Accelerating Magnetic Resonance Mapping Using Simultaneously Spatial Patch-based and Parametric Group-based Low-rank Tensors (SMART)
Abstract
Quantitative magnetic resonance (MR) mapping is a promising approach for characterizing intrinsic tissue-dependent information. However, long scan time significantly hinders its widespread applications. Recently, low-rank tensor models have been employed and demonstrated exemplary performance in accelerating MR mapping. This study proposes a novel method that uses spatial patch-based and parametric group-based low-rank tensors simultaneously (SMART) to reconstruct images from highly undersampled k-space data. The spatial patch-based low-rank tensor exploits the high local and nonlocal redundancies and similarities between the contrast images in mapping. The parametric group-based low-rank tensor, which integrates similar exponential behavior of the image signals, is jointly used to enforce multidimensional low-rankness in the reconstruction process. In vivo brain datasets were used to demonstrate the validity of the proposed method. Experimental results demonstrated that the proposed method achieves 11.7-fold and 13.21-fold accelerations in two-dimensional and three-dimensional acquisitions, respectively, with more accurate reconstructed images and maps than several state-of-the-art methods. Prospective reconstruction results further demonstrate the capability of the SMART method in accelerating MR imaging.
mapping, fast imaging, low-rank tensor, patch
1 Introduction
Quantitative magnetic resonance (MR) (the spin lattice relaxation time in the rotating reference frame)[1] is a promising approach for characterizing intrinsic tissue-dependent information. It has been used as a novel contrast mechanism in many biomedical applications, including the musculoskeletal system[2], brain[3, 4], liver[5, 6], intervertebral discs[7], and cardiovascular imaging[8], to assess early macromolecular changes rather than conventional morphological imaging. However, MR mapping requires acquiring multiple images with different spin-lock times (TSLs). The resulting long scan time significantly hinders its widespread clinical application. Parallel imaging is the most used acceleration method for MR mapping, but it has a limited acceleration factor, usually approximately 2[9]. Compressed sensing (CS) [10, 11, 12] utilizing sparsifying priors has been applied in fast MR parametric mapping to achieve higher acceleration factors. However, the scan time of MR mapping must be further shortened to facilitate clinical use.
In recent years, the low-rankness of the matrix has achieved promising results in accelerating MR parametric mapping by exploiting the anatomical correlation between contrast images globally or locally[13, 14, 15, 16]. Compared with conventional MR images, the contrast images in parametric mapping contain redundant information across the spatial domain and are highly correlated along the temporal dimension. As an extension of the matrix, the high-order tensor can capture the data correlation in multiple dimensions[17] beyond the original spatial-temporal domain. The sparse representation of multidimensional image structures can be effectively exploited using a high-order tensor[18, 19, 20, 21]. Therefore, high-order tensor models have been applied in many medical imaging applications and can accelerate high-dimensional magnetic resonance imaging (MRI), such as cardiac imaging[22, 21, 23, 24, 25], simultaneous multiparameter mapping[4], and functional magnetic resonance imaging[26]. Most of these methods globally construct a tensor by directly using the entire multidimensional image series as a tensor. The sparsity of the tensor, which usually relies on the sparsity of the core tensor coefficients, is modeled as a regularization to enforce global low-rankness using a higher-order singular-value decomposition (SVD). However, global processing jointly treats multiple tissues of different types, which may lead to residual artifacts that can be ameliorated by local processing[13, 21]. Like group sparsity[27, 28], a high-order tensor can be constructed in a patch-based local manner. Image patches with high correlation in the neighborhood are extracted and rearranged to form local tensors. Patch-based low-rank tensor reconstruction using the local processing approach has been demonstrated to outperform low-rank tensor reconstruction globally[21, 17, 24, 25, 26].
The signal evolution in quantitative MRI exhibits a low-rank structure in the temporal dimension that can be exploited to construct a low-rank Hankel matrix[29, 30] to shorten the scan time further. It differs from the spatial low-rankness that processes the entire image[13, 14, 31]; and the Hankel low-rank approximation treats the signal at each spatial location independently. Recently, k-space low-rank Hankel tensor completion approaches have demonstrated the suitability and potential of applying tensor modeling in the k-space of parallel imaging[32, 33]. The block-wise Hankel tensor reconstruction method[33] was proposed by organizing multicontrast k-space datasets into a single block-wise Hankel tensor, which exploits the multilinear low-rankness based on shareable information in datasets of identical geometry. Motivated by this block-wise Hankel tensor method, tissues with equal parametric values can also be clustered in image space. Each Hankel matrix of the same tissue can be concatenated into a Hankel tensor, which exhibits significant low rankness based on high correlations in tissues of similar signal evolution.
This study proposes a novel and fast MR mapping method by exploiting low-rankness in both spatial and temporal directions. First, similar local patches were found and extracted from the images to form high-order spatial tensors using a block matching algorithm[34]. Second, assuming that the values of the same tissue are similar, signals were classified into different tissue groups through the histogram of the values. In each group, signal evolution in the temporal direction was used to construct the Hankel matrix, and all groups were cascaded to form a parametric tensor. Both the spatial and parametric tensors were utilized to reconstruct the contrast images from highly undersampled k-space data through high-order tensor decomposition (simultaneous spatial patch-based and parametric group-based low-rank tensor, (SMART)). We used quantitative mapping of the brain to evaluate the performance of the proposed method. Two-dimensional (2D) and three-dimensional (3D) -weighted images were undersampled with different acceleration factors to substantiate the suitability of SMART in improving the quality of fast mapping regarding several state-of-the-art methods.
2 Material and Methods
2.1 Notation
Scalars are denoted by italic letters (e.g., ). Vectors are denoted by bold lowercase letters (e.g., b ). Matrices are denoted by bold capital letters (e.g., B). Tensors of order three or higher are denoted by Euler script letters (e.g., ). Indexed scalar denotes the th element of third-order tensor . Operators are denoted by capital italic letters (e.g., ). is used to denote the adjoint operator of .
The mode- matricization (unfolding) of a tensor is defined as , arranging the data along the th dimension to be the columns of . The opposite operation of tensor matricization is the folding operation, which arranges the elements of the matrix into the th order tensor . Tensor multiplication is more complex than matrix multiplication. In this study, only the tensor -mode product[35] is considered, which is defined as the multiplication (e.g., ) of a tensor with a matrix in mode . Elementwise, we have , where . The -mode product can also be calculated by the matrix multiplication .
2.2 Measurement Model
Let be the -weighted image series to be reconstructed, where denotes the voxel number of the -weighted image, and is the number of TSLs. denotes the corresponding k-space measurement, where denotes the coil number. The forward model for mapping is given by
| (1) |
where denotes the measurement noise and denotes the encoding operator[36, 37] given by , where is the undersampling operator that undersamples -space data for each -weighted image. denotes the Fourier transform operator. denotes an operator which multiplies the coil sensitivity map by each -weighted image coil-by-coil. The general formulation for recovering from its undersampled measurements can be formulated as
| (2) |
where denotes the Frobenius norm, denotes a combination of regularizations, and is the regularization parameter.
In this study, the SMART reconstruction method assumes that the -weighted image series can be expressed as a high‐order low‐rank representation on a spatial patch-based tensor and a parametric group-based tensor (shown in Fig. 1). The problem in (2) can be formulated as a constrained optimization on the two high‐order low‐rank tensors.
2.3 Proposed Method
2.3.1 Spatial Tensor Construction
We use the block matching algorithm[38, 39] to extract similar anatomical patches for building a spatial patch-based tensor at each spatial location. can be expressed as a high-order low-rank representation on a patch scale. For a given reference patch ( , in 2D imaging and in 3D imaging ) centered at spatial location , let denote the patch selection operator that extracts a group of similar patches to from all time points and constructs a low-rank tensor from them, where denotes the number of similar patches. The process can be expressed as , and the adjoint operation places the patches back to their original spatial locations in the image.
The patch selection process is as follows. For the patch , it is compared with the other image patch based on the normalized -norm distance [34] with the exact formulation of the normalized mean-squared error as
| (3) |
is considered similar to when the distance is less than a predefined threshold . We compare the candidates within a specified search radius and limit the maximum similar patch number to to reduce the complexity. If more image patches are matched to , only the patches with the highest degree of similarity are involved in the group for further processing.
2.3.2 Parametric Tensor Construction
Similar to mapping in previous studies [29], the -weighted images in mapping can be expressed as follows:
| (4) |
where represents the proton density distribution, is the relaxation value of the th tissue component, represents the phase distribution, c indicates the spatial coordinate, is the th TSL, and is the number of linearly combined exponential terms, which is tissue-dependent. For instance, in the three-pool model of white matter, the white matter tissue is composed of a myelin water pool, myelinated axon water pool, and mixed water pool, yielding .
The signals from each voxel along the temporal direction can be used to form a Hankel matrix for (where denotes the spatial support of the tissue.)
| (5) |
with a low rank property (e.g., , where denotes the rank of matrix , and the theoretical proof can be found in [29]). The Hankel matrix is designed as square as possible, where is selected as the nearest integer greater than or equal to half the number of TSLs.
The parametric tensor is constructed using the tissue clustering method as follows: First, a map is estimated from the initial -weighted image reconstructed using zero-filling. A histogram analysis divides the map into groups. Each group is considered a group of signals belonging to one tissue category. According to linear predictability[29, 40], the signals from each voxel along the temporal direction can form a Hankel matrix. The Hankel matrices belonging to the same group are combined as a tensor from X. This can be expressed as , (), where denotes the number of pixels in each group, and denotes the parametric tensor construction operator.
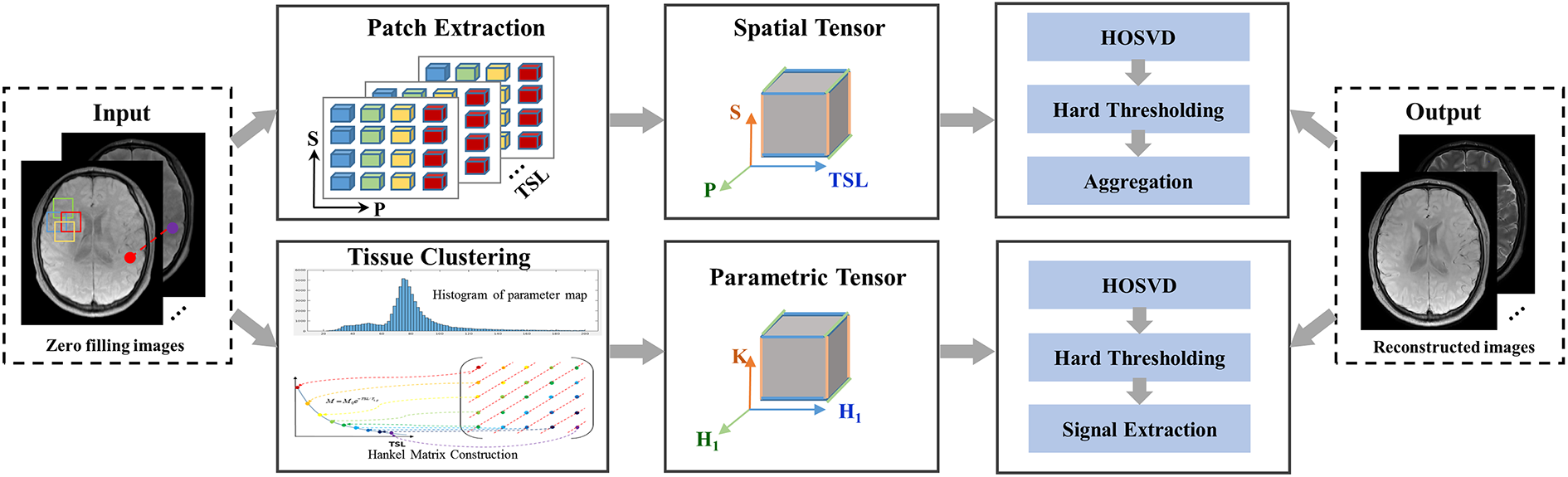
2.3.3 SMART Reconstruction Model
Based on the spatial and parametric tensors, we propose a novel method that simultaneously uses spatial patch-based and parametric group-based low-rank tensor through higher-order tensor decomposition. Let , and . -weighted images can be reconstructed from the undersampled k-space data by solving the following optimization problem:
| (6) |
where is the nuclear norm, and are the regularization parameters. As the operator is time-varying while the operator always extracts mask on the same locations, (6) can be transformed into the following formulation using the Lagrangian optimization scheme:
| (7) |
where and denote the penalty parameters, denotes the th iteration number, and and are the Lagrange multipliers. For simplicity, (7) can be rewritten as follows:
| (8) |
Equation (8) can be efficiently solved through operator splitting via the alternating direction method of multipliers (ADMM)[41] by decoupling the optimization problem into three subproblems:
Update on X (subproblem P1):
| (9) |
The solution X for problem (P1) can be effectively solved using the conjugate gradient (CG) algorithm[42]. Update on (subproblem P2):
| (10) |
Subproblem (P2) can be solved in three steps. First, higher-order singular-value decomposition (HOSVD) is applied to the tensor [21, 32, 43]. It decomposes into a core tensor and three orthonormal bases for the three different subspaces of the -mode vectors[35]:
| (11) |
where is an orthogonal unitary matrix obtained from the SVD of . The low-rank tensor approximation is typically performed by soft thresholding[44] the core tensor or truncating the core tensor and unitary matrices when the -mode ranks are known [26]. Moreover, while the use of hard thresholding only provides an approximate solution to the nuclear norm regularized optimization problem [43, 45, 46], we found that both solutions achieved similar performance in the proposed SMART algorithm. As one of the comparison methods (PROST) [45] in this study used hard thresholding in HOSVD, we also used hard thresholding for a fair comparison.
The low-rank tensor approximation effectively acts as a high-order denoising process, where the small discarded coefficients mainly reflect contributions from noise[43] and noise-like artifacts[32, 45]. An implementation of the HOSVD is shown in Algorithm 1 of the supplementary information. Second, the denoised tensors were rearranged to form the denoised patches. Finally, the image patches overlap can be combined by simple averaging (Fig. 1, “Aggregation”) to generate an estimated image.
Update on (subproblem P3):
| (12) |
Subproblem (P3) can also be solved in three steps. First, perform low-rank tensor approximation similar to the first step in solving subproblem (P2). Second, the image signals were extracted from the Hankel matrix from each horizontal slice of along the first dimension. Finally, an estimated image can be generated after repeating the above two steps for all parametric tensors.
Update on and :
| (13) |
| (14) |
An implementation of the SMART method is shown in Algorithm 2 of the supplementary information.
2.3.4 Space complexity analysis
The proposed SMART method consists of four components: solving the three sub-optimization problems P1, P2, and P3, and updating and . We analyze the above components to investigate their space complexity using the notation. Assume that the number of spatial tensors is , and the number of parametric tensors is . Solving subproblem (P1) is dominated by the CG algorithm with cost of [47]. Solving of subproblem (P2) is dominated by the HOSVD operation, which applies SVD to each mode of the spatial tensor, which costs . Similarly, solving of subproblem (P3) costs . Updating and costs . Therefore, the asymptotic space complexity of the SMART method is the upper bound of the space complexity of the above components.
2.4 Parameter Selection
The SMART method performance is affected by the parameters of the spatial and parametric tensor construction.These include patch size b, maximum similar patch number , normalized -norm distance threshold in the spatial tensor construction, and the group number in the parametric tensor construction. These parameters should be carefully tuned to obtain the best reconstruction performance.
2.5 Map Estimation
maps were obtained by fitting the reconstructed -weighted images with different TSLs pixel-by-pixel:
| (15) |
where denotes the baseline image intensity without applying a spin-lock pulse, and is the signal intensity for the kth TSL image. map was estimated using the nonlinear least-squares fitting method with the Levenberg–Marquardt algorithm[48] from the reconstructed -weighted images.
3 EXPERIMENT
3.1 Evaluation of the Tissue Clustering
Numerical phantom, real phantom, and in vivo experiments were performed to evaluate the tissue clustering method performance. All MR scans involved were performed on 3T scanners. The details of data acquisition are shown in the supplementary information and Table S1.
3.1.1 Numerical phantom dataset
The numerical phantom consisted of five vials (including 2809 pixels in each vial) with different values representing five brain regions: putamen, frontal white matter, genu corpus callosum, head of caudate nucleus, and centrum semiovale. The numerical phantom was simulated using a bi-exponential model [49, 50] with the following formula to mimic multi-component tissue:
| (16) |
where and are the long and short relaxation times, and are the fractions for these two components, respectively. For the five vials, the values were set as 77, 78, 79, 82, and 89 ms. The values were set as 18, 19, 20, 21, 22 ms, and was set as 0.6, according to the previous study[51]. The datasets were simulated with the matrix size = , and TSLs = 1, 20, 40, 60, and 80 ms.
3.1.2 Real phantom dataset
The phantom contained nine -doped agarose vials, with and values in the in vivo range (: 250 ms-1872 ms; : 42 ms-231 ms)[52]. -weighted images with TSLs = 1, 20, 40, 60, and 80 ms were acquired with ten averages, leading to a high signal-to-noise ratio (SNR) of the images. The exponential model of (15) was applied to obtain the map. Supplementary information Fig. S1(a-c) shows a -weighted image of the phantom at TSL = 40 ms, the map, and the estimated values of the nine vials, respectively.
3.1.3 In vivo dataset
One 2D brain dataset was collected from a volunteer with the same TSLs used in the phantom experiment. The average number was set as one, considering the long scan time.
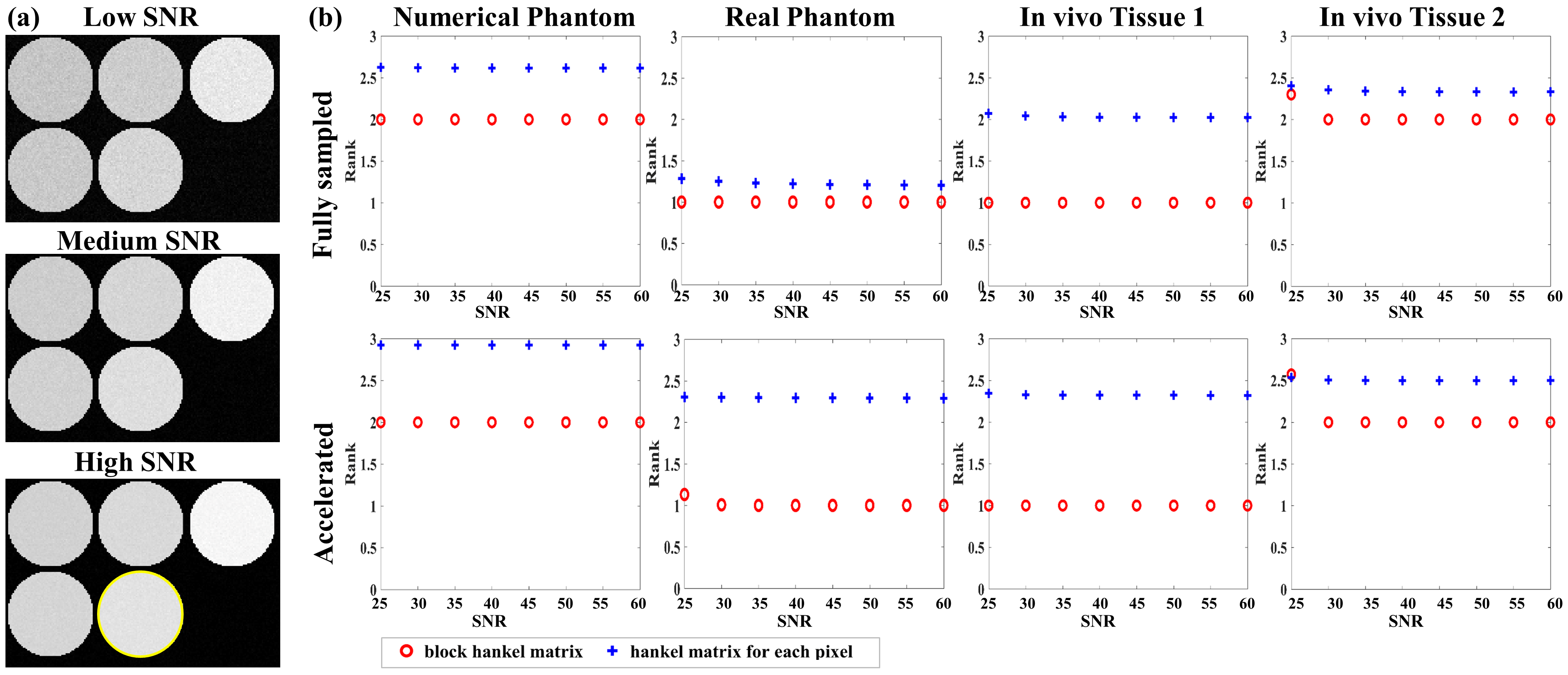
Complex Gaussian noise was added to the numerical, real phantom, and in vivo datasets with SNRs ranging from 25 to 60 with an increment of five. SNR was computed as the ratio between the average value of -weighted images and the standard deviation of the noise [15]. Two rank values were calculated for the images with different SNRs. One group consisted of the mean rank of all the Hankel matrices for each pixel in the region of interest (ROI).The other was the rank of a block Hankel matrix for a specific tissue. Let denote the Hankel matrix constructed from the pixels at a fixed location in the clustered tissue according to (5) (shown in Fig.1). The block Hankel matrix can be defined as , where denotes the total number of pixels in the clustered tissue.
The rank value was calculated using the SVD with a fixed singular-value threshold calculated as the product of an empirical ratio and the most significant singular value. The ratio was set as 0.03 for both groups. The Monte Carlo simulation was performed 1000 times for each SNR to reduce the noise bias on the rank value calculated.
The -space data were undersampled with acceleration factor (R) R = 4 for the numerical and real phantom datasets, and R = 6 for the in vivo dataset to analyze the effect of residual aliasing. Initial reconstructions of the undersampled data were obtained using the Sparse MRI method[11] and were used to calculate the rank value.
3.2 In Vivo Reconstruction Experiments
The proposed method was evaluated on the mapping datasets of the brain collected from six volunteers on 3T scanners[20, 53]. The local institutional review board approved the experiments, and informed consent was obtained from each volunteer. The details of data acquisition are shown in supplementary information and Table S1.
For the 2D datasets, the fully sampled k-space data were retrospectively (Retro) undersampled along the ky dimension using a pseudo-random undersampling pattern [54] with acceleration factors (R) = 4 and 6. For the 3D datasets, the fully sampled k-space datasets were retrospectively undersampled using Poisson disk random[55] patterns with R = 6.76 and 9.04. The sampling masks for each TSL were different. For the prospective (Pro) study , two 2D datasets were acquired from one volunteer (27 years old) with R = 4.48 and 5.76, respectively. Fully sampled data were also acquired as a reference in the prospective experiment.
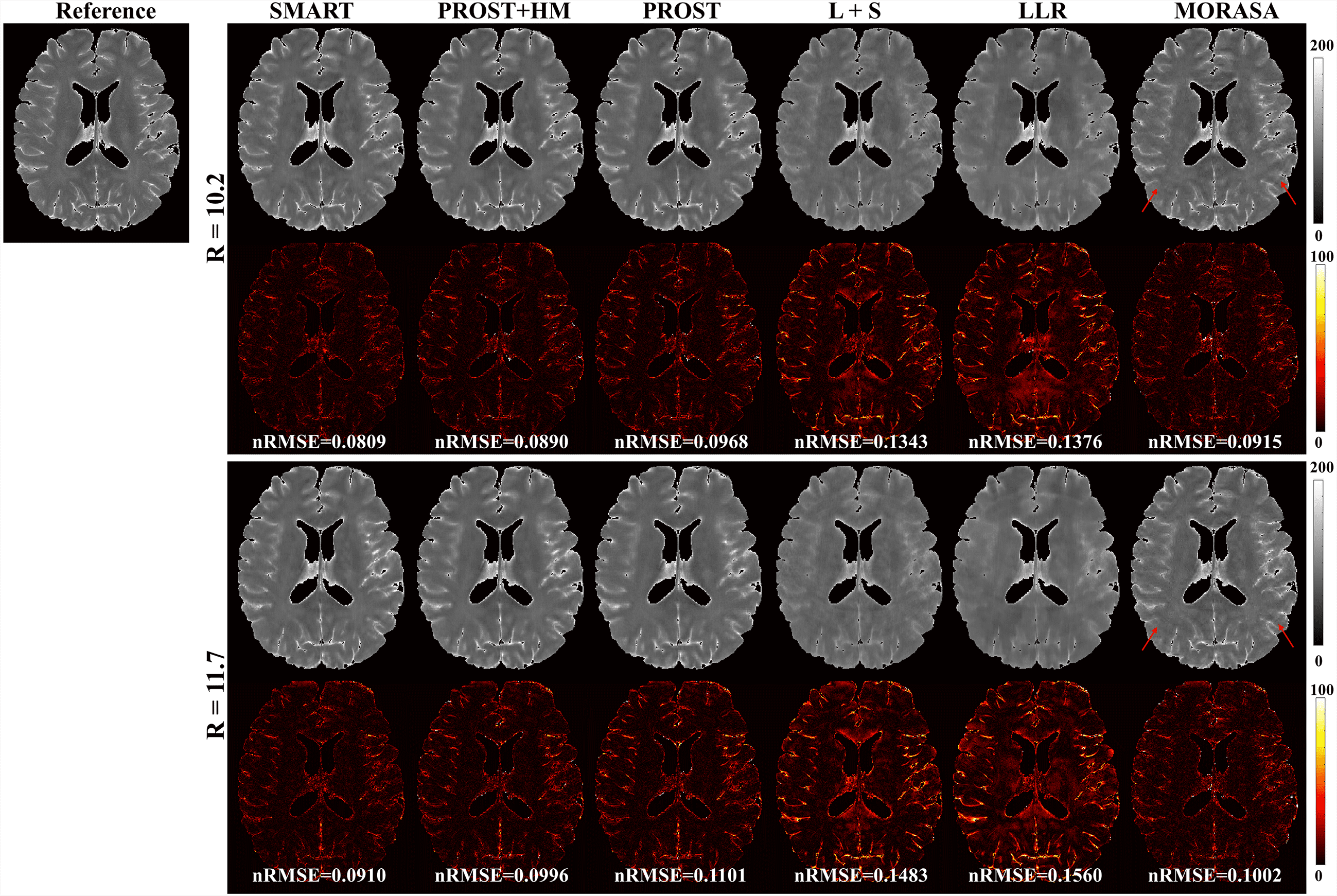
SMART and four state-of-the-art methods were used to reconstruct the undersampled k-space data. These methods include the high-dimensionality undersampled patch-based reconstruction method (PROST) [45] using the spatial patch-based low-rank tensor, low-rank plus sparse (L + S) method[36] enforcing the spatial global low-rank and sparsity of the image matrix, locally low-rank method (LLR)[13] using the spatial patch-based low-rank matrix, and model-driven low rank and sparsity priors method (MORASA)[29] which enforces the global low-rankness of the matrix in both spatial and temporal directions and sparsity of the image matrix. In addition, a modified PROST reconstruction method (PROST + HM) was also compared with SMART to verify the effectiveness of the parametric group-based low-rank tensor in image reconstruction. This jointly uses the spatial patch-based low-rank tensor and a parametric low-rank matrix by replacing the patch-based parameter tensor in SMART with a Hankel matrix. Experiments with high acceleration factors of 10.2 and 11.7 in the 2D scenario and 11.26 and 13.21 in the 3D scenario were also performed to verify the effectiveness of the proposed method.
3.3 Parameter Selection
In this subsection, several different values of the parameters related to the spatial and parametric tensor construction mentioned in the previous section were set and used for 2D image reconstruction. The nRMSE values for the reconstructions of SMART with R = 4 and R = 6 using different parameters were compared.
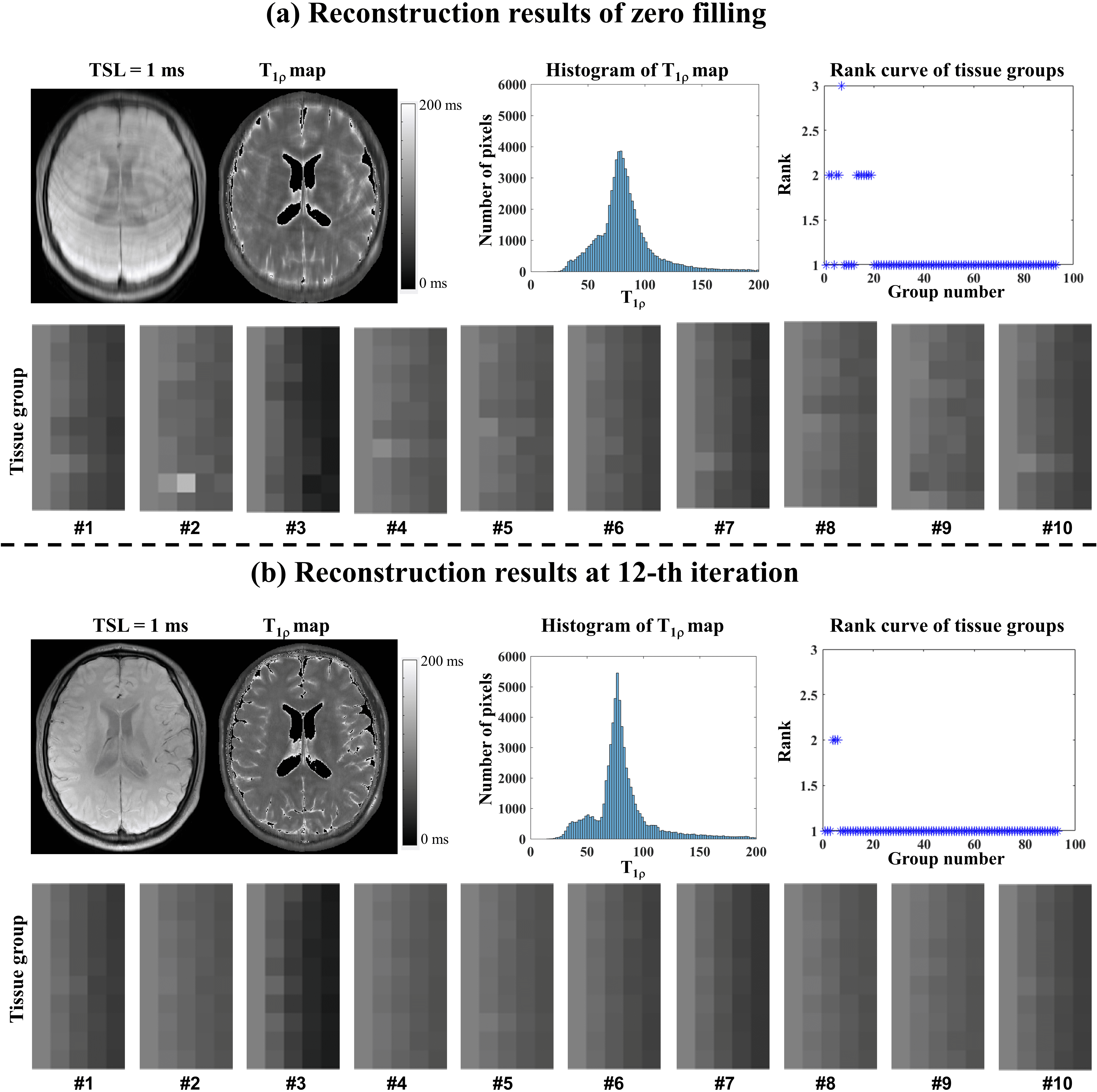
The representative zero-filling reconstruction of the Retro 2D dataset with R = 6, the intermediate reconstruction at the 12th iteration, the parameter histogram, the estimated map, the corresponding tissue groups, and the ranks of tissue groups were also compared to demonstrate the necessity of updating tissue maps in the iteration.
All reconstructions, estimation, and analyses were performed in MATLAB 2017b (MathWorks, Natick, MA, USA) on an HP workstation with 500 GB DDR4 RAM and 32 cores (two 16-core Intel Xeon E5-2660 2.6 GHz processors). The reconstruction parameters used in all methods are presented in the supplementary information Table S2. The tensor transforms, including the folding and unfolding operators, and the tensor multiplication were implemented using the MATLAB tensor toolbox by Brett et al. from Sandia National Laboratories111http://www.tensortoolbox.org/. The HOSVD using algorithm 1 of the supplementary information was implemented based on the transforms from the above toolbox.
3.4 Ablation Experiment
We conducted an ablation study to analyze the spatial and parametric tensors’ effects on the reconstruction. Two models are constructed as follows:
model 1:
| (17) |
model 2:
| (18) |
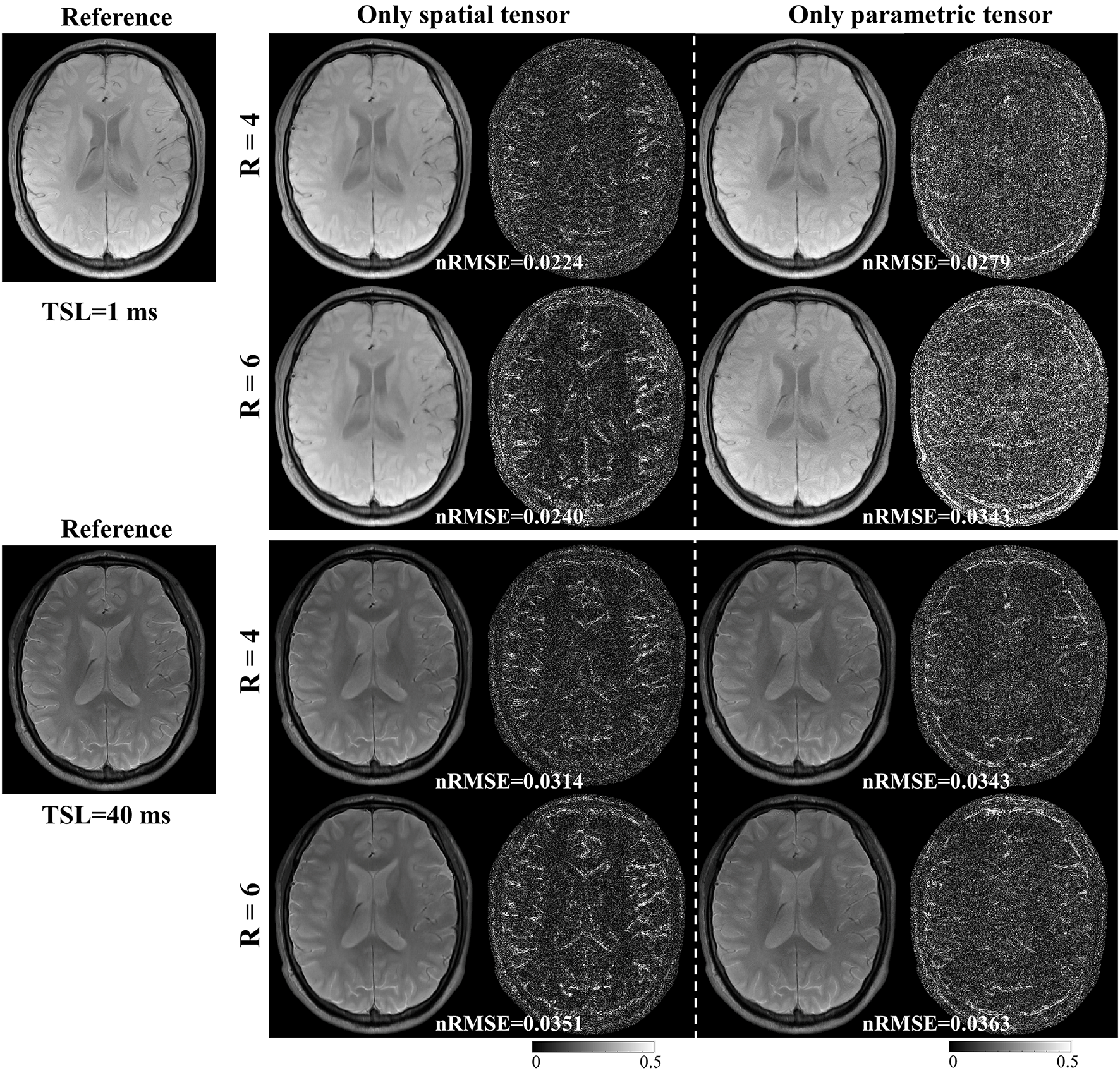
Model 1 only includes the spatial tensor, and model 2 only includes the parametric tensor. Model 1 is the same as the PROST method. Similarly, we applied ADMM to solve the optimization problem in model 2. These two models were used to reconstruct images from the retrospectively undersampled in vivo dataset with R = 4 and 6.

4 RESULTS
4.1 Tissue Clustering Evaluation Experiment
-weighted images at TSL = 80 ms of the numerical phantom with different SNRs are shown in Fig.2(a) to represent low, medium, and high SNRs. Fig.2(b) shows the rank curves of the numerical and real phantom, and in vivo datasets. The first row of Fig.2(b) is for the fully sampled dataset, while the second is for reconstructing the undersampled data.
4.1.1 Numerical phantom dataset
The first column of Fig.2(b) shows rank curves of the numerical phantom. Since the numerical phantom was simulated using the bi-exponential relaxation model, the rank of and the mean rank of the Hankel matrices should be 2. For the fully sampled dataset, the rank of was maintained at 2 for all SNRs, while the mean rank of the Hankel matrices was greater than 2.5. For the accelerated dataset, the rank of was still maintained at 2, while the mean rank of the Hankel matrices for the accelerated dataset increased to nearly 3.
4.1.2 Real phantom dataset
The second column of Fig. 2 (b) shows rank curves of the real phantom dataset. Since each vial of the phantom was considered to be composed of a single component, the rank values of and the Hankel matrices should be 1. For the fully sampled dataset, the rank of was maintained at 1 for all SNRs, while the mean rank of the Hankel matrices was greater than 1. For the accelerated dataset, the rank of increased due to the residual artifacts, especially at low SNR (SNR = 25). The mean rank of the Hankel matrices for the accelerated dataset was even higher than 2.
4.1.3 In vivo dataset
Two different tissues (denoted tissue 1 and tissue 2) were selected to evaluate the performance of the tissue clustering method. Tissue 1 was selected from tissue groups considered composed of a single-component and tissue 2 was selected from tissue groups considered composed of multi-components, according to the rank value of . The third and fourth columns of Fig. 2 (b) show the rank curves of these two tissues, respectively. For tissue 1, the rank of was maintained at 1, while the mean rank of the the Hankel matrices was higher than 2 for both fully sampled and accelerated datasets. For tissue 2, the rank of was maintained at 2 when and increased at low SNR = 25. The mean rank of Hankel matrices was higher than 2 for both fully sampled and accelerated datasets.
The above results imply that the tissue clustering method is robust to noise and residual artifacts, and can improve the low-rank properties of the Hankel structure matrix.
4.2 Retrospective 2D Reconstruction
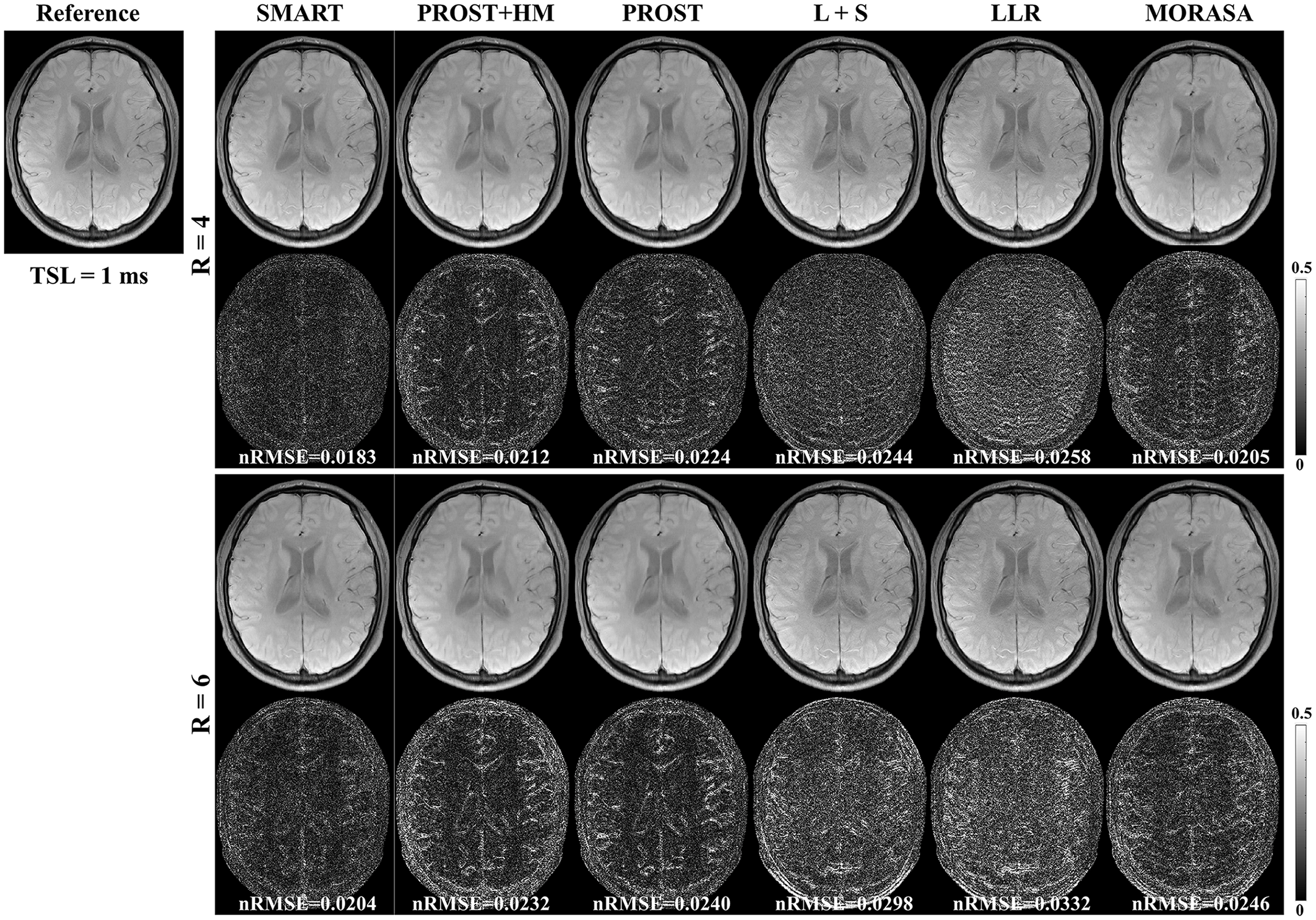
4.2.1 Low acceleration with 4-Fold and 6-Fold
| Metrics | SMART | PROST+HM | PROST | L+S | LLR | MORASA | |
|---|---|---|---|---|---|---|---|
| 4 | HFEN | 0.1858 | 0.2232 | 0.2359 | 0.2453 | 0.2645 | 0.2017 |
| SSIM | 0.9805 | 0.9762 | 0.9761 | 0.9737 | 0.9731 | 0.9780 | |
| PSNR | 43.2262 | 41.5372 | 41.1570 | 40.4791 | 39.8966 | 42.6131 | |
| 6 | HFEN | 0.2224 | 0.2671 | 0.2727 | 0.2897 | 0.3170 | 0.2553 |
| SSIM | 0.9761 | 0.9701 | 0.9704 | 0.9670 | 0.9641 | 0.9715 | |
| PSNR | 42.0636 | 40.0560 | 40.1768 | 39.6337 | 39.0524 | 41.0307 |
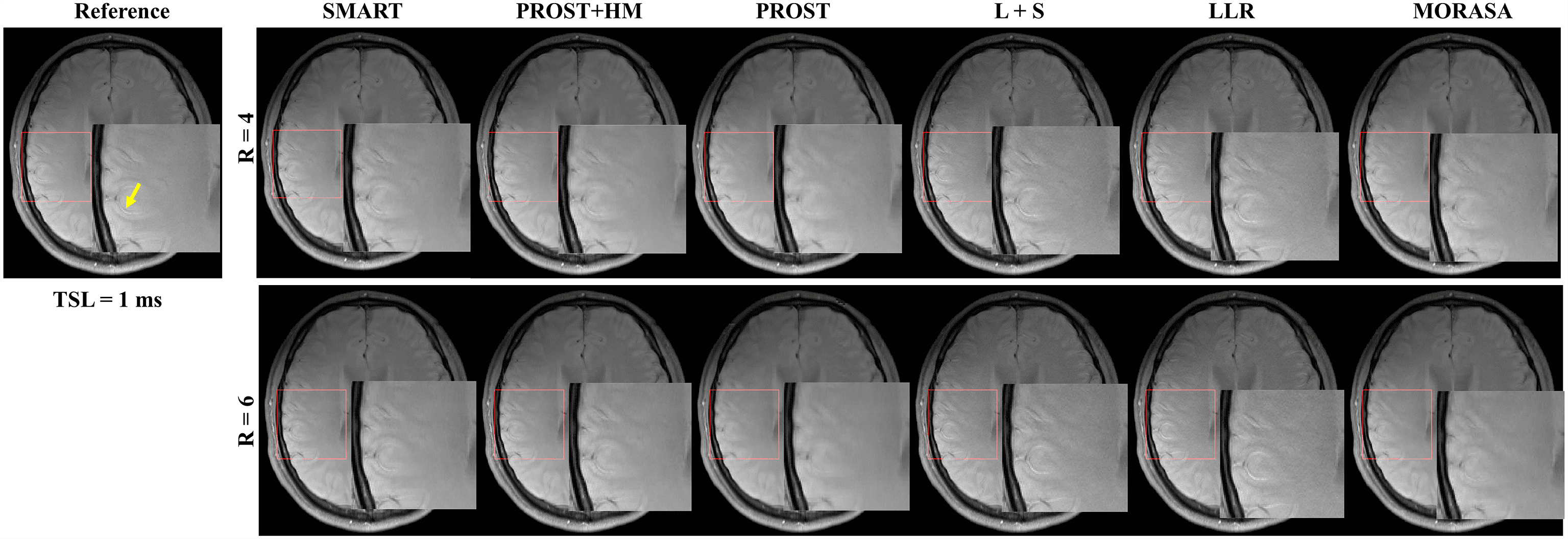
The -weighted images (at TSL = 1 ms) from one volunteer reconstructed using the SMART, PROST+HM, PROST, L+S, LLR, and MORASA methods are shown in Fig. 3. Difference images between the reconstructed and reference images are displayed under the reconstructions, and the nRMSE values are placed below the difference images. Table 1 lists the average HFEN, SSIM, and PSNR values for all reconstructed -weighted images at different TSLs. The estimated maps from the reconstructed and difference images are shown in Fig. 4.
Supplementary information Fig. S2 shows the reconstructed -weighted images (at TSL = 1 ms) and the magnified images of the ROI from another volunteer using the SMART, RROST + HM, PROST, L + S, LLR, and MORASA methods at R = 4 and 6, respectively. The SMART method can better preserve the image resolution and finer details than the RROST + HM, PROST, and MORASA methods. The L + S and LLR methods have an image enhancement effect in the reconstructed images, particularly in the sulcus area, which is indicated by the yellow arrow. Compared to the methods exploiting spatial low-rankness (PROST, L + S, and LLR methods), the reconstruction can be improved by using parametric low-rankness based on high correlations in signal evolution in the reconstruction model.
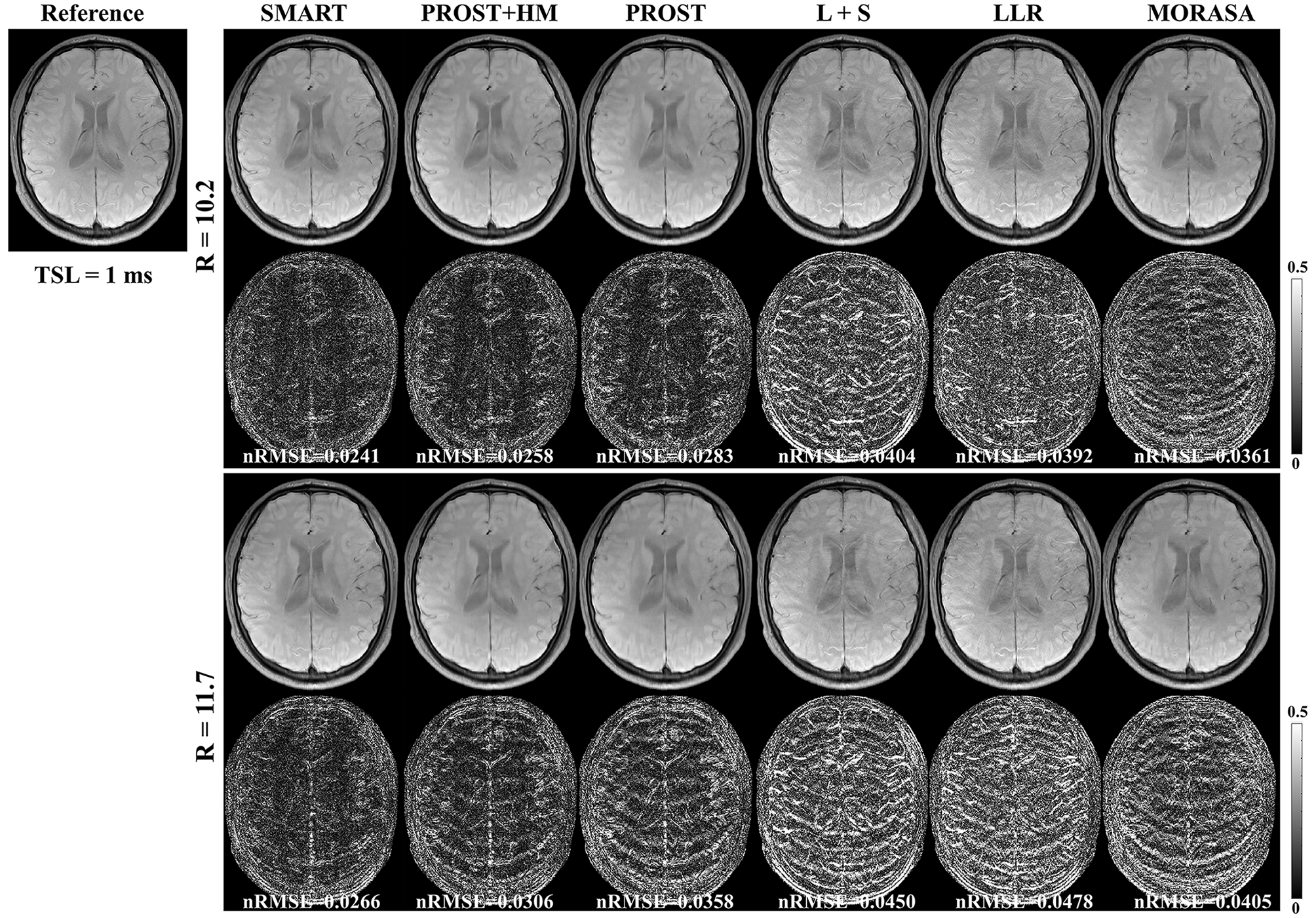
4.2.2 Higher acceleration with 10.2-Fold and 11.7-Fold
The reconstructed -weighted images and the corresponding error images with R = 10.2 and 11.7 are shown in Fig. 5. The nRMSEs are shown at the bottom of each error image. The reconstructed -weighted images using the SMART method have no notable artifacts, even at a high acceleration factor of up to 11.7. The related errors remain noise-like, and the nRMSEs are less than 3. Noticeable aliasing artifacts can be observed from the images or error maps using the PROST+HM, PROST, L+S, LLR, and MORASA methods at different TSLs. The corresponding maps are shown in supplementary information Fig. S3. Table 2 shows the average HFEN, SSIM, and PSNR values for all reconstructed -weighted images. The proposed SMART method qualitatively achieves the best performance among the six methods, especially at R = 11.7.
| Metrics | SMART | PROST+HM | PROST | L+S | LLR | MORASA | |
|---|---|---|---|---|---|---|---|
| 10.2 | HFEN | 0.2558 | 0.2953 | 0.3360 | 0.4057 | 0.4369 | 0.3459 |
| SSIM | 0.9728 | 0.9688 | 0.9637 | 0.9582 | 0.9542 | 0.9674 | |
| PSNR | 40.3712 | 39.4523 | 38.5946 | 36.8233 | 35.3039 | 37.8079 | |
| 11.7 | HFEN | 0.2817 | 0.3460 | 0.4134 | 0.4527 | 0.5148 | 0.3762 |
| SSIM | 0.9701 | 0.9640 | 0.9578 | 0.9533 | 0.9472 | 0.9634 | |
| PSNR | 39.6822 | 38.1819 | 36.8288 | 35.9089 | 33.6896 | 37.2335 |
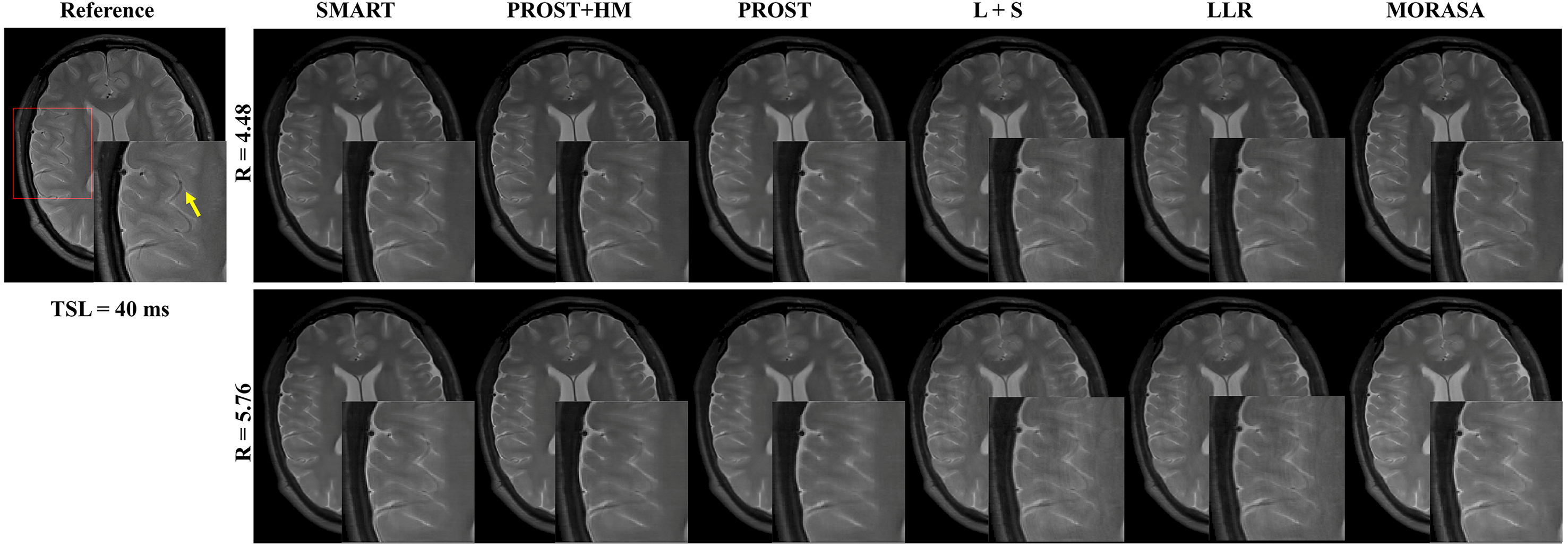
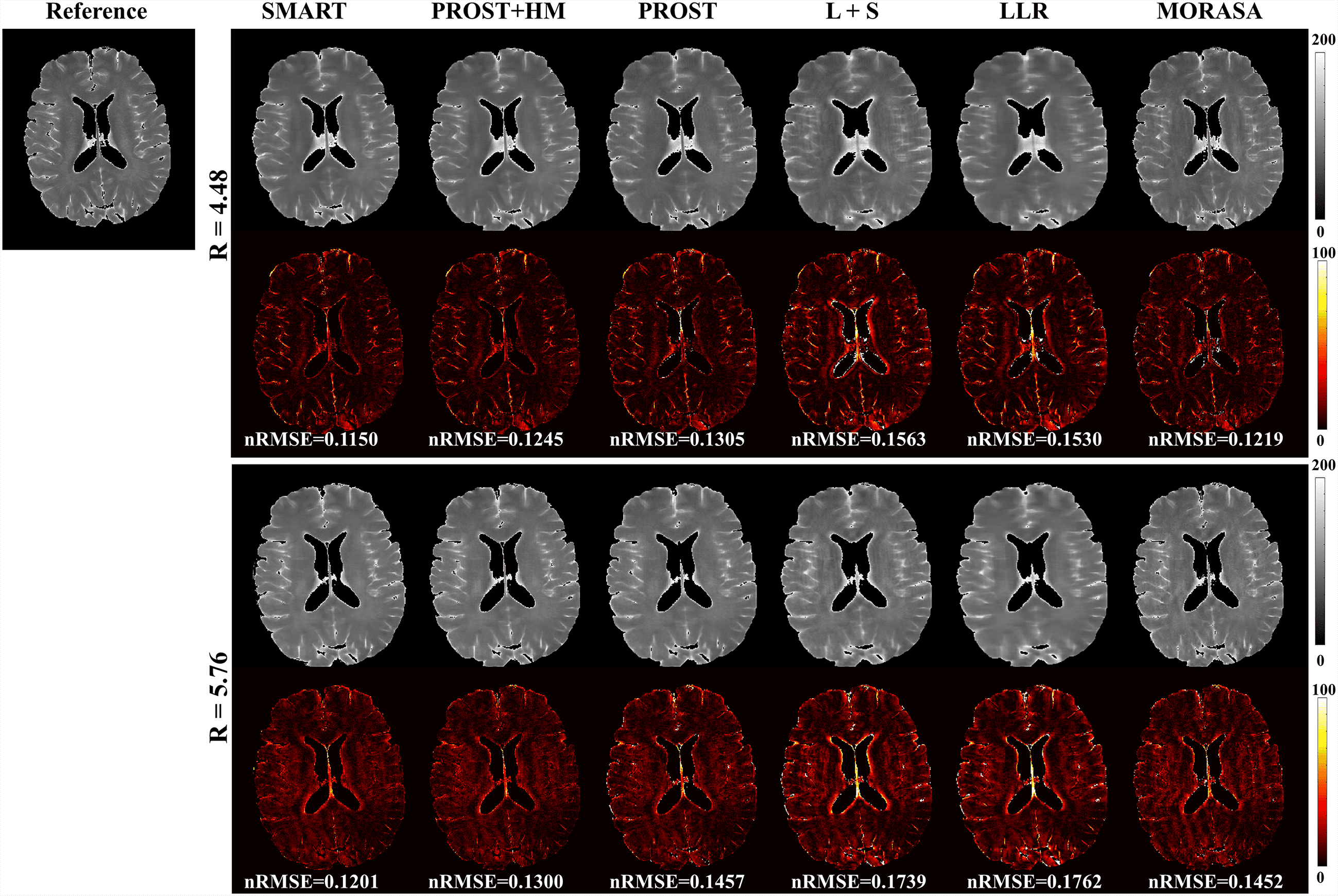
4.3 Prospective 2D Reconstruction
Fig. 6 shows the prospective reconstructed -weighted images (at TSL = 40 ms) from another volunteer and the magnified images using the SMART, PROST + HM, PROST, L + S, LLR, and MORASA methods. Visual artifacts can be observed in the magnified images of reconstructions at all accelerating factors using the L + S and LLR methods. The images reconstructed using the PROST + HM and PROST methods were blurred compared to those reconstructed using the SMART method. Some image details (namely, the blood vessel marked in a yellow arrow) can narrowly be seen in the reconstructions using the PROST + HM and MORASA methods and disappeared in the reconstruction using the PROST method at R = 5.76. In contrast, the image details were well preserved using the SMART method. The maps reconstructed using the methods above are shown in supplementary information Fig. S4. Similar conclusions can be drawn from the maps.
4.4 3D Reconstruction
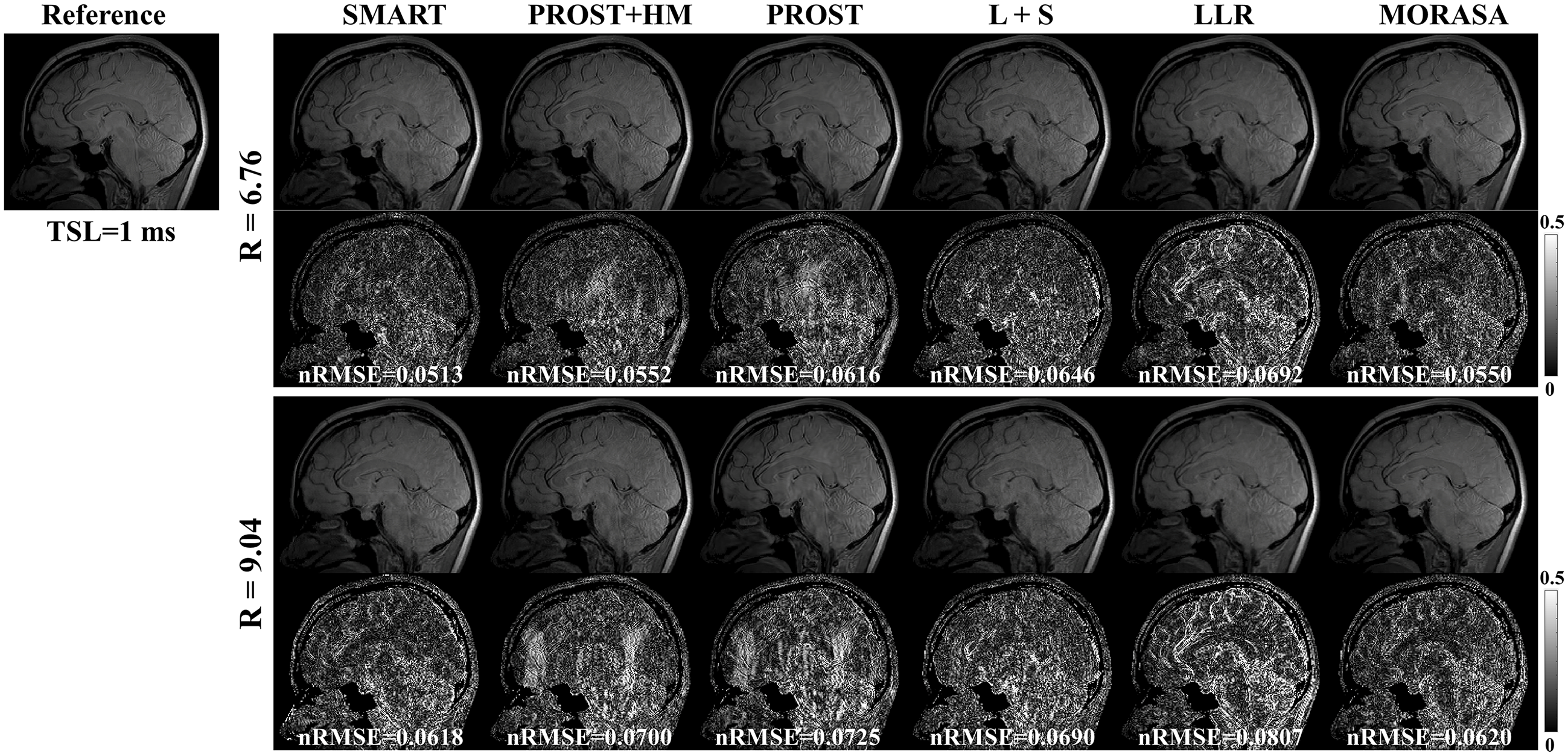
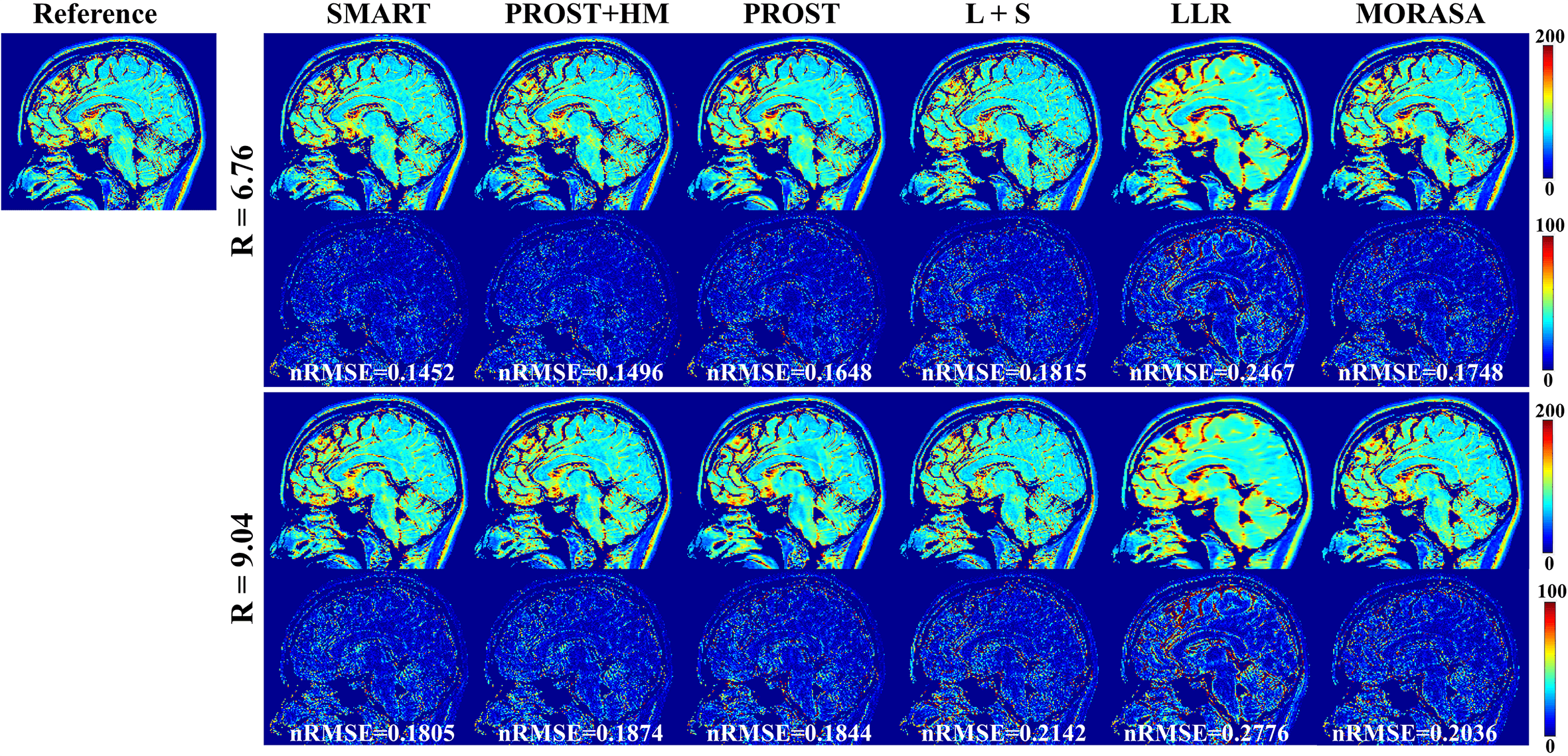
4.4.1 Low acceleration with 6.76-Fold and 9.04-Fold
The -weighted images (at TSL = 1 ms) from one slice of the reconstructed 3D images using the SMART, PROST + HM PROST, L + S, LLR, and MORASA methods for R = 6.76 and 9.04 are shown in Fig.7. The maps reconstructed using the methods above are shown in supplementary information Fig. S5.
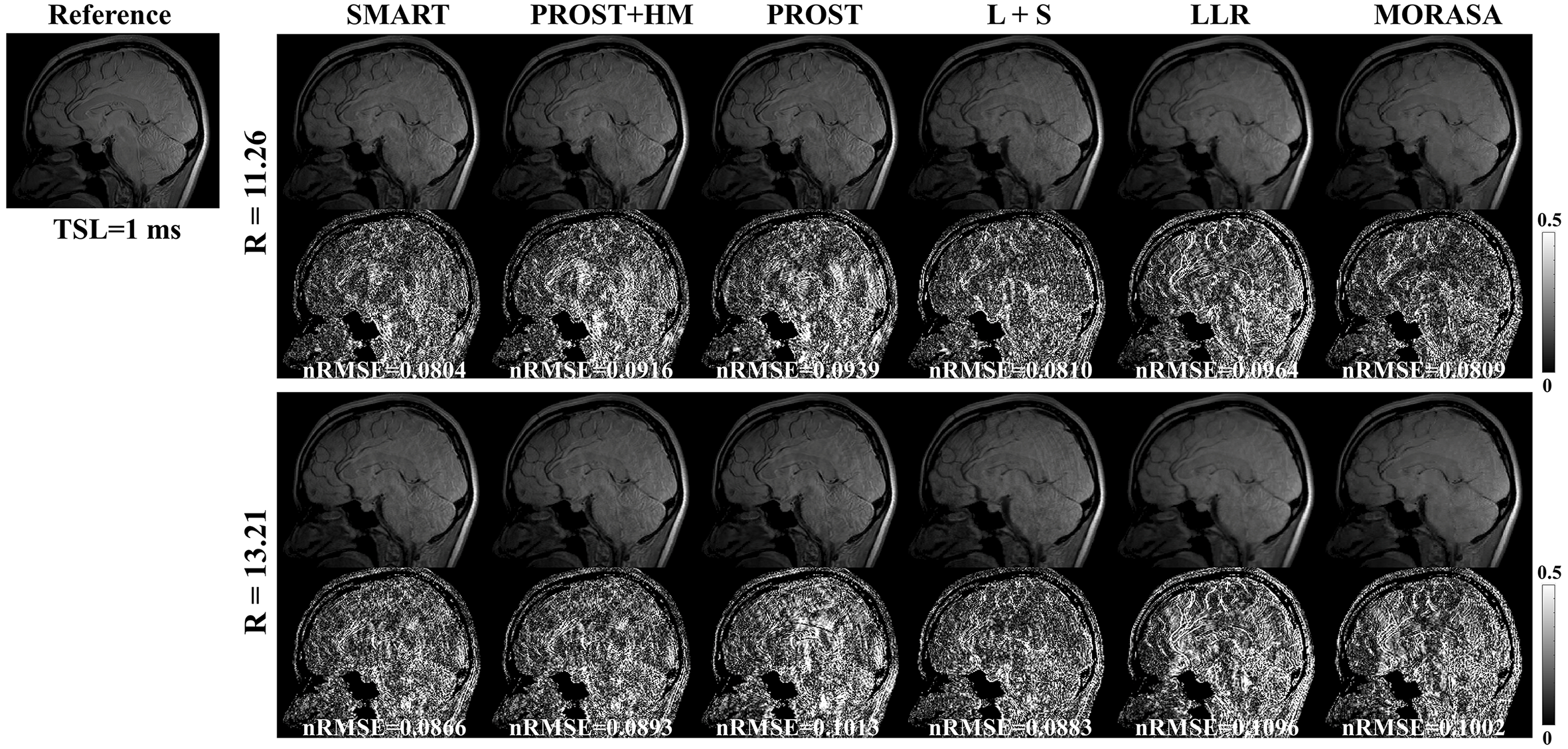
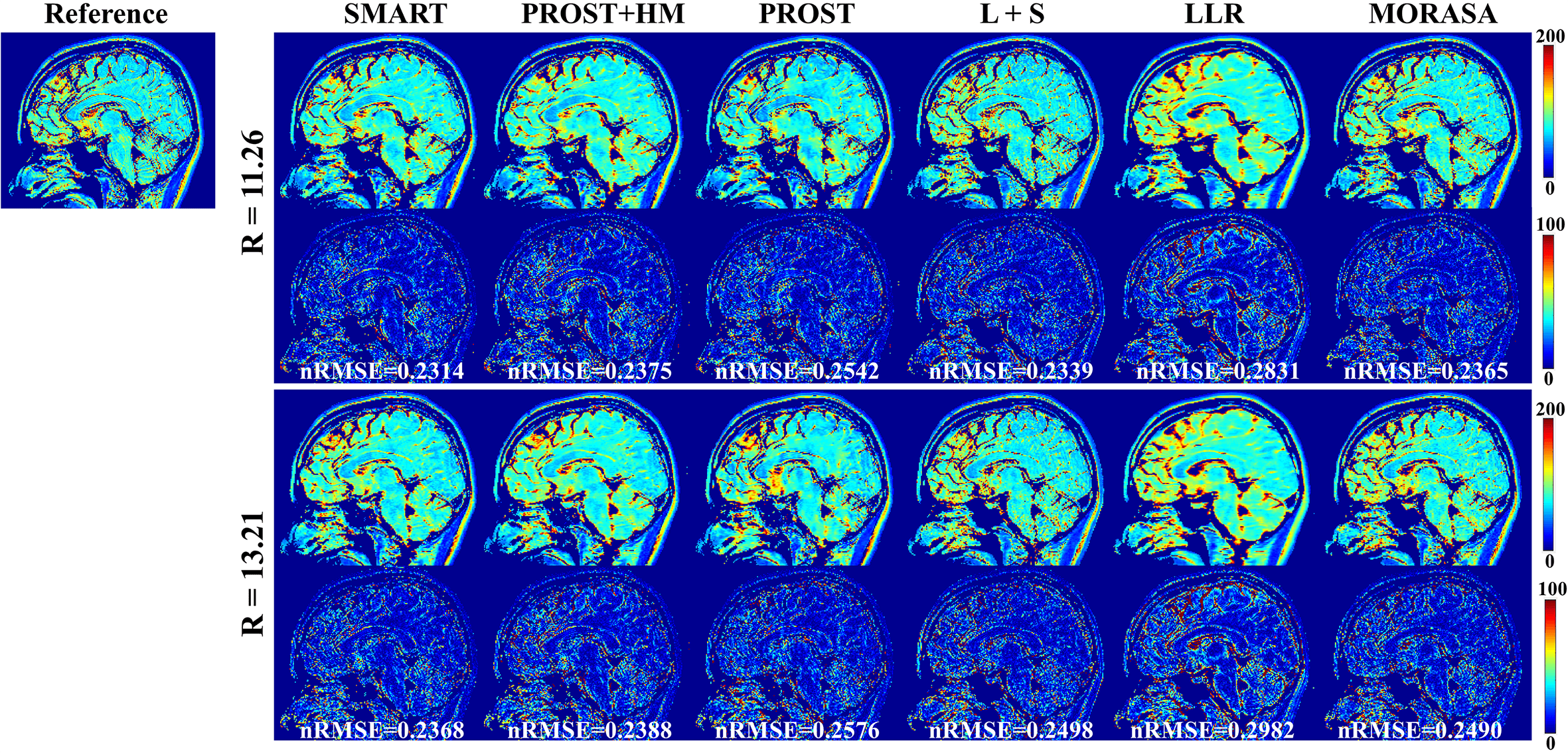
4.4.2 Low acceleration with 11.26-Fold and 13.21-Fold
Fig. 8 shows the reconstructed -weighted images and the related error maps at TSL = 1 ms with R = 11.26 and 13.21 using the six methods in 3D imaging. The estimated maps from the reconstructions are shown in supplementary information Fig. S6. At high acceleration, the low-rank tensor-based reconstruction methods (SMART, PROST, and PROST+HM) show better detail retention than the low-rank matrix-based methods (LLR and MORASA). The SMART method still achieves lower nRMSE than other methods at higher accelerations.
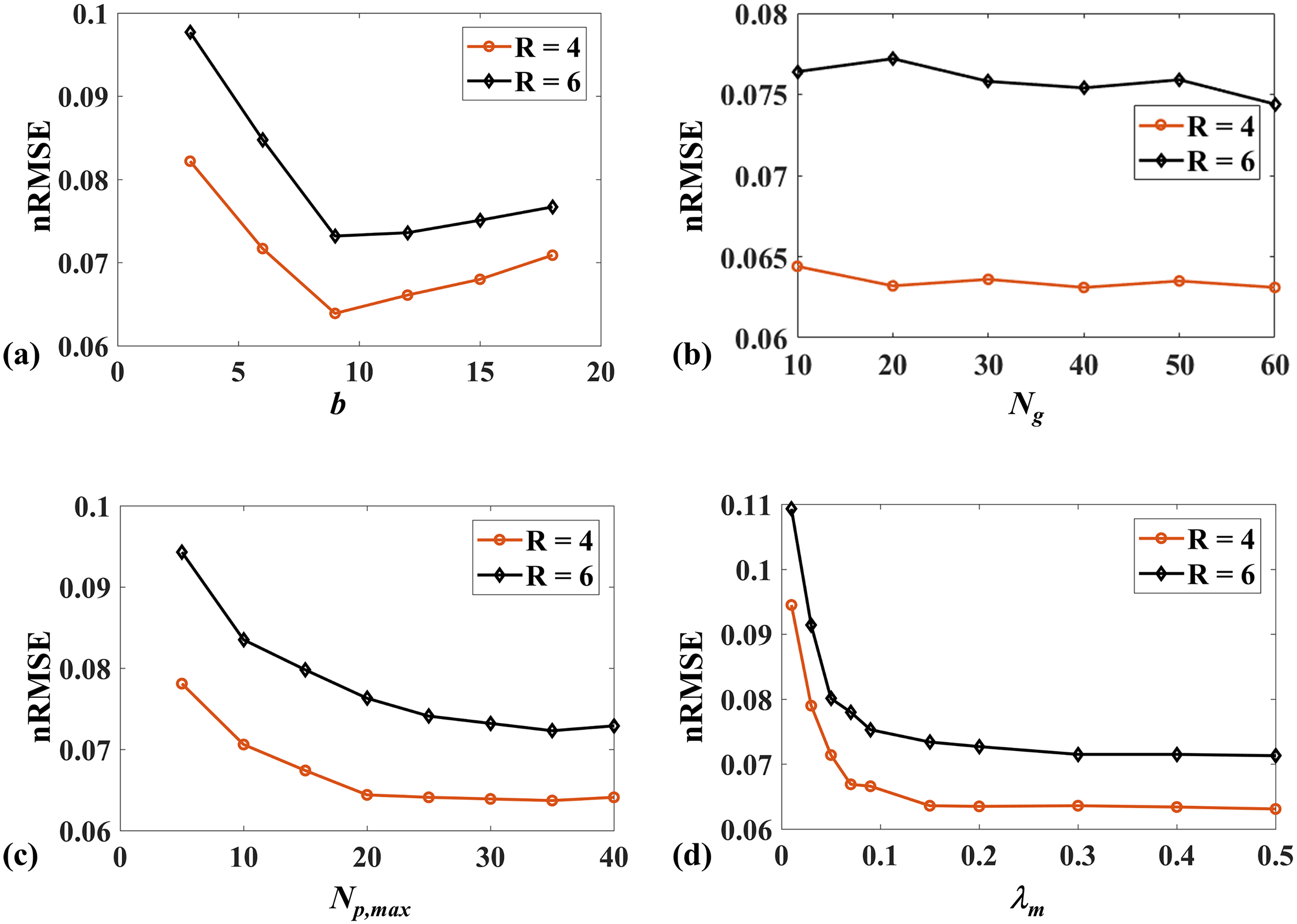
4.5 Parameter Selection
Fig.9 shows the effects of four parameters of the spatial and parametric tensor construction in 2D imaging. As shown in Fig. 9(a), the smallest nRMSE is achieved at . When the patch size decreases from 9 to 3, the nRMSE increases rapidly due to the small image patches’ limited spatial modeling ability. When the patch size is larger than 9, the reconstruction performance slowly degrades since the discrepancy among the patches increases, causing the reduced low rankness of the constructed spatial tensor. The nRMSE of reconstruction decreases with the increase of , as shown in Fig. 9(c), but the trend slows down when . Considering the computational complexity, we chose in this study. Fig. 9(d) shows that needs to be larger than 0.15; otherwise, the nRMSE will significantly increase. As shown in Fig. 9(b), changing has little effect on the nRMSE of the reconstruction for R = 4. In contrast, large shows improved performance for the higher acceleration factor of 6. Therefore, was used in this study.
Supplementary information Fig. S7 shows the representative zero-filling reconstruction with R = 6, the intermediate reconstruction at the 12th iteration, the parameter histogram, the estimated map, the corresponding tissue groups, and the ranks of tissue groups. The initial -weighted image of the zero-filling reconstruction shows strong aliasing artifact, and the map estimated from zero-filling images is quite blurred. The quality of -weighted image and map was significantly improved at the 12th iteration. After iteration, the distribution of the parameter histogram also changed (shown in Fig. S7(b)). In the figure of tissue groups, the pixel intensities along the pixel number direction are not as uniform as those at the 12th iteration. The ranks in several groups are reduced from 2 to 1.
4.6 Ablation Experiment
Fig. 10 shows the reconstructed images for models 1 and 2 with R = 4 and 6, respectively. For the results of model 1, the aliasing artifacts due to undersampling can be well removed from the reconstructed images by applying the spatial tensor, but the reconstructed images are blurry. In contrast, the sharpness of images reconstructed by model 2 is improved, but aliasing artifacts still exist. These results are in line with our hypothesis that the parametric group-based tensor can help improve image sharpness and preserve more image details in the reconstructions.
5 DISCUSSION
This study proposed the SMART method using simultaneous spatial patch-based and parametric group-based low-rank tensors for accelerated MR mapping. We demonstrated that the proposed method could recover high-quality images from highly undersampled data in 2D and 3D imaging. The high local and nonlocal redundancies and similarities between the contrast images were exploited using the spatial patch-based low-rank tensor through HOSVD. Compared with transforms that use fixed bases, such as discrete cosine and wavelet, the HOSVD bases are learned from the multidimensional data and thus more adaptive to the structures in the data. This adaptive nature enables HOSVD to be an excellent sparsifying transform for image reconstruction[43]. Similar overlapping patches are used to form the spatial low-rank tensors as in the PROST method. The optimization subproblem for the tensors can be addressed in the high-order denoising process. The denoised image is obtained by averaging different estimates, which may lead to blurring in the reconstructions. In the proposed SMART method, in addition to the spatial tensor, we jointly used a parametric group-based low-rank tensor in the reconstruction model, which exploits the low rank in spatial and temporal directions. The parametric tensor is formed non-overlapping, which exhibits stronger low-rankness based on high correlations in tissues of similar signal evolution. It may help improve image sharpness and preserve more image details in the reconstructions. Therefore, the SMART method can perform better than existing spatial patch-based methods.
Meanwhile, the SMART method exhibited high robustness in prospective experiments and can be extended to other quantitative imaging methods, such as mapping and mapping.
5.1 Parameters Selection for the SMART Method
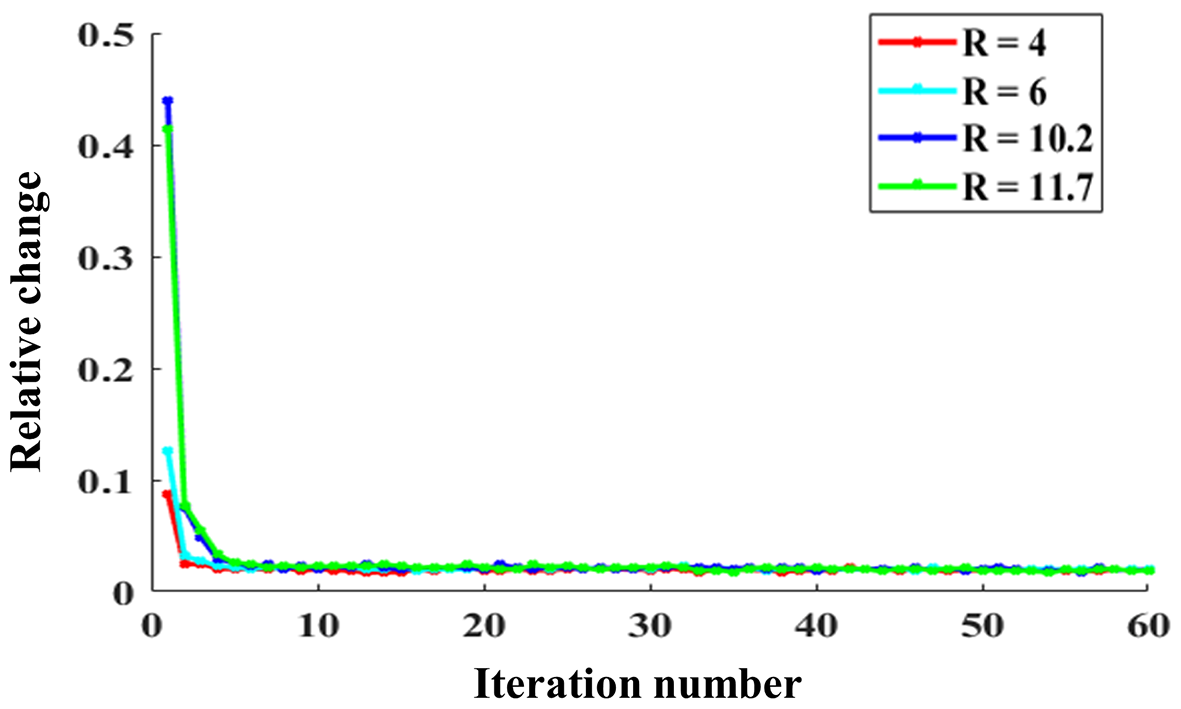
In this study, all the reconstruction parameters included in the ADMM and CG algorithms were selected empirically. The relative change in the solution between two consecutive iterations was used to show the convergence numerically and is defined as follows:
| (19) |
where denotes the reconstructed image at the iterth ADMM iteration. Fig. 11 shows the relative changes of 2D imaging with R = 4, 6, 10.2, and 11.7. The relative change rapidly stabilizes within a few iteration numbers and has no significant alterations when the iteration number reaches 15. Additionally, we changed the CG iteration number from 7 to 20 to test its effects on the reconstruction. The nRMSE variations of the reconstructed images with different CG iteration numbers were less than 1%, indicating the CG iteration number may have little effect on reconstruction after several iterations.
We used several tricks to speed up the reconstruction in our experiments. For the patch extraction step, a patch offset with three was used to reduce the number of searched patches. Also, the patch extraction step was implemented in a graphics processing unit (GPU). The time consumption of this step was reduced from 9.5s to 0.14s for the 2D patch extraction and from 600 mins to 171s for the 3D patch extraction. The memory footprints were 411 MB and 821 MB for the 2D and 3D patch extractions. The estimation for the histogram analysis of the tissue clustering was applied every three iterations to speed up the reconstruction. Additionally, parallel computing was applied in the HOSVD denoising step of tensors and for each spatial and parametric tensor. The reconstruction times of the six methods are listed in supplementary information Table S3.
5.2 2D Patch vs. 3D Patch in the 3D Imaging Application
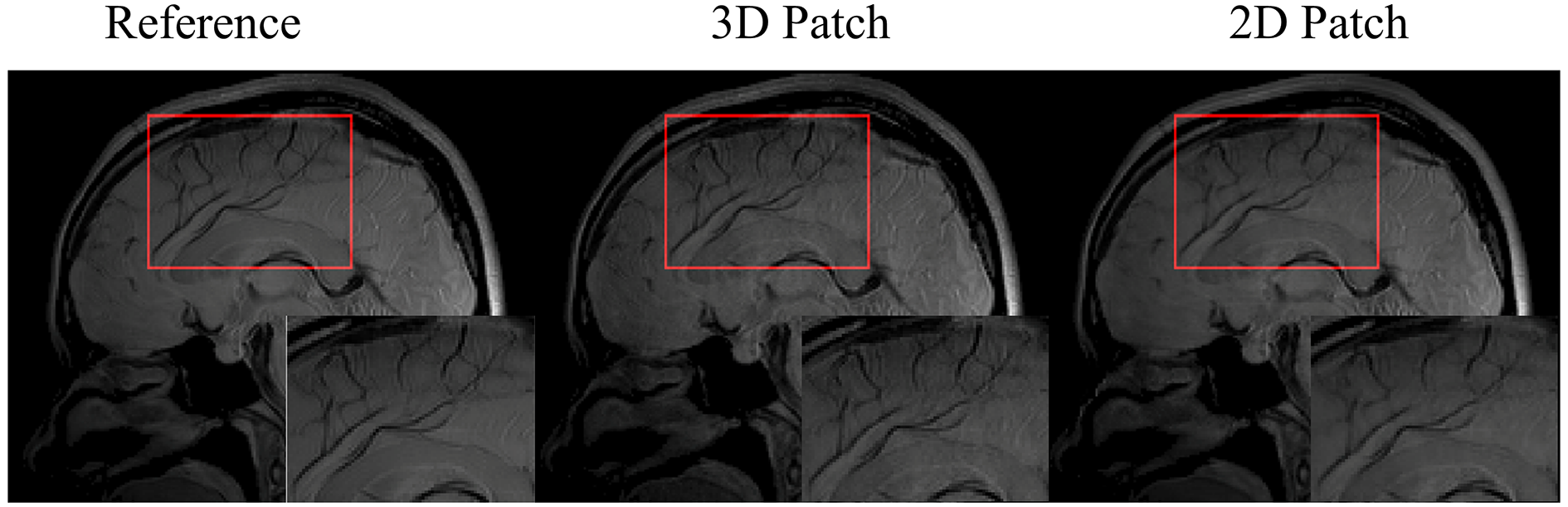
For 3D imaging, the images can be reconstructed slice-by-slice using the SMART method, where the 2D patch extraction is implemented. Compared to the 2D patch extraction, the correlation information between the slices can be utilized to improve the reconstruction. Therefore, in this study, the 3D patch extraction was selected in the SMART method. Fig. 12 shows a slice of the reconstructed images at R = 9.04 using the 2D and 3D patch extraction, respectively. The reference images from the fully sampled data and magnified images are also shown. As shown in the magnified images, the 3D patch extraction displays better image resolution and detail, particularly in the regions indicated by the red frames.
5.3 Comparison with Previous Studies
Previous studies [59, 60] have utilized convolutional sparse coding (CSC) to reconstruct images from undersampled data. Thanh et al.[59] proposed a filter-based dictionary learning method using a 3D CSC to recover the high-frequency information of the MRI images. The CSC employed a sparse representation of the entire image computed by the sum of a set of convolutions with dictionary filters instead of dividing an image into overlapped patches. It can solve high computational complexity and long-running time problems due to patch-based approaches and avoid artifacts caused by patch aggregation. However, filters must be carefully chosen, and artifacts may appear in some reconstructed images due to inaccurate filters[60].
Low rankness has been widely used in fast MR parametric mapping. The annihilating filter-based low-rank Hankel matrix method (ALOHA)[30] exploits the transform domain sparsity and the coil sensitivity smoothness, representing a low-rank Hankel structured matrix in the weighted -space domain. The prior information used in ALOHA differs from the image domain redundancy utilized in our study. Specifically, the spatial and temporal redundancies are mainly represented as a summation of exponentials and the Hankel matrix at each voxel with a low-rank property. Multi-scale low-rank with different patch sizes was also used to capture global and local information. It has a more compact signal representation and may further improve MR reconstruction. Frank Ong et al.[61, 62] have applied multi-scale low-rank in face recognition preprocessing and dynamic contrast-enhanced MRI. However, when constructing multiple low-rank tensors, the memory footprint is large, and time consumption is increased several times compared with a single patch size. Another problem is that the multi-scale low-rank decomposition is not translation invariant; shifting the input changes the resulting decomposition. This translation variant nature often creates blocking artifacts near the block boundaries, which can be visually jarring. Introducing overlapping partitions of the patches so that the overall algorithm is translation invariant can remove these artifacts. The proposed SMART method uses a single patch size with overlapped patches considering the limits of memory and reconstruction time.
5.4 Limitations of SMART
In this study, the setup of the proposed method is non-convex, and the patch selection operator is time-varying. The convergence of the whole algorithm cannot be completely guaranteed. However, based on our experimental results, the proposed method works well despite the lack of a convergence guarantee. We found that after several iterations, the relative change of reconstructions between two consecutive iterations and the patch extract selection varies slightly. Generally, this estimation based on the patch structure remains consistent along with the increasing iteration. In addition, the block matching algorithm for patch extraction is heuristic, and the current selection strategy may not present the best clusters. In future work, patches obtained through a sliding operation throughout the data may be used to construct the high order tensor. The local and nonlocal redundancies and similarities between the contrast images can be exploited using the tensor dictionary learning method by jointly applying the low-rank constraints on the dictionaries, and the sparse constraints on the core coefficient tensors [63]. This may further improves the reconstruction performance.
The iterative method’s long reconstruction time significantly hinders the proposed method’s clinical application. However, there are two potential solutions to this problem. One solution is using parallel computing via GPU. We have already implemented the patch extraction in GPU. Although the reconstruction time is still too long for clinical use, we plan to improve the speed of the SMART method by leveraging parallel computing technology, such as multi-GPU and cluster systems. The other solution is the deep learning-based reconstruction method. In recent years, the unrolling-based strategy has established a bridge from traditional iterative CS reconstruction to deep neural network design [64]. Previous studies have shown that an unrolling-based deep network significantly reduced the reconstruction time and improved the reconstruction quality through the learnable regularizations and parameters. However, deep learning-based reconstruction requires a considerable amount of high-quality training data, and the network performance may degrade due to the motion artifact during the data acquisition. Training data collection is critical and will be the bottleneck of the deep learning-based reconstruction method. In our future work, we will try both strategies to promote the clinical use of the proposed method.
6 CONCLUSIONS
This study explores low-rankness through high-order tensor in MR mapping to obtain improved reconstruction results. In particular, we propose a method that simultaneously uses spatial patch-based and parametric group-based low-rank tensors to reconstruct images from highly undersampled data. The spatial patch-based low-rank tensor exploits the high local and nonlocal redundancies and the similarities between the contrast images. The parametric group-based low-rank tensor, which integrates similar exponential behavior of the image signals, is jointly used to enforce the multidimensional low-rankness in the reconstruction process. Experimental results in both 2D and 3D imaging scenarios show that the proposed method can improve the reconstruction results qualitatively and quantitatively.
References
- [1] Y.-X. J. Wáng, Q. Zhang, X. Li, W. Chen, A. Ahuja, and J. Yuan, “ magnetic resonance: basic physics principles and applications in knee and intervertebral disc imaging,” Quant. Imaging Med. Surg., vol. 5, no. 6, p. 858, 2015.
- [2] L. Wang and R. R. Regatte, “ MRI of human musculoskeletal system,” J. Magn. Reson. Imag., vol. 41, no. 3, pp. 586–600, 2015.
- [3] Y. Zhu, Y. Liu, L. Ying, Z. Qiu, Q. Liu, S. Jia, H. Wang, X. Peng, X. Liu, H. Zheng, and D. Liang, “A 4-minute solution for submillimeter whole-brain quantification,” Magn. Reson. Med., vol. 85, no. 6, pp. 3299–3307, 2021.
- [4] S. Ma, N. Wang, Z. Fan, M. Kaisey, N. L. Sicotte, A. G. Christodoulou, and D. Li, “Three-dimensional whole-brain simultaneous , , and quantification using MR multitasking: Method and initial clinical experience in tissue characterization of multiple sclerosis,” Magn. Reson. Med., vol. 85, no. 4, pp. 1938–1952, 2021.
- [5] T. Allkemper, F. Sagmeister, V. Cicinnati, S. Beckebaum, H. Kooijman, C. Kanthak, C. Stehling, and W. Heindel, “Evaluation of fibrotic liver disease with whole-liver MR imaging: a feasibility study at 1.5 T,” Radiology, vol. 271, no. 2, pp. 408–15, 2014.
- [6] Q. Yang, T. Yu, S. Yun, H. Zhang, X. Chen, Z. Cheng, J. Zhong, J. Huang, T. Okuaki, Q. Chan, B. Liang, and H. Guo, “Comparison of multislice breath-hold and 3D respiratory triggered imaging of liver in healthy volunteers and liver cirrhosis patients in 3.0 T MRI,” J. Magn. Reson. Imag., vol. 44, no. 4, pp. 906–13, 2016.
- [7] Z. Zhou, B. Jiang, Z. Zhou, X. Pan, H. Sun, B. Huang, T. Liang, S. Ringgaard, and X. Zou, “Intervertebral disk degeneration: MR imaging of human and animal models,” Radiology, vol. 268, no. 2, pp. 492–500, 2013.
- [8] H. Qi, Z. Lv, J. Hu, J. Xu, R. Botnar, C. Prieto, and P. Hu, “Accelerated 3d free-breathing high-resolution myocardial mapping at 3 tesla,” Magn. Reson. Med., vol. 88, no. 6, pp. 2520–2531, 2022.
- [9] P. Pandit, J. Rivoire, K. King, and X. J. Li, “Accelerated acquisition for knee cartilage quantification using compressed sensing and data-driven parallel imaging: A feasibility study,” Magn. Reson. Med., vol. 75, no. 3, pp. 1256–1261, 2016.
- [10] S. Bhave, S. G. Lingala, C. P. Johnson, V. A. Magnotta, and M. Jacob, “Accelerated whole-brain multi-parameter mapping using blind compressed sensing,” Magn. Reson. Med., vol. 75, no. 3, pp. 1175–1186, 2016.
- [11] M. Lustig, D. Donoho, and J. M. Pauly, “Sparse MRI : The application of compressed sensing for rapid MR imaging,” Magn. Reson. Med., vol. 58, no. 6, pp. 1182–95, 2007.
- [12] M. V. W. Zibetti, R. Baboli, G. Chang, R. Otazo, and R. R. Regatte, “Rapid compositional mapping of knee cartilage with compressed sensing MRI,” J. Magn. Reson. Imag., vol. 48, no. 5, pp. 1185–1198, 2018.
- [13] T. Zhang, J. M. Pauly, and I. R. Levesque, “Accelerating parameter mapping with a locally low rank constraint,” Magn. Reson. Med., vol. 73, no. 2, pp. 655–61, 2015.
- [14] B. Zhao, W. M. Lu, T. K. Hitchens, F. Lam, C. Ho, and Z. P. Liang, “Accelerated MR parameter mapping with low-rank and sparsity constraints,” Magn. Reson. Med., vol. 74, no. 2, pp. 489–498, 2015.
- [15] Y. Zhu, Y. Liu, L. Ying, X. Peng, Y. J. Wang, J. Yuan, X. Liu, and D. Liang, “SCOPE: signal compensation for low-rank plus sparse matrix decomposition for fast parameter mapping,” Phys. Med. Biol., vol. 63, no. 18, p. 185009, 2018.
- [16] M. V. W. Zibetti, A. Sharafi, R. Otazo, and R. R. Regatte, “Accelerating 3D- mapping of cartilage using compressed sensing with different sparse and low rank models,” Magn. Reson. Med., vol. 80, no. 4, pp. 1475–1491, 2018.
- [17] Y. Zhang, X. Mou, G. Wang, and H. Yu, “Tensor-based dictionary learning for spectral CT reconstruction,” IEEE Trans. Med. Imag., vol. 36, no. 1, pp. 142–154, 2017.
- [18] J. He, Q. Liu, A. Christodoulou, C. Ma, F. Lam, and Z. Liang, “Accelerated high-dimensional MR imaging with sparse sampling using low-rank tensors,” IEEE Trans. Med. Imag., vol. 35, no. 9, pp. 2119–2129, 2016.
- [19] J. Liu, P. Musialski, P. Wonka, and J. P. Ye, “Tensor completion for estimating missing values in visual data,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 35, no. 1, pp. 208–220, 2013.
- [20] Y. Liu, L. Ying, W. Chen, Z. Cui, Q. Zhu, X. Liu, H. Zheng, D. Liang, and Y. Zhu, “Accelerating the 3D mapping of cartilage using a signal-compensated robust tensor principal component analysis model,” Quant. Imaging Med. Surg., vol. 11, no. 8, p. 3376, 2021.
- [21] B. Yaman, S. Weingartner, N. Kargas, N. D. Sidiropoulos, and M. Akcakaya, “Low-rank tensor models for improved multi-dimensional MRI: Application to dynamic cardiac mapping,” IEEE Trans. Comput. Imag, vol. 6, pp. 194–207, 2020.
- [22] A. Christodoulou, J. Shaw, C. Nguyen, Q. Yang, Y. Xie, N. Wang, and D. Li, “Magnetic resonance multitasking for motion-resolved quantitative cardiovascular imaging,” Nature Biomed. Eng., vol. 2, no. 4, pp. 215–226, 2018.
- [23] J. Shaw, Q. Yang, Z. Zhou, Z. Deng, C. Nguyen, D. Li, and A. G. Christodoulou, “Free-breathing, non-ECG, continuous myocardial mapping with cardiovascular magnetic resonance multitasking,” Magn. Reson. Med, vol. 81, no. 4, pp. 2450–2463, 2019.
- [24] F. Liu, D. X. Li, X. Y. Jin, W. Y. Qiu, Q. Xia, and B. Sun, “Dynamic cardiac MRI reconstruction using motion aligned locally low rank tensor (MALLRT),” Magn. Reson. Imaging, vol. 66, pp. 104–115, 2020.
- [25] J. D. Trzasko and A. Manduca, “A unified tensor regression framework for calibrationless dynamic, multi-channel MRI reconstruction,” in Proceeding of the International Society for Magnetic Resonance in Medicine (ISMRM), 2013, p. 603.
- [26] S. Guo, J. A. Fessler, and D. C. Noll, “High-resolution oscillating steady-state fMRI using patch-tensor low-rank reconstruction,” IEEE Trans. Med. Imag., vol. 39, no. 12, pp. 4357–4368, 2020.
- [27] S. Liu, J. Cao, H. Liu, X. Tan, and X. Zhou, “Group sparsity with orthogonal dictionary and nonconvex regularization for exact MRI reconstruction,” Inform. Sciences, vol. 451, pp. 161–179, 2018.
- [28] M. Usman, C. Prieto, T. Schaeffter, and P. G. Batchelor, “k-t group sparse: a method for accelerating dynamic MRI,” Magn. Reson. Med, vol. 66, no. 4, pp. 1163–76, 2011.
- [29] X. Peng, L. Ying, Y. Liu, J. Yuan, X. Liu, and D. Liang, “Accelerated exponential parameterization of relaxation with model-driven low rank and sparsity priors (MORASA),” Magn. Reson. Med., vol. 76, no. 6, pp. 1865–1878, 2016.
- [30] D. Lee, K. H. Jin, E. Y. Kim, S. H. Park, and J. C. Ye, “Acceleration of MR parameter mapping using annihilating filter-based low rank Hankel matrix (ALOHA),” Magn. Reson. Med., vol. 76, no. 6, pp. 1848–1864, 2016.
- [31] S. Lingala, Y. Hu, E. DiBella, and M. Jacob, “Accelerated dynamic MRI exploiting sparsity and low-rank structure: k-t SLR,” IEEE Trans. Med. Imag., vol. 30, no. 5, pp. 1042–54, 2011.
- [32] Y. Liu, Z. Yi, Y. Zhao, F. Chen, Y. Feng, H. Guo, A. T. Leong, and E. Wu, “Calibrationless parallel imaging reconstruction for multislice MR data using low-rank tensor completion,” Magn. Reson. Med., vol. 85, no. 2, pp. 897–911, 2021.
- [33] Z. Yi, Y. Liu, Y. Zhao, L. Xiao, A. T. Leong, Y. Feng, F. Chen, and E. Wu, “Joint calibrationless reconstruction of highly undersampled multicontrast MR datasets using a low-rank Hankel tensor completion framework,” Magn. Reson. Med., vol. 85, no. 6, pp. 3256–3271, 2021.
- [34] M. Akçakaya, T. Basha, B. Goddu, L. Goepfert, K. Kissinger, V. Tarokh, W. Manning, and R. Nezafat, “Low-dimensional-structure self-learning and thresholding: regularization beyond compressed sensing for MRI reconstruction,” Magn. Reson. Med., vol. 66, no. 3, pp. 756–767, 2011.
- [35] T. Kolda and B. Bader, “Tensor decompositions and applications,” SIAM Rew., vol. 51, no. 3, pp. 455–500, 2009.
- [36] R. Otazo, E. Candes, and D. K. Sodickson, “Low-rank plus sparse matrix decomposition for accelerated dynamic MRI with separation of background and dynamic components,” Magn. Reson. Med., vol. 73, no. 3, pp. 1125–36, 2015.
- [37] K. Pruessmann, M. Weiger, P. Bornert, and P. Boesiger, “Advances in sensitivity encoding with arbitrary k-space trajectories,” Magn. Reson. Med., vol. 46, no. 4, pp. 638–51, 2001.
- [38] A. Bustin, D. Voilliot, A. Menini, J. Felblinger, C. de Chillou, D. Burschka, L. Bonnemains, and F. Odille, “Isotropic reconstruction of MR images using 3D patch-based self-similarity learning,” IEEE Trans. Med. Imag., vol. 37, no. 8, pp. 1932–1942, 2018.
- [39] D. Qiu, M. Bai, M. Ng, and X. Zhang, “Nonlocal robust tensor recovery with nonconvex regularization,” Inverse Problems, vol. 37, no. 3, p. 035001, 2021.
- [40] H. Nguyen, X. Peng, M. Do, and Z. Liang, “Denoising MR spectroscopic imaging data with low-rank approximations,” IEEE Trans. Biomed. Eng., vol. 60, no. 1, pp. 78–89, 2013.
- [41] Y. Wang, J. Yang, W. Yin, and Y. Zhang, “A new alternating minimization algorithm for total variation image reconstruction,” SIAM J. Imag. Sci, vol. 1, no. 3, pp. 248–272, 2008.
- [42] M. R. Hestenes and E. Stiefel, “Methods of conjugate gradients for solving,” Journal of research of the National Bureau of Standards, vol. 49, no. 6, p. 409, 1952.
- [43] X. Zhang, J. Peng, M. Xu, W. Yang, Z. Zhang, H. Guo, W. Chen, Q. Feng, E. Wu, and Y. Feng, “Denoise diffusion-weighted images using higher-order singular value decomposition,” Neuroimage, vol. 156, pp. 128–145, 2017.
- [44] J.-F. Cai, E. J. Candès, and Z. Shen, “A singular value thresholding algorithm for matrix completion,” SIAM J. Optimiz, vol. 20, no. 4, pp. 1956–1982, 2010.
- [45] A. Bustin, G. Lima da Cruz, O. Jaubert, K. Lopez, R. M. Botnar, and C. Prieto, “High-dimensionality undersampled patch-based reconstruction (HD-PROST) for accelerated multi-contrast MRI,” Magn. Reson. Med., vol. 81, no. 6, pp. 3705–3719, 2019.
- [46] X. Zhang, Z. Xu, N. Jia, W. Yang, Q. Feng, W. Chen, and Y. Feng, “Denoising of 3D magnetic resonance images by using higher-order singular value decomposition,” Med. Image Anal., vol. 19, no. 1, pp. 75–86, 2015.
- [47] J. Shewchuk, “An introduction to the conjugate gradient method without the agonizing pain,” 1994.
- [48] M. J. J, “The levenberg-marquardt algorithm: implementation and theory,” Numerical analysis, pp. 105–116, 1978.
- [49] Y. Zhu, Y. Liu, L. Ying, X. Liu, H. Zheng, and D. Liang, “Bio-SCOPE: fast biexponential mapping of the brain using signal-compensated low-rank plus sparse matrix decomposition,” Magn. Reson. Med., vol. 83, no. 6, pp. 2092–2106, 2020.
- [50] M. V. W. Zibetti, A. Sharafi, R. Otazo, and R. R. Regatte, “Compressed sensing acceleration of biexponential 3D- relaxation mapping of knee cartilage,” Magn. Reson. Med., vol. 81, no. 2, pp. 863–880, 2019.
- [51] A. Sharafi, D. Xia, G. Chang, and R. R. Regatte, “Biexponential relaxation mapping of human knee cartilage in vivo at 3 T,” NMR Biomed., vol. 30, no. 10, p. e3760, 2017.
- [52] G. Captur, P. Gatehouse, K. E. Keenan, F. G. Heslinga, R. Bruehl, M. Prothmann, M. J. Graves, R. J. Eames, C. Torlasco, G. Benedetti et al., “A medical device-grade and ECV phantom for global mapping quality assurance—the mapping and ECV standardization in cardiovascular magnetic resonance (T1MES) program,” J. Cardiovasc. Magn. Reson., vol. 18, no. 1, pp. 1–20, 2016.
- [53] B. Mitrea, A. Krafft, R. Song, R. Loeffler, and C. Hillenbrand, “Paired self-compensated spin-lock preparation for improved quantification,” J. Magn. Reson., vol. 268, pp. 49–57, 2016.
- [54] A. Rich, M. Gregg, N. Jin, Y. Liu, L. Potter, O. Simonetti, and R. Ahmad, “Cartesian sampling with variable density and adjustable temporal resolution (CAVA),” Magn. Reson. Med, vol. 83, no. 6, pp. 2015–2025, 2020.
- [55] Y. Zhou, P. Pandit, V. Pedoia, J. Rivoire, Y. Wang, D. Liang, X. Li, and L. Ying, “Accelerating cartilage imaging using compressed sensing with iterative locally adapted support detection and JSENSE,” Magn. Reson. Med., vol. 75, no. 4, pp. 1617–29, 2016.
- [56] S. Ravishankar and Y. Bresler, “MR image reconstruction from highly undersampled k-space data by dictionary learning,” IEEE Trans. Med. Imag., vol. 30, no. 5, pp. 1028–41, 2011.
- [57] J. Cheng, S. Jia, L. Ying, Y. Y. Liu, S. S. Wang, Y. J. Zhu, Y. Li, C. Zou, X. Liu, and D. Liang, “Improved parallel image reconstruction using feature refinement,” Magn. Reson. Med., vol. 80, no. 1, pp. 211–223, 2018.
- [58] Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli, “Image quality assessment: from error visibility to structural similarity,” IEEE Trans. Image Process., vol. 13, no. 4, pp. 600–12, 2004.
- [59] T. Nguyen-Duc, T. Quan, and WK.Jeong, “Frequency-splitting dynamic MRI reconstruction using multi-scale 3D convolutional sparse coding and automatic parameter selection,” Med. Image Anal., vol. 53, pp. 179–196, 2019.
- [60] P. Bao, W. Xia, k. Yang, W. Chen, M. Chen, Y. Xi, S. Niu, J. Zhou, H. Zhang, and H. Sun, “Convolutional sparse coding for compressed sensing CT reconstruction,” IEEE Trans. Med. Imag., vol. 38, no. 11, pp. 2607–2619, 2019.
- [61] F. Ong and M. Lustig, “Beyond low rank + sparse: multiscale low rank matrix decomposition,” IEEE J. Sel. Topics Signal Process., vol. 10, no. 4, pp. 672–687, 2016.
- [62] F. Ong, X. . Zhu, J. Cheng, K. Johnson, P. Larson, S. Vasanawala, and M. Lustig, “Extreme MRI: large-scale volumetric dynamic imaging from continuous non-gated acquisitions,” Magn. Reson. Med., vol. 84, no. 4, pp. 1763–1780, 2020.
- [63] Q. Chen, H. She, and Y. Du, “Whole brain myelin water mapping in one minute using tensor dictionary learning with low-rank plus sparse regularization,” IEEE Trans. Med. Imag., vol. 40, no. 4, pp. 1253–1266, 2021.
- [64] D. Liang, J. Cheng, Z. Ke, and L. Ying, “Deep magnetic resonance image reconstruction: Inverse problems meet neural networks,” IEEE Signal Process. Mag., vol. 37, no. 1, pp. 141–151, 2020.
- [65] I. Chun, Z. Huang, H. Lim, and J. Fessler, “Momentum-net: Fast and convergent iterative neural network for inverse problems,” IEEE Trans. Pattern Anal. Mach. Intell., 2020.
- [66] W. Dong, P. Wang, W. Yin, G. Shi, F.Wu, and X. Lu, “Denoising prior driven deep neural network for image restoration,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 41, no. 10, pp. 2305–2318, 2018.
Supplementary Information
6.1 Data Acquisition Information
The 2D dataset was collected on a 3T scanner (TIM TRIO,Siemens, Erlangen, Germany) using a 12-channel head coil from three volunteers (age: 24 ± 2 years). The 3D dataset was collected on a 3T scanner (uMR 790, United Imaging Healthcare, Shanghai, China) using a 32-channel head coil from two healthy volunteers (age: 26 ± 1 years). -weighted images were acquired using the fast spin echo (FSE) sequence for 2D imaging and the modulated flip angle technique in refocused imaging with an extended echo train (MATRIX) sequence for 3D imaging, both using a spin-lock pulse at the beginning of the sequence to generate the -weighting [20, 53]. The main imaging parameters that used in the 2D and 3D imaging applications are listed in Supplementary information Table S1.
The 2D phantom dataset was also collected a 3T scanner (TIM TRIO,Siemens, Erlangen, Germany) using a 12-channel head coil. The imaging sequence was the same as used in the in vivo data acquisition. To obtain an accurate estimation of the phantom, a longer TR of 4000 ms was used. Therefore, the scan time of the phantom data acquisition was longer than that of the in vivo data acquisition.
6.2 Reconstruction Parameters
The reconstruction parameters that used the SMART method are listed in Supplementary information Table S2. In the L + S method, the singular-value thresholding and soft-thresholding algorithms were used to solve for the L and S components, respectively. The ratio for singular-value thresholding was set as 0.02, whereas that for soft-thresholding was set as [0.02, 0.025, 0.025, 0.035, and 0.035] to achieve optimal performance. In the LLR method, the iteration numbers were set as 40, 50, and 60 for R = 4 and 6, respectively. The block size was set as , and the ratio of the largest singular value used for the threshold of the singular value decomposition was initially set as 0.03, reduced to 0.01 after 10 iterations, and finally reduced to 0.005 in the final 10 iterations. The parameters for PROST and PROST + HM were the same as those for SMART. In the MORASA, the rank of the Casorati matrix was 2. The threshold for the wavelet coefficients and that of the Hankel matrix were 0.01 and 0.03, respectively.
6.3 Real Phantom
Supplementary Information Fig.S1(a-c) shows the -weighted image of the real phantom at TSL = 40 ms, the obtained map, and the estimated values of the nine vials, respectively.
6.4 Retrospective 2D Reconstruction
6.4.1 Low acceleration
Supplementary information Fig. S2 shows the reconstructed -weighted images (at TSL = 1 ms) and the magnified images of the region of interest from another volunteer using the SMART, RROST + HM, PROST, L + S, LLR, and MORASA methods at R = 4 and 6, respectively. The SMART method can better preserve the image resolution and finer details than the RROST + HM, PROST, and MORASA methods. The L + S and LLR methods have an image enhancement effect in the reconstructed images, particularly in the sulcus area, which are indicated by the red arrows. Compared to the methods exploiting spatial low-rankness (that is, the PROST, L + S, and LLR methods), the reconstruction can be improved by using parametric low-rankness based on high correlations in signal evolution in the reconstruction model.
6.4.2 Higher acceleration
Supplementary information Fig.S3 compares the maps and the corresponding error maps obtained using different methods for R = 10.2 and 11.7. It can be seen that SMART generates the closest map to the reference with the lowest nRMSE.The maps obtained using L+S and LLR show obvious blurring artifacts, and maps obtained using MORASA show aliasing artifacts (indicated with red arrows). The Patch-based low-rank tensor spatial tensor can reduce aliasing artifacts and preserve more image details. SMART further improves the reconstruction performance and estimation accuracy by using the parametric tensor compared with PROST+HM and PROST.
6.5 Prospective 2D Reconstruction
Supplementary information Fig. S4 shows the corresponding maps reconstructed using the SMART, PROST + HM, PROST, L + S, LLR, and MORASA methods and the error maps between the reconstructed map and the reference map. The maps reconstructed using the SMART method exhibited superior reconstruction performance compared to those reconstructed using the other four methods, with the smallest nRMSEs and error maps for both acceleration factors.
6.6 Retrospective 3D Reconstruction
6.6.1 low acceleration
The maps reconstructed using the SMART, PROST + HM, PROST, L + S, LLR, and MORASA methods are shown in Supplementary information Fig. S5.
6.6.2 Higher acceleration
6.7 Parameter Selection
To clearly demonstrate the necessity of updating tissue maps in the iteration, the representative zero-filled reconstruction with R = 6, the intermediate results at the 12th iteration , the parameter histogram, the estimated map, and the corresponding tissue groups and the ranks of tissue groups are included in the Supplemental information Fig. S7. To show the tissue group, we randomly selected 10 of them and chose 10 pixels from each of the group randomly, since the total tissue groups are too much to be shown. Then, an image block with the size of can be constructed for each tissue group, where 10 is the pixel number chosen and 5 is the TSL number. The image blocks are shown as an example of the tissue groups. To calculate the rank of a tissue group, we construct the low-rank matrix with all pixels in the tissue group. The size of the matrix is where is the pixel number in the group and 5 is the TSL number. The rank value of the matrix was calculated using the SVD method. The rank curves of all tissue groups are shown.
6.8 Reconstruction Time
The reconstruction time for each method used in the 2D (R = 4 ) and 3D (R = 6.76) imaging applications is listed in Supplementary information Table S3.
6.9 Algorithms
The algorithms for HOSVD and the SMART method are shown in Algorithms 1 and 2, respectively.

| Retro | Scanner | Coils | Matrix | FOV( | Thickness | TSL | Scan time | |
|---|---|---|---|---|---|---|---|---|
| 2D | Siemens (phantom) | 12 | 5 | |||||
| 2D | Siemens (in vivo) | 12 | 5 | |||||
| 3D | UIH | 32 | 2 | |||||
| Pro | 2D | Siemens | 12 | 5 |
| ADMM iteration | CG iteration | CG tolerance | |||||
|---|---|---|---|---|---|---|---|
| 15 | |||||||
| 15 |
| Methods | SMART | PROST+HM | PROST | L+S | LLR | MORASA |
|---|---|---|---|---|---|---|
| 2D () | ||||||
| 3D () |
-
•
Unit of reconstruction time: second.
6.10 Convergence analysis
The convergence of the proposed method is still an open problem[18, 39]. Although empirical evidence suggests that the reconstruction algorithm has very strong convergence behavior, the satisfying proof is still under study. In this study, we analyze the time complexity of the SMART method using the notation, and we give a weak convergence result with the following Theorem :
Theorem 1: Suppose Assumption (A1) in the Proof section holds, and the multipliers are bounded. Then, we have
| (20) |
where denotes the subgradient of the augmented Lagrangian function and is the total number of iterations.
The proof of Theorem 1 is described in the next section.
6.11 Proof
In this section, we provide proofs on the following assumptions:
(A1) The sequence of paired proximal operators is asymptotically nonexpansive with a sequence { }, e.g.,
| (21) |
The assumption (A1) is a standard assumption for analyzing the convergence of the learned iterative algorithms, which also can be found in [65, 66].
Considering the operator is performed at every iteration in, let , ,and , where denotes an operator which vectorizes the tensor. Then (7) can be expressed as
| (22) |
According to the -strongly convex of with respect to , we have
| (23) |
Since is also -strongly convex with respect to , we have
| (24) |
According to the update rule of the multiplier , we have
| (25) |
On the other hand, we have
| (26) | |||
where the sencond equality comes from the non-expansion assumption (A1) of . With respect to the first-order optimization condition for the update on , that is, , we have
| (27) |
where and represent the Hermitian adjoint of operators and , respectively. Then we have
| (28) | |||
where denotes the minimum singular value of , and denotes the maximum singular value of .
Combining (23), (24), (25), (26), (28), we have
| (29) | |||
Summing both sides of the above inequality from 0 to , we have
| (30) | ||||
On the other hand, let , we have
| (31) |
where is equal to the sum of and . According to the iterative rule of ADMM algorithm, we have
| (32) |
Combing (31) and (32), we have
| (33) |
Then, we have
| (34) | ||||
where denotes the largest singular values of , the first inequality is due to the nonexpensive assumption of , and the second inequality is due to the relation (28). By the convexity of norm, we have
| (35) | ||||
From aforementioned analysis, we know that we can choose which implies that
| (36) |