in quantum Monte Carlo methods in general is the trial state , which is intended to approximate the ground state at the end of the algorithm. In VMC, the parameters of are chosen using an optimisation algorithm, whereas in projector quantum Monte Carlo, the trial state is intended to approximate the state corresponding to time-evolving the initial state for various imaginary times .
Huggins et al. huggins22 proposed to use a quantum computer to generate trial states in projector QMC from an ansatz not accessible classically. Using these trial states within the QMC framework requires approximately computing amplitudes using a quantum computer, to small relative error. Achieving a sufficiently small error may require a large, and even exponential, number of measurements mazzola22 , although this question is delicate and may depend on which variant of QMC is used lee22response . The approach of huggins22 initially required either the use of a quantum computer iteratively at each stage of the algorithm, or exponentially costly classical processing, but the classical processing cost with offline access to the quantum computer was improved to polynomial by Wan et al. wan23 . Xu and Li xu22 presented a related approach, also based on quantum trial states, with an explicit application to accelerating VMC. Their approach also requires approximate quantum computation of amplitudes, and needs a new quantum circuit to be executed for each trial state.
Y. Zhang et al. zhang22 developed an alternative approach to accelerating the variant of projector quantum Monte Carlo known as FCIQMC. A key issue afflicting this method is the presence of the sign problem (“non-stoquasticity” of the Hamiltonian; a stoquastic Hamiltonian is one where all off-diagonal entries are real and non-positive). Y. Zhang et al. suggest the use of a quantum circuit produced using VQE to approximately diagonalise the Hamiltonian, such that the sign problem is mitigated. Their method requires the use of at each step of the QMC algorithm to estimate entries of the transformed Hamiltonian.
S.-X. Zhang et al. zhang22a proposed the use of VQE combined with a neural network, where the neural network is used to effectively implement a nonunitary operation acting on the state produced via VQE, and expectations of desired operators are estimated via a similar approach to that used in VMC. Their method jointly optimises over the VQE parameters and the neural network parameters, involves modifying the quantum circuit to be executed compared with the original VQE circuit, and seems to require estimating probabilities up to small relative error, in order to accurately compute a ratio of terms.
Bennewitz et al. bennewitz22 developed the concept of “neural error mitigation” (NEM), whereby a neural quantum state (NQS) ansatz is used to improve the energy produced by a quantum circuit via VQE. Similarly to quantum-enhanced VMC, their approach requires only samples from measurements on the quantum state that can be stored offline. Their method is based on training the weights in the NQS such that the corresponding distribution matches the distribution produced via VQE, as far as possible, as an initial step before continuing the VMC optimisation process. This is unlike the approach proposed here, where the distribution produced by VQE is used directly as input to an MCMC algorithm. Indeed, in some cases, NQS sampling can be performed directly, without the need for MCMC.
A similar approach of pre-training NQS weights was used in the context of data from a Rydberg atom experiment (as opposed to data generated by a quantum computer running VQE), by Czischek et al. czischek22 and Moss et al. moss23 . These works show that training NQS weights based on experimental data can reduce convergence time in VMC optimisation (as opposed to reducing MCMC convergence time, which is our primary focus here).
Finally, Yang, Lu and Li yang21 have proposed a hybrid quantum Monte Carlo algorithm for simulating time-dynamics with lower quantum circuit complexity than standard quantum algorithmic techniques.
I Variational Monte Carlo
We begin by reviewing the VMC approach. Imagine that we would like to find the ground state of a Hamiltonian on qubits. The VMC framework assumes efficient access to the following:
-
1.
The ability to sample from an initial distribution on ;
-
2.
A mixer (Markov chain on );
-
3.
The ability to compute amplitudes , perhaps up to an overall normalising constant. Here is one of a family of states parametrised by a vector .
We can use these tools to sample from the distribution , where , via the Metropolis-Hastings algorithm. This algorithm proceeds as follows:
-
1.
Sample .
-
2.
Pick a new configuration from a proposal distribution .
-
3.
Accept the new configuration with probability
-
4.
Go to step 2.
One can prove that (under weak conditions on ) eventually this algorithm produces samples from the distribution up to arbitrary precision. This procedure has two downsides:
-
•
Samples following the first sample are correlated, with samples taken at close times experiencing higher levels of correlation. To avoid this issue, one can discard samples in between the first sample and subsequent ones retained.
-
•
It can take many steps of the random walk to converge to the desired distribution . This is particularly likely to be an issue if is far away from .
Note that all we needed to execute the algorithm is the ability to produce samples from , and evaluate probabilities up to an overall scaling constant. In particular, we did not need to be able to sample from (which is what we were aiming to do), or to evaluate the normalising constant .
Once we have samples from , we can compute observables , using
The quantity , called the local energy in the case where , can be computed efficiently for many operators (e.g. if is a sum of a small number of Pauli matrices). Thus, averaging the local energy over samples from gives an approximation of . Given that this expression is a ratio of two terms involving , does not need to be normalised.
The overall VMC framework then optimises over variational parameters to find a state whose energy with respect to is minimised.
II Quantum-enhanced variational Monte Carlo
In VMC, the initial distribution is taken to be a “simple” distribution which is related to the desired ground state. For example, a uniform distribution (for a spin system), or a Slater determinant (for a fermionic system). Here we propose an approach which we call quantum-enhanced variational Monte Carlo (QEVMC), where these initial samples are replaced with samples from a quantum state prepared using VQE. The rest of the VMC algorithm remains unchanged. In particular, these initial samples can be produced by an experiment using a quantum computer, and then stored offline until they are used in VMC.
The intuition for why this could be advantageous is as follows. The quantum state generated using VQE should have a higher fidelity with the true ground state of than the initial state used in VMC. Therefore, it should take fewer steps to reach the ground state distribution (if one could compute its amplitudes) than starting with the VMC initial state. In VMC, we do not aim to reach the true ground state, but a (variational) approximation. But if this approximation is close to the true ground state, achieving high fidelity with the ground state implies high fidelity with the approximation.
One can make this argument more rigorous as follows. Define the -divergence between distributions and as
Let be an ergodic Markov chain with stationary distribution . Then, given a sequence of distributions , where is produced by applying one step of to , we have fill91
where denotes the second largest eigenvalue of . This implies that, in order to achieve , it is sufficient to take
where is the relaxation time of . This is not straightforward to compute as it depends on the probability of acceptance in the Metropolis-Hastings algorithm.
The -divergence can be related to the fidelity between the corresponding quantum states and obtained by taking the square roots of the probabilities via Jensen’s inequality, which shows that
and hence . This is a lower bound (as opposed to an upper bound), and only holds if and have the same phase for every amplitude, but it is still suggestive: in order to obtain a small -divergence, one needs to have a high fidelity. On the other hand, if the fidelity between the starting state and the desired final distribution is small (for example, exponentially small) we will obtain a high -divergence and expect a long mixing time.
One situation where an initial distribution produced by VQE could outperform an initial distribution produced classically is where , and , for some . Then we would expect a speedup by a factor of . A more significant speedup would be obtained if – corresponding to the VQE state having fidelity with the VMC state – where the expected speedup would be a factor of . These theoretical bounds only provide intuition; the speedups achieved in practice could be better (or worse).
III Results
We apply QEVMC to two well-studied models in condensed matter physics: the Fermi-Hubbard model, using the Gutzwiller wave function ansatz yokoyama87 , and the Ising model with transverse field, using neural network quantum states carleo17 .
III.1 Fermi-Hubbard model
We aim to find the ground state of instances of the Fermi-Hubbard model,
where and the sum is over sites in a rectangular lattice. This model has been extensively used as a benchmark for both classical and quantum variational methods yokoyama87 ; Cade2020 ; Stanisic2021 .
A variational ansatz which is frequently used in VMC is the Gutzwiller wave function gutzwiller63 ,
where is a Slater determinant corresponding to the ground state of the hopping part of , and . The intention behind this ansatz is to penalise basis states with high double occupancy, which will receive a large energy penalty from the onsite part of . Amplitudes of can be evaluated efficiently classically, and to produce this wave function in the VMC framework, it is natural to use as initial state the Slater determinant , whose corresponding distribution can be sampled from directly. As a mixer, one can use the random walk which moves a randomly chosen electron from one site to a neighbouring site yokoyama87 . Computationally, this corresponds to updating the bitstring by flipping a neighbouring pair of bits from 01 to 10 (or vice versa) within one spin sector.
Here we initially applied QEVMC to the Gutzwiller wavefunction for system sizes that are small enough to be simulated exactly classically, and which are also accessible to quantum computing experiments. This enabled us to carry out a full analysis and comparison of the performance of the algorithm.
We applied QEVMC to experimental data that had already been generated in experiments applying VQE to the Fermi-Hubbard model on quantum hardware Stanisic2021 . These experiments optimised over the family of quantum circuits known as the Hamiltonian variational ansatz Wecker2015 to find good circuits for preparing approximate ground states of the Fermi-Hubbard model. Although in some cases the fidelity of the state produced with the true ground state was relatively low, qualitative physical features of the ground state were nevertheless reproduced Stanisic2021 . In this work we focus on three examples from Stanisic2021 : the Fermi-Hubbard model with two variational layers; the Fermi-Hubbard model with one variational layer; and the Fermi-Hubbard model with one variational layer. These are all instances where more variational layers would be required to achieve a high-fidelity approximation to the ground state. In all cases we take and work at half-filling.
First, we looked at the accuracy of the algorithm as it proceeds, for a particular choice of Gutzwiller parameter which approximately minimises the energy ( for , for , for ). We measured the accuracy via the total variation distance from the desired probability distribution, and the error in the energy.
The initial distributions that we compared were:
-
•
Slater determinant ( ground state), the standard starting distribution for this method;
-
•
Theoretical VQE distributions obtained via classical simulation;
-
•
Experimentally obtained distributions, taking advantage of error mitigation via postselection on occupation number, and averaging over time-reversal and reflection symmetries of the Fermi-Hubbard model Stanisic2021 .
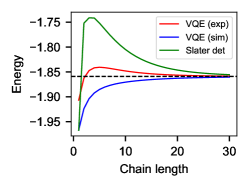
The results are shown in Figures 1, 2 and 3. One can see that in all cases, starting with the VQE distribution does lead to convergence to the desired distribution. Also, in the cases of the experimental results, and all of the simulated results, the distributions obtained by starting with the VQE distribution have a lower total variation distance throughout the algorithm. However, the experimental results do not achieve a lower total variational distance throughout the whole algorithm. In the and cases, the final energies obtained by VMC are lower than the energies achieved by the VQE distribution alone (which are and , respectively, for the experimental distributions Stanisic2021 ). Note that the local energy reported at the start of the VMC algorithm is not necessarily an accurate reflection of the energy achieved by the VQE distribution.
We additionally measured the speedup that would be obtained via VQE, by measuring the number of steps of the Metropolis algorithm that are required to achieve a given total variation distance level, when starting with a Slater determinant, vs the VQE initial distribution. The results are shown in terms of the ratio between the number of steps taken by QEVMC, vs. the number of steps taken when starting with a Slater determinant. Here we found that the simulated VQE distributions achieve a significant speedup (e.g. up to for ). The experimental distribution achieves a speedup up to , but there is little speedup obtained in the and experiments.
In the above experiments, in order to exactly determine the performance of the various VMC starting distributions, we directly implemented the corresponding stochastic matrix multiplication, which is inherently inefficient for large problem sizes. We additionally implemented the true VMC method as described in Section I. In addition to providing a check on the performance of the algorithm in practice, this enabled us to use the VQE distribution within VMC for problem sizes beyond the capacity of classical exact diagonalisation.
To demonstrate this, we considered Fermi-Hubbard instances for , corresponding to problems on up to 96 qubits. We use the VQE distribution for Fermi-Hubbard to generate initial samples from this distribution by concatenating independent samples, and aim to sample from a distribution corresponding to a state with the same Gutzwiller parameter as in (). The results are shown in Figure 4. One can see that even for significantly larger problem sizes than are accessible directly on the quantum computer, use of the VQE initial distribution enables convergence to the target energy within a reasonable number of steps, and in some cases apparently faster than using a Slater determinant. Intriguingly, in the case of the system, use of the experimental VQE distribution seems to give the fastest convergence. However, given that the total variation distance to the desired distribution is not accessible for large system sizes, it is unclear whether this effect would persist across a wide range of other observables.
III.2 Ising model with transverse field
Here we aim to find the ground state of the 1D Ising model with transverse field (TFI),
where is the number of lattice sites, , and we assume open boundary conditions (OBC) unless specified otherwise.











A successful ansatz for this model is the neural network quantum state (NQS) ansatz proposed by Carleo and Troyer carleo17 and given as
where is a computational basis state, is the bitstring which denotes that basis state, and the coefficients are defined as
where , and corresponds to hidden variables. The set of weights are the parameters we optimize to find the closest NQS to the ground state of some given Hamiltonian. As in the original paper carleo17 , we are adding only a single hidden layer to the NQS, therefore we use the traced out expression giving the simplified equation for any bitstring ,
where . While generally the weights for the NQS ansatz are complex-valued, motivated by the solutions for the TFI model on 40 and 80 qubits in carleo17 which are real-valued, we take them to be real-valued, halving the parameter search space on this problem. We examine three regimes. Taking , we have , with being the critical phase-transition point, and we use the number of nodes in the hidden layer to be with . The data presented in the paper here is for unless otherwise specified, however the results for and were not qualitatively different.
To find the NQS that best describes the ground state of TFI model, the algorithm requires us to first run an optimization over the NQS weights (), minimizing the expected energy of the NQS with respect to the TFI Hamiltonian. The standard algorithm used for this optimization is the stochastic reconfiguration (SR) algorithm Sorella1998 ; Sorella2007 . The initial NQS for this optimization is chosen by selecting random weights. Then MCMC is used to acquire the necessary sample distribution and calculate the expected energy values of the NQS at each iteration of the optimization algorithm. The initial distribution is taken to be a uniform distribution, and single spin flip is used as a mixer. This corresponds to updating the bitstring by flipping a single spin chosen at random from to (or vice versa). Each bitstring is updated independently (this corresponds to running the MC algorithm many times from different initial bitstrings randomly chosen from the initial distribution to acquire the bitstring from the final distribution). Given this final distribution of samples at each iteration of SR, to calculate the expected energy we calculate the local energy of the samples. This is given as
where is the full wavefunction NQS describes, and is a given bitstring sample from the final distribution. We then take the average of these local energy estimates for the final energy estimate.
We investigate here a potential speed-up using an already known VQE distribution as the initial distribution for the Monte Carlo procedure. The impact of this could be two-fold. For an already known NQS which describes the ground state of a Hamiltonian, we could speed up the mixing time from the initial distribution to the NQS distribution. If the NQS is not known, the overall number of iterations the SR procedure needs to take to a given error could offer a speed-up, therefore needing a smaller number of samples overall.
To generate the VQE distribution we use the Hamiltonian Variational ansatz using an all plus state as the initial state. To generate the Hamiltonian Variational ansatz, we split up the TFI Hamiltonian into even terms, odd terms, and the the single qubit transverse field terms. In a single layer of the ansatz we first apply all the even term gates parameterized by a single parameter, then odd terms parameterized by another parameter, and finally all the field terms which have a third parameter. Therefore each layer of VQE uses three parameters, and we find optimal VQE states using the BFGS algorithm for a set number of layers. We examine solutions up to four layers as we would like the states produced by VQE not to approximate the ground state too well.
We consider a few different system sizes, similarly to the Fermi-Hubbard model. We examine various aspects of the speed-up for a spin system via exact calculations and we then examine a spin system with the true VMC method. Finally, we also look at spin system using the NQS that was found in the original work carleo17 as approximate ground states of the TFI model to examine potential speed-up by concatenating independent samples from the VQE distribution for a -spin system.
To examine potential speed-up the VQE distribution gives to the MCMC for a known NQS, we first find good NQS states using the stochastic reconfiguration algorithm with a fixed number of iterations. We use 200 iterations for . At each iteration, to estimate the energy of the NQS at the current iteration, we use samples from the initial distribution (here, uniform) and take the last state of the Markov chain of length / for system size /. We estimate the final energy by using the average of local energy estimate from the last five iteration, getting the relative energy errors wrt to the ground state energy to be less than for demonstrating good agreement with the ground state energy.
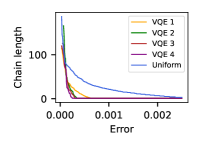
As we now have a good representation of the ground state as an NQS, we can inspect the difference in mixing time between VQE and the uniform distribution, using a similar approach to the small Fermi-Hubbard instances considered above. For the spin system, we can calculate the exact total variation distance (TVD) of the proposed distribution to the desired NQS distribution as a function of the number of steps of the Markov chain. We can also calculate the length of the Markov chain needed to achieve a specific relative energy error (wrt the NQS energy) as well as to achieve a specific TVD (to the NQS distribution). We then compare performance of these different distributions, by comparing the length of MC chain needed to achieve a specific TVD taking the uniform distribution as the baseline. We can see some of the results in Figure 5.
Similarly, for the spin system, we no longer easily have access to exact values, but we can look at energy estimates reached at different points in the Markov chain, and compare the errors of the distributions. For some of the results, refer to Figure 6 (for this specific result we run the SR algorithm slightly longer, for iterations and get a relative energy error with ground state energy to be 0.0017). We can see that in the case of spin system with , there is a speed-up of up to times when using a four layer VQE state compared to the uniform distribution. For the spin system with , we see a speed-up of up-to times when using a one layer VQE state compared to the uniform distribution.






Next, we can also examine the case of - and -spin systems in a similar manner to the spin system, using the NQS results from carleo17 . Here we use samples generated by -spin systems with open boundary conditions (OBC), while the NQS from carleo17 is for systems with periodic boundary conditions (PBC). While one could consider running VQE for -spin systems with PBC, we hypothesize that OBC are more likely to give good results due to how the two distributions are stitched together (specifically, there is no need for correlation between the first and the 20th spin). Here, the initial samples were drawn independently from the -spin VQE distribution and combined to give an initial sample for the larger system. It is an open question whether alternative ways to piece different distributions together given the physics of the model could offer better speedups. We look at the behaviour of the relative energy error over a chain of length with samples taken for the energy estimate. Results can be seen in Figure 7. We can see from the Figure that even though the VQE distribution was acquired on a smaller system, it allows for speedups on larger systems, and the speedup scales up for a larger system size ( vs spins).



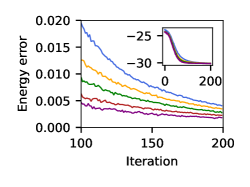
Finally, we will want to see if it is possible to speed-up running of the SR algorithm by using VQE distribution instead of uniform distribution as the starting distribution for the MCMC at each iteration of the SR algorithm. We will make this comparison by comparing the number of SR iterations we need to achieve the same relative error using different distributions. We first have to make sure that the length of the MCMC used before when running the SR algorithm is indeed suitable for these various distributions. We visually inspect the length of chain needed for a randomly chosen NQS target distribution to be approximated given as initial distribution various VQE generated distributions compared to the uniform distribution. We find that after to steps, there is a qualitative agreement between the distributions for the settings inspected here ( qubits and ; in the case of qubits, the number of steps is even lower). So fixing as before the MCMC length to at each iteration of the SR algorithm (taking samples), we find that the VQE distribution as the initial distribution to mix towards the NQS distribution gives improvement over uniform distribution in the case of qubits at various , see Figure 8, with more VQE layers allowing for higher speedup.


III.3 Origin of the QEVMC speedup
It is a natural question whether one can pin down the origin of the speedup achieved by QEVMC. Given that the mixer is unchanged compared with the standard Metropolis-Hastings algorithm, there are two plausible possibilities for how this speedup is achieved:
-
1.
The initial distribution produced by VQE is closer to the target distribution (so fewer steps are required to reach it);
-
2.
The acceptance rate of MCMC steps is higher when starting with the VQE distribution (so more of the steps make progress towards the target distribution).
In Figure 9 we present evidence that the second option is not the case, by showing that the average acceptance rate is lower for QEVMC for both the Fermi-Hubbard model and TFIM, albeit not substantially. This suggests that the first option is likely to be the correct explanation for the acceleration achieved by QEVMC.


IV Discussion
We have shown that QEVMC can outperform standard classical VMC in terms of convergence speed to the target distribution. Whether this advantage translates into a genuine speed improvement in practice depends on a number of factors, including the clock speed of the quantum computer and the behaviour of the MCMC algorithm. For example, the level of correlation considered to be acceptable in samples generated following the first sample from the target distribution affects the gap that must be left between subsequent samples that are kept, and the level of speedup available to the quantum algorithm. Chains which require a long “burn in” time to sample from the target distribution are the most promising candidates to achieve a significant quantum speedup.
An interesting follow-up question in the setting of our NQS results could be regarding the performance of an adaptive algorithm where the length of the chain and the number of samples changes as we get closer to the ground state. As a marker of this proximity to the ground state, one could use the variance of the local energy estimate. Since the VQE distribution gives an increasing boost in performance as the NQS becomes closer to the ground state description, in such an adaptive algorithm, one would expect the VQE distribution to give further speedups over the uniform distribution.
Several works have proposed the use of experimental quantum states or those generated via VQE to train weights in a NQS ansatz bennewitz22 ; czischek22 ; moss23 , and it has been shown that this procedure can reduce the cost of VMC optimisation czischek22 ; moss23 . It would be interesting to compare the performance improvements that can be obtained via this approach with the MCMC convergence speedups achieved here.
An alternative approach to the use of QEVMC is to generate the VMC target distribution directly on a quantum computer. For example, algorithms are known for constructing the Gutzwiller wave function murta21 ; seki21 whose quantum circuit depth is not substantially greater than that of preparing the Slater determinant . However, these algorithms are based on the use of postselection, so may require many runs of the corresponding quantum circuit to prepare the desired state. This state could then be used as initial distribution for VMC, in a similar way to QEVMC. This could be advantageous in the realistic scenario that noise in the quantum circuit leads to errors in the state prepared. Then VMC would enable the generation of samples arbitrarily close to the target distribution.
The simple structure of the QEVMC algorithm opens up a use case for near-term quantum computers, where samples from a classically intractable distribution are produced and stored for later use as input to a classical algorithm. We expect that other applications of this concept may be found.
Acknowledgements
We would like to thank M. Schuyler Moss for pointing out references bennewitz22 ; czischek22 ; moss23 , Jan Lukas Bosse and Lana Mineh for their work on the VQE implementation used in this project, and the rest of the Phasecraft team for helpful comments on this work. This project has received funding from the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (grant agreement No. 817581).
References
- (1) A. Peruzzo, J. McClean, P. Shadbolt, M.-H. Yung, X.-Q. Zhou, P. J. Love, A. Aspuru-Guzik, and J. L. O’Brien. A variational eigenvalue solver on a photonic quantum processor. Nature Communications, 5(1):4213, 2014.
- (2) S. Sorella. Wave function optimization in the variational monte carlo method. Phys. Rev. B, 71:241103, Jun 2005.
- (3) H. Yokoyama and H. Shiba. Variational monte-carlo studies of hubbard model. i. Journal of the Physical Society of Japan, 56(4):1490–1506, 1987.
- (4) T. Giamarchi and C. Lhuillier. Phase diagrams of the two-dimensional hubbard and t-j models by a variational monte carlo method. Phys. Rev. B, 43:12943–12951, Jun 1991.
- (5) G. Carleo and M. Troyer. Solving the quantum many-body problem with artificial neural networks. Science, 355(6325):602–606, 2017.
- (6) M. C. Gutzwiller. Effect of correlation on the ferromagnetism of transition metals. Phys. Rev. Lett., 10:159–162, Mar 1963.
- (7) K. Choo, A. Mezzacapo, and G. Carleo. Fermionic neural-network states for ab-initio electronic structure. Nature Communications, 11(1):2368, 2020.
- (8) T. Zhao, S. De, B. Chen, J. Stokes, and S. Veerapaneni. Overcoming barriers to scalability in variational quantum monte carlo. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, SC ’21, New York, NY, USA, 2021. Association for Computing Machinery.
- (9) D. Layden, G. Mazzola, R. V. Mishmash, M. Motta, P. Wocjan, J.-S. Kim, and S. Sheldon. Quantum-enhanced markov chain monte carlo, 2022.
- (10) W. J. Huggins, B. A. O’Gorman, N. C. Rubin, D. R. Reichman, R. Babbush, and J. Lee. Unbiasing fermionic quantum monte carlo with a quantum computer. Nature, 603(7901):416–420, 2022.
- (11) K. Wan, W. J. Huggins, J. Lee, and R. Babbush. Matchgate shadows for fermionic quantum simulation, 2023.
- (12) X. Xu and Y. Li. Quantum-assisted monte carlo algorithms for fermions, 2022.
- (13) Y. Zhang, Y. Huang, J. Sun, D. Lv, and X. Yuan. Quantum computing quantum monte carlo, 2022.
- (14) S.-X. Zhang, Z.-Q. Wan, C.-K. Lee, C.-Y. Hsieh, S. Zhang, and H. Yao. Variational quantum-neural hybrid eigensolver. Phys. Rev. Lett., 128:120502, Mar 2022.
- (15) E. R. Bennewitz, F. Hopfmueller, B. Kulchytskyy, J. Carrasquilla, and P. Ronagh. Neural error mitigation of near-term quantum simulations. Nature Machine Intelligence, 4(7):618–624, 2022.
- (16) S. Czischek, M. S. Moss, M. Radzihovsky, E. Merali, and R. G. Melko. Data-enhanced variational monte carlo simulations for rydberg atom arrays. Phys. Rev. B, 105:205108, May 2022.
- (17) M. S. Moss, S. Ebadi, T. T. Wang, G. Semeghini, A. Bohrdt, M. D. Lukin, and R. G. Melko. Enhancing variational monte carlo using a programmable quantum simulator, 2023.
- (18) G. Mazzola. Quantum computing for chemistry and physics applications from a monte carlo perspective, 2023.
- (19) G. Mazzola and G. Carleo. Exponential challenges in unbiasing quantum monte carlo algorithms with quantum computers, 2022.
- (20) J. Lee, D. R. Reichman, R. Babbush, N. C. Rubin, F. D. Malone, B. O’Gorman, and W. J. Huggins. Response to "exponential challenges in unbiasing quantum monte carlo algorithms with quantum computers", 2022.
- (21) Y. Yang, B.-N. Lu, and Y. Li. Accelerated quantum monte carlo with mitigated error on noisy quantum computer. PRX Quantum, 2:040361, Dec 2021.
- (22) J. A. Fill. Eigenvalue bounds on convergence to stationarity for nonreversible Markov chains, with an application to the exclusion process. The Annals of Applied Probability, 1(1):62–87, 1991.
- (23) C. Cade, L. Mineh, A. Montanaro, and S. Stanisic. Strategies for solving the Fermi-Hubbard model on near-term quantum computers. Physical Review B, 102(23):235122, 2020.
- (24) S. Stanisic, J. L. Bosse, F. M. Gambetta, R. A. Santos, W. Mruczkiewicz, T. E. O’Brien, E. Ostby, and A. Montanaro. Observing ground-state properties of the Fermi-Hubbard model using a scalable algorithm on a quantum computer, 2021.
- (25) D. Wecker, M. B. Hastings, and M. Troyer. Progress towards practical quantum variational algorithms. Phys. Rev. A, 92(4):042303, 2015.
- (26) S. Sorella. Green function monte carlo with stochastic reconfiguration. Physical Review Letters, 80(20):4558–4561, 1998.
- (27) S. Sorella, M. Casula, and D. Rocca. Weak binding between two aromatic rings: Feeling the van der Waals attraction by quantum Monte Carlo methods. The Journal of Chemical Physics, 127(1):014105, 07 2007.
- (28) B. Murta and J. Fernández-Rossier. Gutzwiller wave function on a digital quantum computer. Phys. Rev. B, 103:L241113, Jun 2021.
- (29) K. Seki, Y. Otsuka, and S. Yunoki. Gutzwiller wave function on a quantum computer using a discrete hubbard-stratonovich transformation. Phys. Rev. B, 105:155119, Apr 2022.