A Topological Solution of Entanglement for Complex-shaped Parts
in Robotic Bin-Picking
Abstract
This paper addresses the problem of picking up only one object at a time avoiding any entanglement in bin-picking. To cope with a difficult case where the complex-shaped objects are heavily entangled together, we propose a topology-based method that can generate non-tangle grasp positions on a single depth image. The core technique is the entanglement map, which is a feature map to measure the entanglement possibilities obtained from the input image. We use an entanglement map to select probable regions containing graspable objects. The optimum grasping pose is detected from the selected regions considering the collision between robot hand and objects. Experimental results show that our analytic method provides a more comprehensive and intuitive observation of the entanglement and exceeds previous learning-based work [1] in success rates. Especially, our topology-based method does not rely on any object models or time-consuming training process, so that it can be easily adapted to more complex bin-picking scenes.
I INTRODUCTION
Bin-picking is commonly utilized in the industrial robot assembly line to provide and arrange necessary parts for assembly. It has been studied over the decades covering vision, planning, system integration, and solutions to specific tasks [2], [3], [4], [5], [6], [7]. However, there remain challenges if the shape of the target objects is complex. For instance, objects with S-shape or C-shape randomly placed in the bin are easily entangled with each other. In this case, the robot has difficulty in picking up only one object without any entanglement due to the complex physical collisions or the uncertainties in the environment.
A few studies address this issue in robotic bin-picking. Matsumura et.al [1] first tackle the problem of picking only one object from a stacked pile without causing entanglement [1]. A Convolutional Neural Network (CNN) is proposed to predict whether if the robot can pick up a single object among several pre-computed grasp candidates. They also use a physics simulator to collect training data by simulating bin-picking processes. However, we found some limitations in this research as follows. On one hand, data-driven method requires a large amount of training data and time-consuming training procedure. On the other hand, since CNN only makes predictions on cropped regions from the image, it cannot observe all the entangled objects from the whole input scene. Especially when the objects are heavily entangled, CNN may predict that all pre-computed grasp candidates share high possibilities of potential entanglement.

Motivated by the previous work, we propose an analytic approach to solve the entanglement issue in bin-picking using topological knowledge. In particular, we propose topology coordinates to obtain a series of metrics which can describe entanglement situation from a single depth image. Besides, we scan the input image in a sliding window manner to generate a feature map called entanglement map, which indicates the possibilities of containing entangled objects for each region. As Fig. 1 shows, the entanglement map is able to discriminate which regions may contain tangled objects and which regions may not from a depth map. The regions marked as blue has high possibilities of containing graspable objects. Once the entanglement map is obtained, we select non-tangle regions and detect collision-free grasp candidates using graspability measure [2] respectively on selected regions. The output is a set of ranked grasp configurations of avoiding all entanglement and collisions.
Our main contributions are as follows.
1) We proposed a topology-based approach that can detect optimal grasps avoiding entanglement, which is a challenging problem in robotic bin-picking.
2) We fix the problems existing in previous work. Besides, our method only requires simple parameter tuning instead of time-consuming training and data collection.
3) We provide a complete observation and intuitive measurement of entanglement so that the bin-picking performance is improved dealing with complex-shaped parts.
4) We develop a vision-based bin-picking system and demonstrate a serious of experiments on a real robot.
Experiments suggest that our analytic method exceeds the previous learning-based method in success rates on a relatively difficult bin-picking task.
II RELATED WORK
Researches in grasp detection for bin-picking can be categorized into two approaches according to how the grasp is determined. Some researches focus on using shape or geometric information directly on a depth map or a point cloud [2], [3], [8]. Some researches use CAD models to better recognize the scene [9], [10], [11]. Recently learning-based method has been widely used to achieve better robustness and generalization [1], [12], [13].
However, robotic bin-picking faces some challenging tasks related to picking up complex-shaped objects. As described in Section I, Matsumura et.al. propose a learning-based approach to train a classifier for several pre-computed grasp candidates from depth images and plan the grasp with the highest predicted score [1]. The major limitation of this work is the time-consuming training process and data collection. Besides, the network is only applied to the cropped regions of an input image, which may increase bias in the prediction. Other works such as [14] and [15] also solve the problem by developing a geometric modeling method to fit multiple cylinders to an input point cloud and plan an singulation trajectory for bin-picking. Nevertheless, modeling and trajectory planning would be unstable when the shape of the object is complex. In this paper, we present an analytic approach without any object model or data collection, which makes it relatively easier to execute on a real robot.

Topological representation has been studied for decades and it is widely used for solving complex robotic motion synthesis. Ho and Komura firstly present the definition of topology coordinates to analyze the whole-body behaviors between two humanoid robots [16], [17], [18]. They calculate the topological relationship between two robot characters applying for different scenes. The most significant representation of entanglement would be Gaussian Link Integral (GLI) developed from knot theory [19]. It describes a mathematical relationship between two tangled strands as Fig. 2 shows. Moreover, topological representation plays an important role in robotic manipulation for deformable objects, such as tubes or ropes [20], [21], [22]. This research is the first one to use topological knowledge in robotic bin-picking. The topological solution provides a more comprehensive measurements for dense clutters than the previous learning-based method.
III Topology Coordinates for Bin-picking
In this section, we introduce our revised topology coordinates based on the original theory proposed by Ho and Komura [17], [18]. The details of the calculation are also presented.
III-A Topology Coordinates
Topology coordinate is constructed between two tangled objects by three attributes [17], [18]. The first attribute is writhe, which explains how much the two curves are twisting around each other. For instance, entangled objects get a higher score than separated objects. Writhe between two objects is calculated by Gaussian Link Integral (GLI) as follows. If we have two curves and which are point sets in Cartesian Coordinate, writhe can be calculated by GLI as follows.
| (1) |
The second attribute is density, which describes how much the twisted area is concentrated on two curves. The third attribute is center, which is a location that explains the center location of the twisted area.
III-B Topology Coordinates in Depth Map
Given a single depth image of a cluttered scene, the topology coordinate can be constructed to measure the entanglement (Fig. 3). Writhe is a scalar attribute that indicates how much the objects are tangled together. A depth map containing tangled objects has higher writhe than the one with objects just overlapped together. Density is also a scalar attribute that indicates the distribution of the entanglement is evenly or intensively on the depth map. Center indicates the center position of entanglement on the depth map.

Original topology coordinates [17] can only be applied for two characters and assume the exact position of characters are known. Different from the definition and calculation, we construct topology coordinates only using a single depth image containing multiple objects so that the position of each object remains unknown. Instead of computing the relationship between two objects, we extract the line segments of edge from the depth map and calculate the topology coordinates using the relationship between each pair of line segments. Edge contains all the information we need to describe the shape and position of objects. Even though the line segments of edges may not indicate the complete contours of all parts, the topological relationship calculated by line segments can still reflect how and where the entanglement occurs.
III-C Calculation
We use a depth map to compute topology coordinates . In order to calculate these three attributes, we need to generate a matrix called writhe matrix firstly. Taken as input, we detect the edges and transfer them to a collection of 3-dimensional vectors . Writhe matrix is a matrix that stores GLI of each segment pair in . Particularly, instead of using Eq.(1), GLI between two 3-dimensional line segments is computed using the algorithm proposed by Klenin and Langowski [23]. For instance, in the writhe matrix between i-th segment and j-th segment can be calculated by
| (2) |
It can be seen that the writhe matrix is an upper-triangle-like matrix where half of the elements in are zero. We can compute the writhe , density and center using writhe matrix . First, writhe is the sum of all values in divided by the number of line segments as follows.
| (3) |
Then, density is calculated by the ratio of the pairs that have higher values in writhe matrix . We extract the non-zero elements from and compute using the number of elements higher than some threshold divided by the total number of non-zero elements. Here, we define the threshold as the mean of extracted non-zero elements. Finally, center is simply obtained by the center of mass for matrix , which is a segment pair that contributes the most to the entanglement. Moreover, we introduce a mask called center mask which has the same size as the input depth image (Fig. 4). A center mask is a binary matrix with an area consisting of both center segments.

III-D Explanations
Let us explain how the topology coordinates service for the entanglement using a depth map.
Firstly, writhe is a quantitative measure that denotes how much the entanglement is on the depth image, while density and center denote the position information for the entanglement. Therefore, we present the visualization of the writhe matrix and the center mask to elaborate the density and center more intuitively. Fig. 4 presents which region is the entanglement center from the input depth image while Fig. 5 shows four different clutters with various writhe and density values by presenting the corresponding input depth images, detected edge segments, and visualized writhe matrices. This visualized matrix derives from in Section.III-C since it only remains the larger elements and is resized to a certain size. We can observe which pairs of edge segments share the larger writhe value and what is the distribution of the segment pairs from the matrix. If the edge segments are tangled with those near them, the brighter values are concentrated around the axis of the matrix. On the contrary, if the edge segments share rather larger writhe values with those all over the image, the distribution in the writhe matrix is rather even. Therefore, the more concentrated around the axis in the writhe matrix, the higher the corresponding density is. The details are elaborated as follows.



Writhe. Fig. 5(a) is the situation where two objects are twisting together while Fig. 5(b) refers to two simply overlapped objects. They have similar density but differ from writhe . The writhe of twisted objects is larger than overlapped ones. If the robot wants to pick objects from these scenes, Fig. 5(b) with lower writhe has s higher possibility of a successful picking.
Density. From Fig. 5(c-d) we can tell by the human observation that Fig. 5(d) would be a better choice for robot simply by taking a look. Visualized writhe matrix and density value can also explain the scene numerically. The visualized matrix in Fig. 5(d) has an even distribution of brighter pixels since every line segment tends to tangle with more segments. Because as the number of segment pairs with larger GLI increases, the number of bright pixels in the visualized matrix also increases. Thus, these brighter pixels distribute more evenly, in other words, the density becomes smaller. On the contrary, every object in Fig. 5(c) is twisted with the other objects, thus, the entanglement is distributed intensely on the depth map. For the visualized matrix, the pixels with larger writhe are concentrated around the axis. Therefore, when writhe values are similar, density can also contribute to entanglement analysis.
Center. The center is computed by the center of mass of the writhe matrix, which is a pair of line segments that contributes the most to the entanglement. We present how the center affects the entanglement by presenting a mask that has the same size as the input depth image (Fig. 4). The center mask indicates the position information of the entanglement but not as much as writhe and density do.
To summarize, by focusing on the metrics of the entanglement regardless of the number of objects, situations with lower writhe and lower density is preferred. Therefore, the topology coordinate proposed in this section can be used to determine where a non-tangle grasp should be located.
IV Grasp Detection of Avoiding Entanglement
This section elaborates grasp detection method for picking up only one object by measuring the entanglement metrics using the proposed topology coordinates.

IV-A Overview
We select a parallel jaw gripper and use a single depth map as input to compute grasp hypotheses. The overview of the proposed grasp detection method is illustrated in Fig. 7. First, a depth map is captured and used to construct the topology coordinate. Then, we use the writhe in topology coordinates to determine if the objects in the bin are tangled. If not, grasp is detected only considering the collision. If the entanglement exists, we calculate the entanglement map which evaluates where the potential tangled parts are in the box. We crop several regions with high possibilities of containing graspable objects from the entanglement map. Finally, grasp is detected and ranked in each selected region using graspability measure [2].
IV-B Entanglement Representation: Entanglement map
We explain how to compute an entanglement map by a given depth map . First, we compute the line segments for edges on input depth map , and generate topology coordinate along with center mask for . Then, we use a pre-defined sliding window function for to obtain expanding information. For each window, we calculate its own writhe and density. This sliding window function returns two matrices , , which respectively store writhe and density of each region. The combination of two matrices refers to the rough entanglement information on each regions from . However, we would like to precisely evaluate the entanglement situation upon the whole image. We use calculated topology coordinate to evaluate the weights for these matrices and center mask. The initial weights are manually defined as , , respetively for , and since writhe affect more on predicting potential tangled regions. If , average of , is larger than of the coordinate , it means that density may affect the result of entanglement map generation. Therefore, the weights are modified as,
| (4) |
The center mask is independent of the sliding window algorithm so that the weight remains the same. Finally, entanglement map is obtained by the addition of weighted metrics as Eq.(5) shows following a bi-linear interpolation.
| (5) |
Some examples are presented in Fig. 8. In our perspective, the entanglement map is the visualization that indicates possibilities of entanglement in every region for the whole depth map. We can observe those areas where objects are heavily tangled with each other are marked as yellow, while blue areas refer to non-tangled regions. We prefer to generate grasps on blue areas.

IV-C Grasp Detection
We present a grasp detection method considering both entanglement and collisions. Another sliding window function is executed to seek several region candidates with smaller values from the entanglement map. In each region, a grasping pose can be computed using graspability measure [2]. Graspability is an index for detecting a grasping point by convoluting a template of contact areas and collision areas for a robot hand. To put it more precisely, it is based on the idea that the object should be in the trajectory of hand closing, and there should be no object in the position to lower the robot hand. We use a parallel jaw gripper and rotate the gripper template along for 4 orientations. For the detected grasp candidates in each region, we rank them simply by pixel values in the entanglement map of the corresponding positions combined with the graspability score. Finally, the best grasp position is selected as the top of ranked grasp candidates.
V Experiments and Results
V-A Experiment Setup
We perform several real-world robot experiments to evaluate our method in bin-picking. We use NEXTAGE from Kawada Robotics and set a fixed 3D camera YCAM3D-II one meter straight above from the bin. We use Choreonoid and graspPlugin to simulate and execute the movement of the robot. The execution time was recorded on a PC running Ubuntu 16.04 with a 2.7 GHz Intel Core i5-6400 CPU. Our experiment system is set as Fig. 9 shows.


As Fig. 10 shows, two types of industrial parts with complex shapes are selected. We prepare three patterns of clutter state by only C-shaped objects, only S-shaped objects, and mixed objects. In particular, three picking trials are performed for each clutter. Each trial contains 20 times of picking to record the success rate of only picking one object.
The purpose of the experiment is to compare our method with two baselines.
1) Graspability. We select graspability measure [2] which is a general grasp detection algorithm only using a hand template. It outputs several grasp candidates ranked by graspability measure.
2) CNN. We also select previous work from [1] which is the first approach to predict potential tangled objects in bin-picking. It takes the same grasp candidates as Graspabilty, but ranks them with a prediction network.
V-B Bin-picking Performance
First, we evaluate the success rates and time costs for bin-picking experiments (Table I). The number after slash denotes to the total picking times of one trial, and the one before the slash is the number of times when the robot picks up only one object. As a baseline, Graspability struggles in success rates since it can not discriminate whether the target is entangled with others or not. Our method and CNN both reach relatively higher success rates for picking a single object. Particularly, our method improves the performance of picking from S-shaped objects by a success rate of 50. The reason why CNN struggles with an S-shaped object is that it uses quarters of depth map to make predictions. Even if the cropped image contains the complete shape of target objects, it still lacks information of entangling with others. Our method directly evaluates entanglement for a complete depth map to solve the problem bothering CNN. For the mixed objects, our method reaches a high success rate of 70 since our model-free method only focuses on the information of edges in the depth map. The superior performance of our method indicates that our hand-engineered approach can analyze the relationship between these objects directly and efficiently. CNN may require more evaluation for generalization while our method can be utilized without training.
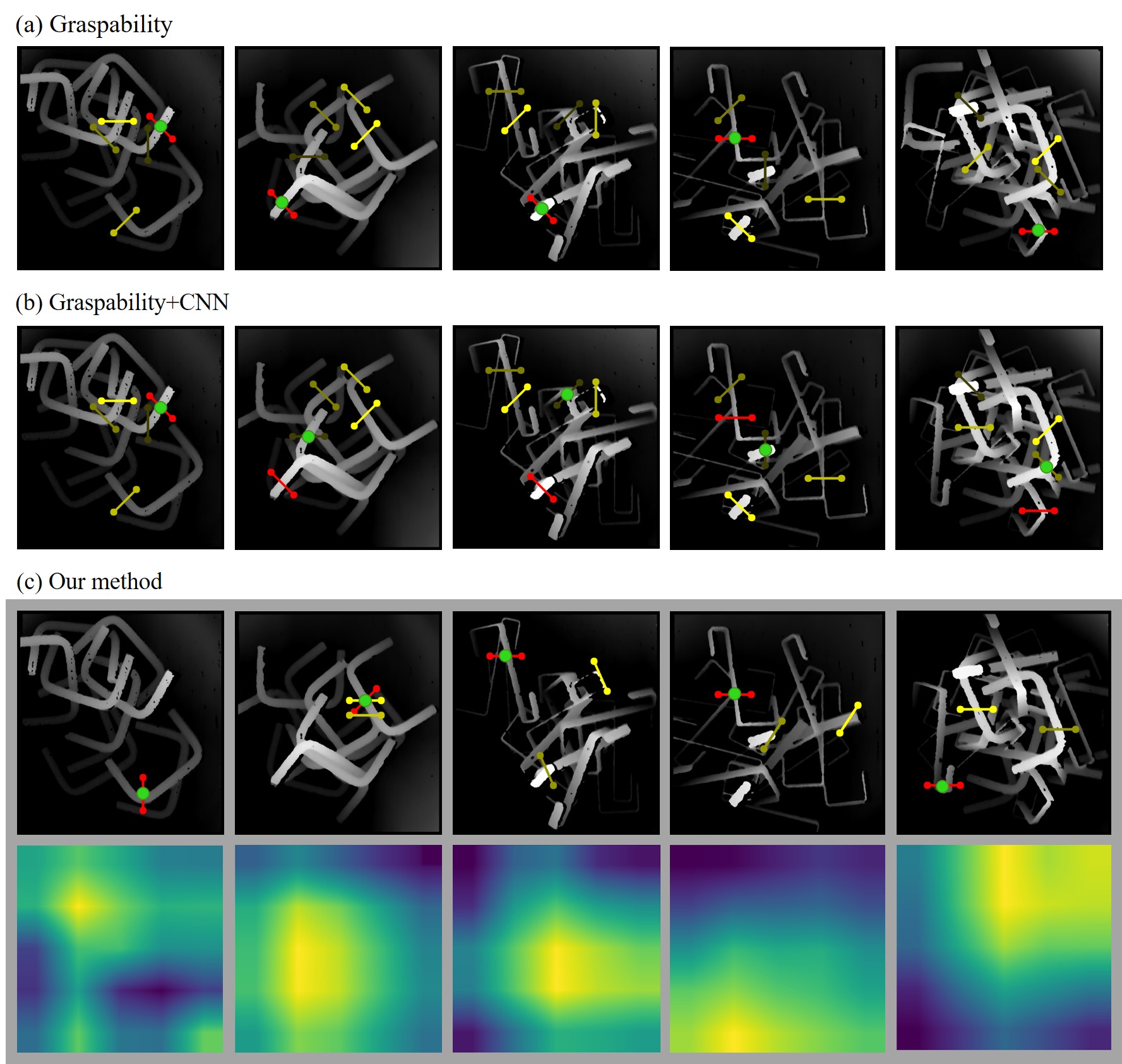
V-C Qualitative Analysis
From the examples presented in Fig. 11, we validate how our method selects graspable objects qualitatively. For the same depth map as input, we use baselines and our method to detect optimal grasp positions, and the top-ranked grasp is marked using green dots. It is observed that our method can directly find the objects that are not tangled with others in the bin, while Graspability and CNN always focus on objects at the top of the clutter. Especially in the fifth column when all five grasp candidates are classified as tangled, both existing approaches predict poorly while our method successfully finds the graspable objects without any entanglement in the bin. Graspable objects selected by the proposed method are similar to the human observations. The reason is that our method uses edge and topological knowledge to explain the entanglement relationship more intuitively, which guarantees a complete observation of all potential entanglement in the bin.
| Graspability[2] | CNN[1] | Ours | ||
|---|---|---|---|---|
| Success rate | C-shaped object | 11/20 | 14/20 | 15/20 |
|
6/20 | 8/20 | 10/20 | |
|
8/20 | 10/20 | 14/20 | |
| Total | 25/60 | 32/60 | 39/60 | |
| Time cost (s) | 2.1 | 2.7 | 7.8 |
In addition, the average time costs of Graspability, CNN, and our method are 2.1s, 2.7s, 7.8s. The time cost of our method depends on how many line segments are detected from the depth map. For our experiment setting of 10 objects placed in the bin, the time cost per trial is limited to 8s.
V-D Discussion
Let us consider other kinds of industrial parts like Fig. 12 shows. This type of object provides too much edge information for topology coordinates, which may cause some misunderstandings. In this case, a learning-based approach would be necessary. However, since our method prefers objects with the shape of pure edges such as rigid linear objects with a smooth edge, it is possible to develop our method on manipulation of deformable linear objects such as tubes or ropes in future work.
Common failures that result from our method are caused by the situation where the selected region does not contain any graspable positions. Even if the entanglement map can be generated correctly, grasps can not be detected due to the collisions in the selected region. In the future, it may be possible to add more collision information during generating the entanglement map to improve the performance.

VI CONCLUSIONS
In this paper, we present a topology-based solution for a robot to only pick only one object in robotic bin-picking. We present a topological feature map called entanglement map to describe the entanglement situation of cluttered objects in a bin. A grasp synthesis method is proposed to search for the optimal grasp without picking up entangled objects from the whole input image. We reach fine success rates on real-world experiments. Our method is dependable upon its generalization capability even if for mixed objects in bin-picking. Particularly, we do not need large training data to make predictions since the proposed method can obtain the topological relationship of entangled objects even for complex-shaped objects.
References
- [1] R. Matsumura, Y. Domae, W. Wan, and K. Harada, “Learning based robotic bin-picking for potentially tangled objects,” in 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 7990–7997, IEEE, 2019.
- [2] Y. Domae, H. Okuda, Y. Taguchi, K. Sumi, and T. Hirai, “Fast graspability evaluation on single depth maps for bin picking with general grippers,” in 2014 IEEE International Conference on Robotics and Automation (ICRA), pp. 1997–2004, IEEE, 2014.
- [3] O. Ghita and P. F. Whelan, “A bin picking system based on depth from defocus,” Machine Vision and Applications, vol. 13, no. 4, pp. 234–244, 2003.
- [4] J. Kirkegaard and T. B. Moeslund, “Bin-picking based on harmonic shape contexts and graph-based matching,” in 18th International Conference on Pattern Recognition (ICPR’06), vol. 2, pp. 581–584, IEEE, 2006.
- [5] J.-K. Oh, S. Lee, and C.-H. Lee, “Stereo vision based automation for a bin-picking solution,” International Journal of Control, Automation and Systems, vol. 10, no. 2, pp. 362–373, 2012.
- [6] K. Harada, W. Wan, T. Tsuji, K. Kikuchi, K. Nagata, and H. Onda, “Initial experiments on learning-based randomized bin-picking allowing finger contact with neighboring objects,” in 2016 IEEE International Conference on Automation Science and Engineering (CASE), pp. 1196–1202, IEEE, 2016.
- [7] K. Harada, W. Wan, T. Tsuji, K. Kikuchi, K. Nagata, and H. Onda, “Experiments on learning based industrial bin-picking with iterative visual recognition,” arXiv preprint arXiv:1805.08449, 2018.
- [8] D. C. Dupuis, S. Léonard, M. A. Baumann, E. A. Croft, and J. J. Little, “Two-fingered grasp planning for randomized bin-picking,” in Proc. of the Robotics: Science and Systems 2008 Manipulation Workshop-Intelligence in Human Environments, 2008.
- [9] B. Drost, M. Ulrich, N. Navab, and S. Ilic, “Model globally, match locally: Efficient and robust 3d object recognition,” in 2010 IEEE computer society conference on computer vision and pattern recognition, pp. 998–1005, Ieee, 2010.
- [10] C. Choi, Y. Taguchi, O. Tuzel, M.-Y. Liu, and S. Ramalingam, “Voting-based pose estimation for robotic assembly using a 3d sensor,” in 2012 IEEE International Conference on Robotics and Automation, pp. 1724–1731, IEEE, 2012.
- [11] D. Chetverikov, D. Svirko, D. Stepanov, and P. Krsek, “The trimmed iterative closest point algorithm,” in Object recognition supported by user interaction for service robots, vol. 3, pp. 545–548, IEEE, 2002.
- [12] J. Mahler, J. Liang, S. Niyaz, M. Laskey, R. Doan, X. Liu, J. A. Ojea, and K. Goldberg, “Dex-net 2.0: Deep learning to plan robust grasps with synthetic point clouds and analytic grasp metrics,” arXiv preprint arXiv:1703.09312, 2017.
- [13] R. Matsumura, K. Harada, Y. Domae, and W. Wan, “Learning based industrial bin-picking trained with approximate physics simulator,” in International Conference on Intelligent Autonomous Systems, pp. 786–798, Springer, 2018.
- [14] G. Leão, C. M. Costa, A. Sousa, and G. Veiga, “Perception of entangled tubes for automated bin picking,” in Iberian Robotics conference, pp. 619–631, Springer, 2019.
- [15] G. Leão, C. M. Costa, A. Sousa, and G. Veiga, “Detecting and solving tube entanglement in bin picking operations,” Applied Sciences, vol. 10, no. 7, p. 2264, 2020.
- [16] E. S. Ho and T. Komura, “Wrestle alone: Creating tangled motions of multiple avatars from individually captured motions,” in 15th Pacific Conference on Computer Graphics and Applications (PG’07), pp. 427–430, IEEE, 2007.
- [17] E. S. Ho and T. Komura, “Character motion synthesis by topology coordinates,” in Computer Graphics Forum, vol. 28, pp. 299–308, Wiley Online Library, 2009.
- [18] E. S. Ho, T. Komura, S. Ramamoorthy, and S. Vijayakumar, “Controlling humanoid robots in topology coordinates,” in 2010 IEEE/RSJ International Conference on Intelligent Robots and Systems, pp. 178–182, IEEE, 2010.
- [19] G. N. Reeke Jr, “Protein folding: Computational approaches to an exponential-time problem,” Annual review of computer science, vol. 3, no. 1, pp. 59–84, 1988.
- [20] H. Wakamatsu, A. Tsumaya, E. Arai, and S. Hirai, “Planning of one-handed knotting/raveling manipulation of linear objects,” in IEEE International Conference on Robotics and Automation, 2004. Proceedings. ICRA’04. 2004, vol. 2, pp. 1719–1725, IEEE, 2004.
- [21] M. Saha and P. Isto, “Manipulation planning for deformable linear objects,” IEEE Transactions on Robotics, vol. 23, no. 6, pp. 1141–1150, 2007.
- [22] V. Ivan, D. Zarubin, M. Toussaint, T. Komura, and S. Vijayakumar, “Topology-based representations for motion planning and generalization in dynamic environments with interactions,” The International Journal of Robotics Research, vol. 32, no. 9-10, pp. 1151–1163, 2013.
- [23] K. Klenin and J. Langowski, “Computation of writhe in modeling of supercoiled dna,” Biopolymers: Original Research on Biomolecules, vol. 54, no. 5, pp. 307–317, 2000.