Absolute Zero-Shot Learning
Abstract
Considering the increasing concerns about data copyright and privacy issues, we present a novel Absolute Zero-Shot Learning (AZSL) paradigm, i.e., training a classifier with zero real data. The key innovation is to involve a teacher model as the data safeguard to guide the AZSL model training without data leaking. The AZSL model consists of a generator and student network, which can achieve date-free knowledge transfer while maintaining the performance of the teacher network. We investigate ‘black-box’ and ‘white-box’ scenarios in AZSL task as different levels of model security. Besides, we also provide discussion of teacher model in both inductive and transductive settings. Despite embarrassingly simple implementations and data-missing disadvantages, our AZSL framework can retain state-of-the-art ZSL and GZSL performance under the ‘white-box’ scenario. Extensive qualitative and quantitative analysis also demonstrates promising results when deploying the model under ’black-box’ scenario.
Introduction
The blossom of deep learning technologies embraces the development of high-performance computing and large-scale multi-modal data. The nature of deep learning is that the pre-trained base model can extract empirical knowledge, e.g. visual features (He et al. 2016) and semantic meanings (Devlin et al. 2018) from large-scale datasets. However, sharing data across different institutes and even between different countries has become increasingly difficult and sensitive. The increasing awareness of data copyright, expensive data cleaning and annotation, and restricted access to data in expert domains, e.g. health and security, has hindered the development of interdisciplinary and intercultural deep models.

As shown in Fig.1, datasets may contain biometric, health, face information etc. (Sudlow et al. 2015) that cost the data owner over billions and tens of years to collect. Strict regulations, such as the GDPR(Voigt and Von dem Bussche 2017) in Europe has been enforced to control the risk of data leaking. When an AI company needs access to such sensitive data to provide AI services, the shared data is confronting the leaking risk even though tedious confidentiality agreements have been signed.
This paper is motivated by the increasing concerns about data and model privacy issues. As a promising machine learning paradigm, Zero-Shot Learning (ZSL) investigates an extreme case when such deep transfer cannot be achieved due to no access to the test domain data (Lampert, Nickisch, and Harmeling 2013; Fu et al. 2015; Annadani and Biswas 2018). The learning objective of ZSL is to build a consistent visual-semantic mapping based on auxiliary information (i.e., attributes or word embeddings) on seen class domain so that model can generalise to unseen class domain at the test time (Lampert, Nickisch, and Harmeling 2009; Frome et al. 2013). The criticizing and rethinking in ZSL task never ceases. For available data during training, existing settings can be divided into inductive and transductive ZSL. Early ZSL models focus mainly on inductive ZSL (IZSL) (Lampert, Nickisch, and Harmeling 2009; Jayaraman and Grauman 2014), which only utilise labeled seen data for training. Transductive ZSL (TZSL) (Kodirov et al. 2015; Song et al. 2018) assumes both seen labeled and unseen unlabeled data are available during the training stage, which aims to utilise the universe information for improving the generalization of model. Besides, generalization ability is also a key issue for ZSL task. In test phase, early ZSL models (Norouzi et al. 2014; Lampert, Nickisch, and Harmeling 2013) can only output unseen class labels during evaluation, which is called conventional ZSL (CZSL), i.e., test images only come from unseen classes. Generalised ZSL (GZSL) (Chao et al. 2016) is then proposed, which aims to combine seen and unseen classifiers into a unified model.
Existing ZSL models are established based on real data from either seen or unseen classes. When adapting a pre-trained model to a new task domain, existing ZSL models assume a large amount of labeled seen class or unlabeled unseen class data are available to establish the visual-semantic relationship. However, sharing data across different institutes and even between different countries is often infeasible. Different from existing ZSL settings, we focus on establishing ZSL model without data sharing during the training process. In this paper, we propose a new paradigm dubbed Absolute Zero-Shot Learning (AZSL) to avoid sensitive data leaking while still enabling AI model can be trained. Figure 1 briefly illustrates the difference between ZSL and AZSL task. As for data privacy preserving, federated learning (McMahan et al. 2017; Hao et al. 2021) provides a promising strategy through model sharing between data owner server and service client. Motivated by this, our AZSL task suggests replacing data with a teacher model (pre-trained on real data) to guide the ZSL model training. Teacher model can be regarded as the implicit representation of data so that AZSL model can be established through the supervision of teacher model, which can prevent real data from being shared. While federated learning has demonstrated promise for data privacy, it only tackles the supervised learning task, which cannot be extended to unseen class classification. Here we propose the data-free knowledge transfer framework for AZSL task. Concretely, we aim to synthesise data conditioned on class-level semantic embeddings depending on the guidance of teacher model, so that ZSL classification will be possible based on synthesised data.
To comprehensively explore our proposed AZSL framework, we also present extensive discussion from the perspective of model weights security and knowledge space of the teacher model. First, we propose two AZSL scenarios in terms of model security. When data owner provides the teacher model as data safeguard for ZSL model training, the data may be leaked to some extent by gradients exchange (Zhu, Liu, and Han 2019). To explore the influence of different guidance provided by the teacher model, we propose the AZSL model in two scenarios for further discussion. In the ‘black-box’ scenario, the teacher only provides output classification scores but does not share weights. In the ‘white-box’ scenario, the teacher will also share the model weights during training, which is more informative. These two scenarios indicate different levels of communication between data owner and AI service provider, which will lead to different ZSL recognition performance. Furthermore, we propose two types of teachers for discussion. Existing ZSL methods can be categorised into IZSL and TZSL depending on whether the unlabeled unseen data are available for training. Motivated by this, we propose inductive and transductive teachers according to whether unseen classes are involved in pre-training teacher model. It is worth discussing the generalization ability of AZSL model with different knowledge spaces when training teacher model. In summary, our contributions are three-fold:
-
•
Absolute Zero-Shot Learning aims to achieve zero-shot classification without access to real data. The paradigm can be applied to many real-world applications when access to real data is not permitted.
-
•
We develop a novel data-free knowledge transfer framework for AZSL task. In addition to the zero data sharing setting, we propose ‘black-box’ and ‘white-box’ scenarios and discuss the pros and cons of model sharing problems. We also present analysis of teacher model in both inductive and transductive settings.
-
•
We show experimental results for both conventional ZSL and GZSL tasks in two scenarios. Our AZSL model achieves promising performance on existing benchmarks despite the disadvantage of data absence. Extensive qualitative analysis demonstrates the effectiveness of our framework.
| IZSL | TZSL | AZSL | |
| Leaking Data | 0 | ||
| Leaking Weights | 0 | ||
| Paradigm |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/463245f7-1905-4fc6-9cb5-8c62bb216c19/x2.png)
|
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/463245f7-1905-4fc6-9cb5-8c62bb216c19/x3.png)
|
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/463245f7-1905-4fc6-9cb5-8c62bb216c19/x4.png)
|
Related Work
The most widely used framework for data privacy preserving is the federated learning (Konevcnỳ et al. 2016; McMahan et al. 2017). A global model is shared with clients to avoid data leaking. However, data-free knowledge transfer and model inversion techniques (Yin et al. 2020; Smith et al. 2021; Yin et al. 2021) can recover data from the pre-trained model and thus can be used to attack shared models in federated learning. Knowledge distillation utilises the domain-expert teacher model to train a compact student model with pursuing competitive recognition accuracy (Xu, Liu, and Loy 2020; Chen et al. 2021). Machine teaching (Zhu 2015; Liu et al. 2017) focuses on training a teacher model to select an optimal data set for the student model. Both knowledge distillation and machine teaching provides promising solutions to separate student model so that teacher model can avoid the attack. Yet, none of these methods have explored their potential in data privacy preserving. This paper presents the first work exploring the data privacy potential via zero-shot learning paradigm. Meanwhile, our proposed AZSL retains the property of traditional ZSL that can generalised to unseen classes without further training.
Zero-Shot learning (Zhang et al. 2018; Larochelle, Erhan, and Bengio 2008; Vyas, Venkateswara, and Panchanathan 2020; Ma and Hu 2020) aims to recognise unknown/unseen classes by establishing the relationship between seen and unseen classes, which can bridge the gap via class semantic information, i.e., attributes (Jayaraman and Grauman 2014), predefined similes (Long and Shao 2017) and word embedding (Zhang and Saligrama 2016). In terms of establishing the relationship between visual and semantic spaces, existing methods can be mainly separated into three groups. Some works (Qin et al. 2016; Kodirov, Xiang, and Gong 2017; Felix et al. 2018) aim to build the mapping from visual to semantic space and then assign class label via nearest neighbor (NN) classifier. Other works (Gao et al. 2020; Xian et al. 2018) focus on unseen class data generation to alleviate data-missing problem. Meanwhile, (Akata et al. 2013, 2015) explore an effective common space for visual and semantic embedding by maximizing their compatibility scores. existing ZSL methods aim to build the effective mapping among visual and semantic spaces to mitigate the gap between seen and unseen classes.
According to whether unseen data is adopted during training, existing ZSL methods can be categorised into inductive (Long et al. 2017; Romera-Paredes and Torr 2015) and transductive settings (Song et al. 2018; Fu et al. 2015). As for the test phase, inductive ZSL methods (Akata et al. 2013; Norouzi et al. 2014) assume the test data only come from unseen classes. Generalised ZSL (GZSL) (Chao et al. 2016; Min et al. 2020) is then proposed to assign both seen and unseen data into corresponding classes. Compared with conventional ZSL, GZSL attempts to model the more challenging real situation.
We present the differences between AZSL and existing ZSL settings in Table 1. In terms of leaking data in the training process, only labeled seen data is available in IZSL while TZSL can use data from both seen and unseen classes. AZSL setting assumes that model is established without access to any real data. As for model security, we refer to the sharing of weights trained on real data as weight leaking. ZSL model weights in both inductive and transductive settings are all leaked. For AZSL, teacher model pre-trained on real data is provided during training. In terms of teacher weights privacy, we propose black- and white-box scenarios. The teacher weights are leaked for guidance during training AZSL models in white-box scenario while no weights are shared in black-box scenario, which preserves the privacy for both data and model weights.

Absolute Zero-Shot Learning
As shown in Fig. 2, AZSL addresses the problem when sensitive data is secured on the Server domain. The key idea is to introduce a teacher model as the data safeguard and guide the model deployed on the Client domain to train an AZSL classifier with absolute zero real data. In addition to data privacy preserving, we introduce white-box and black-box scenarios to discuss the teacher model sharing problem regarding the balance between performance and security.
AZSL Problem Formulation
The basic AZSL setting involves secured images and their extracted visual features . The data safeguard is a pre-trained teacher model on the server domain. For simplicity, we consider the supervised learning model , where is the label space. The ultimate goal of AZSL is to train a student model on the client domain using an objective function that learns from the guidance of the teacher model:
| (1) |
where is generated data that ensures no real data can be accessed.
Inductive vs Transductive AZSL On the server domain, we further breakdown the AZSL into inductive (Ind) and transductive (Trans) teachers according to the label space. Seen classes are defined as , where denotes the -dimensional visual feature in the set of seen class features, denotes the -dimensional auxiliary class-level semantic embedding, and stands for the set of labels for seen classes. Unseen classes are defined as , where represents the unseen class features, denotes the class-level semantic embedding of unseen classes and denotes the unseen class labels. Seen and unseen classes are disjoint, i.e., . For AZSL, both seen and unseen features, and , are unavailable for client. Available information for AZSL client can be represented as , which means only semantic embedding and class labels can be accessed. In this way, we consider the basic AZSL is transductive because the source domain contains both seen and unseen classes. A more challenging Inductive AZSL considers .
ZSL vs GZSL On the client domain, AZSL aims classify test images for conventional ZSL, and for Generalised ZSL. The training of above classifiers using absolutely generated data will be introduced next.
White-Box & Black-Box Scenarios
The objective function of AZSL in Eq. 1 defines a data-free knowledge transfer framework for AZSL task, i.e., through the guidance of the teacher model, our proposed AZSL formula consists of two components: a Generator and a Student network . Figure 2 depicts the detailed AZSL framework in both white-box and black-box scenarios. The system consists of 1) the secured data and teacher model on the server; 2) AZSL model on the client; 3) and the information exchange channels.
Considering the model inversion can attack share models, we also investigate the security levels regarding model sharing in addition to data privacy preserving. For white-box scenario, the teacher weights are involved to compute the gradient for the generator and student network training. In the black-box scenario, the teacher only provides the output as pseudo labels, i.e., teacher model is not involved in back propagation for optimization of AZSL framework.
White-Box Scenario
In white-box scenario, the teacher model provides both gradient and softmax output as the AZSL training guidance as follows. 1) Uploading generated data: the generator synthesises features of same classes with the supervision with teacher based on noise and class-level semantic embedding (attributes or BERT model of class names (Devlin et al. 2018) as the condition). Specifically, we aim to synthesise the features that can be classified into corresponding classes with the constraint of the teacher network. represents the generated features which are uploaded to the server. 2) Gradient and softmax guidance: The teacher model receives and process the data using the loss function:
| (2) |
where represents cross-entropy loss by teacher model for classification, refers to the regularisation term during feature generation with hyperparameter . The regularisation term aims to minimise the distribution distance of real and generated features. Note that the regularization is also completed at the server side and real data will not be accessed for the client. 3) Feedback downloading: a request is sent to the client so that the gradient, the regularisation of distribution divergence, and softmax output can be download. 4) Label verification: Using the softmax to compute pseudo labels and filter out misclassified generated samples:
| (3) | ||||
where denotes the high-quality generated features and denotes the corresponding class labels. 5): Training the student network:
| (4) |
In the white-box scenario, the gradient is imposed directly onto the generated features and can massively improve the performance of the generator. As a trade-off, the gradient feedback is mid-risk information (may lead to teacher model leaking) whereas the softmax and regularisation feedback are low-risk.
Black-Box Scenario
Black-box scenario only differs from the white-box scenario in the guidance provided by the teacher model in the second step. Only low-risk regularisation and softmax output can be requested from the teacher model so as to avoid the model leaking risk. Specifically, the generated features is uploaded to the server to compute the softmax and divergence regularisation. The server then creates a request so that the feedback can be downloaded. Generated data can validate whether its conditional class input can match the teacher softmax output and misclassified samples are filtered out. The generator and student network are then trained as an end-to-end model as follows:
| (5) |
where denotes the optimised parameters of teacher, denotes the parameters of generator and student network respectively.
In summary, there are two crucial tasks in AZSL, i.e. data generation and verification. As the first AZSL, our key contributions focus on investigating key research questions: 1) what are the impacts of different teacher feedback information on the quality and diversity of generated data? 2) different semantic information as generation condition and their impacts; 3) the trade-off between performance and security in white-box and black-box; 4) can student generate new knowledge beyond the limitation of an inductive teacher? 5) previous work uses real seen data and generated unseen data, which causes the prediction bias towards seen classes. In AZSL, both seen and unseen classes are trained using generated data, which improves the consistency between seen and unseen classifier in the GZSL problem. Detailed training procedure in both scenarios is shown in Algorithm 1.
Absolute Zero-Shot Classification
After the training process, the generator can synthesise features of good quality and the student network can predict class labels of test features.
With the transductive teacher, where seen and unseen classes are available, the generator can synthesise features of all classes. Given the test features, we can obtain the predicted class labels as follows:
| (6) |
where denotes optimised parameters of student.
With the inductive teacher, where only seen class data is available, the problem is more challenging because the information of unseen classes is unavailable for both server and client during training. The generator is utilised to synthesise data of unseen classes. Given the noise and unseen class semantic embedding, the generated features can be obtained as . Then it is converted into a supervised learning task. The generated features are adopted to train a classifier as follows:
| (7) |
And class labels of test features can be predicted as follows:
| (8) |
where for the conventional ZSL task, and for GZSL task.
| Dataset | Semantics | Class Number | Image | Teacher (Trans / Ind) | AZSL Training | AZSL Evaluation | |||
| (Trans / Ind) | |||||||||
| S / U | S | U | S | U | S | U | |||
| AWA1 (Lampert, Nickisch, and Harmeling 2013) | BERT / attributes | 40 / 10 | 30475 | 19832 | 4542 / 0 | 0 | 0 | 4958 | 1143 / 5685 |
| AWA2 (Xian et al. 2017) | BERT / attributes | 40 / 10 | 37322 | 23527 | 6328 / 0 | 0 | 0 | 5882 | 1585 / 7913 |
| aPY (Farhadi et al. 2009) | BERT / attributes | 20 / 12 | 15539 | 5932 | 6333 / 0 | 0 | 0 | 1483 | 1591 / 7924 |
Experiments
Datasets
We evaluate our AZSL model on three benchmark datasets: AWA1 (Lampert, Nickisch, and Harmeling 2013), AWA2 (Xian et al. 2017)) and aPY (Farhadi et al. 2009). AWA1 and AWA2 consist of 30,475 and 37,322 images respectively and both datasets have 50 classes. aPY contains 15,539 images of 32 classes. In terms of semantic representation, we adopt the word embedding generated by language representation model BERT (Devlin et al. 2018) and the dimension of semantic embedding is 768 for all datasets. As for data split, there exist differences with two types of teacher models. In terms of inductive teacher, we follow the proposed data split proposed in (Xian et al. 2017), i.e., only seen class data is available for the teacher. Transductive teacher is trained with all classes. We split the unseen classes randomly into training and test with a 4:1 ratio, which follows the proportion of seen data split in (Xian et al. 2017). The detailed information of each dataset under data splits in AZSL is shown in Table 2.
Implementation Details
As for image representation, We adopt the 2048-dimensional ResNet101 (He et al. 2016) features following (Xian et al. 2017). In our proposed framework, all networks are based on multi-Layer perceptrons (MLP) with the LeakyReLU activations (Xu et al. 2015). The teacher and student have the same architecture, which consists of two hidden layers with 1024 and 512 hidden units respectively. The generator contains a single hidden layer with 4096 hidden units and its output layer is ReLU. During the training process, we adopt the Adam (Kingma and Ba 2015) optimiser and the learning rate of each network is set to . The dimension of the noise vector is hyper-parameter, which is empirically set to 20 for all datasets. The weight of regularization term is empirically set to 0.5 for AWA1 and AWA2, and 1 for aPY. The number of generated features is determined considering the trade-off between accuracy and computational efficiency. In practice, we generate 400 generated features in average per class for all datasets.
Evaluation Protocol
We follow the evaluation metrics proposed in (Xian et al. 2017). For conventional ZSL task, we use the per-class average top-1 accuracy to evaluate the classification performance to alleviate the data imbalance of classes. For GZSL task, we use harmonic mean for evaluation, where and denote average per-class top-1 accuracy on unseen and seen classes, respectively. It is noteworthy that existing methods aim to classify unseen data into corresponding unseen classes in conventional ZSL task, while the class space at test time involves both unseen and seen classes in AZSL with transductive teacher. This makes AZSL with a transductive teacher more difficult compared with existing ZSL methods.
| Method | Zero-Shot Learning | Generalised Zero-Shot Learning | |||||||||||
| AWA1 | AWA2 | aPY | AWA1 | AWA2 | aPY | ||||||||
| T1 | T1 | T1 | u | s | H | u | s | H | u | s | H | ||
| Inductive | IAP (Lampert, Nickisch, and Harmeling 2013) | 35.9 | 35.9 | 36.6 | 2.1 | 78.2 | 4.1 | 0.9 | 87.6 | 1.8 | 5.7 | 65.6 | 10.4 |
| DAP (Lampert, Nickisch, and Harmeling 2013) | 44.1 | 46.1 | 33.8 | 0.0 | 88.7 | 0.0 | 0.0 | 84.7 | 0.0 | 4.8 | 78.3 | 9.0 | |
| ALE (Akata et al. 2013) | 59.9 | 62.5 | 39.7 | 16.8 | 76.1 | 27.5 | 14.0 | 81.8 | 23.9 | 4.6 | 73.7 | 8.7 | |
| DEVISE (Frome et al. 2013) | 54.2 | 59.7 | 39.8 | 13.4 | 68.7 | 22.4 | 17.1 | 74.7 | 27.8 | 4.9 | 76.9 | 9.2 | |
| SYNC (Changpinyo et al. 2016) | 54.0 | 46.6 | 23.9 | 8.9 | 87.3 | 16.2 | 10.0 | 90.5 | 18.0 | 7.4 | 66.3 | 13.3 | |
| DEM (Zhang, Xiang, and Gong 2017) | 68.4 | 67.1 | 35.0 | 32.8 | 84.7 | 47.3 | 30.5 | 86.4 | 45.1 | 11.1 | 75.1 | 19.4 | |
| f-CLSWGAN (Xian et al. 2018) | 68.2 | - | - | 57.9 | 61.4 | 59.6 | - | - | - | - | - | - | |
| SE-GZSL (Verma, Arora, and Mishra 2018) | 69.5 | 69.2 | - | 56.3 | 67.8 | 61.5 | 58.3 | 68.1 | 62.8 | - | - | - | |
| ISE-GAN (Pambala, Dutta, and Biswas 2020) | 68.4 | 65.6 | - | 58.7 | 74.4 | 65.6 | 55.9 | 79.3 | 65.5 | - | - | - | |
| Disentangled-VAE (Li et al. 2021) | - | - | - | 60.7 | 72.9 | 66.2 | 56.9 | 80.2 | 66.6 | - | - | - | |
| CE-GZSL (Han et al. 2021) | 71.0 | 70.4 | - | 65.3 | 73.4 | 69.1 | 63.1 | 78.6 | 70.0 | - | - | - | |
| AZSL+BB | 14.1 | 19.9 | 12.3 | 4.1 | 3.7 | 3.9 | 3.5 | 3.7 | 3.6 | 6.8 | 4.0 | 5.1 | |
| AZSL+WB | 34.5 | 36.5 | 18.7 | 23.4 | 34.3 | 27.8 | 27.3 | 44.3 | 33.7 | 17.9 | 52.5 | 26.7 | |
| Transductive | QFSL (Song et al. 2018) | - | 79.1 | - | - | - | - | 66.2 | 93.1 | 77.4 | - | - | - |
| PREN (Ye and Guo 2019) | - | 78.6 | - | - | - | - | 32.4 | 88.6 | 47.4 | - | - | - | |
| GMN (Sariyildiz and Cinbis 2019) | 82.5 | - | - | 70.8 | 79.2 | 74.8 | - | - | - | ||||
| DTN (Zhang et al. 2020a) | 69.0 | - | 41.5 | 54.8 | 88.5 | 67.7 | - | - | - | 37.4 | 87.9 | 52.5 | |
| GMSADE (Gune et al. 2020) | 81.3 | 80.7 | 49.9 | 71.2 | 87.7 | 78.6 | 71.3 | 86.1 | 78.0 | 76.1 | 39.3 | 51.8 | |
| EDE (Zhang et al. 2020b) | 85.3 | 77.5 | 31.3 | 71.4 | 90.1 | 79.7 | 68.4 | 93.2 | 78.9 | 29.8 | 79.4 | 43.3 | |
| AZSL+BB | 33.5 | 29.0 | 30.2 | 33.5 | 28.6 | 30.9 | 29.0 | 25.3 | 27.0 | 30.2 | 42.2 | 35.2 | |
| AZSL+WB | 77.9 | 79.0 | 83.9 | 77.9 | 81.8 | 79.8 | 79.0 | 86.7 | 82.7 | 83.9 | 85.7 | 84.8 | |
| Method | Zero-Shot Learning | Generalised Zero-Shot Learning | ||||||||||
| AWA1 | AWA2 | aPY | AWA1 | AWA2 | aPY | |||||||
| T1 | T1 | T1 | u | s | H | u | s | H | u | s | H | |
| Label-Conditioned | 15.5 | 10.0 | 7.0 | 15.5 | 24.3 | 18.9 | 10.0 | 17.8 | 12.8 | 7.0 | 3.8 | 4.9 |
| Attribute-Conditioned | 10.1 | 23.0 | 8.2 | 10.1 | 11.3 | 10.7 | 23.0 | 17.6 | 20.0 | 8.2 | 5.0 | 6.3 |
| w/o Data Verification | 25.6 | 24.7 | 11.8 | 25.6 | 15.6 | 19.4 | 24.7 | 18.1 | 20.9 | 11.8 | 20.9 | 15.0 |
| w/o Regularization | 26.8 | 23.7 | 23.2 | 26.8 | 26.7 | 26.8 | 23.7 | 23.2 | 23.4 | 23.2 | 25.6 | 24.3 |
| AZSL+BB | 33.5 | 29.0 | 30.2 | 33.5 | 28.6 | 30.9 | 29.0 | 25.3 | 27.0 | 30.2 | 42.2 | 35.2 |
Main Results
Comparisons with State-of-Art Methods
We present experimental results of the proposed AZSL model in both conventional and generalised ZSL task in Table 3. Considering this is the first proposed AZSL work, we provide comparison with traditional state-of-the-art ZSL methods as a reference. Note that all of our AZSL models are at significant disadvantage since no real data is involved during training. Instead, the AZSL model generates 400 features using class semantic embedding only for each class and request guidance feedback from the teacher model.
Our initial assumption was that if the generated feature can approximate the real data distribution, the performance should be close to those methods using real data. To our surprise, AZSL model with transductive teacher achieves promising performance in both conventional and generalised ZSL in white-box scenario despite the disadvantage in no access to the real data. Our model achieves the best performance in GZSL on all three datasets especially on aPY, with 32.3% increases in harmonic mean, indicating the better balance on seen and unseen classes of our AZSL model. In conventional ZSL, AZSL model gains the best performance on aPY and has competitive classification accuracy on AWA1 and AWA2. It is noteworthy that the class space contains all classes during the testing process, so it is more challenging in conventional ZSL task. As for black-box scenario, AZSL model shows good potential to achieve good balance between seen and unseen classes. For example, the accuracy on unseen classes is higher than seen classes on AWA2, with 4.9% higher performance. It indicates that AZSL model is promising to mitigate class-level overfitting issue (Zhang et al. 2018) in GZSL task.
Compared with inductive ZSL methods, results show that our proposed model with inductive teacher in white-box scenario gains the satisfactory performance in GZSL especially on aPY, with 7.3% higher performance on harmonic mean of our AZSL model. Although the improvement on inductive setting is not significant, it is very impressive for us that the student network can generate new knowledge beyond the source data of teacher model. For black-box scenario, the results show that our AZSL model outperforms random guessing, which are around 10% on AWA1, AWA2 and 8% on aPY according to unseen class number. The white-box achieves better performance than black-box, indicating that the gradient guidance provides more information.
Comparisons in Black-Box Scenario In this situation, transductive teacher contains the information of all classes and it gives the output guidance during training. As it is the first time to propose this setting, we provide several baselines for comparison shown in Table 4. We provide several types of class embedding for conditional feature generation. ‘Label-’ and ‘attribute-conditioned’ represent the feature synthesis conditioned on class label and attributes respectively. Compared with these two baselines, our proposed framework with BERT embedding achieves the best performance, i.e., with 18.0% and 23.4% increases in harmonic mean on AWA1. Besides, results show that our framework gains obvious improvement in accuracy with data verification, i.e., with 20.2% higher performance on harmonic mean on aPY dataset. In terms of feature generation constraint, the results indicate the effectiveness to adopt regularization, i.e., it achieves 4.4% and 10.9% increases in Harmonic mean on AWA2 and aPY. The comparison with baseline models demonstrate the effectiveness of our AZSL model in black-box scenario with transductive teacher.
| Method | AWA2 | aPY | ||||
| u | s | H | u | s | H | |
| CE | 76.1 | 83.8 | 79.8 | 83.0 | 84.5 | 83.7 |
| CE+MMD | 79.9 | 85.1 | 82.5 | 81.5 | 85.5 | 83.5 |
| CE+KL | 79.0 | 86.7 | 82.7 | 83.9 | 85.7 | 84.8 |
Discussion and Limitations
Feature Generation Regularization Analysis
The key issue in our data-free knowledge transfer framework is to generate high-quality features, which are expected to have similar distribution to real data. To show the influence of different constraints during feature generation process, we provide analysis with different regularization term for generator training in Table 5. KL and MMD loss (Gretton et al. 2012) aim to minimise the distribution difference between real and generated features. The results show that adding the distribution constraint of synthesised data is beneficial for feature generation. For example, the harmonic mean increases 2.7% and 2.9% with MMD and KL loss respectively compared with the baseline that only contains cross entropy loss. Besides, the results indicate that KL loss and MMD loss are both effective in improving the quality of generated data and KL loss performs better to a small extent, which shows the effectiveness of KL regularization.




Hyper-Parameter Analysis We evaluate the influence of two hyper-parameters, i.e.noise dimension and regularization weight, in our model. We have two ablation studies on AWA1 and aPY based white-box scenario with transductive teacher in Figure 3. We choose four different noise dimensions, i.e., 20,100,400,768, to show the relationship with harmonic mean. Results show that the performance decreases with the increase of noise dimension on both datasets, indicating that noise of high dimension may bring much interference. In terms of regularization weight, We set = 0.01, 0.1, 1, 10 in the experiments. As shown in Figure 3, harmonic mean on both datasets change slightly with different . And the best performance can be achieved when is 0.5 and 1 on AWA1 and aPY respectively.
Student Performance Analysis Here we conduct some experiments to analyze the student performance. We present classification accuracy of teacher and student networks with increasing training steps in both scenarios with transductive teacher on AWA1 and aPY. The teacher acts as the upper bound so student aims to achieve similar performance trained on generated features. As shown in Figure 4, student in white-box scenario obtains the satisfactory result close to teacher, indicating that gradient guidance is effective for framework training. Besides, results show that model achieves better performance with regularization term, indicating the effectiveness of feature distribution during training. And statistics also show that framework performs better with data verification in both scenarios, which indicates its necessity because it can mitigate the negative influence caused by generated features of inferior quality.
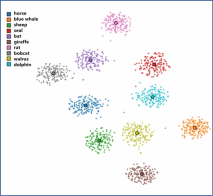
Quality of Generated Features Figure 5 shows the t-SNE visualization of real and generated unseen class features in both scenarios with transductive teacher on AWA1 and aPY dataset. We randomly choose a part of features for clear visualization. The generated features have distribution close to the real ones. And generated features are more class-level clustered than real features, indicating the effectiveness of feature generation under the supervision of teacher guidance, even though real data is unavailable. Therefore, generated features can be viewed as a suitable replacement for the real features.



Conclusions
This paper has presented a privacy preserving AZSL paradigm. A pre-trained teacher model was deployed on the data owner server as the data safeguard to provide guidance for AZSL training, in terms of data generation and verification. We extensively studied the proposed ‘black-box’ and ‘white-box’ scenarios and their trade-off in performance and security. Despite an embarrassingly simple MLP network, our framework maintains promising performance in both CZSL and GZSL tasks despite the absence of real data during training. The AZSL paradigm protected the data privacy and meanwhile mitigated the seen-unseen bias in GZSL tasks. Future development of AZSL can focus on model design, research communication cost, security of black-box and white-box scenario, and improving the performance on inductive AZSL settings.
References
- Akata et al. (2013) Akata, Z.; Perronnin, F.; Harchaoui, Z.; and Schmid, C. 2013. Label-embedding for attribute-based classification. In CVPR.
- Akata et al. (2015) Akata, Z.; Reed, S.; Walter, D.; Lee, H.; and Schiele, B. 2015. Evaluation of output embeddings for fine-grained image classification. In CVPR.
- Annadani and Biswas (2018) Annadani, Y.; and Biswas, S. 2018. Preserving semantic relations for zero-shot learning. In CVPR.
- Changpinyo et al. (2016) Changpinyo, S.; Chao, W.-L.; Gong, B.; and Sha, F. 2016. Synthesized classifiers for zero-shot learning. In CVPR.
- Chao et al. (2016) Chao, W.-L.; Changpinyo, S.; Gong, B.; and Sha, F. 2016. An empirical study and analysis of generalized zero-shot learning for object recognition in the wild. In ECCV.
- Chen et al. (2021) Chen, L.; Wang, D.; Gan, Z.; Liu, J.; Henao, R.; and Carin, L. 2021. Wasserstein contrastive representation distillation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 16296–16305.
- Devlin et al. (2018) Devlin, J.; Chang, M.-W.; Lee, K.; and Toutanova, K. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
- Farhadi et al. (2009) Farhadi, A.; Endres, I.; Hoiem, D.; and Forsyth, D. 2009. Describing objects by their attributes. In CVPR.
- Felix et al. (2018) Felix, R.; Kumar, V. B.; Reid, I.; and Carneiro, G. 2018. Multi-modal cycle-consistent generalized zero-shot learning. In ECCV.
- Frome et al. (2013) Frome, A.; Corrado, G. S.; Shlens, J.; Bengio, S.; Dean, J.; Mikolov, T.; et al. 2013. Devise: A deep visual-semantic embedding model. In NeurIPS.
- Fu et al. (2015) Fu, Y.; Hospedales, T. M.; Xiang, T.; and Gong, S. 2015. Transductive multi-view zero-shot learning. IEEE transactions on pattern analysis and machine intelligence, 37(11): 2332–2345.
- Gao et al. (2020) Gao, R.; Hou, X.; Qin, J.; Chen, J.; Liu, L.; Zhu, F.; Zhang, Z.; and Shao, L. 2020. Zero-VAE-GAN: Generating Unseen Features for Generalized and Transductive Zero-Shot Learning. IEEE Transactions on Image Processing, 29: 3665–3680.
- Gretton et al. (2012) Gretton, A.; Borgwardt, K. M.; Rasch, M. J.; Schölkopf, B.; and Smola, A. 2012. A kernel two-sample test. The Journal of Machine Learning Research, 13(1): 723–773.
- Gune et al. (2020) Gune, O.; Pal, M.; Mukherjee, P.; Banerjee, B.; and Chaudhuri, S. 2020. Generative model-driven structure aligning discriminative embeddings for transductive zero-shot learning. arXiv preprint arXiv:2005.04492.
- Han et al. (2021) Han, Z.; Fu, Z.; Chen, S.; and Yang, J. 2021. Contrastive Embedding for Generalized Zero-Shot Learning. In CVPR.
- Hao et al. (2021) Hao, W.; El-Khamy, M.; Lee, J.; Zhang, J.; Liang, K. J.; Chen, C.; and Duke, L. C. 2021. Towards Fair Federated Learning with Zero-Shot Data Augmentation. In CVPR.
- He et al. (2016) He, K.; Zhang, X.; Ren, S.; and Sun, J. 2016. Deep residual learning for image recognition. In CVPR.
- Jayaraman and Grauman (2014) Jayaraman, D.; and Grauman, K. 2014. Zero-shot recognition with unreliable attributes. In NeurIPS.
- Kingma and Ba (2015) Kingma, D. P.; and Ba, J. 2015. Adam: A method for stochastic optimization. In ICLR.
- Kodirov et al. (2015) Kodirov, E.; Xiang, T.; Fu, Z.; and Gong, S. 2015. Unsupervised domain adaptation for zero-shot learning. In ICCV, 2452–2460.
- Kodirov, Xiang, and Gong (2017) Kodirov, E.; Xiang, T.; and Gong, S. 2017. Semantic Autoencoder for Zero-Shot Learning. In CVPR.
- Konevcnỳ et al. (2016) Konevcnỳ, J.; McMahan, H. B.; Yu, F. X.; Richtárik, P.; Suresh, A. T.; and Bacon, D. 2016. Federated learning: Strategies for improving communication efficiency. arXiv preprint arXiv:1610.05492.
- Lampert, Nickisch, and Harmeling (2009) Lampert, C. H.; Nickisch, H.; and Harmeling, S. 2009. Learning to detect unseen object classes by between-class attribute transfer. In CVPR.
- Lampert, Nickisch, and Harmeling (2013) Lampert, C. H.; Nickisch, H.; and Harmeling, S. 2013. Attribute-based classification for zero-shot visual object categorization. IEEE transactions on pattern analysis and machine intelligence, 36(3): 453–465.
- Larochelle, Erhan, and Bengio (2008) Larochelle, H.; Erhan, D.; and Bengio, Y. 2008. Zero-data learning of new tasks. In AAAI.
- Li et al. (2021) Li, X.; Xu, Z.; Wei, K.; and Deng, C. 2021. Generalized Zero-Shot Learning via Disentangled Representation. In AAAI.
- Liu et al. (2017) Liu, W.; Dai, B.; Humayun, A.; Tay, C.; Yu, C.; Smith, L. B.; Rehg, J. M.; and Song, L. 2017. Iterative machine teaching. In International Conference on Machine Learning, 2149–2158. PMLR.
- Long et al. (2017) Long, Y.; Liu, L.; Shao, L.; Shen, F.; Ding, G.; and Han, J. 2017. From zero-shot learning to conventional supervised classification: Unseen visual data synthesis. In CVPR.
- Long and Shao (2017) Long, Y.; and Shao, L. 2017. Describing unseen classes by exemplars: Zero-shot learning using grouped simile ensemble. In WACV, 907–915. IEEE.
- Ma and Hu (2020) Ma, P.; and Hu, X. 2020. A Variational Autoencoder with Deep Embedding Model for Generalized Zero-Shot Learning. In AAAI.
- McMahan et al. (2017) McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; and y Arcas, B. A. 2017. Communication-efficient learning of deep networks from decentralized data. In Artificial intelligence and statistics. PMLR.
- Min et al. (2020) Min, S.; Yao, H.; Xie, H.; Wang, C.; Zha, Z.-J.; and Zhang, Y. 2020. Domain-aware visual bias eliminating for generalized zero-shot learning. In CVPR.
- Norouzi et al. (2014) Norouzi, M.; Mikolov, T.; Bengio, S.; Singer, Y.; Shlens, J.; Frome, A.; Corrado, G. S.; and Dean, J. 2014. Zero-shot learning by convex combination of semantic embeddings. In ICLR.
- Pambala, Dutta, and Biswas (2020) Pambala, A.; Dutta, T.; and Biswas, S. 2020. Generative model with semantic embedding and integrated classifier for generalized zero-shot learning. In WACV.
- Qin et al. (2016) Qin, J.; Wang, Y.; Liu, L.; Chen, J.; and Shao, L. 2016. Beyond Semantic Attributes: Discrete Latent Attributes Learning for Zero-Shot Recognition. IEEE SPL, 23(11): 1667–1671.
- Romera-Paredes and Torr (2015) Romera-Paredes, B.; and Torr, P. 2015. An embarrassingly simple approach to zero-shot learning. In ICML.
- Sariyildiz and Cinbis (2019) Sariyildiz, M. B.; and Cinbis, R. G. 2019. Gradient matching generative networks for zero-shot learning. In CVPR.
- Smith et al. (2021) Smith, J.; Hsu, Y.-C.; Balloch, J.; Shen, Y.; Jin, H.; and Kira, Z. 2021. Always Be Dreaming: A New Approach for Data-Free Class-Incremental Learning. arXiv preprint arXiv:2106.09701.
- Song et al. (2018) Song, J.; Shen, C.; Yang, Y.; Liu, Y.; and Song, M. 2018. Transductive unbiased embedding for zero-shot learning. In CVPR, 1024–1033.
- Sudlow et al. (2015) Sudlow, C.; Gallacher, J.; Allen, N.; Beral, V.; Burton, P.; Danesh, J.; Downey, P.; Elliott, P.; Green, J.; Landray, M.; et al. 2015. UK biobank: an open access resource for identifying the causes of a wide range of complex diseases of middle and old age. PLoS medicine, 12(3): e1001779.
- Verma, Arora, and Mishra (2018) Verma, V. K.; Arora, G.; and Mishra. 2018. Generalized zero-shot learning via synthesized examples. In CVPR.
- Voigt and Von dem Bussche (2017) Voigt, P.; and Von dem Bussche, A. 2017. The eu general data protection regulation (gdpr). A Practical Guide, 1st Ed., Cham: Springer International Publishing, 10: 3152676.
- Vyas, Venkateswara, and Panchanathan (2020) Vyas, M. R.; Venkateswara, H.; and Panchanathan, S. 2020. Leveraging seen and unseen semantic relationships for generative zero-shot learning. In ECCV.
- Xian et al. (2017) Xian, Y.; Lampert, C. H.; Schiele, B.; and Akata, Z. 2017. Zero-shot learning-A comprehensive evaluation of the good, the bad and the ugly. In CVPR.
- Xian et al. (2018) Xian, Y.; Lorenz, T.; Schiele, B.; and Akata, Z. 2018. Feature generating networks for zero-shot learning. In CVPR.
- Xu et al. (2015) Xu, B.; Wang, N.; Chen, T.; and Li, M. 2015. Empirical Evaluation of Rectified Activations in Convolutional Network. In Proc. ICML Deep Learning Workshop.
- Xu, Liu, and Loy (2020) Xu, G.; Liu, Z.; and Loy, C. C. 2020. Computation-Efficient Knowledge Distillation via Uncertainty-Aware Mixup. arXiv preprint arXiv:2012.09413.
- Ye and Guo (2019) Ye, M.; and Guo, Y. 2019. Progressive ensemble networks for zero-shot recognition. In CVPR.
- Yin et al. (2021) Yin, H.; Mallya, A.; Vahdat, A.; Alvarez, J. M.; Kautz, J.; and Molchanov, P. 2021. See through Gradients: Image Batch Recovery via GradInversion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 16337–16346.
- Yin et al. (2020) Yin, H.; Molchanov, P.; Alvarez, J. M.; Li, Z.; Mallya, A.; Hoiem, D.; Jha, N. K.; and Kautz, J. 2020. Dreaming to distill: Data-free knowledge transfer via deepinversion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 8715–8724.
- Zhang et al. (2020a) Zhang, H.; Liu, L.; Long, Y.; Zhang, Z.; and Shao, L. 2020a. Deep transductive network for generalized zero shot learning. Pattern Recognition, 105: 107370.
- Zhang et al. (2018) Zhang, H.; Long, Y.; Guan, Y.; and Shao, L. 2018. Triple verification network for generalized zero-shot learning. IEEE Transactions on Image Processing, 28(1): 506–517.
- Zhang et al. (2020b) Zhang, L.; Wang, P.; Liu, L.; Shen, C.; Wei, W.; Zhang, Y.; and Van Den Hengel, A. 2020b. Towards effective deep embedding for zero-shot learning. IEEE Transactions on Circuits and Systems for Video Technology, 30(9): 2843–2852.
- Zhang, Xiang, and Gong (2017) Zhang, L.; Xiang, T.; and Gong, S. 2017. Learning a deep embedding model for zero-shot learning. In CVPR.
- Zhang and Saligrama (2016) Zhang, Z.; and Saligrama, V. 2016. Zero-shot recognition via structured prediction. In ECCV.
- Zhu, Liu, and Han (2019) Zhu, L.; Liu, Z.; and Han, S. 2019. Deep Leakage from Gradients. Advances in NeurIPS, 32: 14774–14784.
- Zhu (2015) Zhu, X. 2015. Machine teaching: An inverse problem to machine learning and an approach toward optimal education. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 29.