Absolute State-wise Constrained Policy Optimization: High-Probability State-wise Constraints Satisfaction
Abstract
Enforcing state-wise safety constraints is critical for the application of reinforcement learning (RL) in real-world problems, such as autonomous driving and robot manipulation. However, existing safe RL methods only enforce state-wise constraints in expectation or enforce hard state-wise constraints with strong assumptions. The former does not exclude the probability of safety violations, while the latter is impractical. Our insight is that although it is intractable to guarantee hard state-wise constraints in a model-free setting, we can enforce state-wise safety with high probability while excluding strong assumptions. To accomplish the goal, we propose Absolute State-wise Constrained Policy Optimization (ASCPO), a novel general-purpose policy search algorithm that guarantees high-probability state-wise constraint satisfaction for stochastic systems. We demonstrate the effectiveness of our approach by training neural network policies for extensive robot locomotion tasks, where the agent must adhere to various state-wise safety constraints. Our results show that ASCPO significantly outperforms existing methods in handling state-wise constraints across challenging continuous control tasks, highlighting its potential for real-world applications.
Keywords: State-wise Constraint, Constrained Policy Optimization, High-probability Constraints Satisfaction, Trust Region, Safe Reinforcement Learning
1 Introduction
In the reinforcement learning (RL) literature, safe RL is a specific branch that considers constraint satisfaction in addition to reward maximization (Achiam et al., 2017a). The explicit enforcement of constraint satisfaction is often critical to training RL agents for real-world deployments He et al. (2023a); Noren et al. (2021); Zhao et al. (2020b). That is because even if RL agents are penalized for violating safety constraints, they may still trade safety for overall higher rewards Zhao et al. (2019), which is unacceptable in many practical scenarios. For example, a self-driving car should never get too close to a pedestrian to save travel time. Safe RL aims to address such problems by treating the satisfaction of safety constraints separately from the maximization of task objectives Wei et al. (2024); Zhao et al. (2024c). To achieve that goal, it is important to properly model the safety constraints. Traditional RL builds on Markov Decision Processes (MDPs), which produce trajectories of agent states and actions as the result of agent-environment interactions. Under the framework, safety constraints can be defined in various forms. In general, constraints can be defined in a cumulative sense (Ray et al., 2019; Stooke et al., 2020; Achiam et al., 2017a; Yang et al., 2020) that the total safety violation from all states should be bounded. Constraints can also be defined state-wise, such that safety is ensured at each time step either in expectation (Pham et al., 2018; Amani and Yang, 2022; Zhao et al., 2024a) or almost surely under assumptions of system dynamics knowledge (Berkenkamp et al., 2017; Fisac et al., 2018; Wachi and Sui, 2020; Shi et al., 2023; Wachi et al., 2024a; Zhao et al., 2023c).

Ideally, safety constraints should be strictly satisfied at every time step He et al. (2023b); Zhao et al. (2023d). However, strictly satisfying safety constraints in a model-free setting is challenging, especially when the system has dynamic limits. Hence, in this paper, we consider a slightly relaxed yet still strong safety condition where constraints are guaranteed for each state with a configurable high probability (Wachi et al., 2024b). Notably, such a definition poses significantly stricter safety conditions than cumulative safety and is much more difficult to solve. The most recent advancement in that direction is state-wise constrained policy optimization (SCPO) (Zhao et al., 2024a), which enforces state-wise constraints. However, SCPO only considers constraint satisfaction in expectation without considering the variance of violations. As a result, safety constraints might still be violated at a non-trivial rate if the violations are long-tail distributed.
In this paper, we propose absolute state-wise constrained policy optimization (ASCPO) to guarantee state-wise safety constraints with a high probability. In addition to the expected constraint violation, which SCPO considers, ASCPO also considers the variance to constrain the probability upper bound of violations within a user-specified threshold. The main idea of ASCPO is illustrated in fig. 1. Through experiments, we demonstrate that ASCPO can achieve high rewards in high-dimensional tasks with state-of-the-art low safety violations. Our code is available on Github.111https://github.com/intelligent-control-lab/Absolute-State-wise-Constrained-Policy-Optimization Our contribution is summarized below:
-
•
To the best of the authors’ knowledge, the proposed approach is the first policy optimization method to ensure high-probability satisfaction of state-wise safety constraints without assuming knowledge of the underlying dynamics.
2 Related Work
In safe reinforcement learning (RL), there are two main types of safety specifications: cumulative safety and state-wise safety. Here we primarily discuss state-wise safe RL methods. Interested readers can refer to survey papers (Liu et al., 2021; Gu et al., 2022; Brunke et al., 2022; Wachi et al., 2024b) for more comprehensive discussions. Specifically, state-wise safety (instantaneous safety) aims to constrain the instantaneous cost at every step. In a stochastic environment, strictly satisfying a state-wise safety constraint at every step is impractical because the instantaneous cost is a random variable under a possibly unbounded distribution. Therefore, existing methods either constrain the instantaneous cost at each step in expectation or ensure a high probability of satisfying instantaneous constraints at all steps.
Constraint in expectation
To enforce expected state-wise constraints, OptLayer (Pham et al., 2018) uses a safety layer that modifies potentially unsafe actions generated by a reward-maximizing policy to constraint-satisfying ones. Zhao et al. introduce state-wise constrained policy optimization (SCPO) that guarantees to constrain the maximum violation along a trajectory in expectation based on a novel Maximum MDP framework. Similar idea of constraining the maximum violation can also be found in Hamilton-Jacobi (HJ) reachability analysis (Bansal et al.), which computes a value function to represent the maximum violation in the future. The HJ reachability value function is widely used to learn safety-oriented policies or build constraints for policy optimization in safe RL (Fisac et al.; Yu et al.). Although these methods take state-wise safety into consideration, their constraint in expectation formulations still fall short of controlling the distributions of instantaneous safety violations.
High-probability Constraint
Existing safe exploration literature primarily focuses on addressing high-probability and even surely state-wise constraint satisfaction (Zhao et al., 2023a), including (i) structural solutions and (ii) end-to-end solutions. Structural solutions construct a hierarchical safe agent with an upper layer generating reference actions and a lower layer performing safe action projection at every time step. To achieve this, prior knowledge about system dynamics is required Wei et al. (2022); Zhao et al. (2020a, 2022); Chen et al. (2024a, b); Li et al. (2023), such as analytical dynamics (Cheng et al., 2019; Shao et al., 2021; Fisac et al., 2018; Ferlez et al., 2020), black-box dynamics (Zhao et al., 2021, 2024b), learned dynamics (Dalal et al., 2018; Zhang et al., 2022b; Bharadhwaj et al., 2020; Chow et al., 2019; Thananjeyan et al., 2021), or the Lipschitzness bound of dynamics (Zhao et al., 2023b). Similarly, end-to-end solutions ensure safe actions by considering the uncertainty of learned dynamics at every time step, where high-probability state-wise safety guarantees stem from the knowledge of the Lipschitzness bound of dynamics (Berkenkamp et al., 2017; Wachi et al., 2018, 2024a) and constraints (Wachi and Sui, 2020) or evaluable black-box system dynamics (Wachi and Sui, 2020).
In contrast, our method directly ensures high-probability state-wise constraint satisfaction without assumptions on knowledge of the underlying dynamics.
3 Problem Formulation
3.1 State-wise Constrained Markov Decision Process
This paper studies the persistent satisfaction of cost constraints at every step for episodic tasks, in the framework of State-wise Constrained Markov Decision Process (SCMDP) (Zhao et al., 2023a) for finite horizon. An finite horizon MDP finishes within steps, and is specified by a tuple , where is the state space, and is the control space, is the reward function, is the discount factor, is the initial state distribution, and is the transition probability function. is the probability of transitioning to state given that the previous state was and the agent took action at state . Building upon MDP, SCMDP introduces a set of cost functions, , where maps the state action transition tuple into a cost value. A stationary policy is a map from states to a probability distribution over actions, with denoting the probability of selecting action in state . We denote the set of all stationary policies by .
The goal for SCMDP is to learn a policy that maximizes a performance measure , so that the cost for every state action transition satisfies a constraint. Formally,
| (1) |
where and , . Here is shorthand for that the distribution over trajectories depends on .
Restricting Maximum Cost

It is noteworthy that for (1), each state-action transition pair introduces a constraint, leading to a computational complexity that increases nearly cubically as the MDP horizon () grows (Zhao et al., 2024a). Instead of directly constraining the cost of each possible state-action transition, it is easier to constrain the maximum state-wise cost along the trajectory. To efficiently compute the maximum state-wise cost, we follow maximum Markov decision process (MMDP) (Zhao et al., 2024a) to introduce (i) a set of up-to-now maximum state-wise costs where , and (ii) a set of cost increment functions, , where maps the augmented state action transition tuple into a nonnegative cost increment. We define the augmented state , where is the augmented state space with . Formally,
| (2) |
Setting , we have for . Hence, we define the maximum state-wise cost performance sample for as:
| (3) |
where the state action sequence starts with an initial state , which follows initial state distribution . The intuition of MMDP is illustrated in Figure 2. With (3), (1) can be rewritten as:
| (4) |
where and .
Remark 1
We would like to highlight the core differences between (4) and Constrained Markov Decision Processes (CMDP). Although (4) may appear similar to CMDP due to the inclusion of cost increments, the nature of the constraints is fundamentally different. Specifically, the constraints in (4) take the form of a non-discounted summation over a finite horizon, whereas CMDP considers a discounted summation over an infinite horizon. Additionally, (4) restricts the constraint satisfaction for each individual performance sample, whereas CMDP only requires constraint satisfaction for expected performance. Consequently, conventional techniques or theories used to solve CMDP are not applicable here.
With being the discounted return of a trajectory with infinite horizon, we define the on-policy value function as , the on-policy action-value function as , and the advantage function as . Lastly, we define on-policy value functions, action-value functions, and advantage functions for the cost increments in analogy to , , and . Similarly, we can define , , and for trajectory with horizon. With replacing , respectively. We denote those by , and .
The idea of restricting the maximum cost in a trajectory is widely used in safe RL to ensure state-wise constraint satisfaction (Fisac et al., 2019; Yu et al., 2022). In addition to MMDP formulation, another method to achieve this goal is HJ reachability analysis (Bansal et al., 2017), which computes a value function to represent the maximum cost along the trajectory starting from the current state:
| (5) |
where is the HJ reachability value function of the -th cost under policy . Compared with MMDP, HJ reachability analysis directly computes the maximum cost using the maximum operator, while MMDP transforms the maximum computation into a summation by introducing cost increment functions. Mathematically, in HJ reachability analysis equals in MMDP at the initial state of a trajectory. Therefore, we can equivalently replace with in the constraint of problem (4). However, the advantage of using MMDP formulation is that the summation operator in enables us to use existing theoretical tools to derive bounds on the maximum state-wise cost, which is crucial for constraint satisfaction guarantee (Zhao et al., 2024a). In contrast, deriving similar cost bounds for Hamilton-Jacobi (HJ) reachability analysis is challenging due to the maximum operator in . So far, this max and the associated error bounds can only be evaluated using traditional HJ methods, and no learning-based HJ method is capable of simultaneously evaluating the max and the associated error bounds. To the best of our knowledge, no existing HJ-reachability-based safe RL methods have established such bounds.
3.2 Upper Probability Bound of Maximum State-wise Cost
Restricting every possible maximum state-wise cost performance sample in (4) is impractical since is a continuous random variable under a possibly unbounded distribution. The best we can do is to restrict the upper probability bound (Pishro-Nik, 2014) of the maximum state-wise cost performance with high confidence, defined as:
Definition 1 (Upper Probability Bound of Constraint Satisfaction)
Given a tuple , is defined as the upper probability bound with confidence . Mathematically:
| (6) |
Proposition 1
For an unknown distribution of random variable , denote
as the expectation and variance of the distribution, i.e.
, .
is guaranteed to be a upper probability bound of in 1 with confidence . Here is the probability factor (, ) and , where is the minima of .
Remark 2
1 is proved in Section A.1. 1 shows that more than of the samples from the distribution of will be smaller than the bound . Given a positive constant , we can make by setting a large enough , so that represents the upper probability bound of with with a confidence level close to 1.
3.3 Policy Optimization Problem
In this paper, we focus on restricting the upper probability bound of maximum state-wise cost performance in SCMDP. In accordance with 1, the overarching objective is to identify a policy that effectively maximizes the performance measure and ensures . Mathematically,
| (7) |

4 Absolute State-wise Constrained Policy Optimization
| Notation | Description |
|---|---|
| State space | |
| Action space | |
| Up-to-now maximum state-wise cost space: | |
| Augmented state space | |
| Discount factor: | |
| Reward function: | |
| Transition probability function: | |
| Initial state distribution: | |
| Cost function: | |
| Cost increment function: | |
| Probability distribution over actions | |
| Stationary policy: | |
| Set of all stationary policies | |
| Time step along the trajectory | |
| Number of the constraints | |
| Index of the constraints | |
| Index of the policy update iterations | |
| Maximum cost for constraints | |
| State at step : | |
| Action at step : | |
| Up-to-now maximum state-wise cost at step : | |
| Augmented state at step : | |
| Trajectory: a sequence of action and state | |
| Horizon of a trajectory | |
| Probability of selecting action in state | |
| Probability distribution of all action in state | |
| Probability distribution of all next state in state with action | |
| Expectation performance of policy | |
| Maximum state-wise cost performance sample of policy | |
| Discounted return of a trajectory with infinite horizon | |
| Value function with infinite horizon of policy | |
| Action-value function with infinite horizon of policy | |
| Advantage function with infinite horizon of policy | |
| Value function with horizon of policy | |
| Action-value function with horizon of policy | |
| Advantage function with horizon of policy |
| Value function of cost increment with horizon of policy | |
| Action-value function of cost increment with horizon of policy | |
| Advantage function of cost increment with horizon of policy | |
| HJ reachability value functio | |
| Upper probability bound | |
| Confidence of the probability bound | |
| Probability factor: , | |
| The minima of | |
| Expectation of the distribution of | |
| Variance of the distribution of | |
| Upper probability bound of with confidence | |
| Surrogate function for policy update to bound from below | |
| Surrogate function for policy update to bound from above | |
| Upper bound of expected variance of the maximum state-wise cost | |
| Upper bound of the variance of the expected maximum state-wise cost | |
| KL divergence between two policies at state | |
| Discounted future state distribution of policy | |
| Non-discounted future state distribution of policy | |
| Maximum expected advantage of policy | |
| Discounted return starts at state with infinite horizon of policy | |
| Value of state with infinite horizon of policy | |
| Discounted return starts at state with horizon of policy | |
| Value of state with horizon of policy | |
| Expectation of the distribution of of policy | |
| Variance of the distribution of of policy | |
| Upper probability bound of | |
| MeanVariance of policy | |
| VarianceMean of policy | |
| Variance of the state-action value function at state with horizon | |
| Variance of the state-action value function at state with horizon | |
| The vector of | |
| The vector of | |
| Action probability ratio |
To optimize (7), we need to evaluate the objective and constraints under an unknown . While the exact computations of , , and are infeasible before the actual rollout, we can alternatively find surrogate functions for the objective and constraints of (7) such that (i) they provide a tight lower bound for the objective and a tight upper bound for the constraints, and (ii) they can be easily estimated from samples collected from the most recent policy.
Therefore, we introduce (i) as a surrogate function to bound from below, (ii) as a surrogate function to bound from above, and (iii)
as a surrogate function to bound from above, in the -th iteration. All three surrogate functions could be estimated using samples from . Notice that the upper bound of involves two terms, where reflects the upper bound of expected variance of the maximum state-wise cost over different start states. reflects the upper bound of variance of the expected maximum state-wise cost of different start states. The detailed interpretations are shown in fig. 3.
4.1 Surrogate Functions for Objective and Constraints
In the following discussion, we derive the surrogate functions , , , and .
Lower Bound for Objective
To bound the objective below, we directly follow the policy performance bound introduced by Achiam et al., which provides a tight lower bound for the objective. Mathematically,
| (8) |
where is the KL divergence between two policies at state and is the discounted future state distribution.
Upper Bound of Maximum State-wise Cost Expectation
Different from , takes the form of a non-discounted summation over a finite horizon. Here we follow the tight upper bound of introduced by SCPO from Zhao et al.,
| (9) |
where is the maximum expected advantage and is the non-discounted future state distribution.
Proposition 2
For any policies , the following bound holds:
| (10) |
Upper Bound of Maximum State-wise Cost Variance
To understand maximum state-wise cost variance , we begin with establishing a general version of performance variance, where we regard the cost increment function as a broader reward function with a discount factor . Note that this use of is a symbolic overload and differs from the previously defined reward. This redefinition aims to simplify the following discussion.
First we define as infinite-horizon discounted return starts at state and define expected return as the value of state . Notice that for finite horizon MDP, , where . Then for all trajectories start from state , the expectation and variance of can be respectively defined as and . Following 1, we define as the upper probability bound of with discount term , and we treat . Formally:
| (11) | ||||
| (12) | ||||
| (13) |
Note that for the derivation of , we treat the return of all trajectories as a mixture of one-dimensional distributions. Each distribution consists of the returns of trajectories from the same start state. The variance can then be divided into two parts:
1. MeanVariance reflects the expected variance of the return over different start states.
2. VarianceMean reflects the variance of the average return of different start states.
Subsequently, we can derive the bound of MeanVariance and VarianceMean with the following propositions, where the proofs of 3 and 4 are summarized in Section A.2 and Section A.3, respectively. The analysis of 3 leverages the performance variance expression for finite horizon Markov Decision Processes (MDPs) and applies divergence analysis to establish the difference for each term in the expression between two policies. 4 is analyzed by explicitly breaking down the individual terms within , which are combinations of the value function, and then examining the value function differences between the two policies.
Additionally, 3 and 4 are results with discount term , and we will get to non-discount result in Section 4.2.
Proposition 3 (Bound of MeanVariance)
Denote MeanVariance of policy as . Given two policies , the following bound holds:
| (14) | ||||
where , and is defined as the variance of the state-action value function at state for -horizon MDP.
| (15) | ||||
where .
Proposition 4 (Bound of VarianceMean)
Denote VarianceMean of policy as . Given two policies , the VarianceMean of can be bounded by:
| (16) | ||||
where
| (17) | ||||
| (18) | ||||
By treating as the cost increment function and letting (shown in proof of Theorem 1) from (18), we effectively obtain the upper bound of as , where
| (19) | ||||
| (20) | ||||
where is defined as the variance of the state-action value function; is the vector of variance of state-action value; is the expectation of maximum state-wise cost variance over initial state distribution;
is the action probability ratio;
is the cost advantage;
is the minimal squared expectation of ;
the lower bound surrogate function of is defined as:
| (21) |
Additionally,
| (22) | ||||
| (23) |
where and .
4.2 ASCPO Optimization
With the surrogate functions derived in Section 4.1, ASCPO solves the following optimization by looking for the optimal policy within a set of -parametrized policies:
| (24) |
Theorem 1 (High Probability State-wise Constraints Satisfaction)
Suppose are related by (24), then the maximum state-wise cost for satisfies
Note that according to 3 and 4, we can only get Equation 25 holds when .
To extend the result to non-discounted version, we observe
is a polynomial function and coefficients are all limited with the following conditions holds:
| (26) | ||||
we have exists and is continuous at point ). So , which equals to:
where
We define , and by Equation 25, we have . Thus, by constraining under threshold at each iteration, we guarantee that the true is under .
Mathematically, the following inequality holds true:
| (27) | ||||
Thus by bringing cost increment function into function , we prove that Theorem 1 holds.
Furthermore, according to (Theorem 1, (Achiam et al., 2017a)), we also have a performance guarantee for ASCPO:
Theorem 2 (Monotonic Improvement of Performance)
Suppose are related by (24), then performance satisfies .
5 Practical Implementation
The direct implementation of (24) presents challenges due to (i) small update steps caused by the inclusion of the KL divergence term in the objective function (Schulman et al., 2015), and (ii) the difficulty of precisely computing parameters, such as the infinity norm terms or the supremum terms. In this section, we demonstrate a more practical approach to implement (24) by (i) encouraging larger update steps through the use of a trust region constraint, and (ii) simplifying complex computations by equivalent transformations of the optimization problem. Additinoally, we show how to (iii) encourage learning even when (24) becomes infeasible and (iv) handle the difficulty of fitting augmented value . The ASCPO pseudocode is summarized in Algorithm 1.
Trust Region Constraint
While the theoretical recommendations for the coefficients of the KL divergence terms in (24) often result in very small step sizes when followed strictly, a more practical approach is to impose a constraint on the KL divergence between the new and old policies. This constraint, commonly referred to as a trust region constraint (Schulman et al., 2015), allows for the taking of larger steps in a robust way:
| (28) | ||||
where is the step size, the set is called trust region.
Special Parameter Handling
When implementing 28, we first treat two items as hyperparameters. (i) : Although the infinity norm of is theoretically equal to 1, we found that treating it as a hyperparameter in enhances performance in practical implementation. (ii) : We can either compute from the most recent policy with (22) or treat it as a hyperparameter since is bounded for any system with a bounded reward function. Due to the instability in the estimation error for this item and the highly erratic nature of taking the maximum value, the performance of the effect is highly unreliable. Consequently, we treated it as a hyperparameter in practice, which yielded excellent results. (iii) and : Furthermore, we find that taking the average of the state instead of the maximum yields superior and more stable convergence results. It is noteworthy that a similar technique has been employed in (Schulman et al., 2015) to manage maximum KL divergence.
| s.t. | |||
Infeasible Constraints
An update to is computed every time (24) is solved. However, due to approximation errors, sometimes (24) can become infeasible. In that case, we propose an recovery update that only decreases the constraint value within the trust region. In addition, approximation errors can also cause the proposed policy update (either feasible or recovery) to violate the original constraints in (24). Hence, each policy update is followed by a backtracking line search to ensure constraint satisfaction. If all these fails, we relax the search condition by also accepting decreasing expected advantage with respect to the costs, when the cost constraints are already violated. Define:
| (29) | ||||
| (30) |
where
| (31) | ||||
| (32) |
The above criteria can be summarized into a set of new constraints as
| (33) |
Imbalanced Cost Value Targets

A critical step in solving Equation 28 involves fitting the cost increment value functions . As demonstrated in (Zhao et al., 2024a), is equal to the maximum cost increment in any future state over the maximal state-wise cost increment so far. In other words, forms a step function characterized by (i) pronounced zero-skewness, and (ii) monotonically decreasing trends. Here we visualize an example of in Figure 4.
To alleviate the unbalanced value target population, we adopt the sub-sampling technique introduced in Zhao et al. (2024a). To encourage the fitting of the monotonically decreasing trend, we design an additional loss term for penalizing non-monotonicity:
| (34) |
where represents the i-th true value of cost in episode , denotes the i-th predicted value of cost in episode , and signifies the weight of the monotonic-descent term. In essence, the rationale is to penalize any prediction that violates the non-increasing characteristics of the target sequence, thus improving the fitting quality. Further details and analysis are presented in Section 6.2.
6 Experiments
In our experiments, we aim to answer the following questions:
Q1 How does ASCPO compare with other state-of-the-art methods for safe RL?
Q2 What benefits are demonstrated by constraining the upper probability bound of maximum state-wise cost? How did the illustration in Figure 1 perform in the actual experiment?
Q3 How does the monotonic-descent trick of ASCPO in eq. 34 impact its performance? Does it work for other baselines?
Q4 How does the resource usage of ASCPO compare to other algorithms?
Q5 Can ASCPO be extended to a PPO-based version?
6.1 Experiment Setups
GUARD
To demonstrate the efficacy of our absolute state-wise constrained policy optimization approach, we conduct experiments in the advanced safe reinforcement learning benchmark environment, GUARD (Zhao et al., 2024d). This environment has been augmented with additional robots and constraints integrated into the Safety Gym framework (Ray et al., 2019), allowing for more extensive and comprehensive testing scenarios.
Our experiments are based on seven different robots: (i) Point (Shown in Figure 5(a)): A point mass robot () that can move on the ground. (ii) Swimmer (Shown in: Figure 5(b)) A three-link robot () that can move on the ground. (iii) Arm3 (Shown in: Figure 5(c)) A fixed three-joint robot arm () that can move its end effector around with high flexibility. (iv) Drone (Shown in: Figure 5(d)) A quadrotor robot () that can move in the air. (v) Humanoid (Shown in: Figure 5(e)) A bipedal robot() that has a torso with a pair of legs and arms. Since the benchmark mainly focuses on the navigation ability of the robots in designed tasks, the arm joints of Humanoid are fixed. (vi) Ant (Shown in: Figure 5(f)) A quadrupedal robot () that can move on the ground. (vii) Walker (Shown in: Figure 5(g)) A bipedal robot () that can move on the ground.
All of the experiments are based on the goal task where the robot must navigate to a goal. Additionally, since we are interested in episodic tasks (finite-horizon MDP), the environment will be reset once the goal is reached. Four different types of constraints are considered: (i) Hazard: Dangerous areas as shown in Figure 6(a). Hazards are trespassable circles on the ground. The agent is penalized for entering them. (ii) 3D Hazard: 3D Dangerous areas as shown in Figure 6(b). 3D Hazards are trespassable spheres in the air. The agent is penalized for entering them. (iii) Pillar: Non-traversable obstacles as shown in Figure 6(c). The agent is penalized for hitting them. (iv) Ghost: Moving circles as shown in Figure 6(d). Ghosts can be either trespassable or non-trespassable. The robot is penalized for touching the non-trespassable ghosts and entering the trespassable ghosts.
Considering different robots, constraint types, and constraint difficulty levels, we design 19 test suites with 7 types of robots and 12 types of constraints, which are summarized in Table 3 in Appendix. We name these test suites as {Robot}-{Constraint Number}-{Constraint Type}.











Comparison Group
The comparison group encompasses various methods: (i) the unconstrained RL algorithm TRPO (Schulman et al., 2015); (ii) end-to-end constrained safe RL algorithms including SCPO (Zhao et al., 2024a), CPO (Achiam et al., 2017a), TRPO-Lagrangian (Bohez et al., 2019), TRPO-FAC (Ma et al., 2021), TRPO-IPO (Liu et al., 2020), PCPO (Yang et al., 2020); and (iii) hierarchical safe RL algorithms such as TRPO-SL (TRPO-Safety Layer)(Dalal et al., 2018), TRPO-USL (TRPO-Unrolling Safety Layer)(Zhang et al., 2022a); and (iv) risk-sensitive algorithms TRPO-CVaR and CPO-CVaR (Zhang et al., 2024). TRPO is chosen as the baseline method due to its state-of-the-art status and readily available safety-constrained derivatives for off-the-shelf testing. For hierarchical safe RL algorithms, a warm-up phase constituting one-third of the total epochs is employed, wherein unconstrained TRPO training is conducted. The data generated during this phase is then utilized to pre-train the safety critic for subsequent epochs. Across all experiments, the policy and the values are encoded in feedforward neural networks featuring two hidden layers of size (64,64) with tanh activations. Additional details are provided in Appendix B.
Evaluation Metrics
For comparative analysis, we assess algorithmic performance across three key metrics: (i) reward performance , (ii) average episode cost , and (iii) cost rate (state-wise cost) . Detailed descriptions of these comparison metrics are provided in Section B.3. To ensure consistency, we impose a cost limit of 0 for all safe RL algorithms, aligning with our objective to prevent any constraint violations. In conducting our comparison, we faithfully implement the baseline safe RL algorithms, adhering precisely to the policy update and action correction procedures outlined in their respective original papers. It is essential to note that for a fair comparison, we provide the baseline safe RL algorithms every advantage provided to ASCPO, including equivalent trust region policy updates.























6.2 Evaluating ASCPO and Comparison Analysis
Low Dimensional Systems
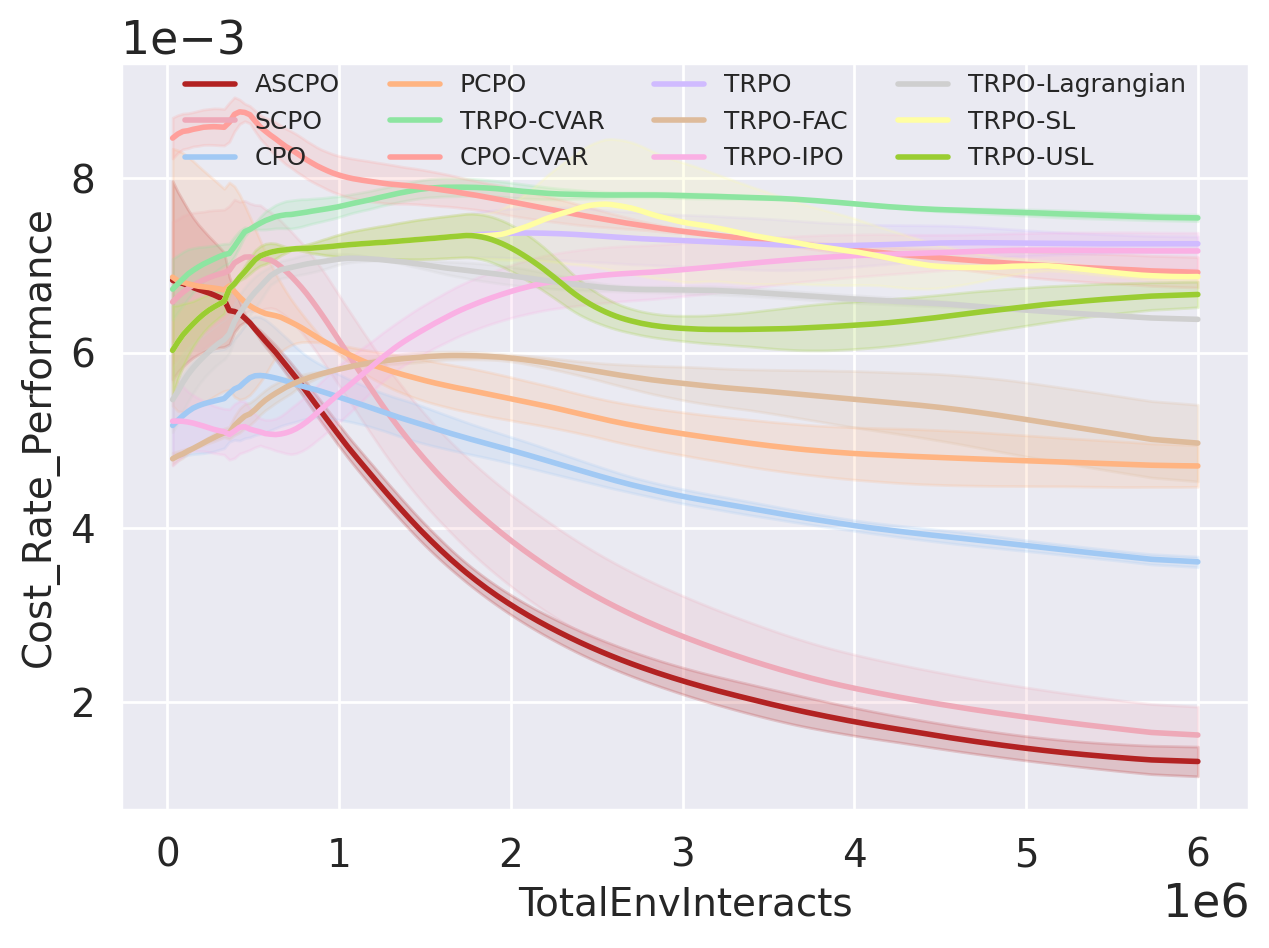
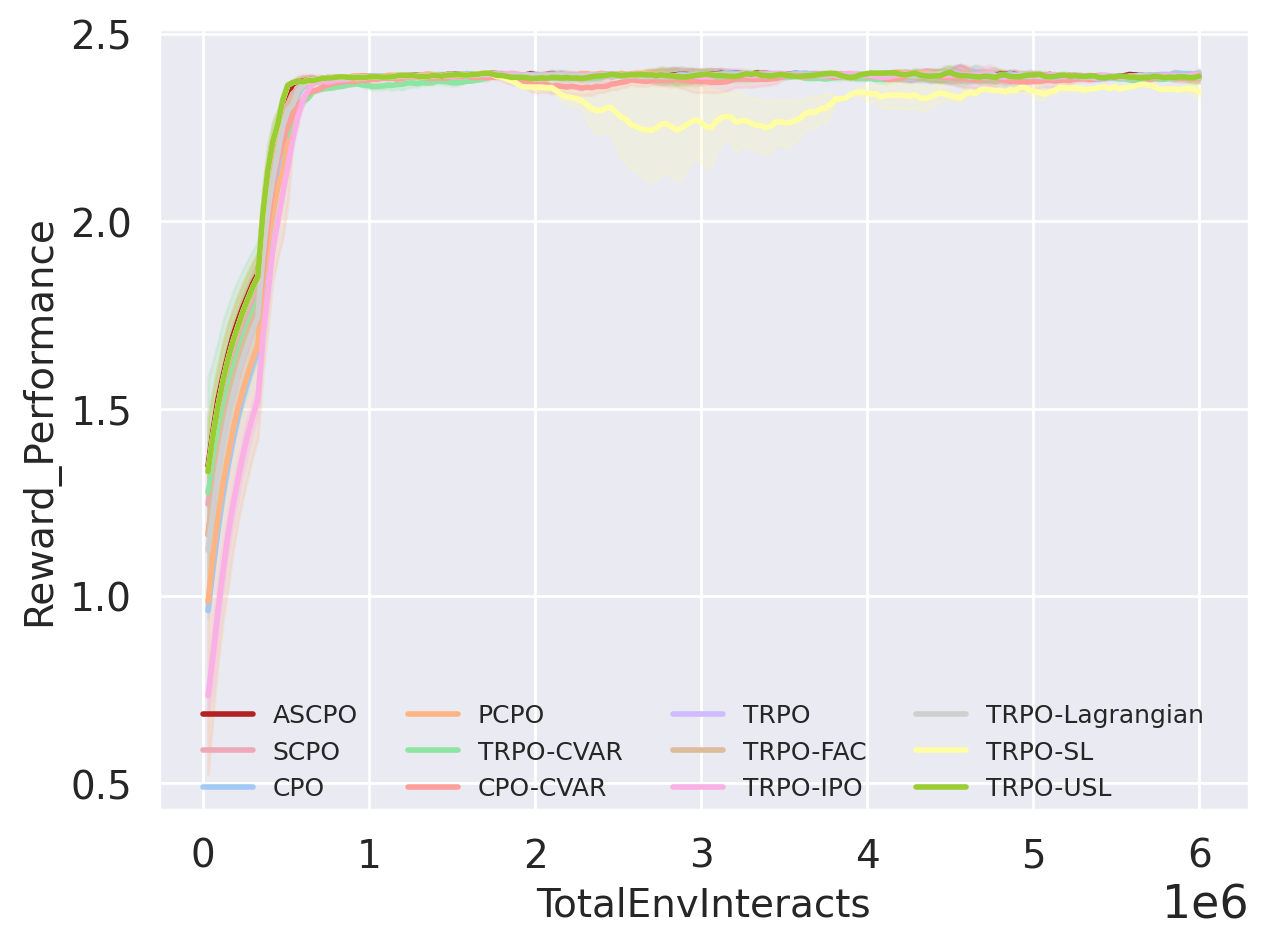
We have selected four representative test suites (figs. 9(a), 9(b), 9(c) and 9(d)) to exemplify ASCPO’s performance on low-dimensional systems. The outcomes underscore ASCPO’s remarkable ability to simultaneously achieve near-zero constraint violations and rapid reward convergence, a feat challenging for other algorithms within our comparison group. Specifically, compared to other baseline methods, ASCPO demonstrates: (i) near-zero average episode cost at the swiftest rate, (ii) substantially reduced cost rates, and (iii) stable and expedited reward convergence. Baseline end-to-end CMDP methods (CPO, PCPO, TRPO-Lagrangian, TRPO-FAC, TRPO-IPO) fall short of achieving near-zero cost performance even under a cost limit of zero. Similarly, while SCPO can approach near-zero cost, it exhibits deficiencies in both convergence speed and cost rate reduction, due to fundamental limitation in only regulating expectation in SCMDP methods. Risk-sensitive methods (TRPO-CVaR, CPO-CVaR) prove unsuitable for achieving optimal synthesis and are incapable of nearly zero cost performance. Even with an explicit safety layer correcting unsafe actions at each time step, baseline hierarchical safe RL methods (TRPO-SL, TRPO-USL) fail to achieve near-zero cost performance due to inaccuracies stemming from the linear approximation of the cost function(Dalal et al., 2018) when confronted with highly nonlinear dynamics as encountered in our MuJoCo environments(Todorov et al., 2012). A comprehensive summary of these results is provided in Section B.3.
Practical Systems and High Dimension Systems
To demonstrate the scalability of ASCPO and potential to solve complex robot learning problems, we conducted a series of experiments on practical and high-dimensional systems (figs. 9(e), 9(f), 9(g) and 9(h)). The results underscore ASCPO’s ability to surpass all other algorithms by rapidly achieving both reward and cost convergence while maintaining a remarkably lower cost rate.

It is noteworthy that the PCPO demonstrates superior cost rate reduction performance in the Drone-8Hazards test suite. However, this comes at the expense of intolerably slow and unstable reward increases, rendering it unsuitable for simulation or real-world implementation. In the remaining three test suites, the Lagrangian method exhibits a favorable cost rate performance but concurrently displays poor performance of cost reduction and reward improvement during the early training stages. This discrepancy arises from the robots’ initial struggle to learn task completion and reward optimization, resulting in longer episode lengths and consequently lower cost rates. This significant flaw in the Lagrangian approach underscores its limitations. More details and ablation experiments about Lagrangian method are provided in Section B.4.
Comprehensive Evaluation
To demonstrate the comprehensive ability of our algorithm, we take TRPO as baseline and design a new metric named synthesised score as follow:
| (35) |
This metric represents the average improvement magnitude of the current algorithm with respect to TRPO under the three metrics , and . It is used to show the comprehensive performance of the safe RL algorithm in a particular task. We averaged the for each of the 12 algorithms across the 19 tasks and present the results in Figure 11. The metrics used for computing can be found in Tables 7(c), 8, 9(c), 10(c), 11(c) and 12(d) in appendix. The results show that our algorithm has a cliff-leading combined effect compared to other algorithms.
Above results demonstrate the superiority of ASCPO in comparison to various other safe RL state-of-the-art methods, which answer Q1.





Absolute Maximum State-wise Cost
In Figure 12, we present a selection of four representative robots across varying dimensions to demonstrate ASCPO’s proficiency in constraining episodic cost values below a specified threshold with exceptionally high probability. We include CPO, CPO-CVaR, SCPO, TRPO, TRPO-FAC and TRPO-Lagrangian as benchmark algorithms for comparison. All algorithms undergo thorough training for 6 million steps, with data collection consisting of 30,000 steps under each of the three random seeds to ensure a robust data distribution. Our analysis reveals that ASCPO not only achieves the lowest mean episodic cost value but also effectively manages the maximum episodic cost, thereby demonstrating ASCPO’s success in controlling the entire distribution with high probability. At the same time, in Figure 13, we take Swimmer-1-Hazard as the representative test suite to concretize the illustration of Figure 1 using real data. The results show that ASCPO can effectively constrain the maximum episodic cost within a safe threshold, demonstrating the superiority of our algorithm in controlling the entire distribution. These results answer Q2.


Ablation on Monotonic-Descent Trick
According to Zhao et al. (Zhao et al., 2024a), algorithms employing the MMDP framework feature cost target functions characterized by step functions, as illustrated in the right panel of Figure 15. These functions delineate the maximum cost increment in any future state relative to the maximal state-wise cost encountered thus far. Consequently, strategies can be employed to enhance the neural network’s fitting of these step functions. A pivotal characteristic of these functions is their monotonically decreasing nature, which informs the design of the loss Equation 34. Moreover, as depicted in Figure 15, the application of the monotonic-descent technique to non-MMDP scenarios (using CPO as an example) appears irrelevant and does not affect their performance. Subsequently, in Figure 18, we demonstrate the impact of employing the monotonic-descent strategy across four test suites. The results demonstrate that this approach accelerates the convergence of cost values towards near-zero values and effectively lowers the cost rate to a desirable level, which answer Q3.










Resources Usage
We conducted comprehensive tests comparing GPU and CPU memory usage, along with wall-clock time, across several algorithms, namely SCPO, CPO, TRPO, TRPO-Lagrangian, and ASCPO. These tests utilized identical system resources in the Goal-8-Hazard task. As illustrated in Figure 20, the results indicate that ASCPO marginally increases GPU and CPU resource consumption compared to CPO and SCPO, while exhibiting nearly identical wall-clock time performance. However, a closer examination of the horizontal coordinate magnitude reveals a significant performance enhancement achieved by ASCPO, requiring less than 1% increase in resources for each aspect. This underscores the effectiveness of our algorithm in delivering exceptional results without imposing substantial demands on system resources and runtime. Furthermore, this observation addresses the pertinent question Q4 regarding the efficacy of our approach.




7 Proximal Absolute State-wise Constrained Policy Optimization
With the proven success of the TRPO-based ASCPO in addressing various control tasks, a natural question arises: Can ASCPO be extended to a PPO-based version, similar to the PPO-Lagrangian implemented in Ray et al. (2019)? To explore this possibility, we introduce PASCPO, which integrates a Clipped Surrogate Objective (Schulman et al., 2017) with the Lagrangian Method Ray et al. (2019). In detail, the original constrained optimization problem within the trust region, as outlined in Algorithm 1, is reformulated as a single-objective optimization problem. The local update is performed using a clipped surrogate objective, while the constraint is incorporated through the Lagrangian method. In Figure 23, we compare our algorithm with fine-tuned PPO-Lagrangian in four representative tasks, demonstrating our effectiveness in achieving lower cost values and more efficient control across the entire distribution. Furthermore, as shown in Figure 25, PASCPO achieves significantly better performance while maintaining essentially the same hardware resource usage and wall-clock time. This demonstrates that our surrogate absolute bound, despite its complexity, does not introduce additional unacceptable computational costs. It is worth noting that PASCPO has significantly higher computing efficiency compared to ASCPO, albeit with some performance loss, making it suitable for specific scenarios. These results address Q5 and highlight the potential of extending ASCPO to a PPO-based method.
8 Conclusion
This paper proposed ASCPO, the first general-purpose policy search algorithm that ensures state-wise constraints satisfaction with high confidence. We demonstrate ASCPO’s effectiveness on challenging continuous control benchmark tasks, showing its significant performance improvement compared to existing methods and ability to handle state-wise constraints.
Acknowledgments and Disclosure of Funding
This work is partially supported by the National Science Foundation, Grant No. 2144489.
Appendix A Additional Proofs
A.1 Proof of 1
Proof According to Selberg’s inequality theory Saw et al. (1984), if random variable has finite non-zero variance and finite expected value . Then for any real number , following inequality holds:
| (36) |
which equals to:
| (37) |
Considering that , then belongs to a corresponding variance space which has a non-zero minima of , which is denoted as . Therefore, by treating , the following condition holds:
| (38) | ||||
A.2 Proof of 3
Proof According to [Finite-horizon Version of Theorem 1, (Sobel, 1982)], the following proposition holds:
Proposition 5
Define , and , where denotes the probability of the transfer from i-th state to j-th state, the following equation holds
| (39) |
where .
With 5, the complete formula follows immediately
| (40) | ||||
With (40), The divergence of MeanVariance we want to bound can be written as:
| (41) | ||||
Next, we will derive the upper bound of
| (42) | ||||
Since we already know
| (43) | |||
| (44) |
We only need to bound and .
To address , we have
| (45) | ||||
To address , we notice that , which means:
| (46) |
Where
| (47) | ||||
Define , we have:
| (48) |
Similar to TRPO Schulman et al. (2015):
| (49) | ||||
Then can be written as:
| (50) |
Define to be the expected advantage of over at state :
| (51) |
Now can be written as:
| (52) |
Define as:
| (53) |
With and the fact that ([Lemma3, (Schulman et al., 2015)]), where , we have:
| (54) | |||
Then according to Brillinger (2018) , we can then bound with:
| (55) | ||||
where . With , we have:
| (56) | ||||
Then we can bound with:
| (57) | ||||
By substituting (43), (44), (45) and (57) into Equation 42, we have:
| (58) | |||
A.3 Proof of 4
Proof
| (59) |
Since both terms on the right of Equation 59 are non-negative, we can bound with the upper bound of and the lower bound of .
Define , where .
Then we have
| (60) | ||||
To address , we have:
| (61) |
According to (49):
| (62) | ||||
Define , then we have:
| (63) | ||||
And according to Brillinger (2018), we can bound with:
| (64) | ||||
Further, we can obtain:
| (65) | ||||
Thus the following inequality holds:
| (66) | ||||
Substitute Equation 66 into Equation 60 the upper bound of is obtained:
| (67) |
The lower bound of can then be obtained according to (Zhao et al., 2024a):
| (68) |
where
By substituting Equation 67 and Equation 68 into Equation 59 4 is proved.
Appendix B Experiment Details
B.1 Environment Settings
Goal Task
In the Goal task environments, the reward function is:
where is the distance from the robot to its closest goal and is the size (radius) of the goal. When a goal is achieved, the goal location is randomly reset to someplace new while keeping the rest of the layout the same. The test suites of our experiments are summarized in Table 3.
| Ground robot | Aerial robot | ||||||
| Task Setting | Low dimension | High dimension | |||||
| Point | Swimmer | Arm3 | Humanoid | Ant | Walker | Drone | |
| 1-Hazard | ✓ | ✓ | |||||
| 4-Hazard | ✓ | ✓ | |||||
| 8-Hazard | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| 1-Pillar | ✓ | ||||||
| 4-Pillar | ✓ | ||||||
| 8-Pillar | ✓ | ||||||
| 1-Ghost | ✓ | ||||||
| 4-Ghost | ✓ | ||||||
| 8-Ghost | ✓ | ||||||
| 3DHazard-1 | ✓ | ||||||
| 3DHazard-4 | ✓ | ||||||
| 3DHazard-8 | ✓ | ||||||
Hazard Constraint
In the Hazard constraint environments, the cost function is:
where is the distance to the closest hazard and is the size (radius) of the hazard.
Pillar Constraint
In the Pillar constraint environments, the cost if the robot contacts with the pillar otherwise .
Ghost Constraint
In the Ghost constraint environments, the cost function is:
where is the distance to the closest ghost and is the size (radius) of the ghost. And dynamics of ghosts are as follow:
| (69) |
where represents the distance from the position of the dynamic object , represents the distance from the dynamic object to the position of the robot , defines a circular area centered at the origin point within which the objects are limited to move. represents the threshold distance that the dynamic objects strive to maintain from the robot and , are configurable non-negative velocity constants for the dynamic objects.
State Space
The state space is composed of two parts. The internal state spaces describe the state of the robots, which can be obtained from standard robot sensors (accelerometer, gyroscope, magnetometer, velocimeter, joint position sensor, joint velocity sensor and touch sensor). The details of the internal state spaces of the robots in our test suites are summarized in Table 4. The external state spaces are describe the state of the environment observed by the robots, which can be obtained from 2D lidar or 3D lidar (where each lidar sensor perceives objects of a single kind). The state spaces of all the test suites are summarized in Table 5. Note that Vase and Gremlin are two other constraints in Safety Gym (Ray et al., 2019) and all the returns of vase lidar and gremlin lidar are zero vectors (i.e., ) in our experiments since none of our test suites environments has vases.
| Internal State Space | Point | Swimmer | Walker | Ant | Drone | Arm3 | Humanoid |
| Accelerometer () | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Gyroscope () | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Magnetometer () | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Velocimeter () | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Joint position sensor () | |||||||
| Joint velocity sensor () | |||||||
| Touch sensor () |
| External State Space | Goal-Hazard | 3D-Goal-Hazard | Goal-Pillar |
| Goal Compass () | ✓ | ✓ | ✓ |
| Goal Lidar () | ✓ | ✓ | |
| 3D Goal Lidar () | ✓ | ||
| Hazard Lidar () | ✓ | ||
| 3D Hazard Lidar () | ✓ | ||
| Pillar Lidar () | ✓ | ||
| Vase Lidar () | ✓ | ✓ | |
| Gremlin Lidar () | ✓ | ✓ |
Control Space
For all the experiments, the control space of all robots are continuous, and linearly scaled to [-1, +1].
B.2 Policy Settings
The hyper-parameters used in our experiments are listed in Table 6 as default.
Our experiments use separate multi-layer perception with activations for the policy network, value network and cost network. Each network consists of two hidden layers of size (64,64). All of the networks are trained using optimizer with learning rate of 0.01.
We apply an on-policy framework in our experiments. During each epoch the agent interact times with the environment and then perform a policy update based on the experience collected from the current epoch. The maximum length of the trajectory is set to 1000 and the total epoch number is set to 200 as default.
The policy update step is based on the scheme of TRPO, which performs up to 100 steps of backtracking with a coefficient of 0.8 for line searching.
For all experiments, we use a discount factor of , an advantage discount factor , and a KL-divergence step size of .
For experiments which consider cost constraints we adopt a target cost to pursue a zero-violation policy.
Other unique hyper-parameters for each algorithms are hand-tuned to attain reasonable performance.
Each model is trained on a server with a 48-core Intel(R) Xeon(R) Silver 6426Y CPU @ 2.5.GHz, Nvidia RTX A6000 GPU with 48GB memory, and Ubuntu 22.04.
For all tasks, we train each model for 6e6 steps which takes around seven hours.
| Policy Parameter | TRPO | TRPO-Lagrangian | TRPO-SL [18’ Dalal] | TRPO-USL | TRPO-IPO | TRPO-FAC | CPO | PCPO | SCPO | TRO-CVaR | CPO-CVaR | ASCPO | |
| Epochs | 200 | 200 | 200 | 200 | 200 | 200 | 200 | 200 | 200 | 200 | 200 | 200 | |
| Steps per epoch | 30000 | 30000 | 30000 | 30000 | 30000 | 30000 | 30000 | 30000 | 30000 | 30000 | 30000 | 30000 | |
| Maximum length of trajectory | 1000 | 1000 | 1000 | 1000 | 1000 | 1000 | 1000 | 1000 | 1000 | 1000 | 1000 | 1000 | |
| Policy network hidden layers | (64, 64) | (64, 64) | (64, 64) | (64, 64) | (64, 64) | (64, 64) | (64, 64) | (64, 64) | (64, 64) | (64, 64) | (64, 64) | (64, 64) | |
| Discount factor | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | |
| Advantage discount factor | 0.97 | 0.97 | 0.97 | 0.97 | 0.97 | 0.97 | 0.97 | 0.97 | 0.97 | 0.97 | 0.97 | 0.97 | |
| TRPO backtracking steps | 100 | 100 | 100 | 100 | 100 | 100 | 100 | - | 100 | 100 | 100 | 100 | |
| TRPO backtracking coefficient | 0.8 | 0.8 | 0.8 | 0.8 | 0.8 | 0.8 | 0.8 | - | 0.8 | 0.8 | 0.8 | 0.8 | |
| Target KL | 0.02 | 0.02 | 0.02 | 0.02 | 0.02 | 0.02 | 0.02 | 0.02 | 0.02 | 0.02 | 0.02 | 0.02 | |
| Value network hidden layers | (64, 64) | (64, 64) | (64, 64) | (64, 64) | (64, 64) | (64, 64) | (64, 64) | (64, 64) | (64, 64) | (64, 64) | (64, 64) | (64, 64) | |
| Value network iteration | 80 | 80 | 80 | 80 | 80 | 80 | 80 | 80 | 80 | 80 | 80 | 80 | |
| Value network optimizer | Adam | Adam | Adam | Adam | Adam | Adam | Adam | Adam | Adam | Adam | Adam | Adam | |
| Value learning rate | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 | |
| Cost network hidden layers | - | (64, 64) | (64, 64) | (64, 64) | - | (64, 64) | (64, 64) | (64, 64) | (64, 64) | (64, 64) | (64, 64) | (64, 64) | |
| Cost network iteration | - | 80 | 80 | 80 | - | 80 | 80 | 80 | 80 | 80 | 80 | 80 | |
| Cost network optimizer | - | Adam | Adam | Adam | - | Adam | Adam | Adam | Adam | Adam | Adam | Adam | |
| Cost learning rate | - | 0.001 | 0.001 | 0.001 | - | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 | |
| Target Cost | - | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | |
| Lagrangian optimizer | - | - | - | - | - | Adam | - | - | - | - | - | - | |
| Lagrangian learning rate | - | 0.005 | - | - | - | 0.0001 | - | - | - | - | - | - | |
| USL correction iteration | - | - | - | 20 | - | - | - | - | - | - | - | - | |
| USL correction rate | - | - | - | 0.05 | - | - | - | - | - | - | - | - | |
| Warmup ratio | - | - | 1/3 | 1/3 | - | - | - | - | - | - | - | - | |
| IPO parameter | - | - | - | - | 0.01 | - | - | - | - | - | - | - | |
| Cost reduction | - | - | - | - | - | - | 0.0 | - | 0.0 | - | 0.0 | 0.0 | |
| Probability factor | k | - | - | - | - | - | - | - | - | - | - | - | 7.0 |
B.3 Metrics Comparison
In Tables 7(c), 8, 9(c), 10(c), 11(c) and 12(d), we report all the results of our test suites by three metrics:
-
•
The average episode return .
-
•
The average episodic sum of costs .
-
•
The average state-wise cost over the entirety of training .
All of the three metrics were obtained from the final epoch after convergence. Each metric was averaged over two random seed.
B.4 Ablation study on large penalty for infractions



In our experiments employing the Lagrangian method, we utilized an adaptive penalty coefficient. Consequently, we augmented this coefficient by a factor denoted as to explore the trade-off between optimizing rewards and satisfying constraints. We designated these experiments as TRPO-Lagrangian- and juxtaposed them with ASCPO in Figure 27. Observably, as increases, both the cost rate and cost value exhibit a notable decrease in the Lagrangian method. However, this reduction in convergence speed of rewards is concurrently observed. Conversely, ASCPO demonstrates the swiftest convergence alongside the most favorable convergence values, achieving notable progress in both reward convergence and cost reduction. Moreover, ASCPO performs comparably, if not superiorly, in terms of cost rate. These results underscore the inadequacy of simplistic coefficient adjustments within the Lagrangian method when compared to the efficacy of our algorithm.
| Algorithm | |||
|---|---|---|---|
| TRPO | 2.3840 | 0.0697 | 0.0010 |
| TRPO-Lagrangian | 2.3777 | 0.0596 | 0.0009 |
| TRPO-SL | 2.3614 | 0.0480 | 0.0009 |
| TRPO-USL | 2.3859 | 0.0894 | 0.0007 |
| TRPO-IPO | 2.3580 | 0.0719 | 0.0009 |
| TRPO-FAC | 2.3646 | 0.0516 | 0.0007 |
| CPO | 2.3937 | 0.0315 | 0.0005 |
| PCPO | 2.3831 | 0.0565 | 0.0006 |
| SCPO | 1.2580 | 0.0021 | 0.0001 |
| TRPO-CVaR | 2.3887 | 0.0764 | 0.0009 |
| CPO-CVaR | 2.3459 | 0.0539 | 0.0008 |
| ASCPO | 2.3415 | 0.0010 | 0.0002 |
| Algorithm | |||
|---|---|---|---|
| TRPO | 2.3397 | 0.2697 | 0.0038 |
| TRPO-Lagrangian | 2.3797 | 0.2197 | 0.0033 |
| TRPO-SL | 2.4054 | 0.4020 | 0.0035 |
| TRPO-USL | 2.4083 | 0.2428 | 0.0029 |
| TRPO-IPO | 2.3807 | 0.2349 | 0.0034 |
| TRPO-FAC | 2.3806 | 0.1225 | 0.0025 |
| CPO | 2.4243 | 0.0924 | 0.0019 |
| PCPO | 2.4123 | 0.1107 | 0.0023 |
| SCPO | 2.3686 | 0.0313 | 0.0011 |
| TRPO-CVaR | 2.4179 | 0.3165 | 0.0036 |
| CPO-CVaR | 2.3999 | 0.2846 | 0.0036 |
| ASCPO | 2.4272 | 0.0290 | 0.0007 |
| Algorithm | |||
|---|---|---|---|
| TRPO | 2.4603 | 0.6222 | 0.0073 |
| TRPO-Lagrangian | 2.4067 | 0.4531 | 0.0064 |
| TRPO-SL | 2.4465 | 0.9176 | 0.0069 |
| TRPO-USL | 2.3686 | 0.5688 | 0.0067 |
| TRPO-IPO | 2.4138 | 0.5673 | 0.0072 |
| TRPO-FAC | 2.3708 | 0.2330 | 0.0049 |
| CPO | 2.4412 | 0.1961 | 0.0036 |
| PCPO | 2.4205 | 0.3953 | 0.0047 |
| SCPO | 2.3666 | 0.0919 | 0.0016 |
| TRPO-CVaR | 2.3783 | 0.5255 | 0.0075 |
| CPO-CVaR | 2.3685 | 0.4479 | 0.0069 |
| ASCPO | 2.4785 | 0.0413 | 0.0013 |
| Algorithm | |||
|---|---|---|---|
| TRPO | 2.3742 | 0.1181 | 0.0015 |
| TRPO-Lagrangian | 2.3823 | 0.0694 | 0.0012 |
| TRPO-SL | 2.3721 | 0.0319 | 0.0008 |
| TRPO-USL | 2.3905 | 0.1753 | 0.0011 |
| TRPO-IPO | 2.3702 | 0.1594 | 0.0013 |
| TRPO-FAC | 2.3745 | 0.0595 | 0.0008 |
| CPO | 2.3779 | 0.0657 | 0.0011 |
| PCPO | 2.3634 | 0.0809 | 0.0012 |
| SCPO | 2.4085 | 0.0523 | 0.0006 |
| TRPO-CVaR | 2.3648 | 0.0724 | 0.0010 |
| CPO-CVaR | 2.3650 | 0.1990 | 0.0012 |
| ASCPO | 2.4202 | 0.0272 | 0.0007 |
| Algorithm | |||
|---|---|---|---|
| TRPO | 2.4169 | 0.4133 | 0.0057 |
| TRPO-Lagrangian | 2.3515 | 0.3376 | 0.0061 |
| TRPO-SL | 2.3071 | 0.2210 | 0.0027 |
| TRPO-USL | 2.4058 | 0.5679 | 0.0044 |
| TRPO-IPO | 2.4075 | 0.2745 | 0.0051 |
| TRPO-FAC | 2.3883 | 0.1982 | 0.0032 |
| CPO | 2.4012 | 0.2964 | 0.0060 |
| PCPO | 2.3992 | 0.3868 | 0.0065 |
| SCPO | 2.3918 | 0.2512 | 0.0042 |
| TRPO-CVaR | 2.3960 | 0.3610 | 0.0063 |
| CPO-CVaR | 2.3970 | 0.3109 | 0.0056 |
| ASCPO | 2.4405 | 0.2341 | 0.0041 |
| Algorithm | |||
|---|---|---|---|
| TRPO | 2.3295 | 2.3581 | 0.0216 |
| TRPO-Lagrangian | 2.3494 | 0.5958 | 0.0114 |
| TRPO-SL | 2.3756 | 0.5944 | 0.0066 |
| TRPO-USL | 2.3309 | 0.7557 | 0.0133 |
| TRPO-IPO | 2.3824 | 1.1487 | 0.0140 |
| TRPO-FAC | 2.4024 | 0.3398 | 0.0082 |
| CPO | 2.4128 | 0.8449 | 0.0157 |
| PCPO | 2.4003 | 4.6241 | 0.0193 |
| SCPO | 2.3897 | 3.2559 | 0.0129 |
| TRPO-CVaR | 2.4081 | 1.1789 | 0.0166 |
| CPO-CVaR | 2.3700 | 1.1933 | 0.0160 |
| ASCPO | 2.4202 | 0.4341 | 0.0106 |
| Algorithm | |||
|---|---|---|---|
| TRPO | 2.4178 | 0.0854 | 0.0008 |
| TRPO-Lagrangian | 2.3868 | 0.0396 | 0.0008 |
| TRPO-SL | 2.3880 | 0.0256 | 0.0006 |
| TRPO-USL | 2.3867 | 0.0487 | 0.0006 |
| TRPO-IPO | 2.4201 | 0.0737 | 0.0007 |
| TRPO-FAC | 2.3861 | 0.0438 | 0.0006 |
| CPO | 2.3718 | 0.0220 | 0.0005 |
| PCPO | 2.4337 | 0.0579 | 0.0006 |
| SCPO | 1.4640 | 0.0000 | 0.0001 |
| TRPO-CVaR | 2.3739 | 0.0716 | 0.0009 |
| CPO-CVaR | 2.4110 | 0.0653 | 0.0007 |
| ASCPO | 2.4014 | 0.0000 | 0.0001 |
| Algorithm | |||
|---|---|---|---|
| TRPO | 2.4035 | 0.2809 | 0.0035 |
| TRPO-Lagrangian | 2.3938 | 0.2694 | 0.0034 |
| TRPO-SL | 2.3657 | 0.4658 | 0.0036 |
| TRPO-USL | 2.4127 | 0.1475 | 0.0027 |
| TRPO-IPO | 2.3940 | 0.3212 | 0.0031 |
| TRPO-FAC | 2.4002 | 0.1206 | 0.0022 |
| CPO | 2.4004 | 0.0962 | 0.0017 |
| PCPO | 2.4123 | 0.1101 | 0.0020 |
| SCPO | 2.2944 | 0.0377 | 0.0009 |
| TRPO-CVaR | 2.4487 | 0.3079 | 0.0034 |
| CPO-CVaR | 2.3877 | 0.2340 | 0.0032 |
| ASCPO | 2.4503 | 0.0262 | 0.0006 |
| Algorithm | |||
|---|---|---|---|
| TRPO | 2.4178 | 0.5109 | 0.0069 |
| TRPO-Lagrangian | 2.3985 | 0.4600 | 0.0063 |
| TRPO-SL | 2.3613 | 0.8013 | 0.0067 |
| TRPO-USL | 2.4162 | 0.4935 | 0.0061 |
| TRPO-IPO | 2.4118 | 0.5494 | 0.0067 |
| TRPO-FAC | 2.3956 | 0.2185 | 0.0046 |
| CPO | 2.4170 | 0.1653 | 0.0033 |
| PCPO | 2.4043 | 0.2444 | 0.0046 |
| SCPO | 2.3784 | 0.0904 | 0.0022 |
| TRPO-CVaR | 2.4333 | 0.5494 | 0.0070 |
| CPO-CVaR | 2.4280 | 0.5318 | 0.0066 |
| ASCPO | 2.4239 | 0.0321 | 0.0013 |
| Algorithm | |||
|---|---|---|---|
| TRPO | 2.4834 | 0.0908 | 0.0013 |
| TRPO-Lagrangian | 2.3957 | 0.0813 | 0.0013 |
| TRPO-SL | 2.3730 | 0.0699 | 0.0021 |
| TRPO-USL | 2.4425 | 0.0605 | 0.0010 |
| TRPO-IPO | 2.4667 | 0.0777 | 0.0012 |
| TRPO-FAC | 2.4553 | 0.0708 | 0.0011 |
| CPO | 2.4484 | 0.0907 | 0.0011 |
| PCPO | 2.4348 | 0.0957 | 0.0012 |
| SCPO | 2.3924 | 0.0885 | 0.0011 |
| TRPO-CVaR | 2.4332 | 0.0759 | 0.0012 |
| CPO-CVaR | 2.4276 | 0.0847 | 0.0012 |
| ASCPO | 2.4531 | 0.0000 | 0.0002 |
| Algorithm | |||
|---|---|---|---|
| TRPO | 2.4441 | 0.3554 | 0.0051 |
| TRPO-Lagrangian | 2.4568 | 0.3284 | 0.0050 |
| TRPO-SL | 2.2038 | 0.9845 | 0.0068 |
| TRPO-USL | 2.4148 | 0.3786 | 0.0046 |
| TRPO-IPO | 2.4327 | 0.3464 | 0.0049 |
| TRPO-FAC | 2.4413 | 0.3097 | 0.0047 |
| CPO | 2.4172 | 0.3648 | 0.0045 |
| PCPO | 2.3920 | 0.2950 | 0.0047 |
| SCPO | 2.4096 | 0.3636 | 0.0043 |
| TRPO-CVaR | 2.4183 | 0.2984 | 0.0051 |
| CPO-CVaR | 2.4208 | 0.3456 | 0.0050 |
| ASCPO | 2.4233 | 0.2933 | 0.0040 |
| Algorithm | |||
|---|---|---|---|
| TRPO | 2.4218 | 0.7754 | 0.0103 |
| TRPO-Lagrangian | 2.4559 | 0.6977 | 0.0099 |
| TRPO-SL | 2.4321 | 2.3075 | 0.0111 |
| TRPO-USL | 2.4297 | 0.5784 | 0.0093 |
| TRPO-IPO | 2.4396 | 0.6749 | 0.0098 |
| TRPO-FAC | 2.4042 | 0.6703 | 0.0096 |
| CPO | 2.4433 | 0.8106 | 0.0088 |
| PCPO | 2.4388 | 0.6881 | 0.0096 |
| SCPO | 2.4581 | 1.0087 | 0.0089 |
| TRPO-CVaR | 2.4535 | 0.7250 | 0.0102 |
| CPO-CVaR | 2.4620 | 0.7371 | 0.0103 |
| ASCPO | 2.4889 | 0.7629 | 0.00751 |
| Algorithm | |||
|---|---|---|---|
| TRPO | 2.4316 | 0.0504 | 0.0002 |
| TRPO-Lagrangian | 2.4052 | 0.0125 | 0.0001 |
| TRPO-SL | 2.3553 | 0.0227 | 0.0000 |
| TRPO-USL | 2.4022 | 0.0157 | 0.0001 |
| TRPO-IPO | 2.3784 | 0.0148 | 0.0002 |
| TRPO-FAC | 2.4197 | 0.0126 | 0.0001 |
| CPO | 2.4345 | 0.0044 | 0.0002 |
| PCPO | 2.3066 | 0.0556 | 0.0001 |
| SCPO | 2.3306 | 0.0104 | 0.0001 |
| TRPO-CVaR | 2.4244 | 0.0183 | 0.0001 |
| CPO-CVaR | 2.3877 | 0.0172 | 0.0001 |
| ASCPO | 2.4181 | 0.0039 | 0.0000 |
| Algorithm | |||
|---|---|---|---|
| TRPO | 2.4336 | 0.0749 | 0.0005 |
| TRPO-Lagrangian | 2.4330 | 0.0644 | 0.0006 |
| TRPO-SL | 2.3883 | 0.0059 | 0.0002 |
| TRPO-USL | 2.4322 | 0.0545 | 0.0004 |
| TRPO-IPO | 2.3787 | 0.0497 | 0.0006 |
| TRPO-FAC | 2.4153 | 0.0663 | 0.0004 |
| CPO | 2.4602 | 0.0640 | 0.0006 |
| PCPO | 2.3981 | 0.0672 | 0.0004 |
| SCPO | 2.3430 | 0.0233 | 0.0002 |
| TRPO-CVaR | 2.4513 | 0.0700 | 0.0006 |
| CPO-CVaR | 2.4458 | 0.0906 | 0.0005 |
| ASCPO | 2.3558 | 0.0059 | 0.0001 |
| Algorithm | |||
|---|---|---|---|
| TRPO | 2.4727 | 0.2310 | 0.0018 |
| TRPO-Lagrangian | 2.4760 | 0.1952 | 0.0013 |
| TRPO-SL | 2.3681 | 0.0225 | 0.0005 |
| TRPO-USL | 2.4470 | 0.1275 | 0.0010 |
| TRPO-IPO | 2.4245 | 0.1355 | 0.0010 |
| TRPO-FAC | 2.4172 | 0.0956 | 0.0008 |
| CPO | 2.4092 | 0.1018 | 0.0009 |
| PCPO | 1.2867 | 0.2227 | 0.0001 |
| SCPO | 2.4766 | 0.0729 | 0.0005 |
| TRPO-CVaR | 2.4068 | 0.1244 | 0.0014 |
| CPO-CVaR | 2.4219 | 0.1809 | 0.0010 |
| ASCPO | 2.3960 | 0.0126 | 0.0003 |
| Algorithm | |||
|---|---|---|---|
| TRPO | 2.2280 | 1.0687 | 0.0136 |
| TRPO-Lagrangian | 2.2478 | 0.3002 | 0.0064 |
| TRPO-SL | 1.8348 | 6.8884 | 0.0109 |
| TRPO-USL | 2.2777 | 1.0435 | 0.0125 |
| TRPO-IPO | 2.2583 | 1.8212 | 0.0168 |
| TRPO-FAC | 2.2672 | 0.5234 | 0.0072 |
| CPO | 2.2449 | 0.5486 | 0.0084 |
| PCPO | 2.2567 | 0.9550 | 0.0099 |
| SCPO | 2.2536 | 0.6708 | 0.0100 |
| TRPO-CVaR | 2.2496 | 2.0251 | 0.0233 |
| CPO-CVaR | 2.2189 | 2.3813 | 0.0248 |
| ASCPO | 2.3452 | 0.2658 | 0.0075 |
| Algorithm | |||
|---|---|---|---|
| TRPO | 2.2280 | 1.0687 | 0.0136 |
| TRPO-Lagrangian | 2.2478 | 0.3002 | 0.0064 |
| TRPO-SL | 1.8348 | 6.8884 | 0.0109 |
| TRPO-USL | 2.2452 | 1.0435 | 0.0125 |
| TRPO-IPO | 2.2583 | 1.8212 | 0.0168 |
| TRPO-FAC | 2.2672 | 0.5234 | 0.0072 |
| CPO | 2.2449 | 0.5486 | 0.0084 |
| PCPO | 2.2567 | 0.9550 | 0.0099 |
| SCPO | 2.2536 | 0.3354 | 0.0100 |
| TRPO-CVaR | 2.2496 | 2.0251 | 0.0233 |
| CPO-CVaR | 2.2189 | 2.3813 | 0.0248 |
| ASCPO | 2.2777 | 0.2658 | 0.0075 |
| Algorithm | |||
|---|---|---|---|
| TRPO | 2.4243 | 0.4039 | 0.0094 |
| TRPO-Lagrangian | 2.4266 | 0.3640 | 0.0084 |
| TRPO-SL | 2.2924 | 11.5143 | 0.0500 |
| TRPO-USL | 2.4599 | 0.4651 | 0.0093 |
| TRPO-IPO | 2.3908 | 2.0326 | 0.0076 |
| TRPO-FAC | 2.4479 | 0.3556 | 0.0079 |
| CPO | 2.4364 | 0.3279 | 0.0082 |
| PCPO | 2.4259 | 0.3630 | 0.0083 |
| SCPO | 2.4244 | 0.2980 | 0.0082 |
| TRPO-CVaR | 2.4284 | 0.4308 | 0.0098 |
| CPO-CVaR | 2.4404 | 0.5410 | 0.0098 |
| ASCPO | 2.4207 | 0.2010 | 0.0070 |
| Algorithm | |||
|---|---|---|---|
| TRPO | 2.3856 | 0.4224 | 0.0098 |
| TRPO-Lagrangian | 2.4049 | 0.3227 | 0.0083 |
| TRPO-SL | 2.4113 | 1.8346 | 0.0256 |
| TRPO-USL | 2.4390 | 0.4296 | 0.0096 |
| TRPO-IPO | 2.4064 | 0.5490 | 0.0094 |
| TRPO-FAC | 2.4363 | 0.3403 | 0.0083 |
| CPO | 2.4429 | 0.3221 | 0.0082 |
| PCPO | 2.4131 | 0.2849 | 0.0081 |
| SCPO | 2.4173 | 0.2761 | 0.0077 |
| TRPO-CVaR | 2.4293 | 0.4696 | 0.0115 |
| CPO-CVaR | 2.3853 | 0.4909 | 0.0114 |
| ASCPO | 2.4090 | 0.1936 | 0.0064 |
































References
- Achiam et al. (2017a) Joshua Achiam, David Held, Aviv Tamar, and Pieter Abbeel. Constrained policy optimization. In International Conference on Machine Learning, pages 22–31. PMLR, 2017a.
- Achiam et al. (2017b) Joshua Achiam, David Held, Aviv Tamar, and Pieter Abbeel. Constrained policy optimization. In International conference on machine learning, pages 22–31. PMLR, 2017b.
- Amani and Yang (2022) Sanae Amani and Lin F Yang. Doubly pessimistic algorithms for strictly safe off-policy optimization. In 2022 56th Annual Conference on Information Sciences and Systems (CISS), pages 113–118. IEEE, 2022.
- Bansal et al. (2017) Somil Bansal, Mo Chen, Sylvia Herbert, and Claire J Tomlin. Hamilton-jacobi reachability: A brief overview and recent advances. In 2017 IEEE 56th Annual Conference on Decision and Control (CDC), pages 2242–2253. IEEE, 2017.
- Berkenkamp et al. (2017) Felix Berkenkamp, Matteo Turchetta, Angela Schoellig, and Andreas Krause. Safe model-based reinforcement learning with stability guarantees. Advances in neural information processing systems, 30, 2017.
- Bharadhwaj et al. (2020) Homanga Bharadhwaj, Aviral Kumar, Nicholas Rhinehart, Sergey Levine, Florian Shkurti, and Animesh Garg. Conservative safety critics for exploration. arXiv preprint arXiv:2010.14497, 2020.
- Bohez et al. (2019) Steven Bohez, Abbas Abdolmaleki, Michael Neunert, Jonas Buchli, Nicolas Heess, and Raia Hadsell. Value constrained model-free continuous control. arXiv preprint arXiv:1902.04623, 2019.
- Brillinger (2018) David R. Brillinger. Information and Information Stability of Random Variables and Processes. Journal of the Royal Statistical Society Series C: Applied Statistics, 13(2):134–135, 12 2018. ISSN 0035-9254. doi: 10.2307/2985711. URL https://doi.org/10.2307/2985711.
- Brunke et al. (2022) Lukas Brunke, Melissa Greeff, Adam W Hall, Zhaocong Yuan, Siqi Zhou, Jacopo Panerati, and Angela P Schoellig. Safe learning in robotics: From learning-based control to safe reinforcement learning. Annual Review of Control, Robotics, and Autonomous Systems, 5:411–444, 2022.
- Chen et al. (2024a) Rui Chen, Weiye Zhao, and Changliu Liu. Safety index synthesis with state-dependent control space. In 2024 American Control Conference (ACC), pages 937–942. IEEE, 2024a.
- Chen et al. (2024b) Rui Chen, Weiye Zhao, Ruixuan Liu, Weiyang Zhang, and Changliu Liu. Real-time safety index adaptation for parameter-varying systems via determinant gradient ascend. arXiv preprint arXiv:2403.14968, 2024b.
- Cheng et al. (2019) Richard Cheng, Gábor Orosz, Richard M Murray, and Joel W Burdick. End-to-end safe reinforcement learning through barrier functions for safety-critical continuous control tasks. In Proceedings of the AAAI Conference on Artificial Intelligence, pages 3387–3395, 2019.
- Chow et al. (2019) Yinlam Chow, Ofir Nachum, Aleksandra Faust, Edgar Duenez-Guzman, and Mohammad Ghavamzadeh. Lyapunov-based safe policy optimization for continuous control. ICML 2019 Workshop RL4RealLife, abs/1901.10031, 2019.
- Dalal et al. (2018) Gal Dalal, Krishnamurthy Dvijotham, Matej Vecerik, Todd Hester, Cosmin Paduraru, and Yuval Tassa. Safe exploration in continuous action spaces. CoRR, abs/1801.08757, 2018.
- Ferlez et al. (2020) James Ferlez, Mahmoud Elnaggar, Yasser Shoukry, and Cody Fleming. Shieldnn: A provably safe nn filter for unsafe nn controllers. CoRR, abs/2006.09564, 2020.
- Fisac et al. (2018) Jaime F Fisac, Anayo K Akametalu, Melanie N Zeilinger, Shahab Kaynama, Jeremy Gillula, and Claire J Tomlin. A general safety framework for learning-based control in uncertain robotic systems. IEEE Transactions on Automatic Control, 64(7):2737–2752, 2018.
- Fisac et al. (2019) Jaime F Fisac, Neil F Lugovoy, Vicenç Rubies-Royo, Shromona Ghosh, and Claire J Tomlin. Bridging hamilton-jacobi safety analysis and reinforcement learning. In 2019 International Conference on Robotics and Automation (ICRA), pages 8550–8556. IEEE, 2019.
- Gu et al. (2022) Shangding Gu, Long Yang, Yali Du, Guang Chen, Florian Walter, Jun Wang, Yaodong Yang, and Alois Knoll. A review of safe reinforcement learning: Methods, theory and applications. arXiv preprint arXiv:2205.10330, 2022.
- He et al. (2023a) Suqin He, Weiye Zhao, Chuxiong Hu, Yu Zhu, and Changliu Liu. A hierarchical long short term safety framework for efficient robot manipulation under uncertainty. Robotics and Computer-Integrated Manufacturing, 82:102522, 2023a.
- He et al. (2023b) Tairan He, Weiye Zhao, and Changliu Liu. Autocost: Evolving intrinsic cost for zero-violation reinforcement learning. Proceedings of the AAAI Conference on Artificial Intelligence, 2023b.
- Li et al. (2023) Zeyang Li, Chuxiong Hu, Weiye Zhao, and Changliu Liu. Learning predictive safety filter via decomposition of robust invariant set. arXiv preprint arXiv:2311.06769, 2023.
- Liu et al. (2020) Yongshuai Liu, Jiaxin Ding, and Xin Liu. Ipo: Interior-point policy optimization under constraints. In Proceedings of the AAAI conference on artificial intelligence, volume 34, pages 4940–4947, 2020.
- Liu et al. (2021) Yongshuai Liu, Avishai Halev, and Xin Liu. Policy learning with constraints in model-free reinforcement learning: A survey. In The 30th International Joint Conference on Artificial Intelligence (IJCAI), 2021.
- Ma et al. (2021) Haitong Ma, Yang Guan, Shegnbo Eben Li, Xiangteng Zhang, Sifa Zheng, and Jianyu Chen. Feasible actor-critic: Constrained reinforcement learning for ensuring statewise safety. arXiv preprint arXiv:2105.10682, 2021.
- Noren et al. (2021) Charles Noren, Weiye Zhao, and Changliu Liu. Safe adaptation with multiplicative uncertainties using robust safe set algorithm. IFAC-PapersOnLine, 54(20):360–365, 2021.
- Pham et al. (2018) Tu-Hoa Pham, Giovanni De Magistris, and Ryuki Tachibana. Optlayer-practical constrained optimization for deep reinforcement learning in the real world. In 2018 IEEE International Conference on Robotics and Automation (ICRA), pages 6236–6243. IEEE, 2018.
- Pishro-Nik (2014) Hossein Pishro-Nik. Introduction to probability, statistics, and random processes. Kappa Research, LLC Blue Bell, PA, USA, 2014.
- Ray et al. (2019) Alex Ray, Joshua Achiam, and Dario Amodei. Benchmarking safe exploration in deep reinforcement learning. CoRR, abs/1910.01708, 2019.
- Saw et al. (1984) John G Saw, Mark CK Yang, and Tse Chin Mo. Chebyshev inequality with estimated mean and variance. The American Statistician, 38(2):130–132, 1984.
- Schulman et al. (2015) John Schulman, Sergey Levine, Pieter Abbeel, Michael Jordan, and Philipp Moritz. Trust region policy optimization. In International conference on machine learning, pages 1889–1897. PMLR, 2015.
- Schulman et al. (2017) John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017.
- Shao et al. (2021) Yifei Simon Shao, Chao Chen, Shreyas Kousik, and Ram Vasudevan. Reachability-based trajectory safeguard (rts): A safe and fast reinforcement learning safety layer for continuous control. IEEE Robotics and Automation Letters, 6(2):3663–3670, 2021.
- Shi et al. (2023) Ming Shi, Yingbin Liang, and Ness Shroff. A near-optimal algorithm for safe reinforcement learning under instantaneous hard constraints. In International Conference on Machine Learning, pages 31243–31268. PMLR, 2023.
- Sobel (1982) Matthew J Sobel. The variance of discounted markov decision processes. Journal of Applied Probability, 19(4):794–802, 1982.
- Stooke et al. (2020) Adam Stooke, Joshua Achiam, and Pieter Abbeel. Responsive safety in reinforcement learning by pid lagrangian methods. In International Conference on Machine Learning, pages 9133–9143. PMLR, 2020.
- Thananjeyan et al. (2021) Brijen Thananjeyan, Ashwin Balakrishna, Suraj Nair, Michael Luo, Krishnan Srinivasan, Minho Hwang, Joseph E Gonzalez, Julian Ibarz, Chelsea Finn, and Ken Goldberg. Recovery rl: Safe reinforcement learning with learned recovery zones. IEEE Robotics and Automation Letters, 6(3):4915–4922, 2021.
- Todorov et al. (2012) Emanuel Todorov, Tom Erez, and Yuval Tassa. Mujoco: A physics engine for model-based control. In 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, pages 5026–5033. IEEE, 2012.
- Wachi and Sui (2020) Akifumi Wachi and Yanan Sui. Safe reinforcement learning in constrained markov decision processes. In Proceedings of the 37th International Conference on Machine Learning, ICML’20. JMLR.org, 2020.
- Wachi et al. (2018) Akifumi Wachi, Yanan Sui, Yisong Yue, and Masahiro Ono. Safe exploration and optimization of constrained mdps using gaussian processes. In Proceedings of the AAAI Conference on Artificial Intelligence, 2018.
- Wachi et al. (2024a) Akifumi Wachi, Wataru Hashimoto, Xun Shen, and Kazumune Hashimoto. Safe exploration in reinforcement learning: A generalized formulation and algorithms. Advances in Neural Information Processing Systems, 36, 2024a.
- Wachi et al. (2024b) Akifumi Wachi, Xun Shen, and Yanan Sui. A survey of constraint formulations in safe reinforcement learning. arXiv preprint arXiv:2402.02025, 2024b.
- Wei et al. (2022) Tianhao Wei, Shucheng Kang, Weiye Zhao, and Changliu Liu. Persistently feasible robust safe control by safety index synthesis and convex semi-infinite programming. IEEE Control Systems Letters, 2022.
- Wei et al. (2024) Tianhao Wei, Liqian Ma, Rui Chen, Weiye Zhao, and Changliu Liu. Meta-control: Automatic model-based control synthesis for heterogeneous robot skills. arXiv preprint arXiv:2405.11380, 2024.
- Yang et al. (2020) Tsung-Yen Yang, Justinian Rosca, Karthik Narasimhan, and Peter J Ramadge. Projection-based constrained policy optimization. arXiv preprint arXiv:2010.03152, 2020.
- Yu et al. (2022) Dongjie Yu, Haitong Ma, Shengbo Li, and Jianyu Chen. Reachability constrained reinforcement learning. In International conference on machine learning, pages 25636–25655. PMLR, 2022.
- Zhang et al. (2022a) Linrui Zhang, Qin Zhang, Li Shen, Bo Yuan, and Xueqian Wang. Saferl-kit: Evaluating efficient reinforcement learning methods for safe autonomous driving. arXiv preprint arXiv:2206.08528, 2022a.
- Zhang et al. (2022b) Linrui Zhang, Qin Zhang, Li Shen, Bo Yuan, Xueqian Wang, and Dacheng Tao. Evaluating model-free reinforcement learning toward safety-critical tasks. arXiv preprint arXiv:2212.05727, 2022b.
- Zhang et al. (2024) Qiyuan Zhang, Shu Leng, Xiaoteng Ma, Qihan Liu, Xueqian Wang, Bin Liang, Yu Liu, and Jun Yang. Cvar-constrained policy optimization for safe reinforcement learning. IEEE Transactions on Neural Networks and Learning Systems, pages 1–12, 2024. doi: 10.1109/TNNLS.2023.3331304.
- Zhao et al. (2019) Wei-Ye Zhao, Xi-Ya Guan, Yang Liu, Xiaoming Zhao, and Jian Peng. Stochastic variance reduction for deep q-learning. arXiv preprint arXiv:1905.08152, 2019.
- Zhao et al. (2020a) Weiye Zhao, Suqin He, Chengtao Wen, and Changliu Liu. Contact-rich trajectory generation in confined environments using iterative convex optimization. arXiv preprint arXiv:2008.03826, 2020a.
- Zhao et al. (2020b) Weiye Zhao, Liting Sun, Changliu Liu, and Masayoshi Tomizuka. Experimental evaluation of human motion prediction toward safe and efficient human robot collaboration. In 2020 American Control Conference (ACC), pages 4349–4354. IEEE, 2020b.
- Zhao et al. (2021) Weiye Zhao, Tairan He, and Changliu Liu. Model-free safe control for zero-violation reinforcement learning. In 5th Annual Conference on Robot Learning, 2021.
- Zhao et al. (2022) Weiye Zhao, Suqin He, and Changliu Liu. Provably safe tolerance estimation for robot arms via sum-of-squares programming. IEEE Control Systems Letters, 6:3439–3444, 2022.
- Zhao et al. (2023a) Weiye Zhao, Tairan He, Rui Chen, Tianhao Wei, and Changliu Liu. State-wise safe reinforcement learning: A survey. The 32nd International Joint Conference on Artificial Intelligence (IJCAI), 2023a.
- Zhao et al. (2023b) Weiye Zhao, Tairan He, and Changliu Liu. Probabilistic safeguard for reinforcement learning using safety index guided gaussian process models. In Learning for Dynamics and Control Conference, pages 783–796. PMLR, 2023b.
- Zhao et al. (2023c) Weiye Zhao, Tairan He, Tianhao Wei, Simin Liu, and Changliu Liu. Safety index synthesis via sum-of-squares programming. In 2023 American Control Conference (ACC), pages 732–737. IEEE, 2023c.
- Zhao et al. (2023d) Weiye Zhao, Yifan Sun, Feihan Li, Rui Chen, Tianhao Wei, and Changliu Liu. Learn with imagination: Safe set guided state-wise constrained policy optimization. arXiv preprint arXiv:2308.13140, 2023d.
- Zhao et al. (2024a) Weiye Zhao, Rui Chen, Yifan Sun, Feihan Li, Tianhao Wei, and Changliu Liu. State-wise constrained policy optimization. Transactions on Machine Learning Research, 2024a. ISSN 2835-8856. URL https://openreview.net/forum?id=NgK5etmhz9.
- Zhao et al. (2024b) Weiye Zhao, Tairan He, Feihan Li, and Changliu Liu. Implicit safe set algorithm for provably safe reinforcement learning. arXiv preprint arXiv:2405.02754, 2024b.
- Zhao et al. (2024c) Weiye Zhao, Feihan Li, Yifan Sun, Rui Chen, Tianhao Wei, and Changliu Liu. Absolute policy optimization: Enhancing lower probability bound of performance with high confidence. In Forty-first International Conference on Machine Learning, 2024c. URL https://openreview.net/forum?id=Ss3h1ixJAU.
- Zhao et al. (2024d) Weiye Zhao, Yifan Sun, Feihan Li, Rui Chen, Ruixuan Liu, Tianhao Wei, and Changliu Liu. GUARD: A safe reinforcement learning benchmark. Transactions on Machine Learning Research, 2024d. ISSN 2835-8856. URL https://openreview.net/forum?id=kZFKwApeQO.